JP6201385B2 - Storage apparatus and storage control method - Google Patents
Storage apparatus and storage control method Download PDFInfo
- Publication number
- JP6201385B2 JP6201385B2 JP2013080769A JP2013080769A JP6201385B2 JP 6201385 B2 JP6201385 B2 JP 6201385B2 JP 2013080769 A JP2013080769 A JP 2013080769A JP 2013080769 A JP2013080769 A JP 2013080769A JP 6201385 B2 JP6201385 B2 JP 6201385B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- hash value
- storage
- value
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images







Description
本発明は、ストレージ装置及びストレージ制御方法に関する。 The present invention relates to a storage apparatus and a storage control method.
従来、データをHDD(Hard Disk Drive)などの不揮発性記憶装置に書き込む前にハッシュ値を計算し、ハッシュ値が同じデータが既に記憶されている場合に、データを書き込むことなしにデータを共有する重複排除ストレージ技術がある。 Conventionally, a hash value is calculated before data is written to a nonvolatile storage device such as an HDD (Hard Disk Drive), and if data having the same hash value is already stored, the data is shared without writing the data. There is deduplication storage technology.
例えば、ハッシュのビット数を512ビットとすると、ハッシュ値が衝突する可能性は10150回に1回程度であり、データの重複排除を行うストレージ装置は、データが同じであるかを確認することなく、ハッシュ値だけでデータが同じであるか否かを判定できる。 For example, if the number of bits of hash is 512 bits, the possibility that hash values collide is about once every 10 150 times, and the storage device that performs data deduplication should check whether the data is the same. In addition, it can be determined whether or not the data is the same only by the hash value.
ここで、データはファイルや例えば大きさが64KB(キロバイト)のブロックであり、データを用いて同一性を確認しようとすると書き込みに要する時間が大きくなる。したがって、ハッシュ値を用いてデータの同一性を判定することにより、ストレージ装置はデータの書き込み時間を短縮することができる。 Here, the data is a file or a block having a size of, for example, 64 KB (kilobytes), and if it is attempted to check the identity using the data, the time required for writing increases. Therefore, the storage apparatus can shorten the data writing time by determining the identity of the data using the hash value.
なお、原画像をJPEG形式に変換する際に、原画像を分割した8×8画素のブロックの夫々にDCTを行って量子化した量子化DCT係数などを用いて秘密情報を求め、各ブロックに秘密情報を埋め込むことにより画像の改竄を防ぐ従来技術がある。また、入力されるコンテンツとメタデータに分離困難な変換処理を施すことによって、コンテンツ又はメタデータの改竄を困難にする従来技術がある。 When the original image is converted into the JPEG format, secret information is obtained by using a quantized DCT coefficient obtained by performing DCT on each of the 8 × 8 pixel blocks obtained by dividing the original image, and for each block. There is a conventional technique for preventing image falsification by embedding confidential information. Further, there is a conventional technique that makes it difficult to falsify content or metadata by performing conversion processing that is difficult to separate between input content and metadata.
重複排除ストレージ技術において、ハッシュ値が偶然衝突する可能性は十分小さくすることができるが、意図的にハッシュ値を衝突させる技術が開発されることがある。かかる技術が開発され、あるデータのハッシュ値と同じハッシュ値を持つデータを作ることが可能となった場合、サービス拒否攻撃が可能になる。 In the deduplication storage technology, the possibility that the hash values collide accidentally can be sufficiently reduced, but a technology for intentionally colliding the hash values may be developed. When such a technique is developed and it becomes possible to create data having the same hash value as that of a certain data, a denial of service attack becomes possible.
例えば、攻撃者が、将来作られることが予想できるデータAと同じハッシュ値を持つデータBを作り、先回りしてデータBをストレージ装置に書き込んでおくことで、データAが書き込まれたときにデータAがデータBに置き換えられる。その結果、攻撃者は、データAを使用する情報処理装置に誤った処理をさせることができる。 For example, an attacker creates data B having the same hash value as data A that can be expected to be created in the future, and data B is written to the storage device in advance, so that data A is written when data A is written. A is replaced with data B. As a result, the attacker can cause the information processing apparatus that uses the data A to perform an incorrect process.
なお、同一ハッシュ値を持つデータが生成可能になったときにハッシュ関数を変えることが考えられるが、ストレージ装置では、全データに対してハッシュ値の再計算が必要になるなど、ハッシュ関数の変更は負担が大きい。 Note that it is possible to change the hash function when data with the same hash value can be generated. However, in the storage device, it is necessary to recalculate the hash value for all data. Is a heavy burden.
本発明は、1つの側面では、重複排除ストレージ技術を利用したサービス拒否攻撃を防ぐことができるストレージ装置及びストレージ制御方法を提供することを目的とする。 An object of one aspect of the present invention is to provide a storage apparatus and a storage control method capable of preventing a denial-of-service attack using deduplication storage technology.
本願の開示するストレージ装置は、1つの態様において、データが不揮発性記憶装置に書き込まれるときに該データから第1の値としてハッシュ値を生成する第1の生成部と、前記データが前記不揮発性記憶装置に書き込まれるときに決定される数に基づいて前記データから取り出された一部のデータを用いて第2の値を生成する第2の生成部と、前記第1の値及び第2の値に基づいて前記データの重複記憶を制御する制御部とを備える。 In one aspect, the storage device disclosed in the present application includes a first generation unit that generates a hash value as a first value from data when the data is written to the nonvolatile storage device, and the data is the nonvolatile A second generator that generates a second value using a portion of the data extracted from the data based on a number determined when written to the storage device; the first value and the second And a control unit for controlling the redundant storage of the data based on the value.
1実施態様によれば、重複排除ストレージ技術を利用したサービス拒否攻撃を防ぐことができる。 According to one embodiment, a denial of service attack using deduplication storage technology can be prevented.
以下に、本願の開示するストレージ装置及びストレージ制御方法の実施例を図面に基づいて詳細に説明する。なお、この実施例は開示の技術を限定するものではない。 Embodiments of a storage apparatus and a storage control method disclosed in the present application will be described below in detail with reference to the drawings. Note that this embodiment does not limit the disclosed technology.
まず、実施例に係るストレージ装置の機能構成について説明する。図1は、実施例に係るストレージ装置の機能構成を示す図である。図1に示すように、ストレージ装置1は、揮発性記憶部10と、制御部20と、不揮発性記憶部30とを有する。
First, the functional configuration of the storage apparatus according to the embodiment will be described. FIG. 1 is a diagram illustrating a functional configuration of the storage apparatus according to the embodiment. As illustrated in FIG. 1, the
揮発性記憶部10は、記憶するデータが電源オフ時に消える記憶部である。制御部20は、揮発性記憶部10が記憶するデータを用いてストレージ装置1を制御する。不揮発性記憶部30は、ネットワークに接続されたサーバ2がストレージ装置1に記憶させるデータを記憶する。不揮発性記憶部30が記憶するデータは、電源オフ時にも消えることはない。
The
揮発性記憶部10は、データ部11と、対応表12と、ハッシュ値テーブル13とを有する。データ部11は、サーバ2が不揮発性記憶部30に記憶させるデータの一部を一時的に記憶する。
The
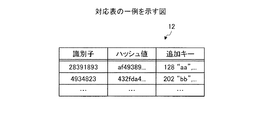
対応表12は、不揮発性記憶部30が記憶するデータの識別子とデータのキーとの対応を示す情報を記憶する。図2は、対応表12の一例を示す図である。図2に示すように、対応表12は、識別子とハッシュ値と追加キーとをデータ毎に記憶する。
The correspondence table 12 stores information indicating correspondence between data identifiers stored in the
識別子は、データを識別するためにデータに付与される値である。ここでは、データは64KBのブロックであり、識別子はブロック番号である。データがファイルである場合には、識別子はファイルのIDである。 The identifier is a value given to the data in order to identify the data. Here, the data is a 64 KB block, and the identifier is a block number. If the data is a file, the identifier is the ID of the file.
ハッシュ値は、データからハッシュ関数を用いて計算される値である。ハッシュ関数としては、MD5(Message Digest Algorithm 5)、SHA(Secure Hash Algorithm)1、SHA256、SHA512などがある。例えば、ハッシュ関数をSHA512とすると、ハッシュ値の長さは64バイトとなる。 The hash value is a value calculated from data using a hash function. Examples of the hash function include MD5 (Message Digest Algorithm 5), SHA (Secure Hash Algorithm) 1, SHA256, SHA512, and the like. For example, if the hash function is SHA512, the length of the hash value is 64 bytes.
追加キーは、データがストレージ装置1に書き込まれるときに決定される値であり、ハッシュ値と合わせてデータのキーとして用いられる。図3は、追加キーのデータ構造の一例を示す図である。
The additional key is a value determined when data is written to the
図3に示すように、追加キーは、2バイト長の「位置」と2バイト長の「内容」が4つ連結されたものである。「位置」は、データがストレージ装置1に書き込まれるときに生成される乱数である。「内容」は、データの先頭から「位置」で示されるバイト目の2バイトデータである。
As shown in FIG. 3, the additional key is a concatenation of four “positions” having a length of 2 bytes and “content” having a length of 2 bytes. “Position” is a random number generated when data is written to the
例えば、対応表12は、識別子としてブロック番号「28391893」、ハッシュ値として「af49389...」、追加キーとして「128“aa”,...」を対応させて記憶する。「128”aa“」は、データの先頭から128バイト目の2バイトデータが”aa“であることを示す。 For example, the correspondence table 12 stores a block number “28391893” as an identifier, “af49389...” As a hash value, and “128“ aa ”,. “128” aa “” indicates that the 2-byte data of the 128th byte from the top of the data is “aa”.
ストレージ装置1は、ハッシュ値と追加キーの組をデータのキーとして用いる。ストレージ装置1が、ハッシュ値に加えて追加キーをデータのキーとして用いることによって、重複排除ストレージ技術を利用したサービス拒否攻撃を防ぐことができる。
The
例えば、正しいデータAと同一ハッシュ値を持つデータBが、データAが書き込まれる前にストレージ装置1に書き込まれた場合でも、データAとデータBでは追加キーが異なるため、データAはストレージ装置1に書き込まれる。
For example, even when data B having the same hash value as the correct data A is written to the
追加キーは、データAがストレージ装置1に書き込まれるときに決定される値であるので、攻撃者は、事前に追加キーを特定することはできない。したがって、攻撃者は、データAと同一ハッシュ値を持つデータBを生成できた場合でも、重複排除ストレージ技術を悪用してデータAをデータBで置き換えることはできない。
Since the additional key is a value determined when the data A is written in the
なお、ここでは、4つの乱数を用いて4つの2バイトデータを追加キーに用いているが、ストレージ装置1は、より多くの数の乱数を用いることによって、追加キーが偶然に衝突する可能性を低減することができる。また、ストレージ装置1は、データがストレージ装置1に書き込まれるときに決定される値として、乱数を生成する代わりに、データを書き込む際の時間に基づく数など他の数を用いて追加キーを生成することもできる。
In this example, four random numbers are used and four 2-byte data are used as additional keys. However, the
図1に戻って、ハッシュ値テーブル13は、不揮発性記憶部30が記憶するデータに関する情報を記憶する。図4は、ハッシュ値テーブル13の一例を示す図である。図4に示すように、ハッシュ値テーブル13は、ハッシュ値と追加キーと位置情報と参照数とをデータ毎に記憶する。
Returning to FIG. 1, the hash value table 13 stores information related to data stored in the
位置情報は、ハッシュ値と追加キーの組で特定されるデータが不揮発性記憶部30で記憶される位置を示す情報である。参照数は、データが異なる識別子で参照されている個数を示す。ストレージ装置1は、同一のデータを重複して記憶することはないので、1つのデータが複数の識別子に対応する可能性がある。
The position information is information indicating a position where the data specified by the combination of the hash value and the additional key is stored in the
例えば、ハッシュ値テーブル13は、ハッシュ値として「af49389...」、追加キーとして「128“aa”,...」、位置情報として「4324932」、参照数として「1」を対応させて記憶する。 For example, the hash value table 13 stores “af49389...” As the hash value, “128“ aa ”,...” As the additional key, “4324932” as the position information, and “1” as the reference number. To do.
図1に戻って、制御部20は、書込部21と読込部22とを有する。書込部21は、サーバ2からの指示に基づいて不揮発性記憶部30にデータを書き込む。書込部21は、データを書き込むときに、データからハッシュ値を生成し、ハッシュ値テーブル13を参照してハッシュ値と追加キーで指定されたデータの両方が一致するかどうかを判定する。
Returning to FIG. 1, the
そして、書込部21は、ハッシュ値と追加キーで指定されたデータの両方が一致する場合には、重複データがある場合の処理を行い、ハッシュ値と追加キーで指定されたデータの両方が一致しない場合には、新規データを不揮発性記憶部30に書き込む処理を行う。
Then, when both the hash value and the data specified by the additional key match, the
書込部21は、生成部211を有する。生成部211は、書込部21が新規データを不揮発性記憶部30に書き込む際に、新規データから追加キーを生成する。そして、書込部21は、書き込み要求で指定された識別子が対応表32にあれば、対応表32のハッシュ値と追記キーを更新し、対応表32になければ、識別子、ハッシュ値、追加キーを用いて新しいエントリを対応表32に作成する。
The
読込部22は、サーバ2からの指示に基づいて不揮発性記憶部30からデータを読み込む。読込部22は、対応表12及びハッシュ値テーブル13を参照して、データの識別子からデータの位置情報を取得し、取得した位置情報を用いて不揮発性記憶部30からデータを読み出す。そして、読込部22は、不揮発性記憶部30から読み出したデータをサーバ2へ送信する。
The reading unit 22 reads data from the
不揮発性記憶部30は、データ部31と、対応表32と、ハッシュ値テーブル33とを有する。データ部31は、サーバ2によりストレージ装置1に書き込まれたデータを記憶する。データ部31が記憶するデータの一部は、データ部11に一時的に記憶される。
The
対応表32は、揮発性記憶部10が有する対応表12と同一であり、ストレージ装置1が起動されると、対応表32が記憶するデータが対応表12へ読み込まれる。また、対応表12が更新されると対応表32も更新される。
The correspondence table 32 is the same as the correspondence table 12 included in the
ハッシュ値テーブル33は、揮発性記憶部10が有するハッシュ値テーブル13と同一であり、ストレージ装置1が起動されると、ハッシュ値テーブル33が記憶するデータがハッシュ値テーブル13へ読み込まれる。また、ハッシュ値テーブル13が更新されるとハッシュ値テーブル33も更新される。
The hash value table 33 is the same as the hash value table 13 included in the
なお、対応表32及びハッシュ値テーブル33は、対応表12及びハッシュ値テーブル13がそれぞれ更新されると同期して更新されるが、ストレージ装置1は、停止するときに、まとめて対応表32及びハッシュ値テーブル33を更新することもできる。ストレージ装置1が、対応表12及びハッシュ値テーブル13に同期してそれぞれ対応表32及びハッシュ値テーブル33を更新するのは、装置の故障に備えるためである。
The correspondence table 32 and the hash value table 33 are updated in synchronization with the update of the correspondence table 12 and the hash value table 13, respectively. However, when the
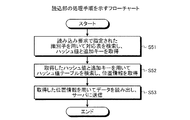
次に、書込部21の処理手順について説明する。図5は、書込部21の処理手順を示すフローチャートである。図5に示すように、書込部21は、サーバ2で動作するアプリケーションがデータの書き込みを要求すると、書き込むデータのハッシュ値を算出する(ステップS1)。
Next, the processing procedure of the
そして、書込部21は、ハッシュ値テーブル13を算出したハッシュ値で検索し(ステップS2)、同一ハッシュ値を持つデータが存在するか否かを判定する(ステップS3)。その結果、同一ハッシュ値を持つデータが存在する場合には、書込部21は、ハッシュ値テーブルから追加キーを読み出し、追加キーで指定された位置のデータが一致するか否かを判定し(ステップS4)、追加キーで指定されたデータも一致する場合には、重複データ処理を行う(ステップS5)。
Then, the
一方、追加キーで指定されたデータが一致しない場合、あるいは、同一ハッシュ値を持つデータが存在しない場合には、書込部21は、新規データ処理を行う(ステップS6)。
On the other hand, if the data specified by the additional key does not match, or if there is no data having the same hash value, the
このように、書込部21が、データを書き込むときに、追加キーも含めて一致するデータの有無を判定することによって、ストレージ装置1は、重複排除ストレージ技術を利用したサービス拒否攻撃を防ぐことができる。
Thus, when the
次に、重複データ処理の処理手順について説明する。図6は、重複データ処理の処理手順を示すフローチャートである。図6に示すように、書込部21は、ハッシュ値テーブル13のハッシュ値及び追加キーが一致するエントリの参照数を1増加する(ステップS11)。
Next, a processing procedure for duplicate data processing will be described. FIG. 6 is a flowchart showing a processing procedure for duplicate data processing. As illustrated in FIG. 6, the
そして、書込部21は、サーバ2からの書き込み要求で指定された識別子を用いて対応表12を検索し(ステップS12)、書き込み要求で指定された識別子が対応表12にあるか否かを判定する(ステップS13)。
Then, the
その結果、対応表12にある場合には、識別子で指定されたデータが更新された場合であるので、書込部21は、対応表12の識別子に対応するハッシュ値と追加キーを新しいハッシュ値と追加キーで更新する(ステップS14)。そして、書込部21は、更新前のデータのハッシュ値テーブル13の参照数を1減少する(ステップS15)。
As a result, when the data is in the correspondence table 12, the data specified by the identifier is updated, so the writing
そして、書込部21は、1減少した参照数は0であるか否かを判定し(ステップS16)、0である場合には、更新前のデータは参照されなくなったので、ハッシュ値テーブル13から更新前のデータのエントリを削除する(ステップS17)。そして、書込部21は、不揮発性記憶部30に対応表12とハッシュ値テーブル13の変更を反映する(ステップS18)。
Then, the
一方、書き込み要求で指定された識別子が対応表12にない場合には、新たな識別子で指定されたデータを書き込む場合であるので、書込部21は、書き込み要求で指定された識別子を用いて新しいエントリを対応表12に作成する(ステップS19)。そして、書込部21は、ステップS18に進む。
On the other hand, when the identifier specified by the write request is not in the correspondence table 12, the data specified by the new identifier is written, so the writing
このように、書込部21が、重複データ処理を行うことによって、ストレージ装置1は、同一データの重複記憶を防ぐことができる。
As described above, the
次に、新規データ処理の処理手順について説明する。図7は、新規データ処理の処理手順を示すフローチャートである。図7に示すように、生成部211は、追加キーを生成する(ステップS30)。具体的には、生成部211は、4つの2バイト長の乱数を生成し、データの先頭から乱数に対応するバイト目の2バイトデータを乱数と結合して4バイトデータを生成する処理を各乱数に対して行う。そして、生成部211は、4つの4バイトデータを結合して追加キーを生成する。続いて、書込部21は、不揮発性記憶部30に新規の領域を確保し、データを書き込む(ステップS31)。
Next, a processing procedure for new data processing will be described. FIG. 7 is a flowchart showing a processing procedure for new data processing. As illustrated in FIG. 7, the
そして、書込部21は、ハッシュ値と追加キーを用いてハッシュ値テーブル13の新規エントリを作成し、データの位置情報と参照数を格納する(ステップS32)。ここで、参照数の値は初期値の1である。
Then, the
そして、書込部21は、サーバ2からの書き込み要求で指定された識別子を用いて対応表12を検索し(ステップS33)、書き込み要求で指定された識別子が対応表12にあるか否かを判定する(ステップS34)。
Then, the
その結果、対応表12にある場合には、識別子で指定されたデータが更新された場合であるので、書込部21は、対応表12の識別子に対応するハッシュ値と追加キーを新しいハッシュ値と追加キーで更新する(ステップS35)。そして、書込部21は、更新前のデータのハッシュ値テーブル13の参照数を1減少する(ステップS36)。
As a result, when the data is in the correspondence table 12, the data specified by the identifier is updated, so the writing
そして、書込部21は、1減少した参照数は0であるか否かを判定し(ステップS37)、0である場合には、更新前のデータは参照されなくなったので、ハッシュ値テーブル13から更新前のデータのエントリを削除する(ステップS38)。そして、書込部21は、不揮発性記憶部30に対応表12とハッシュ値テーブル13の変更を反映する(ステップS39)。
Then, the
一方、書き込み要求で指定された識別子が対応表12にない場合には、新たな識別子で指定されたデータを書き込む場合であるので、書込部21は、書き込み要求で指定された識別子を用いて新しいエントリを対応表12に作成する(ステップS40)。そして、書込部21は、ステップS39に進む。
On the other hand, when the identifier specified by the write request is not in the correspondence table 12, the data specified by the new identifier is written, so the writing
このように、書込部21が、新規データ処理を行うことによって、ストレージ装置1は、同一データが記憶されていないデータを不揮発性記憶部30に格納することができる。
As described above, the
次に、読込部22の処理手順について説明する。図8は、読込部22の処理手順を示すフローチャートである。図8に示すように、サーバ2で動作するアプリケーションがデータの読み込みを要求すると、読込部22は、読み込み要求で指定された識別子を用いて対応表12を検索し、ハッシュ値と追加キーを取得する(ステップS51)。
Next, the processing procedure of the reading unit 22 will be described. FIG. 8 is a flowchart showing the processing procedure of the reading unit 22. As shown in FIG. 8, when an application running on the
そして、読込部22は、取得したハッシュ値と追加キーを用いてハッシュ値テーブル13を検索し、位置情報を取得する(ステップS52)。そして、読込部22は、取得した位置情報を用いて不揮発性記憶部30からデータを読み出し、サーバ2に送信する(ステップS53)。
And the reading part 22 searches the hash value table 13 using the acquired hash value and an additional key, and acquires position information (step S52). And the reading part 22 reads data from the non-volatile memory |
このように、読込部22が、ハッシュ値に加えて追加キーを用いてデータを読み込むことにより、ストレージ装置1は、ハッシュ値が同一なデータの中から適切なデータをサーバ2に送信することができる。
As described above, when the reading unit 22 reads data using the additional key in addition to the hash value, the
上述してきたように、実施例では、書込部21は、データを不揮発性記憶部30に書き込むときに、乱数を生成し、生成した乱数に基づいて追加キーを生成する。そして、ストレージ装置1は、書込部21が生成した追加キーをハッシュ値とともにキーとして用いてデータの重複を排除する。したがって、同一ハッシュ値を持つデータが生成可能な場合でも、ストレージ装置1は、重複排除ストレージ技術を利用したサービス拒否攻撃を防ぐことができる。
As described above, in the embodiment, the
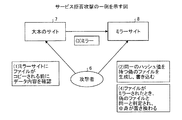
図9は、サービス拒否攻撃の一例を示す図である。図9は、大本のサイト7のファイルがミラーサイト8にコピーされる場合の攻撃例を示す。図9において、攻撃者6は、ミラーサイト8にファイルがコピーされる前にデータ内容を確認する(1)。そして、攻撃者6は、同一のハッシュ値を持つ偽のファイルを生成し、ミラーサイト8に書き込む(2)。
FIG. 9 is a diagram illustrating an example of a service denial attack. FIG. 9 shows an example of an attack when a file of the
その後、大本のサイト7のファイルがミラーサイト8にミラーされる(3)。すると、従来は、同一のハッシュ値を持つ偽のファイルが既にミラーサイト8に書き込まれているので、ミラーされるファイルは偽のファイルと同一と判定され、ミラーサイト8では、ファイルの中身が置き換えられる(4)。
Thereafter, the file of the
しかしながら、実施例に係るストレージ装置1は、攻撃者6がミラーサイト8に偽のファイルを書き込んだ場合でも、ファイルをミラーするときに乱数を用いて追加キーを生成し、ハッシュ値に加えて追加キーをキーとしてデータの同一性を判定する。したがって、ストレージ装置1は、ミラーされるファイルに対して偽のファイルとは異なる追加キーを生成することによって、ミラーされるファイルが偽のファイルで置き換えられることを防ぐことができる。
However, even when the
また、実施例では、対応表12は、ハッシュ値と追加キーとデータの識別子とを対応させて記憶し、ハッシュ値テーブル13は、ハッシュ値と追加キーとデータの格納位置と参照数とを対応させて記憶する。したがって、ストレージ装置1は、データが同一である複数の識別子を管理することができる。
In the embodiment, the correspondence table 12 stores hash values, additional keys, and data identifiers in association with each other, and the hash value table 13 associates hash values, additional keys, data storage positions, and reference numbers. Let me remember. Therefore, the
また、実施例では、ストレージ装置1は、4つの乱数を用いて追加キーを生成したが、より多くの乱数を用いて追加キーを生成することもできる。したがって、ストレージ装置1は、ハッシュ値と追加キーをデータのキーとした場合に、異なるデータに対してキーが偶然一致する可能性を低くすることができる。
In the embodiment, the
なお、実施例で説明したストレージ装置は、CPUでプログラムを動作させることによっても実現される。そこで、CPUでプログラムを動作させることによって実現されるストレージ装置のハードウェア構成について説明する。 Note that the storage apparatus described in the embodiment can also be realized by operating a program with a CPU. Therefore, a hardware configuration of a storage apparatus realized by operating a program with the CPU will be described.
図10は、ストレージ装置のハードウェア構成を示す図である。図10に示すように、ストレージ装置40は、メインメモリ41と、CPU(Central Processing Unit)42と、ホストインタフェース43と、HDD(Hard Disk Drive)44とを有する。
FIG. 10 is a diagram illustrating a hardware configuration of the storage apparatus. As shown in FIG. 10, the
メインメモリ41は、プログラムやプログラムの実行途中結果などを記憶するメモリであり、図1の記憶部10に対応する。CPU42は、メインメモリ41からプログラムを読み出して実行する中央処理装置であり、図1の制御部20に対応する。
The
ホストインタフェース43は、ストレージ装置40をサーバ2に接続するためのインタフェースである。HDD44は、プログラムやデータを格納するディスク装置であり、図1の不揮発性記憶部30に対応する。なお、ストレージ装置40は、HDD44の替わりにSSD(Solid State Drive)を備えることもできる。
The
1 ストレージ装置
2 サーバ
6 攻撃者
7 大本のサイト
8 ミラーサイト
10 揮発性記憶部
11 データ部
12 対応表
13 ハッシュ値テーブル
20 制御部
21 書込部
22 読込部
30 不揮発性記憶部
31 データ部
32 対応表
33 ハッシュ値テーブル
40 ストレージ装置
41 メインメモリ
42 CPU
43 ホストインタフェース
44 HDD
211 生成部
DESCRIPTION OF
43
211 generator
Claims (5)
前記データが前記不揮発性記憶装置に書き込まれるときに決定される数に基づいて前記データから取り出された一部のデータを用いて第2の値を生成する第2の生成部と、
前記第1の値及び第2の値に基づいて前記データの重複記憶を制御する制御部と
を備えたことを特徴とするストレージ装置。 A first generation unit that generates a hash value as a first value from the data when the data is written to the nonvolatile storage device;
A second generator that generates a second value using a portion of the data extracted from the data based on a number determined when the data is written to the non-volatile storage device;
And a control unit that controls the redundant storage of the data based on the first value and the second value.
前記第1の値及び第2の値を前記データを識別する識別子と対応させて記憶する第2のテーブルとをさらに備え、
前記制御部は、前記第1のテーブルと第2のテーブルを用いて前記データの重複記憶を制御することを特徴とする請求項1に記載のストレージ装置。 A first table for storing the first value and the second value in association with the storage position of the data;
A second table for storing the first value and the second value in association with an identifier for identifying the data;
The storage apparatus according to claim 1, wherein the control unit controls duplication storage of the data using the first table and the second table.
前記データが前記不揮発性記憶装置に書き込まれるときに決定される数に基づいて前記データから取り出された一部のデータを用いて第2の値を生成し、
前記第1の値及び第2の値に基づいて前記データの重複記憶を制御する
処理を前記不揮発性記憶装置が有するプロセッサが実行することを特徴とするストレージ制御方法。 Generating a hash value as a first value from the data when the data is written to the non-volatile storage device;
Generating a second value using a portion of the data extracted from the data based on a number determined when the data is written to the non-volatile storage device ;
Controlling the overlapping storage of the data based on the previous SL first value and second value
A storage control method , wherein a process of the nonvolatile storage device is executed by a processor .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013080769A JP6201385B2 (en) | 2013-04-08 | 2013-04-08 | Storage apparatus and storage control method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013080769A JP6201385B2 (en) | 2013-04-08 | 2013-04-08 | Storage apparatus and storage control method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014203362A JP2014203362A (en) | 2014-10-27 |
| JP6201385B2 true JP6201385B2 (en) | 2017-09-27 |
Family
ID=52353724
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013080769A Expired - Fee Related JP6201385B2 (en) | 2013-04-08 | 2013-04-08 | Storage apparatus and storage control method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6201385B2 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105718458A (en) * | 2014-12-02 | 2016-06-29 | 阿里巴巴集团控股有限公司 | Method, apparatus and system for determining existence of data file |
| JP2019028954A (en) * | 2017-08-04 | 2019-02-21 | 富士通株式会社 | Storage control apparatus, program, and deduplication method |
| JP7277754B2 (en) * | 2019-07-29 | 2023-05-19 | 富士通株式会社 | Storage systems, storage controllers and programs |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012164130A (en) * | 2011-02-07 | 2012-08-30 | Hitachi Solutions Ltd | Data division program |
| JP2013045379A (en) * | 2011-08-26 | 2013-03-04 | Fujitsu Ltd | Storage control method, information processing device and program |
-
2013
- 2013-04-08 JP JP2013080769A patent/JP6201385B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014203362A (en) | 2014-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI444826B (en) | Method, system and medium holding computer-executable instructions for providing secure storage for firmware in a computing device | |
| US9773118B1 (en) | Data deduplication with encryption | |
| JP2021505095A (en) | Blockchain communication and ordering | |
| US8108686B2 (en) | Method and system for detecting modified pages | |
| TW201516733A (en) | System and method for verifying changes to UEFI authenticated variables | |
| JP6399763B2 (en) | Information processing apparatus and information processing method | |
| CN111008034B (en) | Patch generation method and device | |
| WO2023071040A1 (en) | System starting method, system starting device, server, and readable storage medium | |
| JP2006268449A (en) | Computer system, storage device, computer software and authentication method for manager in storage control | |
| JP6201385B2 (en) | Storage apparatus and storage control method | |
| JP2009093342A (en) | Information processing apparatus, authentication method, and computer program | |
| JP5255991B2 (en) | Information processing apparatus and computer program | |
| JP2007316944A (en) | Data processor, data processing method and data processing program | |
| JP5600015B2 (en) | Backup system and backup method | |
| JP2006133954A (en) | Document management device, document management method and computer program | |
| CN111291001B (en) | Method and device for reading computer file, computer system and storage medium | |
| KR101247564B1 (en) | Method of protecting data from malicious modification in data base system | |
| CN112347040A (en) | File management method, device, storage medium and terminal | |
| JP2016009220A (en) | Storage device, communication device, and storage control system | |
| WO2020233044A1 (en) | Plug-in verification method and device, and server and computer-readable storage medium | |
| JP2011138514A (en) | Method and device for detecting if computer file has been copied, and method and device for enabling the detection | |
| JP7234096B2 (en) | Security management system and security management method | |
| JP5136561B2 (en) | ARCHIVE SYSTEM CONTROL PROGRAM, ARCHIVE SYSTEM, MANAGEMENT DEVICE, AND CONTROL METHOD | |
| WO2021015204A1 (en) | Access control device, access control method, and program | |
| JP2008257279A (en) | Integrity enhancement method for file system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160113 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161111 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161220 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170217 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170801 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170814 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6201385 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |