JP7210380B2 - 画像学習プログラム、画像学習方法、及び画像認識装置 - Google Patents
画像学習プログラム、画像学習方法、及び画像認識装置 Download PDFInfo
- Publication number
- JP7210380B2 JP7210380B2 JP2019104825A JP2019104825A JP7210380B2 JP 7210380 B2 JP7210380 B2 JP 7210380B2 JP 2019104825 A JP2019104825 A JP 2019104825A JP 2019104825 A JP2019104825 A JP 2019104825A JP 7210380 B2 JP7210380 B2 JP 7210380B2
- Authority
- JP
- Japan
- Prior art keywords
- image
- learning
- teacher
- category
- recognition device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Landscapes
- Image Analysis (AREA)
Description
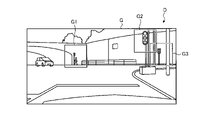
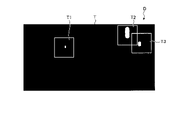
図1は、実施形態に係る画像認識装置の概要を示す図である。図2は、実施形態に係る画像認識装置の学習時における機能の概要を示す図である。画像認識装置1は、入力される入力画像Iに含まれるオブジェクトを認識し、認識した結果を出力画像Oとして出力するものである。画像認識装置1は、カメラ等の撮像装置において撮像された撮影画像が入力画像Iとして入力される。画像認識装置1は、入力画像Iに対して画像セグメンテーションを行う。画像セグメンテーションとは、デジタル画像の分割された画像領域に対してクラスをラベリングすることであり、クラス推論(クラス分類)ともいう。つまり、画像セグメンテーションとは、デジタル画像の分割された所定の画像領域が、何れのクラスであるかを判別して、画像領域が示すクラスを識別するための識別子(カテゴリ)を付すことで、複数のカテゴリに領域分割することである。画像認識装置1は、入力画像Iを画像セグメンテーション(クラス推論)した画像を、出力画像Oとして出力する。
5 制御部
6 記憶部
7 画像認識部
22 エンコーダ
23 デコーダ
I 入力画像
O 出力画像
P 画像学習プログラム
D 学習データセット
G 学習画像
T 教師画像
G1~G3 選択学習画像
T1~T3 選択教師画像
Claims (4)
- 画像セグメンテーションを行う画像認識装置によって実行される画像学習プログラムであって、
前記画像認識装置の学習に用いられる学習データセットは、
前記画像認識装置の学習対象の画像となる学習画像と、
前記学習画像に対応する教師画像と、を含み、
前記教師画像は、複数のカテゴリの画像領域を含み、
複数の前記カテゴリは、前記教師画像中において支配的な画像領域を占める出現頻度の高いカテゴリである第1のカテゴリと、前記第1のカテゴリよりも非支配的な画像領域となる出現頻度の低いカテゴリである第2のカテゴリと、を含み、
前記画像認識装置に、
前記教師画像よりも小さな画像領域となる選択教師画像を、前記教師画像から抽出すると共に、前記選択教師画像に対応する選択学習画像を、前記学習画像から抽出する第1のステップと、
前記第1のステップにより抽出した前記選択学習画像及び前記選択教師画像を用いて画像学習を行う第2のステップと、を実行させ、
前記第1のステップでは、前記第2のカテゴリの画像領域を含むように、前記学習画像及び前記教師画像から、前記選択学習画像及び前記選択教師画像を抽出する画像学習プログラム。 - 前記第2のステップでは、
前記選択学習画像に対して前記画像セグメンテーションを行って、出力画像を取得するステップと、
前記選択教師画像に対する前記出力画像の誤差を取得するステップと、
前記誤差に基づいて、前記画像セグメンテーションの処理を修正するステップと、
を実行させており、
前記画像セグメンテーションは、FCN(Fully Convolutional Network)に基づく処理である請求項1に記載の画像学習プログラム。 - 画像セグメンテーションを行う画像認識装置が実行する画像学習方法であって、
前記画像認識装置の学習に用いられる学習データセットは、
前記画像認識装置の学習対象の画像となる学習画像と、
前記学習画像に対応する教師画像と、を含み、
前記教師画像は、複数のカテゴリの画像領域を含み、
複数の前記カテゴリは、前記教師画像中において支配的な画像領域を占める出現頻度の高いカテゴリである第1のカテゴリと、前記第1のカテゴリよりも非支配的な画像領域となる出現頻度の低いカテゴリである第2のカテゴリと、を含み、
前記画像認識装置は、
前記教師画像よりも小さな画像領域となる選択教師画像を、前記教師画像から抽出すると共に、前記選択教師画像に対応する選択学習画像を、前記学習画像から抽出する第1のステップと、
前記第1のステップにより抽出した前記選択学習画像及び前記選択教師画像を用いて画像学習を行う第2のステップと、を実行し、
前記第1のステップでは、前記第2のカテゴリの画像領域を含むように、前記学習画像及び前記教師画像から、前記選択学習画像及び前記選択教師画像を抽出する画像学習方法。 - 画像セグメンテーションを行う画像認識装置であって、
前記画像認識装置の学習に用いられる学習データセットは、
前記画像認識装置の学習対象の画像となる学習画像と、
前記学習画像に対応する教師画像と、を含み、
前記教師画像は、複数のカテゴリの画像領域を含み、
複数の前記カテゴリは、前記教師画像中において支配的な画像領域を占める出現頻度の高いカテゴリである第1のカテゴリと、前記第1のカテゴリよりも非支配的な画像領域となる出現頻度の低いカテゴリである第2のカテゴリと、を含み、
前記教師画像よりも小さな画像領域となる選択教師画像を、前記教師画像から抽出すると共に、前記選択教師画像に対応する選択学習画像を、前記学習画像から抽出する画像抽出部と、
抽出した前記選択学習画像及び前記選択教師画像を用いて画像学習を行う画像認識部と、を備え、
前記画像抽出部は、前記第2のカテゴリの画像領域を含むように、前記学習画像及び前記教師画像から、前記選択学習画像及び前記選択教師画像を抽出する画像認識装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019104825A JP7210380B2 (ja) | 2019-06-04 | 2019-06-04 | 画像学習プログラム、画像学習方法、及び画像認識装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019104825A JP7210380B2 (ja) | 2019-06-04 | 2019-06-04 | 画像学習プログラム、画像学習方法、及び画像認識装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2020197999A JP2020197999A (ja) | 2020-12-10 |
| JP7210380B2 true JP7210380B2 (ja) | 2023-01-23 |
Family
ID=73648106
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019104825A Active JP7210380B2 (ja) | 2019-06-04 | 2019-06-04 | 画像学習プログラム、画像学習方法、及び画像認識装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7210380B2 (ja) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020003434A1 (ja) | 2018-06-28 | 2020-01-02 | 株式会社島津製作所 | 機械学習方法、機械学習装置、及び機械学習プログラム |
| JP2020154602A (ja) | 2019-03-19 | 2020-09-24 | 日本製鉄株式会社 | 能動学習方法及び能動学習装置 |
-
2019
- 2019-06-04 JP JP2019104825A patent/JP7210380B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020003434A1 (ja) | 2018-06-28 | 2020-01-02 | 株式会社島津製作所 | 機械学習方法、機械学習装置、及び機械学習プログラム |
| JP2020154602A (ja) | 2019-03-19 | 2020-09-24 | 日本製鉄株式会社 | 能動学習方法及び能動学習装置 |
Non-Patent Citations (2)
| Title |
|---|
| Jun Fu;Jing Liu;Yuhang Wang;Jin Zhou;Changyong Wang;Hanqing Lu,Stacked Deconvolutional Network for Semantic Segmentation,IEEE Transactions on Image Processing,IEEE,2019年01月25日,pp.1-13,https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8626494 |
| 薮崎 隼人 他,畳み込みニューラルネットワークを用いた脂肪細胞セグメンテーションにおける分割精度改善手法の提案,情報処理学会 研究報告 数理モデル化と問題解決(MPS),日本,情報処理学会,2017年02月20日,Vol.2017-MPS-112 No.27,pp.1-6 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020197999A (ja) | 2020-12-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109376681B (zh) | 一种多人姿态估计方法及系统 | |
| US20210350168A1 (en) | Image segmentation method and image processing apparatus | |
| CN110176027B (zh) | 视频目标跟踪方法、装置、设备及存储介质 | |
| CN109325954B (zh) | 图像分割方法、装置及电子设备 | |
| CN105981051B (zh) | 用于图像解析的分层互连多尺度卷积网络 | |
| CN111178211A (zh) | 图像分割方法、装置、电子设备及可读存储介质 | |
| CN108229490A (zh) | 关键点检测方法、神经网络训练方法、装置和电子设备 | |
| CN111275034B (zh) | 从图像中提取文本区域的方法、装置、设备和存储介质 | |
| CN110781980B (zh) | 目标检测模型的训练方法、目标检测方法及装置 | |
| CN110991560A (zh) | 一种结合上下文信息的目标检测方法及系统 | |
| JP4567660B2 (ja) | 電子画像内で物体のセグメントを求める方法 | |
| CN112836653A (zh) | 人脸隐私化方法、设备、装置及计算机存储介质 | |
| JP7210380B2 (ja) | 画像学習プログラム、画像学習方法、及び画像認識装置 | |
| CN111738069A (zh) | 人脸检测方法、装置、电子设备及存储介质 | |
| JP7148462B2 (ja) | 画像認識評価プログラム、画像認識評価方法、評価装置及び評価システム | |
| CN113192060B (zh) | 一种图像分割的方法、装置、电子设备及存储介质 | |
| Ong et al. | Efficient deep learning-based wound-bed segmentation for mobile applications | |
| JP2020038572A (ja) | 画像学習プログラム、画像学習方法、画像認識プログラム、画像認識方法、学習データセットの生成プログラム、学習データセットの生成方法、学習データセット、及び画像認識装置 | |
| CN113744141B (zh) | 图像的增强方法、装置和自动驾驶的控制方法、装置 | |
| US11797854B2 (en) | Image processing device, image processing method and object recognition system | |
| JP7238510B2 (ja) | 情報処理装置、情報処理方法及びプログラム | |
| CN109961083B (zh) | 用于将卷积神经网络应用于图像的方法和图像处理实体 | |
| CN112861860A (zh) | 一种基于上下边界提取的自然场景下文字检测方法 | |
| JP7542396B2 (ja) | 物体認識装置、物体認識システム、学習方法、物体認識装置の物体認識方法、学習プログラム及び物体認識装置の物体認識プログラム | |
| KR102436197B1 (ko) | 이미지 객체 검출 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20210914 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220929 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20221011 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221207 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20221213 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230111 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7210380 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |