JP6879552B2 - 株価予測システム、株価予測方法及び株価予測プログラム - Google Patents
株価予測システム、株価予測方法及び株価予測プログラム Download PDFInfo
- Publication number
- JP6879552B2 JP6879552B2 JP2017104050A JP2017104050A JP6879552B2 JP 6879552 B2 JP6879552 B2 JP 6879552B2 JP 2017104050 A JP2017104050 A JP 2017104050A JP 2017104050 A JP2017104050 A JP 2017104050A JP 6879552 B2 JP6879552 B2 JP 6879552B2
- Authority
- JP
- Japan
- Prior art keywords
- output data
- stock price
- prediction
- predicted
- predicted values
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000013277 forecasting method Methods 0.000 title claims description 7
- 238000012549 training Methods 0.000 claims description 84
- 238000000605 extraction Methods 0.000 claims description 21
- 238000000034 method Methods 0.000 claims description 17
- 238000012360 testing method Methods 0.000 description 44
- 238000013528 artificial neural network Methods 0.000 description 10
- 210000002569 neuron Anatomy 0.000 description 8
- 238000004088 simulation Methods 0.000 description 6
- 238000010586 diagram Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 230000002354 daily effect Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000003203 everyday effect Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000002411 adverse Effects 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000013473 artificial intelligence Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000000556 factor analysis Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000000630 rising effect Effects 0.000 description 1
- 238000002945 steepest descent method Methods 0.000 description 1
Images












Landscapes
- Financial Or Insurance-Related Operations Such As Payment And Settlement (AREA)
Description
また、前記集合知取得手段は、前記平均値取得部が取得した予測精度の高い予測値の集合知からコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する標準偏差取得部を有することを特徴とする。
また、前記予測集合取得手段は、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する無作為復元抽出部と、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する集団学習部とを有し、前記集合知取得手段は、前記第2の出力データからコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する標準偏差取得部と、前記第4の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する平均値取得部とを有することを特徴とする。
本発明の株価予測方法は、予測集合取得手段により、株価の変化要素を示す入力データに基づき、株価の予測値の集合を取得する工程と、集合知取得手段により、前記株価の予測値の集合から予測精度の高い株価の集合知を取得する工程とを有し、前記予測集合取得手段は、無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、
集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、前記集合知取得手段は、平均値取得部により、前記第2の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程を有することを特徴とする。
また、前記集合知取得手段は、標準偏差取得部により、前記平均値取得部が取得した予測精度の高い予測値の集合知からコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程を有することを特徴とする。
また、前記予測集合取得手段は、無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、前記集合知取得手段は、標準偏差取得部により、前記第2の出力データからコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程と、平均値取得部により、前記第4の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程とを有することを特徴とする。
本発明の株価予測プログラムは、株価予測システムを制御するコンピューターに実行させる株価予測プログラムであって、予測集合取得手段により、株価の変化要素を示す入力データに基づき、株価の予測値の集合を取得する工程と、集合知取得手段により、前記株価の予測値の集合から予測精度の高い株価の集合知を取得する工程とを有し、前記予測集合取得手段は、無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、前記集合知取得手段は、平均値取得部により、前記第2の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程を有することを特徴とする。
また、前記集合知取得手段は、標準偏差取得部により、前記平均値取得部が取得した予測精度の高い予測値の集合知からコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程を有することを特徴とする。
また、前記予測集合取得手段は、無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、前記集合知取得手段は、標準偏差取得部により、前記第2の出力データからコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程と、平均値取得部により、前記第4の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程とを有することを特徴とする。
本発明の株価予測システム、株価予測方法及び株価予測プログラムでは、予測集合取得手段により、株価の変化要素を示す入力データに基づき、株価の予測値の集合を取得し、集合知取得手段により、株価の予測値の集合から予測精度の高い株価の集合知を取得する。
すなわち、集合知取得手段により、予測集合取得手段が取得した株価の予測値の集合から予測精度の高い株価の集合知を取得でき、収益予測の精度を高めることができる。
なお、本発明の株価予測システムの一実施形態を説明するに先立ち、図12および図13を用い、一般的なニューラルネットワークによる予測精度について説明する。また、以下に説明する予測値は、株価の収益率である。また、以下に説明する予測精度とは、株価の収益率の予測の精度を意味する。
すなわち、未来= F(過去)として記述できる。 ここで、「F」は過去および将来の動きの関係を意味する。関数Fが「過去」のデータを入力として受け取る場合、関数Fからの出力として「未来」を予測することができる。
また、複数のニューロン10を混在させた予測モデルは、次の数2によって表すことができる。

また、数4で示す式は、[0,1]の値である。
ここで、概要を説明すると、数5で示す式が最急降下法によって数6のように修正される。
また、数7での
は出力データであり、数8の
は、教師データ(Teacher data)である。
ここで、i∈{0、...、d}および j ∈{1、...、N}である。
そして、数10の平均二乗誤差Eが十分に小さくなるように、上記の数9の修正を繰り返す。
株価の変化率x(t) = [株価(t) - 株価(t-1)] / 株価(t-1)
株価の対数差分x(t) = log株価(t) - log株価(t-1)
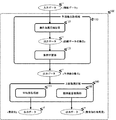
平均値取得部150は、詳細については後述するが、予測集合取得部110からの予測値(株価の収益率)の集合を示す出力データcから予測精度(Prediction accuracy)の低い予測値(株価の収益率)の平均値をとることで互いの予測誤差を相殺し、予測精度(Prediction accuracy)の高い予測値(株価の収益率)の集合知を取得し、取得した集合知を示す出力データdを出力する。標準偏差取得部160は、詳細については後述するが、平均値取得部150が取得した予測精度(Prediction accuracy)の高い予測値(株価の収益率)の集合知からコンセンサス比率(Consensus Ratio)の高い(最も信頼性の高い)予測値(株価の収益率)の集合を取得し、取得した集合知の合意度を示す出力データeを出力する。
訓練データ(Training data)の集合を取得する。
この場合、予測集合取得部110の無作為復元抽出部120が、訓練データ(Training data)を示す入力データaから複数のデータセットを複製し、その訓練データ(Training data)の集合を取得する。
訓練データ(Training data)の集合を出力する。
この場合、無作為復元抽出部120が取得した訓練データ(Training data)の集合を示す出力データbを出力する。
訓練データ(Training data)の集合から複数の予測モデルを独立に訓練し、それぞれの予測モデルから予測値(株価の収益率)を取得する。
この場合、予測集合取得部110の集団学習部130が訓練データ(Training data)の集合を示す出力データbに対し、複数の予測モデルによって予測値(株価の収益率)の集合を取得する。
予測値(株価の収益率)の集合を出力する。
この場合、集団学習部130が取得した予測値(株価の収益率)の集合を示す出力データcを出力する。
予測値(株価の収益率)の集合から予測精度の高い集合知を取得する。
さらに,バックテストとして全ての株価銘柄の集合知を取得し、教師データと比較することで予測精度を取得する。この予測精度は、たとえば上述した図7の予測精度のような結果として得られる。
バックテストを通じて予測精度の低い株式銘柄を取り除いた予測値(株価の収益率)の集合知を出力する。
この場合、平均値取得部150が予測精度の低い株式銘柄を取り除き、予測精度の高い株式銘柄の予測値(株価の収益率)の集合知を、出力データdとして出力する。
フォーワードテストにおいて、予測値(株価の収益率)の集合知からコンセンサス比率(Consensus Ratios)の高い株式銘柄を取得し,その予測値(株価の収益率)の集合知を取得する。
この場合、2段階選択部140の標準偏差取得部160が、平均値取得部150によって取得された予測精度(Prediction accuracy)の高い株式銘柄の集合知からコンセンサス比率(Consensus Ratio)の高い(最も信頼性の高い)集合知の予測値(株価の収益率)を取得する。
集合知の合意度と予測値とを出力する。
この場合、標準偏差取得部160が取得したコンセンサス比率(Consensus Ratio)の高い(最も信頼性の高い)集合知の予測値(株価の収益率)およびその集合知の合意度を示す出力データeを出力する。
この出力データeを利用することにより、たとえば上述した図8の予測精度のような結果が得られる。また、この出力データeは、上述したように、株の予測の自信度の確認に使用できる。
11 非線形フィルタ
100 株価予測システム
110 予測集合取得部
120a〜120n 予測モデル
120 無作為復元抽出部
130 集団学習部
140 2段階選択部
150 平均値取得部
160 標準偏差取得部
a 入力データ
a1〜an データセット
b〜e 出力データ
Claims (9)
- 株価の変化要素を示す入力データに基づき、株価の予測値の集合を取得する予測集合取得手段と、
前記株価の予測値の集合から予測精度の高い株価の集合知を取得する集合知取得手段とを備え、
前記予測集合取得手段は、
前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する無作為復元抽出部と、
前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する集団学習部とを有し、
前記集合知取得手段は、
前記第2の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する平均値取得部を有する
ことを特徴とする株価予測システム。 - 前記集合知取得手段は、前記平均値取得部が取得した予測精度の高い予測値の集合知からコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する標準偏差取得部を有することを特徴とする請求項1に記載の株価予測システム。
- 前記予測集合取得手段は、
前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する無作為復元抽出部と、
前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する集団学習部とを有し、
前記集合知取得手段は、
前記第2の出力データからコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する標準偏差取得部と、
前記第4の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する平均値取得部とを有する
ことを特徴とする請求項1に記載の株価予測システム。 - 予測集合取得手段により、株価の変化要素を示す入力データに基づき、株価の予測値の集合を取得する工程と、
集合知取得手段により、前記株価の予測値の集合から予測精度の高い株価の集合知を取得する工程とを有し、
前記予測集合取得手段は、
無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、
集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、
前記集合知取得手段は、
平均値取得部により、前記第2の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程を有する
ことを特徴とする株価予測方法。 - 前記集合知取得手段は、
標準偏差取得部により、前記平均値取得部が取得した予測精度の高い予測値の集合知からコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程を有する
ことを特徴とする請求項4に記載の株価予測方法。 - 前記予測集合取得手段は、
無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、
集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、
前記集合知取得手段は、
標準偏差取得部により、前記第2の出力データからコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程と、
平均値取得部により、前記第4の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程とを有する
ことを特徴とする請求項4に記載の株価予測方法。 - 株価予測システムを制御するコンピューターに実行させる株価予測プログラムであって、
予測集合取得手段により、株価の変化要素を示す入力データに基づき、株価の予測値の集合を取得する工程と、
集合知取得手段により、前記株価の予測値の集合から予測精度の高い株価の集合知を取得する工程とを有し、
前記予測集合取得手段は、
無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、
集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、
前記集合知取得手段は、
平均値取得部により、前記第2の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程を有する
ことを特徴とする株価予測プログラム。 - 前記集合知取得手段は、
標準偏差取得部により、前記平均値取得部が取得した予測精度の高い予測値の集合知からコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程を有する
ことを特徴とする請求項7に記載の株価予測プログラム。 - 前記予測集合取得手段は、
無作為復元抽出部により、前記入力データが示す訓練データから複数のデータセットを作成して複数の予測モデルを複製し、それぞれの予測モデルの訓練データの集合を示す第1の出力データを出力する工程と、
集団学習部により、前記第1の出力データが示す訓練データを用いて複数の予測モデルを訓練し、個々に予測値を示す第2の出力データを出力する工程とを有し、
前記集合知取得手段は、
標準偏差取得部により、前記第2の出力データからコンセンサス比率の高い予測値の集合を取得し、取得した集合知の合意度を示す第4の出力データを出力する工程と、
平均値取得部により、前記第4の出力データから平均値をとることで互いの予測誤差を相殺し、予測精度の高い予測値の集合知を示す第3の出力データを出力する工程とを有する
ことを特徴とする請求項7に記載の株価予測プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017104050A JP6879552B2 (ja) | 2017-05-26 | 2017-05-26 | 株価予測システム、株価予測方法及び株価予測プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017104050A JP6879552B2 (ja) | 2017-05-26 | 2017-05-26 | 株価予測システム、株価予測方法及び株価予測プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2018200513A JP2018200513A (ja) | 2018-12-20 |
| JP6879552B2 true JP6879552B2 (ja) | 2021-06-02 |
Family
ID=64668175
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017104050A Active JP6879552B2 (ja) | 2017-05-26 | 2017-05-26 | 株価予測システム、株価予測方法及び株価予測プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6879552B2 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102597042B1 (ko) * | 2021-06-15 | 2023-10-31 | 김상율 | 머신러닝 알고리즘을 활용한 주식시장 예측 장치 및 방법 |
| KR102847417B1 (ko) * | 2024-12-18 | 2025-08-19 | 주식회사 커넥트 | 블록딜 거래 후 주식 종가 예측 시스템 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001175735A (ja) * | 1999-12-17 | 2001-06-29 | Canon Inc | 時系列予測装置及びシステム及び方法及び記憶媒体 |
| JP4461245B2 (ja) * | 2003-05-07 | 2010-05-12 | 学校法人慶應義塾 | 株価変動数値解析装置 |
| AU2004284807A1 (en) * | 2003-10-23 | 2005-05-06 | Financial Technology & Research Llc | Analysis system for predicting performance |
| US20100114745A1 (en) * | 2008-10-30 | 2010-05-06 | Sap Ag | System and method for calculating and applying market data change rate sets |
| JP6082657B2 (ja) * | 2013-05-28 | 2017-02-15 | 日本電信電話株式会社 | ポーズ付与モデル選択装置とポーズ付与装置とそれらの方法とプログラム |
-
2017
- 2017-05-26 JP JP2017104050A patent/JP6879552B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2018200513A (ja) | 2018-12-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113099729B (zh) | 生产调度的深度强化学习 | |
| Carbonneau et al. | Application of machine learning techniques for supply chain demand forecasting | |
| Athanassopoulos et al. | A comparison of data envelopment analysis and artificial neural networks as tools for assessing the efficiency of decision making units | |
| Koenig et al. | Improving measurement and prediction in personnel selection through the application of machine learning | |
| Pradhan et al. | Forecasting exchange rate in India: An application of artificial neural network model | |
| WO2015094545A1 (en) | System and method for modeling and quantifying regulatory capital, key risk indicators, probability of default, exposure at default, loss given default, liquidity ratios, and value at risk, within the areas of asset liability management, credit risk, market risk, operational risk, and liquidity risk for banks | |
| US20210117828A1 (en) | Information processing apparatus, information processing method, and program | |
| US20190244299A1 (en) | System and method for evaluating decision opportunities | |
| Naresh Kumar Reddy | Forecasting e-commerce trends: utilizing linear regression, polynomial regression, random forest, and gradient boosting for accurate sales and demand prediction | |
| Costain et al. | Logit price dynamics | |
| KR20190134966A (ko) | 정책망 및 가치망을 이용한 온라인 쇼핑몰에서의 프로모션 성과 예측 및 추천 장치 | |
| López et al. | A scenario-based modeling method for controlling ECM performance | |
| US12223713B2 (en) | Geospatial vegetation correlation system and method | |
| Chica et al. | Identimod: Modeling and managing brand value using soft computing | |
| JP6879552B2 (ja) | 株価予測システム、株価予測方法及び株価予測プログラム | |
| CN109754104B (zh) | 应用人工智能优化企业供应链的方法、系统、设备及介质 | |
| KR20190134967A (ko) | 정책망 및 가치망을 이용한 온라인 쇼핑몰에서의 프로모션 이미지 수정 장치 | |
| Hosseini et al. | Reinforcement learning-based simulation optimization for an integrated manufacturing-warehouse system: a two-stage approach | |
| Tan et al. | Modeling financial ratios of Malaysian plantation stocks using Bayesian Networks | |
| Upreti et al. | Assessing the effect of task automation in labor markets: Case of IT services industry | |
| Chou et al. | Estimating software project effort for manufacturing firms | |
| Khumaidi et al. | Forecasting of Sales Based on Long Short Term Memory Algorithm with Hyperparameter | |
| Reza et al. | An approach to make comparison of ARIMA and NNAR Models for Forecasting Price of Commodities | |
| Chaveesuk et al. | Economic valuation of capital projects using neural network metamodels | |
| Sugiarti et al. | Price Prediction of Aglaonema Ornamental Plants Using the Long Short-Term Memory (LSTM) Algorithm |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200417 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20210217 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210309 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210402 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210420 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210422 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6879552 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |