JP6900190B2 - 認識学習装置、認識学習方法及びプログラム - Google Patents
認識学習装置、認識学習方法及びプログラム Download PDFInfo
- Publication number
- JP6900190B2 JP6900190B2 JP2016256060A JP2016256060A JP6900190B2 JP 6900190 B2 JP6900190 B2 JP 6900190B2 JP 2016256060 A JP2016256060 A JP 2016256060A JP 2016256060 A JP2016256060 A JP 2016256060A JP 6900190 B2 JP6900190 B2 JP 6900190B2
- Authority
- JP
- Japan
- Prior art keywords
- recognition
- information
- recognition target
- learning
- conceptual
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/35—Categorising the entire scene, e.g. birthday party or wedding scene
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2148—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the process organisation or structure, e.g. boosting cascade
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/231—Hierarchical techniques, i.e. dividing or merging pattern sets so as to obtain a dendrogram
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/762—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using clustering, e.g. of similar faces in social networks
- G06V10/7625—Hierarchical techniques, i.e. dividing or merging patterns to obtain a tree-like representation; Dendograms
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G06V10/7747—Organisation of the process, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Computational Linguistics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
Description
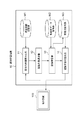
以下、本発明の第1の実施形態の詳細について図面を参照しつつ説明する。本実施形態における認識学習システム1について、認識器の提供者が、利用者の特定のドメインに合わせて、認識器をプレトレーニングする場合について説明する。具体的には、認識学習システム1は、特定のドメインと認識対象の候補である概念情報との関係を表す概念情報に基づき、該概念情報の中から認識対象を選定してプレトレーニングを施す。そして、認識学習システム1は、プレトレーニングされた認識器の認識対象の範囲をオントロジーに基づいて可視化し、提供者に提示する。ここで、特定のドメインに対するオントロジー上の概念情報の集合が、プレトレーニングの認識対象の候補である。この概念情報とは、概念化および言語化可能な物体の状態であり、該状態を言語的に示すラベル情報により特徴付けられる。概念情報には、例えば、「人」、「車」などの物体の属性や、「歩いている」、「走っている」などの物体の行動や、「鞄」、「カゴ」などの人の所持品などが含まれる。また、概念構造情報には、例えば、図17で後述する意味ネットワークなどがある。

ここで、hi(cj)は、ドメインiのオントロジー情報におけるcjの階層を表し、Ri(cj)の最大値は1である。
ここで、Ni(xj)は、ドメインiのオントロジー情報におけるcjの出現回数であり、Ri(cj)の最大値は2である。
ここで、αは比例定数である。そして、認識学習部13は、該重要度情報が高い認識対象の認識精度を優先するように、R−CNNの学習を施す。具体的には、次の数式4のようにR−CNNの最小化するドメインiの識別誤差に、重要度情報Ii(cj)が重みとして適用される。
ここで、Nは学習データの数、Cは学習データが含む認識対象の数、ynはn番目の学習データの出力に対応する認識対象の数の大きさのベクトルである。n番目のyの各要素は、学習データの出力に対応する場合は1、それ以外0の値をとる。そして、xnは、n番目の学習データの入力に対応する。この入力は上述した方法で生成されたパッチ画像である。そしてtiはR−CNNが入力データxnに対して予測した出力値であり、認識対象の数の大きさのベクトルである。
次に、本発明に係る第2の実施形態について説明する。なお、上述した第1の実施形態における各構成と同一の構成については、同一の符号を付し、その説明を省略する。本実施形態における認識学習システム1aについて、プレトレーニング済みの認識器をファインチューニングする場合を例に説明する。つまり、本実施形態の認識学習装置10は、第1の実施形態により認識器のプレトレーニングが済み、認識対象可視化情報が端末装置100に表示された状態から処理を開始することを前提にしている。そして、利用者からの認識対象可視化情報に対するフィードバックを示す操作情報に基づいて、認識学習装置10aが適応的に認識器を学習する点において、第1の実施形態と異なる。
次に、本発明を実施するための第3の実施形態について、図面を参照して説明する。なお、上述した第1、第2の実施形態における各構成と同一の構成については、同一の符号を付して説明を省略する。本実施形態における認識学習システム1bは、利用者が所有している独自の動画像データを追加し、認識器をファインチューニングする場合に適用できるものである。
次に、本発明を実施するための第4の実施形態について、図面を参照して説明する。なお、上述した第1〜第3の実施形態における各構成と同一の構成については、同一の符号を付して説明を省略する。本実施形態における認識学習システム1cは、文章データから自動的に生成したオントロジー情報に基づきプレトレーニング用の認識対象を選定する場合に適用できるものである。
次に、本発明を実施するための第4の実施形態について、図面を参照して説明する。なお、上述した第1〜第3の実施形態における各構成と同一の構成については、同一の符号を付して説明を省略する。本実施形態の認識学習システム1eについて、認識オンラインサービスとして提供する場合について説明する。ここで、認識オンラインサービスとは、インターネットまたはLAN(Local Area Network)などに接続されたサーバ端末上で動作するディープラーニングなどの認識器を、ユーザが自身のデータに合わせて調整し活用できるサービスである。例えば、ユーザはウェブブラウザ上で動作するユーザインタフェースを操作し、自身のデータをサーバ端末にアップロードし、認識器をファインチューニングすることができる。この認識オンラインサービスには,例えば、Google Cloud Platformなどがある。
なお、上記の各実施形態では、オントロジー情報は、特定ドメインに関連する網羅的な概念情報を含む場合について説明したが、該オントロジー情報は、ドメイン内の特定のユースケースや特定のユーザ層ごとに構築されてもよい。例えば、「店舗」ドメイン内の特定のユースケースとしては、「レジ前用」、「商品棚用」、「強盗検知用」、「万引き検知用」および「客層分析用」などがある。また、「店舗」ドメイン内の特定のユーザ層の例としては、「店員用」、「店長用」、および「スーパバイザー用」などがある。そして、端末装置に表示されたメニューから特定のユースケースや特定のユーザ層を選ぶことにより、自動的に該当するオントロジー情報を読み込んでもよい。
11 意味的関連度生成部
12 認識対象生成部
13 認識学習部
14 認識対象可視化部
15 認識対象更新部
16 動画像データ編集部
17 オントロジー生成部
18 オントロジー選択部
M1 概念構造記憶部
M2 動画像データ記憶部
M3 認識器記憶部
M4 文章データ記憶部
Claims (15)
- 特定ドメインの概念構造を表す概念構造情報であって、認識対象の候補を概念情報として含む概念構造情報に基づいて、前記特定ドメインと前記認識対象の候補との関連度を生成する生成手段と、
前記生成手段により生成された関連度に基づいて、前記認識対象の候補から認識対象を選択する選択手段と、
前記選択手段により選択された認識対象に係る学習データを用いて認識器を学習する学習手段と、
を有することを特徴とする認識学習装置。 - 前記生成手段は、前記概念構造情報における前記認識対象の候補の階層に基づいて前記関連度を生成することを特徴とする請求項1に記載の認識学習装置。
- 前記生成手段は、更に前記概念構造情報における前記認識対象の候補の発生頻度に基づいて前記関連度を生成することを特徴とする請求項2に記載の認識学習装置。
- 前記生成手段は、前記概念構造情報における前記認識対象の候補より下位階層の概念情報の数に基づいて前記関連度を生成することを特徴とする請求項1に記載の認識学習装置。
- 前記選択手段により選択された前記認識対象を前記概念構造情報に重畳した可視化情報を生成する可視化手段を更に有することを特徴とする請求項1から4のいずれか1項に記載の認識学習装置。
- 前記可視化手段は、前記選択手段により選択された認識対象それぞれに対する前記認識器の認識精度を算出し、当該算出した認識精度を前記可視化情報として生成することを特徴とする請求項5に記載の認識学習装置。
- 前記可視化手段により生成された可視化情報に対するユーザの操作に応じて、前記認識対象を更新する更新手段を更に有し、
前記学習手段は、前記更新手段により更新された認識対象に係る学習データを用いて前記認識器を再度学習することを特徴とする請求項5または6に記載の認識学習装置。 - 前記可視化手段は、前記認識対象それぞれの動画像データを前記可視化情報として生成し、
前記可視化手段により生成された可視化情報に対するユーザの指示に応じて、前記認識対象に係る学習データに追加または削除を行う編集手段を更に有することを特徴とする請求項5から7のいずれか1項に記載の認識学習装置。 - 前記学習手段は、前記関連度に基づいて選択された前記認識対象の重要度を示す重要度情報を生成し、当該生成した前記重要度情報に基づいて学習することを特徴とする請求項1から請求項8のいずれか1項に記載の認識学習装置。
- 文章データから前記特定ドメインに関する前記概念構造情報を生成する概念構造生成手段を更に有し、
前記生成手段は、前記概念構造生成手段により生成された概念構造情報に基づいて、前記特定ドメインと前記認識対象の候補との前記関連度を生成することを特徴とする請求項1から請求項9のいずれか1項に記載の認識学習装置。 - ユーザの入力に応じて、前記特定ドメイン、特定の利用者、特定のユースケースの少なくとも1つに対して構築された前記概念構造情報を選択する概念情報選択手段を更に有することを特徴とする請求項1から10のいずれか1項に記載の認識学習装置。
- 前記概念構造情報として、オントロジー情報を用いることを特徴とする請求項1から11のいずれか1項に記載の認識学習装置。
- 認識学習装置により実行される認識学習方法であって、
特定ドメインの概念構造を表す概念構造情報であって、認識対象の候補を概念情報として含む概念構造情報に基づいて、前記特定ドメインと前記認識対象の候補との関連度を生成するステップと、
前記生成された関連度に基づいて、前記認識対象の候補から認識対象を選択するステップと、
前記選択された認識対象に係る学習データを用いて認識器を学習するステップと、
を有することを特徴とする認識学習方法。 - コンピュータを、請求項1から12のいずれか1項に記載の認識学習装置として機能させるためのプログラム。
- オントロジー情報である前記概念情報を記憶する第1の記憶手段と、
前記認識対象を特定するための動画データを記憶する第2の記憶手段とを更に有することを特徴とする請求項1から12のいずれか1項に記載の認識学習装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016005598 | 2016-01-14 | ||
| JP2016005598 | 2016-01-14 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017130196A JP2017130196A (ja) | 2017-07-27 |
| JP2017130196A5 JP2017130196A5 (ja) | 2020-02-06 |
| JP6900190B2 true JP6900190B2 (ja) | 2021-07-07 |
Family
ID=59314780
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016256060A Active JP6900190B2 (ja) | 2016-01-14 | 2016-12-28 | 認識学習装置、認識学習方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10217027B2 (ja) |
| JP (1) | JP6900190B2 (ja) |
Families Citing this family (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11238334B2 (en) | 2017-04-04 | 2022-02-01 | Hailo Technologies Ltd. | System and method of input alignment for efficient vector operations in an artificial neural network |
| US11551028B2 (en) | 2017-04-04 | 2023-01-10 | Hailo Technologies Ltd. | Structured weight based sparsity in an artificial neural network |
| US10387298B2 (en) | 2017-04-04 | 2019-08-20 | Hailo Technologies Ltd | Artificial neural network incorporating emphasis and focus techniques |
| US11615297B2 (en) | 2017-04-04 | 2023-03-28 | Hailo Technologies Ltd. | Structured weight based sparsity in an artificial neural network compiler |
| US11544545B2 (en) | 2017-04-04 | 2023-01-03 | Hailo Technologies Ltd. | Structured activation based sparsity in an artificial neural network |
| EP3607495A4 (en) * | 2017-04-07 | 2020-11-25 | Intel Corporation | METHODS AND SYSTEMS USING IMPROVED TRAINING AND LEARNING FOR DEEP NEURAL NETWORKS |
| CN108205684B (zh) * | 2017-04-25 | 2022-02-11 | 北京市商汤科技开发有限公司 | 图像消歧方法、装置、存储介质和电子设备 |
| JP6800820B2 (ja) | 2017-07-14 | 2020-12-16 | パナソニック株式会社 | 人流分析方法、人流分析装置、及び人流分析システム |
| JP7228961B2 (ja) * | 2018-04-02 | 2023-02-27 | キヤノン株式会社 | ニューラルネットワークの学習装置およびその制御方法 |
| JP7382930B2 (ja) * | 2018-06-28 | 2023-11-17 | 富士フイルム株式会社 | 医療画像処理装置 |
| TW202006738A (zh) * | 2018-07-12 | 2020-02-01 | 國立臺灣科技大學 | 應用機器學習的醫學影像分析方法及其系統 |
| KR20200131664A (ko) * | 2019-05-14 | 2020-11-24 | 삼성전자주식회사 | 차량의 주행을 보조하는 전자 장치 및 방법 |
| US11908177B2 (en) * | 2019-05-29 | 2024-02-20 | Nec Corporation | Updated learning of feature extraction model that extracts moving image feature amount from moving image data and still image feature amount from still image data |
| CN114730388A (zh) | 2019-10-29 | 2022-07-08 | 索尼集团公司 | 偏差调整装置、信息处理装置、信息处理方法以及信息处理程序 |
| CN111079377B (zh) * | 2019-12-03 | 2022-12-13 | 哈尔滨工程大学 | 一种面向中文医疗文本命名实体识别的方法 |
| JP7046239B2 (ja) * | 2020-01-24 | 2022-04-01 | 株式会社日立製作所 | 画像内のオブジェクト認識のためにニューラルネットワークを生成するための方法及びシステム |
| JP7467157B2 (ja) | 2020-02-19 | 2024-04-15 | キヤノン株式会社 | 学習装置、画像認識装置、学習方法、画像認識装置の制御方法およびプログラム |
| CN111832282B (zh) * | 2020-07-16 | 2023-04-14 | 平安科技(深圳)有限公司 | 融合外部知识的bert模型的微调方法、装置及计算机设备 |
| US11811421B2 (en) | 2020-09-29 | 2023-11-07 | Hailo Technologies Ltd. | Weights safety mechanism in an artificial neural network processor |
| US11221929B1 (en) | 2020-09-29 | 2022-01-11 | Hailo Technologies Ltd. | Data stream fault detection mechanism in an artificial neural network processor |
| US11874900B2 (en) | 2020-09-29 | 2024-01-16 | Hailo Technologies Ltd. | Cluster interlayer safety mechanism in an artificial neural network processor |
| US11237894B1 (en) | 2020-09-29 | 2022-02-01 | Hailo Technologies Ltd. | Layer control unit instruction addressing safety mechanism in an artificial neural network processor |
| US11263077B1 (en) | 2020-09-29 | 2022-03-01 | Hailo Technologies Ltd. | Neural network intermediate results safety mechanism in an artificial neural network processor |
| CN112799658B (zh) * | 2021-04-12 | 2022-03-01 | 北京百度网讯科技有限公司 | 模型训练方法、模型训练平台、电子设备和存储介质 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7406459B2 (en) * | 2003-05-01 | 2008-07-29 | Microsoft Corporation | Concept network |
| JP4246120B2 (ja) | 2004-07-21 | 2009-04-02 | シャープ株式会社 | 楽曲検索システムおよび楽曲検索方法 |
| JP2011108085A (ja) * | 2009-11-19 | 2011-06-02 | Nippon Hoso Kyokai <Nhk> | 知識構築装置およびプログラム |
| US9811754B2 (en) * | 2014-12-10 | 2017-11-07 | Ricoh Co., Ltd. | Realogram scene analysis of images: shelf and label finding |
| US9836671B2 (en) * | 2015-08-28 | 2017-12-05 | Microsoft Technology Licensing, Llc | Discovery of semantic similarities between images and text |
-
2016
- 2016-12-28 JP JP2016256060A patent/JP6900190B2/ja active Active
-
2017
- 2017-01-13 US US15/406,391 patent/US10217027B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20170206437A1 (en) | 2017-07-20 |
| JP2017130196A (ja) | 2017-07-27 |
| US10217027B2 (en) | 2019-02-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6900190B2 (ja) | 認識学習装置、認識学習方法及びプログラム | |
| US11113598B2 (en) | Dynamic memory network | |
| US20160350653A1 (en) | Dynamic Memory Network | |
| JP6895276B2 (ja) | 行動認識システムおよび行動認識方法 | |
| US20210217409A1 (en) | Electronic device and control method therefor | |
| JP7488871B2 (ja) | 対話推薦方法、装置、電子機器、記憶媒体ならびにコンピュータプログラム | |
| CN113557521B (zh) | 使用机器学习从动画媒体内容项目提取时间信息的系统和方法 | |
| Kumar et al. | ESUMM: event summarization on scale-free networks | |
| CN111434118A (zh) | 用户感兴趣信息生成的装置和方法 | |
| CN111612178A (zh) | 一种模型的诊断方法及相关设备 | |
| JP2018010626A (ja) | 情報処理装置、情報処理方法 | |
| Dharaniya et al. | A design of movie script generation based on natural language processing by optimized ensemble deep learning with heuristic algorithm | |
| US20220269935A1 (en) | Personalizing Digital Experiences Based On Predicted User Cognitive Style | |
| Chen et al. | Ontology-based activity recognition framework and services | |
| US20210240892A1 (en) | Tool for designing artificial intelligence systems | |
| US12079856B2 (en) | Method for providing shopping information for individual products and electronic device performing same | |
| US11907508B1 (en) | Content analytics as part of content creation | |
| Machado et al. | State of the art in hybrid strategies for context reasoning: A systematic literature review | |
| Silva de Oliveira et al. | Visual content learning in a cognitive vision platform for hazard control (CVP-HC) | |
| CN112052402B (zh) | 信息推荐方法、装置、电子设备及存储介质 | |
| KR102568274B1 (ko) | 공통 데이터 모델 단어를 추천하는 방법 및 이를 수행하는 전자 장치 | |
| CN117121021A (zh) | 用于用户界面预测和生成的经机器学习的模型 | |
| Trivedi | Machine learning fundamental concepts | |
| Sahu et al. | Movie Rating Prediction and Viewers’ Sentiment Trend Analysis Using YouTube Trailer Comments | |
| Ahamed et al. | Effective emoticon based framework for sentimental analysis of web data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191223 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20191223 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20201023 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20201124 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210115 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210518 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210616 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 6900190 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |