以下に、本願の開示する検出方法、検出プログラムおよび情報処理装置の実施例を図面に基づいて詳細に説明する。なお、この実施例によりこの発明が限定されるものではない。
本実施例1の説明を行う前に、機械学習モデルの精度劣化を検知する参考技術について説明する。参考技術では、異なる条件でモデル適用領域を狭めた複数の監視器を用いて、機械学習モデルの精度劣化を検知する。以下の説明では、監視器を「インスペクターモデル」と表記する。
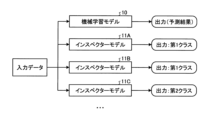
図1は、参考技術を説明するための図である。機械学習モデル10は、教師データを用いて機械学習した機械学習モデルである。参考技術では、機械学習モデル10の精度劣化を検知する。たとえば、教師データには、訓練データと、検証データとが含まれる。訓練データは、機械学習モデル10のパラメータを機械学習する場合に用いられるものであり、正解ラベルが対応付けられる。検証データは、機械学習モデル10を検証する場合に用いられるデータである。
インスペクターモデル11A,11B,11Cは、それぞれ異なる条件でモデル適用領域が狭められ、異なる決定境界を有する。参考技術では、訓練データに何らかの改変を加え、改変を加えた訓練データを用いて、インスペクターモデル11A~11Cを作成している。
インスペクターモデル11A~11Cは、それぞれ決定境界が異なるため、同一の入力データを入力しても、出力結果が異なる場合がある。参考技術では、インスペクターモデル11A~11Cの出力結果の違いを基にして、機械学習モデル10の精度劣化を検知する。図1に示す例では、インスペクターモデル11A~11Cを示すが、他のインスペクターモデルを用いて、精度劣化を検知してもよい。インスペクターモデル11A~11CにはDNN(Deep Neural Network)を利用する。
参考技術では、インスペクターモデル11A~11Cの出力結果が全て同じである場合に、機械学習モデル10の精度が劣化していないと判定する。一方、参考技術では、インスペクターモデル11A~11Cの出力結果が異なる場合に、機械学習モデル10の精度劣化を検知する。
図2は、精度劣化予測の一例を示す図である。図2のグラフの縦軸は、精度に対応する軸であり、横軸は時刻に対応する軸である。図2に示すように、時間経過に伴って、精度が低下しており、時刻t1において、精度の許容限界を下回る。たとえば、参考技術では、時刻t1において、精度劣化(許容限界を下回ったこと)を検知する。
時間経過に伴う入力データの分布(特徴量)の変化をコンセプトドリフトと呼ぶ。図3は、コンセプトドリフトの一例を示す図である。図3の縦軸は、第1の特徴量に対応する軸であり、横軸は、第2の特徴量に対応する軸である。たとえば、機械学習モデル10の運用開始時において、第1クラスに対応する第1データの分布を分布A1とし、第2クラスに対応する第2データの分布を分布Bとする。
時間経過に伴って、第1データの分布A1が、分布A2に変化する場合がある。オリジナルの機械学習モデル10は、第1データの分布を、分布A1として学習を行っているため、時間経過に伴って精度が下がり、再学習が必要となる。
コンセプトドリフトが発生するデータには、スパムメール、電気需要予測、株価予測、ポーカーハンドの戦略手順、画像等が含まれる。たとえば、画像は、季節や時間帯によって、同一の被写体であっても、画像の特徴量が異なる。
ここで、上述した参考技術では、機械学習モデル10の精度劣化を検知するために、複数のインスペクターモデル11A~11Cを作成している。そして、複数のインスペクターモデル11A~11Cを作成するためには、機械学習モデル10や、機械学習モデル10の学習時に用いた、訓練データに何らかの改変を加えることができるという条件が必須である。たとえば、機械学習モデル10が確信度を算出するモデルであること等、機械学習モデル10が特定の学習モデルであることが求められる。
そうすると、機械学習モデル10の精度劣化を検知する手法が、機械学習モデルに依存してしまう。機械学習モデルの分類アルゴリズムには、NN(Neural Network)、決定木、k近傍法、サポートベクターマシン等様々な分類アルゴリズムが該当するため、分類アルゴリズム毎に、どの検知手法が精度劣化の検知に適する手法であるかを試行錯誤する必要がある。
すなわち、どのような分類アルゴリズムであっても、汎用的に使用可能なインスペクターモデルを作成し、機械学習モデル10の精度劣化を検知することが望ましい。
図4は、インスペクターモデルの基本的な仕組みを説明するための図である。たとえば、インスペクターモデルは、第1クラスに属する訓練データの分布A1と、第2クラスに属する訓練データの分布Bとの境界となる決定境界5を学習することで、作成される。時間経過に伴う、運用データに対する機械学習モデル10の精度劣化を検出するためには、決定境界5の危険領域5aを監視し、危険領域5aに含まれる運用データの数が増加(または減少)したか否かを特定し、運用データの数が増加(または減少)した場合に、精度劣化を検出する。
以下の説明において、訓練データは、監視対象となる機械学習モデルを学習する場合に用いるデータである。運用データは、機械学習モデルを用いて、各分類クラスに分類するデータであり、運用開始時からの時間経過に応じて特徴量が変化するものとする。
本実施例1に係る情報処理装置は、知識蒸留(KD:Knowledge Distiller)を用いて、決定境界5の危険領域5aに含まれる運用データの数の増減を算出し、機械学習モデルの精度劣化を検出する。
図5は、知識蒸留を説明するための図である。知識蒸留では、Teacherモデル7Aの出力値を模倣するような、Studentモデル7Bを構築する。たとえば、訓練データ6が与えられ、訓練データ6には正解ラベル「犬」が付与されているものとする。説明の便宜上、Teacherモデル7AおよびStudentモデル7BをNNとするが、これに限定されるものではない。
情報処理装置は、訓練データ6を入力した際のTeacherモデル7Aの出力結果が、正解ラベル「犬」に近づくように、Teacherモデル7Aのパラメータを学習(誤差逆伝播法による学習)する。また、情報処理装置は、訓練データ6を入力した際のStudentモデル7Bの出力結果が、訓練データ6を入力した際のTeacherモデル7Aの出力結果に近づくように、Studentモデル7Bのパラメータを学習する。Teacherモデル7Aの出力を「ソフトターゲット(Soft Target)」と呼ぶ。訓練データの正解ラベルを「ハードターゲット(Hard Target)」と呼ぶ。
上記のように、Teacherモデル7Aに関する学習を、訓練データ6とハードターゲットとを用いて学習し、Studentモデル7Bに関する学習を、訓練データ6とソフトターゲットとを用いて学習する手法を、知識蒸留と呼ぶ。情報処理装置は、他の訓練データについても同様にして、Teacherモデル7AおよびStudentモデル7Bを学習する。
ここで、データ空間を入力としたソフトターゲットで、Studentモデル7Bの学習を考える。Teacherモデル7Aと、Studentモデル7Bとを異なるモデルで構築すれば、Studentモデル7Bの出力結果は、Teacherモデル7Aの出力結果の決定境界に類似するように学習される。そうすると、Teacherモデル7Aを監視対象の機械学習モデル、Studentモデル7Bをインスペクターモデルとして扱うことが可能となる。Teacherモデル7Aのモデルアーキテクチャを絞らないことで、汎用的に使用可能なインスペクターモデルを作成することができる。
図6は、決定境界周辺の危険領域の算出手法を説明するための図である。本実施例1に係る情報処理装置は、特徴量空間の決定境界5が直線になるような高次元空間(再生核ヒルベルト空間)Hkにデータ(ソフトターゲット)を射影して、危険領域5aを算出する。たとえば、データ8を入力した場合に、高次元空間Hkの決定境界5と、データ8との距離(符号付きの距離)m8を算出するインスペクターモデルを構築する。危険領域5aの幅を幅mとし、距離m8がm未満である場合には、データ8は、危険領域5aに含まれることを意味する。距離(ノルム)の計算は、再生核ヒルベルト空間の内積によって計算され、カーネルトリックに対応する。距離(ノルム)は、式(1)によって定義される。
情報処理装置は、インスペクターモデルを、Hard-Margin RBF(Radial Basis Function)カーネルSVM(Support Vector Machine)によって構築する。情報処理装置は、再生核ヒルベルト空間に、決定境界5が直線になるようにデータ空間を射影する。危険領域5aの幅mは、精度劣化に関する検知の感度であり、決定境界5付近のデータ密度で決定される。
たとえば、情報処理装置は、ソフトターゲットの領域を領域Xおよび領域Yに分類する。情報処理装置は、領域Xおよび領域Yを、再生核ヒルベルト空間に射影し、決定境界5側に一番近いサポートベクトルXa、Yaを特定する。情報処理装置は、サポートベクトルXaおよび決定境界5のマージンと、サポートベクトルYaおよび決定境界5のマージンとの差が最小となるように、決定境界5を特定する。つまり、情報処理装置は、監視した機械学習モデルの決定境界5との乖離を損失として学習しながら、ユークリッド空間上の決定境界付近の空間をねじ曲げることに相当する処理を実行する。
ここで、本実施例1に係る情報処理装置が、上記処理によって作成したインスペクターモデルを用いて、監視対象の機械学習モデルの精度劣化を検知する処理の一例について説明する。なお、機械学習モデルは、複数の訓練データによって、学習済みとする。以下の説明では、複数の訓練データを「訓練データセット」と表記する。
情報処理装置は、訓練データセットに含まれる各訓練データを、インスペクターモデルに入力し、全訓練データのうち、危険領域5aに含まれる訓練データの割合を算出しておく。以下の説明において、全訓練データのうち、危険領域5aに含まれる訓練データの割合を「第一割合」と表記する。
情報処理装置は、機械学習モデルの運用開始時から時間経過した後に、運用データセットを取得する。運用データセットには、複数の運用データが含まれる。情報処理装置は、運用データセットに含まれる各運用データを、インスペクターモデルに入力し、全運用データのうち、危険領域5aに含まれる運用データの割合を算出する。以下の説明において、全運用データのうち、危険領域5aに含まれる訓練データの割合を「第二割合」と表記する。
情報処理装置は、第一割合と第二割合とを比較して、第二割合が増加または減少した場合、機械学習モデルの精度劣化を検知する。第一割合を基準として、第二割合が変化したということは、運用開始時と比較して、多くの運用データが、危険領域5aに含まれており、コンセプトドリフトが発生していることを示す。情報処理装置は、時間経過に伴って、運用データセットを取得し、上記処理を繰り返し実行する。これによって、どのような分類アルゴリズムであっても、汎用的に使用可能なインスペクターモデルを作成し、機械学習モデルの精度劣化を検知することができる。
次に、同一の訓練データセットを複数種類の機械学習モデルにそれぞれ入力した場合の決定境界の性質について説明する。図7は、各機械学習モデルの決定境界の性質を示す図である。図7に示す例では、訓練データセット15を用いて、サポートベクターマシン(Soft-Margin SVM)、ランダムフォレスト(Ramdom Forest)、NNをそれぞれ学習する。
そうすると、学習したサポートベクターマシンにデータセットを入力した場合の分布は、分布20Aとなり、各データは、決定境界21Aで第1クラス、第2クラスに分類される。学習したランダムフォレストにデータセットを入力した場合の分布は、分布20Bとなり、各データは、決定境界21Bで第1クラス、第2クラスに分類される。学習したNNにデータセットを入力した場合の分布は、分布20Cとなり、各データは、決定境界21Cで第1クラス、第2クラスに分類される。
図7に示すように、同一の訓練データセット15で学習を行った場合でも、機械学習モデルの種類によっては、決定境界の性質が違うことがわかる。
続いて、各機械学習モデルを用いた知識蒸留によって、インスペクターモデルを作成した場合の決定境界の一例について説明する。説明の便宜上、機械学習モデル(サポートベクターマシン)を用いた知識蒸留によって作成したインスペクターモデルを、第1インスペクターモデルと表記する。機械学習モデル(ランダムフォレスト)を用いた知識蒸留によって作成したインスペクターモデルを、第2インスペクターモデルと表記する。機械学習モデル(NN)を用いた知識蒸留によって作成したインスペクターモデルを、第3インスペクターモデルと表記する。
図8は、各インスペクターモデルの決定境界を可視化した結果を示す図である。情報処理装置は、分布20Aを基にして、第1インスペクターモデルを作成すると、第1インスペクターモデルの分布は、22Aに示すものとなり、決定境界は、決定境界23Aとなる。
情報処理装置は、分布20Bを基にして、第2インスペクターモデルを作成すると、第2インスペクターモデルの分布は、22Bに示すものとなり、決定境界は、決定境界23Bとなる。情報処理装置は、分布20Cを基にして、第3インスペクターモデルを作成すると、第3インスペクターモデルの分布は、22Cに示すものとなり、決定境界は、決定境界23Cとなる。
図9は、各インスペクターモデルによる危険領域を可視化した図である。第1インスペクターモデルの決定境界23Aを基にした危険領域は、危険領域24Aとなる。第2インスペクターモデルの決定境界23Bを基にした危険領域は、危険領域24Bとなる。第3インスペクターモデルの決定境界23Cを基にした危険領域は、危険領域24Cとなる。
次に、本実施例1に係る情報処理装置の構成について説明する。図10は、本実施例1に係る情報処理装置の構成を示す機能ブロック図である。図10に示すように、情報処理装置100は、通信部110と、入力部120と、表示部130と、記憶部140と、制御部150とを有する。
通信部110は、ネットワークを介して、外部装置(図示略)とデータ通信を実行する処理部である。通信部110は、通信装置の一例である。後述する制御部150は、通信部110を介して、外部装置とデータをやり取りする。
入力部120は、情報処理装置100に対して各種の情報を入力するための入力装置である。入力部120は、キーボードやマウス、タッチパネル等に対応する。
表示部130は、制御部150から出力される情報を表示する表示装置である。表示部130は、液晶ディスプレイ、有機EL(Electro Luminescence)ディスプレイ、タッチパネル等に対応する。
記憶部140は、教師データ141、機械学習モデルデータ142、蒸留データテーブル143、インスペクターモデルデータ144、運用データテーブル145を有する。記憶部140は、RAM(Random Access Memory)、フラッシュメモリ(Flash Memory)などの半導体メモリ素子や、HDD(Hard Disk Drive)などの記憶装置に対応する。
教師データ141は、訓練データセット141aと、検証データ141bを有する。訓練データセット141aは、訓練データに関する各種の情報を保持する。
図11は、本実施例1に係る訓練データセットのデータ構造の一例を示す図である。図11に示すように、この訓練データセットは、レコード番号と、訓練データと、正解ラベルとを対応付ける。レコード番号は、訓練データと、正解ラベルとの組を識別する番号である。訓練データは、メールスパムのデータ、電気需要予測、株価予測、ポーカーハンドのデータ、画像データ等に対応する。正解ラベルは、第1クラスまたは第2クラスを一意に識別する情報である。
検証データ141bは、訓練データセット141aによって学習された機械学習モデルを検証するためのデータである。検証データ141bは、正解ラベルが付与される。たとえば、検証データ141bを、機械学習モデルに入力した場合に、機械学習モデルから出力される出力結果が、検証データ141bに付与される正解ラベルに一致する場合、訓練データセット141aによって、機械学習モデルが適切に学習されたことを意味する。
機械学習モデルデータ142は、機械学習モデルのデータである。本実施例1に機械学習モデルは、所定の分類アルゴリズムによって、入力データを、第1クラスまたは第2クラスに分類する機械学習モデルである。分類アルゴリズムは、NN、ランダムフォレスト、k近傍法、サポートベクターマシン等のうち、いずれの分類アルゴリズムであってもよい。
ここでは一例として、機械学習モデルを、NNとして説明を行う。図12は、機械学習モデルの一例を説明するための図である。図12に示すように、機械学習モデル50は、ニューラルネットワークの構造を有し、入力層50a、隠れ層50b、出力層50cを持つ。入力層50a、隠れ層50b、出力層50cは、複数のノードがエッジで結ばれる構造となっている。隠れ層50b、出力層50cは、活性化関数と呼ばれる関数とバイアス値とを持ち、エッジは、重みを持つ。以下の説明では、バイアス値、重みを「パラメータ」と表記する。
入力層50aに含まれる各ノードに、データ(データの特徴量)を入力すると、隠れ層20bを通って、出力層20cのノード51a,51bから、各クラスの確率が出力される。たとえば、ノード51aから、第1クラスの確率が出力される。ノード51bから、第2クラスの確率が出力される。
蒸留データテーブル143は、データセットの各データを、機械学習モデル50に入力した場合の出力結果(ソフトターゲット)を格納するテーブルである。図13は、本実施例1に係る蒸留データテーブルのデータ構造の一例を示す図である。図13に示すように、この蒸留データテーブル143は、レコード番号と、入力データと、ソフトターゲットとを対応付ける。レコード番号は、入力データと、ソフトターゲットとの組を識別する番号である。入力データは、学習された機械学習モデル50の決定境界(決定境界を含む特徴空間)を基にして、作成部152に選択されるデータである。
ソフトターゲットは、入力データを学習済みの機械学習モデル50に入力した場合に出力されるものである。たとえば、本実施例1に係るソフトターゲットは、第1クラスまたは第2クラスのうち、いずれかの分類クラスを示すものとする。
インスペクターモデルデータ144は、Hard-Margin RBFカーネルSVMによって構築されたインスペクターモデルのデータである。以下の説明では、Hard-Margin RBFカーネルSVMを「kSVM」と表記する。かかるインスペクターモデルに、データを入力すると、符号付きの距離の値が出力される。たとえば、符号がプラスであれば、入力したデータは第1クラスに分類される。符号がマイナスであれば、データは、第2クラスに分類される。距離は、データと決定境界との距離を示す。
運用データテーブル145は、時間経過に伴って、追加される運用データセットを有する。図14は、運用データテーブルのデータ構造の一例を示す図である。図14に示すように、運用データテーブル145は、データ識別情報と、運用データセットとを有する。データ識別情報は、運用データセットを識別する情報である。運用データセットは、複数の運用データが含まれる。運用データは、メールスパムのデータ、電気需要予測、株価予測、ポーカーハンドのデータ、画像データ等に対応する。
図10の説明に戻る。制御部150は、学習部151と、作成部152と、検出部153と、予測部154とを有する。制御部150は、CPU(Central Processing Unit)やMPU(Micro Processing Unit)などによって実現できる。また、制御部150は、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)などのハードワイヤードロジックによっても実現できる。
学習部151は、訓練データセット141aを取得し、訓練データセット141aを基にして、機械学習モデル50のパラメータを学習する処理部である。たとえば、学習部151は、訓練データセット141aの訓練データを、機械学習モデル50の入力層に入力した場合、出力層の各ノードの出力結果が、入力した訓練データの正解ラベルに近づくように、機械学習モデル50のパラメータを更新する(誤差逆伝播法による学習)。学習部151は、訓練データセット141aに含まれる各訓練データについて、上記処理を繰り返し実行する。また、学習部151は、検証データ141bを用いて、機械学習モデル50の検証を行ってもよい。学習部151は、学習済みの機械学習モデル50のデータ(機械学習モデルデータ142)を、記憶部140に登録する。機械学習モデル50は、「運用モデル」の一例である。
図15は、本実施例1に係る特徴空間の決定境界を説明するための図である。特徴空間30は、訓練データセット141aの各訓練データを可視化したものある。特徴空間30の横軸は、第1特徴量の軸に対応し、縦軸は、第2特徴量の軸に対応する。ここでは説明の便宜上、2軸で各訓練データを示すが、訓練データは、多次元のデータであるものとする。たとえば、丸印の訓練データに対応する正解ラベルを「第1クラス」とし、三角印の訓練データに対応する正解ラベルを「第2クラス」とする。
たとえば、訓練データセット141aによって、機械学習モデル50を学習すると、特徴空間30は、決定境界31によって、モデル適用領域31Aと、モデル適用領域31Bとに分類される。たとえば、機械学習モデル50が、NNである場合、機械学習モデル50にデータを入力すると、第1クラスの確率と、第2クラスの確率とが出力される。第1クラスの確率が、第2クラスよりも大きい場合には、データは、第1クラスに分類される。第2クラスの確率が、第1クラスよりも大きい場合には、データは、第2クラスに分類される。
作成部152は、機械学習モデル50の知識蒸留を基にして、モデル適用領域31Aとモデル適用領域31Bとの決定境界31を学習した、インスペクターモデルを作成する処理部である。このインスペクターモデルにデータ(訓練データまたは運用データ)を入力すると、決定境界31とデータとの距離(符号付きの距離の値)が出力される。
作成部152は、蒸留データテーブル143を生成する処理、インスペクターモデルデータ144を作成する処理を実行する。
作成部152が、蒸留データテーブル143を生成する処理について説明する。図16は、作成部の処理を説明するための図(1)である。作成部152は、機械学習モデルデータ142を用いて、機械学習モデル50を実行し、特徴空間30上の各データを、機械学習モデル50に入力する。これにより、特徴空間30の各データが、第1クラスに分類されるか、第2クラスに分類するのかを特定する。かかる処理を実行することで、作成部152は、特徴空間をモデル適用領域31Aと、モデル適用領域31Bとに分類し、決定境界31を特定する。
作成部152は、特徴空間30上において、所定間隔毎に複数の縦線と横線とを配置する。所定間隔毎に複数の縦線と横線とを配置したものを「グリッド」と表記する。グリッドの幅は、予め設定されているものとする。作成部152は、グリッドの交点座標のデータを選択し、選択したデータを、機械学習モデル50に出力することで、選択したデータに対応するソフトターゲットを算出する。作成部152は、選択したデータ(入力データ)と、ソフトターゲットとを対応付けて、蒸留データテーブル143に登録する。作成部152は、グリッドの各交点座標のデータについても、上記処理を繰り返し実行することで、蒸留データテーブル143を生成する。
続いて、作成部152が、インスペクターモデルデータ144を作成する処理について説明する。図17は、作成部の処理を説明するための図(2)である。作成部152は、蒸留データテーブル143に登録された入力データと、ソフトターゲットとの関係を基にして、kSVMによって構築されたインスペクターモデル35を作成する。作成部152は、作成したインスペクターモデル35のデータ(インスペクターモデルデータ144)を、記憶部140に登録する。
たとえば、作成部152は、蒸留データテーブル143に格納された各入力データを、再生核ヒルベルト空間に射影する。作成部152は、再生核ヒルベルト空間に含まれる第1クラスの入力データのうち、決定境界31に最も近い入力データを、第1サポートベクトルとして選択する。作成部152は、再生核ヒルベルト空間に含まれる第2クラスの入力データのうち、決定境界31に最も近い入力データを、第2サポートベクトルとして選択する。作成部152は、第1サポートベクトルと、第2サポートベクトルとの中間を通る決定境界31を特定することで、インスペクターモデル(kSVM)のハイパーパラメータを特定する。再生核ヒルベルト空間において、決定境界31は直線となり、決定境界31からの距離がmとなる領域を、危険領域32に設定する。距離mは、決定境界31と、第1サポートベクトル(第2サポートベクトル)との距離である。
図10の説明に戻る。検出部153は、インスペクターモデル35を実行して、機械学習モデル50の精度劣化を検出する処理部である。検出部153は、訓練データセット141aの各訓練データを、インスペクターモデル35に入力する。検出部153が、訓練データをインスペクターモデル35に入力すると、特徴空間上の決定境界31と訓練データとの距離(ノルム)が出力される。
検出部153は、決定境界31と訓練データとの距離がm未満である場合、かかる訓練データが危険領域32に含まれると判定する。検出部153は、訓練データセット141aに含まれる各訓練データについて、上記処理を繰り返し実行する。検出部153は、全訓練データのうち、危険領域32に含まれる訓練データの割合を「第一割合」として算出する。
検出部153は、運用データテーブル145に格納された運用データセットを選択し、運用データセットの各運用データを、インスペクターモデル35に入力する。検出部153が、運用データをインスペクターモデル35に入力すると、特徴空間上の決定境界31と運用データとの距離(ノルム)が出力される。
検出部153は、決定境界31と運用データとの距離がm未満である場合、かかる運用データが危険領域32に含まれると判定する。検出部153は、運用データセットに含まれる各運用データについて、上記処理を繰り返し実行する。検出部153は、全運用データのうち、危険領域32に含まれる運用データの割合を「第二割合」として算出する。
検出部153は、第一割合と、第二割合とを比較し、第一割合に対して第二割合が変化した場合に、コンセプトドリフトが発生したと判定し、機械学習モデル50の精度劣化を検出する。たとえば、検出部153は、第一割合と第二割合との絶対値の差分が、閾値以上となる場合に、コンセプトドリフトが発生したと判定する。
図18および図19は、本実施例1に係る検出部の処理を説明するための図である。図18は、第一割合の一例を示す。たとえば、検出部153は、訓練データセット141aの各訓練データをインスペクターモデル35に入力すると、第一割合は「0.02」となる場合を示している。
図19は、第二割合の一例を示す。たとえば、運用データセットC0の各運用データをインスペクターモデル35に入力すると、第二割合は「0.02」となる。第一割合と、運用データセットC0の第二割合とは同じであるため、運用データセットC0において、コンセプトドリフトは発生していない。このため、検出部153は、運用データセットC0について、機械学習モデル50の精度劣化を検出しない。
たとえば、運用データセットC1の各運用データをインスペクターモデル35に入力すると、第二割合は「0.09」となる。第一割合と比較して、運用データセットC1の第二割合が増加しており、運用データセットC1において、コンセプトドリフトは発生している。このため、検出部153は、運用データセットC1について、機械学習モデル50の精度劣化を検出する。
たとえば、運用データセットC2の各運用データをインスペクターモデル35に入力すると、第二割合は「0.05」となる。第一割合と比較して、運用データセットC2の第二割合が増加しており、運用データセットC2において、コンセプトドリフトは発生している。このため、検出部153は、運用データセットC2について、機械学習モデル50の精度劣化を検出する。
たとえば、運用データセットC3の各運用データをインスペクターモデル35に入力すると、第二割合は「0.0025」となる。第一割合と比較して、運用データセットC3の第二割合が減少しており、運用データセットC3において、コンセプトドリフトは発生している。このため、検出部153は、運用データセットC3について、機械学習モデル50の精度劣化を検出する。
検出部153は、機械学習モデル50の精度劣化を検出した場合には、精度劣化を検出した旨の情報を、表示部130に表示してもよいし、外部装置(図示略)に、精度劣化を検出した旨を通知してもよい。検出部153は、精度劣化を検出した根拠となる運用データセットのデータ識別情報を、表示部130に出力して表示させてもよい。また、検出部153は、精度劣化を検出した旨を学習部151に通知して、機械学習モデルデータ142を再学習させてもよい。この場合、学習部151は、新たに指定される訓練データセットを用いて、機械学習モデル50を再学習する。
検出部153は、機械学習モデル50の精度劣化を検出しない場合には、精度劣化を検出していない旨の情報を予測部154に出力する。
予測部154は、機械学習モデル50の精度劣化が検出されていない場合、機械学習モデル50を実行して、運用データセットを入力し、各運用データの分類クラスを予測する処理部である。予測部154は、予測結果を、表示部130に出力して表示させてもよいし、外部装置に送信してもよい。
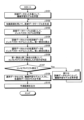
次に、本実施例1に係る情報処理装置100の処理手順の一例について説明する。図20は、本実施例1に係る情報処理装置の処理手順を示すフローチャートである。図20に示すように、情報処理装置100の学習部151は、訓練データセット141aを基にして、機械学習モデル50を学習する(ステップS101)。
情報処理装置100の作成部152は、知識蒸留を用いて、蒸留データテーブル143を生成する(ステップS102)。作成部152は、蒸留データテーブル143を基にして、インスペクターモデルを生成する(ステップS103)。
情報処理装置100の検出部153は、訓練データセット141aの各訓練データをインスペクターモデルに入力し、第一割合を算出する(ステップS104)。情報処理装置100は、運用データセットの各運用データをインスペクターモデルに入力し、第二割合を算出する(ステップS105)。
情報処理装置100の検出部153は、第一割合と第二割合とを基にして、コンセプトドリフトが発生したか否かを判定する(ステップS106)。情報処理装置100は、コンセプトドリフトが発生した場合には(ステップS107,Yes)、ステップS108に移行する。一方、情報処理装置100は、コンセプトドリフトが発生していない場合には(ステップS107,No)、ステップS109に移行する。
ステップS108以降の処理について説明する。学習部151は、新たな訓練データセットによって、機械学習モデル50を再学習し(ステップS108)、ステップS102に移行する。
ステップS109以降の処理について説明する。情報処理装置100の予測部154は、運用データセットを、機械学習モデルに入力し、各運用データの分類クラスを予測する(ステップS109)。予測部154は、予測結果を出力する(ステップS110)。
次に、本実施例1に係る情報処理装置100の効果について説明する。情報処理装置100は、訓練データセット141aを基にして、機械学習モデル50を生成し、知識蒸留を用いて、インスペクターモデルを作成する。情報処理装置100は、インスペクターモデルに訓練データセットを入力した場合の第一割合と、運用データセットを入力した場合の第二割合とを算出し、第一割合と第二割合とを基にして、機械学習モデル50の精度劣化を検出する。これによって、機械学習モデルの精度劣化を検出することができる。
情報処理装置100は、第一割合と第二割合とを比較して、第二割合が増加または減少した場合、機械学習モデルの精度劣化を検知する。第一割合を基準として、第二割合が変化したということは、運用開始時と比較して、多くの運用データが、危険領域に含まれており、コンセプトドリフトが発生していることを示す。情報処理装置100は、時間経過に伴って、運用データセットを取得し、上記処理を繰り返し実行する。これによって、どのような分類アルゴリズムであっても、汎用的に使用可能なインスペクターモデルを作成し、機械学習モデルの精度劣化を検知することができる。
たとえば、本実施例1に係る情報処理装置100は、機械学習モデル50を用いた知識蒸留によって、インスペクターモデル(カーネルSVM)を構築するため、図7~図9で説明したように、どのような分類アルゴリズムであっても、汎用的に使用可能なインスペクターモデルを作成できる。
本実施例2に係る情報処理装置は、3種類以上の分類クラスについて、分類クラス毎に1対他の蒸留を行うことによって、監視対象となる機械学習モデルの精度劣化を検知する。また、情報処理装置は、精度劣化を検知した場合に、どの分類クラスに影響が出ているのかを特定する。
図21は、本実施例2に係る情報処理装置の処理を説明するための図である。本実施例2では、第1クラスに対応する第1訓練データセット40Aと、第2クラスに対応する第2訓練データセット40Bと、第3クラスに対応する第3訓練データセット40Cとを用いて説明する。
ここでは、第1訓練データセット40Aに含まれる複数の第1訓練データをバツ印で示す。第2訓練データセット40Bに含まれる複数の第2訓練データを三角印で示す。第3訓練データセット40Cに含まれる複数の第3訓練データを丸印で示す。
情報処理装置は、知識蒸留を用いて、「第1訓練データセット40A」と、「第2訓練データセット40Bおよび第2訓練データセット40B」との決定境界41Aを学習したインスペクターモデルM1を作成する。インスペクターモデルM1では、決定境界41A周辺の危険領域42Aを設定する。
情報処理装置は、知識蒸留を用いて、「第2訓練データセット40B」と、「第1訓練データセット40Aおよび第3訓練データセット40C」との決定境界41Bを学習したインスペクターモデルM2を作成する。インスペクターモデルM1では、決定境界41B周辺の危険領域42Bを設定する。
情報処理装置は、知識蒸留を用いて、「第3訓練データセット40C」と、「第1訓練データセット40Aおよび第2訓練データセット40B」との決定境界41Cを学習したインスペクターモデルM3を作成する。インスペクターモデルM3では、決定境界41C周辺の危険領域42Cを設定する。
情報処理装置は、インスペクターモデルM1,M2,M3それぞれについて、第一割合および第二割合をそれぞれ算出する。以下の説明において、インスペクターモデルM1を用いて算出した第一割合を「割合M1-1」と表記し、インスペクターモデルM1を用いて算出した第二割合を「割合M1-2」と表記する。インスペクターモデルM2を用いて算出した第一割合を「割合M2-1」と表記し、インスペクターモデルM2を用いて算出した第二割合を「割合M2-2」と表記する。インスペクターモデルM3を用いて算出した第一割合を「割合M3-1」と表記し、インスペクターモデルM3を用いて算出した第二割合を「割合M3-2」と表記する。
たとえば、割合M1-1は、第1、2、3訓練データセットをインスペクターモデルM1に入力した場合に、全訓練データのうち、危険領域42Aに含まれる訓練データの割合を示す。割合M1-2は、運用データセットをインスペクターモデルM1に入力した場合に、全運用データのうち、危険領域42Aに含まれる運用データの割合を示す。
割合M2-1は、第1、2、3訓練データセットをインスペクターモデルM2に入力した場合に、全訓練データのうち、危険領域42Bに含まれる訓練データの割合を示す。割合M2-2は、運用データセットをインスペクターモデルM2に入力した場合に、全運用データのうち、危険領域42Bに含まれる運用データの割合を示す。
割合M3-1は、第1、2、3訓練データセットをインスペクターモデルM3に入力した場合に、全訓練データのうち、危険領域42Cに含まれる訓練データの割合を示す。割合M3-2は、運用データセットをインスペクターモデルM3に入力した場合に、全運用データのうち、危険領域42Cに含まれる運用データの割合を示す。
情報処理装置は、第一割合と第二割合との差分(差分の絶対値)が閾値以上となった場合に、監視対象の機械学習モデルの精度劣化を検出する。また、情報処理装置は、差分が最も大きい第一割合と第二割合との組を基にして、精度劣化の要因となる分類クラスを特定する。閾値は、予め設定されているものとする。図21の説明では、閾値を「0.1」とする。
具体的には、情報処理装置は、割合M1-1と割合M1-2との差分の絶対が閾値以上となった場合には、第1クラスが精度劣化の要因と判定する。割合M2-1と割合M2-2との差分の絶対が閾値以上となった場合には、第2クラスが精度劣化の要因と判定する。情報処理装置は、割合M3-1と割合M3-2との差分の絶対が閾値以上となった場合には、第3クラスが精度劣化の要因と判定する。
たとえば、割合M1-1=0.09とし、割合M1-2=0.32とすると、割合M1-1と割合M1-2との差分の絶対値が「0.23」となり、閾値以上となる。割合M2-1=0.05とし、割合M2-2=0.051とすると、割合M2-1と割合M2-2との差分の絶対値が「0.01」となり閾値未満となる。割合M3-1=0.006とし、割合M3-2=0.004とすると、割合M3-1と割合M3-2との差分の絶対値が「0.002」となり、閾値未満となる。この場合には、情報処理装置は、運用データセットのコンセプトドリフトを検知し、精度劣化の要因を、第1クラスとして判定する。
このように、本実施例2に係る情報処理装置は、3種類以上の分類クラスについて、分類クラス毎に1対他の蒸留を行うことによって、監視対象となる機械学習モデルの精度劣化を検知する。また、情報処理装置は、精度劣化を検知した場合に、インスペクターモデルM1~M3の第一割合と第二割合とを比較することで、どの分類クラスに影響が出ているのかを特定することができる。
次に、本実施例2に係る情報処理装置の構成について説明する。図22は、本実施例2に係る情報処理装置の構成を示す機能ブロック図である。図22に示すように、情報処理装置200は、通信部210と、入力部220と、表示部230と、記憶部240と、制御部250とを有する。
通信部210は、ネットワークを介して、外部装置(図示略)とデータ通信を実行する処理部である。通信部210は、通信装置の一例である。後述する制御部250は、通信部110を介して、外部装置とデータをやり取りする。
入力部220は、情報処理装置200に対して各種の情報を入力するための入力装置である。入力部220は、キーボードやマウス、タッチパネル等に対応する。
表示部230は、制御部250から出力される情報を表示する表示装置である。表示部230は、液晶ディスプレイ、有機ELディスプレイ、タッチパネル等に対応する。
記憶部240は、教師データ241、機械学習モデルデータ242、蒸留データテーブル243、インスペクターモデルテーブル244、運用データテーブル245を有する。記憶部140は、RAM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
教師データ241は、訓練データセット241aと、検証データ241bを有する。訓練データセット241aは、訓練データに関する各種の情報を保持する。
図23は、本実施例2に係る訓練データセットのデータ構造の一例を示す図である。図23に示すように、この訓練データセットは、レコード番号と、訓練データと、正解ラベルとを対応付ける。レコード番号は、訓練データと、正解ラベルとの組を識別する番号である。訓練データは、メールスパムのデータ、電気需要予測、株価予測、ポーカーハンドのデータ、画像データ等に対応する。正解ラベルは、第1クラスまたは第2クラスを一意に識別する情報である。本実施例2では、正解ラベルとして、第1クラス、第2クラス、第3クラスのいずれか一つが、訓練データに対応付けられる。
検証データ241bは、訓練データセット241aによって学習された機械学習モデルを検証するためのデータである。検証データ241bに関するその他の説明は、実施例1で説明した検証データ141bと同様である。
機械学習モデルデータ242は、機械学習モデルのデータである。本実施例2に機械学習モデルは、所定の分類アルゴリズムによって、入力データを、第1クラス、第2クラスまたは第3クラスに分類する機械学習モデルである。分類アルゴリズムは、NN、ランダムフォレスト、k近傍法、サポートベクターマシン等のうち、いずれの分類アルゴリズムであってもよい。
本実施例2では、機械学習モデルを、NNとして説明を行う。図24は、本実施例2に係る機械学習モデルの一例を説明するための図である。図24に示すように、機械学習モデル55は、ニューラルネットワークの構造を有し、入力層50a、隠れ層50b、出力層50cを持つ。入力層50a、隠れ層50b、出力層50cは、複数のノードがエッジで結ばれる構造となっている。隠れ層50b、出力層50cは、活性化関数と呼ばれる関数とバイアス値とを持ち、エッジは、重みを持つ。以下の説明では、バイアス値、重みを「パラメータ」と表記する。
機械学習モデル55において、入力層50a、隠れ層50bは、図12で説明した機械学習モデル50と同様である。機械学習モデル55は、出力層50cのノード51a,51b,51cから、各クラスの確率が出力される。たとえば、ノード51aから、第1クラスの確率が出力される。ノード51bから、第2クラスの確率が出力される。ノード51cから、第3クラスの確率が出力される。
蒸留データテーブル243は、データセットの各データを、機械学習モデル55に入力した場合の出力結果を格納するテーブルである。蒸留データテーブルのデータ構造は、実施例1で説明した蒸留データテーブル143のデータ構造と同様である。なお、蒸留データテーブル243に含まれるソフトターゲットは、第1クラス、第2クラス、第3クラスのうち、いずれかの分類クラスを示すものとする。
インスペクターモデルテーブル244は、kSVMによって構築されたインスペクターモデルM1,M2,M3のデータを格納するテーブルである。各インスペクターモデルM1,M2,M3に、データを入力すると、符号付きの距離の値が出力される。
インスペクターモデルM1にデータを入力し、符号がプラスであれば、入力したデータは第1クラスに分類される。符号がマイナスであれば、データは、第2クラスまたは第3クラスに分類される。
インスペクターモデルM2にデータを入力し、符号がプラスであれば、入力したデータは第2クラスに分類される。符号がマイナスであれば、データは、第1クラスまたは第3クラスに分類される。
インスペクターモデルM3にデータを入力し、符号がプラスであれば、入力したデータは第3クラスに分類される。符号がマイナスであれば、データは、第1クラスまたは第2クラスに分類される。
運用データテーブル245は、時間経過に伴って、追加される運用データセットを有する。運用データテーブル245のデータ構造は、実施例1で説明した運用データテーブル145のデータ構造と同様である。
図22の説明に戻る。制御部250は、学習部251と、作成部252と、検出部253と、予測部254とを有する。制御部250は、CPUやMPUなどによって実現できる。また、制御部250は、ASICやFPGAなどのハードワイヤードロジックによっても実現できる。
学習部251は、訓練データセット241aを取得し、訓練データセット241aを基にして、機械学習モデル55のパラメータを学習する処理部である。たとえば、学習部251は、訓練データセット241aの訓練データを、機械学習モデル55の入力層に入力した場合、出力層の各ノードの出力結果が、入力した訓練データの正解ラベルに近づくように、機械学習モデル55のパラメータを更新する(誤差逆伝播法による学習)。学習部251は、訓練データセット241aに含まれる各訓練データについて、上記処理を繰り返し実行する。また、学習部251は、検証データ241bを用いて、機械学習モデル55の検証を行ってもよい。学習部251は、学習済みの機械学習モデル55のデータ(機械学習モデルデータ242)を、記憶部240に登録する。機械学習モデル55は、「運用モデル」の一例である。
図25は、本実施例2に係る特徴空間の決定境界を説明するための図である。特徴空間30は、訓練データセット241aの各訓練データを可視化したものある。特徴空間30の横軸は、第1特徴量の軸に対応し、縦軸は、第2特徴量の軸に対応する。ここでは説明の便宜上、2軸で各訓練データを示すが、訓練データは、多次元のデータであるものとする。たとえば、×印の訓練データに対応する正解ラベルを「第1クラス」とし、三角印の訓練データに対応する正解ラベルを「第2クラス」とし、丸印の訓練データに対応する正解ラベルを「第3クラス」とする。
たとえば、訓練データセット241aによって、機械学習モデル55を学習すると、特徴空間30は、決定境界36によって、モデル適用領域36Aと、モデル適用領域36Bと、モデル適用領域36Cとに分類される。たとえば、機械学習モデル55が、NNである場合、機械学習モデル55にデータを入力すると、第1クラスの確率と、第2クラスの確率と、第3クラスの確率がそれぞれ出力される。第1クラスの確率が、他のクラスよりも大きい場合には、データは、第1クラスに分類される。第2クラスの確率が、他のクラスよりも大きい場合には、データは、第2クラスに分類される。第3クラスの確率が、他のクラスよりも大きい場合には、データは、第3クラスに分類される。
作成部252は、機械学習モデル55の知識蒸留を基にして、インスペクターモデルM1,M2,M3を作成する処理部である。たとえば、作成部252は、「モデル適用領域36A」と「モデル適用領域36B,36C」との決定境界(図21の決定境界41Aに相当)を学習した、インスペクターモデルM1を作成する。このインスペクターモデルM1にデータ(訓練データまたは運用データ)を入力すると、決定境界41Aとデータとの距離(符号付きの距離の値)が出力される。
作成部252は、「モデル適用領域36B」と「モデル適用領域36A,36C」との決定境界(図21の決定境界41Bに相当)を学習した、インスペクターモデルM2を作成する。このインスペクターモデルM2にデータ(訓練データまたは運用データ)を入力すると、決定境界41Bとデータとの距離(符号付きの距離の値)が出力される。
作成部252は、「モデル適用領域36C」と「モデル適用領域36A,36B」との決定境界(図21の決定境界41Cに相当)を学習した、インスペクターモデルM3を作成する。このインスペクターモデルM3にデータ(訓練データまたは運用データ)を入力すると、決定境界41Cとデータとの距離(符号付きの距離の値)が出力される。
図26は、インスペクターモデルの決定境界および危険領域の一例を示す図である。図26では、一例として、インスペクターモデルM2の決定境界および危険領域42Bを示す。インスペクターモデルM1,M3に係る決定境界および危険領域の図示を省略する。
作成部252は、蒸留データテーブル243を生成する処理、インスペクターモデルテーブル244を作成する処理を実行する。
まず、作成部252が、蒸留データテーブル243を生成する処理について説明する。作成部252は、機械学習モデルデータ242を用いて、機械学習モデル55を実行し、特徴空間上の各データを、機械学習モデル55に入力する。これにより、特徴空間の各データが、第1クラス、第2クラス、第3クラスのうち、いずれの分類クラスに分類されるのかを特定する。かかる処理を実行することで、作成部252は、特徴空間をモデル適用領域36Aと、モデル適用領域36B,モデル適用領域36Cとに分類し、決定境界36を特定する。
作成部252は、特徴空間30上において「グリッド」を配置する。グリッドの幅は、予め設定されているものとする。作成部252は、グリッドの交点座標のデータを選択し、選択したデータを、機械学習モデル55に出力することで、選択したデータに対応するソフトターゲットを算出する。作成部252は、選択したデータ(入力データ)と、ソフトターゲットとを対応付けて、蒸留データテーブル243に登録する。作成部252は、グリッドの各交点座標のデータについても、上記処理を繰り返し実行することで、蒸留データテーブル243を生成する。
続いて、作成部252が、インスペクターモデルテーブル244を作成する処理について説明する。作成部252は、蒸留データテーブル243に登録された入力データと、ソフトターゲットとの関係を基にして、kSVMによって構築されたインスペクターモデルM1~M3を作成する。作成部252は、作成したインスペクターモデルM1~M3のデータを、インスペクターモデルテーブル244に登録する。
作成部252が、「インスペクターモデルM1」を作成する処理の一例について説明する。作成部252は、蒸留データテーブル243に格納された各入力データを、再生核ヒルベルト空間に射影する。作成部252は、再生核ヒルベルト空間に含まれる第1クラスの入力データのうち、決定境界41Aに最も近い入力データを、第1サポートベクトルとして選択する。作成部152は、再生核ヒルベルト空間に含まれる第2クラスまたは第3クラスの入力データのうち、決定境界41Aに最も近い入力データを、第2サポートベクトルとして選択する。作成部252は、第1サポートベクトルと、第2サポートベクトルとの中間を通る決定境界41Aを特定することで、インスペクターモデルM1のハイパーパラメータを特定する。再生核ヒルベルト空間において、決定境界41Aは直線となり、決定境界41Aからの距離がmM1となる領域を、危険領域42Aに設定する。距離mM1は、決定境界41Aと、第1サポートベクトル(第2サポートベクトル)との距離である。
作成部252が、「インスペクターモデルM2」を作成する処理の一例について説明する。作成部252は、蒸留データテーブル243に格納された各入力データを、再生核ヒルベルト空間に射影する。作成部252は、再生核ヒルベルト空間に含まれる第2クラスの入力データのうち、決定境界41Bに最も近い入力データを、第3サポートベクトルとして選択する。作成部252は、再生核ヒルベルト空間に含まれる第1クラスまたは第3クラスの入力データのうち、決定境界41Bに最も近い入力データを、第4サポートベクトルとして選択する。作成部252は、第3サポートベクトルと、第4サポートベクトルとの中間を通る決定境界41Bを特定することで、インスペクターモデルM2のハイパーパラメータを特定する。再生核ヒルベルト空間において、決定境界41Bは直線となり、決定境界41Bからの距離がmM2となる領域を、危険領域42Bに設定する。距離mM2は、決定境界41Bと、第3サポートベクトル(第4サポートベクトル)との距離である。
作成部252が、「インスペクターモデルM3」を作成する処理の一例について説明する。作成部252は、蒸留データテーブル243に格納された各入力データを、再生核ヒルベルト空間に射影する。作成部252は、再生核ヒルベルト空間に含まれる第3クラスの入力データのうち、決定境界41Cに最も近い入力データを、第5サポートベクトルとして選択する。作成部252は、再生核ヒルベルト空間に含まれる第1クラスまたは第2クラスの入力データのうち、決定境界41Cに最も近い入力データを、第6サポートベクトルとして選択する。作成部252は、第5サポートベクトルと、第6サポートベクトルとの中間を通る決定境界41Cを特定することで、インスペクターモデルM3のハイパーパラメータを特定する。再生核ヒルベルト空間において、決定境界41Cは直線となり、決定境界41Cからの距離がmM3となる領域を、危険領域42Cに設定する。距離mM3は、決定境界41Cと、第5サポートベクトル(第6サポートベクトル)との距離である。
検出部253は、インスペクターモデルM1~M3を実行して、機械学習モデル55の精度劣化を検出する処理部である。また、検出部253は、機械学習モデル55の精度劣化を検出した場合、精度劣化の要因となる分類クラスを特定する。
検出部253は、インスペクターモデルM1~M3に訓練データセット241aをそれぞれ入力することで、各第一割合(割合M1-1、割合M2-1、割合M3-1)を算出する。
検出部253は、訓練データを、インスペクターモデルM1に入力すると、特徴空間上の決定境界41Aと訓練データとの距離が出力される。検出部253は、決定境界41Aと訓練データとの距離が距離mM1未満である場合、かかる訓練データが危険領域42Aに含まれると判定する。検出部253は、各訓練データに対して、上記処理を繰り返し実行し、全訓練データのうち、危険領域42Aに含まれる訓練データの数を特定し、割合M1-1を算出する。
検出部253は、訓練データを、インスペクターモデルM2に入力すると、特徴空間上の決定境界41Bと訓練データとの距離が出力される。検出部253は、決定境界41Bと訓練データとの距離が距離mM2未満である場合、かかる訓練データが危険領域42Bに含まれると判定する。検出部253は、各訓練データに対して、上記処理を繰り返し実行し、全訓練データのうち、危険領域42Bに含まれる訓練データの数を特定し、割合M2-1を算出する。
検出部253は、訓練データを、インスペクターモデルM3に入力すると、特徴空間上の決定境界41Cと訓練データとの距離が出力される。検出部253は、決定境界41Cと訓練データとの距離が距離mM3未満である場合、かかる訓練データが危険領域42Cに含まれると判定する。検出部253は、各訓練データに対して、上記処理を繰り返し実行し、全訓練データのうち、危険領域42Cに含まれる訓練データの数を特定し、割合M3-1を算出する。
検出部253は、インスペクターモデルM1~M3に運用データセットをそれぞれ入力することで、各第二割合(割合M1-2、割合M2-2、割合M3-2)を算出する。
検出部253は、運用データを、インスペクターモデルM1に入力すると、特徴空間上の決定境界41Aと運用データとの距離が出力される。検出部253は、決定境界41Aと訓練データとの距離が距離mM1未満である場合、かかる運用データが危険領域42Aに含まれると判定する。検出部253は、各運用データに対して、上記処理を繰り返し実行し、全運用データのうち、危険領域42Aに含まれる運用データの数を特定し、割合M1-2を算出する。
検出部253は、運用データを、インスペクターモデルM2に入力すると、特徴空間上の決定境界41Bと運用データとの距離が出力される。検出部253は、決定境界41Bと運用データとの距離が距離mM2未満である場合、かかる運用データが危険領域42Bに含まれると判定する。検出部253は、各運用データに対して、上記処理を繰り返し実行し、全運用データのうち、危険領域42Bに含まれる運用データの数を特定し、割合M2-1を算出する。
検出部253は、運用データを、インスペクターモデルM3に入力すると、特徴空間上の決定境界41Cと運用データとの距離が出力される。検出部253は、決定境界41Cと運用データとの距離が距離mM3未満である場合、かかる運用データが危険領域42Cに含まれると判定する。検出部253は、各運用データに対して、上記処理を繰り返し実行し、全運用データのうち、危険領域42Cに含まれる運用データの数を特定し、割合M3-1を算出する。
検出部253は、対応する第一割合と第二割合とを比較して、第一割合に対して第二割合が変化した場合に、コンセプトドリフトが発生したと判定し、機械学習モデル55の精度劣化を検出する。たとえば、検出部253は、第一割合と第二割合との差分の絶対値が閾値以上である場合に、コンセプトドリフトが発生したと判定する。
ここで、対応する第一割合と第二割合との組を、割合M1-1と割合M1-2との組、割合M2-1と割合M2-2との組、割合M3-1と割合M3-2との組とする。
また、検出部253は、割合M1-1と割合M1-2との差分の絶対値が閾値以上となる場合に、精度劣化の要因となるクラスを「第1クラス」と判定する。検出部253は、割合M2-1と割合M2-2との差分の絶対値が閾値以上となる場合に、精度劣化の要因となるクラスを「第2クラス」と判定する。検出部253は、割合M3-1と割合M3-2との差分の絶対値が閾値以上となる場合に、精度劣化の要因となるクラスを「第3クラス」と判定する。
検出部253は、上記処理によって、機械学習モデル55の精度劣化を検出した場合、精度劣化を検知した旨と、精度劣化の要因となる分類クラスの情報を、表示部230に出力して表示する。また、検出部253は、精度劣化を検知した旨と、精度劣化の要因となる分類クラスの情報を、外部装置に送信してもよい。
検出部253は、機械学習モデル55の精度劣化を検出しない場合には、精度劣化を検出していない旨の情報を予測部254に出力する。
予測部254は、機械学習モデル55の精度劣化が検出されていない場合、機械学習モデル55を実行して、運用データセットを入力し、各運用データの分類クラスを予測する処理部である。予測部254は、予測結果を、表示部230に出力して表示させてもよいし、外部装置に送信してもよい。
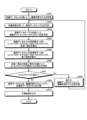
次に、本実施例2に係る情報処理装置200の処理手順の一例について説明する。図27は、本実施例2に係る情報処理装置の処理手順を示すフローチャートである。図27に示すように、情報処理装置200の学習部251は、訓練データセット241aを基にして、機械学習モデル55を学習する(ステップS201)。
情報処理装置200の作成部252は、知識蒸留を用いて、蒸留データテーブル243を生成する(ステップS202)。情報処理装置200の作成部252は、蒸留データテーブル243を基にして、複数のインスペクターモデルM1~M3を作成する(ステップS203)。
情報処理装置200の検出部253は、訓練データセットの各訓練データをインスペクターモデルM1~M3にそれぞれ入力し、各第一割合(割合M1-1、割合M2-1、割合M3-1)を算出する(ステップS204)。
検出部253は、運用データセットの各運用データをインスペクターモデルM1~M3にそれぞれ入力し、各第二割合(割合M1-2、割合M2-2、割合M3-2)を算出する(ステップS205)。
検出部253は、各第一割合と各第二割合とを基にして、コンセプトドリフトが発生したか否かを判定する(ステップS206)。情報処理装置200は、コンセプトドリフトが発生した場合には(ステップS207,Yes)、ステップS208に移行する。一方、情報処理装置200は、コンセプトドリフトが発生していない場合には(ステップS207,No)、ステップS209に移行する。
ステップS208以降の処理について説明する。学習部251は、新たな訓練データセットによって、機械学習モデル55を再学習し(ステップS208)、ステップS202に移行する。
ステップS209以降の処理について説明する。情報処理装置200の予測部254は、運用データセットを、機械学習モデル55に入力し、各運用データの分類クラスを予測する(ステップS209)。予測部254は、予測結果を出力する(ステップS210)。
次に、本実施例2に係る情報処理装置200の効果について説明する。情報処理装置200は、3種類以上の分類クラスについて、分類クラス毎に1対他の蒸留を行うことによって、監視対象となる機械学習モデルの精度劣化を検知する。また、情報処理装置200は、精度劣化を検知した場合に、どの分類クラスに影響が出ているのかを特定することができる。
たとえば、分類クラスが3つ以上の場合には、決定境界からの距離のみでは、どの方向に運用データがコンセプトドリフトしているかを特定することができない。これに対して、1対他のクラスの分類モデル(複数のインスペクターモデルM1~M3)を作成することで、どの方向にコンセプトドリフトしているのかを特定でき、どの分類クラスに影響が出ているのかを特定することができる。
本実施例3に係る情報処理装置は、運用データセットに含まれる一つの運用データ毎に、コンセプトドリフト(精度劣化の要因)が発生しているか否かを判定する。以下の説明では、データセットに含まれる一つのデータ(訓練データまたは運用データ)を、「インスタンス」と表記する。
図28は、本実施例3に係る情報処理装置の処理を説明するための図である。本実施例3に係る情報処理装置は、実施例1の情報処理装置100と同様にして、知識蒸留を用いて、インスペクターモデルを作成する。インスペクターモデルによって学習した決定境界を、決定境界60とする。情報処理装置は、特徴空間上のインスタンスと、決定境界60との距離を基にして、精度劣化の要因となるインスタンスとして検出する。
たとえば、図28において、運用データセット61に含まれるインスタンス毎に、確信度は異なる。たとえば、インスタンス61aと、決定境界60との距離はdaである。インスタンス61bと、決定境界60との距離はdbである。距離daは、距離dbよりも小さいため、インスタンス61aは、インスタンス61bよりも、精度劣化の要因となり得る。
ここで、決定境界とインスタンスとの距離はスカラー値であり、運用データセット毎に大きさが変化するため、どれくらいの決定境界からの距離が危ないのかを特定するための閾値を設定することが難しい。このため、情報処理装置は、決定境界からの距離を確率値へと変換し、変換した確率値を確信度として取り扱う。これによって、確信度は、運用データセットによらず、「0~1」の値をとる。
たとえば、情報処理装置は、式(2)に基づいて、確信度を算出する。式(2)に示す例では、あるインスタンスが第1クラスである確率を示すものである。インスタンスの特徴量を「x」とし、決定境界とインスタンスとの距離を「f(x)」とする。「A」および「B」は、訓練データセットから学習されるハイパーパラメータである。
P(y=1|x)=1/(1+exp(Af(x)+B))・・・(2)
情報処理装置は、式(2)に基づいて、運用データセットのインスタンスの確信度を算出し、確信度が予め設定された閾値未満である場合に、かかるインスタンスを、精度劣化の要因として特定する。これによって、運用データセットによらず、確信度を「0~1」の範囲で算出でき、精度劣化の要因となるインスタンスを適切に特定する。
ところで、本実施例3に係る情報処理装置は、更に、次の処理を実行して、監視対象となる機械学習モデルの精度劣化を検出してもよい。情報処理装置は、訓練データセットの各訓練データを、インスペクターモデルに入力して、各訓練データと決定境界60との距離をそれぞれ算出し、各距離の平均値を「第1の距離」として特定する。
情報処理装置は、運用データセットの各運用データを、インスペクターモデルに入力して、各運用データと決定境界60との距離をそれぞれ算出し、各距離の平均値を「第2の距離」として特定する。
情報処理装置は、第1の距離と、第2の距離との差分が予め設定された閾値以上の場合に、コンセプトドリフトが発生したものとして、機械学習モデルの精度劣化を検出する。
上記のように、本実施例3に係る情報処理装置は、決定境界60と、インスタンスとの距離を算出することで、精度劣化の要因となるインスタンスを特定することが可能になる。また、訓練データセットの各インスタンスに基づく第1の距離と、運用データセットの各インスタンスに基づく第2の距離とを利用することで、機械学習モデルの精度劣化を検出することもできる。
次に、本実施例3に係る情報処理装置の構成の一例について説明する。図29は、本実施例3に係る情報処理装置の構成を示す機能ブロック図である。図29に示すように、この情報処理装置300は、通信部310と、入力部320と、表示部330と、記憶部340と、制御部350とを有する。
通信部310は、ネットワークを介して、外部装置(図示略)とデータ通信を実行する処理部である。通信部310は、通信装置の一例である。後述する制御部350は、通信部310を介して、外部装置とデータをやり取りする。
入力部320は、情報処理装置300に対して各種の情報を入力するための入力装置である。入力部320は、キーボードやマウス、タッチパネル等に対応する。
表示部330は、制御部350から出力される情報を表示する表示装置である。表示部330は、液晶ディスプレイ、有機ELディスプレイ、タッチパネル等に対応する。
記憶部340は、教師データ341、機械学習モデルデータ342、蒸留データテーブル343、インスペクターモデルデータ344、運用データテーブル345を有する。記憶部340は、RAM、フラッシュメモリなどの半導体メモリ素子や、HDDなどの記憶装置に対応する。
教師データ341は、訓練データセット341aと、検証データ341bを有する。訓練データセット341aは、訓練データに関する各種の情報を保持する。訓練データセット341aのデータ構造に関する説明は、実施例1で説明した訓練データセット141aのデータ構造に関する説明と同様である。
検証データ341bは、訓練データセット341aによって学習された機械学習モデルを検証するためのデータである。
機械学習モデルデータ342は、機械学習モデルのデータである。機械学習モデルデータ342に関する説明は、実施例1で説明した機械学習モデルデータ142に関する説明と同様である。本実施例3では、監視対象の機械学習モデルを、機械学習モデル50として説明を行う。なお、機械学習モデルの分類アルゴリズムは、NN、ランダムフォレスト、k近傍法、サポートベクターマシン等のうち、いずれの分類アルゴリズムであってもよい。
蒸留データテーブル343は、データセットの各データを、機械学習モデル50に入力した場合の出力結果(ソフトターゲット)を格納するテーブルである。蒸留データテーブル343のデータ構造に関する説明は、実施例1で説明した蒸留データテーブル143のデータ構造に関する説明と同様である。
インスペクターモデルデータ344は、kSVMによって構築されたインスペクターモデルのデータである。インスペクターモデルデータ344に関する説明は、実施例1で説明したインスペクターモデルデータ144に関する説明と同様である。
運用データテーブル345は、時間経過に伴って、追加される運用データセットを有する。運用データテーブル345のデータ構造に関する説明は、実施例1で説明した運用データテーブル145に関する説明と同様である。
制御部350は、学習部351と、作成部352と、検出部353と、予測部354とを有する。制御部350は、CPUやMPUなどによって実現できる。また、制御部350は、ASICやFPGAなどのハードワイヤードロジックによっても実現できる。
学習部351は、訓練データセット341aを取得し、訓練データセット341aを基にして、機械学習モデル50のパラメータを学習する処理部である。学習部351の処理に関する説明は、実施例1で説明した学習部151の処理に関する説明と同様である。
作成部352は、機械学習モデル50の知識蒸留を基にして、モデル適用領域31Aとモデル適用領域31Bとの決定境界31を学習した、インスペクターモデルを作成する処理部である。作成部352が、インスペクターモデルを作成する処理は、実施例1で説明した作成部152が、インスペクターモデルを作成する処理と同様である。
なお、作成部352は、訓練データセット341aの各訓練データおよび正解ラベルを基にして、式(2)で説明したハイパーパラメータA,Bを学習する。たとえば、作成部352は、正解ラベル「第1クラス」に対応する訓練データの特徴量xを、式(2)に入力した場合の値が1に近づくように、ハイパーパラメータA、Bを調整する。作成部352は、正解ラベル「第2クラス」に対応する訓練データの特徴量xを、式(2)に入力した場合の値が0に近づくように、ハイパーパラメータA、Bを調整する。作成部352は、各訓練データを用いて、上記処理を繰り返し実行することで、ハイパーパラメータA,Bを学習する。作成部352は、学習したハイパーパラメータA,Bのデータを、検出部353に出力する。
検出部353は、機械学習モデル50の精度劣化の要因となるインスタンスを検出する処理部である。検出部353は、インスペクターモデル35を実行する。検出部353は、運用データセットに含まれるインスタンス(運用データ)を選択し、選択したインスタンスを、インスペクターモデル35に入力することで、決定境界31と、インスタンスとの距離を特定する。また、検出部353は、特定した距離f(x)を、式(2)に入力することで、選択したインスタンスの確信度を算出する。
検出部353は、確信度が閾値未満である場合に、選択したインスタンスを、精度劣化の要因となるインスタンスとして検出する。検出部353は、運用データセットに含まれる各運用データについて、上記処理を繰り返し実行することで、精度劣化の要因となる運用データを検出する。
検出部353は、精度劣化の要因となる各インスタンス(運用データ)のデータを、表示部330に出力して表示させてもよいし、外部装置に送信してもよい。
ところで、検出部353は、更に、次の処理を実行して、監視対象となる機械学習モデル50の精度劣化を検出してもよい。検出部353は、訓練データセット341aの各訓練データを、インスペクターモデル35に入力して、各訓練データと決定境界60との距離をそれぞれ算出し、各距離の平均値を「第1の距離」として特定する。
検出部353は、運用データテーブル345から運用データセットを選択する。検出部353は、運用データセットの各運用データを、インスペクターモデル35に入力して、各運用データと決定境界60との距離をそれぞれ算出し、各距離の平均値を「第2の距離」として特定する。
検出部353は、第1の距離と、第2の距離との差分が予め設定された閾値以上の場合に、コンセプトドリフトが発生したものとして、機械学習モデル50の精度劣化を検出する。検出部353は、時間経過に伴って追加され各運用データセットについて、上記処理を繰り返し実行し、機械学習モデル50の精度劣化を検出する。
検出部353は、機械学習モデル50の精度劣化を検出した場合には、精度劣化を検出した旨の情報を、表示部330に表示してもよいし、外部装置(図示略)に、精度劣化を検出した旨を通知してもよい。検出部353は、精度劣化を検出した根拠となる運用データセットのデータ識別情報を、表示部330に出力して表示させてもよい。また、検出部353は、精度劣化を検出した旨を学習部351に通知して、機械学習モデルデータ342を再学習させてもよい。
予測部354は、機械学習モデル50の精度劣化が検出されていない場合、機械学習モデル50を実行して、運用データセットを入力し、各運用データの分類クラスを予測する処理部である。予測部354は、予測結果を、表示部330に出力して表示させてもよいし、外部装置に送信してもよい。
次に、本実施例3に係る情報処理装置300の処理手順の一例について説明する。図30は、本実施例3に係る情報処理装置の処理手順を示すフローチャートである。図30に示すように、情報処理装置300の学習部351は、訓練データセット341aを基にして、機械学習モデル50を学習する(ステップS301)。
情報処理装置300の作成部352は、知識蒸留を用いて、蒸留データテーブル343を生成する(ステップS302)。作成部352は、蒸留データテーブル343を基にして、インスペクターモデルを作成する(ステップS303)。作成部352は、訓練データセット341aを用いて、式(2)のハイパーパラメータA,Bを学習する(ステップS304)。
情報処理装置300の検出部353は、運用データセットのインスタンスを選択する(ステップS305)。検出部353は、選択したインスタンスをインスペクターモデルに入力し、決定境界とインスタンスとの距離を算出する(ステップS306)。検出部353は、インスタンスの確信度を算出する(ステップS307)。
検出部353は、インスタンスの確信度が閾値未満でない場合には(ステップS308,No)、ステップS310に移行する。一方、検出部353は、インスタンスの確信度が閾値未満である場合には(ステップS308,Yes)、ステップS309に移行する。
検出部353は、選択したインスタンスを、精度劣化の要因として特定する(ステップS309)。情報処理装置300は、全てのインスタンスを選択していない場合には(ステップS310,No)、ステップS312に移行する。情報処理装置300は、全てのインスタンスを選択した場合には(ステップS310,Yes)、ステップS311に移行する。検出部353は、精度劣化の要因として特定したインスタンスを出力する(ステップS311)。
ステップS312以降の処理について説明する。検出部353は、運用データセットから次のインスタンスを選択し(ステップS312)、ステップS306に移行する。
次に、本実施例3に係る情報処理装置300の効果について説明する。情報処理装置300は、知識蒸留を用いてインスペクターモデルを学習し、特徴空間上のインスタンスと、決定境界60との距離を確信度に変換する。確信度に変換することにより、情報処理装置300は、運用データセットによらず、精度劣化の要因となるインスタンスを検出することができる。
情報処理装置300は、訓練データセットの各インスタンスに基づく第1の距離と、運用データセットの各インスタンスに基づく第2の距離とを利用することで、機械学習モデルの精度劣化を検出することもできる。
次に、本実施例に示した情報処理装置100(200,300)と同様の機能を実現するコンピュータのハードウェア構成の一例について説明する。図31は、本実施例に係る情報処理装置と同様の機能を実現するコンピュータのハードウェア構成の一例を示す図である。
図31に示すように、コンピュータ400は、各種演算処理を実行するCPU401と、ユーザからのデータの入力を受け付ける入力装置402と、ディスプレイ403とを有する。また、コンピュータ400は、記憶媒体からプログラム等を読み取る読み取り装置404と、有線または無線ネットワークを介して、外部装置等との間でデータの授受を行うインタフェース装置405とを有する。コンピュータ400は、各種情報を一時記憶するRAM406と、ハードディスク装置407とを有する。そして、各装置401~407は、バス408に接続される。
ハードディスク装置407は、学習プログラム407a、作成プログラム407b、検出プログラム407c、予測プログラム407dを有する。CPU401は、学習プログラム407a、作成プログラム407b、検出プログラム407c、予測プログラム407dを読み出してRAM406に展開する。
学習プログラム407aは、学習プロセス406aとして機能する。作成プログラム407bは、作成プロセス406bとして機能する。検出プログラム407cは、検出プロセス406cとして機能する。予測プログラム407dは、予測プロセス406dとして機能する。
学習プロセス406aの処理は、学習部151,251,351の処理に対応する。作成プロセス406bの処理は、作成部152,252,352の処理に対応する。検出プロセス406cの処理は、検出部153,253,353の処理に対応する。予測プロセス406dは、予測部154,254,354の処理に対応する。
なお、各プログラム407a~407dついては、必ずしも最初からハードディスク装置407に記憶させておかなくてもよい。例えば、コンピュータ400に挿入されるフレキシブルディスク(FD)、CD-ROM、DVDディスク、光磁気ディスク、ICカードなどの「可搬用の物理媒体」に各プログラムを記憶させておく。そして、コンピュータ400が各プログラム407a~407dを読み出して実行するようにしてもよい。