JP7291106B2 - Content delivery system, content delivery method, and content delivery program - Google Patents
Content delivery system, content delivery method, and content delivery program Download PDFInfo
- Publication number
- JP7291106B2 JP7291106B2 JP2020121962A JP2020121962A JP7291106B2 JP 7291106 B2 JP7291106 B2 JP 7291106B2 JP 2020121962 A JP2020121962 A JP 2020121962A JP 2020121962 A JP2020121962 A JP 2020121962A JP 7291106 B2 JP7291106 B2 JP 7291106B2
- Authority
- JP
- Japan
- Prior art keywords
- user
- specific
- action
- content
- avatar
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Landscapes
- Processing Or Creating Images (AREA)
- Information Transfer Between Computers (AREA)
- User Interface Of Digital Computer (AREA)
Description
本開示の一側面は、コンテンツ配信システム、コンテンツ配信方法、及びコンテンツ配信プログラムに関する。 One aspect of the present disclosure relates to a content distribution system, a content distribution method, and a content distribution program.
ユーザの要望に応じて、仮想空間(仮想現実空間)を他のユーザと共有するか否かを切り換える仕組みが知られている。例えば、特許文献1には、切替ボタンをクリックすることにより、仮想空間を他のユーザと共有する共有モードと、仮想空間を他のユーザと共有しない非共有モードと、を交互に切り換える情報処理装置が開示されている。
A mechanism is known for switching whether or not to share a virtual space (virtual reality space) with another user according to a user's request. For example,
上記特許文献1に開示された仕組みでは、仮想空間を他のユーザと共有するか否かは、ユーザによって選択されたモードに依存する。このため、例えば、仮想空間内におけるユーザのアバターの動作を他のユーザに対して隠すべき状況(例えば、当該アバターが仮想空間内で他のユーザに対して秘匿すべき暗証コード等を入力する状況等)であったとしても、当該ユーザによる選択が適切ではない場合(すなわち、共有モードに設定されている場合)、当該ユーザのアバターの動作が他のユーザに見られてしまうおそれがある。
In the mechanism disclosed in
そこで、本開示の一側面は、仮想空間内におけるユーザのアバターの動作を状況に応じて適切に他のユーザに対して隠すことができるコンテンツ配信システム、コンテンツ配信方法、及びコンテンツ配信プログラムを提供することを目的とする。 Accordingly, one aspect of the present disclosure provides a content distribution system, a content distribution method, and a content distribution program capable of appropriately hiding the actions of a user's avatar in a virtual space from other users depending on the situation. for the purpose.
本開示の一側面に係るコンテンツ配信システムは、仮想空間を表現するコンテンツを複数のユーザ端末に配信するコンテンツ配信システムであり、少なくとも一つのプロセッサを備える。少なくとも一つのプロセッサは、仮想空間内に配置される第1ユーザに対応するアバターの予め定められた特定動作であって、第1ユーザとは異なる第2ユーザに対して隠すべき特定動作が行われる特定状況を検知し、特定状況が検知された場合に、特定動作が視認できない態様で仮想空間を表現するコンテンツ画像を、第2ユーザのユーザ端末上に表示させる。 A content distribution system according to one aspect of the present disclosure is a content distribution system that distributes content representing a virtual space to a plurality of user terminals, and includes at least one processor. At least one processor performs a predetermined specific action of an avatar corresponding to a first user placed in the virtual space, the specific action to be hidden from a second user different from the first user. A specific situation is detected, and when the specific situation is detected, a content image expressing a virtual space in a manner in which the specific action cannot be visually recognized is displayed on the user terminal of the second user.
本開示の一側面によれば、仮想空間内におけるユーザのアバターの動作を状況に応じて適切に他のユーザに対して隠すことができるコンテンツ配信システム、コンテンツ配信方法、及びコンテンツ配信プログラムを提供することができる。 According to one aspect of the present disclosure, there is provided a content distribution system, a content distribution method, and a content distribution program capable of appropriately hiding actions of a user's avatar in a virtual space from other users depending on the situation. be able to.
以下、添付図面を参照しながら本開示での実施形態を詳細に説明する。なお、図面の説明において同一又は同等の要素には同一の符号を付し、重複する説明を省略する。 Hereinafter, embodiments of the present disclosure will be described in detail with reference to the accompanying drawings. In the description of the drawings, the same or equivalent elements are denoted by the same reference numerals, and overlapping descriptions are omitted.
[システムの概要]
実施形態に係るコンテンツ配信システムは、複数のユーザにコンテンツを配信するコンピュータシステムである。コンテンツは、コンピュータ又はコンピュータシステムによって提供され、人が認識可能な情報である。コンテンツを示す電子データのことをコンテンツデータという。コンテンツの表現形式は限定されない。コンテンツは、例えば、画像(例えば、写真、映像等)、文書、音声、音楽、又はこれらの中の任意の2以上の要素の組合せによって表現されてもよい。コンテンツは、様々な態様の情報伝達又はコミュニケーションのために用いることができる。コンテンツは、例えば、エンターテインメント、ニュース、教育、医療、ゲーム、チャット、商取引、講演、セミナー、研修等の様々な場面又は目的で利用され得る。配信とは、通信ネットワーク又は放送ネットワークを経由して情報をユーザに向けて送信する処理である。
[System overview]
A content delivery system according to an embodiment is a computer system that delivers content to a plurality of users. Content is human-perceivable information provided by a computer or computer system. Electronic data representing content is called content data. The content expression format is not limited. Content may be represented by, for example, images (eg, photographs, videos, etc.), documents, sounds, music, or a combination of any two or more of these elements. Content can be used for various aspects of information transfer or communication. The content can be used for various occasions or purposes such as entertainment, news, education, medical care, games, chats, commercial transactions, lectures, seminars, and training. Distribution is the process of transmitting information to users via a communication network or broadcast network.
コンテンツ配信システムは、コンテンツデータをユーザ端末に送信することで、コンテンツをユーザに提供する。本実施形態では一例として、複数のユーザのユーザ端末の各々に対して、同一の仮想空間を表現するコンテンツが提供される。これにより、複数のユーザ間において、共通の仮想空間を共有することが可能となる。また、本実施形態では、コンテンツは、少なくとも仮想空間を表現する画像を用いて表現される。すなわち、コンテンツデータには、少なくともコンテンツを示すコンテンツ画像が含まれる。コンテンツ画像は、人が視覚を通して何らかの情報を認識することができる像である。コンテンツ画像は、動画像(映像)でもよいし静止画でもよい。 A content distribution system provides content to users by transmitting content data to user terminals. In this embodiment, as an example, content expressing the same virtual space is provided to each of user terminals of a plurality of users. This makes it possible for a plurality of users to share a common virtual space. Also, in the present embodiment, the content is expressed using at least an image that expresses the virtual space. That is, the content data includes at least a content image representing the content. A content image is an image from which a person can visually recognize some information. A content image may be a moving image (video) or a still image.
一例では、コンテンツ画像は、仮想オブジェクトが存在する仮想空間を表現する。仮想オブジェクトは、現実世界には存在せず、コンピュータシステム上でのみ表現される物体である。仮想オブジェクトは、実写画像とは独立した画像素材を用いて、2次元又は3次元のコンピュータグラフィックス(CG)によって表現される。仮想オブジェクトの表現方法は限定されない。例えば、仮想オブジェクトは、アニメーション素材を用いて表現されてもよいし、実写画像に基づいて本物に近いように表現されてもよい。仮想空間は、コンピュータ上に表示される画像によって表現される仮想の2次元又は3次元の空間である。コンテンツ画像は、例えば、仮想空間内に設定された仮想カメラから見える風景を示す画像である。仮想カメラは、コンテンツ画像を見るユーザの視線に対応するように仮想空間内に設定される。コンテンツ画像又は仮想空間は、現実世界に実際に存在する物体である現実オブジェクトを更に含んでもよい。 In one example, the content image represents a virtual space in which virtual objects exist. A virtual object is an object that does not exist in the real world and is represented only on a computer system. A virtual object is represented by two-dimensional or three-dimensional computer graphics (CG) using image materials independent of actual images. The representation method of the virtual object is not limited. For example, the virtual object may be represented using animation material, or may be represented as realistically based on a photographed image. A virtual space is a virtual two-dimensional or three-dimensional space represented by images displayed on a computer. A content image is, for example, an image showing a landscape seen from a virtual camera set in the virtual space. A virtual camera is set in the virtual space so as to correspond to the line of sight of the user viewing the content image. The content image or virtual space may further include real objects, which are objects that actually exist in the real world.
仮想オブジェクトの一例として、ユーザの分身であるアバターがある。アバターは、撮影された人そのものではなく、原画像とは独立した画像素材を用いて、2次元又は3次元のコンピュータグラフィックス(CG)によって表現される。アバターの表現方法は限定されない。例えば、アバターは、アニメーション素材を用いて表現されてもよいし、実写画像に基づいて本物に近いように表現されてもよい。なお、上述した仮想カメラの位置及び向きは、アバターの視点及び視線と一致してもよい。この場合、一人称視点のコンテンツ画像がユーザに提供される。或いは、仮想カメラの位置及び向きは、アバターの視点及び視線と一致しなくてもよい。例えば、仮想カメラは、アバターの背後の空間等に配置されてもよい。この場合、三人称視点のコンテンツ画像がユーザに提供される。ユーザは、コンテンツ画像を見ることで、拡張現実(AR:Augmented Reality)、仮想現実(VR:Virtual Reality)、又は複合現実(MR:Mixed Reality)を体験することができる。 An example of a virtual object is an avatar that is a user's alter ego. The avatar is represented by two-dimensional or three-dimensional computer graphics (CG) using image materials independent of the original image, rather than the person being photographed. The avatar expression method is not limited. For example, avatars may be represented using animation materials, or may be represented as realistically based on actual images. Note that the position and direction of the virtual camera described above may match the viewpoint and line of sight of the avatar. In this case, the user is provided with a first-person-view content image. Alternatively, the position and orientation of the virtual camera may not match the avatar's viewpoint and line of sight. For example, the virtual camera may be placed in the space behind the avatar, or the like. In this case, the content image of the third person viewpoint is provided to the user. A user can experience augmented reality (AR), virtual reality (VR), or mixed reality (MR) by viewing content images.
本開示において、データ又は情報を第1コンピュータから第2コンピュータ“に送信する”との表現は、第2コンピュータに最終的にデータ又は情報を届けるための送信を意味する。すなわち、上記表現は、その送信において別のコンピュータ又は通信装置がデータ又は情報を中継する場合を含む。 In this disclosure, the phrase "transmitting" data or information from a first computer to a second computer means transmitting data or information for eventual delivery to the second computer. That is, the phrase includes cases where another computer or communication device relays the data or information in its transmission.
コンテンツの目的及び利用場面は限定されない。本実施形態では一例として、コンテンツは、複数のユーザによって共有される仮想空間内に設けられた仮想の施設において、現実と同じような体験をユーザに提供するものである。例えば、コンテンツは、仮想空間内に設けられたショッピング施設でショッピングを行う体験をユーザに提供するものであってもよいし、仮想空間内におけるゲーム体験(例えば、いわゆるVR脱出ゲーム等)をユーザに提供するものであってもよい。 The purpose and use scene of the content are not limited. As an example in this embodiment, the content provides users with an experience similar to reality in a virtual facility provided in a virtual space shared by a plurality of users. For example, the content may provide the user with an experience of shopping at a shopping facility provided in the virtual space, or provide the user with a game experience (for example, a so-called VR escape game) in the virtual space. may be provided.
[コンテンツ配信システムの全体構成]
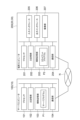
図1は、実施形態に係るコンテンツ配信システム1の適用の一例を示す図である。本実施形態では、コンテンツ配信システム1は、サーバ10と、複数のユーザ端末20,30と、コンテンツデータベースDBと、を備える。
[Overall configuration of content distribution system]
FIG. 1 is a diagram showing an example of application of a
サーバ10は、コンテンツデータをユーザ端末20,30に配信するコンピュータである。サーバ10は、通信ネットワークNを介して、各ユーザ端末20,30及びコンテンツデータベースDBと接続されている。通信ネットワークNの構成は限定されない。例えば、通信ネットワークNは、インターネットを含んで構成されてもよいし、イントラネットを含んで構成されてもよい。
The
ユーザ端末20,30は、コンテンツを利用するユーザによって用いられるコンピュータである。本実施形態では、ユーザ端末20,30は、映像を撮影する機能と、コンテンツ配信システム1にアクセスしてその映像を示す電子データ(映像データ)を送信する機能と、コンテンツ配信システム1からコンテンツデータを受信及び表示する機能と、を有する。ユーザ端末20,30の種類及び構成は限定されない。例えば、ユーザ端末20,30は、高機能携帯電話機(スマートフォン)、タブレット端末、ウェアラブル端末(例えば、ヘッドマウントディスプレイ(HMD)、スマートグラス等)、ラップトップ型パーソナルコンピュータ、携帯電話機等の携帯端末でもよい。或いは、ユーザ端末20,30は、デスクトップ型パーソナルコンピュータ等の据置型端末でもよい。
本実施形態では、ユーザ端末20は、複数のユーザのうち着目する一のユーザ(第1ユーザ)のユーザ端末(すなわち、第1ユーザによって使用されるユーザ端末)であり、ユーザ端末30は、第1ユーザとは異なるユーザ(第2ユーザ)のユーザ端末(すなわち、第2ユーザによって使用されるユーザ端末)である。図1は、2台のユーザ端末30を例示しているが、ユーザ端末30の台数(すなわち、第2ユーザの数)は特に限定されない。本実施形態では、上述したとおり、あるユーザに着目した場合に、便宜上、当該ユーザを第1ユーザと称し、他のユーザを第2ユーザと称している。従って、ユーザ端末20とユーザ端末30とは、同一のハードウェア構成及び機能構成を備える。つまり、各ユーザ端末は、ある場面においては、後述するユーザ端末20として機能し、他の場面においては、後述するユーザ端末30として機能する。
In the present embodiment, the
ユーザは、例えば、ユーザ端末20,30を操作してコンテンツ配信システム1にログインすることにより、コンテンツを利用することができる。一例として、ユーザは、自身のアバターを介して、コンテンツにより表現される仮想空間内で各種体験を行うことができる。本実施形態では、コンテンツ配信システム1のユーザが既にログインしていることを前提とする。
The user can use the content by, for example, operating the
コンテンツデータベースDBは、生成されたコンテンツデータを記憶する非一時的な記憶媒体又は記憶装置である。コンテンツデータベースDBは、既存のコンテンツのライブラリであるといえる。コンテンツデータは、サーバ10、ユーザ端末20,30、又は別のコンピュータ等の任意のコンピュータによって、コンテンツデータベースDBに格納される。
The content database DB is a non-temporary storage medium or storage device that stores generated content data. The content database DB can be said to be a library of existing content. Content data is stored in the content database DB by any computer such as the
コンテンツデータは、コンテンツを一意に識別するコンテンツIDと関連付けられた上でコンテンツデータベースDBに格納される。一例では、コンテンツデータは、仮想空間データ、モデルデータ、及びシナリオを含んで構成される。 The content data is stored in the content database DB after being associated with a content ID that uniquely identifies the content. In one example, content data includes virtual space data, model data, and scenarios.
仮想空間データは、コンテンツを構成する仮想空間を示す電子データである。例えば、仮想空間データは、背景を構成する個々の仮想オブジェクトの配置、仮想カメラの位置、又は仮想光源の位置等を示す情報を含み得る。 Virtual space data is electronic data representing a virtual space that constitutes content. For example, the virtual space data may include information indicating the arrangement of individual virtual objects that make up the background, the position of the virtual camera, the position of the virtual light source, or the like.
モデルデータは、コンテンツを構成する仮想オブジェクトの仕様を規定するために用いられる電子データである。仮想オブジェクトの仕様とは、仮想オブジェクトを制御するための取り決め又は方法のことをいう。例えば、仮想オブジェクトの仕様は、仮想オブジェクトの構成(例えば形状及び寸法)、動作、及び音声のうちの少なくとも一つを含む。アバターのモデルデータのデータ構造は限定されず、任意に設計されてよい。例えば、モデルデータは、アバターを構成する複数のジョイント及び複数のボーンに関する情報と、アバターの外観デザインを示すグラフィックデータと、アバターの属性と、アバターの識別子であるアバターIDとを含んでもよい。ジョイント及びボーンに関する情報の例として、個々のジョイントの3次元座標と、隣り合うジョイントの組合せ(すなわちボーン)とが挙げられる。ただし、当該情報の構成は、これらに限定されず、任意に設計されてよい。アバターの属性とは、アバターを特徴付けるために設定される任意の情報であり、例えば公称寸法、声質、又は性格等を含み得る。 Model data is electronic data used to define the specifications of virtual objects that make up content. A specification of a virtual object refers to the conventions or methods for controlling the virtual object. For example, the virtual object specification includes at least one of the virtual object's configuration (eg, shape and size), behavior, and audio. The data structure of the avatar model data is not limited and may be arbitrarily designed. For example, the model data may include information on multiple joints and multiple bones that make up the avatar, graphic data indicating the appearance design of the avatar, attributes of the avatar, and an avatar ID that is an identifier of the avatar. Examples of information about joints and bones include the three-dimensional coordinates of individual joints and combinations of adjacent joints (ie, bones). However, the configuration of the information is not limited to these and may be arbitrarily designed. An avatar's attributes are any information set to characterize the avatar, and may include, for example, nominal dimensions, voice quality, or personality.
シナリオとは、仮想空間内での時間の経過に伴う個々の仮想オブジェクト、仮想カメラ、又は仮想光源の動作を規定する電子データである。シナリオは、コンテンツのストーリーを決めるための情報であるこということができる。仮想オブジェクトの動作は、視覚で認識できる動きに限定されず、聴覚で認識される音声の発生を含んでよい。 A scenario is electronic data that defines the behavior of an individual virtual object, virtual camera, or virtual light source over time within a virtual space. It can be said that the scenario is information for determining the story of the content. Behavior of a virtual object is not limited to visually perceptible movement, and may include auditory perceivable sound production.
コンテンツデータは、現実オブジェクトに関する情報を含んでもよい。例えば、コンテンツデータは、現実オブジェクトが映された実写画像を含んでもよい。コンテンツデータが現実オブジェクトを含む場合には、シナリオは、その現実オブジェクトをどのタイミングでどこに映すかをさらに規定し得る。 Content data may include information about real objects. For example, content data may include a photographed image of a real object. If the content data includes a physical object, the scenario may further define when and where the physical object should be displayed.
コンテンツデータベースDBの設置場所は限定されない。例えば、コンテンツデータベースDBは、コンテンツ配信システム1とは別のコンピュータシステム内に設けられてもよいし、コンテンツ配信システム1の構成要素であってもよい。
The installation location of the content database DB is not limited. For example, the content database DB may be provided in a computer system separate from the
[コンテンツ配信システムのハードウェア構成]
図2は、コンテンツ配信システム1に関連するハードウェア構成の一例を示す図である。図2は、サーバ10として機能するサーバコンピュータ100と、ユーザ端末20又はユーザ端末30として機能する端末コンピュータ200とを示す。
[Hardware configuration of content distribution system]
FIG. 2 is a diagram showing an example of a hardware configuration related to the
一例として、サーバコンピュータ100は、ハードウェア構成要素として、プロセッサ101、主記憶部102、補助記憶部103、及び通信部104を備える。
As an example, the
プロセッサ101は、オペレーティングシステム及びアプリケーションプログラムを実行する演算装置である。プロセッサの例としては、CPU(Central Processing Unit)及びGPU(Graphics Processing Unit)が挙げられるが、プロセッサ101の種類はこれらに限定されない。例えば、プロセッサ101は、センサ及び専用回路の組合せでもよい。専用回路は、FPGA(Field-Programmable Gate Array)のようなプログラム可能な回路でもよいし、他の種類の回路でもよい。
The
主記憶部102は、サーバ10を実現するためのプログラム、プロセッサ101から出力された演算結果等を記憶する装置である。主記憶部102は、例えばROM(Read Only Memory)又はRAM(Random Access Memory)等により構成される。
The
補助記憶部103は、一般に主記憶部102よりも大量のデータを記憶することが可能な装置である。補助記憶部103は、例えばハードディスク、フラッシュメモリ等の不揮発性記憶媒体によって構成される。補助記憶部103は、サーバコンピュータ100をサーバ10として機能させるためのサーバプログラムP1と各種のデータとを記憶する。例えば、補助記憶部103は、アバター等の仮想オブジェクト及び仮想空間のうちの少なくとも一つに関するデータを記憶してもよい。本実施形態では、コンテンツ配信プログラムは、サーバプログラムP1として実装される。
通信部104は、通信ネットワークNを介して他のコンピュータとの間でデータ通信を実行する装置である。通信部104は、例えばネットワークカード又は無線通信モジュールにより構成される。
The
サーバ10の各機能要素は、プロセッサ101又は主記憶部102にサーバプログラムP1を読み込ませ、プロセッサ101に当該サーバプログラムP1を実行させることにより実現される。サーバプログラムP1は、サーバ10の各機能要素を実現するためのコードを含む。プロセッサ101は、サーバプログラムP1に従って通信部104を動作させ、主記憶部102又は補助記憶部103におけるデータの読み出し及び書き込みを実行する。このような処理により、サーバ10の各機能要素が実現される。
Each functional element of the
サーバ10は、一つ又は複数のコンピュータにより構成され得る。複数のコンピュータが用いられる場合には、通信ネットワークを介して当該複数のコンピュータが互いに接続されることにより、論理的に一つのサーバ10が構成される。
The
一例として、端末コンピュータ200は、ハードウェア構成要素として、プロセッサ201、主記憶部202、補助記憶部203、通信部204、入力インタフェース205、出力インタフェース206、及び撮像部207を備える。
As an example, the terminal computer 200 includes a
プロセッサ201は、オペレーティングシステム及びアプリケーションプログラムを実行する演算装置である。プロセッサ201は、例えばCPU又はGPUであり得るが、プロセッサ201の種類はこれらに限定されない。
主記憶部202は、ユーザ端末20,30を実現させるためのプログラム、プロセッサ201から出力された演算結果等を記憶する装置である。主記憶部202は、例えばROM又はRAM等により構成される。
The
補助記憶部203は、一般に主記憶部202よりも大量のデータを記憶することが可能な装置である。補助記憶部203は、例えばハードディスク、フラッシュメモリ等の不揮発性記憶媒体によって構成される。補助記憶部203は、端末コンピュータ200をユーザ端末20,30として機能させるためのクライアントプログラムP2と各種のデータとを記憶する。例えば、補助記憶部203は、アバター等の仮想オブジェクト及び仮想空間のうちの少なくとも一つに関するデータを記憶してもよい。
通信部204は、通信ネットワークNを介して他のコンピュータとの間でデータ通信を実行する装置である。通信部204は、例えばネットワークカード又は無線通信モジュールにより構成される。
The
入力インタフェース205は、ユーザの操作又は動作に基づいて、データを受け付ける装置である。例えば、入力インタフェース205は、コントローラ、キーボード、操作ボタン、ポインティングデバイス、マイクロフォン、センサ、及びカメラのうちの少なくとも一つによって構成される。キーボード及び操作ボタンは、タッチパネル上に表示されてもよい。入力インタフェース205の種類が限定されないことに対応して、入力インタフェース205に入力されるデータも限定されない。例えば、入力インタフェース205は、キーボード、操作ボタン、又はポインティングデバイスによって入力又は選択されたデータを受け付けてもよい。或いは、入力インタフェース205は、マイクロフォンにより入力された音声データを受け付けてもよい。或いは、入力インタフェース205は、カメラによって撮影された画像データ(例えば、映像データ又は静止画データ)を受け付けてもよい。或いは、入力インタフェース205は、センサ又はカメラを用いたモーションキャプチャ機能によって検知されたユーザの非言語活動(例えば、視線、ジェスチャ、表情等)を示すデータをモーションデータとして受け付けてもよい。
The
出力インタフェース206は、端末コンピュータ200で処理されたデータを出力する装置である。例えば、出力インタフェース206は、モニタ、タッチパネル、HMD及びスピーカのうちの少なくとも一つによって構成される。モニタ、タッチパネル、HMD等の表示装置は、処理されたデータを画面上に表示する。スピーカは、処理された音声データにより示される音声を出力する。
The
撮像部207は、現実世界を写した画像を撮影する装置であり、具体的にはカメラである。撮像部207は、動画像(映像)を撮影してもよいし、静止画(写真)を撮影してもよい。動画像を撮影する場合には、撮像部207は、映像信号を所与のフレームレートに基づいて処理することにより、時系列に並ぶ一連のフレーム画像を動画像として取得する。撮像部207は、入力インタフェース205としても機能し得る。
The
ユーザ端末20,30の各機能要素は、プロセッサ201又は主記憶部202にクライアントプログラムP2を読み込ませ、当該クライアントプログラムP2を実行させることにより実現される。クライアントプログラムP2は、ユーザ端末20,30の各機能要素を実現するためのコードを含む。プロセッサ201は、クライアントプログラムP2に従って、通信部204、入力インタフェース205、出力インタフェース206、又は撮像部207を動作させ、主記憶部202又は補助記憶部203におけるデータの読み出し及び書き込みを行う。この処理により、ユーザ端末20,30の各機能要素が実現される。
Each functional element of the
サーバプログラムP1及びクライアントプログラムP2の少なくとも一つは、CD-ROM、DVD-ROM、半導体メモリ等の有形の記録媒体に固定的に記録された上で提供されてもよい。或いは、これらのプログラムの少なくとも一つは、搬送波に重畳されたデータ信号として通信ネットワークを介して提供されてもよい。これらのプログラムは、別々に提供されてもよいし、一緒に提供されてもよい。 At least one of the server program P1 and the client program P2 may be provided after being fixedly recorded on a tangible recording medium such as a CD-ROM, DVD-ROM, semiconductor memory, or the like. Alternatively, at least one of these programs may be provided via a communication network as a data signal superimposed on a carrier wave. These programs may be provided separately or together.
[コンテンツ配信システムの機能構成]
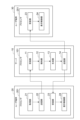
図3は、コンテンツ配信システム1に関連する機能構成の一例を示す図である。サーバ10は、機能要素として、受信部11、検知部12、生成部、及び送信部14を備える。
[Functional configuration of content distribution system]
FIG. 3 is a diagram showing an example of a functional configuration related to the
受信部11は、ユーザ端末20から送信されたデータ信号を受信する。データ信号は、動作情報及び操作情報の少なくとも一方を含み得る。動作情報とは、仮想空間内に配置される第1ユーザに対応するアバター(以下、単に「アバター」という。)の動作を規定する情報である。操作情報は、アバターの動作以外のイベント(例えば、設定画面の起動等)の実行を指示する情報である。
The receiving
検知部12は、ユーザ端末20から受信したデータ信号に基づいて、アバターの特定動作が行われる特定状況を検知する。特定動作は、第2ユーザに対して隠すべき動作として予め定められた動作である。一例として、特定動作は、仮想空間内において、第1ユーザが他のユーザ(第2ユーザ)に知られたなくない情報(例えば、PIN(Personal Identification Number)コード等の暗証番号)を入力する動作(例えば、仮想空間内に配置された仮想的な入力装置の操作ボタンをアバターの指で押下する動作等)である。特定状況は、上述したような特定動作が実際に行われている最中だけでなく、特定動作がこれから行われようとする状況(すなわち、特定動作が行われる直前の状況)を含み得る。
Based on the data signal received from the
生成部13は、検知部12の検知結果に応じて、各ユーザ(すなわち、各ユーザ端末20,30)に配信するためのコンテンツデータを生成する。コンテンツデータは、ユーザ端末20,30の表示装置上で表示させるためのコンテンツ画像に関するコンテンツ画像データを含む。コンテンツデータは、画像以外のデータ(例えば、音声等)を含んでもよい。送信部14は、生成部13により生成されたコンテンツデータを各ユーザ端末20,30に送信する。
The
ユーザ端末20は、機能要素として、取得部21、送信部22、受信部23、及び表示制御部24を備える。
The
取得部21は、ユーザ端末20の入力インタフェース205によって受け付けられた動作情報又は操作情報を取得する。動作情報は、例えば、上述したモーションデータである。この場合、現実空間における第1ユーザの動作が、仮想空間内におけるアバターの動作に反映される。或いは、動作情報は、コントローラに対するユーザの所定の入力操作の内容を示す情報であってもよい。この場合、当該入力操作の内容に応じた動作が、アバターの動作として反映され、現実空間における第1ユーザの動作はアバターの動作には直接反映されない。このように、アバターの動作を規定する動作情報は、第1ユーザの実際の動作を反映したものであってもよいし、第1ユーザの実際の動作を反映したものでなくてもよい。操作情報の例としては、上述したPINコード等の暗証番号を入力するための仮想オブジェクト(後述する非共有オブジェクト)を仮想空間内に出現させるための操作を示す情報等が挙げられる。
The
送信部22は、取得部21により取得された動作情報又は操作情報をサーバ10に送信する。受信部23は、サーバ10からコンテンツ画像データを含むコンテンツデータを受信する。表示制御部24は、受信部23により受信されたコンテンツデータに基づいて、コンテンツをユーザ端末20の表示装置上に表示する機能要素である。
The
ユーザ端末30は、上述したとおり、ユーザ端末20と同様の機能要素を備える。なお、本実施形態では、第1ユーザのアバターを含む仮想空間を表現するコンテンツを第2ユーザのユーザ端末30に表示させる際の処理に着目するため、図3では、当該処理を実行するための受信部23及び表示制御部24のみを図示している。
The
[コンテンツ配信システムの動作]
図4を参照して、コンテンツ配信システム1の動作(より具体的にはサーバ10の動作)を説明すると共に、本実施形態に係るコンテンツ配信方法について説明する。図4は、コンテンツ配信システム1の動作の一例を示すシーケンス図である。
[Operation of content distribution system]
The operation of the content distribution system 1 (more specifically, the operation of the server 10) will be described with reference to FIG. 4, and the content distribution method according to the present embodiment will be described. FIG. 4 is a sequence diagram showing an example of the operation of the
まず、第1ユーザのユーザ端末20の取得部21は、第1ユーザによる入力情報を取得する。具体的には、取得部21は、上述した動作情報又は操作情報を取得する(ステップS1)。続いて、ユーザ端末20の送信部22は、取得部21により取得された動作情報又は操作情報をサーバ10に送信する(ステップS2)。当該動作情報又は操作情報は、サーバ10の受信部11によって受信される。
First, the
続いて、サーバ10の生成部13は、受信部11により取得された動作情報又は操作情報に基づいて、第1コンテンツデータを生成する(ステップS3)。第1コンテンツデータは、第1コンテンツ画像データを含む。受信部11により動作情報が取得された場合、生成部13は、動作情報に基づいて動作させられるアバターを含む仮想空間を表現する第1コンテンツ画像データを生成する。また、受信部11により操作情報が取得された場合、生成部13は、当該操作情報に基づいて変更された仮想空間を表現する第1コンテンツ画像データを生成する。なお、アバターの動作が仮想空間内に配置された仮想オブジェクトに作用する場合(例えば、アバターの一部が他の仮想オブジェクトに接触する場合等)には、生成部13は、当該作用により生じる仮想空間内における挙動(例えば、アバター又は他の仮想オブジェクトの移動又は変形等)を演算により求めてもよい。この場合、第1コンテンツ画像データは、当該演算により求まった挙動が反映された仮想空間(すなわち、移動又は変形等が反映された各仮想オブジェクトの状態)の情報を含み得る。
Subsequently, the
第1コンテンツ画像データは、第1ユーザの動作情報が反映されたアバターの様子(すなわち、第1ユーザの動作情報に対応するアバターの動作)を視認可能な態様で仮想空間を表現するコンテンツ画像に関するデータである。第1コンテンツ画像データは、コンテンツ画像それ自体であってもよいし、コンテンツ画像を生成するためのデータであってもよい。前者の場合、第1コンテンツ画像データは、仮想空間における各仮想オブジェクト(アバターを含む)の状態に関する情報に基づくレンダリングを実行することにより生成されたコンテンツ画像そのもの(すなわち、レンダリング後のデータ)である。後者の場合、第1コンテンツ画像データは、レンダリングを実行することによりコンテンツ画像を生成する基となるデータ(すなわち、レンダリング前のデータ)である。 The first content image data relates to a content image representing a virtual space in a manner in which the state of the avatar reflecting the action information of the first user (that is, the action of the avatar corresponding to the action information of the first user) can be visually recognized. Data. The first content image data may be the content image itself or data for generating the content image. In the former case, the first content image data is the content image itself (that is, data after rendering) generated by executing rendering based on information regarding the state of each virtual object (including avatars) in the virtual space. . In the latter case, the first content image data is data (that is, pre-rendering data) that serves as a basis for generating a content image by executing rendering.
図5は、第1コンテンツ画像に係る仮想空間の一例を示す図である。図5は、仮想空間V内において、第1ユーザが当該第1ユーザに対応するアバターAを介してショッピング(決済)を行う場面を例示している。この例では、アバターAが、仮想空間V内でショッピング(決済)を行うために、暗証コード(一例としてPINコード)を入力するためのデバイスを模した仮想オブジェクト40を操作している。具体的には、アバターAの手A1の動作によって仮想オブジェクト40に設けられた入力ボタン41が押下されると、押下された入力ボタン41に応じた情報(例えば数字等)が入力される。第1コンテンツ画像は、このようなアバターAの動作が反映された仮想空間Vを表現した画像である。すなわち、仮想カメラの位置及び向きに応じた撮影範囲にアバターAの手A1が含まれる場合、第1コンテンツ画像は、当該アバターAの手A1の動作を視認可能なものとなる。
FIG. 5 is a diagram showing an example of a virtual space related to the first content image. FIG. 5 exemplifies a scene in which the first user performs shopping (settlement) in the virtual space V via the avatar A corresponding to the first user. In this example, avatar A operates a
アバターAの動作が反映された第1コンテンツ画像がアバターAに対応するユーザ(すなわち第1ユーザ)自身に提供されることは、特に問題ない。むしろ、第1ユーザは、アバターAを介して暗証コードの入力操作を的確に行うために、第1コンテンツ画像を見ることで、自身の指の動き(或いはコントローラに対する所定操作)に対応するアバターAの指の動きを確認する必要がある。一方、第1ユーザ以外の第2ユーザにアバターAの指の動きが見られてしまうこと(すなわち、第1ユーザの暗証コードが盗み見られてしまうこと)には、セキュリティ上の問題がある。そこで、サーバ10は、以下のような処理を行う。
There is no particular problem in that the first content image reflecting the action of Avatar A is provided to the user corresponding to Avatar A (that is, the first user). Rather, the first user sees the first content image in order to accurately perform the input operation of the personal identification code via avatar A. It is necessary to check the movement of the fingers of the On the other hand, there is a security problem if a second user other than the first user sees the movement of the avatar A's fingers (that is, the first user's personal identification code is stolen). Therefore, the
上述したように、第1ユーザに対しては、アバターAの動作が反映された第1コンテンツ画像が提供されることが好ましい。そこで、サーバ10は、第1ユーザのユーザ端末20に対しては、第1コンテンツデータを送信する。具体的には、送信部14は、第1コンテンツデータをユーザ端末20に送信する(ステップS4)。当該第1コンテンツデータは、ユーザ端末20の受信部23によって受信される。そして、ユーザ端末20の表示制御部24は、当該第1コンテンツデータに含まれる第1コンテンツ画像データを処理することにより、コンテンツ画像を表示装置上に表示する(ステップS5)。サーバ10でレンダリングが実行されている場合(すなわち、第1コンテンツ画像データがコンテンツ画像そのものである場合)、表示制御部24は、当該コンテンツ画像をそのまま表示すればよい。一方、サーバ10でレンダリングが実行されていない場合、表示制御部24は、第1コンテンツ画像データに基づくレンダリングを実行することにより、コンテンツ画像を生成及び表示すればよい。
As described above, it is preferable that the first user is provided with the first content image in which the action of the avatar A is reflected. Therefore, the
一方、図5に例示したように、仮想空間V内において第2ユーザに対して隠すべきアバターAの動作(特定動作)が行われる状況(特定状況)では、セキュリティの観点から、アバターAの特定動作が反映されたコンテンツ画像が第2ユーザに提供されることは好ましくない。そこで、まず、サーバ10の検知部12は、アバターAの特定動作が行われる特定状況を検知する(ステップS6)。なお、特定動作又は特定状況を定義する情報は、予めサーバ10から参照可能な場所(例えば、コンテンツデータベースDB、補助記憶部103等)に記憶されている。
On the other hand, as exemplified in FIG. 5, in a situation (specific situation) in which an action (specific action) of avatar A to be hidden from the second user is performed in virtual space V, it is difficult to specify avatar A from the viewpoint of security. It is not preferable for the second user to be provided with a content image that reflects the action. Therefore, first, the
検知部12により特定状況が検知された場合(ステップS6:YES)、生成部13は、当該特定動作が視認できない態様で仮想空間Vを表現するコンテンツ画像に関する第2コンテンツ画像データを含む第2コンテンツデータを生成する(ステップS7)。そして、送信部14は、第2コンテンツデータを第2ユーザのユーザ端末30に送信する(ステップS8)。当該第2コンテンツデータは、ユーザ端末30の受信部23によって受信される。そして、ユーザ端末30の表示制御部24は、当該第2コンテンツデータに含まれる第2コンテンツ画像データを処理することにより、コンテンツ画像を表示装置上に表示する(ステップS10)。サーバ10でレンダリングが実行されている場合(すなわち、第2コンテンツ画像データがコンテンツ画像そのものである場合)、表示制御部24は、当該コンテンツ画像をそのまま表示すればよい。一方、サーバ10でレンダリングが実行されていない場合、表示制御部24は、第2コンテンツ画像データに基づくレンダリングを実行することにより、コンテンツ画像を生成及び表示すればよい。このように、アバターの特定動作が視認できない態様で表現された第2コンテンツ画像がユーザ端末30に提供されることにより、第2ユーザに対して特定動作の内容を秘匿することができる。その結果、第1ユーザの機密情報が第2ユーザに漏れてしまうことを防ぐことができ、仮想空間内におけるセキュリティを適切に確保することができる。
If the
なお、検知部12により特定状況が検知されていない場合(ステップS6:NO)には、生成部13は、第2ユーザ用のコンテンツデータ(すなわち、特定動作が秘匿化されたコンテンツ画像に関するデータ)を生成する必要がない。よって、この場合、生成部13による第2コンテンツデータの生成処理(ステップS7)は省略され、送信部14により、第1コンテンツデータが第2ユーザのユーザ端末30に送信される(ステップS9)。この場合、ステップS10において、第1コンテンツ画像データに対応するコンテンツ画像が表示装置上に表示される。
Note that if the
次に、上述したステップS6における検知部12による検知処理のいくつかの例(第1~第3の検知処理)について説明する。
Next, several examples (first to third detection processes) of detection processing by the
(第1の検知処理)
第1の検知処理では、特定動作は、予め定められた特定の仮想オブジェクト(以下、「特定オブジェクト」という。)に対する動作(操作)として、予め定められている。特定オブジェクトは、アバターによる特定動作の対象となる仮想オブジェクトである。図5の例において、仮想オブジェクト40が、特定オブジェクトとして予め定められている場合、例えば当該仮想オブジェクト40の入力ボタン41に対する入力操作が、特定動作として予め定められ得る。この場合、検知部12は、仮想オブジェクト40に対するアバターAの特定動作(ここでは、入力ボタン41に対する入力操作)が行われる状況を、特定状況として検知することができる。
(First detection process)
In the first detection process, the specific action is predetermined as an action (operation) for a predetermined specific virtual object (hereinafter referred to as "specific object"). A specific object is a virtual object targeted for a specific action by an avatar. In the example of FIG. 5, when the
例えば、検知部12は、仮想空間V内に配置された特定オブジェクトの位置と仮想空間V内におけるアバターAの位置とに基づいて、特定オブジェクトから予め定められた距離範囲内にアバターが配置されている状態を検知し、当該状態が検知されたことに応じて特定状況を検知してもよい。図5の例では、検知部12は、例えば、仮想オブジェクト40の位置(例えば、仮想空間V内における入力ボタン41の位置座標)とアバターAの位置(例えば、仮想空間V内におけるアバターAの手A1の位置座標)との距離d1を算出する。そして、検知部12は、当該距離d1と予め設定された閾値Thとを比較し、距離d1が閾値Th以下(又は距離d1が閾値Th未満)である場合に、特定状況を検知することができる。この場合、閾値Thをある程度大きい値に設定することにより、アバターAの特定動作が実際に開始される時点よりも前の時点に特定状況を検知することができる。
For example, based on the position of the specific object placed in the virtual space V and the position of the avatar A in the virtual space V, the
(第2の検知処理)
第2の検知処理では、特定動作は、第1ユーザのみが視認可能な仮想オブジェクト(以下、「非共有オブジェクト」という。)に対する動作(操作)として、予め定められている。例えば、サーバ10は、第1ユーザによる所定の操作(例えば、ユーザ端末20のコントローラ(入力インタフェース205)に対する予め定められた操作)に関する操作情報を受け付けたことに応じて、非共有オブジェクトを仮想空間内に発生させてもよい。非共有オブジェクトは、第1ユーザのみが視認可能なオブジェクトであり、第2ユーザに配信されるコンテンツ画像には表示されないように制御された仮想オブジェクトである。また、非共有オブジェクトは、第1ユーザのアバターを介した操作のみを受け付ける仮想オブジェクトである。
(Second detection process)
In the second detection process, the specific action is predetermined as an action (operation) with respect to a virtual object (hereinafter referred to as "non-shared object") visible only to the first user. For example, the
図5の例において、仮想オブジェクト40が、第1ユーザによる所定の操作をトリガとして仮想空間V内に生成された非共有オブジェクトである場合について考える。ここで、アバターAの操作対象であり且つ非共有オブジェクトである仮想オブジェクト40が仮想空間V内に発生したことは、これから当該非共有オブジェクトに対してアバターAによる操作(特定動作)が実行される予定であることを意味する。そこで、検知部12は、非共有オブジェクトである仮想オブジェクト40が仮想空間V内に発生したことに応じて、特定状況を検知してもよい。この場合にも、アバターAの特定動作が実際に開始される時点よりも前の時点に特定状況を検知することができる。
In the example of FIG. 5, consider the case where the
(第3の検知処理)
第3の検知処理では、特定動作を規定するテンプレートが、予めサーバ10から参照可能な場所(例えば、コンテンツデータベースDB、補助記憶部103等)に記憶されている。テンプレートの例として、暗証コードを入力する操作を行う際のアバターAの手A1の動きを特徴付けるパターンを示す情報が挙げられる。例えば、このような動作に対応するテンプレートは、アバターAの手A1の指先で複数の異なる場所を指し示す動作を連続的に実行する際の手A1の動作のパターンを示す情報である。テンプレートは、実際のアバターAの動作(すなわち、ステップS2においてユーザ端末20から受け付けた動作情報)との類似度を算出可能なものであればよく、テンプレートのデータ形式は特定の形式に限定されない。この場合、検知部12は、ステップS2において取得された動作情報とテンプレートとを比較することにより、特定動作を規定する動作情報(以下、「特定動作情報」という。)を検知する。そして、検知部12は、特定動作情報が検知されたことに応じて、特定状況を検知する。
(Third detection process)
In the third detection process, a template that defines a specific action is stored in advance in a location that can be referenced from the server 10 (for example, content database DB,
例えば、検知部12は、ステップS2において取得された動作情報及びテンプレートの類似度を所定の計算処理によって算出する。そして、検知部12は、当該類似度と予め設定された閾値とを比較することにより、ステップS2において取得された動作情報が特定動作情報に該当するか否かを判定する。具体的には、検知部12は、類似度が閾値以上である(或いは閾値より大きい)場合に、ステップS2において取得された動作情報が特定動作情報に該当すると判定してもよい。そして、このようにして特定動作情報(すなわち、ステップS2において取得された動作情報)が検知された場合に、検知部12は、特定状況を検知することができる。
For example, the
次に、上述したステップS7における生成部13による生成処理のいくつかの例(第1~第3の生成処理)について説明する。
Next, several examples (first to third generation processes) of generation processing by the
(第1の生成処理)
第1の生成処理では、生成部13は、仮想空間V内におけるアバターAの動作を規定する動作情報のうち、特定動作情報を含まない第2コンテンツ画像データを生成する。第2コンテンツ画像データがレンダリング前のデータである場合、第2コンテンツ画像データは、ステップS2において取得された特定動作情報を含まない情報である。例えば、生成部13は、ステップS2において取得された動作情報から特定動作情報を除外した情報を第2コンテンツ画像データに含めることにより、特定動作情報を含まない第2コンテンツ画像データを生成することができる。一方、第2コンテンツ画像データがレンダリング後のデータ(すなわち、コンテンツ画像そのもの)である場合、第2コンテンツ画像データは、ステップS2において取得された動作情報から特定動作情報を除外した情報に基づいて生成されたコンテンツ画像である。例えば、生成部13は、ステップS2において取得された動作情報から特定動作情報を除外した情報に基づいてアバターAの動作を決定し、当該アバターAの動作が反映されたコンテンツ画像を生成することにより、特定動作情報を含まないレンダリング後の第2コンテンツ画像データを生成することができる。
(First generation process)
In the first generation process, the
上記いずれの場合にも、サーバ10からユーザ端末30へと特定動作情報が送信されない。その結果、ユーザ端末30の表示装置上には、アバターAの特定動作が視認できない態様で表現された(すなわち、アバターAの特定動作が表現されていない)第2コンテンツ画像が表示されることになる。また、ユーザ端末30に送信される第2コンテンツ画像データ自体に特定動作情報が含まれていないため、第2ユーザは、第2コンテンツ画像データを解析したとしても、アバターAの特定動作を把握することはできない。すなわち、ユーザ端末30の表示装置上に表示される第2コンテンツ画像においてアバターAの特定動作を視認できないだけでなく、第2コンテンツ画像データの解析を実行したとしても、アバターAの特定動作を把握することができない。従って、第1の生成処理で生成される第2コンテンツ画像データによれば、特定動作の秘匿性(セキュリティ)が効果的に確保される。
In any of the above cases, specific action information is not transmitted from the
なお、生成部13は、ステップS2において取得された動作情報から、特定状況が検知された時点から特定状況が検知されなくなった時点までの動作情報を全て除外した情報に基づいて、第2コンテンツ画像データを生成してもよい。例えば、上述した第1の検知処理が実行される場合、生成部13は、特定状況が検知されてから実際に特定動作が行われるまでの動作(例えば、入力ボタン41を押下するために仮想オブジェクト40に近づく予備的動作)に関する動作情報も除外した上で、第2コンテンツ画像データを生成してもよい。この場合、第2ユーザに対して、アバターの特定動作だけでなく、当該特定動作を実行するための予備的動作も隠すことができる。これにより、特定動作の秘匿性をより一層高めることができる。
Note that the
図6は、第1の生成処理で生成された第2コンテンツ画像データに係る第2コンテンツ画像について説明するための図である。ここでは一例として、検知部12が、第1の検知処理により、アバターAの手A1が仮想オブジェクト40の入力ボタン41の閾値距離範囲内に入った状態が検知されたことに応じて、特定状況を検知する。そして、生成部13が、特定状況が検知された後のアバターAの動作(すなわち、仮想オブジェクト40に近づいて入力ボタン41を手A1で押下する動作)に関する動作情報を用いることなく、第2コンテンツ画像データを生成する。その結果、アバターAの特定動作及び上述した予備的動作が視認できない態様の仮想空間V(図6参照)を表現する第2コンテンツ画像データが生成される。すなわち、この例では、第2コンテンツ画像において、特定状況が検知された時点以降のアバターAの動作が表現されない。これにより、第1ユーザに提供される第1コンテンツ画像(アバターAの実際の動作が反映された画像)とは同期が取れていない第2コンテンツ画像(ここでは、特定状況が検知された時点でアバターAが停止している画像)が、第2ユーザに提供される。なお、仮想オブジェクト40が上述した非共有オブジェクトである場合、仮想オブジェクト40は、第2コンテンツ画像には表示されない。また、検知部12が第2の検知処理を実行する場合には、生成部13は、非共有オブジェクトが仮想空間内に発生してから仮想空間内から消滅するまでのアバターの動作情報を用いることなく、第2コンテンツ画像データを生成してもよい。この場合にも、図6に示されるように、ある時点(ここでは非共有オブジェクトが仮想空間内に発生した時点)でアバターが停止している画像が、第2ユーザ提供される。
FIG. 6 is a diagram for explaining the second content image related to the second content image data generated by the first generation process. Here, as an example, when the
上述したように、特定状況が検知された時点でアバターAが停止している第2コンテンツ画像を第2ユーザに提供することにより、第2ユーザに対してアバターAの特定動作を隠すことができる。しかし、第2ユーザはアバターAが不自然に停止している状態を視認することになるため、第2ユーザに違和感を与えてしまい、仮想空間Vへの没入感を阻害してしまうおそれがある。そこで、生成部13は、以下の第2の生成処理を実行してもよい。
As described above, by providing the second content image in which the avatar A stops when the specific situation is detected to the second user, it is possible to hide the specific action of the avatar A from the second user. . However, since the second user sees the state in which the avatar A is unnaturally stopped, it may give the second user a sense of discomfort and hinder the sense of immersion in the virtual space V. . Therefore, the
(第2の生成処理)
第2の生成処理では、生成部13は、特定動作を覆い隠すオブジェクトが配置されたコンテンツ画像に関する第2コンテンツ画像データを生成する。当該オブジェクトは、少なくともアバターの特定動作に係る部分を覆い隠すオブジェクトである。例えば、当該第2コンテンツ画像データに係る第2コンテンツ画像は、ステップS2において取得された動作情報(特定動作情報を含む)に基づくアバターAの動作が表現されたコンテンツ画像に、モザイクオブジェクトを重畳表示させることによって得られる。この場合、サーバ10は、検知部12により特定状況が検知された場合に、当該特定動作を覆い隠すオブジェクトが配置された第2コンテンツ画像を、第2ユーザのユーザ端末30上に表示させることが可能となる。
(Second generation process)
In the second generation process, the
図7は、第2の生成処理で生成された第2コンテンツ画像データに係る第2コンテンツ画像について説明するための図である。図7の例では、アバターAの特定動作に係る部分(ここでは、手A1を含む領域)を覆い隠すように、略円形のモザイクオブジェクトMが重畳表示されている。この場合、第2ユーザに対して、違和感のない画像(アバターAが不自然に停止していない画像)を提供できると共に、モザイクオブジェクトMによってアバターAの特定動作に係る部分を第2ユーザに対して隠すことができる。ただし、第2の生成処理では、第2コンテンツ画像データにアバターAの動作情報(特定動作情報を含む)が含まれてしまうため、第2コンテンツ画像データを解析することにより特定動作の内容が第2ユーザに把握されてしまうおそれもある。そこで、生成部13は、上述した第1の生成処理及び第2の生成処理の長所を組み合わせた、以下の第3の生成処理を実行してもよい。
FIG. 7 is a diagram for explaining the second content image related to the second content image data generated by the second generation process. In the example of FIG. 7, a substantially circular mosaic object M is superimposed and displayed so as to cover the part (here, the area including the hand A1) related to the specific action of the avatar A. As shown in FIG. In this case, it is possible to provide the second user with a natural image (an image in which the avatar A does not stop unnaturally), and to display the part related to the specific action of the avatar A by the mosaic object M to the second user. can be hidden. However, in the second generation process, since the second content image data includes the action information (including the specific action information) of the avatar A, the content of the specific action is determined by analyzing the second content image data. There is also a possibility that it will be grasped by two users. Therefore, the
(第3の生成処理)
第3の生成処理では、生成部13は、特定動作の代わりにダミー動作を行うアバターが表現されたコンテンツ画像に関する第2コンテンツ画像データを生成する。当該第2コンテンツデータは、第1の生成処理で生成される第2コンテンツデータと同様に、特定動作情報を含んでいない。具体的には、当該第2コンテンツデータは、実際にステップS2において取得された動作情報ではなく、ダミー動作を示すダミーの動作情報が含まれている。アバターのダミー動作は、例えば、予めサーバ10から参照可能な場所(例えば、コンテンツデータベースDB、補助記憶部103等)に記憶されている。この場合、サーバ10は、検知部12により特定状況が検知された場合に、特定動作の代わりにダミー動作を行うアバターが表現された第2コンテンツ画像を、第2ユーザのユーザ端末30上に表示させることが可能となる。
(Third generation process)
In the third generation process, the
図8は、第3の生成処理で生成された第2コンテンツ画像データに係る第2コンテンツ画像について説明するための図である。図8の例では、実際の動作(ここでは、図5に示される暗証番号の入力動作)の代わりにダミー動作(ここでは、アバターAが立ち止まった状態で飲料を飲む動作)を行うアバターAが表現されている。この場合、第2ユーザに対して、違和感のない画像を提供できると共に、アバターAの特定動作を第2ユーザに対して隠すことができる。さらに、第2コンテンツ画像データに特定動作情報が含まれないため、上述した第1の生成処理で生成される第2コンテンツ画像データと同様に、特定動作の秘匿性が効果的に確保される。 FIG. 8 is a diagram for explaining the second content image related to the second content image data generated by the third generation process. In the example of FIG. 8, avatar A performs a dummy action (here, avatar A stands still and drinks a drink) instead of the actual action (here, the password input action shown in FIG. 5). expressed. In this case, it is possible to provide a natural image to the second user and to hide the specific action of the avatar A from the second user. Furthermore, since the second content image data does not include the specific action information, the secrecy of the specific action is effectively ensured, similarly to the second content image data generated in the first generation process described above.
[効果]
以上説明したように、本開示の一側面に係るコンテンツ配信システムは、仮想空間を表現するコンテンツを複数のユーザ端末に配信するコンテンツ配信システムであり、少なくとも一つのプロセッサを備える。少なくとも一つのプロセッサは、仮想空間内に配置される第1ユーザに対応するアバターの予め定められた特定動作であって、第1ユーザとは異なる第2ユーザに対して隠すべき特定動作が行われる特定状況を検知し、特定状況が検知された場合に、特定動作が視認できない態様で仮想空間を表現するコンテンツ画像を、第2ユーザのユーザ端末上に表示させる。
[effect]
As described above, the content distribution system according to one aspect of the present disclosure is a content distribution system that distributes content expressing virtual space to a plurality of user terminals, and includes at least one processor. At least one processor performs a predetermined specific action of an avatar corresponding to a first user placed in the virtual space, the specific action to be hidden from a second user different from the first user. A specific situation is detected, and when the specific situation is detected, a content image expressing a virtual space in a manner in which the specific action cannot be visually recognized is displayed on the user terminal of the second user.
本開示の一側面に係るコンテンツ配信方法は、少なくとも一つのプロセッサを備えるコンテンツ配信システムによって実行される。コンテンツ配信方法は、仮想空間内に配置される第1ユーザに対応するアバターの予め定められた特定動作であって、第1ユーザとは異なる第2ユーザに対して隠すべき特定動作が行われる特定状況を検知するステップと、特定状況が検知された場合に、特定動作が視認できない態様で仮想空間を表現するコンテンツ画像を、第2ユーザのユーザ端末上に表示させるステップと、を含む。 A content distribution method according to one aspect of the present disclosure is performed by a content distribution system including at least one processor. The content distribution method is a predetermined specific action of an avatar corresponding to a first user placed in a virtual space, and specifies a specific action to be hidden from a second user different from the first user. detecting a situation; and, when the specific situation is detected, displaying a content image representing a virtual space in a manner in which the specific action cannot be visually recognized on the user terminal of the second user.
本開示の一側面に係るコンテンツ配信プログラムは、仮想空間内に配置される第1ユーザに対応するアバターの予め定められた特定動作であって、第1ユーザとは異なる第2ユーザに対して隠すべき特定動作が行われる特定状況を検知するステップと、特定状況が検知された場合に、特定動作が視認できない態様で仮想空間を表現するコンテンツ画像を、第2ユーザのユーザ端末上に表示させるステップと、をコンピュータに実行させる。 A content distribution program according to one aspect of the present disclosure is a predetermined specific action of an avatar corresponding to a first user placed in a virtual space, which is hidden from a second user different from the first user. a step of detecting a specific situation in which the specific action to be performed is performed; and a step of displaying, when the specific situation is detected, a content image representing a virtual space in a manner in which the specific action cannot be visually recognized on the user terminal of the second user. and cause the computer to execute
このような側面においては、第1ユーザから見た他ユーザ(第2ユーザ)に対して隠すべきアバターの特定動作が行われる特定状況が検知されたことに応じて、当該特定動作が視認できない態様で仮想空間を表現するコンテンツ画像(上記実施形態の第2コンテンツ画像)が第2ユーザに提供される。これにより、仮想空間内における第1ユーザのアバターの動作を状況に応じて適切に他のユーザに対して隠すことができる。すなわち、アバターの動作を他のユーザと共有するか否かに関する設定を第1ユーザに予め行わせることなく、他のユーザに対して隠す必要のないアバターの動作については、第2ユーザに提供されるコンテンツ画像に表示し、他のユーザに対して隠す必要のあるアバターの動作(特定動作)については、第2ユーザに提供されるコンテンツ画像に表示させないようにすることが可能となる。 In this aspect, in response to detection of a specific situation in which a specific action of the avatar to be hidden from the other user (second user) seen from the first user is detected, the specific action cannot be visually recognized. A second user is provided with a content image (the second content image in the above embodiment) that expresses the virtual space in . Thereby, the action of the first user's avatar in the virtual space can be appropriately hidden from other users according to the situation. That is, the second user is provided with the avatar's motions that do not need to be hidden from other users without having the first user set in advance whether to share the avatar's motions with other users. An avatar action (specific action) that must be displayed in the content image provided to the second user and hidden from other users can be prevented from being displayed in the content image provided to the second user.
上記実施形態のように、特定動作が第1ユーザの機密情報(例えば、銀行、クレジットカード等のPINコード等)を仮想空間内で入力する動作である場合、このような動作が第2ユーザに対して秘匿されることにより、仮想空間内におけるセキュリティが的確に確保される。 As in the above embodiment, when the specific action is the action of inputting the confidential information of the first user (for example, the PIN code of a bank, credit card, etc.) in the virtual space, such an action is performed by the second user. Security in the virtual space is properly ensured by keeping it secret.
特定動作の他の例としては、例えばVR脱出ゲーム等において、第1ユーザがゲームで出題された問題に対して、仮想空間内の所定エリアで回答する場面(例えば、アバターを介して仮想空間内に配置されたホワイトボードを模した仮想オブジェクトに回答を記載したり、アバターの身振り等によって回答を提示したりする場面等)が考えられる。この場合、アバターを介した回答動作が、特定動作として予め定められてもよい。例えば、アバターが予め定められた仮想空間内の回答エリアに入った状態が検知されたことに応じて、特定状況が検知されてもよい。このような構成によれば、第1ユーザの回答内容が第2ユーザに見られてしまうことを適切に防止でき、コンテンツの娯楽性及び公平性が適切に確保される。 As another example of the specific action, for example, in a VR escape game, etc., a scene in which the first user answers a question set in the game in a predetermined area in the virtual space (for example, in the virtual space via an avatar). a scene in which an answer is written on a virtual object that imitates a whiteboard placed on the screen, or an answer is presented by an avatar's gestures, etc.). In this case, the response action via the avatar may be predetermined as the specific action. For example, the specific situation may be detected in response to detecting that the avatar has entered an answer area in a predetermined virtual space. According to such a configuration, it is possible to appropriately prevent the first user's answer content from being seen by the second user, and to appropriately ensure entertainment and fairness of the content.
特定動作の更に他の例としては、他者に見せるのにふさわしくない動作(例えば、他者を挑発するような下品なポーズをとる動作等)が考えられる。このような動作も、特定動作として予め定められてもよい。この場合、第1ユーザのアバターを介した不適切な動作が第2ユーザに提示されることが防止される。これにより、第2ユーザに不快感を与えることを防止することができる。 Still another example of the specific action is an action that is inappropriate to be shown to others (for example, an action that poses vulgarly to provoke others). Such an operation may also be predetermined as a specific operation. In this case, inappropriate actions are prevented from being presented to the second user via the first user's avatar. This can prevent the second user from feeling uncomfortable.
コンテンツ配信システムでは、少なくとも一つのプロセッサは、仮想空間内におけるアバターの動作を規定する動作情報のうち、少なくとも特定動作を規定する特定動作情報を第2ユーザのユーザ端末に送信しなくてもよい。すなわち、例えば上記実施形態の第1の生成処理が実行されてもよい。この場合、第2ユーザのユーザ端末に送信されるデータに特定動作情報が含まれないことにより、特定動作の秘匿性を効果的に確保することができる。 In the content distribution system, the at least one processor may not transmit at least the specific action information defining the specific action among the action information defining the action of the avatar in the virtual space to the user terminal of the second user. That is, for example, the first generation process of the above embodiment may be executed. In this case, since the specific action information is not included in the data transmitted to the user terminal of the second user, it is possible to effectively ensure the confidentiality of the specific action.
コンテンツ配信システムでは、少なくとも一つのプロセッサは、仮想空間内に配置された特定動作の対象となる特定オブジェクトの位置と仮想空間内におけるアバターの位置とに基づいて、特定オブジェクトから予め定められた距離範囲内にアバターが配置されている状態を検知し、当該状態が検知されたことに応じて、特定状況を検知してもよい。すなわち、例えば上記実施形態の第1の検知処理が実行されてもよい。この場合、特定オブジェクトの位置とアバターの位置とに基づいて、特定状況を容易に検知することができる。また、上記距離範囲(閾値)をある程度大きい値に設定することにより、アバターの特定動作が実際に開始される時点よりも前の時点に特定状況を検知することができる。これにより、特定動作の全体を第2ユーザに対して確実に秘匿することができる。 In the content distribution system, at least one processor controls a predetermined distance range from a specific object based on the position of the specific object placed in the virtual space and the target of the specific action and the position of the avatar in the virtual space. A state in which an avatar is placed within the object may be detected, and a specific situation may be detected in response to the state being detected. That is, for example, the first detection process of the above embodiment may be executed. In this case, the specific situation can be easily detected based on the position of the specific object and the position of the avatar. Also, by setting the distance range (threshold value) to a relatively large value, it is possible to detect the specific situation at a point in time before the specific action of the avatar actually starts. As a result, the entire specific action can be reliably kept secret from the second user.
コンテンツ配信システムでは、特定動作は、仮想空間内に配置された第1ユーザのみが視認可能な非共有オブジェクトに対するアバターによる操作を含んでもよい。また、少なくとも一つのプロセッサは、非共有オブジェクトが仮想空間内に発生したことに応じて、特定状況を検知してもよい。すなわち、例えば上記実施形態の第2の検知処理が実行されてもよい。この場合、非共有オブジェクトが仮想空間内に発生したこと(例えば、第1ユーザの操作に基づいて仮想空間内に生成されたこと)に応じて、特定状況を容易に検知することができる。また、非共有オブジェクトに対する実際の操作が開始される時点よりも前の時点に特定状況を検知することができるため、特定動作の全体を第2ユーザに対して確実に秘匿することができる。 In the content delivery system, the specific action may include an avatar's operation on a non-shared object that is visible only to the first user and placed in the virtual space. Also, the at least one processor may detect a particular condition in response to the occurrence of a non-shared object within the virtual space. That is, for example, the second detection process of the above embodiment may be executed. In this case, it is possible to easily detect a specific situation according to occurrence of a non-shared object in the virtual space (for example, generation in the virtual space based on the operation of the first user). Moreover, since the specific situation can be detected before the actual operation of the non-shared object is started, the entire specific action can be reliably kept secret from the second user.
なお、上記実施形態(第2の検知処理)では、仮想オブジェクト40が非共有オブジェクトである場合を例示したが、非共有オブジェクトは、必ずしも現実の物体を模したものでなくてもよく、例えば第1ユーザのアバターの前に宙に浮いた状態で現れるウィンドウ等であってもよい。また、非共有オブジェクトは、他のユーザ(第2ユーザ)に対して秘匿すべき情報を入力するためのオブジェクトに限られない。そのような場合であっても、アバターを介した非共有オブジェクトに対する操作を特定動作として、第2ユーザに対して秘匿することにより、以下の効果が得られる。すなわち、第2ユーザから見て何もない空間(第1ユーザから見て非共有オブジェクトが配置された空間)に対して意味のわからない身振りを行っているように見えるアバターの動作を、第2ユーザに対して隠すことができる。その結果、第2ユーザに違和感を与えることを防止し、第2ユーザの仮想空間への没入感が阻害されることを防止することができる。
In the above-described embodiment (second detection process), the
コンテンツ配信システムでは、少なくとも一つのプロセッサは、第1ユーザのユーザ端末により取得されたアバターの動作を規定する動作情報と予め用意されたテンプレートとを比較することにより、特定動作を規定する動作情報を検知し、特定動作を規定する動作情報が検知されたことに応じて、特定状況を検知してもよい。すなわち、例えば上記実施形態の第3の検知処理が実行されてもよい。この場合、特定動作として検知したい対象となるアバターの動作(特定動作)に対応するテンプレートを予め用意しておくことにより、アバターの任意の動作を特定動作として検知できると共に、当該特定動作が行われる状況を特定状況として検知することが可能となる。 In the content distribution system, at least one processor compares the action information defining the action of the avatar acquired by the user terminal of the first user with a template prepared in advance, thereby obtaining the action information defining the specific action. A particular situation may be sensed in response to sensing motion information defining a particular motion. That is, for example, the third detection process of the above embodiment may be executed. In this case, by preparing in advance a template corresponding to the target avatar's action (specific action) to be detected as the specific action, any action of the avatar can be detected as the specific action, and the specific action is performed. It becomes possible to detect the situation as a specific situation.
コンテンツ配信システムでは、少なくとも一つのプロセッサは、特定状況が検知された場合に、特定動作の代わりにダミー動作を行うアバターが表現されたコンテンツ画像を、第2ユーザのユーザ端末上に表示させてもよい。すなわち、例えば上記実施形態の第3の生成処理が実行されてもよい。この場合、特定動作の秘匿性を確保しつつ、第2ユーザに対して違和感のないコンテンツ画像を提供することができる。 In the content distribution system, at least one processor may display, on the user terminal of the second user, a content image representing an avatar performing a dummy action instead of the specific action when a specific situation is detected. good. That is, for example, the third generation process of the above embodiment may be executed. In this case, it is possible to provide the second user with a content image that does not give a sense of discomfort while ensuring the secrecy of the specific action.
コンテンツ配信システムでは、少なくとも一つのプロセッサは、特定状況が検知された場合に、特定動作を覆い隠すオブジェクトが配置されたコンテンツ画像を、第2ユーザのユーザ端末上に表示させてもよい。すなわち、例えば上記実施形態の第2の生成処理が実行されてもよい。この場合、特定動作を覆い隠すオブジェクトにより、特定動作の秘匿性を確保することができる。なお、特定動作を覆い隠すオブジェクトの態様は、上記実施形態で示したモザイクオブジェクトM(図7参照)に限られない。例えば、上記オブジェクトの形状は、円形に限られず、矩形状等の他の形状であってもよい。また、上記オブジェクトの模様は、モザイクに限られない。例えば、上記オブジェクトは、いわゆるニコちゃんマーク等の任意のキャラクター、又は星、ハート等の任意の装飾等を模した任意のオブジェクトによって構成されてもよい。 In the content distribution system, the at least one processor may display, on the user terminal of the second user, a content image in which an object that obscures a specific action is arranged when the specific situation is detected. That is, for example, the second generation process of the above embodiment may be executed. In this case, the confidentiality of the specific action can be ensured by the object that hides the specific action. Note that the aspect of the object that hides the specific action is not limited to the mosaic object M (see FIG. 7) shown in the above embodiment. For example, the shape of the object is not limited to a circle, and may be another shape such as a rectangle. Also, the pattern of the object is not limited to mosaic. For example, the object may be composed of an arbitrary character such as the so-called Nico-chan mark, or an arbitrary object imitating arbitrary decoration such as a star, a heart, or the like.
[変形例]
以上、本開示について、実施形態に基づいて詳細に説明した。しかし、本開示は、上記実施形態に限定されない。本開示は、その要旨を逸脱しない範囲で様々な変形が可能である。
[Modification]
The present disclosure has been described in detail above based on the embodiments. However, the present disclosure is not limited to the above embodiments. Various modifications can be made to the present disclosure without departing from the gist thereof.
上記実施形態では、コンテンツ配信システム1がサーバ10を用いて構成されたが、コンテンツ配信システムは、サーバ10を用いないユーザ端末間の直接配信に適用されてもよい。この場合には、サーバ10の各機能要素は、いずれかのユーザ端末に実装されてもよく、複数のユーザ端末に分かれて実装されてもよい。これに関連して、コンテンツ配信プログラムはクライアントプログラムとして実現されてもよい。コンテンツ配信システムはサーバを用いて構成されてもよいし、サーバを用いることなく構成されてもよい。
Although the
また、上述したサーバ10の機能の一部は、ユーザ端末20,30で実行されてもよい。例えば、サーバ10の検知部12の処理はユーザ端末20で実行されてもよい。この場合、ユーザ端末20の送信部22は、アバターの特定動作に関する特定動作情報が除外された動作情報をサーバ10に送信してもよい。このような構成によっても、上述したコンテンツ配信システム1と同様の効果が奏される。
Also, some of the functions of the
本開示において、「少なくとも一つのプロセッサが、第1の処理を実行し、第2の処理を実行し、…第nの処理を実行する。」との表現、又はこれに対応する表現は、第1の処理から第nの処理までのn個の処理の実行主体(すなわちプロセッサ)が途中で変わる場合を含む概念である。すなわち、この表現は、n個の処理のすべてが同じプロセッサで実行される場合と、n個の処理においてプロセッサが任意の方針で変わる場合との双方を含む概念である。
In the present disclosure, the expression “at least one processor executes the first process, the second process, . . . This is a concept including the case where the executing subject (that is, the processor) of n processes from
少なくとも一つのプロセッサにより実行される方法の処理手順は上記実施形態での例に限定されない。例えば、上述したステップ(処理)の一部が省略されてもよいし、別の順序で各ステップが実行されてもよい。また、上述したステップのうちの任意の2以上のステップが組み合わされてもよいし、ステップの一部が修正又は削除されてもよい。あるいは、上記の各ステップに加えて他のステップが実行されてもよい。 The processing steps of the method executed by at least one processor are not limited to the examples in the above embodiments. For example, some of the steps (processes) described above may be omitted, or the steps may be performed in a different order. Also, any two or more of the steps described above may be combined, and some of the steps may be modified or deleted. Alternatively, other steps may be performed in addition to the above steps.
1…コンテンツ配信システム、10…サーバ、11…受信部、12…検知部、13…生成部、14…送信部、20,30…ユーザ端末、21…取得部、22…送信部、23…受信部、24…表示制御部、40…仮想オブジェクト(特定オブジェクト、非共有オブジェクト)、101…プロセッサ、A…アバター、DB…コンテンツデータベース、P1…サーバプログラム、P2…クライアントプログラム、V…仮想空間。
DESCRIPTION OF
Claims (9)
少なくとも一つのプロセッサを備え、
前記少なくとも一つのプロセッサは、
前記仮想空間内に配置される第1ユーザに対応するアバターの予め定められた特定動作であって、前記第1ユーザとは異なる第2ユーザに対して隠すべき情報を入力する操作である前記特定動作が行われる特定状況を検知し、
前記特定状況が検知された場合に、前記特定動作が視認できない態様で前記仮想空間を表現するコンテンツ画像を、前記第2ユーザのユーザ端末上に表示させ、
前記少なくとも一つのプロセッサは、
前記仮想空間内において、前記隠すべき情報を入力する対象となる特定オブジェクトに対して前記隠すべき情報を入力する入力操作が行われる状況を、前記特定状況として検知する、コンテンツ配信システム。 A content distribution system for distributing content representing a virtual space to a plurality of user terminals,
comprising at least one processor,
The at least one processor
A predetermined specific action of an avatar corresponding to a first user placed in the virtual space, the specific action being an operation of inputting information to be hidden from a second user different from the first user. Detect specific situations in which actions are taken;
displaying a content image representing the virtual space in a manner in which the specific action cannot be visually recognized on the user terminal of the second user when the specific situation is detected;
The at least one processor
A content distribution system that detects, as the specific situation, a situation in which an input operation to input the information to be hidden is performed on a specific object to which the information to be hidden is input in the virtual space.
請求項1に記載のコンテンツ配信システム。The content distribution system according to claim 1.
請求項1に記載のコンテンツ配信システム。 wherein the at least one processor does not transmit specific action information that defines at least the specific action among the action information that defines the action of the avatar in the virtual space to the user terminal of the second user;
The content distribution system according to claim 1.
請求項1~3のいずれか一項に記載のコンテンツ配信システム。 The specific action includes an operation by the avatar on a non-shared object that is visible only to the first user and placed in the virtual space.
The content delivery system according to any one of claims 1 to 3 .
請求項4に記載のコンテンツ配信システム。 The at least one processor detects the specific situation in response to occurrence of the non-shared object within the virtual space.
5. The content distribution system according to claim 4 .
前記第1ユーザのユーザ端末により取得された前記アバターの動作を規定する動作情報と予め用意されたテンプレートとを比較することにより、前記特定動作を規定する前記動作情報を検知し、
前記特定動作を規定する前記動作情報が検知されたことに応じて、前記特定状況を検知する、
請求項1~4のいずれか一項に記載のコンテンツ配信システム。 The at least one processor
detecting the action information defining the specific action by comparing action information defining the action of the avatar acquired by the user terminal of the first user with a template prepared in advance;
detecting the specific situation in response to detection of the action information defining the specific action;
The content distribution system according to any one of claims 1-4.
請求項1~6のいずれか一項に記載のコンテンツ配信システム。 The at least one processor displays the content image representing the avatar performing a dummy action instead of the specific action on the user terminal of the second user when the specific situation is detected.
The content distribution system according to any one of claims 1-6 .
仮想空間内に配置される第1ユーザに対応するアバターの予め定められた特定動作であって、前記第1ユーザとは異なる第2ユーザに対して隠すべき情報を入力する操作である前記特定動作が行われる特定状況を検知するステップと、
前記特定状況が検知された場合に、前記特定動作が視認できない態様で前記仮想空間を表現するコンテンツ画像を、前記第2ユーザのユーザ端末上に表示させるステップと、
を含み、
前記特定状況を検知するステップは、
前記仮想空間内において、前記隠すべき情報を入力する対象となる特定オブジェクトに対して前記隠すべき情報を入力する入力操作が行われる状況を、前記特定状況として検知するステップと、を含むコンテンツ配信方法。 A content distribution method performed by a content distribution system comprising at least one processor, comprising:
A predetermined specific action of an avatar corresponding to a first user placed in a virtual space, the specific action being an operation of inputting information to be hidden from a second user different from the first user. detecting a particular situation in which
displaying a content image representing the virtual space in a manner in which the specific action cannot be visually recognized on the user terminal of the second user when the specific situation is detected;
including
The step of detecting the specific situation includes:
and detecting, as the specific situation, a situation in which an input operation to input the information to be hidden is performed on a specific object to which the information to be hidden is input in the virtual space. .
前記特定状況が検知された場合に、前記特定動作が視認できない態様で前記仮想空間を表現するコンテンツ画像を、前記第2ユーザのユーザ端末上に表示させるステップと、
をコンピュータに実行させ、
前記特定状況を検知するステップは、
前記仮想空間内において、前記隠すべき情報を入力する対象となる特定オブジェクトに対して前記隠すべき情報を入力する入力操作が行われる状況を、前記特定状況として検知するステップと、を含むコンテンツ配信プログラム。 A predetermined specific action of an avatar corresponding to a first user placed in a virtual space, the specific action being an operation of inputting information to be hidden from a second user different from the first user. detecting a particular situation in which
displaying a content image representing the virtual space in a manner in which the specific action cannot be visually recognized on the user terminal of the second user when the specific situation is detected;
on the computer, and
The step of detecting the specific situation includes:
and detecting, as the specific situation, a situation in which an input operation to input the information to be hidden is performed on a specific object to which the information to be hidden is input in the virtual space. .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020121962A JP7291106B2 (en) | 2020-07-16 | 2020-07-16 | Content delivery system, content delivery method, and content delivery program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020121962A JP7291106B2 (en) | 2020-07-16 | 2020-07-16 | Content delivery system, content delivery method, and content delivery program |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019180710A Division JP6737942B1 (en) | 2019-09-30 | 2019-09-30 | Content distribution system, content distribution method, and content distribution program |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2021057017A JP2021057017A (en) | 2021-04-08 |
| JP2021057017A5 JP2021057017A5 (en) | 2022-08-02 |
| JP7291106B2 true JP7291106B2 (en) | 2023-06-14 |
Family
ID=75270921
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020121962A Active JP7291106B2 (en) | 2020-07-16 | 2020-07-16 | Content delivery system, content delivery method, and content delivery program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7291106B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7409467B1 (en) | 2022-11-18 | 2024-01-09 | Toppanホールディングス株式会社 | Virtual space generation device, virtual space generation program, and virtual space generation method |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016525741A (en) | 2013-06-18 | 2016-08-25 | マイクロソフト テクノロジー ライセンシング,エルエルシー | Shared holographic and private holographic objects |
| WO2017002473A1 (en) | 2015-06-30 | 2017-01-05 | ソニー株式会社 | Information processing device, information processing method, and program |
| WO2018139203A1 (en) | 2017-01-26 | 2018-08-02 | ソニー株式会社 | Information processing device, information processing method, and program |
-
2020
- 2020-07-16 JP JP2020121962A patent/JP7291106B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016525741A (en) | 2013-06-18 | 2016-08-25 | マイクロソフト テクノロジー ライセンシング,エルエルシー | Shared holographic and private holographic objects |
| WO2017002473A1 (en) | 2015-06-30 | 2017-01-05 | ソニー株式会社 | Information processing device, information processing method, and program |
| WO2018139203A1 (en) | 2017-01-26 | 2018-08-02 | ソニー株式会社 | Information processing device, information processing method, and program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021057017A (en) | 2021-04-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11615596B2 (en) | Devices, methods, and graphical user interfaces for interacting with three-dimensional environments | |
| US20220270302A1 (en) | Content distribution system, content distribution method, and content distribution program | |
| US11625091B2 (en) | Obfuscated control interfaces for extended reality | |
| KR20220012990A (en) | Gating Arm Gaze-Driven User Interface Elements for Artificial Reality Systems | |
| JP2021002288A (en) | Image processor, content processing system, and image processing method | |
| TW202206978A (en) | Private control interfaces for extended reality | |
| US20160320833A1 (en) | Location-based system for sharing augmented reality content | |
| KR20220018561A (en) | Artificial Reality Systems with Personal Assistant Element for Gating User Interface Elements | |
| KR20220018562A (en) | Gating Edge-Identified Gesture-Driven User Interface Elements for Artificial Reality Systems | |
| US11367416B1 (en) | Presenting computer-generated content associated with reading content based on user interactions | |
| JP2021152785A (en) | Video application program, video object rendering method, video distribution system, video distribution server, and video distribution method | |
| CN118786648A (en) | Apparatus, method and graphical user interface for authorizing secure operations | |
| TW202123128A (en) | Virtual character live broadcast method, system thereof and computer program product | |
| JP7291106B2 (en) | Content delivery system, content delivery method, and content delivery program | |
| WO2024114584A1 (en) | Information prompt method, information prompt apparatus, electronic device and readable storage medium | |
| CN107408186A (en) | The display of privacy content | |
| US11961190B2 (en) | Content distribution system, content distribution method, and content distribution program | |
| JP6609078B1 (en) | Content distribution system, content distribution method, and content distribution program | |
| CN111651054A (en) | Sound effect control method and device, electronic equipment and storage medium | |
| TWI839830B (en) | Mixed reality interaction method, device, electronic equipment and medium | |
| JP7548785B2 (en) | Content distribution system, content distribution method, and content distribution program | |
| JP7418498B2 (en) | Program, information processing device, and method | |
| US20240104861A1 (en) | Devices, Methods, and Graphical User Interfaces for Interacting with Three-Dimensional Environments | |
| US20240152244A1 (en) | Devices, Methods, and Graphical User Interfaces for Interacting with Three-Dimensional Environments | |
| CN118760382A (en) | Multimedia resource interaction method, device, terminal and computer readable storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220725 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220725 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230214 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230308 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230523 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230602 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7291106 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |