JP6232075B2 - 映像符号化装置及び方法、映像復号装置及び方法、及び、それらのプログラム - Google Patents
映像符号化装置及び方法、映像復号装置及び方法、及び、それらのプログラム Download PDFInfo
- Publication number
- JP6232075B2 JP6232075B2 JP2015551543A JP2015551543A JP6232075B2 JP 6232075 B2 JP6232075 B2 JP 6232075B2 JP 2015551543 A JP2015551543 A JP 2015551543A JP 2015551543 A JP2015551543 A JP 2015551543A JP 6232075 B2 JP6232075 B2 JP 6232075B2
- Authority
- JP
- Japan
- Prior art keywords
- depth
- setting
- motion information
- image
- representative
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/10—Processing, recording or transmission of stereoscopic or multi-view image signals
- H04N13/106—Processing image signals
- H04N13/161—Encoding, multiplexing or demultiplexing different image signal components
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N13/00—Stereoscopic video systems; Multi-view video systems; Details thereof
- H04N13/20—Image signal generators
- H04N13/271—Image signal generators wherein the generated image signals comprise depth maps or disparity maps
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/573—Motion compensation with multiple frame prediction using two or more reference frames in a given prediction direction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
Description
なお、自由視点映像は、自由視点テレビ、任意視点映像、任意視点テレビなどと呼ばれることもある。
ここで、デプスマップとは、カメラから被写体までのデプス(距離)を画素ごとに表現したものであり、被写体の三次元的な位置を表現している。ある条件を満たす場合、デプスは二つのカメラ間の視差の逆数に比例しているため、ディスパリティマップ(視差画像)と呼ばれることもある。
なお、カメラから被写体までの距離の他に、表現対象空間上に張られた三次元座標系のZ軸に対する座標値をデプスとして用いることもある。一般に、撮影された画像に対して水平方向をX軸、垂直方向をY軸とするため、Z軸はカメラの向きと一致するが、複数のカメラに対して共通の座標系を用いる場合など、Z軸がカメラの向きと一致しない場合もある。
以下では、距離・Z値を区別せずにデプスと呼び、デプスを画素値として表した画像をデプスマップと呼ぶ。ただし、厳密にはディスパリティマップでは基準となるカメラ対を設定する必要がある。
また、等間隔に量子化する際に、物理量をそのまま量子化する方法と物理量の逆数を量子化する方法とがある。距離の逆数は視差に比例した値となるため、距離を高精度に表現する必要がある場合には、前者が使用され、視差を高精度に表現する必要がある場合には、後者が使用されることが多い。
以下では、デプスの画素値化の方法や量子化の方法に関係なく、デプスが画像として表現されたものを全てデプスマップと呼ぶ。
以下では、デプスマップとそれにより構成される映像を区別せずにデプスマップと呼ぶ。
映像符号化では、被写体が空間的および時間的に連続しているという特徴を利用して効率的な符号化を実現するために、映像の各フレームをマクロブロックと呼ばれる処理単位ブロックに分割し、マクロブロックごとにその映像信号を空間的または時間的に予測し、その予測方法を示す予測情報と予測残差とを符号化する。
映像信号を空間的に予測する場合は、例えば空間的な予測の方向を示す情報が予測情報となり、時間的に予測する場合は、例えば参照するフレームを示す情報とそのフレーム中の位置を示す情報とが予測情報となる。
空間的に行う予測は、フレーム内の予測であることから、フレーム内予測(画面内予測、イントラ予測)と呼ばれ、時間的に行う予測は、フレーム間の予測であることから、フレーム間予測(画面間予測、インター予測)と呼ばれる。
さらに、同じシーンを複数の位置や向きから撮影した映像からなる多視点映像を符号化する際には、映像の視点間の変化、すなわち視差を補償して映像信号の予測を行うことになるため、視差補償予測が用いられる。
例えば、MPEG−C Part.3を用いて、多視点映像とそれに対するデプスマップを表現する場合は、それぞれを既存の映像符号化方式を用いて符号化する。
非特許文献2では、処理対象の領域に対して、視差ベクトルを用いて、既に処理済みの別の視点の映像の領域を決定し、その領域を符号化する際に使用された動き情報を、処理対象の領域の動き情報またはその予測値として用いている。このとき効率的な符号化を実現するためには、処理対象の領域に対して精度の高い視差ベクトルを獲得する必要がある。
非特許文献2では、最も単純な方法として、処理対象の領域と時間または空間的に隣接する領域に対して与えられた視差ベクトルを、処理対象領域の視差ベクトルとする方法が用いられている。更に、より正確な視差ベクトルを求めるために、処理対象の領域に対するデプスを推定または取得し、そのデプスを変換して視差ベクトルを獲得する方法も用いられている。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と、
前記符号化対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定手段と、
前記符号化対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定手段と
を有し、
前記代表デプス設定手段は、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定手段は、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像符号化装置を提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と、
前記変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像符号化装置も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と、
前記対応位置と前記合成動き情報とに基づいて、前記デプスマップから過去デプスを設定する過去デプス設定手段と、
前記過去デプスに基づいて、前記参照視点画像上の位置を前記符号化対象画像上の位置へと変換する逆変換行列を設定する逆変換行列設定手段と、前記逆変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像符号化装置も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と
を有し、
前記符号化対象画像の視点と前記参照視点との位置関係の変化がない、または所定の大きさ以下の場合には、前記変換行列設定手段による変換行列の設定を行わずに、前記対応位置設定手段は直前に符号化された画像で用いた前記変換行列を用いることを特徴とする映像符号化装置も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と、
前記復号対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定手段と、
前記復号対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定手段と
を有し、
前記代表デプス設定手段は、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定手段は、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像復号装置も提供する。
典型的には、前記デプス参照視差ベクトル設定手段は、前記復号対象領域に隣接する領域を復号する際に使用した視差ベクトルを用いて、前記デプス参照視差ベクトルを設定する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と、
前記変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像復号装置も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と、
前記対応位置と前記合成動き情報とに基づいて、前記デプスマップから過去デプスを設定する過去デプス設定手段と、
前記過去デプスに基づいて、前記参照視点画像上の位置を前記復号対象画像上の位置へと変換する逆変換行列を設定する逆変換行列設定手段と、
前記逆変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像復号装置も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と
を有し、
前記復号対象画像の視点と前記参照視点との位置関係の変化がない、または所定の大きさ以下の場合には、前記変換行列設定手段による変換行列の設定を行わずに、前記対応位置設定手段は直前に復号された画像で用いた前記変換行列を用いることを特徴とする映像復号装置置も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと、
前記復号対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定ステップと、
前記復号対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定ステップと
を有し、
前記代表デプス設定ステップは、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定ステップは、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像復号方法も提供する。
典型的には、前記デプス参照視差ベクトル設定ステップは、前記復号対象領域に隣接する領域を復号する際に使用した視差ベクトルを用いて、前記デプス参照視差ベクトルを設定する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと、
前記変換行列を用いて、前記合成動き情報を変換する合成動き情報変換ステップと
を有し、
前記予測画像生成ステップは、前記変換された合成動き情報を用いることを特徴とする映像復号方法も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと、
前記対応位置と前記合成動き情報とに基づいて、前記デプスマップから過去デプスを設定する過去デプス設定ステップと、
前記過去デプスに基づいて、前記参照視点画像上の位置を前記復号対象画像上の位置へと変換する逆変換行列を設定する逆変換行列設定ステップと、
前記逆変換行列を用いて、前記合成動き情報を変換する合成動き情報変換ステップと
を有し、
前記予測画像生成ステップは、前記変換された合成動き情報を用いることを特徴とする映像復号方法も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと
を有し、
前記復号対象画像の視点と前記参照視点との位置関係の変化が所定の大きさ以下の場合には、前記変換行列設定ステップによる変換行列の設定を行わずに、前記対応位置設定ステップは直前に復号された画像で用いた前記変換行列を用いることを特徴とする映像復号方法も提供する。
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成ステップと、
前記符号化対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定ステップと、
前記符号化対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定ステップと
を有し、
前記代表デプス設定ステップは、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定ステップは、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像符号化方法も提供する。
本発明はまた、コンピュータに、前記映像符号化方法を実行させるための映像符号化プログラムも提供する。
以下の説明においては、第1のカメラ(カメラAという)、第2のカメラ(カメラBという)の2つのカメラで撮影された多視点映像を符号化する場合を想定し、カメラAを参照視点としてカメラBの映像の1フレームを符号化または復号するものとして説明する。
なお、デプスから視差を得るために必要となる情報は、別途与えられているものとする。具体的には、カメラAとカメラBの位置関係を表す外部パラメータや、カメラによる画像平面への投影情報を表す内部パラメータである、これらと同じ意味をもつものであれば、別の形式で必要な情報が与えられていてもよい。
これらのカメラパラメータに関する詳しい説明は、例えば、文献「Oliver Faugeras, "Three-Dimension Computer Vision", MIT Press; BCTC/UFF-006.37 F259 1993, ISBN:0-262-06158-9.」に記載されている。この文献には、複数のカメラの位置関係を示すパラメータや、カメラによる画像平面への投影情報を表すパラメータに関する説明が記載されている。
また、座標値やブロックに対応付け可能なインデックス値とベクトルとの加算によって、その座標やブロックをベクトルの分だけずらした位置の座標値やブロックを表すものとする。
映像符号化装置100は、図1に示すように、符号化対象画像入力部101、符号化対象画像メモリ102、参照視点動き情報入力部103、デプスマップ入力部104、動き情報生成部105、画像符号化部106、画像復号部107及び参照画像メモリ108を備えている。
符号化対象画像メモリ102は、入力した符号化対象画像を記憶する。
参照視点動き情報入力部103は、参照視点の映像に対する動き情報(動きベクトルなど)を映像符号化装置100に入力する。以下では、ここで入力された動き情報を、参照視点動き情報と呼ぶ。ここではカメラAの動き情報を入力するものとする。
なお、デプスマップとは、対応する画像の各画素に写っている被写体の3次元位置を表すものである。例えば、カメラから被写体までの距離や、画像平面とは平行ではない軸に対する座標値、別のカメラ(例えばカメラA)に対する視差量を用いることができる。
なお、ここではデプスマップとして画像の形態で提供されるものとしているが、同様の情報が得られるのであれば、画像の形態でなくても構わない。
画像符号化部106は、生成された動き情報を用いながら、符号化対象画像を予測符号化する。
画像復号部107は、符号化対象画像のビットストリームを復号する。
参照画像メモリ108は、符号化対象画像のビットストリームを復号した際に得られる画像を記憶する。
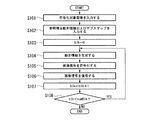
まず、符号化対象画像入力部101は、符号化対象画像Orgを入力し、符号化対象画像メモリ102に記憶する(ステップS101)。
次に、参照視点動き情報入力部103は参照視点動き情報を映像符号化装置100に入力し、デプスマップ入力部104はデプスマップを映像符号化装置100に入力し、それぞれ動き情報生成部105へ出力される(ステップS102)。
デプスマップに関しては、既に符号化済みのものを復号したもの以外に、複数のカメラに対して復号された多視点映像に対してステレオマッチング等を適用することで推定したデプスマップや、復号された視差ベクトルや動きベクトルなどを用いて推定されるデプスマップなども、復号側で同じものが得られるものとして用いることができる。
すなわち、符号化対象領域インデックスをblk、1フレーム中の総符号化対象領域数をnumBlksで表すとすると、blkを0で初期化し(ステップS103)、その後、blkに1を加算しながら(ステップS107)、blkがnumBlksになるまで(ステップS108)、以下の処理(ステップS104〜S106)を繰り返す。
一般的な符号化では16画素×16画素のマクロブロックと呼ばれる処理単位ブロックへ分割するが、復号側と同じであればその他の大きさのブロックに分割しても構わない。また、画像全体を同じサイズで分割せず、領域ごとに異なるサイズのブロックに分割しても構わない。
符号化対象領域blkに対する動き情報が得られたら、画像符号化部106は、その動き情報と参照画像メモリ108に記憶された画像とを用いて動き補償予測を行いながら、符号化対象領域blkにおける符号化対象画像の映像信号(画素値)を符号化する(ステップ105)。符号化の結果得られるビットストリームが映像符号化装置100の出力となる。なお、符号化する方法には、どのような方法を用いても構わない。
MPEG−2やH.264/AVCなどの一般的な符号化では、ブロックblkの映像信号と予測画像との差分信号に対して、DCTなどの周波数変換、量子化、2値化、エントロピー符号化を順に施すことで符号化を行う。
ここでは、符号化時に用いた手法に対応する手法を用いる。例えば、MPEG−2やH.264/AVCなどの一般的な符号化であれば、符号データに対して、エントロピー復号、逆2値化、逆量子化、IDCTなどの周波数逆変換を順に施し、得られた2次元信号に対して予測画像を加え、最後に画素値の値域でクリッピングを行うことで映像信号を復号する。
なお、符号化側での処理がロスレスになる直前のデータと予測画像を受け取り、簡略化した復号処理によって復号処理を行っても構わない。
なお、符号化対象画像とデプスマップの解像度が異なる場合は、解像度比に応じてスケーリングした領域を設定する。符号化対象視点と異なる視点の1つをデプス視点とするとき、デプス視点に対するデプスマップを用いる場合は、符号化対象領域blkにおける符号化対象視点とデプス視点の視差DVを求め、blk+DVにおけるデプスマップを設定する。符号化対象画像とデプスマップの解像度が異なる場合は、上述のように、解像度比に応じて位置および大きさのスケーリングを行う。
例えば、符号化対象領域blkの周辺領域を符号化する際に使用された視差ベクトルや、符号化対象画像全体や符号化対象領域を含む部分画像に対して設定されたグローバル視差ベクトル、符号化対象領域に対して別途設定し符号化される視差ベクトルなどを用いることが可能である。また、異なる領域や過去に符号化された画像で使用した視差ベクトルを記憶しておき、用いても構わない。
更に、符号化対象視点に対して過去に符号化されたデプスマップの符号化対象領域と同位置のデプスマップを変換して得られる視差ベクトルを用いても構わない。
代表画素位置posを設定する代表的な方法としては、代表画素位置として符号化対象領域内の中央や左上など予め定められた位置を設定する方法や、代表デプスを求めた後に、その代表デプスと同じデプスを持つ符号化対象領域内の画素の位置を設定する方法がある。
具体的には、符号化対象領域内の中央に位置する4つの画素や、(四角形状の符号化対象領域の)4頂点に位置する画素、4頂点と中央に位置する画素を対象とし、最大のデプスや、最小のデプス、中央値のデプスなどを与える画素を選択する方法である。
代表デプスrepを設定する代表的な方法としては、符号化対象領域blkに対するデプスマップの平均値や中央値、最大値、最小値などを用いる方法がある。
また、符号化対象領域内の全ての画素ではなく、一部の画素に対するデプス値の平均値や中央値、最大値、最小値などを用いても構わない。一部の画素としては、4頂点や4頂点と中央などを用いても構わない。更に、符号化対象領域に対して、左上や中央など予め定められた位置に対するデプス値を用いる方法もある。
ここで、変換行列はホモグラフィ行列と呼ばれ、代表デプスで表現される平面に被写体が存在すると仮定したときに、視点間での画像平面上の点の対応関係を与えるものである。なお、変換行列Hrepはどのように求めても構わない。例えば、次の数式を用いて求めることが可能である。
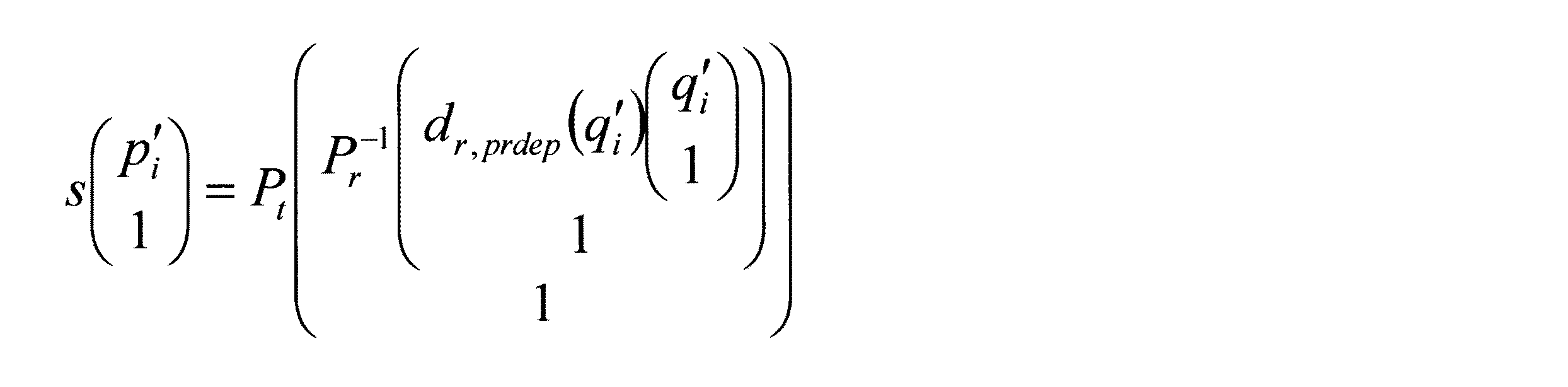
dt(pi)は、符号化対象画像上の点piにおけるデプスが代表デプスであるとしたときの、符号化対象視点から点piにおける被写体までの光軸上の距離を示す。
sは任意の実数であるが、カメラパラメータの誤差がない場合、sは参照視点の画像上の点qiにおける参照視点から点qiにおける被写体までの光軸上の距離dr(qi)と等しい。
また、上記定義に従い式2を計算すると、次の数式となる。なお、内部パラメータA、回転行列R、並進ベクトルtの添え字tとrは各カメラを表し、それぞれ符号化対象視点と参照視点を示す。
なお、対応位置(u,v)を含む領域に対して参照視点動き情報が記憶されていない場合は、動き情報なしの情報を設定しても、ゼロベクトルなどデフォルトの動き情報を設定しても、対応位置(u,v)に最も近い動き情報を記憶している領域を同定して、その領域において記憶されている参照視点動き情報を設定しても構わない。ただし、復号側と同じ規則で動き情報を設定する。
このようにすることで、異なる領域に対して生成される動き情報が全て同じ時間間隔を持つことになり、動き補償予測を行う際の参照画像を統一し、アクセスするメモリ空間を限定することが可能となる。なお、アクセスするメモリ空間が限定されることによって、キャッシュメモリのヒット率を向上させ、処理速度を向上することが可能となる。
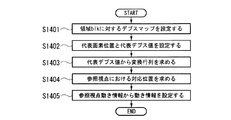
すなわち、ステップS1405において設定された動き情報をmv=(mvx,mvy)Tとすると、変換した動き情報mv’は次の数式で表される。
符号化対象視点と参照視点とで共通する軸を用いてデプスを表現している場合、この変換は、引数で与えられたデプスをそのまま返す。
直接計算する場合、まず、参照視点に対する画像中の異なる4点q’i(i=1,2,3,4)に対して、次の式に基づいて、符号化対象視点の画像上の対応点p’iを求める。
図4は本実施形態による映像復号装置の構成を示すブロック図である。映像復号装置200は、図4に示すように、ビットストリーム入力部201、ビットストリームメモリ202、参照視点動き情報入力部203、デプスマップ入力部204、動き情報生成部205、画像復号部206及び参照画像メモリ207を備えている。
ビットストリームメモリ202は、入力した復号対象画像に対するビットストリームを記憶する。
参照視点動き情報入力部203は、参照視点の映像に対する動き情報(動きベクトルなど)を映像復号装置200に入力する。以下では、ここで入力された動き情報を、参照視点動き情報と呼ぶ。ここではカメラAの動き情報が入力されるものとする。
なお、デプスマップとは、対応する画像の各画素に写っている被写体の3次元位置を表すものである。例えば、カメラから被写体までの距離や、画像平面とは平行ではない軸に対する座標値、別のカメラ(例えばカメラA)に対する視差量を用いることができる。
なお、ここではデプスマップとして画像の形態で提供されるものとしているが、同様の情報が得られるのであれば、画像の形態でなくても構わない。
画像復号部206は、生成された動き情報を用いながら、上記ビットストリームから復号対象画像を復号して出力する。
参照画像メモリ207は、得られた復号対象画像を、以降の復号のために記憶する。
まず、ビットストリーム入力部201は、復号対象画像を符号化したビットストリームを映像復号装置200に入力し、ビットストリームメモリ202に記憶する(ステップS201)。
次に、参照視点動き情報入力部203は参照視点具置き情報を映像復号装置200に入力し、デプスマップ入力部204はデプスマップを映像復号装置200に入力し、それぞれ動き情報生成部205へ出力される(ステップS202)。
デプスマップに関しては、別途復号したもの以外に、複数のカメラに対して復号された多視点映像に対してステレオマッチング等を適用することで推定したデプスマップや、復号された視差ベクトルや動きベクトルなどを用いて推定されるデプスマップなどを用いることもある。
すなわち、復号対象領域インデックスをblk、1フレーム中の総復号対象領域数をnumBlksで表すとすると、blkを0で初期化し(ステップS203)、その後、blkに1を加算しながら(ステップS206)、blkがnumBlksになるまで(ステップS207)、以下の処理(ステップS204〜S205)を繰り返す。
一般的な復号では16画素×16画素のマクロブロックと呼ばれる処理単位ブロックへ分割するが、符号化側と同じであればその他の大きさのブロックに分割しても構わない。また、画像全体を同じサイズで分割せず、領域ごとに異なるサイズのブロックに分割しても構わない。
例えば、MPEG−2やH.264/AVCなどの一般的な符号化が用いられている場合は、ビットストリームに対して、エントロピー復号、逆2値化、逆量子化、IDCTなどの周波数逆変換を順に施し、得られた2次元信号に対して予測画像を加え、最後に画素値の値域でクリッピングを行うことで映像信号を復号する。
この場合、処理を適用するか否かを判断して、それを示すフラグを符号化/復号しても構わないし、なんらかの別の手段でそれを指定しても構わない。例えば、領域ごとの予測画像を生成する手法を示すモードの1つとして、処理を適用するか否かを表現するようにしても構わない。
すなわち、符号化対象画像または復号対象画像が変わるごとに、別途与えられるカメラパラメータによって表される符号化対象視点または復号対象視点と参照視点との位置関係と、直前のフレームにおけるカメラパラメータによって表される符号化対象視点または復号対象視点と参照視点との位置関係とを比較し、位置関係の変化がない又は小さいときには、直前のフレームで使用した変換行列の集合をそのまま用い、それ以外の場合にのみ変換行列の集合を求めるようにしても構わない。
なお、変換行列の集合を求める際に、全ての変換行列を求め直すのではなく、直前のフレームと位置関係の異なる参照視点に対するものと、定義の変化したデプスに対するものを同定し、それらに対してだけ求め直しても構わない。
再計算が必要か否かを示す情報は、フレーム全体に対して1つだけ設定しても構わないし、参照視点ごとに設定しても構わないし、デプスごとに設定しても構わない。
また、符号化側のみでチェックを行い、どちらの手法を用いるかを示す情報を符号化しても構わない。その場合、復号側ではその情報を復号し、どちらの手法を用いるかを決定する。
別の変換行列を用いることで、変換の精度や演算量、変換行列の更新頻度、変換行列を伝送する場合の符号量などを適宜制御することが可能である。なお、符号化ノイズの発生を防ぐためには、符号化時と復号時とで同じ変換行列を使用するようにする。
図6に示すシステムは:
・プログラムを実行するCPU50
・CPU50がアクセスするプログラムやデータが格納されるRAM等のメモリ51
・カメラ等からの符号化対象の映像信号を映像符号化装置内に入力する符号化対象画像入力部52(ディスク装置等による、映像信号を記憶する記憶部でもよい)
・メモリ等から参照視点の動き情報を映像符号化装置内に入力する参照視点動き情報入力部53(ディスク装置等による、動き情報を記憶する記憶部でもよい)
・(デプス情報を取得するための)デプスカメラ等からの符号化対象画像を撮影した視点に対するデプスマップを映像符号化装置内に入力するデプスマップ入力部54(ディスク装置等による、デプスマップを記憶する記憶部でもよい)
・映像像符号化処理をCPU50に実行させるソフトウェアプログラムである映像符号化プログラム551が格納されたプログラム記憶装置55
・CPU50がメモリ51にロードされた映像符号化プログラム551を実行することにより生成されたビットストリームを、例えばネットワークを介して出力するビットストリーム出力部56(ディスク装置等による、ビットストリームを記憶する記憶部でもよい)
とが、バスで接続された構成になっている。
図7に示すシステムは:
・プログラムを実行するCPU60
・CPU60がアクセスするプログラムやデータが格納されるRAM等のメモリ61
・映像符号化装置が本手法により符号化したビットストリームを映像復号装置内に入力するビットストリーム入力部62(ディスク装置等による、ビットストリームを記憶する記憶部でもよい)
・メモリ等からの参照視点の動き情報を映像復号装置内に入力する参照視点動き情報入力部63(ディスク装置等による、動き情報を記憶する記憶部でもよい)
・デプスカメラ等からの復号対象を撮影した視点に対するデプスマップを映像復号装置内に入力するデプスマップ入力部64(ディスク装置等による、デプス情報を記憶する記憶部でもよい)
・映像復号処理をCPU60に実行させるソフトウェアプログラムである映像復号プログラム651が格納されたプログラム記憶装置65
・CPU60がメモリ61にロードされた映像復号プログラム651を実行することにより、ビットストリームを復号して得られた復号対象画像を、再生装置などに出力する復号対象画像出力部66(ディスク装置等による、映像信号を記憶する記憶部でもよい)
とが、バスで接続された構成になっている。
なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。
さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含んでもよい。
また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであってもよく、PLD(Programmable Logic Device)やFPGA(Field Programmable Gate Array)等のハードウェアを用いて実現されるものであってもよい。
101・・・符号化対象画像入力部
102・・・符号化対象画像メモリ
103・・・参照視点動き情報入力部
104・・・デプスマップ入力部
105・・・動き情報生成部
106・・・画像符号化部
107・・・画像復号部
108・・・参照画像メモリ
200・・・映像復号装置
201・・・ビットストリーム入力部
202・・・ビットストリームメモリ
203・・・参照視点動き情報入力部
204・・・デプスマップ入力部
205・・・動き情報生成部
206・・・画像復号部
207・・・参照画像メモリ
Claims (18)
- 複数の異なる視点の映像からなる多視点映像の1フレームである符号化対象画像を符号化する際に、前記符号化対象画像を分割した領域である符号化対象領域ごとに、異なる視点間で予測しながら符号化を行う映像符号化装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置との対応関係を与える変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と、
前記符号化対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定手段と、
前記符号化対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定手段と
を有し、
前記代表デプス設定手段は、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定手段は、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像符号化装置。 - 前記デプス参照視差ベクトル設定手段は、前記符号化対象領域に隣接する領域を符号化する際に使用した視差ベクトルを用いて、前記デプス参照視差ベクトルを設定することを特徴とする請求項1に記載の映像符号化装置。
- 複数の異なる視点の映像からなる多視点映像の1フレームである符号化対象画像を符号化する際に、前記符号化対象画像を分割した領域である符号化対象領域ごとに、異なる視点間で予測しながら符号化を行う映像符号化装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と、
前記変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像符号化装置。 - 複数の異なる視点の映像からなる多視点映像の1フレームである符号化対象画像を符号化する際に、前記符号化対象画像を分割した領域である符号化対象領域ごとに、異なる視点間で予測しながら符号化を行う映像符号化装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と、
前記対応位置と前記合成動き情報とに基づいて、前記デプスマップから過去デプスを設定する過去デプス設定手段と、
前記過去デプスに基づいて、前記参照視点画像上の位置を前記符号化対象画像上の位置へと変換する逆変換行列を設定する逆変換行列設定手段と、
前記逆変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像符号化装置。 - 複数の異なる視点の映像からなる多視点映像の1フレームである符号化対象画像を符号化する際に、前記符号化対象画像を分割した領域である符号化対象領域ごとに、異なる視点間で予測しながら符号化を行う映像符号化装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成手段と
を有し、
前記符号化対象画像の視点と前記参照視点との位置関係の変化がない、または所定の大きさ以下の場合には、前記変換行列設定手段による変換行列の設定を行わずに、前記対応位置設定手段は直前に符号化された画像で用いた前記変換行列を用いることを特徴とする映像符号化装置。 - 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置との対応関係を与える変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と、
前記復号対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定手段と、
前記復号対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定手段と
を有し、
前記代表デプス設定手段は、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定手段は、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像復号装置。 - 前記デプス参照視差ベクトル設定手段は、前記復号対象領域に隣接する領域を復号する際に使用した視差ベクトルを用いて、前記デプス参照視差ベクトルを設定することを特徴とする請求項6に記載の映像復号装置。
- 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と、
前記変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像復号装置。 - 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と、
前記対応位置と前記合成動き情報とに基づいて、前記デプスマップから過去デプスを設定する過去デプス設定手段と、
前記過去デプスに基づいて、前記参照視点画像上の位置を前記復号対象画像上の位置へと変換する逆変換行列を設定する逆変換行列設定手段と、
前記逆変換行列を用いて、前記合成動き情報を変換する合成動き情報変換手段と
を有し、
前記予測画像生成手段は、前記変換された合成動き情報を用いることを特徴とする映像復号装置。 - 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号装置であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定手段と、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定手段と、
前記復号対象領域内の位置から代表位置を設定する代表位置設定手段と、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定手段と、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成手段と、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成手段と
を有し、
前記復号対象画像の視点と前記参照視点との位置関係の変化がない、または所定の大きさ以下の場合には、前記変換行列設定手段による変換行列の設定を行わずに、前記対応位置設定手段は直前に復号された画像で用いた前記変換行列を用いることを特徴とする映像復号装置。 - 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号方法であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置との対応関係を与える変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと、
前記復号対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定ステップと、
前記復号対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定ステップと
を有し、
前記代表デプス設定ステップは、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定ステップは、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像復号方法。 - 前記デプス参照視差ベクトル設定ステップは、前記復号対象領域に隣接する領域を復号する際に使用した視差ベクトルを用いて、前記デプス参照視差ベクトルを設定することを特徴とする請求項11に記載の映像復号方法。
- 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号方法であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと、
前記変換行列を用いて、前記合成動き情報を変換する合成動き情報変換ステップと
を有し、
前記予測画像生成ステップは、前記変換された合成動き情報を用いることを特徴とする映像復号方法。 - 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号方法であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステップと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと、
前記対応位置と前記合成動き情報とに基づいて、前記デプスマップから過去デプスを設定する過去デプス設定ステップと、
前記過去デプスに基づいて、前記参照視点画像上の位置を前記復号対象画像上の位置へと変換する逆変換行列を設定する逆変換行列設定ステップと、
前記逆変換行列を用いて、前記合成動き情報を変換する合成動き情報変換ステップと
を有し、
前記予測画像生成ステップは、前記変換された合成動き情報を用いることを特徴とする映像復号方法。 - 複数の異なる視点の映像からなる多視点動画像の符号データから、復号対象画像を復号する際に、前記復号対象画像を分割した領域である復号対象領域ごとに、異なる視点間で予測しながら復号を行う映像復号方法であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記復号対象画像上の位置を、該復号対象画像とは異なる参照視点に対する参照画像上の位置へと変換する変換行列を設定する変換行列設定ステッ
プと、
前記復号対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記復号対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記復号対象領域に対する予測画像を生成する予測画像生成ステップと
を有し、
前記復号対象画像の視点と前記参照視点との位置関係の変化がない、または所定の大きさ以下の場合には、前記変換行列設定ステップによる変換行列の設定を行わずに、前記対応位置設定ステップは直前に復号された画像で用いた前記変換行列を用いることを特徴とする映像復号方法。 - 複数の異なる視点の映像からなる多視点映像の1フレームである符号化対象画像を符号化する際に、前記符号化対象画像を分割した領域である符号化対象領域ごとに、異なる視点間で予測しながら符号化を行う映像符号化方法であって、
前記多視点映像中の被写体に対するデプスマップから代表デプスを設定する代表デプス設定ステップと、
前記代表デプスに基づいて、前記符号化対象画像上の位置を、該符号化対象画像とは異なる参照視点に対する参照視点画像上の位置との対応関係を与える変換行列を設定する変換行列設定ステップと、
前記符号化対象領域内の位置から代表位置を設定する代表位置設定ステップと、
前記代表位置と前記変換行列を用いて、前記代表位置に対する前記参照視点画像上での対応位置を設定する対応位置設定ステップと、
前記対応位置に基づいて、前記参照視点画像の動き情報である参照視点動き情報から前記符号化対象領域における合成動き情報を生成する動き情報生成ステップと、
前記合成動き情報を用いて、前記符号化対象領域に対する予測画像を生成する予測画像生成ステップと、
前記符号化対象領域に対して、前記デプスマップ上での対応領域であるデプス領域を設定するデプス領域設定ステップと、
前記符号化対象領域に対して、前記デプスマップに対する視差ベクトルであるデプス参照視差ベクトルを設定するデプス参照視差ベクトル設定ステップと
を有し、
前記代表デプス設定ステップは、前記デプス領域に対する前記デプスマップから代表デプスを設定し、
前記デプス領域設定ステップは、前記デプス参照視差ベクトルによって示される領域を前記デプス領域として設定することを特徴とする映像符号化方法。 - コンピュータに、請求項11に記載の映像復号方法を実行させるための映像復号プログラム。
- コンピュータに、請求項16に記載の映像符号化方法を実行させるための映像符号化プログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013250429 | 2013-12-03 | ||
| JP2013250429 | 2013-12-03 | ||
| PCT/JP2014/081986 WO2015083742A1 (ja) | 2013-12-03 | 2014-12-03 | 映像符号化装置及び方法、映像復号装置及び方法、及び、それらのプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2015083742A1 JPWO2015083742A1 (ja) | 2017-03-16 |
| JP6232075B2 true JP6232075B2 (ja) | 2017-11-22 |
Family
ID=53273503
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015551543A Active JP6232075B2 (ja) | 2013-12-03 | 2014-12-03 | 映像符号化装置及び方法、映像復号装置及び方法、及び、それらのプログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20160295241A1 (ja) |
| JP (1) | JP6232075B2 (ja) |
| KR (1) | KR20160079068A (ja) |
| CN (1) | CN105934949A (ja) |
| WO (1) | WO2015083742A1 (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018056181A1 (ja) * | 2016-09-26 | 2018-03-29 | ソニー株式会社 | 符号化装置、符号化方法、復号化装置、復号化方法、送信装置および受信装置 |
| US10389994B2 (en) * | 2016-11-28 | 2019-08-20 | Sony Corporation | Decoder-centric UV codec for free-viewpoint video streaming |
| FR3075540A1 (fr) * | 2017-12-15 | 2019-06-21 | Orange | Procedes et dispositifs de codage et de decodage d'une sequence video multi-vues representative d'une video omnidirectionnelle. |
| CN109974707B (zh) * | 2019-03-19 | 2022-09-23 | 重庆邮电大学 | 一种基于改进点云匹配算法的室内移动机器人视觉导航方法 |
| CN112672150A (zh) * | 2020-12-22 | 2021-04-16 | 福州大学 | 基于视频预测的视频编码方法 |
| US11501447B2 (en) * | 2021-03-04 | 2022-11-15 | Lemon Inc. | Disentangled feature transforms for video object segmentation |
| WO2023053444A1 (ja) * | 2021-10-01 | 2023-04-06 | 日本電気株式会社 | 移動体制御システム、移動体制御方法、および画像通信装置 |
| CN119676463A (zh) * | 2024-11-26 | 2025-03-21 | 天翼云科技有限公司 | 一种多视点视频的编码方法、装置、电子设备及介质 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3519594B2 (ja) * | 1998-03-03 | 2004-04-19 | Kddi株式会社 | ステレオ動画像用符号化装置 |
| JP4414379B2 (ja) * | 2005-07-28 | 2010-02-10 | 日本電信電話株式会社 | 映像符号化方法、映像復号方法、映像符号化プログラム、映像復号プログラム及びそれらのプログラムを記録したコンピュータ読み取り可能な記録媒体 |
| JP4999860B2 (ja) * | 2006-10-30 | 2012-08-15 | 日本電信電話株式会社 | 動画像符号化方法及び復号方法、それらの装置、及びそれらのプログラム並びにプログラムを記録した記憶媒体 |
| JP4828506B2 (ja) * | 2007-11-05 | 2011-11-30 | 日本電信電話株式会社 | 仮想視点画像生成装置、プログラムおよび記録媒体 |
| WO2013001813A1 (ja) * | 2011-06-29 | 2013-01-03 | パナソニック株式会社 | 画像符号化方法、画像復号方法、画像符号化装置および画像復号装置 |
| JP5749595B2 (ja) * | 2011-07-27 | 2015-07-15 | 日本電信電話株式会社 | 画像伝送方法、画像伝送装置、画像受信装置及び画像受信プログラム |
| US8898178B2 (en) * | 2011-12-15 | 2014-11-25 | Microsoft Corporation | Solution monitoring system |
| JP2013229674A (ja) * | 2012-04-24 | 2013-11-07 | Sharp Corp | 画像符号化装置、画像復号装置、画像符号化方法、画像復号方法、画像符号化プログラム、及び画像復号プログラム |
-
2014
- 2014-12-03 KR KR1020167014366A patent/KR20160079068A/ko not_active Ceased
- 2014-12-03 WO PCT/JP2014/081986 patent/WO2015083742A1/ja not_active Ceased
- 2014-12-03 CN CN201480065693.0A patent/CN105934949A/zh active Pending
- 2014-12-03 JP JP2015551543A patent/JP6232075B2/ja active Active
- 2014-12-03 US US15/038,611 patent/US20160295241A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2015083742A1 (ja) | 2017-03-16 |
| KR20160079068A (ko) | 2016-07-05 |
| CN105934949A (zh) | 2016-09-07 |
| US20160295241A1 (en) | 2016-10-06 |
| WO2015083742A1 (ja) | 2015-06-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6232075B2 (ja) | 映像符号化装置及び方法、映像復号装置及び方法、及び、それらのプログラム | |
| JP6232076B2 (ja) | 映像符号化方法、映像復号方法、映像符号化装置、映像復号装置、映像符号化プログラム及び映像復号プログラム | |
| JP6307152B2 (ja) | 画像符号化装置及び方法、画像復号装置及び方法、及び、それらのプログラム | |
| JP6053200B2 (ja) | 画像符号化方法、画像復号方法、画像符号化装置、画像復号装置、画像符号化プログラム及び画像復号プログラム | |
| JP6027143B2 (ja) | 画像符号化方法、画像復号方法、画像符号化装置、画像復号装置、画像符号化プログラム、および画像復号プログラム | |
| JPWO2008035665A1 (ja) | 画像符号化方法及び復号方法、それらの装置、画像復号装置、及びそれらのプログラム並びにプログラムを記録した記憶媒体 | |
| WO2014010584A1 (ja) | 画像符号化方法、画像復号方法、画像符号化装置、画像復号装置、画像符号化プログラム、画像復号プログラム及び記録媒体 | |
| JP5926451B2 (ja) | 画像符号化方法、画像復号方法、画像符号化装置、画像復号装置、画像符号化プログラム、および画像復号プログラム | |
| KR101750421B1 (ko) | 동화상 부호화 방법, 동화상 복호 방법, 동화상 부호화 장치, 동화상 복호 장치, 동화상 부호화 프로그램, 및 동화상 복호 프로그램 | |
| JP4944046B2 (ja) | 映像符号化方法,復号方法,符号化装置,復号装置,それらのプログラムおよびコンピュータ読み取り可能な記録媒体 | |
| US20160286212A1 (en) | Video encoding apparatus and method, and video decoding apparatus and method | |
| WO2015098827A1 (ja) | 映像符号化方法、映像復号方法、映像符号化装置、映像復号装置、映像符号化プログラム及び映像復号プログラム | |
| US20170019683A1 (en) | Video encoding apparatus and method and video decoding apparatus and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170321 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170516 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171017 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171020 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6232075 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |