JP6436806B2 - 音声合成用データ作成方法、及び音声合成用データ作成装置 - Google Patents
音声合成用データ作成方法、及び音声合成用データ作成装置 Download PDFInfo
- Publication number
- JP6436806B2 JP6436806B2 JP2015019009A JP2015019009A JP6436806B2 JP 6436806 B2 JP6436806 B2 JP 6436806B2 JP 2015019009 A JP2015019009 A JP 2015019009A JP 2015019009 A JP2015019009 A JP 2015019009A JP 6436806 B2 JP6436806 B2 JP 6436806B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- speech
- colloquial
- text
- tone
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000015572 biosynthetic process Effects 0.000 title claims description 72
- 238000003786 synthesis reaction Methods 0.000 title claims description 71
- 238000000034 method Methods 0.000 title claims description 47
- 230000014509 gene expression Effects 0.000 claims description 81
- 238000012545 processing Methods 0.000 claims description 48
- 230000008569 process Effects 0.000 claims description 27
- 230000033764 rhythmic process Effects 0.000 claims description 10
- 238000013179 statistical model Methods 0.000 claims description 5
- 238000000605 extraction Methods 0.000 description 58
- 238000002156 mixing Methods 0.000 description 13
- 238000004364 calculation method Methods 0.000 description 10
- 238000005516 engineering process Methods 0.000 description 7
- 240000000220 Panda oleosa Species 0.000 description 6
- 235000016496 Panda oleosa Nutrition 0.000 description 6
- 239000000284 extract Substances 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 239000000203 mixture Substances 0.000 description 6
- 238000004891 communication Methods 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 230000001755 vocal effect Effects 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 3
- 239000000470 constituent Substances 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 230000008859 change Effects 0.000 description 2
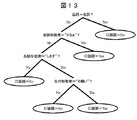
- 238000003066 decision tree Methods 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 238000010801 machine learning Methods 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000004140 cleaning Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000011158 quantitative evaluation Methods 0.000 description 1
- 238000000611 regression analysis Methods 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 238000001308 synthesis method Methods 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
Images

















Landscapes
- Machine Translation (AREA)
Description
<ハードウェア構成>
図1は、本発明の実施形態による音声合成システムのハードウェア構成例を示す図である。音声合成システム1は、各種プログラムを実行するプロセッサ(CPU:Central Processing Unit)101と、各種プログラムを格納するメモリ102と、各種データを格納する記憶装置103と、出力装置104と、入力装置105と、必要に応じて通信デバイス106と、を有している。
図2は、本発明の第1の実施形態による音声合成システム1の機能ブロック図である。音声合成システム1は、読み上げ調データ作成処理10と、口語調データ作成処理(口語調の音声合成用データを作成する処理)11と、口語調データを用いた音声合成処理12を実行する。
口語調データ作成処理11は、収録した口語調音声と、読み上げ韻律・音韻予測モデルを入力すると、口語調音声から口語調表現部分を自動抽出し、口語調音声合成に必要な口語調表現抽出ルール、口語調韻律・音韻モデル、口語調音声DB(データベースの略)を生成する処理である。この口語調データ作成処理11を実現するために、韻律・音韻特徴抽出部202、韻律・音韻自動学習部206、音声DB作成部207という通常の音声データ作成装置が持つ処理単位を備える。これに加えて、本発明に特徴的な、読み上げ調韻律・音韻予測部201、口語調度算出部203、口語調表現部分の自動抽出部204が設けられ、さらに、入力テキストから口語調テキスト表現を自動検出できる口語調表現抽出ルールを生成する口語調表現抽出ルール作成部205が設けられる。
+|強さ係数*強さ差分| ・・・・・ (式1)
ここで、“|A|”は“A”の絶対値を示すものとする。
ここで、“|A|”は“A”の絶対値を示している。
音声合成処理では、まずテキスト入力部に音声合成すべきテキスト(例えば、かな漢字文)がユーザによって入力され、テキスト解析部で解析される。
図16は、本発明の第1の実施形態による口語調データ作成処理を説明するためのフローチャートである。
プロセッサ101は、収録した口語調音声コーパスデータ1034の入力を受け付ける。当該データには、収録音声データとそれに対応するテキストデータ(発話テキスト)がセットとなっている。
プロセッサ101は、収録した収録した口語調音声コーパスデータ1034の収録音声データから、その音声の韻律・音韻特徴量を抽出する。詳細については上述した通りである。
プロセッサ101は、収録した口語調音声コーパスデータ1034の発話テキストに対して読み上げ韻律・音韻予測モデル1032を適用し、読み上げ調の韻律特徴量および音韻特徴量を予測する。つまり、ここでは、発話者がこのテキストに対して、読み上げ調スタイルで発話した場合は、韻律・音韻特徴がどのようなものであるかが分かる。詳細は上述した通りである。
プロセッサ101は、ステップ1602で抽出した収録口語調音声の特徴量と、ステップ1603で予測した韻律・音韻特徴量とを比較し、口語調への寄与度(口語調度)を計算する。
プロセッサ101は、ステップ1604で得られた口語調度を用いて、音声を構成する各セグメントについて、セグメントの口語調度を計算し、口語調度が所定の閾値以上を示すセグメントを口語調表現部分として自動抽出する。抽出された口語調表現部分は、口語調抽出データ1035に格納される。詳細は上述した通りである。
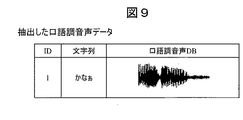
プロセッサ101は、ステップ1605で得られた口語調抽出データの音声波形を蓄積し、音声合成に用いる口語調音声DB1038を作成する
プロセッサ101は、口語調抽出データの韻律・音韻情報(図10参照)を用いて、音声合成に用いる口語調韻律・音韻モデル1037を作成する。詳細は上述した通りである。
プロセッサ101は、ステップ1605で得られた口語調抽出データのテキスト(図11)を用いて、口語調表現抽出ルール1036を作成する。詳細は上述した通りである。
第2の実施形態は、特許文献1のような音声合成装置に用いる口語調音声合成用データを作成することを想定したものである。ハードウェア構成は第1の実施形態と同様であるので、説明は省略する。ただし、記憶装置103は、口語調抽出データ1035の代わりに口語調度付き口語調音声データ1702、口語調表現抽出ルール1036の代わりに口語調度予測モデル1704を格納する。
図17は、本発明の第2の実施形態による音声合成システムの機能ブロックを示す図である。第2の実施形態では、従来手作業による音声の口語調度ラベリングに代わって、収録した口語調音声にセグメントごとに、口語調度の定量的な評価を実現し、入力テキストの各セグメントに対する口語調度を予測する。この予測した口語調度によって、口語調音声から学習した韻律・音韻モデルと読み上げ調音声から学習した読み上げ調韻律・音韻モデルと、セグメント毎の混合割合を計算し、文全体の韻律・音韻特徴の予測を行う。第1の実施形態とは異なり、入力テキストを分割することがないので、分割された口語調表現部分と口語調表現でない部分と接続するときの不連続感を低減できると考えられる。
(i)口語調データ作成処理
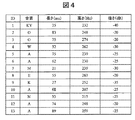
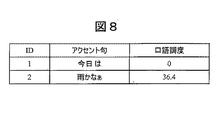
口語調度付与部1701は、口語調度算出部203で算出された韻律特徴の差分情報を用いて、収録した口語調音声の各セグメントに口語調度を付与し、口語調度付き口語調音声データ1702を生成する。ここで、セグメントの単位は、音素、音節、形態素、アクセント句、フレーズ、文などが考えられるが、口語調音声の特徴を担う最小単位として、形態素を用いたことが好ましい。各セグメントの口語調度の計算については、口語調度算出部203で算出された韻律特徴の差分情報から求められるが、その具体例については、第1の実施形態で説明したので、ここでは詳細については省略する。「お願いします」「今日は雨かなぁ」の文に対して、口語調テキストを形態素単位に分解し、それぞれコンテキストと口語調度を付与すると、図18のようになる。
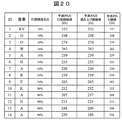
第2の実施形態では、テキスト解析部が入力テキストを解析した後、口語調度予測&韻律混合比決定部が、口語調度予測モデル1704を用いて、テキスト文を構成する各セグメントについて、口語調度を予測する。さらに、口語調度予測&韻律混合比決定部は、この予測した口語調度に基づいて、口語調韻律と読み上げ調韻律の混合比率を計算する。例えば、「今日は晴れかなぁ」というテキスト文が入力された場合、すべての形態素について口語調を予測した結果は、図19のようになる。ここで、口語調混合比を式6のように定義した場合(口語調下限値=0,口語調上限値=50とする)、口語調混合比は、図19に示される値となる。
・・・・・ (式6)
ここで、MIN(A,B)は、AとBとの間で小さい方の値を選ぶことを意味するものとする。
図22は、本発明の第2の実施形態による口語調データ作成処理を説明するためのフローチャートである。
プロセッサ101は、収録した口語調音声コーパスデータ1034の入力を受け付ける。当該データには、収録音声データとそれに対応するテキストデータ(発話テキスト)がセットとなっている。
プロセッサ101は、収録した収録した口語調音声コーパスデータ1034の収録音声データから、その音声の韻律・音韻特徴量を抽出する。詳細については上述した通りである。
プロセッサ101は、収録した口語調音声コーパスデータ1034の発話テキストに対して読み上げ韻律・音韻予測モデル1032を適用し、読み上げ調の韻律特徴量および音韻特徴量を予測する。つまり、ここでは、発話者がこのテキストに対して、読み上げ調スタイルで発話した場合は、韻律・音韻特徴がどのようなものであるかが分かる。詳細は上述した通りである。
プロセッサ101は、ステップ2202で抽出した収録口語調音声の特徴量と、ステップ2203で予測した韻律・音韻特徴量とを比較し、口語調への寄与度(口語調度)を計算する。
プロセッサ101は、ステップ2204で算出された口語調度(韻律特徴の差分情報)を用いて、収録した口語調音声の各セグメントに口語調度を付与し、口語調度付き口語調音声データ1702を生成する。詳細は上述した通りである。
プロセッサ101は、ステップ2205で得られた口語調度付き口語調音声データ1702の音声波形を蓄積し、音声合成に用いる口語調音声DB1038を作成する。
プロセッサ101は、口語調度付き口語調音声データ1702の韻律・音韻情報(図10参照)を用いて、音声合成に用いる口語調韻律・音韻モデル1037を作成する。詳細は上述した通りである。
プロセッサ101は、ステップ2204で得られた口語調度付き口語調音声データ1702を用いて、口語調予測モデル(口語調度予測モデル)1704を生成する。詳細は上述した通りである。
(i)第1の実施形態では、口語調音声データから韻律特徴量を抽出し、一方、当該口語調音声データに対応するテキストデータに対して読み上げ韻律・音韻予測モデルを適用して読み上げ調の韻律特徴量を予測する。次に、これらの韻律特徴量の差分を取り、差分値が所定の閾値(経験から設定される値)よりも大きい箇所を口語調の特徴部分(音声合成に用いる口語調データ)として抽出する。これらの処理は、収録した口語調音声コーパスと読み上げ韻律・音韻予測モデルを与えれば自動的に実行される。このように、口語調音声を始めとする韻律や声質の変化が大きい発話スタイルの合成音声から、その特徴を担う部分(口語調音声の場合は、口語調表現部分)を自動的に抽出するので、作業コストを抑えることができるうえ、異なった作業者による基準の不統一を改善できる。
10 読み上げ調データ作成処理
11 口語調データ作成処理
12 音声合成処理
101 CPU
102 メモリ
103 記憶装置
104 出力装置
105 入力装置
106 通信デバイス
Claims (6)
- メモリから各種プログラムを読みだして実行し、音声合成処理で用いられる音声合成用データを作成するプロセッサが、第1種音声のコーパスデータの入力を受け付け、当該コーパスデータに含まれる音声データから第1韻律を抽出するステップと、
前記プロセッサが、予め用意されている第2種音声の韻律モデルを前記コーパスデータに含まれるテキストに対して適用し、前記テキストに対応する第2韻律を予測するステップと、
前記プロセッサが、前記第1韻律と前記第2韻律の差分値を算出するステップと、
前記プロセッサが、前記テキストに含まれる文字のうち、前記差分値が所定の閾値よりも大きい文字を判定するステップと、
前記プロセッサが、前記判定するステップの結果に基づいて、前記第1韻律と前記第2韻律との違いに起因する特徴テキスト部分に対応するデータを抽出するステップと、
を含み、
前記第1種音声は口語調音声であり、前記第2種音声は読み上げ調音声であり、
前記第2種音声の韻律モデルは、読み上げ韻律・音韻予測モデルであり、
前記抽出された特徴テキスト部分に対応するデータは、前記特徴テキスト部分の音声波形データ、韻律・音韻情報、及びテキストデータを含み、
さらに、前記プロセッサが、前記特徴テキスト部分のテキストデータを用いて、与えられるテキストデータにおける口語調表現を抽出するためのルールを生成するステップを含むことを特徴とする音声合成用データ作成方法。 - 請求項1において、
前記プロセッサは、前記特徴テキスト部分のテキストデータに加えて、当該テキストデータが含まれる口語調テキストの前後のコンテキスト情報を用いて前記ルールを生成することを特徴とする音声合成用データ作成方法。 - メモリから各種プログラムを読みだして実行し、音声合成処理で用いられる音声合成用データを作成するプロセッサが、口語調音声のコーパスデータの入力を受け付け、当該コーパスデータに含まれる音声データから口語調韻律データを抽出するステップと、
前記プロセッサが、予め用意されている読み上げ調の韻律モデルを前記コーパスデータに含まれるテキストに対して適用し、前記テキストに対応する読み上げ調韻律データを予測するステップと、
前記プロセッサが、前記口語調韻律データと前記読み上げ調韻律データの差分値を算出するステップと、
前記プロセッサが、前記差分値に基づいて、前記テキストのセグメントに対して、当該セグメントの口語調の程度を示す口語調度を算出し、前記口語調韻律データに付与するステップと、
前記プロセッサが、前記口語調度が付与された前記口語調韻律データを用いて、前記音声合成用データを生成するステップと、
を含むことを特徴とする音声合成用データ作成方法。 - 請求項3において、
前記音声合成用データを生成するステップは、前記プロセッサが、前記口語調度が付与された前記口語調韻律データを用いて、入力テキストの口語調度を予測するための統計モデルである口語調度予測モデルを生成することを含むことを特徴とする音声合成用データ作成方法。 - 各種プログラムを格納するメモリと、
前記メモリから前記各種プログラムを読みだして実行し、音声合成処理で用いられる音声合成用データを作成するプロセッサと、を有し、
前記プロセッサは、
第1種音声のコーパスデータの入力を受け付け、当該コーパスデータに含まれる音声データから第1韻律を抽出する処理と、
予め用意されている第2種音声の韻律モデルを前記コーパスデータに含まれるテキストに対して適用し、前記テキストに対応する第2韻律を予測する処理と、
前記第1韻律と前記第2韻律の差分を算出する処理と、
前記テキストに含まれる文字のうち、前記差分が所定の閾値よりも大きい文字を判定する処理と、
前記第1韻律と前記第2韻律との違いに起因する特徴テキスト部分を抽出する処理と、
を実行し、
前記第1種音声は口語調音声であり、前記第2種音声は読み上げ調音声であり、
前記第2種音声の韻律モデルは、読み上げ韻律・音韻予測モデルであり、
前記抽出された特徴テキスト部分に対応するデータは、前記特徴テキスト部分の音声波形データ、韻律・音韻情報、及びテキストデータを含み、
前記プロセッサは、さらに、前記特徴テキスト部分のテキストデータを用いて、与えられるテキストデータにおける口語調表現を抽出するためのルールを生成する処理を実行する音声合成用データ作成装置。 - 請求項5において、
前記プロセッサは、前記特徴テキスト部分のテキストデータに加えて、当該テキストデータが含まれる口語調テキストの前後のコンテキスト情報を用いて前記ルールを生成することを特徴とする音声合成用データ作成装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015019009A JP6436806B2 (ja) | 2015-02-03 | 2015-02-03 | 音声合成用データ作成方法、及び音声合成用データ作成装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015019009A JP6436806B2 (ja) | 2015-02-03 | 2015-02-03 | 音声合成用データ作成方法、及び音声合成用データ作成装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2016142936A JP2016142936A (ja) | 2016-08-08 |
| JP2016142936A5 JP2016142936A5 (ja) | 2017-04-27 |
| JP6436806B2 true JP6436806B2 (ja) | 2018-12-12 |
Family
ID=56568702
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015019009A Active JP6436806B2 (ja) | 2015-02-03 | 2015-02-03 | 音声合成用データ作成方法、及び音声合成用データ作成装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6436806B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108538313B (zh) * | 2017-03-06 | 2021-01-15 | 中国移动通信有限公司研究院 | 一种语音质量测试方法、装置、主叫终端及语料播放设备 |
| CN112331177B (zh) * | 2020-11-05 | 2024-07-02 | 携程计算机技术(上海)有限公司 | 基于韵律的语音合成方法、模型训练方法及相关设备 |
| CN113178188B (zh) * | 2021-04-26 | 2024-05-28 | 平安科技(深圳)有限公司 | 语音合成方法、装置、设备及存储介质 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003302992A (ja) * | 2002-04-11 | 2003-10-24 | Canon Inc | 音声合成方法及び装置 |
| JP2003337592A (ja) * | 2002-05-21 | 2003-11-28 | Toshiba Corp | 音声合成方法及び音声合成装置及び音声合成プログラム |
| JP2004226505A (ja) * | 2003-01-20 | 2004-08-12 | Toshiba Corp | ピッチパタン生成方法、音声合成方法とシステム及びプログラム |
| JP2012198277A (ja) * | 2011-03-18 | 2012-10-18 | Toshiba Corp | 文書読み上げ支援装置、文書読み上げ支援方法および文書読み上げ支援プログラム |
| JP5588932B2 (ja) * | 2011-07-05 | 2014-09-10 | 日本電信電話株式会社 | はなし言葉分析装置とその方法とプログラム |
| JP5967578B2 (ja) * | 2012-04-27 | 2016-08-10 | 日本電信電話株式会社 | 局所韻律コンテキスト付与装置、局所韻律コンテキスト付与方法、およびプログラム |
| JP6013104B2 (ja) * | 2012-09-20 | 2016-10-25 | 株式会社日立超エル・エス・アイ・システムズ | 音声合成方法、装置、及びプログラム |
| JP6002598B2 (ja) * | 2013-02-21 | 2016-10-05 | 日本電信電話株式会社 | 強調位置予測装置、その方法、およびプログラム |
-
2015
- 2015-02-03 JP JP2015019009A patent/JP6436806B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2016142936A (ja) | 2016-08-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7500020B2 (ja) | 多言語テキスト音声合成方法 | |
| US8015011B2 (en) | Generating objectively evaluated sufficiently natural synthetic speech from text by using selective paraphrases | |
| US7809572B2 (en) | Voice quality change portion locating apparatus | |
| JP4054507B2 (ja) | 音声情報処理方法および装置および記憶媒体 | |
| JP6523893B2 (ja) | 学習装置、音声合成装置、学習方法、音声合成方法、学習プログラム及び音声合成プログラム | |
| US8352270B2 (en) | Interactive TTS optimization tool | |
| US20070136062A1 (en) | Method and apparatus for labelling speech | |
| US20200365137A1 (en) | Text-to-speech (tts) processing | |
| JP2001282279A (ja) | 音声情報処理方法及び装置及び記憶媒体 | |
| JPWO2006123539A1 (ja) | 音声合成装置 | |
| JP2006293026A (ja) | 音声合成装置,音声合成方法およびコンピュータプログラム | |
| WO2015025788A1 (ja) | 定量的f0パターン生成装置及び方法、並びにf0パターン生成のためのモデル学習装置及び方法 | |
| JP6436806B2 (ja) | 音声合成用データ作成方法、及び音声合成用データ作成装置 | |
| JPWO2016103652A1 (ja) | 音声処理装置、音声処理方法、およびプログラム | |
| JP6013104B2 (ja) | 音声合成方法、装置、及びプログラム | |
| JP2016151736A (ja) | 音声加工装置、及びプログラム | |
| Kayte et al. | A Marathi Hidden-Markov Model Based Speech Synthesis System | |
| JP5874639B2 (ja) | 音声合成装置、音声合成方法及び音声合成プログラム | |
| JP2003186489A (ja) | 音声情報データベース作成システム,録音原稿作成装置および方法,録音管理装置および方法,ならびにラベリング装置および方法 | |
| Janyoi et al. | An Isarn dialect HMM-based text-to-speech system | |
| JP3378547B2 (ja) | 音声認識方法及び装置 | |
| Iyanda et al. | Development of a Yorúbà Textto-Speech System Using Festival | |
| Phan et al. | An improvement of prosodic characteristics in vietnamese text to speech system | |
| Kardava | Georgian speech recognizer in famous searching systems and management of software package by voice commands in Georgian language | |
| Ijima et al. | Statistical model training technique based on speaker clustering approach for HMM-based speech synthesis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170322 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20170322 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20180327 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20180403 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180523 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20181030 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20181113 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6436806 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |