特許法第30条第2項適用 平成30年2月19日~23日開催 「NTT R&D フォーラム 2018」にて公開 平成30年4月19日 http://www.ntt.co.jp/news2018/1804/180419a.htmlにて公開 平成30年4月28日~29日開催 「ニコニコ超会議2018」にて公開 平成30年5月7日~12日開催 Eleventh International Conference on Language Resources and Evaluation(LREC 2018)にて公開 平成30年5月22日 http://www.ai-gakkai.or.jp/jsai2018/ http://www.ai-gakkai.or.jp/jsai2018/proceedingsにて公開 平成30年5月31日 https://link.springer.com/chapter/10.1007/978-3-319-91485-5_29にて公開 平成30年6月27日 一般社団法人情報処理学会 マルチメディア、分散、協調とモバイル(DICOMO2018)シンポジウム 論文集 pp.1863-1868 にて公開 平成30年8月27日~31日開催 The 27th IEEE International Conference on Robot and Human Interactive Communication(RO-MAN2018)にて公開
以下、図面を参照して、本発明を実施するための形態の一例について詳細に説明する。
<本実施形態の概要>
本発明の実施形態では、人間がコミュニケーションを行う際、音声情報及び音声情報に含まれる言語情報の発信と、非言語行動とが共起して起こるという特性を利用する。具体的には、本実施形態では、発話の音声情報及び発話の内容を表すテキスト情報の少なくとも一方を入力Xとして、話者の発話と一緒に生成される話者の非言語行動を表す非言語情報を出力Yとして、入力Xから出力Yを機械学習により生成する。非言語情報とは、行動に関する情報であって、言語そのもの以外の情報とする。非言語行動の例としては、例えば、頭部動作、視線方向、ハンドジェスチャ、上半身の動作、及び下半身の動作の種別(クラス)などが挙げられる。
本実施形態で得られる非言語情報は、人間と同じような身体性を持ち、人間とコミュニケーションを行う、コミュニケーションロボット、コミュニケーションエージェント、ゲームやインタラクティブシステムで利用されるCG(Computer Graphics)アニメーションにおけるジェスチャ生成等で用いられる。
[第1の実施形態]
<非言語情報生成モデル学習装置の構成>
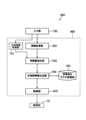
図1は、第1の実施形態に係る非言語情報生成モデル学習装置10の構成の一例を示すブロック図である。図1に示すように、本実施形態に係る非言語情報生成モデル学習装置10は、CPU(Central Processing Unit)と、RAM(Random Access Memory)と、後述する学習処理ルーチンを実行するためのプログラムを記憶したROM(Read Only Memory)とを備えたコンピュータで構成されている。非言語情報生成モデル学習装置10は、機能的には、学習用入力部20と、学習用演算部30を備えている。
学習用入力部20は、学習用の音声情報と、言語とは異なる行動に関する情報を表す学習用の非言語情報とを受け付ける。
本実施形態の非言語情報生成モデル学習装置10の入力データである学習用の音声情報と学習用の非言語情報との組み合わせを表す学習データは、例えば、図2のようなシーンにおいて、発話中の話者の音声情報(X)を取得するのと同時に、所定の計測装置を用いて発話中の話者の非言語情報(Y)も取得することで作成される。なお、音声情報(X)は、発話中の話者が外部へ発話する際の音声情報に相当する。
学習用演算部30は、学習用入力部20によって受け付けた学習データに基づいて、時刻情報付きの非言語情報を生成するための非言語情報生成モデルを生成する。学習用演算部30は、図1に示されるように、学習用情報取得部31と、学習用特徴量抽出部32と、非言語情報取得部33と、生成パラメータ抽出部34と、学習部35と、学習済みモデル記憶部36とを備えている。
学習用情報取得部31は、学習用入力部20によって受け付けられた学習用の音声情報を取得する。また、学習用情報取得部31は、学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
学習用特徴量抽出部32は、学習用情報取得部31によって取得された学習用の音声情報及び時刻情報から、当該学習用の音声情報の特徴量を表す、時刻情報付きの学習用の音声特徴量を抽出する。
例えば、学習用特徴量抽出部32は、学習用情報取得部31によって取得された学習用の音声情報に対して所定の音声情報処理を行い、基本周波数(F0)、パワー、MFCC(Mel Frequency Cepstral Coefficients)等を音声特徴量として抽出する。これらの音声特徴量は、図3に示されるように、任意の時間の窓幅TA,wと音声情報とを用いて算出することができる。図3に示されるように、これらの多次元の音声特徴量を
とする。ここで、
は、時刻tA,sから、窓幅TA,wの時間に対応する音声情報から算出された音声特徴量とする。なお、窓幅は、すべての音声特徴量で同じである必要は無く、別々に特徴量を抽出しても良い。これらの音声特徴量の抽出法は一般的であり、様々な手法がすでに提案されている(例えば、参考文献1を参照。)。このため、あらゆる手法を利用して良い。
[参考文献1]:中川 聖一,「音声言語処理と自然言語処理」,2013/3/1, コロナ社
非言語情報取得部33は、学習用入力部20によって受け付けられた学習用の非言語情報を取得し、当該学習用の非言語情報が表す行動が行われるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
非言語情報取得部33は、学習用の非言語情報として、頷き、顔向き、ハンドジェスチャ、視線、表情、及び身体の姿勢等に関する情報を取得する。頷き、顔向き、ハンドジェスチャ、視線、表情、及び身体の姿勢等に関する情報を表すパラメータの一例を以下に示す。
なお、FACSとは(Facial Action Coding System:顔面表情記号化システム)を表し、AUとは(Action Unit;活動単位)を表す。例えば、AU1は「眉の内側を持ち上げ(AU1)」というように、非言語情報がラベルによって表現される。上記以外の非言語情報としては、例えば、話者の視線行動、頭部動作、呼吸動作、及び口形変化等が挙げられる。
上記に示すように、非言語情報は、身体の関節、位置、及び動き等のイベントに関するあらゆるパラメータであって良い。計測手法は様々な手法が考えられており、どのような手法を用いても良い(例えば、参考文献2および参考文献3を参照)。
[参考文献2]:牧川方昭、南部雅幸、塩澤成弘、岡田志麻、吉田正樹、「ヒト心身状態の計測技術―人に優しい製品開発のための日常計測」,2010/10/1,コロナ社
[参考文献3]:Shihong Xia, Lin Gao, Yu-Kun Lai, Ming-Ze Yuan, Jinxiang Chai, "A Survey on Human Performance Capture and Animation",Journal of Computer Science and Technology, Volume 32, Issue 3, pp 536-554, (2017).
上記図2に示されるように、例えば、顔の向きは、人間や対話ヒューマノイドの頭部方向を頭部計測装置(ヘッドトラッカ)などの行動キャプチャ装置で計測することが可能である。また、CGなどのアニメーションデータから顔の向きを取得することも可能である。また、図2に示されるように、顔の向きは、例えば、Yaw, Roll, Pitchの3軸の角度で表現される。
生成パラメータ抽出部34は、非言語情報取得部33で取得された学習用の非言語情報が表すパラメータ(感覚尺度)を離散化して、時刻情報付きの離散化された非言語情報を抽出する。例えば、顔向きは、Yaw, Roll, Pitchの角度情報によって表されるが、任意の閾値α,β(α<β)を予め定めて、以下に示すような名義尺度に変換しても良い。なお、以下に示す例はYawのみが提示されている。
-α<Yaw<α:正面
α≦Yaw<β:少し左を向いている
β≦Yaw:大きく左を向いている
-β<Yaw≦-α:少し右を向いている
-β≧Yaw:大きく右を向いている
このように、非言語情報取得部33で取得された学習用の非言語情報を離散化し、時刻情報を付けたものを、多次元ベクトル
とする。tN,s,tN,eは、非言語情報の得られた開始時刻、終了時刻とする。
学習部35は、学習用特徴量抽出部32によって抽出された時刻情報付きの学習用の音声特徴量と、生成パラメータ抽出部34によって取得された、時刻情報付きの離散化された非言語情報とに基づいて、時刻情報付きの音声特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。
具体的には、学習部35は、学習用特徴量抽出部32によって抽出された時刻情報付きの学習用の音声特徴量
を入力として、時刻情報付きの非言語情報
を出力する非言語情報生成モデルを構築する。非言語情報生成モデルを構築するにあたり、あらゆる機械学習手法を用いて良いが、本実施形態ではSVM(Support Vector Machine)を用いる。例えば、SVMを利用して、
における各次元のパラメータのクラス分類器を構築したり、SVMを回帰へ適用したSVR(Support Vector Machine for Regression)による回帰モデルを構築したりする。
また、本実施の形態では、非言語情報が表す行動の種類毎に、当該種類の行動の有無を推定するためのSVMモデルを作成する。
なお、非言語情報生成モデルは、どのような時間分解能で、どの時刻のパラメータを使用して、非言語情報を推定するかは任意である。ここで、任意の時間区間T1~T2におけるジェスチャ
を推定する場合を例に使用する特徴量の一例を示す。推定対象となる時刻T1~T2の時刻で得られる、音声特徴量
と出力となるジェスチャ
をペアとし、これらのペアの複数データである学習データを用いて学習が行われる。その学習済みの非言語情報生成モデルを、
とする。
学習済みモデル記憶部36には、学習部35によって学習された学習済みの非言語情報生成モデルが格納される。学習済みの非言語情報生成モデルは、時刻情報付きの音声特徴量から時刻情報付きの非言語情報を生成する。
<非言語情報生成装置のシステム構成>
図4は、第1の実施形態に係る非言語情報生成装置40の構成の一例を示すブロック図である。図4に示すように、本実施形態に係る非言語情報生成装置40は、CPU(Central Processing Unit)と、RAM(Random Access Memory)と、後述する非言語情報生成処理ルーチンを実行するためのプログラムを記憶したROM(Read Only Memory)とを備えたコンピュータで構成されている。非言語情報生成装置40は、機能的には、入力部50と、演算部60と、発現部70とを備えている。
入力部50は、音声情報と当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報とを受け付ける。
演算部60は、情報取得部61と、特徴量抽出部62と、学習済みモデル記憶部63と、非言語情報生成部64とを備えている。
情報取得部61は、入力部50によって受け付けられた、音声情報と当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報とを取得する。
特徴量抽出部62は、学習用特徴量抽出部32と同様に、情報取得部61によって取得された音声情報及び時刻情報から、該音声情報の特徴量を表す、時刻情報付きの音声特徴量を抽出する。
学習済みモデル記憶部63には、学習済みモデル記憶部36に格納されている学習済みの非言語情報生成モデルと同一の学習済みの非言語情報生成モデルが格納されている。
非言語情報生成部64は、特徴量抽出部62によって抽出された時刻情報付きの音声特徴量と、学習済みモデル記憶部63に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部62によって抽出された時刻情報付きの音声特徴量に対応する時刻情報付きの非言語情報を生成する。
例えば、非言語情報生成部64は、学習済みモデル記憶部63に格納された学習済みの非言語情報生成モデル
を用いて、時刻情報付きの音声特徴量としての任意の特徴量
を入力として、時刻情報付きの非言語情報としてのジェスチャ
を取得する。
そして、非言語情報生成部64は、生成された時刻情報付きの非言語情報が、当該非言語情報に付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御する。
具体的には、非言語情報生成部64は、発現部70において、ジェスチャ
を任意の対象(例えば、アニメーションキャラクタ、ロボット等)の動作として反映させる。
発現部70は、非言語情報生成部64による制御に応じて、入力部50によって受け付けられた音声情報と非言語情報生成部64によって生成された非言語情報とを発現させる。
発現部70の一例としては、コミュニケーションロボットや、ディスプレイに表示されるコミュニケーションエージェント、ゲームやインタラクティブシステムで利用されるCGアニメーション等が挙げられる。
<非言語情報生成モデル学習装置10の作用>
次に、本実施形態に係る非言語情報生成モデル学習装置10の作用について説明する。まず、非言語情報生成モデル学習装置10の学習用入力部20に、複数の学習用の音声情報と複数の学習用の非言語情報との組み合わせを表す学習データが入力されると、非言語情報生成モデル学習装置10は、図5に示す学習処理ルーチンを実行する。
まず、ステップS100において、学習用情報取得部31は、学習用入力部20によって受け付けられた複数の学習データのうちの、学習用の音声情報と当該学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS102において、非言語情報取得部33は、学習用入力部20によって受け付けられた複数の学習データのうちの、学習用の非言語情報と当該学習用の非言語情報が表す行動が行われるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS104において、学習用特徴量抽出部32は、上記ステップS100で取得された学習用の音声情報及び時刻情報から、時刻情報付きの学習用の音声特徴量を抽出する。
ステップS106において、生成パラメータ抽出部34は、上記ステップS102で取得された学習用の非言語情報及び時刻情報から、時刻情報付きの離散化された非言語情報を抽出する。
ステップS108において、学習部35は、上記ステップS104で抽出された時刻情報付きの学習用の音声特徴量と、上記ステップS106で取得された時刻情報付きの非言語情報とに基づいて、時刻情報付きの音声特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。
ステップS110において、学習部35は、上記ステップS108で得られた学習済みの非言語情報生成モデルを、学習済みモデル記憶部36へ格納して、学習処理ルーチンを終了する。
<非言語情報生成装置40の作用>
次に、本実施形態に係る非言語情報生成装置40の作用について説明する。まず、非言語情報生成モデル学習装置10の学習済みモデル記憶部36に格納された学習済みの非言語情報生成モデルが、非言語情報生成装置40へ入力されると、非言語情報生成装置40の学習済みモデル記憶部63へ学習済みの非言語情報生成モデルが格納される。そして、入力部50に、非言語情報生成対象の音声情報が入力されると、非言語情報生成装置40は、図6に示す非言語情報生成処理ルーチンを実行する。
ステップS200において、情報取得部61は、入力部50によって受け付けられた、音声情報と当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報とを取得する。
ステップS202において、特徴量抽出部62は、学習用特徴量抽出部32と同様に、上記ステップS200で取得された音声情報及び時刻情報から、時刻情報付きの音声特徴量を抽出する。
ステップS204において、非言語情報生成部64は、学習済みモデル記憶部63に格納された学習済みの非言語情報生成モデルを読み出す。
ステップS206において、非言語情報生成部64は、上記ステップS202で抽出された時刻情報付きの音声特徴量と、上記ステップS204で読み出された学習済みの非言語情報生成モデルとに基づいて、上記ステップS202で抽出された時刻情報付きの音声特徴量に対応する時刻情報付きの非言語情報を生成する。
ステップS208において、非言語情報生成部64は、上記ステップS206で生成された時刻情報付きの非言語情報が、当該非言語情報に付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御して、非言語情報生成処理ルーチンを終了する。
以上説明したように、第1の実施形態に係る非言語情報生成装置40によれば、音声情報及び時刻情報から時刻情報付きの音声特徴量を抽出し、抽出された時刻情報付きの音声特徴量と、時刻情報付きの非言語情報を生成するための学習済みの非言語情報生成モデルとに基づいて、時刻情報付きの音声特徴量に対応する時刻情報付きの非言語情報を生成する。これにより、音声情報と非言語情報との対応付けを自動的に行い、そのコストを低減させることができる。
コミュニケーションロボットや対話エージェント等の発話音声、またはそれに対応するテキストに合わせ、ジェスチャ等の動作を行わせる際には、発話に合わせてどのようなタイミングで、どのような動作を行わせるかを決める必要がある。従来では、これらがシナリオとして全て人手で作成、設定されており、作成コストが高かった。
これに対し、本実施形態では、時刻情報付きの音声特徴量から時刻情報付きの非言語情報を生成するための学習済みの非言語情報生成モデルを生成することにより、音声情報を入力とし、入力に対応する動作に対応する時刻情報付きの非言語情報(出力のタイミングが付与された非言語情報)が出力される。
これにより、本実施形態によれば、音声情報から非言語情報を自動的に生成することが可能となるため、従来技術のように、発話に対して非言語情報を個別に登録する必要がなく、コストが大幅に削減される。また、本実施形態を用いることで、入力された音声情報に対し、人間らしい自然なタイミングでの非言語行動を生成可能であり、エージェント、及びロボット等の人間らしさや自然さの向上や、非言語行動による意図の伝達の円滑化、会話の活性化などが効果として得られる。
また、予め学習済みの非言語情報生成モデルを用いて、発話音声またはテキストを入力とし、入力に対応する動作とそのタイミングの情報を出力する。これにより、シナリオ作成コストを下げることができる。また、実際の人間の動作を元に動作が生成されるので、より自然なタイミングで動きを再現できる。
また、第1の実施形態に係る非言語情報生成モデル学習装置10によれば、時刻情報付きの学習用の音声特徴量と時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きの音声特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。これにより、音声情報と非言語情報との対応付けのコストを低減させつつ、音声特徴量から非言語情報を生成するための非言語情報生成モデルを得ることができる。
また、学習済みの非言語情報生成モデルを用いることにより、自然なタイミングでの非言語行動を生成することができる。
上記第1の実施形態では音声特徴量から非言語情報を生成する場合を例に説明した。上記第1の実施形態では、話されている内容には踏み込まず、音声特徴量として表れる情報(例えば、感情など)を手掛かりに、必要最小限の構成で非言語情報を生成することが可能である。
なお、上記第1の実施形態では、話している内容には踏み込まない(言語情報を用いない)ため、例えば動物にセンサをつけて非言語情報と音声情報(例えば、鳴き声等)とを取得し、動物型のロボットを動かしてもよい。
[第2の実施形態]
<非言語情報生成モデル学習装置の構成>
次に、本発明の第2の実施形態について説明する。なお、第1の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
第2の実施形態では、入力として音声情報の代わりにテキスト情報を用いる。そして、テキスト情報から非言語情報を生成する非言語情報生成モデルの学習を行う点が第1の実施形態と異なる。なお、第2の実施形態で用いるテキスト情報は、話者が音声によって外部へ発話する際の、発話内容を表すテキスト情報である。
図7は、第2の実施形態に係る非言語情報生成モデル学習装置210の構成の一例を示すブロック図である。図7に示すように、第2の実施形態に係る非言語情報生成モデル学習装置210は、CPUと、RAMと、後述する学習処理ルーチンを実行するためのプログラムを記憶したROMとを備えたコンピュータで構成されている。非言語情報生成モデル学習装置210は、機能的には、学習用入力部220と、学習用演算部230とを備えている。
学習用入力部220は、学習用のテキスト情報と学習用の非言語情報とを受け付ける。
学習用演算部230は、学習用入力部220によって受け付けた学習データに基づいて、時刻情報付きの非言語情報を生成するための非言語情報生成モデルを生成する。学習用演算部230は、図7に示されるように、学習用情報取得部231と、学習用特徴量抽出部232と、非言語情報取得部33と、生成パラメータ抽出部34と、学習部235と、学習済みモデル記憶部236とを備えている。
学習用情報取得部231は、学習用のテキスト情報に対応する学習用の音声情報を取得し、当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。学習用情報取得部231は、図8に示されるように、学習用テキスト解析部237と、学習用音声合成部238とを備えている。
学習用テキスト解析部237は、学習用のテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。例えば、学習用テキスト解析部237は、学習用のテキスト情報に対して形態素解析をはじめとするテキスト解析を行って、形態素毎に、単語表記(形態素)情報、品詞、カテゴリ情報、評価表現、感情表現、感性表現、擬音語・擬態語・擬声語、固有表現、主題、文字数、位置、及びシソーラス情報等を抽出し、文毎に、発話の対話行為等を抽出する。なお、形態素毎ではなく、文節毎に、単語表記(形態素)情報、品詞、カテゴリ情報、評価表現、感情表現、固有表現、主題、文字数、位置、及びシソーラス情報等を抽出してもよい。また、形態素や文節以外の任意の単位で、単語表記(形態素)情報、品詞、カテゴリ情報、評価表現、感情表現、感性表現、擬音語・擬態語・擬声語、固有表現、主題、文字数、位置、及びシソーラス情報等を抽出してもよい。例えば、文字単位でもよく、英語であれば、空白で区切った文字列単位でもよいし、句単位でもよい。また、主題の抽出については、文ごとや発話単位ごとに行ってもよい。ここで、対話行為とは、発話における意図を抽象化し、ラベルとして抽象化したものである。主題とは、テキストにおける話題や焦点を表す情報である。文字数とは、形態素又は文節内の文字数である。位置とは、文頭、文末からの形態素又は文節の位置である。シソーラス情報とは、日本語語彙大系に基づく形態素又は文節内の単語のシソーラス情報である。これらのテキスト特徴量の抽出法は一般的なものでよく、様々な手法がすでに提案されている(上記参考文献1及び下記参考文献4~6を参照)。本実施形態では、これらの情報のうち、単語表記(形態素)情報、品詞、対話行為、文字数、位置、及びシソーラス情報を用いる場合を例に説明を行う。
[参考文献4]:R Higashinaka, K Imamura, T Meguro, C Miyazaki, N Kobayashi, H Sugiyama, T Hirano, T Makino, Y Matsuo, "Towards an open-domain conversational system fully based on natural language processing", In Proceedings of International conference on Computational linguistics, pp. 928-939, 2014
[参考文献5]:日本特開2014-222399号公報
[参考文献6]:日本特開2015-045915号公報
学習用音声合成部238は、学習用テキスト解析部237によって取得されたテキスト解析結果に基づいて、学習用のテキスト情報に対応する学習用の音声情報を合成する。例えば、学習用音声合成部238は、テキスト解析結果を用いて音声合成を行い、テキスト情報に対応する発話を生成し、学習用のテキスト情報に対応する学習用の音声情報とする。
また、学習用音声合成部238は、学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。具体的には、学習用音声合成部238は、音声合成により生成された発話の音声の開始時刻から終了時刻に対応する時刻情報を取得する。この時刻情報は、発話に対応するテキスト情報の各形態素に対応したものとする。なお、テキスト情報に含まれる文字毎に開始時刻と終了時刻とを取得するようにしてもよい。
学習用特徴量抽出部232は、学習用音声合成部238によって取得された学習用のテキスト情報及び時刻情報から、当該学習用のテキスト情報の特徴量を表す、時刻情報付きの学習用のテキスト特徴量を抽出する。具体的には、学習用特徴量抽出部232は、所定の解析単位毎に当該テキスト情報に対して時刻情報を付与して、時刻情報付きのテキスト特徴量を抽出する。
具体的には、学習用特徴量抽出部232は、学習用音声合成部238によって出力された学習用のテキスト情報に対して文分割を行う。次に、学習用特徴量抽出部232は、学習用テキスト解析部237で得られた対話行為に関するテキスト特徴量
を一文ごとに抽出する。なお、
は、一文に該当する発話の開始時刻及び終了時刻とする。
また、学習用特徴量抽出部232は、分割により得られた各文を構成する複数の形態素の各々について、当該形態素の単語表記情報、品詞、カテゴリ情報(例えば、名詞、固有表現、及び用言等)、評価表現、感情表現、固有表現、文字数、文中の位置、シソーラス情報等のうち、少なくとも単語表記情報を抽出する。そして、学習用特徴量抽出部232は、これらの多次元特徴量を
とする。なお、
は、形態素単位に該当する発話音声の開始時刻及び終了時刻とする。時刻情報付きのテキスト特徴量の一例を図3に示す。図3に示されるように、テキスト情報の各形態素の開始時刻及び終了時刻が取得されている。
なお、分割により得られた各文を構成する複数の文節の各々について、当該文節の単語表記情報、品詞、カテゴリ情報(例えば、名詞、固有表現、及び用言等)、評価表現、感情表現、固有表現、文字数、文中の位置、シソーラス情報等を抽出してもよい。そして、学習用特徴量抽出部232は、これらの多次元特徴量を
とする。なお、
は、文節単位に該当する発話音声の開始時刻及び終了時刻とする。
学習用情報取得部231において、音声認識及び音声合成を行った際に得られる情報を流用してもよい。
学習部235は、学習用特徴量抽出部232によって抽出された時刻情報付きの学習用のテキスト特徴量と、生成パラメータ抽出部34によって抽出された時刻情報付きの学習用の離散化された非言語情報とに基づいて、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。
具体的には、学習部235は、学習用特徴量抽出部232によって抽出された時刻情報付きの学習用のテキスト特徴量
を入力として、非言語情報
を出力する非言語情報生成モデルを構築する。非言語情報生成モデルを構築する際には、あらゆる機械学習手法を用いて良いが、本実施形態ではSVMを用いる。
なお、非言語情報生成モデルは、どのような時間分解能で、どの時刻のパラメータを使用して、非言語情報を推定するかは任意である。ここで、任意の時間区間T1~T2におけるジェスチャ
を推定する場合を例に使用する特徴量の一例を示す。推定対象となる時刻T1~T2の時刻で得られる、言語特徴量
と出力となるジェスチャ
をペアとし、これらのペアの複数データである学習データを用いて学習が行われる。その学習済みの非言語情報生成モデルを、
とする。なお、T1,T2の設定方法として、例えば、形態素単位で非言語情報の推定が行われる場合には、各形態素の開始時刻及び終了時刻をT1,T2とする。この場合には、形態素毎にT2からT1までのウィンドウ幅は異なる。
学習済みモデル記憶部236には、学習部235によって学習された学習済みの非言語情報生成モデルが格納される。学習済みの非言語情報生成モデルは、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成する。
<非言語情報生成装置の構成>
図9は、第2の実施形態に係る非言語情報生成装置240の構成の一例を示すブロック図である。図9に示すように、本実施形態に係る非言語情報生成装置240は、CPU(Central Processing Unit)と、RAM(Random Access Memory)と、後述する非言語情報生成処理ルーチンを実行するためのプログラムを記憶したROM(Read Only Memory)とを備えたコンピュータで構成されている。非言語情報生成装置240は、機能的には、入力部250と、演算部260と、発現部70とを備えている。
入力部250は、テキスト情報を受け付ける。
演算部260は、情報取得部261と、特徴量抽出部262と、学習済みモデル記憶部263と、非言語情報生成部264とを備えている。
情報取得部261は、入力部250によって受け付けられたテキスト情報を取得する。また、情報取得部261は、テキスト情報に対応する音声情報を取得し、当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。情報取得部261は、図10に示されるように、テキスト解析部265と、音声合成部266とを備えている。
テキスト解析部265は、学習用テキスト解析部237と同様に、入力部250によって受け付けられたテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。
音声合成部266は、学習用音声合成部238と同様に、テキスト解析部265によって取得されたテキスト解析結果に基づいて、テキスト情報に対応する音声情報を合成する。そして、音声合成部266は、音声合成により生成された発話の音声の開始時刻から終了時刻に対応する時刻情報を取得する。
特徴量抽出部262は、学習用特徴量抽出部232と同様に、情報取得部261によって取得されたテキスト情報及び時刻情報から、該テキスト情報の特徴量を表す、時刻情報付きのテキスト特徴量を抽出する。
学習済みモデル記憶部263には、学習済みモデル記憶部236に格納されている学習済みの非言語情報生成モデルと同一の学習済みの非言語情報生成モデルが格納されている。
非言語情報生成部264は、特徴量抽出部262によって抽出された時刻情報付きのテキスト特徴量と、学習済みモデル記憶部263に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部262によって抽出された時刻情報付きのテキスト特徴量に対応する時刻情報付きの非言語情報を生成する。
例えば、非言語情報生成部264は、学習済みモデル記憶部263に格納された学習済みの非言語情報生成モデル
を用いて、時刻情報付きのテキスト特徴量としての任意の特徴量
を入力として、時刻情報付きの非言語情報に対応する生成パラメータとしてのジェスチャ
を取得する。
そして、非言語情報生成部264は、生成された時刻情報付きの生成パラメータが、発現部70から出力されるように発現部70を制御する。
具体的には、非言語情報生成部264は、発現部70において、ジェスチャ
を任意の対象(例えば、アニメーションキャラクタ、ロボット等)の動作として反映させる。
発現部70は、非言語情報生成部264による制御に応じて、入力部250によって受け付けられたテキスト情報に対応する音声情報と非言語情報生成部264によって生成された非言語情報とを発現させる。
<非言語情報生成モデル学習装置210の作用>
次に、第2の実施形態に係る非言語情報生成モデル学習装置210の作用について説明する。まず、非言語情報生成モデル学習装置210の学習用入力部220に、複数の学習用のテキスト情報と複数の学習用の非言語情報との組み合わせを表す学習データが入力されると、非言語情報生成モデル学習装置210は、図11に示す学習処理ルーチンを実行する。
まず、ステップS300において、学習用情報取得部231は、学習用入力部220によって受け付けられた複数の学習データ(具体的には、テキスト情報と非言語情報との対)のうちの、学習用のテキスト情報を取得する。
ステップS303において、学習用テキスト解析部237は、上記ステップS300で取得された学習用のテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、学習用音声合成部238は、学習用テキスト解析部237によって取得されたテキスト解析結果に基づいて、学習用のテキスト情報に対応する学習用の音声情報を合成する。そして、学習用音声合成部238は、学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS304において、学習用特徴量抽出部232は、上記ステップS303で取得された学習用のテキスト情報及び時刻情報から、時刻情報付きの学習用のテキスト特徴量を抽出する。
ステップS308において、学習部235は、上記ステップS304で抽出された時刻情報付きの学習用のテキスト特徴量と、ステップS106で取得された時刻情報付きの学習用の生成パラメータとに基づいて、時刻情報付きのテキスト特徴量から時刻情報付きの生成パラメータを生成するための非言語情報生成モデルを学習する。
<非言語情報生成装置240の作用>
次に、第2の実施形態に係る非言語情報生成装置240の作用について説明する。まず、非言語情報生成モデル学習装置210の学習済みモデル記憶部236に格納された学習済みの非言語情報生成モデルが、非言語情報生成装置240へ入力されると、非言語情報生成装置240の学習済みモデル記憶部263へ学習済みの非言語情報生成モデルが格納される。そして、入力部250に、非言語情報生成対象のテキスト情報が入力されると、非言語情報生成装置240は、図12に示す非言語情報生成処理ルーチンを実行する。
ステップS400において、情報取得部261は、入力部250によって受け付けられた、テキスト情報を取得する。
ステップS401において、テキスト解析部265は、上記ステップS400で取得されたテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、音声合成部266は、テキスト解析部265によって取得されたテキスト解析結果に基づいて、テキスト情報に対応する音声情報を合成する。そして、音声合成部266は、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS402において、特徴量抽出部262は、上記ステップS401で取得されたテキスト情報及び時刻情報から、時刻情報付きのテキスト特徴量を抽出する。
ステップS404において、非言語情報生成部264は、学習済みモデル記憶部263に格納された学習済みの非言語情報生成モデルを読み出す。
ステップS406において、非言語情報生成部264は、上記ステップS402で抽出された時刻情報付きのテキスト特徴量と、上記ステップS404で読み出された学習済みの非言語情報生成モデルとに基づいて、上記ステップS402で抽出された時刻情報付きのテキスト特徴量に対応する時刻情報付きの生成パラメータを生成する。
なお、第2の実施形態に係る非言語情報生成装置及び非言語情報生成モデル学習装置の他の構成及び作用については、第1の実施形態と同様であるため、説明を省略する。
以上説明したように、第2の実施形態に係る非言語情報生成装置240によれば、テキスト情報に対応する音声情報を取得し、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得し、時刻情報付きのテキスト特徴量と時刻情報付きの非言語情報を生成するための学習済みモデルとに基づいて、時刻情報付きのテキスト特徴量に対応する時刻情報付きの非言語情報を生成する。これにより、テキスト情報と非言語情報との対応付けを自動的に行い、そのコストを低減させることができる。
また、本実施形態では、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための学習済みの非言語情報生成モデルを生成することにより、テキスト情報を入力とし、入力に対応する動作に対応する時刻情報付きの非言語情報(出力のタイミングが付与された非言語情報)が出力される。
これにより、本実施形態によれば、テキスト情報から非言語情報を自動的に生成することが可能となるため、従来技術のように、発話に対して非言語情報を個別に登録する必要がなく、コストが大幅に削減される。また、本実施形態を用いることで、入力されたテキスト情報に対し、人間らしい自然なタイミングでの非言語行動を生成可能であり、エージェント、及びロボット等の人間らしさや自然さの向上や、非言語行動による意図の伝達の円滑化、会話の活性化などが効果として得られる。
また、第2の実施形態に係る非言語情報生成モデル学習装置210によれば、時刻情報付きの学習用のテキスト特徴量と時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。これにより、テキスト情報と非言語情報との対応付けのコストを低減させつつ、テキスト特徴量から非言語情報を生成するための非言語情報生成モデルを得ることができる。
また、上記第2の実施形態ではテキスト特徴量から非言語情報を生成する場合を例に説明した。上記第2の実施形態では、単語表記や品詞、対話行為等の情報を手掛かりに、非言語情報を生成することが可能である。この構成を用いれば、チャットにおける対話のように、入力に音声を伴わない場合に、必要最小限の構成で非言語情報を生成することが可能である。
[第3の実施形態]
次に、本発明の第3の実施形態について説明する。なお、第1又は第2の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
第3の実施形態では、入力として音声情報及びテキスト情報の両方を用いる。音声情報及びテキスト情報から非言語情報を生成する点が第1及び第2の実施形態と異なる。なお、第3の実施形態で用いるテキスト情報は、話者が音声によって外部へ発話する際の、発話内容を表すテキスト情報である。
第3の実施形態の非言語情報生成モデル学習装置における学習用情報取得部331と学習用特徴量抽出部332との構成例を図13Aに示す。
図13Aに示されるように、学習用の音声情報が入力されると、学習用音声認識部337は、学習用の音声情報に対して所定の音声認識処理を行い、学習用の音声情報に対応するテキスト情報(以下、学習用の認識テキストと称する。)を取得する。
そして、学習用テキスト解析部338は、学習用の認識テキストに対して所定のテキスト解析を行い、テキスト解析結果を取得する。
そして、学習用特徴量抽出部332は、学習用の音声情報から時刻情報付きの音声特徴量を抽出する。また、学習用特徴量抽出部332は、学習用の認識テキストから時刻情報付きのテキスト特徴量を抽出する。
そして、第3の実施形態の学習部(図示省略)は、学習用の時刻情報付きの音声特徴量及び学習用の時刻情報付きのテキスト特徴量と、学習用の非言語情報とに基づいて、非言語情報生成モデルを学習させる。これにより、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを得ることができる。
第3の実施形態の非言語情報生成装置における情報取得部361と特徴量抽出部362との構成例を図13Bに示す。
図13Bに示されるように、音声情報が入力されると、音声認識部365は、音声情報に対して所定の音声認識処理を行い、音声情報に対応するテキスト情報(以下、認識テキストと称する。)を取得する。そして、テキスト解析部366は、認識テキストに対して所定のテキスト解析を行い、テキスト解析結果を取得する。
そして、特徴量抽出部362は、音声情報から時刻情報付きの音声特徴量を抽出する。また、特徴量抽出部362は、認識テキストから時刻情報付きのテキスト特徴量を抽出する。
そして、第3の実施形態の非言語情報生成部(図示省略)は、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量と学習済みの非言語情報生成モデルとに基づいて、時刻情報付きの非言語情報を生成する。これにより、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量の両方を用いて、非言語情報を適切に生成することができる。
なお、音声特徴量とテキスト特徴量との両方を用いて非言語情報を生成する場合には、時刻情報の時間軸は、上記図3に示されるように、音声特徴量とテキスト特徴量との間で対応が取られ一致していることが望ましい。
また、音声特徴量とテキスト特徴量との両方を用いて非言語情報を生成し、非言語情報を発現部により発現させる場合には、入力となる音声情報やテキスト情報、テキスト情報から得られた合成音声や音声情報から得られた認識テキストと合わせて提示することも可能である。
以上説明したように、第3の実施形態に係る非言語情報生成装置によれば、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量と、時刻情報付きの非言語情報を生成するための学習済みの非言語情報生成モデルとに基づいて、時刻情報付きの非言語情報を生成する。これにより、音声情報及びテキスト情報と非言語情報との対応付けのコストを低減させることができる。
また、第3の実施形態に係る非言語情報生成モデル学習装置によれば、学習用の時刻情報付きの音声特徴量及び学習用の時刻情報付きのテキスト特徴量に基づいて、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを得ることができる。
なお、上記第3の実施形態では、入力情報が音声情報である場合を例に説明したが、これに限定されるものではない。例えば、入力情報がテキスト情報であってもよい。
入力情報がテキスト情報である場合の、非言語情報生成モデル学習装置における学習用情報取得部431と学習用特徴量抽出部432との構成例を図14Aに示す。
図14Aに示されるように、学習用のテキスト情報が入力されると、学習用テキスト解析部437は、学習用のテキスト情報に対して所定のテキスト解析処理を行い、学習用のテキスト情報に対応するテキスト解析結果を取得する。
そして、学習用音声合成部438は、テキスト解析結果に対して所定の音声合成処理を行い、学習用の音声情報を取得する。
そして、学習用特徴量抽出部432は、学習用の音声情報から時刻情報付きの音声特徴量を抽出する。また、学習用特徴量抽出部432は、学習用のテキスト情報から時刻情報付きのテキスト特徴量を抽出する。
そして、学習部(図示省略)は、学習用の時刻情報付きの音声特徴量及び学習用の時刻情報付きのテキスト特徴量と、学習用の非言語情報とに基づいて、非言語情報生成モデルを学習させる。これにより、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを得ることができる。
また、入力情報がテキスト情報である場合の、非言語情報生成装置における情報取得部461と特徴量抽出部462との構成例を図14Bに示す。
図14Bに示されるように、テキスト情報が入力されると、テキスト解析部465は、テキスト情報に対して所定のテキスト解析処理を行い、テキスト情報に対応するテキスト解析結果を取得する。
そして、音声合成部466は、テキスト解析結果に対して所定の音声合成処理を行い、音声情報を取得する。
そして、特徴量抽出部462は、音声情報から時刻情報付きの音声特徴量を抽出する。また、特徴量抽出部462は、テキスト情報から時刻情報付きのテキスト特徴量を抽出する。
そして、非言語情報生成部(図示省略)は、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量と、予め学習された非言語情報生成モデルとに基づいて、非言語情報を表す生成パラメータを取得する。
なお、本発明は、上述した実施形態に限定されるものではなく、この発明の要旨を逸脱しない範囲内で様々な変形や応用が可能である。
例えば、上記各実施形態における、情報取得部(又は学習用情報取得部)と特徴量抽出部(又は学習用特徴量抽出部)との組み合わせに対応する構成は、図15に示される全4パターンである。また、学習時と非言語情報生成時との構成の組み合わせとして、可能なバリエーションは、図16に示されるパターンとなる。なお、学習時と生成時の特徴量が一致している方が、非言語情報生成時の精度は高くなる。
また、本発明は、周知のコンピュータに媒体もしくは通信回線を介して、プログラムをインストールすることによっても実現可能である。
また、上述の装置は、内部にコンピュータシステムを有しているが、「コンピュータシステム」は、WWW(World Wide Web)システムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
また、本願明細書中において、プログラムが予めインストールされている実施形態について説明したが、当該プログラムを、コンピュータ読み取り可能な記録媒体に格納して提供することも可能である。
なお、以下に、他の実施形態を説明する。
[他の実施形態の概要]
非言語情報生成モデル学習装置において用いる学習データとして、例えば、上記図2に示されるようなシーンにおいて、発話中の話者の音声情報(X)を取得するのと同時に、計測装置を用いて発話中の話者の話し相手である会話相手の非言語情報(Y)を取得することにより作成する。
そのようにして作成された学習データに基づいて、非言語情報生成モデルの学習を行うと、入力情報である音声情報又はテキスト情報に対し、適切なタイミングでリアクション(例えば、相槌など)の非言語行動を行うエージェント及びロボット等が実現可能となる。
さらに、上記図2のようなシーンにおいて、発話中の話者の音声情報(X)を取得するのと同時に、計測装置を用いて他の参加者の非言語情報(Y)を取得することにより、学習データを作成することもできる。
そのようにして複数の参加者のそれぞれの非言語情報を元に、非言語情報生成モデルの学習を行えば、複数ロボットやエージェントに、入力情報である音声情報又はテキスト情報に対し、適切かつ異なるタイミングでリアクションを行わせることが可能となる。
この場合には、話者から取得された音声情報と当該話者の相手(例えば、会話の聞き手又は会話の参加者)の行動に関する情報を表す非言語情報との組み合わせを学習データとして、学習済みの非言語情報生成モデルを学習させる。ここで、当該話者の相手として、会話の聞き手、会話の参加者だけでなく、会話の傍聴者等も含めてもよく、これら「話者の音声(及びその内容)を受けて何らかの反応を示す実体」について、「発声の聞き手」とも表現する。
また、テキスト情報を対象とする場合には、話者から取得された音声情報に対応するテキスト情報と当該話者の相手(例えば、会話の聞き手又は会話の参加者)の行動に関する情報を表す非言語情報との組み合わせを学習データとして、学習済みの非言語情報生成モデルを学習させる。
なお、以下の第4の実施形態~第6の実施形態は、第1の変形例~第3の変形例である。
[第4の実施形態]
第4の実施形態では、音声情報を対象とし、非言語情報生成モデル学習装置は、話者(図2の「話者」)から出力された学習用の音声情報から抽出される時刻情報付きの学習用の音声特徴量と、話者の相手(図2の「他の参加者」または「話者の会話相手」)の行動に関する情報を表す学習用の非言語情報とに基づいて、時刻情報付きの音声特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習させる。これにより、話者から取得される音声情報に応じて、話者の相手の行動を表現する学習済みの非言語情報生成モデルが得られる。なお、図2に示されるように、「話者」とは、発話等の音声を発する人物を表す。また、「話者の相手」とは、例えば、話者から発せられた発話等を聞いている人物を表し、図2に示される「他の参加者」及び「話者の会話相手」に相当する。また、話者の相手の行動とは、話者が発した音声に対する、話者の相手のリアクション等である。
また、非言語情報生成対象の音声情報が入力された場合には、非言語情報生成装置は、話者から取得された音声情報から抽出される時刻情報付きの音声特徴量と、学習済みの非言語情報生成モデルとに基づいて、時刻情報付きの非言語情報を生成する。
なお、第4の実施形態の非言語情報生成モデル学習装置及び非言語情報生成装置の他の構成及び作用については、第1の実施形態と同様であるため、説明を省略する。
[第5の実施形態]
第5の実施形態では、テキスト情報を対象とし、非言語情報生成モデル学習装置は、話者から取得された学習用の音声情報に対応するテキストから抽出される時刻情報付きの学習用のテキスト特徴量と、話者の相手の行動に関する情報を表す学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習させる。これにより、話者から取得される音声情報に対応するテキスト情報に応じて、話者の相手の行動を表現する学習済みの非言語情報生成モデルが得られる。
また、非言語情報生成対象のテキスト情報が入力された場合には、非言語情報生成装置は、話者から取得された音声情報に対応するテキスト情報から抽出される時刻情報付きのテキスト特徴量と、学習済みの非言語情報生成モデルとに基づいて、時刻情報付きの非言語情報を生成する。
なお、第5の実施形態の非言語情報生成モデル学習装置及び非言語情報生成装置の他の構成及び作用については、第2の実施形態と同様であるため、説明を省略する。
[第6の実施形態]
第6の実施形態では、音声情報とテキスト情報との両方を対象とし、非言語情報生成モデル学習装置は、時刻情報付きの学習用の音声特徴量及び時刻情報付きの学習用のテキスト特徴量と、話者の相手の行動に関する情報を表す学習用の非言語情報とに基づいて、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習させる。これにより、音声情報及びテキスト情報に応じて、話者の相手の行動を表現する学習済みの非言語情報生成モデルが得られる。
また、非言語情報生成対象の音声情報とテキスト情報との両方が入力された場合には、非言語情報生成装置は、時刻情報付きの音声特徴量及び時刻情報付きのテキスト特徴量と、学習済みの非言語情報生成モデルとに基づいて、時刻情報付きの非言語情報を生成する。
なお、第6の実施形態の非言語情報生成モデル学習装置及び非言語情報生成装置の他の構成及び作用については、第3の実施形態と同様であるため、説明を省略する。
[第7の実施形態]
<非言語情報生成モデル学習装置の構成>
次に、本発明の第7の実施形態について説明する。なお、第1の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
第7の実施形態では、入力された発話に対応するジェスチャを、学習済みの機械学習モデルに基づいて生成する。その際、ジェスチャとして、行動の有無だけでなく、大きさ、回数、ポーズ長の割合の情報も生成する。また、入力として用いる発話音声またはテキストに加えて、ジェスチャの生成に影響を与える変数を「付加情報」として更に用いて、非言語情報を生成する非言語情報生成モデルの学習を行う点が第1の実施形態と異なる。
なお、第7の実施形態で用いるテキスト情報は、話者が音声によって外部へ発話する際の、発話内容を表すテキスト情報である。
図17は、第7の実施形態に係る非言語情報生成モデル学習装置710の構成の一例を示すブロック図である。図17に示すように、第7の実施形態に係る非言語情報生成モデル学習装置710は、CPUと、RAMと、後述する学習処理ルーチンを実行するためのプログラムを記憶したROMとを備えたコンピュータで構成されている。非言語情報生成モデル学習装置710は、機能的には、学習用入力部720と、学習用演算部730とを備えている。
学習用入力部720は、学習用のテキスト情報と学習用の非言語情報と学習用の付加情報との組み合わせを含む学習データを受け付ける。
受け付ける非言語情報は、行動の有無だけでなく、大きさ、回数、ポーズ長の割合の情報も含む。
具体的には、非言語情報には、以下の表2~表4に示す行動リスト表に含まれる何れかの行動が含まれる。
ここで、学習用のテキスト情報は、発話音声データを基に、それぞれ1人ずつの発話を人手で書き起こしたものであり、発話区間は、200msec以上の無音区間で区切った。
また、学習用の非言語情報は、発話音声データに対応する発話時の動きを考慮して付与されたものである。非言語情報は、例えば、頷き、顔向き、ハンドジェスチャ、視線、表情、身体の姿勢、身体の関節、位置、動き、瞳孔径の大きさ、及び瞬きの有無等である。
学習用の非言語情報に含まれるハンドジェスチャは、例えば、発話時の手の動きに加えて、発話内容を考慮しながらアノテーションを行ったものである。また、学習用の非言語情報に含まれるハンドジェスチャは、自動認識により得られたものでもよい。ハンドジェスチャの自動認識については、画像処理などを利用した方法(例えば、参考文献7)が多く提案されており、どのような方法でもよい。
[参考文献7]Siddharth S. Rautaray, Anupam Agrawal, "Vision based hand gesture recognition for human computer interaction: a survey", Artificial Intelligence Review, January 2015, Volume 43, Issue 1, pp. 1-54.
ここで、ハンドジェスチャの種別として参考文献8に記載されたものと同様なものを用いればよい。例えば、(A) Iconic、(B) Metaphoric、(C) Beat、(D) Deictic、(E) Feedback、(F) Compellation、(G) Hesitate、(H) Othersが、ハンドジェスチャの詳細な種別である。
[参考文献8]D. McNeill, "Hand and Mind: What Gestures Reveal About Thought", Chicago: University of Chicago Press, 1992
(A) Iconicは、情景描写、動作を表現するために使われるジェスチャである。(B) Metaphoricは、Iconicと同様、絵画的、図形的なジェスチャであるが、指示される内容は抽象的な事柄、概念となる(時間の流れなど)。(C) Beatは、発話の調子を整えたり、発言を強調したりするジェスチャであり、手を振動させたり、発話に合わせて手を振ったりするジェスチャである。(D) Deicticは、指差しなど、直接的に方向や、場所、事物を指し示すジェスチャである。(E) Feedbackは、他人の発話に同調・同意・呼応して出るジェスチャや、他人の前の発話・ジェスチャに対して、呼応して発言したときに付随するジェスチャ、相手のジェスチャを模倣して同じ形のジェスチャを行ったものである。(F) Compellationは、相手に呼びかけを行うジェスチャである。(G) Hesitateは、言いよどみ時に出るジェスチャである。(H) Othersは、判断に迷うが、何か意味がありそうなジェスチャである。
なお、ハンドジェスチャのアノテーションでは、上記のハンドジェスチャの種別だけでなく、Prep、Hold、Stroke、Returnの4つの状態を示すアノテーションも付与するようにしてもよい。
Prepは、ホームポジションからジェスチャをするために手を上げる状態を示し、Holdは、空中に手をあげたままの状態(ジェスチャ開始までの待機時間)を示す。また、Strokeは、ジェスチャを実施する状態を示し、この状態の詳細情報として、上記(A)~(H)までの種別のアノテーションを与える。Returnは、手をホームポジションに戻す状態を示す。
また、学習用の非言語情報に含まれる頷きジェスチャは、例えば、発話時に頭を下げて戻すまでの頷き区間に対してアノテーションを行ったものである。また、頭を前に出して戻す動作、あるいは後ろに引いて戻す動作も頷きとし、アノテーションを行った。首をかしげる動作や、左右に振る動作は、頷きとはしなかった。
休止を挟まずに連続して2回以上頷いた場合は、連続した区間をひとまとまりに付け、頷いた回数を付与した。頷きの回数は、「1回、2回、3回、4回、5回以上」で分類した。
受け付ける学習用の付加情報は、所定の処理単位毎(例えば、形態素毎)の付加情報である。付加情報として、個人属性、環境変数、身体的特徴、動作対象の姿勢、対話の内容、人間関係、及び感情の少なくとも1つを受け付ける。具体的には、個人属性は、性別、年齢、性格、国籍、文化圏を含み、環境変数は、対話時の人数(1対1、1対多、多対多)、気温、屋内/屋外、陸上/空中/水中、明るい/暗い、等を含む。また、身体的特徴は、3頭身、服装:ポケットがある、スカートをはいている、帽子を被っている等、動作に影響を与えるものを含み、動作対象の姿勢は、立っている、座っている、何か手に持っている、を含む。また、対話の内容は、議論、雑談、説明などを含み、人間関係は、ジェスチャを生成させる人物と対話相手との人間関係、どちらが立場が優位か、好意をもっているかなどを含む。感情は、喜び、怒り、悲しみなどの他、緊張/リラックス等の精神状態も含む、内部状態を表すものである。
なお、付加情報が、所定の処理単位毎に変化しないもの(例えば、性別)である場合には、所定の処理単位毎に受け付けなくてもよい。この場合には、付加情報を受け付けた際に、装置側で、所定の処理単位毎の付加情報に展開すればよい。
学習用演算部730は、学習用入力部720によって受け付けた学習データに基づいて、時刻情報付きの非言語情報を生成するための非言語情報生成モデルを生成する。学習用演算部730は、図17に示されるように、学習用情報取得部231と、学習用付加情報取得部731と、学習用特徴量抽出部732と、非言語情報取得部33と、生成パラメータ抽出部34と、学習部735と、学習済みモデル記憶部736とを備えている。
学習用情報取得部231は、学習用のテキスト情報に対応する学習用の音声情報を取得し、当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
学習用付加情報取得部731は、学習用の付加情報を取得する。
学習用特徴量抽出部732は、学習用情報取得部231によって取得された学習用のテキスト情報及び時刻情報から、当該学習用のテキスト情報の特徴量を表す、時刻情報付きの学習用のテキスト特徴量を抽出する。具体的には、学習用特徴量抽出部732は、所定の解析単位毎に当該テキスト情報に対して時刻情報を付与して、時刻情報付きのテキスト特徴量を抽出する。時刻情報付きのテキスト特徴量の一例を図18に示す。図18に示されるように、テキスト情報の各形態素の開始時刻及び終了時刻が取得されている。
また、学習用特徴量抽出部732は、学習用付加情報取得部731によって取得された学習用の付加情報と、学習用情報取得部231によって取得された時刻情報とから、時刻情報付きの学習用の付加情報を生成する。具体的には、学習用特徴量抽出部732は、所定の解析単位毎に当該付加情報に対して時刻情報を付与して、時刻情報付きの付加情報を生成する。
時刻情報付きの付加情報の一例を図18に示す。図18に示されるように、各形態素の付加情報に、当該形態素の開始時刻及び終了時刻が取得されている。また、付加情報が複数種類ある場合(例えば、対話人数と感情と気温)には、付加情報が、複数種類の付加情報を格納したベクトル配列として表されている。
学習用特徴量抽出部732は、付加情報のベクトル配列を
とする。なお、
は、形態素単位に該当する発話音声の開始時刻及び終了時刻とする。
学習部735は、学習用特徴量抽出部732によって抽出された時刻情報付きの学習用のテキスト特徴量及び時刻情報付きの付加情報と、生成パラメータ抽出部34によって抽出された時刻情報付きの学習用の離散化された非言語情報とに基づいて、時刻情報付きのテキスト特徴量及び付加情報から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。
具体的には、学習部735は、学習用特徴量抽出部732によって抽出された時刻情報付きの学習用のテキスト特徴量
、及び時刻情報付きの学習用の付加情報
を入力として、非言語情報
を出力する非言語情報生成モデルを構築する。非言語情報生成モデルを構築する際には、あらゆる機械学習手法を用いて良いが、本実施形態ではSVMを用いる。例えば、上記(A)~(H)までの種別毎に、ジェスチャが、当該種別に属する何れの行動であるかを推定するためのSVMモデルを作成する。すわなち、上記(A)~(H)までの種別毎に、ジェスチャが、上記の行動リスト表の、当該種別に属する内容として記載されている複数の行動のうち、何れの行動であるかを推定するためのSVMモデルを作成する。
なお、非言語情報生成モデルは、どのような時間分解能で、どの時刻のパラメータを使用して、非言語情報を推定するかは任意である。ここで、任意の時間区間T1~T2におけるジェスチャ
を推定する場合を例に使用する特徴量の一例を示す。推定対象となる時刻T1~T2の時刻で得られる、言語特徴量
、及び付加情報
と、出力となるジェスチャ
をペアとし、これらのペアの複数データである学習データを用いて学習が行われる。その学習済みの非言語情報生成モデルを、
とする。なお、T1,T2の設定方法として、例えば、形態素単位で非言語情報の推定が行われる場合には、各形態素の開始時刻及び終了時刻をT1,T2とする。この場合には、形態素毎にT2からT1までのウィンドウ幅は異なる。
また、
は、T1からT2内で得られる非言語情報の平均値や、出現した非言語情報の組み合わせや、その出現順序を考慮したパターンでも良い。例えば、ハンドジェスチャID
が、T1からT3(T1<T3<T2)内で
、T3からT2内で
であったとき、
として、より出現時間の高かったIDや、組み合わせ情報である
、ngramパターンとしての
を採用する。
n-gramパターンを用いる場合、n-gramパターン内の非言語情報の時刻情報(上の例では、
の、それぞれの開始時刻など)は、各非言語情報ごとにあらかじめ設定された所定の方法で割り振られることになる。しかし、このn-gramパターン内の非言語情報の時刻情報も推定するようにしてもよい。この場合、n-gramパターンを推定する際に用いた特徴量と、推定されたn-gramを用いて、学習データに基づき、時刻情報の推定を行うようにする。
学習済みモデル記憶部736には、学習部735によって学習された学習済みの非言語情報生成モデルが格納される。学習済みの非言語情報生成モデルは、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成する。
<非言語情報生成装置の構成>
図19は、第7の実施形態に係る非言語情報生成装置740の構成の一例を示すブロック図である。図19に示すように、本実施形態に係る非言語情報生成装置740は、CPU(Central Processing Unit)と、RAM(Random Access Memory)と、後述する非言語情報生成処理ルーチンを実行するためのプログラムを記憶したROM(Read Only Memory)とを備えたコンピュータで構成されている。非言語情報生成装置740は、機能的には、入力部750と、演算部760と、発現部70とを備えている。
入力部750は、テキスト情報及び付加情報を受け付ける。受け付ける付加情報は、所定の処理単位毎(例えば、形態素毎)の付加情報である。
演算部760は、情報取得部261と、付加情報取得部761と、特徴量抽出部762と、学習済みモデル記憶部763と、非言語情報生成部764とを備えている。
情報取得部261は、入力部750によって受け付けられたテキスト情報を取得する。また、情報取得部261は、テキスト情報に対応する音声情報を取得し、当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
付加情報取得部761は、入力部750によって受け付けられた付加情報を取得する。
特徴量抽出部762は、学習用特徴量抽出部732と同様に、情報取得部261によって取得されたテキスト情報及び時刻情報から、該テキスト情報の特徴量を表す、時刻情報付きのテキスト特徴量を抽出する。また、特徴量抽出部762は、学習用特徴量抽出部732と同様に、付加情報取得部761によって取得された付加情報と、情報取得部261によって取得された時刻情報とから、時刻情報付きの付加情報を生成する。
学習済みモデル記憶部763には、学習済みモデル記憶部736に格納されている学習済みの非言語情報生成モデルと同一の学習済みの非言語情報生成モデルが格納されている。
非言語情報生成部764は、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び時刻情報付きの付加情報と、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの非言語情報を生成する。
例えば、非言語情報生成部764は、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデル
を用いて、時刻情報付きのテキスト特徴量としての任意の特徴量
、及び時刻情報付きの付加情報
を入力として、時刻情報付きの非言語情報に対応する生成パラメータとしてのジェスチャ
を取得する。
そして、非言語情報生成部764は、生成された時刻情報付きの生成パラメータが、当該生成パラメータに付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御する。
具体的には、非言語情報生成部764は、発現部70において、ジェスチャ
を任意の対象(例えば、アニメーションキャラクタ、ロボット等)の動作として反映させる。
発現部70は、非言語情報生成部764による制御に応じて、入力部750によって受け付けられたテキスト情報に対応する音声情報と非言語情報生成部764によって生成された非言語情報とを発現させる。
<非言語情報生成モデル学習装置710の作用>
次に、第7の実施形態に係る非言語情報生成モデル学習装置710の作用について説明する。まず、非言語情報生成モデル学習装置710の学習用入力部720に、複数の学習用のテキスト情報と複数の学習用の付加情報と複数の学習用の非言語情報との組み合わせを表す学習データが入力されると、非言語情報生成モデル学習装置710は、図20に示す学習処理ルーチンを実行する。
まず、ステップS300において、学習用情報取得部231は、学習用入力部720によって受け付けられた複数の学習データ(具体的には、テキスト情報と付加情報と非言語情報との対)のうちの、学習用のテキスト情報を取得する。
ステップS102において、非言語情報取得部33は、学習用入力部720によって受け付けられた複数の学習データのうちの、学習用の非言語情報と当該学習用の非言語情報が表す行動が行われるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS303において、学習用テキスト解析部237は、上記ステップS300で取得された学習用のテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、学習用音声合成部238は、学習用テキスト解析部237によって取得されたテキスト解析結果に基づいて、学習用のテキスト情報に対応する学習用の音声情報を合成する。そして、学習用音声合成部238は、学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS700において、学習用付加情報取得部731は、学習用入力部720によって受け付けられた複数の学習データのうちの、学習用の付加情報を取得する。
ステップS702において、学習用特徴量抽出部732は、上記ステップS303で取得された学習用のテキスト情報及び時刻情報から、時刻情報付きの学習用のテキスト特徴量を抽出する。また、学習用特徴量抽出部732は、上記ステップS700で取得された学習用の付加情報と、上記ステップS303で取得された時刻情報とから、時刻情報付きの学習用の付加情報を生成する。
ステップS106において、生成パラメータ抽出部34は、上記ステップS102で取得された学習用の非言語情報及び時刻情報から、時刻情報付きの離散化された非言語情報を抽出する。
ステップS708において、学習部735は、上記ステップS702で抽出された時刻情報付きの学習用のテキスト特徴量及び時刻情報付きの学習用の付加情報と、ステップS106で取得された時刻情報付きの学習用の生成パラメータとに基づいて、時刻情報付きのテキスト特徴量及び付加情報から時刻情報付きの生成パラメータを生成するための非言語情報生成モデルを学習する。
ステップS110において、学習部735は、上記ステップS708で得られた学習済みの非言語情報生成モデルを、学習済みモデル記憶部736へ格納して、学習処理ルーチンを終了する。
<非言語情報生成装置740の作用>
次に、第7の実施形態に係る非言語情報生成装置740の作用について説明する。まず、非言語情報生成モデル学習装置710の学習済みモデル記憶部736に格納された学習済みの非言語情報生成モデルが、非言語情報生成装置740へ入力されると、非言語情報生成装置740の学習済みモデル記憶部763へ学習済みの非言語情報生成モデルが格納される。そして、入力部750に、非言語情報生成対象のテキスト情報及び付加情報が入力されると、非言語情報生成装置740は、図21に示す非言語情報生成処理ルーチンを実行する。
ステップS400において、情報取得部261は、入力部750によって受け付けられた、テキスト情報を取得する。
ステップS401において、テキスト解析部265は、上記ステップS400で取得されたテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、音声合成部266は、テキスト解析部265によって取得されたテキスト解析結果に基づいて、テキスト情報に対応する音声情報を合成する。そして、音声合成部266は、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS750において、付加情報取得部761は、入力部750によって受け付けられた、付加情報を取得する。
ステップS752において、特徴量抽出部762は、上記ステップS401で取得されたテキスト情報及び時刻情報から、時刻情報付きのテキスト特徴量を抽出し、上記ステップS750で取得された付加情報及び上記ステップS401で取得された時刻情報から、時刻情報付きの付加情報を生成する。
ステップS754において、非言語情報生成部764は、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルを読み出す。
ステップS756において、非言語情報生成部764は、上記ステップS752で抽出された時刻情報付きのテキスト特徴量及び付加情報と、上記ステップS754で読み出された学習済みの非言語情報生成モデルとに基づいて、上記ステップS752で抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの生成パラメータを生成する。
ステップS208において、非言語情報生成部764は、上記ステップS756で生成された時刻情報付きの非言語情報が、当該非言語情報に付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御して、非言語情報生成処理ルーチンを終了する。
なお、第7の実施形態に係る非言語情報生成装置及び非言語情報生成モデル学習装置の他の構成及び作用については、第1の実施形態と同様であるため、説明を省略する。
以上説明したように、第7の実施形態に係る非言語情報生成装置740によれば、付加情報を取得し、時刻情報付きのテキスト特徴量及び付加情報と、行動の回数又は大きさを含む時刻情報付きの非言語情報を生成するための学習済みモデルとに基づいて、時刻情報付きのテキスト特徴量に対応する時刻情報付きの非言語情報を生成する。これにより、テキスト情報と、行動の回数又は大きさを含む非言語情報との対応付けを自動的に行い、そのコストを低減させることができる。
また、非言語情報の種類を、行動の大きさ、回数を含めて細かく設定することにより、より詳細なニュアンスを表現でき、非言語情報により意図を表しやすい。また、時刻情報が対応付いていることや、付加情報と組み合わせることで、付加情報の違いによる動作の変化を、より細やかに表現でき、これにより、例えば、感情を表現しやすくなる。
また、第7の実施形態に係る非言語情報生成モデル学習装置710によれば、時刻情報付きの学習用のテキスト特徴量及び付加情報と、行動の回数又は大きさを含む時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量及び付加情報から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。これにより、テキスト情報と、行動の回数又は大きさを含む非言語情報との対応付けのコストを低減させつつ、テキスト特徴量から非言語情報を生成するための非言語情報生成モデルを得ることができる。
なお、上記の実施の形態では、付加情報が入力される場合を例に説明したが、これに限定されるものではなく、付加情報を推定するようにしてもよい。この場合には、図22に示すように、非言語情報生成モデル学習装置710Aの学習用演算部730Aは、学習用入力部720によって受け付けた学習データに含まれるテキスト情報から、付加情報を推定して学習用付加情報取得部731へ出力する学習用付加情報推定部731Aを備えるようにすればよい。例えば、テキスト情報から、対話の内容や感情を推定することができる。
また、図23に示すように、非言語情報生成装置740Aの演算部760Aは、入力部750によって受け付けたテキスト情報から、付加情報を推定して付加情報取得部761へ出力する付加情報推定部761Aを備えるようにすればよい。
テキスト情報ではなく、音声情報や動画情報が入力される場合には、音声情報や動画情報から付加情報を推定するようにすればよい。例えば、動画情報から年齢や性別、環境変数、身体的特徴等を推定したり、音声情報から、対話時の人数、感情、国籍、室内/屋内等を推定したりするようにしてもよい。
上記のように、付加情報を推定する場合には、付加情報にも時刻情報を自動的に付与することができる。また、付加情報を推定する場合、推定する際の単位ごとに、非言語情報の推定値を生成することができる。
また、非言語情報生成装置では、推定して得られる特定の付加情報に応じて、他の付加情報を変更してもよい。具体的には、特定の付加情報に対して予め定義しておいた指定情報に切り替わるように、他の付加情報を変更してもよい。例えば、音声情報から室内/屋内が切り替わったことが推定出来た際に、身体的特徴である服装の指定内容を変更するように、他の付加情報を変更する。また、感情に応じて、音声合成の発話速度や、テキストの表示速度を変更するようにしてもよい。その他、満腹状態を検知すると体形をふくよかに設定するように付加情報を変更したり、怒りの感情を検出すると対話の内容を「議論」に変更するように付加情報を変更したりする。
また、付加情報の推定の結果として、所定の処理単位の感情のラベルが時系列で「通常」「怒り」の順で並んでおり、ジェスチャと同時に音声を出力する場合、所定の処理単位毎の付加情報を音声合成部(図示省略)へのパラメータ(話速)として渡す。これにより、感情のラベル「怒り」が推定された所定の処理単位に対して、話速を所定の数足すとか、所定倍するように、テキスト情報の時刻情報を短縮するように変更する(図24)。なお、図24では、矢印付きの横軸が、時間軸を示している。
また、「怒り」が推定された期間の時刻情報付きの音声特徴量の時刻情報を変更するようにしてもよい。
また、非言語情報が、行動の大きさや回数を含む場合を例に説明したが、これに限定されるものではなく、さらに、ポーズ長の割合を含むようにしてもよい。
[第8の実施形態]
次に、本発明の第8の実施形態について説明する。なお、第1の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
<第8の実施形態の概要>
入力がテキストの場合に、テキストの詳細な時刻情報が得られないことがある。例えば、(1)音声合成(または音声認識)に、各テキストに対応する必要な粒度の時刻情報を出力する機能が無い場合や、(2)ジェスチャ生成時に、テキストのみを出力する(音声合成する必要が無い)場合で、かつ音声合成を行うリソースが無い、または音声合成処理時間が確保できない場合(入力が音声の場合は、元の音声情報を出力する必要が無い、またはリソース不足など)である。
上記(1)のケースについては、DNN(Deep Neural Network)ベース合成音声を用いる場合などに発生する。また、上記(2)のケースは、実サービスの際の制約等から発生する。
そこで、本実施の形態では、上記(1)のような、必要な粒度(例えば文字や形態素)の時刻情報が得られない場合に、音声合成器を利用して、テキストに対応する音声を生成した際に取得可能な、各文節(必要となる粒度より粗いが、最も近いもの)の音声時間長を用いて、必要となる粒度の時刻情報を求める。具体的には、対象言語の発音の特性に合わせた単位数(日本語であればモーラ数、英語であればアクセント数など)により、時刻情報が獲得可能な単位を分割し、必要な単位の時刻情報として利用する。
<非言語情報生成モデル学習装置の構成>
図25に示すように、第8の実施形態に係る非言語情報生成モデル学習装置810の学習用演算部830は、学習用情報取得部231と、学習用付加情報取得部731と、学習用特徴量抽出部732と、非言語情報取得部33と、生成パラメータ抽出部34と、学習データ作成部833と、学習部735と、学習済みモデル記憶部736とを備えている。
学習データ作成部833は、学習用情報取得部231によって取得された学習用のテキスト情報について、詳細な時刻情報を求め、詳細な時刻情報付きのテキスト情報を生成する。
ここで、詳細な時刻情報は、学習用のテキストを出力する際の時刻の範囲を、テキストを所定単位で分割したときの分割数で分割した結果に基づいて付与されたものである。
例えば、テキスト情報について得られている時刻情報が、発話単位の時刻情報であり、所定の単位(モーラ単位)の時刻情報を求めたい場合には、以下のように時刻情報を求める。
まず、テキストの発話長を1に正規化し、時刻情報が得られる単位の発話長を所定の単位の数(この場合はモーラ数)で分割する(図26A参照)。そして、分割して得られた時刻情報を、所定の単位の時刻情報として利用する。
また、学習データ作成部833は、学習用特徴量抽出部732によって抽出された時刻情報付きの学習用のテキスト特徴量及び時刻情報付きの付加情報と、生成パラメータ抽出部34によって抽出された時刻情報付きの学習用の離散化された非言語情報とについて、上記で求めた詳細な時刻情報を用いて、詳細な時刻情報付きの学習用のテキスト特徴量、学習用の付加情報、及び学習用の非言語情報を生成する。
学習データ作成部833は、詳細な時刻情報付きの学習用のテキスト特徴量、詳細な時刻情報付きの学習用の付加情報、及び詳細な時刻情報付きの学習用の非言語情報の組み合わせを学習データとして、学習部735に出力する。
<非言語情報生成装置の構成>
図26Bに示すように、第8の実施形態に係る非言語情報生成装置840の演算部860は、情報取得部261と、付加情報取得部761と、特徴量抽出部762と、学習済みモデル記憶部763と、非言語情報生成部764と、制御部870と、を備えている。
発現部70は、上記の第1の実施形態及び第2の実施形態と同様に、テキスト情報を出力すると共に、生成された時刻情報付きの非言語情報が示す行動を、時刻情報に合わせて発現する。また、テキスト情報に対応する音声も出力するようにしてもよい。
特徴量抽出部762が、学習用特徴量抽出部732と同様に、情報取得部261によって取得されたテキスト情報及び時刻情報から、該テキスト情報の特徴量を表す、時刻情報付きのテキスト特徴量を抽出する。また、特徴量抽出部762は、学習用特徴量抽出部732と同様に、付加情報取得部761によって取得された付加情報と、情報取得部261によって取得された時刻情報とから、時刻情報付きの付加情報を生成する。
また、特徴量抽出部762が、テキスト情報について、学習データ作成部833と同様に、詳細な時刻情報を求め、テキスト情報の詳細な時刻情報を求める。
また、特徴量抽出部762が、時刻情報付きのテキスト特徴量及び付加情報について、上記で求めた詳細な時刻情報を用いて、詳細な時刻情報付きのテキスト特徴量及び付加情報を生成する。
非言語情報生成部764は、特徴量抽出部762によって生成された詳細な時刻情報付きのテキスト特徴量及び詳細な時刻情報付きの付加情報と、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部762によって抽出された詳細な時刻情報付きのテキスト特徴量及び付加情報に対応する詳細な時刻情報付きの非言語情報を生成する。
そして、制御部870は、生成された詳細な時刻情報付きの非言語情報に対応する生成パラメータが、発現部70から出力されるように発現部70を制御すると共に、発現部70により時刻情報に合わせてテキスト情報を出力するように制御する。
発現部70は、制御部870による制御に応じて、入力部750によって受け付けられたテキスト情報又はテキスト情報に対応する音声情報を詳細な時刻情報に合わせて出力すると共に、非言語情報生成部764によって生成された非言語情報を、詳細な時刻情報に合わせて発現させる。
<非言語情報生成モデル学習装置810の作用>
次に、第8の実施形態に係る非言語情報生成モデル学習装置810の作用について説明する。まず、非言語情報生成モデル学習装置810の学習用入力部720に、複数の学習用のテキスト情報と複数の学習用の付加情報と複数の学習用の非言語情報との組み合わせを表す学習データが入力されると、非言語情報生成モデル学習装置810は、図27に示す学習処理ルーチンを実行する。
まず、ステップS300において、学習用情報取得部231は、学習用入力部720によって受け付けられた複数の学習データ(具体的には、テキスト情報と非言語情報と付加情報との組み合わせ)のうちの、学習用のテキスト情報を取得する。
ステップS102において、非言語情報取得部33は、学習用入力部720によって受け付けられた複数の学習データのうちの、学習用の非言語情報と当該学習用の非言語情報が表す行動が行われるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS303において、学習用テキスト解析部237は、上記ステップS300で取得された学習用のテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、学習用音声合成部238は、学習用テキスト解析部237によって取得されたテキスト解析結果に基づいて、学習用のテキスト情報に対応する学習用の音声情報を合成する。そして、学習用音声合成部238は、学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS700において、学習用付加情報取得部731は、学習用入力部720によって受け付けられた複数の学習データのうちの、学習用の付加情報を取得する。
ステップS702において、学習用特徴量抽出部732は、上記ステップS303で取得された学習用のテキスト情報及び時刻情報から、時刻情報付きの学習用のテキスト特徴量を抽出する。また、学習用特徴量抽出部732は、上記ステップS700で取得された学習用の付加情報と、上記ステップS303で取得された時刻情報とから、時刻情報付きの学習用の付加情報を生成する。
ステップS106において、生成パラメータ抽出部34は、上記ステップS102で取得された学習用の非言語情報及び時刻情報から、時刻情報付きの離散化された非言語情報を抽出する。
ステップS800において、学習データ作成部833は、上記ステップS303で取得された学習用のテキスト情報及び時刻情報から、学習用のテキスト情報について、詳細な時刻情報を求める。
また、学習データ作成部833は、学習用特徴量抽出部732によって抽出された時刻情報付きのテキスト特徴量及び付加情報と、生成パラメータ抽出部34によって抽出された時刻情報付きの学習用の離散化された非言語情報とについて、上記で求めた詳細な時刻情報を用いて、詳細な時刻情報付きの学習用のテキスト特徴量、学習用の付加情報、及び学習用の非言語情報を生成する。
学習データ作成部833は、詳細な時刻情報付きの学習用のテキスト特徴量、詳細な時刻情報付きの学習用の付加情報、及び詳細な時刻情報付きの学習用の非言語情報の組み合わせを学習データとして、学習部735に出力する。
ステップS708において、学習部735は、上記ステップS800で生成された詳細な時刻情報付きの学習用のテキスト特徴量及び詳細な時刻情報付きの学習用の付加情報と、ステップS800で取得された詳細な時刻情報付きの学習用の生成パラメータとに基づいて、詳細な時刻情報付きのテキスト特徴量及び付加情報から詳細な時刻情報付きの生成パラメータを生成するための非言語情報生成モデルを学習する。
ステップS110において、学習部735は、上記ステップS708で得られた学習済みの非言語情報生成モデルを、学習済みモデル記憶部736へ格納して、学習処理ルーチンを終了する。
<非言語情報生成装置の作用>
次に、第8の実施形態に係る非言語情報生成装置840の作用について説明する。まず、非言語情報生成モデル学習装置810の学習済みモデル記憶部736に格納された学習済みの非言語情報生成モデルが、非言語情報生成装置840へ入力されると、非言語情報生成装置840の学習済みモデル記憶部763へ学習済みの非言語情報生成モデルが格納される。そして、入力部750に、非言語情報生成対象のテキスト情報及び付加情報が入力されると、非言語情報生成装置840は、図28に示す非言語情報生成処理ルーチンを実行する。
ステップS400において、情報取得部261は、入力部750によって受け付けられた、テキスト情報を取得する。
ステップS401において、テキスト解析部265は、上記ステップS400で取得されたテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、音声合成部266は、テキスト解析部265によって取得されたテキスト解析結果に基づいて、テキスト情報に対応する音声情報を合成する。そして、音声合成部266は、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS750において、付加情報取得部761は、入力部750によって受け付けられた、付加情報を取得する。
ステップS752において、特徴量抽出部762は、上記ステップS401で取得されたテキスト情報及び時刻情報から、時刻情報付きのテキスト特徴量を抽出し、上記ステップS750で取得された付加情報及び上記ステップS401で取得された時刻情報から、時刻情報付きの付加情報を生成する。
ステップS850において、特徴量抽出部762が、上記ステップS401で取得されたテキスト情報及び時刻情報から、テキスト情報について詳細な時刻情報を求める。また、特徴量抽出部762が、時刻情報付きのテキスト特徴量について、上記で求めた詳細な時刻情報を用いて、詳細な時刻情報付きのテキスト特徴量を生成する。
また、特徴量抽出部762が、時刻情報付きの付加情報について、上記で求めた詳細な時刻情報を用いて、詳細な時刻情報付きの付加情報を生成する。
ステップS754において、非言語情報生成部764は、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルを読み出す。
ステップS756において、非言語情報生成部764は、上記ステップS850で生成された詳細な時刻情報付きのテキスト特徴量及び付加情報と、上記ステップS754で読み出された学習済みの非言語情報生成モデルとに基づいて、上記ステップS850で生成された詳細な時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの生成パラメータを生成する。
ステップS852において、制御部870は、上記ステップS400で取得したテキストと、上記ステップS756で生成された時刻情報付きの非言語情報とが、時刻情報に合わせて発現部70から出力されるように発現部70を制御して、非言語情報生成処理ルーチンを終了する。
なお、第8の実施形態に係る非言語情報生成装置及び非言語情報生成モデル学習装置の他の構成及び作用については、第1の実施形態と同様であるため、説明を省略する。
以上説明したように、第8の実施形態に係る非言語情報生成装置によれば、テキスト情報の時刻情報を、所定単位毎の時刻情報に分割して付与することにより、テキスト情報について必要な粒度の時刻情報が得られない場合であっても、所定単位毎の時刻情報に従ってテキスト情報を、非言語情報が示す行動の発現と共に出力することができる。
なお、上記の実施の形態では、対象言語の発音の特性に合わせた単位数として、モーラ数を用いて時刻情報を分割する場合を例に説明したが、これに限定されるものではなく、英語の場合には、アクセント数を用いて時刻情報を分割してもよい。また、モーラ数やアクセント数以外に、品詞数、シソーラスにおけるカテゴリ数などで時刻情報を分割して付与してもよい。
また、所定の単位数で時刻情報を分割した後、重みづけを行うようにしてもよい。重みづけは、機械学習により決定してもよいし、重み付け用のDB(対象言語の発音の特性に合わせた単位の種類ごとに、重みを設定してある)をあらかじめ用意しておいてもよい。機械学習のための学習データは、詳細な時刻情報を付与できる音声合成器を用いて作成しても、人手で作成してもよい。
また、非言語情報生成装置において、テキストのみを出力すればよい場合には、発話テキストの再生速度情報を取得し、発話のテキスト表示に合わせて行動の発現を同期させればよい。また、その際には、非言語情報に付与する時刻情報について所定の単位数で分割せずに、再生される発話長(あるいは文節の時間長)に合わせて、行動を発現させればよい。
[第9の実施形態]
次に、本発明の第9の実施形態について説明する。なお、第1の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
<第9の実施形態の概要>
非言語情報の生成を行う際に、時系列情報の考慮が不十分な場合や、複数の動作ごとに非言語情報生成モデルを学習し、動作ごとに個別に非言語情報の生成を行う場合には、非言語情報として自然ではないもの、不可能なものが生成される。自然ではない非言語情報とは、同時に行うと適切でない行動であり、例えば、お辞儀しながらジャンプするような行動である。また、不可能な非言語情報とは、時系列順に見ると適切でない行動であり、例えば、1形態素のみに付与された、ゆっくり5回頷く、という行動である。この行動は、1形態素のみに付与されており、時間が足りないため、不可能な行動である。
そこで、本実施の形態では、生成される非言語情報に関して制約条件を設定し、生成後のデータの修正(挿入・削除・置換)を行う。
例えば、自然な非言語情報を発現させるため、制約条件を用いて、学習データや生成された非言語情報から不自然な非言語情報を削除する。あるいは、制約条件を用いて非言語情報を追加する。
制約条件として、非言語情報自体の制約条件、発現部の形状(CGキャラクタ・ロボット)による制約条件、及び付加情報を用いた制約条件の少なくとも1つを用いる。また、制約条件は、ルールの集合として、人手で定義される。
<非言語情報生成モデル学習装置の構成>
第9の実施形態に係る非言語情報生成モデル学習装置は、第8の実施形態に係る非言語情報生成モデル学習装置810の構成と同様であるため、同一符号を付して説明を省略する。
第9の実施形態に係る非言語情報生成モデル学習装置では、学習データ作成部833は、生成パラメータ抽出部34によって抽出された時刻情報付きの学習用の離散化された非言語情報について、非言語情報の時系列に関する制約条件、又は時刻が対応する非言語情報に関する制約条件を満たすように、学習用の非言語情報又は時刻情報を変更する。
例えば、行動ごとに必要最低限の時刻の情報またはテキスト単位(文節、形態素など)の数を制約条件として設定しておく。これは、発現部70の形状や、可能な動作速度、ひとつ前の行動による現在の姿勢などから、制約条件が設定される。
具体的には、文節単位で行動を生成する場合を例に説明する。ハンドジェスチャAは、必ず3文節にまたがって行動を行う、という制約条件が設定されている場合には、1文節のみにハンドジェスチャAが生成されると、その前、あるいは後、またはその両方の文節に、ハンドジェスチャAのラベルを付与するように変更する。それが不可能な場合は、ハンドジェスチャAの行動ラベルを削除する。なお、生成された非言語情報の発現が不可能であると判定された場合は、その代替行動を用意しておくとよい
また、制約条件の設定について、実際の人間の行動データを元に、どの行動がどれくらいの時間(またはテキスト単位数)で生成されるべきかを事前に作成することができる。このとき、上記図2に示すように、発話中の話者の音声情報(X)を取得するのと同時に、所定の計測装置を用いて発話中の話者の非言語情報(Y)も取得することで作成されるデータを用いる事が出来る。これにより、より人間として自然な動きが可能になる制約条件を設定することができる。なお、発現部70が人間を模擬したものではない場合には、あえて不自然な動きを許容するように制約条件を設定してもよい。
また、学習データ作成部833は、学習用特徴量抽出部732によって抽出された時刻情報付きの付加情報を考慮して、付加情報を用いて設定された制約条件を満たすように、学習用の非言語情報又は時刻情報を変更する。例えば、感情によって話速が上がったりすると、それまではできていた動作が出来なくなったりすることが考えられるため、学習用の非言語情報に付与された時刻情報を変更する。
学習部735は、学習用特徴量抽出部732によって抽出された時刻情報付きの学習用のテキスト特徴量及び時刻情報付きの付加情報と、学習データ作成部833によって変更された、時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量及び付加情報から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。このとき、系列ラベリング(CRF(Conditional Random Fields))を用いて非言語情報生成モデルを学習することが好ましい。
この場合には、
において、ラベルの時系列関係を考慮する為に、BIO(Begin, Inside, Outside)タグなどの系列情報を付与しても良い。例えば、あるラベルが連続して出現した際に、開始ラベルにB(Begin)ラベルを付与し、以降のラベルにI(Inside)を付与する。これにより、連続したラベルを推定する際に精度が高くなる。
このようにラベリングしたデータを用いて、系列ラベリングの手法によりジェスチャの生成を行う非言語情報生成モデルを学習する。これにはSVMを用いる事も可能だが、HMM(Hidden Markov Model)やCRF(Conditional Random Fields、参考文献9)を用いるとなお良い。
[参考文献9]日本特許第5152918号公報
<非言語情報生成装置の構成>
第9の実施形態に係る非言語情報生成装置は、第7の実施形態に係る非言語情報生成装置740の構成と同様であるため、同一符号を付して説明を省略する。
第9の実施形態に係る非言語情報生成装置では、非言語情報生成部764は、特徴量抽出部762によって生成された時刻情報付きのテキスト特徴量及び時刻情報付きの付加情報と、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの非言語情報を生成する。
非言語情報生成部764は、生成された時刻情報付きの非言語情報について、学習データ作成部833と同様に、非言語情報の時系列に関する制約条件、又は時刻が対応する非言語情報に関する制約条件を満たすように、非言語情報又は非言語情報に付与された時刻情報を変更する。
そして、非言語情報生成部764は、変更された時刻情報付きの非言語情報に対応する生成パラメータが、当該生成パラメータに付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御する。
発現部70は、非言語情報生成部764による制御に応じて、入力部750によって受け付けられたテキスト情報又はテキスト情報に対応する音声情報を詳細な時刻情報に合わせて出力すると共に、非言語情報生成部764によって生成された非言語情報を、詳細な時刻情報に合わせて発現させる。
<非言語情報生成モデル学習装置の作用>
次に、第9の実施形態に係る非言語情報生成モデル学習装置の作用について説明する。まず、非言語情報生成モデル学習装置の学習用入力部720に、複数の学習用のテキスト情報と複数の学習用の付加情報と複数の学習用の非言語情報との組み合わせを表す学習データが入力されると、非言語情報生成モデル学習装置は、図29に示す学習処理ルーチンを実行する。
まず、ステップS300において、学習用情報取得部231は、学習用入力部720によって受け付けられた複数の学習データ(具体的には、テキスト情報と非言語情報と付加情報の組み合わせ)のうちの、学習用のテキスト情報を取得する。
ステップS102において、非言語情報取得部33は、学習用入力部720によって受け付けられた複数の学習データのうちの、学習用の非言語情報と当該学習用の非言語情報が表す行動が行われるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS303において、学習用テキスト解析部237は、上記ステップS300で取得された学習用のテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、学習用音声合成部238は、学習用テキスト解析部237によって取得されたテキスト解析結果に基づいて、学習用のテキスト情報に対応する学習用の音声情報を合成する。そして、学習用音声合成部238は、学習用の音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS700において、学習用付加情報取得部731は、学習用入力部720によって受け付けられた複数の学習データのうちの、学習用の付加情報を取得する。
ステップS702において、学習用特徴量抽出部732は、上記ステップS303で取得された学習用のテキスト情報及び時刻情報から、時刻情報付きの学習用のテキスト特徴量を抽出する。また、学習用特徴量抽出部732は、上記ステップS700で取得された学習用の付加情報と、上記ステップS303で取得された時刻情報とから、時刻情報付きの学習用の付加情報を生成する。
ステップS106において、生成パラメータ抽出部34は、上記ステップS102で取得された学習用の非言語情報及び時刻情報から、時刻情報付きの離散化された非言語情報を抽出する。
ステップS900では、学習データ作成部833は、上記ステップS106で取得された時刻情報付きの離散化された非言語情報について、非言語情報の時系列に関する制約条件、又は時刻が対応する非言語情報に関する制約条件を満たすように、非言語情報、または非言語情報に付与された時刻情報を変更する。
ステップS708において、学習部735は、上記ステップS702で抽出された時刻情報付きの学習用のテキスト特徴量及び時刻情報付きの学習用の付加情報と、ステップS900で変更された時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量及び付加情報から時刻情報付きの生成パラメータを生成するための非言語情報生成モデルを学習する。
ステップS110において、学習部735は、上記ステップS708で得られた学習済みの非言語情報生成モデルを、学習済みモデル記憶部736へ格納して、学習処理ルーチンを終了する。
<非言語情報生成装置の作用>
次に、第9の実施形態に係る非言語情報生成装置の作用について説明する。まず、非言語情報生成モデル学習装置810の学習済みモデル記憶部736に格納された学習済みの非言語情報生成モデルが、非言語情報生成装置へ入力されると、非言語情報生成装置の学習済みモデル記憶部763へ学習済みの非言語情報生成モデルが格納される。そして、入力部750に、非言語情報生成対象のテキスト情報及び付加情報が入力されると、非言語情報生成装置は、図30に示す非言語情報生成処理ルーチンを実行する。
ステップS400において、情報取得部261は、入力部750によって受け付けられた、テキスト情報を取得する。
ステップS401において、テキスト解析部265は、上記ステップS400で取得されたテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、音声合成部266は、テキスト解析部265によって取得されたテキスト解析結果に基づいて、テキスト情報に対応する音声情報を合成する。そして、音声合成部266は、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS750において、付加情報取得部761は、入力部750によって受け付けられた、付加情報を取得する。
ステップS752において、特徴量抽出部762は、上記ステップS401で取得されたテキスト情報及び時刻情報から、時刻情報付きのテキスト特徴量を抽出し、上記ステップS750で取得された付加情報及び上記ステップS401で取得された時刻情報から、時刻情報付きの付加情報を生成する。
ステップS754において、非言語情報生成部764は、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルを読み出す。
ステップS950において、非言語情報生成部764は、上記ステップS752で抽出された時刻情報付きのテキスト特徴量及び付加情報と、上記ステップS754で読み出された学習済みの非言語情報生成モデルとに基づいて、上記ステップS752で抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの生成パラメータを生成する。そして、非言語情報生成部764は、生成された時刻情報付きの生成パラメータについて、非言語情報の時系列に関する制約条件、又は時刻が対応する非言語情報に関する制約条件を満たすように、非言語情報、または非言語情報に付与された時刻情報を変更する。
ステップS208において、非言語情報生成部764は、上記ステップS950で変更された時刻情報付きの非言語情報が、当該非言語情報に付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御して、非言語情報生成処理ルーチンを終了する。
なお、第9の実施形態に係る非言語情報生成装置及び非言語情報生成モデル学習装置の他の構成及び作用については、第1の実施形態と同様であるため、説明を省略する。
以上説明したように、第9の実施形態に係る非言語情報生成装置によれば、テキスト情報に対応する音声情報を取得し、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得し、時刻情報付きのテキスト特徴量と時刻情報付きの非言語情報を生成するための学習済みモデルとに基づいて、時刻情報付きのテキスト特徴量に対応する時刻情報付きの非言語情報を生成し、制約条件を満たすように、非言語情報又は非言語情報の時刻情報を変更する。これにより、非言語情報として自然ではないものを排除して、テキスト情報と非言語情報との対応付けを自動的に行い、そのコストを低減させることができる。
また、第9の実施形態に係る非言語情報生成モデル学習装置によれば、時刻情報付きの学習用の非言語情報について、制約条件を満たすように、非言語情報又は非言語情報の時刻情報を変更する。そして、時刻情報付きの学習用のテキスト特徴量と時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。これにより、非言語情報として自然ではないものを排除して、テキスト情報と非言語情報との対応付けのコストを低減させつつ、テキスト特徴量から非言語情報を生成するための非言語情報生成モデルを得ることができる。なお、制約条件を元に、書き換えに関する機械学習モデルを作成してもよい。
[第10の実施形態]
次に、本発明の第10の実施形態について説明する。なお、第1の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
<第10の実施形態の概要>
制約条件により不可能な非言語情報を検出した場合に、制約条件を満たすように、音声データ(合成音声を含む)にポーズを入れる、またはテキストの表示速度(合成音声の話速)を変更するために、テキスト情報に付与された時刻情報を変更する点が、第9の実施形態と異なっている。
本実施形態は、非言語情報の方が、音声(テキスト)より重要な場合に有効である。特に、出力である音声を音声合成で作成する場合や、テキストを出力する場合において、高い効果が見込める。
<非言語情報生成モデル学習装置の構成>
第10の実施形態に係る非言語情報生成モデル学習装置は、第8の実施形態に係る非言語情報生成モデル学習装置810の構成と同様であるため、同一符号を付して説明を省略する。
第10の実施形態に係る非言語情報生成モデル学習装置では、学習データ作成部833は、学習用のテキスト情報、及び学習用特徴量抽出部732によって取得された時刻情報付きの学習用のテキスト特徴量について、非言語情報の時系列に関する制約条件を満たすように、学習用のテキスト情報の時刻情報、及び学習用のテキスト特徴量に付与された時刻情報を変更する。
例えば、制約条件を満たすように、非言語情報に合わせてポーズを入れるように、学習用のテキスト情報及び学習用のテキスト特徴量に付与された時刻情報を変更したり、非言語情報に合わせてテキストの表示速度(合成音声の話速)を変更するように、学習用のテキスト情報及びテキスト特徴量に付与された時刻情報を変更したりする。
また、学習データ作成部833は、学習用特徴量抽出部732によって抽出された時刻情報付きの付加情報を考慮して、付加情報を用いて設定された制約条件を満たすように、テキスト情報に付与された時刻情報を変更する。
学習部735は、学習データ作成部833によって変更された時刻情報付きの学習用のテキスト特徴量と、学習用特徴量抽出部732によって抽出された時刻情報付きの付加情報と、生成パラメータ抽出部34によって抽出された、時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量及び付加情報から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。
<非言語情報生成装置の構成>
第10の実施形態に係る非言語情報生成装置は、第7の実施形態に係る非言語情報生成装置740の構成と同様であるため、同一符号を付して説明を省略する。
第10の実施形態に係る非言語情報生成装置では、非言語情報生成部764は、特徴量抽出部762によって生成された時刻情報付きのテキスト特徴量及び時刻情報付きの付加情報と、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの非言語情報を生成する。
非言語情報生成部764は、テキスト情報及び時刻情報付きのテキスト特徴量について、学習データ作成部833と同様に、非言語情報の時系列に関する制約条件を満たすように、時刻情報を変更する。
そして、非言語情報生成部764は、生成された時刻情報付きの非言語情報に対応する生成パラメータが、当該生成パラメータに付与された時刻情報に基づいて発現部70から出力されるように発現部70を制御する。
発現部70は、非言語情報生成部764による制御に応じて、入力部750によって受け付けられたテキスト情報又はテキスト情報に対応する音声情報を、変更された時刻情報に合わせて出力すると共に、非言語情報生成部764によって生成された非言語情報を、時刻情報に合わせて発現させる。
なお、第10の実施形態に係る非言語情報生成装置及び非言語情報生成モデル学習装置の他の構成及び作用については、第9の実施形態と同様であるため、説明を省略する。
以上説明したように、第10の実施形態に係る非言語情報生成装置によれば、テキスト情報に対応する音声情報を取得し、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得し、時刻情報付きのテキスト特徴量と時刻情報付きの非言語情報を生成するための学習済みモデルとに基づいて、時刻情報付きのテキスト特徴量に対応する時刻情報付きの非言語情報を生成し、制約条件を満たすように、テキスト情報の時刻情報を変更する。これにより、自然ではないものを排除して、テキスト情報と非言語情報との対応付けを自動的に行い、そのコストを低減させることができる。
また、第10の実施形態に係る非言語情報生成モデル学習装置によれば、時刻情報付きの学習用のテキスト特徴量と学習用の非言語情報について、制約条件を満たすように、テキスト特徴量の時刻情報を変更する。そして、時刻情報付きの学習用のテキスト特徴量と時刻情報付きの学習用の非言語情報とに基づいて、時刻情報付きのテキスト特徴量から時刻情報付きの非言語情報を生成するための非言語情報生成モデルを学習する。これにより、自然ではないものを排除して、テキスト情報と非言語情報との対応付けのコストを低減させつつ、テキスト特徴量から非言語情報を生成するための非言語情報生成モデルを得ることができる。
[第11の実施形態]
次に、本発明の第11の実施形態について説明する。なお、第1の実施形態と同様の構成となる部分については、同一符号を付して説明を省略する。
<第11の実施形態の概要>
ジェスチャシナリオや非言語情報生成モデルのための学習データを作成する際には、発話に対して適切な動作、すなわち意図した通りの動作が行われるかの確認や修正作業が必須となる。しかし、動作の確認や修正作業の際に、どのような発話に対し、どのような動作が割り当てられているか分かりづらく、作業コストが高くなりやすい。そこで、本実施の形態では、どのようなテキスト情報に対し、どのような非言語情報が割り当てられているのかを可視化することで、動作の確認や修正作業を容易にする。
具体的には、所定の単位で分割された言語情報(テキスト又は音声)に対し、非言語情報を対応付けて表示し、各所定の単位ごとに実際の動作を確認可能にすることで、修正しやすいインタフェースを提供する。また、修正結果に応じて、学習データを追加/修正することができ、さらに、非言語情報生成モデルを再学習することができる。
ここで、本実施の形態で説明するインタフェースの使用シーンは、例えば、以下の5つである。
(1)ジェスチャシナリオを作成する場合に、本実施の形態に係るインタフェースが使用される。例えば、入力されたテキスト情報について、学習済みの非言語情報生成モデルに基づいて時刻情報付きの非言語情報を生成し、ユーザの操作により、生成された非言語情報を修正し、修正結果を、固定シナリオとして出力する。
(2)学習データを修正する場合に、本実施の形態に係るインタフェースが使用される。例えば、入力された学習データを読み込み、ユーザの操作により、学習データに含まれるテキスト情報又は非言語情報を修正し、修正結果を、学習データとして出力する。
(3)学習データを追加する場合に、本実施の形態に係るインタフェースが使用される。例えば、入力されたテキスト情報について、学習済みの非言語情報生成モデルに基づいて時刻情報付きの非言語情報を生成し、ユーザの操作により、生成された非言語情報を修正し、修正結果を、当該非言語情報生成モデルに対応する学習データとして出力する。
(4)学習済みの非言語情報生成モデルを再学習する場合に、本実施の形態に係るインタフェースが使用される。例えば、入力されたテキスト情報について、学習済みの非言語情報生成モデルに基づいて時刻情報付きの非言語情報を生成し、ユーザの操作により、生成された非言語情報を修正し、修正結果を、当該非言語情報生成モデルに対応する学習データとして追加して、当該非言語情報生成モデルを再学習する。
(5)上記第9の実施の形態、第10の実施の形態で説明した制約条件を生成する場合に、本実施の形態に係るインタフェースが使用される。例えば、上記(1)~(4)の何れかと同様の方法で得られた修正結果を用いて、制約条件を規定する。
<非言語情報生成装置の構成>
図31は、第11の実施形態に係る非言語情報生成装置1140の構成の一例を示すブロック図である。図31に示すように、第11の実施形態に係る非言語情報生成装置1140は、CPUと、RAMと、後述する非言語情報生成処理ルーチンを実行するためのプログラムを記憶したROMとを備えたコンピュータで構成されている。非言語情報生成装置1140は、機能的には、入力部750と、演算部1160と、表示部1190と、出力部1192を備えている。
入力部750は、テキスト情報及び付加情報を受け付ける。受け付ける付加情報は、所定の処理単位毎(例えば、形態素毎や文節毎)の付加情報である。なお、付加情報が、所定の処理単位毎に変化しないもの(例えば、性別)である場合には、所定の処理単位毎に受け付けなくてもよい。この場合には、付加情報を受け付けた際に、装置側で、所定の処理単位毎の付加情報に展開すればよい。
演算部1160は、情報取得部261と、付加情報取得部761と、特徴量抽出部762と、学習済みモデル記憶部763と、非言語情報生成部764と、制御部1170と、学習データ生成部1172と、再学習制御部1174とを備えている。なお、付加情報取得部761を省略してもよい。上記(1)、(5)の使用シーンでは、更に、学習データ生成部1172及び再学習制御部1174を省略してもよい。また、上記(2)、(3)の使用シーンでは、更に、再学習制御部1174を省略してもよい。
情報取得部261は、上記第2の実施の形態に係る非言語情報生成装置240の情報取得部261と同様に、入力部750によって受け付けられたテキスト情報を取得すると共に、テキスト情報に対応する音声情報を取得し、当該音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
付加情報取得部761は、上記第7の実施の形態に係る非言語情報生成装置740の付加情報取得部761と同様に、入力部750によって受け付けられた付加情報を取得する。
特徴量抽出部762は、上記第7の実施の形態に係る非言語情報生成装置740の特徴量抽出部762と同様に、情報取得部261によって取得されたテキスト情報及び時刻情報から、該テキスト情報の特徴量を表す、時刻情報付きのテキスト特徴量を抽出する。また、特徴量抽出部762は、付加情報取得部761によって取得された付加情報と、情報取得部261によって取得された時刻情報とから、時刻情報付きの付加情報を生成する。
学習済みモデル記憶部763には、上記第7の実施の形態に係る非言語情報生成装置740の学習済みモデル記憶部763と同様に、学習済みモデル記憶部736に格納されている学習済みの非言語情報生成モデルと同一の学習済みの非言語情報生成モデルが格納されている。
非言語情報生成部764は、上記第7の実施の形態に係る非言語情報生成装置740の非言語情報生成部764と同様に、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び時刻情報付きの付加情報と、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルとに基づいて、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの非言語情報を生成する。
制御部1170は、非言語情報生成部764によって生成された時刻情報付きの非言語情報と、入力部750によって受け付けられたテキスト情報及び付加情報とを表示するように表示部1190を制御する。
表示部1190は、表示画面1190Aと、発現部1190Bとを備えている。なお、本実施の形態では、発現部1190Bが、表示部1190に含まれている場合を例に説明するが、これに限定されるものではなく、表示部1190とは別の装置(例えば、ロボット)で構成されていてもよい。
発現部1190Bは、テキスト情報に対応する音声を出力するとともに、生成された時刻情報付きの非言語情報が示す行動を、時刻情報に合わせて発現する。あるいは、テキスト情報を含む吹き出しを表示するようにしてもよい。
このとき、表示部1190により表示される表示画面1190Aの一例を図32に示す。
表示画面1190Aでは、テキストを所定単位毎に分割して表示すると共に、テキスト特徴量に付与された時刻情報及び非言語情報に付与された時刻情報に基づいて、テキストの所定単位毎に対応付けて、非言語情報を示すラベルを表示する。また、表示画面1190Aでは、テキスト情報に対応する音声の音声波形も表示するようにしてもよい。
なお、付与された時刻情報は、テキストを出力する際の時刻であり、例えば、上記第8の実施の形態と同様に、テキストを出力する際の時刻の範囲を、テキストを所定単位で分割したときの分割数で分割した結果に基づいて付与されたものであってもよい。
また、表示部1190は、非言語情報を示す行動を発現させる発現部1190Bを含み、発現部1190Bによる行動の発現の開始、停止、所定単位ずつ(例えば、1形態素ずつや、1文節ずつ)の早送り、又は巻き戻しの指示を受付可能な状態で表示画面1190Aを表示する。例えば、再生ボタン、ポーズボタン、巻き戻しボタン、及び早送りボタンを表示画面1190Aに表示する。
なお、発現部1190Bによる行動の発現の早送り、又は巻き戻しの指示を受付可能なスライドバーを表示画面1190Aに表示してもよい。
制御部1170は、発現の開始、停止、早送り、又は巻き戻しの指示を受け付けると、当該指示に応じて、発現部1190Bによる行動の発現を制御する。
また、表示部1190は、発現部1190Bによって発現されている行動が、テキスト中のどの部分に対応するものであるか識別可能となるように表示画面1190Aに表示してもよい。例えば、発現部1190Bによって発現されている行動に対応するテキスト中の対応部分に、再生バーを表示したり、発現部1190Bによって発現されている行動に対応するテキスト中の対応部分のマス目の色を変更したり、点滅させたりしてもよい。
また、表示部1190は、付加情報の設定を受付可能な状態で表示画面1190Aを表示する。制御部1170は、付加情報の設定を受け付けると、当該付加情報を、特徴量抽出部762へ出力し、当該付加情報を更に用いて非言語情報生成部764により生成された非言語情報を示すラベルと、テキストとを表示画面1190Aに表示させるように表示部1190を制御する。
また、表示部1190は、非言語情報を示すラベルの変更指示を受付可能な状態で表示画面1190Aを表示する。
学習データ生成部1172は、非言語情報を示すラベルの変更指示を受け付けると、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び付加情報と、変更指示に従って変更された非言語情報を示すラベルとの組み合わせを、非言語情報生成モデルを学習するための学習データとして生成する。
また、表示部1190は、非言語情報生成モデルの再学習指示、及び学習データ生成部1172により生成された学習データに対する重みの設定を受付可能な状態で表示画面1190Aを表示する。ここで、学習データに対する重みとは、再学習時に、既存の学習データと比較して、追加する学習データをどれぐらい重視するかに応じて設定されるものである。例えば、この重みを最大値に設定した場合、追加した学習データ中の対(X,Y)のXに対し、必ずYが生成されるように、非言語情報生成モデルが再学習される。
再学習制御部1174は、再学習指示及び重みの設定を受け付けると、学習データ生成部1172によって生成された学習データ及び設定された重みを用いて、非言語情報生成モデル学習装置710に非言語情報生成モデルを学習させる。
具体的には、表示画面1190Aに対して以下のStep1~Step5のようにユーザにより操作される。
(Step1)非言語情報を生成する対象となる発話文を示すテキストを入力するか、あるいは選択することでテキストを設定する。例えば、上記(1)の使用シーンのように、ジェスチャシナリオを生成する場合や、上記(3)、(4)の使用シーンのように、学習データを追加する場合には、テキストを入力する。また、上記(2)の使用シーンのように、学習データを修正する場合には、学習データの集合が提示され、修正対象となる学習データのテキストを選択する。
(Step2)発話文を示すテキストが所定単位ごとに分割され、分割された単位ごとに生成された非言語情報を示すラベルYが表示される。
(Step3)発現の開始が指示されると、生成された非言語情報により、発現部1190Bが動く。
(Step4)ユーザが、発現部1190Bの動作を目視で確認する。
(Step5)おかしな動きをする時のマスM(ラベル付きのマスMor空白のマスM)をクリックすると、正しい非言語情報を示すラベルに書き換えることができる。その結果、当該ラベルが、入力発話に対する、正解の非言語情報を示すラベルとして、学習データに追加できるようにしてもよい(その際、重みづけも設定できるようにしてもよい)。
なお、所定単位ごとの時刻情報を表示し、時刻情報の変更指示を受け付け可能に表示画面1190Aを表示してもよい(図33参照)。例えば、時刻情報の値をクリックすることで値が編集可能となり、時刻情報の値を変更することができる。あるいは、所定単位ごとの開始時刻を示す縦棒の位置を左右に変更することにより、所定単位ごとの開始時刻を変更することができる。
また、音声データ(合成音声を含む)にポーズを入れる変更指示を受け付け可能に表示画面1190Aに表示してもよい。例えば、図34に示すように、テキスト情報の所定の単位毎に、ポーズPの開始位置(図34の点線の縦線参照)を挿入する変更指示を受け付けると共に、ポーズPの開始位置を調整することによりポーズ長の割合を変更する変更指示を受け付けることができる。また、上記第10の実施の形態で説明したように制約条件を満たすように挿入されたポーズに対しても同様に、ポーズPの開始位置を調整することによりポーズ長の割合を変更する変更指示を受け付けるようにしてもよい。
また、所定単位(例えば文節)ごとのテキスト特徴量と非言語情報に対応する生成パラメータとが、変更指示を受付可能に表示されても良い。例えば、図32に示すように、ユーザが、テキスト情報のマスMまたは非言語情報のマスMにマウスカーソルを合わせ、右クリックした際に、マスMに対応するテキスト特徴量がオーバーレイ表示され、変更指示が受付可能となるようにしてもよい。また、テキスト情報のマスMに対応するテキスト特徴量がオーバーレイ表示される場合、マスMのテキスト情報から抽出されたテキスト特徴量全てが表示され、非言語情報のマスMに対応するテキスト特徴量がオーバーレイ表示される際、非言語情報が生成される根拠となったテキスト特徴量がオーバーレイ表示されるようにしてもよい。
第11の実施形態に係る非言語情報生成モデル学習装置は、第7の実施形態に係る非言語情報生成モデル学習装置710と同様であるため、同一符号を付して説明を省略する。
<非言語情報生成装置の作用>
次に、第11の実施形態に係る非言語情報生成装置の作用について説明する。まず、非言語情報生成モデル学習装置710の学習済みモデル記憶部736に格納された学習済みの非言語情報生成モデルが、非言語情報生成装置へ入力されると、非言語情報生成装置の学習済みモデル記憶部763へ学習済みの非言語情報生成モデルが格納される。そして、入力部750に、非言語情報生成対象のテキスト情報及び付加情報が入力されると、非言語情報生成装置は、図35に示す非言語情報生成処理ルーチンを実行する。
ステップS400において、情報取得部261は、入力部750によって受け付けられた、テキスト情報を取得する。
ステップS401において、テキスト解析部265は、上記ステップS400で取得されたテキスト情報に対して所定のテキスト解析を行い、テキスト解析結果を取得する。また、音声合成部266は、テキスト解析部265によって取得されたテキスト解析結果に基づいて、テキスト情報に対応する音声情報を合成する。そして、音声合成部266は、音声情報が発せられるときの開始時刻から終了時刻までの時刻を表す時刻情報を取得する。
ステップS750において、付加情報取得部761は、入力部750によって受け付けられた、付加情報を取得する。
ステップS752において、特徴量抽出部762は、上記ステップS401で取得されたテキスト情報及び時刻情報から、時刻情報付きのテキスト特徴量を抽出し、上記ステップS750で取得された付加情報及び上記ステップS401で取得された時刻情報から、時刻情報付きの付加情報を生成する。
ステップS754において、非言語情報生成部764は、学習済みモデル記憶部763に格納された学習済みの非言語情報生成モデルを読み出す。
ステップS756において、非言語情報生成部764は、上記ステップS752で抽出された時刻情報付きのテキスト特徴量及び付加情報と、上記ステップS754で読み出された学習済みの非言語情報生成モデルとに基づいて、上記ステップS752で抽出された時刻情報付きのテキスト特徴量及び付加情報に対応する時刻情報付きの生成パラメータを生成する。
ステップS1100において、制御部1170は、非言語情報生成部764によって生成された時刻情報付きの非言語情報と、入力部750によって受け付けられたテキスト情報及び付加情報とを表示するように表示部1190を制御して、非言語情報生成処理ルーチンを終了する。
上記ステップS1100の処理は、図36に示す処理ルーチンによって実現される。
まず、ステップS1150において、制御部1170は、テキストを所定単位毎に分割して表示すると共に、テキスト特徴量に付与された時刻情報及び非言語情報に付与された時刻情報に基づいて、テキストの所定単位毎に対応付けて、非言語情報を示すラベルを表示画面1190Aに表示する。
ステップS1152では、制御部1170は、表示画面1190Aに対する操作を受け付けたか否かを判定する。表示画面1190Aに対する操作を制御部1170が受け付けた場合には、処理がステップS1154へ進む。
ステップS1154において、制御部1170は、上記ステップS1152で受け付けた操作の種別が、変更指示であるか、発現指示であるか、再学習指示であるかを判定する。受け付けた操作が、付加情報の設定や、非言語情報を示すラベルの変更指示である場合には、ステップS1156において、制御部1170は、変更指示に従った変更を反映した結果を表示画面1190Aに表示する。受け付けた操作が付加情報の設定であった場合には、制御部1170は、更に、当該付加情報を、特徴量抽出部762へ出力し、当該付加情報を更に用いて非言語情報生成部764により生成された非言語情報を示すラベルと、テキストとを表示画面1190Aに表示する。
また、受け付けた操作が非言語情報を示すラベルの変更指示であった場合には、学習データ生成部1172は、特徴量抽出部762によって抽出された時刻情報付きのテキスト特徴量及び付加情報と、変更指示に従って変更された非言語情報を示すラベルとの組み合わせを、非言語情報生成モデルを学習するための学習データとして生成して、非言語情報生成モデル学習装置710へ出力する。そして、処理が上記ステップS1152へ戻る。
また、発現部1190Bによる行動の発現の開始、停止、1文節ずつの早送り、又は巻き戻しの指示を受け付けた場合には、ステップS1158において、制御部1170は、受け付けた指示に従って、発現部1190Bによる行動の発現を制御して、処理が上記ステップS1152へ戻る。
また、再学習指示及び重みの設定を受け付けた場合には、ステップS1160において、制御部1170は、学習データ生成部1172によって生成された学習データ及び設定された重みを用いて、非言語情報生成モデル学習装置710に非言語情報生成モデルを学習させて、処理ルーチンを終了する。
上記のように、入力されたテキスト情報及び付加情報に対して非言語情報生成モデルを用いて非言語情報が生成された結果に対して、ユーザが修正を行うことによって、非言語情報生成モデルの学習データを生成することができ、非言語情報生成モデルの学習データを追加することができる。また、非言語情報生成モデルの再学習をユーザが指示することにより、追加された学習データを用いた再学習を行って、非言語情報生成モデルを更新することができる。
以上説明したように、第11の実施形態に係る非言語情報生成装置によれば、どのようなテキスト情報に対し、どのような非言語情報が割り当てられているのかを可視化することにより、非言語情報の修正作業を容易にする。
なお、ユーザが修正を行うことによって生成された時刻情報付きのテキスト情報及び非言語情報からなるジェスチャシナリオを、固定シナリオとして出力するようにしてもよい。
また、上記第9の実施の形態又は第10の実施の形態で説明した方法と同様に、制約条件を元に時刻情報付きのテキスト情報及び非言語情報の組み合わせに対して書き換えを行った場合に、書き換え結果に対してユーザによる修正を行い、そのデータを学習データとして、書き換えに関する機械学習モデルを作成するようにしてもよい。
また、制約条件を元に時刻情報付きのテキスト情報及び非言語情報の組み合わせに対して書き換えを行った場合には、書き換え履歴や、どの制約条件が適用させたかを表示するようにしてもよいし、さらに、制約条件自体の修正を受け付けるようにしてもよい。
また、学習データから、当該非言語情報を示すラベルと対応付けられたテキスト特徴量のランキングを求めて、ユーザに提示してもよい。この場合には、まず、学習データからテキスト特徴量と非言語情報を示すラベルの対を取得し、非言語情報を示すラベルごとに、対となっているテキスト特徴量の種類と、その出現数をカウントする。そして、非言語情報を示すラベルごとに、カウント数が多い順にテキスト特徴量の種類を並べ替えたものを、テキスト特徴量のランキングとして提示すればよい。
また、テキスト特徴量のランキングを提示した後、学習データの選択を受け付け、選択された学習データの編集を受け付けるようにしてもよい。例えば、図32に示すように、ユーザが、非言語情報のマスMにマウスカーソルを合わせ、右クリックした際に、マスMのラベルに対する特徴量のランキングがオーバーレイ表示される。そして、特徴量のランキングの各特徴量名の選択指示(例えば、クリック)が受付可能となっており、特徴量名が選択されると、当該マスMの非言語情報ラベルと選択されたテキスト特徴量とからなる学習データが表示される。このとき、学習データは、直接編集可能に表示され、削除や追記、編集等が行われることにより、学習データが編集される。
また、学習データを修正した場合に、修正前の学習データを負例として追加できるようにしてもよい。
また、音声合成のパラメータ(話速など)の修正を受付可能に表示するようにしてもよい。
なお、上記第7の実施形態~第11の実施形態では、入力情報がテキスト情報である場合を例に説明したが、これに限定されるものではない。例えば、入力情報が音声情報であってもよい。入力情報が音声情報である場合の、非言語情報生成モデル学習装置における学習用情報取得部は、上記第1の実施形態の学習用情報取得部31と同様である。入力情報が音声情報である場合の、非言語情報生成装置における情報取得部は、上記第1の実施形態の情報取得部61と同様である。
例えば、上記各実施形態における、情報取得部(又は学習用情報取得部)と特徴量抽出部(又は学習用特徴量抽出部)との組み合わせに対応する構成は、上記図15に示される全4パターンである。また、学習時と非言語情報生成時との構成の組み合わせとして、可能なバリエーションは、上記図16に示されるパターンとなる。
また、上記第4の実施形態~第6の実施形態で説明した、非言語情報生成モデル学習装置において用いる学習データとして、例えば、上記図2に示されるようなシーンにおいて、発話中の話者の音声情報(X)を取得するのと同時に、計測装置を用いて発話中の話者の話し相手である会話相手の非言語情報(Y)を取得することを、上記第7の実施形態~第11の実施形態の各々に適用してもよい。
[実験例]
次に、上記第5の実施形態に関する実験例について説明する。
[実験データについて]
2者対話を対象に、発話を表すテキスト情報およびそれに伴う頷きを表す非言語情報を含む、コーパスデータの構築を行った。2者対話の参加者は、20~50代の日本人男性・女性であり初対面であった。参加者は計24人(12ペア)であった。参加者は互いに向き合って着座した。対話内容は、発話に伴う頷きに関するデータを多く収集するために、アニメーションの説明課題を採用した。参加者はそれぞれ、異なる内容のアニメーションを視聴した後、対話相手にアニメーション内容を説明した。10分間の対話セッションにおいて、1人の参加者が対話相手にアニメーションの内容を詳細に説明した。対話相手は、説明者に自由に質問をし、自由に会話を行うことを許可した。発話の収録のために各被験者の胸につけられた指向性ピンマイクを用いた。対話状況の全体的な外観や参加者の様子の収録として、ビデオカメラを用いた。映像は30Hzで収録された。下記に、取得したテキスト情報及び非言語情報を示す。
発話を表すテキスト情報:人手で音声情報から発声言語の書き起こしを行った後、発話内容から文を分割した。さらに、係り受け解析エンジン(参考文献10および参考文献11を参照)を利用して、各文を文節に分割した。分割された文節数は11877であった。
[参考文献10] 今村賢治,「系列ラベリングによる準話し言葉の日本語係り受け解析」,言語処理学会第13回年次大会発表論文集,pp. 518-521,2007.
[参考文献11] E. Charniak,"A Maximum-Entropy-Inspired Parser",Proceedings of the 1st North American chapter of the Association for Computational Linguistics conference,pp. 132-139,2000.
頷きを表す非言語情報:人手で映像から頷きが発生した区間をラベリングした。連続的に発生した頷きは1つの頷きイベントとして扱った。
人手によるラベリング(アノテーション)では上記のすべてのデータを30Hzの時間分解能で統合した。
[非言語情報生成モデル]
構築したコーパスデータを用いて、単語、その品詞およびシソーラス、単語位置、テキスト情報全体の対話行為を入力として、文節単位ごとに頷きを表す非言語情報を生成する非言語情報生成モデルを構築した。それぞれのテキスト情報が有効であるかを検証するために、各テキスト特徴量を用いた非言語情報生成モデルと、全てのテキスト特徴量を用いた非言語情報生成モデルを構築した。具体的に、文節単位ごとに、対象となる文節およびその前後の文節から得られるテキスト特徴量を入力として、頷きの有無の2値を出力する非言語情報生成モデルを、決定木アルゴリズムC4.5(参考文献12を参照)を用いて実装した。使用したテキスト特徴量は以下の通りである。
[参考文献12] J. R. Quinlan, "Improved use of continuous attributes in c4.5", Journal of Artificial Intelligence Research, 4:77-90, 1996.
文字数:文節内の文字数
位置:文頭、文末からの文節の位置
単語:形態素解析ツールJtag(参考文献13を参照)により抽出された文節内の単語情報(Bag-of-words)
品詞:Jtagにより抽出された文節内の単語の品詞情報
シソーラス:日本語語彙大系(参考文献14を参照)に基づく文節内の単語のシソーラス情報
対話行為:単語n-gramおよびシソーラス情報を用いた対話行為推定手法(参考文献4、15を参照)により文ごとに抽出された対話行為(33種類)
[参考文献13] Takeshi Fuchi and Shinichiro Takagi, "Japanese morphological analyzer using word co-occurrence -Jtag-", In Proceedings of International conference on Computational linguistics, pages 409-413, 1998.
[参考文献14] 池原悟, 宮崎正弘, 白井諭, 横尾昭男, 中岩浩巳, 小倉健太郎, 大山芳史, 林良彦,「日本語語彙大系」, 岩波書店,1997.
[参考文献15] Toyomi Meguro, Ryuichiro Higashinaka, Yasuhiro Minami, and Kohji Dohsaka, "Controlling listening-oriented dialogue using partially observable markov decision processes", In Proceedings of International conference on computational linguistics, pages 761-769, 2010.
[実験結果について]
24人の参加者のデータのうち、23人のデータを学習に用いて、残りの1人のデータで評価を行う24交差検定法により評価を行った。これにより、他者のデータからどれだけ頷きを生成できるかを評価した。なお、各施行で頷きの有無データは、データ量が一致するように、データ数の少ない方に合わせてデータ数を削減した。よって、ベースラインであるチャンスレベルは0.50となる。性能評価結果の平均値を表5に示す。
非言語情報生成モデルの評価の結果、語彙大系、品詞、単語の順で精度が良い事が分かった。機械学習においては、抽出するテキスト特徴量の分解能が高すぎる(種類数が多い)と、各テキスト特徴量の出現頻度が相対的に低くなり、学習データに一度も現れなかったテキスト特徴量が実行時に出現することが増えるため、生成の精度が低下する傾向がある。また逆に、分解能を低く(抽象化することで、種類数を少なくする)していくほど、前記した問題は起きなくなるが、データの違いが表現できなくなり、生成の精度が低下する傾向にある。
シソーラス情報は単語を意味や属性でクラス化したもので、その種類数は単語より少なく、品詞より多いため、本実験の学習データ量であっても効率的に学習ができたと考えられる。シソーラス情報は階層構造を持っており、複数段階での単語の上位概念化(抽象化)が可能であるため、学習データのサイズに合わせ、抽象化の程度をコントロールしやすい。
膨大な量のコーパスデータを作成するコストは高く、困難である。学習データが十分に用意できない際には、シソーラス情報を用いる事で、比較的少ないデータ量でもより良い学習効果が期待できる。