KR100893123B1 - Method and apparatus for generating audio fingerprint data and comparing audio data using the same - Google Patents
Method and apparatus for generating audio fingerprint data and comparing audio data using the same Download PDFInfo
- Publication number
- KR100893123B1 KR100893123B1 KR1020070044251A KR20070044251A KR100893123B1 KR 100893123 B1 KR100893123 B1 KR 100893123B1 KR 1020070044251 A KR1020070044251 A KR 1020070044251A KR 20070044251 A KR20070044251 A KR 20070044251A KR 100893123 B1 KR100893123 B1 KR 100893123B1
- Authority
- KR
- South Korea
- Prior art keywords
- data
- audio
- audio data
- frames
- segment
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 138
- 238000009826 distribution Methods 0.000 claims abstract description 63
- 239000013598 vector Substances 0.000 claims description 35
- 230000005236 sound signal Effects 0.000 claims description 17
- 239000000284 extract Substances 0.000 claims description 6
- 238000010586 diagram Methods 0.000 description 10
- 238000007796 conventional method Methods 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000005070 sampling Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 241000237858 Gastropoda Species 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 210000000959 ear middle Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 108090000623 proteins and genes Proteins 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
Images












Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/018—Audio watermarking, i.e. embedding inaudible data in the audio signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/087—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters using mixed excitation models, e.g. MELP, MBE, split band LPC or HVXC
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
본 발명은 오디오 핑거프린트 데이터 생성 방법 및 장치 및 이를 이용한 오디오 데이터 비교 방법 및 장치에 관한 것으로서, 오디오 데이터로부터 오디오 핑거프린트 데이터를 생성하는 오디오 핑거프린트 데이터 생성 방법에 있어서, 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하는 단계; 상기 분할된 제1 프레임들 각각에 대하여 특징 데이터를 추출하는 단계; 상기 분할된 제1 프레임들 각각에 대하여 상기 특징 데이터의 분포 특징을 나타내는 특징 분포 데이터를 생성하는 단계; 상기 오디오 데이터를 적어도 하나 이상의 제2 프레임들로 분할하는 단계; 상기 제1 프레임들에 대하여 생성된 특징 분포 데이터를 이용하여, 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터를 생성하는 단계; 및 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터의 집합에 의해 상기 오디오 데이터 전체에 대한 오디오 핑거프린트 데이터를 생성하는 단계를 포함하는 오디오 핑거프린트 데이터 생성 방법 및 이를 이용한 장치와 이를 이용한 오디오 데이터 비교 방법을 제공한다.The present invention relates to a method and apparatus for generating audio fingerprint data, and to a method and apparatus for comparing audio data using the same, the method comprising: generating audio fingerprint data from audio data, the method comprising: generating at least one audio data; Dividing into one frames; Extracting feature data for each of the divided first frames; Generating feature distribution data representing a distribution feature of the feature data for each of the divided first frames; Dividing the audio data into at least one second frame; Generating audio fingerprint data for each of the second frames using the feature distribution data generated for the first frames; And generating audio fingerprint data for the whole audio data by a set of audio fingerprint data for each of the second frames, and a method using the same and an apparatus using the same. Provide a method.
오디오 데이터, 오디오 핑거프린트, 히스토그램 Audio data, audio fingerprints, histograms
Description
도 1은 본 발명에 의한 오디오 핑거프린트 데이터 생성 방법 및 이를 이용한 오디오 데이터 비교 방법을 수행하기 위한 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100)와 다른 구성 요소간의 결합 관계를 나타낸 구성도,1 is a block diagram illustrating a coupling relationship between an audio fingerprint generation and audio data comparison apparatus 100 and other components for performing the audio fingerprint data generation method and the audio data comparison method using the same;
도 2는 본 발명에 의한 오디오 핑거프린트 데이터 생성 방법 및 이를 이용한 오디오 데이터 비교 방법의 전체 과정을 개략적으로 설명하기 위한 도면,FIG. 2 is a diagram schematically illustrating an entire process of an audio fingerprint data generation method and an audio data comparison method using the same according to the present invention; FIG.
도 3은 본 발명의 바람직한 일 실시예에 따른 오디오 핑거프린트 데이터 생성 방법의 전체 과정을 나타낸 흐름도,3 is a flowchart illustrating an entire process of a method for generating audio fingerprint data according to an embodiment of the present invention;
도 4는 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하는 방법을 설명하기 위한 도면,4 is a diagram for describing a method of dividing audio data into at least one first frame;
도 5는 MFCC 방법에 의하여 특징 벡터를 추출하는 과정을 설명하기 위한 도면,5 is a view for explaining a process of extracting a feature vector by the MFCC method;
도 6은 코드북을 생성하는 과정을 설명하기 위한 도면,6 is a view for explaining a process of generating a codebook;
도 7은 코드북 구성의 일예를 나타낸 도면,7 is a diagram illustrating an example of a codebook configuration;
도 8은 본 발명에 의한 오디오 핑거프린트 생성 과정을 참고적으로 설명하기 위한 도면,8 is a view for explaining the audio fingerprint generation process according to the present invention for reference;
도 9는 특징 분포 데이터로부터 제2 프레임별 오디오 핑거프린트 데이터를 구성하는 방법의 일예를 나타낸 도면,9 illustrates an example of a method of configuring audio fingerprint data for each second frame from feature distribution data;
도 10은 본 발명에 의한 오디오 핑거프린트 데이터를 이용하여 오디오 데이터를 비교하는 방법의 일실시예를 나타낸 흐름도,10 is a flowchart illustrating an embodiment of a method for comparing audio data using audio fingerprint data according to the present invention;
도 11은 오디오 데이터를 적어도 하나 이상의 세그먼트로 분할하는 과정을 설명하기 위한 도면,11 is a diagram illustrating a process of dividing audio data into at least one segment;
도 12는 적어도 하나 이상의 원본 오디오 데이터들을 포함하는 오디오 데이터베이스와 비교 대상 외도 데이터를 비교하는 경우의 전체 흐름도,12 is an overall flowchart of a case where an audio database including at least one or more original audio data is compared with the object data to be compared;
도 13은 임계치를 설정하는 방법의 일예를 설명하기 위한 도면이다.13 is a view for explaining an example of a method for setting a threshold.
<도면의 주요 부분에 대한 부호의 설명><Explanation of symbols for main parts of the drawings>
10 : 오디오 데이터 입력 장치10: audio data input device
20 : 오디오 핑거프린트 데이터 생성부20: audio fingerprint data generation unit
30 : 오디오 데이터 비교 서버30: audio data comparison server
40 : 오디오 데이터베이스40: audio database
본 발명은 오디오 핑거프린트 데이터 생성 방법 및 장치 및 이를 이용한 오디오 데이터 비교 방법 및 장치에 관한 것으로서, 보다 상세하게는 오디오 데이터로부터 오디오 데이터의 특징을 나타내는 오디오 핑거프린트 데이터를 생성하고, 이를 이용하여 오디오 데이터들 간의 동일성 여부를 신속하고 용이하게 판별할 수 있는 방법 및 장치에 관한 것이다. The present invention relates to a method and apparatus for generating audio fingerprint data, and to a method and apparatus for comparing audio data using the same, and more particularly, to generate audio fingerprint data indicating characteristics of audio data from the audio data and to use the audio data. The present invention relates to a method and apparatus for quickly and easily determining whether or not there is an identicalness between them.
오디오 핑거프린트(audio finger print)라 함은, 일반적으로 오디오 데이터의 특징을 설명할 수 있는 데이터를 의미하는 것으로서, 주파수 변환 등의 방법에 의하여 오디오 데이터를 여러 가지 방법으로 분석하여 생성하고, 이를 이용하여 오디오 데이터의 무단 도용 여부를 판별하거나 오디오 핑거프린트에 의해 오디오 데이터를 검색하는 등의 방법에 사용되고 있다.Audio finger print refers to data that can generally describe the characteristics of audio data. The audio finger print is generated by analyzing audio data by various methods such as frequency conversion and using the same. To determine whether an unauthorized use of audio data is illegal or to search for audio data by an audio fingerprint.
이러한 오디오 핑거프린트를 생성하는 종래의 방법으로는 여러 가지 방식이 제안되어 있으나, 종래의 오디오 핑거프린트 생성 방식은 검색하고자 하는 검색 대상 오디오 데이터의 양이 많아질 경우(약 10000개 이상) 오디오 데이터의 핑거프린트를 생성하는 속도가 현저하게 느려지는 단점이 있어서, 많은 양의 오디오 데이터를 비교하는 경우에는 적절치 않다는 문제점이 있었다.Conventional methods for generating such an audio fingerprint have been proposed, but the conventional audio fingerprint generation method has a large amount of audio data to be searched (about 10000 or more). There is a disadvantage in that the speed of fingerprint generation is significantly slowed down, which is not suitable when comparing a large amount of audio data.
또한, 국내특허등록 제10-0456408호에는 이진 특징(binary feature)을 사용하는 오디오 유전자 추출 방식이 개시되어 있으나, 이는 데이터베이스 내의 각 오디오 데이터의 매 프레임마다 스펙트럼의 에너지를 32개의 주파수 대역별로 0 또는 1의 값으로 표현하고, 이 값을 검색 테이블 값에 (오디오 신호 ID, 해당 프레임 i) 로 추가 등록한 뒤, 임의의 수 초 구간의 입력 오디오에 대해 동일한 방식으로 32비트 패턴을 추출하여 이 테이블을 검색하는 방식으로서, 검색 테이블의 각 엔트리에 등록된 (오디오 신호 ID, 프레임 index)의 개수가 가변적이어서 충분한 검색 속도를 보장할 수 없다는 단점이 있으며, 또한 바이너리 특징벡터 추출방식이 고정적이어서 입력 신호에 발생한 손상에 상대적으로 취약한 단점이 있다.In addition, Korean Patent Registration No. 10-0456408 discloses an audio gene extraction method using a binary feature, but this means that the energy of the spectrum is zero or every 32 frequency bands for each frame of each audio data in the database. Express this value as 1, add this value to the lookup table value as (audio signal ID, frame i), and extract this 32-bit pattern in the same way for the input audio in any number of seconds. As a method of searching, the number of (audio signal ID, frame index) registered in each entry of the search table is variable, so that a sufficient search speed cannot be guaranteed. Also, the binary feature vector extraction method is fixed so that the input signal is fixed to the input signal. It has the disadvantage of being relatively vulnerable to damage that has occurred.
본 발명은 상기한 바와 같은 문제점을 감안하여 안출된 것으로서, 종래의 오디오 핑거프린트 생성 방식에 비하여 속도가 현저하게 개선되며 생성 방법이 상대적으로 간편한 오디오 핑거프린트 데이터 생성 방법 및 장치를 제공하는 것을 목적으로 한다.The present invention has been made in view of the above problems, and an object of the present invention is to provide a method and apparatus for generating audio fingerprint data, which has a markedly improved speed and relatively simple generation method compared to a conventional audio fingerprint generation method. do.
또한, 본 발명은 오디오 데이터를 분석하여 오디오 데이터의 특징 데이터의 분포 특성 데이터를 이용하여 오디오 핑거프린트 데이터를 생성하므로, 종래의 방법에 비하여 오디오 데이터의 특징을 보다 정밀하게 반영할 수 있는 오디오 핑거프린트 데이터 생성 방법 및 장치를 제공하는 것을 또 다른 목적으로 한다.In addition, the present invention analyzes the audio data to generate the audio fingerprint data using the distribution characteristic data of the characteristic data of the audio data, so that the audio fingerprint that can accurately reflect the characteristics of the audio data compared to the conventional method Another object is to provide a data generating method and apparatus.
또한, 본 발명은 상기한 바와 같은 오디오 핑거프린트 데이터 생성 방법 및 장치에 의하여 생성되는 오디오 핑거프린트 데이터를 갖는 오디오 데이터들을 비교함에 있어서, 종래의 방식에 비하여 신속하고 정확한 비교 결과를 얻을 수 있으며 동일성 여부의 판단 오차를 현저하게 감소시킬 수 있는 오디오 데이터 비교 방법 및 장치를 제공하는 것을 또 다른 목적으로 한다.In addition, the present invention compares the audio data having the audio fingerprint data generated by the method and apparatus for generating audio fingerprint data as described above, it is possible to obtain a fast and accurate comparison result compared to the conventional method and whether or not the same Another object of the present invention is to provide a method and apparatus for comparing audio data, which can significantly reduce a determination error of an audio signal.
또한, 본 발명은 오디오 핑거프린트 데이터를 세그먼트로 나누어서 세그먼트별로 비교 판단할 수 있으므로 원본 오디오 데이터와 비교 대상 오디오 데이터가 부분적으로 동일한 경우에도 적용할 수 있고, 또한 부분적으로 동일한 경우 부분적으로 동일한 위치도 검출할 수 있는 오디오 데이터 비교 방법 및 장치를 제공하는 것을 또 다른 목적으로 한다.Further, according to the present invention, since the audio fingerprint data can be divided into segments and compared and judged for each segment, the present invention can be applied to the case where the original audio data and the comparison target audio data are partially the same, and when the portions are the same, the same position is also detected. Another object of the present invention is to provide a method and apparatus for comparing audio data.
또한, 본 발명은 비디오 신호 및 오디오 신호가 포함되어 있는 동영상 데이터로부터 오디오 신호를 추출하여 오디오 신호에 대한 오디오 핑거프린트 데이터를 생성 및 비교함으로써 오디오 데이터 뿐 아니라 동영상 데이터의 무단 복사 및 도용 여부를 간편하게 판별할 수 있으며, 나아가 동영상 데이터의 일부만을 편집하여 도용하는 경우에도 손쉽게 적용할 수 있는 오디오 데이터 비교 방법 및 장치를 제공하는 것을 또 다른 목적으로 한다.In addition, the present invention extracts the audio signal from the video data including the video signal and the audio signal to generate and compare the audio fingerprint data for the audio signal to easily determine whether unauthorized copying and theft of the video data as well as the audio data. Another object of the present invention is to provide a method and apparatus for comparing audio data, which can be easily applied even when only a part of video data is edited and stolen.
상기한 바와 같은 목적을 달성하기 위한 본 발명은, 오디오 데이터로부터 오디오 핑거프린트 데이터를 생성하는 오디오 핑거프린트 데이터 생성 방법에 있어서, 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하는 단계; 상기 분할된 제1 프레임들 각각에 대하여 특징 데이터를 추출하는 단계; 상기 분할된 제1 프레임들 각각에 대하여 상기 특징 데이터의 분포 특징을 나타내는 특징 분포 데이터를 생성하는 단계; 상기 오디오 데이터를 적어도 하나 이상의 제2 프레임들로 분할하는 단계; 상기 제1 프레임들에 대하여 생성된 특징 분포 데이터를 이용하여, 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터를 생성하는 단계; 및 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터의 집합에 의해 상기 오디오 데이터 전체에 대한 오디오 핑거프린트 데이터를 생성하는 단계를 포함하는 오디오 핑거프린트 데이터 생성 방법을 제공한다.According to an aspect of the present invention, there is provided a method of generating audio fingerprint data from audio data, the method comprising: dividing audio data into at least one first frame; Extracting feature data for each of the divided first frames; Generating feature distribution data representing a distribution feature of the feature data for each of the divided first frames; Dividing the audio data into at least one second frame; Generating audio fingerprint data for each of the second frames using the feature distribution data generated for the first frames; And generating audio fingerprint data for the entirety of the audio data by a set of audio fingerprint data for each of the second frames.
여기에서, 상기 오디오 데이터는 비디오 신호 및 오디오 신호가 포함된 동영상 데이터로부터 추출된 것일 수 있다. The audio data may be extracted from video data including a video signal and an audio signal.
또한, 상기 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하는 단계 이전에, 상기 오디오 데이터를 소정 주파수 대역으로 정규화하는 단계를 더 포함할 수 있다.The method may further include normalizing the audio data to a predetermined frequency band before dividing the audio data into at least one first frame.
또한, 상기 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하는 단계는, 분할되는 하나의 프레임과 인접하는 다음 시간 간격의 프레임이 서로 공통되는 부분을 갖도록 분할할 수 있다.The dividing of the audio data into at least one first frame may be performed such that one frame to be divided and a frame having a next time interval adjacent to each other have a portion in common with each other.
또한, 상기 오디오 데이터를 적어도 하나 이상의 제2 프레임들로 분할하는 단계는, 분할되는 하나의 프레임과 인접하는 다음 시간 간격의 프레임이 서로 공통되는 부분을 갖도록 분할할 수 있다.The dividing of the audio data into at least one second frame may be performed such that one frame to be divided and a frame having a next time interval adjacent to each other have a portion in common with each other.
또한, 상기 제2 프레임 각각의 길이는 상기 제1 프레임 각각의 길이 보다 긴 것일 수 있다.In addition, the length of each of the second frames may be longer than the length of each of the first frames.
또한, 상기 분할된 제1 프레임들 각각에 대하여 특징 데이터를 추출하는 단계는, 상기 분할된 제1 프레임들 각각에 대하여, MFCC(Mel Frequency Cepstral Coefficient), PLPC(Perceptual Linear Prediction Coefficient) 또는 LPC(Linear Prediction Coefficient) 중에서 적어도 어느 하나 이상의 조합을 사용하여 특징 벡터를 추출하도록 구성할 수 있다.The extracting of the feature data for each of the divided first frames may include, for each of the divided first frames, a Mel Frequency Cepstral Coefficient (MFCC), a Perceptual Linear Prediction Coefficient (PLPC), or an LPC (Linear). Prediction Coefficient) can be configured to extract a feature vector using at least one combination.
또한, 상기 분할된 제1 프레임들 각각에 대하여 상기 특징 데이터의 분포 특징을 나타내는 특징 분포 데이터를 생성하는 단계는, 특징 벡터들을 적어도 하나 이상의 그룹들로 그룹화하고 각각의 그룹에 대한 인덱스값을 저장하고 있는 코드북을 참조하여, 상기 분할된 제1 프레임들 각각에 대하여 인덱스값을 산출함으로써 특징 분포 데이터를 생성할 수 있다.In addition, generating the feature distribution data representing the distribution feature of the feature data for each of the divided first frames, grouping the feature vectors into at least one or more groups, and stores the index value for each group The feature distribution data may be generated by calculating an index value for each of the divided first frames with reference to the codebook.
여기에서, 상기 코드북은 상기 그룹별로 특징 벡터들의 평균값을 가지며, 상기 분할된 제1 프레임들 각각에 대한 특징 벡터들과 상기 각 그룹별 특징 벡터들의 평균값과의 거리에 의해 인덱스값을 산출하는 것일 수 있다.Here, the codebook may have an average value of feature vectors for each group, and calculate an index value based on a distance between feature vectors for each of the divided first frames and an average value of feature vectors for each group. have.
또한, 상기 제1 프레임들에 대하여 생성된 특징 분포 데이터를 이용하여, 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터를 생성하는 단계에 있어서, 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터는, 상기 각각의 제2 프레임들에 포함되는 제1 프레임들 각각에 대한 특징 분포 데이터의 빈도를 계산함으로써 생성될 수 있다.Further, in the generating audio fingerprint data for each of the second frames using the feature distribution data generated for the first frames, the audio fingerprint data for each of the second frames is It may be generated by calculating the frequency of the feature distribution data for each of the first frame included in each of the second frame.
본 발명의 다른 측면에 의하면, 오디오 데이터로부터 오디오 핑거프린트 데이터를 생성하는 오디오 핑거프린트 데이터 생성 장치에 있어서, 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하고, 상기 분할된 제1 프레임들 각각에 대하여 특징 데이터를 추출하고, 상기 분할된 제1 프레임들 각각에 대하여 상기 특징 데이터의 분포 특징을 나타내는 특징 분포 데이터를 생성하고, 상기 오디오 데 이터를 적어도 하나 이상의 제2 프레임들로 분할하고, 상기 제1 프레임들에 대하여 생성된 특징 분포 데이터를 이용하여, 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터를 생성하고, 상기 제2 프레임들 각각에 대한 오디오 핑거프린트 데이터의 집합에 의해 상기 오디오 데이터 전체에 대한 오디오 핑거프린트 데이터를 생성하는 오디오 핑거프린트 데이터 생성부를 포함하는 오디오 핑거프린트 데이터 생성 장치를 제공할 수 있다.According to another aspect of the present invention, in an audio fingerprint data generating apparatus for generating audio fingerprint data from audio data, the audio data is divided into at least one or more first frames, and each of the divided first frames is provided. Extract feature data, generate feature distribution data representing a distribution feature of the feature data for each of the divided first frames, divide the audio data into at least one second frame, and Generate audio fingerprint data for each of the second frames using the feature distribution data generated for one frame, and generate the entire audio data by a set of audio fingerprint data for each of the second frames. Audio ping to generate audio fingerprint data for Generating print data that can provide audio fingerprint data generating apparatus comprising: a.
본 발명의 또 다른 측면에 의하면, 상기한 방법에 의하여 생성된 오디오 핑거프린트 데이터를 갖는 비교 대상 오디오 데이터와 원본 오디오 데이터의 동일성 여부를 비교하는 오디오 데이터 비교 방법에 있어서, 상기 원본 오디오 데이터를 상기 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트로 분할하는 단계; 상기 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터와 상기 적어도 하나 이상의 세그먼트 각각의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 산출하는 단계; 상기 세그먼트별로 산출된 거리의 최대값을 결정하는 단계; 및 상기 최대값과 임계치의 크기를 비교하여, 상기 최대값이 임계치보다 큰 경우에는 상기 비교 대상 오디오 데이터가 상기 원본 오디오 데이터와 동일성이 있는 것으로 결정하고, 상기 최대값이 임계치보다 작은 경우에는 상기 비교 대상 오디오 데이터는 상기 원본 오디오 데이터와 동일성이 없는 것으로 결정하는 단계를 포함하는 오디오 데이터 비교 방법을 제공한다.According to another aspect of the present invention, in the audio data comparison method for comparing whether or not the comparison target audio data having the audio fingerprint data generated by the above method and the original audio data, the original audio data is compared Dividing the data into at least one segment so as to correspond to the size of the target audio data; Calculating a distance for each segment between audio fingerprint data of the comparison target audio data and audio fingerprint data of each of the at least one segment; Determining a maximum value of the distances calculated for each segment; And comparing the maximum value with a magnitude of the threshold value, and when the maximum value is larger than the threshold value, determines that the compared audio data is equal to the original audio data, and when the maximum value is smaller than the threshold value, comparing the maximum value with a threshold value. And determining that the target audio data is not identical to the original audio data.
여기에서, 상기 원본 오디오 데이터를 상기 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트로 분할하는 단계는, 분할되는 하나의 세그먼트와 인접하는 다음 시간 간격의 세그먼트가 서로 공통되는 부분을 갖도록 분할할 수 있다.The dividing of the original audio data into at least one segment so as to correspond to the size of the comparison target audio data may be performed such that one segment to be divided and a segment of a next time interval adjacent to each other have a portion common to each other. Can be.
또한, 상기 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터와 상기 적어도 하나 이상의 세그먼트 각각의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 산출하는 단계는, 상기 각각의 세그먼트에 대하여 상기 비교 대상 오디오 데이터의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들과 상기 각 세그먼트의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들 사이의 거리를 순차적으로 대응하여 계산하는 단계; 및 상기 각각의 세그먼트 별로 상기 계산된 거리의 합을 산출하는 단계를 포함할 수 있다.The calculating of the distance between the audio fingerprint data of the comparison target audio data and the audio fingerprint data of each of the at least one segment may be performed by segmenting the divided audio data of the comparison target audio data with respect to each segment. Sequentially calculating a distance between frame-by-frame audio fingerprint data for each of two frames and frame-by-frame audio fingerprint data for each of the divided second frames of each segment; And calculating the sum of the calculated distances for each segment.
또한, 상기 각각의 세그먼트에 대하여 상기 비교 대상 오디오 데이터의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들과 상기 각 세그먼트의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들 사이의 거리를 순차적으로 대응하여 계산하는 단계는, 상기 각각의 세그먼트에 대하여, 상기 비교 대상 오디오 데이터의 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들을 구성하는 특징 분포 데이터들에 의해 생성된 빈도 데이터와, 상기 각 세그먼트의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들을 구성하는 특징 분포 데이터들에 의해 생성된 빈도 데이터를 순차적으로 대응 비교하여 제2 프레임별로 최소값을 구하고, 제2 프레임별로 구한 최소값들의 합을 각 세그먼트별로 산출할 수 있다.In addition, frame-by-frame audio fingerprint data for each of the divided second frames of the comparison target audio data for each segment and frame-by-frame audio fingerprint data for each of the divided second frames of each segment The step of sequentially calculating the distance between them is generated by feature distribution data constituting frame-by-frame audio fingerprint data for each of the second frames of the comparison target audio data, for each segment. The corresponding frequency data and frequency data generated by the feature distribution data constituting the audio fingerprint data for each frame for each of the divided second frames of each segment are sequentially compared to obtain a minimum value for each second frame. , The sum of the minimum values obtained for each second frame It can be calculated per unit.
또한, 상기 산출된 합을 제2 프레임의 갯수로 나누는 단계를 더 포함할 수 있다.The method may further include dividing the calculated sum by the number of second frames.
또한, 상기 최대값과 임계치의 크기를 비교하여, 상기 최대값이 임계치보다 큰 경우에는 상기 비교 대상 오디오 데이터가 상기 원본 오디오 데이터와 동일성이 있는 것으로 결정하고, 상기 최대값이 임계치보다 작은 경우에는 상기 비교 대상 오디오 데이터는 상기 원본 오디오 데이터와 동일성이 없는 것으로 결정하는 단계는, 상기 최대값이 임계치보다 큰 경우, 상기 원본 오디오 데이터의 크기와 상기 비교 대상 오디오 데이터의 크기를 비교하여 상기 비교 대상 오디오 데이터의 크기가 상기 원본 오디오 데이터의 크기와 동일한 경우에는 상기 비교 대상 오디오는 상기 원본 오디오 데이터와 완전히 동일한 것으로 결정하고, 상기 비교 대상 오디오 데이터의 크기가 상기 원본 오디오 데이터의 크기보다 작은 경우에는 상기 비교 대상 오디오는 상기 원본 오디오 데이터와 부분적으로 동일한 것으로 결정할 수 있다.In addition, when the maximum value is greater than the threshold value, the maximum value is determined to be equal to the original audio data when the maximum value is greater than the threshold value, and when the maximum value is smaller than the threshold value, the comparison value is determined. The determining that the comparison target audio data is not identical to the original audio data may include comparing the size of the original audio data with the size of the comparison audio data when the maximum value is greater than a threshold. Is equal to the size of the original audio data, the comparison target audio is determined to be exactly the same as the original audio data, and when the size of the comparison audio data is smaller than the size of the original audio data, the comparison target Audio remind It can be determined to be partly identical to the original audio data.
본 발명의 또 다른 측면에 의하면, 상기한 방법에 의하여 생성된 오디오 핑거프린트 데이터를 갖는 비교 대상 오디오 데이터와 원본 오디오 데이터의 동일성 여부를 비교하는 오디오 데이터 비교 장치에 있어서, 상기 원본 오디오 데이터를 상기 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트로 분할하고, 상기 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터와 상기 적어도 하나 이상의 세그먼트 각각의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 산출하고, 상기 세그먼트별로 산출된 거리의 최대값을 결정하고, 상기 최대값과 임계치의 크기를 비교하여, 상기 최대값이 임계치보다 큰 경우에는 상기 비교 대상 오디오 데이터가 상기 원본 오디오 데이터와 동일성이 있는 것으로 결정하고, 상기 최대값이 임계치보다 작은 경우에는 상기 비교 대상 오디오 데이터는 상기 원본 오디오 데이터와 동일성이 없는 것으로 결정하는 오디오 데이터 비교부를 포함하는 오디오 데이터 비교 장치를 제공할 수 있다.According to another aspect of the present invention, in the audio data comparison device for comparing whether or not the comparison target audio data having the audio fingerprint data generated by the above method and the original audio data, the original audio data is compared The segment is divided into at least one segment to correspond to the size of the target audio data, and the distance between the audio fingerprint data of the comparison target audio data and the audio fingerprint data of each of the at least one segment is calculated for each segment, and for each segment. The maximum value of the calculated distance is determined, and the maximum value is compared with the magnitude of the threshold value. When the maximum value is larger than the threshold value, the comparison target audio data is determined to have the same identity as the original audio data, and the maximum value is determined. value Is smaller than the threshold value, the comparison-object audio data may provide an audio data comparison device including the audio data compared to determine that there is no audio data and the original identity.
본 발명의 또 다른 측면에 의하면, 상기한 방법에 의하여 생성된 오디오 핑거프린트 데이터를 갖는 비교 대상 오디오 데이터와, 상기한 방법에 의하여 생성된 오디오 핑거프린트 데이터를 갖는 원본 오디오 데이터들로 구성된 오디오 데이터의 동일성 여부를 비교하는 오디오 데이터 비교 방법에 있어서, 상기 오디오 데이터베이스에 포함된 원본 오디오 데이터들 각각을 상기 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트로 분할하는 단계; 상기 각각의 원본 오디오 데이터들에 대하여, 각 원본 오디오 데이터의 각각의 세그먼트의 오디오 핑거프린트 데이터와 상기 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 산출하는 단계; 상기 모든 원본 오디오 데이터들의 모든 세그먼트에 대하여, 상기 산출된 거리의 최대값을 결정하는 단계; 및 상기 최대값과 임계치의 크기를 비교하여, 상기 최대값이 임계치보다 큰 경우에는 상기 비교 대상 오디오 데이터가 상기 오디오 데이터베이스의 원본 오디오 데이터 중의 적어도 어느 하나와 동일성이 있는 것으로 결정하고, 상기 최대값이 임계치보다 작은 경우에는 상기 비교 대상 오디오 데이터는 상기 오디오 데이터베이스의 모든 원본 오디오 데이터와 동일성이 없는 것으로 결정하는 단계를 포함하는 오디오 데이터 비교 방법을 제공한다.According to still another aspect of the present invention, there is provided an audio data comprising audio data composed of comparison target audio data having audio fingerprint data generated by the above method and original audio data having audio fingerprint data generated by the above method. An audio data comparison method for comparing equality, the method comprising: dividing each of original audio data included in the audio database into at least one segment so as to correspond to a size of the comparison target audio data; Calculating, for each of the original audio data, the distance between the audio fingerprint data of each segment of each original audio data and the audio fingerprint data of the comparison target audio data for each segment; For all segments of all the original audio data, determining a maximum value of the calculated distance; And comparing the maximum value with a magnitude of a threshold value, and when the maximum value is larger than a threshold value, determines that the comparison target audio data is identical to at least one of the original audio data of the audio database. And if less than a threshold, determining that the compared audio data is not equal to all original audio data of the audio database.
여기에서, 상기 오디오 데이터베이스에 포함된 원본 오디오 데이터들 각각을 상기 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트로 분할하는 단계는, 분할되는 하나의 세그먼트와 인접하는 다음 시간 간격의 세그먼트가 서로 공통되는 부분을 갖도록 분할할 수 있다.Here, the step of dividing each of the original audio data included in the audio database into at least one segment so as to correspond to the size of the comparison target audio data, the one segment and the segments of the next time interval adjacent to each other It can be divided to have a common part.
또한, 상기 각각의 원본 오디오 데이터들에 대하여, 각 원본 오디오 데이터의 각각의 세그먼트의 오디오 핑거프린트 데이터와 상기 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 산출하는 단계는, 상기 각각의 원본 오디오 데이터들의 각각의 세그먼트에 대하여, 상기 비교 대상 오디오 데이터의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들과 상기 각 세그먼트의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들 사이의 거리를 순차적으로 대응하여 계산하는 단계; 및 상기 각각의 원본 오디오 데이터들에 대하여, 상기 각각의 세그먼트 별로 상기 계산된 거리의 합을 산출하는 단계를 포함할 수 있다.Further, for each of the original audio data, calculating the distance between the audio fingerprint data of each segment of the respective original audio data and the audio fingerprint data of the comparison target audio data for each segment may include: For each segment of original audio data, frame-by-frame audio fingerprint data for each of the divided second frames of the comparison audio data and frame-by-frame audio finger for each of the divided second frames of each segment Sequentially calculating corresponding distances between the print data; And calculating, for each of the original audio data, the sum of the calculated distances for each segment.
또한, 상기 각각의 원본 오디오 데이터들의 각각의 세그먼트에 대하여, 상기 비교 대상 오디오 데이터의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들과 상기 각 세그먼트의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들 사이의 거리를 순차적으로 대응하여 계산하는 단계는, 상기 각각의 원본 오디오 데이터들의 상기 각각의 세그먼트에 대하여, 상기 비교 대상 오디오 데이터의 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들을 구성하는 특징 분포 데이터들에 의해 생성된 빈도 데이터와, 상기 각 세그먼트의 분할된 제2 프레임들 각각에 대한 프레임별 오디오 핑거프린트 데이터들을 구성하는 특징 분포 데이터들에 의해 생성된 빈도 데이터를 순차적으로 대응 비교하여 제2 프레임별로 최소값을 구하고, 제2 프레임별로 구한 최소값들의 합을 각 세그먼트별로 산출할 수 있다.Further, for each segment of the respective original audio data, the audio fingerprint data for each frame for each of the divided second frames of the comparison target audio data and for each of the divided second frames of the segment Computing the distance between frame-by-frame audio fingerprint data with respect to each segment of the respective original audio data, for each frame, for each frame of each of the second frame of the comparison target audio data Frequency data generated by the feature distribution data constituting the audio fingerprint data and frequency generated by the feature distribution data constituting the audio fingerprint data per frame for each of the divided second frames of each segment Second frame by comparing the data sequentially The minimum value may be obtained for each segment, and the sum of the minimum values obtained for each second frame may be calculated for each segment.
여기에서, 상기 산출된 합을 제2 프레임의 갯수로 나누는 단계를 더 포함할 수 있다.Here, the method may further include dividing the calculated sum by the number of second frames.
또한, 상기 최대값과 임계치의 크기를 비교하여, 상기 최대값이 임계치보다 큰 경우에는 상기 비교 대상 오디오 데이터가 상기 오디오 데이터베이스의 원본 오디오 데이터 중의 적어도 어느 하나와 동일성이 있는 것으로 결정하고, 상기 최대값이 임계치보다 작은 경우에는 상기 비교 대상 오디오 데이터는 상기 오디오 데이터베이스의 모든 원본 오디오 데이터와 동일성이 없는 것으로 결정하는 단계는, 상기 최대값이 임계치보다 큰 경우, 상기 최대값을 갖는 원본 오디오 데이터의 크기와 상기 비교 대상 오디오 데이터의 크기를 비교하여 상기 비교 대상 오디오 데이터의 크기가 상기 최대값을 갖는 원본 오디오 데이터의 크기와 동일한 경우에는 상기 비교 대상 오디오는 상기 최대값을 갖는 원본 오디오 데이터와 완전히 동일한 것으로 결정하고, 상기 비교 대상 오디오 데이터의 크기가 상기 최대값을 갖는 원본 오디오 데이터의 크기보다 작은 경우에는 상기 비교 대상 오디오는 상기 최대값을 갖는 원본 오디오 데이터와 부분적으로 동일한 것으로 결정할 수 있다.The maximum value is compared with the magnitude of the threshold value, and when the maximum value is larger than the threshold value, it is determined that the comparison target audio data is identical to at least one of the original audio data of the audio database. If it is less than this threshold, determining that the comparison target audio data is not equal to all original audio data of the audio database may include determining the size of the original audio data having the maximum value when the maximum value is greater than the threshold value. Comparing the size of the compared audio data and determining that the compared audio is exactly the same as the original audio data having the maximum value when the size of the compared audio data is equal to the size of the original audio data having the maximum value; Doing When the size of the audio data to be compared is smaller than the size of the original audio data having the maximum value, the comparison audio may be determined to be partially the same as the original audio data having the maximum value.
본 발명의 또 다른 측면에 의하면, 상기한 방법에 의하여 생성된 오디오 핑거프린트 데이터를 갖는 비교 대상 오디오 데이터와, 상기한 방법에 의하여 생성된 오디오 핑거프린트 데이터를 갖는 원본 오디오 데이터들로 구성된 오디오 데이터의 동일성 여부를 비교하는 오디오 데이터 비교 장치에 있어서, 상기 오디오 데이터베이스에 포함된 원본 오디오 데이터들 각각을 상기 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트로 분할하고, 상기 각각의 원본 오디오 데이터들에 대하여, 각 원본 오디오 데이터의 각각의 세그먼트의 오디오 핑거프린트 데이터와 상기 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 산출하고, 상기 모든 원본 오디오 데이터들의 모든 세그먼트에 대하여, 상기 산출된 거리의 최대값을 결정하고, 상기 최대값과 임계치의 크기를 비교하여, 상기 최대값이 임계치보다 큰 경우에는 상기 비교 대상 오디오 데이터가 상기 오디오 데이터베이스의 원본 오디오 데이터 중의 적어도 어느 하나와 동일성이 있는 것으로 결정하고, 상기 최대값이 임계치보다 작은 경우에는 상기 비교 대상 오디오 데이터는 상기 오디오 데이터베이스의 모든 원본 오디오 데이터와 동일성이 없는 것으로 결정하는 오디오 데이터 비교부를 포함하는 오디오 데이터 비교 장치를 제공한다.According to still another aspect of the present invention, there is provided an audio data comprising audio data composed of comparison target audio data having audio fingerprint data generated by the above method and original audio data having audio fingerprint data generated by the above method. An audio data comparison device for comparing equality, the audio data comparison apparatus comprising: dividing each of the original audio data included in the audio database into at least one segment to correspond to the size of the comparison target audio data, and comparing the original audio data to the respective original audio data. For each segment, a distance between the audio fingerprint data of each segment of each original audio data and the audio fingerprint data of the comparison target audio data is calculated for each segment, and for all segments of all the original audio data, The maximum value of the calculated distance is determined, and the maximum value is compared with the magnitude of the threshold value. When the maximum value is larger than the threshold value, the comparison target audio data is equal to at least one of the original audio data of the audio database. And an audio data comparison unit for determining that the comparison target audio data is not identical to all original audio data of the audio database when the maximum value is smaller than a threshold.
이어서, 첨부한 도면들을 참조하여 본 발명의 바람직한 실시예를 상세히 설명하기로 한다.Next, preferred embodiments of the present invention will be described in detail with reference to the accompanying drawings.
도 1은 본 발명에 의한 오디오 핑거프린트 데이터 생성 방법 및 이를 이용한 오디오 데이터 비교 방법을 수행하기 위한 오디오 핑거프린트 생성 및 오디오 데이 터 비교 장치(100)와 다른 구성 요소간의 결합 관계를 나타낸 구성도이다.1 is a block diagram illustrating a coupling relationship between an audio fingerprint generation and audio data comparison apparatus 100 and other components for performing an audio fingerprint data generation method and an audio data comparison method using the same.
도 1을 참조하면, 본 발명에 의한 오디오 핑거프린트 데이터 생성 방법 및 이를 이용한 오디오 데이터 비교 방법을 수행하기 위한 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100)는, 오디오 핑거프린트 데이터 생성부(20), 오디오 데이터 비교 서버(30) 및 오디오 데이터베이스(40)를 포함한다. 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100)는, 오디오 데이터 입력 장치(10)와 결합하여 이들로부터 오디오 데이터를 입력받는다.Referring to FIG. 1, an audio fingerprint data generation and audio data comparison apparatus 100 for performing an audio fingerprint data generation method and an audio data comparison method using the same may include an audio fingerprint
오디오 데이터 입력 장치(10)는 예컨대, 인터넷의 웹페이지, PC 및 모바일 단말기일 수 있으며, 오디오 데이터 또는 비디오 데이터 및 오디오 데이터가 포함된 동영상 데이터를 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100)로 전송한다. 여기서, 오디오 데이터 입력 장치(10)는 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100)로 오디오 데이터 또는 동영상 데이터를 전송하기 위한 기능을 수행할 수 있는 모든 수단을 의미하며 도 1에 도시한 것에 한정되는 것은 아니다. 예컨대, 오디오 데이터 입력장치(10) 중의 인터넷의 웹페이지의 경우에는 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100) 내에 인터넷상의 웹페이지에 포함되어 있는 오디오 데이터 또는 동영상 데이터를 자동으로 추출하는 로봇을 포함시키고, 이러한 로봇에 의해 오디오 데이터 또는 동영상 데이터를 오디오 핑거프린트 생성 및 오디오 데이터 비교 장치(100)로 전송할 수 있다.The audio
오디오 핑거프린트 데이터 생성부(20)는 오디오 데이터 입력 장치(10)로부터 오디오 데이터 또는 동영상 데이터를 입력받아 이로부터 오디오 데이터의 특징을 나타내는 오디오 핑거프린트 데이터를 생성하는 역할을 수행한다. 오디오 핑거프린트 데이터 생성부(20)는, 원본 오디오 데이터들에 대해서는 미리 오디오 핑거프린트 데이터를 생성하여 두고 이들을 오디오 데이터베이스(40)로 전송하여 저장하도록 하며, 원본 오디오 데이터들과 비교할 비교 대상 오디오 데이터에 대해서는 오디오 핑거프린트 데이터를 생성하여 이를 오디오 데이터 비교 서버(30)로 전송하여 오디오 데이터 비교 서버(30)에서 오디오 데이터베이스(40) 내에 저장되어 있는 원본 오디오 데이터들의 오디오 핑거프린트 데이터와 비교하여 동일성 여부를 비교할 수 있도록 한다. 여기에서, 오디오 핑거프린트 데이터 생성부(20)는 입력되는 데이터가 비디오 데이터 및 오디오 데이터가 포함되어 있는 동영상 데이터인 경우에는, 이 동영상 데이터로부터 오디오 데이터만을 추출하는 수단을 포함할 수 있으며, 이러한 수단에 의하여 동영상 데이터로부터 오디오 데이터만을 추출하고 추출된 오디오 데이터에 대한 오디오 핑거프린트 데이터를 생성하여 이를 오디오 데이터베이스(40)로 전송한다. 오디오 핑거프린트 데이터의 구체적인 생성 방법에 대해서는 후술한다. The audio
오디오 데이터베이스(40)는 오디오 핑거프린트 데이터 생성부(20)에서 생성된 원본 오디오 데이터에 대한 오디오 핑거프린트 데이터를 저장한다. 또한 필요한 경우 원본 오디오 데이터 자체도 저장한다.The
오디오 데이터 비교 서버(30)는 오디오 핑거프린트 데이터 생성부(20)에 의해 생성된 오디오 핑거프린트 데이터를 갖는 오디오 데이터들을 서로 비교하여 이들의 일치 여부를 판별하는 역할을 수행하기 위한 것으로서, 원본 오디오 데이터들 에 대하여 미리 생성된 오디오 핑거프린트 데이터들을 저장하는 오디오 데이터베이스(40)와 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터를 비교하여 이들의 일치 여부를 판별한다.The audio
도 2는 본 발명에 의한 오디오 핑거프린트 데이터 생성 방법 및 이를 이용한 오디오 데이터 비교 방법의 전체 과정을 개략적으로 설명하기 위한 도면이다.FIG. 2 is a diagram schematically illustrating an entire process of an audio fingerprint data generation method and an audio data comparison method using the same according to the present invention.
도 2를 참조하면, 우선, 도 1의 오디오 핑거프린트 데이터 생성부(20)에 의해 원본 오디오 데이터들에 대한 오디오 핑거프린트 데이터를 미리 생성해 두고(S201), 생성된 원본 오디오 데이터들의 오디오 핑거프린트 데이터들을 오디오 데이터베이스(40)에 저장한다(S203). Referring to FIG. 2, first, the audio fingerprint data for the original audio data is generated in advance by the audio fingerprint
다음으로, 오디오 핑거프린트 데이터 생성부(20)는 오디오 데이터 입력 장치(10)로부터 비교 대상이 되는 비교 대상 오디오 데이터를 입력받고(S205), 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터를 생성하고(S207), 생성된 비교 대상 오디오 핑거프린트 데이터를 오디오 데이터 비교 서버(30)로 전송된다.Next, the audio fingerprint
다음으로, 오디오 데이터 비교 서버(30)는 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터와 오디오 데이터베이스(40)에 포함되어 있는 원본 오디오 데이터의 오디오 핑거프린트 데이터들을 비교하여 비교 대상 오디오 데이터가 오디오 데이터베이스(40)에 포함되어 있는 오디오 데이터 중의 적어도 어느 하나와 동일성이 있는지를 판별하게 된다(S209). 여기에서, 오디오 데이터베이스(40)에 포함되어 있는 오디오 데이터들과 비교한다는 것은, 오디오 데이터베이스(40)에 포함되어 있는 모든 오디오 데이터들과 비교하여 비교 대상 오디오 데이터가 오디오 데이터베이스(40)에 포함되어 있는 오디오 데이터들 중의 적어도 어느 하나와 동일성이 있는지의 여부를 판별하는 경우와, 오디오 데이터베이스(40)에 포함되어 있는 어느 하나의 오디오 데이터와 비교하여 이와 동일성이 있는지의 여부를 판별하는 경우를 포함하는 의미이다. Next, the audio
도 3은 본 발명의 바람직한 일 실시예에 따른 오디오 핑거프린트 데이터 생성 방법의 전체 과정을 나타낸 흐름도이다.3 is a flowchart illustrating an entire process of a method for generating audio fingerprint data according to an embodiment of the present invention.
도 3을 참조하면, 우선 오디오 핑거프린트 데이터를 생성할 대상 데이터가 비디오 데이터를 포함하는 동영상 데이터인 경우 이로부터 오디오 데이터만을 추출한다(S301). 이는 본 발명과는 직접적인 관련은 없는 과정으로서, 동영상 데이터로부터 오디오 데이터를 추출하는 기술은 공지의 기술 중 어느 것을 사용하여도 무방하다. 물론, 오디오 핑거프린트 데이터를 생성할 대상 데이터가 오디오 데이터인 경우에는 상기 단계(S301)은 생략할 수 있다.Referring to FIG. 3, first, when the target data for generating audio fingerprint data is video data including video data, only audio data is extracted therefrom (S301). This is a process that is not directly related to the present invention. Any technique for extracting audio data from moving image data may be used. Of course, if the target data for generating the audio fingerprint data is audio data, step S301 may be omitted.
다음으로, 추출된 오디오 데이터를 소정 주파수 대역으로 정규화한다(S303). 정규화는 소정의 샘플링 주파수에 의해 샘플링 변환에 의해 이루어질 수 있으며, 이는 입력되는 오디오 데이터들은 예컨대 8kHz, 11kHz, 16kHz, 22kHz, 44kHz등의 여러가지 형태의 주파수를 사용할 수 있으므로 이들을 특정 주파수 대역으로 정규화할 필요가 있기 때문이다. 정규화는 예컨대 16kHz로 정규화할 수 있는데, 16kHz 이상의 샘플링 주파수에는 고주파에 해당하는 오디오 신호 성분이 포함되어 있어 이를 처리할 신호의 양이 많아지게 되며, 이로 인해 오디오 핑거프린트 데이터 생성 속도가 저하될 수 있기 때문이다.Next, the extracted audio data is normalized to a predetermined frequency band (S303). Normalization can be achieved by sampling conversion by a predetermined sampling frequency, which means that the input audio data can use various types of frequencies, such as 8 kHz, 11 kHz, 16 kHz, 22 kHz, 44 kHz, etc. Because there is. Normalization can be normalized to 16 kHz, for example, and sampling frequencies above 16 kHz contain audio signal components corresponding to high frequencies, which increases the amount of signal to process, which can slow down the audio fingerprint data generation rate. Because.
다음으로, 정규화된 오디오 데이터를 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할한다(S305). 제1 프레임들이란 오디오 데이터를 일정 시간의 길이를 갖는 복수개의 프레임들을 의미하는 것으로서, '제1' 프레임이라는 용어는 후술하는 '제2' 프레임과 다른 시간 간격을 갖는다는 점을 구별하기 위한 것이다. 오디오 데이터를 적어도 하나 이상의 제1 프레임들로 분할하는 방법은 도 4를 참조하여 설명한다. 도 4를 참조하면, 전체 오디오 데이터를 4개의 서브 프레임 시간 간격 마다 하나의 프레임으로 구성하고, 하나의 프레임은 하나의 서브 프레임 시간 간격마다 이동되어 구성되어 있음을 알 수 있다. 도 4에서, f0은 첫 번째 프레임, f1은 두 번째 프레임, f2는 세 번째 프레임을 각각 나타내고, 각각의 프레임은 4개의 서브 프레임으로 구성되어 있다. 또한, f1은 f0에 비하여 하나의 서브 프레임 시간 간격 만큼 이동되어 있으며, f2는 f1에 비하여 하나의 서브 프레임 시간 간격 만큼 이동되어 있음을 알 수 있다. 물론, 도 4의 경우에서와는 달리 하나의 프레임이 서로 겹치는 부분이 없도록 분할하는 것도 가능하지만, 도 4의 경우와 같이 분할되는 각 프레임들이 인접하는 다음 프레임과 서로 공통되는 부분을 갖도록 분할하는 것이 같은 길이의 오디오 데이터에 대하여 보다 정밀한 오디오 핑거프린트 데이터를 생성할 수 있으므로 바람직하다. Next, the normalized audio data is divided into at least one first frame (S305). The first frames refer to a plurality of frames having a length of time for audio data, and the term 'first' frame is used to distinguish that the first frames have a different time interval from the 'second' frame described later. . A method of dividing audio data into at least one first frame will be described with reference to FIG. 4. Referring to FIG. 4, it can be seen that all audio data is composed of one frame for every four sub frame time intervals, and one frame is moved for one sub frame time interval. In FIG. 4, f 0 represents the first frame, f 1 represents the second frame, f 2 represents the third frame, and each frame includes four subframes. Further, f 1 it is moved by a subframe time interval, and compared to f 0, f 2 It can be seen that it is shifted by one sub-frame time period than the f 1. Of course, unlike in the case of FIG. 4, it is possible to divide one frame so that there is no overlapping portion, but as in the case of FIG. This is preferable because more accurate audio fingerprint data can be generated with respect to the audio data of.
다음으로, 상기와 같이 분할된 제1 프레임들 각각에 대하여 오디오 데이터의 특징을 나타내는 특징 데이터를 추출한다(S307). 특징 데이터를 추출한다는 것은 오디오 데이터 자체의 고유 특징을 나타내는 특징 데이터를 오디오 데이터로부터 추출한다는 것으로서, 예컨대 분할된 제1 프레임 각각에 대하여, 종래 기술에서 사용되고 있는 MFCC(Mel Frequency Cepstral Coefficient), PLPC(Perceptual Linear Prediction Coefficient) 또는 LPC(Linear Prediction Coefficient) 중에서 적어도 어느 하나 이상의 조합을 사용하여 특징 벡터를 추출하는 방법을 사용할 수 있다.Next, feature data representing a feature of audio data is extracted for each of the divided first frames as described above (S307). Extracting the feature data extracts feature data representing an inherent characteristic of the audio data itself from the audio data. For example, for each of the divided first frames, the MFCC (Mel Frequency Cepstral Coefficient) and PLPC (Perceptual) used in the prior art are used. A method of extracting a feature vector using at least one combination of a linear prediction coefficient (LPC) or a linear prediction coefficient (LPC) may be used.
예컨대, 종래 기술의 MFCC 방식에 의해 특징 벡터를 추출하는 과정을 개략적으로 설명하면 다음과 같다. 아날로그 음성 신호는 A/D 변환을 거쳐서 디지털 음성 신호 x(n)로 변환된다. 디지털 음성 신호는 고대역 통과 특성을 갖는 디지털 프리엠퍼시스 필터(pre-emphasis filter)를 거치게 되는데, 이 필터를 사용하는 이유는 첫째로 인간의 외이/중이의 주파수 특성을 모델링하기 위하여 고대역 필터링을 수행하기 위함이다. 이는 인간의 입술에서의 방사에 의하여 20dB/decade로 감쇄되는 것을 보상하게 되어 음성 신호로부터 성도 특성만을 얻게 된다. 둘째, 청각 시스템이 1 kHz이상의 스펙트럼 영역에 대하여 민감하다는 사실을 어느 정도 보상하게 된다. 이러한 프리엠퍼시스 필터의 특성 H(z)는 다음과 같으며, a는 0.95~0.98 범위의 값을 사용할 수 있다.For example, a process of extracting feature vectors by the conventional MFCC method will be described below. The analog audio signal is converted to the digital audio signal x (n) through A / D conversion. The digital speech signal is subjected to a digital pre-emphasis filter with a high pass characteristic. The reason for using this filter is to first apply high band filtering to model the frequency characteristics of the human ear / middle ear. To do this. This compensates for the 20 dB / decade attenuation by radiation on the human lips, so that only the vocal characteristics are obtained from the speech signal. Second, it compensates to some extent that the auditory system is sensitive to spectral regions above 1 kHz. The characteristic H (z) of the pre-emphasis filter is as follows, and a may be a value in the range of 0.95 to 0.98.
H(z) = 1 - az-1 H (z) = 1-az -1
프리엠퍼시스 필터에 의해 프리엠퍼시스된 신호는 해밍 윈도우(hamming window)를 씌워서 블록 단위의 프레임으로 나누어진다. 이후부터의 처리는 모두 프레임 단위로 이루어진다. 프레임의 크기는 보통 20 ms이며 프레임 이동은 10 ms가 흔히 사용된다. 한 프레임의 음성 신호는 FFT(Fast Fourier Transform)를 이용하여 주파수 영역으로 변환된다. 주파수 대역을 여러 개의 필터 뱅크로 나누고 각 뱅크에서의 에너지를 구한다. 밴드 에너지에 로그를 취한 후 분산 코사인 변환(discrete cosine transform, DCT)를 하면 최종적인 MFCC가 얻어진다. 필터 뱅크의 모양 및 중심 주파수의 설정 방법은 귀의 청각적 특성(달팽이관에서의 주파수 특성)을 고려하여 결정된다. 도 5를 참조하면, 도 5에서는 삼각형 모양의 필터를 사용하였으며 중심주파수는 1kHz 까지는 선형적으로 위치하고 그 이상에서는 멜(mel) 척도로 분포하는 20개의 뱅크로 이루어져 있다. MFCC 계수는 예컨대 c1~c12까지의 12개를 사용할 수 있으며 이와는 별도로 구한 프레임 로그 에너지가 추가적으로 사용되어 특징벡터는 13차 벡터를 구할 수 있다. 여기에 이전 MFCC 프레임과의 차이를 고려한 1차 차분(DELTA) 13차와 1차 차분(DELTA) 간의 차이을 고려한 2차 차분(ACCELERATION) 13차를 합쳐 39차원의 특징벡터를 구할 수 있다.The signal pre-emphasized by the preemphasis filter is divided into frames in units of blocks covering a hamming window. Subsequent processing is performed in units of frames. The frame size is usually 20 ms and the frame shift is 10 ms. An audio signal of one frame is transformed into a frequency domain by using a fast fourier transform (FFT). Divide the frequency band into several filter banks and find the energy in each bank. Logging the band energy and performing a discrete cosine transform (DCT) yields the final MFCC. The shape of the filter bank and the method of setting the center frequency are determined in consideration of the acoustic characteristics of the ear (frequency characteristics in the snail tube). Referring to FIG. 5, a triangular filter is used in FIG. 5, and the center frequency is linearly located up to 1 kHz, and there are 20 banks distributed on a mel scale. For example, 12 MFCC coefficients from c 1 to c 12 may be used, and separately obtained frame log energy may be used to obtain a 13 th order vector. In addition, a 39-dimensional feature vector can be obtained by combining the 13th order DELTA considering the difference from the previous MFCC frame and the 13rd order ACCELERATION considering the difference between the first order DELTA.
이와 같은 방식에 의하여, 제1 프레임별로 특징 데이터(특징 벡터)가 추출되면, 분할된 제1 프레임들 각각에 대하여 추출한 특징 데이터를 이용하여 특징 데이터의 분포 특징을 나타내는 특징 분포 데이터를 생성한다(S309).In this manner, when feature data (feature vector) is extracted for each first frame, feature distribution data indicating a distribution feature of feature data is generated using feature data extracted for each of the divided first frames (S309). ).
특징 분포 데이터라 함은, 특징 데이터가 분포되어 있는 특성을 나타내는 데이터로서, 이러한 특징 분포 데이터는 미리 생성해 둔 코드북(codebook)을 참조하여 생성할 수 있다. 여기서, 코드북은 다수의 오디오 데이터들의 특징 벡터들을 미리 추출하여 이들이 벡터 공간에 분포시키고, 벡터 공간 상에서 특징 벡터들을 그룹화하고 각각의 그룹에 포함되어 있는 특징 벡터들의 평균값을 계산하여 이 평균값과 각 그룹에 대한 인덱스값을 저장하고 있는 데이터로 구성된다.The feature distribution data is data representing a feature in which feature data is distributed. The feature distribution data may be generated by referring to a codebook generated in advance. Here, the codebook extracts feature vectors of a plurality of audio data in advance, distributes them in the vector space, groups the feature vectors in the vector space, calculates an average value of the feature vectors included in each group, and calculates an average value of the feature vectors in each group. Consists of data that stores index values.
도 6은 이러한 코드북을 생성하는 과정을 설명하기 위한 도면으로서, 설명의 편의를 위하여 2차원의 특징 벡터에 대한 코드북을 생성하는 경우를 예로 들어 설명한다.FIG. 6 is a diagram for describing a process of generating such a codebook. For convenience of description, the codebook for generating a two-dimensional feature vector will be described as an example.
도 6을 참조하면, 2차원의 벡터 공간에 미리 획득해 놓은 다수의 오디오 데이터들에 대한 특징 벡터들을 분포시키고 이들 특징 벡터들을 그룹화한다. 그룹화하는 기준은 벡터 공간상에서 서로 인접하는 특징 벡터들을 묶는 방법을 사용할 수 있으며, 예컨대 공지의 기술인 케이-민(k-Mean) 알고리즘, LBG(Linde-Buzo-Gray) 등의 방법을 사용할 수 있다. 도 6에는 총 7개로 묶인 그룹들이 도시되어 있으며, 각 그룹별로 그룹에 속한 특징 벡터들의 평균값을 구할 수 있다. 각 그룹별로 평균값을 구하면, 도 7과 같은 형태의 코드북을 구성할 수 있다. 도 7을 참조하면, 코드북은 각 그룹의 인덱스와 평균값으로 구성되어 있음을 알 수 있다. 여기서, 코드북은 예컨대 64차, 128차 또는 256차 등이 될 수 있으며, 차수가 증가할수록 즉, 그룹의 개수가 증가할수록 코드북을 보다 정밀하게 구성할 수 있고, 결과적으로 특징 벡터의 분포 특징 데이터 또한 정밀하게 구할 수 있다.Referring to FIG. 6, feature vectors for a plurality of audio data acquired in advance in a two-dimensional vector space are distributed and grouped. As a criterion for grouping, a method of grouping feature vectors adjacent to each other in a vector space may be used. For example, a known k-Mean algorithm, a Linde-Buzo-Gray (LBB) method, and the like may be used. A total of seven groups are illustrated in FIG. 6, and an average value of feature vectors belonging to the group can be obtained for each group. When the average value is obtained for each group, a codebook of the form shown in FIG. 7 may be configured. Referring to FIG. 7, it can be seen that the codebook is composed of indexes and average values of each group. Here, the codebook may be, for example, 64th, 128th, or 256th order, and as the order increases, that is, as the number of groups increases, the codebook may be configured more precisely, and as a result, the distribution feature data of the feature vector may also be Can be obtained precisely.
이와 같이 미리 생성해 둔 코드북을 참조하면, 분할된 제1 프레임들 각각에 대한 특징 데이터(특징 벡터)들이 속해야 하는 그룹의 인덱스값을 산출할 수 있다. 특징 벡터가 속해야 하는 그룹을 찾는 것은, 제1 프레임들 각각의 특징 벡터와 코드북의 각 그룹의 평균값간의 거리를 계산하여 최소값을 갖는 그룹을 특징 벡터가 속해야 하는 그룹으로 결정하는 방법을 사용할 수 있으며, 속해야 할 그룹이 결정되면 그 그룹의 인덱스값을 특징 벡터에 대한 특징 분포 데이터로서 생성하게 된다.Referring to the previously generated codebook, the index value of the group to which the feature data (feature vector) for each of the divided first frames may belong may be calculated. Finding a group to which the feature vector should belong may use a method of determining a group having a minimum value as a group to which the feature vector belongs by calculating a distance between the feature vector of each of the first frames and the average value of each group of the codebook. When the group to belong to is determined, the index value of the group is generated as the feature distribution data for the feature vector.
다음으로, 오디오 데이터를 적어도 하나 이상의 제2 프레임들로 분할한다(S311). 오디오 데이터를 제2 프레임들로 분할하는 것은 앞서 단계(S305)에서 설명한 바와 같은 방식에 의하여 분할할 수 있다. 다만, 여기에서 분할되는 제2 프레임들 각각의 길이는 제1 프레임보다 큰 값을 갖는다는 점에서 차이가 있다. 예컨대, 하나의 제1 프레임의 프레임 길이가 20ms이고, 하나의 제1 프레임이 4개의 서브 프레임으로 구성되는 경우 하나의 서브 프레임 길이는 5ms이다. 이 경우, 하나의 제2 프레임의 전체 길이를 4s로 하면 하나의 제2 프레임에는 200개의 제1 프레임이 포함된다. 제2 프레임의 서브 프레임은 예컨대 1s 단위로 구성할 수 있으며 이 경우 하나의 제2 프레임과 인접하는 다음 프레임은 1s 단위로 간격을 두고 겹치는 부분을 갖게 된다.Next, the audio data is divided into at least one or more second frames (S311). Dividing the audio data into second frames may be divided by a method as described above in operation S305. However, there is a difference in that the length of each of the divided second frames has a larger value than that of the first frame. For example, when a frame length of one first frame is 20 ms and one first frame is composed of four sub frames, one sub frame length is 5 ms. In this case, when the total length of one second frame is 4s, 200 first frames are included in one second frame. The subframe of the second frame may be configured, for example, in units of 1s. In this case, the next frame adjacent to one second frame has an overlapping portion at intervals of 1s.
이와 같이, 오디오 데이터를 적어도 하나 이상의 제2 프레임들로 분할한 후, 각 제2 프레임들에 대하여 제2 프레임별 오디오 핑거프린트 데이터를 생성한다(S313). 여기서, i번째 제2 프레임에 대한 오디오 핑거프린트 데이터를 hi라고 정의하면, hi는 (i,o1,o2,o3,...oL)로 정의할 수 있다. 여기서, i는 제2 프레임의 번 호(순서)를 나타내며, L은 앞서 설명한 바와 같은 코드북의 차수를 의미한다. o1,o2,o3,...oL은 각각 1~L 범위의 코드북의 그룹의 인덱스가 하나의 제2 프레임에 포함되어 있는 제1 프레임들의 특징 분포 데이터 중에서 몇 번 나타났는가를 나타내는 빈도 데이터를 의미한다. As described above, after the audio data is divided into at least one or more second frames, second fingerprint-specific audio fingerprint data is generated for each of the second frames (S313). Here, if the audio fingerprint data for the i-th second frame is defined as h i , h i may be defined as (i, o 1 , o 2 , o 3 , ... o L ). Here, i denotes the number (order) of the second frame, and L denotes the order of the codebook as described above. o 1 , o 2 , o 3 , ... o L indicates how many times among the feature distribution data of the first frames in which the indexes of the group of codebooks in the range of 1 to L are included in one second frame Refers to frequency data.
예컨대, 상기 단계(S305)에서 오디오 데이터를 T개의 제1 프레임으로 분할한 경우, 각각의 제1 프레임에 대한 특징 데이터를 f1,f2,f3...fT라 할 수 있고, 이들에 대한 특징 분포 데이터는 각각 c1,c2,c3,...cT라고 할 수 있다. 여기서, c1,c2,c3,...cT는 각각 앞서 설명한 바와 같이 코드북의 인덱스값으로서 L차의 코드북인 경우 0~L-1 범위의 값을 갖는다. 이 경우, o1은 하나의 제2 프레임에 포함되는 제1 프레임들의 특징 분포 데이터 중에서 코드북의 첫번째 인덱스값이 해당하는 값이 몇 번 나타났는가를 나타내는 빈도 데이터를 의미한다. 예컨대, 하나의 제2 프레임이 10개의 제1 프레임들로 구성되어 있는 경우, 이들 10개의 제1 프레임들 각각의 특징 분포 데이터(c1,c2,...c10)들 중에서 코드북의 첫번째 인덱스가 몇 번 포함되어 있는지를 카운트함으로써 o1을 구할 수 있고 같은 방식으로 두번째 인덱스가 몇번 포함되어 있는지를 카운트함으로써 o2를 구할 수 있게 된다. For example, when the audio data is divided into T first frames in step S305, the feature data for each first frame may be referred to as f 1 , f 2 , f 3 ... f T , The feature distribution data for may be c 1 , c 2 , c 3 , ... c T , respectively. Here, c 1 , c 2 , c 3 , ... c T are index values of the codebooks as described above, respectively, and have values ranging from 0 to L-1 in the case of L-order codebooks. In this case, o 1 means frequency data indicating how many times a corresponding value of the first index value of the codebook has appeared among feature distribution data of the first frames included in one second frame. For example, when one second frame consists of ten first frames, the first of the codebook among the feature distribution data c 1 , c 2 ,... C 10 of each of the ten first frames. We can get o 1 by counting how many times the index is included, and we can get o 2 by counting how many times the second index is included.
이와 같은 방식에 의하여, i번째 제2 프레임에 대한 o1,o2,o3,...oL을 구하고, (t,o1,o2,o3,...oL)과 같은 형태로 i번째 제2 프레임에 대한 오디오 핑거프린트 데이터(hi)를 구할 수 있다.In this manner, o 1 , o 2 , o 3 , ... o L for the i-th second frame is obtained, and (t, o 1 , o 2 , o 3 , ... o L ) In this form, audio fingerprint data h i for the i-th second frame may be obtained.
이와 같이 각각의 제2 프레임들에 대하여 오디오 핑거프린트 데이터를 구한 후, 제2 프레임들 전체의 오디오 핑거프린트 데이터에 의해 오디오 데이터 전체에 대한 오디오 핑거프린트 데이터를 생성한다(S315). 오디오 데이터 전체에 대한 오디오 핑거프린트 데이터를 H라고 하면, H={h1,h2,h3....hN}으로 정의할 수 있다. 여기서 N은 제2 프레임의 갯수에 해당한다.After the audio fingerprint data is obtained for each of the second frames, the audio fingerprint data for the entire audio data is generated by the audio fingerprint data of the entire second frames (S315). If the audio fingerprint data for the entire audio data is H, it may be defined as H = {h 1 , h 2 , h 3 ... H N }. Where N corresponds to the number of second frames.
도 8은 도 3 내지 도 7을 참조하여 설명한 오디오 핑거프린트 생성 과정을 참고적으로 설명하기 위한 도면이다.FIG. 8 is a diagram for explaining an audio fingerprint generation process described with reference to FIGS. 3 to 7.
도 8을 참조하면, 우선 오디오 데이터 전체를 적어도 하나 이상의 제1 프레임들로 분할하고(S501), 분할된 제1 프레임들 중 맨 처음의 프레임으로부터 순차적으로 앞서 설명한 방법에 의하여 특징 데이터를 추출한다(도 3의 단계 S307). 제1 프레임들 각각에 대해 특징 데이터가 추출되면, 코드북을 참조하여 특징 데이터들에 대한 특징 분포 데이터를 생성한다(도 3의 단계 S309, S803). Referring to FIG. 8, first, the entire audio data is divided into at least one or more first frames (S501), and feature data is sequentially extracted from the first frame among the divided first frames by the above-described method ( Step S307 of Figure 3). When the feature data is extracted for each of the first frames, the feature distribution data for the feature data is generated with reference to the codebook (steps S309 and S803 of FIG. 3).
제1 프레임들 각각에 대한 특징 분포 데이터가 생성되면, 적어도 하나 이상의 제1 프레임을 포함하는 제2 프레임들 각각에 대하여 제2 프레임별 오디오 핑거프린트 데이터를 생성한다(도 3의 단계 S313, S805). 앞서 설명한 바와 같이, 제2 프레임별 오디오 핑거프린트 데이터는 특징 데이터의 분포 특성을 나타내는 특징 분포 데이터의 빈도 데이터들로 구성되며, 이들은 도 8에 나타낸 바와 같이 히스토 그램(histogram) 형태로 표현할 수 있으므로, 본 발명에 의한 오디오 핑거프린트 데이터 생성 방법은 히스토그램 기반의 오디오 핑거프린트 데이터 생성 방법이라고 부를 수도 있을 것이다.When feature distribution data for each of the first frames is generated, audio fingerprint data for each second frame is generated for each of the second frames including the at least one first frame (steps S313 and S805 of FIG. 3). . As described above, the audio fingerprint data for each second frame is composed of frequency data of the feature distribution data representing the distribution characteristic of the feature data, and they can be expressed in the form of a histogram as shown in FIG. 8. The audio fingerprint data generation method according to the present invention may be referred to as a histogram-based audio fingerprint data generation method.
도 9는 전술한 오디오 핑거프린트 데이터 생성 과정에 있어서 특징 분포 데이터로부터 제2 프레임별 오디오 핑거프린트 데이터를 구성하는 방법의 일예를 나타낸 것이다.FIG. 9 illustrates an example of a method of configuring audio fingerprint data for each second frame from feature distribution data in the above-described process of generating audio fingerprint data.
도 9에서, 오디오 데이터에 대한 제1 프레임의 개수를 12개라고 가정하면, 오디오 데이터에 대한 특징 분포 데이터는 도 9에 나타낸 바와 같이 12개의 제1 프레임의 특징 분포 데이터의 집합으로 정의될 수 있다. 도 9의 경우에서 인덱스의 수 즉, 코드북에서 그룹화해놓은 그룹의 수는 4개라고 가정하였으며, 이 경우 각 특징 분포 데이터는 도시한 바와 같이 1~4 범위의 숫자 중 어느 하나의 값을 가진다.In FIG. 9, assuming that the number of first frames for audio data is 12, the feature distribution data for audio data may be defined as a set of feature distribution data of twelve first frames as shown in FIG. 9. . In the case of FIG. 9, it is assumed that the number of indices, that is, the number of groups grouped in the codebook, is four. In this case, each feature distribution data has a value of any one of numbers in the range of 1 to 4 as shown.
하나의 제2 프레임이 4개씩의 제1 프레임을 포함하고, 하나의 제2 프레임은 하나의 제1 프레임만큼의 시간 간격 만큼 슬라이딩 이동되어 구성되는 것으로 가정하면, 제2 프레임은 총 9개(h1~h9)로 구성할 수 있다. 각각의 제2 프레임별 오디오 핑거프린트 데이터 hi는 {i,o1,o2,o3,o4}의 5개의 데이터로 표현되는데, 여기서 맨 앞의 i는 제2 프레임의 번호이며, o1,o2,o3,o4 는 각각 전술한 바와 같이 제2 프레임 하나에 포함된 제1 프레임들의 특징 분포 데이터가 몇 번 나타났는지를 나타내는 빈도 데이터이다.Assuming that one second frame includes four first frames and one second frame is slidably moved by a time interval of one first frame, a total of nine second frames (h 1 to h 9 ) can be configured. Audio fingerprint data h i for each second frame is represented by five data of {i, o 1 , o 2 , o 3 , o 4 }, where the first i is the number of the second frame, o 1 , o 2 , o 3 , o 4 As described above, frequency data representing how many times the feature distribution data of the first frames included in the second frame is shown.
예컨대, 도 9에서 h1은 {1,1,2,1,0}의 5개의 데이터로 표현되는데, 여기서 맨 앞의 1은 제2 프레임 번호로서 첫번째의 제2 프레임임을 나타내는 데이터이고, 그 다음의 1은 c1~c4까지의 최초 4개의 제1 프레임들의 특징 분포 데이터(2,3,2,1)중에서 인덱스 1의 값이 1번 나타났다는 것을 나타내는 데이터이다. 마찬가지로, h1의 세번쩨 데이터인 2는 c1~c4까지의 최초 4개의 제1 프레임들의 특징 분포 데이터(2,3,2,1)중에서 인덱스 2의 값이 2번 나타났다는 것을 나타내며, h1의 네번쩨 데이터인 1은 c1~c4까지의 최초 4개의 제1 프레임들의 특징 분포 데이터(2,3,2,1)중에서 인덱스 3의 값이 1번 나타났다는 것을 나타내며, h1의 다섯번쩨 데이터인 0은 c1~c4까지의 최초 4개의 제1 프레임들의 특징 분포 데이터(2,3,2,1)중에서 인덱스 4의 값이 0번 나타났다는 것을 나타내는 데이터들이다.For example, in FIG. 9, h 1 is represented by five data of {1,1,2,1,0}, where the first 1 is data indicating that the first second frame is a second frame number, and then 1 is data indicating that the value of
이와 같은 방식에 의하여, h1의 오디오 핑거프린트 데이터를 구할 수 있고, 마찬가지 방식에 의하여 h2~h9 각각에 대한 제2 프레임별 오디오 핑거프린트 데이터를 구할 수 있고, 따라서 오디오 데이터 전체에 대한 오디오 핑거프린트 데이터를 구성할 수 있다.In this manner, audio fingerprint data of h 1 can be obtained, and in the same manner, audio fingerprint data for each second frame for each of h 2 to h 9 can be obtained, and thus audio for the entire audio data can be obtained. Fingerprint data can be configured.
이하에서는, 전술한 바와 같은 방법에 의해 생성된 오디오 핑거프린트 데이 터를 이용하여 오디오 데이터를 비교하여 동일성 여부를 판단하는 방법에 대하여 설명한다.Hereinafter, a method of comparing the audio data using the audio fingerprint data generated by the method described above and determining whether or not the same will be described.
도 10은 본 발명에 의한 오디오 핑거프린트 데이터를 이용하여 오디오 데이터를 비교하는 방법의 일실시예를 나타낸 흐름도이다.10 is a flowchart illustrating an embodiment of a method for comparing audio data using audio fingerprint data according to the present invention.
우선, 오디오 데이터들을 비교하기에 앞서서, 도 1 내지 도 9를 참조하여 설명한 바와 같은 방식에 의하여 오디오 데이터들에 대한 오디오 핑거프린트 데이터를 생성해 둔다. 원본 오디오 데이터들에 대해서는 미리 오디오 핑거프린트 데이터를 각각 생성하여 오디오 데이터베이스(40, 도 1 참조)에 저장하여 두고, 이들과 비교할 비교 대상이 되는 비교 대상 오디오 데이터에 대해서도 오디오 핑거프린트 데이터를 생성하고 이를 오디오 데이터 비교 서버(30)로 전송하며, 오디오 데이터 비교 서버(30)는 비교 대상 오디오 데이터에 대해 생성된 오디오 핑거프린트 데이터와 오디오 데이터베이스(40)에 저장되어 있는 원본 오디오 데이터들에 대한 오디오 핑거프린트 데이터들을 다음의 과정에 의해 비교하게 된다. 물론, 오디오 데이터베이스(40)에 저장되어 있는 원본 오디오 데이터들을 비교하는 것도 가능하며, 오디오 데이터베이스(40)에 따로 저장하지 않고 오디오 데이터 비교 서버(30)에서 2 이상의 오디오 데이터들을 바로 비교하는 방법도 가능하다. First, prior to comparing the audio data, audio fingerprint data for the audio data is generated by the method described with reference to FIGS. 1 to 9. The audio fingerprint data is generated in advance for the original audio data and stored in the audio database 40 (see FIG. 1), and the audio fingerprint data is also generated for the compared audio data to be compared with them. The audio
도 10을 참조하면, 우선 원본 오디오 데이터를 비교 대상 오디오 데이터의 크기에 상응하도록 적어도 하나 이상의 세그먼트(segment)로 분할한다(S1001). 도 11을 참조하면, 비교 대상 오디오 데이터의 크기와 원본 오디오 데이터의 크기가 같은 (a)의 경우에는 원본 오디오 데이터를 복수개의 개의 세그먼트로 분할할 필요가 없으며, 이러한 경우는 하나의 세그먼트만 존재한다. 그러나, (b)의 경우와 같이 원본 오디오 데이터의 크기가 비교 대상 오디오 데이터보다 큰 경우에는 도 11에 나타낸 바와 같이 하나의 세그먼트의 크기가 비교 대상 오디오 데이터의 크기에 상응하도록 원본 오디오 데이터를 k1,k2,k3..의 복수개의 세그먼트로 분할할 수 있다. 이 때, 세그먼트의 분할은, 전술한 제1 프레임 및 제2 프레임 분할시 설명했던 바와 마찬가지로, 분할되는 하나의 세그먼트와 인접하는 다음 시간 간격의 세그먼트가 서로 공통되는 부분을 갖도록 분할하는 것이 보다 정교한 비교가 가능하므로 바람직하다. 세그먼트의 수가 많을 수록 보다 좁은 구간별로 오디오 핑거프린트 데이터를 비교할 수 있으므로 보다 정교한 비교가 가능하게 된다. Referring to FIG. 10, first, original audio data is divided into at least one segment to correspond to the size of audio data to be compared (S1001). Referring to FIG. 11, in the case of (a) in which the size of the comparison target audio data and the size of the original audio data are the same, there is no need to divide the original audio data into a plurality of segments, and in this case, only one segment exists. . However, as in the case of (b), when the size of the original audio data is larger than the audio data to be compared, as shown in FIG. 11, the original audio data is k 1 such that the size of one segment corresponds to the size of the audio data to be compared. It can be split into multiple segments of, k 2 , k 3 .. At this time, segmentation, as described in the above-described first and second frame division, it is more complicated to divide so that one segment to be divided and the segment of the next time interval adjacent to each other have a common part with each other Is preferred since it is possible. As the number of segments increases, audio fingerprint data can be compared for each narrower section, thereby allowing more sophisticated comparison.
다음으로, 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터와 상기와 같이 분할된 적어도 하나 이상의 세그먼트 각각의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 각각 산출한다(S1003). 오디오 핑거프린트 데이터 간의 거리를 계산하는 것은 다음과 같은 방식에 의해 수행될 수 있다.Next, the distance between the audio fingerprint data of the comparison target audio data and the audio fingerprint data of each of the at least one segment divided as described above is calculated for each segment (S1003). Calculating the distance between audio fingerprint data may be performed in the following manner.
전술한 바와 같이, 본 발명에 의하여 생성된 오디오 핑거프린트 데이터는 제2 프레임별 오디오 핑거프린트의 집합 H={h1,h2,h3....hN}으로 구성되며(여기서, N은 제2 프레임의 개수), 각 제2 프레임별 오디오 핑거프린트 데이터(hi)는 hi=(i,o1,o2,o3,...oL)로 정의할 수 있다. 여기서, i는 제2 프레임의 순번을 나타내 며, L은 앞서 설명한 바와 같은 코드북의 차수를 의미하고, o1,o2,o3,...oL은 각각 제2 프레임에 포함된 제1 프레임들의 특징 분포 데이터(즉, 코드북의 인덱스값)이 각 인덱스별로 하나의 제2 프레임에서 몇 번 나타났는가를 나타내는 빈도 데이터를 의미한다. As described above, the audio fingerprint data generated by the present invention is composed of a set H = {h 1 , h 2 , h 3 .... h N } of audio fingerprints per second frame (where N Is the number of second frames), and audio fingerprint data h i for each second frame may be defined as h i = (i, o 1 , o 2 , o 3 ,... O L ). Here, i denotes a sequence number of the second frame, L denotes the order of the codebook as described above, o 1 , o 2 , o 3 , ... o L are each the first frame included in the second frame It means frequency data indicating how many times the feature distribution data of the frames (that is, the index value of the codebook) appears in one second frame for each index.
이 경우, 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터를 H={h1,h2,h3....hN}라 하고, 원본 오디오 데이터의 k번째 세그먼트의 오디오 핑거프린트 데이터를 Hk={hk 1,hk 2,hk 3....hk N}라 하면, 이들간의 거리는 다음과 같은 수식에 의해 계산할 수 있다.In this case, the audio fingerprint data of the audio data to be compared is referred to as H = {h 1 , h 2 , h 3 .... h N }, and the audio fingerprint data of the kth segment of the original audio data is referred to as H k = If {h k 1 , h k 2 , h k 3 .... h k N }, the distance between them can be calculated by the following equation.
수식 1.

이 수식이 의미하는 것은, 비교하고자 하는 두 개의 오디오 핑거프린트 데이터의 거리는, 비교하고자 하는 두 개의 오디오 핑거프린트 데이터 각각을 구성하는 제2 프레임별 오디오 핑거프린트 데이터를 제2 프레임별로 맨 처음부터 마지막까지 순차적으로 대응시키면서 제2 프레임별 오디오 핑거프린트 데이터간의 거리(d)를 구하여 이를 합산한다는 것이다. 여기에서, 제2 프레임별 오디오 핑거프린트 데이터간의 거리(d)는 다음과 같은 수식에 의하여 계산할 수 있다.This formula means that the distance between two audio fingerprint data to be compared is the first to last audio fingerprint data for each second frame constituting each of the two audio fingerprint data to be compared. The distances d between the audio fingerprint data for each second frame are calculated and corresponded sequentially. Here, the distance d between the audio fingerprint data for each second frame may be calculated by the following equation.
수식 2
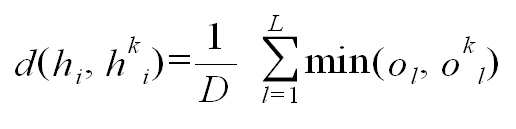
상기 수식이 의미하는 것은, 대응되는 제2 프레임별 오디오 핑거프린트 데이터를 구성하는 특징 분포 데이터(코드북의 인덱스값)이 하나의 제2 프레임에서 나타난 빈도를 나타내는 빈도 데이터(ol)를 맨 처음부터 마지막까지 순차적으로 대응시키면서 최소값을 산출하여 이들의 합을 구한 후 프레임의 개수로 나눈다는 것이다. 여기서, 프레임의 개수로 나누는 과정은 생략할 수 있다.The formula means that the frequency data o l representing the frequency at which feature distribution data (index value of the codebook) constituting corresponding audio fingerprint data for each second frame appears in one second frame from the beginning. The minimum values are calculated by sequential correspondence until the end, and the sums are divided by the number of frames. Here, the process of dividing by the number of frames may be omitted.
예컨대, hi={3,2,3,5,3,7,9,23}이고, hk i={3,4,5,2,23,56,3,2}라고 가정하면, 맨 앞의 데이터는 프레임의 번호이므로 이를 제외하고 두번째 값부터 순차적으로 대응시켜 최소값을 구하면, 2,3,2,3,7,3,2를 얻을 수 있고 이들의 합을 구하면 22이며, 이를 제2 프레임의 갯수로 나누면 원본 오디오 데이터와 비교 대상 오디오 데이터의 i번째 제2 프레임들의 오디오 핑거프린트 데이터 사이의 거리를 구할 수 있다. 이와 같이 각 제2 프레임별로 거리를 구한 후, 상기 수식 1에 의하여 제2 프레임별 거리의 합을 계산하면 비교하고자 하는 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터와 원본 오디오 데이터의 k번째 세그먼트의 오디오 핑거프린트 데이터간의 거리를 구할 수 있게 된다. 이와 같은 과정을 모든 세그먼트에 대해 반복하여 수행함으로써, 원본 오디오 데이터의 모든 세그먼트의 오디오 핑거프 린트 데이터와 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터 사이의 거리를 세그먼트별로 계산할 수 있다. For example, suppose h i = {3,2,3,5,3,7,9,23} and h k i = {3,4,5,2,23,56,3,2}. Since the previous data is the frame number, except for this, if the minimum value is obtained by sequentially matching the second value, 2,3,2,3,7,3,2 can be obtained, and the sum thereof is 22, which is the second value. By dividing by the number of frames, the distance between the original audio data and the audio fingerprint data of the i th second frames of the comparison target audio data may be obtained. In this way, after calculating the distance for each second frame and calculating the sum of the distances for each second frame according to
이와 같이 모든 세그먼트에 대해 세그먼트 별로 거리가 계산되면, 이들중의 최대값을 결정한다(S1005). In this way, if the distance is calculated for each segment for each segment, the maximum value among them is determined (S1005).
최대값이 결정되면, 최대값과 미리 설정해 둔 임계치의 크기를 비교하여(S1007), 비교 대상 오디오 데이터가 원본 오디오 데이터와 동일성이 있는지의 여부를 판단하게 된다. 동일성이 있다는 것은 비교 대상 오디오 데이터가 원본 오디오 데이터와 완전히 동일하거나 포함되어 있다(부분 동일)는 것을 의미한다. When the maximum value is determined, it is determined whether or not the comparison target audio data is identical to the original audio data by comparing the maximum value with a preset threshold value (S1007). The equality means that the audio data to be compared is exactly the same or contained (partially identical) with the original audio data.
비교 결과 최대값이 임계치보다 큰 경우, 완전 동일 또는 일부 동일 여부를 판별하기 위해서, 원본 오디오 데이터와 비교 대상 오디오 데이터의 크기를 비교한다(S1009). 비교 결과, 비교 대상 오디오 데이터의 크기가 원본 오디오 데이터의 크기와 동일한 경우에는 비교 대상 오디오는 원본 오디오 데이터와 완전히 동일한 것으로 결정하고(S1011), 비교 대상 오디오 데이터의 크기가 원본 오디오 데이터의 크기보다 작은 경우에는 비교 대상 오디오는 원본 오디오 데이터와 부분적으로 동일한 것으로 결정한다(S1013).If the maximum value is greater than the threshold as a result of the comparison, the original audio data is compared with the size of the comparison target audio data in order to determine whether they are completely identical or partially identical (S1009). As a result of the comparison, if the size of the compared audio data is equal to the size of the original audio data, the compared audio is determined to be exactly the same as the original audio data (S1011), and the size of the compared audio data is smaller than the size of the original audio data. In the case, the comparison target audio is determined to be partially identical to the original audio data (S1013).
한편, 상기 단계(S1007)에서 최대값이 임계치보다 작은 경우에는 비교 대상 오디오 데이터는 원본 오디오 데이터와 동일성이 없는 것으로 결정한다(S1015).On the other hand, if the maximum value is less than the threshold in step S1007, it is determined that the comparison target audio data is not the same as the original audio data (S1015).
한편, 도 10 내지 도 11을 참조하여 설명한 본 발명에 의한 오디오 핑거프린트 데이터를 이용하여 오디오 데이터를 비교하는 방법의 일실시예는 적어도 하나 이상의 원본 오디오 데이터들을 포함하는 오디오 데이터베이스와 비교하는 경우에도 거의 그대로 적용할 수 있다. 오디오 데이터베이스 전체와 비교하는 경우, 오디오 데이터베이스에 포함되어 있는 각각의 오디오 데이터에 대하여 도 10 내지 도 11을 참조하여 설명한 과정을 반복하여 수행하며, 이러한 과정을 도 12의 흐름도에 나타내었다. 도 12의 흐름도는 도 10의 흐름도와 비교할 때, 오디오 데이터베이스에 포함되어 있는 모든 오디오 데이터들 각각에 대하여 도 10 내지 도 11의 과정을 반복 수행한다는 점에서 차이가 있다. Meanwhile, an embodiment of the method for comparing audio data using the audio fingerprint data according to the present invention described with reference to FIGS. 10 to 11 is almost the same when comparing with an audio database including at least one or more original audio data. You can apply it as it is. In comparison with the audio database as a whole, the process described with reference to FIGS. 10 to 11 is repeated for each audio data included in the audio database, which is illustrated in the flowchart of FIG. 12. 12 is different from the flowchart of FIG. 10 in that the processes of FIGS. 10 to 11 are repeated for each of the audio data included in the audio database.
따라서, 도 12의 흐름도에서, 원본 오디오 데이터를 복수개의 세그먼트로 분할하는 것은 오디오 데이터베이스에 포함된 모든 원본 오디오 데이터들 각각에 대해서 수행하며(S1201, 도 10의 단계 S1001 참조), 각각의 원본 오디오 데이터들에 대하여 세그먼트별로 오디오 핑거프린트 데이터간의 거리를 산출한다(S1203, 도 10의 단계 S1003 참조). Therefore, in the flowchart of FIG. 12, dividing original audio data into a plurality of segments is performed for each of all original audio data included in the audio database (S1201, see step S1001 of FIG. 10), and each original audio data The distance between the audio fingerprint data for each segment is calculated (S1203, see step S1003 of FIG. 10).
또한, 단계(S1205)에서 거리의 최대값을 결정하는 것은, 모든 오디오 데이터의 및 모든 세그먼트 별로 구한 거리로부터 최대값을 결정한다. 또한, 단계(S1209)에서 파일 크기를 비교하는 것은, 오디오 데이터베이스에 포함된 오디오 데이터들 중에서 상기 결정된 최대값을 갖는 원본 오디오 데이터와 비교 대상 오디오 데이터의 크기를 비교하고, 크기가 동일한 경우에는 비교 대상 오디오 데이터는 오디오 데이터베이스에 포함된 오디오 데이터들 중 적어도 어느 하나와 완전히 동일한 것으로 결정하고(S1213), 원본 오디오 데이터의 크기가 비교 대상 오디오 데이터보다 큰 경우에는 비교 대상 오디오 데이터는 오디오 데이터베이스에 포함된 오디오 데이터들 중 적어도 어느 하나와 부분적으로 동일한 것으로 결정한다(S1211).Further, determining the maximum value of the distance in step S1205 determines the maximum value from the distances obtained for all the audio data and for every segment. In addition, comparing the file size in step S1209, comparing the size of the original audio data having the determined maximum value with the comparison target audio data among the audio data included in the audio database, and if the size is the same The audio data is determined to be exactly the same as at least one of the audio data included in the audio database (S1213). When the size of the original audio data is larger than the compared audio data, the compared audio data is included in the audio database. It is determined to be partially identical to at least one of the data (S1211).
한편, 상기 단계(S1207)에서 최대값이 임계치보다 작은 경우에는 비교 대상 오디오 데이터는 오디오 데이터베이스에 포함된 모든 오디오 데이터와 동일성이 없는 것으로 결정한다(S1215).On the other hand, if the maximum value is less than the threshold in the step (S1207) it is determined that the comparison target audio data is not the same as all audio data included in the audio database (S1215).
다음으로, 도 10 및 도 12에서의 임계값을 결정하기 위한 방법의 일예를 설명한다.Next, an example of a method for determining the threshold in FIGS. 10 and 12 will be described.
도 13은 앞서 살펴 본 바와 같은 원본 오디오 데이터와 비교 대상 오디오 데이터의 오디오 핑거프린트 데이터간의 거리의 최대값의 분포도로서, 오디오 데이터베이스에 포함되어 있는 원본 오디오 데이터들의 집합의 갯수를 Q개라고 하고, 비교 대상 오디오 데이터 들 중에서 오디오 데이터베이스에 포함된 오디오 데이터가 P개, 비교 대상 오디오 데이터들 중에서 오디오 데이터베이스에 포함되지 않는 오디오 데이터들이 R개라고 할 때, P개의 비교 대상 오디오 데이터 및 R개의 비교 대상 오디오 데이터와 오디오 데이터베이스에 포함된 원본 오디오 데이터들의 오디오 핑거프린트 데이터간의 거리의 최대값에 대한 분포도는 도 13의 S1, S2로 각각 나타난다.FIG. 13 is a distribution diagram of the maximum value of the distance between the original audio data and the audio fingerprint data of the comparison target audio data. The number of sets of the original audio data included in the audio database is referred to as Q. FIG. When there are P audio data included in the audio database among the target audio data and R audio data not included in the audio database among the compared audio data, P compared audio data and R compared audio data And distributions for the maximum value of the distance between the audio fingerprint data of the original audio data included in the audio database are shown as S1 and S2 of FIG. 13, respectively.
이 때 임계치(Th)는 다음과 같은 수식에 의해 결정할 수 있다.At this time, the threshold Th can be determined by the following equation.
수식 3.
Th = μ 1 - α·σ 1 Th = μ 1 -ασ 1
여기서, μ 1 은 S1 곡선의 평균값이며, σ 1 은 S1 곡선의 표준편차이고, α는 상수로서 통계적 특성에 의해 적절한 값을 사용할 수 있다. 예컨대, α는 1~7 사이의 실수값을 사용할 수 있다. 상기 임계치를 결정하는 수식은 예시적인 것이며, 오디오 데이터베이스와 비교 대상 오디오 데이터들의 분포 특성에 따라 기타 다른 여러 가지 통계적 방법을 사용하여 결정할 수 있음은 물론이다.Here, μ 1 is an average value of the S1 curve, sigma 1 is a standard deviation of the S1 curve, and α is a constant, and an appropriate value can be used depending on statistical characteristics. For example, α may use a real value between 1 and 7. The formula for determining the threshold is exemplary and may be determined using various other statistical methods according to the distribution characteristics of the audio database and the audio data to be compared.
이상에서, 본 발명의 바람직한 실시예를 참조하여 본 발명의 구성을 설명하였으나 본 발명이 상기의 실시예들에 한정되는 것이 아님은 물론이며, 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자라면 첨부한 특허청구범위 및 도면 전체를 참조하여 파악되는 본 발명의 범위 내에서 여러 가지의 변형, 수정 및 개선 실시가 가능하다는 점은 자명할 것이다. 예컨대, 본 발명은 오디오 데이터에 대해 적용한 실시예를 참고하여 설명하였으나, 전술한 바와 같이 오디오 및 비디오 신호가 포함되어 있는 동영상 데이터의 경우에도 그대로 적용할 수 있다. 즉, 동영상 데이터로부터 오디오 신호를 추출하여 오디오 신호에 대해 오디오 핑거프린트를 생성하고 이들을 비교함으로써 동영상 데이터의 동일성 여부도 손쉽게 판별할 수 있다.In the above, the configuration of the present invention has been described with reference to the preferred embodiment of the present invention, of course, the present invention is not limited to the above embodiments, and those skilled in the art to which the present invention pertains It will be apparent that various modifications, changes and improvements can be made within the scope of the invention as seen with reference to the appended claims and the accompanying drawings. For example, although the present invention has been described with reference to an embodiment applied to audio data, as described above, the present invention may also be applied to video data including audio and video signals. That is, by extracting an audio signal from the video data to generate an audio fingerprint with respect to the audio signal and comparing the same, it is possible to easily determine whether the video data is identical.
본 발명에 의하면, 종래의 오디오 핑거프린트 생성 방식에 비하여 속도가 현저하게 개선되며 생성 방법이 상대적으로 간편한 오디오 핑거프린트 데이터 생성 방법 및 장치를 제공할 수 있다.According to the present invention, it is possible to provide a method and apparatus for generating audio fingerprint data, which is remarkably improved compared to the conventional audio fingerprint generation method and whose generation method is relatively simple.
또한, 본 발명에 의하면, 오디오 데이터를 분석하여 오디오 데이터의 특징 데이터의 분포 특성 데이터를 이용하여 오디오 핑거프린트 데이터를 생성하므로, 종래의 방법에 비하여 오디오 데이터의 특징을 보다 정밀하게 반영할 수 있는 오디오 핑거프린트 데이터 생성 방법 및 장치를 제공할 수 있다.In addition, according to the present invention, audio fingerprint data is generated using the distribution characteristic data of the characteristic data of the audio data by analyzing the audio data, so that audio characteristics capable of reflecting the characteristics of the audio data more precisely than in the conventional method are provided. A fingerprint data generating method and apparatus may be provided.
또한, 본 발명에 의하면, 상기한 바와 같은 오디오 핑거프린트 데이터 생성 방법 및 장치에 의하여 생성되는 오디오 핑거프린트 데이터를 갖는 오디오 데이터들을 비교함에 있어서, 종래의 방식에 비하여 신속하고 정확한 비교 결과를 얻을 수 있으며 동일성 여부의 판단 오차를 현저하게 감소시킬 수 있는 오디오 데이터 비교 방법 및 장치를 제공할 수 있다.In addition, according to the present invention, when comparing the audio data having the audio fingerprint data generated by the method and apparatus for generating audio fingerprint data as described above, it is possible to obtain a quick and accurate comparison result compared to the conventional method It is possible to provide a method and apparatus for comparing audio data that can significantly reduce a determination error of identity.
또한, 본 발명에 의하면, 오디오 핑거프린트 데이터를 세그먼트로 나누어서 세그먼트별로 비교 판단할 수 있으므로 원본 오디오 데이터와 비교 대상 오디오 데이터가 부분적으로 동일한 경우에도 적용할 수 있고, 또한 부분적으로 동일한 경우 부분적으로 동일한 위치도 검출할 수 있는 오디오 데이터 비교 방법 및 장치를 제공할 수 있다.Further, according to the present invention, since the audio fingerprint data can be divided into segments and compared and judged for each segment, the present invention can be applied even when the original audio data and the comparison target audio data are partially the same. It is possible to provide a method and apparatus for comparing audio data that can be detected.
또한, 본 발명에 의하면, 비디오 신호 및 오디오 신호가 포함되어 있는 동영상 데이터로부터 오디오 신호를 추출하여 오디오 신호에 대한 오디오 핑거프린트 데이터를 생성 및 비교함으로써 오디오 데이터 뿐 아니라 동영상 데이터의 무단 복 사 및 도용 여부를 간편하게 판별할 수 있으며, 나아가 동영상 데이터의 일부만을 편집하여 도용하는 경우에도 손쉽게 적용할 수 있는 오디오 데이터 비교 방법 및 장치를 제공할 수 있다.In addition, according to the present invention, by extracting the audio signal from the video data including the video signal and the audio signal to generate and compare audio fingerprint data for the audio signal whether the unauthorized copying and theft of the video data as well as the audio data The present invention can provide a method and device for easily comparing audio data, which can be easily applied even when only a part of video data is edited and stolen.
Claims (25)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020070044251A KR100893123B1 (en) | 2007-05-07 | 2007-05-07 | Method and apparatus for generating audio fingerprint data and comparing audio data using the same |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020070044251A KR100893123B1 (en) | 2007-05-07 | 2007-05-07 | Method and apparatus for generating audio fingerprint data and comparing audio data using the same |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20080098878A KR20080098878A (en) | 2008-11-12 |
| KR100893123B1 true KR100893123B1 (en) | 2009-04-10 |
Family
ID=40286098
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020070044251A KR100893123B1 (en) | 2007-05-07 | 2007-05-07 | Method and apparatus for generating audio fingerprint data and comparing audio data using the same |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR100893123B1 (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101315970B1 (en) * | 2012-05-23 | 2013-10-08 | (주)엔써즈 | Apparatus and method for recognizing content using audio signal |
| US8886635B2 (en) | 2012-05-23 | 2014-11-11 | Enswers Co., Ltd. | Apparatus and method for recognizing content using audio signal |
| WO2016024734A1 (en) * | 2014-08-14 | 2016-02-18 | 주식회사 비글컴퍼니 | Audio signal processing system and method for searching for sound source of broadcast content |
| KR101608849B1 (en) | 2014-08-14 | 2016-04-04 | 주식회사 비글컴퍼니 | Audio signal processing system and method for searching sound source used broadcast contents |
| KR101647012B1 (en) * | 2015-11-13 | 2016-08-23 | 주식회사 비글컴퍼니 | Apparatus and method for searching music including noise environment analysis of audio stream |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20110010084A (en) * | 2010-11-26 | 2011-01-31 | (주)엔써즈 | Method and system for providing contents related service using fingerprint data |
| KR101382356B1 (en) * | 2013-07-05 | 2014-04-10 | 대한민국 | Apparatus for forgery detection of audio file |
| KR102172321B1 (en) | 2014-05-20 | 2020-10-30 | 삼성전자주식회사 | Method for data deduplication |
| KR101672123B1 (en) * | 2015-03-02 | 2016-11-03 | 한국방송공사 | Apparatus and method for generating caption file of edited video |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060033867A (en) * | 2003-06-23 | 2006-04-20 | 소니 픽쳐스 엔터테인먼트, 인크. | Fingerprinting of data |
| KR20060047451A (en) * | 2004-04-22 | 2006-05-18 | 삼성전자주식회사 | Method for determining variable length of frame for preprocessing of a speech signal and method and apparatus for preprocessing a speech signal using the same |
| JP2007065659A (en) | 2005-09-01 | 2007-03-15 | Seet Internet Ventures Inc | Extraction and matching of characteristic fingerprint from audio signal |
-
2007
- 2007-05-07 KR KR1020070044251A patent/KR100893123B1/en active IP Right Grant
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060033867A (en) * | 2003-06-23 | 2006-04-20 | 소니 픽쳐스 엔터테인먼트, 인크. | Fingerprinting of data |
| KR20060047451A (en) * | 2004-04-22 | 2006-05-18 | 삼성전자주식회사 | Method for determining variable length of frame for preprocessing of a speech signal and method and apparatus for preprocessing a speech signal using the same |
| JP2007065659A (en) | 2005-09-01 | 2007-03-15 | Seet Internet Ventures Inc | Extraction and matching of characteristic fingerprint from audio signal |
Non-Patent Citations (1)
| Title |
|---|
| 송원식 외 2명, '다중 레벨 양자화 기법을 적용한 오디오 핑거프린트 추출방법' ,한국음향학회지 제25권 제4호 pp. 151-158 ,2006.05.02. |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101315970B1 (en) * | 2012-05-23 | 2013-10-08 | (주)엔써즈 | Apparatus and method for recognizing content using audio signal |
| WO2013176329A1 (en) * | 2012-05-23 | 2013-11-28 | (주)엔써즈 | Device and method for recognizing content using audio signals |
| US8886635B2 (en) | 2012-05-23 | 2014-11-11 | Enswers Co., Ltd. | Apparatus and method for recognizing content using audio signal |
| WO2016024734A1 (en) * | 2014-08-14 | 2016-02-18 | 주식회사 비글컴퍼니 | Audio signal processing system and method for searching for sound source of broadcast content |
| KR101608849B1 (en) | 2014-08-14 | 2016-04-04 | 주식회사 비글컴퍼니 | Audio signal processing system and method for searching sound source used broadcast contents |
| KR101647012B1 (en) * | 2015-11-13 | 2016-08-23 | 주식회사 비글컴퍼니 | Apparatus and method for searching music including noise environment analysis of audio stream |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20080098878A (en) | 2008-11-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100893123B1 (en) | Method and apparatus for generating audio fingerprint data and comparing audio data using the same | |
| Hossan et al. | A novel approach for MFCC feature extraction | |
| EP0891618B1 (en) | Speech processing | |
| WO2019232829A1 (en) | Voiceprint recognition method and apparatus, computer device and storage medium | |
| JP4272050B2 (en) | Audio comparison using characterization based on auditory events | |
| KR100888804B1 (en) | Method and apparatus for determining sameness and detecting common frame of moving picture data | |
| Hu et al. | Pitch‐based gender identification with two‐stage classification | |
| Bharti et al. | Real time speaker recognition system using MFCC and vector quantization technique | |
| Nasr et al. | Speaker identification based on normalized pitch frequency and Mel Frequency Cepstral Coefficients | |
| CN103794207A (en) | Dual-mode voice identity recognition method | |
| Imtiaz et al. | Isolated word automatic speech recognition (ASR) system using MFCC, DTW & KNN | |
| KS et al. | Comparative performance analysis for speech digit recognition based on MFCC and vector quantization | |
| Birla | A robust unsupervised pattern discovery and clustering of speech signals | |
| Qais et al. | Deepfake audio detection with neural networks using audio features | |
| El-Henawy et al. | Recognition of phonetic Arabic figures via wavelet based Mel Frequency Cepstrum using HMMs | |
| Nijhawan et al. | Speaker recognition using support vector machine | |
| Alkhatib et al. | Voice identification using MFCC and vector quantization | |
| KR100842310B1 (en) | Method and system for clustering moving picture date according to the sameness with each other | |
| Sukor et al. | Speaker identification system using MFCC procedure and noise reduction method | |
| CN112309404B (en) | Machine voice authentication method, device, equipment and storage medium | |
| Yulita et al. | Feature extraction analysis for hidden Markov models in Sundanese speech recognition | |
| Arora et al. | An efficient text-independent speaker verification for short utterance data from Mobile devices | |
| Hossan et al. | Speaker recognition utilizing distributed DCT-II based Mel frequency cepstral coefficients and fuzzy vector quantization | |
| D'haes et al. | Discrete cepstrum coefficients as perceptual features | |
| KR102389610B1 (en) | Method and apparatus for determining stress in speech signal learned by domain adversarial training with speaker information |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20130218 Year of fee payment: 5 |
|
| FPAY | Annual fee payment |
Payment date: 20140327 Year of fee payment: 6 |
|
| FPAY | Annual fee payment |
Payment date: 20160304 Year of fee payment: 8 |
|
| FPAY | Annual fee payment |
Payment date: 20170406 Year of fee payment: 9 |
|
| FPAY | Annual fee payment |
Payment date: 20180404 Year of fee payment: 10 |