JP7636088B2 - 音声強調方法、装置、機器及びコンピュータプログラム - Google Patents
音声強調方法、装置、機器及びコンピュータプログラム Download PDFInfo
- Publication number
- JP7636088B2 JP7636088B2 JP2023527431A JP2023527431A JP7636088B2 JP 7636088 B2 JP7636088 B2 JP 7636088B2 JP 2023527431 A JP2023527431 A JP 2023527431A JP 2023527431 A JP2023527431 A JP 2023527431A JP 7636088 B2 JP7636088 B2 JP 7636088B2
- Authority
- JP
- Japan
- Prior art keywords
- speech frame
- glottal
- target speech
- spectrum
- complex spectrum
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G06N3/0442—Recurrent networks, e.g. Hopfield networks characterised by memory or gating, e.g. long short-term memory [LSTM] or gated recurrent units [GRU]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0316—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/26—Pre-filtering or post-filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L21/0232—Processing in the frequency domain
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Signal Processing (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Quality & Reliability (AREA)
- Telephonic Communication Services (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Cable Transmission Systems, Equalization Of Radio And Reduction Of Echo (AREA)
Description
x(n)=G・r(n)・ar(n)(式1)
ここで、x(n)は入力された音声信号を表し、Gはゲインを表し、線形予測ゲインと呼ばれることもでき、r(n)は励起信号を表し、ar(n)は声門フィルターを表す。
Ap(z)=1+a1z-1+a2z-2+…+apz-p (式2)として表されてもよい。
ここで、a1、a2、…、apはLPC係数であり、pは声門フィルターの次数であり、zは声門フィルターの入力信号である。
P(z)=Ap(z)-z-(p+1)Ap(z-1) (式3)
Q(z)=Ap(z)+z-(p+1)Ap(z-1) (式4)のように設定する場合、
以下[数1] (式5)を得ることができる。

以下[数2] (式6)として表される。

(E+jF)*(A+jB)=(E*A-F*B)+j(E*B+F*A) (式7)
C=E*A-F*B、D=E*B+F*Aに設定する場合、上式7はさらに、
(E+jF)*(A+jB)=C+jD (式8)に転換する。
f(x)=max(ax,x)(aが定数である) (式9)である。
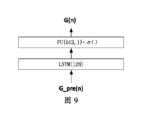
G_pre(n)={G(n-1)、G(n-2)、G(n-3)、G(n-4)}である。
Pa(n)=Real(S′(n))2+Imag(S′(n))2 (式10)である。
AC(n)=Real(iFFT(Pa(n))) (式11)
AC(n)は第nフレームの音声フレームの対応する自己相関係数を表し、iFFT(Inverse Fast Fourier Transform、逆高速フーリエ変換)とはFFT(Fast Fourier Transform、高速フーリエ変換)の逆変換を指し、Realは逆高速フーリエ変換で得られた結果の実部を表す。AC(n)はp個のパラメータを含み、pが声門フィルターの次数であり、AC(n)中の係数はさらにACj(n)として表されてもよく、1≦j≦pである。
k-KA=0 (式12)
ここで、kは自己相関ベクトルであり、Kは自己相関行列であり、AはLPC係数行列である。具体的には、[数3]である。

[数4] (式14)
S_AR(n)=FFT(s_AR(n)) (式15)
FFT係数S_AR(n)を得たことに加えて、下式16にしたがって1つずつのサンプルについて第nフレームの音声フレームに対応する声門フィルターのパワースペクトルを取得することができ、
AR_LPS(n,k)=(Real(S_AR(n,k)))2+(Imag(S_AR(n,k)))2 (式16)
ここで、Real(S_AR(n,k))はS_AR(n,k)の実部を表し、Imag(S_AR(n,k))はS_AR(n,k)の虚部を表し、kはFFT係数の数列を表し、0≦k≦m、kは正の整数である。
AR_LPS1(n)=log10(AR_LPS(n)) (式17)
上記AR_LPS1(n)を下式18にしたがって反転し、すなわち、声門フィルターの逆対応するパワースペクトルAR_LPS2(n)を得て、
AR_LPS2(n)=-1*AR_LPS1(n) (式18)
次に下式19にしたがって目標音声フレームに対応する励起信号のパワースペクトルR(n)を計算して取得することができる。
R(n)=Pa(n)*(G1(n))2*AR_LPS3(n) (式19)
ここで、[数5] (式20)
[数6] (式21)
[数7] (式22)
S_e(n)=G2(n)*S_filt(n) (式24)
ここで、[数8] (式25)
111 収集モジュール
112 前強調処理モジュール
113 符号化モジュール
120 受信端
121 復号モジュール
122 後強調モジュール
123 再生モジュール
1710 プリエンファシスモジュール
1720 音声分解モジュール
1730 合成処理モジュール
1800 コンピュータシステム
1801 中央処理ユニット(CPU)
1804 バス
1805 I/Oインターフェース
1805 出力(Input/Output、I/O)インターフェース
1806 入力部分
1807 出力部分
1808 記憶部分
1809 通信部分
1810 ドライバ
1811 媒体
Claims (15)
- コンピュータ機器によって実行される、音声強調方法であって、
目標音声フレームの対応する複素スペクトルに基づいて前記目標音声フレームに対してプリエンファシス処理を行い、第1複素スペクトルを得るステップと、
前記第1複素スペクトルに基づいて前記目標音声フレームに対して音声分解を行い、前記目標音声フレームの対応する声門パラメータ、ゲイン及び励起信号を得るステップと、
前記声門パラメータ、前記ゲイン及び前記励起信号に基づいて合成処理を行い、前記目標音声フレームの対応する強調音声信号を得るステップと
を含む、音声強調方法。 - 目標音声フレームの対応する複素スペクトルに基づいて前記目標音声フレームに対してプリエンファシス処理を行い、第1複素スペクトルを得る前記ステップは、
前記目標音声フレームの対応する複素スペクトルを第1ニューラルネットワークに入力するステップであって、前記第1ニューラルネットワークはサンプル音声フレームの対応する複素スペクトルと前記サンプル音声フレームにおける元の音声信号の対応する複素スペクトルとに基づいてトレーニングを行って得られ、前記サンプル音声フレームは、前記元の音声信号とノイズ信号とを組み合わせることにより得られる、ステップと、
前記第1ニューラルネットワークによって、前記目標音声フレームの対応する複素スペクトルに基づいて前記第1複素スペクトルを出力するステップと
を含む、請求項1に記載の方法。 - 前記第1ニューラルネットワークは複素畳み込み層、ゲート付き回帰型ユニット層及び
全結合層を含み、
前記第1ニューラルネットワークによって、前記目標音声フレームの対応する複素スペ
クトルに基づいて前記第1複素スペクトルを出力する前記ステップは、
前記複素畳み込み層によって前記目標音声フレームに対応する複素スペクトルにおける実部及び虚部に基づいて複素畳み込み処理を行うステップと、
前記ゲート付き回帰型ユニット層によって前記複素畳み込み層の出力に対して変換処理を行うステップと、
前記全結合層によって前記ゲート付き回帰型ユニットの出力に対して全結合処理を行い、前記第1複素スペクトルを出力するステップと
を含む、請求項2に記載の方法。 - 前記第1複素スペクトルに基づいて前記目標音声フレームに対して音声分解を行い、前記目標音声フレームの対応する声門パラメータ、ゲイン及び励起信号を得る前記ステップは、
前記第1複素スペクトルに基づいて前記目標音声フレームに対して声門パラメータ予測を行い、前記目標音声フレームの対応する声門パラメータを得るステップと、
前記第1複素スペクトルに基づいて前記目標音声フレームに対して励起信号予測を行い、前記目標音声フレームの対応する励起信号を得るステップと、
前記目標音声フレームの前の履歴音声フレームの対応するゲインに基づいて前記目標音声フレームに対してゲイン予測を行い、前記目標音声フレームの対応するゲインを得るステップと
を含む、請求項1に記載の方法。 - 前記第1複素スペクトルに基づいて前記目標音声フレームに対して声門パラメータ予測を行い、前記目標音声フレームの対応する声門パラメータを得る前記ステップは、
前記第1複素スペクトルを第2ニューラルネットワークに入力するステップであって、前記第2ニューラルネットワークはサンプル音声フレームの対応する複素スペクトルと前記サンプル音声フレームの対応する声門パラメータとに基づいてトレーニングを行って得られるものである、ステップと、
前記第2ニューラルネットワークによって、前記第1複素スペクトルに基づいて前記目標音声フレームの対応する声門パラメータを出力するステップと
を含む、請求項4に記載の方法。 - 前記第1複素スペクトルに基づいて前記目標音声フレームに対して声門パラメータ予測を行い、前記目標音声フレームの対応する声門パラメータを得る前記ステップは、
前記第1複素スペクトルと前記目標音声フレームの前の履歴音声フレームの対応する声門パラメータとを第2ニューラルネットワークに入力するステップであって、前記第2ニューラルネットワークはサンプル音声フレームの対応する複素スペクトル、サンプル音声フレームの前の履歴音声フレームの対応する声門パラメータ及びサンプル音声フレームの対応する声門パラメータに基づいてトレーニングを行って得られるものである、ステップと、
前記第2ニューラルネットワークによって、前記第1複素スペクトルと前記目標音声フレームの前の履歴音声フレームの対応する声門パラメータとに基づいて前記目標音声フレームの対応する声門パラメータを出力するステップと
を含む、請求項4に記載の方法。 - 前記目標音声フレームの前の履歴音声フレームの対応するゲインに基づいて前記目標音声フレームに対してゲイン予測を行い、前記目標音声フレームの対応するゲインを得る前記ステップは、
前記目標音声フレームの前の履歴音声フレームの対応するゲインを第3ニューラルネットワークに入力するステップであって、前記第3ニューラルネットワークはサンプル音声フレームの前の履歴音声フレームの対応するゲインと前記サンプル音声フレームの対応するゲインとに基づいてトレーニングを行って得られるものである、ステップと、
前記第3ニューラルネットワークによって、前記目標音声フレームの前の履歴音声フレームの対応するゲインに基づいて前記目標音声フレームの対応するゲインを出力するステップと
を含む、請求項4に記載の方法。 - 前記第1複素スペクトルに基づいて前記目標音声フレームに対して励起信号予測を行い、前記目標音声フレームの対応する励起信号を得る前記ステップは、
前記第1複素スペクトルを第4ニューラルネットワークに入力するステップであって、前記第4ニューラルネットワークはサンプル音声フレームの対応する複素スペクトルと前記サンプル音声フレームに対応する励起信号の周波数領域表現とに基づいてトレーニングを行って得られるものである、ステップと、
前記第4ニューラルネットワークによって、前記第1複素スペクトルに基づいて前記目標音声フレームに対応する励起信号の周波数領域表現を出力するステップと
を含む、請求項4に記載の方法。 - 前記声門パラメータ、前記ゲイン及び前記励起信号に基づいて合成処理を行い、前記目標音声フレームの対応する強調音声信号を得る前記ステップは、
声門フィルターにより前記目標音声フレームの対応する励起信号に対してフィルタリングを行い、フィルタリング出力信号を得るステップであって、前記声門フィルターは前記目標音声フレームの対応する声門パラメータに基づいて構築されるものである、ステップと、
前記目標音声フレームの対応するゲインに応じて前記フィルタリング出力信号に対して増幅処理を行い、前記目標音声フレームの対応する強調音声信号を得るステップと
を含む、請求項4に記載の方法。 - 前記第1複素スペクトルに基づいて前記目標音声フレームに対して音声分解を行い、前記目標音声フレームの対応する声門パラメータ、ゲイン及び励起信号を得る前記ステップは、
前記第1複素スペクトルに基づいてパワースペクトルを計算して取得するステップと、
前記パワースペクトルに基づいて自己相関係数を計算して取得するステップと、
前記自己相関係数に基づいて前記声門パラメータを計算して取得するステップと、
前記声門パラメータと前記自己相関係数とに基づいて前記ゲインを計算して取得するステップと、
前記ゲインと声門フィルターのパワースペクトルとに基づいて前記励起信号のパワースペクトルを計算して取得するステップであって、前記声門フィルターは前記声門パラメータに基づいて構築されるフィルターである、ステップと
を含む、請求項1に記載の方法。 - 前記声門パラメータ、前記ゲイン及び前記励起信号に基づいて合成処理を行い、前記目標音声フレームの対応する強調音声信号を得る前記ステップは、
前記声門フィルターのパワースペクトルと前記励起信号のパワースペクトルとに基づいて第1振幅スペクトルを生成するステップと、
前記ゲインに応じて前記第1振幅スペクトルに対して増幅処理を行い、第2振幅スペクトルを得るステップと、
前記第2振幅スペクトルと前記第1複素スペクトル中から抽出された位相スペクトルとに基づいて、前記目標音声フレームの対応する強調音声信号を決定するステップとを含む、請求項10に記載の方法。 - 前記第2振幅スペクトルと前記第1複素スペクトル中から抽出された位相スペクトルとに基づいて、前記目標音声フレームの対応する強調音声信号を決定する前記ステップは、
前記第2振幅スペクトルと前記第1複素スペクトル中から抽出された位相スペクトルとを組み合わせ、第2複素スペクトルを得るステップと、
前記第2複素スペクトルを時間領域に変換し、前記目標音声フレームに対応する強調音声信号の時間領域信号を得るステップと
を含む、請求項11に記載の方法。 - 音声強調装置であって、
目標音声フレームの複素スペクトルに基づいて前記目標音声フレームに対してプリエンファシス処理を行い、第1複素スペクトルを得ることに用いられるプリエンファシスモジュールと、
前記第1複素スペクトルに基づいて前記目標音声フレームに対して音声分解を行い、前記目標音声フレームの対応する声門パラメータ、ゲイン及び励起信号を得ることに用いられる音声分解モジュールと、
前記声門パラメータ、前記ゲイン及び前記励起信号に基づいて合成処理を行い、前記目標音声フレームの対応する強調音声信号を得ることに用いられる合成処理モジュールと
を含む、音声強調装置。 - 電子機器であって、
プロセッサと、
メモリであって、前記メモリ上にコンピュータ可読指令が記憶され、前記コンピュータ可読指令が前記プロセッサによって実行されるときに、請求項1~12のいずれか一項に記載の方法を実現するメモリと
を含む、電子機器。 - コンピュータプログラムであって、プロセッサによって実行されるときに、請求項1~12のいずれか一項に記載の方法を実現する、コンピュータプログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110181389.4 | 2021-02-08 | ||
| CN202110181389.4A CN113571080B (zh) | 2021-02-08 | 2021-02-08 | 语音增强方法、装置、设备及存储介质 |
| PCT/CN2022/074003 WO2022166710A1 (zh) | 2021-02-08 | 2022-01-26 | 语音增强方法、装置、设备及存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023548707A JP2023548707A (ja) | 2023-11-20 |
| JP7636088B2 true JP7636088B2 (ja) | 2025-02-26 |
Family
ID=78161113
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023527431A Active JP7636088B2 (ja) | 2021-02-08 | 2022-01-26 | 音声強調方法、装置、機器及びコンピュータプログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US12315488B2 (ja) |
| EP (1) | EP4261825B1 (ja) |
| JP (1) | JP7636088B2 (ja) |
| CN (1) | CN113571080B (ja) |
| WO (1) | WO2022166710A1 (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113571079B (zh) * | 2021-02-08 | 2025-07-11 | 腾讯科技(深圳)有限公司 | 语音增强方法、装置、设备及存储介质 |
| CN113571080B (zh) * | 2021-02-08 | 2024-11-08 | 腾讯科技(深圳)有限公司 | 语音增强方法、装置、设备及存储介质 |
| CN114495965B (zh) * | 2022-01-29 | 2025-05-13 | 中国传媒大学 | 一种干净语音重构方法、装置、设备和介质 |
| CN114678036B (zh) * | 2022-04-29 | 2024-09-03 | 思必驰科技股份有限公司 | 语音增强方法、电子设备和存储介质 |
| CN115862581A (zh) * | 2023-02-10 | 2023-03-28 | 杭州兆华电子股份有限公司 | 一种重复模式噪声的二次消除方法及系统 |
| CN116758930A (zh) * | 2023-07-06 | 2023-09-15 | 维沃移动通信有限公司 | 语音增强方法、装置、电子设备及存储介质 |
| CN117933305B (zh) * | 2023-09-27 | 2025-06-13 | 南开大学 | 一种缓解累积误差的偏置误差模块及其应用方法 |
| CN119049489B (zh) * | 2024-10-31 | 2025-01-03 | 安徽大学 | 一种基于双分支网络的单声道语音增强方法及装置 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000347698A (ja) | 1999-06-08 | 2000-12-15 | Nagano Japan Radio Co | 受信装置 |
| JP2002041085A (ja) | 2000-07-21 | 2002-02-08 | Denso Corp | 音声認識装置及び記録媒体 |
| JP2002366200A (ja) | 2001-06-06 | 2002-12-20 | Mitsubishi Electric Corp | 雑音抑圧装置 |
| JP2020060612A (ja) | 2018-10-05 | 2020-04-16 | 富士通株式会社 | 音声信号処理プログラム、音声信号処理方法及び音声信号処理装置 |
| JP2020122896A (ja) | 2019-01-31 | 2020-08-13 | 日本電信電話株式会社 | 時間周波数マスク推定器学習装置、時間周波数マスク推定器学習方法、プログラム |
Family Cites Families (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2753716B2 (ja) * | 1988-11-18 | 1998-05-20 | 株式会社エイ・ティ・アール自動翻訳電話研究所 | 音声変換装置 |
| US5148488A (en) * | 1989-11-17 | 1992-09-15 | Nynex Corporation | Method and filter for enhancing a noisy speech signal |
| US5381512A (en) * | 1992-06-24 | 1995-01-10 | Moscom Corporation | Method and apparatus for speech feature recognition based on models of auditory signal processing |
| JP3464371B2 (ja) * | 1996-11-15 | 2003-11-10 | ノキア モービル フォーンズ リミテッド | 不連続伝送中に快適雑音を発生させる改善された方法 |
| US6985913B2 (en) * | 2000-12-28 | 2006-01-10 | Casio Computer Co. Ltd. | Electronic book data delivery apparatus, electronic book device and recording medium |
| US8566086B2 (en) * | 2005-06-28 | 2013-10-22 | Qnx Software Systems Limited | System for adaptive enhancement of speech signals |
| CN102483926B (zh) * | 2009-07-27 | 2013-07-24 | Scti控股公司 | 在处理语音信号中通过把语音作为目标和忽略噪声以降噪的系统及方法 |
| WO2012003523A1 (en) * | 2010-07-06 | 2012-01-12 | Rmit University | Emotional and/or psychiatric state detection |
| US9837078B2 (en) * | 2012-11-09 | 2017-12-05 | Mattersight Corporation | Methods and apparatus for identifying fraudulent callers |
| GB2508417B (en) * | 2012-11-30 | 2017-02-08 | Toshiba Res Europe Ltd | A speech processing system |
| US9484044B1 (en) * | 2013-07-17 | 2016-11-01 | Knuedge Incorporated | Voice enhancement and/or speech features extraction on noisy audio signals using successively refined transforms |
| US9412395B1 (en) * | 2014-09-30 | 2016-08-09 | Audible, Inc. | Narrator selection by comparison to preferred recording features |
| EP3382701A1 (en) * | 2017-03-31 | 2018-10-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for post-processing an audio signal using prediction based shaping |
| US20180330713A1 (en) * | 2017-05-14 | 2018-11-15 | International Business Machines Corporation | Text-to-Speech Synthesis with Dynamically-Created Virtual Voices |
| US10381020B2 (en) * | 2017-06-16 | 2019-08-13 | Apple Inc. | Speech model-based neural network-assisted signal enhancement |
| US20190019500A1 (en) * | 2017-07-13 | 2019-01-17 | Electronics And Telecommunications Research Institute | Apparatus for deep learning based text-to-speech synthesizing by using multi-speaker data and method for the same |
| US10726826B2 (en) * | 2018-03-04 | 2020-07-28 | International Business Machines Corporation | Voice-transformation based data augmentation for prosodic classification |
| CN108735213B (zh) * | 2018-05-29 | 2020-06-16 | 太原理工大学 | 一种基于相位补偿的语音增强方法及系统 |
| US11869482B2 (en) * | 2018-09-30 | 2024-01-09 | Microsoft Technology Licensing, Llc | Speech waveform generation |
| US11354586B2 (en) * | 2019-02-15 | 2022-06-07 | Q Bio, Inc. | Model parameter determination using a predictive model |
| KR20210017252A (ko) * | 2019-08-07 | 2021-02-17 | 삼성전자주식회사 | 다채널 오디오 신호 처리 방법 및 전자 장치 |
| US11437050B2 (en) * | 2019-09-09 | 2022-09-06 | Qualcomm Incorporated | Artificial intelligence based audio coding |
| CN110808063A (zh) * | 2019-11-29 | 2020-02-18 | 北京搜狗科技发展有限公司 | 一种语音处理方法、装置和用于处理语音的装置 |
| CN111554322B (zh) | 2020-05-15 | 2025-05-27 | 腾讯科技(深圳)有限公司 | 一种语音处理方法、装置、设备及存储介质 |
| CN111653288B (zh) * | 2020-06-18 | 2023-05-09 | 南京大学 | 基于条件变分自编码器的目标人语音增强方法 |
| CN112242147B (zh) * | 2020-10-14 | 2023-12-19 | 福建星网智慧科技有限公司 | 一种语音增益控制方法及计算机存储介质 |
| CN113571080B (zh) * | 2021-02-08 | 2024-11-08 | 腾讯科技(深圳)有限公司 | 语音增强方法、装置、设备及存储介质 |
-
2021
- 2021-02-08 CN CN202110181389.4A patent/CN113571080B/zh active Active
-
2022
- 2022-01-26 WO PCT/CN2022/074003 patent/WO2022166710A1/zh not_active Ceased
- 2022-01-26 JP JP2023527431A patent/JP7636088B2/ja active Active
- 2022-01-26 EP EP22748989.5A patent/EP4261825B1/en active Active
- 2022-12-06 US US18/076,047 patent/US12315488B2/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000347698A (ja) | 1999-06-08 | 2000-12-15 | Nagano Japan Radio Co | 受信装置 |
| JP2002041085A (ja) | 2000-07-21 | 2002-02-08 | Denso Corp | 音声認識装置及び記録媒体 |
| JP2002366200A (ja) | 2001-06-06 | 2002-12-20 | Mitsubishi Electric Corp | 雑音抑圧装置 |
| JP2020060612A (ja) | 2018-10-05 | 2020-04-16 | 富士通株式会社 | 音声信号処理プログラム、音声信号処理方法及び音声信号処理装置 |
| JP2020122896A (ja) | 2019-01-31 | 2020-08-13 | 日本電信電話株式会社 | 時間周波数マスク推定器学習装置、時間周波数マスク推定器学習方法、プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113571080A (zh) | 2021-10-29 |
| EP4261825A1 (en) | 2023-10-18 |
| EP4261825A4 (en) | 2024-05-15 |
| CN113571080B (zh) | 2024-11-08 |
| JP2023548707A (ja) | 2023-11-20 |
| US12315488B2 (en) | 2025-05-27 |
| US20230097520A1 (en) | 2023-03-30 |
| EP4261825B1 (en) | 2025-10-01 |
| WO2022166710A1 (zh) | 2022-08-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7636088B2 (ja) | 音声強調方法、装置、機器及びコンピュータプログラム | |
| JP7615510B2 (ja) | 音声強調方法、音声強調装置、電子機器、及びコンピュータプログラム | |
| CN112820315B (zh) | 音频信号处理方法、装置、计算机设备及存储介质 | |
| US20210343305A1 (en) | Using a predictive model to automatically enhance audio having various audio quality issues | |
| CN114333892B (zh) | 一种语音处理方法、装置、电子设备和可读介质 | |
| CN113140225A (zh) | 语音信号处理方法、装置、电子设备及存储介质 | |
| CN114333893B (zh) | 一种语音处理方法、装置、电子设备和可读介质 | |
| WO2024027295A1 (zh) | 语音增强模型的训练、增强方法、装置、电子设备、存储介质及程序产品 | |
| CN113345460A (zh) | 音频信号处理方法、装置、设备及存储介质 | |
| CN114333891B (zh) | 一种语音处理方法、装置、电子设备和可读介质 | |
| CN108198566B (zh) | 信息处理方法及装置、电子设备及存储介质 | |
| WO2024055751A1 (zh) | 音频数据处理方法、装置、设备、存储介质及程序产品 | |
| CN111326166B (zh) | 语音处理方法及装置、计算机可读存储介质、电子设备 | |
| CN117809671A (zh) | 一种基于扩散模型的通用语音增强后端细化方法 | |
| CN113571081B (zh) | 语音增强方法、装置、设备及存储介质 | |
| HK40052885A (en) | Speech enhancement method, device, equipment and storage medium | |
| HK40052886A (en) | Speech enhancement method, device, equipment and storage medium | |
| HK40052887A (en) | Speech enhancement method, device, equipment and storage medium | |
| HK40052885B (zh) | 语音增强方法、装置、设备及存储介质 | |
| HK40070826A (en) | Voice processing method and apparatus, electronic device, and readable medium | |
| HK40052886B (zh) | 语音增强方法、装置、设备及存储介质 | |
| HK40071037A (en) | Voice processing method and apparatus, electronic device, and readable medium | |
| HK40071035A (zh) | 一种语音处理方法、装置、电子设备和可读介质 | |
| HK40070826B (zh) | 一种语音处理方法、装置、电子设备和可读介质 | |
| HK40071035B (zh) | 一种语音处理方法、装置、电子设备和可读介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230508 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230508 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240531 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240708 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240920 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250210 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7636088 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |