JP6790286B2 - 強化学習を用いたデバイス配置最適化 - Google Patents
強化学習を用いたデバイス配置最適化 Download PDFInfo
- Publication number
- JP6790286B2 JP6790286B2 JP2019552038A JP2019552038A JP6790286B2 JP 6790286 B2 JP6790286 B2 JP 6790286B2 JP 2019552038 A JP2019552038 A JP 2019552038A JP 2019552038 A JP2019552038 A JP 2019552038A JP 6790286 B2 JP6790286 B2 JP 6790286B2
- Authority
- JP
- Japan
- Prior art keywords
- embedding
- placement
- sequence
- neural network
- operations
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000002787 reinforcement Effects 0.000 title claims description 9
- 238000005457 optimization Methods 0.000 title 1
- 238000013528 artificial neural network Methods 0.000 claims description 102
- 230000000306 recurrent effect Effects 0.000 claims description 72
- 238000000034 method Methods 0.000 claims description 54
- 238000010801 machine learning Methods 0.000 claims description 51
- 238000012545 processing Methods 0.000 claims description 30
- 230000008569 process Effects 0.000 claims description 27
- 238000004891 communication Methods 0.000 claims description 9
- 238000012549 training Methods 0.000 claims description 8
- 238000004364 calculation method Methods 0.000 claims description 4
- 238000005070 sampling Methods 0.000 claims 1
- 238000004590 computer program Methods 0.000 description 13
- 230000006870 function Effects 0.000 description 7
- 230000009471 action Effects 0.000 description 6
- 230000015654 memory Effects 0.000 description 5
- 230000001537 neural effect Effects 0.000 description 4
- 238000003491 array Methods 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 230000004913 activation Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000013515 script Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 230000006403 short-term memory Effects 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000001953 sensory effect Effects 0.000 description 1
- 230000026676 system process Effects 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/10—Interfaces, programming languages or software development kits, e.g. for simulating neural networks
- G06N3/105—Shells for specifying net layout
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/04—Inference or reasoning models
Description
本出願は、2017年3月24日に出願された米国仮出願第62/476,618号の優先権を主張する。先行出願の開示は、本出願の開示の一部とみなされ、参照により本開示に組み込まれる。

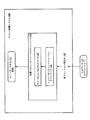
102 配置リカレントニューラルネットワーク
104 エンコーダリカレントニューラルネットワーク
106 デコーダニューラルネットワーク
108 オペレーション埋込み
110 入力データ110
112 ネットワーク出力
211〜220 埋込み
251 デバイス
262 デコーダ入力
292 エンコーダ
294 デコーダ
402〜416 オペレーション
418〜424 デバイス
432〜450 エッジ
452 計算グラフ
454 システム
Claims (20)
- コンピュータ実装方法であって、
複数のハードウェアデバイス上での分散処理のために配置されるべき機械学習モデルを指定するデータを受け取るステップと、
前記機械学習モデルを指定する前記データから、オペレーション埋込みのシーケンスを生成するステップであって、前記シーケンスでの各オペレーション埋込みが、前記機械学習モデルの前記分散処理を行うことの一部である1つまたは複数のそれぞれのオペレーションを特徴づける、ステップと、
配置リカレントニューラルネットワークの複数のネットワークパラメータの第1の値に従って、前記配置リカレントニューラルネットワークを使用して、オペレーション埋込みの前記シーケンスを処理するステップであって、
前記配置リカレントニューラルネットワークが、前記複数のデバイスにわたる前記シーケンスでの前記オペレーション埋込みによって特徴づけられた前記オペレーションの配置を定義するネットワーク出力を生成するために、前記第1の値に従ってオペレーション埋込みの前記シーケンスを処理するように構成される、ステップと、
前記ネットワーク出力によって定義された前記配置に従って前記複数のデバイスに前記オペレーションを配置することによって、前記複数のハードウェアデバイスによる処理のために前記機械学習モデルをスケジュールするステップと
を含む、方法。 - 前記オペレーション埋込みによって特徴づけられた前記オペレーションが、前記機械学習モデルを訓練することの一部であるオペレーションである、請求項1に記載の方法。
- 前記オペレーション埋込みによって特徴づけられた前記オペレーションが、前記機械学習モデルを使用して推論を行うことの一部であるオペレーションである、請求項1に記載の方法。
- 前記機械学習モデルを指定する前記データが、オペレーションを表す頂点と、前記オペレーション間のデータ通信を表すエッジとを有する計算グラフを表すデータである、請求項1に記載の方法。
- オペレーション埋込みの前記シーケンスを生成するステップが、
前記計算グラフ中の頂点によって表される前記オペレーションの2つ以上が、同じデバイス上に併置されるべきであることを決定するステップと、
それに応じて、前記2つ以上のオペレーションを特徴づける単一のオペレーション埋込みを生成するステップと
を含む、請求項4に記載の方法。 - 特定のオペレーションを特徴づけるオペレーション埋込みを生成するステップが、
前記特定のオペレーションのオペレーションタイプのタイプ埋込みを生成するステップと、
前記特定のオペレーションによって生成される出力のサイズを特徴づける出力サイズ埋込みを生成するステップと、
入力を提供し、前記特定のオペレーションによって生成された出力を受け取るオペレーションを識別する隣接性埋込みを生成するステップと、
前記特定のオペレーションを特徴づける前記オペレーション埋込みを生成するために、前記タイプ埋込み、前記出力サイズ埋込み、および前記隣接性埋込みを結合するステップと
を含む、請求項1に記載の方法。 - 前記配置リカレントニューラルネットワークが、前記シーケンスでの前記オペレーション埋込みの各々に対して、前記複数のデバイスの各々に対するそれぞれのスコアを含むスコアのセットを生成するように構成され、
オペレーション埋込みの前記シーケンスを処理するステップが、前記オペレーションを特徴づける前記オペレーション埋込みのためのスコアの前記セットを使用して前記オペレーションの各々に対してデバイスを選択するステップを含む、
請求項1に記載の方法。 - 前記オペレーションの各々に対して前記デバイスを選択するステップが、前記オペレーションを特徴づける前記オペレーション埋込みのためのスコアの前記セットに従って、最も高いスコアを有する前記デバイスを選択するステップを含む、請求項7に記載の方法。
- 前記オペレーションの各々に対して前記デバイスを選択するステップが、前記オペレーションを特徴づける前記オペレーション埋込みのためのスコアの前記セットによって定義された確率に従って、前記複数のデバイスからデバイスをサンプリングするステップを含む、請求項7に記載の方法。
- 前記配置リカレントニューラルネットワークが、
前記オペレーション埋込みの各々に対してそれぞれのエンコーダ隠れ状態を生成するために、オペレーション埋込みの前記シーケンスを処理するように構成されたエンコーダリカレントニューラルネットワークと、
前記オペレーション埋込みの各々に対して、
デコーダ入力を受け取ることと、
前記オペレーション埋込みのためのスコアの前記セットを生成するために、前記デコーダ入力および前記エンコーダ隠れ状態を処理することと
を行うように構成された、デコーダニューラルネットワークと
を備える、請求項7に記載の方法。 - 前記シーケンスでの第1のオペレーション埋込み後の前記オペレーション埋込みの各々に対する前記デコーダ入力が、前記シーケンスでの先行するオペレーション埋込みによって表される前記1つまたは複数のオペレーションに選択されるデバイスを識別する、請求項10に記載の方法。
- 前記ネットワークパラメータの初期値から、前記ネットワークパラメータの前記第1の値を決定するステップであって、
前記複数のデバイスにわたる前記オペレーションの1つまたは複数の配置を選択するために、配置リカレントニューラルネットワークの複数のネットワークパラメータの現在の値に従って、前記配置リカレントニューラルネットワークを使用して、オペレーション埋込みの現在のシーケンスを処理することと、
各選択された配置に対して、
前記配置に従って前記複数のデバイスにわたる前記オペレーションで前記機械学習モデルの前記処理を行い、
前記処理が完了するために必要な時間を決定することと、
前記選択された配置の各々に対して前記処理が完了するために必要な前記時間から導出される報酬を使用する強化学習技法を使用して前記複数のネットワークのパラメータの前記現在の値を調整することと
を繰り返し行うことによって、前記ネットワークパラメータの前記第1の値を決定するステップ
をさらに含む、請求項1に記載の方法。 - 前記強化学習技法がREINFORCE技法である、請求項12に記載の方法。
- 前記強化学習技法が、前記必要な時間の移動平均であるベースラインを含む、請求項12に記載の方法。
- 前記パラメータの前記現在の値を調整するステップが、前記強化学習技法の一部として前記現在のシーケンスでの前記オペレーション埋込みを調整することをさらに含む、請求項12に記載の方法。
- 1つまたは複数のコンピュータと、
前記1つまたは複数のコンピュータによって実行されると、前記1つまたは複数のコンピュータに、
複数のハードウェアデバイス上での分散処理のために配置されるべき機械学習モデルを指定するデータを受け取るステップと、
前記機械学習モデルを指定する前記データから、オペレーション埋込みのシーケンスを生成するステップであって、前記シーケンスでの各オペレーション埋込みが、前記機械学習モデルの前記分散処理を行うことの一部である1つまたは複数のそれぞれのオペレーションを特徴づける、ステップと、
配置リカレントニューラルネットワークの複数のネットワークパラメータの第1の値に従って、前記配置リカレントニューラルネットワークを使用して、オペレーション埋込みの前記シーケンスを処理するステップであって、
前記配置リカレントニューラルネットワークが、前記複数のデバイスにわたる前記シーケンスでの前記オペレーション埋込みによって特徴づけられた前記オペレーションの配置を定義するネットワーク出力を生成するために、前記第1の値に従ってオペレーション埋込みの前記シーケンスを処理するように構成される、ステップと、
前記ネットワーク出力によって定義された前記配置に従って前記複数のデバイスに前記オペレーションを配置することによって、前記複数のハードウェアデバイスによる処理のために前記機械学習モデルをスケジュールするステップと
を行わせる命令を記憶した1つまたは複数のストレージデバイスと
を備える、システム。 - 1つまたは複数のコンピュータによって実行されると、前記1つまたは複数のコンピュータに、
複数のハードウェアデバイス上での分散処理のために配置されるべき機械学習モデルを指定するデータを受け取るステップと、
前記機械学習モデルを指定する前記データから、オペレーション埋込みのシーケンスを生成するステップであって、前記シーケンスでの各オペレーション埋込みが、前記機械学習モデルの前記分散処理を行うことの一部である1つまたは複数のそれぞれのオペレーションを特徴づける、ステップと、
配置リカレントニューラルネットワークの複数のネットワークパラメータの第1の値に従って、前記配置リカレントニューラルネットワークを使用して、オペレーション埋込みの前記シーケンスを処理するステップであって、
前記配置リカレントニューラルネットワークが、前記複数のデバイスにわたる前記シーケンスでの前記オペレーション埋込みによって特徴づけられた前記オペレーションの配置を定義するネットワーク出力を生成するために、前記第1の値に従ってオペレーション埋込みの前記シーケンスを処理するように構成される、ステップと、
前記ネットワーク出力によって定義された前記配置に従って前記複数のデバイスに前記オペレーションを配置することによって、前記複数のハードウェアデバイスによる処理のために前記機械学習モデルをスケジュールするステップと
を行わせる命令を記憶した1つまたは複数のコンピュータ記憶媒体。 - 特定のオペレーションを特徴づけるオペレーション埋込みを生成するステップが、
前記特定のオペレーションのオペレーションタイプのタイプ埋込みを生成するステップと、
前記特定のオペレーションによって生成される出力のサイズを特徴づける出力サイズ埋込みを生成するステップと、
入力を提供し、前記特定のオペレーションによって生成された出力を受け取るオペレーションを識別する隣接性埋込みを生成するステップと、
前記特定のオペレーションを特徴づける前記オペレーション埋込みを生成するために、前記タイプ埋込み、前記出力サイズ埋込み、および前記隣接性埋込みを結合するステップと
を含む、請求項17に記載の1つまたは複数のコンピュータ記憶媒体。 - 前記配置リカレントニューラルネットワークが、前記シーケンスでの前記オペレーション埋込みの各々に対して、前記複数のデバイスの各々に対するそれぞれのスコアを含むスコアのセットを生成するように構成され、
オペレーション埋込みの前記シーケンスを処理するステップが、前記オペレーションを特徴づける前記オペレーション埋込みのためのスコアの前記セットを使用して前記オペレーションの各々に対してデバイスを選択するステップを含む、
請求項17に記載の1つまたは複数のコンピュータ記憶媒体。 - 前記オペレーションの各々に対して前記デバイスを選択するステップが、前記オペレーションを特徴づける前記オペレーション埋込みのためのスコアの前記セットに従って、最も高いスコアを有する前記デバイスを選択するステップを含む、請求項19に記載の1つまたは複数のコンピュータ記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762476618P | 2017-03-24 | 2017-03-24 | |
| US62/476,618 | 2017-03-24 | ||
| PCT/US2018/024155 WO2018175972A1 (en) | 2017-03-24 | 2018-03-23 | Device placement optimization with reinforcement learning |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2020512639A JP2020512639A (ja) | 2020-04-23 |
| JP2020512639A5 JP2020512639A5 (ja) | 2020-07-27 |
| JP6790286B2 true JP6790286B2 (ja) | 2020-11-25 |
Family
ID=61913686
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019552038A Active JP6790286B2 (ja) | 2017-03-24 | 2018-03-23 | 強化学習を用いたデバイス配置最適化 |
Country Status (6)
| Country | Link |
|---|---|
| US (3) | US10692003B2 (ja) |
| EP (1) | EP3559868A1 (ja) |
| JP (1) | JP6790286B2 (ja) |
| KR (1) | KR102208989B1 (ja) |
| CN (2) | CN110268422B (ja) |
| WO (1) | WO2018175972A1 (ja) |
Families Citing this family (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11556520B2 (en) | 2017-11-13 | 2023-01-17 | Lendingclub Corporation | Techniques for automatically addressing anomalous behavior |
| US11354301B2 (en) | 2017-11-13 | 2022-06-07 | LendingClub Bank, National Association | Multi-system operation audit log |
| SG11202105629SA (en) * | 2018-12-04 | 2021-06-29 | Google Llc | Generating integrated circuit floorplans using neural networks |
| JP7050023B2 (ja) * | 2019-03-22 | 2022-04-07 | Kddi株式会社 | ネットワーク障害復旧システム、コンピュータプログラム及びネットワーク障害復旧方法 |
| KR102371927B1 (ko) * | 2019-10-17 | 2022-03-11 | (주)유밥 | 학습 콘텐츠 추천 방법 및 장치 |
| KR102272501B1 (ko) | 2020-04-24 | 2021-07-01 | 연세대학교 산학협력단 | 분산 강화 학습 장치 및 방법 |
| US11288097B2 (en) | 2020-06-12 | 2022-03-29 | Disney Enterprises, Inc. | Automated hardware resource optimization |
| US20200327392A1 (en) * | 2020-06-26 | 2020-10-15 | Intel Corporation | Methods, systems, articles of manufacture, and apparatus to optimize layers of a machine learning model for a target hardware platform |
| US20220083824A1 (en) * | 2020-09-11 | 2022-03-17 | Actapio, Inc. | Execution control apparatus, execution control method, and a non-transitory computer-readable storage medium |
| KR20220045800A (ko) * | 2020-10-06 | 2022-04-13 | 삼성전자주식회사 | 인공지능 모델을 분산 처리하는 시스템 및 그 동작 방법 |
| KR102257028B1 (ko) * | 2020-10-06 | 2021-05-27 | 주식회사 딥이티 | 컴퓨팅 플랫폼 기반의 적응형 딥러닝 작업 할당 장치 및 방법 |
| JP2023020264A (ja) * | 2021-07-30 | 2023-02-09 | 株式会社Screenホールディングス | スケジュール作成方法、スケジュール作成装置、基板処理装置、基板処理システム、記録媒体、及びスケジュール作成プログラム |
| KR102573644B1 (ko) * | 2021-08-24 | 2023-09-01 | 주식회사 에너자이 | 실행 엔진 최적화 방법, 실행 엔진 최적화 장치, 및 실행 엔진 최적화 시스템 |
| US11509836B1 (en) | 2021-12-29 | 2022-11-22 | Insight Direct Usa, Inc. | Dynamically configured processing of a region of interest dependent upon published video data selected by a runtime configuration file |
| US11704891B1 (en) | 2021-12-29 | 2023-07-18 | Insight Direct Usa, Inc. | Dynamically configured extraction, preprocessing, and publishing of a region of interest that is a subset of streaming video data |
| WO2023163453A1 (ko) * | 2022-02-23 | 2023-08-31 | 주식회사 에너자이 | 임베디드 장치에서 실행될 신경망 모델 최적화 방법, 신경망 모델 최적화 장치, 및 신경망 모델 최적화 시스템 |
| WO2023243896A1 (ko) * | 2022-06-17 | 2023-12-21 | 삼성전자 주식회사 | 인공신경망의 추론 분산 비율 결정 전자 장치 및 그 동작 방법 |
| US11778167B1 (en) | 2022-07-26 | 2023-10-03 | Insight Direct Usa, Inc. | Method and system for preprocessing optimization of streaming video data |
| WO2024053910A1 (ko) * | 2022-09-08 | 2024-03-14 | 삼성전자주식회사 | 기계학습 모델에 적합한 가속기를 선택하는 장치 및 방법 |
| KR102603130B1 (ko) | 2022-12-27 | 2023-11-17 | 주식회사 애자일소다 | 강화학습 기반의 면적 및 매크로 배치 최적화를 위한 설계 시스템 및 방법 |
| KR102645072B1 (ko) | 2023-05-31 | 2024-03-08 | 주식회사 애자일소다 | 매크로의 핀 방향 최적화를 위한 후처리 장치 및 방법 |
| KR102634706B1 (ko) | 2023-05-31 | 2024-02-13 | 주식회사 애자일소다 | 데드 스페이스의 최소화를 위한 집적회로 설계 장치 및 방법 |
| CN117058491B (zh) * | 2023-10-12 | 2024-04-02 | 深圳大学 | 基于递归神经网络的结构化网格布局生成方法及设备 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05108595A (ja) * | 1991-10-17 | 1993-04-30 | Hitachi Ltd | ニユーラルネツトワークの分散学習装置 |
| KR100676863B1 (ko) | 2004-08-31 | 2007-02-02 | 주식회사 코난테크놀로지 | 음악 검색 서비스 제공 시스템 및 방법 |
| US7870556B2 (en) * | 2006-05-16 | 2011-01-11 | Ab Initio Technology Llc | Managing computing resources in graph-based computations |
| KR20100067174A (ko) | 2008-12-11 | 2010-06-21 | 한국전자통신연구원 | 음성 인식을 이용한 메타데이터 검색기, 검색 방법, iptv 수신 장치 |
| KR20120034378A (ko) | 2010-10-01 | 2012-04-12 | 엔에이치엔(주) | 사운드 인식을 통한 광고 정보 제공 시스템 및 방법 |
| US9189730B1 (en) * | 2012-09-20 | 2015-11-17 | Brain Corporation | Modulated stochasticity spiking neuron network controller apparatus and methods |
| US9767419B2 (en) * | 2014-01-24 | 2017-09-19 | Microsoft Technology Licensing, Llc | Crowdsourcing system with community learning |
| US10102480B2 (en) * | 2014-06-30 | 2018-10-16 | Amazon Technologies, Inc. | Machine learning service |
| EP3204896A1 (en) * | 2014-10-07 | 2017-08-16 | Google, Inc. | Training neural networks on partitioned training data |
| CN110443351B (zh) * | 2014-11-14 | 2021-05-28 | 谷歌有限责任公司 | 生成映像的自然语言描述 |
| US11080587B2 (en) * | 2015-02-06 | 2021-08-03 | Deepmind Technologies Limited | Recurrent neural networks for data item generation |
| US10373054B2 (en) * | 2015-04-19 | 2019-08-06 | International Business Machines Corporation | Annealed dropout training of neural networks |
| US10515307B2 (en) * | 2015-06-05 | 2019-12-24 | Google Llc | Compressed recurrent neural network models |
| US9652712B2 (en) * | 2015-07-27 | 2017-05-16 | Google Inc. | Analyzing health events using recurrent neural networks |
| US11151446B2 (en) * | 2015-10-28 | 2021-10-19 | Google Llc | Stream-based accelerator processing of computational graphs |
-
2018
- 2018-03-23 KR KR1020197026115A patent/KR102208989B1/ko active IP Right Grant
- 2018-03-23 CN CN201880011282.1A patent/CN110268422B/zh active Active
- 2018-03-23 CN CN202311517807.8A patent/CN117648971A/zh active Pending
- 2018-03-23 EP EP18716863.8A patent/EP3559868A1/en active Pending
- 2018-03-23 WO PCT/US2018/024155 patent/WO2018175972A1/en unknown
- 2018-03-23 JP JP2019552038A patent/JP6790286B2/ja active Active
-
2019
- 2019-06-19 US US16/445,330 patent/US10692003B2/en active Active
-
2020
- 2020-05-20 US US16/878,720 patent/US11803747B2/en active Active
-
2023
- 2023-10-03 US US18/376,362 patent/US20240062062A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US11803747B2 (en) | 2023-10-31 |
| US20190303761A1 (en) | 2019-10-03 |
| US20240062062A1 (en) | 2024-02-22 |
| CN110268422A (zh) | 2019-09-20 |
| WO2018175972A1 (en) | 2018-09-27 |
| KR102208989B1 (ko) | 2021-01-28 |
| KR20190113928A (ko) | 2019-10-08 |
| US20200279163A1 (en) | 2020-09-03 |
| CN110268422B (zh) | 2023-12-01 |
| EP3559868A1 (en) | 2019-10-30 |
| JP2020512639A (ja) | 2020-04-23 |
| CN117648971A (zh) | 2024-03-05 |
| US10692003B2 (en) | 2020-06-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6790286B2 (ja) | 強化学習を用いたデバイス配置最適化 | |
| JP7157154B2 (ja) | 性能予測ニューラルネットワークを使用したニューラルアーキテクチャ探索 | |
| US11669744B2 (en) | Regularized neural network architecture search | |
| JP6758406B2 (ja) | ワイドアンドディープマシンラーニングモデル | |
| JP7043596B2 (ja) | ニューラルアーキテクチャ検索 | |
| JP6671515B2 (ja) | 比較セットを使用する入力例の分類 | |
| CN110663049B (zh) | 神经网络优化器搜索 | |
| CN110476173B (zh) | 利用强化学习的分层设备放置 | |
| CA3155320A1 (en) | Generating audio using neural networks | |
| CN109478254A (zh) | 使用合成梯度来训练神经网络 | |
| CN110402445A (zh) | 使用递归神经网络处理序列数据 | |
| JP7293729B2 (ja) | 学習装置、情報出力装置、及びプログラム | |
| JP2022523666A (ja) | ニューラルネットワークのための複合モデルスケーリング | |
| JP2023533631A (ja) | ハードウェア用に最適化されたニューラルアーキテクチャ検索 | |
| US20230124177A1 (en) | System and method for training a sparse neural network whilst maintaining sparsity |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20191024 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200612 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20200612 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20200616 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20200923 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20201005 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20201104 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6790286 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |