JP7234057B2 - Image processing method, image processing device, imaging device, lens device, program, storage medium, and image processing system - Google Patents
Image processing method, image processing device, imaging device, lens device, program, storage medium, and image processing system Download PDFInfo
- Publication number
- JP7234057B2 JP7234057B2 JP2019124790A JP2019124790A JP7234057B2 JP 7234057 B2 JP7234057 B2 JP 7234057B2 JP 2019124790 A JP2019124790 A JP 2019124790A JP 2019124790 A JP2019124790 A JP 2019124790A JP 7234057 B2 JP7234057 B2 JP 7234057B2
- Authority
- JP
- Japan
- Prior art keywords
- image
- pupil
- images
- imaging
- image processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012545 processing Methods 0.000 title claims description 101
- 238000003384 imaging method Methods 0.000 title claims description 84
- 238000003672 processing method Methods 0.000 title claims description 25
- 238000003860 storage Methods 0.000 title claims description 19
- 210000001747 pupil Anatomy 0.000 claims description 104
- 230000003287 optical effect Effects 0.000 claims description 69
- 238000000034 method Methods 0.000 claims description 28
- 238000013528 artificial neural network Methods 0.000 claims description 27
- 238000006243 chemical reaction Methods 0.000 claims description 16
- 238000009826 distribution Methods 0.000 claims description 14
- 230000008569 process Effects 0.000 claims description 8
- 238000002834 transmittance Methods 0.000 claims description 7
- 238000000926 separation method Methods 0.000 claims description 5
- 238000005070 sampling Methods 0.000 claims description 3
- 230000005540 biological transmission Effects 0.000 claims description 2
- PCTMTFRHKVHKIS-BMFZQQSSSA-N (1s,3r,4e,6e,8e,10e,12e,14e,16e,18s,19r,20r,21s,25r,27r,30r,31r,33s,35r,37s,38r)-3-[(2r,3s,4s,5s,6r)-4-amino-3,5-dihydroxy-6-methyloxan-2-yl]oxy-19,25,27,30,31,33,35,37-octahydroxy-18,20,21-trimethyl-23-oxo-22,39-dioxabicyclo[33.3.1]nonatriaconta-4,6,8,10 Chemical compound C1C=C2C[C@@H](OS(O)(=O)=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2.O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 PCTMTFRHKVHKIS-BMFZQQSSSA-N 0.000 description 36
- 238000007493 shaping process Methods 0.000 description 34
- 238000010586 diagram Methods 0.000 description 22
- 238000013527 convolutional neural network Methods 0.000 description 16
- 238000012549 training Methods 0.000 description 7
- 238000005315 distribution function Methods 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 230000008859 change Effects 0.000 description 4
- 238000013135 deep learning Methods 0.000 description 4
- 238000007781 pre-processing Methods 0.000 description 4
- 229920006395 saturated elastomer Polymers 0.000 description 4
- 238000004088 simulation Methods 0.000 description 4
- 239000000284 extract Substances 0.000 description 3
- 230000004907 flux Effects 0.000 description 3
- 230000004913 activation Effects 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 238000005520 cutting process Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000009499 grossing Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 229910044991 metal oxide Inorganic materials 0.000 description 1
- 150000004706 metal oxides Chemical class 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
Images















Description
本発明は、光学系の瞳を分割して撮像した画像に対して、デフォーカスによるぼけを整形し、良好なぼけ味の画像を得る画像処理方法に関する。 The present invention relates to an image processing method for correcting blur due to defocus in an image captured by splitting the pupil of an optical system, and obtaining an image with a good blur.
特許文献1には、光学系の瞳を複数に分割して、各分割瞳から被写体空間を観察した複数の視差画像を撮像し、複数の視差画像を合成する際の重みを調整することで、デフォーカスによるぼけ(デフォーカスぼけ)の形状を制御する方法が開示されている。 In Patent Document 1, a pupil of an optical system is divided into a plurality of divisions, and a plurality of parallax images obtained by observing an object space from each divided pupil are captured, and weights are adjusted when synthesizing the plurality of parallax images. A method for controlling the shape of defocus blur (defocus blur) is disclosed.
しかし、特許文献1に開示された方法は、各分割瞳の重みを調整して複数の視差画像を合成するため、光学系の瞳よりも大きい瞳に対応するデフォーカスぼけを再現することができない。つまり、この方法では、ヴィネッティングによるデフォーカスぼけの欠けを埋めることができない。また、複数の視差画像の合成の重みが不均一になると、ノイズが増大する。また、二線ぼけや、光学系に含まれる非球面レンズ等に起因するデフォーカスぼけの輪帯模様は、構造が細かいため、それらの影響を軽減するには、光学系の瞳を細かく分割する必要がある。この場合、各視差画像における空間解像度の低下、又はノイズの増大が生じる。 However, the method disclosed in Patent Document 1 adjusts the weight of each divided pupil and synthesizes a plurality of parallax images, so it is not possible to reproduce the defocus blur corresponding to the pupil larger than the pupil of the optical system. . In other words, this method cannot fill the lack of defocus blur due to vignetting. In addition, noise increases when weights for synthesizing a plurality of parallax images become uneven. In addition, since the annular pattern of defocus blur caused by two-line blur and the aspherical lens included in the optical system has a fine structure, in order to reduce their effects, the pupil of the optical system should be finely divided. There is a need. In this case, a decrease in spatial resolution or an increase in noise occurs in each parallax image.
そこで本発明は、画像のデフォーカスによるぼけを整形し、良好なぼけ味の画像を得ることが可能な画像処理方法、画像処理装置、撮像装置、レンズ装置、プログラム、および、記憶媒体を提供することを目的とする。 Accordingly, the present invention provides an image processing method, an image processing apparatus, an imaging apparatus, a lens apparatus, a program, and a storage medium capable of correcting blur due to defocusing of an image and obtaining an image with good blur. for the purpose.
本発明の一側面としての画像処理方法は、光学系における第1の瞳を介して被写体を撮像することで得られた第1の画像と、前記光学系における前記第1の瞳とは異なる第2の瞳を介して前記被写体を撮像することで得られた第2の画像と、を取得する工程と、前記第1及び第2の画像を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する工程とを有する。 An image processing method as one aspect of the present invention includes a first image obtained by imaging a subject through a first pupil in an optical system, and the first pupil in the optical system. obtaining a second image obtained by imaging the subject through different second pupils; and inputting the first and second images to a multi-layered neural network. and generating an output image in which blur due to defocusing has been corrected .
本発明の他の側面としての画像処理装置は、光学系における第1の瞳を介して被写体を撮像することで得られた第1の画像と、前記光学系における前記第1の瞳とは異なる第2の瞳を介して前記被写体を撮像することで得られた第2の画像と、を取得する取得手段と、前記第1及び第2の画像を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する生成手段とを有する。 An image processing apparatus as another aspect of the present invention comprises a first image obtained by imaging a subject through a first pupil in an optical system, and the first pupil in the optical system; a second image obtained by imaging the subject through different second pupils; and an obtaining means for obtaining the first and second images to a multilayer neural network and generating means for generating an output image in which blur due to defocus is shaped by inputting.
本発明の他の側面としての撮像装置は、光学系により形成された光学像を光電変換する撮像素子と前記画像処理装置とを有する。 An image pickup device as another aspect of the present invention includes an image pickup device that photoelectrically converts an optical image formed by an optical system, and the image processing device.
本発明の他の側面としてのレンズ装置は、撮像装置に着脱可能なレンズ装置であって、光学系と、多層のニューラルネットワークに入力されるウエイトに関する情報を記憶する記憶手段とを有し、前記撮像装置は、前記光学系における第1の瞳を介して被写体を撮像することで得られた第1の画像と、前記光学系における前記第1の瞳とは異なる第2の瞳を介して前記被写体を撮像することで得られた第2の画像とを取得する取得手段と、前記第1及び第2の画像と前記ウエイトに関する情報を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する生成手段とを有する。 A lens device according to another aspect of the present invention is a lens device that is detachable from an imaging device, has an optical system, and storage means for storing information about weights to be input to a multi-layered neural network. The imaging device captures a first image obtained by imaging a subject through a first pupil in the optical system and a second pupil different from the first pupil in the optical system. an acquisition means for acquiring a second image obtained by imaging the subject through an image sensor; and generating means for generating an output image in which defocus blur has been corrected .
本発明の他の側面としてのプログラムは、前記画像処理方法をコンピュータに実行させる。 A program as another aspect of the present invention causes a computer to execute the image processing method.
本発明の他の側面としての記憶媒体は、前記プログラムを記憶している。 A storage medium as another aspect of the present invention stores the program.
本発明の他の側面としての画像処理システムは、第1の処理装置と第2の処理装置とを有する画像処理システムであって、前記第1の処理装置は、光学系における第1の瞳を介して被写体を撮像することで得られた第1の画像と、前記光学系における前記第1の瞳とは異なる第2の瞳を介して前記被写体を撮像することで得られた第2の画像と、を用いた画像処理の要求を前記第2の処理装置に対して送信する送信手段を有し、前記第2の処理装置は、前記第1の処理装置から送信された前記要求を受信する受信手段と、前記第1及び第2の画像とを取得する取得手段と、前記第1及び第2の画像を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する生成手段とを有する。 An image processing system as another aspect of the present invention is an image processing system having a first processing device and a second processing device, wherein the first processing device is configured to convert a first pupil in an optical system into a a first image obtained by imaging a subject through the optical system; and a second image obtained by imaging the subject via a second pupil different from the first pupil in the optical system and transmitting means for transmitting a request for image processing using a second image to the second processing device, wherein the second processing device receives the request sent from the first processing device A receiving means for receiving the request, an obtaining means for obtaining the first and second images , and inputting the first and second images to a multi-layered neural network to reduce blur due to defocus. and generating means for generating a shaped output image .
本発明の他の目的及び特徴は、以下の実施例において説明される。 Other objects and features of the invention are illustrated in the following examples.
本発明によれば、画像のデフォーカスによるぼけを整形し、良好なぼけ味の画像を得ることが可能な画像処理方法、画像処理装置、撮像装置、レンズ装置、プログラム、および、記憶媒体を提供することができる。 According to the present invention, there is provided an image processing method, an image processing apparatus, an imaging apparatus, a lens apparatus, a program, and a storage medium capable of correcting blur due to image defocus and obtaining an image with good blur. can do.
以下、本発明の実施例について、図面を参照しながら詳細に説明する。各図において、同一の部材については同一の参照符号を付し、重複する説明は省略する。 BEST MODE FOR CARRYING OUT THE INVENTION Hereinafter, embodiments of the present invention will be described in detail with reference to the drawings. In each figure, the same members are denoted by the same reference numerals, and overlapping descriptions are omitted.
まず、各実施例にて具体的な説明を行う前に、本発明の要旨を述べる。本発明は、ディープラーニングを用いることで、画像中のデフォーカスぼけを整形し、良好なぼけ味の画像を得る。デフォーカスぼけの整形とは、ヴィネッティングによるデフォーカスぼけの欠け、デフォーカスぼけのピークの分離による多重ぼけ(例えば、二線ぼけ)、非球面レンズの金型の切削痕に起因するデフォーカスぼけの輪帯模様等を抑制することを指す。 First, the gist of the present invention will be described prior to specific description of each embodiment. The present invention uses deep learning to shape defocus blur in an image and obtain an image with good blur. Shaping of defocus blur means loss of defocus blur due to vignetting, multiple blur due to separation of defocus blur peaks (e.g., double-line blur), and defocus blur caused by cutting traces of aspherical lens molds. It refers to suppressing the ring pattern etc.
デフォーカスぼけの整形は、ミラーレンズのデフォーカスぼけがリング状になる現象を抑制することも含む。図16は、ミラーレンズを備えた光学系10の構成図である。図16に示されるように、光学系10は、主鏡M1および副鏡M2を備えて構成されるミラーレンズを有する。リング状のデフォーカスぼけは、副鏡M2でミラーレンズ(光学系10)の瞳が遮蔽されることにより引き起こされる。図16において、L1乃至L4はレンズを示し、L4は接合レンズである。また、IPは像面であり、撮像素子が配置される位置に相当する。整形により、デフォーカスぼけをユーザにとって望ましい形状(例えばフラットな円形、又はガウス分布関数等)へ変化させることで、デフォーカスぼけの良好なぼけ味を実現する。
Shaping of defocus blur also includes suppressing a phenomenon in which defocus blur of a mirror lens becomes ring-shaped. FIG. 16 is a configuration diagram of an
高精度なデフォーカスぼけの整形を実現するため、本発明では光学系の瞳(第1の瞳)で撮像された第1の画像と、瞳の一部(第1の瞳とは異なる第2の瞳)で撮像された第2の画像を、ディープラーニングへ入力する。第1の画像および第2の画像は瞳の大きさが異なるため、合焦距離からずれた際のデフォーカスぼけの大きさが異なる。このため、第1の画像および第2の画像のいずれか一方のみを入力する場合に対して、画像内のデフォーカスぼけと被写体の構造とを区別することができる。これにより、ディープラーニングによるデフォーカスぼけの整形を高精度に実現することができる。 In order to achieve highly accurate shaping of defocus blur, in the present invention, a first image captured by a pupil (first pupil) of an optical system and a part of the pupil (second pupil different from the first pupil) are used. The second image captured in the pupil of the eye) is input to deep learning. Since the first image and the second image have different pupil sizes, the magnitude of defocus blur when shifted from the in-focus distance is different. Therefore, when only one of the first image and the second image is input, the defocus blur in the image and the structure of the subject can be distinguished. As a result, defocus blur can be shaped with high accuracy by deep learning.
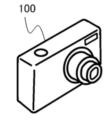
まず、図2および図3を参照して、本発明の実施例1における撮像装置について説明する。図2は、撮像装置100のブロック図である。図3は、撮像装置100の外観図である。なお、本実施例の撮像装置100は、カメラ本体とカメラ本体に一体的に構成されたレンズ装置とを備えて構成されるが、これに限定されるものではない。本発明は、カメラ本体(撮像装置本体)と、カメラ本体に着脱可能なレンズ装置(交換レンズ)とを備えて構成される撮像システムにも適用可能である。まず、撮像装置100の各部の概略を説明し、その詳細については後述する。
First, an imaging apparatus according to a first embodiment of the present invention will be described with reference to FIGS. 2 and 3. FIG. FIG. 2 is a block diagram of the
図2に示されるように、撮像装置100は、被写体空間の像を画像(撮像画像)として取得する撮像部101を有する。撮像部101は、被写体空間からの入射光を集光する光学系(撮像光学系)101aと、複数の画素を有する撮像素子101bとを有する。撮像素子101bは、例えば、CCD(Charge Coupled Device)センサやCMOS(Complementary Metal-Oxide Semiconductor)センサである。
As shown in FIG. 2, the
図4は、撮像部101の説明図である。図4(A)は、撮像部101の断面図を示し、一点鎖線は軸上光束を表している。図4(B)は、撮像素子101bの上面図である。撮像素子101bは、マイクロレンズアレイ122と複数の画素121とを有する。マイクロレンズアレイ122は、光学系101aを介して被写体面120と共役の位置に配置されている。図4(B)に示されるように、マイクロレンズアレイ122を構成するマイクロレンズ122(マイクロレンズ122aのみ表記し、122b以降は省略)は、複数の画素121(画素121aのみ表記し、121b以降は省略)のそれぞれと対応している。ここで、複数の部位をまとめて指定する際は番号のみを付し、そのうちの1つを示す際は番号とaなどの記号を付す。
FIG. 4 is an explanatory diagram of the
複数の画素121のそれぞれは、光学系101aを介して形成された光学像を光電変換する第1の光電変換部123および第2の光電変換部124を有する。これにより、例えば画素121aに入射した光は、その入射角に依存して、第1の光電変換部123aと第2の光電変換部124aとに分離して受光される(第1の光電変換部123aと第2の光電変換部124aは、互いに異なる入射角で入射する光を受光する)。光の入射角は、その光が光学系101aにおける瞳のいずれの位置を通過したかにより決定される。このため、光学系101aの瞳は2つの光電変換部により2つの部分瞳に分割され、一つの画素内の2つの光電変換部は互いに異なる視点(瞳の位置)から被写体空間を観察した情報を取得する。なお本実施例において、瞳の分割方向は水平方向であるが、これに限定されるものではなく、垂直方向や斜め方向などの他の方向であってもよい。
Each of the plurality of
撮像素子101bは、第1の光電変換部123で取得された信号(第2の画像、A画像)と、この信号(A画像)と第2の光電変換部124で取得された信号(第3の画像、B画像)との加算信号(第1の画像、A+B画像)を出力する。このように本実施例において、第1の画像および第2の画像は、光学系101aを介して被写体空間を同時に撮像して得られた画像である。また本実施例において、第1の画像および第2の画像は、同一の撮像素子101bにより撮像された画像である。
The
A画像およびA+B画像は、記憶部103に一時保存される。画像処理部(画像処理装置)102は、情報取得部(取得手段)102aおよび画像生成部(生成手段)102bを有し、本実施例の画像処理方法(デフォーカスぼけを整形するぼけ整形処理)を実行する。この際、情報取得部102aは記憶部(記憶手段)103からA画像とA+B画像とを取得し、画像生成部102bはA画像とA+B画像とからデフォーカスぼけを整形したぼけ整形画像を生成する。本実施例のぼけ整形画像は、デフォーカスぼけに対して、ヴィネッティング、点像強度分布のピーク分離による多重ぼけ、輪帯模様、または、光学系の瞳の遮蔽のうち少なくとも一つの影響を軽減した画像である。なお、この処理の詳細に関しては後述する。
The A image and the A+B image are temporarily stored in the
生成されたぼけ整形画像は、記録媒体105に保存される。ユーザから撮像画像の表示に関する指示が出された場合、保存されたぼけ整形画像が読み出され、表示部104に表示される。なお、記録媒体105に既に保存されたA画像とA+B画像とを読み出し、画像処理部102でぼけ整形画像を生成してもよい。以上の一連の制御は、システムコントローラ106によって行われる。
The generated deblurred image is saved in the
次に、図5を参照して、画像処理部102で実行されるデフォーカスぼけを整形するぼけ整形処理(ぼけ整形画像の生成)に関して説明する。図5は、ぼけ整形画像の生成処理を示すフローチャートである。図5の各ステップは、システムコントローラ106の指令に基づいて画像処理部102により実行される。
Next, blur shaping processing (blur shaping image generation) for shaping defocus blur executed by the
まず、ステップS101において、画像処理部102(情報取得部102a)は、記憶部103に一時保存されたA+B画像(第1の画像)201とA画像(第2の画像)202とを取得する。A画像202は、光学系101aの瞳の一部である部分瞳(第2の瞳)を通過する光束に基づいて被写体空間を撮像して得られた画像である。A+B画像201は、光学系101aの瞳(第1の瞳)を通過する光束に基づいて被写体空間を撮像して得られた画像である。本実施例において、第2の瞳は、第1の瞳に含まれ、第1の瞳の一部である。A+B画像とA画像はデフォーカスぼけの大小が異なり、第2の瞳は第1の瞳より小さいため、A画像のデフォーカスぼけはA+B画像よりも小さい。本実施例によれば、A+B画像とA画像との両方を用いることで、画像中のデフォーカスぼけと被写体の構造とを区別することができる。すなわち、画像内に高周波の情報が無い、ぼけている領域が存在する場合、この領域がデフォーカスしているためにぼけているのか、または、合焦しているが被写体に高周波の情報がないためにぼけているように見えるのかを区別することが可能である。また、図4に示される撮像部101の構成を用いることで、互いに異なる瞳の大きさのA+B画像とA画像とを同時に撮像可能であり、被写体の動きによる画像間のずれ等を回避することができる。
First, in step S<b>101 , the image processing unit 102 (
A+B画像には、光学系101aのヴィネッティングによるデフォーカスぼけの欠け、デフォーカスぼけのピークの分離による多重ぼけ、光学系101aに含まれる非球面レンズに起因するデフォーカスぼけの輪帯模様等が発生している。次に、図6および図7を参照して、これらに関して説明する。
In the A+B image, there is a lack of defocus blur due to vignetting of the
図6は、各像高とアジムスでの瞳分割の説明図である。図6はA+B画像を示し、×印の像高およびアジムスにおける分割瞳を×印の横に描画している。デフォーカスぼけは、反転を除いて瞳と略同一の形状になるため、ヴィネッティングの発生している軸外の像高において、デフォーカスぼけは円形から欠けた形状となる。図6中の破線は、瞳の分割線(分割直線)であり、A画像に対応する第2の瞳は破線に対して右側の部分瞳である。このため、A画像のデフォーカスぼけも同様に円形から欠けた形状となる。 FIG. 6 is an explanatory diagram of pupil division at each image height and azimuth. FIG. 6 shows an A+B image, with the split pupil at the x's image height and azimuth plotted next to the x's. Since the defocus blur has substantially the same shape as the pupil except for inversion, the defocus blur has a shape that is not circular at an off-axis image height where vignetting occurs. A dashed line in FIG. 6 is a dividing line (dividing straight line) of the pupil, and the second pupil corresponding to the A image is a partial pupil on the right side of the dashed line. For this reason, the defocus blur of the A image also has a shape that is not circular.
次に、図7(A)を参照して、多重ぼけに関して説明する。図7(A)は、デフォーカス距離でのぼけ整形前の点像強度分布(PSF)を示す図である。図7(A)において、横軸は空間座標(位置)、縦軸は強度を示す。この点は、後述の図7(B)~(D)関しても同様である。図7(A)に示されるように、多重ぼけの一例である二線ぼけは、ピークが分離したPSFを有する。デフォーカス距離におけるPSFが図7(A)のような形状を有する場合、本来は1本の線である被写体が、デフォーカスした際に2重にぼけているように見える。同様に、PSFのピークが中心と両端の3つに分離していれば、3重にぼけて見える。このため、PSFのピークの分離によるデフォーカスぼけへの影響を、多重ぼけと呼ぶ。 Next, multi-bokeh will be described with reference to FIG. 7(A). FIG. 7A is a diagram showing a point spread (PSF) before blur shaping at a defocus distance. In FIG. 7A, the horizontal axis indicates spatial coordinates (position) and the vertical axis indicates intensity. This point also applies to FIGS. 7B to 7D, which will be described later. As shown in FIG. 7A, the bilinear blur, which is an example of the multiple blur, has a PSF with separated peaks. When the PSF at the defocus distance has a shape as shown in FIG. 7A, the subject, which is originally a single line, appears to be double blurred when defocused. Similarly, if the PSF peak is separated into three peaks, ie, the center and both ends, it will appear triple blurred. For this reason, the influence of separation of PSF peaks on defocus blur is called multiple blur.
次に、図7(B)を参照して、輪帯模様に関して説明する。図7(B)は、デフォーカス距離でのぼけ整形前の点像強度分布(PSF)を示す図である。図7(B)に示されるように、輪帯模様は、PSFが振動成分を有することで実現される。このような振動成分は、光学系101aに含まれる非球面レンズを製造する際に用いた金型の削りムラが、主な原因である。これらの望ましくない形状のデフォーカスぼけを、後述のぼけ整形処理によって整形することができる。
Next, the annular pattern will be described with reference to FIG. 7(B). FIG. 7B is a diagram showing a point spread (PSF) before blur shaping at a defocus distance. As shown in FIG. 7B, the annular pattern is realized by the PSF having a vibration component. Such a vibration component is mainly caused by uneven cutting of the mold used when manufacturing the aspherical lens included in the
続いてステップS102において、画像生成部102bは、多層のニューラルネットワークを用いて、デフォーカスぼけを整形したぼけ整形画像を生成する。多層のニューラルネットワークには、A+B画像(第1の画像)およびA画像(第2の画像)を入力する。ぼけ整形画像は、光学系101aの瞳全体で撮像した画像(A+B画像)に対し、デフォーカス領域におけるぼけの形状を変化させた画像である。この際、ぼけ整形画像とA+B画像において、合焦被写体は変化しない。本実施例では、多層のニューラルネットワークとして、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)が用いられる。ただし、本発明はこれに限定されるものではなく、GAN(Generative Adversarial Network)等の他の方法を用いてもよい。
Subsequently, in step S102, the
ここで、図1を参照して、CNNによりぼけ整形画像213を生成する処理について詳述する。図1は、ぼけ整形画像を生成するネットワーク構造を示す図である。CNNは、複数の畳み込み層を有する。本実施例において、入力画像201は、A+B画像(第1の画像)とA画像(第2の画像)がチャンネル方向に連結(Concatenation)された画像である。第1の画像と第2の画像のそれぞれが複数のカラーチャンネルを有している場合、そのチャンネル数の2倍のチャンネル数を持つ画像となる。入力画像201は、第1畳み込み層202で複数のフィルタとの畳み込みとバイアスの和を算出される。ここで、フィルタの係数をウエイト(ウエイト情報)と呼ぶ。各層におけるフィルタおよびバイアスの値は、望ましくないデフォーカスぼけを良好な形状へ整形するように事前の学習で決定されるが、この学習に関する詳細は後述する。
第1の特徴マップ203は、各フィルタに対して算出された結果をまとめたものである。第1の特徴マップ203は、第2の畳み込み層204に入力され、同様に新たな複数のフィルタとの畳み込みとバイアスの和が算出される。これを繰り返し、第N-1の特徴マップ211を第Nの畳み込み層212に入力して得られた結果が、ぼけ整形画像213である。ここで、Nは3以上の自然数である。一般には3層以上の畳み込み層を有するCNNが、ディープラーニングに該当すると言われる。各畳み込み層では、畳み込みの他に活性化関数を用いた非線型変換が実行される。活性化関数の例としては、シグモイド関数やReLU(Rectified Linear Unit)等がある。本実施例では以下の式(1)で表されるReLUを用いる。
Here, with reference to FIG. 1, the process of generating the blur-corrected
A
![]()
![]()
式(1)において、xは特徴マップ、maxは引数のうち最大値を出力するMAX関数をそれぞれ表す。ただし、最後の第N畳み込み層では、非線形変換を実行しなくてもよい。 In Equation (1), x represents a feature map, and max represents a MAX function that outputs the maximum value among arguments. However, the last Nth convolutional layer does not need to perform a nonlinear transform.
なお本実施例では、A+B画像とA画像のそれぞれに前処理を実行し、前処理後のA+B画像とA画像をそれぞれCNNへ入力する。前処理は、A+B画像とA画像の分割と、分割された画像またはフィルタの反転に関する制御(反転処理)である。すなわち画像生成部102bは、光軸上の物点に対する第2の瞳が線対称となる軸と平行で、かつA+B画像とA画像のそれぞれの基準点(光軸、または光軸の近傍)を通過する直線で、A+B画像とA画像のそれぞれを分割する。また画像生成部102bは、分割されたA+B画像とA画像、またはウエイト情報に対して、反転を制御する前処理(反転処理)を施す。そして、反転処理後のA+B画像とA画像と(又は、反転処理後のウエイト情報)に基づいてぼけ整形画像を生成することにより、ウエイト情報の容量を削減することができる。これに関して、図6を参照して説明する。
In this embodiment, preprocessing is performed on each of the A+B image and the A image, and the preprocessed A+B image and the A image are input to the CNN. The pre-processing is the division of the A+B image and the A image, and control (inversion processing) regarding the inversion of the divided image or filter. That is, the
図6に示されるように、本実施例では一点鎖線を軸としてA+B画像(またはA画像)の上下いずれか一方を反転すると、他方の瞳分割と重なり、線対称になっている。このため、デフォーカスのぼけも同様に、一点鎖線に対して線対称となる。したがって、一点鎖線の上下いずれか一方の領域に関して、ぼけを補正するウエイト情報を保持しておけば、他方は画像またはウエイト情報を反転することでぼけ整形画像を推定することができる。 As shown in FIG. 6, in this embodiment, when one of the upper and lower sides of the A+B image (or the A image) is inverted about the dashed-dotted line, the image overlaps the other pupil division and is line symmetrical. For this reason, the defocus blur is also symmetrical with respect to the dashed line. Therefore, if weight information for correcting blur is stored for one of the areas above and below the dashed-dotted line, a blurred image can be estimated for the other area by inverting the image or the weight information.
ここで、反転とは、画像とウエイト情報との積を取る際の参照の順序を逆にする場合を含む。上下の一方のみに対してウエイト情報を学習することで、CNNで整形するデフォーカスぼけの幅が限定され、より小さなネットワークで高精度なぼけ整形を実現することができる。本実施例では、上下方向にA+B画像とA画像を2分割し、A+B画像とA画像の上半分または下半分を入力画像201とする。上下の分割画像をそれぞれ個別にCNNで処理し、出力されたぼけ整形画像を合わせることで、画像全体に対してぼけ整形が行われた画像を得ることができる。
Here, inversion includes the case of reversing the reference order when taking the product of the image and the weight information. By learning the weight information for only one of the upper and lower sides, the width of the defocus blur to be shaped by the CNN is limited, and highly accurate blur shaping can be achieved with a smaller network. In this embodiment, the A+B image and the A image are vertically divided into two, and the upper half or the lower half of the A+B image and the A image is used as the
なお本実施例では、水平方向に瞳を分割しているため、対称軸は水平な直線である。仮に、垂直方向に瞳を分割すると、対称軸も垂直な直線になる。これをさらに一般的に表現すると、以下のようになる。分割した瞳の関係が画像全体に対して線対称となる軸は、光軸を通過し、かつ光軸上で第2の瞳が線対称になる軸と平行である。この軸で分割されたA+B画像とA画像に対し、一方の分割領域のみウエイト情報を保持しておけば、他方は反転を制御することで同じウエイト情報でデフォーカスぼけの整形処理を行うことができる。 In this embodiment, since the pupil is divided in the horizontal direction, the axis of symmetry is a horizontal straight line. If the pupil is divided in the vertical direction, the axis of symmetry will also be a vertical straight line. A more general expression of this is as follows. The axis along which the relationship of the divided pupils is linearly symmetrical with respect to the entire image passes through the optical axis and is parallel to the axis along which the second pupil is linearly symmetrical on the optical axis. For the A+B image and the A image divided by this axis, if weight information is held only for one of the divided areas, the other can be reversed to perform defocus blur shaping processing with the same weight information. can.
生成されたぼけ整形画像は、デフォーカスぼけの拡がりが、A+B画像のデフォーカスぼけの拡がり以上になっている。ヴィネッティングによるデフォーカスぼけの欠けを整形した場合、A+B画像よりもデフォーカスぼけの拡がりが大きくなる。多重ぼけや輪帯模様を整形した場合、デフォーカスぼけの拡がりはA+B画像と同じである。本実施例によれば、画像のデフォーカスぼけを整形し、良好なぼけ味を有する画像を生成することが可能になる。 In the generated blur-corrected image, the spread of defocus blur is greater than or equal to the spread of defocus blur of the A+B image. When the lack of defocus blur due to vignetting is corrected, the spread of the defocus blur becomes larger than in the A+B image. When the multi-bokeh or ring pattern is shaped, the spread of the defocused blur is the same as the A+B image. According to the present embodiment, it is possible to shape the defocus blur of an image and generate an image with good blur.
次に、図8を参照して、多層のニューラルネットワーク(本実施例ではCNN)で使用するウエイト情報の学習に関して説明する。図8は、ウエイト情報の学習に関するフローチャートである。本実施例において、学習は撮像装置100以外の画像処理装置で事前に実行され、その結果(複数のウエイト情報)が記憶部103に記憶されている。ただし本発明は、これに限定されるものではなく、撮像装置100内に学習を実行する部位が存在していてもよい。
Next, with reference to FIG. 8, learning of weight information used in a multilayer neural network (CNN in this embodiment) will be described. FIG. 8 is a flowchart regarding learning of weight information. In this embodiment, learning is performed in advance by an image processing apparatus other than the
まず、ステップS201において、画像処理装置は、複数の学習ペアを取得する。学習ペアとは、CNNの入力画像としてのA+B画像およびA画像と、CNNの出力画像(ぼけ整形画像)として得たい画像(正解画像)である。学習ペアの入力画像と正解画像との関係によって、CNNが補正する対象は変化する。 First, in step S201, the image processing apparatus acquires a plurality of learning pairs. A learning pair is an A+B image and an A image as CNN input images, and an image (correct image) to be obtained as a CNN output image (deblurring image). The object to be corrected by the CNN changes depending on the relationship between the input image of the learning pair and the correct image.
ここで、学習ペアの生成方法に関して説明する。まず、入力画像(A+B画像とA画像)と正解画像を生成する元となるソースデータを用意する。ソースデータは、広い範囲の空間周波数までスペクトル強度を有する3次元モデル、または2次元画像である。3次元モデルは、CG(コンピュータ・グラフィクス)等で生成することができる。2次元画像は、CGまたは実写画像のいずれでもよい。A画像とB画像は、撮像部101でソースデータを撮像したシミュレーション(撮像シミュレーション)によって生成することができる。撮像シミュレーションでは、撮像部101で発生するデフォーカスぼけを付与する。A+B画像は、生成されたA画像とB画像とを加算して得られる。正解画像は、光学系101aとは異なる良好なデフォーカスぼけを付与することで生成される。良好なデフォーカスぼけの例としては、例えば図7(C)に示されるフラットな円形ぼけや、図7(D)に示されるガウス分布関数が挙げられる。また、異なる分散を有する複数のガウス分布関数を加重平均したPSFを用いてもよい。ソースデータが3次元モデルの場合、合焦距離から各被写体の距離に対応したデフォーカスぼけを付与する。
Here, a method for generating learning pairs will be described. First, input images (A+B image and A image) and source data from which a correct image is generated are prepared. The source data are 3D models or 2D images with spectral intensities over a wide range of spatial frequencies. A three-dimensional model can be generated by CG (computer graphics) or the like. A two-dimensional image may be either CG or a photographed image. The A image and the B image can be generated by simulation (imaging simulation) in which source data is captured by the
ソース画像が2次元画像の場合、様々なデフォーカス距離に2次元画像を配置して撮像シミュレーションを行い、それらに対応した複数の学習ペアを作成する。ただし、この際、2次元画像が合焦距離にいる学習ペアも作成する。デフォーカスぼけの整形は、合焦距離の被写体に対して変化を起こさないことが好ましい。合焦距離での学習ペアに対しては変化がないことをCNNに学習させなければ、合焦被写体に対してCNNがどのような結果を出力するか予測できない。このため、2次元画像が合焦距離にいる学習ペアも作成する必要がある。本実施例では、A+B画像とA画像とを上下方向に2分割してぼけ整形を行う。このため、学習ペアに付与するデフォーカスぼけは、画像中の上下のいずれか一方のみで発生するものに限定してよい。また、入力画像に撮像素子101bで発生するノイズを付与し、正解画像はノイズのない画像としてもよい。この学習ペアで学習することで、CNNは、ぼけ整形と同時にデノイジングも実行するようになる。
When the source image is a two-dimensional image, imaging simulation is performed by arranging the two-dimensional image at various defocus distances, and a plurality of learning pairs corresponding to them are created. However, at this time, a learning pair in which the two-dimensional image is at the in-focus distance is also created. It is preferable that the defocus blur shaping does not change with respect to the subject at the in-focus distance. Unless the CNN learns that there is no change for the learning pairs at the in-focus distance, it is impossible to predict what results the CNN will output for the in-focus object. Therefore, it is also necessary to create a learning pair in which the two-dimensional image is at the in-focus distance. In this embodiment, the A+B image and the A image are divided into two in the vertical direction and the blur shaping is performed. For this reason, the defocus blur given to the learning pair may be limited to one that occurs only in either the top or bottom of the image. Alternatively, noise generated by the
好ましくは、ソースデータは、撮像素子101bのダイナミックレンジを越える幅の輝度を有する。これは、実際の被写体においても、特定の露出条件で撮像装置101により撮像を行った際、輝度飽和値に収まらない被写体が存在するためである。正解画像は、ソースデータに良好なデフォーカスぼけを付与し、撮像素子101bの輝度飽和値で信号をクリップすることで生成される。訓練画像は、撮像部101で発生するデフォーカスぼけを付与し、輝度飽和値によってクリップすることで生成される。輝度飽和値によるクリップで発生する問題は、大きく2つある。1つ目は、デフォーカスぼけの形状が変化することである。例えば、点光源のデフォーカスぼけの形状は、そのデフォーカス位置でのPSFと一致するはずであるが、輝度飽和値でクリップされることで異なる形状となってしまう。2つ目は、偽エッジの出現である。偽エッジは高周波を有するため、合焦被写体なのか、輝度飽和しているデフォーカスぼけなのかを判定することが難しい。しかし、1つ目の問題は、撮像素子101bのダイナミックレンジを越えるソースデータから生成された学習ペアを用いることで、輝度飽和値のクリップによるデフォーカスぼけの変化も、多層のニューラルネットワークが学習するため、解決することができる。さらに、異なる瞳の2画像をニューラルネットワークの入力とすることで、偽エッジが合焦被写体なのかデフォーカスぼけなのかを判定することも容易となり、2つ目の問題も解決することができる。
Preferably, the source data has luminance in a width exceeding the dynamic range of the
続いて、図8のステップS202において、画像処理装置は、複数の学習ペアから学習を行い、ウエイト情報を生成する。学習の際には、ステップS102のぼけ整形画像の生成と同じネットワーク構造を用いる。本実施例では、図1に示されるネットワーク構造に対してA+B画像とA画像を入力し、その出力結果(推定されたぼけ整形画像)と正解画像との誤差を算出する。この誤差が最小になるように、誤差逆伝播法(Backpropagation)等を用いて、各層で用いるフィルタ(ウエイト情報)とバイアスを更新して最適化する。フィルタとバイアスの初期値はそれぞれ任意であり、例えば乱数から決定することができる。または、各層ごとに初期値を事前学習するAuto Encoder等のプレトレーニングを行ってもよい。 Subsequently, in step S202 of FIG. 8, the image processing apparatus performs learning from a plurality of learning pairs to generate weight information. For learning, the same network structure as that for generating the deblurred image in step S102 is used. In this embodiment, the A+B image and the A image are input to the network structure shown in FIG. 1, and the error between the output result (estimated blur corrected image) and the correct image is calculated. In order to minimize this error, the error back propagation method or the like is used to update and optimize the filter (weight information) and bias used in each layer. The initial values of the filter and bias are arbitrary and can be determined, for example, from random numbers. Alternatively, pre-training such as Auto Encoder that pre-learns initial values for each layer may be performed.
学習ペアを全てネットワーク構造へ入力し、それら全ての情報を使って学習情報を更新する手法をバッチ学習と呼ぶ。ただし、この学習方法は学習ペアの数が増えるにつれて、計算負荷が膨大になる。逆に、学習情報の更新に1つの学習ペアのみを使用し、更新ごとに異なる学習ペアを使用する学習手法をオンライン学習と呼ぶ。この手法は、学習ペアが増えても計算量が増大しない利点があるが、その代わりに1つの学習ペアに存在するノイズの影響を大きく受ける。このため、これら2つの手法の中間に位置するミニバッチ法を用いて学習することが好ましい。ミニバッチ法は、全学習ペアの中から少数を抽出し、それらを用いて学習情報を更新する。次の更新では、異なる小数の学習ペアを抽出して使用する。これを繰り返すことにより、バッチ学習とオンライン学習の欠点を小さくすることができる。 A method of inputting all learning pairs into a network structure and updating learning information using all the information is called batch learning. However, this learning method increases the computational load as the number of learning pairs increases. Conversely, a learning method that uses only one learning pair for updating learning information and uses a different learning pair for each update is called online learning. This method has the advantage that the amount of calculation does not increase even if the number of learning pairs increases, but instead it is greatly affected by noise that exists in one learning pair. Therefore, it is preferable to learn using the mini-batch method, which is located between these two methods. The mini-batch method extracts a small number of all training pairs and uses them to update the learning information. In the next update, we will extract and use a different fractional training pair. By repeating this, the shortcomings of batch learning and online learning can be reduced.
なお、ウエイト情報の学習およびぼけ整形画像の生成を行う際に扱う画像は、RAW画像または現像後の画像のいずれでもよい。A+B画像とA画像が符号化されている場合、復号してから学習および生成を行う。学習に使用した画像とぼけ整形画像生成時の入力画像でガンマ補正の有無や、ガンマ値が異なる場合、入力画像を処理して学習の画像に合わせることが好ましい。また、A+B画像とA画像(学習の際は正解画像も)は、ニューラルネットワークへ入力する前に信号値を規格化しておくことが好ましい。規格化しない場合、学習とぼけ整形画像生成時にbit数が異なっていると、ぼけ整形画像を正しく推定することができない。また、bit数によってスケールが変化するため、学習時の最適化で収束に影響を及ぼす可能性もある。規格化には、信号が実際に取り得る最大値(輝度飽和値)を用いる。例えばA+B画像が16bitで保存されていたとしても、輝度飽和値は12bitの場合等があり、この際は12bitの最大値(4095)で規格化しなければ信号の範囲が0~1にならない。また、規格化の際にはオプティカルブラックの値を減算することが好ましい。これにより、実際に画像が取り得る信号の範囲をより0~1に近づけることができる。具体的には、以下の式(2)に従って規格化することが好ましい。 An image to be handled when weight information is learned and a blur-corrected image is generated may be either a RAW image or a developed image. If the A+B and A images are encoded, then decode before training and generation. If the image used for learning and the input image for generating the deblurred image are different in gamma correction or gamma value, it is preferable to process the input image to match the image for learning. In addition, it is preferable to normalize the signal values of the A+B image and the A image (and the correct image during learning) before inputting them to the neural network. Without normalization, if the number of bits differs between learning and blur-corrected image generation, the blur-corrected image cannot be estimated correctly. Also, since the scale changes depending on the number of bits, optimization during learning may affect convergence. For normalization, the maximum value (brightness saturation value) that the signal can actually take is used. For example, even if the A+B image is stored in 16 bits, the luminance saturation value may be 12 bits. Also, it is preferable to subtract the value of optical black when normalizing. As a result, the range of signals that the image can actually take can be brought closer to 0 to 1. Specifically, it is preferable to standardize according to the following formula (2).

式(2)において、sはA+B画像(またはA画像もしくは正解画像)の信号、sOBはオプティカルブラックの信号値(画像が取り得る信号の最小値)、ssatuは信号の輝度飽和値、snorは規格化された信号を示す。 In equation (2), s is the signal of the A+B image (or A image or correct image), s OB is the signal value of optical black (minimum signal value that the image can take), s satu is the luminance saturation value of the signal, s nor indicates a normalized signal.
本実施例によれば、画像のデフォーカスぼけを整形し、良好なぼけ味を有する画像を生成することが可能な画像処理方法、画像処理装置、撮像装置、および、レンズ装置を提供することができる。 According to this embodiment, it is possible to provide an image processing method, an image processing apparatus, an imaging apparatus, and a lens apparatus capable of shaping the defocus blur of an image and generating an image having a favorable blur. can.
次に、本発明の実施例2における画像処理システムについて説明する。本実施例では、ぼけ整形画像を推定する画像処理装置、撮像画像を取得する撮像装置、および、学習を行うサーバが個別に存在している。 Next, an image processing system according to Embodiment 2 of the present invention will be described. In this embodiment, an image processing device for estimating a blurred image, an imaging device for acquiring a captured image, and a server for learning exist separately.
図9および図10を参照して、本実施例における画像処理システムについて説明する。図9は、画像処理システム300のブロック図である。図10は、画像処理システム300の外観図である。図9および図10に示されるように、画像処理システム300は、撮像装置301、画像処理装置302、サーバ308、表示装置311、記録媒体312、および、出力装置313を備えて構成される。
The image processing system in this embodiment will be described with reference to FIGS. 9 and 10. FIG. FIG. 9 is a block diagram of the
撮像装置301の基本構成は、ぼけ整形画像を生成する画像処理部、および撮像部を除いて、図2に示される撮像装置100と同様である。なお、本実施例の撮像装置301は、レンズ装置(光学系)の交換が可能である。撮像装置301の撮像素子は、図11に示されるように構成されている。図11は、本実施例における撮像素子の構成図である。図11において、破線はマイクロレンズを示す。画素320(a、b以降は省略)のそれぞれには4つの光電変換部321、322、323、324(a、b以降は省略)が設けられ、光学系の瞳を2×2の四つに分割している。光電変換部321~324で取得される画像を、順に、A画像、B画像、C画像、D画像とし、それらの加算結果をABCD画像とする。撮像素子からは撮像画像として、ABCD画像(第1の画像)とA画像(第2の画像)の2画像が出力される。
The basic configuration of the
撮像装置301と画像処理装置302とが接続されると、ABCD画像とA画像は記憶部303に記憶される。画像処理装置302は、情報取得部304、画像生成部305、デプス推定部306にて、ABCD画像とA画像からぼけ整形画像を生成する。この際、画像処理装置302は、ネットワーク307を介してサーバ308にアクセスし、生成に用いるウエイト情報を読み出す。ウエイト情報は、学習部310で予め学習され、記憶部309に記憶されている。ウエイト情報は、レンズの種類、F値、整形後のデフォーカスぼけ形状等により個別に学習されており、複数のウエイト情報が存在する。
When the
画像処理装置302は、使用するウエイト情報を、ユーザの選択指示、または入力されたABCD画像から決定される自動選択により、記憶部303に取得し、ぼけ整形画像の生成を行う。ぼけ整形画像は、表示装置311、記録媒体312、および、出力装置313の少なくとも一つに出力される。表示装置311は、例えば液晶ディスプレイやプロジェクタ等である。ユーザは、表示装置311を介して、処理途中の画像を確認しながら作業を行うことができる。記録媒体312は、例えば半導体メモリ、ハードディスク、ネットワーク上のサーバ等である。出力装置313は、プリンタ等である。画像処理装置302は、必要に応じて現像処理やその他の画像処理を行う機能を有する。また本実施例において、撮像装置301に接続されているレンズ装置内の記憶手段にウエイト情報を保持しておき、デフォーカスぼけ整形の際に呼び出してもよい。
The
次に、図12を参照して、画像処理装置302により実行されるぼけ整形画像の生成処理について説明する。図12は、ぼけ整形画像の生成処理を示すフローチャートである。図12の各ステップは、主に、画像処理装置302(情報取得部304、画像生成部305、デプス推定部306)により実行される。
Next, with reference to FIG. 12, the process of generating a blurred image performed by the
まずステップS301において、情報取得部304は、ABCD画像とA画像を取得する。本実施例において、第1の画像はABCD画像であり、第2の画像はA画像である。ただし、第1の画像は光学系の瞳全体に対応する画像である必要はなく、A画像、B画像、C画像、D画像の少なくとも二つを加算した画像でもよい。
First, in step S301, the
続いてステップS302において、情報取得部304は、デフォーカスぼけの整形条件を決定する。整形条件の決定は、デフォーカスぼけを望ましくない形状へ変化させる複数の要因(デフォーカスぼけの欠け、多重ぼけ、輪帯模様等)のうち、ぼけ整形によって影響を抑制する要因を選択することを含む。または、整形条件の決定は、ぼけ整形によって変化させるデフォーカスぼけ形状の目標(強度がフラットなPSFまたはガウス分布関数等)を指定することを含む。なお、整形条件は、ユーザが手動で決定することができ、または、ステップS301にて取得された画像から自動的に決定してもよい。
Subsequently, in step S302, the
整形条件の自動決定に関して、以下に例を説明する。ABCD画像(またはA画像)には、撮像に用いられたレンズの種類がメタデータとして保存されている。撮像に用いたレンズの種類を特定することにより、ヴィネッティングの大きさ、および、二重ぼけや輪帯模様の有無を知ることができる。このため、ABCD画像の撮像に用いたレンズの種類に基づいて、ぼけ整形によって影響を抑制する要因(デフォーカスぼけの欠けなど)を決定することができる。また、メタデータ内に撮影した際の焦点距離が保存されている場合、焦点距離の情報に基づいて、整形条件を決定することもできる。広角レンズではヴィネッティングが大きくなる傾向があるため、ある閾値よりも焦点距離が小さい場合、ぼけ整形によってデフォーカスぼけの欠けを抑制するように整形条件を決定する。また、デフォーカスぼけ形状の目標は、例えば、以下のようにABCD画像の輝度値に基づいて決定してもよい。ABCD画像の輝度飽和している領域は、図7(C)に示されるような強度がフラットなPSFとし、それ以外の領域は図7(D)に示されるようなガウス分布関数とする。または、撮像時に判定された撮影シーンの情報をメタデータから読み取り、撮影シーンが夜景の場合、強度がフラットなPSFとし、それ以外の場合はガウス分布関数とする等のようにしてもよい。 Regarding the automatic determination of shaping conditions, an example is described below. ABCD images (or A images) store the type of lens used for imaging as metadata. By specifying the type of lens used for imaging, it is possible to know the magnitude of vignetting and the presence or absence of double blurring and annular patterns. Therefore, it is possible to determine a factor (such as lack of defocus blur) that suppresses the influence of blur shaping based on the type of lens used to capture the ABCD image. Also, if the focal length at the time of photographing is stored in the metadata, the shaping conditions can be determined based on the focal length information. Since vignetting tends to increase with a wide-angle lens, when the focal length is smaller than a certain threshold, the shaping condition is determined so as to suppress the loss of defocus blur by blur shaping. Also, the defocus blur shape target may be determined, for example, based on the luminance value of the ABCD image as follows. A PSF having a flat intensity as shown in FIG. 7(C) is used for the ABCD image with saturated brightness, and a Gaussian distribution function as shown in FIG. 7(D) is used for other regions. Alternatively, the information of the shooting scene determined at the time of shooting may be read from the metadata, and if the shooting scene is a night scene, a PSF with a flat intensity may be used, otherwise a Gaussian distribution function may be used.
続いてステップS303において、情報取得部304は、複数のウエイト情報から、ステップS302にて決定されたデフォーカスぼけの整形条件に対応するウエイト情報を取得する。なお、複数のウエイト情報の学習方法に関しては後述する。
Subsequently, in step S303, the
続いてステップS304において、デプス推定部306は、ABCD画像とA画像からデプスマップを算出する。デプスマップの算出には、画像間の視差を用いることができ、または、デフォーカスぼけの大きさの違いに基づくDFD(Depth From Defocus)を用いてもよい。デプスマップの代わりに、ABCD画像とA画像との間における視差ずれ量を表した視差マップを算出してもよい。なお、ステップS304は、ステップS301とステップS307との間であれば、いつ実行してもよい。
Subsequently, in step S304, the
続いてステップS305において、画像生成部305は、ABCD画像とA画像の明るさを合わせる処理を行う。A画像は、ABCD画像に対して瞳が小さいため、暗い画像となっている。また、光軸上以外の像高ではヴィネッティングが発生するため、像高とアジムスとにより、ABCD画像とA画像の明るさの比(光量比)は変化する。これに関し、図13を参照して説明する。
Subsequently, in step S305, the
図13は、分割瞳と像高とヴィネッティングとの関係を示す図である。図13(A)は、撮像装置301の光学系の光軸上における瞳を示している。図13中の破線は、4つの光電変換部により分割される瞳の分割線を表している。図13(B)は、図13(A)の場合とは異なる像高における瞳を示している。図13(A)では4つの分割瞳の光量は均一だが、図13(B)ではヴィネッティングにより両者の光量比に偏りが生じている。図13(C)は、図13(B)と同一像高(光軸に垂直な平面内で光軸から同一の距離の位置)でアジムス(光軸に垂直な平面内で光軸を回転軸とした方位角)が異なる場合である。この際も部分瞳の光量比が変化する。このため、ABCD画像とA画像を後述の多層のニューラルネットワークへ入力すると、画像内の像高およびアジムスにより2つの画像の明るさの関係がばらつくことにより、ぼけ生成の精度が低下する可能性がある。したがって、本実施例では、ABCD画像とA画像の明るさを合わせる前処理を実行することが好ましい。なお本実施例では、A画像の明るさをABCD画像に合わせるが、逆でも構わない。また、各像高とアジムスに対して、第1の瞳と第2の瞳それぞれの透過率分布を積分した第1の積分値と第2の積分値を取得し、明るさ合わせに使用してもよい。第1の画像の各像高とアジムスの画素に対して、対応する第1の積分値の逆数をかけ、第2の画像の各像高とアジムスの画素に対して、対応する第2の積分値の逆数をかけることでも、明るさを合わせることができる。
FIG. 13 is a diagram showing the relationship between split pupil, image height, and vignetting. FIG. 13A shows a pupil on the optical axis of the optical system of the
2つの画像の明るさを合わせる方法として、以下に2つの例を挙げる。1つ目は、第1の瞳(光学系の瞳全体)と第2の瞳(A画像に対応する部分瞳)の光量比(第1の瞳と第2の瞳の透過率分布の比)に基づいて、明るさを合わせる方法である。A画像の各像高とアジムスの画素に対して、第2の瞳に対する第1の瞳の光量比(第2の瞳の透過率分布に対する第1の瞳の透過率分布の比)を記憶部303から読み出して積をとり、ABCD画像と明るさを合わせる。光量比は1以上の値であり、像高とアジムスによって異なる値を有する。 Two examples of methods for matching the brightness of two images are given below. The first is the light amount ratio between the first pupil (entire pupil of the optical system) and the second pupil (partial pupil corresponding to the A image) (the ratio of the transmittance distribution between the first pupil and the second pupil). This is a method of matching the brightness based on . A light amount ratio of the first pupil to the second pupil (the ratio of the transmittance distribution of the first pupil to the transmittance distribution of the second pupil) is stored in a storage unit for each image height and azimuth pixel of the A image. The product is read from 303 and the brightness is matched with the ABCD image. The light amount ratio is a value of 1 or more, and has different values depending on the image height and the azimuth.
2つ目は、ABCD画像とA画像の局所的な平均画素値を用いる方法である。ABCD画像とA画像は、収差やノイズが異なり、また視差を有するが、同じ被写体を撮像しているため、部分領域における平均画素値の比は、前述の光量比におおよそ対応する。このため、例えば、ABCD画像とA画像に平滑化フィルタをかけて各画素に対して平均画素値を求め、同一位置の画素における平均画素値の比から、この位置での光量比を求め、明るさを合わせることができる。ただし、平均画素値を求める際、輝度飽和している画素が含まれている場合、光量比から値が乖離する可能性がある。このため本実施例では、輝度飽和した画素を除いて平均画素値を求めることが好ましい。仮に、輝度飽和の面積が大きく、その位置での平均画素値が求められない場合、周辺で算出された光量比から補間を行い、その位置に対応する光量比を算出することができる。部分領域の大きさは、ぼけの大きさと、第1の瞳と第2の瞳の基線長(重心位置の間の長さ)に基づいて決定することが好ましい。なおステップS305は、ステップS301とステップS307との間であれば、いつ実行してもよい。 The second method is to use local average pixel values of the ABCD image and the A image. Although the ABCD image and the A image have different aberrations and noises and have parallax, the same subject is captured, so the ratio of the average pixel values in the partial area roughly corresponds to the above-described light amount ratio. For this reason, for example, a smoothing filter is applied to the ABCD image and the A image to obtain the average pixel value for each pixel, and from the ratio of the average pixel values of the pixels at the same position, the light amount ratio at this position is obtained. can match. However, when calculating the average pixel value, if a pixel with saturated luminance is included, the value may deviate from the light amount ratio. For this reason, in this embodiment, it is preferable to calculate the average pixel value by excluding pixels whose luminance is saturated. If the luminance saturation area is large and the average pixel value at that position cannot be obtained, interpolation can be performed from the light quantity ratios calculated in the periphery to calculate the light quantity ratio corresponding to that position. The size of the partial region is preferably determined based on the size of the blur and the baseline length (the length between the centroid positions) of the first pupil and the second pupil. Note that step S305 may be executed at any time between steps S301 and S307.
続いて、図12のステップS306において、画像生成部305は、多層のニューラルネットワークへ入力するABCD画像およびA画像の入力領域を決定する。画像全体をニューラルネットワークへ入力してもよいが、後述のステップS307にてデフォーカスぼけを整形するため、デフォーカスしていない領域(合焦領域)を入力する必要はない。画像のうち合焦領域を除いた領域のみをニューラルネットワークの入力領域とすることで、計算負荷を軽減することができる。合焦領域の判定には、ABCD画像(またはA画像)のエッジ分布を用いる。エッジ分布は、例えば、ABCD画像をWavelet変換することで得られる。エッジ(エッジ領域)は、高周波成分が一定以上の強度を有する領域に相当する。エッジが存在するのは合焦領域であるから、エッジを含まない領域を入力領域とする。また、エッジ分布の代わりに、ステップS304にて算出したデプスマップ(または視差マップ)に基づいて、入力領域を決定してもよい。この場合、デプスがABCD画像のメタデータ内の合焦距離と一致する領域以外を入力領域とする。また、撮像装置301は、合焦距離で視差がゼロになるように構成されているため、視差マップの場合には視差が閾値より大きい領域を入力領域とする。なおステップS306は、ステップS301とステップS307との間であれば、いつ実行してもよい。
Subsequently, in step S306 of FIG. 12, the
続いてステップS307において、画像生成部305は、ぼけ整形画像を生成する。このとき画像生成部305は、ABCD画像とA画像から入力領域を抽出し、抽出した入力領域を多層のニューラルネットワークへ入力画像として入力する。また画像生成部305は、入力領域に対応するデプスマップ(または視差マップ)も入力画像として加える。
Subsequently, in step S307, the
本実施例において、画像生成部305は、図14に示されるネットワーク構造を用いる。図14は、本実施例におけるぼけ整形画像を生成するネットワーク構造を示す図である。図14において、入力画像401は、入力領域全体、または、入力領域を分割した一部(分割領域)でもよい。入力画像401は、ABCD画像とA画像とデプスマップ(または視差マップ)とがチャンネル方向に連結された画像である。図14において、CNは畳み込み層、DSは入力される特徴マップのサンプリングレートをダウンサンプリングするダウンサンプリング層、DCは逆畳み込み層、USは特徴マップをアップサンプリングするアップサンプリング層をそれぞれ示す。ダウンサンプリング層のダウンサンプリングレートと、アップサンプリング層のアップサンプリングレートは、逆数の関係にある。各畳み込み層および逆畳み込み層で使用されるフィルタは、ウエイト情報に基づいて決定される。
In this embodiment, the
スキップコネクション412、413は、連続していない層から出力された特徴マップを合成する。特徴マップの要素ごとの和をとってもよいし、チャンネル方向に連結してもよい。複数のダウンサンプリング層とスキップコネクションによって、互いに異なる解像度の複数の特徴マップ(互いに異なるサンプリングレートのダウンサンプリングが実行された複数の特徴マップ)が生成される。これにより、畳み込み層のフィルタサイズを大きくすることなく、局所的な特徴と、より大域的な特徴の両方を算出することができる。デフォーカスぼけは、合焦距離からのずれやF値に応じて大きくなるため、大域的な特徴を算出することが好ましい。また、スキップコネクションは、フィルタの学習時に収束性を良くする役割も有する。スキップコネクション411は、入力画像401のうちのABCD画像401aと、多層のニューラルネットワークの出力との和をとる。これにより、ぼけ整形画像402が得られる。入力領域を分割して入力画像401を得ている場合、入力領域全体に対してぼけ整形画像402を算出する。ニューラルネットワークで算出されたぼけ整形画像と、入力領域以外のABCD画像とを合わせることで、画像全体に対するぼけ整形画像が生成される。
Skip
なお本実施例において、畳み込み層、逆畳み込み層、ダウンサンプリング層、アップサンプリング層、および、スキップコネクションのそれぞれの数は、図14に示される数に限定されるものではない。また、ネットワーク構造も図14に示される構造に限定されるものではない。例えば、図15に示されるようなネットワーク構造を使用してもよい。図15は、本実施例におけるぼけ整形画像を生成する他のネットワーク構造を示す図である。 In this embodiment, the numbers of convolution layers, deconvolution layers, downsampling layers, upsampling layers, and skip connections are not limited to the numbers shown in FIG. Also, the network structure is not limited to the structure shown in FIG. For example, a network structure such as that shown in FIG. 15 may be used. FIG. 15 is a diagram showing another network structure for generating a blurred image in this embodiment.
図15のネットワーク構造は、複数のステージ500、510、520に分かれており、それぞれ解像度が異なる。ステージ520は、解像度がABCD画像の(1/m)2倍(mは正の整数)である。入力画像521は、解像度が(1/m)2倍にダウンサンプリングされたABCD画像、A画像、および、デプスマップである。なおスキップコネクションは、図14と同様である。ステージ520における解像度でのぼけ整形画像522は、アップサンプリング層592でm倍にアップサンプリングされ、元の1/m倍の解像度であるステージ510に入力される。
The network structure of FIG. 15 is divided into
ステージ510における入力画像511は、解像度が1/m倍のABCD画像、A画像、デプスマップ、および、ぼけ整形画像522のアップサンプリング結果が連結されたデータである。同様に、ステージ510のぼけ整形画像512は、アップサンプリング層591でm倍にアップサンプリングされ、ステージ500へ入力される。
An
ステージ500は、元のABCD画像と同じスケールの解像度を有する。入力画像501は、ABCD画像、A画像、デプスマップ、および、ぼけ整形画像512のアップサンプリング結果が連結されたデータである。最終的なぼけ整形画像として、ステージ500で算出されるぼけ整形画像502が出力される。なお本実施例において、ステージの数は3に限定されず、ステージ内のネットワーク構造も図15に示される構造に限定されるものではない。また、各ステージにおけるフィルタのウエイトを共通(ステージに依らず、同じフィルタを使用)にしてもよい。これにより、ウエイト情報のデータ容量を削減することができる。
学習部310で実行されるウエイト情報の学習は、実施例1と同様に図8のフローチャートに従って行われる。本実施例では、レンズの種類に応じて、収差(多重ぼけに影響)、ヴィネッティング、および、非球面レンズの有無が異なるため、レンズの種類および目標とする整形後のデフォーカスぼけ形状ごとに学習ペアを作成し、ウエイト情報を学習する。なお本実施例では、第2の画像が1枚の例を挙げたが、第2の画像が複数(例えば、A画像、C画像、D画像の3枚)ある構成としてもよい。
Learning of the weight information executed by the
本実施例によれば、画像のデフォーカスぼけを整形し、良好なぼけ味を有する画像を生成することが可能な画像処理システムを提供することができる。 According to this embodiment, it is possible to provide an image processing system capable of shaping the defocus blur of an image and generating an image with a favorable blur.
(その他の実施例)
本発明は、上述の実施例の1以上の機能を実現するプログラムを、ネットワーク又は記憶媒体を介してシステム又は装置に供給し、そのシステム又は装置のコンピュータにおける1つ以上のプロセッサーがプログラムを読出し実行する処理でも実現可能である。また、1以上の機能を実現する回路(例えば、ASIC)によっても実現可能である。
(Other examples)
The present invention supplies a program that implements one or more functions of the above-described embodiments to a system or apparatus via a network or a storage medium, and one or more processors in the computer of the system or apparatus reads and executes the program. It can also be realized by processing to It can also be implemented by a circuit (for example, ASIC) that implements one or more functions.
また本発明は、例えば、画像処理に関する要求を行う第1の処理装置(撮像装置、スマートフォン、PCなどのユーザ端末)と、該要求に応じて実体的に本発明の画像処理を行う第2の処理装置(サーバー)で構成された画像処理システムとしても実現可能である。例えば、実施例2の画像処理システム300における情報取得部304、画像生成部305、および、デプス推定部306を、第2の処理装置としてのサーバ308に設けることができる。また、第1の処理装置としての画像処理装置302は、サーバ308に対して第1の画像および第2の画像を用いた画像処理の要求を行うように構成することができる。この場合、第1の処理装置(ユーザ端末)は、画像処理に関する要求を第2の処理装置(サーバ)に送信するための送信手段を有し、第2の処理装置(サーバ)は第1の処理装置(ユーザ端末)から送信された要求を受信する受信手段を有する。
Further, the present invention provides, for example, a first processing device (imaging device, smartphone, user terminal such as a PC) that requests image processing, and a second processing device that substantially performs the image processing of the present invention in response to the request. It can also be implemented as an image processing system configured by a processing device (server). For example, the
なお、この場合、第1の処理装置は、画像処理の要求と共に第1の画像および第2の画像を第2の処理装置に送信しても良い。ただし、第2の処理装置は、第1の処理装置の要求に応じて第1の処理装置以外の場所(外部記憶装置)に記憶された第1の画像および第2の画像を取得しても良い。また、第2の処理装置による第1の画像および第2の画像に対するぼけ整形処理が行われた後、第2の処理装置はぼけ整形画像を第1の処理装置に送信するようにしても良い。このように画像処理システムを構成することにより、比較的処理付加の重い画像生成部による処理を第2の処理装置側で行うことが可能となり、ユーザの負担を低減することが可能となる。 In this case, the first processing device may transmit the first image and the second image together with the image processing request to the second processing device. However, the second processing device may acquire the first image and the second image stored in a location (external storage device) other than the first processing device in response to a request from the first processing device. good. Further, after the second processing device performs blur shaping processing on the first image and the second image, the second processing device may transmit the blurred images to the first processing device. . By configuring the image processing system in this way, it is possible to perform the processing by the image generation unit, which requires relatively heavy processing load, on the second processing device side, and it is possible to reduce the burden on the user.
各実施例によれば、画像のデフォーカスによるぼけを整形し、良好なぼけ味の画像を得ることが可能な画像処理方法、画像処理装置、撮像装置、レンズ装置、プログラム、および、記憶媒体を提供することができる。 According to each embodiment, an image processing method, an image processing device, an imaging device, a lens device, a program, and a storage medium capable of correcting blur due to defocusing of an image and obtaining an image with good blurring are provided. can provide.
以上、本発明の好ましい実施形態について説明したが、本発明はこれらの実施形態に限定されず、その要旨の範囲内で種々の変形及び変更が可能である。 Although preferred embodiments of the present invention have been described above, the present invention is not limited to these embodiments, and various modifications and changes are possible within the scope of the gist.
102 画像処理部(画像処理装置)
102a 情報取得部(取得手段)
102b 画像生成部(生成手段)
102 image processing unit (image processing device)
102a information acquisition unit (acquisition means)
102b image generator (generating means)
Claims (24)
前記第1及び第2の画像を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する工程と、を有することを特徴とする画像処理方法。 A first image obtained by imaging a subject through a first pupil in an optical system, and the subject through a second pupil different from the first pupil in the optical system obtaining a second image obtained by imaging the body ;
and inputting the first and second images to a multi-layer neural network to generate an output image in which blur due to defocus has been corrected .
前記第1の光電変換部は前記第1の瞳からの光を受光し、前記第2の光電変換部は前記第2の瞳からの光を受光することを特徴とする請求項7に記載の画像処理方法。8. The method according to claim 7, wherein the first photoelectric conversion section receives light from the first pupil, and the second photoelectric conversion section receives light from the second pupil. Image processing method.
前記出力画像を生成する工程は、前記明るさを合わせる処理が行われた前記第1及び第2の画像に基づいて実行されることを特徴とする請求項1乃至8のいずれか一項に記載の画像処理方法。 further comprising performing a process of matching the brightness of the first and second images ;
9. The method according to any one of claims 1 to 8 , wherein said step of generating said output image is performed based on said first and second images on which said brightness matching process has been performed. image processing method .
前記出力画像を生成する工程は、前記反転処理が行われた前記第1及び第2の画像に基づいて実行されることを特徴とする請求項1乃至11のいずれか一項に記載の画像処理方法。 Inversion processing is performed on the first and second images divided by a straight line passing through the respective reference points of the first and second images, parallel to the axis of line symmetry of the second pupil . further comprising a step of
12. An image according to any one of claims 1 to 11, wherein said step of generating said output image is performed based on said first and second images on which said inverting process has been performed. Processing method.
前記出力画像を生成する工程は、前記視差マップまたは前記デプスマップに基づいて実行されることを特徴とする請求項1乃至12のいずれか一項に記載の画像処理方法。 further comprising calculating a parallax map or depth map corresponding to the subject based on the first and second images;
13. The image processing method according to any one of claims 1 to 12 , wherein the step of generating the output image is performed based on the parallax map or the depth map.
前記多層のニューラルネットワークを用いて、互いに異なるサンプリングレートのダウンサンプリングが実行された複数の特徴マップを算出する工程と、
前記複数の特徴マップに基づいて前記出力画像を生成する工程と、を含むことを特徴とする請求項1乃至16のいずれか一項に記載の画像処理方法。 The step of generating the output image includes:
calculating a plurality of feature maps down-sampled at different sampling rates using the multi-layered neural network;
and generating the output image based on the plurality of feature maps.
前記第1及び第2の画像を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する生成手段と、を有することを特徴とする画像処理装置。 A first image obtained by imaging a subject through a first pupil in an optical system, and the subject through a second pupil different from the first pupil in the optical system an acquisition means for acquiring a second image obtained by imaging the body ;
and generating means for inputting the first and second images to a multi-layered neural network to generate an output image in which blur due to defocus has been corrected .
請求項18に記載の画像処理装置と、を有することを特徴とする撮像装置。 an imaging device that photoelectrically converts an optical image formed by an optical system;
An imaging apparatus comprising: the image processing apparatus according to claim 18 .
該複数の画素のそれぞれは、複数の光電変換部を有し、
前記画素は、前記複数の光電変換部のそれぞれで互いに異なる入射角で入射する光を受光して複数の信号を生成し、
前記撮像素子は、前記複数の信号を加算した加算信号に対応する前記第1の画像と、前記複数の信号の一つの信号または該複数の信号の一部を加算した加算信号に対応する前記第2の画像と、を出力することを特徴とする請求項19に記載の撮像装置。 The imaging element has a plurality of pixels,
each of the plurality of pixels has a plurality of photoelectric conversion units,
each of the pixels receives light incident on each of the plurality of photoelectric conversion units at different incident angles to generate a plurality of signals;
The imaging element is configured to produce the first image corresponding to an added signal obtained by adding the plurality of signals, and the first image corresponding to an added signal obtained by adding one of the plurality of signals or a part of the plurality of signals. 20. The imaging device according to claim 19, wherein the image of 2 is output.
光学系と、
多層のニューラルネットワークに入力されるウエイトに関する情報を記憶する記憶手段と、を有し、
前記撮像装置は、
前記光学系における第1の瞳を介して被写体を撮像することで得られた第1の画像と、前記光学系における前記第1の瞳とは異なる第2の瞳を介して前記被写体を撮像することで得られた第2の画像と、を取得する取得手段と、
前記第1及び第2の画像と前記ウエイトに関する情報を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する生成手段と、を有することを特徴とするレンズ装置。 A lens device detachable from an imaging device,
an optical system;
a storage means for storing information about weights input to the multi-layered neural network;
The imaging device is
A first image obtained by imaging a subject through a first pupil in the optical system and the subject through a second pupil different from the first pupil in the optical system an acquisition means for acquiring a second image obtained by imaging a subject ;
generating means for generating an output image in which blur due to defocus has been corrected by inputting information about the first and second images and the weights to a multi-layered neural network. Device.
前記第1の処理装置は、光学系における第1の瞳を介して被写体を撮像することで得られた第1の画像と、前記光学系における前記第1の瞳とは異なる第2の瞳を介して前記被写体を撮像することで得られた第2の画像と、を用いた画像処理の要求を前記第2の処理装置に対して送信する送信手段を有し、
前記第2の処理装置は、
前記第1の処理装置から送信された前記要求を受信する受信手段と、
前記第1及び第2の画像とを取得する取得手段と、
前記第1及び第2の画像を多層のニューラルネットワークに入力することで、デフォーカスによるぼけが整形された出力画像を生成する生成手段と、
を有することを特徴とする画像処理システム。 An image processing system having a first processing device and a second processing device,
The first processing device provides a first image obtained by imaging a subject through a first pupil in an optical system and a second image obtained by imaging a subject through a first pupil in the optical system and a second a transmission means for transmitting a request for image processing using a second image obtained by imaging the subject through the pupil of the second processing device,
The second processing device is
receiving means for receiving the request transmitted from the first processing device;
acquisition means for acquiring the first and second images ;
generating means for inputting the first and second images to a multi-layered neural network to generate an output image in which blur due to defocus has been corrected ;
An image processing system comprising:
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/535,386 US11195257B2 (en) | 2018-08-24 | 2019-08-08 | Image processing method, image processing apparatus, imaging apparatus, lens apparatus, storage medium, and image processing system |
| EP19192533.8A EP3614336A1 (en) | 2018-08-24 | 2019-08-20 | Image processing method, image processing apparatus, imaging apparatus, lens apparatus, program, and image processing system |
| CN201910768726.2A CN110858871B (en) | 2018-08-24 | 2019-08-20 | Image processing method, image processing apparatus, imaging apparatus, lens apparatus, storage medium, and image processing system |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018156813 | 2018-08-24 | ||
| JP2018156813 | 2018-08-24 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2020036310A JP2020036310A (en) | 2020-03-05 |
| JP2020036310A5 JP2020036310A5 (en) | 2022-07-06 |
| JP7234057B2 true JP7234057B2 (en) | 2023-03-07 |
Family
ID=69668846
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019124790A Active JP7234057B2 (en) | 2018-08-24 | 2019-07-03 | Image processing method, image processing device, imaging device, lens device, program, storage medium, and image processing system |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7234057B2 (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7414745B2 (en) | 2020-03-09 | 2024-01-16 | キヤノン株式会社 | Learning data production method, learning method, learning data production device, learning device, and program |
| EP3879483A1 (en) | 2020-03-09 | 2021-09-15 | Canon Kabushiki Kaisha | Learning data manufacturing method, learning method, learning data manufacturing apparatus, learning apparatus, program, and memory medium |
| KR102336103B1 (en) * | 2020-09-09 | 2021-12-08 | 울산과학기술원 | Deep learning-based image deblurring method and apparartus performing the same |
| JP7451443B2 (en) * | 2021-02-09 | 2024-03-18 | キヤノン株式会社 | Image processing method and device, machine learning model training method and device, and program |
| KR20230006106A (en) * | 2021-07-02 | 2023-01-10 | 주식회사 뷰웍스 | Method and apparatus for generating high depth of field image, apparatus for training high depth of field image generation model using stereo image |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018081378A (en) | 2016-11-14 | 2018-05-24 | キヤノン株式会社 | Image processing apparatus, imaging device, image processing method, and image processing program |
| JP2018084982A (en) | 2016-11-24 | 2018-05-31 | キヤノン株式会社 | Image processing apparatus, image processing method, and program |
-
2019
- 2019-07-03 JP JP2019124790A patent/JP7234057B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018081378A (en) | 2016-11-14 | 2018-05-24 | キヤノン株式会社 | Image processing apparatus, imaging device, image processing method, and image processing program |
| JP2018084982A (en) | 2016-11-24 | 2018-05-31 | キヤノン株式会社 | Image processing apparatus, image processing method, and program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020036310A (en) | 2020-03-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11195257B2 (en) | Image processing method, image processing apparatus, imaging apparatus, lens apparatus, storage medium, and image processing system | |
| JP7234057B2 (en) | Image processing method, image processing device, imaging device, lens device, program, storage medium, and image processing system | |
| RU2716843C1 (en) | Digital correction of optical system aberrations | |
| US9185272B2 (en) | Image processing method, image processing apparatus, image pickup apparatus, and storage medium storing image processing program | |
| JP5968107B2 (en) | Image processing method, image processing apparatus, and program | |
| RU2523028C2 (en) | Image processing device, image capturing device and image processing method | |
| US11188777B2 (en) | Image processing method, image processing apparatus, learnt model manufacturing method, and image processing system | |
| US9992478B2 (en) | Image processing apparatus, image pickup apparatus, image processing method, and non-transitory computer-readable storage medium for synthesizing images | |
| JP2019121252A (en) | Image processing method, image processing apparatus, image processing program and storage medium | |
| JP5984493B2 (en) | Image processing apparatus, image processing method, imaging apparatus, and program | |
| US10062153B2 (en) | Image processing apparatus, image pickup apparatus, image processing method, and storage medium | |
| JP2014150498A (en) | Image processing method, image processing apparatus, image processing program, and imaging apparatus | |
| JP2017208641A (en) | Imaging device using compression sensing, imaging method, and imaging program | |
| US20190355101A1 (en) | Image refocusing | |
| JP5479187B2 (en) | Image processing apparatus and imaging apparatus using the same | |
| JP2024024012A (en) | Learning data generation method, learning method, learning data production device, learning device, and program | |
| JP2015115733A (en) | Image processing method, image processor, imaging device, and image processing program | |
| JP7191588B2 (en) | Image processing method, image processing device, imaging device, lens device, program, and storage medium | |
| JP2017011652A (en) | Image processing device, imaging apparatus, image processing method and program | |
| JP6682184B2 (en) | Image processing method, image processing program, image processing device, and imaging device | |
| CN109923853B (en) | Image processing apparatus, image processing method, and program | |
| JP7414745B2 (en) | Learning data production method, learning method, learning data production device, learning device, and program | |
| JP7009219B2 (en) | Image processing method, image processing device, image pickup device, image processing program, and storage medium | |
| JP2017050662A (en) | Image processing system, imaging apparatus, and image processing program | |
| CN110958382A (en) | Image processing method, image processing apparatus, imaging apparatus, and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220628 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220628 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230113 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230124 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230222 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7234057 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |