JP6244993B2 - Encouraging sound determination device, encouraging sound determination method, and encouraging sound determination computer program - Google Patents
Encouraging sound determination device, encouraging sound determination method, and encouraging sound determination computer program Download PDFInfo
- Publication number
- JP6244993B2 JP6244993B2 JP2014045580A JP2014045580A JP6244993B2 JP 6244993 B2 JP6244993 B2 JP 6244993B2 JP 2014045580 A JP2014045580 A JP 2014045580A JP 2014045580 A JP2014045580 A JP 2014045580A JP 6244993 B2 JP6244993 B2 JP 6244993B2
- Authority
- JP
- Japan
- Prior art keywords
- sound
- reading
- kanji
- candidate
- prompt
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Description
本発明は、例えば、語句の読みに含まれる音が拗音または促音であるか否かを判定する拗促音判定装置、拗促音判定方法及び拗促音判定用コンピュータプログラムに関する。 The present invention relates to, for example, a prompt sound determination device, a prompt sound determination method, and a prompt sound determination computer program for determining whether or not a sound included in a phrase reading is a stutter sound or a prompt sound.
近年、音声で情報を提供するサービスが利用されている。このようなサービスを提供する装置は、例えば、提供対象となる情報を記した文章を表すテキストデータに対して音声合成処理を適用することで、その情報の音声データを生成する。 In recent years, services that provide information by voice have been used. For example, an apparatus that provides such a service generates speech data of information by applying speech synthesis processing to text data representing a sentence describing information to be provided.
提供対象となる情報の音声データを生成するために、その情報を記した文章中に登場する各語句を漢字などを用いて表した「表記」に対する、その語句の音声を表す「読み」を記述した辞書が用いられる。この辞書に登録されていない語句が、入力されたテキストデータまたは音声に含まれていると、その語句の読みが不明であるために、読みが誤った合成音声が生成されてしまうことがある。そこで、辞書には、できるだけ多くの語句が登録されていることが好ましい。例えば、このような辞書には、数万個〜数十万個の語句が登録される。 In order to generate audio data of the information to be provided, describe "reading" that represents the audio of the word for "notation" that represents each word that appears in the sentence describing the information using kanji The dictionary is used. If a phrase that is not registered in the dictionary is included in the input text data or speech, the pronunciation of the phrase may be unknown, and thus synthesized speech that is misread may be generated. Therefore, it is preferable that as many words as possible be registered in the dictionary. For example, tens of thousands to hundreds of thousands of phrases are registered in such a dictionary.
そのため、新規に辞書を作成する際、作業者が手作業で語句を辞書に登録しようとすると、その作業量は膨大となる。そこで、語句の表記とともにその語句の読みの情報を含む既存のデータベース、例えば、様々なWebページなどに対して、コンピュータにより様々な語句を抽出し、抽出した語句の表記と読みを辞書に自動的に登録することが好ましい。 For this reason, when a new dictionary is created, if an operator tries to manually register words in the dictionary, the amount of work becomes enormous. Therefore, various words and phrases are extracted by a computer from an existing database that contains information on the reading of the words as well as the wording of the words, for example, various web pages, and the notation and readings of the extracted words are automatically stored in the dictionary. It is preferable to register with.
しかしながら、既存のデータベースには、「ャ」、「ュ」、「ョ」といった拗音、及び「ッ」といった促音を文字コードとして利用できず、拗音及び促音が直音と区別されず、例えば、拗音または促音を含む読みが全て大文字の仮名で表記されたものがある。このようなデータベースを辞書作成に利用するデータベースから排除するには、作業者が、例えば、目視で読み表記を確認する作業が必要となり、煩雑である。また、辞書作成に利用できるデータベースが限定されるので、結果的に辞書に登録されない語句の数が増えるおそれがある。そこで、拗音及び促音が正しく表記されていないデータベースも、辞書作成に利用できることが好ましい。 However, the existing database cannot use the stuttering sounds such as “a”, “u”, “yo”, and the prompting sounds such as “t” as the character code, and the stuttering sound and the prompting sound are not distinguished from the direct sound. Or, there is a reading that includes a sound and is written in all capital letters. In order to exclude such a database from a database used for creating a dictionary, for example, an operator needs to visually confirm the reading and is complicated. In addition, since databases that can be used for creating a dictionary are limited, the number of words that are not registered in the dictionary may increase as a result. Therefore, it is preferable that a database in which stuttering sounds and prompt sounds are not correctly written can also be used for creating a dictionary.
一方、入力された文字列の中に含まれる拗促音候補の文字を拗促音化可能か否かを判断し、可能と判断した場合に拗音化または促音化された文字列を表示する技術が提案されている(例えば、特許文献1を参照)。特許文献1に記載の技術は、拗音候補直前文字と拗音化可能文字の組み合わせを表すテーブルなどを参照することで、拗促音候補の文字を拗促音化可能か否か判定する。 On the other hand, a technique is proposed for determining whether or not a prompt sound candidate character included in an input character string can be made a prompt sound, and displaying the character string that is stuttered or sounded when it is determined that it is possible (For example, refer to Patent Document 1). The technique described in Patent Literature 1 determines whether or not the character of the prompt sound candidate can be converted to a prompt sound by referring to a table or the like that represents a combination of the immediately preceding sound candidate and the character that can be stuttered.
しかし、特許文献1に記載の技術では、入力された文字列中において拗促音化可能な部分が表示されるにすぎず、結局、作業者が、その部分を拗促音化するか否かを最終的に判断する必要が有る。 However, in the technique described in Patent Document 1, only a portion that can be urged to sound is displayed in the input character string, and the operator finally determines whether or not the portion should be sounded. It is necessary to judge it.
そこで本明細書は、一つの側面として、語句の読みのうちで拗音化または促音化する音を適切に判定できる拗促音判定装置を提供することを目的とする。 Accordingly, an object of one aspect of the present specification is to provide a prompt sound determination device that can appropriately determine a sound to be sounded or sounded during reading of a phrase.
一つの実施形態によれば、拗促音判定装置が提供される。この拗促音判定装置は、少なくとも一つの漢字を含む語句の表記を表す表記データ及びその語句の読みを拗音及び促音と直音とを区別せずに表す読みデータを取得する取得部と、複数の漢字のそれぞれの読み及びその読みの音訓種別が登録された単漢字辞書を記憶する記憶部と、単漢字辞書を参照して、表記データに表された語句に含まれる少なくとも一つの漢字のそれぞれの読みの候補を検出する読み候補検出部と、読みデータに表された語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出する拗促音候補抽出部と、表記データに表された語句に含まれる少なくとも一つの漢字のそれぞれについて、その漢字の読みの候補のうち、その語句の読みと最も一致する候補を特定し、特定された候補に対応するその語句の読みの部分を、その漢字の読みとする対応付け部と、表記データに表された語句に含まれる少なくとも一つの漢字のうちの拗促音候補と対応する第1の漢字の読みにおける拗促音候補の位置、及び、第1の漢字の読みの音訓種別に応じて拗促音候補を拗音及び促音の何れかか否か判定する判定部とを有する。 According to one embodiment, a prompt sound determination device is provided. The prompt sound determination device includes notation data representing a notation of a phrase including at least one kanji and an acquisition unit that acquires reading data representing the reading of the phrase without distinguishing the stuttering sound and the prompt sound from the direct sound, and a plurality of A storage unit that stores a single kanji dictionary in which each reading of kanji and the learning type of the reading are registered, and each of at least one kanji included in the phrase represented in the notation data with reference to the single kanji dictionary Reading candidate detection unit for detecting reading candidates, and sounds included in the reading of the word or phrase represented in the reading data, among sounds that may be a prompting sound or a stuttering sound, and a sound that may include a prompting sound or a stuttering sound For each of at least one kanji included in the word represented in the notation data, and the candidate for the word A matching part that identifies the candidate that most closely matches the word and the reading of the word corresponding to the specified candidate is the reading of the kanji, and at least one kanji included in the word represented in the notation data Whether or not the prompting sound candidate is either a stuttering sound or a sounding sound according to the position of the prompting sound candidate in the reading of the first Chinese character corresponding to the prompting sound candidate and the tone type of the reading of the first Chinese character A determination unit.
本発明の目的及び利点は、請求項において特に指摘されたエレメント及び組み合わせにより実現され、かつ達成される。
上記の一般的な記述及び下記の詳細な記述の何れも、例示的かつ説明的なものであり、請求項のように、本発明を限定するものではないことを理解されたい。
The objects and advantages of the invention will be realized and attained by means of the elements and combinations particularly pointed out in the appended claims.
It should be understood that both the foregoing general description and the following detailed description are exemplary and explanatory and are not restrictive of the invention as claimed.
本明細書に開示された拗促音判定装置は、語句の読みのうちで拗音化または促音化する音を適切に判定できる。 The prompt sound determination device disclosed in the present specification can appropriately determine a sound to be stuttered or sounded in reading a phrase.
以下、図を参照しつつ、拗促音判定装置について説明する。
発明者は、拗音化または促音化される音は、特定の音の並びに含まれるとともに、その音に対応する漢字の読みにおける位置に関して特定の条件を満たすことに着目した。そこでこの拗促音判定装置は、拗音及び促音が直音と区別されることなく表された語句の読みを表す読みデータを取得する。そしてこの拗促音判定装置は、着目する語句の読みに含まれる、拗音または促音となり得る音のうち、拗音または促音を含む可能性がある特定の音の並びに含まれるとともに、対応する漢字の読みにおける位置に関する条件を満たすものを、拗音化または促音化する。
Hereinafter, the prompt sound determination device will be described with reference to the drawings.
The inventor has focused on the fact that the sound to be stuttered or sounded is included in a specific sound sequence and satisfies a specific condition regarding the position in the reading of kanji corresponding to the sound. Therefore, this prompt sound determination device acquires reading data representing the reading of a phrase expressed without distinguishing the stuttering sound and the prompt sound from the direct sound. The prompt sound determination device includes a sequence of specific sounds that may include a stuttering sound or a prompting sound included in the reading of the word of interest, and a corresponding kanji reading. Stuttering or stimulating those that satisfy the location requirements.
図1は、拗促音判定装置の一例である、辞書登録装置の概略構成図である。本実施形態では、辞書登録装置1は、通信部2と、記憶部3と、表示部4と、処理部5とを有する。通信部2、記憶部3及び表示部4は、処理部5とバスを介して接続されている。
FIG. 1 is a schematic configuration diagram of a dictionary registration device, which is an example of a prompt sound determination device. In the present embodiment, the dictionary registration device 1 includes a
通信部2は、通信ネットワークに辞書登録装置1を接続するためのインターフェース回路を有する。通信部2は、取得部の一例であり、登録対象となる語句の表記データ及び読みデータを通信ネットワークを介して辞書登録装置1と接続された他の機器から取得する。そして通信部2は、表記データと読みデータを処理部5へ渡す。
The
なお、語句の表記は、例えば、漢字と仮名の組み合わせ、または漢字のみで表記され、一方、語句の読みは、例えば、仮名で表記される。なお、以下では、説明の便宜上、語句の表記を漢字仮名混じり文で表記し、一方、語句の読みを片仮名で表記する。また、拗音及び促音を、それぞれ、小文字で表記する。
また、取得される読みデータでは、拗音及び促音は、直音と区別されずに表記されるものとする。例えば、取得される読みデータでは、拗音及び促音は小文字の仮名で表記されず、直音と同様に大文字の仮名で表記される。
また、表記データ及び読みデータは、どのようなファイル形式で表されていてもよく、例えば、表記データ及び読みデータはテキストファイルで表される。
In addition, the notation of a phrase is described, for example, with a combination of kanji and kana or only kanji, while the reading of a phrase is expressed, for example, with kana. In the following, for convenience of explanation, the phrase notation is expressed as a kanji-kana mixed sentence, while the phrase reading is expressed as a katakana. In addition, the stuttering sound and the prompt sound are written in lower case letters.
In the acquired reading data, the stuttering sound and the prompt sound are described without being distinguished from the direct sound. For example, in the acquired reading data, the stuttering sound and the prompt sound are not written in lowercase kana, but are written in uppercase kana like straight sounds.
The notation data and the reading data may be represented in any file format. For example, the notation data and the reading data are represented by a text file.
また通信部2は、処理部5から受け取った、語句の表記データ及び拗音または促音についての修正がなされた読みデータを、その語句が登録される辞書を記憶した装置へ通信ネットワークを介して出力してもよい。
In addition, the
記憶部3は、例えば、半導体メモリ回路、磁気記憶装置または光記憶装置のうちの少なくとも一つを有する。そして記憶部3は、処理部5で用いられる各種コンピュータプログラム、及び、拗促音判定処理を含む辞書登録処理に用いられる各種のデータを記憶する。例えば、記憶部3は、様々な漢字の表記及び読みと、その読みが音読みか訓読みかを表す音訓種別情報が登録された単漢字辞書を記憶する。
The storage unit 3 includes, for example, at least one of a semiconductor memory circuit, a magnetic storage device, and an optical storage device. The storage unit 3 stores various computer programs used by the
また記憶部3は、辞書に登録する対象となる語句の表記データと読みデータを記憶していてもよい。さらに、記憶部3は、二つ以上の漢字が一つの単語として並べて使用される共起確率を表す共起確率データベースを記憶していてもよい。あるいは、記憶部3は、そのような共起確率データベースを決定するために利用される検索コーパスを記憶していてもよい。なお、共起確率データベース及び検索コーパスの詳細については後述する。さらに、記憶部3は、語句の表記及び読みを登録すべき辞書を記憶していてもよい。語句の表記及び読みが登録される辞書は、例えば、音声合成または音声認識において使用される単語辞書であってもよい。 Further, the storage unit 3 may store notation data and reading data of a word to be registered in the dictionary. Furthermore, the memory | storage part 3 may memorize | store the co-occurrence probability database showing the co-occurrence probability in which two or more Chinese characters are used side by side as one word. Or the memory | storage part 3 may memorize | store the search corpus utilized in order to determine such a co-occurrence probability database. Details of the co-occurrence probability database and the search corpus will be described later. Furthermore, the memory | storage part 3 may memorize | store the dictionary which should register the notation and reading of a phrase. The dictionary in which the notation and reading of words are registered may be a word dictionary used in speech synthesis or speech recognition, for example.
表示部4は、例えば、液晶ディスプレイといった表示装置を有する。そして表示部4は、例えば、登録対象の語句の表記データと、拗音及び促音の表記の修正がなされたその語句の読みデータとを表示する。 The display unit 4 includes a display device such as a liquid crystal display, for example. Then, the display unit 4 displays, for example, the notation data of the word to be registered and the reading data of the word in which the notation of stuttering and prompting has been corrected.
処理部5は、一つまたは複数のプロセッサと、メモリ回路と、周辺回路とを有する。そして処理部5は、登録対象の語句の読みデータに含まれる、拗音または促音となり得る音が拗音または促音であるか否かを判定する。そして処理部5は、その音が拗音または促音である場合、読みデータに含まれる、語句の読みの拗音または促音と判定された音の表記を修正した上で、その語句の読みを、対応する表記とともに辞書に登録する。
The
図2は、処理部5の機能ブロック図である。処理部5は、読み候補検出部11と、拗促音候補抽出部12と、対応付け部13と、判定部14と、登録部15とを有する。
処理部5が有するこれらの各部は、例えば、処理部5が有するプロセッサ上で動作するコンピュータプログラムにより実現される機能モジュールである。あるいは、処理部5が有するこれらの各部は、その各部の機能を実現する一つの集積回路として辞書登録装置1に実装されてもよい。
FIG. 2 is a functional block diagram of the
Each of these units included in the
読み候補検出部11は、登録対象の語句を、その語句の表記に含まれる漢字ごとに分解する。そして読み候補検出部11は、単漢字辞書を参照して、その語句の表記に含まれる各漢字の読みを、その漢字の読み候補として検出する。
The reading
例えば、登録対象の語句の表記が「滅菌」である場合、漢字「滅」と「菌」が含まれている。単漢字辞書に登録されている漢字「滅」の読みが「メツ」及び「メチ」であり、漢字「菌」の読みが「キン」及び「ゴン」であるとする。この場合、読み候補検出部11は、漢字「滅」の読み候補として、「メツ」及び「メチ」を検出し、漢字「菌」の読み候補として、「キン」及び「ゴン」を検出する。さらに、読み候補検出部11は、単漢字辞書を参照して、各読み候補の音訓種別情報を取得する。
For example, when the notation of the word to be registered is “sterilization”, the kanji characters “Kan” and “fungi” are included. It is assumed that the reading of the Chinese character “Kan” registered in the single kanji dictionary is “Metsu” and “Mech”, and the reading of the Chinese character “Bacteria” is “Kin” and “Gon”. In this case, the reading
読み候補検出部11は、登録対象の語句に含まれる各漢字の読み候補及びその読み候補の音訓種別情報を対応付け部13へ出力する。
The reading
拗促音候補抽出部12は、登録対象の語句の読みデータから、拗音または促音となり得る音を抽出し、抽出した音が、拗音または促音が含まれる可能性がある特定の音の並びに含まれる場合に、その抽出した音を拗音または促音の候補とする。本実施形態では、拗音となり得る音の候補を拗音候補とし、促音となり得る音の候補を促音候補とする。
The prompting sound
例えば、拗促音候補抽出部12は、登録対象の語句の読みから、拗音となり得る音「ヤ」、「ユ」、「ヨ」を抽出する。そして拗促音候補抽出部12は、抽出した音の直前の音が複数の特定の音の何れかである場合、抽出した音を拗音候補とする。
For example, the prompting sound
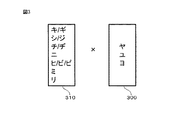
図3は、拗音を含む可能性がある音の並びのパターンを示す図である。リスト300は、拗音となり得る音の一覧を示す。具体的には、リスト300には、「ヤ」、「ユ」、「ヨ」が含まれる。また、リスト310は、直後の音がリスト300に含まれる音である場合に、リスト300に含まれる音が拗音となる可能性がある音の一覧を示す。具体的には、リスト310には、「キ/ギ」、「シ/ジ」、「チ/ヂ」、「ニ」、「ヒ/ビ/ピ」、「ミ」、「リ」が含まれる。
FIG. 3 is a diagram illustrating a sound arrangement pattern that may include stuttering. The
例えば、読みが「ジユウ」であれば、拗音となり得る音「ユ」の直前の音が、リスト310に含まれる音「ジ」であるので、拗促音候補抽出部12は、読み「ジユウ」に含まれる音「ユ」を拗音候補とする。また、読みが「キヨウイク」であれば、拗音となり得る音「ヨ」の直前の音が、リスト310に含まれる音「キ」であるので、拗促音候補抽出部12は、読み「キヨウイク」に含まれる音「ヨ」を拗音候補とする。
一方、読み「イヤク」には、拗音となり得る音「ヤ」が含まれている。しかし、「ヤ」の直前の音「イ」は、リスト310に含まれていない。そのため、拗促音候補抽出部12は、読み「イヤク」に含まれる音「ヤ」を拗音候補にしない。
For example, if the reading is “Jiyu”, the sound immediately before the sound “Yu” that can be a roaring sound is the sound “Ji” included in the
On the other hand, the reading “yaku” includes a sound “ya” that can be a roar. However, the sound “I” immediately before “YA” is not included in the
また、拗促音候補抽出部12は、登録対象の語句の読みから、促音となり得る音「ツ」を抽出する。そして拗促音候補抽出部12は、抽出した音の直前の音が特定の音の何れかであり、かつ、抽出した音の直後の音が複数の特定の音の何れかである場合、抽出した音を促音候補とする。
Further, the prompting sound
図4は、促音を含む可能性がある音の並びのパターンを示す図である。リスト400は、促音となり得る音の一覧を示す。具体的には、リスト400には、「ツ」が含まれる。また、リスト410は、促音の直前に位置する可能性がある音の一覧を表す。一方、リスト420は、促音の直後に位置する可能性がある音の一覧を表す。すなわち、リスト400に含まれる音「ツ」の直前に、リスト410に含まれる何れかの音が位置し、かつ、音「ツ」の直後に、リスト420に含まれる何れかの音が位置する場合に、音「ツ」は促音候補となる。
FIG. 4 is a diagram illustrating a sound arrangement pattern that may include a prompt sound. The
具体的には、リスト410には、「ヲ」及び「ン」以外の全ての音が含まれ、リスト420には、「カ行」、「サ行」、「タ行」及び「パ行」の音が含まれる。
Specifically, the
例えば、読みが「ガツコウ」であれば、促音となり得る音「ツ」の直前の音が、リスト410に含まれる音「ガ」であり、かつ、「ツ」の直後の音「コ」が、リスト420に含まれる。そこで、拗促音候補抽出部12は、読み「ガツコウ」に含まれる音「ツ」を促音候補とする。
一方、読み「フツウ」には、促音となり得る音「ツ」が含まれている。しかし、「ツ」の直後の音「ウ」は、リスト420に含まれていない。そのため、拗促音候補抽出部12は、読み「フツウ」に含まれる音「ツ」を促音候補にしない。
For example, if the reading is “GATSUKO”, the sound immediately before the sound “TSU” that can be a prompt sound is the sound “GA” included in the
On the other hand, the reading “Foot” includes a sound “T” that can be a prompt sound. However, the sound “ U ” immediately after “ TSU ” is not included in the
拗促音候補抽出部12は、拗音候補及び促音候補を対応付け部13及び判定部14へ出力する。
The prompting sound
対応付け部13は、登録対象の語句に含まれる各漢字ごとに、その漢字の読み候補のうち、その語句についての読みと最も一致する候補を特定し、特定された候補に対応する語句の読みの部分を、その漢字の読みとする。
The associating
本実施形態では、対応付け部13は、対象語句の読みに含まれる促音候補である音「ツ」を、音「ウ/ク/ス/チ」の何れかと置換した上で、各漢字の読みと比較する。なお、促音候補と置換する音「ウ/ク/ス/チ」は、ある漢字の読みで用いられ、かつ、促音に置き換えられる可能性がある音である。
さらに、対応付け部13は、漢字の読み候補に含まれる拗音または促音については、直音と一致するとみなして、語句の読みと漢字の読み候補を比較する。例えば、漢字の読みの候補において拗音及び促音が小文字で表記され、直音が大文字で表記されている場合、対応付け部13は、語句の読みと漢字の読み候補とを小文字と大文字を区別せずに比較する。このような置換などを行うことにより、対応付け部13は、語句の中で用いられることにより読みが変化した漢字についても、語句の読みとその漢字の読みとを対応付けることができる。そのため、対応付け部13は、語句の読みのうち、その語句に含まれる各漢字に対応する部分を正確に決定できる。
In this embodiment, the associating
Further, the associating
対応付け部13は、対象語句の先頭から順に、その語句に含まれる漢字の読みの候補とその語句の読みとを比較し、漢字の読みの候補のうちで最も一致する候補を、対象語句の読みのうちのその漢字に対応する部分とする。
あるいは、対応付け部13は、対象語句に含まれる各漢字の読みの候補の組み合わせのそれぞれと、その語句の読みとを、動的計画法(Dynamic Programming, DP)マッチングにより対応付けることで、最も一致する組み合わせを特定してもよい。そして対応付け部13は、その組み合わせにおいて各漢字の読みの候補と対応付けられた、対象語句の読みの部分を、その漢字に対応する読みとしてもよい。
The associating
Alternatively, the associating
対応付け部13は、登録対象の語句の読みと、その語句に含まれる各漢字との対応関係を表す情報、例えば、漢字ごとの読みの境界の位置を判定部14へ通知する。
The associating
判定部14は、登録対象の語句の読みに含まれる拗音候補と対応するその語句に含まれる漢字の読みにおける拗音候補の位置、及び、その漢字の読みの音訓種別に応じて、拗音候補が拗音か否か判定する。同様に、判定部14は、登録対象の語句の読みに含まれる促音候補と対応するその語句に含まれる漢字の読みにおける促音候補の位置、及び、その漢字の読みの音訓種別に応じて、促音候補が促音か否か判定する。
The
本実施形態では、判定部14は、拗音候補が、対応する漢字の読みにおける先頭に位置するか、対応する漢字の読みが訓読みの場合、拗音候補は拗音でないと判定する。一方、判定部14は、拗音候補が、対応する漢字の読みにおける先頭以外に位置し、かつ、対応する漢字の読みが音読みであれば、拗音候補は拗音であると判定する。
In the present embodiment, the
図5は、拗音候補と対応漢字の読みとの位置関係の一例を示す図である。図5には、登録対象語句に含まれる漢字とその漢字に対応する読みとの3種類の組み合わせ501〜503が示されている。組み合わせ501には、漢字「銃」に対して読み「ジユウ」が対応付けられており、このうち、音「ユ」が拗音候補である。そしてこの拗音候補は、対応する漢字「銃」の読みの先頭ではなく、かつ、読み「ジユウ」は、音読みである。したがって、判定部14は、拗音候補「ユ」を拗音とする。
FIG. 5 is a diagram illustrating an example of a positional relationship between stuttering candidates and corresponding kanji readings. FIG. 5 shows three types of
また、組み合わせ502には、漢字「教」に対して読み「キヨウ」が対応付けられており、かつ、漢字「育」に対して読み「イク」が対応付けられている。このうち、音「ヨ」が拗音候補である。そしてこの拗音候補は、対応する漢字「教」の読みの先頭ではなく、かつ、読み「キヨウ」は、音読みである。したがって、判定部14は、拗音候補「ヨ」を拗音とする。
In addition, in the
一方、組み合わせ503には、漢字「自」に対して読み「ジ」が対応付けられており、かつ、漢字「由」に対して読み「ユウ」が対応付けられている。このうち、音「ユ」が拗音候補である。そしてこの拗音候補は、対応する漢字「由」の読みの先頭に位置している。したがって、判定部14は、拗音候補「ユ」は、拗音でないと判定する。
On the other hand, in the
また、判定部14は、促音候補が、対応する漢字の読みにおける末尾以外に位置するか、単語境界に接する位置にあるか、あるいは、対応する漢字の読みが訓読みである場合、促音候補は促音でないと判定する。一方、判定部14は、促音候補が、対応する漢字の読みにおける末尾に位置し、単語境界に接しておらず、かつ、対応する漢字の読みが音読みであれば、促音候補は促音であると判定する。なお、単語境界は、互いに独立して用いられる単語間の境界である。
In addition, the
図6は、促音候補と対応漢字の読み及び単語境界との位置関係の一例を示す図である。図6には、登録対象語句に含まれる漢字とその漢字に対応する読みとの3種類の組み合わせ601〜603が示されている。組み合わせ601には、二つの漢字「学校」に対して読み「ガツコウ」が対応付けられており、このうち、音「ツ」が促音候補である。そしてこの促音候補は、対応する漢字「学」の読みの末尾に位置し、かつ、漢字「学」「校」の間は単語境界ではない。さらに、読み「ガツコウ」は、音読みである。したがって、判定部14は、促音候補「ツ」を促音とする。
FIG. 6 is a diagram illustrating an example of the positional relationship between the prompt sound candidate, the reading of the corresponding kanji, and the word boundary. FIG. 6 shows three types of
また、組み合わせ602には、二つの漢字「大月」に対して読み「オオツキ」が対応付けられており、このうち、音「ツ」が促音候補である。そしてこの促音候補は、対応する漢字「月」の読みの先頭に位置するので、判定部14は、促音候補「ツ」を促音ではないと判定する。
Also, in the
一方、組み合わせ603には、二つの漢字「脱税」に対して読み「ダツゼイ」が対応付けられている。このうち、音「ツ」が促音候補である。この拗音候補は、対応する漢字「脱」の読みの末尾に位置しているものの、漢字「脱」「税」の間は単語境界である。したがって、判定部14は、促音候補「ツ」は、促音でないと判定する。
On the other hand, in the
判定部14は、二つの漢字の境界が単語境界に相当するか否かを判定するために、例えば、共起確率データベースを参照する。
For example, the
図7は、共起確率データベースの一例を示す図である。共起確率データベース700では、上端の各欄に、二つの漢字の並びのうちの前側に位置する漢字が示され、左端の各欄に、二つの漢字の並びのうちの後側に位置する漢字が示される。そして共起確率データベース700のその他の各欄には、その欄と同じ列の上端に示された漢字に後続して、その欄と同じ行の左端に示された漢字が表れる共起確率を表す。例えば、この例では、漢字「滅」に後続して漢字「菌」が表れる共起確率は0.75である。
なお、共起確率データベースは、二つの漢字の組み合わせの共起確率を示すものに限られず、一方または両方が2以上の漢字を含む語句の組み合わせの共起確率を示していてもよい。
FIG. 7 is a diagram illustrating an example of a co-occurrence probability database. In the
Note that the co-occurrence probability database is not limited to the one that indicates the co-occurrence probability of a combination of two Chinese characters, and one or both may indicate the co-occurrence probability of a combination of words including two or more Chinese characters.
判定部14は、促音候補が読みの末尾に位置する漢字と、その次の漢字の組み合わせに対する共起確率を、共起確率データベースを参照して決定する。そして判定部14は、その共起確率が所定の閾値未満である場合、その二つの漢字の境界は単語境界であると判定し、一方、共起確率が所定の閾値以上である場合、その二つの漢字の境界は単語境界でないと判定する。なお、所定の閾値は、例えば、0.6に設定される。
The
さらに、判定部14は、登録対象の語句の先頭及び末尾を単語境界としてもよい。
Furthermore, the
また、判定部14は、単語境界の位置を他の方法に従って決定してもよい。例えは、判定部14は、登録対象の語句に対して形態素解析を適用して、その語句を形態素ごとに分割してもよい。そして判定部14は、形態素間の境界を単語境界としてもよい。
Moreover, the
あるいは、判定部14は、接尾語と、その直前の漢字との間を単語境界としてもよい。同様に、判定部14は、接頭語と、その直後の漢字との間を単語境界としてもよい。例えば、「初○○」あるいは「活○○」といった接頭語が付された語句(ただし、○は任意の漢字を表す)では、判定部14は、「初」及び「活」が接頭語なので、「初」または「活」とその直後の漢字の間を単語境界としてもよい。また、「○○期」といった接尾語が付された語句(ただし、○は任意の漢字を表す)では、判定部14は、「期」が接尾語なので、「期」とその直前の漢字の間を単語境界としてもよい。
Or the
あるいはまた、判定部14は、人名の一部として用いられる漢字と、その直前又は直後の漢字との境界を、単語境界としてもよい。人名の一部として用いられる漢字は、例えば、「子」、「夫」、「男」、「雄」、あるいは、「美」である。例えば、「○○子」といった語句(ただし、○は任意の漢字を表す)では、判定部14は、「子」が人名の一部を表す漢字なので、「子」とその直前の漢字の間を単語境界としてもよい。
Or the
判定部14は、読みデータにおいて、拗音と判定された拗音候補を、拗音に補正する。同様に、判定部14は、読みデータにおいて、促音と判定された促音候補を、促音に補正する。例えば、読みデータがテキストデータである場合、判定部14は、拗音及び促音を、小文字表記に補正する。判定部14は、登録対象の語句の表記データと、拗音候補及び促音候補のうち、拗音及び促音と判定された音が補正されたその語句の読みデータ(以下、修正済み読みデータと呼ぶ)とを、表示部4に表示させる。
The
登録部15は、登録対象の語句の表記データと、修正済み読みデータとを、記憶部3に記憶されている辞書に登録する。なお、語句を登録すべき辞書が、辞書登録装置1と通信ネットワークを介して接続される他の装置に記憶されている場合、登録部15は、登録対象の語句の表記データと、修正済み読みデータとを、通信部2を介して他の装置へ送信してもよい。
The
図8は、辞書登録装置1の処理部5によって実行される、拗促音判定処理を含む辞書登録処理の動作フローチャートである。なお、以下に示す動作フローチャートにおいて、ステップS101〜S108の処理が拗促音判定処理に相当する。処理部5は、通信部2を介して登録対象語句の表記データと読みデータを取得する度に、以下の動作フローチャートに従って、辞書登録処理を実行する。
FIG. 8 is an operation flowchart of dictionary registration processing including prompting sound determination processing executed by the
読み候補検出部11は、単漢字辞書を参照して、登録対象の語句に含まれる漢字ごとに、その漢字の読みを読み候補として検出する(ステップS101)。読み候補検出部11は、登録対象の語句に含まれる各漢字の読み候補及びその読み候補の音訓種別情報を対応付け部13へ出力する。
The reading
拗促音候補抽出部12は、登録対象の語句の読みに含まれる拗音となり得る音のうち、拗音を含む可能性がある特定の音の並びに含まれる音を拗音候補として抽出する(ステップS102)。また、拗促音候補抽出部12は、登録対象の語句の読みに含まれる促音となり得る音のうち、促音を含む可能性がある特定の音の並びに含まれる音を促音候補として抽出する(ステップS103)。拗促音候補抽出部12は、抽出された拗音候補及び促音候補を対応付け部13及び判定部14へ出力する。
The prompting sound
対応付け部13は、登録対象の語句に含まれる漢字ごとに、その漢字の読みの候補と、その語句についての読みとを比較して、その語句の読みのうち、各漢字に対応する部分を特定する(ステップS104)。対応付け部13は、登録対象の語句の読みと各漢字との対応関係を表す情報を判定部14へ通知する。
The associating
判定部14は、拗音候補が、対応する漢字の読みにおける先頭以外に位置し、かつ、対応する漢字の読みが音読みか否か判定する(ステップS105)。拗音候補が、対応する漢字の読みにおける先頭以外に位置し、かつ、対応する漢字の読みが音読みであれば(ステップS105−Yes)、判定部14は、拗音候補は拗音であると判定する。そして判定部14は、読みデータにおいて、その拗音候補を拗音に補正する(ステップS106)。
一方、拗音候補が、対応する漢字の読みにおける先頭に位置するか、あるいは、対応する漢字の読みが訓読みであれば(ステップS105−No)、判定部14は、拗音候補は拗音でないと判定する。
The
On the other hand, if the stuttering candidate is located at the head of the corresponding kanji reading or if the corresponding kanji reading is a kanji reading (step S105-No), the
ステップS106の後、あるいは、判定部14が拗音候補は拗音でないと判定した後、判定部14は、促音候補が、対応する漢字の読みにおける末尾に位置し、単語境界と接しておらず、かつ、対応する漢字の読みが音読みか否か判定する(ステップS107)。促音候補が、対応する漢字の読みにおける末尾に位置し、単語境界と接しておらず、かつ、対応する漢字の読みが音読みである場合(ステップS107−Yes)、判定部14は、促音候補は促音であると判定する。そして判定部14は、読みデータにおいて、その促音候補を促音に補正する(ステップS108)。
一方、促音候補が、対応する漢字の読みの末尾以外に位置するか、単語境界に接しているか、あるいは、対応する漢字の読みが訓読みであれば(ステップS107−No)、判定部14は、促音候補は促音でないと判定する。
After step S106, or after the
On the other hand, if the prompt sound candidate is located at a position other than the end of the corresponding kanji reading, touches a word boundary, or if the corresponding kanji reading is a knot reading (step S107-No), the
ステップS108の後、あるいは、判定部14が促音候補は促音でないと判定した後、登録部15は、登録対象の語句の表記データと修正済み読みデータとを辞書に登録する(ステップS109)。その後、処理部5は、辞書登録処理を終了する。
なお、処理部5は、ステップS101の処理と、ステップS102及びS103の処理の順序を入れ替えてもよい。また処理部5は、ステップS105及びS106の処理と、ステップS107及びS108の処理の順序を入れ替えてもよい。
After step S108, or after the
Note that the
以上に説明してきたように、この辞書登録装置は、拗音または促音を含む可能性がある特定の音の並びに含まれる拗音候補または促音候補が、拗音または促音となり得る、対応する漢字の読みの位置にあるか否か、及び対応する漢字の読みの音訓種別を調べる。これにより、この辞書登録装置は、拗音候補及び促音候補が、それぞれ、拗音であるか、または促音であるかを適切に判定できる。そのため、この辞書登録装置は、作業者が手作業で読みデータ中の拗音及び促音の表記を修正しなくても、自動的に拗音及び促音の表記を修正した上で、語句の表記データと読みデータを辞書に登録できるので、辞書作成の際の工数を削減できる。 As described above, this dictionary registration device is adapted for the position of the corresponding kanji reading at which the specific sound that may contain stuttering or sounding sounds and the included sounding or sounding sound candidates can be stuttering or sounding sounds. And whether or not the corresponding kanji reading is learned. Thereby, this dictionary registration apparatus can determine appropriately whether a stuttering candidate and a prompting sound candidate are a stuttering sound or a sounding sound, respectively. Therefore, this dictionary registration device automatically corrects the notation of stuttering and sounding sounds and automatically reads the wording and notation data without correcting the notation of stuttering and sounding sounds in the reading data manually. Since data can be registered in the dictionary, man-hours for dictionary creation can be reduced.
なお、処理部5は、促音候補に対応する漢字とその直後の漢字の組み合わせについての共起確率を、検索用コーパスに基づいて求めてよい。
Note that the
図9は、変形例による辞書登録装置1の処理部5の機能ブロック図である。この変形例では、処理部5は、読み候補検出部11と、拗促音候補抽出部12と、対応付け部13と、判定部14と、登録部15と、共起確率算出部16とを有する。この変形例による処理部5は、図2に示された処理部5と比較して、共起確率算出部16を有する点で異なる。そこで、以下では、共起確率算出部16及びその関連部分について説明する。
FIG. 9 is a functional block diagram of the
判定部14は、促音候補が対応する漢字の読みの末尾に位置する場合、その漢字及び直後の漢字の組み合わせを、共起確率の算出対象の漢字の組み合わせとして、共起確率算出部16へ通知する。
The
共起確率算出部16は、共起確率の算出対象の漢字の組み合わせを含む検索用コーパスを取得する。共起確率算出部16は、検索用コーパスとして、例えば、辞書登録装置1と通信ネットワークを介して接続されている様々なWebサイト上で公開されているWebページに含まれる、漢字仮名混じり文のテキストデータを、利用できる。あるいは、検索用コーパスとして、例えば、製品のマニュアル、議事録、メールなどに含まれる漢字仮名混じり文のテキストデータを利用できる。共起確率算出部16は、例えば、これらの検索用コーパスを、記憶部3から読み込む。あるいは、共起確率算出部16は、通信部2を介して、辞書登録装置1と通信ネットワークを介して接続されている他の機器から、検索用コーパスを取得する。
The co-occurrence
共起確率算出部16は、例えば、検索用コーパスに含まれるテキストデータに含まれる、共起確率の算出対象の漢字の組み合わせの個数と、その組み合わせに含まれる各漢字の個数を、それぞれカウントする。そして共起確率算出部16は、次式に従って、共起確率CoPを算出する。
CoP = 2N12/(N1+N2)
ここで、N1は、共起確率の算出対象の漢字の組み合わせに含まれる先頭の漢字の個数を表し、N2は、共起確率の算出対象の漢字の組み合わせに含まれる後続の漢字の個数を表す。そしてN12は、その漢字の組み合わせの個数を表す。
例えば、共起確率算出対象となる漢字の組み合わせが「滅菌」であり、検索用コーパスに、その組み合わせ「滅菌」が3個ふくまれており、個々の漢字「滅」及び「菌」がそれぞれ4個含まれているとする。この場合、共起確率Copは、2*3/(4+4)=0.75となる。
また、共起確率算出部16は、別の共起確率の算出方法として、Web検索サービスの検索件数を利用して共起確率を算出してもよい。Web検索サービスを用いる場合、共起確率算出部16は、次式で共起確率CoPを算出する。
CoP=(単語の組み合わせの検索件数)/(単語1と単語2のand条件での検索件数)
例えば、Web検索サービスで「滅菌」と検索した場合と、「滅 and 菌」で検索した場合の検索結果が、それぞれ1,270,000件、1,750,000件であるとすると、共起確率CoPは、1,270,000/1,750,000 = 0.72となる。
For example, the co-occurrence
CoP = 2N 12 / (N 1 + N 2 )
Here, N 1 represents the number of leading Chinese characters included in the combination of kanji for which the co-occurrence probability is to be calculated, and N 2 represents the number of subsequent kanji characters included in the combination of kanji for which the co-occurrence probability is to be calculated. Represents. N 12 represents the number of combinations of the Chinese characters.
For example, the combination of kanji for which the co-occurrence probability is to be calculated is “sterilization”, and three combinations “sterilization” are included in the search corpus, and each of the kanji “disaster” and “fungus” is four. Suppose that they are included. In this case, the co-occurrence probability Cop is 2 * 3 / (4 + 4) = 0.75.
In addition, the co-occurrence
CoP = (number of searches for word combinations) / (number of searches for word 1 and
For example, if the search results when searching for “sterilization” using the Web search service and searching for “sterile and germs” are 1,270,000 and 1,750,000, respectively, the co-occurrence probability CoP is 1,270,000 / 1,750,000 = 0.72.
共起確率算出部16は、算出された共起確率を判定部14へ通知する。そして判定部14は、通知された共起確率に基づいて、促音候補が単語境界に接しているか否かを判定すればよい。
また、共起確率算出部16は、共起確率データベースに、その算出対象となった漢字の組み合わせ及び共起確率を追加してもよい。
The co-occurrence
In addition, the co-occurrence
この変形例によれば、辞書登録装置1は、登録対象の語句から得られた促音候補に関連する漢字の組み合わせについての共起確率が事前に分かっていなくても、その組み合わせについての共起確率を算出できる。そのため、辞書登録装置1は、予め多数の漢字の組み合わせに対する共起確率を表した大規模な共起確率データベースを持たなくても、促音候補が単語境界に接しているか否かを判定できるので、その促音候補が促音か否かを適切に判定できる。 According to this modified example, the dictionary registration device 1 does not know the co-occurrence probability for the combination of kanji characters related to the prompt sound candidate obtained from the word to be registered, but the co-occurrence probability for the combination. Can be calculated. Therefore, the dictionary registration apparatus 1 can determine whether or not the prompt sound candidate is in contact with the word boundary without having a large-scale co-occurrence probability database that represents the co-occurrence probabilities for a large number of combinations of Chinese characters in advance. It is possible to appropriately determine whether the prompt sound candidate is a prompt sound.
また、他の変形例によれば、記憶部3は、促音候補に対応する漢字及びその前後の漢字の組み合わせに関して、促音候補を促音とする例外リストを記憶していてもよい。そして判定部14は、促音候補に対応する漢字及びその前後の漢字の組み合わせが例外リストに登録されている場合、促音候補が単語境界に接しているか否か、及び、促音候補に対応する漢字の読みの音訓種別に関わらず、促音候補と促音としてもよい。
例えば、「勝平(カッペイ)」といった人名、または「鳥取(トットリ)」といった地名のように、固有名詞では、漢字の読みが訓読みであっても、その読みの中に促音が含まれることがある。そこでこのような例外的な漢字の組み合わせを例外リストとして予め登録しておくことで、判定部14は、より正確に促音候補を促音か否か判定できる。
According to another modification, the storage unit 3 may store an exception list that uses the prompting sound candidate as the prompting sound for the combination of the Chinese character corresponding to the prompting sound candidate and the preceding and following Chinese characters. Then, when the combination of the kanji corresponding to the prompt sound candidate and the preceding and following kanji is registered in the exception list, the
For example, a proper noun, such as a name of a person such as “Kappei” or a place name such as “Tottori”, may contain a sounding sound even if the kanji is a kanji reading. . Therefore, by registering such an exceptional combination of kanji in advance as an exception list, the
さらに他の変形例によれば、辞書登録装置は、複数の語句を含む文字列の表記データとその文字列の読みデータとを含むデータベースを、例えば、通信部2を介して取得してもよい。この場合、処理部5は、表記データに表された文字列に対して、例えば、形態素解析を適用することにより、その文字列を語句ごとに分解する。そして処理部5は、得られた語句のうち、辞書に登録されていない語句に対して、上記の実施形態または変形例による辞書登録処理を実行してもよい。これにより、辞書登録装置は、一つのデータベースから、複数の語句を自動的に辞書に登録することができる。
According to still another modification, the dictionary registration device may acquire a database including notation data of a character string including a plurality of words and reading data of the character string via the
さらに、上記の実施形態または変形例による辞書登録装置は、登録対象の語句の表記データ及び読みデータを、それらのデータが記録された磁気記録媒体あるいは光記録媒体といった記録媒体から読み込んでもよい。この場合には、辞書登録装置は、取得部として、そのような記録媒体のアクセス装置を有していてもよい。 Furthermore, the dictionary registration device according to the above-described embodiment or modification may read notation data and reading data of a word to be registered from a recording medium such as a magnetic recording medium or an optical recording medium in which those data are recorded. In this case, the dictionary registration device may have an access device for such a recording medium as the acquisition unit.
さらに、上記の実施形態または変形例による辞書登録装置の処理部が有する各機能をコンピュータに実現させるコンピュータプログラムは、コンピュータによって読み取り可能な媒体、例えば、磁気記録媒体、光記録媒体または半導体メモリに記録された形で提供されてもよい。 Furthermore, a computer program that causes a computer to realize each function of the processing unit of the dictionary registration device according to the above-described embodiment or modification is recorded on a computer-readable medium, for example, a magnetic recording medium, an optical recording medium, or a semiconductor memory. It may be provided in a customized form.
ここに挙げられた全ての例及び特定の用語は、読者が、本発明及び当該技術の促進に対する本発明者により寄与された概念を理解することを助ける、教示的な目的において意図されたものであり、本発明の優位性及び劣等性を示すことに関する、本明細書の如何なる例の構成、そのような特定の挙げられた例及び条件に限定しないように解釈されるべきものである。本発明の実施形態は詳細に説明されているが、本発明の精神及び範囲から外れることなく、様々な変更、置換及び修正をこれに加えることが可能であることを理解されたい。 All examples and specific terms listed herein are intended for instructional purposes to help the reader understand the concepts contributed by the inventor to the present invention and the promotion of the technology. It should be construed that it is not limited to the construction of any example herein, such specific examples and conditions, with respect to showing the superiority and inferiority of the present invention. Although embodiments of the present invention have been described in detail, it should be understood that various changes, substitutions and modifications can be made thereto without departing from the spirit and scope of the present invention.
以上説明した実施形態及びその変形例に関し、更に以下の付記を開示する。
(付記1)
少なくとも一つの漢字を含む語句の表記を表す表記データ及び当該語句の読みを拗音及び促音と直音とを区別せずに表す読みデータを取得する取得部と、
複数の漢字のそれぞれの読み及び当該読みが音読みか訓読みかを表す音訓種別が登録された単漢字辞書を記憶する記憶部と、
前記単漢字辞書を参照して、前記表記データに表された前記語句に含まれる前記少なくとも一つの漢字のそれぞれの読みの候補を検出する読み候補検出部と、
前記読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出する拗促音候補抽出部と、
前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定し、該特定された候補に対応する前記語句の読みの部分を、当該漢字の読みとする対応付け部と、
前記語句に含まれる前記少なくとも一つの漢字のうちの前記拗促音候補と対応する第1の漢字の読みにおける前記拗促音候補の位置、及び、前記第1の漢字の前記読みの音訓種別に応じて前記拗促音候補を拗音及び促音の何れかか否か判定する判定部と、
を有する拗促音判定装置。
(付記2)
前記判定部は、前記拗促音候補が、促音となり得る音であり、前記第1の漢字の前記読みの末尾に位置し、かつ、互いに独立して用いられる単語間の境界と接しておらず、かつ、前記第1の漢字の前記読みが音読みである場合、前記拗促音候補を促音とする、付記1に記載の拗促音判定装置。
(付記3)
前記判定部は、前記第1の漢字と当該第1の漢字に後続する第2の漢字とが組み合わせて使用される共起確率が所定の閾値未満である場合、前記第1の漢字と前記第2の漢字の境界は前記単語間の境界であると判定する、付記2に記載の拗促音判定装置。
(付記4)
前記判定部は、前記拗促音候補が、拗音となり得る音であり、かつ、前記第1の漢字の読みの先頭以外に位置し、かつ、前記第1の漢字の前記読みが音読みである場合、前記拗促音候補を拗音とする、付記1〜3の何れか一項に記載の拗促音判定装置。
(付記5)
前記対応付け部は、前記拗促音候補のうち、促音となり得る音を、促音に置換される可能性がある音に置換して、前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定する、付記1〜4の何れか一項に記載の拗促音判定装置。
(付記6)
前記対応付け部は、前記漢字の読みの候補に含まれる拗音及び促音が、当該拗音及び促音を直音化した音と一致するとみなして、前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定する、付記1〜5の何れか一項に記載の拗促音判定装置。
(付記7)
前記表記データと、促音または拗音と判定された前記拗促音候補を促音または拗音を表す表記に修正した前記読みデータとを、語句の表記と読みの関係を表す辞書に登録する登録部をさらに有する、付記1〜6の何れか一項に記載の拗促音判定装置。
(付記8)
複数の漢字のそれぞれの読み及び当該読みが音読みか訓読みかを表す音訓種別が登録された単漢字辞書を参照して、少なくとも一つの漢字を含む語句の表記を表す表記データに表された前記語句に含まれる前記少なくとも一つの漢字のそれぞれの読みの候補を検出し、
拗音及び促音と直音とを区別せずに表す読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出し、
前記読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出し、
前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定し、該特定された候補に対応する前記語句の読みの部分を、当該漢字の読みとし、
前記語句に含まれる前記少なくとも一つの漢字のうちの前記拗促音候補と対応する第1の漢字の読みにおける前記拗促音候補の位置、及び、前記第1の漢字の前記読みの音訓種別に応じて前記拗促音候補を拗音及び促音の何れかか否か判定する、
ことを含む拗促音判定方法。
(付記9)
複数の漢字のそれぞれの読み及び当該読みが音読みか訓読みかを表す音訓種別が登録された単漢字辞書を参照して、少なくとも一つの漢字を含む語句の表記を表す表記データに表された前記語句に含まれる前記少なくとも一つの漢字のそれぞれの読みの候補を検出し、
拗音及び促音と直音とを区別せずに表す読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出し、
前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定し、該特定された候補に対応する前記語句の読みの部分を、当該漢字の読みとし、
前記語句に含まれる前記少なくとも一つの漢字のうちの前記拗促音候補と対応する第1の漢字の読みにおける前記拗促音候補の位置、及び、前記第1の漢字の前記読みの音訓種別に応じて前記拗促音候補を拗音及び促音の何れかか否か判定する、
ことをコンピュータに実行させるための拗促音判定用コンピュータプログラム。
The following supplementary notes are further disclosed regarding the embodiment described above and its modifications.
(Appendix 1)
An acquisition unit for acquiring notation data representing a notation of a word including at least one kanji and reading data representing the reading of the word without distinguishing stuttering and prompt sounds and direct sounds;
A storage unit for storing a single kanji dictionary in which each reading of a plurality of kanji characters and a phonetic type indicating whether the reading is a phonetic reading or a kanji reading is registered;
A candidate reading detection unit that detects each candidate for reading of the at least one kanji included in the phrase represented in the notation data with reference to the single kanji dictionary;
A prompting sound candidate that extracts a sound that may be a prompting sound or a stuttering sound included in the reading of the word represented in the reading data as a prompting sound candidate. An extractor;
For each of the at least one kanji included in the phrase, a candidate that most closely matches the reading of the phrase among the candidate readings of the kanji is identified, and the reading portion of the phrase corresponding to the identified candidate Is an association part for reading the kanji,
According to the position of the prompt sound candidate in the reading of the first Chinese character corresponding to the prompt sound candidate among the at least one Chinese character included in the word and the learning type of the reading of the first Chinese character A determination unit that determines whether the prompt sound candidate is either a stutter sound or a prompt sound;
A prompt sound determination device having
(Appendix 2)
The determination unit is a sound that the prompting sound candidate can be a prompting sound, is located at the end of the reading of the first kanji and does not touch a boundary between words used independently of each other, The prompt sound determination device according to appendix 1, wherein when the reading of the first Chinese character is a sound reading, the prompt sound candidate is a prompt sound.
(Appendix 3)
When the co-occurrence probability that the first kanji and the second kanji following the first kanji are used in combination is less than a predetermined threshold, the determination unit determines that the first kanji and the first kanji The prompt sound determination apparatus according to
(Appendix 4)
The determination unit, when the prompting sound candidate is a sound that can be a stuttering and is located at a position other than the beginning of the reading of the first kanji, and the reading of the first kanji is a reading aloud, 4. The prompt sound determination apparatus according to any one of appendices 1 to 3, wherein the prompt sound candidate is a stutter.
(Appendix 5)
The association unit replaces a sound that can be a prompt sound among the prompt sound candidates with a sound that may be replaced with a prompt sound, and for each of the at least one Chinese character included in the phrase, The prompting sound determination device according to any one of appendices 1 to 4, wherein a candidate that most closely matches the reading of the word is identified among the reading candidates of the above.
(Appendix 6)
The associating unit regards the stuttering sound and the prompt sound included in the candidate for reading the kanji as matching the sound obtained by directing the stuttering sound and the prompt sound, and for each of the at least one kanji character included in the phrase, The prompting sound determination device according to any one of appendices 1 to 5, wherein a candidate that most closely matches the reading of the word is identified among candidates for reading the kanji.
(Appendix 7)
And a registration unit for registering the notation data and the reading data obtained by correcting the prompting sound candidate determined to be a prompting sound or a stuttering sound into a notation representing a prompting sound or a stuttering in a dictionary representing a relationship between the notation of the phrase and the reading. The prompt sound determination device according to any one of appendices 1 to 6.
(Appendix 8)
The phrase represented in the notation data representing the notation of a word including at least one kanji, with reference to a single kanji dictionary in which each kanji reading and a phonetic type indicating whether the reading is a kanji reading or a kanji reading is registered A candidate for reading each of the at least one kanji included in
A series of sounds that may contain a sound or a stutter among the sounds that can be a sound or a sound included in the reading of the word represented in the reading data expressed without distinguishing between a sound and a sound. To be extracted as a prompt sound candidate,
Extracting sounds included in the reading of the word represented in the reading data, which may be a prompting sound or a stuttering sound, that may contain a prompting sound or a stuttering sound as a prompting sound candidate,
For each of the at least one kanji included in the phrase, a candidate that most closely matches the reading of the phrase among the candidate readings of the kanji is identified, and the reading portion of the phrase corresponding to the identified candidate As the reading of the kanji
According to the position of the prompt sound candidate in the reading of the first Chinese character corresponding to the prompt sound candidate among the at least one Chinese character included in the word and the learning type of the reading of the first Chinese character Determining whether the prompting sound candidate is either a stuttering sound or a prompting sound;
A prompt sound determination method including the above.
(Appendix 9)
The phrase represented in the notation data representing the notation of a word including at least one kanji, with reference to a single kanji dictionary in which each kanji reading and a phonetic type indicating whether the reading is a kanji reading or a kanji reading is registered A candidate for reading each of the at least one kanji included in
A series of sounds that may contain a sound or a stutter among the sounds that can be a sound or a sound included in the reading of the word represented in the reading data expressed without distinguishing between a sound and a sound. To be extracted as a prompt sound candidate,
For each of the at least one kanji included in the phrase, a candidate that most closely matches the reading of the phrase among the candidate readings of the kanji is identified, and the reading portion of the phrase corresponding to the identified candidate As the reading of the kanji
According to the position of the prompt sound candidate in the reading of the first Chinese character corresponding to the prompt sound candidate among the at least one Chinese character included in the word and the learning type of the reading of the first Chinese character Determining whether the prompting sound candidate is either a stuttering sound or a prompting sound;
A computer program for determining a prompting sound for causing a computer to execute the above.
1 辞書登録装置(拗促音判定装置)
2 通信部
3 記憶部
4 表示部
5 処理部
11 読み候補検出部
12 拗促音候補抽出部
13 対応付け部
14 判定部
15 登録部
16 共起確率算出部
1 Dictionary registration device (encouragement sound judgment device)
2 communication unit 3 storage unit 4
Claims (7)
複数の漢字のそれぞれの読み及び当該読みが音読みか訓読みかを表す音訓種別が登録された単漢字辞書を記憶する記憶部と、
前記単漢字辞書を参照して、前記表記データに表された前記語句に含まれる前記少なくとも一つの漢字のそれぞれの読みの候補を検出する読み候補検出部と、
前記読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出する拗促音候補抽出部と、
前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定し、該特定された候補に対応する前記語句の読みの部分を、当該漢字の読みとする対応付け部と、
前記語句に含まれる前記少なくとも一つの漢字のうちの前記拗促音候補と対応する第1の漢字の読みにおける前記拗促音候補の位置、及び、前記第1の漢字の前記読みの音訓種別に応じて前記拗促音候補を拗音及び促音の何れかか否か判定する判定部と、
を有し、
前記判定部は、前記拗促音候補が促音となり得る音である場合、前記第1の漢字と前記第1の漢字に後続する漢字の組み合わせに対して、互いに独立して用いられる単語間の境界を検出する所定の手法を適用することで、前記第1の漢字と前記第1の漢字に後続する漢字との間が前記境界であるか否か判定し、前記第1の漢字の前記読みにおける前記拗促音候補の位置、前記拗促音候補が前記境界と接しているか否か、及び、前記第1の漢字の前記読みの音訓種別に応じて、前記拗促音候補が促音か否かを判定する拗促音判定装置。 An acquisition unit for acquiring notation data representing a notation of a word including at least one kanji and reading data representing the reading of the word without distinguishing stuttering and prompt sounds and direct sounds;
A storage unit for storing a single kanji dictionary in which each reading of a plurality of kanji characters and a phonetic type indicating whether the reading is a phonetic reading or a kanji reading is registered;
A candidate reading detection unit that detects each candidate for reading of the at least one kanji included in the phrase represented in the notation data with reference to the single kanji dictionary;
A prompting sound candidate that extracts a sound that may be a prompting sound or a stuttering sound included in the reading of the word represented in the reading data as a prompting sound candidate. An extractor;
For each of the at least one kanji included in the phrase, a candidate that most closely matches the reading of the phrase among the candidate readings of the kanji is identified, and the reading portion of the phrase corresponding to the identified candidate Is an association part for reading the kanji,
According to the position of the prompt sound candidate in the reading of the first Chinese character corresponding to the prompt sound candidate among the at least one Chinese character included in the word and the learning type of the reading of the first Chinese character A determination unit that determines whether the prompt sound candidate is either a stutter sound or a prompt sound;
I have a,
The determination unit determines a boundary between words that are used independently of each other for a combination of the first kanji and the kanji following the first kanji when the prompting sound candidate is a sound that can be a sound. By applying a predetermined method of detecting, it is determined whether or not the boundary between the first kanji and the kanji following the first kanji is the boundary, and the reading in the reading of the first kanji Depending on the position of the prompt sound candidate, whether the prompt sound candidate touches the boundary, and whether or not the prompt sound candidate is the prompt sound according to the reading type of the reading of the first kanji Prompt sound determination device.
前記コンピュータが、拗音及び促音と直音とを区別せずに表す読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出し、
前記コンピュータが、前記読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出し、
前記コンピュータが、前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定し、該特定された候補に対応する前記語句の読みの部分を、当該漢字の読みとし、
前記コンピュータが、前記語句に含まれる前記少なくとも一つの漢字のうちの前記拗促音候補と対応する第1の漢字の読みにおける前記拗促音候補の位置、及び、前記第1の漢字の前記読みの音訓種別に応じて前記拗促音候補を拗音及び促音の何れかか否か判定する、
ことを含み、
前記拗促音候補を拗音及び促音の何れかか否か判定することは、前記拗促音候補が促音となり得る音である場合、前記第1の漢字と前記第1の漢字に後続する漢字の組み合わせに対して、互いに独立して用いられる単語間の境界を検出する所定の手法を適用することで、前記第1の漢字と前記第1の漢字に後続する漢字との間が前記境界であるか否か判定し、前記第1の漢字の前記読みにおける前記拗促音候補の位置、前記拗促音候補が前記境界と接しているか否か、及び、前記第1の漢字の前記読みの音訓種別に応じて、前記拗促音候補が促音か否かを判定する
ことを含む拗促音判定方法。 The computer refers to a single kanji dictionary in which each kanji character reading and a phonetic type indicating whether the reading is sound reading or kanji reading is registered, and is represented in notation data representing the notation of a word including at least one kanji. Detecting candidates for reading each of the at least one kanji included in the word,
There is a possibility that a sound or a stuttering sound is included among the sounds that can be a sound or a sound that is included in the reading of the word or phrase that is expressed by the computer without distinguishing between the sound and the sound and the sound. Extract sounds included in the sequence as prompting sound candidates,
The computer extracts sounds included in the reading of the word represented in the reading data, which may be a prompting sound or a stuttering sound, which may contain a prompting sound or a stuttering sound, as a prompting sound candidate And
The computer specifies, for each of the at least one kanji included in the phrase, a candidate that most closely matches the reading of the phrase among candidates for reading the kanji, and the phrase corresponding to the identified candidate The part of reading is the reading of the kanji,
The computer has the position of the prompting sound candidate in the reading of the first Chinese character corresponding to the prompting sound candidate of the at least one Chinese character included in the phrase, and the phonetic of the reading of the first Chinese character According to the type, it is determined whether the prompting sound candidate is either a stuttering sound or a prompting sound,
Look at including it,
The determination of whether the prompt sound candidate is either a stutter sound or a sound is a combination of the first Chinese character and the Chinese character that follows the first Chinese character when the prompt sound candidate is a sound that can be a prompt sound. On the other hand, by applying a predetermined method for detecting a boundary between words used independently of each other, whether or not the boundary between the first kanji and the kanji following the first kanji is the boundary. Depending on the position of the prompting sound candidate in the reading of the first Chinese character, whether the prompting sound candidate is in contact with the boundary, and the learning type of the reading of the first Chinese character Determine whether the prompt sound candidate is a prompt sound
Including a screw double consonants determination method that.
拗音及び促音と直音とを区別せずに表す読みデータに表された前記語句の読みに含まれる、促音または拗音となり得る音のうち、促音または拗音が含まれる可能性がある音の並びに含まれる音を拗促音候補として抽出し、
前記語句に含まれる前記少なくとも一つの漢字のそれぞれについて、当該漢字の読みの候補のうち、前記語句の読みと最も一致する候補を特定し、該特定された候補に対応する前記語句の読みの部分を、当該漢字の読みとし、
前記語句に含まれる前記少なくとも一つの漢字のうちの前記拗促音候補と対応する第1の漢字の読みにおける前記拗促音候補の位置、及び、前記第1の漢字の前記読みの音訓種別に応じて前記拗促音候補を拗音及び促音の何れかか否か判定する、
ことをコンピュータに実行させ、
前記拗促音候補を拗音及び促音の何れかか否か判定することは、前記拗促音候補が促音となり得る音である場合、前記第1の漢字と前記第1の漢字に後続する漢字の組み合わせに対して、互いに独立して用いられる単語間の境界を検出する所定の手法を適用することで、前記第1の漢字と前記第1の漢字に後続する漢字との間が前記境界であるか否か判定し、前記第1の漢字の前記読みにおける前記拗促音候補の位置、前記拗促音候補が前記境界と接しているか否か、及び、前記第1の漢字の前記読みの音訓種別に応じて、前記拗促音候補が促音か否かを判定する
ことを含む拗促音判定用コンピュータプログラム。 The phrase represented in the notation data representing the notation of a word including at least one kanji, with reference to a single kanji dictionary in which each kanji reading and a phonetic type indicating whether the reading is a kanji reading or a kanji reading is registered A candidate for reading each of the at least one kanji included in
A series of sounds that may contain a sound or a stutter among the sounds that can be a sound or a sound included in the reading of the word represented in the reading data expressed without distinguishing between a sound and a sound. To be extracted as a prompt sound candidate,
For each of the at least one kanji included in the phrase, a candidate that most closely matches the reading of the phrase among the candidate readings of the kanji is identified, and the reading portion of the phrase corresponding to the identified candidate As the reading of the kanji
According to the position of the prompt sound candidate in the reading of the first Chinese character corresponding to the prompt sound candidate among the at least one Chinese character included in the word and the learning type of the reading of the first Chinese character Determining whether the prompting sound candidate is either a stuttering sound or a prompting sound;
Let the computer do
The determination of whether the prompt sound candidate is either a stutter sound or a sound is a combination of the first Chinese character and the Chinese character that follows the first Chinese character when the prompt sound candidate is a sound that can be a prompt sound. On the other hand, by applying a predetermined method for detecting a boundary between words used independently of each other, whether or not the boundary between the first kanji and the kanji following the first kanji is the boundary. Depending on the position of the prompting sound candidate in the reading of the first Chinese character, whether the prompting sound candidate is in contact with the boundary, and the learning type of the reading of the first Chinese character Determine whether the prompt sound candidate is a prompt sound
Screw assimilated sound judgment computer program includes.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014045580A JP6244993B2 (en) | 2014-03-07 | 2014-03-07 | Encouraging sound determination device, encouraging sound determination method, and encouraging sound determination computer program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014045580A JP6244993B2 (en) | 2014-03-07 | 2014-03-07 | Encouraging sound determination device, encouraging sound determination method, and encouraging sound determination computer program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015170218A JP2015170218A (en) | 2015-09-28 |
| JP6244993B2 true JP6244993B2 (en) | 2017-12-13 |
Family
ID=54202869
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014045580A Expired - Fee Related JP6244993B2 (en) | 2014-03-07 | 2014-03-07 | Encouraging sound determination device, encouraging sound determination method, and encouraging sound determination computer program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6244993B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6694804B2 (en) * | 2016-12-02 | 2020-05-20 | 株式会社日立産機システム | Abduction type rotating electric machine |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH064520A (en) * | 1992-06-18 | 1994-01-14 | Sharp Corp | Japanese word processor |
| JP2004139530A (en) * | 2002-10-21 | 2004-05-13 | Osaka Gas Co Ltd | Reading correction program |
| JP2010009294A (en) * | 2008-06-26 | 2010-01-14 | Sharp Corp | Electronic device and display method of electronic device |
| JP2013041421A (en) * | 2011-08-16 | 2013-02-28 | Nec Corp | Input character string error detection device |
-
2014
- 2014-03-07 JP JP2014045580A patent/JP6244993B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015170218A (en) | 2015-09-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5997217B2 (en) | A method to remove ambiguity of multiple readings in language conversion | |
| JP5362095B2 (en) | Input method editor | |
| JP5599662B2 (en) | System and method for converting kanji into native language pronunciation sequence using statistical methods | |
| JP2014145842A (en) | Speech production analysis device, voice interaction control device, method, and program | |
| US20150081270A1 (en) | Speech translation apparatus, speech translation method, and non-transitory computer readable medium thereof | |
| US9594742B2 (en) | Method and apparatus for matching misspellings caused by phonetic variations | |
| WO2022267353A1 (en) | Text error correction method and apparatus, and electronic device and storage medium | |
| Scherrer et al. | Word-based dialect identification with georeferenced rules | |
| KR101936208B1 (en) | Method for providing notation of standard chinese pronunciation utilizing hangul block building rules and hangul vowel letters which fulfilling traditional four hu theory of chinese language as they are pronounced in modern korean hangul*language and system thereof | |
| US20120109633A1 (en) | Method and system for diacritizing arabic language text | |
| JP7481999B2 (en) | Dictionary editing device, dictionary editing method, and dictionary editing program | |
| JP6244993B2 (en) | Encouraging sound determination device, encouraging sound determination method, and encouraging sound determination computer program | |
| KR20120045906A (en) | Apparatus and method for correcting error of corpus | |
| JP2018066800A (en) | Japanese speech recognition model learning device and program | |
| JP6366179B2 (en) | Utterance evaluation apparatus, utterance evaluation method, and program | |
| JP7102710B2 (en) | Information generation program, word extraction program, information processing device, information generation method and word extraction method | |
| JP2008059389A (en) | Vocabulary candidate output system, vocabulary candidate output method, and vocabulary candidate output program | |
| Núñez et al. | Phonetic normalization for machine translation of user generated content | |
| JP2007086404A (en) | Speech synthesizer | |
| JP4941495B2 (en) | User dictionary creation system, method, and program | |
| KR101658598B1 (en) | Korean-based chinese input apparatus and method using the roman phonetic alphabet | |
| JP5169602B2 (en) | Morphological analyzer, morphological analyzing method, and computer program | |
| Celikkaya et al. | A mobile assistant for Turkish | |
| CN112560493B (en) | Named entity error correction method, named entity error correction device, named entity error correction computer equipment and named entity error correction storage medium | |
| US11809831B2 (en) | Symbol sequence converting apparatus and symbol sequence conversion method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20161102 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170815 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170810 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20171004 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171017 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171030 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6244993 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |