JP6659724B2 - 並列プロセッサカーネルのディスパッチサイズのコンカレンシーファクタを決定するシステム及び方法 - Google Patents
並列プロセッサカーネルのディスパッチサイズのコンカレンシーファクタを決定するシステム及び方法 Download PDFInfo
- Publication number
- JP6659724B2 JP6659724B2 JP2017554900A JP2017554900A JP6659724B2 JP 6659724 B2 JP6659724 B2 JP 6659724B2 JP 2017554900 A JP2017554900 A JP 2017554900A JP 2017554900 A JP2017554900 A JP 2017554900A JP 6659724 B2 JP6659724 B2 JP 6659724B2
- Authority
- JP
- Japan
- Prior art keywords
- kernel
- parallel processor
- workgroups
- sequence
- application
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 32
- 230000015654 memory Effects 0.000 claims description 29
- 230000006399 behavior Effects 0.000 claims description 16
- 230000035945 sensitivity Effects 0.000 claims description 16
- 238000005259 measurement Methods 0.000 claims description 9
- 230000008859 change Effects 0.000 claims description 8
- 238000012886 linear function Methods 0.000 claims description 5
- 230000000007 visual effect Effects 0.000 claims description 3
- 238000010586 diagram Methods 0.000 description 7
- 238000004519 manufacturing process Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000021715 photosynthesis, light harvesting Effects 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 230000008901 benefit Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000001788 irregular Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/54—Interprogram communication
- G06F9/545—Interprogram communication where tasks reside in different layers, e.g. user- and kernel-space
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3404—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for parallel or distributed programming
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3409—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment
- G06F11/3433—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for performance assessment for load management
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3466—Performance evaluation by tracing or monitoring
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/445—Program loading or initiating
- G06F9/44505—Configuring for program initiating, e.g. using registry, configuration files
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
- G06F9/4893—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues taking into account power or heat criteria
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Debugging And Monitoring (AREA)
- Multi Processors (AREA)
Description
本願は、2015年5月13日に出願された米国特許出願第14/710,879号の利益を主張し、その内容は、参照により本明細書に援用される。
Claims (23)
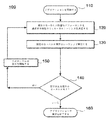
- 並列プロセッサ上で実行するアプリケーション内のワークグループを含むカーネルのコンカレンシーファクタ(concurrency factor)を決定する方法であって、
前記ワークグループをミニカーネルに分割することであって、各ミニカーネルは、同時に実行するワークグループの数を含み、前記ワークグループの数は、前記ミニカーネルのコンカレンシーファクタであり、少なくとも1つの前記ミニカーネルの前記コンカレンシーファクタは、1よりも大きい、ことと、
前記並列プロセッサが、前記カーネルの少なくとも一部を前記ミニカーネルのシーケンスとして実行することと、
ミニカーネルの各シーケンスのパフォーマンス測定値を決定することと、
前記パフォーマンス測定値に基づいて、前記カーネルの所望のパフォーマンスを達成する特定のシーケンスを前記シーケンスから選択することと、
前記並列プロセッサが、前記カーネルを前記特定のシーケンスで実行することと、を含む、
方法。 - ミニカーネルにおいて同時に実行される全てのワークグループが連続している、請求項1の方法。
- 前記ミニカーネルの少なくとも1つのシーケンス内の全てのミニカーネルは、共通のコンカレンシーファクタを有する、請求項1の方法。
- 前記アプリケーションの実行中に新たなアプリケーションカーネルが呼び出される毎に、前記カーネルの少なくとも一部を実行することと、前記決定することと、前記選択することと、前記実行することと、を行うことをさらに含む、請求項1の方法。
- 前記アプリケーションの実行中に動的に、前記カーネルの少なくとも一部を実行することと、前記決定することと、前記選択することと、前記実行することと、を行うことをさらに含む、請求項1の方法。
- 前記所望のパフォーマンスを達成することは、実行時間を最小にすることと、熱的制限内で前記並列プロセッサを維持することと、電力効率及びエネルギー効率のうち少なくとも1つを最大にすることと、前記並列プロセッサ又は前記並列プロセッサを含むシステムの信頼性を最大にすることと、メモリの使用のためにワークグループ間の競合を最小にすることと、のうち少なくとも1つを含む、請求項1の方法。
- 前記パフォーマンス測定値は、パフォーマンス測定値の変化を、前記カーネルを実行する計算ユニットの数の対応する変化で除算したパフォーマンス測定値である計算ユニットの感度(compute-unit sensitivity)を含む、請求項1の方法。
- 前記アプリケーションの実行結果を、前記実行結果を表示するディスプレイに提供することをさらに含む、請求項1の方法。
- アプリケーション内のワークグループを含むカーネルのコンカレンシーファクタ(concurrency factor)を決定するように構成されたシステムであって、
前記アプリケーションを実行するように構成された並列プロセッサと、
前記並列プロセッサと情報を交換し、前記アプリケーションを記憶し、前記アプリケーションを前記並列プロセッサ内にロードするように構成された第1メモリと、
前記並列プロセッサと情報を交換するように構成された第2メモリと、を備え、
前記並列プロセッサは、
前記ワークグループをミニカーネルに分割することであって、各ミニカーネルは、同時に実行するワークグループの数を含み、前記ワークグループの数は、前記ミニカーネルのコンカレンシーファクタであり、少なくとも1つの前記ミニカーネルの前記コンカレンシーファクタは、1よりも大きい、ことと、
前記カーネルの少なくとも一部を前記ミニカーネルのシーケンスとして実行することと、
ミニカーネルの各シーケンスのパフォーマンス測定値を決定することと、
前記パフォーマンス測定値に基づいて、前記カーネルの所望のパフォーマンスを達成する特定のシーケンスを前記シーケンスから選択することと、
前記カーネルを前記特定のシーケンスで実行することと、
を行うように構成されている、
システム。 - 前記並列プロセッサは、連続しており同時に実行されるワークグループを備えるミニカーネルのシーケンスとして、前記カーネルの少なくとも一部を実行するように構成されている、請求項9のシステム。
- 前記並列プロセッサは、前記カーネルの少なくとも一部をミニカーネルのシーケンスとして実行するように構成されており、前記シーケンスの少なくとも1つのシーケンス内の全てのミニカーネルは、共通のコンカレンシーファクタを含む、請求項9のシステム。
- 前記並列プロセッサは、前記アプリケーションの実行中に新たなアプリケーションカーネルが呼び出される毎に、前記カーネルの少なくとも一部を実行することと、前記決定することと、前記選択することと、前記実行することと、を行うように構成されている、請求項9のシステム。
- 前記並列プロセッサは、前記アプリケーションの実行中に動的に、前記カーネルの少なくとも一部を実行することと、前記決定することと、前記選択することと、前記実行することと、を行うように構成されている、請求項9のシステム。
- 前記並列プロセッサは、実行時間を最小にすることと、熱的制限内で前記システムを維持することと、電力効率及びエネルギー効率のうち少なくとも1つを最大にすることと、前記システムの信頼性を最大にすることと、前記第1メモリ、前記第2メモリ又はこれらの両方のメモリの使用のためにワークグループ間の競合を最小にすることと、のうち少なくとも1つによって、前記カーネルの所望のパフォーマンスを達成する特定のシーケンスを選択するように構成されている、請求項9のシステム。
- 前記並列プロセッサは、前記パフォーマンス測定値として、パフォーマンス測定値の変化を、前記カーネルを実行する計算ユニットの数の対応する変化で除算したパフォーマンス測定値である計算ユニットの感度(compute-unit unit sensitivity)を測定するように構成されている、請求項9のシステム。
- 前記アプリケーションの実行結果を提供するように構成された出力デバイスをさらに備える、請求項9のシステム。
- 前記出力デバイスは、視覚的ディスプレイを備える、請求項16のシステム。
- 前記共通のコンカレンシーファクタは2の累乗である、請求項3の方法。
- 前記計算ユニットの感度は、計算挙動(compute behavior)、メモリ挙動(memory behavior)、1つ以上のランタイム統計、及び、実行するワークグループの数、のうち少なくとも1つに基づいて決定される、請求項7の方法。
- 前記計算ユニットの感度は、計算挙動、メモリ挙動、1つ以上のランタイム統計、及び、実行するワークグループの数、のうち少なくとも1つの線形関数としてモデル化される、請求項7の方法。
- 前記並列プロセッサは、計算挙動、メモリ挙動、1つ以上のランタイム統計、及び、実行するワークグループの数、のうち少なくとも1つに基づいて、前記計算ユニットの感度を測定するように構成されている、請求項15のシステム。
- 前記並列プロセッサは、計算挙動、メモリ挙動、1つ以上のランタイム統計、及び、実行するワークグループの数、のうち少なくとも1つの線形関数として前記計算ユニットの感度を測定するように構成されている、請求項15のシステム。
- 前記共通のコンカレンシーファクタは2の累乗である、請求項11のシステム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/710,879 US9965343B2 (en) | 2015-05-13 | 2015-05-13 | System and method for determining concurrency factors for dispatch size of parallel processor kernels |
| US14/710,879 | 2015-05-13 | ||
| PCT/US2016/023560 WO2016182636A1 (en) | 2015-05-13 | 2016-03-22 | System and method for determining concurrency factors for dispatch size of parallel processor kernels |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2018514869A JP2018514869A (ja) | 2018-06-07 |
| JP2018514869A5 JP2018514869A5 (ja) | 2019-05-09 |
| JP6659724B2 true JP6659724B2 (ja) | 2020-03-04 |
Family
ID=57248294
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017554900A Active JP6659724B2 (ja) | 2015-05-13 | 2016-03-22 | 並列プロセッサカーネルのディスパッチサイズのコンカレンシーファクタを決定するシステム及び方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9965343B2 (ja) |
| EP (1) | EP3295300B1 (ja) |
| JP (1) | JP6659724B2 (ja) |
| KR (1) | KR102548402B1 (ja) |
| CN (1) | CN107580698B (ja) |
| WO (1) | WO2016182636A1 (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10324730B2 (en) * | 2016-03-24 | 2019-06-18 | Mediatek, Inc. | Memory shuffle engine for efficient work execution in a parallel computing system |
| US20180115496A1 (en) * | 2016-10-21 | 2018-04-26 | Advanced Micro Devices, Inc. | Mechanisms to improve data locality for distributed gpus |
| US10558499B2 (en) * | 2017-10-26 | 2020-02-11 | Advanced Micro Devices, Inc. | Wave creation control with dynamic resource allocation |
| US11900123B2 (en) * | 2019-12-13 | 2024-02-13 | Advanced Micro Devices, Inc. | Marker-based processor instruction grouping |
| US11809902B2 (en) * | 2020-09-24 | 2023-11-07 | Advanced Micro Devices, Inc. | Fine-grained conditional dispatching |
| US20220334845A1 (en) * | 2021-04-15 | 2022-10-20 | Nvidia Corporation | Launching code concurrently |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6516310B2 (en) * | 1999-12-07 | 2003-02-04 | Sybase, Inc. | System and methodology for join enumeration in a memory-constrained environment |
| US8136104B2 (en) | 2006-06-20 | 2012-03-13 | Google Inc. | Systems and methods for determining compute kernels for an application in a parallel-processing computer system |
| US8375368B2 (en) * | 2006-06-20 | 2013-02-12 | Google Inc. | Systems and methods for profiling an application running on a parallel-processing computer system |
| US9354944B2 (en) * | 2009-07-27 | 2016-05-31 | Advanced Micro Devices, Inc. | Mapping processing logic having data-parallel threads across processors |
| CN102023844B (zh) * | 2009-09-18 | 2014-04-09 | 深圳中微电科技有限公司 | 并行处理器及其线程处理方法 |
| KR101079697B1 (ko) * | 2009-10-05 | 2011-11-03 | 주식회사 글로벌미디어테크 | 범용 그래픽 처리장치의 병렬 프로세서를 이용한 고속 영상 처리 방법 |
| US8250404B2 (en) * | 2009-12-31 | 2012-08-21 | International Business Machines Corporation | Process integrity of work items in a multiple processor system |
| US8782645B2 (en) * | 2011-05-11 | 2014-07-15 | Advanced Micro Devices, Inc. | Automatic load balancing for heterogeneous cores |
| US9092267B2 (en) * | 2011-06-20 | 2015-07-28 | Qualcomm Incorporated | Memory sharing in graphics processing unit |
| US20120331278A1 (en) | 2011-06-23 | 2012-12-27 | Mauricio Breternitz | Branch removal by data shuffling |
| US8707314B2 (en) * | 2011-12-16 | 2014-04-22 | Advanced Micro Devices, Inc. | Scheduling compute kernel workgroups to heterogeneous processors based on historical processor execution times and utilizations |
| US9823927B2 (en) * | 2012-11-30 | 2017-11-21 | Intel Corporation | Range selection for data parallel programming environments |
| WO2014142876A1 (en) * | 2013-03-14 | 2014-09-18 | Bottleson Jeremy | Kernel functionality checker |
| US9772864B2 (en) * | 2013-04-16 | 2017-09-26 | Arm Limited | Methods of and apparatus for multidimensional indexing in microprocessor systems |
| US10297073B2 (en) * | 2016-02-25 | 2019-05-21 | Intel Corporation | Method and apparatus for in-place construction of left-balanced and complete point K-D trees |
-
2015
- 2015-05-13 US US14/710,879 patent/US9965343B2/en active Active
-
2016
- 2016-03-22 KR KR1020177033219A patent/KR102548402B1/ko active IP Right Grant
- 2016-03-22 CN CN201680026495.2A patent/CN107580698B/zh active Active
- 2016-03-22 WO PCT/US2016/023560 patent/WO2016182636A1/en unknown
- 2016-03-22 EP EP16793114.6A patent/EP3295300B1/en active Active
- 2016-03-22 JP JP2017554900A patent/JP6659724B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN107580698A (zh) | 2018-01-12 |
| KR20180011096A (ko) | 2018-01-31 |
| EP3295300A1 (en) | 2018-03-21 |
| US20160335143A1 (en) | 2016-11-17 |
| EP3295300A4 (en) | 2019-01-09 |
| JP2018514869A (ja) | 2018-06-07 |
| WO2016182636A1 (en) | 2016-11-17 |
| EP3295300B1 (en) | 2022-03-23 |
| US9965343B2 (en) | 2018-05-08 |
| KR102548402B1 (ko) | 2023-06-27 |
| CN107580698B (zh) | 2019-08-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6659724B2 (ja) | 並列プロセッサカーネルのディスパッチサイズのコンカレンシーファクタを決定するシステム及び方法 | |
| KR101839544B1 (ko) | 이종 코어의 자동 부하 균형 | |
| US9672035B2 (en) | Data processing apparatus and method for performing vector processing | |
| KR101688983B1 (ko) | 멀티-코어 프로세서용 멀티스레드 애플리케이션-인지 메모리 스케줄링 기법 | |
| US20160085551A1 (en) | Heterogeneous function unit dispatch in a graphics processing unit | |
| JP2009169935A (ja) | 並列プロセッサアーキテクチャを使用して単一ビット値のシーケンスに対してスキャン演算を実施するためのシステム、方法及びコンピュータプログラム製品 | |
| US20110161637A1 (en) | Apparatus and method for parallel processing | |
| US20120331278A1 (en) | Branch removal by data shuffling | |
| JP2022160691A (ja) | 複数の計算コア上のデータドリブンスケジューラ | |
| KR102493859B1 (ko) | 듀얼 모드 로컬 데이터 저장 | |
| US9830731B2 (en) | Methods of a graphics-processing unit for tile-based rendering of a display area and graphics-processing apparatus | |
| KR20210089247A (ko) | 그래픽 처리 장치에서 행렬 곱셈의 파이프라인 처리 | |
| Chu et al. | Efficient Algorithm Design of Optimizing SpMV on GPU | |
| US9898333B2 (en) | Method and apparatus for selecting preemption technique | |
| US11893502B2 (en) | Dynamic hardware selection for experts in mixture-of-experts model | |
| JP2002049603A (ja) | 動的負荷分散方法及び動的負荷分散装置 | |
| Prodromou et al. | Deciphering predictive schedulers for heterogeneous-ISA multicore architectures | |
| US11144428B2 (en) | Efficient calculation of performance data for a computer | |
| JP2012014591A (ja) | モンテカルロ法の効率的な並列処理手法 | |
| US20230195439A1 (en) | Apparatus and method with neural network computation scheduling | |
| US20230367633A1 (en) | Gpu and gpu method | |
| KR101721341B1 (ko) | 이종 멀티코어 환경에서 사용되는 수행장치 결정 모듈 및 이를 이용한 수행장치 결정방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20171220 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190322 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20190322 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20190322 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20190710 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20190717 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190730 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191030 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200107 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200206 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6659724 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |