JP7507172B2 - 情報処理方法、情報処理システム及び情報処理装置 - Google Patents
情報処理方法、情報処理システム及び情報処理装置 Download PDFInfo
- Publication number
- JP7507172B2 JP7507172B2 JP2021562535A JP2021562535A JP7507172B2 JP 7507172 B2 JP7507172 B2 JP 7507172B2 JP 2021562535 A JP2021562535 A JP 2021562535A JP 2021562535 A JP2021562535 A JP 2021562535A JP 7507172 B2 JP7507172 B2 JP 7507172B2
- Authority
- JP
- Japan
- Prior art keywords
- inference
- data
- model
- result
- inference model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 54
- 238000003672 processing method Methods 0.000 title claims description 18
- 238000012549 training Methods 0.000 claims description 66
- 238000012545 processing Methods 0.000 claims description 28
- 238000010801 machine learning Methods 0.000 claims description 26
- 238000000034 method Methods 0.000 claims description 15
- 238000004364 calculation method Methods 0.000 claims description 14
- 238000013215 result calculation Methods 0.000 claims description 12
- 238000003062 neural network model Methods 0.000 claims description 4
- 230000006399 behavior Effects 0.000 description 65
- 238000010586 diagram Methods 0.000 description 10
- 230000008569 process Effects 0.000 description 5
- 238000013459 approach Methods 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 238000004590 computer program Methods 0.000 description 2
- 238000013135 deep learning Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 230000011218 segmentation Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
本開示は、推論モデルを機械学習により訓練するための情報処理方法、情報処理システム及び情報処理装置に関する。
近年、エッジ端末でDeep Learningを実行する際に、処理の軽量化のために、推論モデルを軽量な推論モデルに変換することがなされている。例えば、特許文献1には、推論モデルの変換前後で推論性能をなるべく維持したまま、推論モデルの変換を行う技術が開示されている。この文献では、推論性能が落ちないように推論モデルの変換(例えば第1推論モデルから第2推論モデルへの変換)が実施される。
しかしながら、上記特許文献1に開示された技術では、第1推論モデルと第2推論モデルとで推論性能(例えば認識率などの認識性能)が同じでも、ある推論対象について、第1推論モデルの振る舞い(例えば正解/不正解)と第2推論モデルの振る舞いとが異なる場合がある。つまり、第1推論モデルと第2推論モデルとで、統計的な推論結果は同じであっても、個別的な推論結果が異なる場合がある。この差異が問題を引き起こすおそれがある。
そこで、本開示は、第1推論モデルの振る舞いと第2推論モデルの振る舞いとを近づけることができる情報処理方法等を提供する。
本開示に係る情報処理方法は、コンピュータにより実行される方法であって、第1データを取得し、前記第1データを第1推論モデルに入力して第1推論結果を算出し、前記第1データを第2推論モデルに入力して第2推論結果を算出し、前記第1推論結果及び前記第2推論結果の類似度を算出し、前記類似度に基づいて機械学習における訓練データである第2データを決定し、前記第2データを用いて前記第2推論モデルを機械学習により訓練する処理を含み、前記類似度は、前記第1推論結果と前記第2推論結果とが一致しているか否か、であり、前記第1推論結果と前記第2推論結果とが一致しない場合、前記決定では、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータを前記第2データとして決定する、または、前記類似度は、前記第1推論結果における第1推論値の大きさと前記第2推論結果における第2推論値の大きさとの類似度であり、前記第1推論値と前記第2推論値との差分が閾値以上である場合、前記決定では、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータを前記第2データとして決定する。
なお、これらの包括的又は具体的な態様は、システム、方法、集積回路、コンピュータプログラム又はコンピュータ読み取り可能なCD-ROMなどの記録媒体で実現されてもよく、システム、方法、集積回路、コンピュータプログラム及び記録媒体の任意な組み合わせで実現されてもよい。
本開示の一態様に係る情報処理方法等によれば、第1推論モデルの振る舞いと第2推論モデルの振る舞いとを近づけることができる。
従来技術では、推論性能が落ちないように推論モデルの変換が実施されるが、第1推論モデルと第2推論モデルとで推論性能が同じでも、ある推論対象について、第1推論モデルでの振る舞いと第2推論モデルでの振る舞いとが異なる場合がある。ここで、振る舞いは、複数の入力のそれぞれに対する推論モデルの出力である。つまり、第1推論モデルと第2推論モデルとで、統計的な推論結果は同じであっても、個別的な推論結果が異なる場合がある。この差異が問題を引き起こすおそれがある。例えば、ある推論対象について、第1推論モデルでは推論結果が正解で、第2推論モデルでは推論結果が不正解となる場合があったり、第1推論モデルでは推論結果が不正解で、第2推論モデルでは推論結果が正解となる場合があったりする。
このように、第1推論モデルと第2推論モデルとで振る舞いが異なると、例えば、第1推論モデルの推論性能が改善され、改善後の第1推論モデルから第2推論モデルが生成された場合であっても、第2推論モデルの推論性能が改善されない又は劣化することがある。また、例えば、推論モデルの推論結果を用いた後続の処理において、同じ入力に対して第1推論モデルと第2推論モデルとで異なる処理結果が出力されるおそれもある。特に、当該処理が安全に関わる処理(例えば車両における物体認識処理)である場合は、上記振る舞いの差異は危険をもたらすおそれがある。
本開示の一態様に係る情報処理方法は、コンピュータにより実行される方法であって、第1データを取得し、前記第1データを第1推論モデルに入力して第1推論結果を算出し、前記第1データを第2推論モデルに入力して第2推論結果を算出し、前記第1推論結果及び前記第2推論結果の類似度を算出し、前記類似度に基づいて機械学習における訓練データである第2データを決定し、前記第2データを用いて前記第2推論モデルを機械学習により訓練する処理を含む。
第1推論モデルと第2推論モデルとは異なるモデルであるため、それぞれに同じ第1データを入力しても、第1推論モデルの振る舞いと第2推論モデルの振る舞いとが一致しない場合がある。しかし、第1推論モデルの振る舞いと第2推論モデルの振る舞いとが一致しないときの第1推論結果及び第2推論結果の類似度を用いることで、第1推論モデルの振る舞いと第2推論モデルの振る舞いとが一致しない第1データを決定することができる。そして、第2推論モデルの振る舞いを第1推論モデルの振る舞いに近づけるように第2推論モデルを機械学習により訓練するための訓練データである第2データを第1データから決定することができる。したがって、本開示によれば、第1推論モデルの振る舞いと第2推論モデルの振る舞いとを近づけることができる。
また、前記第1推論モデルの構成と前記第2推論モデルの構成は異なっていてもよい。
これによれば、それぞれ異なる構成(例えばネットワーク構成)である第1推論モデル及び第2推論モデルについて、それぞれの振る舞いを近づけることができる。
また、前記第1推論モデルの処理精度と前記第2推論モデルの処理精度は異なっていてもよい。
これによれば、それぞれ異なる処理精度(例えばビット精度)である第1推論モデル及び第2推論モデルについて、それぞれの振る舞いを近づけることができる。
また、前記第2推論モデルは、前記第1推論モデルの軽量化により得られてもよい。
これによれば、第1推論モデルの振る舞いと、軽量化された第2推論モデルの振る舞いとを近づけることができる。軽量化された第2推論モデルの振る舞いが第1推論モデルの振る舞いに近づくように第2推論モデルが訓練されることで、軽量化された第2推論モデルの性能を第1推論モデルの性能に近づけることができ、第2推論モデルの精度の改善も可能となる。
また、前記類似度は、前記第1推論結果と前記第2推論結果とが一致しているか否か、を含んでいてもよい。
これによれば、第1推論結果と第2推論結果とが一致しているか否かに基づいて、第1推論モデルの振る舞いと第2推論モデルとの振る舞いが一致しない第1データを決定することができる。具体的には、第1推論モデルの振る舞いと第2推論モデルの振る舞いとが一致しない第1データとして、第1推論結果と第2推論結果とが一致していないときの第1データを決定できる。
また、前記決定では、前記第1推論結果と前記第2推論結果とが一致しない場合の入力である前記第1データに基づいて前記第2データを決定してもよい。
これによれば、第1推論結果と第2推論結果とが一致していない第1データに基づいて第2推論モデルを訓練することができる。これは一致/不一致が明確な推論において有効である。
また、前記類似度は、前記第1推論結果における第1推論値の大きさと前記第2推論結果における第2推論値の大きさとの類似度、を含んでいてもよい。
これによれば、第1推論結果における推論値の大きさと第2推論結果における推論値の大きさとの類似度に基づいて、第1推論モデルの振る舞いと第2推論モデルの振る舞いとが一致しない第1データを決定することができる。具体的には、第1推論モデルと第2推論モデルとの振る舞いが一致しない第1データとして、第1推論結果における推論値の大きさと第2推論結果における推論値の大きさとの差が大きいときの第1データを決定できる。
また、前記決定では、前記第1推論値と前記第2推論値との差分が閾値以上である場合の入力である前記第1データに基づいて前記第2データを決定してもよい。
これによれば、第1推論値と第2推論値との差分が閾値以上である第1データに基づいて第2推論モデルを訓練することができる。これは一致/不一致を明確に判断しにくい推論において有効である。
また、前記第2データは、前記第1データを加工したデータであってもよい。
これによれば、第1推論モデルの振る舞いと第2推論モデルの振る舞いとが一致しない第1データを加工したデータを第2データとして決定することができる。
また、前記訓練では、前記第2データを他の訓練データより多く用いて前記第2推論モデルを訓練してもよい。
これによれば、第2推論モデルの訓練データとして有効な第2データを多く用いることで、第2推論モデルの機械学習を効果的に進めることができる。
また、前記第1推論モデル及び前記第2推論モデルは、ニューラルネットワークモデルであってもよい。
このように、それぞれニューラルネットワークモデルである第1推論モデル及び第2推論モデルについて、それぞれの振る舞いを近づけることができる。
本開示の一態様に係る情報処理システムは、第1データを取得する取得部と、前記第1データを第1推論モデルに入力して第1推論結果を算出し、前記第1データを第2推論モデルに入力して第2推論結果を算出する推論結果算出部と、前記第1推論結果及び前記第2推論結果の類似度を算出する類似度算出部と、前記類似度に基づいて機械学習における訓練データである第2データを決定する決定部と、前記第2データを用いて第2推論モデルを機械学習により訓練する訓練部と、を備える。
これによれば、第1推論モデルの振る舞いと第2推論モデルの振る舞いとを近づけることができる情報処理システムを提供できる。
本開示の一態様に係る情報処理装置は、センシングデータを取得する取得部と、前記センシングデータを第2推論モデルに入力して推論結果を取得する制御部と、取得された前記推論結果に基づくデータを出力する出力部と、を備え、前記第2推論モデルは、第2データを用いて機械学習により訓練され、前記第2データは、機械学習における訓練データであり、類似度に基づいて決定され、前記類似度は、第1推論結果及び第2推論結果から算出され、前記第1推論結果は、第1データを前記第1推論モデルに入力して算出され、前記第2推論結果は、前記第1データを前記第2推論モデルに入力して算出される。
これによれば、第1推論モデルの振る舞いに近づけられた第2推論モデルを装置に用いることができる。これにより、組込み環境における推論モデルを用いた推論処理の性能を向上させることができる。
以下、実施の形態について、図面を参照しながら具体的に説明する。
なお、以下で説明する実施の形態は、いずれも包括的又は具体的な例を示すものである。以下の実施の形態で示される数値、形状、材料、構成要素、構成要素の配置位置及び接続形態、ステップ、ステップの順序などは、一例であり、本開示を限定する主旨ではない。
(実施の形態)
以下、実施の形態に係る情報処理システムについて説明する。
以下、実施の形態に係る情報処理システムについて説明する。
図1は、実施の形態に係る情報処理システム1の一例を示すブロック図である。情報処理システム1は、取得部10、推論結果算出部20、第1推論モデル21、第2推論モデル22、類似度算出部30、決定部40、訓練部50及び学習データ100を備える。
情報処理システム1は、第2推論モデル22を機械学習により訓練するためのシステムであり、機械学習の際に学習データ100を用いる。情報処理システム1は、プロセッサ及びメモリ等を含むコンピュータである。メモリは、ROM(Read Only Memory)及びRAM(Random Access Memory)等であり、プロセッサにより実行されるプログラムを記憶することができる。取得部10、推論結果算出部20、類似度算出部30、決定部40及び訓練部50は、メモリに格納されたプログラムを実行するプロセッサ等によって実現される。
例えば、情報処理システム1は、サーバであってもよい。また、情報処理システム1を構成する構成要素は、複数のサーバに分散して配置されてもよい。
学習データ100には、数多くの種類のデータが含まれており、例えば、画像認識をさせるモデルを機械学習により訓練する場合、学習データ100には、画像データが含まれる。学習データ100には、様々な種類(例えばクラス)のデータが含まれる。なお、画像は、撮像画像であってもよく、生成画像であってもよい。
第1推論モデル21及び第2推論モデル22は、例えば、ニューラルネットワークモデルであり、入力されたデータに対して推論を行う。推論は、ここでは例えば分類とするが、物体検出、セグメンテーション又はカメラから被写体までの距離の推定等であってもよい。なお、振る舞いは、推論が分類の場合、正解/不正解又はクラスであってよく、推論が物体検出の場合、正解/不正解又はクラスに代えて又はそれと共に検出枠の大きさ又は位置関係であってよく、推論がセグメンテーションの場合、領域のクラス、大きさ又は位置関係であってよく、推論が距離推定である場合、推定距離の長さであってよい。
例えば、第1推論モデル21の構成と第2推論モデル22の構成は異なっていてもよく、また、第1推論モデル21の処理精度と第2推論モデル22の処理精度は異なっていてもよく、第2推論モデル22は、第1推論モデル21の軽量化により得られる推論モデルであってもよい。例えば、第1推論モデル21の構成と第2推論モデル22の構成が異なる場合、第2推論モデル22は、第1推論モデル21よりも枝数が少ない又はノード数が少ない。例えば、第1推論モデル21の処理精度と第2推論モデル22の処理精度が異なる場合、第2推論モデル22は、第1推論モデル21よりもビット精度が低い。具体的には、第1推論モデル21は浮動小数点モデルであり、第2推論モデル22は固定小数点モデルであってもよい。なお、第1推論モデル21の構成と第2推論モデル22の構成が異なり、かつ、第1推論モデル21の処理精度と第2推論モデル22の処理精度が異なっていてもよい。
取得部10は、学習データ100から第1データを取得する。
推論結果算出部20は、取得部10が取得した第1データを第1推論モデル21及び第2推論モデル22に入力して第1推論結果及び第2推論結果を算出する。また、推論結果算出部20は、学習データ100から第2データを選択して、第2データを第1推論モデル21及び第2推論モデル22に入力して第3推論結果及び第4推論結果を算出する。
類似度算出部30は、第1推論結果及び第2推論結果の類似度を算出する。
決定部40は、算出された類似度に基づいて機械学習における訓練データである第2データを決定する。
訓練部50は、決定された第2データを用いて第2推論モデル22を機械学習により訓練する。例えば、訓練部50は、パラメタ算出部51及び更新部52を機能構成要素として有する。パラメタ算出部51及び更新部52の詳細については、後述する。
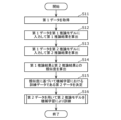
情報処理システム1の動作について図2を用いて説明する。
図2は、実施の形態に係る情報処理方法の一例を示すフローチャートである。情報処理方法は、コンピュータ(情報処理システム1)により実行される方法である。このため、図2は、実施の形態に係る情報処理システム1の動作の一例を示すフローチャートでもある。すなわち、以下の説明は、情報処理システム1の動作の説明でもあり、情報処理方法の説明でもある。
まず、取得部10は、第1データを取得する(ステップS11)。例えば、第1データを画像とすると、取得部10は、あるクラスの物体が写る画像を取得する。
次に、推論結果算出部20は、第1データを第1推論モデル21に入力して第1推論結果を算出し(ステップS12)、第1データを第2推論モデル22に入力して第2推論結果を算出する(ステップS13)。つまり、推論結果算出部20は、同じ第1データを第1推論モデル21と第2推論モデル22とに入力することで、第1推論結果と第2推論結果とを算出する。なお、ステップS12及びステップS13は、ステップS13、ステップS12の順序で実行されてもよいし、並行して実行されてもよい。
次に、類似度算出部30は、第1推論結果と第2推論結果との類似度を算出する(ステップS14)。類似度は、同じ第1データを異なる第1推論モデル21と第2推論モデル22とに入力したときに算出される第1推論結果と第2推論結果との類似度である。類似度の詳細については後述する。
次に、決定部40は、算出された類似度に基づいて機械学習における訓練データである第2データを決定する(ステップS15)。例えば、第2データは、第1データそのものであってもよいし、第1データを加工したデータであってもよい。例えば、決定部40は、決定した第2データを学習データ100に追加する。なお、決定部40は、第2データを繰り返し学習データ100に追加してもよい。学習データ100に繰り返し追加される第2データのそれぞれは、追加されるごとに異なる加工が施されたものであってもよい。
なお、1つの第1データについてステップS11からステップS15までの処理が行われ、次に別の第1データについてステップS11からステップS15までの処理が行われ、・・・というのが繰り返されて複数の第2データが決定されてもよいし、複数の第1データについてまとめてステップS11からステップS15までの処理が行われて、複数の第2データが決定されてもよい。
そして、訓練部50は、決定された第2データを用いて第2推論モデル22を機械学習により訓練する(ステップS16)。例えば、訓練部50は、第2データを他の訓練データより多く用いて第2推論モデル22を訓練する。例えば、学習データ100には複数の第2データが新たに追加されているため、学習データ100における第2データの数が多くなっており、訓練部50は、第2データを他のデータより多く用いて第2推論モデル22を訓練することができる。例えば、第2データを他の訓練データより多く用いるとは、訓練における第2データの数が他の訓練データより多いことである。また例えば、第2データを他の訓練データより多く用いるとは、訓練における第2データの使用回数が他の訓練データより多いことであってもよい。訓練部50は、例えば、決定部40から、第2データを学習データ100における他のデータより多く用いて第2推論モデル22を訓練するように指示を受け、当該指示に応じて第2データを用いた訓練回数が他のデータより多くなるように第2推論モデル22を訓練してもよい。第2推論モデル22の訓練の詳細については後述する。
ここで、第1推論モデル21において識別層手前の層の出力によって張られる特徴量空間と第2推論モデル22において識別層手前の層の出力によって張られる特徴量空間について図3Aを用いて説明する。
図3Aは、第1推論モデル21において識別層手前の層の出力によって張られる特徴量空間と第2推論モデル22において識別層手前の層の出力によって張られる特徴量空間との一例を示す図である。なお、図3Aに示される第2推論モデル22での特徴量空間は、訓練部50による訓練がされていない、又は、訓練部50による訓練途中の第2推論モデル22での特徴量空間である。各特徴量空間における10個の丸は、各推論モデルに入力されたデータの特徴量を示し、5つの白丸はそれぞれ同じ種類(例えばクラスX)のデータの特徴量であり、5つのドットが付された丸はそれぞれ同じ種類(例えばクラスY)のデータの特徴量である。クラスXとクラスYとは異なるクラスである。例えば、各推論モデルについて、特徴量空間において特徴量が識別境界より左側にあるデータの推論結果はクラスXを示し、特徴量が識別境界より右側にあるデータの推論結果はクラスYを示すとする。
図3Aには、特徴量が識別境界付近にある第1データとして第1データ101、102、103及び104の特徴量が、第1推論モデル21での特徴量空間及び第2推論モデル22での特徴量空間のそれぞれに示されている。第1データ101は、クラスXのデータであり、同じ第1データ101が第1推論モデル21及び第2推論モデル22に入力されたときに、第1推論結果はクラスXを示し、第2推論結果はクラスYを示している。第1データ102は、クラスYのデータであり、同じ第1データ102が第1推論モデル21及び第2推論モデル22に入力されたときに、第1推論結果はクラスXを示し、第2推論結果はクラスYを示している。第1データ103は、クラスYのデータであり、同じ第1データ103が第1推論モデル21及び第2推論モデル22に入力されたときに、第1推論結果はクラスYを示し、第2推論結果はクラスXを示している。第1データ104は、クラスXのデータであり、同じ第1データ104が第1推論モデル21及び第2推論モデル22に入力されたときに、第1推論結果はクラスYを示し、第2推論結果はクラスXを示している。
クラスXの第1データ101に対する第1推論結果及び第2推論結果について、第1推論結果はクラスXと正解になっているが、第2推論結果はクラスYと不正解になっている。また、クラスYの第1データ102に対する第1推論結果及び第2推論結果について、第2推論結果はクラスYと正解になっているが、第1推論結果はクラスXと不正解となっている。また、クラスYの第1データ103に対する第1推論結果及び第2推論結果について、第1推論結果はクラスYと正解になっているが、第2推論結果はクラスXと不正解になっている。また、クラスXの第1データ104に対応する第1推論結果及び第2推論結果について、第2推論結果はクラスXと正解になっているが、第1推論結果はクラスYと不正解となっている。この例では、第1推論モデル21及び第2推論モデル22はそれぞれ10個中8個が正解となっており、認識率は80%と同じであるが、同じ第1データについて特徴量が識別境界付近の第1データの推論結果が第1推論モデル21と第2推論モデル22とで異なっており、第1推論モデル21と第2推論モデル22とで振る舞いがずれている。
これに対して、本開示では、同じ第1データが第1推論モデル21及び第2推論モデル22に入力されたときに算出される第1推論結果及び第2推論結果の類似度に着目し、当該類似度に基づいて決定される訓練データである第2データから振る舞いを一致させるために有効なデータを重点サンプリングする。例えば、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しないときの第1推論結果及び第2推論結果の類似度に基づいて第2データが決定される。
図3Bは、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しないときの第1データの一例を示す図である。各特徴量空間における4個の丸に斜線が付されているが、これらは、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しないときに第1推論モデル21及び第2推論モデル22に入力されていた第1データの特徴量を示す。例えば、類似度は、第1推論結果と第2推論結果とが一致しているか否か、を含む。例えば、第1データ101に対する第1推論結果が示すクラス(クラスX)と第2推論結果が示すクラス(クラスY)とが一致していない。また、第1データ102に対する第1推論結果が示すクラス(クラスX)と第2推論結果が示すクラス(クラスY)とが一致していない。また、第1データ103に対する第1推論結果が示すクラス(クラスY)と第2推論結果が示すクラス(クラスX)とが一致していない。また、第1データ104に対する第1推論結果が示すクラス(クラスY)と第2推論結果が示すクラス(クラスX)とが一致していない。
このように、決定部40は、第1推論結果及び第2推論結果の類似度(例えば、第1推論結果と第2推論結果とが一致しているか否か)に基づいて、具体的には、第1推論結果と第2推論結果とが一致しない場合の入力である第1データに基づいて、第1推論モデル21及び第2推論モデル22の振る舞いが一致しない第1データ(図3A及び図3Bの例では第1データ101、102、103及び104)を、第2データとして決定する。入力される推論モデルによって推論結果が変わってくるような第1データを訓練データとして利用して推論モデルを訓練することで、推論モデルの改善を図ることができるためである。なお、決定部40は、第1推論結果と第2推論結果とが一致している第1データであっても、特徴量が識別境界付近となっている場合には、当該第1データを第2データとして決定してもよい。特徴量が識別境界付近となっている第1データは、当該第1データが入力されたときに第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しない可能性が高いデータであり、訓練データとして利用するのに有効なデータとなるためである。
なお、類似度は、第1推論結果における第1推論値の大きさと第2推論結果における第2推論値の大きさとの類似度を含んでいてもよい。例えば、第1データに対する第1推論結果における第1推論値の大きさと当該第1データに対する第2推論結果における第2推論値の大きさとの差が大きい場合、決定部40は、当該第1データを第2データとして決定してもよい。つまり、決定部40は、第1推論値と第2推論値との差分が閾値以上である場合の入力である第1データに基づいて第2データを決定してもよい。第1推論結果における第1推論値の大きさと第2推論結果における第2推論値の大きさとの差が大きくなるような第1データは、推論モデルの推論の信頼度又は尤度等を低くするデータであり、すなわち、当該第1データが入力されたときに第1推論モデル21の振る舞いと第2推論モデル22の振る舞いが一致しない可能性が高いデータであり、訓練データとして利用するのに有効なデータとなるためである。
なお、決定部40は、第1データをそのまま第2データとして決定して学習データ100に追加してもよいが、第1データを加工したデータを第2データとして決定して学習データ100に追加してもよい。例えば、第1データを加工した第2データは、第1データに幾何学的な変換が施されたデータであってもよいし、第1データの値にノイズが付与されたデータであってもよいし、第1データの値に線形変換が施されたデータであってもよい。
次に、第2推論モデル22の訓練方法について説明する。
図4は、実施の形態に係る第2推論モデル22の訓練方法の一例を示すフローチャートである。
推論結果算出部20は、第2データを用いて重点サンプリングを行うために、第2データを取得する(ステップS21)。
推論結果算出部20は、第2データを第1推論モデル21に入力して第3推論結果を算出し(ステップS22)、第2データを第2推論モデル22に入力して第4推論結果を算出する(ステップS23)。つまり、推論結果算出部20は、同じ第2データを第1推論モデル21と第2推論モデル22とに入力することで、第3推論結果と第4推論結果とを算出する。なお、ステップS22及びステップS23は、ステップS23、ステップS22の順序で実行されてもよいし、並行して実行されてもよい。
次に、パラメタ算出部51は、第3推論結果及び第4推論結果に基づいて訓練パラメタを算出する(ステップS24)。例えば、パラメタ算出部51は、第3推論結果と第4推論結果との誤差が小さくなるように、訓練パラメタを算出する。誤差が小さくなるとは、異なる第1推論モデル21及び第2推論モデル22に同じ第2データを入力したときに得られる第3推論結果及び第4推論結果が近い推論結果となることを意味する。誤差は、第3推論結果と第4推論結果との距離が近いほど小さくなる。推論結果の距離は、例えば、クロスエントロピーによって求めることができる。
そして、更新部52は、算出された訓練パラメタを用いて第2推論モデル22を更新する(ステップS25)。
なお、取得部10が学習データ100から第1データを取得する例について説明したが、取得部10は、学習データ100から第1データを取得しなくてもよい。これについて、図5を用いて説明する。
図5は、実施の形態の変形例に係る情報処理システム2の一例を示すブロック図である。
実施の形態の変形例に係る情報処理システム2は、追加データ200を備え、取得部10は、学習データ100ではなく追加データ200から第1データを取得する点が、実施の形態に係る情報処理システム1と異なる。その他の点は、実施の形態におけるものと同じであるため説明は省略する。
図5に示されるように、学習データ100に追加される第2データを決定するための第1データを含む追加データ200が学習データ100とは別に用意されていてもよい。つまり、学習データ100にもともと含まれているデータではなく、学習データ100とは別に用意された追加データ200に含まれているデータが第2データの決定のために用いられてもよい。
以上説明したように、第1推論モデル21と第2推論モデル22とは異なるモデルであるため、それぞれに同じ第1データを入力しても、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しない場合がある。しかし、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しないときの第1推論結果及び第2推論結果の類似度を用いることで、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとが一致しない第1データを決定することができる。そして、第2推論モデル22の振る舞いを第1推論モデル21の振る舞いに近づけるように第2推論モデル22を機械学習により訓練するための訓練データである第2データを第1データから決定することができる。したがって、本開示によれば、第1推論モデル21の振る舞いと第2推論モデル22の振る舞いとを近づけることができる。
また、通常の重点サンプリング学習では、1つの推論モデルについて識別境界付近のデータが重点サンプリングされるが、本開示では、推論モデル間で振る舞いが一致したり、不一致になったりするデータを重点的に学習するため、学習の安定化が可能となる。
また、第2推論モデル22が第1推論モデル21の軽量化により得られるモデルである場合、第2推論モデル22は第1推論モデル21よりも精度が劣るが、軽量化された第2推論モデル22の振る舞いが第1推論モデル21に近づくことで、軽量化された第2推論モデル22の性能を第1推論モデル21に近づけることができ、第2推論モデル22の精度の改善も可能となる。
(その他の実施の形態)
以上、本開示の一つ又は複数の態様に係る情報処理方法及び情報処理システム1について、実施の形態に基づいて説明したが、本開示は、これらの実施の形態に限定されるものではない。本開示の趣旨を逸脱しない限り、当業者が思いつく各種変形を各実施の形態に施したものや、異なる実施の形態における構成要素を組み合わせて構築される形態も、本開示の一つ又は複数の態様の範囲内に含まれてもよい。
以上、本開示の一つ又は複数の態様に係る情報処理方法及び情報処理システム1について、実施の形態に基づいて説明したが、本開示は、これらの実施の形態に限定されるものではない。本開示の趣旨を逸脱しない限り、当業者が思いつく各種変形を各実施の形態に施したものや、異なる実施の形態における構成要素を組み合わせて構築される形態も、本開示の一つ又は複数の態様の範囲内に含まれてもよい。
例えば、上記実施の形態では、第2推論モデル22が、第1推論モデル21の軽量化により得られる例について説明したが、第2推論モデル22は、第1推論モデル21の軽量化により得られるモデルでなくてもよい。
例えば、上記実施の形態では、第1データ及び第2データが画像である例を説明したが、他のデータであってもよい。具体的には、画像以外のセンシングデータであってもよい。例えば、マイクロフォンから出力される音声データ、LiDAR等のレーダから出力される点群データ、圧力センサから出力される圧力データ、温度センサ又は湿度センサから出力される温度データ又は湿度データ、香りセンサから出力される香りデータなどの正解データが取得可能なセンシングデータであれば、処理の対象とされてよい。
例えば、上記実施の形態に係る訓練後の第2推論モデル22は、装置に組み込まれてもよい。これについて、図6を用いて説明する。
図6は、その他の実施の形態に係る情報処理装置300の一例を示すブロック図である。なお、図6には、情報処理装置300の他にセンサ400も示している。
図6に示されるように、情報処理装置300は、センシングデータを取得する取得部310と、上記第第2データに基づいて機械学習により訓練された第2推論モデル22にセンシングデータを入力して推論結果を取得する制御部320と、取得された推論結果に基づくデータを出力する出力部330と、を備える。このように、センシングデータをセンサ400から取得する取得部310と、訓練後の第2推論モデル22を用いた処理を制御する制御部320と、第2推論モデル22の出力である推論結果に基づくデータを出力する出力部330と、を備える情報処理装置300が提供されてよい。なお、情報処理装置300にセンサ400が含まれてもよい。また、取得部310は、センシングデータが記録されたメモリからセンシングデータを取得してもよい。
例えば、本開示は、情報処理方法に含まれるステップを、プロセッサに実行させるためのプログラムとして実現できる。さらに、本開示は、そのプログラムを記録したCD-ROM等である非一時的なコンピュータ読み取り可能な記録媒体として実現できる。
例えば、本開示が、プログラム(ソフトウェア)で実現される場合には、コンピュータのCPU、メモリ及び入出力回路等のハードウェア資源を利用してプログラムが実行されることによって、各ステップが実行される。つまり、CPUがデータをメモリ又は入出力回路等から取得して演算したり、演算結果をメモリ又は入出力回路等に出力したりすることによって、各ステップが実行される。
なお、上記実施の形態において、情報処理システム1に含まれる各構成要素は、専用のハードウェアで構成されるか、各構成要素に適したソフトウェアプログラムを実行することによって実現されてもよい。各構成要素は、CPU又はプロセッサなどのプログラム実行部が、ハードディスク又は半導体メモリなどの記録媒体に記録されたソフトウェアプログラムを読み出して実行することによって実現されてもよい。
上記実施の形態に係る情報処理システム1の機能の一部又は全ては典型的には集積回路であるLSIとして実現される。これらは個別に1チップ化されてもよいし、一部又は全てを含むように1チップ化されてもよい。また、集積回路化はLSIに限るものではなく、専用回路又は汎用プロセッサで実現してもよい。LSI製造後にプログラムすることが可能なFPGA(Field Programmable Gate Array)、又はLSI内部の回路セルの接続や設定を再構成可能なリコンフィギュラブル・プロセッサを利用してもよい。
さらに、本開示の主旨を逸脱しない限り、本開示の各実施の形態に対して当業者が思いつく範囲内の変更を施した各種変形例も本開示に含まれる。
本開示は、例えば、エッジ端末でDeep Learningを実行する際に用いられる推論モデルの開発に適用できる。
1、2 情報処理システム
10、310 取得部
20 推論結果算出部
21 第1推論モデル
22 第2推論モデル
30 類似度算出部
40 決定部
50 訓練部
51 パラメタ算出部
52 更新部
100 学習データ
101、102、103、104 第1データ
200 追加データ
300 情報処理装置
320 制御部
330 出力部
10、310 取得部
20 推論結果算出部
21 第1推論モデル
22 第2推論モデル
30 類似度算出部
40 決定部
50 訓練部
51 パラメタ算出部
52 更新部
100 学習データ
101、102、103、104 第1データ
200 追加データ
300 情報処理装置
320 制御部
330 出力部
Claims (8)
- コンピュータにより実行される方法であって、
第1データを取得し、
前記第1データを第1推論モデルに入力して第1推論結果を算出し、
前記第1データを第2推論モデルに入力して第2推論結果を算出し、
前記第1推論結果及び前記第2推論結果の類似度を算出し、
前記類似度に基づいて機械学習における訓練データである第2データを決定し、
前記第2データを用いて前記第2推論モデルを機械学習により訓練し、
前記類似度は、前記第1推論結果と前記第2推論結果とが一致しているか否か、であり、
前記第1推論結果と前記第2推論結果とが一致しない場合、前記決定では、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータを前記第2データとして決定する、
または、
前記類似度は、前記第1推論結果における第1推論値の大きさと前記第2推論結果における第2推論値の大きさとの類似度であり、
前記第1推論値と前記第2推論値との差分が閾値以上である場合、前記決定では、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータを前記第2データとして決定する、
情報処理方法。 - 前記第1推論モデルの構成と前記第2推論モデルの構成は異なる
請求項1に記載の情報処理方法。 - 前記第1推論モデルの処理精度と前記第2推論モデルの処理精度は異なる
請求項1又は2に記載の情報処理方法。 - 前記第2推論モデルは、前記第1推論モデルの軽量化により得られる
請求項2又は3に記載の情報処理方法。 - 前記訓練では、前記第2データを他の訓練データより多く用いて前記第2推論モデルを訓練する
請求項1~4のいずれか1項に記載の情報処理方法。 - 前記第1推論モデル及び前記第2推論モデルは、ニューラルネットワークモデルである
請求項1~5のいずれか1項に記載の情報処理方法。 - 第1データを取得する取得部と、
前記第1データを第1推論モデルに入力して第1推論結果を算出し、前記第1データを第2推論モデルに入力して第2推論結果を算出する推論結果算出部と、
前記第1推論結果及び前記第2推論結果の類似度を算出する類似度算出部と、
前記類似度に基づいて機械学習における訓練データである第2データを決定する決定部と、
前記第2データを用いて第2推論モデルを機械学習により訓練する訓練部と、を備え、
前記類似度は、前記第1推論結果と前記第2推論結果とが一致しているか否か、であり、
前記第1推論結果と前記第2推論結果とが一致しない場合、前記決定部は、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータを前記第2データとして決定する、
または、
前記類似度は、前記第1推論結果における第1推論値の大きさと前記第2推論結果における第2推論値の大きさとの類似度であり、
前記第1推論値と前記第2推論値との差分が閾値以上である場合、前記決定部は、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータを前記第2データとして決定する、
情報処理システム。 - センシングデータを取得する取得部と、
前記センシングデータを第2推論モデルに入力して推論結果を取得する制御部と、
取得された前記推論結果に基づくデータを出力する出力部と、を備え、
前記第2推論モデルは、第2データを用いて機械学習により訓練され、
前記第2データは、機械学習における訓練データであり、類似度に基づいて決定され、
前記類似度は、第1推論結果及び第2推論結果から算出され、
前記第1推論結果は、第1データを第1推論モデルに入力して算出され、
前記第2推論結果は、前記第1データを前記第2推論モデルに入力して算出され、
前記類似度は、前記第1推論結果と前記第2推論結果とが一致しているか否か、であり、
前記第1推論結果と前記第2推論結果とが一致しない場合、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータが前記第2データとして決定される、
または、
前記類似度は、前記第1推論結果における第1推論値の大きさと前記第2推論結果における第2推論値の大きさとの類似度であり、
前記第1推論値と前記第2推論値との差分が閾値以上である場合、前記第1推論モデルおよび前記第2推論モデルに入力された前記第1データを加工したデータが前記第2データとして決定される、
情報処理装置。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962944668P | 2019-12-06 | 2019-12-06 | |
| US62/944,668 | 2019-12-06 | ||
| JP2020099961 | 2020-06-09 | ||
| JP2020099961 | 2020-06-09 | ||
| PCT/JP2020/042082 WO2021111832A1 (ja) | 2019-12-06 | 2020-11-11 | 情報処理方法、情報処理システム及び情報処理装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JPWO2021111832A1 JPWO2021111832A1 (ja) | 2021-06-10 |
| JPWO2021111832A5 JPWO2021111832A5 (ja) | 2022-08-01 |
| JP7507172B2 true JP7507172B2 (ja) | 2024-06-27 |
Family
ID=76222359
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021562535A Active JP7507172B2 (ja) | 2019-12-06 | 2020-11-11 | 情報処理方法、情報処理システム及び情報処理装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220292371A1 (ja) |
| JP (1) | JP7507172B2 (ja) |
| WO (1) | WO2021111832A1 (ja) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202984A (ja) | 2000-11-02 | 2002-07-19 | Fujitsu Ltd | ルールベースモデルに基づくテキスト情報自動分類装置 |
| JP2016110082A (ja) | 2014-12-08 | 2016-06-20 | 三星電子株式会社Samsung Electronics Co.,Ltd. | 言語モデル学習方法及び装置、音声認識方法及び装置 |
| JP2017531255A (ja) | 2014-09-12 | 2017-10-19 | マイクロソフト コーポレーションMicrosoft Corporation | 出力分布による生徒dnnの学習 |
| JP2019133628A (ja) | 2018-01-29 | 2019-08-08 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | 情報処理方法及び情報処理システム |
| JP2019139277A (ja) | 2018-02-06 | 2019-08-22 | オムロン株式会社 | 評価装置、動作制御装置、評価方法、及び評価プログラム |
-
2020
- 2020-11-11 JP JP2021562535A patent/JP7507172B2/ja active Active
- 2020-11-11 WO PCT/JP2020/042082 patent/WO2021111832A1/ja active Application Filing
-
2022
- 2022-05-31 US US17/828,615 patent/US20220292371A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002202984A (ja) | 2000-11-02 | 2002-07-19 | Fujitsu Ltd | ルールベースモデルに基づくテキスト情報自動分類装置 |
| JP2017531255A (ja) | 2014-09-12 | 2017-10-19 | マイクロソフト コーポレーションMicrosoft Corporation | 出力分布による生徒dnnの学習 |
| JP2016110082A (ja) | 2014-12-08 | 2016-06-20 | 三星電子株式会社Samsung Electronics Co.,Ltd. | 言語モデル学習方法及び装置、音声認識方法及び装置 |
| JP2019133628A (ja) | 2018-01-29 | 2019-08-08 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | 情報処理方法及び情報処理システム |
| JP2019139277A (ja) | 2018-02-06 | 2019-08-22 | オムロン株式会社 | 評価装置、動作制御装置、評価方法、及び評価プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021111832A1 (ja) | 2021-06-10 |
| US20220292371A1 (en) | 2022-09-15 |
| WO2021111832A1 (ja) | 2021-06-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6755849B2 (ja) | 人工ニューラルネットワークのクラスに基づく枝刈り | |
| CN112508186A (zh) | 训练用于图像识别的神经网络的方法和神经网络设备 | |
| JP6833620B2 (ja) | 画像解析装置、ニューラルネットワーク装置、学習装置、画像解析方法およびプログラム | |
| US11514315B2 (en) | Deep neural network training method and apparatus, and computer device | |
| JP7047498B2 (ja) | 学習プログラム、学習方法および学習装置 | |
| CN110705573A (zh) | 一种目标检测模型的自动建模方法及装置 | |
| WO2022027913A1 (zh) | 目标检测模型生成方法、装置、设备及存储介质 | |
| US11301723B2 (en) | Data generation device, data generation method, and computer program product | |
| KR102548519B1 (ko) | 준합성 데이터 생성 장치 및 데이터 생성 방법 | |
| CN112966818A (zh) | 一种定向引导模型剪枝方法、系统、设备及存储介质 | |
| JP2019105871A (ja) | 異常候補抽出プログラム、異常候補抽出方法および異常候補抽出装置 | |
| CN115457492A (zh) | 目标检测方法、装置、计算机设备及存储介质 | |
| CN110490058B (zh) | 行人检测模型的训练方法、装置、系统和计算机可读介质 | |
| CN111832693A (zh) | 神经网络层运算、模型训练方法、装置及设备 | |
| JP7507172B2 (ja) | 情報処理方法、情報処理システム及び情報処理装置 | |
| CN117079305A (zh) | 姿态估计方法、姿态估计装置以及计算机可读存储介质 | |
| KR102073362B1 (ko) | 웨이퍼 맵을 불량 패턴에 따라 분류하는 방법 및 컴퓨터 프로그램 | |
| CN115984671A (zh) | 模型在线更新方法、装置、电子设备及可读存储介质 | |
| CN110889316A (zh) | 一种目标对象识别方法、装置及存储介质 | |
| WO2021111831A1 (ja) | 情報処理方法、情報処理システム及び情報処理装置 | |
| CN115393914A (zh) | 多任务模型训练方法、装置、设备及存储介质 | |
| CN112016571A (zh) | 一种基于注意力机制的特征提取方法、装置及电子设备 | |
| KR20210087494A (ko) | 인체 방향 검출 방법, 장치, 전자 기기 및 컴퓨터 저장 매체 | |
| CN106529374A (zh) | 一种级联式人脸关键点定位方法和系统 | |
| JP7000586B2 (ja) | データ処理システムおよびデータ処理方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220606 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230824 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240604 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240617 |