JP6251663B2 - Task allocation device, task allocation method, and task allocation program - Google Patents
Task allocation device, task allocation method, and task allocation program Download PDFInfo
- Publication number
- JP6251663B2 JP6251663B2 JP2014224801A JP2014224801A JP6251663B2 JP 6251663 B2 JP6251663 B2 JP 6251663B2 JP 2014224801 A JP2014224801 A JP 2014224801A JP 2014224801 A JP2014224801 A JP 2014224801A JP 6251663 B2 JP6251663 B2 JP 6251663B2
- Authority
- JP
- Japan
- Prior art keywords
- time
- task
- worker
- database
- pair
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images

Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
本発明は、コンピュータを用いて複数の仕事を複数人に振り分けるタスク割当て処理の技術に関する。 The present invention relates to a task assignment processing technique for distributing a plurality of tasks to a plurality of people using a computer.
現在、複数の仕事(以下,タスクという。)を複数の人(以下,ワーカという。)に割り振る際に1人あたりのタスク数の上下限や、1タスクあたりのワーカ数の上下限などの制約条件を満たしながらワーカ対タスクの割当て数を最大にする最適化計算を行うことで効率的な割当てを実現する取組みが行われている。 Currently, when assigning multiple jobs (hereinafter referred to as tasks) to multiple people (hereinafter referred to as workers), restrictions such as the upper and lower limits of the number of tasks per person and the upper and lower limits of the number of workers per task Efforts are being made to achieve efficient allocation by performing optimization calculations that maximize the number of worker-to-task allocations while satisfying conditions.
さらに、あるワーカ「i」が、あるタスク「j」を受け持つときにコスト「cij」が必要な場合、総コストが最小となる最適化計算を行うことで効率的な割当てを実現する取り組みが行われている。これらのワーカ対タスクの最適な割当て方法を見つける問題は、「割当て問題」と呼ばれる。 In addition, when a worker “i” is responsible for a task “j” and a cost “c ij ” is required, an effort is made to realize efficient allocation by performing optimization calculation that minimizes the total cost. Has been done. The problem of finding the optimal allocation method for these worker-to-tasks is called the “allocation problem”.
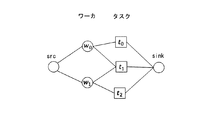
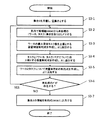
一般に、ワーカ対タスクの「最大割当て問題」は、2部グラフ(頂点集合が2分割され,辺がその部分集合の間を結ぶものに限られるグラフ)の2つの頂点集合にそれぞれワーカとタスクを対応させ、割当て可能なワーカとタスクの頂点間の辺を結ぶことで、「2部グラフの最大マッチング問題」に置き換えることができる。この「2部グラフの最大マッチング問題」とは、与えられた制約条件のもと2部グラフの割当て数を最大にするペアを選択するものである。 In general, the worker-to-task “maximum allocation problem” involves assigning workers and tasks to two vertex sets in a bipartite graph (a graph in which the vertex set is divided into two and the edges are limited to connecting the subsets). Corresponding and connecting edges between assignable workers and task vertices can be replaced with the “maximum matching problem for bipartite graphs”. The “maximum matching problem of bipartite graph” is to select a pair that maximizes the number of assignments of the bipartite graph under given constraints.
また、「2部グラフの最大マッチング問題」は、図1に示すように、ソース(src)となる頂点を新たに加え、ワーカが対応した頂点集合に向かう辺を追加するとともに、シンク(sink)となる頂点を新たに加え、タスクが対応した頂点集合からの辺を追加することで、ソースからシンクへ流れる流量を最大化する「最大フロー問題」に変換することが可能となる。なお、ワーカ対タスクの「最大割当て最小コスト問題」は、先ほどと同様にグラフを変換してソースからシンクへ流れる流量を最大化したときに、コストが最小となる辺を選ぶ「最小コストフロー問題」に変換することができる。 Further, as shown in FIG. 1, the “maximum matching problem of bipartite graph” adds a new vertex as a source (src), adds an edge toward a vertex set corresponding to the worker, and a sink (sink). By adding new vertices and adding edges from the vertex set to which the task corresponds, it becomes possible to convert to a “maximum flow problem” that maximizes the flow rate from the source to the sink. Note that the “maximum allocation minimum cost problem” for worker vs. task is the “minimum cost flow problem” that selects the edge that minimizes the cost when the graph is converted to maximize the flow from the source to the sink. Can be converted.
「最大フロー問題」、「最小コストフロー問題」のいずれも線形計画法で解くことができ,特に「最大フロー問題」を解くための効率的なアルゴリズムが非特許文献1に複数提案されている。 Both the “maximum flow problem” and the “minimum cost flow problem” can be solved by linear programming. In particular, a plurality of efficient algorithms for solving the “maximum flow problem” have been proposed in Non-Patent Document 1.
以下、クラウドソーシングサービスにおけるワーカ対タスクの割当て問題を解く際の背景技術を説明する。ここでクラウドソーシングとは、不特定多数のワーカにタスクを委託する枠組みのことであり、例えば非特許文献2のランサーズのように既に商用サービスとして成立しているものもある。
In the following, background techniques for solving the worker-to-task assignment problem in the crowdsourcing service will be described. Here, crowdsourcing is a framework in which tasks are entrusted to an unspecified number of workers. For example, there are some that have already been established as commercial services, such as Lancers in Non-Patent
その中でも特に、タスクに時空間条件が付与されており、ワーカが指定された場所に物理的に移動しなければタスクを完了できない場合が想定される。この場合については、ワーカがタスクを行うことができる最大許容数と最大許容半径を定義することで、ワーカ対タスクの「最大割当て問題」を「最大フロー問題」に変換して解いた非特許文献3の研究が存在する。 In particular, there is a case where a task is given a spatio-temporal condition and the task cannot be completed unless the worker physically moves to a designated location. In this case, non-patent literature solved by converting the “maximum allocation problem” of worker-to-task into “maximum flow problem” by defining the maximum allowable number and maximum allowable radius that a worker can perform tasks. There are three studies.
この技術は、1時点のワーカおよびタスクの情報を用いてグラフを作成し,最適化計算をおこなっているため,時刻によってワーカ集合やワーカによるタスク完了のコストが変化する場合を同時に扱うことができず、1時点ずつ順番にタスク割当てを行う貪欲法をとっている。 Since this technology creates a graph using information on workers and tasks at a single point in time and performs optimization calculations, it can simultaneously handle the case where the cost of completing a worker and the task completion by the worker changes with time. Instead, it uses a greedy method of assigning tasks one by one in order.
しかしながら、非特許文献3の技術を用いて複数時点のタスク割当てをタスク完了時刻が最速になるように行う際、タスク完了時刻をコストとして「最小コストフロー問題」を解いても1時点分の最適解しか得られない。 However, when assigning tasks at multiple points in time using the technology of Non-Patent Document 3 so that the task completion time is the fastest, even if the “minimum cost flow problem” is solved using the task completion time as the cost, Only a solution can be obtained.
したがって、時刻によってワーカ集合やワーカによるタスク完了のコストが変化する場合を同時に扱うことができないおそれがある。また、1時点ずつ順番に最適化を行う貪欲法では、必ずしも時間的な大域的最適解は得られず,局所最適解しか求められていないおそれもある。 Therefore, there may be a case where the worker set and the cost of task completion by the worker change depending on the time cannot be handled at the same time. In addition, in the greedy method in which optimization is performed in order for each time point, a temporal global optimal solution cannot always be obtained, and only a local optimal solution may be obtained.
本発明は、このような従来の問題を解決するためになされ、複数時点での最適化を1度に行って時間方向での大域的最適解を得ることを解決課題としている。 The present invention has been made to solve such a conventional problem, and an object of the present invention is to obtain a global optimum solution in the time direction by performing optimization at a plurality of points in time.
本発明のタスク割当て装置は、時刻IDとワーカIDとタスクIDとが対応付けられた第1データベースと、タスクが発生する位置情報が格納された第2データベースと、第1データベースからワーカIDとタスクIDのペアと、該ペアの時刻IDとを抽出する手段と、抽出されたタスクIDをキーにして第2データベースからタスクの位置情報を検索する手段と、抽出されたワーカIDをキーにしてワーカの時刻毎の位置情報が格納された第3データベースから時刻毎のワーカの位置情報を検索する手段と、時刻IDが示す時刻毎にワーカがタスクの発生する位置に移動した場合の時刻を算出する手段と、算出された時刻のうち最も早い時刻と、該時刻に対応するワーカとタスクと該時刻の時刻IDとを選択して出力する手段と、を備える。 The task assignment device of the present invention includes a first database in which a time ID, a worker ID, and a task ID are associated with each other, a second database in which position information where the task occurs is stored, and a worker ID and a task from the first database. Means for extracting a pair of IDs, time ID of the pair, means for searching task position information from the second database using the extracted task ID as a key, and worker using the extracted worker ID as a key Means for retrieving the worker's position information for each time from the third database storing the position information for each time, and calculates the time when the worker moves to the position where the task occurs for each time indicated by the time ID. And means for selecting and outputting the earliest time among the calculated times, the worker corresponding to the time, the task, and the time ID of the time.
本発明のタスク割当て方法は、時刻IDとワーカIDとタスクIDとが対応付けられた第1データベースに基づきワーカIDとタスクIDのペアと、該ペアの時刻IDとを抽出する第1ステップと、抽出されたタスクIDをキーにしてタスクが発生する位置情報が格納された第2データベースからタスクの位置情報を検索する第2ステップと、抽出されたワーカIDをキーにしてワーカの時刻毎の位置情報が格納された第3データベースから時刻毎のワーカの位置情報を検索する第3ステップと、時刻IDが示す時刻毎にワーカがタスクの発生する位置に移動した場合の時刻を算出する第4ステップと、算出された時刻のうち最も早い時刻と、該時刻に対応するワーカとタスクと該時刻の時刻IDとを選択して出力する第5ステップと、を有する。 The task assignment method of the present invention includes a first step of extracting a worker ID / task ID pair and a time ID of the pair based on a first database in which a time ID, a worker ID, and a task ID are associated with each other; A second step of searching for task position information from a second database in which position information where the task occurs is stored using the extracted task ID as a key, and a position for each worker time using the extracted worker ID as a key A third step of retrieving worker position information for each time from a third database in which information is stored; and a fourth step of calculating a time when the worker moves to a position where a task occurs at each time indicated by the time ID. And a fifth step of selecting and outputting the earliest time among the calculated times, the worker corresponding to the time, the task, and the time ID of the time. That.
なお、本発明は、前記タスク割当て装置としてコンピュータを機能させるプログラムの態様としてもよい。このプログラムは、ネットワークや記録媒体などを通じて提供することができる。 In addition, this invention is good also as an aspect of the program which functions a computer as the said task allocation apparatus. This program can be provided through a network or a recording medium.
本発明によれば、複数時点での最適化を1度に行って時間方向での大域的最適解を得ることができる。 According to the present invention, it is possible to obtain a global optimum solution in the time direction by performing optimization at a plurality of points in time.
≪装置構成例≫
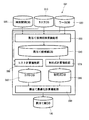
図2に基づき本発明の実施形態に係るタスク割当て装置の構成例を説明する。このタスク割当て装置001は、クラウドソーシングにおけるワーカ対タスクの割当て問題の解決を図っている。
≪Example of device configuration≫
A configuration example of the task assignment device according to the embodiment of the present invention will be described based on FIG. This
具体的にはタスク割当て装置001は、コンピュータにより構成され、CPU,主記憶装置(RAM,ROM等),補助記憶装置(ハードディスクドライブ装置,ソリッドステートドライブ装置等)などのハードウェアリースを備える。
Specifically, the
このハードウェアリソースとソフトウェアリソース(OS,アプリケーションなど)との協同の結果、タスク割当て装置001は、時刻間隔DB005,タスクDB010,ワーカDB020,割当て候補組検索機能部030,割当て候補組DB040,コスト計算機能部050,コストDB060,制約式計算機能部070,制約式DB080,割当て最適化計算機能部090,割当て組DB100を実装する。
As a result of cooperation between the hardware resource and the software resource (OS, application, etc.), the
この各DB005,010,020,040,060,080,100は、前記記憶装置に構築されているものとする。なお、タスク割当て装置001は、単一のコンピュータに構成してもよく、あるいは複数のコンピュータに前記各部010〜100を分散して構成してもよいものとする。以下、前記構成要素010〜100の処理内容を説明する。
Each
≪時刻間隔DB005,タスクDB010,ワーカDB020≫ << Time interval DB005, Task DB010, Worker DB020 >>
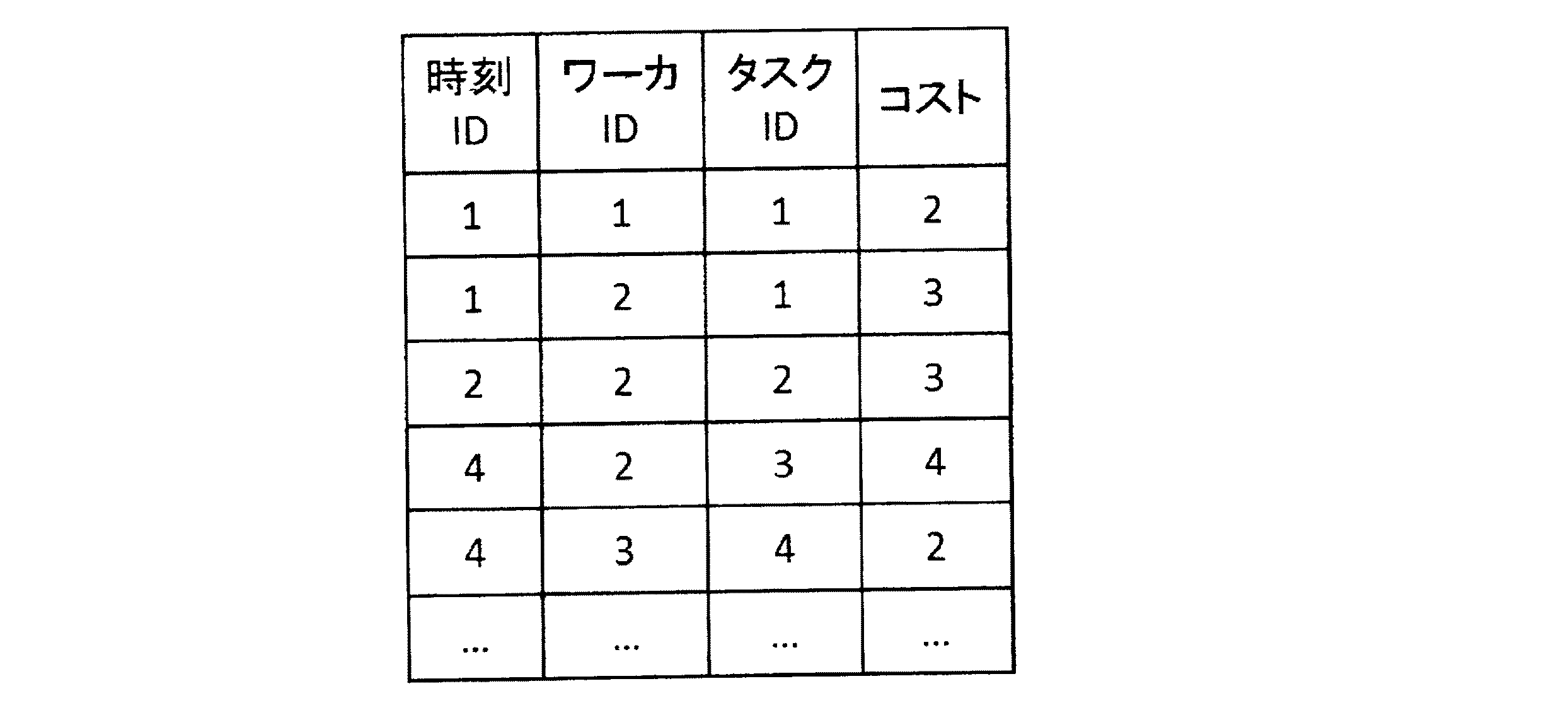
表1は、時刻間隔DB005のデータ構造例を示している。この時刻間隔DB005には、ワーカとタスクの割当て間隔の情報が「YYY−MM−DD」の時刻形式で格納されている。例えば表1では、2014年2月2日の時刻情報が1時間おきに格納されている。なお、時刻間隔DB005は、外部からレコードを指定するために、各レコードに時刻間隔IDが付与されている。
Table 1 shows an example of the data structure of the
表2は、タスクDB010のデータ構造例を示している。このタスクDB010には、タスクの緯度経度の情報が格納されている。なお、タスクDB010も、外部からレコードを指定するために、各レコードにタスクIDが付与されている。
Table 2 shows an example of the data structure of the
表3は、ワーカDB020のデータ構造例を示している。このワーカDB020には、ワーカの時刻毎に緯度経度情報と最大移動距離情報と最大受容タスク数の情報と移動手段情報とが格納されている。
Table 3 shows an example of the data structure of the
表3中の最大移動距離は、ワーカがその時刻にタスクをするために移動できる最大距離を示している。また、最大受容タスク数は、ワーカが行うことができる最大のタスク数を示し、時刻毎に変化することなく一人のワーカには同一の値が付与されて格納されている。 The maximum movement distance in Table 3 indicates the maximum distance that the worker can move to perform a task at that time. The maximum number of accepted tasks indicates the maximum number of tasks that can be performed by a worker, and the same value is assigned to one worker and stored without changing every time.
さらに移動手段は、徒歩や車あるいはバスなどの移動手段情報を示している。ここではワーカの将来の場所や最大移動距離、移動手段がワーカによって既に入力され、それらの情報が既知であることを想定している。あるいはワーカの過去のログを利用して将来のスケジュールを推定していることを想定している。なお、ワーカDB020も、外部からレコードを指定するために、それぞれのレコードにはワーカIDが付与されている。
Further, the moving means indicates moving means information such as walking, car or bus. Here, it is assumed that the worker's future location, maximum moving distance, and moving means have already been input by the worker and that information is known. Alternatively, it is assumed that the future schedule is estimated using the worker's past log. The
≪割当て候補組検索機能部030,割当て候補組DB040≫
割当て候補組検索機能部030は、前記DB005,010,020の格納データを入力とし、その処理情報を割当て候補組DB040に出力して格納させる。ここでは割当て候補組検索機能部030は、前記DB005,010,020の格納データに基づき割当てが可能な「時刻,ワーカ,タスク」の組(ペア)を検索し、検索結果を割当て候補組とする。
<< Allocation Candidate Group
The allocation candidate group
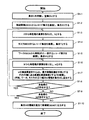
以下、図3に基づき割当て候補組検索機能部030の処理内容を説明する。まず処理を開始すると集合Nを用意して空集合とする(S1−1)。その後に時刻間隔DB005からレコード集合を検索して検索結果を集合「H」とし(S1−2)、集合Hから未処理の要素を取り出して取りだした要素を「h」とし(S1−3)、タスクDB010からレコード集合を検索して検索結果を集合「T」とする(S1−4)。
The processing contents of the allocation candidate group
つぎにワーカDB020から時刻が要素「h」と一致するレコード集合を検索して検索結果を集合「W」とし(S1−5)、該集合「W」から未処理の要素を取り出して「w」とする(S1−6)。
Next, a record set whose time coincides with the element “h” is searched from the
続いて要素「w」の緯度経度を中心として、最大移動距離を半径とする円の内側にある座標を緯度経度とする「T」を検索する。これにより「時刻,ワーカ,タスク」の割当て候補組が特定され、特定された割当て候補組の各ID(時刻間隔ID,ワーカID,タスクID)を集合「N」に追加する(S1−7)。 Subsequently, “T” having the latitude and longitude as coordinates at the inner side of the circle having the radius of the maximum movement distance with the latitude and longitude of the element “w” as the center is searched. Thereby, an allocation candidate set of “time, worker, task” is specified, and each ID (time interval ID, worker ID, task ID) of the specified allocation candidate set is added to the set “N” (S1-7). .
この処理は、ワーカの指定する距離条件にタスクの位置が該当するか否かを確認するため、円の内外判定でもよく、あるいは最大移動距離を対角線とする矩形の内外判定などでもよい。 This process may be a circle inside / outside determination or a rectangle inside / outside determination with the maximum moving distance as a diagonal line in order to confirm whether or not the task position corresponds to the distance condition designated by the worker.
そして、未処理の要素「w」が集合「W」に存在するか否かを確認し(S1−8)、存在すればS1−6に戻る一方、存在しなければS1−9に進む。このS1−9では、未処理の要素「h」が集合「H」に存在するか否かを確認し、存在すればS1−3に戻る一方、存在しなければS1−10に進む。このS1−10では、集合Nの情報を割当て候補組DB040に出力して格納させ、処理を終了する。
Then, it is confirmed whether or not the unprocessed element “w” exists in the set “W” (S1-8). If it exists, the process returns to S1-6, and if it does not exist, the process proceeds to S1-9. In S1-9, it is confirmed whether or not an unprocessed element “h” exists in the set “H”. If it exists, the process returns to S1-3, and if it does not exist, the process proceeds to S1-10. In S1-10, the information of the set N is output and stored in the allocation candidate set
表4は、割当て候補組DB040のデータ構造例を示している。この割当て候補DB040には、割当て候補組の時刻間隔ID,ワーカID,タスクIDが格納されている。
Table 4 shows an example of the data structure of the allocation candidate set DB040. The
≪コスト計算機能部050,コストDB060≫
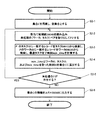
コスト計算機能部050は、割当て候補組DB040の格納データを入力として、その処理データをコストDB060に出力して格納させる。具体的にはコスト計算機能部050は、割当て候補組の「ワーカ,タスク」のペアのうち最小タスク完了時刻をとるものを複数時刻から選択して、コスト情報としてコストDB060に出力する。以下、図4に基づきコスト計算機能部050の処理内容を説明する。
<< Cost
The cost
S2−1:まず、処理が開始されると集合Cを用意する。この段階の集合Cは空集合とする。 S2-1: First, a set C is prepared when processing is started. The set C at this stage is an empty set.
S2−2:つぎに割当て候補組DB040を読み込み、未処理の「ワーカ,タスク」のペアを取り出して複数時点分の集合「P」とする。すなわち、複数時刻分の未処理の「ワーカ,タスク」ペアを集めて集合Pとする。
S2-2: Next, the allocation
この処理を表4のデータ例に基づき説明する。ここでは時刻を「τ」で表し、ワーカを「w」で表し、タスクを「t」で表し、添え字をそれぞれのIDで表し、割当て候補DB040において上の行から順に処理するものとする。
This process will be described based on the data example in Table 4. Here, the time is represented by “τ”, the worker is represented by “w”, the task is represented by “t”, the subscript is represented by each ID, and the
したがって、未処理の「ワーカ,タスク」ペアとして(w1,t1)が最初に選択され、複数時点分の集合「P」は「P={(τ1,w1,t1),(τ2,w1,t1),(τ3,w1,t1)}」となる。 Therefore, (w 1 , t 1 ) is first selected as an unprocessed “worker, task” pair, and the set “P” for a plurality of time points is “P = {(τ 1 , w 1 , t 1 ), ( τ 2 , w 1 , t 1 ), (τ 3 , w 1 , t 1 )} ”.
S2−3:集合PのタスクIDに一致するレコードをタスクDB010から検索し、集合PのワーカIDに一致するレコードをワーカDB020から検索し、最速タスク完了時刻「min_time」を計算する。
S2-3: The record that matches the task ID of the set P is searched from the
ここではタスクとして、指定された場所の写真を撮影するなどの少ない時間で終わらせられるものを想定している。したがって、タスクに指定された場所に到着することは、タスク完了と同義あるいは近似したものとする。 Here, it is assumed that the task can be completed in a short time such as taking a picture of a specified place. Therefore, arriving at the location specified for a task is synonymous with or close to task completion.
最速タスク完了時刻「min_time」の計算を、「P={(τ1,w1,t1),(τ2,w1,t1),(τ3,w1,t1)}に基づき説明する。まずワーカとタスクの緯度経度情報を用いて各時刻「τ1,τ2,τ3」における距離「dist1,dist2,dist3」を計算する。 The calculation of the fastest task completion time “min_time” is calculated based on “P = {(τ 1 , w 1 , t 1 ), (τ 2 , w 1 , t 1 ), (τ 3 , w 1 , t 1 )}. First, the distance “dist 1 , dist 2 , dist 3 ” at each time “τ 1 , τ 2 , τ 3 ” is calculated using the latitude and longitude information of the worker and the task.
ここではワーカの移動手段は、ワーカによって既にタスク割当て装置001に入力され、ワーカDB020に格納されていることを前提とする。そこで、ある時刻「τk」にワーカがタスクの位置までに前記移動手段で移動するのに必要な所要時間「durationk」は、式(1)により求めることができる。
Here, it is assumed that the worker moving means is already input to the
また、ある時刻「τk」にワーカがタスクの位置までに前記移動手段で移動した際の時刻「timei」は、所要時間「durationk」に移動開始時刻を加算すればよいので、式(2)で求められる。 Also, the time “time i ” when the worker has moved to the task position at a certain time “τ k ” by the moving means may be obtained by adding the movement start time to the required time “duration k ”. 2).
その結果、ワーカがタスクを完了させる最も早い時刻「min_time」は、式(3)に示すように、これらの最小値を取ることで求めることができる。 As a result, the earliest time “min_time” at which the worker completes the task can be obtained by taking these minimum values as shown in Expression (3).
S2−4:時刻「min_time」とワーカIDとタスクIDと時刻「min_time」を取った時刻IDとを集合Cに追加する。なお、時刻「min_time」を取った時刻IDが複数存在する場合は、一番早い時刻選択するなどのルールを設けることで集合Cに追加する時刻IDを一意に定めることができる。 S2-4: The time “min_time”, the worker ID, the task ID, and the time ID of the time “min_time” are added to the set C. When there are a plurality of time IDs having the time “min_time”, a time ID to be added to the set C can be uniquely determined by providing a rule such as selecting the earliest time.
S2−5,S2−6:未処理の集合Pが存在するか否かを確認し(S2−5)、存在すればS2−2に戻る一方、存在しなければS2−6に進む。S2−6では、集合Cの情報をコストDB060に出力して格納させ、処理を終了する。
S2-5, S2-6: It is confirmed whether or not there is an unprocessed set P (S2-5). If it exists, the process returns to S2-2, but if it does not exist, the process proceeds to S2-6. In S2-6, the information of the set C is output and stored in the
このとき時刻「min_time」は、コスト情報としてコストDB060に格納される。なお、表5はコストDB060のデータ構造例を示し、時刻IDとワーカIDとタスクIDとコスト情報が格納されている。
At this time, the time “min_time” is stored in the
≪制約式計算機能部070,制約式DB080≫
制約式計算機能部070は、割当て候補DB040の格納データを入力とし、その処理情報を制約式DB080に出力して格納させる。ここではワーカ対タスクの最大割当て問題を前述の最小コストフロー問題に置き換えるものとする。
<< Constraint Expression
The constraint equation
具体的には制約式計算機能部070は、図1で表されたグラフにおける容量制約式と流量保存制約式とを計算して出力する。以下、図5に基づき制約式計算機能部070の処理内容を説明する。
Specifically, the constraint equation
S3−1:まず、処理が開始されると集合「R」を用意する。この段階の集合「R」は空集合とする。 S3-1: First, when processing is started, a set “R” is prepared. The set “R” at this stage is an empty set.
S3−2:つぎに割当て候補組DB040を読み込んで未処理の「ワーカ,タスク」ペアを取り出し、取り出されたペアを「P´」とする。この処理を表4のデータ例に基づき説明する。
S3-2: Next, the allocation candidate set
ここでは割当て候補組DB040の上の行から順に処理されるため、最初に処理される「ワーカ,タスク」のペアP´として「P´={w1,t1}」が取り出され、その後に「P´={w2,t1}」,「P´={w2,t2}」,「P´={w2,t3}」と順に取りだされる。
Here, since processing is performed in order from the upper row of the allocation
S3−3:図1のような2部グラフのソース(src)から各ワーカを結ぶ辺について、ワーカの最大受容タスク数を上限とする容量制限制約式を作成し、作成した容量制限制約式をRに追加する。 S3-3: For the edge connecting each worker from the source (src) of the bipartite graph as shown in FIG. 1, a capacity restriction constraint formula with the maximum number of tasks accepted by the worker as an upper limit is created. Add to R.
この際、最適化計算を行うための決定変数として、「ノードm」から「ノードn」に流れる水の流量を「xm,n」とする。ここで容量制約は、各辺の流量が容量を超えないという制約を意味する。 At this time, the flow rate of water flowing from “node m” to “node n” is set to “x m, n ” as a decision variable for performing the optimization calculation. Here, the capacity constraint means a constraint that the flow rate of each side does not exceed the capacity.
すなわち、ソースから各ワーカについて、ワーカの最大受容タスク数を上限とする容量制限制約式を作成するとは、「ワーカwi」の最大受容タスク数を「maxTi」とすると、式(4)を作成することとなる。 In other words, for each worker from the source, to create a capacity restriction constraint equation with the maximum number of accepted tasks of the worker as an upper limit, if the maximum number of accepted tasks of “worker w i ” is “maxT i ”, Equation (4) Will be created.
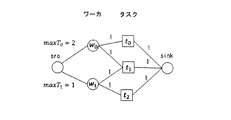
例えば図6の2部グラフでいえば、式(5)を作成することとなる。 For example, in the bipartite graph of FIG. 6, formula (5) is created.
なお、この処理は非特許文献1と同様な処理である。 This process is the same process as in Non-Patent Document 1.
S3−4:各タスクとシンク(sink)を結ぶ辺と各ワーカと各タスクを結ぶ辺について「1」を上限とする容量制約式を作成し、「R」に追加する。ここでS3−3と同様にして決定変数「xm,n」を用いると、各タスクとシンクを結ぶ辺と各ワーカと各タスクを結ぶ辺について「1」を上限とする容量制約式を作成するとは、式(6)を作成することとなる。 S3-4: A capacity constraint expression having an upper limit of “1” is created for the side connecting each task and the sink and the side connecting each worker and each task, and is added to “R”. When the decision variable “x m, n ” is used in the same manner as in S3-3, a capacity constraint expression with “1” as the upper limit is created for the side connecting each task and the sink and the side connecting each worker and each task. Then, formula (6) is created.
例えば図6の2部グラフでいえば、式(7)を作成することとなる。 For example, in the bipartite graph of FIG. 6, formula (7) is created.
なお、この処理は非特許文献3と同様な処理である。 This process is the same process as in Non-Patent Document 3.
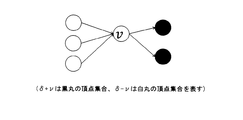
S3−5:ワーカ頂点とタスク頂点について流量保存則の制約式を作成し、「R」に追加する。流量保存則は、その頂点に流入する流量が流出する流量に等しくなるという制約を意味する。 S3-5: A constraint expression for the flow rate conservation rule is created for worker vertices and task vertices and added to “R”. The flow conservation law means a constraint that the flow rate flowing into the apex is equal to the flow rate flowing out.
すなわち、ワーカ頂点とタスク頂点について流量保存則の制約式を作成するとは、図7に示すように「δ+ν,δ−ν」をそれぞれ頂点νから流出する辺の終点集合・頂点νへ流入する辺の始点集合とすれば、式(8)を作成することとなる。 That is, to create a constraint equation for the flow rate conservation rule for worker vertices and task vertices, as shown in FIG. If it is set as the starting point set of (8), Formula (8) will be created.
例えば図6の2部グラフでいれば、式(9)を作成することとなる。 For example, if it is the bipartite graph of FIG. 6, Formula (9) will be created.
なお、この処理は非特許文献3と同様な処理である。 This process is the same process as in Non-Patent Document 3.
S3−6:割当て候補組DB040に未処理のペア「P´」が存在するか否か確認する。確認の結果、存在すればS3−2に戻る一方、存在しなければS3−7に進む。 S3-6: It is confirmed whether or not an unprocessed pair “P ′” exists in the allocation candidate group DB040. As a result of the confirmation, if it exists, the process returns to S3-2, and if it does not exist, the process proceeds to S3-7.
S3−7:集合Rの情報を制約式DB080に出力して格納させ(S3−8)、処理を終了する。なお、表6は、制約式DB080のデータ構造例を示し、最適化計算を行う際に利用する各制約式の情報がテキスト形式で格納されている。この各制約式には、レコード検索のため、制約式IDが付与されている。
S3-7: The information of the set R is output and stored in the constraint expression DB 080 (S3-8), and the process is terminated. Table 6 shows an example of the data structure of the
≪割当て最適化計算機能部090≫
割当て最適化計算機能部090は、コストDB060および制約式DB080の格納データを入力として、その処理情報を割当て組DB100に出力する。具体的には割当て最適化計算機能部090は、制約式DB080から与えられた制約式のなかで「最大フロー問題」を解き、その結果を利用して「最小コストフロー問題」を解く。図8に基づき割当て最適化計算機能部090の処理内容を説明する。
<< Allocation optimization
The allocation optimization
S4−1:制約式DB080からレコード集合を検索し、検索結果を集合「R´」とする。
S4-1: A record set is searched from the
S4−2:「R」の制約式による条件の元でソースから流出する最大流量を求め、「maxF」とする。この最大流量「maxF」は、前記決定変数より式(10)のように求められる。 S4-2: The maximum flow rate flowing out from the source under the condition of the constraint equation “R” is obtained and is set to “maxF”. This maximum flow rate “maxF” is obtained from the above decision variable as shown in equation (10).
この最大流量「maxF」を求める最適化計算は、線形計画法で解くことができるし、また効率的なアルゴリズムも複数提案されているため、これらを利用してもよい(例えば非特許文献1など)。 The optimization calculation for obtaining the maximum flow rate “maxF” can be solved by linear programming, and a plurality of efficient algorithms have been proposed, so these may be used (for example, Non-Patent Document 1) ).
S4−3:ソースから流出する流量上限とシンクへ流入する流量上限とを「maxF」とする制約式を作成し、「R´」に追加する。ここでは式(11)の制約式を作成すればよい。 S4-3: Create a constraint equation with “maxF” as the upper limit of the flow rate flowing out from the source and the upper limit of the flow rate flowing into the sink, and add it to “R ′”. Here, the constraint expression of Expression (11) may be created.
S4−4:コストDB060からレコード集合を検索し、コスト関数を作成する。コスト関数とは、最適化の目的関数となる割当て(ワーカ,タスク)間のコストの和のことである。すなわち、コストDB060に格納されたワーカ集合とタスク集合とをそれぞれ「w」と「T」とし、ワーカ「wi」とタスク「tj」とのコストを「cij」とすれば、式(12)を計算すればよい。
S4-4: A record set is searched from the
ただし、S3−4の容量制約からワーカとタスク間の辺との容量は「1」以下とされる。また、コストDB060には必ずしもすべてのワーカとタスクとのペアにおいてコストが計算されているわけではないが、コスト「cij=∞」とみなして十分おおきい数を代入すれば、計算することができる。さらに存在しないペアの場合は計算を抜かせば計算することができる.
S4−5:「R´」の条件の元でコスト関数を最小化する。ここでコスト関数の最小化は、線形計画法で解くことができる。最小化した際に選択された「ワーカ,タスク」のペア集合、即ちワーカ・タスク間の決定変数「xm、n」が1以上の「ワーカ,タスク」のペア集合を「opt_p」とする。
However, the capacity between the worker and the side between the tasks is set to “1” or less because of the capacity restriction of S3-4. In addition, the
S4-5: The cost function is minimized under the condition of “R ′”. Here, the minimization of the cost function can be solved by linear programming. A pair set of “workers and tasks” selected at the time of minimization, that is, a pair set of “workers and tasks” whose decision variable “x m, n ” between worker and task is 1 or more is defined as “opt_p”.
S4−6:コストDB060から「opt_p」を検索し、その時の時刻IDを含めた「時刻,ワーカ,タスク」のペアの情報(時刻ID,ワーカID,タスクID)を割当て組DB100・に出力して格納させ、処理を終了する.
S4-6: Search for “opt_p” from the
表7は、割当て組DB100のデータ構造例を示している。ここでは最適化計算の結果、タスク完了までの時間の和が最小となる「時刻,ワーカ,タスク」のペアについての「時刻ID,ワーカID,タスクID」が格納されている。
Table 7 shows an example of the data structure of the allocation set
このようなタスク割当て装置001によれば、コスト計算機能部050のS2−3において、割当て候補組DB040の割当て候補組「時刻,ワーカ,タスク」から取り出された「ワーカ,タスク」のペアのうち、複数時点のタスク完了時刻の最小時刻が計算されることから、最速タスク完了時刻をコストとするコスト関数を計算することが可能となる。
According to such a
その結果、複数時点での最適化を1度に行うことが可能となり、時間方向での大局的最適解を得ることができる。したがって、タスクに時間空間条件が付与されたクラウドソーシングサービスのような時間によってワーカ集合やワーカによるタスク完了時間が変化する場合であっても、タスク完了時刻が最小となる「ワーカ,タスク」ペアを選択でき、タスク完了時刻の最速化を実現することが可能となる。 As a result, optimization at a plurality of points in time can be performed at a time, and a global optimum solution in the time direction can be obtained. Therefore, even if the task completion time varies depending on the worker set or the worker completion time depending on the time like the crowdsourcing service where the space-time condition is given to the task, the “worker, task” pair that minimizes the task completion time It can be selected, and the fastest task completion time can be realized.
これにより少しでも早く仕事を終わらせたいと考えるタスク依頼者の満足度を向上させることができる。また、タスク割当て装置001は、特にワーカの将来のスケジュール把握や予測ができる環境では有意義である。
As a result, the satisfaction of the task requester who wants to finish the work as soon as possible can be improved. The
≪プログラム≫
本発明は、上記実施形態に限定されるものではなく、各請求項に記載された範囲内で応用・変形して実施することができる。例えば本発明は、タスク割当て装置001の各部005〜100の一部もしくは全部として、コンピュータを機能させる文書検索プログラムとして構成することもできる。
≪Program≫
The present invention is not limited to the above-described embodiments, and can be applied and modified within the scope of the claims. For example, the present invention can be configured as a document search program that causes a computer to function as a part or all of the
このプログラムによれば、S1−1〜S1−10,S2・1〜S2−6,S3−1〜S3−7,S4−1〜S4−6の一部あるいは全部をコンピュータに実行させることが可能となる。 According to this program, it is possible to cause a computer to execute part or all of S1-1 to S1-10, S2 · 1 to S2-6, S3-1 to S3-7, and S4-1 to S4-6. It becomes.
前記プログラムは、Webサイトや電子メールなどネットワークを通じて提供することができる。また、前記プログラムは、CD−ROM,DVD−ROM,CD−R,CD−RW,DVD−R,DVD−RW,MO,HDD,BD−ROM,BD−R,BD−REなどの記録媒体に記録して、保存・配布することも可能である。この記録媒体は、記録媒体駆動装置を利用して読み出され、そのプログラムコード自体が前記実施形態の処理を実現するので、該記録媒体も本発明を構成する。 The program can be provided through a network such as a website or e-mail. The program is stored in a recording medium such as a CD-ROM, DVD-ROM, CD-R, CD-RW, DVD-R, DVD-RW, MO, HDD, BD-ROM, BD-R, or BD-RE. It is also possible to record, save and distribute. This recording medium is read using a recording medium driving device, and the program code itself realizes the processing of the above embodiment, so that the recording medium also constitutes the present invention.
001…タスク割当て装置001
005…時刻間隔DB
010…タスクDB(第2データベース)
010…ワーカDB(第3データベース)
030…割当て候補組検索機能部
040…割当て候補組DB040(第1データベース)
050…コスト計算機能部050
060…コストDB(第4データベース)
070…制約式計算機能部
080…制約式DB(第5データベース)
090…割当て最適化計算機能部
100…割当て組DB
001 ...
005 ... Time interval DB
010 ... Task DB (second database)
010 ... Worker DB (third database)
030 ... Allocation candidate group
050 ... Cost
060 ... Cost DB (4th database)
070: Constraint equation calculation function unit 080: Constraint equation DB (fifth database)
090 ... Allocation optimization
Claims (7)
タスクが発生する位置情報が格納された第2データベースと、
第1データベースからワーカIDとタスクIDのペアと、該ペアの時刻IDとを抽出する手段と、
抽出されたタスクIDをキーにして第2データベースからタスクの位置情報を検索する手段と、
抽出されたワーカIDをキーにしてワーカの時刻毎の位置情報が格納された第3データベースから時刻毎のワーカの位置情報を検索する手段と、
時刻IDが示す時刻毎にワーカがタスクの発生する位置に移動した場合の時刻を算出する手段と、
算出された時刻のうち最も早い時刻と、該時刻に対応するワーカとタスクと該時刻の時刻IDとを選択して出力する手段と、
を備えることを特徴とするタスク割当て装置。 A first database in which a time ID, a worker ID, and a task ID are associated;
A second database storing location information where the task occurs;
Means for extracting a worker ID and task ID pair and a time ID of the pair from the first database;
Means for retrieving task position information from the second database using the extracted task ID as a key;
Means for retrieving worker position information for each time from a third database in which the position information for each worker time is stored using the extracted worker ID as a key;
Means for calculating a time when the worker moves to a position where the task occurs at each time indicated by the time ID;
Means for selecting and outputting the earliest time among the calculated times, the worker and task corresponding to the time, and the time ID of the time;
A task assignment device comprising:
前記移動手段を用いて時刻IDの示す時間にワーカが、タスクの発生する位置に移動した場合の時刻を、
式(1)(2)により算出する手段を備えることを特徴とする請求項1記載のタスク割当て装置。
distk:各時間におけるタスクの発生する位置までの距離,
vk:移動速度
The time when the worker moves to the position where the task occurs at the time indicated by the time ID using the moving means,
2. The task assignment apparatus according to claim 1, further comprising means for calculating according to equations (1) and (2).
dist k : distance to the position where the task occurs at each time,
v k : moving speed
前記2データベースおよび前記第3データベースに基づきワーカの最大移動距離内にタスクが存在するか否かを判定し、時刻IDとワーカIDとタスクIDとを対応付けて前記第1データベースに格納する手段と、
前記選択された最も早い時刻とワーカとタスクと時刻IDとを対応付けて格納する第4データベースと、
該第4データベースに基づきワーカ対タスクの最大割当て問題を2部グラフの最小コストフロー問題に置き換えたときに与えられる制約式を作成し、作成された制約式を第5データベースに格納させる手段と、
前記第4データベースおよび前記第5データベースに基づき時刻ID毎にタスク完了までの時間が最小となる時刻・ワーカ・タスクのペアを算出する手段と、
をさらに備えることを特徴とする請求項2記載のタスク割当て装置。 The third database stores the maximum movement distance for each worker ID,
Means for determining whether there is a task within the maximum movement distance of the worker based on the two databases and the third database, and storing the time ID, worker ID and task ID in association with each other in the first database; ,
A fourth database for storing the selected earliest time, worker, task, and time ID in association with each other;
Means for creating a constraint equation given when the worker-to-task maximum allocation problem is replaced with a bipartite graph minimum cost flow problem based on the fourth database, and storing the created constraint equation in the fifth database;
Means for calculating a time / worker / task pair that minimizes the time until task completion for each time ID based on the fourth database and the fifth database;
The task assignment apparatus according to claim 2, further comprising:
時刻IDとワーカIDとタスクIDとが対応付けられた第1データベースに基づきワーカIDとタスクIDのペアと、該ペアの時刻IDとを抽出する第1ステップと、
抽出されたタスクIDをキーにしてタスクが発生する位置情報が格納された第2データベースからタスクの位置情報を検索する第2ステップと、
抽出されたワーカIDをキーにしてワーカの時刻毎の位置情報が格納された第3データベースから時刻毎のワーカの位置情報を検索する第3ステップと、
時刻IDが示す時刻毎にワーカがタスクの発生する位置に移動した場合の時刻を算出する第4ステップと、
算出された時刻のうち最も早い時刻と、該時刻に対応するワーカとタスクと該時刻の時刻IDとを選択して出力する第5ステップと、
を有することを特徴とするタスク割当て方法。 A task assignment method for distributing a plurality of tasks to a plurality of workers using a computer,
A first step of extracting a worker ID / task ID pair and a time ID of the pair based on a first database in which a time ID, a worker ID, and a task ID are associated;
A second step of retrieving task position information from a second database in which position information where the task occurs is stored using the extracted task ID as a key;
A third step of retrieving worker position information for each time from a third database in which position information for each worker time is stored using the extracted worker ID as a key;
A fourth step of calculating a time when the worker moves to a position where the task occurs at each time indicated by the time ID;
A fifth step of selecting and outputting the earliest time among the calculated times, the worker and task corresponding to the time, and the time ID of the time;
A task assignment method characterized by comprising:
前記第4ステップは、前記移動手段を用いて時刻IDの示す時刻にワーカがタスクの発生する位置に移動した場合の時刻を、
式(1)(2)により算出するステップを有することを特徴とする請求項4記載のタスク割当て方法。
distk:各時間におけるタスクの発生する位置までの距離,
vk:移動速度
In the fourth step, the time when the worker moves to the position where the task occurs at the time indicated by the time ID using the moving means,
5. The task assignment method according to claim 4, further comprising a step of calculating according to equations (1) and (2).
dist k : distance to the position where the task occurs at each time,
v k : moving speed
前記選択された最も早い時刻とワーカとタスクと時刻IDとが対応付けられて第4データベースに格納されている場合において、
前記第2データベースおよび前記第3データベースに基づきワーカの最大移動距離内にタスクが存在するか否かを判定し、時刻IDとワーカIDとタスクIDとを対応付けて前記第1データベースに格納するステップと、
前記第4データベースに基づきワーカ対タスクの最大割当て問題を2部グラフの最小コストフロー問題に置き換えたときに与えられる制約式を作成し、作成された制約式を第5データベースに格納させるステップと、
前記第4データベースおよび前記第5データベースに基づき時刻ID毎にタスク完了までの時間が最小となる時刻・ワーカ・タスクのペアを算出するステップと、
をさらに有することを特徴とする請求項5記載のタスク割当て方法。 The third database stores the maximum movement distance for each worker ID,
In the case where the selected earliest time, worker, task, and time ID are associated and stored in the fourth database,
Determining whether a task exists within the maximum movement distance of the worker based on the second database and the third database, and storing the time ID, worker ID, and task ID in the first database in association with each other. When,
Creating a constraint equation given when replacing the worker-to-task maximum allocation problem with a bipartite graph minimum cost flow problem based on the fourth database, and storing the created constraint equation in the fifth database;
Calculating a time / worker / task pair that minimizes the time until task completion for each time ID based on the fourth database and the fifth database;
The task assignment method according to claim 5, further comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014224801A JP6251663B2 (en) | 2014-11-05 | 2014-11-05 | Task allocation device, task allocation method, and task allocation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014224801A JP6251663B2 (en) | 2014-11-05 | 2014-11-05 | Task allocation device, task allocation method, and task allocation program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2016091286A JP2016091286A (en) | 2016-05-23 |
| JP6251663B2 true JP6251663B2 (en) | 2017-12-20 |
Family
ID=56016951
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014224801A Expired - Fee Related JP6251663B2 (en) | 2014-11-05 | 2014-11-05 | Task allocation device, task allocation method, and task allocation program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6251663B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111539592A (en) * | 2019-09-23 | 2020-08-14 | 拉扎斯网络科技(上海)有限公司 | Task allocation method and device, readable storage medium and electronic equipment |
| US10949782B2 (en) | 2018-12-06 | 2021-03-16 | At&T Intellectual Property I, L.P. | Telecommunication network technician scheduling via multi-agent randomized greedy search |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110866687A (en) * | 2019-11-07 | 2020-03-06 | 中盈优创资讯科技有限公司 | Task allocation method and device |
| CN111144789A (en) * | 2019-12-31 | 2020-05-12 | 中国银行股份有限公司 | Service distribution method and device |
| CN111882152B (en) * | 2020-06-18 | 2024-07-05 | 科大讯飞股份有限公司 | Task allocation method and related device |
| CN112150029A (en) * | 2020-10-09 | 2020-12-29 | 浙江专线宝网阔物联科技有限公司 | Block chain elastic architecture design method supporting dynamic and distributed task allocation |
| CN112882805A (en) * | 2021-01-26 | 2021-06-01 | 上海应用技术大学 | Profit optimization scheduling method based on task resource constraint |
| CN116976600B (en) * | 2023-07-14 | 2024-03-22 | 陕西师范大学 | Crowd sensing environment monitoring task recommendation method based on concurrent task bundling |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008033433A (en) * | 2006-07-26 | 2008-02-14 | Kai:Kk | Method for assigning property to be patrolled and system for assigning property to be patrolled using the same |
| JP2012003660A (en) * | 2010-06-21 | 2012-01-05 | Chugoku Electric Power Co Inc:The | Meter reading job adjustment system and meter reading job adjustment method |
| JP5762873B2 (en) * | 2011-07-29 | 2015-08-12 | 株式会社東芝 | Repeating schedule generation apparatus and method |
| JP6097105B2 (en) * | 2013-03-15 | 2017-03-15 | オムロン株式会社 | Information processing apparatus and worker assignment method |
-
2014
- 2014-11-05 JP JP2014224801A patent/JP6251663B2/en not_active Expired - Fee Related
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10949782B2 (en) | 2018-12-06 | 2021-03-16 | At&T Intellectual Property I, L.P. | Telecommunication network technician scheduling via multi-agent randomized greedy search |
| CN111539592A (en) * | 2019-09-23 | 2020-08-14 | 拉扎斯网络科技(上海)有限公司 | Task allocation method and device, readable storage medium and electronic equipment |
| CN111539592B (en) * | 2019-09-23 | 2021-07-16 | 拉扎斯网络科技(上海)有限公司 | Method, apparatus, readable storage medium and electronic device for task assignment |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2016091286A (en) | 2016-05-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6251663B2 (en) | Task allocation device, task allocation method, and task allocation program | |
| US11599958B2 (en) | Incremental search based multi-modal journey planning | |
| Gionis et al. | Customized tour recommendations in urban areas | |
| CN102915401B (en) | Travelling planning in public transportation network | |
| Wang et al. | Real-time multisensor data retrieval for cloud robotic systems | |
| US20230004727A1 (en) | Task-action prediction engine for a task management system | |
| Pietz et al. | Generalized orienteering problem with resource dependent rewards | |
| US8600659B1 (en) | Method and system for geographic search for public transportation commuters | |
| Wang et al. | R3: a real-time route recommendation system | |
| WO2019000785A1 (en) | Order allocation method and device | |
| KR20160054728A (en) | Method, system, terminal device and non-transitory computer-readable recording medium for providing information on trip route | |
| Gong et al. | RT-DBSCAN: real-time parallel clustering of spatio-temporal data using spark-streaming | |
| US20140343974A1 (en) | Selecting a Subset of Transit Trips Based on Time and Duration | |
| JP6262505B2 (en) | Distributed data virtualization system, query processing method, and query processing program | |
| Jiang et al. | Computing the fewest-turn map directions based on the connectivity of natural roads | |
| George | Build a realtime data pipeline: Scalable application data analytics on amazon web services (AWS) | |
| JP6110281B2 (en) | Moving unit prediction model generation apparatus, moving unit prediction model generation method, and moving unit prediction model generation program | |
| Sigala et al. | Web map services in tourism: a framework exploring the organisational transformations and implications on business operations and models | |
| Kulakov et al. | An approach to creation of smart space-based trip planning service | |
| US20130046467A1 (en) | Method and apparatus for determining traveling route | |
| WO2021038928A1 (en) | Scheduling system, scheduling program, scheduling method, and storage medium | |
| US20150170063A1 (en) | Pattern Based Transit Routing | |
| Xi et al. | Intelligent recommendation scheme of scenic spots based on association rule mining algorithm | |
| Shen et al. | Collaborative and distributed search system with mobile devices | |
| JP6618012B2 (en) | Cyclic route identification server, cyclic route identification device, and cyclic route identification method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20161208 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20171108 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171121 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171127 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6251663 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |