次に、本発明の一実施形態について、図面を参照しながら説明する。本実施形態の顔追跡装置は、時間的に連続して出現する人物の顔認識、オクルージョンや一時的な人物の消失にも対応した頑健な顔領域追跡手法、映像中のシーンチェンジや動きボケなどの変化に対応した頑健な手法といった技術要素を実現する。これにより、顔認識の結果に基づいて、トラック情報に人物名などのセマンティック性の高い情報を与えることを可能とする。また、本実施形態の顔追跡装置は、映像を対象とする人物検索を容易にするための、認識処理結果のデータを出力する。これにより、顔認識結果を活用したアプリケーションソフトウェアの開発が容易になる。本実施形態の顔追跡装置は、そのために、追跡処理と顔認識処理を統合したデータ構造で、処理結果を出力する。
本実施形態は、時間的に連続する画像(言い換えれば、時間的に前後するフレーム画像)に基づいて、時間的な関係性を考慮して、顔を追跡する。また、顔追跡処理と顔認識処理とを統合する。これにより、本実施形態の顔追跡装置は、顔追跡に関する情報(顔領域の位置の情報や、顔領域の動き予測に関する情報)を、顔認識処理の精度向上のために利用する。また、本実施形態の顔追跡装置は、顔認識処理に関する情報(顔領域の特徴量の類似性(特徴量間の距離))を、顔追跡(トラッキング)の精度向上のために利用する。
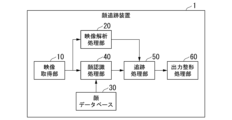
図1は、本実施形態による顔追跡装置の概略機能構成を示すブロック図である。図示するように、顔追跡装置1は、映像取得部10と、映像解析処理部20と、顔データベース30と、顔認識処理部40と、追跡処理部50と、出力整形処理部60と、を含んで構成される。これらの各機能部は、例えば、コンピューターと、プログラムとで実現することが可能である。また、各機能部は、必要に応じて、記憶手段を有する。記憶手段は、例えば、プログラム上の変数や、プログラムの実行によりアロケーションされるメモリーである。また、必要に応じて、磁気ハードディスク装置やソリッドステートドライブ(SSD)といった不揮発性の記憶手段を用いるようにしてもよい。また、各機能部の少なくとも一部の機能を、プログラムではなく専用の電子回路として実現してもよい。
顔追跡装置1は、映像を入力し、映像内に含まれる顔を認識し、顔認識結果と映像情報とを統合したデータを出力する。顔追跡装置1が出力するデータは、所定のデータ構造で構成されるものである。顔追跡装置1を構成する各部の機能は、次に説明する通りである。
映像取得部10は、処理対象(顔追跡対象)の映像を外部から取得する。ここで「外部」とは、他の装置等であってもよいし、データを記録する記録媒体等であってもよい。なお、映像は、所定のフレームレート(例えば、30フレーム毎秒、あるいは60フレーム毎秒等)で連続するフレーム画像のシーケンスである。
映像解析処理部20は、映像取得部10が取得した映像の解析を行う。具体的には、映像解析処理部20は、映像を構成するフレーム画像間での物体や人物等の動き予測処理(動きパラメーター値の抽出)を行ったり、シーンチェンジ解析処理を行ったり、フレーム画像内の領域ごとのボケ検出を行ったりする。映像解析処理部20は、映像解析処理の結果を追跡処理部50に供給する。
言い換えれば、映像解析処理部20は、映像に含まれる顔領域の動き予測の処理を行うことによって、前記顔領域の動き予測結果の情報(動き予測のモデルの情報)を出力する。
顔データベース30は、人物を識別するための情報である人物IDと、顔画像の特徴量と、を関連付けて記憶するデータベースである。データベース自体は既存の技術を用いて実現される。データベースは、記憶手段として、例えば磁気ディスク装置や半導体記憶装置などを用いることができる。なお、顔データベース30に登録される特徴量は、収集された大量の顔画像を基に、機械学習処理等によって得られる情報である。言い換えれば、顔データベース30は、顔認識モデルの情報を記憶する。
なお、顔データベース30が、人物IDの他に、当該人物の属性情報(「政治家」、「俳優」などといったジャンル等の情報)を合わせて保持するようにしてもよい。
顔認識処理部40は、映像取得部10が取得した映像中の顔領域の部分を検出し、その顔領域部分から計算される特徴量と、顔データベース30が記憶している特徴量とを照合することによって顔認識の結果を出力する。顔認識処理部40は、顔認識処理の結果として、人物を特定する情報である人物IDを出力する。あるいは、顔認識処理部40は、映像内の特定の顔領域に対応して、人物IDごとのスコアを出力するようにしてもよい。このスコアは、当該顔領域に含まれる顔が、その人物IDによって識別される人の顔であることの尤度を表す。なお、顔認識処理自体は、既存技術を用いて行うことができる。
顔認識処理部40は、言い換えれば、映像に含まれる顔領域の特徴量を抽出するとともに、その特徴量に基づいて顔領域の顔認識処理を行うことによって、顔領域の位置情報(第1位置情報と呼ぶ)と、顔認識処理の結果として人物を識別する情報である人物識別情報と人物識別情報に対応する認識スコアとの組(第1の組と呼ぶ)と、を出力する。
追跡処理部50は、映像解析処理部20からの映像解析処理結果を活用して、顔認識処理部40が出力するフレーム画像内の顔領域の追跡処理を行う。これにより、追跡処理部50は、時間的に連続する顔領域トラックを求める。ここで「時間的に連続する」とは、隣接し合うフレーム画像間で連続することを意味する。これにより、顔認識の精度が向上する。
つまり、追跡処理部50は、顔領域の時間方向のトラックを求める。ここで、トラックは、追跡情報(軌跡情報)のデータである。トラックは、顔領域の位置情報(第2位置情報と呼ぶ)と、顔領域の人物識別情報と認識スコアとの組(第2の組と呼ぶ)と、を持つ。追跡処理部50は、映像解析処理部20から渡される顔領域の動き予測結果の情報に基づいて顔領域が動いた後の第2位置情報を求め、顔認識処理部から渡される第1の組と、元々トラックが持っている第2の組と、に基づいて、且つ前記第1位置情報と前記第2位置情報との関係(重なり度合い)にも基づいて、トラックを更新する。これによって、追跡処理部は、トラックに、新たな第2位置情報と新たな第2の組(人物識別情報と認識スコアの組)とを付与する。
出力整形処理部60は、所定のデータ構造に整形した形で、追跡結果データを出力する。出力整形処理部60が出力するデータの構造は、映像検索処理等の映像インタラクションシステムから利用しやすい構造であり、顔認識結果の情報と、映像に関する情報とを含むものである。出力整形処理部60が出力するデータ構造により、出力データを利用する機能(アプリケーションソフトウェア等)は、映像中の人物をキーとした検索などの操作を効果的に実現する。
つまり、出力整形処理部60は、追跡処理部50から渡される追跡処理の結果のデータを整形し、出力する。一例として、出力整形処理部60は、トラックの情報に人物識別情報(人物ID)と認識スコアとの組の情報を付与した形の、トラックの集合のデータを整形して出力する。人物識別情報と認識スコアの組は、複数であってよい。
顔追跡装置1は、映像解析処理部20や、追跡処理部50や、出力整形処理部60の処理によって、従来技術では為し得なかった効果を生じさせる。次に、映像解析処理部20、追跡処理部50、出力整形処理部60のそれぞれの、より詳細な処理内容について説明する。
映像解析処理部20は、映像のシーンチェンジの検出や、フレーム画像間におけるグローバルな動きおよび領域ごとのローカルな動きの予測や、領域がボケているかどうかを判定する処理を行う。これらの映像解析処理の結果は、顔認識処理部40の結果とともに追跡処理部50および出力整形処理部60に供給され、顔認識精度向上のために活用される。
映像解析処理部20が行うシーンチェンジの検出は、映像内に映っている内容が大きく変わる切れ目を検出する処理である。シーンチェンジが生じるときには、追跡処理部50が行う映像内の顔の追跡処理をリセットすることが必要となる。シーンチェンジの検出のために、映像解析処理部20は、前後するフレーム画像間の相関度合いを計算する。シーンチェンジが生じていない状況においては、前後するフレーム画像間の相関度合いは所定の閾値以上のレベルを維持する。シーンチェンジが生じるときには、前後するフレーム画像間の相関度合いが上記閾値を大きく下回る。映像解析処理部20は、上記の相関度合いがこの閾値を下回っているか否かに基づいて、シーンチェンジが生じたか否かを判定する。このシーンチェンジの検出自体は、既存技術を利用して行うことができる。時刻(t-1)のフレーム画像と時刻tのフレーム画像との間(ここでのtは整数値)でシーンチェンジが生じたか否かを表す情報を、映像解析処理部20は出力する。映像解析処理部20は、例えば変数is_sc_changeの値を出力することにより、シーンチェンジの検出結果を追跡処理部50に伝える。is_sc_change=1は「シーンチェンジ有り」を表す。is_sc_change=0は「シーンチェンジ無し」を表す。
映像解析処理部20が行う動き予測の処理は、前後のフレーム画像間で画像内に映っている物や人の動きの程度を予測するものである。映像解析処理部20は、動きの程度の予測値を、追跡処理部50に渡す。これにより、追跡処理部50は、映像解析処理部20から渡された予測値にしたがった動き補償処理を行い、追跡処理の精度を向上させることができる。
なお、映像解析処理部20は、動き予測の処理として、画面全体の動きであるグローバル動き(撮影用カメラのパン等)と、検出された顔領域に特化した動きであるローカル動きとの、2種類の動きを予測する。映像解析処理部20は、グローバル動きの予測として、フレーム画像間の相関度に基づいて、画面全体のグローバル動きをモデル化したパラメーターを計算する。グローバル動きのモデルの代表的な例として、アフィンモデルがある。アフィンモデル自体は、既存技術によって処理可能なモデルである。グローバル動きについてのパラメーターは、globalMというマトリックスで表現される。このマトリックスglobalMを用いた動き補償は、下の式(1)を用いて計算可能である。
p(t)=glabalM・p(t-1) ・・・(1)
この式(1)において、p(t-1)は、時刻(t-1)におけるフレーム画像上の位置を表す2次元座標(フレーム画像内の、水平方向座標および垂直方向座標)のベクトルである。また、p(t)は、同様に、時刻tにおけるフレーム画像上の位置を表す2次元座標のベクトルである。マトリックスglobalMは、時刻(t-1)から時刻tまでの間のグローバル動きを表す2行2列のマトリックスである。
一方、ローカル動きの予測として、映像解析処理部20は、対象の顔領域内での顔の動きを予測する。ローカル動きの予測のために、映像解析処理部20は、カルマンフィルターの枠組みを用いる。ローカル動きの予測の処理手順は、例えば前記の非特許文献2にも開示されている。ローカル動きの予測のモデルは領域ごとに異なる。領域rのローカル動きのモデルをkf(r)と表現する。カルマンフィルターの予測関数kf(r).predを用いた、領域rの時刻(t-1)から時刻tまでの動き補償は、下の式(2)を用いて計算可能である。
r(t)=kf(r).pred(r(t-1)) ・・・(2)
本実施形態では、映像解析処理部20は、上記のグローバル動き予測とローカル動き予測とを組み合わせて、従来手法よりも精密な動き予測を行う。グローバル動き予測とローカル動き予測とを組み合わせた時刻(t-1)から時刻(t)までの動き予測は、下の式(3)で表わされる。
r(t)=integrateM(r(t-1))=kf(r).pred(globalM・r(t-1))
・・・(3)
式(3)において、integrateMは、グローバル動き予測とローカル動き予測とを統合した動き予測モデルを表す。
顔追跡装置1の全体的な処理負荷を適切にするため、比較的処理時間のかかる顔認識処理(顔認識処理部40の処理)をローレートで行う場合がある。言い換えれば、顔追跡装置1は、動き予測の処理を相対的に高い頻度で行い、顔認識処理を相対的に低い頻度で行うことができる。仮に動き予測の処理の頻度を顔認識処理の頻度に合わせてローレートで行った場合には、動き予測の精度が低くなる可能性がある。しかしながら、本実施形態の顔追跡装置1は、上記の通り、顔認識処理を相対的ローレートで行いながら、動き予測処理を相対的ハイレートで行うことができる。これにより、顔認識処理のための装置への負荷を軽減しながら、動き予測の精度を高く維持することができる。言い換えれば、本実施形態の顔追跡装置1は、顔認識処理のレートと動き予測処理のレートとを異ならせることにより、処理コストを抑制しながら、動き予測の精度を維持することができる。
言い換えれば、顔追跡装置1は、映像解析処理部20による映像解析処理を、顔認識処理部40による顔認識処理よりも高頻度で行う。そして、映像解析処理部20は、複数回の動き予測の処理の結果である動き予測結果の情報(動き予測モデルが持つ動き量)を蓄積する。そして、追跡処理部50は、映像解析処理部20から渡される蓄積された動き予測結果の情報に基づいて処理を行う。
なお、追跡処理(追跡処理部50の処理)やデータ出力のための処理(出力整形処理部60の処理)のレートは、顔認識処理のレートに合わせられる。
図2は、顔追跡装置1における、映像解析処理と追跡処理との時間的関係を示す概略図である。図示するように、顔追跡装置1が処理対象とする映像は、フレーム画像のシーケンスである。映像は、例えば、30FPSあるいは60FPSなどといったレートでのフレーム画像のシーケンスである。なお、「FPS」は、「frames per second」(秒あたりフレーム枚数)の略である。映像解析処理部20は、これらのフレーム画像の各々について、映像解析処理を行い、映像解析結果を出力する。一方、追跡処理部50は、適宜定められる所定数の連続するフレーム画像を対象として、顔の追跡処理を行う。なお、追跡処理部50が追跡処理を行う際には、映像解析処理部20が出力する映像解析結果を利用する。
図2における映像解析処理は、前述の動き予測処理を含むものである。また、追跡処理は、顔認識処理と同じ頻度で、顔認識処理の結果を利用して実行されるものである。図2に示す時間的関係で処理を行う場合、1回の顔認識処理および追跡処理に、複数回の動き予測処理が対応する。このとき、顔追跡装置1は、映像解析処理部20による動き予測処理で求められる動きパラメーターを蓄積しておくようにする。
つまり、映像解析処理部20は、時刻(t-1)におけるフレーム画像と時刻tにおけるフレーム画像とに基づいて、時刻tにおける映像解析結果を求め、出力する。以下、同様に、映像解析処理部20は、時間的に隣接する2つのフレーム画像に基づいて、映像解析結果を求める。つまり、映像解析処理部20は、第1の映像解析処理の結果として動き予測パラメーターM1(グローバル動きの予測パラメーター)を出力する。以下、同様に、映像解析処理部20は、第k(kは正整数)の映像解析処理の結果として動き予測パラメーターMk(グローバル動きの予測パラメーター)を出力する。映像解析処理部20は、この各回の動き予測パラメーターMk(k=1,2,・・・)を蓄積して、追跡処理用のグローバル動き予測パラメーターGlobalMを計算する。また、映像解析処理部20は、それぞれの顔領域rについてのローカル動きの予測モデルも、同様に蓄積し、追跡処理用のローカル動き予測パラメーターを計算する。映像解析処理部20は、これらの蓄積された動き予測パラメーターを、追跡処理のタイミングで、追跡処理部50に渡す。
また、映像解析処理部20は、シーンチェンジ検出の処理も、同様に、ハイレートの頻度で行うことができる。この場合、第1の映像解析処理の結果として、is_sc_change_1(値は、前述の通り、0(シーンチェンジ無し)または1(シーンチェンジ有り))を求める。以下同様に、映像解析処理部20は、第k(kは正整数)の映像解析処理の結果としてis_sc_change_kを求める。そして、映像解析処理部20は、各回の映像解析処理の結果としてのシーンチェンジの有無の判定結果is_sc_change_k(k=1,2,・・・)に基づいて、追跡処理用のis_sc_changeを求める。なお、k=1,2,・・・の中のいずれかに1つにおいてis_sc_change_k=1ならば、映像解析処理部20は、is_sc_change=1とする。また、k=1,2,・・・の中のすべてにおいてis_sc_change=0ならば、映像解析処理部20は、is_sc_change=0とする。映像解析処理部20は、蓄積されたシーンチェンジ判定結果であるis_sc_changeの値を、追跡処理のタイミングで、追跡処理部50に渡す。なお、is_sc_change=1の場合には、追跡処理部50は、動き予測パラメーターをリセットする。一旦シーンチェンジが検出されて動き予測パラメーターがリセットされた場合には、映像解析処理部20は、次の顔認識処理(および追跡処理)のタイミングまで、すべての動き予測処理を中止するようにしてもよい。
映像解析処理部20が行うボケ判定は、処理対象の映像内の顔領域ごとに、その領域がボケの領域であるか否かを判定するものである。なお、映像解析処理部20は、顔領域がボケている場合にも、顔領域の検出を行う。ボケ領域の映像に基づいて顔認識処理を行うと、認識精度が悪くなる。つまり、ボケ顔画像を対象として顔認識処理を行っても、認識精度が低く、正しくない人物を認識してしまう可能性が高い。これは、顔追跡装置1全体の顔認識精度の低下を招いてしまう。そのような精度劣化要因を避けるため、本実施形態の顔追跡装置1は、領域ごとのボケ判定(ボケている領域であるか否かの判定)を行い、ボケ領域である場合には顔認識処理を行わない。ただし、顔追跡装置1は、顔認識処理を行わない場合にも、顔領域の検出結果の情報については、追跡処理部50への引き渡しを行う。
映像解析処理部20は、顔領域rがボケ領域であるか否かを判定し、判定結果を変数is_blur(r)の値として設定する。is_blur(r)=1は、領域rがボケ画像であると判定されたことを表す。is_blur(r)=0は、領域rがボケ画像ではないと判定されたことを表す。映像解析処理部20は、それぞれの顔領域についてボケ領域であるか否かの判定を行う。
映像解析処理部20は、一例として、顔領域rの画像が含むエッジ成分を解析することによってボケの有無を判定する。この方法自体は、従来技術を用いて実現可能である。具体的には、映像解析処理部20は、顔領域r内のエッジ成分を検出し、そのエッジ成分のシャープさの度合いが所定レベル以下である(その部分の画像が高い周波数成分を持たない)場合に「ボケ有り」(is_blur(r)=1)と判定する。また、映像解析処理部20は、顔領域r内のエッジ成分のシャープさの度合いが所定レベル以上である(その部分の画像が高い周波数成分を持つ)場合に「ボケ無し」(is_blur(r)=0)と判定する。
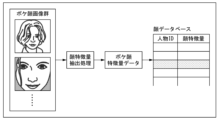
映像解析処理部20は、別の方法でボケ画像の判定を行うようにしてもよい。この手法では、映像解析処理部20は、顔認識処理部40が顔認識処理を行う際に同時にボケ画像の有無の判定を行う。即ち、この手法を用いる場合、顔データベース30は、多数のボケ顔画像から抽出した画像の特徴量を、ボケ画像の人物IDに関連付けて、予め保持しておく。これにより、顔の認識処理の対象の顔領域rの特徴量を、顔データベース30が持つ特徴量と照合したときに、当該顔領域rがボケ領域であることを表す。つまり、映像解析処理部20によるボケ画像の有無の判定と、顔認識処理部40による顔認識の処理とを一体の処理として行うことができる。つまり、顔追跡装置1全体の計算量を削減することが可能となる。
図3は、顔認識処理と一体化したボケ判定処理のための、顔データベースの構築方法を模式的に示す概略図である。図示するように、本手法では、多数のボケ顔の画像を準備する。そして、顔追跡装置1は、これらのボケ顔の画像の特徴量を抽出する。画像の特徴量を抽出する処理は、顔認識処理部40が持つ機能を用いて行うことができる。そして、顔追跡装置1は、得られたボケ顔特徴量のデータを、ボケ顔を表す人物IDに関連付けて、顔データベース30に登録する。なお、不特定多数の人のボケ顔に対して、ボケ顔を表す人物IDを1つ与えれば十分である。
つまり、映像解析処理部20は、顔領域がボケ領域であるか否かの判定を行う。追跡処理部50は、その判定結果に基づき、ボケ領域である顔領域に関しては、顔領域のトラックを更新する際には認識スコアの値を最低値(最悪スコア値)とする。ボケ判定の一つの手法は、次の通りである。顔認識処理部40は、顔領域がボケ領域である場合の特徴量と、当該ボケ領域の特徴量に関連付けられた特殊な人物ID識別情報と、を関連付けた情報(顔データベース30等)にアクセス可能と予めしておく。映像解析処理部20は、顔認識処理部40が顔領域についての顔認識処理を行った結果としてボケ領域の特徴量に関連付けられた特殊な人物IDを同定した場合に、当該顔領域がボケ領域であると判定する、ようにできる。
追跡処理部50による追跡処理の詳細は、下記の通りである。追跡処理部50は、顔認識処理部40が出力する結果と、映像解析処理部20が出力する結果とを用いて、時間軸上での対応関係から、同一人物の顔領域のトラックを求める処理を行う。追跡処理部50のこの処理によって、同一人物の顔領域のトラックが映像中で同定できれば、たとえある時刻のフレーム画像において顔認識処理結果の信頼性が低くても、同一トラックに属する他の時刻のフレーム画像で信頼性の高い顔認識処理結果を得られれば、置き換えにより、結果として精度の高い顔認識を実現することができる。
図4は、追跡処理部50による追跡処理の手順を示すフローチャートである。以下、このフローチャートに沿って説明する。なお、このフローチャートは、ある1時点での追跡処理の手順を示すものである。つまり、追跡処理部50は、追跡処理を行うタイミングごとに、図4に示す処理を実行する。
時刻tにおける追跡処理部50の処理の前提となるデータは次の通りである。追跡処理部50は、顔認識処理部40と映像解析処理部20からの出力信号(データ)を取得する。顔認識処理部40から追跡処理部50へは、検出した顔領域(フレーム画像内の位置情報)や、顔認識処理の結果である認識スコアや、認識結果である人物IDや、上記顔領域の特徴量が渡される。映像解析処理部20から追跡処理部50へは、シーンチェンジ検出信号is_sc_changeや、顔領域の統合動き予測パラメーターintegrateMが渡される。
また、追跡処理部50は、前回の追跡処理時、即ち時刻(t-1)において追跡できているトラックの集合を保持している。時刻(t-1)におけるトラックの集合は、下の式(4)の通りである。なお、式(4)においてn_Trは、当該トラックの集合に含まれるトラックの数である。
Tr(t-1) = [tr[0](t-1), tr[1](t-1), …, tr[n_Tr-1](t-1)] ・・・(4)
なお、各トラックtr[k](t-1)(0≦k≦n_Tr-1)は、データの構造体であり、その構造体の要素は下記のbbox、feat、recog_ids、recog_scoresを含む。
bboxは、時刻(t-1)におけるトラックに対応する顔領域の矩形領域情報(フレーム画像内の位置情報)である。
featは、時刻(t-1)のトラックにおける顔領域の特徴量である。
recog_idsは、時刻(t-1)の当該トラックに対応する顔認識結果の人物IDの候補である。人物IDの候補が複数であってもよい。複数の人物IDの候補は、例えば、スコアの高い順に並べられている。
recog_scoresは、時刻(t-1)の当該トラックにおける上記人物ID候補に対応するスコアの値である。上記の人物IDが並べられている順と同じ順(例えばスコアの高い順)にソートされている。
構造体の要素にアクセスする際の記法は、次の通りである。例えば、時刻(t-1)におけるトラック集合全体についてのbbox(矩形領域情報)は、Tr(t-1).bboxと表わされる。例えば、時刻(t-1)における個別トラックについてのbboxは、tr[k](t-1).bboxと表わされる。但し、kは、トラックの集合内における個別トラックの指標値であり、0≦k≦n_Tr-1である。
なお、追跡処理部50の初回の処理の前(即ち、時刻0のとき)には、トラック集合の初期化処理が行われる。つまり、Tr(0)=[](空集合)とする初期化が行われる。なお、シーンチェンジによってトラックをリセットする場合にも、トラック集合は空集合に再設定される。
また、追跡処理部50が顔認識処理部40から受け取る時刻tの顔検出領域および顔認識結果の情報は、下の式(5)の通りである。なお、式(5)において、n_Detは、時刻tの顔認識処理における顔検出領域の数(即ち、顔認識の数)である。
Det(t) = [det[0](t), det[1](t), …, det[n_Det-1](t)] ・・・(5)
トラックの場合と同様に、各顔検出領域det[k](t)(0≦k≦n_Det-1)は、データの構造体であり、その構造体の要素は下記のbbox、feat、recog_ids、recog_scoresを含む。
bboxは、時刻tにおける顔検出領域の矩形領域情報(フレーム画像内の位置情報)である。
featは、時刻tにおける上記顔検出領域の特徴量である。
recog_idsは、時刻tの当該顔検出領域に対応する顔認識結果の人物IDの候補である。人物IDの候補が複数であってもよい。複数の人物IDの候補は、例えば、スコアの高い順に並べられている。
recog_scoresは、時刻tの当該顔検出領域における上記人物ID候補に対応するスコアの値である。上記の人物IDが並べられている順と同じ順(例えばスコアの高い順)にソートされている。
構造体の要素にアクセスする際の記法は、次の通りである。例えば、時刻tおける顔検出領域の集合全体についてのbbox(矩形領域情報)は、Det(t).bboxと表わされる。例えば、時刻tにおける個別の顔検出領域についてのbboxは、det[k](t-1).bboxと表わされる。但し、kは、顔検出領域の集合内における個別の顔検出領域の指標値であり、0≦k≦n_Det-1である。
追跡処理部50が扱うデータは、さらに、矩形領域間の重なり度合いを表すマトリックスと、特徴量間の距離を表すマトリックスとを含む。
矩形領域間の重なり度合いを表すマトリックスは、IoU(bboxA,bboxB)と表わされる。IoUは、「Intersection over Union」(領域同士の和集合に対する、当該領域同士の積集合の比率)を表す。追跡処理部50は、トラックが持つ矩形領域(上記のbboxA)と、顔検出領域が持つ矩形領域(上記のbboxB)との重なり度合いを求め、追跡処理に利用する。このマトリックスは、n_bboxA×n_bboxBのサイズを持つ2次元のマトリックスである。ただし、n_bboxAはbboxAの領域の数であり、n_bboxBはbboxBの領域の数である。このマトリックスの要素の値が1のとき、対応する領域が完全に一致する。要素の値が正の値(0以上且つ1以下)の場合には、値が小さいほど、対応する領域間の重なり度合いが小さくなっていく。要素の値が負の値である場合には、対応する領域は重なる部分を全く持たず、その値の絶対値が大きいほど、両領域間の距離は離れている。
特徴量間の距離を表すマトリックスは、Dis(FeatA,FeatB)と表わされる。追跡処理部50は、トラックが持つ矩形領域の特徴量(上記のFeatA)と、顔検出領域が持つ矩形領域の特徴量(上記のFeatB)との距離を求め、追跡処理に利用する。このマトリックスは、n_FeatA×n_FeatBのサイズを持つ2次元のマトリックスである。ただし、n_FeatAはFeatAの特徴量の数(トラックが持つ矩形領域の数と同一)であり、n_FeatBはFeatBの特徴量の数(顔検出領域が持つ矩形領域の数と同一)である。距離の値は、0または正の値である。2つの特徴量が同一である場合には、当該2つの特徴量間の距離は0である。2つの特徴量が似ていない度合いが高いほど、当該特徴量間の距離は大きくなる。
追跡処理部50は、以上のデータに基づいて追跡処理を行う。言い換えれば、追跡処理部50が行う追跡処理は、時刻(t-1)におけるトラック集合Tr(t-1)と、時刻tにおける顔検出領域の集合Det(t)との対応付けの問題に還元される。追跡処理部50は、時刻の経過(例えば、時刻(t-1)から時刻tに)に伴って図4に示す処理を1回ずつ行い、これを繰り返すことにより、トラック集合Tr(t)のデータを順次更新していく。
追跡処理部50の時刻tにおける処理手順は次の通りである。まず、ステップS11において、追跡処理部50は、映像解析処理部20から渡される情報に基づいて、前回の追跡処理のときからシーンチェンジがあったか否かを判定する。シーンチェンジの有無は、変数is_sc_changeの値によって示される。シーンチェンジがあったとき、即ちis_sc_changeの値が1のとき(ステップS11:YES)には、ステップS21に飛ぶ。シーンチェンジがなかったとき、即ちis_sc_changeの値が0のとき(ステップS11:NO)には、時刻(t-1)におけるトラック集合を現トラック集合として(existTr=Tr(t-1))、次のステップS12に進む。
次に、ステップS12において、追跡処理部50は、動き補正処理を行う。つまり、追跡処理部50は、現トラック集合existTr.bboxが持つ各トラックに対して、映像解析処理部20から渡された統合動き予測モデルintegrateMによる動き補正の処理を行う。
次に、ステップS13において、追跡処理部50は、領域の重なり度を計算する。具体的には、追跡処理部50は、ステップS12における動き補正処理の結果として得られる矩形領域を、sc倍に拡張する。この拡張は、動き補正処理が含み得る動き補正の誤差をカバーするためのものである。拡張倍率scの値は、1.0以上の、適宜定める値とする。例えば、1.5≦sc≦2.5などとしてよい。本実施形態では、一例としてsc=2.0とする。この拡張により、矩形領域の中心位置は変わらず、矩形領域の大きさがsc倍となる。そして、追跡処理部は、拡張後の矩形領域と、顔認識処理部40から渡されたDet(t).bboxの重なり度合いを計算する。そして、追跡処理部50は、重なり度合いのマトリックス(前記のIoU)の各要素を、予め定められた閾値で閾値処理して、閾値処理済みのマトリックスGateMtxを作成する。つまり、閾値処理済みのマトリックスGateMtxにおいては、所定の閾値より下の重なり度合いを持つ領域同士は、相互にまったく重ならない領域として扱われる。
つまり、追跡処理部50は、前記第1位置情報と前記第2位置情報との重なり度合いに基づいて、前記トラックを更新する処理を行う。
次に、ステップS14において、追跡処理部50は、現トラックが持つ顔領域の特徴量と、顔認識処理部40から渡された時刻tにおける顔領域の特徴量とを比較する。つまり、追跡処理部50は、現トラックにおける特徴量であるExistTr.featと、顔認識処理部40から渡された特徴量であるDet(t).featとの、特徴量間の距離を表すマトリックスDisMtxを求める。
次に、ステップS15において、追跡処理部50は、領域フィルター処理を行う。つまり、追跡処理部は、ステップS13で求めたGateMtxを用いて、ステップS14で求めたマトリックスDisMtxに含まれる無効成分をフィルターアウトする。言い換えれば、ステップS13における閾値処理の結果として、トラックが持つ顔領域と、顔検出領域が持つ顔領域とが、相互に全く重ならない領域として扱われる場合には、追跡処理部50がそのトラックとその顔検出領域とを対応付けることはない。
次に、ステップS16において、追跡処理部50は、ステップS15の結果として得られたDisMtxに基づいて、時刻(t-1)までの顔領域トラックと時刻tでの顔検出領域との対応関係を判定する。言い換えれば、追跡処理部50は、領域間の重なり度合い(ただし、閾値処理済み)と、各領域の特徴量間の距離とに基づいて、時刻(t-1)のけるトラックと時刻tにおける顔検出領域との対応付けを行う。なお、本ステップにおいて、追跡処理部50は、例えばハンガリアンアルゴリズム(Hungarian algorithm、ハンガリー法)を用いて上記の対応関係を求める。ハンガリアンアルゴリズム自体は、既存技術によるものである。言い換えれば、追跡処理部50は、顔領域トラックの番号(tr_no)と、顔検出領域の番号(det_no)との対応付けを試みる。追跡処理部50は、求められた対応関係に応じて、顔領域の処理を次の通り分岐させる。顔領域トラックと顔検出領域とが対応している場合(matched_pairs)には、ステップS17に進む。顔検出領域に対応する顔領域トラックが存在しない場合(unmatched_dets)には、ステップS18に進む。顔領域トラックに対応する顔検出領域が存在しない場合(unmatched_tracks)には、ステップS19に進む。なお、上記matched_pairsは、顔領域トラックの番号と顔検出領域の番号との組合せの集合である(matched_pairs∈{(tr_no,det_no)})。また、上記unmatched_detsは、顔検出領域の番号の集合である(unmatched_dets∈{det_no})。また、unmatched_tracksは、顔領域トラックの番号の集合である(unmatched_tracks∈{tr_no})。
なお、追跡処理部50は、ステップS16における条件分岐を、領域ごと(matched_pairごと、unmatched_detごと、そしてunmatched_tracksごと)に行う。そして、追跡処理部50は、ステップS16で分類された領域ごとに、次のステップS17、S18、S19のそれぞれの処理を行う。
次に、ステップS17において、追跡処理部50は、該当する顔検出領域(Detection)の情報を、対応する既存の顔領域トラック(Track)に追加する。
次に、ステップS18において、追跡処理部50は、該当する顔検出領域(unmatched detection)に基づいて新しい顔領域トラック(Track)を登録する。つまり、追跡処理部50は、その顔検出領域を、新たなトラックとして、既存トラック集合に追加する。
次に、ステップS19において、追跡処理部50は、該当する顔領域トラック(unmatched track)を、喪失された(lost)トラック、あるいは削除された(deleted)トラックとして登録する。具体的には、追跡処理部50は、既存トラックに対応する顔検出領域がなくなった時点でその既存トラックを喪失状態(lost)として、所定期間この喪失状態が続く場合には、そのトラックを終了(削除、deleted)として、以後の追跡処理の対象から外してよい。
すべての領域について上記ステップS17、S18、S19の処理が完了すると、次にステップS20において、追跡処理部50は、Tracksを更新する。つまり、追跡処理部50は、ステップS16で判定した対応関係に基づいて、トラックを更新し、時刻tにおけるトラック集合Tr(t)を生成する。
なお、トラックを更新する際に、領域tr[i](t)がボケ顔領域である(is_blur=1)である場合には、追跡処理部50は、当該領域の認識スコアを強制的に最低値(通常は、0.0)とする。即ち、追跡処理部50は、そのような領域について、tr[i](t).recog_score=0.0とする。
一方、ステップS21に進んだ場合(ステップS11の判定においてシーンチェンジ有だった場合)には、追跡処理部は、トラックをリセットする。即ち、時刻tにおけるトラックをTr(t)=[](空集合)とする。つまり、この場合、Tr(t-1)までのトラック情報は以後において使用されなくなる。
つまり、追跡処理部50は、シーンチェンジが検出された場合には、トラックを初期状態にリセットする。
以上説明した図4のフローチャートの処理を繰り返した結果として、追跡処理部50は、顔認識結果の情報を持つ複数の顔領域トラックを、出力する。追跡処理部50は、この複数の顔領域トラックのデータを、出力整形処理部60に渡す。
出力整形処理部60は、追跡処理部50から渡される追跡処理の結果のデータを整形し、出力する。具体的には、出力整形処理部60は、追跡処理部50が出力したトラック(図4の追跡処理による更新後のトラック)が持つ各フレーム画像での顔認識処理の結果を、認識スコアの高い順に出力するように整形する。時刻tにおけるトラックtr[k](kは、特定のトラックに対する指標値)を例にとると、次の通りである。
時刻(t-1)までにおいては、当該トラックは、顔認識に関係する下記のデータを含む。
tr[k](t-1).recog_scoresは、時刻(t-1)までの認識スコアを並べたものである。ここでは、認識スコアは、高い順から(即ち降順に)並んでいるものとする。
tr[k](t-1).recog_idsは、上記のtr[k](t-1).recog_scoresに対応する人物IDの並びである。つまり、tr[k](t-1).recog_idsは、当該トラックの時刻(t-1)までの、認識スコアの降順に並べられた人物ID(認識結果)である。
ここで、時刻tにおける顔検出領域det[j]が、トラックtr[k]に追加される場合を想定する。すると、顔検出領域det[j]に関する顔認識結果であるdet[j].recog_scoresおよびdet[j].recog_idsも、認識結果に関する情報としてトラックtr[k]に追加されることになる。このとき、トラックtr[k]が元々持っていた認識スコアおよび人物ID(認識結果)の情報に加えて、新たに追加される情報も含めて、認識スコアの降順でのソーティングが行われる。このソーティングを、出力整形処理部60が行う。この処理は、下の式(6)および式(7)で表わされる。
tr[k](t).recog_scores =
sort([tr[k](t-1).recog_scores+det[j].recog_scores],topK) ・・・(6)
tr[k}(t).recog_ids =
argsort([tr[k](t-1).recog_ids+det[j].recog_ids],topK) ・・・(7)
なお、式(6)に示す処理sort(listA,topK)は、値のリストlistAの要素を、その値順に(ここでは降順に)、topK文だけ並べ替える処理を表す。なお、式(6)内の演算子「+」は、リスト同士の連結を行う演算子である。つまり、式(6)は、認識スコアのリストtr[k](t-1).recog_scoresと認識スコアのリストdet[j].recog_scoresとを連結して成るリストに対するソート処理を表す。
また、式(7)に示す処理argsort(listA,topK)は、対応するrecog_scores(認識スコア)をソートキーとして、listAを降順に、topK文だけ並べ替える処理を表す。ここでも、演算子「+」はリスト同士の連結を行う演算子である。つまり、式(7)は、式(6)に対応する順に、人物IDのリストtr[k](t-1).recog_idsおよび人物IDのリストdet[j].recog_idsをソートする処理を表す。
このように、本実施形態では、あるトラックに関して、時間軸にわたって、ある人物IDについての認識スコアの最大値が残るように、トラックの更新の処理を繰り返す。これにより、ある顔領域のスコアが低い時間帯(顔領域がボケ領域である時間帯を含む)の認識結果に左右されずに、顔領域のスコアが高い時間帯の認識結果に基づいて、トラックの顔認識を行うことができるようになる。
つまり、顔追跡装置1は、トラック単位で、認識スコアの高い順にソートされた顔認識結果のデータ(人物IDおよび認識スコア)を保持し、更新する。これにより、処理対象の映像中に登場する人物に対して、安定した認識結果を得ることが可能となる。
図5は、あるトラックについての認識スコアの時間推移の例を示す概略図である。図示するように、このトラックは、認識結果の候補として、人物Aおよび人物Bの人物IDを持つものである。当該トラックに関して、人物Aについてのスコアは、時刻t1において0.5であり、時刻t2において0.8である。一方、人物Bについてのスコアは、時刻t1において0.6であり、時刻t2において0.6である。
このようなスコアが生じるのは、例えば、このトラックについての顔認識の正解が「人物A」であり、時刻t1においては人物Aが横を向いていたことによって「人物A」の認識スコアが0.5に低下し、時刻t2においては人物Aが正面を向いていたことによって認識スコアが0.8に上昇している場合である。つまりこの場合、時刻t1においては、正解であるべき人物Aのスコアが、不正解である人物Bのスコアよりも低くなってしまっている。なお、ここではt1<t2である。
上記の場合、時刻t1において、当該トラックが持つデータは、次の通りである。
tr(t1).recog_socres = [0.6,05]
tr(t1).recog_ids = [B,A]
また、時刻t2において、当該トラックが持つデータは、次の通りである。
tr(t2).recog_scores = [0.8,0.5]
tr(t2).recog_ids = [A,B]
時刻t1における認識スコアと、時刻t2における認識スコアとを統合すると、次の通りである。
tr.recog_score = [0.8,0.6]
tr.recog_ids = [A,B]
つまり、時間経過を通したトラックの認識結果としては、顔追跡装置1は、人物Aの、よりスコアの高い正面顔のときの状態を優先して用いていることとなる。これにより、顔追跡装置は、正解である人物Aを、人物Bよりも上位の認識結果として出力する。このように、顔追跡装置1は、時間経過を通したトラックの期間中において最も認識スコアの高い人物を、認識結果とする。これにより、顔追跡装置1は、より信頼性の高い認識処理を実現することが可能となる。
なお、前述の通り、ボケ検出結果is_blurが1のときには、顔追跡装置1は、当該トラックのその時刻における顔認識スコアを強制的0.0とする。つまり、トラックの顔領域がボケているときの認識結果は、時間を通したトラック全体の認識スコアの計算に影響を与えない。
以上説明したように、顔追跡装置1は、映像内に出現する顔を追跡しながら、その顔の人物IDを特定する。これにより、顔追跡装置1は、トラックごとの、人物IDの候補と、その人物IDに対応付けられたスコアとのデータを求め、出力することができる。
図6は、顔追跡装置1による追跡処理の結果として得られるデータ構成の一例を示す概略図である。図示するように、顔追跡装置1は、特定の映像コンテンツに関して、トラックを実体とするデータの集合を出力することができる。図示するトラックの主キーは、例えば、トラックIDである。処理対象とした映像コンテンツは、ユニークなコンテンツIDを持つことができる。つまり、1つのコンテンツIDは、複数の(多数の)トラックに関連付けられる。トラックの属性は、開始時刻(開始フレーム)、終了時刻(終了フレーム)、認識スコア(リスト)、人物ID(リスト)を含む。開始時刻および終了時刻のそれぞれは、当該映像コンテンツにおける相対時刻である。開始時刻は、開始フレームに対応する。終了時刻は、終了フレームに対応する。各トラックの、開始時刻および終了時刻の精度は、追跡処理を行う頻度に依存する(図2参照)。つまり、追跡処理を十分に頻繁に(例えば、1秒に1回、あるいは0.5秒に1回等)行うことにより、トラックの開始時刻および終了時刻の精度は、実用上十分なものとなる。ただし、追跡処理の頻度についての制約はない。認識スコアは、人物IDに対応するスコアの値のリストである。認識スコアは、スコアが降順に並べられたリストのデータである。人物IDは、映像内に登場する人物のリストである。人物IDのソート順は、対応する認識スコアの降順である。このように、人物IDをキーとしてトラックの集合のデータを検索することにより、該当する人物が登場する映像内のシーン(開始時刻および終了時刻)を、所定の精度で得ることが可能となる。
図6内に示すように、人物IDは、人物をユニークに特定するための識別情報である。人物IDは、1つまたは複数の人物名(表記)のデータに関連付けられる。また、人物IDは、1つまたは複数のサムネール画像のデータに関連付けられる。つまり、人物名表記から、人物IDを求めることが可能である。また、サムネール画像が選択されると、人物IDを求めることが可能である。
図7は、人物名あるいはサムネール画像を起点として、当該人物が登場する映像コンテンツのシーンを取り出すための情報経路の例を示す概略図である。図6を参照しながら説明した通り、例えば人物名表記が文字列として入力されたり、提示された多数のサムネール画像(人物の顔の画像)から特定のサムネール画像が選択されたりすると、人物IDを特定することが可能である。人物IDが得られると、図6に示したトラックの集合のデータを検索することにより、当該人物IDに対応する、映像コンテンツのコンテンツIDと、その相対位置(開始時刻(開始フレーム)および終了時刻(終了フレーム))の情報を、1セットまたは複数セット、特定することができる。これにより、当該人物IDに対応する映像シーンを、利用者等に対して提示することが可能となる。
図8は、図7で説明した映像シーンの検索のためのGUI(グラフィカルユーザーインターフェース)の一例を示す概略図である。言い換えれば、同図は、顔認識結果に基づく映像検索システムのGUIの例を示す。なお、この映像検索システムは、本実施形態の顔追跡装置1による処理の結果として得られたトラックのデータを用いて、映像を検索することができる。図示する画面は、PCや、タブレット端末や、スマートフォン等の携帯型端末の表示画面である。同図において、701は、映像表示領域である。また、702は、人物名表示領域である。また、703は、サムネール画像表示領域である。また、704は、シーン特定情報表示領域である。本システムの利用者は、人物名表示領域702に表示されている人物名(文字列)の一つ、あるいは、サムネール画像表示領域703に表示されているサムネール画像(顔画像)の一つを選択してクリック(あるいはタップ)することができる。その結果、映像検索システムは、図7に示したように、当該人物に該当するトラックを抽出することができる。そして、映像検索システムは、抽出されたトラックの情報に基づき、特定の映像コンテンツの特定のシーン(相対位置)を、映像表示領域701に表示する。選択された人物に関連するトラックが複数存在する場合には、例えば、当該映像検索システムは、認識スコアの値に基づいて、当該人物に関して高いスコアを有するトラックを選択してもよい。
なお、顔追跡装置1自身が検索処理部を備えて、図8に示す映像検索を行うようにしてもよい。その場合、検索処理部は、GUIの画面等から、人物ID(人物識別情報)と、人物IDに関連付けられた人物名表記文字列と、人物IDに関連付けられたサムネール画像の指定と、のいずれかの検索キーを取得する。検索処理部は、取得した検索キーに基づいて、出力整形処理部60が出力したトラックの集合のデータを検索することによって、特定の人物IDに関連付けられた単数または複数のトラックを特定する。これによって特定されたトラックは、コンテンツIDと映像コンテンツ内の相対位置の情報とを持っている。よって、検索処理部は、トラックによって特定される映像シーンを、記憶装置等から取得し、デコードし、映像として画面(映像表示領域701)に表示することができる。
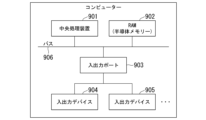
図9は、顔追跡装置の内部構成の例を示すブロック図である。顔追跡装置1は、コンピューターを用いて実現され得る。図示するように、そのコンピューターは、中央処理装置901と、RAM902と、入出力ポート903と、入出力デバイス904や905等と、バス906と、を含んで構成される。コンピューター自体は、既存技術を用いて実現可能である。中央処理装置901は、RAM902等から読み込んだプログラムに含まれる命令を実行する。中央処理装置901は、各命令にしたがって、RAM902にデータを書き込んだり、RAM902からデータを読み出したり、算術演算や論理演算を行ったりする。RAM902は、データやプログラムを記憶する。RAM902に含まれる各要素は、アドレスを持ち、アドレスを用いてアクセスされ得るものである。なお、RAMは、「ランダムアクセスメモリー」の略である。入出力ポート903は、中央処理装置901が外部の入出力デバイス等とデータのやり取りを行うためのポートである。入出力デバイス904や905は、入出力デバイスである。入出力デバイス904や905は、入出力ポート903を介して中央処理装置901との間でデータをやりとりする。バス906は、コンピューター内部で使用される共通の通信路である。例えば、中央処理装置901は、バス906を介してRAM902のデータを読んだり書いたりする。また、例えば、中央処理装置901は、バス906を介して入出力ポートにアクセスする。
なお、顔追跡装置1の少なくとも一部の機能をコンピューターで実現することができる。その場合、この機能を実現するためのプログラムをコンピューター読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピューターシステムに読み込ませ、実行することによって実現しても良い。なお、ここでいう「コンピューターシステム」とは、OSや周辺機器等のハードウェアを含むものとする。また、「コンピューター読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD-ROM、DVD-ROM、USBメモリー等の可搬媒体、コンピューターシステムに内蔵されるハードディスク等の記憶装置のことをいう。つまり、「コンピューター読み取り可能な記録媒体」とは、非一過性の(non-transitory)コンピューター読み取り可能な記録媒体であってよい。さらに「コンピューター読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、一時的に、動的にプログラムを保持するもの、その場合のサーバーやクライアントとなるコンピューターシステム内部の揮発性メモリーのように、一定時間プログラムを保持しているものも含んでも良い。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピューターシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
以上、実施形態を説明したが、本発明はさらに次のような変形例でも実施することが可能である。
[第1変形例]
例えば、顔認識処理部40による顔認識処理は、ニューラルネットワーク等の機械学習手段を用いて行うようにしてもよい。その場合、顔データベース30が保持する人物IDごとの画像特徴量は、ニューラルネットワーク内の内部パラメーター値の集合として表わされ、保持されるものである。つまり、画像特徴量と人物IDとの関係の情報は、ニューラルネットワーク内の各ノードのパラメーター値として埋め込まれる。
[第2変形例]
上記実施形態では、映像の過去側から未来側に向かって(順方向で)、顔領域を追跡し、トラックを更新する処理を行った。この方向が逆でもよい。即ち、顔追跡装置1は、映像の未来側から過去側に向かって(逆方向で)、顔領域を追跡し、トラックを更新するようにしてもよい。また、顔追跡装置1が、順方向の追跡と、逆方向の追跡とを、組み合わせて処理するようにしてもよい。これにより、動画ファイル内の複数のトラックを開始から終了まで特定でき、そのトラックに対する認識結果を付与することが可能となる。
以上説明したように、本実施形態(その変形例を含む。以下において同様。)によれば、映像中に映っている人物の顔認識処理と、顔領域を追跡する処理とを組み合わせることによって、顔認識精度の向上および追跡精度の向上の両方を実現する。本実施形態の顔追跡装置1は、映像内の、時間方向にわたって人物が出現する領域に対して、一貫した認識結果を付与することが可能となる。
また、本実施形態は、顔の追跡処理の際に、シーンチェンジ(カット)の検出結果を利用する。つまり、本実施形態は、シーンチェンジが検出されると、追跡していたトラックを初期化する。これにより、例えば長時間の映像でシーンチェンジを含む場合にも、適切な追跡を行うことができる。言い換えれば、処理の混乱を生じないようにすることができる。
また、本実施形態は、認識処理の精度を下げる要因であるボケ画像に対応するために、積極的にボケ画像の検出処理を行い、ボケ画像が検出される場合にはその認識スコアを最低値にするなお、ボケによる認識への影響を軽減している。
また、本実施形態では、2種類の処理のレート(頻度)を変えて、それらの処理を組み合わせている。具体的には、映像解析処理部20による映像解析処理と、顔認識処理部40および追跡処理部50による認識および追跡処理とを、異なるレートで行えるようにしている。これにより、本実施形態は、2種類の動き予測処理の結果である動き予測を蓄積し、追跡処理時に利用している。これにより、装置全体での処理負荷を軽減しながら、必要な処理を高いレート(頻度)で実行することが可能となっている。
また、本実施形態は、顔領域の軌跡(トラック)の単位のデータを出力し、そのトラックに認識結果のデータを付与するようにしている。このような形式のデータを出力することにより、本実施形態は、トラック単位で、最も確からしい(単数または複数の)認識結果を与えることができるようになっている。このような出力データは、人物IDをキーとして、その人物が出現している映像シーンを検索するのに向いている。これにより、人物を起点として映像検索を容易にすることができる。また、本実施形態は、そのような映像検索のためのGUIの一例を提示した。
つまり、本実施形態は、映像内に出現する人物の顔認識を時間的な変化にも対応して一貫した形式で実施することを可能とする。認識結果を対象映像へのメタデータ付加に簡単に利用できるようなデータ構造を考案することにより、登場人物の検索を効果的に行える検索システムの開発が容易となる。
以上、この発明の実施形態について図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計等も含まれる。