KR101495240B1 - Method and system for statistical context-sensitive spelling correction using confusion set - Google Patents
Method and system for statistical context-sensitive spelling correction using confusion set Download PDFInfo
- Publication number
- KR101495240B1 KR101495240B1 KR20130081911A KR20130081911A KR101495240B1 KR 101495240 B1 KR101495240 B1 KR 101495240B1 KR 20130081911 A KR20130081911 A KR 20130081911A KR 20130081911 A KR20130081911 A KR 20130081911A KR 101495240 B1 KR101495240 B1 KR 101495240B1
- Authority
- KR
- South Korea
- Prior art keywords
- vocabulary
- context
- spelling error
- pair
- correction
- Prior art date
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/268—Morphological analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Pure & Applied Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Computational Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Operations Research (AREA)
- Software Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Machine Translation (AREA)
- Databases & Information Systems (AREA)
- Probability & Statistics with Applications (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Algebra (AREA)
Abstract
본 발명은 문맥 철자오류(context-sensitive spelling error) 교정을 위하여 미리 구축한 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 출현빈도에 바탕을 둔 통계적 언어모형을 이용하여 문맥 철자오류 교정의 정확도와 재현율 모두를 일정 수준 이상으로 유지할 수 있도록 한 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법에 관한 것으로, 문맥 철자오류를 검색하고 교정하기 위한 문장을 입력하는 입력부;입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 형태소 분석부;상기 형태소 분석부에서 분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 품사 태깅부;해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 연관성 분석부;상기 연관성 분석부에서 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하는 철자오류 교정부;를 포함하는 것이다.The present invention uses a statistical language model based on each vocabulary of a pair of corrected vocabulary pairs constructed in advance for context-sensitive spelling error correction and the occurrence frequency between vocabularies appearing in the surrounding context, The present invention relates to an apparatus and method for correcting a statistical context spelling error using a pair of corrective vocabulary words so as to maintain both a recall rate and a recall rate at a predetermined level or higher. The input apparatus includes an input unit for inputting sentences for searching and correcting context spelling errors, A morphological analysis unit for performing a morphological analysis for separating a word into morpheme units based on an analysis dictionary, a part-of-speech tagging unit for removing morphological features from the morphological features analyzed by the morphological analysis unit, And the relationship between the vocabulary in the surrounding context, using conditional probability and reliability. Correlation analysis unit for Chemistry; intended to include; misspelling calibration unit for determining whether spelling errors and correcting a spelling error by using the value derived from said correlation analyzer.
Description
본 발명은 문맥 철자오류(context-sensitive spelling error) 교정에 관한 것으로, 구체적으로 미리 구축한 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 출현빈도에 바탕을 둔 통계적 언어모형을 이용하여 문맥 철자오류 교정의 정확도와 재현율 모두를 일정 수준 이상으로 유지할 수 있도록 한 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법에 관한 것이다.The present invention relates to context-sensitive spelling error correction. Specifically, a context-sensitive spelling error correction is performed by using a statistical language model based on the frequency of occurrence of each vocabulary in the pre- And more particularly, to a device and method for correcting a statistical context spelling error using a pair of correction words so that both the accuracy of error correction and the recall rate can be maintained at a certain level or more.
컴퓨터, 인터넷과 스마트폰(smart phone)이 융합된 정보환경은 SNS(social network service)를 비롯한 새로운 정보유통 환경을 구축하였고, 모든 사람이 정보의 생산자이자 소비자가 되었다. 이에 따라 실수든 의도적이든 또는 무지든 문서에 포함된 철자 오류는 더욱 증가하고 있다.The information environment in which the computer, the Internet and the smart phone converge has established a new information distribution environment including social network service (SNS), and everyone has become a producer and consumer of information. As a result, spelling mistakes that are included in a document, whether accidental, intentional or unintentional, are increasing.
여기에 더해 두벌식 자판, 세벌식 자판, 스마트폰과 피처폰(feature phone; 일반 휴대전화) 등 다양한 입력 환경에 따라 입력 오류의 형태도 다양한 다른 특성을 보이면서 발생하고 있다. 여기에 더해 한류, 국제결혼의 증가와 같은 국제화에 따라 한국어를 사용하거나 배우는 외국인이 크게 늘고 있다.In addition to this, according to various input environments, such as two-word keyboard, three-word keyboard, smart phone and feature phone, the type of input error is occurring with different characteristics. In addition, there are a growing number of foreigners who use or learn Korean according to internationalization, such as the increasing number of Korean marriages and international marriages.
이런 환경 변화에 따라 한국어 문서 교정기의 성능 향상에 대한 요구가 증대하고 있다.Due to such changes in the environment, there is an increasing demand for improvement of the performance of the Korean document calibrator.
그런데 기존의 규칙에 기반을 둔 철자 검사 기술로는 이런 변화에 적응하는 문서 교정기를 개발하기는 불가능하다. 그 가장 큰 이유는 '문맥 철자오류'가 현재 해결해야 할 중요한 대상이지만, 기존 문서 교정기는 규칙에 기반을 둔 접근이므로 한국어 사용자가 자주 틀리는 정형화된 문맥 철자오류 외에는 고칠 수 없기 때문이다. However, with spell checking technology based on existing rules, it is impossible to develop document calibrators that adapt to these changes. The main reason is that 'context spelling error' is an important object to be solved at present, but the existing document corrector is a rule-based approach, so Korean users can not fix other than formalized spelling mistakes that are frequently wrong.

일반적으로 한국어 문장에서 나타나는 오류어의 유형은 크게 단순 철자오류(non-word spelling error)와 문맥 철자오류로 구분할 수 있다.In general, the types of error words appearing in Korean sentences can be classified into non-word spelling errors and context spelling errors.
전자는 '결죄'와 같이 사전에 등재되지 않은 어휘를 사용한 오류로서 텍스트를 형태적으로 분석하는 것만으로 쉽게 오류어를 검색할 수 있다. 반면에 후자는 '요금 결재'의 '결재'와 같이 문맥의 의미통사적 관계를 고려해야만 해당 어휘의 오류 여부를 알 수 있다.The former is an error using a vocabulary that is not listed before, such as 'a sentence.' It is easy to search for an error word simply by analyzing the text morphologically. On the other hand, the latter can only know whether the vocabulary is erroneous by taking into account the semantic and syntactic relationship of the context, such as the 'settlement' of 'payment'.
표 1은 문맥 철자 오류의 유형을 구분한 것으로, 문맥 철자 오류를 교정하는 방법은 크게 규칙을 이용한 방법과 통계적 방법으로 나뉜다.Table 1 summarizes the types of context spelling errors. The method for correcting context spelling errors is divided into two groups: rules and statistical methods.
규칙을 이용한 방법은 사람이 직접 규칙을 만드는 방법과 기계 학습을 이용하는 방법으로 나뉜다.The rule-based method is divided into two methods, one is to create rules directly and the other is to use machine learning.
통계적 문맥 철자 오류 검사와 교정 방법은 영어를 대상으로 활발히 연구되었으며, 다음과 같이 크게 3가지를 들 수 있다. The statistical context spelling error checking and correction methods have been studied actively in English.
첫 번째는 교정 어휘 쌍을 이용한 방법으로 기본적으로 어의 중의성 해결(word sense disambiguation, WSD) 방식과 같은 방법론을 이용한다. 즉, 교정 어휘 쌍에 해당하는 단어가 중의적이라 보고, 통계적 방법으로 중의성을 해결한 후 그 결과와 원래 단어가 같으면 철자가 바르다고 보고, 아니면 문맥 철자 오류로 본다. The first is a method using a pair of calibration lexicons and basically uses the same methodology as word sense disambiguation (WSD). In other words, if the word corresponding to the correction lexical pair is an ambiguous word and the ambiguity is solved by a statistical method, then if the result is the same as the original word, the word is spelled correctly or it is regarded as a spelling error.
두 번째 방법은 n-gram에 기반을 둔 언어모형을 사용하는 것이다. 이 방법은 대용량 말뭉치에서 어절 n-gram을 구하고, 이를 바탕으로 각 문장 또는 부분 문장의 확률을 계산한다. 그리고 그 문장 또는 부분 문장에서 빈도가 낮은 n-gram 중 철자 오류로 생성될 수 있으면서 확률이 높은 n-gram으로 대치한 문장이나 부분 문장의 확률을 원래 확률과 비교하여 문맥 철자 오류를 찾는 방법이다. The second method is to use a n-gram based language model. This method computes the probability of each sentence or partial sentence based on the obtained word n-gram in a large corpora. In the sentence or partial sentence, the probability of a sentence or a partial sentence that is generated by a spelling error in a low-frequency n-gram is compared with the original probability by a probability n-gram.
세 번째 방법은 문서 전체를 분석하여 사용된 어휘가 문맥상으로 일관성을 유지하는지를 검증하는 방법이다. 이 방법은 어휘 간의 관계를 분석하기 위한 일종의 지식베이스가 필요하다. The third method is to analyze the entire document to verify that the used vocabulary is consistent in context. This method requires a kind of knowledge base for analyzing the relationship between vocabularies.
그러나 이와 같은 통계적 문맥 철자 오류 검사와 교정 방법은 교정 결과의 정확도와 재현율이 크기 떨어지거나, 실제 구현이 어려운 문제가 있다.However, such statistical context spelling error checking and calibration methods have a problem that the accuracy and recall rate of the calibration result are reduced or the actual implementation is difficult.
특히, 문맥 철자오류 유형 중 가장 빈번하게 발생하는 오류는 오타에 의해 발생하는 오류이다.Especially, the most frequently occurring type of context spelling error is an error caused by typos.
예를 들어, 자판을 이용하여 "오류 교정"을 입력할 때 글쇠 위치가 가까워 "오류 교정"을 "오류 고정"으로 입력할 수 있다. 그런데 "교정"에서 "ㅛ"를 위에 있는 "ㅗ"로 잘못 입력한 결과가 우리가 사용하는 단어인 "고정"이 되어 의미 분석 없이 이 오류를 찾기는 쉽지 않다.For example, when typing "Error Correction" using keyboard, you can enter "Error Correction" as "Error Correction" because the key position is near. However, it is not easy to find this error without semantic analysis because the result of erroneously typing "ㅛ" in "Correction" to "ㅗ" above is "fixed"
"교정"은 편집거리 1인 "고정", "교장", "교전", "교종" 따위로 잘못 입력되어도 오류를 교정하려면 의미 분석이 필요하다. 하지만 현재 개발된 의미분석 기술로 문맥 철자 오류를 교정하는 것은 불가능하다."Correction" requires semantic analysis to correct an error even if it is mistakenly entered as an edit distance of 1 "fixed", "principal", "engaged", "gifted" However, it is impossible to correct context spelling errors with the currently developed semantic analysis technology.
본 발명은 이와 같은 종래 기술의 문맥 철자 오류 검사와 교정 방법의 문제를 해결하기 위한 것으로, 미리 구축한 교정 어휘 쌍을 이용하여 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 출현빈도에 바탕을 둔 통계 모형을 이용하여 문맥 철자오류를 검색하고 교정하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법을 제공하는데 그 목적이 있다.The present invention solves the problems of the context spelling error checking and correcting method of the related art as described above. It is based on the occurrence frequency of each vocabulary in the corrected vocabulary pair and surrounding vocabulary using a pair of calibration vocabulary constructed in advance And to provide a statistical context spelling error correction apparatus and method using a pair of correction lexical elements for searching and correcting context spelling errors using a statistical model.
본 발명은 미리 구축한 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 출현빈도에 바탕을 둔 통계적 언어모형을 이용하여 문맥 철자오류 교정의 정확도와 재현율 모두를 일정 수준 이상으로 유지할 수 있도록 한 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법을 제공하는데 그 목적이 있다.The present invention uses a statistical language model based on the vocabulary occurrence frequency of each of the vocabulary words and the surrounding contexts of the previously constructed correction vocabulary pairs to correct both the accuracy of the spelling error correction and the recall rate, The present invention provides a device and method for correcting a spelling error in a statistical context using a lexical pair.
본 발명은 오타 발생률(typing error rate)에 바탕을 둔 신뢰도를 이용하여 문맥 철자오류 교정의 정확도를 일정 수준 이상으로 유지하면서, 문맥 철자오류 검색과 교정에 이용하는 주변 문맥 어휘의 범위를 제한하면서 문맥 철자오류를 검색하고 교정하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법을 제공하는데 그 목적이 있다.The present invention utilizes the reliability based on the typing error rate to maintain the accuracy of the context spelling error correction to a certain level or more, while limiting the scope of the surrounding context vocabulary used for context spelling error detection and correction, And to provide a statistical context spelling error correction apparatus and method using a pair of correction lexical items for detecting and correcting errors.
본 발명의 목적들은 이상에서 언급한 목적들로 제한되지 않으며, 언급되지 않은 또 다른 목적들은 아래의 기재로부터 당업자에게 명확하게 이해될 수 있을 것이다.The objects of the present invention are not limited to the above-mentioned objects, and other objects not mentioned can be clearly understood by those skilled in the art from the following description.
이와 같은 목적을 달성하기 위한 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치는 문맥 철자오류를 검색하고 교정하기 위한 문장을 입력하는 입력부;입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 형태소 분석부;상기 형태소 분석부에서 분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 품사 태깅부;해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 연관성 분석부;상기 연관성 분석부에서 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하는 철자오류 교정부;를 포함하는 것을 특징으로 한다.According to an aspect of the present invention, there is provided a statistical context spelling error correcting apparatus using a pair of corrective vocabularies according to the present invention includes an input unit for inputting sentences for searching and correcting context spelling errors, A morphological analyzing unit for performing a morphological analysis for separating a morpheme into morpheme units, a morphological analyzing unit for morphologically analyzing the morpheme unit, A correlation analyzing unit for quantifying the inter-correlation using the conditional probability and the reliability, and a spelling error gauge for determining whether the spelling error is correct using the numerical value derived from the correlation analyzing unit, and correcting the spelling error .
여기서, 상기 철자오류 교정부는, 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 조건부 확률값과 오타율에 기반을 둔 신뢰도의 곱을 이용하여 문맥 철자오류 교정을 수행하는 것을 특징으로 한다.Here, the spelling error correction unit corrects the spelling error correction using the product of the conditional probability value between the vocabulary terms and the mistake rate based on each vocabulary of the correction vocabulary pair and the surrounding context in the context spelling error correction process using the correction vocabulary pair .
그리고 상기 철자오류 교정부는, 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 오타율에 기반을 둔 신뢰도를 변화시켜 교정의 정확도와 재현율을 조절하는 것을 특징으로 한다.In addition, the spelling error correction unit adjusts the accuracy and recall rate of the calibration by changing the reliability based on the misty rate in the context spelling error correction process using the correction lexical pair.
그리고 상기 연관성 분석부는, 조건부 확률값을 구할 때, 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 의미 연관성이 일정값을 넘지 않을 때는 해당 어휘는 제외하는 것을 특징으로 한다.When the conditional probability value is found, the association analyzing unit excludes the corresponding vocabulary when the semantic relation between the vocabulary in the correction vocabulary pair and the vocabulary in the surrounding context does not exceed a predetermined value.
그리고 상기 연관성 분석부는, 조건부 확률값을 구할 때, 주변 문맥에 나타나는 어휘를 교정 어휘 쌍의 각 어휘가 발생한 위치를 기준으로 윈도우 크기(window size)를 이용하여 선별하는 것을 특징으로 한다.When the conditional probability value is found, the association analyzing unit selects a vocabulary appearing in the surrounding context by using a window size based on a position where each vocabulary of the calibration vocabulary pair is generated.
그리고 상기 연관성 분석부는, 윈도우 크기(window size)를 고정하지 않고 동적으로 구하면서 주변 문맥에 나타나는 어휘를 선별하는 것을 특징으로 한다.The association analyzer may dynamically obtain a window size without fixing the window size, and select vocabularies appearing in the surrounding context.
다른 목적을 달성하기 위한 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 방법은 문맥 철자오류를 검색하고 교정하기 위한 문장을 입력하는 단계;입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 단계;분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 단계;해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 단계;정량화하여 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하는 단계;를 포함하는 것을 특징으로 한다.According to another aspect of the present invention, there is provided a method for correcting a spelling error in a statistical context using a calibration word pair, the method comprising: inputting a sentence for searching and correcting a spelling error; The morphological analysis that separates morphemes into morpheme units, the morphological elimination of morphemes when the morphemes of the analyzed morphemes are generated, the correlation between the vocabularies of the vocabulary and the surrounding contexts by using conditional probability and reliability And quantifying the spelling error, determining whether the spelling error is correct using the numerical value, and correcting the spelling error.
여기서, 상기 해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 단계에서,Here, in the step of quantifying the correlation between the vocabulary and the surrounding vocabulary using the conditional probability and the reliability,
나이브베이즈(naive bayes)를 이용하여 '교정 어휘 쌍' 중 문맥에 해당하는 어휘를 선택하는 방법을 수식화하면,By using the naive bayes to formulate a way to select the vocabulary corresponding to the context of the 'correction lexical pair'
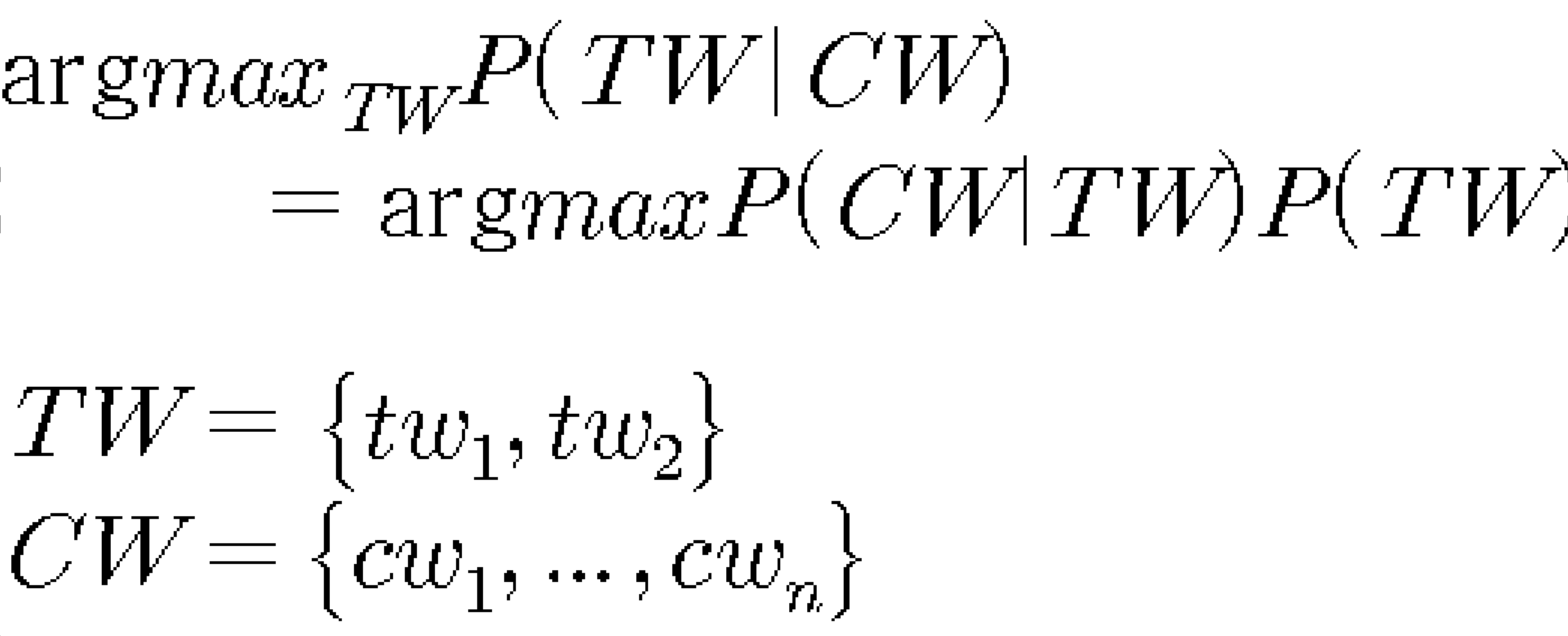
상기 사전 확률을 오타 발생률로 보고 수식을 정리하면,
이와 같은 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법은 다음과 같은 효과를 갖는다.The apparatus and method for correcting a statistical context spelling error using the corrected vocabulary pair according to the present invention have the following effects.
첫째, 미리 구축한 교정 어휘 쌍을 이용하여 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 출현빈도에 바탕을 둔 통계 모형을 이용하여 문맥 철자오류를 검색하고 교정할 수 있다.First, we can retrieve and correct context spelling errors using a statistical model based on the frequency of occurrence of each vocabulary in the correction vocabulary pair and the vocabulary in the surrounding context by using a pair of calibration vocabulary constructed in advance.
둘째, 통계적 언어모형을 이용하여 문맥 철자오류 교정의 정확도와 재현율 모두를 일정 수준 이상으로 유지할 수 있다.Second, the accuracy and recall of context spelling error correction can be maintained above a certain level by using statistical language model.
셋째, 오타 발생률(typing error rate)에 바탕을 둔 신뢰도를 이용하여 문맥 철자오류 교정의 정확도를 일정 수준 이상으로 유지할 수 있다.Third, accuracy of context spelling error correction can be maintained above a certain level by using reliability based on typing error rate.
넷째, 한국어 문서 교정 과정에서 가장 난도가 높은 문맥 철자오류를 교정함으로써 좁게는 한국어 문서 교정기의 성능을 높일 수 있다.Fourth, it is possible to improve the performance of the Korean document corrector narrowly by correcting the most difficult spelling errors in the Korean document revision process.
다섯째, 한국어 정보검색과 정보추출, 한국어 사용자 인터페이스, 기계번역, 자동통역 등 다양한 한국어 관련 응용 시스템의 기반 기술로 활용할 수 있다.Fifth, it can be utilized as a base technology of various Korean related application systems such as Korean information retrieval and information extraction, Korean user interface, machine translation, and automatic interpretation.
여섯째, 다양한 한국어 관련 응용 시스템이 최적의 성능을 낼 수 있게 함으로써 사용자 만족도를 높이면서 새로운 응용을 창출하게 하는 효과가 있다.
Sixth, various Korean related application systems can achieve optimum performance, thereby enhancing user satisfaction and creating new applications.
도 1은 본 발명에 따른 문맥 철자오류 교정 장치의 구성도
도 2는 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 방법을 나타낸 플로우 차트1 is a block diagram of a context spelling error correcting apparatus according to the present invention;
FIG. 2 is a flowchart showing a method of correcting a statistical context spelling error using a pair of calibration words according to the present invention.
이하, 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법의 바람직한 실시 예에 관하여 상세히 설명하면 다음과 같다.Hereinafter, a preferred embodiment of a statistical context spelling error correcting apparatus and method using a pair of corrective vocabularies according to the present invention will be described in detail.
본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법의 특징 및 이점들은 이하에서의 각 실시 예에 대한 상세한 설명을 통해 명백해질 것이다.The features and advantages of the apparatus and method for statistical context spelling error correction using a pair of calibration vocabularies according to the present invention will be apparent from the following detailed description of each embodiment.
도 1은 본 발명에 따른 문맥 철자오류 교정 장치의 구성도이고, 도 2는 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 방법을 나타낸 플로우 차트이다.FIG. 1 is a block diagram of a context spelling error correcting apparatus according to the present invention, and FIG. 2 is a flowchart illustrating a statistical context spelling error correcting method using a pair of corrective words according to the present invention.
본 발명은 사용자가 입력한 한국어 문장에서 나타나는 여러 맞춤법 문법 오류 중에서 사전(事典) 검색을 통해 해결할 수 없는 문맥철자오류(context-sensitive spelling error)를 검색하고, 이를 교정할 대치어를 제시하는 문맥 철자오류 교정 장치 및 그 방법에 관한 것이다.The present invention relates to a method and apparatus for detecting a context-sensitive spelling error that can not be solved through dictionary search among a plurality of spelling grammar errors appearing in a Korean sentence input by a user, And an error correction apparatus and method thereof.
문맥 철자오류의 처리를 위한 연구는 크게 규칙을 이용한 방법과 통계적 방법으로 나눌 수 있다.The study on the processing of context spelling errors can be broadly divided into a rule-based method and a statistical method.
규칙을 이용한 방법은 통계적 방법과 비교하면 정확도(precision)는 높지만, 재현율(recall)은 낮다. 이론적으로 정확도와 재현율은 반대로 움직이기 때문에, 정확도를 높이는 방법은 재현율의 감소를 동반한다.The rule-based method has a higher precision than the statistical method, but a lower recall. Theoretically, accuracy and recall rate move inversely, so the method of increasing accuracy is accompanied by a decrease in recall.
맞춤법에 관한 지식이 없는 일반 사용자는 정확도가 높은 방법을 선호하겠지만, 교과서나 도서 교열을 담당하는 전문가는 정확도가 너무 떨어져 불편한 정도가 아니라면 오류 검색과 대치어 제시가 최대한으로 이루어지기를 원한다.Regular users without knowledge of spelling will prefer a method with a high degree of accuracy, but experts in textbooks or book chapters want to maximize error detection and substitution unless the accuracy is too low.
즉, 정확도가 어느 정도 유지되는 선에서 재현율이 높아지기를 원한다. 본 발명은 문맥 철자오류 교정의 정확도와 재현율 모두를 일정 수준 이상으로 유지하면서 재현율을 높이기 위해 통계적 언어모형을 이용하여 문맥 철자오류를 교정할 수 있도록 한 것이다.That is, we want to increase the recall rate on the line where accuracy is maintained to some extent. The present invention allows correction of context spelling errors using a statistical language model in order to increase the recall rate while maintaining both the accuracy and the recall rate of the context spelling error correction at a certain level or more.
이를 위한 본 발명은 통계적 문맥 철자오류 교정을 위하여 "교정 어휘 쌍"을 이용하는 것이다.For this purpose, the present invention utilizes a "correction lexical pair" for statistical context spelling error correction.
이를 위한 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치는 도 1에서와 같이, 문맥 철자오류를 검색하고 교정하기 위한 문장을 입력하는 입력부(101)와, 입력부(101)를 통해 입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 형태소 분석부(102)와, 형태소 분석부(102)에서 분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 품사 태깅부(103)와, 해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 연관성 분석부(104)와, 연관성 분석부(104)에서 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하여 출력부(106)로 교정 결과를 보내는 철자오류 교정부(105)를 포함한다.As shown in FIG. 1, an apparatus for correcting a statistical context spelling error using a pair of calibration words according to the present invention includes an
여기서, 철자오류 교정부(105)는 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 조건부 확률값과 오타율에 기반을 둔 신뢰도의 곱을 이용하여 문맥 철자오류 교정을 수행한다.Here, the spelling
그리고 철자오류 교정부(105)는 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 오타율에 기반을 둔 신뢰도를 변화시켜 교정의 정확도와 재현율을 조절할 수 있다.And the spelling
그리고 연관성 분석부(104)는 조건부 확률값을 구할 때, 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 의미 연관성이 일정값을 넘지 않을 때는 해당 어휘는 제외한다.When the conditional probability value is obtained, the
그리고 연관성 분석부(104)는 조건부 확률값을 구할 때, 주변 문맥에 나타나는 어휘를 교정 어휘 쌍의 각 어휘가 발생한 위치를 기준으로 윈도우 크기(window size)를 이용하여 선별한다.When the conditional probability value is found, the
여기서, 윈도우 크기(window size)를 고정하지 않고 동적으로 구하면서 주변 문맥에 나타나는 어휘를 선별하는 것도 가능하다.Here, it is also possible to select vocabulary appearing in the surrounding context while dynamically calculating the window size without fixing it.
이와 같은 본 발명에 따른 문맥 철자오류 교정 장치에서의 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정은 다음과 같은 방법으로 이루어진다.In the context spelling error correcting apparatus according to the present invention, the statistical context spelling error correction using the pair of correction words is performed by the following method.
도 2에서와 같이, 문맥 철자오류를 검색하고 교정하기 위한 문장을 입력하는 단계(S201)와, 입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 단계(S202)와, 분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 단계(S203)와, 해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 단계(S204)와, 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하고(S205), 교정 결과를 출력하는 단계(S206)를 포함한다.As shown in FIG. 2, a step (S201) of inputting a sentence to search for and correct a context spelling error (S201) and a morpheme analysis for dividing the input sentence into morpheme units based on a morpheme dictionary (S203) of removing morphological features from the morpheme if the morpheme ambiguity of the analyzed morpheme is generated (S203), quantifying the association between the vocabulary and the surrounding vocabulary using the conditional probability and reliability S204), judging whether or not a spelling error is found by using the derived numerals, correcting the spelling error (S205), and outputting the calibration result (S206).
여기서, 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 조건부 확률값과 오타율에 기반을 둔 신뢰도의 곱을 이용하여 문맥 철자오류 교정을 수행한다.Here, context spelling error correction is performed by using the product of the conditional probability value between the vocabulary words and the reliability based on the misspellings in each of the vocabulary of the correction vocabulary pair and the surrounding context in the context spelling error correction process using the correction vocabulary pair.
그리고 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 오타율에 기반을 둔 신뢰도를 변화시켜 교정의 정확도와 재현율을 조절할 수 있다.In addition, it is possible to control the accuracy and recall of the calibration by changing the reliability based on the error rate in the context spelling error correction process using the correction lexical pair.
그리고 조건부 확률값을 구할 때, 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 의미 연관성이 일정값을 넘지 않을 때는 해당 어휘는 제외한다. 조건부 확률값을 구할 때, 주변 문맥에 나타나는 어휘를 교정 어휘 쌍의 각 어휘가 발생한 위치를 기준으로 윈도우 크기(window size)를 이용하여 선별한다.When a conditional probability value is obtained, the corresponding vocabulary is excluded when the semantic relation between the vocabulary and the vocabulary in the surrounding context is not more than a predetermined value. When the conditional probability value is obtained, the vocabulary appearing in the surrounding context is selected using the window size based on the position of each vocabulary of the correction vocabulary pair.
여기서, 윈도우 크기(window size)를 고정하지 않고 동적으로 구하면서 주변 문맥에 나타나는 어휘를 선별하는 것도 가능하다.Here, it is also possible to select vocabulary appearing in the surrounding context while dynamically calculating the window size without fixing it.
이상에서 설명한 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법에 관하여 좀더 구체적으로 설명하면 다음과 같다.The apparatus and method for correcting a statistical context spelling error using the pair of corrected vocabularies according to the present invention will be described in more detail as follows.
본 발명은 편집거리 1(edit distance)에 해당하는 어휘들을 '교정 어휘 쌍'으로 선정하고, '교정 어휘 쌍'의 어휘들과 문맥에 나타난 공기 어휘 간 확률을 계산하여 문맥 철자오류를 검색하고 교정한다.The present invention selects vocabularies corresponding to the
편집거리는 일반적으로 하나의 문자열을 다른 문자열로 변환할 때 필요한 최소한의 연산의 개수를 의미한다.The edit distance is usually the minimum number of operations required to convert one string to another.
수학식 1의 수식은 나이브베이즈(naive bayes)를 이용하여 '교정 어휘 쌍' 중 문맥에 해당하는 어휘를 선택하는 방법을 수식화한 것이다.The formula in

수학식 1에서 TW(target words)는 교정 어휘 쌍이고, tw1과 tw2는 편집거리 1에 해당하는 어휘이다. CW(context words)는 교정 어휘 쌍과 함께 나타나는 문맥 정보이다.In the equation (1), TW (target words) is a pair of calibration words, and tw 1 and tw 2 are vocabularies corresponding to an edit distance of 1. CW (context words) are contextual information that appears with a pair of calibration lexicals.
나이브베이즈에 의해 사후 확률(posterior probability) P(CW|TW)는 tw와 CW 간 조건부 확률로 계산할 수 있다. 그리고 사전 확률(prior probability) P(TW)는 TW의 발생빈도로 계산할 수 있다.The posterior probability P (CW | TW) by the Naive Bayes can be calculated by the conditional probability between tw and CW. And the prior probability P (TW) can be calculated by the occurrence frequency of TW.
나이브베이즈에 의한 문맥 철자오류 교정은 특정 단어 자체의 발생 빈도를 사전 확률로 사용하기 때문에 교정 어휘 쌍의 어휘 중 발생 빈도가 높은 어휘에 유리하게 작용한다.Since the contextual spelling error correction by Naive Bayes uses the probability of occurrence of a certain word itself in advance, it is advantageous for the vocabulary which occurs frequently in the correction vocabulary pair.
본 발명에서는 사전 확률을 오타 발생률로 보고 수식을 다음과 같이 수학식 2에서와 같이 변경하여 정의한다.In the present invention, the pre-probability is reported as a rate of occurrence of a typo, and the formula is modified as shown in Equation (2) as follows.

CR(credibility reliability)은 어휘의 신뢰도이고, CR (credibility reliability) is the reliability of the vocabulary,
교정 어휘 쌍의 어휘 중 문맥 철자오류 발생 여부를 검사하는 문맥에 나타난 대상어에는 CR의 신뢰도를 대치어에는 1-CR의 신뢰도롤 부여한다.Among the vocabularies of the correction vocabulary pair, the reliability of the CR is assigned to the target word in the context of checking the occurrence of the context spelling error, and the reliability roll of 1-CR is assigned to the substitute word.
이는 기존 발표된 오타 발생률이 0.95%로서 매우 낮으므로 실제 텍스트에 쓰인 단어가 오류가 아닐 확률이 높기 때문이다. 위 수학식 2에서 CR의 값에 따라 문맥 철자오류 교정의 정확도와 재현율이 달라질 수 있다. This is because the rate of occurrence of a typo is 0.95%, which is very low, so words used in actual text are not likely to be errors. In the above equation (2), the accuracy and recall rate of the context spelling error correction may vary depending on the value of CR.
나이브베이즈에서와 같이 사후 확률(posterior probability) P(CW|TW)는 tw와 CW 간 조건부 확률로 계산할 수 있다. 이때, CW의 모든 단어를 이용하여 사후 확률을 계산하지는 않는다. 왜냐하면, tw에서 멀리 떨어져서 발생하는 단어일수록 tw에 영향을 덜 미치기 때문이다.As in Naive Bay, the posterior probability P (CW | TW) can be calculated by the conditional probability between tw and CW. At this time, posterior probabilities are not calculated using all the words of CW. Because words that occur farther from tw are less affected by tw.
또한, 윈도우 크기(windows size)를 특정값으로 고정하지 않고 동적으로 윈도우 크기(windows size)를 정하기 위해 부분적인 구문 분석을 수행하여 tw와 같은 구에 위치한 cw만 이용하도록 한다.In addition, we do partial parsing to dynamically set the window size without fixing the window size to a specific value, and use only cw located in the sphere such as tw.
부분적인 구문 분석은 구를 찾는 방법으로서 tw를 기준으로 tw에 선행하는 동사의 바로 다음 어절부터 tw에 후행하는 동사까지의 cw만 문맥 철자오류 교정에 이용한다.Partial parsing is a way to find phrases. Only cw from the immediately following verb of the tw preceding the ver to the verb following the tw is used to correct the spelling error.
이와 같은 본 발명에 따른 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치 및 방법은 사용자가 입력한 한국어 문장에서 나타나는 여러 맞춤법 문법 오류 중에서 사전(事典) 검색을 통해 해결할 수 없는 문맥철자오류(context-sensitive spelling error)를 검색하고, 이를 교정할 대치어를 제시하는 것이다. 이를 위하여 미리 구축한 교정 어휘 쌍을 이용하여 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 출현빈도에 바탕을 둔 통계 모형을 이용하여 문맥 철자오류를 검색하고 교정하는 것이다.The apparatus and method for correcting statistical context spelling errors using the corrective lexical pair according to the present invention can be applied to context-sensitive spelling errors that can not be solved through dictionary search among a plurality of spelling grammar errors appearing in a Korean sentence input by a user spelling error, and propose a replacement word to correct it. To do this, we use a pre - constructed calibration lexical pair to retrieve and correct the spelling errors using a statistical model based on the frequency of occurrence of each vocabulary in the corrected vocabulary pair and the vocabulary in the surrounding context.
이상에서의 설명에서와 같이 본 발명의 본질적인 특성에서 벗어나지 않는 범위에서 변형된 형태로 본 발명이 구현되어 있음을 이해할 수 있을 것이다.As described above, it will be understood that the present invention is implemented in a modified form without departing from the essential characteristics of the present invention.
그러므로 명시된 실시 예들은 한정적인 관점이 아니라 설명적인 관점에서 고려되어야 하고, 본 발명의 범위는 전술한 설명이 아니라 특허청구 범위에 나타나 있으며, 그와 동등한 범위 내에 있는 모든 차이점은 본 발명에 포함된 것으로 해석되어야 할 것이다.It is therefore to be understood that the specified embodiments are to be considered in an illustrative rather than a restrictive sense and that the scope of the invention is indicated by the appended claims rather than by the foregoing description and that all such differences falling within the scope of equivalents thereof are intended to be embraced therein It should be interpreted.
101. 입력부 102. 형태소 분석부
103. 품사 태깅부 104. 연관성 분석부
105. 철자 오류 교정부 106. 출력부101.
103. Part of the tagging
105. Spelling
Claims (9)
입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 형태소 분석부;
상기 형태소 분석부에서 분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 품사 태깅부;
해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 연관성 분석부;
상기 연관성 분석부에서 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하고, 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 오타율에 기반을 둔 신뢰도를 변화시켜 교정의 정확도와 재현율을 조절하는 철자오류 교정부;를 포함하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치.An input unit for inputting a sentence for retrieving and correcting a context spelling error;
A morphological analysis unit for performing a morphological analysis on the inputted sentence based on morphological analysis dictionary and separating the morpheme into morpheme units;
A speech tagging unit that removes the morpheme from the morpheme analyzed when the morpheme analyzer analyzes the morpheme analyzed by the morpheme analysis unit;
A correlation analyzing unit for quantifying the correlation between the vocabulary and the surrounding vocabulary using the conditional probability and reliability;
Using the numerical values derived from the association analysis unit, it is judged whether or not the spelling error is correct, the spelling error is corrected, and in the context spelling error correction process using the correction lexical pair, the reliability based on the misty rate is changed to adjust the accuracy and recall rate And a spelling error correcting unit for correcting the spelling error of the statistical context spelling error correcting unit.
교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 조건부 확률값과 오타율에 기반을 둔 신뢰도의 곱을 이용하여 문맥 철자오류 교정을 수행하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치.The apparatus of claim 1, wherein the spelling error correction unit comprises:
Wherein the context spelling error correction is performed by using the product of the conditional probability value between the vocabulary and the mistake rate based on each vocabulary of the correction vocabulary pair and the surrounding context in the context spelling error correction process using the correction vocabulary pair, A statistical context spelling error correction device using pairs.
조건부 확률값을 구할 때, 교정 어휘 쌍의 각 어휘와 주변 문맥에 나타난 어휘 간 의미 연관성이 일정값을 넘지 않을 때는 해당 어휘는 제외하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치.The apparatus according to claim 1,
Wherein the vocabulary is excluded when the semantic relation between the vocabulary of the correction vocabulary pair and the vocabulary in the surrounding context does not exceed a predetermined value when the conditional probability value is obtained.
조건부 확률값을 구할 때, 주변 문맥에 나타나는 어휘를 교정 어휘 쌍의 각 어휘가 발생한 위치를 기준으로 윈도우 크기(window size)를 이용하여 선별하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치.The apparatus according to claim 1,
Wherein when a conditional probability value is obtained, a vocabulary appearing in a surrounding context is selected by using a window size based on a position where each vocabulary of a correction vocabulary pair is generated, and a statistical context spelling error correction device .
윈도우 크기(window size)를 고정하지 않고 동적으로 구하면서 주변 문맥에 나타나는 어휘를 선별하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 장치.6. The apparatus according to claim 5,
Wherein the vocabulary displayed in the surrounding context is selected while dynamically calculating the window size without fixing the window size.
입력된 문장에 대하여 형태소 분석 사전에 기반을 두고 어절을 형태소 단위로 분리해내는 형태소 분석을 수행하는 단계;
분석된 형태소 중 형태소 중의성이 발생하면 형태소 중의성 제거를 하는 단계;
해당 어휘와 주변 문맥에 나타난 어휘 간 연관성을 조건부 확률과 신뢰도를 이용하여 정량화하는 단계;
정량화하여 도출한 수치를 이용하여 철자오류 여부를 판단하고 철자오류를 교정하고, 교정 어휘 쌍을 이용한 문맥 철자오류 교정 과정에서 오타율에 기반을 둔 신뢰도를 변화시켜 교정의 정확도와 재현율을 조절하는 단계;를 포함하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 방법.Inputting a sentence for searching and correcting a context spelling error;
Performing morpheme analysis on the inputted sentence based on the morpheme dictionary and dividing the word into morpheme units;
Removing morphologic impurities from the analyzed morphemes if they occur;
Quantifying the association between the vocabulary and the surrounding vocabulary using the conditional probability and reliability;
Determining accuracy of spelling errors by using numerical values derived by quantification, correcting spelling errors, and adjusting accuracy and recall of calibration by varying reliability based on misspellings in a context spelling error correction process using calibration word pairs; And a correcting unit for correcting the spelling error of the statistical context using the calibration word pair.
나이브베이즈(naive bayes)를 이용하여 '교정 어휘 쌍' 중 문맥에 해당하는 어휘를 선택하는 방법을 수식화하면,

나이브베이즈에 의해 사후 확률(posterior probability) P(CW|TW)는 tw와 CW 간 조건부 확률로 계산하고, 사전 확률(prior probability) P(TW)는 TW의 발생빈도로 계산하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 방법.8. The method according to claim 7, wherein, in the step of quantifying the association between the vocabulary and the surrounding vocabulary using the conditional probability and the reliability,
By using the naive bayes to formulate a way to select the vocabulary corresponding to the context of the 'correction lexical pair'
The posterior probability P (CW | TW) is calculated by the Naive Bayes with the conditional probability between tw and CW, and the prior probability P (TW) is calculated with the occurrence frequency of TW Correction Method of Statistical Context Spelling Error Using Corrected Lexical Pairs.

CR(credibility reliability)은 어휘의 신뢰도이고, 교정 어휘 쌍의 어휘 중 문맥 철자오류 발생 여부를 검사하는 문맥에 나타난 대상어에는 CR의 신뢰도를 대치어에는 1-CR의 신뢰도롤 부여하고, 나이브베이즈에서와 같이 사후 확률(posterior probability) P(CW|TW)는 tw와 CW 간 조건부 확률로 계산하는 것을 특징으로 하는 교정 어휘 쌍을 이용한 통계적 문맥 철자오류 교정 방법.
9. The method according to claim 8,
The reliability of CR is the reliability of the vocabulary. The reliability of the CR is given to the target word in the context of checking the occurrence of the spelling error of the corrective vocabulary pair. The reliability of 1-CR is assigned to the target word. The posterior probability P (CW | TW) is calculated by using the conditional probability between tw and CW.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20130081911A KR101495240B1 (en) | 2013-07-12 | 2013-07-12 | Method and system for statistical context-sensitive spelling correction using confusion set |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20130081911A KR101495240B1 (en) | 2013-07-12 | 2013-07-12 | Method and system for statistical context-sensitive spelling correction using confusion set |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20150007647A KR20150007647A (en) | 2015-01-21 |
| KR101495240B1 true KR101495240B1 (en) | 2015-02-25 |
Family
ID=52570505
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR20130081911A KR101495240B1 (en) | 2013-07-12 | 2013-07-12 | Method and system for statistical context-sensitive spelling correction using confusion set |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101495240B1 (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190133624A (en) | 2018-05-23 | 2019-12-03 | 부산대학교 산학협력단 | A method and system for context sensitive spelling error correction using realtime candidate generation |
| KR20210128315A (en) | 2020-04-16 | 2021-10-26 | 부산대학교 산학협력단 | Context sensitive spelling error correction system or method using masked language model |
| KR20220075807A (en) | 2020-11-30 | 2022-06-08 | 부산대학교 산학협력단 | System and Method for correcting Context sensitive spelling error using Generative Adversarial Network |
| KR102453373B1 (en) * | 2021-10-08 | 2022-10-07 | 한국전자기술연구원 | Apparatus and method for deep learning-based automatic typo correction |
| KR20230054223A (en) | 2021-10-15 | 2023-04-24 | 부산대학교 산학협력단 | Context-sensitive spelling error correction system or method based on word relationship graph information |
| KR20230057238A (en) | 2021-10-21 | 2023-04-28 | 부산대학교 산학협력단 | System and Method for correcting Context sensitive spelling error using predictive information for subsequent sentences in a real-time chatting environment |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101965887B1 (en) * | 2017-04-07 | 2019-07-05 | 주식회사 카카오 | Method for semantic rules generation and semantic error correction based on mass data, and error correction system implementing the method |
| KR102008145B1 (en) * | 2017-09-20 | 2019-08-07 | 장창영 | Apparatus and method for analyzing sentence habit |
| KR102182248B1 (en) * | 2020-06-16 | 2020-11-24 | 정승택 | System and method for checking grammar and computer program for the same |
| KR102540293B1 (en) * | 2020-11-16 | 2023-06-07 | 주식회사 솔트룩스 | Korean spelling correction system based on deep learning language model |
| CN114997148B (en) * | 2022-08-08 | 2022-11-04 | 湖南工商大学 | Chinese spelling proofreading pre-training model construction method based on contrast learning |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100496873B1 (en) | 2003-10-24 | 2005-06-22 | 한국전자통신연구원 | A device for statistically correcting tagging errors based on representative lexical morpheme context and the method |
| KR20110017129A (en) * | 2009-08-13 | 2011-02-21 | 부산대학교 산학협력단 | Apparatus and method for words sense disambiguation using korean wordnet and its program stored recording medium |
-
2013
- 2013-07-12 KR KR20130081911A patent/KR101495240B1/en active IP Right Grant
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100496873B1 (en) | 2003-10-24 | 2005-06-22 | 한국전자통신연구원 | A device for statistically correcting tagging errors based on representative lexical morpheme context and the method |
| KR20110017129A (en) * | 2009-08-13 | 2011-02-21 | 부산대학교 산학협력단 | Apparatus and method for words sense disambiguation using korean wordnet and its program stored recording medium |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190133624A (en) | 2018-05-23 | 2019-12-03 | 부산대학교 산학협력단 | A method and system for context sensitive spelling error correction using realtime candidate generation |
| KR20210128315A (en) | 2020-04-16 | 2021-10-26 | 부산대학교 산학협력단 | Context sensitive spelling error correction system or method using masked language model |
| KR102531114B1 (en) | 2020-04-16 | 2023-05-11 | 부산대학교 산학협력단 | Context sensitive spelling error correction system or method using masked language model |
| KR20220075807A (en) | 2020-11-30 | 2022-06-08 | 부산대학교 산학협력단 | System and Method for correcting Context sensitive spelling error using Generative Adversarial Network |
| KR102453373B1 (en) * | 2021-10-08 | 2022-10-07 | 한국전자기술연구원 | Apparatus and method for deep learning-based automatic typo correction |
| KR20230054223A (en) | 2021-10-15 | 2023-04-24 | 부산대학교 산학협력단 | Context-sensitive spelling error correction system or method based on word relationship graph information |
| KR20230057238A (en) | 2021-10-21 | 2023-04-28 | 부산대학교 산학협력단 | System and Method for correcting Context sensitive spelling error using predictive information for subsequent sentences in a real-time chatting environment |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20150007647A (en) | 2015-01-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101495240B1 (en) | Method and system for statistical context-sensitive spelling correction using confusion set | |
| US10762293B2 (en) | Using parts-of-speech tagging and named entity recognition for spelling correction | |
| JP5362353B2 (en) | Handle collocation errors in documents | |
| US7774193B2 (en) | Proofing of word collocation errors based on a comparison with collocations in a corpus | |
| Derczynski et al. | Microblog-genre noise and impact on semantic annotation accuracy | |
| US10061768B2 (en) | Method and apparatus for improving a bilingual corpus, machine translation method and apparatus | |
| CN107247707B (en) | Enterprise association relation information extraction method and device based on completion strategy | |
| KR101573854B1 (en) | Method and system for statistical context-sensitive spelling correction using probability estimation based on relational words | |
| US20060149557A1 (en) | Sentence displaying method, information processing system, and program product | |
| US20120297294A1 (en) | Network search for writing assistance | |
| KR102348845B1 (en) | A method and system for context sensitive spelling error correction using realtime candidate generation | |
| US20100332217A1 (en) | Method for text improvement via linguistic abstractions | |
| KR101500617B1 (en) | Method and system for Context-sensitive Spelling Correction Rules using Korean WordNet | |
| CN110147546B (en) | Grammar correction method and device for spoken English | |
| US20140093845A1 (en) | Example-based error detection system for automatic evaluation of writing, method for same, and error detection apparatus for same | |
| US20190005028A1 (en) | Systems, methods, and computer-readable medium for validation of idiomatic expressions | |
| US20190303437A1 (en) | Status reporting with natural language processing risk assessment | |
| US10509812B2 (en) | Reducing translation volume and ensuring consistent text strings in software development | |
| KR102552811B1 (en) | System for providing cloud based grammar checker service | |
| Gamon et al. | Search right and thou shalt find... using web queries for learner error detection | |
| Duran et al. | Some issues on the normalization of a corpus of products reviews in Portuguese | |
| Kumar et al. | Design and implementation of nlp-based spell checker for the tamil language | |
| Naemi et al. | Informal-to-formal word conversion for persian language using natural language processing techniques | |
| US10984191B2 (en) | Experiential parser | |
| JP4934115B2 (en) | Keyword extraction apparatus, method and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20180110 Year of fee payment: 4 |
|
| FPAY | Annual fee payment |
Payment date: 20190130 Year of fee payment: 5 |