JP6236093B2 - 並列パイプラインにおいてブランチを分岐するためのハードウェアおよびソフトウェアソリューション - Google Patents
並列パイプラインにおいてブランチを分岐するためのハードウェアおよびソフトウェアソリューション Download PDFInfo
- Publication number
- JP6236093B2 JP6236093B2 JP2015555420A JP2015555420A JP6236093B2 JP 6236093 B2 JP6236093 B2 JP 6236093B2 JP 2015555420 A JP2015555420 A JP 2015555420A JP 2015555420 A JP2015555420 A JP 2015555420A JP 6236093 B2 JP6236093 B2 JP 6236093B2
- Authority
- JP
- Japan
- Prior art keywords
- instruction
- given
- instructions
- processor
- lane
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000003860 storage Methods 0.000 claims description 22
- 230000004044 response Effects 0.000 claims description 19
- 230000007958 sleep Effects 0.000 claims description 18
- 238000000034 method Methods 0.000 claims description 17
- 230000006870 function Effects 0.000 description 17
- 238000010586 diagram Methods 0.000 description 14
- 238000012545 processing Methods 0.000 description 10
- 238000013507 mapping Methods 0.000 description 9
- 238000012360 testing method Methods 0.000 description 6
- 238000004364 calculation method Methods 0.000 description 5
- 238000012546 transfer Methods 0.000 description 5
- 238000012986 modification Methods 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000003068 static effect Effects 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 208000033986 Device capturing issue Diseases 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 230000003542 behavioural effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
- G06F8/45—Exploiting coarse grain parallelism in compilation, i.e. parallelism between groups of instructions
- G06F8/451—Code distribution
- G06F8/452—Loops
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3005—Arrangements for executing specific machine instructions to perform operations for flow control
- G06F9/30058—Conditional branch instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3818—Decoding for concurrent execution
- G06F9/3822—Parallel decoding, e.g. parallel decode units
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
- G06F9/3851—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution from multiple instruction streams, e.g. multistreaming
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
- G06F9/3853—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution of compound instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
- G06F9/38873—Iterative single instructions for multiple data lanes [SIMD]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Devices For Executing Special Programs (AREA)
- Advance Control (AREA)
- Executing Machine-Instructions (AREA)
- Computer Hardware Design (AREA)
Description
Claims (20)
- コンピュータシステムの少なくとも1つのプロセッサによる実行のために構成された少なくとも1つのプログラムを格納するコンピュータ可読記憶媒体であって、
前記少なくとも1つのプログラムは、前記プロセッサによって実行されると、
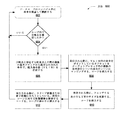
複数のプログラム命令を解析することと、
前記複数のプログラム命令内でループおよび対応する基本ブロックを識別することと、
前記複数のプログラム命令内の識別されたループ内の所与の分岐点を識別したことに応じて、前記識別されたループ内の複数の命令を複数の超大命令語(VLIW)に配置することであって、少なくとも1つのVLIWは、前記所与の分岐点と対応する収束点との間の異なる基本ブロックから混ぜ合わされた命令を含む、ことと、
を前記プロセッサに実行させる命令を含む、
コンピュータ可読記憶媒体。 - 前記少なくとも1つのプログラムは、前記識別されたループ内の前記所与の分岐点を検出したことに応じて、第1の命令を前記複数のプログラム命令に追加すること、を前記プロセッサに実行させるための命令をさらに含み、
前記第1の命令は、所与のVLIW内の命令を、単一命令複数データ(SIMD)マイクロアーキテクチャを含むターゲットプロセッサ内の複数の並列実行レーンに実行時に割り当てることを前記ターゲットプロセッサに実行させるためのものである、請求項1に記載のコンピュータ可読記憶媒体。 - 前記第1の命令は、実行時に、前記所与の分岐点において所与のレーンに対して検出された分岐方向に少なくとも部分的に基づいて、前記複数の命令のうち何れかの命令を前記所与のレーンに割り当てることを前記ターゲットプロセッサに実行させる、請求項2に記載のコンピュータ可読記憶媒体。
- 前記少なくとも1つのプログラムの前記命令は、次のプログラムカウンタ(PC)に対応するVLIWの格納されたサイズを前記ターゲットプロセッサに更新させるように構成された第2の命令を追加することを前記プロセッサに実行させる、請求項2に記載のコンピュータ可読記憶媒体。
- 前記少なくとも1つのプログラムの前記命令は、前記ターゲットプロセッサに対して、前記検出された所与の分岐点と前記対応する収束点との間で第1の命令シーケンスが第2の命令シーケンスよりも小さいことに応じて、nopを、VLIW内の前記第2の命令シーケンスに対応する命令とグループ化させるように構成された第3の命令を追加することを前記プロセッサに実行させる、請求項4に記載のコンピュータ可読記憶媒体。
- 実行時に、前記所与のVLIW内の命令を前記複数の並列実行レーンに割り当てるために、前記第1の命令は、前記複数の実行レーンのうち対応するレーンと関連付けられているベクトルレジスタ内の特定のビット範囲にオフセットを書き込むように前記ターゲットプロセッサに実行させ、前記オフセットは、実行のために関連付けられたレーンに対してフェッチされた所与のVLIW内の所与の命令を識別する、請求項4に記載のコンピュータ可読記憶媒体。
- 前記少なくとも1つのプログラムの前記命令は、
所与の命令シーケンスが、前記識別されたループの終わりに達していることに応じて、
実行時に、前記所与の命令シーケンスが、前記識別されたループの開始に分岐して戻るようにスケジューリングされているという判断に応じて、前記ベクトルレジスタ内の対応するビット範囲内にスリープ状態を書き込むことと、
実行時に、前記所与の命令シーケンスが、前記識別されたループの外部に分岐するようにスケジューリングされているという判断に応じて、前記ベクトルレジスタ内の前記対応するビット範囲内に終了状態を書き込むことと、
を前記ターゲットプロセッサに実行させるように構成された第4の命令を追加することを前記プロセッサに実行させる、
請求項6に記載のコンピュータ可読記憶媒体。 - 前記少なくとも1つのプログラムの前記命令は、
前記複数のレーンのうち、前記スリープ状態または前記終了状態にある前記所与の命令シーケンスに対応するレーンを検出したことに応じて、
前記所与の命令シーケンスの実行を停止することと、
少なくとも次のプログラムカウンタ(PC)および前記所与の命令シーケンスに対応する識別子(ID)を格納することと、
を前記ターゲットプロセッサに実行させるように構成された第5の命令を追加することを前記プロセッサに実行させる、
請求項7に記載のコンピュータ可読記憶媒体。 - 前記少なくとも1つのプログラムの前記命令は、
レーンが前記スリープ状態にあるか前記終了状態にあることに応じて、前記レーン内の命令の実行を、個別に格納された次のPCで再開することを前記ターゲットプロセッサに実行させるように構成された第6の命令を追加することを前記プロセッサに実行させる、請求項8に記載のコンピュータ可読記憶媒体。 - 前記少なくとも1つのプログラムの前記命令は、
スリープ状態にある命令のみの実行を、個別に格納された次のPCで再開することを前記ターゲットプロセッサに実行させるように構成された第7の命令を追加することを前記プロセッサに実行させる、請求項8に記載のコンピュータ可読記憶媒体。 - 単一命令複数データ(SIMD)マイクロアーキテクチャ内の複数の並列実行レーンと、
超大命令語(VLIW)のサイズを格納するように構成されたサイズレジスタと、
プログラムコードを実行するように構成された制御ロジックと、
を備え、
前記プログラムコードは、
複数のプログラム命令内でループおよび対応する基本ブロックを識別することと、
前記複数のプログラム命令内の識別されたループ内の所与の分岐点を識別したことに応じて、前記識別されたループ内の複数の命令を複数の超大命令語(VLIW)に配置することであって、少なくとも1つのVLIWは、前記所与の分岐点と対応する収束点との間の異なる基本ブロックから混ぜ合わされた命令を含む、ことと、により生成される、複数のVLIWを含むものである、
プロセッサ。 - 前記複数の並列実行レーンのうち対応するレーンと関連付けられている特定のビット範囲内にオフセットを格納するように構成されたベクトルレジスタをさらに備え、
前記オフセットは、実行のために関連付けられたレーンに対してフェッチされた所与のVLIW内の所与の命令を識別する、請求項11に記載のプロセッサ。 - 前記ベクトルレジスタの前記ビット範囲に格納される前記オフセットの有効な値としてありうる、互いに異なる値の数は、前記サイズレジスタに格納されたサイズと等しい、請求項12に記載のプロセッサ。
- オフセットが、前記VLIW内の複数の資源に依存しない命令に対応しているとの検出に応じて、前記複数の並列実行レーンのうち前記オフセットに関連付けられたレーンは、関連付けられたレーン内の前記複数の命令を同時に実行するようにさらに構成されている、請求項12に記載のプロセッサ。
- 所与の命令シーケンスが前記識別されたループの終わりに達しており、且つ、前記所与の命令シーケンス、及び、対応するレーンが、前記識別されたループの開始に分岐して戻るようにスケジューリングされていることを示すスリープ状態、または、前記識別されたループの外側に分岐するようにスケジューリングされていることを示す終了状態のいずれかであることに応じて、前記制御ロジックは、
前記所与の命令シーケンスの実行を停止することと、
少なくとも次のプログラムカウンタ(PC)および前記所与の命令シーケンスに対応する前記レーンの識別子(ID)を格納することと、
を行うようにさらに構成されている、請求項12に記載のプロセッサ。 - 前記複数の並列実行レーンの各レーンが、前記スリープ状態または前記終了状態にあることに応じて、前記制御ロジックは、個別に格納された次のPCに分岐することにより、レーンごとの実行を再開するようにさらに構成されている、請求項15に記載のプロセッサ。
- 前記複数の並列実行レーンの各レーンが、前記スリープ状態または前記終了状態にあることに応じて、前記制御ロジックは、個別に格納された次のPCに分岐することにより、スリープ状態にあるレーンのみの実行を再開するようにさらに構成されている、請求項15に記載のプロセッサ。
- 複数のプログラム命令内でループおよび対応する基本ブロックを識別することと、
識別されたループ内の所与の分岐点に応じて、前記識別されたループ内の複数の命令を複数の超大命令語(VLIW)に配置することとであって、少なくとも1つのVLIWは、前記所与の分岐点と対応する収束点との間の異なる基本ブロックから混ぜ合わされた命令を含む、ことと、
を含む、方法。 - 前記識別されたループ内の前記所与の分岐点に応じて、前記所与の分岐点において所与のレーンの実行時に検出した分岐方向に基づいて、実行時に、所与のVLIW内の命令を、単一命令複数データ(SIMD)マイクロアーキテクチャを含むターゲットプロセッサ内の複数の並列実行レーンに割り当てることをさらに含む、請求項18に記載の方法。
- 実行時に、前記所与のVLIW内の命令を前記複数の並列実行レーンに割り当てるために、前記複数の並列実行レーンのうち対応するレーンと関連付けられている指示を格納することをさらに含み、
前記指示は、実行するために関連付けられたレーンに対して前記所与のVLIW内の所与の命令を識別する、請求項19に記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/753,098 | 2013-01-29 | ||
| US13/753,098 US9830164B2 (en) | 2013-01-29 | 2013-01-29 | Hardware and software solutions to divergent branches in a parallel pipeline |
| PCT/US2014/013455 WO2014120690A1 (en) | 2013-01-29 | 2014-01-28 | Hardware and software solutions to divergent branches in a parallel pipeline |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2016504699A JP2016504699A (ja) | 2016-02-12 |
| JP6236093B2 true JP6236093B2 (ja) | 2017-11-22 |
Family
ID=51224341
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015555420A Active JP6236093B2 (ja) | 2013-01-29 | 2014-01-28 | 並列パイプラインにおいてブランチを分岐するためのハードウェアおよびソフトウェアソリューション |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9830164B2 (ja) |
| EP (1) | EP2951682B1 (ja) |
| JP (1) | JP6236093B2 (ja) |
| KR (1) | KR101787653B1 (ja) |
| CN (1) | CN105074657B (ja) |
| WO (1) | WO2014120690A1 (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9612811B2 (en) * | 2014-01-21 | 2017-04-04 | Nvidia Corporation | Confluence analysis and loop fast-forwarding for improving SIMD execution efficiency |
| EP3106982B1 (en) * | 2015-06-18 | 2021-03-10 | ARM Limited | Determination of branch convergence in a sequence of program instructions |
| JP6167193B1 (ja) * | 2016-01-25 | 2017-07-19 | 株式会社ドワンゴ | プロセッサ |
| CN110716750A (zh) * | 2018-07-11 | 2020-01-21 | 超威半导体公司 | 用于部分波前合并的方法和系统 |
| KR102329368B1 (ko) * | 2019-02-26 | 2021-11-19 | 미쓰비시덴키 가부시키가이샤 | 정보 처리 장치, 정보 처리 방법 및 기록 매체에 저장된 정보 처리 프로그램 |
| CN112230995B (zh) * | 2020-10-13 | 2024-04-09 | 广东省新一代通信与网络创新研究院 | 一种指令的生成方法、装置以及电子设备 |
| CN113885877A (zh) * | 2021-10-11 | 2022-01-04 | 北京超弦存储器研究院 | 编译的方法、装置、设备及介质 |
| US11762762B1 (en) * | 2022-03-24 | 2023-09-19 | Xilinx, Inc. | Static and automatic inference of inter-basic block burst transfers for high-level synthesis |
Family Cites Families (29)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4435758A (en) * | 1980-03-10 | 1984-03-06 | International Business Machines Corporation | Method for conditional branch execution in SIMD vector processors |
| EP0374419A3 (en) | 1988-12-21 | 1991-04-10 | International Business Machines Corporation | Method and apparatus for efficient loop constructs in hardware and microcode |
| DE69424370T2 (de) | 1993-11-05 | 2001-02-15 | Intergraph Corp., Huntsville | Befehlscachespeicher mit Kreuzschienenschalter |
| GB2311882B (en) | 1996-04-04 | 2000-08-09 | Videologic Ltd | A data processing management system |
| US6003128A (en) | 1997-05-01 | 1999-12-14 | Advanced Micro Devices, Inc. | Number of pipeline stages and loop length related counter differential based end-loop prediction |
| US5898865A (en) | 1997-06-12 | 1999-04-27 | Advanced Micro Devices, Inc. | Apparatus and method for predicting an end of loop for string instructions |
| US6157988A (en) | 1997-08-01 | 2000-12-05 | Micron Technology, Inc. | Method and apparatus for high performance branching in pipelined microsystems |
| US6032252A (en) | 1997-10-28 | 2000-02-29 | Advanced Micro Devices, Inc. | Apparatus and method for efficient loop control in a superscalar microprocessor |
| US6366999B1 (en) | 1998-01-28 | 2002-04-02 | Bops, Inc. | Methods and apparatus to support conditional execution in a VLIW-based array processor with subword execution |
| US6356994B1 (en) | 1998-07-09 | 2002-03-12 | Bops, Incorporated | Methods and apparatus for instruction addressing in indirect VLIW processors |
| JP2000259579A (ja) | 1999-03-11 | 2000-09-22 | Hitachi Ltd | 半導体集積回路 |
| JP3616556B2 (ja) * | 1999-06-29 | 2005-02-02 | 株式会社東芝 | 拡張命令を処理する並列プロセッサ |
| US6986025B2 (en) * | 2001-06-11 | 2006-01-10 | Broadcom Corporation | Conditional execution per lane |
| EP1367485B1 (en) * | 2002-05-31 | 2012-10-31 | STMicroelectronics Limited | Pipelined processing |
| US7159103B2 (en) | 2003-03-24 | 2007-01-02 | Infineon Technologies Ag | Zero-overhead loop operation in microprocessor having instruction buffer |
| US7200688B2 (en) * | 2003-05-29 | 2007-04-03 | International Business Machines Corporation | System and method asynchronous DMA command completion notification by accessing register via attached processing unit to determine progress of DMA command |
| US7124318B2 (en) * | 2003-09-18 | 2006-10-17 | International Business Machines Corporation | Multiple parallel pipeline processor having self-repairing capability |
| GB2409065B (en) * | 2003-12-09 | 2006-10-25 | Advanced Risc Mach Ltd | Multiplexing operations in SIMD processing |
| US7366885B1 (en) | 2004-06-02 | 2008-04-29 | Advanced Micro Devices, Inc. | Method for optimizing loop control of microcoded instructions |
| US7814487B2 (en) | 2005-04-26 | 2010-10-12 | Qualcomm Incorporated | System and method of executing program threads in a multi-threaded processor |
| US7330964B2 (en) * | 2005-11-14 | 2008-02-12 | Texas Instruments Incorporated | Microprocessor with independent SIMD loop buffer |
| US8327115B2 (en) * | 2006-04-12 | 2012-12-04 | Soft Machines, Inc. | Plural matrices of execution units for processing matrices of row dependent instructions in single clock cycle in super or separate mode |
| JP2008090744A (ja) | 2006-10-04 | 2008-04-17 | Matsushita Electric Ind Co Ltd | プロセッサおよびオブジェクトコード生成装置 |
| EP2106584A1 (en) | 2006-12-11 | 2009-10-07 | Nxp B.V. | Pipelined processor and compiler/scheduler for variable number branch delay slots |
| US7937574B2 (en) | 2007-07-17 | 2011-05-03 | Advanced Micro Devices, Inc. | Precise counter hardware for microcode loops |
| US20090327674A1 (en) * | 2008-06-27 | 2009-12-31 | Qualcomm Incorporated | Loop Control System and Method |
| US20100281483A1 (en) | 2009-04-30 | 2010-11-04 | Novafora, Inc. | Programmable scheduling co-processor |
| CN101930358B (zh) * | 2010-08-16 | 2013-06-19 | 中国科学技术大学 | 一种单指令多数据流结构上的数据处理方法及处理器 |
| KR101700406B1 (ko) | 2010-11-16 | 2017-01-31 | 삼성전자주식회사 | 재구성 가능 어레이의 실행 모드를 동적으로 결정하기 위한 장치 및 방법 |
-
2013
- 2013-01-29 US US13/753,098 patent/US9830164B2/en active Active
-
2014
- 2014-01-28 WO PCT/US2014/013455 patent/WO2014120690A1/en active Application Filing
- 2014-01-28 JP JP2015555420A patent/JP6236093B2/ja active Active
- 2014-01-28 EP EP14746711.2A patent/EP2951682B1/en active Active
- 2014-01-28 KR KR1020157023380A patent/KR101787653B1/ko active IP Right Grant
- 2014-01-28 CN CN201480017686.3A patent/CN105074657B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP2951682A4 (en) | 2016-12-28 |
| CN105074657B (zh) | 2018-11-30 |
| WO2014120690A1 (en) | 2014-08-07 |
| EP2951682A1 (en) | 2015-12-09 |
| JP2016504699A (ja) | 2016-02-12 |
| KR20150112017A (ko) | 2015-10-06 |
| KR101787653B1 (ko) | 2017-11-15 |
| CN105074657A (zh) | 2015-11-18 |
| EP2951682B1 (en) | 2018-08-22 |
| US20140215183A1 (en) | 2014-07-31 |
| US9830164B2 (en) | 2017-11-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6159825B2 (ja) | ハードウェアポインタを使用したsimdコア内での分岐ブランチに対するソリューション | |
| JP6236093B2 (ja) | 並列パイプラインにおいてブランチを分岐するためのハードウェアおよびソフトウェアソリューション | |
| EP2710467B1 (en) | Automatic kernel migration for heterogeneous cores | |
| Yang et al. | A GPGPU compiler for memory optimization and parallelism management | |
| JP3601341B2 (ja) | 並列プログラム生成方法 | |
| KR101417597B1 (ko) | 제로 프레디케이트 브랜치 예측실패에 대한 브랜치 예측실패 거동 억제 | |
| US20120331278A1 (en) | Branch removal by data shuffling | |
| US20100250564A1 (en) | Translating a comprehension into code for execution on a single instruction, multiple data (simd) execution | |
| US9921838B2 (en) | System and method for managing static divergence in a SIMD computing architecture | |
| CN113360157A (zh) | 一种程序编译方法、设备以及计算机可读介质 | |
| Hong et al. | Improving simd parallelism via dynamic binary translation | |
| US20130067196A1 (en) | Vectorization of machine level scalar instructions in a computer program during execution of the computer program | |
| US20160328236A1 (en) | Apparatus and method for handling registers in pipeline processing | |
| KR101118321B1 (ko) | 리타게팅된 그래픽 프로세서 가속 코드의 범용 프로세서에 의한 실행 | |
| US20170315807A1 (en) | Hardware support for dynamic data types and operators | |
| Masuda et al. | Software and Hardware Design Issues for Low Complexity High Performance Processor Architecture | |
| Cowley | Extending the Capabilities of Von Neumann with a Dataflow Sub-ISA | |
| Berr | Efficient Simulation of PRAM Algorithms on Shared Memory Machines | |
| 王昊 et al. | A GCC Vectorizer based Instruction Translating Method for An Array Accelerator |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160203 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20160203 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20160222 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160622 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160802 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20161101 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20161228 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170202 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170516 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20170816 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170912 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171003 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171027 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6236093 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |