JP6375367B2 - 反論生成方法,反論生成システム - Google Patents
反論生成方法,反論生成システム Download PDFInfo
- Publication number
- JP6375367B2 JP6375367B2 JP2016511280A JP2016511280A JP6375367B2 JP 6375367 B2 JP6375367 B2 JP 6375367B2 JP 2016511280 A JP2016511280 A JP 2016511280A JP 2016511280 A JP2016511280 A JP 2016511280A JP 6375367 B2 JP6375367 B2 JP 6375367B2
- Authority
- JP
- Japan
- Prior art keywords
- objection
- condition
- precondition
- opinion
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims description 72
- 238000000605 extraction Methods 0.000 claims description 15
- 239000000284 extract Substances 0.000 claims description 12
- 230000008094 contradictory effect Effects 0.000 description 12
- 238000013500 data storage Methods 0.000 description 10
- 230000000875 corresponding effect Effects 0.000 description 9
- 238000010586 diagram Methods 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 230000002596 correlated effect Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
Description
反論対象意見から、第2前提条件を抽出する第3ステップと、第1前提条件のうちの第1条件と対応する第2条件を、第2前提条件のうちから判定する第4ステップと、第1条件と前記第2条件との関連性について、否定的な意見が記載されているデータである反論根拠データを検索する第5ステップと、反論根拠データのうち、反論対象意見との関連性が最も高いデータを、反論対象意見に対する反論文として文章化し、出力する第6ステップと、を有することを特徴とする。
続いて反論対象意見αから抽出された上記単語のそれぞれに対して,反論文βから得られた単語の中に類義語もしくは反義語が存在するかどうかを調べる。類義語もしくは反義語については知識データベース829に予め用意しておく。この例では「B国」と「C国」が類義語,「宿題」と「宿題」が一致,「廃止」と「廃止」が一致,「成績」と「成績」が一致,「伸び」と「落ち」が反義語という関係が得られる。「2000年」と「データ」に対しては対応する単語が存在しないと判定される。
λ=反義語の個数+αの否定詞の個数-βの否定詞の個数+1
である。
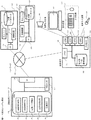
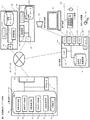
108、110,121,128:入出力インターフェース
109:操作端末
117:表示装置
118:文字入力装置
119:音声入力装置
120:ネットワーク
125:文書データ蓄積装置
130:知識データ蓄積装置
131:端末内データ蓄積装置。
Claims (10)
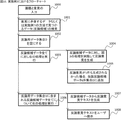
- 入力装置、記憶装置、およびプロセッサを備える反論生成システムにより反論を生成する反論生成方法であって、前記記憶装置はデータベースを格納し、
前記入力装置から入力される議題と、議題に関する意見である反論対象意見と、を前記記憶装置にテキスト情報として記憶する第1ステップと、
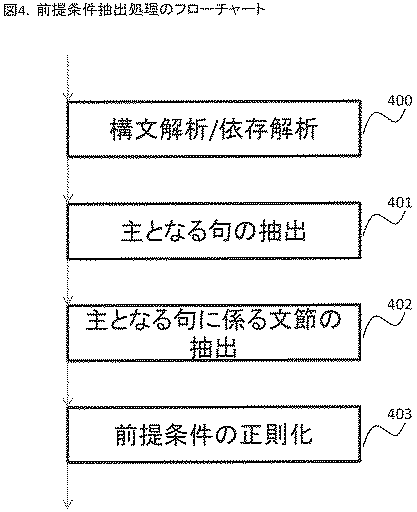
前記プロセッサが、構文解析および依存解析を用いて、前記議題から、第1前提条件を抽出する第2ステップと、
前記プロセッサが、構文解析および依存解析を用いて、前記反論対象意見から、第2前提条件を抽出する第3ステップと、
前記プロセッサが、前記第1前提条件に含まれる第1条件と意味的に対応する第2条件が、前記第2前提条件に含まれるか判定する第4ステップと、
前記プロセッサが、前記データベースに対して、前記第1条件、前記第2条件、および所定の否定表現を含む語のAND条件の検索を行なうことにより、前記第1条件と前記第2条件との関連性について、否定的な意見が記載されているデータである反論根拠データを検索する第5ステップと、
前記プロセッサが、前記反論根拠データを、前記反論対象意見に対する反論文として文章化し、出力する第6ステップと、を有することを特徴とする反論生成方法。 - 請求項1に記載の反論生成方法において,
前記第3ステップは、前記反論対象意見からさらに、第1の主となる句を抽出し、
前記第5ステップは、前記第1条件と前記第2条件とに加え、前記第1の主となる句を検索語として用いることを特徴とする反論生成方法。 - 請求項1に記載の反論生成方法において、
前記プロセッサが、構文解析および依存解析を用いて、前記反論文から、第3前提条件を抽出する第7ステップと、
前記プロセッサが、前記第2前提条件に含まれる第3条件と意味的に対応する第4条件が、前記第3前提条件に含まれるか判定する第8ステップと、
前記プロセッサが、前記データベースに対して、前記第3条件、前記第4条件、および所定の否定表現を含む語のAND条件の検索を行なうことにより、前記第3条件と前記第4条件との関連性について否定的な意見が記載されているデータである再反論根拠データを検索する第9ステップと、
前記プロセッサが、複数の前記反論文のうち、前記再反論根拠データの数が最も少ない前記反論文を出力する第10ステップと、をさらに有することを特徴とする反論生成方法。 - 請求項3に記載の反論生成方法において、
前記第7ステップは、前記反論対象意見からさらに、第2の主となる句を抽出し、
前記第9ステップは、前記第3条件と前記第4条件とに加え、前記第2の主となる句を検索語として用いることを特徴とする反論生成方法。 - 請求項3に記載の反論生成方法において、
前記プロセッサが、単語の類義語および反義語関係を用いて、前記第6ステップで生成した前記反論文と、前記反論対象意見との間に矛盾が存在するかを判定する第11ステップをさらに有し、
前記第7ステップでは、前記矛盾が存在すると判定された前記反論文から前記第3前提条件を抽出することを特徴とする反論生成方法。 - 議題と、議題に関する意見である反論対象意見と、を記憶する記憶部と、
構文解析および依存解析を用いて、前記議題から、第1前提条件を抽出し、前記反論対象意見から、第2前提条件を抽出する抽出部と、
前記第1前提条件に含まれる第1条件と意味的に対応する第2条件が、前記第2前提条件に含まれるか判定する判定部と、
データベースに対して、前記第1条件、前記第2条件、および所定の否定表現を含む語のAND条件の検索を行なうことにより、前記第1条件と前記第2条件との関連性について、否定的な意見が記載されているデータである反論根拠データを検索する検索部と、
前記反論根拠データを、前記反論対象意見に対する反論文として文章化し、出力する出力部と、を有することを特徴とする反論生成システム。 - 請求項6に記載の反論生成システムにおいて,
前記抽出部は、前記反論対象意見からさらに、第1の主となる句を抽出し、
前記検索部は、前記第1条件と前記第2条件とに加え、前記第1の主となる句を検索語として用いることを特徴とする反論生成システム。 - 請求項6に記載の反論生成システムにおいて、
前記抽出部は、さらに、構文解析および依存解析を用いて、前記反論文から、第3前提条件を抽出し、
前記判定部は、さらに、前記第2前提条件に含まれる第3条件と意味的に対応する第4条件が、前記第3前提条件に含まれるか判定し、
前記検索部は、さらに、前記データベースに対して、前記第3条件、前記第4条件、および所定の否定表現を含む語のAND条件の検索を行なうことにより、前記第3条件と前記第4条件との関連性について否定的な意見が記載されているデータである再反論根拠データを検索し、
前記出力部は、複数の前記反論文のうち、前記再反論根拠データの数が最も少ない前記反論文を出力することを特徴とする反論生成システム。 - 請求項8に記載の反論生成システムにおいて、
前記抽出部は、さらに、前記反論対象意見から第2の主となる句を抽出し、
前記検索部は、さらに、前記第3条件と前記第4条件とに加え、前記第2の主となる句を検索語として用いることを特徴とする反論生成システム。 - 請求項8に記載の反論生成システムにおいて、
前記出力部は、さらに、単語の類義語および反義語関係を用いて、生成した前記反論文と、前記反論対象意見との間に矛盾が存在するかを判定し、
前記抽出部は、前記矛盾が存在すると判定された前記反論文から前記第3前提条件を抽出することを特徴とする反論生成システム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2014/059917 WO2015151268A1 (ja) | 2014-04-04 | 2014-04-04 | 反論生成方法,反論生成システム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2015151268A1 JPWO2015151268A1 (ja) | 2017-04-13 |
| JP6375367B2 true JP6375367B2 (ja) | 2018-08-15 |
Family
ID=54239629
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016511280A Expired - Fee Related JP6375367B2 (ja) | 2014-04-04 | 2014-04-04 | 反論生成方法,反論生成システム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP6375367B2 (ja) |
| WO (1) | WO2015151268A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017119060A1 (ja) * | 2016-01-05 | 2017-07-13 | 株式会社日立製作所 | 情報提示システム |
| JP7362577B2 (ja) * | 2020-09-15 | 2023-10-17 | 株式会社東芝 | 情報処理装置、情報処理方法およびプログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5369813B2 (ja) * | 2009-03-25 | 2013-12-18 | 富士通株式会社 | 説得支援装置、説得支援プログラム及び説得支援方法 |
| JP2011113400A (ja) * | 2009-11-27 | 2011-06-09 | Fujitsu Ltd | 説得支援装置、説得支援プログラム及び説得支援方法 |
-
2014
- 2014-04-04 JP JP2016511280A patent/JP6375367B2/ja not_active Expired - Fee Related
- 2014-04-04 WO PCT/JP2014/059917 patent/WO2015151268A1/ja active Application Filing
Also Published As
| Publication number | Publication date |
|---|---|
| WO2015151268A1 (ja) | 2015-10-08 |
| JPWO2015151268A1 (ja) | 2017-04-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8010539B2 (en) | Phrase based snippet generation | |
| JP3856778B2 (ja) | 複数言語を対象とした文書分類装置及び文書分類方法 | |
| KR101136007B1 (ko) | 문서 감성 분석 시스템 및 그 방법 | |
| US10296584B2 (en) | Semantic textual analysis | |
| US20190278812A1 (en) | Model generation device, text search device, model generation method, text search method, data structure, and program | |
| US20140180728A1 (en) | Natural Language Processing | |
| JP2006244262A (ja) | 質問回答検索システム、方法およびプログラム | |
| JP2011118689A (ja) | 検索方法及びシステム | |
| JP2018005690A (ja) | 情報処理装置及びプログラム | |
| KR101333485B1 (ko) | 온라인 사전을 이용한 개체명 사전 구축 방법 및 이를 실행하는 장치 | |
| JP6433937B2 (ja) | キーワード評価装置、類似度評価装置、検索装置、評価方法、検索方法、及びプログラム | |
| JP6375367B2 (ja) | 反論生成方法,反論生成システム | |
| KR102351745B1 (ko) | 사용자 리뷰 기반 평점 재산정 장치 및 방법 | |
| Tovar et al. | A metric for the evaluation of restricted domain ontologies | |
| JP5291351B2 (ja) | 評価表現抽出方法、評価表現抽出装置、および、評価表現抽出プログラム | |
| JP6735711B2 (ja) | 学習装置、映像検索装置、方法、及びプログラム | |
| JP4428703B2 (ja) | 情報検索方法及びそのシステム並びにコンピュータプログラム | |
| JP2008204133A (ja) | 回答検索装置及びコンピュータプログラム | |
| JP2006119697A (ja) | 質問応答システム、質疑応答方法および質疑応答プログラム | |
| CN102346777A (zh) | 一种对例句检索结果进行排序的方法和装置 | |
| Nishy Reshmi et al. | Textual entailment classification using syntactic structures and semantic relations | |
| Garcıa-Pablos et al. | OpeNER: Open tools to perform natural language processing on accommodation | |
| JP2006331246A (ja) | 意見分析処理方法、意見分析処理装置およびプログラム | |
| KR20200122089A (ko) | 지역 색인을 이용한 전자문서 검색 방법 및 장치 | |
| Zidouni et al. | Efficient combined approach for named entity recognition in spoken language |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20171205 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180117 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20180703 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20180723 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6375367 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |