KR102094659B1 - 헤드라인의 자동 생성 - Google Patents
헤드라인의 자동 생성 Download PDFInfo
- Publication number
- KR102094659B1 KR102094659B1 KR1020207005313A KR20207005313A KR102094659B1 KR 102094659 B1 KR102094659 B1 KR 102094659B1 KR 1020207005313 A KR1020207005313 A KR 1020207005313A KR 20207005313 A KR20207005313 A KR 20207005313A KR 102094659 B1 KR102094659 B1 KR 102094659B1
- Authority
- KR
- South Korea
- Prior art keywords
- news
- patterns
- entities
- syntax
- headline
- Prior art date
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/258—Heading extraction; Automatic titling; Numbering
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/55—Rule-based translation
- G06F40/56—Natural language generation
Abstract
등가 구문 패턴들의 세트들이 문서들의 코퍼스로부터 학습된다. 하나 이상의 입력 문서의 세트가 수신된다. 하나 이상의 입력 문서의 세트는 등가 구문 패턴들의 세트들 중에서 한 세트의 등가 구문 패턴들과 일치하는 하나 이상의 표현을 위해 처리된다. 등가 구문 패턴들 중에서 헤드라인을 위한 구문 패턴이 선택된다. 구문 패턴은 하나 이상의 입력 문서의 세트에 의해 기술되는 메인 이벤트를 반영한다. 헤드라인은 구문 패턴을 이용하여 생성된다.
Description
관련 출원들에 대한 상호 참조
본 출원은 2013년 6월 27일자로 "Automatic Generation of Headlines"이라는 명칭으로 출원된 미국 가출원 제61/840,417호, 및 2013년 10월 22일자로 "Automatic Generation of Headlines"이라는 명칭으로 출원된 미국 특허출원 제14/060,562호의 우선권을 주장하며, 그 출원들 각각의 내용은 전체가 본 명세서에 참고로 포함된다.
본 개시 내용은 헤드라인들을 자동으로 생성하는 것에 관한 것이다.
뉴스 기사들을 위한 헤드라인들을 생성하기 위해, 현재의 일부 접근법은 헤드라인들을 수동으로 생성하거나 또는 기사로부터 문장을 제목으로서 자동 식별하고 선택하는 것을 포함한다. 그러나 이들 접근법은 종종 웹으로부터 크롤링된(crawled) 뉴스를 커버하도록 확장 가능하지 않다. 이는 때때로 대량의 수동 개입이 요구되기 때문이거나 또는 그런 접근법들이 일관된 콘텐츠 및 포매팅을 가진 기사들의 모델 세트에 기초하는데, 웹으로부터 크롤링된 기사들은 종종 다양한 콘텐츠 및 포매팅을 가지기 때문일 수 있다.
일부 기존 해결책은 이들 기사를 위한 헤드라인으로서 기사들의 주요 구절을 이용하려고 시도한다. 그러나 이들 해결책은 종종, 중요한 정보가 기사의 여러 문장에 걸쳐 분포될 수 있거나 선택된 문장이 원하는 또는 허용 가능한 헤드라인 크기보다 길 수 있기 때문에 현실적이지 않다. 문장의 크기를 줄이기 위해, 일부 해결책은 문장의 단어들을 재정리하려고 시도했다. 그러나 이들에 의해 사용된 재배열 기술들은 부정확한 문법을 포함하기 쉬운 헤드라인들을 초래하였다. 하나 이상의 문장을 선택하고 그 후 이들을 목표 헤드라인 크기로 줄이는 다른 접근법들은, 수동 관리 및/또는 주석들에게 의지하고, 이에 따라 일반적으로 확장 가능하지 않고, 일반적으로 단일 문서에만 적용 가능하고, 2 이상의 뉴스 기사의 모음에는 적용 가능하지 않다.
또한, 지식 데이터베이스들을 최신 헤드라인들로 계속 업데이트하는 것은 종종, 데이터베이스들을 최신 상태에 계속 두는데 요구되는 인간 노력의 수준 때문에 어려웠다. 예를 들어, 일부 기존 시스템들에서, 주목할 만한 이벤트가 발생된 경우, 지식 데이터베이스들은 그 이벤트에 대한 정보로 수동 업데이트되어야 한다.
본 명세서에 설명되는 주제의 한가지 혁신적인 양태에 따르면, 시스템은 문서들의 코퍼스(corpus)로부터 등가 구문 패턴들의 세트들을 학습한다. 시스템은 하나 이상의 입력 문서의 세트를 수신한다. 시스템은 등가 구문 패턴들의 세트들 중에서 한 세트의 등가 구문 패턴들과 일치하는(matching) 하나 이상의 표현을 위해 하나 이상의 입력 문서의 세트를 처리한다. 시스템은 등가 구문 패턴들의 세트 중에서 헤드라인을 위한 구문 패턴을 선택하고, 구문 패턴은 하나 이상의 입력 문서의 세트에 의해 기술되는 메인 이벤트를 반영한다. 시스템은 구문 패턴을 이용하여 헤드라인을 생성한다.
일반적으로, 본 명세서에 설명된 주제의 또 다른 혁신적인 양태는 방법으로 구현될 수 있으며, 방법은, 문서들의 코퍼스로부터 등가 구문 패턴들의 세트들을 학습하는 단계; 하나 이상의 입력 문서의 세트를 수신하는 단계; 등가 구문 패턴들의 세트들 중에서 한 세트의 등가 구문 패턴들과 일치하는 하나 이상의 표현을 위해 하나 이상의 입력 문서들의 세트를 처리하는 단계; 등가 구문 패턴들의 세트 중에서 헤드라인을 위한 구문 패턴을 선택하는 단계 - 구문 패턴은 하나 이상의 입력 문서의 세트에 의해 기술되는 메인 이벤트를 반영함 -; 및 구문 패턴을 이용하여 헤드라인을 생성하는 단계를 포함한다.
이들 양태 중 하나 이상의 다른 구현은 컴퓨터 저장 디바이스들 상에 인코딩된 방법들의 액션들을 수행하도록 구성된, 대응하는 시스템들, 장치들 및 컴퓨터 프로그램들을 포함한다.
이들 및 다른 구현은 각각 다음의 특징들 중 하나 이상을 선택적으로 포함할 수 있다. 예를 들어, 동작들은, 등가 구문 패턴들의 세트들을 지식 그래프 내의 대응하는 아이템들에 매핑하는 동작; 등가 구문 패턴들의 세트와 일치하는 하나 이상의 표현으로부터 하나 이상의 엔티티를 결정하는 동작; 하나 이상의 표현으로 기술된 하나 이상의 엔티티들에 대응하는 지식 그래프 내의 하나 이상의 엔트리를 결정하는 동작; 헤드라인을 이용하여 메인 이벤트를 반영하기 위해 지식 그래프 내의 하나 이상의 엔트리를 업데이트하는 동작; 하나 이상의 표현으로부터 하나 이상의 엔티티를 처리하는 동작 - 헤드라인을 생성하는 것은 하나 이상의 엔티티로 구문 패턴을 채우는 것을 포함함 -; 관련된 문서들의 세트들을 수신하는 동작; 관련된 문서들의 세트들 각각에 대해, 대응하는 정보를 수반하는 표현들을 결정하는 동작; 표현들에 기초하여 등가 구문 패턴들의 세트들을 결정하는 동작; 등가 구문 패턴들의 세트들을 데이터 스토어에 저장하는 동작; 확률 모델을 이용하여 등가 구문 패턴들의 세트들 중 하나 이상에 포함시킬 추가적인 숨겨진 구문 패턴들을 결정하는 동작; 하나 이상의 입력 문서로부터 처리되는 다수의 표현이 미리 정해진 증거 임계치를 충족한다고 결정하는 동작; 및 증거 임계치가 충족되는 것에 기초하여 등가 구문 패턴들의 세트가 하나 이상의 입력 문서의 세트와 관련 있다고 결정하는 동작을 더 포함할 수 있다. 예를 들어, 특징들은 하나 이상의 입력 문서의 세트가 관련된 뉴스 기사들의 뉴스 모음을 포함하는 것을 포함할 수 있다.
본 명세서에 설명된 기술은 다수의 측면에서 유리하다. 예를 들어, 기술은 등가 표현들의 모델을 학습할 수 있고, 이를 이용하여 무엇이 하나 이상의 뉴스 문서에 보도된 메인 이벤트인지 이해할 수 있으며, 웹 사이즈 데이터를 취급하도록 스케일링할 수 있고, 수백만의 뉴스 기사는 시스템의 한번 실행으로 처리된다. 게다가, 기술은 자동으로 학습되는 이벤트를 기술하는 등가 표현들에 기초하여 원래 문서에 나타나지 않았던 여러 문서를 위한 헤드라인들을 생성할 수 있다. 이는 일부 경우에, 저작권의 대상이 되지 않는 헤드라인들을 생성하는 이득을 제공할 수 있다(이들이 간행물들과 동일한 단어들을 이용하지 않을 때). 이 기술은 또한 학습된 패턴들과 지식 베이스에서의 관계들 간의 연관을 자동으로 결정할 수 있고, 다양한 엔티티들에 대한 최신 뉴스가 처리될 때 이들 관계를 업데이트할 수 있다. 그 결과, 지식 베이스를 계속 현재 상태로 유지하기 위한 절차는 이 기술을 이용하여 완전 자동화될 수 있으며, 이에 따라 인간 주석에 대한 필요성을 제거할 수 있다.
그러나, 특징들과 장점들의 이런 리스트가 모두를 포함하는 것이 아니고 수많은 특징 및 장점이 예상되고 본 개시 내용의 범위 내에 포함된다는 것을 이해하여야 한다. 더욱이, 본 개시 내용에 사용되는 언어가 주로 가독성과 교육상의 목적들을 위해 선택되었고, 본 명세서에 개시된 주제의 범위를 제한하지 않음을 이해하여야 한다.
본 개시 내용은 예로서 예시된 것이지 첨부 도면을 제한하는 것으로 예시된 것이 아니며, 도면에서 유사한 참조 번호들은 유사한 요소들을 참조하기 위해 사용된다.
도 1은 헤드라인들을 자동으로 생성하고 최근 지식 그래프를 유지하기 위한 예시적 시스템을 도시한 블록도이다.
도 2는 예시적 뉴스 시스템을 도시한 블록도이다.
도 3은 헤드라인들을 자동으로 생성하는 예시적 방법의 흐름도이다.
도 4는 뉴스 문서들로부터의 엔티티들과 이벤트들에 기초하여 등가 구문 패턴들을 세트들로 클러스터링하는 예시적 방법의 흐름도이다.
도 5a 및 5b는 등가 구문 패턴들의 클러스터들에 기초하여 뉴스 문서들을 위한 헤드라인들을 생성하는 것과 관련된 예시적 방법들의 흐름도들이다.
도 6은 등가 구문 패턴들의 클러스터들에 기초하여 지식 그래프를 자동으로 업데이트하는 예시적 방법의 흐름도이다.
도 7은 예시적 패턴 결정 프로세스를 도시하는 예시적 방법이다.
도 8은 예시적 확률 모델을 도시한다.
도 9는 관련 있는 발췌된 헤드라인들을 생성하는 예시적 방법을 도시하는 블록도이다.
도 10은 관련 있는 발췌된 헤드라인들의 샘플을 포함하는 예시적 그래픽 사용자 인터페이스이다.
도 1은 헤드라인들을 자동으로 생성하고 최근 지식 그래프를 유지하기 위한 예시적 시스템을 도시한 블록도이다.
도 2는 예시적 뉴스 시스템을 도시한 블록도이다.
도 3은 헤드라인들을 자동으로 생성하는 예시적 방법의 흐름도이다.
도 4는 뉴스 문서들로부터의 엔티티들과 이벤트들에 기초하여 등가 구문 패턴들을 세트들로 클러스터링하는 예시적 방법의 흐름도이다.
도 5a 및 5b는 등가 구문 패턴들의 클러스터들에 기초하여 뉴스 문서들을 위한 헤드라인들을 생성하는 것과 관련된 예시적 방법들의 흐름도들이다.
도 6은 등가 구문 패턴들의 클러스터들에 기초하여 지식 그래프를 자동으로 업데이트하는 예시적 방법의 흐름도이다.
도 7은 예시적 패턴 결정 프로세스를 도시하는 예시적 방법이다.
도 8은 예시적 확률 모델을 도시한다.
도 9는 관련 있는 발췌된 헤드라인들을 생성하는 예시적 방법을 도시하는 블록도이다.
도 10은 관련 있는 발췌된 헤드라인들의 샘플을 포함하는 예시적 그래픽 사용자 인터페이스이다.
뉴스 이벤트들은 종종 예를 들어, 단일 관점이 아니라 다양한 통신사에 의한 다수의 관점으로부터 상이한 방식으로 보도된다. 상이한 통신사들은 주어진 이벤트를 상이한 방식으로 해석할 수 있고, 다양한 국가 또는 위치는 이벤트의 상이한 양상들을 강조할 수 있거나, 이들이 어떻게 영향받는지에 따라 이들 양상을 다르게 기술할 수 있다. 게다가, 이벤트에 대한 견해들과 심도있는 분석은 통상 사실 이후에 작성된다. 다양한 콘텐츠와 스타일은 모두 기회와 도전이 될 수 있다. 예를 들어, 상이한 뉴스 공급원들이 주어진 이벤트를 기술하는 상이한 방식은, 대부분의 뉴스 공급원들에 의해 보도된 정보 콘텐츠가 종종 이벤트의 중심부를 아마도 나타낼 수 있기 때문에, 요약에 유용한 중복을 제공할 수 있다. 그러나 이들 상이한 기사들의 가변성 및 주관성을 감안하면, 일어난 것을 객관적 방식으로 표현하는 것이 어려울 수 있다.
비제한적 예로서, 표 1은 2명의 예시적인 유명 인사, 저명한 농구 선수, James Jones와 잘 알려진 여배우, Jill Anderson 간에 결혼을 보도하는 뉴스에서 관찰된 상이한 헤드라인들을 보여준다.

상기 예시적 헤드라인들로부터 알 수 있는 것처럼, 상이한 관점들, 하이라이트된 양상들, 및 독단적인 진술을 포함하는, 동일 이벤트를 보도하기 위한 다양한 방식이 있다. 뉴스 기반 정보 검색 또는 추천 시스템에서 이런 이벤트를 사용자에게 제공할 때, 상이한 이벤트 기술들이 더 적절할 수 있다. 예를 들어, 사용자는 보도자 쪽의 어떤 해석도 없는 객관적인, 유익한 요약들에만 관심을 둘 수 있다.
본 명세서에서 설명되는 기술은 관련되는 문서들의 모음(예를 들어, 표 1로부터의 헤드라인들을 갖는 뉴스 기사들)이 주어지면 그 모음으로부터 메인(예를 들어, 가장 중요한/핵심적인/관련 있는) 이벤트를 기술하는 간결한, 유익한, 및/또는 편파적이지 않은 제목(예를 들어, 헤드라인)을 생성할 수 있는 시스템을 포함한다. 이 기술은 충분히 오픈-도메인(open-domain) 가능하고 웹 사이즈 데이터로 확장 가능하다. 단일 뉴스 스토리 또는 뉴스 모음의 경계들에 걸쳐 이벤트들을 일반화하기 위해 학습함으로써, 기술은 객관적으로 관련 있는 정보를 전달하는 간결하고 효과적인 헤드라인들을 생성할 수 있다. 예를 들어, 기술은 동일 이벤트를 지칭하는 동의어 표현들에 걸쳐 일반화될 수 있고, 신규성, 객관성 및 범용성을 가진 헤드라인을 생성하기 위해, 발췌 방식으로 그렇게 한다. 생성된 헤드라인은 일부 경우에 심지어 뉴스 모음의 문서들 어디에도 언급되거나 포함되지 않을 수 있다.
일부 구현들에서, 뉴스의 웹 스케일 코퍼스로부터, 기술은 구문 패턴들을 처리하고 이들 패턴을 Noisy-OR 모델을 이용하여 이벤트 기술로 일반화할 수 있다. 추론 시에, 기술은 새로운/이전에 보이지 않은 뉴스 모음에서 관찰된 패턴들을 이용하여 모델에게 질의하고, 모음의 요지를 가장 잘 캡처하는 이벤트를 식별하고, 헤드라인을 생성하기 위해 가장 적절한 패턴을 검색할 수 있다. 이런 기술은 수동 평가 및/또는 개입을 요구함이 없이, ROUGE(요약들을 평가하기 위한 표준 소프트웨어 패키지)에 의해서 평가된 것처럼, 이것이 인간-생성 헤드라인들과 비교할 만하게 달성되는 헤드라인들을 생성할 수 있기 때문에 유리하다.
본 명세서에 설명되는 기술은 또한 단일 뉴스 문서를 위한 헤드라인을 생성하는데 이용될 수 있다. 예를 들어, 입력(예를 들어, 뉴스의 모음)은 단지 하나의 문서를 포함할 수 있고, 출력은 입력에 보도된 가장 핵심적인 이벤트를 기술하는 헤드라인일 수 있다. 헤드라인들은 또한 뉴스에 언급된 엔티티들(예를 들어, 위치들, 회사들 또는 유명인사들)의 사용자 선택 서브세트를 위한 기술에 의해 생성될 수 있다. 기술은 지식 베이스를 최신 이벤트들과 정보를 갖는 최신 상태로 유지하기 위해 이에 의해 수행되는 헤드라인 처리를 유리하게 이용할 수 있다.
도 1은 헤드라인들을 자동으로 생성하고 최신 지식 그래프를 유지하기 위한 예시적 시스템(100)의 블록도이다. 예시된 시스템(100)은 클라이언트 디바이스들(106a...106n)(또한 106으로서 개별적 및/또는 집합적으로 지칭된다), 뉴스 서버들(128a...128n)(또한 128로서 개별적 및/또는 집합적으로 지칭된다), 뉴스 시스템(116), 및 서버(132)를 포함하고, 이들은 서로 상호 작용하기 위해 네트워크(102)를 통해 통신 가능하게 결합된다. 예를 들어, 클라이언트 디바이스들(106a...106n)은 각각 신호 라인들(104a...104n)을 통해 네트워크(102)에 결합될 수 있고, 라인들(110a...110n)에 의해 예시된 바와 같이 사용자들(112a...112n)(또한 112로서 개별적 및/또는 집합적으로 지칭된다)에 의해 액세스 가능할 수 있다. 뉴스 서버들(128a...128n)은 각각 신호 라인들(126a...126n)을 통해 네트워크(102)에 결합될 수 있고, 뉴스 시스템(116)은 신호 라인(114)을 통해 네트워크(102)에 결합될 수 있다. 서버(132)는 신호 라인(134)을 통해 네트워크(102)에 결합될 수 있다. 참조 번호들에서 명명법 "a" 및 "n"의 사용은 시스템(100)이 해당 명명법을 갖는 이들 요소의 임의의 수를 포함할 수 있는 것을 나타낸다.
도 1에 예시된 시스템(100)이 헤드라인을 생성하고 최신 지식 그래프를 유지하기 위한 예시적 시스템을 나타내며, 다양한 상이한 시스템 환경 및 구성이 예상되고 본 개시 내용의 범위에 포함된다는 것을 이해해야 한다. 예를 들어, 다양한 기능은 서버로부터 클라이언트로 또는 그 반대로 이동될 수 있고, 일부 구현들은 추가의 또는 더 적은 컴퓨팅 디바이스들, 서비스들 및/또는 네트워크들을 포함할 수 있고, 다양한 기능 클라이언트 또는 서버-측을 구현할 수 있다. 또한, 시스템의 다양한 엔티티들은 단일 컴퓨팅 디바이스 또는 시스템 또는 추가 컴퓨팅 디바이스들 또는 시스템들 등에 통합될 수 있다.
네트워크(102)는 임의의 수 및/또는 타입의 네트워크들을 포함할 수 있고, 단일 네트워크 또는 다수의 상이한 네트워크를 나타낼 수 있다. 예를 들어, 네트워크(102)는 하나 이상의 근거리 통신망(local area network)(LAN)들, 광역 통신망(wide area network)(WAN)들(예를 들어, 인터넷), 가상 사설망(virtual private network)(VPN)들, 모바일(셀룰러) 네트워크들, 무선 광역 통신망(wireless wide area network)(WWAN)들, WiMAX(등록상표) 네트워크들, 블루투스(등록상표) 통신 네트워크들, 이들의 다양한 조합들 등을 포함할 수 있지만, 이에 제한되지 않는다.
클라이언트 디바이스들(106a...106n)(또한 106으로서 개별적 및 집합적으로 지칭된다)은 데이터 처리 및 통신 능력들을 갖는 컴퓨팅 디바이스들이다. 일부 구현들에서, 클라이언트 디바이스(106)는 프로세서(예를 들어, 가상, 물리적 등), 메모리, 전력원, 통신 유닛, 및/또는 다른 소프트웨어 및/또는 하드웨어 컴포넌트들을 포함할 수 있으며, 이들 컴포넌트는 예를 들어, 디스플레이, 그래픽 프로세서, 무선 송수신기들, 키보드, 카메라, 센서들, 펌웨어, 운영 체계들, 드라이버들, 다양한 물리적 연결 인터페이스들(예를 들어, USB, HDMI 등)을 포함한다. 클라이언트 디바이스들(106a...106n)은 서로 결합되고 통신할 수 있으며, 무선 및/또는 유선 연결을 이용하여 네트워크(102)를 통해 서로 시스템(100)의 다른 엔티티들에 결합되고 통신할 수 있다.
클라이언트 디바이스들(106)의 예들은 이동 전화기들, 태블릿들, 랩톱들, 데스크톱들, 넷북들, 서버 기구들, 서버들, 가상 머신들, TV들, 셋톱 박스들, 미디어 스트리밍 디바이스들, 휴대용 미디어 플레이어들, 내비게이션 디바이스들, 개인용 휴대 단말기들을 포함할 수 있지만 이에 제한되지 않는다. 2 이상의 클라이언트 디바이스(106)가 도 1에 도시되지만, 시스템(100)은 임의의 수의 클라이언트 디바이스들(106)을 포함할 수 있다. 게다가, 클라이언트 디바이스들(106a...106n)은 컴퓨팅 디바이스들의 동일한 또는 상이한 타입들일 수 있다.
도시된 구현에서, 클라이언트 디바이스들(106a...106n)은 각각 클라이언트 애플리케이션의 인스턴스들(108a...108n)(또한 108로서 개별적 및/또는 집합적으로 지칭된다)을 포함한다. 클라이언트 애플리케이션(108)은 메모리(도시 생략)에 저장 가능하고 클라이언트 디바이스(106)의 프로세서(도시 생략)에 의해 실행 가능할 수 있다. 클라이언트 애플리케이션(108)은 시스템(100)의 하나 이상의 엔티티(예를 들어, 뉴스 서버(128) 및/또는 뉴스 시스템(116))에 의해 호스팅되는 정보를 검색하고, 저장하고/하거나 처리할 수 있으며 클라이언트 디바이스(106) 상에 디스플레이 디바이스(도시 생략)를 제공할 수 있는 브라우저 애플리케이션(예를 들어, 웹 브라우저, 전용 애플리케이션 등)을 포함할 수 있다.
뉴스 서버들(128a...128n)(또한 128로서 개별적 및 집합적으로 지칭된다) 및 서버(132)는 각각 데이터 처리, 저장, 및 통신 능력들을 갖는 하나 이상의 컴퓨팅 디바이스를 포함할 수 있다. 예를 들어, 뉴스 서버(128) 및/또는 서버(132)는 하나 이상의 하드웨어 서버, 서버 어레이, 저장 디바이스, 가상 디바이스 및/또는 시스템 등을 포함할 수 있다. 일부 구현들에서, 뉴스 서버들(128a...128n) 및/또는 서버(132)는 하나 이상의 가상 서버를 포함할 수 있고, 이는 호스트 서버 환경에서 동작하고, 추상화 계층(예를 들어, 가상 머신 관리자)을 통해, 예를 들어 프로세서, 메모리, 스토리지, 네트워크 인터페이스 등을 포함하는 호스트 서버의 물리적 하드웨어에 액세스한다.
도시된 구현에서, 뉴스 서버들(128a...128n)은 다양한 컴퓨팅 기능, 서비스 및/또는 자원을 제공하고 데이터를 네트워크(102)의 다른 엔티티들에 송신하고 이로부터 수신하도록 동작 가능한 공개 엔진들(130a...130n)(또한 130으로서 개별적 및/또는 집합적으로 지칭된다)을 포함한다. 예를 들어, 공개 엔진들(130)은 네트워크(102)를 통해 다양한 상이한 주제에 대한 뉴스를 제공하고, 공개하고/하거나 신디케이트하는(syndicate) 뉴스 소스들을 구현할 수 있다. 이들 뉴스 소스로부터의 콘텐츠(예를 들어, 뉴스)는 예를 들어 검색 엔진(118)을 포함하는 네트워크의 하나 이상의 컴포넌트에 의해 모일 수 있다.
뉴스는 확립된 뉴스 소스들, 블로그들, 마이크로블로그들, 쇼설 미디어 스트림들, 웹사이트 포스팅들 및/또는 업데이트들에 의해 제공되는 바와 같은 새로운 정보를 포함할 수 있으며, 뉴스는 다양한 포맷들(예를 들어, HTML, RSS, XML, JSON 등)로 제공된다. 일부 경우에, 공개 엔진들(130)은 예를 들어, 지역 뉴스, 국가 뉴스, 스포츠, 정치, 세계 뉴스, 엔터테인먼트, 연구, 기술, 지역 이벤트, 및 뉴스 등을 포함하는, (예를 들어, 실시간으로) 일어나고 있는 이벤트에 대한 문서를 제공하며, 사용자들(112)은 콘텐츠를 소모하기 위해 뉴스 포털들에 액세스할 수 있다. 문서들은 예를 들어, 텍스트, 사진, 비디오 등을 포함하는 임의의 타입의 디지털 콘텐츠를 포함할 수 있다. 뉴스 서버들(128)은 네트워크(102)에 액세스 가능하고 인식 가능하며, 시스템(100)의 다른 엔티티들은 뉴스 서버들(128)로부터 정보를 요청하고 수신할 수 있다. 일부 구현들에서, 뉴스는 쇼설 네트워크, 마이크로블로그들, 또는 사용자들이 정보를 서로 방송할 수 있는 다른 쇼설 가능 컴퓨팅 플랫폼상에서 사용자에 의해 제출된 콘텐츠(예를 들어, 포스트들)에 의해 구현될 수 있다.
뉴스 시스템(116)은, 뉴스를 수집하고, 뉴스 모음을 처리하고, 등가 구문 패턴들을 자동으로 학습하고, 헤드라인들을 자동으로 생성하고, 구문 패턴들을 이용하여 지식 그래프를 업데이트할 수 있는 컴퓨팅 시스템이다. 또한, 뉴스 시스템(116)에 의해 헤드라인들이 생성되고 트레이닝이 수행되고 지식 그래프 관리가 수행되는 것이, (예를 들어, 사용자 요청시) 실시간으로 행해질 수 있으며, 이들이 검색 엔진(118)에 의해 모일 때 뉴스 모음을 위해 처리될 수 있고, 다른 적용 가능한 방식들로 정규 시간 간격들(예를 들어, 분(들), 시간(들), 일(들), 일과종료 등)에서 처리될 수 있다는 것을 이해해야 한다. 일부 예들에서, 뉴스 시스템(116)은 관련 있는 뉴스 문서들을 찾는 능력을 사용자들에게 제공할 수 있고, 사용자들이 관심을 두는 새로운 객체에 대한 뉴스 모음 및 관련 있는 헤드라인들을 포함하는 뉴스 요약을 수신할 수 있다. 도시된 구현에서, 뉴스 시스템(116)은 검색 엔진(118), 헤드라인 생성 엔진(120), 지식 그래프 관리 엔진(122), 지식 그래프(124a), 및 뉴스 포털(125)을 포함한다.
검색 엔진(118)은 찾기 가능성 및 검색 가능성을 위해 다양한 뉴스 소스들로부터 뉴스 문서들을 수집하고/수집하거나, 차후 액세스 및/또는 검색을 위해 데이터 스토어에 뉴스 문서들을 저장할 수 있다. 일부 구현들에서, 검색 엔진(118)은 다양한 엔티티들을 크롤링할 수 있으며, 이들 엔티티는 이들에 저장된 문서들을 위해 네트워크(102)를 통해 서로 연결되고, 예를 들어 웹 콘텐츠(예를 들어, HTML, 휴대용 문서들, 오디오 및 비디오 콘텐츠, 이미지들), 구조화된 데이터(예를 들어, XML, JSON), 객체들(예를 들어, 실행 가능한 것들) 등을 포함한다. 검색 엔진(118)은 문서들(및/또는 이에 대한 점진적 업데이트들)을 수집하고, 최적의 찾기 가능성을 위해 수집된 데이터를 처리하고, 수집된/처리된 데이터를 시스템(100)의 다른 컴포넌트들에 제공하고/하거나 시스템(100)의 다른 컴포넌트들에 의한 액세스 및/또는 검색을 위해 수집된 데이터(214)로서 데이터 스토어(예를 들어, 도 2a의 데이터 스토어(210))에 저장할 수 있으며, 시스템의 다른 컴포넌트는 예를 들어, 헤드라인 생성 엔진(120) 및/또는 그 구성 컴포넌트들, 지식 그래프 관리 엔진(122) 및/또는 뉴스 포털(125)을 포함한다. 검색 엔진(118)은 데이터를 송신하고/하거나 수신하기 위해 이들 컴포넌트, 데이터 스토어(210) 및/또는 지식 그래프들(124a...124n)(또한 124로서 본 명세서에서 개별적 및/또는 집합적으로 지칭된다)에 결합될 수 있다.
일부 구현들에서, 검색 엔진(118)은 뉴스 문서를 수집하기 위해 네트워크(102)를 통해 뉴스 서버들(128)의 공개 엔진들(130)과 상호 작용하고, 뉴스 문서들을 관련된 세트들로 처리하고, 새로운 문서들의 수집된 세트들을 뉴스 시스템(116)의 다른 컴포넌트들에 저장하고/하거나 제공할 수 있다. 예를 들어, 검색 엔진(118)은 시간의 근접성 및/또는 코사인 유사도(예를 들어, 벡터-공간 모델 및 가중치들을 이용하는)에 기초하여 수집된 문서들을 그룹화함으로써 이들로부터 뉴스 모음을 생성할 수 있다. 일부 예들에서, 뉴스 모음은 단일 문서를 포함할 수 있다. 추가 경우들에서, 뉴스 모음은 임의의 수의 문서들(예를 들어, 2+, 5+, 50+ 등)을 포함할 수 있다.
헤드라인 생성 엔진(120)(예를 들어, 도 2에 도시된 바와 같은 패턴 엔진(220) 및/또는 트레이닝 엔진(222))은 (예를 들어, 데이터 스토어(210), 검색 엔진(118) 등으로부터) 관련된 뉴스 문서들의 세트들을 수신하고, 이들 각각을 이벤트들과 엔티티들의 등가 구문 패턴들의 클러스터들을 위해 처리할 수 있다. 헤드라인 생성 엔진(120)(예를 들어, 도 2에 도시된 바와 같은 추론 엔진(224))은 등가 구문 패턴들의 클러스터들에 기초하여 뉴스 문서들의 세트들을 위한 헤드라인들을 자동으로 생성할 수 있다.
지식 그래프 관리 엔진(122)은 등가 구문 패턴들의 클러스터들에 기초하여 지식 그래프들(124a...124n)을 자동으로 업데이트할 수 있다. 지식 그래프(124)는 조직화된 정보를 저장하고 이에 대한 액세스를 제공하기 위한 데이터베이스를 포함할 수 있다. 일부 구현들에서, 지식 그래프(124)는 엔티티들을 세계에서 이들의 위치와 이들의 관계에 관하여 조직화할 수 있다. 지식 그래프는 백과사전 또는 다른 지식 소스와 같은 지식의 코퍼스를 구현할 수 있다. 지식 그래프는 데이터에 대한 액세스를 처리, 저장 및 제공하기 위한 하나 이상의 컴퓨팅 디바이스들 및 비일시적 저장 매체를 포함할 수 있다. 일부 구현들에서, 지식 그래프는 뉴스 시스템(116)과 통합될 수 있거나, 또는 뉴스 시스템(116)과 별개의 컴퓨팅 디바이스 또는 시스템에 포함할 수 있으며, 이들은 예를 들어, 서버(132)를 포함한다. 지식 그래프의 비제한적 예들은 Freebase, Wikipedia 등을 포함한다. 본 명세서에 설명된 기술은 본 명세서의 다른 곳에서 추가로 논의되는 바와 같이, 지식 그래프 추세를 유지하는데 필요한 인간 노력을 감소할 수 있기 때문에 유리하다.
뉴스 포털(125)을 이용하면, 사용자들은 헤드라인 생성 엔진(120)에 의해 생성된 헤드라인들을 이용하여 요약된 다양한 뉴스 모음들을 찾고, 액세스하고, 이에 대한 경보를 수신하고, 공유하고, 보증할 수 있다. 일부 구현들에서, 뉴스 포털(125)은 뉴스 시스템(116)과 별개의 컴퓨팅 시스템(예를 들어, 서버)에서 호스팅될 수 있다. 이 기술이 뉴스의 문맥으로 설명될지라도, 이것이 예를 들어, 쇼설 미디어(예를 들어, 쇼설 네트워크들, 마이크로블로그들, 블로그들 등)를 포함하는 임의의 콘텐츠 플랫폼에 적용 가능하고 콘텐츠 포스트들, 동향 활동 등을 요약하기 위해 이들 컴퓨팅 서비스에 의해 이용될 수 있음을 이해해야 한다.
일부 구현들에서, 뉴스 포털(125)은 하나 이상의 객체와 연관되는 하나 이상의 뉴스 모임 및/또는 대응하는 문서를 결정하고, 뉴스 모음(들) 및/또는 문서(들)을 포함하는 뉴스 요약들을 생성하고 제공하도록 실행 가능한 소프트웨어 및/또는 로직을 포함한다. 일부 구현들에서, 뉴스 요약은 검색 질의에 응답하여 생성될 수 있고, 질의의 파라미터들에 기초하여 생성될 수 있다. 예시적 파라미터들은 하나 이상의 객체, 시간 프레임, 포함될 수많은 문서 및/또는 모임, 분류 기준 등을 기술하는 데이터를 포함할 수 있다. 예를 들어, 검색 질의는 객체(예를 들어, 사람, 사물, 이벤트, 토픽 등)의 명칭을 포함할 수 있다. 일부 경우에서, 질의 파라미터들은 텍스트, 이미지, 오디오, 비디오, 및/또는 처리될 수 있고 저장된 데이터에 일치될 수 있는 임의의 데이터 구조를 포함할 수 있다.
뉴스 포털(125)은 뉴스 모음들 및/또는 그들의 컴포넌트 문서들의 관련성에 기초로 하여 주어진 객체에 대한 정보를 포함하는지 결정할 수 있다. 예를 들어, 검색 엔진(118)은 뉴스 모음들을 위한 관련성 랭킹을 생성하고, 랭킹을 대응하는 뉴스 모음들과 연관지어 데이터 스토어(210)에 저장할 수 있다. 요약들에서, 뉴스 포털(125)은 뉴스 모임들 각각의 일반적인 설명 및/또는 뉴스 요약에 포함된 문서들과 함께, 뉴스 시스템(116)에 의해 생성되는, 뉴스 모음을 위한 헤드라인을 포함할 수 있다. 뉴스 포털(125)이 생성할 수 있는 예시적 요약을 도시하는 예시적 사용자 인터페이스는 도 10에 도시되고, 본 명세서의 다른 곳에서 더욱 상세히 논의한다. 뉴스 모음에 대한 일반적인 설명은 뉴스 모음을 구성한 문서들에 기초하여 생성될 수 있다. 뉴스 포털(125)은 시간, 관련성, 이벤트 타입, 사용자 정의 기준 등에 기초하여 뉴스 요약에 포함될 아이템들을 분류할 수 있다. 예를 들어, 뉴스 요약은 질의 받은 객체 또는 객체들과 연관된 가장 관련성 있는 이벤트들의 시간순의 뉴스 요약일 수 있다.
뉴스 포털(125)에 의해 제공된 뉴스 요약은 프레젠테이션 정보를 포함하기 위해 뉴스 포털(125)에 의해 처리될 수 있고, 클라이언트 애플리케이션(108)은 사용자 인터페이스의 룩 앤드 필(look and feel)을 형성하기 위해 프레젠테이션 정보를 이용하고 그 후 그 정보를 사용자 인터페이스를 통해 사용자(112)에 제공할 수 있다. 예를 들어, 뉴스 요약들은 마크업 언어(예를 들어, HTML, XML 등), 스타일 시트들(예를 들어, CSS, XSL 등), 그래픽들 및/또는 스크립트들(예를 들어, JavaScript, ActionScript 등)을 이용하여 포매팅될 수 있고, 클라이언트 애플리케이션(108)은 인터페이스 명령을 해석하고 이에 기초하여 사용자 디바이스(106) 상에 표시를 위해 대화형 웹 사용자 인터페이스(WUI, Web User Interface)를 렌더링할 수 있다. 일부 구현들에서, 클라이언트 애플리케이션(108)은 사용자 인터페이스의 포매팅과 룩 앤드 필을 독립적으로 결정할 수 있다. 예를 들어, 클라이언트 애플리케이션(108)은 뉴스 요약을 포함하는 구조화된 데이터세트(예를 들어, JSON, XML 등)를 수신할 수 있고, 사용자 인터페이스 클라이언트 측의 포매팅 및/또는 룩 앤드 필을 결정할 수 있다. 클라이언트 애플리케이션(108)에 의해 제시된 사용자 인터페이스들을 사용하여, 사용자는 다양한 사용자 액션들을 선택하는 커맨드들을 입력할 수 있다. 예를 들어, 이들 인터페이스들을 이용하여, 사용자들은 검색 요청을 전송하고, 검색을 위한 제안을 암시적으로 요청하고, 검색 제안들을 보고 이와 상호작용하며, 뉴스 요약들 및 그 구성 요소를 보고 이와 상호작용 등을 할 수 있다.
뉴스 포털(125)은 뉴스 요약들을 요청하는 컴퓨팅 디바이스에 이들을 송신하기 위해 네트워크(102)에 결합될 수 있으며, 컴퓨팅 디바이스는 예를 들어, 클라이언트 디바이스(106)를 포함한다. 뉴스 포털(125)은 또한 데이터를 송신 및/또는 수신하기 위해 헤드라인 생성 엔진(120)의 다른 컴포넌트들에 결합될 수 있다.
일부 구현들에서, 뉴스 포털(125)은 주어진 엔티티에 대한 검색 제안을, 해당 엔티티에 대한 뉴스를 보도하는 뉴스 모음을 위해 생성된 헤드라인들에 기초하여 생성할 수 있다. 예를 들어, 뉴스 포털(125)은 제안 요청을 수신하고, 요청으로부터 검색 파라미터들을 결정하고, 검색 제안들을 생성하고 제공할 수 있다. 일부 구현들에서, 요청은 클라이언트 애플리케이션(108)(예를 들어, 웹 브라우저)에 의해 뉴스 시스템(116)에 전송된 비동기식 요청일 수 있고, 이에 응답하여, 뉴스 포털(125)은 제안들을 포함하는 구조 데이터세트(예를 들어, JSON, XML 등)를 생성하고, 그 데이터세트를 (거의) 실시간으로 프레젠테이션을 위해 클라이언트 디바이스(106)로 다시 전송할 수 있다.
뉴스 포털(125)은 추론 엔진(224)에 의해 처리되는 헤드라인들(예를 들어, 헤드라인 데이터)에 기초하여 제안들을 결정할 수 있다. 일부 구현들에서, 검색 엔진(118)에 의한 연속적인 모음, 트레이닝 엔진(222)에 의한 트레이닝, 추론 엔진(224)에 의한 헤드라인 생성, 및/또는 지식 그래프 관리 엔진(122)에 의한 지식 관리에 기초하여, 헤드라인 데이터는 주어진 엔티티에 관련한 가장 최근 헤드라인들 및/또는 이벤트들을 포함하고, 뉴스 포털(125)은 헤드라인들에 기초하여 제안들을 생성하고 이들을 요청에 응답하여 제공할 수 있다.
뉴스 포털(125)은 검색 제안들을, 예를 들어 클라이언트 디바이스(106)를 포함하는 시스템(100)의 다른 엔티티들에 제공하기 위해 네트워크(102)에 결합될 수 있다. 뉴스 포털(125)은 또한, 예를 들어 엔티티 관련 데이터, 헤드라인 데이터 등을 포함하는 데이터를 검색, 저장 아니면 조작하기 위해 데이터 스토어(210)(예를 들어, 직접, 네트워크, API 등)에 결합될 수 있다.
사용자들이 종종 일어나고 있거나 방금 일어난 중요한 이벤트들에 대한 정보를 검색하기 때문에, 뉴스 시스템(116)은 이들 이벤트 및/또는 관련된 엔티티들에 대한 가장 최신의, 유용한, 적절한, 인기있는, 믿을만한, 등등의 정보의 정확한 기술을, 이것이 검색 제안들, 뉴스 요약들, 또는 뉴스 시스템(116)에 의해 사용자에게 제공된 다른 콘텐츠의 형태에 있든지 간에(예를 들어, 전자 메시지 경보, 쇼설 네트워크 업데이트 등을 통해), 제공할 수 있다.
뉴스 시스템(116)의 추가 기능은 적어도 도 2와 관련하여 아래에 더 상세히 설명된다.
도 2는 예시적 뉴스 시스템(116)의 블록도이다. 도시된 바와 같이, 뉴스 시스템(116)은 프로세서(202), 메모리(204), 통신 유닛(208), 데이터 스토어(210), 및 통신 버스(206)에 통신 가능하게 결합될 수 있는 지식 그래프(124)를 포함할 수 있다. 도 2에 도시된 뉴스 시스템(116)은 예로서 제공되고, 이것이 본 개시 내용의 범위에서 벗어남이 없이 다른 형태들을 취하고 추가적이거나 더 적은 컴포넌트들을 포함할 수 있음을 이해해야 한다. 예를 들어, 뉴스 시스템(116)의 다양한 컴포넌트들은 동일한 또는 상이한 컴퓨팅 디바이스들에 상주할 수 있고, 다양한 통신 프로토콜들 및/또는 기술들(예를 들어, 통신 버스, 소프트웨어 통신 메커니즘, 컴퓨터 네트워크 등을 포함함)을 이용하여 통신을 위해 결합될 수 있다.
프로세서(202)는 다양한 입/출력, 논리 및/또는 수학 연산들을 수행함으로써 소프트웨어 명령어들을 실행할 수 있다. 프로세서(202)는 예를 들어, 복합 명령어 세트 컴퓨터(complex instruction set computer)(CISC) 아키텍처, 축소 명령어 세트 컴퓨터(reduced instruction set computer)(RISC) 아키텍처, 및/또는 명령어 세트들의 조합을 구현하는 아키텍처를 포함하는, 데이터 신호들을 처리하기 위한 다양한 컴퓨팅 아키텍처들을 가질 수 있다. 프로세서(202)는 물리적이고/이거나 가상적일 수 있고, 단일 처리 유닛 또는 복수의 처리 유닛 및/또는 코어들을 포함할 수 있다. 일부 구현들에서, 프로세서(202)는 전자 표시 신호들을 생성하고 이를 디스플레이 디바이스(도시 생략)에 제공하며, 이미지들의 표시를 지원하고, 이미지들을 캡처 및 전송하고, 여러 유형의 특징 추출 및 샘플링 등을 포함하는 복잡한 작업을 수행할 수 있다. 일부 구현들에서, 프로세서(202)는 버스(206)를 통해 메모리(204)에 결합되어 이로부터 데이터 및 명령어에 액세스하고 데이터를 이에 저장할 수 있다. 버스(206)는 프로세서(202)를, 예를 들어 메모리(204), 통신 유닛(208), 및 데이터 스토어(210)를 포함하는 뉴스 시스템(116)의 다른 컴포넌트들에 결합할 수 있다,
메모리(204)는 데이터에 대한 액세스를 저장하고 이를 뉴스 시스템(116)의 다른 컴포넌트들에 제공할 수 있다. 메모리(204)는 본 명세서의 다른 곳에 논의되는 바와 같이 단일 컴퓨팅 디바이스 또는 복수의 컴퓨팅 디바이스들에 포함될 수 있다. 일부 구현들에서, 메모리(204)는 프로세서(202)에 의해 실행될 수 있는 명령어들 및/또는 데이터를 저장할 수 있다. 예를 들어, 도시된 바와 같이, 메모리(204)는 검색 엔진(118), 헤드라인 생성 엔진(120), 지식 그래프 관리 엔진(122), 및 뉴스 포털(125)을 저장할 수 있다. 메모리(204)는 또한, 예를 들어 운영 체계, 하드웨어 드라이버들, 다른 소프트웨어 애플리케이션들, 데이터베이스들 등을 포함하는 다른 명령어들 및 데이터를 저장할 수 있다. 메모리(204)는 프로세서(202) 및 뉴스 시스템(116)의 다른 컴포넌트들과 통신을 위해 버스(206)에 결합될 수 있다.
메모리(204)는 하나 이상의 비일시적 컴퓨터 사용 가능(예를 들어, 판독 가능 등) 매체들을 포함하고, 이는 프로세서(202)에 의하거나 이와 관련하여 처리를 위해 명령어들, 데이터, 컴퓨터 프로그램들, 소프트웨어, 코드, 루틴들 등을 포함 또는 저장할 수 있는 임의의 유형(tangible)의 장치 또는 디바이스일 수 있다. 일부 구현들에서, 메모리(204)는 하나 이상의 휘발성 메모리와 비휘발성 메모리를 포함할 수 있다. 예를 들어, 메모리(204)는 DRAM(dynamic random access memory) 디바이스, SRAM(static random access memory) 디바이스, 내장된 메모리 디바이스, 개별 메모리 디바이스(예를 들어, PROM, FPROM, ROM), 하드 디스크 드라이브, 광디스크 드라이브(CD, DVD, 블루레이-디스크(등록상표) 등)의 하나 이상을 포함할 수 있지만, 이에 제한되지 않는다. 메모리(204)가 단일 디바이스일 수 있거나, 다수의 타입의 디바이스 및 구성을 포함할 수 있다는 것을 이해해야 한다.
버스(206)는 컴퓨팅 디바이스의 컴포넌트들 사이 또는 컴퓨팅 디바이스들 사이에 데이터를 전달하기 위한 통신 버스를 포함할 수 있으며, 네트워크 버스 시스템은 네트워크(102) 또는 그 일부, 프로세서 메시, 다양한 커넥터들, 그 조합을 포함한다. 일부 구현들에서, 뉴스 시스템(116)상에 동작하는, 검색 엔진(118), 헤드라인 생성 엔진(120), 및 지식 그래프 관리 엔진(122)은 버스(206)와 연관하여 구현된 소프트웨어 통신 메커니즘을 통해 협력하고 통신할 수 있다. 소프트웨어 통신 메커니즘은, 예를 들어 프로세스 간 통신, 로컬 기능 또는 절차 호출, 원격 절차 호출, 오브젝트 브로커(예를 들어, CORBA), 소프트웨어 모듈들 중에서 직접 소켓 통신(예를 들어, TCP/IP 소켓들), UDP 방송 및 수신, HTTP 연결 등을 포함하고/하거나 용이하게 할 수 있다. 또한, 임의의 또는 모든 통신은 안전할 수 있다(예를 들어, SSH, HTTPS 등).
통신 유닛(208)은 네트워크(102), 및 예를 들어 클라이언트 디바이스(106), 뉴스 서버(128) 등을 포함하는 시스템(100)의 다른 엔티티들 및/또는 컴포넌트들과의 유선 및/또는 무선 연결을 위한 하나 이상의 인터페이스 디바이스를 포함할 수 있다. 예를 들어, 통신 유닛(208)은, CAT-타입 인터페이스들; Wi-Fi(등록상표)를 이용하여 신호들을 송신 및 수신하기 위한 무선 송수신기들; 블루투스(등록상표), 셀룰러 통신 등; USB 인터페이스들; 이들의 다양한 조합들 등을 포함할 수 있지만 이에 제한되지 않는다. 통신 유닛(208)은 신호 라인(114)을 통해 네트워크(102)에 결합될 수 있고, 버스(206)를 통해 뉴스 시스템(116)의 다른 컴포넌트들에 결합될 수 있다. 일부 구현들에서, 통신 유닛(208)은 프로세서(202)를 네트워크(102)에 링크할 수 있고, 결과적으로 다른 처리 시스템들에 결합될 수 있다. 통신 유닛(208)은, 예를 들어 본 명세서의 다른 곳에서 논의된 것들을 포함하는 다양한 표준 통신 프로토콜들을 이용하여 네트워크(102) 및 시스템(100)의 다른 엔티티들에게 다른 연결을 제공할 수 있다.
데이터 스토어(210)는 데이터에 대한 액세스를 저장하고 제공하기 위한 정보 소스이다. 일부 구현들에서, 데이터 스토어(210)는 데이터에 대한 액세스를 수신하고 제공하기 위해 버스(206)를 통해 뉴스 시스템(116)의 컴포넌트들(202, 204, 208, 118, 120, 122, 124 및/또는 125)에 결합될 수 있다. 일부 구현들에서, 데이터 스토어(210)는 시스템(100)의 다른 엔티티들(106, 128, 및 132)로부터 수신되는 데이터를 저장할 수 있고, 이들 엔티티에 대한 데이터 액세스를 제공할 수 있다. 데이터 스토어(210)에 의해 저장되는 데이터의 타입들의 예들은, 트레이닝 데이터(212)(예를 들어, 학습된 구문 패턴들, 확률 모델(들), 엔티티 클러스터들 등), 수집된 데이터(214)(예를 들어, 검색 엔진(118)에 의해 수집되고 처리된 문서들), 뉴스 모음 데이터, 문서 데이터, 이벤트 데이터, 엔티티 데이터, 사용자 데이터 등을 포함할 수 있지만 이에 한정되지 않는다.
데이터 스토어(210)는 데이터를 저장하기 위한 하나 이상의 비일시적 컴퓨터 판독 가능 매체들을 포함할 수 있다. 일부 구현들에서, 데이터 스토어(210)는 메모리(204)와 통합될 수 있거나, 이와 별개일 수 있다. 일부 구현들에서, 데이터 스토어(210)는 뉴스 시스템(116)에 의해 동작 가능한 데이터베이스 관리 시스템(DBMS, DataBase Management System)를 포함할 수 있다. 예를 들어, DBMS는 구조화된 질의어(SQL, structured query language) DBMS, NoSQL DMBS, 이들의 다양한 조합들 등을 포함할 수 있다. 일부 경우에, DBMS는 로우들과 칼럼들로 구성되는 다차원 테이블에 데이터를 저장할 수 있고, 프로그램 동작들을 이용하여 데이터의 로우들을 조작할 수 있는, 즉 삽입, 질의, 업데이트 및/또는 삭제할 수 있다.
도 2에 도시된 바와 같이, 헤드라인 생성 엔진(120)은 패턴 엔진(220), 트레이닝 엔진(222), 및 추론 엔진(224)을 포함할 수 있다. 컴포넌트들(118, 120, 220, 222, 224, 122 및/또는 125)은 버스(206) 및/또는 프로세서(202)에 의해 통신 가능하게 서로 결합되고/되거나 뉴스 시스템(116)의 다른 컴포넌트들(204, 208, 210 및/또는 124)에 결합될 수 있다. 일부 구현들에서, 컴포넌트들(118, 120, 220, 222, 224, 122 및/또는 125) 중 하나 이상은 그들의 기능을 제공하기 위해 프로세서(202)에 의해 실행 가능한 명령어들의 세트들이다. 다른 구현들에서, 컴포넌트들(118, 120, 220, 222, 224, 122 및/또는 125) 중 하나 이상은 뉴스 검색 시스템(116)의 메모리(204)에 저장되고, 그들의 기능을 제공하기 위해 프로세서(202)에 의해 액세스 가능하고 실행 가능하다. 상기 구현들 중 임의의 구현에서, 이들 컴포넌트(204, 208, 210 및/또는 124)는 프로세서(202) 및 뉴스 시스템(116)의 다른 컴포넌트들과의 협력 및 통신을 위해 적응될 수 있다.
패턴 엔진(220)은 하나 이상의 뉴스 모음의 구문 패턴들을 결정하기 위해 프로세서(202)에 의해 실행 가능한 소프트웨어 및/또는 로직을 포함한다. 일부 구현들에서, 패턴 엔진(220)은 뉴스 모음의 각각의 문서의 문장들을 다이어그래밍(diagraming)함으로써 뉴스 모음을 전처리하고, 뉴스 모음의 각각의 문서에 의해 언급된 엔티티들을 결정하고, 이들 엔티티 각각에 대한 엔티티 관련 정보를 결정할 수 있다. 패턴 엔진(220)은 또한 뉴스 모음에 관련 있는 엔티티들을 결정하고(예를 들어, 임계치, 확률, 휴리스틱 등에 기초하여); 뉴스 모음에서 이들 엔티티와 연관된 엔티티 타입들을 수반하는 구문 패턴들을 결정하고; 등가 구문 패턴들을 함께 클러스터링할 수 있다. 예를 들어, 동일한 뉴스 모음으로부터 엔티티들의 동일한 세트에 대해 패턴 엔진(220)에 의해 처리되는 패턴들은 헤드라인 생성 및/또는 지식 그래프 관리 동안 사용을 위해 함께 그룹화될 수 있다.
일부 구현들에서, 패턴 엔진(220)은 본 명세서에서 추가로 논의되는 바와 같이, 트레이닝/학습, 헤드라인 생성, 및/또는 지식 그래프 관리 동안 사용을 위해 하나 이상의 뉴스 모음에 대한 등가 구문 패턴들을 결정할 수 있다. 예를 들어, 본 명세서에서 더 상세히 논의되는 바와 같이, 패턴 엔진(220)은, 주어진 뉴스 모음에 대해, k 엔티티들(예를 들어, k ≥ 1)을 연결하는 등가 구문 패턴들을 식별할 수 있고(그 패턴들은 뉴스 모음에 의해 기술되는 이벤트들을 표현함), 헤드라인 생성을 위해 사용될 수 있다. 트레이닝 엔진(222), 추론 엔진(224) 및/또는 지식 그래프 관리 엔진(122)은 뉴스 모음 데이터를 제공하고/하거나 구문 패턴 데이터(예를 들어, 등가 구문 패턴들의 클러스터들)를 수신하기 위해 패턴 엔진(220)에 결합될 수 있다. 일부 예들에서, 패턴 엔진(220)은 이것이 생성하는 구문 패턴 데이터를, 패턴 엔진 및/또는 시스템(116)의 다른 엔티티에 의한 액세스 및/또는 검색을 위해 데이터 스토어(210)에 저장할 수 있고, 다른 엔티티들은 예를 들어, 트레이닝 엔진(222), 추론 엔진(224) 및/또는 지식 그래프 관리 엔진(122)을 포함한다.
주어진 뉴스 모음의 하나 이상의 문서로부터 패턴들을 식별하기 위해, 패턴 엔진(220)은 메타데이터, 문서 본문, 내장된 콘텐츠 등을 포함하는 문서들의 하나 이상의 부분을 처리할 수 있다. 일부 구현에서, 패턴 엔진(220)은 문서 본문의 제목과 첫 번째 문장만을 고려할 수 있다. 이는 각각의 뉴스 모음의 처리를 해당 모음에 의해 보도되는 가장 관련 있는 이벤트(들)로 제한함으로써 성능을 증가시킬 수 있고, 이는 종종 이들 2개의 콘텐츠 영역으로 보도된다. 예를 들어, 제목들과는 달리, 첫 번째 문장들은, 기억하기 쉽기보다는 오히려 문법에 맞는 유용한 정보를 제공하는 경향이 있기 때문에, 일반적으로 말장난 또는 다른 미사여구를 광범위하게 이용하지 않는다. 다양한 구현들에서, 패턴 엔진(220)이 제목과 첫 번째 문장을 이용하는 것으로 제한되지 않고, 애플리케이션과 필요에 따라 문서에 포함된 콘텐츠 중 임의의 콘텐츠를 이용할 수 있음을 이해해야 한다.
일부 구현들에서, 패턴들은 하나 이상의 뉴스 모음들  의 리포지토리
의 리포지토리  으로부터 결정될 수 있다. 각각의 뉴스 모음
으로부터 결정될 수 있다. 각각의 뉴스 모음  은 관련된 뉴스의 무질서한 모음일 수 있으며, 이들 각각은 문장들의 질서있는 시퀀스, 예를 들어
은 관련된 뉴스의 무질서한 모음일 수 있으며, 이들 각각은 문장들의 질서있는 시퀀스, 예를 들어  으로서 보여질 수 있다. 트레이닝 동안, 리포지토리는 헤드라인 생성 및/또는 지식 그래프 관리 동안 매칭을 위해 이용될 수 있는 베이스 패턴들의 확장 세트를 제공하기 위해 여러 뉴스 모음들을 포함할 수 있다.
으로서 보여질 수 있다. 트레이닝 동안, 리포지토리는 헤드라인 생성 및/또는 지식 그래프 관리 동안 매칭을 위해 이용될 수 있는 베이스 패턴들의 확장 세트를 제공하기 위해 여러 뉴스 모음들을 포함할 수 있다.
패턴 엔진(220)은 하나 이상의 뉴스 모음들  의 리포지토리로부터 등가 구문 패턴들의 하나 이상의 클러스터를 식별하기 위해 패턴 식별 프로세스를 제어하는 한 세트의 파라미터들 Ψ을 이용하는 하기 알고리즘
의 리포지토리로부터 등가 구문 패턴들의 하나 이상의 클러스터를 식별하기 위해 패턴 식별 프로세스를 제어하는 한 세트의 파라미터들 Ψ을 이용하는 하기 알고리즘 을 사용할 수 있다:
을 사용할 수 있다:

상기  알고리즘에서, 서브-루틴
알고리즘에서, 서브-루틴 은 뉴스 모음들 각각에 포함되는 각각의 문서들을 전처리할 수 있다. 일부 구현들에서, 이 전처리는 토큰화(tokenization)와 문장 경계 검출을 포함하는 NLP 파이프라인, 품사 태깅(part-of-speech tagging), 종속성 파싱(dependency parsing), 코레퍼런스 레졸루션(coreference resolution), 및 지식 그래프(예를 들어, 지식 그래프(124))에 기초하는 엔티티 링킹(entity linking)을 이용하여 수행될 수 있다. 일부 예들에서, 패턴 엔진(220)은 모음의 각각의 문서에 언급된 각각의 엔티티를, 고유 라벨, 엔티티가 문서에서 언급될 때 포함하는 리스트, 및 하나 이상의 지식 그래프로부터 해당 엔티티에 대한 클래스 라벨의 리스트로 라벨링할 수 있다. 예를 들어, 지식 그래프 데이터세트를 이용하여, 패턴 엔진(220)은 해당 엔티티에 적용하는 지식 그래프 타입들(분류 라벨들)로 각각의 엔티티에 주석을 달 수 있다. 추가 예로서, 엔티티, Barack Obama(미국의 44번째 대통령)에 대해, 패턴 엔진(220)은, 예를 들어 미국 대통령; 정치가; 정치인 지명; 미국 연방 의회 의원; 여론조사 엔티티 등을 포함하는, 적용하는 프리베이스 클래스 라벨들로 그 엔티티에 주석을 달 수 있다, 그 결과, 각각의 문서에 언급된 각각의 엔티티에 대한, 고유 식별자, 언급 리스트, 및 클래스 라벨들의 리스트는 전처리에 의해 생성될 수 있고, 이는 (예를 들어, 데이터 스토어(210), 메모리(204) 등에서) 차후에 참조 및/또는 처리를 위해 저장되고/되거나 캐시될 수 있다.
은 뉴스 모음들 각각에 포함되는 각각의 문서들을 전처리할 수 있다. 일부 구현들에서, 이 전처리는 토큰화(tokenization)와 문장 경계 검출을 포함하는 NLP 파이프라인, 품사 태깅(part-of-speech tagging), 종속성 파싱(dependency parsing), 코레퍼런스 레졸루션(coreference resolution), 및 지식 그래프(예를 들어, 지식 그래프(124))에 기초하는 엔티티 링킹(entity linking)을 이용하여 수행될 수 있다. 일부 예들에서, 패턴 엔진(220)은 모음의 각각의 문서에 언급된 각각의 엔티티를, 고유 라벨, 엔티티가 문서에서 언급될 때 포함하는 리스트, 및 하나 이상의 지식 그래프로부터 해당 엔티티에 대한 클래스 라벨의 리스트로 라벨링할 수 있다. 예를 들어, 지식 그래프 데이터세트를 이용하여, 패턴 엔진(220)은 해당 엔티티에 적용하는 지식 그래프 타입들(분류 라벨들)로 각각의 엔티티에 주석을 달 수 있다. 추가 예로서, 엔티티, Barack Obama(미국의 44번째 대통령)에 대해, 패턴 엔진(220)은, 예를 들어 미국 대통령; 정치가; 정치인 지명; 미국 연방 의회 의원; 여론조사 엔티티 등을 포함하는, 적용하는 프리베이스 클래스 라벨들로 그 엔티티에 주석을 달 수 있다, 그 결과, 각각의 문서에 언급된 각각의 엔티티에 대한, 고유 식별자, 언급 리스트, 및 클래스 라벨들의 리스트는 전처리에 의해 생성될 수 있고, 이는 (예를 들어, 데이터 스토어(210), 메모리(204) 등에서) 차후에 참조 및/또는 처리를 위해 저장되고/되거나 캐시될 수 있다.
데이터의 전처리는 또한, 예를 들어 도 7의 아이템(1)에 예시된 바와 같이, 문장 구조를 나타내는 데이터의 세트를 각각의 뉴스 모음의 문서(들)에서의 각각의 문장에 제공할 수 있다. 이 예에서, 문장에서 언급된 3개의 구별되는 엔티티들, 예를 들어 e1, e2, 및 e3은 식별되고, 각각의 엔티티의 전처리 동안 결정된 엔티티 타입(예를 들어, 클래스 라벨)을 이용하여 라벨링한다. 예를 들어, 타입들(클래스 라벨들)의 지식 그래프 리스트에서, e1은 사람이고, e2는 여배우 및 유명 인사이고, e3은 상태 및 위치이다.
다음에,  서브-루틴은 각각의 뉴스 모음 N 내에서 관련 있는 한 세트의 엔티티들 E를 수집할 수 있다(예를 들어, 임계치에 기초하여 가장 자주 언급된 것은 (예를 들어, 위치/배치 등에 기초하여) 가장 중심적인 것이다). 엔티티들의 세트 E에 대해, 알고리즘은 그 후 예를 들어, 반복된 엔티티들 없이 E의 비어 있지 않은(non-empty) 서브세트들을 갖는 세트
서브-루틴은 각각의 뉴스 모음 N 내에서 관련 있는 한 세트의 엔티티들 E를 수집할 수 있다(예를 들어, 임계치에 기초하여 가장 자주 언급된 것은 (예를 들어, 위치/배치 등에 기초하여) 가장 중심적인 것이다). 엔티티들의 세트 E에 대해, 알고리즘은 그 후 예를 들어, 반복된 엔티티들 없이 E의 비어 있지 않은(non-empty) 서브세트들을 갖는 세트  를 생성함으로써 한 세트의 고유 엔티티 조합들을 결정할 수 있다. 각각의 모임에서 고려하는 엔티티들의 수, 및 엔티티들의 서브세트들이 고려하는 최대 사이즈는 Ψ에 내장된 메타-파라미터들이다. 짧은 제목들(예를 들어, 10개 단어 이하)을 생성하는 것을 목적으로 하는 구현들에서, 시스템은 일부 경우에 E의 소정 수(예를 들어, 3) 요소까지의 조합들만을 고려할 수 있다. 추가 예로서, 세트
를 생성함으로써 한 세트의 고유 엔티티 조합들을 결정할 수 있다. 각각의 모임에서 고려하는 엔티티들의 수, 및 엔티티들의 서브세트들이 고려하는 최대 사이즈는 Ψ에 내장된 메타-파라미터들이다. 짧은 제목들(예를 들어, 10개 단어 이하)을 생성하는 것을 목적으로 하는 구현들에서, 시스템은 일부 경우에 E의 소정 수(예를 들어, 3) 요소까지의 조합들만을 고려할 수 있다. 추가 예로서, 세트  는 다양한 엔티티들 E가 뉴스 모음(들)의 문장들에 의해 기술되는 고유 방식을 설명할 수 있다.
는 다양한 엔티티들 E가 뉴스 모음(들)의 문장들에 의해 기술되는 고유 방식을 설명할 수 있다.
다음에, 알고리즘은 관련 있는 엔티티들을 언급하는 문장들의 노드들을 결정하고, 엔티티들을 언급하는 구문 패턴들을 결정하고, 필요하다면 구문 패턴들이 문법적으로 적당하도록 이들을 변환하고, 동일한 타입을 함께 언급하는 등가 구문 패턴들을 클러스터링할 수 있다. 이들 클러스터링된 구문 패턴들은 타입들을 수반하는 이벤트를 반영할 수 있다. 특히, 예를 들어 서브-루틴  은 그 후 각각의 뉴스 모음 N에서 문서들 n으로부터 관련 있는 엔티티들 Ei의 각각의 서브세트에 대한 이벤트 패턴들
은 그 후 각각의 뉴스 모음 N에서 문서들 n으로부터 관련 있는 엔티티들 Ei의 각각의 서브세트에 대한 이벤트 패턴들  를 처리할 수 있다.
를 처리할 수 있다.
일부 구현들에서,  을 실행하는 것은 하기 알고리즘을 이용하여 문서들 n으로부터 한 세트의 등가 구문 패턴들
을 실행하는 것은 하기 알고리즘을 이용하여 문서들 n으로부터 한 세트의 등가 구문 패턴들  를 처리하고 리턴할 수 있으며, 이는 도 7의 아이템들(2-4)에 그래프로 예시된다:
를 처리하고 리턴할 수 있으며, 이는 도 7의 아이템들(2-4)에 그래프로 예시된다:

상기 알고리즘에서, 서브-루틴  은 문장 s에 대한 서브 루틴
은 문장 s에 대한 서브 루틴  을 이용하여 엔티티들
을 이용하여 엔티티들  를 언급하는 노드들의 세트
를 언급하는 노드들의 세트  를 먼저 식별할 수 있으며, 이는 종속성 파서 T를 리턴한다. T가
를 먼저 식별할 수 있으며, 이는 종속성 파서 T를 리턴한다. T가  에서 각각의 목표 엔티티 중 하나의 언급을 정확히 포함하지 않으면, 문장은 무시된다. 그렇지 않으면, 서브-루틴
에서 각각의 목표 엔티티 중 하나의 언급을 정확히 포함하지 않으면, 문장은 무시된다. 그렇지 않으면, 서브-루틴  은 노드세트 Pi에 대한 최소 스패닝 트리(minimum spanning tree)(MST)를 계산할 수 있다. Pi는 패턴들이 그 주위에 구성될 수 있는 노드들의 세트이며, 최소 스패닝 트리는 도 7의 아이템(2)에 예시된 바와 같이, Mi에서 모든 노드들을 연결하는 종속성 트리에서 가장 짧은 경로를 반영한다.
은 노드세트 Pi에 대한 최소 스패닝 트리(minimum spanning tree)(MST)를 계산할 수 있다. Pi는 패턴들이 그 주위에 구성될 수 있는 노드들의 세트이며, 최소 스패닝 트리는 도 7의 아이템(2)에 예시된 바와 같이, Mi에서 모든 노드들을 연결하는 종속성 트리에서 가장 짧은 경로를 반영한다.
다음에, 알고리즘은  서브루틴을 이용하여 휴리스틱을 적용할지 결정할 수 있다. 일부 경우에, 시스템이 계산할 수 있는 노드세트 Pi에 대한 MST는 본래 문장 s의 문법적 또는 유용한 외삽을 구성하지 않을 수 있다. 예를 들어, 도 7의 아이템(2)에 도시된 예에서 엔티티 쌍 <e1;e2>에 대한 MST는 이것이 충분하지도 유창하지도 않기 때문에 이벤트의 양호한 기술을 제공하지 못한다. 이러한 이유로, 시스템은 의미 있는 노드들의 최소 세트를 제공하는 후처리 휴리스틱 변환들의 세트를 적용할 수 있다. 도 7의 아이템(3)에 도시된 바와 같이, 변환은 절의 어근과 그 주제 모두가 추출된 패턴에 나타나고 엔티티들 간의 접속사들이 누락되지 않는 것을 제공할 수 있다.
서브루틴을 이용하여 휴리스틱을 적용할지 결정할 수 있다. 일부 경우에, 시스템이 계산할 수 있는 노드세트 Pi에 대한 MST는 본래 문장 s의 문법적 또는 유용한 외삽을 구성하지 않을 수 있다. 예를 들어, 도 7의 아이템(2)에 도시된 예에서 엔티티 쌍 <e1;e2>에 대한 MST는 이것이 충분하지도 유창하지도 않기 때문에 이벤트의 양호한 기술을 제공하지 못한다. 이러한 이유로, 시스템은 의미 있는 노드들의 최소 세트를 제공하는 후처리 휴리스틱 변환들의 세트를 적용할 수 있다. 도 7의 아이템(3)에 도시된 바와 같이, 변환은 절의 어근과 그 주제 모두가 추출된 패턴에 나타나고 엔티티들 간의 접속사들이 누락되지 않는 것을 제공할 수 있다.
알고리즘은 도 7의 아이템(4)에 예시된 바와 같이, 그 후 서브 루틴  을 이용하여 노드세트 Pi로부터 엔티티 타입을 결합할 수 있으며, 이 서브 루틴은 참여 엔티티들 ei에 대한 엔티티 타입 할당의 각각의 가능한 조합으로부터 개별 패턴
을 이용하여 노드세트 Pi로부터 엔티티 타입을 결합할 수 있으며, 이 서브 루틴은 참여 엔티티들 ei에 대한 엔티티 타입 할당의 각각의 가능한 조합으로부터 개별 패턴  를 생성할 수 있다. 패턴 및/또는 엔티티 관련 정보(예를 들어, ID들과 클래스 라벨들을 포함하는 엔티티 정보, 엔티티 관련 이벤트들을 기술하는 등가 구문 패턴들의 클러스터들 등)를 포함하는, 패턴 엔진(220)에 의해 생성되는 데이터는 데이터 스토어(210)에 저장되거나, 또는 예를 들어, 트레이닝 엔진(222), 추론 엔진(224) 및/또는 그에 의한 사용을 위한 지식 그래프 관리 엔진(122)을 포함하는 시스템(116)의 다른 컴포넌트들에 제공될 수 있다.
를 생성할 수 있다. 패턴 및/또는 엔티티 관련 정보(예를 들어, ID들과 클래스 라벨들을 포함하는 엔티티 정보, 엔티티 관련 이벤트들을 기술하는 등가 구문 패턴들의 클러스터들 등)를 포함하는, 패턴 엔진(220)에 의해 생성되는 데이터는 데이터 스토어(210)에 저장되거나, 또는 예를 들어, 트레이닝 엔진(222), 추론 엔진(224) 및/또는 그에 의한 사용을 위한 지식 그래프 관리 엔진(122)을 포함하는 시스템(116)의 다른 컴포넌트들에 제공될 수 있다.
추가 예시로서, 도 9는 등가 구문 패턴들의 클러스터들을 생성하기 위한 예시적 프로세스(900)의 그래픽 표현이다. 이 도면에서, 2명의 예시적인 유명인, Jill Popular 및 Joe Celebrity 간의 결혼에 대한 뉴스 기사들의 모음(902)은, 콘텍스트(예를 들어, 기사에서 이들의 자리, 이들이 인용된 횟수, 엔티티들을 이들 엔티티에 대한 다른 관련 있는 정보에 링킹하는 임의의 하이퍼링크들, 이들 엔티티에 대한 검색 엔진(118)으로부터의 검색 데이터 등)에 기초하여 엔티티들의, 이들의 저명성, 관련성, 중심성 등(간단히 관련성으로 지칭함)의 정량화된 측정(910)과 함께 기사에 의해 논의되는 엔티티들(912)의 관련성 리스트(904)를 생성하도록 패턴 엔진(220)에 의해 처리된다. 뉴스 모음에서 이들 엔티티를 링킹하는 단어들(예를 들어, 제목, 첫 번째 문장, 첫 번째 단락 등)과 함께 이 관련성 리스트(910)를 이용하여, 패턴 엔진(220)은 뉴스 모음의 메인 이벤트를 반영하는 한 세트의 관련 있는 등가 구문 패턴들(906)을 생성할 수 있다. 이들 패턴에 대해, 패턴 엔진(220)은 패턴들이 뉴스 모음에 어떻게 관련되는지를 정량화하고 패턴들이 대응하는 엔티티들을 리스트화할 수 있다. 대조적으로, 패턴 엔진(220)은 또한 어느 패턴들이 덜 관련되고/무관한지 결정할 수 있고, 관련성 스코어에 기초하여 이들을 배제할 수 있다. 패턴 엔진(220)에 의해 처리되는 엔티티들의 리스트, 관련성 스코어들 및/또는 표현들은 본 명세서의 다른 곳에서 더 설명되는 바와 같이, 트레이닝, 헤드라인 생성 및/또는 지식 그래프 관리 동안 이용될 수 있다.
트레이닝 엔진(222)은 복수의 뉴스 모음을 처리함으로써 대응하는 정보를 포함하는 등가 구문 패턴들을 자동으로 학습하기 위해 프로세서(202)에 의해 실행 가능한 소프트웨어 및/또는 로직을 포함한다. 대응하는 정보는 동일 또는 유사한 콘텍스트(예를 들어, 이벤트)와 관련되는 동일한 엔티티들을 언급하는 표현들을 포함할 수 있다. 관련된 문서들의 모음(예를 들어, 현재 이벤트에 대한 뉴스 기사들)을 처리함으로써, 트레이닝 엔진(222)은 동일한 엔티티 타입들 및/또는 이벤트를 표현하는 대안적인 방식들을 학습할 수 있다. 이는 트레이닝 엔진(222)이 동일한 엔티티 타입들 및/또는 이벤트들을 기술하기 위해 다양한 콘텐츠 프로듀서들에 의해 상이한 단어들 및/또는 동의어들의 사용을 고려하기 때문에 유리하다. 일부 구현들에서, 트레이닝 엔진(222)은 확률 모델을 이용하여 패턴 엔진(220)에 의해 결정된 등가 구문 패턴들의 클러스터로부터 추가적인 숨겨진 패턴들을 자동으로 식별할 수 있다. 이는 헤드라인들이, 패턴들이 도출되는 뉴스 모음에 명확히 포함되지 않는 패턴들로부터 자동으로 생성되게 할 수 있기 때문에 유리하다.
제한적이지 않는 예로서, 스포츠 또는 결혼을 포함하는 하나 이상의 뉴스 모음을 처리함으로써, 트레이닝 엔진(222)은, 패턴 엔진(220)과 협력하여, 하기 구문 패턴들이 팀에 합류하는 운동선수의 동일한 이벤트를 모두 표현한다는 것을 학습할 수 있다:
[player] joins [sports team]
[sports team] signs [player]
[player] completes move to [sports team].
또는 하기 패턴들이 결혼 이벤트의 모든 등가의 표현들임을 학습할 수 있다:
[person] wed [person]
[person] has married [person]
[person] tied the knot with [person].
상기 비제한적 예들이, 일부 경우에, 패턴들의 표면 형태를 묘사하고, 패턴들과 연관되는 추가 메타데이터가 생성되고 패턴들과 연관되는 정보를 포함할 수 있다는 것을 이해해야 한다. 예를 들어, 메타데이터는 패턴들의 단어들 간의 구문 종속성을 기술하는 데이터(예를 들어, 지시자들, 라벨들 등)를 포함할 수 있다. 일부 구현들에서, 이 메타데이터는 차후 참조, 학습 등을 위한 트레이닝 데이터(212)로서 데이터 스토어(210)에 저장될 수 있다.
트레이닝 엔진(222)은 소정 시간프레임(예를 들어, 같은 날, 며칠, 주, 달 등) 동안 및/또는 트레이닝을 위한 공통 어휘(예를 들어, 동일한 엔티티들, 엔티티들의 타입들 등을 언급함)로 공개된 뉴스를 이용할 수 있다. 이는 주어진 뉴스 모음의 문서들 및 이에 포함되는 표현들이 뉴스에 기술되는 동일한 엔티티들 및/또는 이벤트와 관련되는 가능성을 유리하게 증가시킬 수 있고, 그로 인해 추론 엔진(224)에 의해 생성된 헤드라인들의 정확성을 증가시킬 수 있다.
일부 구현들에서, 트레이닝 엔진(222)은 패턴 엔진(220)과 협력하여, 뉴스 모음들의 문서들에 의해 기술되는 엔티티들에 대한 콘텍스트를 결정하기 위해 콘텍스트 유사성을 이용할 수 있고, 콘텍스트 유사성에 기초하여 엔티티들을 자동으로 클러스터링할 수 있다. 일부 경우에, 상호 교환 가능하게 이용되고/되거나 표현들에 의해 동일한 또는 유사한 의미(예를 들어, 동의어들, 알려진 변형들 등)를 갖는 단어들, 구문들 및/또는 관용구들의 경우, 트레이닝 엔진(222) 및/또는 패턴 엔진(220)은 이들 표현의 콘텍스트 간의 유사도의 레벨을 반영하는 메트릭을 계산할 수 있고, 그 메트릭의 강도에 기초하여(예를 들어, 미리 결정된 유사도 임계치가 충족되는지)에 기초하여 이들 표현에 의해 참조되는 엔티티들을 그룹화할 수 있다. 이는 유리하게 트레이닝 엔진(222)이 엔티티들을 타입(스타 운동선수, 이혼한 여자, 사업 실패 등)별로 자동 그룹화하게 할 수 있다.
일부 경우들에서, 트레이닝 엔진(222)은 가장 공통적/유명 엔티티 타입들 및/또는 이벤트들을 커버하는 등가 구문 패턴들의 신뢰성 있는 베이스를 생성하기 위해 뉴스 모음에 조직화된 뉴스 문서들의 미리 결정된 코퍼스를 이용하여 초기화될 수 있고, 트레이닝 데이터/모델(212)이 생성되고 데이터 스토어(210)에 저장될 때, 이는 본 명세서에서 추가로 상세히 설명되는 바와 같이 뉴스 모음을 위한 헤드라인들을 생성하기 위해 패턴 엔진(220) 및/또는 트레이닝 엔진(222)에 의해 이용될 수 있다. 예를 들어, 일부 경우에, 다수의 뉴스 모음은 추론 엔진(224)에 의해 신뢰성 있는 헤드라인 추론을 생성할 수 있는 의미 있는 클러스터를 학습하기 위해 트레이닝 엔진(222)에 의해 처리될 수 있다. 추가 예로서, 트레이닝 엔진에 의해 처리되는 문서들의 코퍼스는 일 년 이상(예를 들어, 1-10+)에 걸쳐있는 뉴스 기사들을 포함할 수 있다.
일부 구현들에서, 2개의 상이한 표현이 동일한 기간(아마도 동일한 이벤트를 기술하는)에서 2개의 뉴스에 나타날 가능성을 나타내는 측정치를 생성하는 것들을 포함하는 다른 모델들이 추론 엔진(224) 및/또는 트레이닝 엔진(222)에 의해 추가적으로 또는 대안적으로 이용될 수 있을지라도, 트레이닝 엔진(222)은 Noisy-OR 네트워크들로 불리는 확률 모델을 이용하여 등가 구문 패턴들을 학습할 수 있다. 예를 들어, 일부 구현들에서, 트레이닝 엔진(222)은 잠재 디리클레 할당(LDA, Latent Dirichlet Allocation)을 이용하여 패턴들을 클러스터링할 수 있다.
Noisy-OR Bayesian 네트워크가 이용되는 구현에서, 트레이닝 엔진(222)은 구문 패턴들의 동시 발생에 대한 트레이닝을 베이스한다. 패턴 엔진(220)에 의해 식별된 각각의 패턴은 관찰된 변수로서 추가될 수 있고, 잠재 변수들은 패턴들을 생성하는 숨겨진 이벤트들을 나타내는데 사용될 수 있다. 추가적인 노이즈 변수는 트레이닝 엔진(222)에 의해 하나 이상의 터미널 노드에 링킹될 수 있으며, 링킹된 터미널이 실제 이벤트보다는 언어 배경(노이즈)에 의해 생성되게 할 수 있다.
추가 예로서, 패턴 엔진(220)에 의해 식별된 패턴들은 각각의 (관찰된) 패턴이 하나 이상의 (숨겨진) 이벤트들을 활성화하는 확률을 추정함으로써 Noisy-OR 모델을 학습하기 위해 트레이닝 엔진(222)에 의해 이용될 수 있다. 도 8은 2개의 예시적 레벨들을 도시한다: 상부에서의 숨겨진 이벤트 변수들 및 하부에서의 관찰된 패턴 변수들. 이 도면에서, 추가 노이즈 변수는 모든 터미널 모드에 링크되어, 모든 터미널이 실제 이벤트보다는 언어 배경(노이즈)에 의해 생성되게 할 수 있다. 잠재 이벤트들과 관찰된 패턴들 간의 연관들은 noisy-OR 게이트에 의해 모델링될 수 있다.
이 모델에서, 관찰된 패턴들  의 구성이 주어질 때 숨겨진 이벤트 ei의 조건부 확률은 다음과 같이 계산된다:
의 구성이 주어질 때 숨겨진 이벤트 ei의 조건부 확률은 다음과 같이 계산된다:

여기서,  는 활성 이벤트들의 세트(즉,
는 활성 이벤트들의 세트(즉,  이고,
이고, 
 은 관측된 패턴 pi가 홀로 이벤트 e를 활성화할 수 있는 추정된 확률이다. 용어 qi0은 소위 모델의 "노이즈" 항이고, 관측된 이벤트 ei가 절대 관측될 수 없는 일부 패턴에 의해 활성화될 수 있다는 사실을 설명할 수 있다.
은 관측된 패턴 pi가 홀로 이벤트 e를 활성화할 수 있는 추정된 확률이다. 용어 qi0은 소위 모델의 "노이즈" 항이고, 관측된 이벤트 ei가 절대 관측될 수 없는 일부 패턴에 의해 활성화될 수 있다는 사실을 설명할 수 있다.
패턴 엔진(220)에 의해 동일한 뉴스 모음 N과 엔티티 서브세트 Ei로부터 처리된 모든 패턴들은  로 그룹화될 수 있다(예를 들어, 상술한 것을 참조한다). 일부 경우에, 이들 그룹은 모델 파라미터들
로 그룹화될 수 있다(예를 들어, 상술한 것을 참조한다). 일부 경우에, 이들 그룹은 모델 파라미터들  의 최적화를 부트스트랩하는데 사용될 수 있는 등가 패턴들의 러프 클러스터(rough cluster)들을 나타낸다. 트레이닝 엔진(222)은 랜덤하게 선택된 그룹들의 세트(예를 들어, 100,000)를 수신하고 다수의 예상-극대화(expectation-maximization)(EM) 반복들(예를 들어, 40)을 통해 모델의 가중치들을 최적화함으로써 트레이닝 프로세스를 개시한다.
의 최적화를 부트스트랩하는데 사용될 수 있는 등가 패턴들의 러프 클러스터(rough cluster)들을 나타낸다. 트레이닝 엔진(222)은 랜덤하게 선택된 그룹들의 세트(예를 들어, 100,000)를 수신하고 다수의 예상-극대화(expectation-maximization)(EM) 반복들(예를 들어, 40)을 통해 모델의 가중치들을 최적화함으로써 트레이닝 프로세스를 개시한다.
트레이닝 엔진(222)은 이것과 패턴 엔진(220) 등에 의해 처리되고/되거나 생성된 데이터를 트레이닝 데이터(212)로서, 패턴 엔진(220) 및/또는 추론 엔진(224)에 의한 사용을 위해 데이터 스토어(210)에 저장할 수 있거나, 또는 그런 데이터를 이들 컴포넌트에 직접 제공할 수 있다.
추론 엔진(224)은 뉴스 모음 및/또는 문서(들)로 보도된 메인 이벤트에 기초하여, 주어진 뉴스 모음 또는 이에 포함된 문서(들)를 위한 헤드라인을 생성하기 위해 프로세서(202)에 의해 실행 가능한 소프트웨어 및/또는 로직을 포함한다. 비제한적 예로서, 추론 엔진(224)은 (예를 들어, 패턴 엔진(220)을 이용하여) 등가 구문 패턴들에 대한 하나 이상의 문서를 포함하는 입력 모음을 처리하고, 이들 패턴을 트레이닝 동안 학습된 대응하는 패턴들과 일치시킬 수 있다. 일치하는 패턴들을 사용하여, 추론 엔진(224)은 그 후 입력 모음에 의해 반영되는 이벤트를 가장 잘 나타내는 패턴을 선택하고 해당 패턴을 뉴스 모음으로부터의 대응하는 중심 엔티티들로 채움으로써 헤드라인을 생성할 수 있다. 추론 엔진(224)은 입력 모음의 구문 패턴(들)을 결정하기 위해 패턴 엔진(220)과 상호작용하도록 결합될 수 있다.
일부 구현들에서, 패턴 엔진(220)에 의해 처리되는 패턴들을 이용하여, 추론 엔진(224)은 숨겨진 이벤트 변수들의 사후 확률을 추정할 수 있다. 그 후, 활성화된 숨겨진 이벤트로부터, 이들이 모음에 나타나지 않을지라도, 모든 패턴의 가능성은 추정될 수 있다. 최대 확률을 가진 단일 패턴은 새로운 헤드라인을 생성하기 위해 선택되고 이용된다. 검색된 패턴은, 일반화된다면, 뉴스 모음에서 직접 관찰된 구문보다 객관적이고 유용한 정보일 가능성이 더 높다. 이 확률 접근법을 이용하여, 추론 엔진(224)은 이벤트(예를 들어, 트레이닝에 대하여 설명된 바와 같이 한 세트의 등가 표현들로 표현되는)가 한 세트의 문서들(예를 들어, 뉴스 모음)에서 가장 중요한 이벤트일 확률을 신뢰성 있게 추정할 수 있다.
일부 구현들에서, 추론 엔진(224)은 입력 문서들에서 가장 큰 지지를 받는 표현/패턴을 선택함으로써 하나 이상의 문서(예를 들어, 이전의 뉴스 모음)의 입력 모음을 위한 소정 헤드라인을 생성할 수 있다. 예를 들어, 여러 등가 구문 패턴들이 하나 이상의 문서(들)의 소정 모음으로부터의 패턴들과 일치하면, 이들 일치는 이들 패턴들에 의해 반영되는 이벤트가 그 모음에 의해 보도되는 메인 이벤트라는 더 확실한 증거 지원을 제공함으로써 서로 보강될 수 있다. 예를 들어, 동일한 입력 모음 내에서, 추론 엔진(224)이 [X has married Y], [X wed Y], 및 [X married Y]와 일치할 수 있다면, 추론 엔진(224)은 더 적은 횟수로 나타날 수 있는 다른 이벤트들과 비교해, 이것이 보도된 메인 이벤트라는 더 확실한 증거를 갖는다.
추가 예로서, 추론 엔진(224)이 입력 문서(들)로부터 패턴 엔진(220)에 의해 처리되는 패턴들을 학습된 패턴들 [X has married Y], [X wed Y], 및 [X married Y]에 일치시킨다고 가정한다. 또한, 이들 표현이 다른 등가의 학습된 표현 [X tied the knot with Y]과 연관된다고 가정한다. 추론 엔진(224)은 생성된 헤드라인의 텍스트가 입력 문서(들)에서 이같이 제시되거나 제시되지 않을 수 있을지라도, 헤드라인을 생성하기 위해 표현 [X tied the knot with Y]을 이용할 수 있다.
일부 구현들에서, 하나 이상의 문서의 뉴스 모음 N으로 보도된 메인 이벤트를 캡처하는 헤드라인을 생성하기 위해, 추론 엔진(224)은 N에 특히 관련되는 단일 이벤트-패턴 p*을 선택하고, p*에서의 엔티티 타입/플레이스홀더를 N에서 관찰된 엔티티들의 실제 이름으로 대체할 수 있다. p*을 식별하기 위해, 시스템은 N에 의해 구현되는 대부분의 기술 이벤트가 N에서 관련 있는 엔티티들 E의 일부 서브세트가 수반되는 중요한 상황을 기술한다고 가정할 수 있다.
추론 엔진(224)은 하나 이상의 문서의 뉴스 모음에 포함되는 패턴들을 결정하기 위해 패턴 엔진(220)과 협력할 수 있다. 예를 들어, 한 세트의 엔티티들 E와 문장들 n이 주어지면, 추론 엔진(224)은 이들 엔티티를 수반하는 패턴들을 수집하기 위해 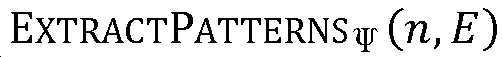 알고리즘을 이용할 수 있다. 추론 엔진(224)은 그 후 식별된 패턴들의 빈도를 정규화하고, 네트워크에서의 관찰된 변수들에 대한 확률 분포를 결정할 수 있다. 이벤트들 전체에 걸쳐 일반화하기 위해, 추론 엔진(224)은 잠재 이벤트 노드와 패턴 노드를 가로지를 수 있다.
알고리즘을 이용할 수 있다. 추론 엔진(224)은 그 후 식별된 패턴들의 빈도를 정규화하고, 네트워크에서의 관찰된 변수들에 대한 확률 분포를 결정할 수 있다. 이벤트들 전체에 걸쳐 일반화하기 위해, 추론 엔진(224)은 잠재 이벤트 노드와 패턴 노드를 가로지를 수 있다.
일부 구현들에서, 추론 엔진(224)은  로서 본 명세서에 언급되는 알고리즘을 이용하여 헤드라인에 포함되는 가장 관련 있는 이벤트들의 세트를 결정할 수 있으며, 이 알고리즘은 하기 프로세스를 포함할 수 있다.
로서 본 명세서에 언급되는 알고리즘을 이용하여 헤드라인에 포함되는 가장 관련 있는 이벤트들의 세트를 결정할 수 있으며, 이 알고리즘은 하기 프로세스를 포함할 수 있다.
뉴스 모음에 언급된 한 세트의 엔티티들 E가 주어지면, 시스템은 각각의 엔티티 서브세트  를 고려할 수 있다. 서브세트는 임의의 수의 엔티티들을 포함할 수 있다. 일부 구현들에서, 비교적 낮은 수(예를 들어, 3, 4 등)까지의 엔티티들이 효율을 위해, 생성된 헤드라인들을 비교적 짧게 유지하고 데이터 결핍 문제들을 제한하는데 사용될 수 있다. 각각의 Ei에 대해, 추론 엔진(224)은
를 고려할 수 있다. 서브세트는 임의의 수의 엔티티들을 포함할 수 있다. 일부 구현들에서, 비교적 낮은 수(예를 들어, 3, 4 등)까지의 엔티티들이 효율을 위해, 생성된 헤드라인들을 비교적 짧게 유지하고 데이터 결핍 문제들을 제한하는데 사용될 수 있다. 각각의 Ei에 대해, 추론 엔진(224)은  을 실행할 수 있고, 이는 Ei에서 엔티티들을 수반하는 패턴들에 걸친 분산 ωi를 계산한다.
을 실행할 수 있고, 이는 Ei에서 엔티티들을 수반하는 패턴들에 걸친 분산 ωi를 계산한다.
다음에, 추론 엔진(224)은  의 모든 서브세트에 대해 추출된 모든 패턴들을 이용하여 추론을 다시 호출할 수 있다. 이는 모음에서 언급된 엔티티들의 임의의 인정 가능한 서브세트를 수반하는 모든 패턴들에 걸친 확률분포 ω를 계산한다.
의 모든 서브세트에 대해 추출된 모든 패턴들을 이용하여 추론을 다시 호출할 수 있다. 이는 모음에서 언급된 엔티티들의 임의의 인정 가능한 서브세트를 수반하는 모든 패턴들에 걸친 확률분포 ω를 계산한다.
다음에, 추론 엔진(224)은 양호한 전체 분포  를 근사화하는 엔티티-특정 분포를 선택할 수 있다. 일부 예들에서, 추론 엔진(224)은 다른 변동들도 가능하지만, 대응하는 엔티티들의 세트 Ei가 모음에서 가장 중심적인 엔티티들이고 이에 따라 임의의 헤드라인이 그들 모두를 통합해야 한다고 가정할 수 있다. 시스템은 다음의 수학식에 의해 반영되는 바와 같이, 뉴스 모음에 보도된 메인 이벤트를 양호하게 캡처하는 패턴으로서 ω*에서의 가장 높은 가중치를 갖는 패턴 p*을 선택할 수 있다:
를 근사화하는 엔티티-특정 분포를 선택할 수 있다. 일부 예들에서, 추론 엔진(224)은 다른 변동들도 가능하지만, 대응하는 엔티티들의 세트 Ei가 모음에서 가장 중심적인 엔티티들이고 이에 따라 임의의 헤드라인이 그들 모두를 통합해야 한다고 가정할 수 있다. 시스템은 다음의 수학식에 의해 반영되는 바와 같이, 뉴스 모음에 보도된 메인 이벤트를 양호하게 캡처하는 패턴으로서 ω*에서의 가장 높은 가중치를 갖는 패턴 p*을 선택할 수 있다:
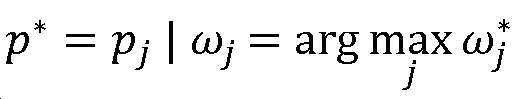
그러나, 다른 가중치 값들도 물론 신뢰성 있는 근사를 제공할 수 있음을 이해해야 한다.
추론 엔진(224)은 그 후 플레이스홀더들을 패턴이 추출되는 문서에서의 엔티티들로 대체함으로써 p*로부터 헤드라인을 생성할 수 있다. 일부 경우에 엔티티 타입들에 대한 정보가 추론 엔진(224)이 소정 헤드라인(예를 들어, 엔티티 세트{ea = “Mr. Brown”; eb = “Los Angeles”}에 대한 "[person] married in [location]")에 대한 엔티티들의 정확한 순서를 확실히 결정하기에 충분할지라도, 다른 경우의 클래스에서 정확한 순서화(예를 들어, {ea = “Mr. A”; eb = “Mr. B”}에 대한 "[person] killed [person]")는 모호하고 추론하기 어렵다. 추론 엔진(224)은 엔티티 세트{ea ; eb}에 대한 패턴들을 추출할 때 패턴 엔진(220)이 엔티티들의 알파벳 순서화의 트랙을 유지하게 함으로써 이들 경우를 다룰 수 있으며, 이는 다른 순서 메커니즘이 또한 사용될지라도 추론 엔진(224)이 정확한 순서화를 생성하게 할 수 있다. 예를 들어, "Mr. B" killing "Mr. A"에 대한 뉴스 모음으로부터, 패턴 엔진(220)은 ea = “Mr. A” < eb = “Mr. B”의 가정에 기초하여 "[person:2] killed [person:1]" 또는 "[person:1] was killed by [person:2]"를 포함하지만 이에 제한되지 않는 패턴들을 생성할 수 있다. 그 후, 추론 시에, 추론 엔진(224)은 그런 패턴들을 이용하여 모델에게 질의하고 관찰된 엔티티들과 호환 가능한 할당을 갖는 이벤트들만을 활성화할 수 있다. 이는 엔티티들의 교체를 간단하고 명료하게 할 수 있기 때문에 유리하다.
추론 엔진은 이에 의해 생성되는 헤드라인들을 데이터 스토어(210)에 저장할 수 있거나, 헤드라인들을 뉴스 포털(125) 및/또는 지식 그래프 관리 엔진(122)을 포함하는, 시스템(116)의 다른 엔티티들에 제공할 수 있다.
지식 그래프 관리 엔진(122)은 뉴스에 보도된 메인 이벤트를 결정하고 지식 그래프를 업데이트하기 위해 이벤트를 이용하는 프로세서(202)에 의해 실행 가능한 소프트웨어 및/또는 로직을 포함한다. 지식 그래프 관리 엔진(122)은 시스템(116)의 다른 엔티티들과 협력하여 공개된 뉴스를 자동으로 처리함으로써 지식 그래프의 콘텐츠를 최신으로 유지할 수 있다. 예를 들어, 뉴스에 포함된 적절한 이벤트에 대한 업데이트를 자동으로 결정하고 업데이트를 이용하여 지식 그래프에서 대응하는 엔트리들을 수정하기 위한 기술은 헤드라인 생성 엔진(120) 및/또는 그 구성 컴포넌트들을 레버리지화할 수 있다. 일부 경우에, 지식 그래프 관리 엔진(122)은 업데이트에 대한 신뢰도 및/또는 추적 능력을 제공하기 위한 속성을, 업데이트를 생성하는데 사용되는 문서(들)에 다시 제공할 수 있다.
예로서, 유명 인사가 사망하면, 지식 그래프는 유명 인사가 지금 사망한 것과 그 날짜 및 사망 장소를 나타내면서 업데이트될 필요가 있을 수 있다. 추가 예로서, 시스템이 뉴스로부터 한 사람이 방금 결혼했다고 결정하는 경우, 시스템은 그 사람의 배우자와 그들의 결혼의 시작 날짜에 대한 정보를 변경하기 위해 지식 그래프를 업데이트할 수 있다. 유사하게, 뉴스 보도가 이직하는 사람 또는 다른 회사를 인수하는 회사에 대한 것이라면, 이들은 지식 그래프에 업데이트될 수 있는 관계들이다. 뉴스에 언급될 수 있는 가상의 임의의 것은, 수집된 블로그들, 쇼설 네트워크들, 마이크로블로그들, 뉴스 네트워크들, 인터넷 포털들, 웹사이트들, 보도 자료들, 또는 정보의 임의의 다른 전자 소스 등을 통해 있든지 간에, 정치 이벤트들, 유명인사 이벤트들, 스포츠 이벤트들, 대중문화 이벤트들, 금융 이벤트들 등을 포함하는 지식 베이스의 콘텐츠들에 대한 변경들을 요구할 수 있다.
패턴 엔진(220) 및/또는 트레이닝 엔진(222)에 의해 결정된 등가 패턴들의 각각의 클러스터들에 대해, 지식 그래프 관리 엔진(122)은 새롭게 수집된 문서들 및/또는 문서 모음들에서 발견되고 있는 일치하는 패턴에 기초하는 업데이트를 이용하여 지식 그래프에서 대응하는 엔트리를 업데이트하고/주석을 달 수 있다. 일부 구현들에서, 이 주석은 (예를 들어, 지난 뉴스에서 관찰된 패턴들을 지식 그래프로의 지난 편집들과 일치시킴으로써) 자동으로 행해질 수 있다. 일부 구현들에서, 시스템은 자동으로 패턴들의 클러스터를 지식 그래프에서의 관계들에 연관시키려고 시도할 수 있으며, 사람이 이들 연관을 유효화하는 매뉴얼 큐레이션 단계(manual curation step)를 갖는다. 예를 들어, 지식 그래프 관리 엔진(122)은 관찰된 클러스터들에 관한 정보, 및/또는 확인을 위해 사람 사용자에게 업데이트되어야 할 아이템에 대한 제안을 사람 사용자에게 제공함으로써 매뉴얼 보조를 이용할 수 있다.
공개된 것으로 관찰된 각각의 뉴스 또는 뉴스 모음(지난 뉴스 또는 실시간 뉴스 중 어느 하나)에서, 시스템은 어느 패턴들이 엔티티들 간에 언급되는지 결정할 수 있고, 지식 베이스에서 어느 관계가 업데이트되어야 하는지 발견하기 위해 트레이닝 엔진(222)에 의해 데이터 스토어(210)에 저장된 매핑을 이용할 수 있다. 예를 들어, 지식 그래프 관리 엔진(122)이 헤드라인 생성 엔진(120)과 협력하여, 예를 들어 [X married Y], [X wed Y] 및 [X tied the know with Y]를 포함하는 표현들을 포함하는 뉴스 모음을 처리하고 지식 그래프 관리 엔진(122)이, X와 Y가 지식 베이스에서 배우자 관계(이들이 서로 각각의 배우자임)를 가질 수 있는 경우, 지식 그래프 관리 엔진(122)은 이것이 향후에 이들 패턴을 볼 때, 지식 베이스에서 업데이트될 관계가 배우자라고 자동으로 학습할 수 있다. 예를 들어, 지식 그래프 관리 엔진(122)이 [X married Y]을 언급하는 뉴스 문서를 처리하고 이 패턴이 지식 베이스에서 배우자 관계와 연관된다고 결정할 수 있는 경우, 지식 그래프 관리 엔진(122)은 Y가 X의 배우자이고 X가 Y의 배우자인 것을 나타내는 지식 베이스를 업데이트할 수 있다.
검색 엔진(118), 헤드라인 생성 엔진(120)과 그 구성 컴포넌트들, 지식 그래프 관리 엔진(122), 및 뉴스 포털(125)의 추가 구조, 행동 및/또는 기능은 본 명세서의 다른 곳에서 추가로 논의된다.
도 3은 헤드라인들을 자동으로 생성하는 예시적인 방법(300)의 흐름도이다. 방법(300)은 문서들의 코퍼스로부터 등가 구문 패턴들의 세트를 자동으로 학습하는 것으로(302) 시작될 수 있다. 예를 들어, 트레이닝 엔진(222)은 복수의 뉴스 모음들로 보도된 다양한 토픽들 및/또는 이벤트들에 대한 등가 구문 패턴들을 학습할 수 있고, 헤드라인 생성 동안 참조 및/또는 매칭을 위해 트레이닝 데이터(212)로서 이들 패턴을 데이터 스토어(210)에 저장한다.
다음에, 방법(330)은 입력 문서들의 세트(예를 들어, 뉴스 기사들의 뉴스 모음)를 수신할 수 있다(304). 입력 문서들의 세트(예를 들어, 뉴스 모음)는 하나 이상의 문서를 포함할 수 있다. 문서들은 임의의 포매팅 및 콘텐츠(예를 들어, 텍스트, 그래픽, 내장된 미디어 등)를 갖는 전자 파일들을 포함할 수 있다. 예를 들어, 문서는 검색 엔진(118)에 의해 수집된 뉴스 기사를 구체화하는 웹페이지로부터의 콘텐츠를 포함할 수 있다. 2 이상의 문서의 경우에, 문서들은 관련될 수 있다(예를 들어, 문서들의 콘텐츠에 기초하여, 동일 또는 유사한 기간에서 온, 동일 또는 유사한 이벤트들, 엔티티들 등을 기술할 수 있다).
다음에, 방법(300)은 등가 구문 패턴들의 하나 이상의 세트와 일치하는 표현(들)에 대한 입력 문서들의 세트를 처리할 수 있다(306). 예를 들어, 추론 엔진(224)은 패턴 엔진(220)과 협력하여, 입력 문서들의 세트(예를 들어, 뉴스 모음)에 대한 패턴들의 클러스터를 결정할 수 있고, 추론 엔진(224)은 일치하는 패턴들을 식별하기 위해 이들 패턴을, 트레이닝 엔진(222)에 의해 학습된 등가 구문 패턴들의 세트들과 비교할 수 있다.
방법(300)은 그 후 헤드라인에 대한 구문 패턴들의 일치하는 세트(들) 중에서 구문 패턴을 선택할 수 있다(308). 선택된 패턴은 입력 문서들의 세트로부터 처리된 대응하는 패턴과 일치하는 패턴일 수 있거나, 또는 트레이닝 엔진(222)에 의해 학습된 등가 패턴일 수 있다. 선택된 패턴은 입력 문서들의 세트(예를 들어, 뉴스 모음으로 보도된 뉴스)의 중심 이벤트를 기술할 수 있다. 다음에, 방법(300)은 선택된 구문 패턴을 이용하여 헤드라인을 생성할 수 있다(310). 예를 들어, 추론 엔진(224)은 구문 패턴에서의 엔티티 타입들을 입력 문서들의 세트로부터 처리된 대응하는 엔티티들로 대체할 수 있다.
도 4는 입력 문서들의 세트들로부터 처리된 엔티티들 및 이벤트들에 기초하여 등가 구문 패턴들을 클러스터링하는 예시적 방법(400)의 흐름도이다. 방법(400)은 관련된 문서들의 세트들(예를 들어, 관련된 뉴스 기사들의 뉴스 모음들)을 수신하는 것(402)으로 시작할 수 있다. 일부 구현에서, 관련된 문서들의 세트들은 사용자들이 정보를 수신하는데 관심을 갖거나 가질 다양한 상이한 이벤트들을 기술하는 뉴스 모음의 쿠퍼스를 반영할 수 있다.
각각의 세트에서, 방법(400)은 가장 많이 언급된 엔티티들(예를 들어, 가장 빈번하게 나타나는 엔티티들)을 식별할 수 있고(404), 가장 많이 언급된 엔티티들과 이들 엔티티에 대응하는 이벤트들을 포함하는 구문 패턴들의 하나 이상의 클러스터를 결정할 수 있다(406). 예를 들어, 트레이닝 엔진(222)은 패턴 엔진(220)과 협력하여, 하나 이상의 엔티티 티입들과 엔티티 타입을 수반하는 이벤트를 각각 기술하는 동의어 표현들(예를 들어, 등가 구문 패턴들)의 세트들을 결정하고 최적화할 수 있으며, 이들을 데이터 스토어(210)에 저장한다(408). 추가 예로서, 트레이닝 엔진(222)은, 문서들의 세트가 한 세트의 등가 구문 패턴들에 대한 주어진 이벤트를 아래로 기술하는 상이한 방식들을 추론할 수 있고, 충분한 증거가 존재한다면 확률 모델을 이용하여 하나 이상의 추가 대응하는 동의어 구문 패턴들을 결정하고, 이들을 헤드라인 생성 동안 추론 엔진(224)에 의한 참고를 위해 세트로서 저장한다. 방법(400)은 그 후 모든 문서들이 처리되었든지 결정할 수 있고(410), 이들이 처리된다면, 다른 동작을 반복하고 계속할 수 있거나, 종료할 수 있다. 모든 세트들이 처리되지 않았다면, 방법(400)은 블록 404로 복귀하고 다음 세트를 처리할 수 있다.
도 5a는 등가 구문 패턴들의 클러스터들에 기초하여 한 세트의 뉴스 문서들을 위한 헤드라인들을 생성하는 예시적 방법(500)의 흐름도이다. 방법(500)은 한 세트의 문서들을 수신하는 것으로(502) 시작될 수 있다. 예를 들어, 문서들의 세트는 검색 엔진(118)에 의해 수집되고 헤드라인이 객관적으로 현재 이벤트를 특징화하기 위해 생성되어야 하는 현재 이벤트에 대해 보도하는 관련된 뉴스 기사들의 모음일 수 있다. 다음에, 방법(400)은 세트의 문서들로부터의 표현들을 처리하고(504), 표현들로부터의 엔티티들을 처리하고(506), 그 표현을 등가 구문 패턴들의 하나 이상의 미리 정해진 클러스터에 매칭시킬 수 있다(506). 예를 들어, 특정 이벤트를 기술하는 5개의 관련된 뉴스 기사를 포함하는 뉴스 모음을 가정하면, 추론 엔진(224)은 패턴 엔진(220)과 협력하여, 기사들의 제목 및/또는 텍스트로부터 이벤트에 대한 한 세트의 상이한 단어들의 표현들을 처리하고 그 표현들을 해당 이벤트를 기술하는 등가 구문 패턴들의 하나 이상의 클러스터와 일치시킬 수 있다.
방법(500)은 일치하는 클러스터들이 하나 이상 있는 경우 이들 중 어느 것이 관련 있는지(예를 들어, 가장 관련 있는지), 또는 하나만 있는 경우 일치하는 클러스터가 관련 있는지 또는 충분히 관련 있는지 결정하는 것으로(510) 계속될 수 있다. 이런 결정을 하기 위한 하나의 예시적 방법(550)은 도 5b에 도시된다. 블록 552에서, 방법(550)은 일치하는 클러스터들 중 이용하기 위한 클러스터를 선택하고(552), 해당 클러스터에 대한 일치 증거가 미리 정해진 임계치를 충족하는지 결정한다(554). 예를 들어, 문서들의 세트로부터 상이한 단어를 쓴 표현 프로세스(differently worded expressions process)의 수(예를 들어, 2, 3, 4 등)가 선택된 클러스터로부터의 등가 구문 패턴들의 미리 정해진 임계치를 각각 충족하는 경우, 방법(550)은 블록 556으로 이어질 수 있다. 이는 선택된 클러스터가 문서들의 세트로 보도된 메인 이벤트를 기술하는지 결정할 수 있기 때문에 유리하다. 554에서 임계치가 충족되지 않으면, 방법(550)은 사용하기 위한 상이한 클러스터를 선택하기 위해 블록 552로 복귀할 수 있고, 문서들로부터 추가 표현들을 처리할 수 있고, 일치 시퀀스(matching sequence)를 반복하고 종료 등을 할 수 있다.
블록 556에서, 방법(550)은 선택된 클러스터에 대응하는 이벤트를 문서들의 세트의 메인 이벤트를 기술하는 것으로 결정할 수 있고(556), 그 후 예를 들어, 트레이닝 모듈(222)을 참고하여 본 명세서의 다른 곳에서 설명되는 바와 같이, 문서들의 세트에 적용하는 숨겨진 이벤트를 기술하는 임의의 대응하는 숨겨진 구문 패턴들이 있는지 결정할 수 있다(558).
도 5a를 참고하면, 방법(500)은 헤드라인을 생성할 가장 관련 있는 클러스터로부터 구문 패턴을 선택하는 것으로(512) 계속될 수 있고, 구문 표현을 문서들의 세트로부터 처리된 표현들로부터 처리된 엔티티들로 채움으로써 헤드라인을 생성하도록(514) 처리될 수 있다.
도 6은 등가 구문 패턴들의 세트들에 기초하여 지식 그래프를 자동으로 업데이트하는 예시적 방법(600)의 흐름도이다. 방법(600)은 본 명세서의 다른 곳에서 더 상세히 설명되는 바와 같이, 등가 구문 패턴들의 클러스터들을 결정하는 것으로(602) 시작될 수 있다. 방법(600)은 그 후 패턴들의 각각의 세트를 지식 그래프 내의 대응하는 아이템에 매핑할 수 있다(604). 예를 들어, 지식 그래프는 유사도를 공유하는 엔티티들에 대한 다양한 아이템(예를 들어, 이벤트)들을 지속적으로 기술할 수 있다. 예를 들어, 지식 그래프에 기술된 사람들에 대해, 지식 그래프는 사람들에게 고유한 정보의 기본 세트를 포함할 수 있다. 예를 들어, 지식 그래프는 한 사람의 생애에서 일어나는 중요한 이벤트들에 대한 정보를 포함할 수 있다. 추가 예로서, 지식 베이스는 출생에 대해, 출생 일자 및 출생지, 아기의 성별 등을 포함할 수 있다. 사망에 대해, 고인의 이름 및 이와의 관계(그 사람이 아닐지라도), 죽음의 환경 등을 포함할 수 있다. 결혼에 대해, 누구와 결혼했는지, 이전 결혼 횟수, 결혼에 대한 상세 등을 포함할 수 있다. 지식 그래프 관리 엔진(122)은 이들 아이템을 이들 이벤트를 기술하는 등가 구문 패턴들의 대응하는 세트/클러스터들에 매핑할 수 있다.
다음에, 방법(600)은 한 세트의 입력 문서들을 결정하고(606), 본 명세서의 다른 곳에서 논의되는 바와 같이 등가 구문 패턴들의 하나 이상의 세트와 일치하는 표현들을 위해 입력 문서들의 세트를 처리할 수 있다(608). 방법(600)은 그 후 등가 구문 패턴들의 일치하는 세트 중에서 구문 패턴을 선택하는 것으로(610) 계속될 수 있으며, 선택된 패턴은 입력 문서들의 중심 이벤트를 반영한다. 일부 경우에, 선택된 패턴은 본 명세서의 다른 곳에서 설명되는 바와 같이 숨겨진 동의어 패턴일 수 있다.
방법(600)은 입력 문서들로부터 처리된 표현들에 의해 기술된 엔티티(들)에 대응하는 지식 그래프에서 하나 이상의 엔트리를 결정하도록(612) 처리될 수 있으며, 선택된 구문 패턴을 이용하여 이벤트를 반영하기 위해 하나 이상의 엔트리를 업데이트할 수 있다(614). 예를 들어, 결혼의 아이템(예를 들어, 관계)에 대해, 지식 그래프 관리 엔진(122)은 뉴스(예를 들어, 약혼 또는 결혼에 대한 기사들의 뉴스 모음)로 보도된 바와 같이, 2명의 유명인사 간의 최근에 발표된 약혼 또는 거행된 결혼을 포함하도록 2명의 유명인사에 대응하는 엔트리들의 결혼 부문을 업데이트하기 위해 지식 그래프(124)에 의해 노출되는 API를 레버리지화할 수 있다.
도 7은 예시적 패턴 결정 프로세스를 도시하는 예시적 방법이다. 패턴 결정 프로세스는 본 명세서의 다른 곳에서 논의된 바와 같이 주석을 단 종속성 파스(annotated dependency parse)를 포함할 수 있다. (1)에서, MST는 엔티티 쌍 e1, e2를 위해 처리된다. (2)에서, 노드들은 (3)에서 문법을 적용하기 위해 MST에 휴리스틱적으로 추가된다. (4)에서, 엔티티 타입들은 최종 패턴들을 생성하기 위해 재결합된다.
도 8은 예시적 확률 모델을 도시한다. 이 모델에서, 잠재 이벤트 변수들과 관찰된 패턴 변수들 사이의 연관들은 noisy-OR 게이트들에 의해 모델링된다. 본 명세서의 다른 곳에 논의되는 바와 같이, 이벤트들은 약간 독립적인 것으로 추정될 수 있으며, 패턴들은 주어진 이벤트들에 조건부로 독립적인 것으로 추정될 수 있다.
도 10은 뉴스 시스템(116)에 의해 생성된 예시적 헤드라인을 도시하는 예시적 사용자 인터페이스(900)의 그래픽 표현이다. 사용자 인터페이스(900)는 유명인사 예로서, Jill Popular에 대한 뉴스 기사들에 대한 검색과 일치하는 한 세트의 결과들(904)을 포함한다. 결과들(904)은 유명인사 Joe와 Jill Popular의 결혼에 대한 뉴스 모음을 포함하며, 여기서 예시적 제목 "Jill Popular marries Joe Celebrity"가 뉴스 시스템(116)에 의해 생성된다. 이 예에서, 뉴스 시스템(116)에 의해 생성되는 헤드라인들이 상이한 목적들을 서빙하도록 의도된 상이한 특징들로 생성될 수 있다고 이해될지라도, 제목은 뉴스 모음(906)에 포함되는 문서들의 객관적인 간결한 표현이다.
다음의 설명에서, 설명의 목적으로, 본 개시 내용의 철저한 이해를 제공하기 위해서 다수의 특정 상세가 제시된다. 그러나, 본 명세서에 설명된 기술이 이러한 특정 상세 없이 실시해도 된다는 점을 이해할 것이다. 또한, 본 설명을 모호하게 하지 않도록 다양한 시스템, 디바이스들 및 구조들이 블록도 형태로 도시된다. 예를 들어, 다양한 구현들은 특별한 하드웨어, 소프트웨어 및 사용자 인터페이스들을 갖는 것으로 설명된다. 그러나, 본 개시 내용은 데이터와 커맨드들을 수신할 수 있는 임의의 유형의 컴퓨팅 디바이스, 및 서비스들을 제공하는 임의의 주변 장치들에 적용된다.
일부 경우에, 다양한 구현들은 본 명세서에서 컴퓨터 메모리 내의 데이터 비트들에 대한 연산들의 알고리즘들 및 심볼 표현들의 관점에서 제시된다. 알고리즘은 여기서 일반적으로 원하는 결과를 가져오는 자체 일관성있는 연산들의 세트인 것으로 고려된다. 연산들은 물리적 양들의 물리적 조작을 요구하는 것들이다. 일반적으로, 반드시 그러하지는 않지만, 이러한 양들은 저장, 전송, 조합, 비교, 아니면 조작이 가능한 전기 또는 자기 신호들의 형태를 취한다. 주로 통상적인 사용의 이유 때문에, 이들 신호를 비트, 값, 요소, 심벌, 문자, 용어, 숫자 등으로 지칭하는 것이 때로는 편리한 것으로 밝혀졌다.
그러나, 이러한 용어들 및 유사한 용어들 모두가 적절한 물리적 양들과 연관되는 것이며, 이러한 양들에 적용되는 단지 편리한 라벨들일 뿐이라는 점을 명심해야 한다. 하기의 설명에서 명백하게 특별히 달리 언급되지 않는 한, 본 개시 내용 전체에 걸쳐서, "처리" 또는 "계산" 또는 "연산" 또는 "결정" 또는 "표시" 등과 같은 용어들을 사용하는 설명은, 컴퓨터 시스템의 레지스터들 및 메모리들 내의 물리적(전자) 양들로서 표현되는 데이터를 조작하고 이 데이터를 컴퓨터 시스템 메모리 또는 레지스터 또는 기타 그러한 정보 스토리지, 전송, 또는 디스플레이 디바이스들 내의 물리적 양들로 유사하게 표현되는 다른 데이터로 변환하는 컴퓨터 시스템 또는 유사한 전자 컴퓨팅 디바이스의 작용 및 프로세스들을 지칭한다는 것을 이해할 것이다.
본 명세서에서 설명되는 다양한 구현들은 본 명세서에서 동작으로 수행하기 위한 장치와 관련될 수 있다. 이러한 장치는 특별히 요구된 목적을 위해 구성될 수 있거나, 또는 컴퓨터에 저장되는 컴퓨터 프로그램에 의해 대안적으로 활성화되거나 재구성되는 범용 컴퓨터를 포함할 수 있다. 그러한 컴퓨터 프로그램은, 컴퓨터 시스템 버스에 각각 결합되는, 플로피 디스크, 광디스크, CD-ROM 및 자기 디스크를 포함하는 임의의 유형의 디스크, 판독 전용 메모리(ROM), 랜덤 액세스 메모리(RAM), EPROM, EEPROM, 자기 또는 광학 카드, 비휘발성 메모리를 갖는 USB 키를 포함하는 플래쉬 메모리, 또는 전자 명령어들을 저장하기에 적합한 임의의 유형의 매체 등을 포함하는, 그러나 이들로 한정되지 않는 컴퓨터 판독 가능 저장 매체에 저장될 수 있다.
본 명세서에 설명된 기술은 하드웨어로만 된 구현, 소프트웨어로만 된 구현, 또는 소프트웨어 요소 및 하드웨어 요소를 겸비한 구현의 형태를 취할 수 있다. 예를 들어, 기술은 소프트웨어로 구현될 수 있고, 이것은 펌웨어, 상주 소프트웨어, 마이크로 코드 등을 포함하지만 이에 제한되지 않는다. 더욱이, 기술은 컴퓨터 또는 임의의 명령어 실행 시스템에 의해 또는 그와 관련하여 사용하기 위한 프로그램 코드를 제공하는 컴퓨터 사용 가능 또는 컴퓨터 판독 가능 매체로부터 액세스 가능한 컴퓨터 프로그램 제품의 형태를 취할 수 있다. 본 설명의 목적을 위해, 컴퓨터 사용 가능 또는 컴퓨터 판독 가능 매체는 명령어 실행 시스템, 장치, 또는 디바이스에 의해 또는 그와 관련하여 사용하기 위한 프로그램을 포함 또는 저장할 수 있는 임의의 비일시적 저장 장치일 수 있다.
프로그램 코드를 저장하고/하거나 실행하기에 적합한 데이터 처리 시스템은 시스템 버스를 통해 직접적으로 또는 간접적으로 메모리 요소에 결합된 적어도 하나의 프로세서를 포함할 수 있다. 메모리 요소는, 프로그램 코드의 실제 실행 동안에 채택된 로컬 메모리, 대용량 스토리지(bulk storage), 및 실행 동안에 대용량 스토리지로부터 코드가 검색되어야 하는 횟수를 감소시키기 위하여 적어도 일부 프로그램 코드의 일시 저장을 제공하는 캐시 메모리를 포함할 수 있다. (키보드, 디스플레이, 포인팅 디바이스 등을 포함하지만 이에 제한되지 않는) 입/출력 또는 I/O 디바이스는 직접적으로 또는 중개(intervening) I/O 제어기를 통해 시스템에 결합될 수 있다.
네트워크 어댑터는 데이터 처리 시스템으로 하여금 중개 사설 및/또는 공용 네트워크를 통해 다른 데이터 처리 시스템, 저장 디바이스, 원격 프린터 등에 결합되는 것을 가능하게 하기 위해 시스템에 결합될 수 있다. 무선(예를 들어, Wi-Fi(등록상표)) 송수신기들, 이더넷 어댑터들 및 모뎀들이 바로 네트워크 어댑터들의 몇몇 예들이다. 사설 및 공용 네트워크들은 임의의 수의 구성 및/또는 토폴로지를 가질 수 있다. 데이터는, 예를 들어 다양한 인터넷 계층, 송신 계층, 또는 애플리케이션 계층 프로토콜들을 포함하는 다양한 상이한 통신 프로토콜들을 이용하여 네트워크들을 통해 이러한 디바이스들 사이에 송신될 수 있다. 예를 들어, 데이터는 전송 제어 프로토콜/인터넷 프로토콜(transmission control protocol/Internet protocol)(TCP/IP), 사용자 데이터그램 프로토콜(user datagram protocol)(UDP), 송신 제어 프로토콜(transmission control protocol)(TCP), 하이퍼텍스트 전송 프로토콜(hypertext transfer protocol)(HTTP), 안전한 하이퍼텍스트 전송 프로토콜(secure hypertext transfer protocol)(HTTPS), HTTP를 통한 동적 적응성 스트리밍(dynamic adaptive streaming over HTTP)(DASH), 실시간 스트리밍 프로토콜(real-time streaming protocol)(RTSP), 실시간 전송 프로토콜(real-time transport protocol)(RTP) 및 실시간 전송 제어 프로토콜(real-time transport control protocol)(RTCP), 음성 오버 인터넷 프로토콜(voice over Internet protocol)(VOIP), 파일 전송 프로토콜(file transfer protocol)(FTP), WebSocket(WS), 무선 액세스 프로토콜(wireless access protocol)(WAP), 다양한 메시징 프로토콜들(SMS, MMS, XMS, IMAP, SMTP, POP, WebDAV 등), 또는 다른 알려진 프로토콜들을 이용하는 네트워크들을 통해 송신될 수 있다.
마지막으로, 본 명세서에 제시된 구조, 알고리즘 및/또는 인터페이스는 임의의 특정 컴퓨터 또는 다른 장치에 고유하게 관련되지 않는다. 본 명세서의 교시에 따라 다양한 범용 시스템들이 프로그램들과 함께 사용될 수 있으며, 또는 요구되는 방법의 블록들을 수행하기 위해 더 특수화된 장치를 구성하는 것이 편리하다고 판명될 수 있다. 다양한 이들 시스템에 필요한 구조는 상기 설명으로부터 자명할 것이다. 게다가, 본 개시 내용은 임의의 특정 프로그래밍 언어와 관련하여 설명되지 않는다. 본 명세서에 기술된 본 발명의 교시들을 구현하기 위해 각종 프로그래밍 언어들이 사용될 수 있음을 이해할 것이다.
상기 설명은 도시와 설명을 목적으로 제시되었다. 이는 배타적인 것으로 의도되거나 또는 본 개시내용을 개시된 정확한 형태들로 제한하려고 의도되는 것은 아니다. 많은 수정 예와 변형 예가 상기의 교시에 비추어 가능하다. 본 개시 내용의 범위는 이러한 상세한 설명에 의해 한정되지 않고, 오히려 본 명세서의 청구범위에 의해 한정되도록 의도된다. 본 분야의 통상의 기술자가 이해하는 바와 같이, 본 명세서는 그 사상 또는 본질적인 특징으로부터 벗어나지 않고서 다른 특정 형태들로 실시될 수 있다. 마찬가지로, 모듈, 루틴, 특징, 속성, 방법론, 및 기타의 양태들의 특정 명명 및 구분은 의무적이거나 중요한 것은 아니며, 본 명세서 또는 그 특징을 구현하는 메커니즘들은 상이한 명칭들, 구분들, 및/또는 형태들을 가질 수 있다.
게다가, 모듈, 루틴, 특징, 속성, 방법론 및 본 개시 내용의 다른 양태들은 소프트웨어, 하드웨어, 펌웨어, 또는 이들의 임의의 조합으로 수행될 수 있다. 또한, 본 개시 내용 중, 예로서 모듈인 컴포넌트가 소프트웨어로서 구현되든, 그 컴포넌트는, 독립형 프로그램으로서, 더 큰 프로그램의 일부로서, 복수의 개별 프로그램으로서, 정적 또는 동적으로 링크된 라이브러리로서, 커널 로딩 가능한 모듈로서, 디바이스 드라이버로서, 및/또는 현재 또는 미래에 알려진 모든 기타 임의의 방식으로 구현될 수 있다. 추가로, 본 개시 내용은, 어떤 식으로든, 임의의 특정 프로그래밍 언어로의 구현, 또는 임의의 특정 운영 체계 또는 환경에 대한 구현으로 한정되지 않는다. 따라서, 본 개시 내용은 하기의 특허청구범위에 기재된 주제의 범위를 제한이 아닌 예시하도록 의도된다.
Claims (15)
- 컴퓨터 구현 방법으로서,
뉴스 요약을 요청하는 오디오 질의(audio query)를 수신하는 단계 - 상기 오디오 질의는 엔티티를 특정하는 하나 이상의 파라미터를 특정함 -;
문서들의 코퍼스(corpus)로부터 학습되었고 상기 엔티티를 포함하는 등가 구문 패턴들의 세트들 중에서, 한 세트의 등가 구문 패턴들과 일치하는 하나 이상의 표현을 위해 하나 이상의 입력 문서의 세트를 처리하는 단계;
미리 정의된 임계치 미만의 관련성 스코어를 갖는 상기 구문 패턴들을 배제하는 것에 의해 등가 구문 패턴들의 정제된(refined) 세트를 생성하는 단계;
상기 등가 구문 패턴들의 정제된 세트 중에서 헤드라인을 위한 구문 패턴을 선택하는 단계 - 상기 구문 패턴은 상기 하나 이상의 입력 문서의 세트에 의해 기술되는 메인 이벤트를 반영함 -; 및
상기 구문 패턴을 이용하여 상기 헤드라인을 생성하는 단계 - 상기 헤드라인은 상기 엔티티를 특정함 -;
를 포함하는 컴퓨터 구현 방법. - 제1항에 있어서,
상기 등가 구문 패턴들의 세트들을 지식 그래프 내의 대응하는 아이템들에 매핑하는 단계;
상기 등가 구문 패턴들의 세트와 일치하는 상기 하나 이상의 표현으로부터의 하나 이상의 엔티티를 결정하는 단계;
상기 하나 이상의 표현에 의해 기술되는 상기 하나 이상의 엔티티에 대응하는 상기 지식 그래프 내의 하나 이상의 엔트리를 결정하는 단계; 및
상기 헤드라인을 이용하여 상기 메인 이벤트를 반영하기 위해 상기 지식 그래프 내의 상기 하나 이상의 엔트리를 업데이트하는 단계
를 더 포함하는, 컴퓨터 구현 방법. - 제1항에 있어서, 상기 하나 이상의 입력 문서의 세트는 관련된 뉴스 기사들의 뉴스 모음을 포함하는, 컴퓨터 구현 방법.
- 제1항에 있어서,
상기 하나 이상의 표현으로부터의 하나 이상의 엔티티를 처리하는 단계를 더 포함하고, 상기 헤드라인을 생성하는 단계는 상기 구문 패턴을 상기 하나 이상의 엔티티로 채우는 단계를 포함하는, 컴퓨터 구현 방법. - 제1항에 있어서, 상기 하나 이상의 입력 문서의 세트를 처리하는 단계는
상기 하나 이상의 입력 문서로부터 처리된 표현의 수가 미리 결정된 증거 임계치를 충족한다고 결정하는 단계; 및
상기 증거 임계치가 충족되는 것에 기초하여 상기 등가 구문 패턴들의 세트가 상기 하나 이상의 입력 문서의 세트와 관련 있다고 결정하는 단계를 포함하는, 컴퓨터 구현 방법. - 컴퓨터 판독 가능 프로그램을 기록하는 컴퓨터 판독 가능 기록 매체로서, 상기 컴퓨터 판독 가능 프로그램은 컴퓨터상에서 실행될 때, 상기 컴퓨터로 하여금,
뉴스 요약을 요청하는 오디오 질의를 수신하고 - 상기 오디오 질의는 엔티티를 특정하는 하나 이상의 파라미터를 특정함 -;
문서들의 코퍼스로부터 학습되었고 상기 엔티티를 포함하는 등가 구문 패턴들의 세트들 중에서, 한 세트의 등가 구문 패턴들과 일치하는 하나 이상의 표현을 위해 하나 이상의 입력 문서의 세트를 처리하고;
미리 정의된 임계치 미만의 관련성 스코어를 갖는 상기 구문 패턴들을 배제하는 것에 의해 등가 구문 패턴들의 정제된 세트를 생성하고;
상기 등가 구문 패턴들의 정제된 세트 중에서 헤드라인을 위한 구문 패턴을 선택하고 - 상기 구문 패턴은 상기 하나 이상의 입력 문서의 세트에 의해 기술되는 메인 이벤트를 반영함 -;
상기 구문 패턴을 이용하여 상기 헤드라인을 생성하게 하는 - 상기 헤드라인은 상기 엔티티를 특정함 -, 컴퓨터 판독 가능 기록 매체. - 제6항에 있어서, 상기 컴퓨터 판독 가능 프로그램은 상기 컴퓨터상에서 실행될 때, 상기 컴퓨터로 하여금 또한,
상기 등가 구문 패턴들의 세트들을 지식 그래프 내의 대응하는 아이템들에 매핑하고;
상기 등가 구문 패턴들의 세트와 일치하는 상기 하나 이상의 표현으로부터의 하나 이상의 엔티티를 결정하고;
상기 하나 이상의 표현에 의해 기술되는 상기 하나 이상의 엔티티에 대응하는 상기 지식 그래프 내의 하나 이상의 엔트리를 결정하고;
상기 헤드라인을 이용하여 상기 메인 이벤트를 반영하기 위해 상기 지식 그래프 내의 상기 하나 이상의 엔트리를 업데이트하게 하는, 컴퓨터 판독 가능 기록 매체. - 제6항에 있어서, 상기 하나 이상의 입력 문서의 세트는 관련된 뉴스 기사들의 뉴스 모음을 포함하는, 컴퓨터 판독 가능 기록 매체.
- 제6항에 있어서, 상기 컴퓨터 판독 가능 프로그램은 상기 컴퓨터상에서 실행될 때, 상기 컴퓨터로 하여금 또한,
상기 하나 이상의 표현으로부터의 하나 이상의 엔티티를 처리하게 하고, 상기 헤드라인을 생성하는 것은 상기 구문 패턴을 상기 하나 이상의 엔티티로 채우는 것을 포함하는, 컴퓨터 판독 가능 기록 매체. - 제6항에 있어서, 상기 하나 이상의 입력 문서의 세트를 처리하는 것은,
상기 하나 이상의 입력 문서로부터 처리된 표현들의 수가 미리 결정된 증거 임계치를 충족한다고 결정하고;
상기 증거 임계치가 충족되는 것에 기초하여 상기 등가 구문 패턴들의 세트가 상기 하나 이상의 입력 문서의 세트와 관련 있다고 결정하는 것을 포함하는, 컴퓨터 판독 가능 기록 매체. - 헤드라인 생성 시스템으로서,
프로세서; 및
명령어들을 저장하는 메모리를 포함하고, 상기 명령어들은 상기 프로세서에 의해 실행될 때, 상기 시스템으로 하여금,
뉴스 요약을 요청하는 오디오 질의를 수신하고 - 상기 오디오 질의는 엔티티를 특정하는 하나 이상의 파라미터를 특정함 -;
문서들의 코퍼스로부터 학습되었고 상기 엔티티를 포함하는 등가 구문 패턴들의 세트들 중에서, 한 세트의 등가 구문 패턴들과 일치하는 하나 이상의 표현을 위해 하나 이상의 입력 문서의 세트를 처리하고;
미리 정의된 임계치 미만의 관련성 스코어를 갖는 상기 구문 패턴들을 배제하는 것에 의해 등가 구문 패턴들의 정제된 세트를 생성하고;
상기 등가 구문 패턴들의 정제된 세트 중에서 헤드라인을 위한 구문 패턴을 선택하고 - 상기 구문 패턴은 상기 하나 이상의 입력 문서의 세트에 의해 기술되는 메인 이벤트를 반영함 -;
상기 구문 패턴을 이용하여 상기 헤드라인을 생성하게 하는 - 상기 헤드라인은 상기 엔티티를 특정함 -, 헤드라인 생성 시스템. - 제11항에 있어서, 상기 명령어들은 실행될 때, 상기 시스템으로 하여금 또한,
상기 등가 구문 패턴들의 세트들을 지식 그래프 내의 대응하는 아이템들에 매핑하고;
상기 등가 구문 패턴들의 세트와 일치하는 상기 하나 이상의 표현으로부터의 하나 이상의 엔티티를 결정하고;
상기 하나 이상의 표현에 의해 기술되는 상기 하나 이상의 엔티티에 대응하는 상기 지식 그래프 내의 하나 이상의 엔트리를 결정하고;
상기 헤드라인을 이용하여 상기 메인 이벤트를 반영하기 위해 상기 지식 그래프 내의 상기 하나 이상의 엔트리를 업데이트하게 하는, 헤드라인 생성 시스템. - 제11항에 있어서, 상기 하나 이상의 입력 문서의 세트는 관련된 뉴스 기사들의 뉴스 모음을 포함하는, 헤드라인 생성 시스템.
- 제11항에 있어서, 상기 명령어들은 실행될 때, 상기 시스템으로 하여금 또한
상기 하나 이상의 표현으로부터의 하나 이상의 엔티티를 처리하게 하고, 상기 헤드라인을 생성하는 것은 상기 구문 패턴을 상기 하나 이상의 엔티티로 채우는 것을 포함하는, 헤드라인 생성 시스템. - 제11항에 있어서, 상기 하나 이상의 입력 문서의 세트를 처리하는 것은,
상기 하나 이상의 입력 문서로부터 처리된 표현들의 수가 미리 결정된 증거 임계치를 충족한다고 결정하고;
상기 증거 임계치가 충족되는 것에 기초하여 상기 등가 구문 패턴들의 세트가 상기 하나 이상의 입력 문서의 세트와 관련 있다고 결정하는 것을 포함하는, 헤드라인 생성 시스템.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361840417P | 2013-06-27 | 2013-06-27 | |
| US61/840,417 | 2013-06-27 | ||
| US14/060,562 US9619450B2 (en) | 2013-06-27 | 2013-10-22 | Automatic generation of headlines |
| US14/060,562 | 2013-10-22 | ||
| PCT/US2014/020436 WO2014209435A2 (en) | 2013-06-27 | 2014-03-04 | Automatic generation of headlines |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167002279A Division KR102082886B1 (ko) | 2013-06-27 | 2014-03-04 | 헤드라인의 자동 생성 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200022540A KR20200022540A (ko) | 2020-03-03 |
| KR102094659B1 true KR102094659B1 (ko) | 2020-03-27 |
Family
ID=52116664
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167002279A KR102082886B1 (ko) | 2013-06-27 | 2014-03-04 | 헤드라인의 자동 생성 |
| KR1020207005313A KR102094659B1 (ko) | 2013-06-27 | 2014-03-04 | 헤드라인의 자동 생성 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167002279A KR102082886B1 (ko) | 2013-06-27 | 2014-03-04 | 헤드라인의 자동 생성 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9619450B2 (ko) |
| EP (1) | EP3014480A2 (ko) |
| KR (2) | KR102082886B1 (ko) |
| CN (1) | CN105765566B (ko) |
| AU (1) | AU2014299290A1 (ko) |
| CA (1) | CA2916856C (ko) |
| WO (1) | WO2014209435A2 (ko) |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2954431B1 (en) * | 2012-12-14 | 2019-07-31 | Robert Bosch GmbH | System and method for event summarization using observer social media messages |
| US9881077B1 (en) * | 2013-08-08 | 2018-01-30 | Google Llc | Relevance determination and summary generation for news objects |
| CN104754629B (zh) * | 2013-12-31 | 2020-01-07 | 中兴通讯股份有限公司 | 一种基站设备自愈的实现方法及装置 |
| US20150254213A1 (en) * | 2014-02-12 | 2015-09-10 | Kevin D. McGushion | System and Method for Distilling Articles and Associating Images |
| US10607253B1 (en) * | 2014-10-31 | 2020-03-31 | Outbrain Inc. | Content title user engagement optimization |
| JP6456162B2 (ja) * | 2015-01-27 | 2019-01-23 | 株式会社エヌ・ティ・ティ ピー・シー コミュニケーションズ | 匿名化処理装置、匿名化処理方法及びプログラム |
| US11030534B2 (en) * | 2015-01-30 | 2021-06-08 | Longsand Limited | Selecting an entity from a knowledge graph when a level of connectivity between its neighbors is above a certain level |
| CN104679848B (zh) * | 2015-02-13 | 2019-05-03 | 百度在线网络技术(北京)有限公司 | 搜索推荐方法和装置 |
| US10102291B1 (en) | 2015-07-06 | 2018-10-16 | Google Llc | Computerized systems and methods for building knowledge bases using context clouds |
| US10198491B1 (en) | 2015-07-06 | 2019-02-05 | Google Llc | Computerized systems and methods for extracting and storing information regarding entities |
| US10296527B2 (en) * | 2015-12-08 | 2019-05-21 | Internatioanl Business Machines Corporation | Determining an object referenced within informal online communications |
| CN107408116B (zh) | 2015-12-14 | 2021-02-02 | 微软技术许可有限责任公司 | 使用动态知识图谱来促进信息项的发现 |
| US10838992B2 (en) * | 2016-08-17 | 2020-11-17 | International Business Machines Corporation | Content selection for usage within a policy |
| US10423614B2 (en) | 2016-11-08 | 2019-09-24 | International Business Machines Corporation | Determining the significance of an event in the context of a natural language query |
| US10459960B2 (en) | 2016-11-08 | 2019-10-29 | International Business Machines Corporation | Clustering a set of natural language queries based on significant events |
| CN106610927B (zh) * | 2016-12-19 | 2021-03-16 | 厦门二五八网络科技集团股份有限公司 | 一种基于翻译模板的互联网文章的建构方法与系统 |
| CN106933808A (zh) * | 2017-03-20 | 2017-07-07 | 百度在线网络技术(北京)有限公司 | 基于人工智能的文章标题生成方法、装置、设备及介质 |
| CN107203509B (zh) * | 2017-04-20 | 2023-06-20 | 北京拓尔思信息技术股份有限公司 | 标题生成方法和装置 |
| US10762146B2 (en) * | 2017-07-26 | 2020-09-01 | Google Llc | Content selection and presentation of electronic content |
| JP6979899B2 (ja) * | 2017-09-20 | 2021-12-15 | ヤフー株式会社 | 生成装置、学習装置、生成方法、学習方法、生成プログラム、及び学習プログラム |
| US11809825B2 (en) | 2017-09-28 | 2023-11-07 | Oracle International Corporation | Management of a focused information sharing dialogue based on discourse trees |
| US10853574B2 (en) | 2017-09-28 | 2020-12-01 | Oracle International Corporation | Navigating electronic documents using domain discourse trees |
| JP7258047B2 (ja) | 2018-05-09 | 2023-04-14 | オラクル・インターナショナル・コーポレイション | 収束質問に対する回答を改善するための仮想談話ツリーの構築 |
| US20200026767A1 (en) * | 2018-07-17 | 2020-01-23 | Fuji Xerox Co., Ltd. | System and method for generating titles for summarizing conversational documents |
| CN110245204A (zh) * | 2019-06-12 | 2019-09-17 | 桂林电子科技大学 | 一种基于定位及知识图谱的智能推荐方法 |
| CN110377891B (zh) * | 2019-06-19 | 2023-01-06 | 北京百度网讯科技有限公司 | 事件分析文章的生成方法、装置、设备及计算机可读存储介质 |
| CN110532344A (zh) * | 2019-08-06 | 2019-12-03 | 北京如优教育科技有限公司 | 基于深度神经网络模型的自动选题系统 |
| US11580298B2 (en) | 2019-11-14 | 2023-02-14 | Oracle International Corporation | Detecting hypocrisy in text |
| JP7212642B2 (ja) * | 2020-03-19 | 2023-01-25 | ヤフー株式会社 | 情報処理装置、情報処理方法及び情報処理プログラム |
| CN111460801B (zh) * | 2020-03-30 | 2023-08-18 | 北京百度网讯科技有限公司 | 标题生成方法、装置及电子设备 |
| US20220318521A1 (en) * | 2021-03-31 | 2022-10-06 | Storyroom Inc. | System and method of headline generation using natural language modeling |
| US11947898B2 (en) | 2021-03-31 | 2024-04-02 | Storyroom Inc. | System and method of content brief generation using machine learning |
| US11816177B2 (en) * | 2021-07-21 | 2023-11-14 | Yext, Inc. | Streaming static web page generation |
| CN113569027B (zh) * | 2021-07-27 | 2024-02-13 | 北京百度网讯科技有限公司 | 一种文档标题处理方法、装置及电子设备 |
| US20230153341A1 (en) * | 2021-11-17 | 2023-05-18 | Adobe Inc. | Using neural networks to detect incongruence between headlines and body text of documents |
| US20240104055A1 (en) * | 2022-09-22 | 2024-03-28 | Microsoft Technology Licensing, Llc | Method and system of intelligently generating a title for a group of documents |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070213973A1 (en) | 2006-03-08 | 2007-09-13 | Trigent Software Ltd. | Pattern Generation |
| US20100138216A1 (en) | 2007-04-16 | 2010-06-03 | The European Comminuty, Represented By The European Commission | method for the extraction of relation patterns from articles |
| US8429179B1 (en) | 2009-12-16 | 2013-04-23 | Board Of Regents, The University Of Texas System | Method and system for ontology driven data collection and processing |
| US20130311462A1 (en) | 2012-05-15 | 2013-11-21 | Whyz Technologies Limited | Method and system relating to re-labelling multi-document clusters |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101079031A (zh) * | 2006-06-15 | 2007-11-28 | 腾讯科技(深圳)有限公司 | 一种网页主题提取系统和方法 |
| US8442969B2 (en) | 2007-08-14 | 2013-05-14 | John Nicholas Gross | Location based news and search engine |
| US8504490B2 (en) * | 2010-04-09 | 2013-08-06 | Microsoft Corporation | Web-scale entity relationship extraction that extracts pattern(s) based on an extracted tuple |
| CN102298576B (zh) * | 2010-06-25 | 2014-07-02 | 株式会社理光 | 文档关键词生成方法和装置 |
-
2013
- 2013-10-22 US US14/060,562 patent/US9619450B2/en active Active
-
2014
- 2014-03-04 EP EP14712898.7A patent/EP3014480A2/en not_active Withdrawn
- 2014-03-04 KR KR1020167002279A patent/KR102082886B1/ko active IP Right Grant
- 2014-03-04 KR KR1020207005313A patent/KR102094659B1/ko active IP Right Grant
- 2014-03-04 CN CN201480045648.9A patent/CN105765566B/zh active Active
- 2014-03-04 WO PCT/US2014/020436 patent/WO2014209435A2/en active Application Filing
- 2014-03-04 AU AU2014299290A patent/AU2014299290A1/en not_active Abandoned
- 2014-03-04 CA CA2916856A patent/CA2916856C/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070213973A1 (en) | 2006-03-08 | 2007-09-13 | Trigent Software Ltd. | Pattern Generation |
| US20100138216A1 (en) | 2007-04-16 | 2010-06-03 | The European Comminuty, Represented By The European Commission | method for the extraction of relation patterns from articles |
| US8429179B1 (en) | 2009-12-16 | 2013-04-23 | Board Of Regents, The University Of Texas System | Method and system for ontology driven data collection and processing |
| US20130311462A1 (en) | 2012-05-15 | 2013-11-21 | Whyz Technologies Limited | Method and system relating to re-labelling multi-document clusters |
Non-Patent Citations (2)
| Title |
|---|
| R. Barzilay et al., Learning to Paraphrase: An Unsupervised Approach Using Multiple-Sequence Alignment, Proc. of HLT-NAACL, pp.16-23 (2003.) 1부. |
| 이공주, 작은 화면 기기에서의 출력을 위한 신문기사 헤드라인 형식의 문장 축약 시스템, 정보처리학회논문지, 제12-B권 제6호, pp.691-696 (2005.10.) 1부. |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3014480A2 (en) | 2016-05-04 |
| WO2014209435A3 (en) | 2015-03-12 |
| WO2014209435A2 (en) | 2014-12-31 |
| CA2916856C (en) | 2022-06-21 |
| CN105765566B (zh) | 2019-04-16 |
| AU2014299290A1 (en) | 2016-01-07 |
| CN105765566A (zh) | 2016-07-13 |
| US9619450B2 (en) | 2017-04-11 |
| CA2916856A1 (en) | 2014-12-31 |
| KR20200022540A (ko) | 2020-03-03 |
| KR20160025007A (ko) | 2016-03-07 |
| KR102082886B1 (ko) | 2020-02-28 |
| US20150006512A1 (en) | 2015-01-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102094659B1 (ko) | 헤드라인의 자동 생성 | |
| US9576241B2 (en) | Methods and devices for customizing knowledge representation systems | |
| KR101793222B1 (ko) | 어플리케이션 검색들을 가능하게 하기 위해 사용되는 검색 인덱스의 업데이트 | |
| US10366107B2 (en) | Categorizing questions in a question answering system | |
| US20200042505A1 (en) | Methods and devices for customizing knowledge representation systems | |
| Collier | Uncovering text mining: A survey of current work on web-based epidemic intelligence | |
| US9996604B2 (en) | Generating usage report in a question answering system based on question categorization | |
| US9881077B1 (en) | Relevance determination and summary generation for news objects | |
| US9817908B2 (en) | Systems and methods for news event organization | |
| JP6404106B2 (ja) | コンテント及び関係距離に基づいて人々をつなげるコンピューティング装置及び方法 | |
| US9773166B1 (en) | Identifying longform articles | |
| Hoppe et al. | Corporate Semantic Web–Applications, Technology, Methodology: Summary of the Dagstuhl Workshop 2015 | |
| Arafat et al. | Analyzing public emotion and predicting stock market using social media | |
| US11809388B2 (en) | Methods and devices for customizing knowledge representation systems | |
| US11928437B2 (en) | Machine reading between the lines | |
| Xu et al. | An upper-ontology-based approach for automatic construction of IOT ontology | |
| JP2016197438A (ja) | 1人以上のユーザに関心ある情報を提供する方法及び装置 | |
| Pertsas et al. | Ontology-driven information extraction from research publications | |
| CA2886202C (en) | Methods and devices for customizing knowledge representation systems | |
| Dinani | Question Answering over Knowledge Graphs. | |
| Alajlan et al. | From semi-automated to automated methods of ontology learning from twitter data | |
| Lee et al. | On instant knowledge evolution from learning user search intent | |
| Python et al. | Natural Language Processing Recipes | |
| Wojtinnek | Generation and application of semantic networks from plain text and Wikipedia |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant |