ネットワーク環境における分散型ロードバランス方法およびシステムの様々な実施形態が記載される。分散型ロードバランス方法およびシステムの実施形態は、様々なネットワーク環境における分散型ロードバランサの実施形態によって実装されてもよいように記載される。例として、分散型ロードバランサの実施形態は、図33Aおよび33Bに示されるようなプロバイダネットワーク1900等のローカルネットワーク上のインターネットや宛先、通常はサーバ(例、ウェブサーバ、アプリケーションサーバ、データサーバ等)のような外部ネットワーク上の顧客間のパケットフロー、例えばトランスミッションコントロールプロトコル(TCP)技術を用いたパケットフロー等を円滑化し、維持するために用いられてもよい。本明細書に記載の実施形態は主にTCPパケットフローの処理に関するが、実施形態はTCP以外のデータ通信プロトコルや、パケットフロー処理以外の用途に適用されてもよいことに留意する。
分散型ロードバランサは、特定の顧客と選択したサーバ(例、ウェブサーバ)との間のTCPパケットフローを円滑化し維持する役割を担ってもよい。しかし分散型ロードバランサは、従来のロードバランサにおけるやり方では、顧客からのTCPフローを遮断せず、また、サーバへのプロキシの役割も担わない。代わりに分散型ロードバランサのロードバランサノードが顧客から受信されたTCPパケットを対象のサーバへルーティングし、サーバがそのTCPスタックを用いて顧客へのTCP接続を管理する。すなわち、サーバが顧客からのTCPパケットフローを遮断する。
また、従来のロードバランサ技術において行われるように、サーバから収集された情報に適用されるロードバランス技術またはアルゴリズムに基づいて、どのサーバが接続要求を送信するかに関して決定を下す1つまたは複数のロードバランサノードの代わりに、ロードバランサノードが新規接続要求を受信するサーバを無作為に選択してもよく、サーバノード上にある分散型ロードバランサの構成要素がそれぞれのサーバの現状の1つまたは複数の測定基準に基づき、選択したサーバが新規接続要求を受け入れるか拒否するかに関する決定をローカルで下す。したがって、どのサーバが接続要求を受け入れるかに関する決定は、1つまたは複数のロードバランサノードから、接続を処理するサーバノードへと移行する。すなわち、接続要求の送信により近い場所およびタイミングへと決定が移行される。
顧客とサーバ間のパケットフローを円滑化し、維持するため、分散型ロードバランサの実施形態は様々な技術を用いてもよい。またそのような技術は、マルチパスルーティング技術、一貫したハッシュ技術、分散型ハッシュテーブル(DHT)技術、境界ゲートウェイプロトコル(BGP)技術、メンバーシップトラッキング、ヘルスチェック、接続公開、およびパケットのカプセル化および脱カプセル化を含むが、これらに限定されない。これらは分散型ロードバランスシステムの他の態様と同様に、図面に関連して以下に記載される。
分散型ロードバランスシステム
図1は、少なくともいくつかの実施形態による、分散型ロードバランスシステムの実施例のブロック図である。分散型ロードバランサの実施形態は、例えば図33Aおよび33Bで示されるサービスプロバイダのプロバイダネットワーク1900等のネットワーク100において実装されてもよい。分散型ロードバランサシステムにおける顧客のパケット処理のハイレベル概観図に示される通り、ネットワーク100の1つまたは複数の顧客160は、例えばインターネット等の外部ネットワーク150を通じて、ネットワーク100の境界ルータ102に接続してもよい。境界ルータ102は、顧客160からの受信パケット(例、TCPパケット)を分散型ロードバランサの構成要素エッジルータ104へとルーティングしてもよい。エッジルータ104は受信パケットを、分散型ロードバランサシステムのロードバランサノードレイヤー上のロードバランサ(LB)ノード110へとルーティングする。少なくともいくつかの実施形態において、エッジルータ104は例えば等価コストマルチパス(ECMP)ハッシュ技術のようなフローごとにハッシュ化されたマルチパスルーティング技術に従って、ルーティングの決定を行ってもよい。次にロードバランサノード110がパケットをカプセル化し(例、ユーザデータグラムプロトコル(UDP)に従って)、ネットワーク100上のネットワークファブリック120(例、L3ネットワーク)を通じて、カプセル化されたパケットをサーバノード130上のローカルロードバランサモジュール132へとルーティングする。ファブリック120は、1つまたは複数のネットワーク装置または構成要素を含んでもよく、そのようなネットワーク装置または構成要素にはスイッチ、ルータ、およびケーブルが含まれるがこれらに限定されない。サーバノード130上では、ローカルロードバランサモジュール132がパケットを脱カプセル化し、顧客のTCPパケットをサーバ134のTCPスタックに送信する。サーバノード130上のサーバ134はその後そのTCPスタックを利用し、顧客160への接続を管理する。
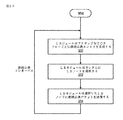
図2は少なくともいくつかの実施形態による、図1の分散型ロードバランサシステムにより実装されてもよいロードバランス方法のハイレベルフローチャートである。分散型ロードバランサシステムの実施形態は、従来のロードバランサ技術において行われるような複数の宛先(例、ウェブサーバ)間の負荷の割り当てに関する困難問題の解決を行わなくてもよい。例えば従来のロードバランサは通常、最大接続、ラウンドロビン、および/または最小接続等の技術やアルゴリズムを用い、どのサーバが接続の処理を行うべきかを選択する。しかしこれら技術には欠点があり、特にロードバランスに関する決定を行うために用いられるデータがほぼすぐに古くなってしまうような分散型システムにおいては良好に行うことが難しい。少なくともいくつかの分散型ロードバランサシステムの実施形態においては、従来のロードバランサにおいて行われるように接続要求を満たすために1つまたは複数のロードバランス技術を用いてサーバノード130の選択を試みる代わりに、ロードバランサノードレイヤー上のロードバランサノード110が、顧客の接続のための要求を受信するサーバノード130を無作為に決定してもよい。そのサーバノード130が自身に負荷がかかり過ぎていると見なす場合は、サーバノード130はロードバランサノード110に接続要求を送信し返し、それによってサーバノード130が現在接続を処理できないことをロードバランサノード110に伝えてもよい。ロードバランサノードレイヤーはその後、接続要求を受信する別のサーバノード130を無作為に決定してもよいし、もしくはその代わりに、要求を行う顧客160に対してエラーメッセージを返信し、現在接続を確立できないことを顧客160に伝えてもよい。
図2の10で示すように、分散型ロードバランサシステムのロードバランサノードレイヤーがソースから通信セッション(例、TCP接続)のための要求を受信する。ソースは例えば、分散型ロードバランサシステムを実装するネットワーク100への外部ネットワーク150上の顧客160であってもよい。少なくともいくつかの実施形態においては、要求はネットワーク100の境界ルータ102で顧客160から受信されてもよく、また、エッジルータ104にルーティングされてもよい。エッジルータ104は例えば顧客160からの特定の接続要求のルーティング先となるロードバランサノード110を擬似ランダムに選択するフローごとの等価コストマルチパス(ECMP)ハッシュ技術を用いて、受信パケットをロードバランサノードレイヤー上のロードバランサ(LB)ノード110にルーティングする。
20で示すように、ロードバランサノードレイヤーが宛先ノードを無作為に選択し、選択した宛先ノードに接続要求を転送する。宛先ノードは例えば、ロードバランサによってフロントに配置された複数のサーバノード130のうちの1つであってもよい。少なくともいくつかの実施形態において、ロードバランサレイヤー上のロードバランサノード110はすべての既知のサーバノード130の中から接続要求を受信するサーバノード130を無作為に選択してもよい。しかしいくつかの実施形態においては、すべての既知のサーバノード130の中から純粋に無作為に選択する以外の方法を用いて接続要求を受信するサーバノード130を選択してもよい。例えばいくつかの実施形態においては、サーバノード130の無作為な選択の重みづけを行うために、ロードバランサノード110によってサーバノード130に関する情報が利用されてもよい。実施例として、異なるサーバノード130が異なる種類の装置であるかまたは異なるCPUによって構成されているために異なる能力や可能性を有するとロードバランサノード110が認識している場合、無作為な選択をサーバノード130の1つまたは複数の特定の種類または構成の方に(またはそれを避けるように)偏らせるために情報が用いられてもよい。
30で示すように、宛先ノードが、通信セッションを受け入れることが可能か決定する。少なくともいくつかの実施形態において、サーバノード130上のローカルロードバランサ(LB)モジュール132がそれぞれのサーバ134の現状の1つまたは複数の測定基準に基づき、サーバノード130上のそれぞれのサーバ134が新規接続を受け入れることが可能であるかどうかを決定する。
40において接続要求が受け入れられる場合は、その後50で示すように宛先ノードが接続を処理できることを宛先ノードからロードバランサノードレイヤーに伝える。その後60で示すようにソース(例、顧客160)と宛先ノード(例、サーバノード130上のサーバ134)との間にロードバランサノードレイヤーを通じて通信セッションが構築される。少なくともいくつかの実施形態において、サーバノード130上のサーバ134がTCPスタックを用いて顧客160への接続を管理する。
40において接続要求が受け入れられない場合は、その後70で示すように宛先ノードがロードバランサノードレイヤーに通知し、メソッドは要素20に戻ってもよい。ロードバランサノードレイヤーはその後20において別の宛先ノードを無作為に選択してもよいし、もしくはその代わりに、要求を行う顧客160に対して現在接続を確立できないことを顧客160に伝えてもよい。顧客160は、必ずそうするわけではないが、要素10においてメソッドを再び開始するために接続要求を再提出してもよいことに留意する。
図1を再び参照する。分散型ロードバランサシステムの少なくともいくつかの実施形態は、コモディティハードウェアを用いてネットワーク100上のエッジルータ104で受信された顧客のトラフィックをネットワーク100上のサーバノード130へとルーティングしてもよい。分散型ロードバランサの少なくともいくつかの実施形態は、複数のロードバランサノード110を含むロードバランサノードレイヤーを含んでもよい。少なくともいくつかの実施形態において、各ロードバランサノード110はロードバランサノードレイヤーにおける複数の役割のうち、1つまたは複数の役割を担ってもよい。これらロードバランサノード110の役割には、入口ノード、また出口ノード、そして(所与のパケットフローのための1次フロートラッカーまたは2次フロートラッカーとしての)フロートラッカーノードの役割が含まれてもよい。少なくともいくつかの実施形態において各ロードバランサノード110は、ラック搭載型のコモディティコンピューティング装置等の個別のコンピューティング装置として、またはそういった個別のコンピューティング装置において、ロードバランサノードレイヤー上に実装されてもよい。ロードバランサノード110は一般的に、特定のパケットフローのための役割のうちただ1つ(しかし可能であれば2つまたは3つ)を担うが、少なくともいくつかの実施形態において、各ロードバランサノード110は入口ノード、また出口ノード、そして(所与のパケットフローのための1次フロートラッカーまたは2次フロートラッカーとしての)フロートラッカーノードの3つの役割それぞれを担う。しかし少なくともいくつかの実施形態において、ロードバランサノード110は特定のパケットフローのための1次フロートラッカーおよび2次フロートラッカーの両方の役割を担うことはできないことに留意する。その代わりにいくつかの実施形態においては、各ロードバランサノード110が3つの役割のうちただ1つを担ってもよい。この実施形態においては、コンピューティング装置の個別の組が、特に入口ノード、出口ノード、およびフロートラッカーノードとしてロードバランサノードレイヤー上で実装されてもよい。
少なくともいくつかの実施形態において、パケットフローのための1次および2次フロートラッカーの決定するために、一貫したハッシュおよび一貫したハッシュリング技術が適用されてもよい。顧客からの各パケットフローは、例えば顧客のIPアドレス、顧客用ポート、サーバ(パブリック)IPアドレス、およびサーバポートから成る4タプルによって一意に識別されてもよい。この識別子は、顧客およびパブリックエンドポイントのペアを示すCPまたはCcPpとして略されてもよい。与えられた任意のTCPフロー(またはCPペア)に関連するパケットは、エッジルータ104からのハッシュ化されたマルチパス(例、ECMP)フロー分散により、入口サーバ112として動作するいずれのロードバランサノード110上にも表れることができる。パケットが入口ノードとして動作するロードバランサノード110に到達する際に、どのロードバランサノード110がパケットフローのための状態維持の役割を担うか(すなわち、1次フロートラッカーノード)を入口ノードが決定できるように、一貫したハッシュが用いられる。どのロードバランサノード110がパケットフローのための状態維持の役割を担うかを決定するために、CPペアは入口ノードにより一貫したハッシュリング内にハッシュ化されてもよい。一貫したハッシュリング内でパケットフローのためのCPペアの一貫したハッシュに従って決定されたノード110が、パケットフローのための1次フロートラッカーの役割を担うノード110である。少なくともいくつかの実施形態において、一貫したハッシュリングにおける後続ノードがパケットフローのための2次フロートラッカーの役割を担う。
図3は少なくともいくつかの実施形態による、3つの役割すべて(入口、出口、およびフロートラッカー)を実装する構成要素を含む、ロードバランサ(LB)ノード110の実施例を示す。この実施例において構成要素である入口サーバ112は、1つまたは複数の顧客からインバウンドTCPパケットを受信し、TCPパケットをカプセル化されたパケットとして1つまたは複数のサーバに送信する、入口の役割を果たす。構成要素である出口サーバ114は、1つまたは複数のサーバからアウトバウンドのカプセル化されたパケットを受信し、脱カプセル化されたTCPパケットを1つまたは複数の顧客に送信する、出口の役割を果たす。構成要素であるフロートラッカー116は、1つまたは複数の顧客160と1つまたは複数のサーバ134との間に確立された1つまたは複数のパケットフローのための1次または2次フロートラッカーの役割を果たす。それぞれの顧客160から受信された接続要求に応じて顧客とサーバ134の1つとの間のTCP接続を開始するため、またはパケットフローのためにマッピング情報を取得するため、入口サーバ112はまた、ロードバランサノード110上のフロートラッカー116または別のロードバランサノード110上のフロートラッカー116と通信してもよい。
ロードバランサノード
図1を再び参照する。少なくともいくつかの実施形態において、ロードバランサノードレイヤーにおけるロードバランサノード110は、ネットワーク上の1つまたは複数のルータ104から顧客のトラフィック(例えばTCPパケット等のパケット)を受信し、ファブリック120上の分散型ロードバランサシステムにより用いられるプロトコル(例、ユーザデータグラムプロトコル(UDP))に従ってパケットをカプセル化する。ロードバランサノードレイヤーはその後ファブリック120を介してカプセル化されたパケットを宛先サーバノード130に転送する。各サーバノード130はロードバランサシステムの構成要素であるローカルモジュール132を含む。モジュール132は本明細書内ではロードバランサモジュールまたは単にLBモジュールと称されてもよく、サーバノード130上のソフトウェア、ハードウェア、またはそれらの組み合わせにおいて実装されてもよい。各サーバノード130において、それぞれのロードバランサモジュール132がパケットを脱カプセル化し、通常のTCP処理のためにTCPパケットをローカルTCPスタックに送信する。少なくともいくつかの実施形態においては、ロードバランサノードレイヤーがすべての顧客サーバのTCPフローのために状態情報を維持してもよい。しかし、ロードバランサノードレイヤー上のロードバランサノード110は、TCPフローに関する一切の解釈を実行することはできない。各フローは、それぞれのサーバノード130のサーバ134と顧客160との間で管理される。分散型ロードバランサシステムはTCPパケットが正確な宛先サーバ134に確実に到着するようにする。各サーバノード130におけるロードバランサモジュール132は、ロードバランサノード110から受信した顧客の接続要求に応じてそれぞれのサーバ134が新規接続を受け入れるか拒否するかに関する決定を下す。
少なくともいくつかの実施形態において、分散型ロードバランスシステムは一貫したハッシュ技術を、例えば、どのサーバノード130が特定のTCPパケットフローのための役割を担うかについてどの1つまたは複数のロードバランサノード110が記憶すべきかなどを決定するために用いてもよい。一貫したハッシュ技術を利用し、ロードバランサノードレイヤーにおけるロードバランサノード110は一貫したハッシュリングとして見なされてもよく、ロードバランサノード110はリングにおけるメンバーシップのトラッキングを継続し、一貫したハッシュ関数に従って、特定のパケットフローのための役割を果たすリングにおける特定のメンバーを決定してもよい。少なくともいくつかの実施形態においては、顧客160とサーバ134との間の各パケットフローのトラッキングの役割を担う2つのロードバランサノード110が存在する。これらのノード110は、1次フロートラッカー(PFT)ノードおよび2次フロートラッカー(SFT)ノードと称されてもよい。少なくともいくつかの実施形態において、1次フロートラッカーはフローのための一貫したハッシュリングにおける第1のロードバランサノード110であり、2次フロートラッカーは一貫したハッシュリングにおける次のまたは後続の、1次フロートラッカーノードとは異なるロードバランサノード110である。この場合、1次フロートラッカーノードが故障した際には、その後2次フロートラッカーノードが新規1次フロートラッカーになってもよく、別のロードバランサノード110(例、一貫したハッシュリングにおける次のノード110)が2次フロートラッカーの役割を担ってもよい。少なくともいくつかの実施形態において、ロードバランサノード110は所与のパケットフローのための1次フロートラッカーおよび2次フロートラッカーの両方の役割を担うことはできないことに留意する。一貫したハッシュリングにおけるこのまたは別のメンバーシップの変更については、本明細書にて後述される。少なくともいくつかの実施形態において、ロードバランサの実装のための構成情報(例、現在実装されているロードバランサノード110およびサーバノード130の1つまたは複数の信頼すべきリスト)は、例えばファブリック120を通じてロードバランサノード110に接続される1つまたは複数のサーバ装置上で実装されてもよい分散型ロードバランスシステムの構成要素である、構成サービス122によって維持されてもよい。
少なくともいくつかの実施形態において、1次および2次フロートラッカーノードとしての役割に加えて、ロードバランサノード110は所与のフローのために、他の2つののうち1つの役割を果たしてもよい。すなわち、入口ノードの役割および出口ノードの役割である。パケットフローのための入口ノードは、エッジルータ104からそれぞれのパケットフローを受信し、パケットフローを(カプセル化されたパケットとして)ファブリック120を通じてサーバノード130上の選択されたサーバ134に転送する、ロードバランサノード110である。入口ノードは、実際の顧客データ(TCPデータパケット)をそれぞれの宛先サーバノード130へと移動させる唯一のロードバランサノード110である。入口ノードは、宛先サーバノード130上のそれぞれのロードバランサモジュール132へのTCPフローのマッピングを維持し、顧客のトラフィックをどのロードバランサモジュール132へと転送すべきかを把握する。出口ノードは、ファブリック120を通じてサーバノード130から受信されたパケットフローのための応答トラフィックを、境界ネットワークを通じてそれぞれの顧客160に転送する役割を担うロードバランサノード110である。ロードバランサモジュール132は、応答パケットをロードバランサプロトコル(例、UDP)に従ってサーバ134から得た応答パケットをカプセル化し、カプセル化された応答パケットを、ファブリック120を通じてフローのためのそれぞれの出口ノードに送信する。出口ノードはステートレスであり、単にデータパケットを脱カプセル化して境界ネットワーク上の応答パケット(例、TCPパケット)を境界ルータ102に送信し、外部ネットワーク150を通じてそれぞれの顧客160に送達する。
上述のように少なくともいくつかの実施形態において、各ロードバランサノード110は異なるパケットフローのための入口ノード、出口ノード、および/またはフロートラッカーノード(1次または2次いずれかのフロートラッカーとして)の役割を果たす。ロードバランサノードレイヤー上の単一のロードバランサノード110は、ノードが何のパケットフローを処理しているかに応じて、役割のうちのいずれか1つを担ってもよい。例えば、少なくともいくつかの実施形態において、ロードバランサノード110は、1つのパケットフローのために入口ノードの役割を、また別のパケットフローのために1次または2次フロートラッカーの役割を、そしてさらに別のパケットフローのために出口ノードの役割を果たしてもよい。また少なくともいくつかの実施形態においてロードバランサノード110は、例えば所与のパケットフローのために入口ノードおよび1次(または2次)フロートラッカーノードの役割をというように、同一のパケットフローのために複数の役割を果たしてもよい。しかし少なくともいくつかの実施形態において、ロードバランサノード110は冗長化および回復を目的として、同一のパケットフローのために1次および2次フロートラッカーの両方の役割を担うことはできない。
上記は、各ロードバランサノード110が入口サーバ、出口サーバ、およびフロートラッカーの3つの役割のうちいずれの役割を担ってもよい実施形態である。しかしいくつかの実施形態においては、コンピューティング装置の異なるグループが、ロードバランスシステムにおける異なる役割に割り当てられてもよい。例えばいくつかの実施形態においては、個別のコンピューティング装置上でそれぞれ実装される入口ノード、出口ノードおよびフロートラッカーノードの異なる組があってもよい。別の実施例として、いくつかの実施形態においては、コンピューティング装置の別の組が出口ノードの役割のみを担う一方で、コンピューティング装置の組の1つが入口ノードおよびフロートラッカーノードの両方の役割を担ってもよい。
ロードバランサモジュール
上述のように各サーバノード130は、ロードバランサシステムの構成要素であるローカルロードバランサモジュール132を含む。モジュール132は、サーバノード130のソフトウェア、ハードウェア、またはそれらの組み合わせにおいて実装されてもよい。少なくともいくつかの実施形態において、サーバノード130のロードバランサモジュール132は、発信パケットのカプセル化および受信パケットの脱カプセル化、ノード130上のサーバ134のためのロードバランスに関するローカルでの決定、ならびに接続公開の、3つの主要な役割を果たしてもよい。これら3つの役割は以下に簡単に記され、さらに本明細書で詳細に後述される。
分散型ロードバランスシステムの少なくともいくつかの実施形態は、TCP接続を遮断せず、パケットのスプーフィングも行わない。ロードバランサノードレイヤーを通じて送信されるすべてのパケットのソースおよび宛先IPアドレスは、パケットフローに関与するエンドポイント(すなわち、顧客160およびサーバ134)の実際のIPアドレスである。スプーフィングの代わりに、これら実施形態は、ロードバランサノード110とサーバノード130との間で送信される、例えばUDPパケット等のすべてのパケットを、ファブリック120上でカプセル化する。フローのための入口ノードの役割を担うロードバランサノード110からサーバノード130に到着するパケットフロー内のインバウンドパケットはロードバランサノード110によってカプセル化されるため、パケットはノード130上のサーバ134のために脱カプセル化され、ローカルホストのTCPフローへと方向を変えられる必要がある。ノード130上のロードバランサモジュール132がこの脱カプセル化を行う。同様に、サーバ134からのパケットフローのための発信データパケットは、ロードバランサモジュール132によってカプセル化され、ファブリック120を通じてパケットフローのための出口ノードの役割を果たすロードバランサノード110へと送信される。
少なくともいくつかの実施形態において、サーバノード130上のロードバランサモジュール132は、それぞれのサーバノード130上のサーバ134のためのロードバランスに関してローカルで決定を下す。特にサーバノード130上のロードバランサモジュール132は、それぞれのサーバ134が新規TCP接続要求の受信に応じて別のTCPフローを受け入れるかどうかの決定を行う。上述のように、ロードバランサノード110はロードバランサモジュール132に送信されるすべてのパケットをカプセル化するため、ロードバランサモジュール132は実際にはTCP同期(SYN)パケットを顧客160から受信することはなく、その代わりにロードバランサモジュール132はカプセル化プロトコル(例、UDP)に従ったフロートラッカー116からの接続要求メッセージを、受信する。ロードバランサモジュール132はこの接続要求メッセージを受け入れるか拒否することができる。ロードバランサモジュール132が接続要求メッセージを受け入れる場合、ロードバランサモジュール132はローカルホストに向けたSYNパケットを作成する。ローカルホストが接続を受け入れる場合、これはそれぞれの顧客接続を処理する実際のTCPスタックとなる。
少なくともいくつかの実施形態において、接続要求メッセージを受け入れるべきかどうかに関する決定を下すため、ロードバランサモジュール132はサーバノード130上の現在のリソース消費に関する1つまたは複数の測定基準を確認し、新規接続の処理のために使用可能なリソースが十分にある場合は、ロードバランサモジュール132が接続を受け入れる。少なくともいくつかの実施形態において、ロードバランサモジュール132により考慮されてもよいリソースの測定基準は、CPU使用率、最新の帯域占有量、および確立された接続の数のうちの1つまたは複数を含んでもよいが、これらに限定されない。いくつかの実施形態においては、これらの測定基準の代わりに、またはこれらの測定基準に加えて他の測定基準が考慮されてもよい。例えばいくつかの実施形態においては、ロードバランサモジュールがサーバ待ち時間(すなわち、要求がサーバ接続バックログに留まる時間)を測定基準として考慮してもよく、また、サーバ待ち時間が閾値を超える場合には接続要求を拒否してもよい。これらのおよび/または他の測定基準を利用して、ロードバランサモジュール132はそれぞれのサーバ134のために、サーバ134が新規パケットフローを受け入れるか拒否するかに関する決定を下すことができる。少なくともいくつかの実施形態において、リソース利用率(例、N%利用)は個別の、または組み合わせた、また、閾値(例、90%利用)と比較した測定基準から決定されてもよい。決定されたリソース利用率が閾値以上である場合、または、接続を追加することによりリソース利用率が閾値を超えることになる場合には、その後接続要求が拒否されてもよい。
少なくともいくつかの実施形態において、ロードバランサモジュール132は、接続要求メッセージを拒否するべきかどうか決定するために確率論的手法を実装してもよい。上記のようにリソース利用が閾値以上である場合にすべての接続要求を拒否する代わりに、この方法では2つ以上の異なる利用レベルにおいて異なる確率で接続要求を拒否してもよい。例えばリソース利用が80%の場合にロードバランサモジュール132が20%の確率で接続要求を拒否してもよく、リソース利用が90%の場合にロードバランサモジュール132が25%の確率で接続要求を拒否してもよく、リソース利用が95%の場合にロードバランサモジュール132が50%の確率で接続要求を拒否してもよく、そしてリソース利用が98%以上の場合にロードバランサモジュール132がすべての接続要求を拒否してもよい。
少なくともいくつかの実施形態において、各接続要求メッセージには、ロードバランサモジュール132が接続要求メッセージを拒否した回数が含まれていてもよい。自身が閾値以上の回数に渡り拒否されたことをロードバランサモジュール130により受信された接続要求メッセージが示す場合、パフォーマンス測定基準がサーバノード130の接続要求を拒否すべきだと示していても、ロードバランサモジュール130は接続を受け入れてもよい。
場合によっては、接続要求メッセージの送信先であるロードバランサモジュール132がすべて、接続要求を拒否する可能性もある。少なくともいくつかの実施形態において、接続要求メッセージがロードバランサモジュール132同士の間で無期限にバウンスされるのを防ぐために、各接続要求メッセージには生存時間が与えられてもよい。この生存時間の期限が切れると、フロートラッカーノードは要求を遮断し、要求を現在伝達することができないことをそれぞれの顧客160に通知してもよい。
少なくともいくつかの実施形態において、サーバノード130上のロードバランサモジュール132はまた、ロードバランサノード110への接続公開を行う。少なくともいくつかの実施形態において、接続公開を行うために、各ロードバランサモジュール132は定期的または非定期的に(例、1秒に1回)サーバノード130上のルーティングテーブル(例、ネットスタットルーティングテーブル)を確認し、アクティブな接続(TCPフロー)のリストをロードバランサノード110に公開する。所与のパケットフローの存在について通知を受ける必要のあるロードバランサノード110は、それぞれのパケットフローのために入口ノードおよび1次および2次フロートラッカーとしての役割を担っているロードバランサノード110である。いくつかの実施形態においては、ロードバランサモジュール132は一貫したハッシュ技術を用いて、サーバノード130上のアクティブなTCPフローについて通知を受ける必要のあるロードバランサノード110のリストをフィルターにかけてもよい。例えばロードバランサモジュール132は一貫したハッシュリングに従って、どのロードバランサノード110が所与のパケットフローのために1次および2次フロートラッカーの役割を担っているかを決定してもよい。いくつかの実施形態においては、ロードバランサモジュール132は各パケットフローのためにどのロードバランサノード110が最後にデータパケットをロードバランサモジュール132に送信したかをトラッキングし、この情報を用いてどのロードバランサノード110がパケットフローのための入口ノードの役割を担っているかを決定する。これは入口ノードのみが顧客データをロードバランサモジュール132に転送するためである。いくつかの実施形態においてはロードバランサモジュール132がその後、パケットフローについて通知を受ける必要があると決定したロードバランサノード110の各々のためのメッセージを作成し、メッセージをロードバランサノード110へ送信してそれぞれのサーバノード130が1つまたは複数の接続を1つまたは複数の顧客160に対してまだ維持していることをノード110に通知する。このロードバランサモジュール132によるロードバランサノード110への接続公開はリースのロードバランサノード110への延長と見なされてもよい。ロードバランサノード110が一定の時間(例、10秒)内に特定のパケットフローを示す接続公開メッセージを受信しない場合、ロードバランサノード110はその後それぞれのパケットフローについて忘れることもできる。
ロードバランサノードへのマルチパスルーティング
図4は少なくともいくつかの実施形態による、分散型ロードバランサにおけるルーティングおよびパケットフローの態様を示す。少なくともいくつかの実施形態において、各入口ノード(入口ノードは図4において入口サーバ112として示される)が分散型ロードバランサのために、例えば境界ゲートウェイプロトコル(BGP)を通じて1つまたは複数のパブリックエンドポイント(例、IPアドレスおよびポート)をエッジルータ104へとルーティングする能力を提供する。少なくともいくつかの実施形態においては、各入口ノードがBGPセッションを通じて自身をエッジルータ104に提供するのではなく、1つまたは複数の他の入口ノード、例えば2つの近傍ノードがエッジルータ104とのBGPセッションを確立し、図5で示されるように入口ノードを提供してもよい。
従来のロードバランサは通常、単一のパブリックエンドポイントとしての役割しか担うことができない。それに対して、分散型ロードバランサの実施形態は複数のロードバランサノード110が単一のパブリックエンドポイントとしての役割を担うことを可能にする。これによりルータの能力に応じて、すべての入口サーバ112にルーティングされた単一のパブリックIPアドレスが1つまたは複数のエッジルータ104を通じて全帯域(例、160Gbps)の処理を行ってもよい構成が可能になる。少なくともいくつかの実施形態においてこれを達成するために、1つまたは複数のエッジルータ104がレイヤー4のフローごとにハッシュ化されたマルチパスルーティング技術、例えば等価コストマルチパス(ECMP)ルーティング技術を利用し、各々が同一のパブリックIPアドレスを提供する複数の入口サーバ112を介してトラフィックを分散してもよい。一般的に、1つまたは複数のエッジルータ104のフローハッシュの一部としてフローのためのレイヤー4のソースおよび宛先ポートを用いてすべての入口サーバ112に受信パケットを分散することにより、入口サーバ112としての役割を担う同一のロードバランサノード110へとルーティングされた各接続のためのパケットに、故障したパケットを避けさせてもよい。しかしいくつかの実施形態においては、1つまたは複数のエッジルータ104は他の技術を利用して入口サーバ112を通じてトラフィックを分散させてもよいことに留意する。
図4はまた、2つ以上の分散型ロードバランサがネットワーク100上に実装されてもよいことを示す。2つ以上の分散型ロードバランサは、複数のサーバ130をフロントに配置し各々が異なるパブリックIPアドレスを提供するそれぞれ独立したロードバランサとして動作してもよく、またはその代わりに、図4に示されるように、2つ以上の分散型ロードバランサがそれぞれ同一のIPアドレスを提供してもよく、ハッシュ技術(例、レイヤー4のフローごとにハッシュ化されたマルチパスルーティング技術)は1つまたは複数の境界ルータ102において、次にパケットフローをそれぞれの区分する入口サーバ112に分散させるエッジルータ104からパケットフローを隔てるために用いられてもよい。
図5は少なくともいくつかの実施形態による、エッジルータへの入口ノードの提供のための境界ゲートウェイプロトコル(BGP)の利用を示す。この実施例においては、ロードバランサの実装において入口ノード110A〜110Dの役割を担う、4つのロードバランサノードがある。エッジルータ104は顧客(図示せず)からの受信パケットをロードバランサノード110にルーティングする。少なくともいくつかの実施形態において、エッジルータ104はレイヤー4のフローごとにハッシュ化されたマルチパスルーティング技術、例えば等価コストマルチパス(ECMP)ルーティング技術に従って、ルーティングに関する決定を下してもよい。
少なくともいくつかの実施形態において、エッジルータ104は、ロードバランサの実装において、入口ノード110により開始されるセッションを提供する境界ゲートウェイプロトコル(BGP)技術を通じて顧客のトラフィックを受信することが現在可能である入口ノード110に関して把握する。各入口ノード110はBGPを用いて自身をエッジルータ104に提供することができる。しかし、BGPは通常、収束に比較的長い時間がかかる(3秒以上)。各入口ノード110がBGPを介して自身を提供するこの技術を用いる場合、入口ノード110の故障時には、ネットワーク時間(3秒以上)において、エッジルータ104上のBGPセッションがタイムアウトするまでに相当な時間がかかる可能性があり、したがって、エッジルータ104が失敗による終了について把握し現在のTCPフローを入口ノード110に再度ルーティングするまでには相当な時間がかかる可能性がある。
BGPの収束問題を回避し、ノード110の故障時の回復を早めるため、少なくともいくつかの実施形態において、入口ノード110がBGPセッションを介して自身をエッジルータ104に提供する代わりに、ロードバランの実装において少なくとも1つの他の入口ノード110がBGPを通じてその入口ノード110をエッジルータ104に提供する役割を担う。例えば図5に示されるいくつかの実施形態においては、所与の入口ノード110の左右の近傍入口ノード110、例えばノード110の番号付きリストにおける左右の近傍ノードや、例えばノード110により形成された一貫したハッシュリングが、所与の入口ノード110をエッジルータ104に提供してもよい。例えば図5では、入口ノード110Aが入口ノード110Bおよび110Dを提供し、入口ノード110Bが入口ノード110Aおよび110Cを提供し、入口ノード110Cが入口ノード110Bおよび110Dを提供し、そして入口ノード110Dが入口ノード110Cおよび110Aを提供する。入口ノード110は本明細書にて後述するように、互いのヘルス状態をチェックしゴシップする。記載のヘルスチェック方法を用いて、異常なノードを検知することができ、1秒以内、例えば100ミリ秒(ms)以内にノード110間に情報を伝播することができる。入口ノード110が正常でないと決定された際には、異常なノードを提供する入口ノード110は直ちに異常なノード110の提供を停止してもよい。少なくともいくつかの実施形態において、入口ノード110がTCPクローズまたはBGPセッションのための類似のメッセージをエッジルータ104に送信することによりエッジルータ104とのBGPセッションを終了する。したがって、故障したノード110により確立されたBGPセッションがノード110の故障の検知についてタイムアウトするのを待つ必要なく、故障したノード110の代わりに提供を行う他の入口ノード110が、ノード110の異常の検知時にノード110を提供するエッジルータ104とのBGPセッションを遮断する時に、エッジルータ104が故障したノード110を発見することができる。ロードバランサノードの故障の処理については図18Aおよび18Bに関連して本明細書にてさらに後述される。
図6は分散型ロードバランスシステムの少なくともいくつかの実施形態による、マルチパスルーティング方法のフローチャートである。900で示すように、ロードバランサの実装における入口ノード110がその近傍ノード110をエッジルータ104に提供する。少なくともいくつかの実施形態において、入口ノード110は一貫したハッシュリングのようなノード110の番号付きリストに従って、その近傍ノード110を決定してもよい。少なくともいくつかの実施形態において、入口ノード110はBGPセッションを用いてその1つまたは複数の近傍ノード110をエッジルータ104に提供する。それらBGPセッションのうち1つは、提供されるノード110の各々のために確立されたエッジルータ104へのBGPセッションである。
902で示すように、エッジルータ104はフローごとにハッシュ化されたマルチパスルーティング技術、例えば等価コストマルチパス(ECMP)ルーティング技術に従って、顧客160から受信したトラフィックをアクティブな(提供された)入口ノード110に分散させる。少なくともいくつかの実施形態において、エッジルータ104はパブリックIPアドレスを顧客160に公開し、すべての入口ノード110が同一のパブリックIPアドレスをエッジルータ104に提供する。エッジルータレイヤー4のソースおよび宛先ポートをエッジルータ104のフローハッシュの一部として用い、受信パケットを入口ノード110間に分散させる。一般的に、これによって各接続のためのパケットを同一の入口ノード110に分散させる。
902で示すように、入口ノードがデータフローを対象のサーバノード130に転送する。少なくともいくつかの実施形態において、入口ノード110はデータフローのための1次および2次フロートラッカーノードと対話し、データフローを対象のサーバノード130へとマッピングする。こうして各入口ノード110は、受信されたパケットを対象のサーバノード130へと適切に転送するノード110を通じ、アクティブなデータフローのマッピングを維持してもよい。
要素906〜910は入口ノード110の故障の検知およびそこからの回復に関する。906で示すように、例えば本明細書に記載のヘルスチェック技術に従って入口ノード110は入口ノード110のダウンを検知してもよい。ノード110のダウンの検知時には、近傍ノード110がそのノード110のエッジルータ104への提供を停止する。少なくともいくつかの実施形態において、これにはそれぞれのBGPセッションのためのエッジルータ104へのTCPクローズの送信が関与する。
908で示すように、入口ノード110のダウンをBGPセッションの終了を通じて検知する際に、エッジルータ104はフローごとにハッシュ化されたマルチパスルーティング技術に従い、顧客160の受信トラフィックを残りの入口ノード110に再分散させる。したがって、少なくともいくつかのデータフローを入口ノード110にルーティングしてもよい。
910で示すように、入口ノード110は必要に応じてマッピングを回復し、データフローを適切な対象のサーバノードに転送してもよい。入口ノード110におけるノード110の故障からの回復方法については、本明細書の別の部分でも論じる。1つの実施例として、入口ノード110は、そのための現在のマッピングがないパケットの受信の際に、一貫したハッシュリングに従ってデータフローのためのフロートラッカーノードを決定し、フロートラッカーノードからマッピングを回復するために、一貫したハッシュ関数を用いてもよい。
非対称パケットフロー
少なくともいくつかの実施形態において、アウトバウンドトラフィックとインバウンドデータとの比が1より大きい場合に入口ノードの帯域およびCPUの使用率を効率的に利用するために、分散型ロードバランスシステムは図7で示すようにアウトバウンドパケットをサーバノード130から複数の出口ノードへと転送する。少なくともいくつかの実施形態において、各接続のために、それぞれのサーバノード130上のロードバランサモジュール132が顧客エンドポイント/パブリックエンドポイントのタプルをハッシュし、それぞれのアウトバウンドパケットフローのための出口サーバ114の役割を担うロードバランサノード110を選択するために、一貫したハッシュアルゴリズムを用いる。しかし、いくつかの実施形態においては、接続のために出口サーバ114を選択するために、他の方法および/またはデータが用いられてもよい。選択した出口サーバ114は必ずではないが、通常は接続のための入口サーバ112の役割を担うロードバランサノード110とは異なるロードバランサノード110である。少なくともいくつかの実施形態において、そのロードバランサノード110/出口サーバ114に故障がない限りは、特定の接続のためのすべてのアウトバウンドパケットは故障したパケットを回避するために、同一の出口サーバ114に転送される。
少なくともいくつかの実施形態において、出口サーバ114の選択のためにサーバノード130によって用いられる方法およびデータは、1つまたは複数のエッジルータ104により行われる入口サーバ112の選択に用いられる方法およびデータとは異なってもよい。一般的には異なる方法およびデータの利用により、所与の接続のための出口ノードには、その接続のために入口ノードとして選択されたロードバランサノード110とは異なるロードバランサノード110が結果的に選択されてもよく、また複数のロードバランサノード110が、入口ノードの役割を担う単一のロードバランサノード110を通過する接続のための発信トラフィックを処理する出口ノードとして結果的に選択されてもよい。
図7は少なくともいくつかの実施形態による、非対称パケットフローを図示する。外部ネットワーク150上の顧客160から入口サーバ112を通り、サーバノード130A、130B、130Cおよび130Dのそれぞれに至る接続が少なくとも1つは確立されている。少なくともいくつかの実施形態において、接続のための出口ノードを選択するため、各接続についてそれぞれのサーバノード130上のロードバランサモジュール132が、顧客エンドポイント/パブリックエンドポイントのタプルをハッシュし、それぞれのアウトバウンドパケットフローのための出口サーバ114の役割を担うロードバランサノード110を選択するために一貫したハッシュアルゴリズムを利用する。例えばサーバノード130Aが接続のために出口サーバ114Aを選択し、サーバノード130Bがある接続のために出口サーバ114Aを、また別の接続のために出口サーバ114Bを選択している。しかし、いくつかの実施形態においては他の方法および/またはデータが接続のための出口ノードの選択に用いられてもよい。
顧客接続を破棄しないロードバランサノードの故障からの回復
どのサーバノード130が顧客のトラフィックを受信するべきか決定するためにロードバランサノード110は一貫したハッシュを用いることができるが、いくつかの接続は寿命が長いために、この手法では、新規サーバノード130が一貫したハッシュメンバーシップに参加し、入口ロードバランサノード110の故障が続いて起こる場合に既存のフローを維持できない可能性がある。この場合、サーバ130のための一貫したハッシュリングが異なるメンバーシップを有することになるため、故障したノード110からのフローを引き継ぐロードバランサノード110はもともと選択したマッピングを決定することができない可能性がある。したがって少なくともいくつかの実施形態においては、接続のためのサーバノード130を選択し、選択したサーバノード130にパケットをルーティングするために、ロードバランサノード110が分散型ハッシュテーブル(DHT)技術を用いてもよい。DHTに従って、サーバノード130が特定の接続を受信するために選択された場合に、サーバノード130が正常を保ち、サーバノード130上のロードバランサモジュール132がそのアクティブな接続の状態を(例、接続公開を介して)DHTに定期的に伝達することでリースを継続的に延長すると仮定すると、DHTは接続が完了するまでマッピングを保持する。入口ノード110の故障はエッジルータ104から残りのロードバランサノード110へのパケットの分散に影響を及ぼし、その結果、ロードバランサノード110は異なる顧客接続の組からトラフィックを受信することになる。しかしDHTはすべてのアクティブな接続をトラッキングするので、アクティブなマッピングのいずれかのリースを取得するためにロードバランサノード110がDHTに問い合わせを行うことは可能である。その結果、すべてのロードバランサノード110がトラフィックを正しいサーバノード130へと渡し、それによって入口ロードバランサノード110の故障時であってもアクティブな顧客接続の故障を防ぐ。
分散型ロードバランスシステムにおけるパケットフロー
図8は少なくともいくつかの実施形態による、分散型ロードバランスシステムにおけるパケットフローを示す。図8において実線矢印はTCPデータパケットを表し、破線矢印はUDPデータパケットを表すことに留意する。図8では、入口サーバ112が1つまたは複数の顧客160からエッジルータ104を通じてTCPデータパケットを受信する。TCPパケットの受信時に、入口サーバ112はTCPパケットフローのためのサーバノード130へのマッピングを有しているかどうかを判断する。入口サーバ112がTCPパケットフローのためのマッピングを有する場合には、サーバ112はその後TCPパケットを(例えばUDPに従って)カプセル化し、カプセル化されたパケットを対象のサーバノード130へと送信する。入口サーバ112がTCPパケットフローのためのマッピングを有していない場合には、入口サーバ112はその後、サーバノード130への接続を確立するために、さらに/またはTCPパケットフローのためのマッピングを取得するために、TCPパケットから抽出されたTCPパケットフローに関する情報を含むUDPメッセージを1次フロートラッカー116Aへと送信してもよい。図9Aおよび9Bならびに図10A〜10Gは、顧客160とサーバノード130との間の接続の確立方法を示す。サーバノード130上のロードバランサモジュール132は、サーバノード130上の1つまたは複数のTCP接続のための1つまたは複数の出口サーバ114の役割を担う1つまたは複数のロードバランサノード110を無作為に選択し、1つまたは複数の出口サーバ114を通じてUDPによりカプセル化されたTCP応答データパケットを1つまたは複数の顧客160へと送信する。
図9Aおよび9Bは少なくともいくつかの実施形態による、分散型ロードバランスシステムにおいて接続を確立する際のパケットフローのフローチャートを提示する。図9Aの200で示すように、入口サーバ112は顧客160のTCPパケットを、エッジルータ104を通じて受信する。202で入口サーバ112がTCPフローのためのサーバノード130へのマッピングを有する場合、204で示すように、入口サーバ112がその後TCPパケットをカプセル化し、それぞれのサーバノード130へと送信する。入口サーバ112は継続的に、2つ以上の顧客160から2つ以上のTCPフローのためのパケットを受信し処理してもよいということに留意する。
202において入口サーバ112がTCPフローのためのマッピングを有していない場合、パケットは顧客160からのTCP同期(SYN)パケットであってもよい。206で示すように、SYNパケットの受信時には、入口サーバ112がSYNパケットからデータを抽出し、例えばUDPメッセージにおいて、データを1次フロートラッカー116Aへと転送する。少なくともいくつかの実施形態において、入口サーバ112はTCPフローのための1次フロートラッカー116Aおよび/または2次フロートラッカー116Bを一貫したハッシュ関数に従って決定することができる。208では、1次フロートラッカー116Aがデータを例えばハッシュテーブル内に格納し、TCP接続のサーバノード130側のための最初のTCPシーケンス番号を生成し、データおよびTCPシーケンス番号を2次フロートラッカー116Bへと転送する。210では、2次フロートラッカー116Bもデータを格納してもよく、少なくともTCPシーケンス番号を含むSYN/ACKパケットを生成して顧客160に送信する。
212で示すように、入口サーバ112は顧客160からTCP受信確認(ACK)パケットを、エッジルータ104を通じて受信する。入口サーバ112はこの時点ではTCPフローのためのサーバ130ノードへのマッピングは有していないため、214で入口サーバ112がACKパケットから抽出されたデータを含むメッセージを1次フロートラッカー116Aへと送信する。216で示すように、メッセージの受信時に1次フロートラッカー116Aは格納されたデータに従ってTCPフローを確認し、承認されたACKパケットからのシーケンス番号(+1)がSYN/ACKにおいて送信された数値に一致することを確認する。1次フロートラッカー116Aはその後、TCPフローを受信するサーバノード130を選択し、選択したサーバノード130上のローカルロードバランサモジュール132のデータ、TCPシーケンス番号およびIPアドレスを含むメッセージを2次フロートラッカー116Bに送信する。218で示すように、2次フロートラッカー116BもまたデータおよびTCPシーケンス番号を確認し、SYNメッセージを生成し、生成されたSYNメッセージを選択したサーバノード130上のローカルロードバランサモジュール132へと送信する。メソッドは図9Bの要素220に続く。
図9Bの220で示すように、ロードバランサモジュール132は生成されたSYNメッセージに応じて、サーバノード130の1つまたは複数の測定基準を調べてサーバノード130が接続を受け入れることが可能かどうかを決定してもよい。222においてサーバノード130が接続を現在受け入れることができないとロードバランサモジュール132が決定した場合、その後224においてロードバランサモジュール132が2次フロートラッカー116Bへの伝達を行う。2次フロートラッカー116Bは、すでに格納したフローのための情報を削除してもよい。226において、2次フロートラッカー116Bは1次フロートラッカー116Aへの伝達を行う。図9Aの216で示されるように1次フロートラッカー116Aはその後、新規対象のサーバノード130を選択し、2次フロートラッカー116Bへの伝達を行ってもよい。
222では、サーバノード130が接続を受け入れることが可能であるとロードバランサモジュール132が決定した場合、その後図9Bの228で示すように、ローカルロードバランサモジュール132は生成されたSYNからTCP SYNパケットを構成し、TCP SYNパケットをサーバノード130上のサーバ134に送信する。TCP SYNパケットのソースIPアドレスに顧客160の実際のIPアドレスが取り込まれ、それによりサーバ134は、顧客160への直接TCP接続を受信したことを知る。ロードバランサモジュール132はTCPフローに関連する詳細を、例えばローカルハッシュテーブルに格納する。230で示すように、サーバ134はロードバランサモジュール132が遮断するSYN/ACKパケットで応答する。232で示すように、ロードバランサモジュール132はその後接続情報を含むメッセージを2次フロートラッカー116Bに送信し、接続が受け入れられたことを示す。このメッセージの受信時に、234において2次フロートラッカー116Bがサーバ134へのマッピングを記録し、類似のメッセージを1次フロートラッカー116Aに送信し、1次フロートラッカー116Aもまたマッピング情報を記録する。236で示すように、その後1次フロートラッカー116Aがマッピングメッセージを入口サーバ112に転送する。入口サーバ112はそうして顧客160からサーバ130へのTCPフローのためのマッピングを有する。
238において入口サーバ112はサーバノード130上のロードバランサモジュール132へのデータフローのためのいずれかのバッファされたデータパケットをカプセル化し転送する。入口サーバ112により顧客160から受信されたデータのための追加の受信データパケットはカプセル化され、ロードバランサモジュール132へと直接転送され、ロードバランサモジュール132がデータパケットを脱カプセル化し、サーバ134へと送信する。
240において、ロードバランサモジュール132はデータフローのための出口サーバ114を無作為に選択する。後続のサーバ134からのアウトバウンドTCPデータパケットはロードバランサモジュール132により遮断され、UDPに従ってカプセル化され、任意に選択された出口サーバ114へと転送される。出口サーバ114は発信パケットを脱カプセル化し、TCPデータパケットを顧客160に送信する。
上記の通り202において、入口サーバ112が受信されたパケットのTCPフローのためのマッピングを有していない場合、パケットは顧客160からのTCP同期(SYN)パケットであってもよい。しかし、パケットはTCP SYNパケットでなくてもよい。例えばロードバランサノード110のメンバーシップがロードバランサノード110の追加や故障により変更される場合、エッジルータ104は入口サーバ112がマッピングを有しない入口サーバ112へのTCPフローのためのデータパケットのルーティングを開始してもよい。少なくともいくつかの実施形態において、入口サーバ112がマッピングを有しないこのようなパケットの受信時には、入口サーバ112は、一貫したハッシュリングに従ってTCPフローのための1次フロートラッカー116Aおよび/または2次フロートラッカー116Bを決定するために一貫したハッシュ関数を用い、マッピングを要求するために1次フロートラッカー116Aあるいは2次フロートラッカー116Bのいずれかへの伝達を行ってもよい。TCPフローのためのフロートラッカー116へのマッピング受信時には、入口サーバ112はマッピングを格納し、TCPフローのための1つまたは複数のTCPパケットのカプセル化および正しい宛先サーバノード130への転送を開始することができる。
ロードバランサノードの説明
少なくともいくつかの実施形態において、おのおののロードバランサノード110は3つの役割を有する:
* 入口−顧客接続における顧客160からのすべての受信パケットの受信、マッピングが把握されている場合のデータパケットのサーバノード130へのルーティング、またはマッピングが把握されていない場合のフロートラッカーへの伝達。入口ノードからの発信パケットは(例、UDPに従って)入口ノードによりカプセル化される。
* フロートラッキング−接続状態(例えば、各顧客接続を伝達するためにどのサーバノード130/サーバ134が割り当てられているか)の継続的な追跡。フロートラッカーも顧客160とサーバ134との間の接続の確立に参加する。
* 出口−サーバ134から受信されたアウトバウンドパケットの脱カプセル化および顧客160への転送。
少なくともいくつかの実施形態において、顧客−>サーバのマッピングが把握されている場合に、ロードバランサノード110は入口の役割として、サーバ134へのパケットの転送をし、マッピングが把握されていない場合に、要求のフロートラッカーへの転送の役割を担う。少なくともいくつかの実施形態において、特定の顧客接続/データフローのための入口ノードの役割を担うロードバランサノード110はまた、顧客接続のための1次フロートラッカーまたは2次フロートラッカーのいずれかの役割も担ってもよいが、その両方の役割を果たすことはできない。
少なくともいくつかの実施形態において、ロードバランサノード110はフロートラッカーの役割として、すでに確立された接続の顧客−>サーバのマッピングの維持と同様にいまだ確立されつつある接続状態の維持の役割を担う。1次フロートラッカーおよび2次フロートラッカーと呼ばれる2つのフロートラッカーは個別の各顧客接続に関与する。少なくともいくつかの実施形態において、顧客接続に関するフロートラッカーは一貫したハッシュアルゴリズムを用いて決定されてもよい。フロートラッカーはまた、各新規顧客接続のためのサーバノード130の擬似ランダム選択を含むがそれに限定されないロードバランス機能も果たす。選択されたサーバノード130上のローカルロードバランサモジュール132は、サーバ134が接続を処理することができないと決定された場合に接続要求を拒否してもよいことに留意する。この場合、フロートラッカーはその後別のサーバノード130を選択し接続要求を他のサーバノード130に送信してもよい。少なくともいくつかの実施形態において、所与の接続のための1次フロートラッカーの役割および2次フロートラッカーの役割は異なるロードバランサノード110によって果たされる。
少なくともいくつかの実施形態において、ロードバランサノード110は出口の役割として、ステートレスであり、サーバノード130から受信された受信パケットを脱カプセル化し、いくつかの検証を行い、アウトバウンドTCPデータパケットをそれぞれの顧客160に転送する。少なくともいくつかの実施形態において、サーバノード130上のロードバランサモジュール132は所与の接続のためのロードバランサノード110を任意に選択してもよい。
ロードバランサノード一貫したハッシュリングトポロジ
少なくともいくつかの実施形態において、ロードバランサノード110は入力キー空間(顧客エンドポイント、パブリックエンドポイント)の一貫したハッシュに基づくリングトポロジを形成する。入力キー空間は利用可能なフロートラッカーノードの間で区分されてもよく、すべてのフロートラッカーノードがそのキー空間に応じた質問への回答の役割を担ってもよい。少なくともいくつかの実施形態において、一貫したハッシュリングにおける後続処理に基づいて(例、2次フロートラッカーノードが1次フロートラッカーノードへの後続ノードであるか、または一貫したハッシュリングにおいて次のノードである)、データは1次および2次フロートラッカーノードに複製されてもよい。フロートラッカーノードが何らかの理由によりダウンした場合、一貫したハッシュリングにおける次のロードバランサノードが故障したノードのキー空間を獲得する。新規フロートラッカーノードが参加する際には、ノードは(例、図1で示すように構成サービス122を用いて)そのエンドポイントを登録し、それにより他のロードバランサノードはロードバランサの実装における構成変化および、その結果の一貫したハッシュリングにおける構成変化を把握してもよい。一貫したハッシュリングにおけるフロートラッカーの追加および故障の処理については、図11A〜11Dに関連して詳細に後述される。
入口ノード<−>フロートラッカーノードの通信
少なくともいくつかの実施形態において、入口ノードの役割を担うロードバランサノード110は、構成サービス122からフロートラッカーノードの役割を担うロードバランサノード110について把握してもよい。入口ノードは、ロードバランサの実装において変更され、その結果の一貫したハッシュリングにおいても変更されたメンバーシップのための構成サービス122を監視してもよい。入口ノードがマッピングを有しない顧客160からのパケットを受信する際には、どのフロートラッカーノードがパケットを伝達すべきか決定するために、入口ノードは一貫したハッシュ関数を用いてもよい。少なくともいくつかの実施形態において、ハッシュ関数への入力はパケットからの(顧客エンドポイント、パブリックエンドポイントの)ペアである。少なくともいくつかの実施形態において、入口ノードおよびフロートラッカーノードは、UDPメッセージを用いた通信を行う。
1次フロートラッカーノードが入口ノードから新規パケットフローのためのメッセージを受信する際には、1次フロートラッカーノードが無作為にTCPシーケンス番号を決定し、別のメッセージを2次フロートラッカーノードに転送する。2次フロートラッカーノードは顧客のためのTCP SYN/ACKメッセージを生成する。両方のフロートラッカーが顧客接続のエンドポイントのペアおよびTCPシーケンス番号を記憶し、メモリ圧迫または期限により状態が消去されるまでこの情報を保持する。
TCP ACKパケットが受信された入口ノードから1次フロートラッカーノードがメッセージを受信する際には、1次フロートラッカーノードが、承認されたTCPシーケンス番号がSYN/ACKパケットにおいて送信済みの格納された数値と一致することを検証し、要求を伝達するサーバノード130を選択し、メッセージを2次フロートラッカーノードに転送する。2次フロートラッカーノードは、サーバノード130でTCPスタックを用いた実際のTCP接続を開始するためにメッセージを選択されたサーバノード130上のロードバランサモジュール132へと送信し、その後サーバノード130からの確認応答を待つ。
2次フロートラッカーノードがサーバノード130上のロードバランサモジュール132から接続確認を受信する際に、1次フロートラッカーを通って入口ノードに至るリバースメッセージフローが開始され、それにより両方のフローにおいてサーバノード130に関連する情報が格納される。この時点より、入口ノードにおいて受信された追加のTCPデータパケットがサーバノード130上のロードバランサモジュール132に直接転送される。
ロードバランサモジュール<−>ロードバランサノードの通信
少なくともいくつかの実施形態において、すべてのロードバランサモジュール132が構成サービス122を用いてそのエンドポイントを登録し、ロードバランサノードレイヤー内のメンバーシップ変更のために構成サービス122を継続的に監視する。少なくともいくつかの実施形態による、ロードバランサモジュール132の関数が以下に記載される:
* 接続公開−定期的に(例、1秒に1回)または非定期的に、それぞれのサーバノード130上のアクティブな接続(顧客エンドポイント、パブリックエンドポイント)の組を、それら接続のために最後にパケットをロードバランサモジュール132へと送信した入口ノードへと同様に、それら接続のための役割を担う1次および2次フロートラッカーノードの両方にも公開する。接続公開関数はそのための役割を担うロードバランサノード110において、接続状態のリースを更新する。
* ロードバランサレイヤーにおけるメンバーシップ変更の監視。メンバーシップが変更された際に、ロードバランサモジュール132はこの変更情報を用いて、接続のための役割を担うロードバランサノードへとアクティブな接続を直ちに送信してもよい。
分散型ロードバランスシステムにおけるパケットフロー−詳細
分散型ロードバランスシステムは複数のロードバランサノード110を含んでもよい。少なくともいくつかの実施形態において、分散型ロードバランスシステムにおける各ロードバランサノード110はサーバ134への顧客160の接続のために、フロートラッカーノード、出口ノード、および入口ノードの役割を担ってもよい。分散型ロードバランスシステムはまた、各サーバノード130上のロードバランサモジュール132を含んでもよい。
図10A〜10Gは、少なくともいくつかの実施形態による、分散型ロードバランスシステムにおけるパケットフローを示す。図10A〜10Gにおいて、ロードバランサノード110の間で交換されるパケットと、ロードバランサノード110とサーバノード130との間で交換されるパケットは、UDPメッセージまたはUDPによりカプセル化された顧客TCPパケットのいずれかである。少なくともいくつかの実施形態において、顧客TCPパケットはネットワーク100に脱カプセル化された形式で、ロードバランサノード110の北側で境界ルータ102との間の相互の移行(図1参照)においてのみ存在する。図10A〜10Gの実線矢印はTCPパケットを表し、破線矢印はUDPパケットを表すことに留意する。
少なくともいくつかの実施形態において、単一のロードバランサノード110の故障時に、分散型ロードバランスシステムは確立された接続の保持を試みてもよい。少なくともいくつかの実施形態において、1次フロートラッカーノードまたは2次フロートラッカーノードのいずれかの故障時に、接続の顧客−>サーバのマッピングが残りのフロートラッカーノードにより格納できるように、1次フロートラッカーノードおよび2次フロートラッカーノードにおける接続の詳細の複製を行うことで、これは達成されてもよい。少なくともいくつかの実施形態において、ノードの故障時にはパケットの一部が喪失される可能性があるが、顧客/サーバTCPパケットの再移行により、喪失されたパケットが回復する可能性もある。
顧客からの各TCP接続は、TCPフローとよばれてもよく、顧客のIPアドレス、顧客用ポート、サーバ(パブリック)IPアドレス、およびサーバポートから成る4タプルによって一意に識別される。この識別子は、顧客およびパブリックエンドポイントのペアを示すCPまたはCcPpとして略されてもよい。与えられた任意のTCPフロー(またはCPペア)に関連するパケットは、上流のエッジルータ104からのハッシュ化された等価コストマルチパス(ECMP)フロー分散により、入口サーバ112として動作するどのロードバランサノード110上にも表れることができる。しかし一般的にTCPフローのためのパケットはTCPフローの方向を変えるリンクやロードバランサノード110の故障がない限りは、同一のロードバランサノード110に到着し続けてもよい。上流のルータ104からTCPフローのためのパケットを受信するロードバランサノード110はTCPフローのための入口ノードと称される。
少なくともいくつかの実施形態において、パケットがTCPフローのための入口ノードの役割を担うロードバランサノード110に到着した際に、どのロードバランサノード110がTCPフローのための状態を含むか(すなわち、フロートラッカーノード)を入口ノードが決定できるように、一貫したハッシュが用いられる。TCPフローに関する状態の維持の役割をどのロードバランサノード110が担うか決定するために、CPペアは入口ノードによって一貫したハッシュリングへとハッシュされてもよい。このノードは、TCPフローのための1次フロートラッカーの役割を担う。一貫したハッシュリングにおける後続ノードは、TCPフローのための2次フロートラッカーの役割を担う。
少なくともいくつかの実施形態において、すべてのロードバランサノード110は、入口ノード、1次フロートラッカーノード、および2次フロートラッカーノードとしての役割を担ってもよい。TCPフローのための一貫したハッシュの結果に応じて、TCPフローのための入口ノードの役割を担うロードバランサノード110はまた、TCPフローのための1次または2次フロートラッカーノードの役割を担ってもよい。しかし、少なくともいくつかの実施形態において、異なる物理ロードバランサノード110がTCPフローのための1次および2次フロートラッカーの役割を果たす。
接続の確立
図10Aを参照すると、顧客160からの新規接続は顧客TCP同期(SYN)パケットによって起こってもよい。ロードバランサノード110は実際にはSYNパケットの受信時にサーバノード130との接続を確立せず、また、接続を受信するためのサーバノード130の選択も直ちには行わない。代わりに、ロードバランサノード110は顧客のSYNパケットからの関連データを格納し、まだ未選択のサーバノード130のためにSYN/ACKパケットを生成する。図10Cを参照すると、顧客160がTCPのスリーウェイハンドシェイクにおける第1のACKパケットで応答すると、ロードバランサノード110はサーバノード130を選択し、サーバノード130のための同等のSYNパケットを生成し、サーバノード130を用いて実際のTCP接続の確立を試みる。
図10Aを再度参照すると、TCPフローのための入口サーバ112の役割を担うロードバランサノード110における顧客SYNパケットの受信時には、入口サーバ112がSYNパケットからデータフィールドを抽出し、TCPフローのための1次フロートラッカー116Aにデータを転送する。1次フロートラッカー116Aは例えばハッシュテーブル内にデータを格納し、最初のTCPシーケンス番号(TCP接続のサーバ側のための)を生成し、同一のデータを次フロートラッカー116Bへ転送する。2次フロートラッカー116Bは、サーバのTCPシーケンス番号を含む顧客160のためのSYN/ACKパケットを生成する。
図10Aでは、入口サーバ112、1次フロートラッカー116A、2次フロートラッカー116Bの役割が異なるロードバランサノード110により果たされる。しかし場合によっては、TCPフローのための入口サーバ112の役割を担うロードバランサノード110は、TCPフローのための1次フロートラッカー116Aまたは2次フロートラッカー116Bいずれか(しかし両方ではない)の役割を担う同一のノード110であってもよい。パケットフローのための入口サーバ112がフローのためのフロートラッカー116と同一のノード110上にあってもよい理由は、パケットフローのためのフロートラッカー116がパケットフローのアドレス情報に適用される一貫したハッシュ関数に従って一貫したハッシュリング上で決定される一方で、エッジルータ104がフローごとにハッシュ化されたマルチパスルーティング技術(例、ECMPルーティング技術)に従ってフローのための入口サーバ112を擬似ランダムに選択するからである。パケットフローのための入口サーバ112は、パケットフローのためのフロートラッカー116と同一のノード110上にある場合、SYNパケットからのデータは、入口サーバ112を実装するノード110から他のフロートラッカー116ノード110へのみ転送されてもよい。例えば図10Bにおいて、1次フロートラッカー116AはTCPフローのための入口サーバ112と同一のロードバランサノード110A上にあるが2次フロートラッカー116Bは異なるロードバランサノード110B上にあり、したがってSYNパケットからのデータがノード110Aから(フロートラッカー116Aによって)ロードバランサノード110B上の2次フロートラッカー116Bへと転送される
図10Cを参照すると、非SYNパケットが入口サーバ112に到着した際、入口サーバ112はどのサーバノード130がパケットの転送先となるべきかを把握しているか把握していないかのいずれかである。TCPフローのための入口サーバ112に到着する第1の非SYNパケットは、TCP確認番号フィールドが図10AにおいてSYN/ACKパケットが送信されたサーバシーケンス番号(+1)に一致するTCPスリーウェイハンドシェイクにおける第1のTCP受信確認(ACK)パケット(または後続のデータパケットである可能性もある)であるべきである。入口サーバ112がサーバマッピングを有しない非SYNパケットを受信した際には、入口サーバ112はシーケンス番号といったACKパケットからの情報を含む、またはその代わりにACKパケット自体を含むメッセージをTCPフローのための1次フロートラッカー116Aへと転送する。少なくともいくつかの場合に、1次フロートラッカー116AはTCPフローのために格納されたデータを記憶し、承認されたシーケンス番号(+1)がSYN/ACKパケットにおいて顧客160へ送信された数値に一致することを確認する。1次フロートラッカーはその後TCPフローのためのサーバノード130を選択し、TCPフローのためにすでに格納されたデータ、サーバシーケンス番号、および選択されたサーバノード130上のロードバランサモジュール132のためのIPアドレスを含む別のメッセージを2次フロートラッカー116Bに転送する。2次フロートラッカー116Bはサーバシーケンス番号を確認し、情報を記録し、生成されたSYNメッセージを選択されたサーバノード130上のロードバランサモジュール132に送信する。TCPフローのCPエンドポイントペアはここでロードバランサモジュール132/サーバノード130へとマッピングされる。サーバノード130上のロードバランサモジュール132は、2次フロートラッカー116Bから生成されたSYNメッセージを受信する際に、サーバノード130上のサーバ134のための正しいTCP SYNパケットを作成する役割を担う。SYNパケットの増加時には、ソースIPアドレスに顧客160の実際のIPアドレスが取り込まれ、それによってサーバ134は顧客160から直接TCP接続要求を受信したことを把握する。ロードバランサモジュール132はTCPフローに関連する詳細を、例えばローカルハッシュテーブル内に格納し、TCP SYNパケットをサーバ134に送信する(例、SYNパケットをサーバ134のLinuxカーネルに注入する)。
図10Cにおいて、入口サーバ112、1次フロートラッカー116A、および2次フロートラッカー116Bの役割はそれぞれ異なるロードバランサノード110により果たされる。しかし場合によっては、TCPフローのための入口サーバ112の役割を担うロードバランサノード110は、TCPフローのための1次フロートラッカー116Aまたは2次フロートラッカー116Bの役割を担うノードと同一のノード110である(しかし両方ではない)。例えば、図10Dにおいて、1次フロートラッカー116Aが異なるロードバランサノード110B上にある一方で、2次フロートラッカー116BはTCPフローのための入口サーバ112の役割を担う同一のロードバランサノード110A上にある。
図10Eを参照すると、サーバ134(例、Linuxカーネル)はロードバランサモジュール132も遮断するSYN/ACKパケットで応答する。SYN/ACKパケットは、もともとSYN/ACKにおいて2次フロートラッカー116Bから顧客160へと伝達されたもの(図10Aを参照)とは異なるTCPシーケンス番号を含んでもよい。ロードバランサモジュール132はシーケンス番号デルタを受信および発信データパケットへと適用させる役割を担う。サーバ134からのSYN/ACKパケットはまた、ロードバランサモジュール132から2次フロートラッカー116Bへと戻るメッセージ(例、UDPメッセージ)のきっかけとなり、選択したサーバノード130/ロードバランサモジュール132/サーバ134への接続が成功したことを示す。このメッセージの受信時に2次フロートラッカー116Aは、顧客160とサーバ134との間の顧客およびパブリックエンドポイントのペア(CP)マッピングを送信されたとおりに記録し、同様にCPマッピングを記録する1次フロートラッカー116Aへと類似のメッセージを送信してもよい。1次フロートラッカー116Aはその後入口サーバ112へとCPマッピングメッセージを転送してもよく、それにより入口サーバ112は接続のためにあらゆるバッファされたデータパケットをカプセル化されたデータパケットとしてローカルサーバノード130上のロードバランサモジュール132へと転送できるようになる。
図10Fを参照すると、接続のためのCPマッピングは入口サーバによって把握され、したがって接続のための入口サーバ112により受信された受信TCPパケットは、(例、UDPに従って)カプセル化され、カプセル化されたデータパケットとしてサーバノード130上のローカルロードバランサモジュール132に直接転送されてもよい。ロードバランサモジュール132はデータパケットを脱カプセル化し、例えばカーネルのTCPスタック上へとTCPパケットを注入することでTCPパケットをサーバノード130上のサーバ134へと送信する。サーバ134からのアウトバウンドパケットは、サーバノード130上のロードバランサモジュール132によって遮断され、(例、UDPに従って)カプセル化され、そしてロードバランサモジュール132がこの接続のための出口サーバ114として無作為に選択する任意のロードバランサノード110へと転送される。出口サーバ114はパケットを脱カプセル化し、脱カプセル化されたデータパケットを顧客116へと送信する。選択したロードバランサノード110の出口関数はステートレスであり、そのため出口サーバの役割を担うロードバランサノード110の故障時には、異なるロードバランサノード110を接続のための出口サーバ114としてとして選択することが可能である。しかし一般的には、接続の維持のための出口サーバ114と同一のロードバランサノード110が、アウトバウンドパケットの再配置を減少させ、または取り除くために用いられる。
図10Gを参照すると、少なくともいくつかの実施形態において、1次フロートラッカー116Aによって選択されたサーバノード130A上のロードバランサモジュール132A(図10Cを参照)は、自身に負荷がかかり過ぎていると判断した場合に、2次フロートラッカー116Bから受信された、生成されたSYNメッセージ(図10Cを参照)を拒否する選択肢を有する。少なくともいくつかの実施形態において、生成されたSYNメッセージは拒否の最大値を許す生存時間(TTL)の数値またはカウンターを含む。少なくともいくつかの実施形態において、このTTL値がゼロに達した場合、ロードバランサモジュール132Aが負荷を制限するために接続の受け入れまたは接続の破棄のいずれかを行ってもよい。ロードバランサモジュール132Aは接続の拒否を決定した場合、TTL値をディクリメントし、2次フロートラッカー116Bに拒否メッセージを送信する。2次フロートラッカー116BはCPマッピングをリセットし、リリースメッセージを同様のことを行う1次フロートラッカー116Aに送信する。1次フロートラッカー116Aは別のサーバノード130B上の新規ロードバランサモジュール132Bを選択し、2次フロートラッカー116Bに新規対象のメッセージを返信し、2次フロートラッカー116Bが新規生成されたSYNメッセージを新規に選択されたロードバランサモジュール132Bに送信する。パケットの破棄によりこれらのシーケンスが完了しない可能性があることに留意する。しかし、顧客160からの再伝達によりロードバランサモジュールの選択処理が1次フロートラッカー116Aにおいて再び行われてもよい。1次フロートラッカー116Aは必ずそうするとは限らないが、生成されたSYNパケットの前回の拒否について把握していない場合、接続のための同一のロードバランサモジュール132を選択してもよい。
少なくともいくつかの実施形態において、TTLカウンターは継続的に接続要求をサーバノード130に送るのを阻止してもよく、これは例えばすべてのサーバノード130がビジー状態である場合に発生してもよい。少なくともいくつかの実施形態において、ロードバランサモジュール132が、それぞれのサーバノード130に代わり接続要求を拒否する時は毎回、ロードバランサモジュール132がTTLカウンターをディクリメントする。フロートラッカーノード116は、TTLカウンターがゼロではない(すなわちある特定の閾値を超える)限りTTLカウンターを監視してもよく、別のサーバノード130を選択し再度試みてもよい。TTLカウンターがゼロに達する(すなわちある特定の閾値を超える)場合、接続要求は破棄され、その接続のために選択されたサーバノード130のうちの1つに接続要求を送信する試みをフロートラッカーノード116が再び行うことはない。少なくともいくつかの実施形態において、エラーメッセージがそれぞれの顧客160に送信されてもよい。
少なくともいくつかの実施形態において、分散型ロードバランサシステムは複数のパブリックIPアドレスをサポートする。こうして、顧客160が同一の顧客用ポート番号から2つの異なるパブリックIPアドレスへの2つのTCP接続を開始することが可能になる。これらのTCP接続は顧客160の観点とは異なるが、内部では分散型ロードバランサが同一のサーバノード130への接続をマッピングしてもよく、これにより衝突が起こる。少なくともいくつかの実施形態において、可能性のある衝突を検知し処理するために、ロードバランサモジュール132は図10Cおよび10Dで示すように2次フロートラッカー116Bから生成されたSYNパケットを受信する際に、アドレス情報をアクティブな接続と比較してもよく、この接続が衝突を発生させる場合には、図10Gで示すように接続要求を拒否してもよい。
ロードバランサノードの故障および追加の処理
従来のロードバランサの多くにおいては、ロードバランサの故障時には既存の接続の一部またはすべてが喪失される。少なくともいくつかの実施形態において、単一のロードバランサノード110の故障時には、接続が完全に正常に戻るまで顧客およびサーバが接続を通じてパケットの交換を継続できるように、分散型ロードバランスシステムが確立された接続のうち少なくともいくつかを維持してもよい。また分散型ロードバランスシステムは、故障時に確立の処理中であった接続の伝達を継続してもよい。
分散型ロードバランスシステムの少なくともいくつかの実施形態において、単一のロードバランサノード110の故障時に既存の顧客接続を回復させることができる故障回復プロトコルが実装されてもよい。しかし複数のロードバランサノード110の故障により、顧客接続が喪失される場合がある。少なくともいくつかの実施形態において、顧客160とサーバ134との間のTCPの再伝達がロードバランサノード110の故障後の回復手段として用いられてもよい。
可能性のあるロードバランサノード110の故障に加えて、新規ロードバランサノード110が分散型ロードバランサシステムに追加されてもよい。これら新規ノード110はロードバランサレイヤーに、またそれにより一貫したハッシュリング追加されてもよく、ロードバランサノード110の既存の顧客接続に関する役割は、必要に応じて変更に従い調整される。
フロートラッカーノードの故障および追加の処理
少なくともいくつかの実施形態において、各接続が確立される(例、図10A〜10Gを参照)にしたがって、接続状態の情報が1次および2次フロートラッカーと呼ばれる2つのロードバランサノード110を通じて渡される。これらは例えば(顧客IP:ポート、パブリックIP:ポート)タプルをハッシュ関数入力として用いる一貫したハッシュアルゴリズムを利用して決定されてもよい。単一のロードバランサノード110の故障時には、パケットを接続のための選択されたサーバノード130へと導くために、少なくとも1つの生存するロードバランサノード110は一貫したハッシュ関数を通じて継続的にマッピングされてもよく、また接続のために必要な状態情報を含んでもよい。また、ロードバランサノード110を一貫したハッシュリングへと追加する場合、接続のための状態情報は適切なフロートラッカーへとリフレッシュされてもよい。
図11A〜11Dは少なくともいくつかの実施形態による、ロードバランサノードの一貫したハッシュリングにおいてメンバーシップに影響を与えるイベントの処理を示す。これらのイベントは、新規1次フロートラッカーノードの追加、新規2次フロートラッカーノードの追加、1次フロートラッカーノードの故障、および2次フロートラッカーノードの故障を含んでもよいがこれらに限定されない。
図11Aは、新規1次フロートラッカーノードの一貫したハッシュリングへの追加処理を示す。図11Aの上部列は、1つまたは複数の顧客接続のための1次フロートラッカーとしてのフロートラッカー116Aおよび1つまたは複数の同一の接続のための2次フロートラッカーとしてのフロートラッカーノード116Bを示す。図11Aの下部列においては、新規フロートラッカーノード116Cが追加され、1つまたは複数の顧客接続のための1次フロートラッカーとなっている。以前は1次フロートラッカーであったフロートラッカーノード116Aは2次フロートラッカーとなり、以前は2次フロートラッカーであったフロートラッカーノード116Bは、一貫したハッシュリングにおける次のフロートラッカーとなる。フロートラッカー116Aおよび116Bにより維持された1つまたは複数の顧客接続のための状態情報は新規1次フロートラッカー116Cに提供されてもよい。また、フロートラッカー116Bは2次フロートラッカーの役割として以前トラッキングしていた接続を「忘れて」もよい。
図11Bは、新規2次フロートラッカーノードの一貫したハッシュリングへの追加処理を示す。図11Bの上部列は、1つまたは複数の顧客接続のための1次フロートラッカーとしてのフロートラッカー116Aおよび1つまたは複数の同一の接続ための2次フロートラッカーとしてのフロートラッカーノード116Bを示す。図11Bの下部列においては、新規フロートラッカーノード116Cが追加され、1つまたは複数の顧客接続のための2次フロートラッカーとなっている。フロートラッカーノード116Aは1つまたは複数の接続のための1次フロートラッカーのままであり、以前は2次フロートラッカーであったフロートラッカーノード116Bは一貫したハッシュリングにおける次のフロートラッカーとなる。フロートラッカー116Aおよび116Bによって維持された1つまたは複数の顧客接続のための状態情報は新規2次フロートラッカー116Cに提供されてもよい。また、フロートラッカー116Bは2次フロートラッカーの役割として以前トラッキングしていた接続を「忘れて」もよい。
図11Cは、一貫したハッシュリングにおける1次フロートラッカーノードの故障の処理を示す。図11Cの上部列は、1つまたは複数の顧客接続のための1次フロートラッカーとしてのフロートラッカー116A、1つまたは複数の同一の接続のための2次フロートラッカーとしてのフロートラッカーノード116B、および一貫したハッシュリングにおける次のフロートラッカーとしてのフロートラッカーノード116Cを示す。図11Cの下部列においては、1次フロートラッカーノード116Aが故障している。フロートラッカーノード116Bは1つまたは複数の接続のための1次フロートラッカーとなり、フロートラッカーノード116Cは1つまたは複数の接続のための2次フロートラッカーとなる。1つまたは複数の顧客接続のための状態情報はフロートラッカー116Bによって維持され、新規2次フロートラッカー116Cへと提供されてもよい。
図11Dは一貫したハッシュリングにおける2次フロートラッカーノードの故障の処理を示す。図11Dの上部列は、1つまたは複数の顧客接続のための1次フロートラッカーとしてのフロートラッカー116A、1つまたは複数の同一の接続のための2次フロートラッカーとしてのフロートラッカーノード116B、および一貫したハッシュリングにおける次のフロートラッカーとしてのフロートラッカーノード116Cを示す。図11Dの下部列においては、2次フロートラッカーノード116Bが故障している。フロートラッカーノード116Aは1つまたは複数の接続のための1次フロートラッカーのままであり、フロートラッカーノード116Cは1つまたは複数の接続のための2次フロートラッカーとなる。1つまたは複数の顧客接続のための状態情報はフロートラッカー116Bにより維持され、新規2次フロートラッカー116Cに提供されてもよい。
少なくともいくつかの実施形態において、サーバノード130上のロードバランサモジュール132はロードバランサノード110への接続公開を行う。少なくともいくつかの実施形態において、接続公開は定期的に(例、1秒に1回)または非定期的に現在の接続状態の情報をサーバノード130から、接続のための1次および2次フロートラッカーノード両方への接続マッピングのリフレッシュまたは復元を行うフロートラッカーノードおよび入口ノードの役割を担うロードバランサノード110へとプッシュする。少なくともいくつかの実施形態において、ロードバランサモジュール132は例えば図11A〜11Dで示される通り、フロートラッカーのメンバーシップ変更を検知してもよい。それに応じてロードバランサモジュール132は、メンバーシップが変更された際に接続のために変更されたかもしれない、1次および2次フロートラッカーノードにおける接続のための状態情報を追加するために、接続公開を行ってもよい。接続公開により、複数のロードバランサノードの故障時に少なくともいくつかの確立された接続が回復されてもよいことに留意する。
故障に関連するメッセージフロー
少なくともいくつかの実施形態において、1次および2次フロートラッカーノードの間のプロトコルは、修正または同期機能を含んでもよい。例えば図11Aを参照すると、新規1次フロートラッカーノード116Cが一貫したハッシュリングに参加する際には、新規ノード116Cがいくつかの数(〜1/N)の接続のための一貫したハッシュのキー空間に要求を出し、エッジルータ104からこれらの接続に関連するトラフィックの受信を開始してもよい。しかし新規1次フロートラッカーノード116Cは接続のために格納された状態を一切有さないため、各パケットに対して、顧客160から受信された第1のパケットとして動作してもよい。1次フロートラッカーはSYNデータパケットに応じてサーバのTCPシーケンス番号の生成(例、図10Aを参照)および顧客160からの第1のACKパケットに応じてサーバノード130の選択(例、図1を参照)の役割を担い、これらの生成された数値は前の1次フロートラッカー(図11Aにおけるフロートラッカーノード116A)により選択された数値と相違してもよい。しかし少なくともいくつかの実施形態において、一貫したハッシュアルゴリズムは前の1次フロートラッカー(図11Aにおけるフロートラッカーノード116A)を2次フロートラッカーの役割に割り当て、このフロートラッカーは接続のためのすでに格納された状態をいまだに保持する。したがって少なくともいくつかの実施形態において2次フロートラッカー(図11Aにおけるフロートラッカーノード116A)は、1次フロートラッカー116Cから受信された情報における不一致を検知した時、2次フロートラッカーは接続のためのフロートラッカーとしての役割を担う2つのロードバランサノード110を同期するために更新メッセージを1次フロートラッカー116Cへと返信することができる。一貫したハッシュリングのメンバーシップにおいて他の変更がなされた後にフロートラッカーを同期するために類似の方法が用いられてもよい。
ロードバランサモジュールの説明
少なくともいくつかの実施形態において、ロードバランサモジュール132は各サーバノード130上にある分散型ロードバランサシステムの構成要素である。ロードバランサノード132の役割は、ロードバランサノード110から受信されたパケットの脱カプセル化および脱カプセル化されたパケットのサーバノード130上のサーバ134への送信、ならびにサーバ134からの発信パケットのカプセル化およびカプセル化されたパケットのロードバランサノード110への送信を含むがそれに限定されない。
少なくともいくつかの実施形態において、入口サーバ112の役割を担うロードバランサノード110からサーバノード130上のロードバランサモジュール132への受信パケットは、実際の顧客データパケットをカプセル化するステートレスプロトコル(例、UDP)パケットである。カプセル化された顧客データパケットは各々、ソースアドレスとしてそれぞれの顧客160のオリジナルの顧客IP:ポートを、そして宛先アドレスとしてサーバ134パブリックIP:ポートを有する。ロードバランサモジュール132は顧客データパケットを脱カプセル化し、例えばパケットの方向をローカルホストTCPフローへと変更することで、それぞれのサーバノード130上のサーバ134へと送信する。
少なくともいくつかの実施形態において、サーバ134から出口サーバ114の役割を担うロードバランサノード110への発信パケットは、発信IPパケットをカプセル化するステートレスプロトコル(例、UDP)パケットである。ロードバランサモジュール132は発信IPパケットをカプセル化し、ファブリック120を通してカプセル化されたパケットを出口サーバ114へと送信する。各カプセル化された発信IPパケットは、ソースアドレスとしてサーバ134パブリックIP:ポートを、そして宛先アドレスとしてそれぞれの顧客160の顧客IP:ポートを有する。
ロードバランサモジュール機能
少なくともいくつかの実施形態において、サーバノード130上のロードバランサモジュール132の機能は以下の1つまたは複数を含んでもよいが、それらに限定されない:
* 1つまたは複数のロードバランサノード110からの、例えば顧客160への接続を処理する入口サーバ112からの、UDPトンネルの終了。これは入口サーバ112から受信された受信顧客データパケットのUDP脱カプセル化を含む。
* 接続のための発信トラフィックを受信する出口サーバ114の選択。
* それぞれのサーバ134上の接続における発信IPパケットの遮断、接続のための発信IPパケットのカプセル化、およびカプセル化されたデータパケットの出口サーバ114への送信。
* フロートラッカーノード116が顧客160にSYN/ACKを送信する際にシーケンス番号がフロートラッカーノード116により生成されたシーケンス番号と整列させるための、受信および発信パケットにおけるシーケンス番号のマングリング。
* 例えばそれぞれのサーバ134の現在の負荷を示す1つまたは複数の測定基準に基づく、それぞれのサーバ134のための接続を受け入れるか拒否するかの決定。
* 顧客IP:ポートアドレスの衝突を回避するためのアクティブな接続がある場合の、同一の顧客IP:ポートアドレスからそれぞれのサーバ134への接続の検知および拒否。
* 接続トラッキングおよび接続公開。
ロードバランサモジュールの構成情報
少なくともいくつかの実施形態において、各ロードバランサモジュール132は構成のために、以下の情報の組の1つまたは複数を獲得し、ローカルに格納してもよいが、それらに限定されない:ロードバランサノード110エンドポイントの組、伝達する有効なパブリックIPアドレスの組、およびそれぞれのサーバ134が受信接続を受け入れる1つまたは複数のポート番号。少なくともいくつかの実施形態において、図1で示すようにこの情報は、分散型ロードバランサシステムの構成要素である構成サービス122から獲得されるか、またはそれへのアクセスか問い合わせにより更新されてもよい。いくつかの実施形態においては、他の情報獲得方法が用いられてもよい。
ロードバランサモジュールのパケット処理
少なくともいくつかの実施形態による、インバウンドトラフィックおよびアウトバウンドトラフィックのためのロードバランサモジュール132の動作を以下に記載する。少なくともいくつかの実施形態において、インバウンドデータパケットがロードバランサモジュール132により受信される際に、データパケットがUDPパケットから脱カプセル化され、脱カプセル化されたTCPパケットにおける宛先アドレスは構成された有効なパブリックIPアドレスの組に対して最初に検証される。一致がない場合、パケットは破棄されるかまたは無視される。少なくともいくつかの実施形態において、シーケンス番号がSYN/ACKパケットを顧客160に送信したフロートラッカーノード116により生成され無作為に選択されたシーケンス番号に一致するように、ロードバランサモジュール132はTCPヘッダにおけるシーケンス番号を定数デルタにより調整してもよい。ロードバランサモジュール132は[顧客:パブリック]エンドポイントから[顧客/サーバ]エンドポイントへのマッピングを内部状態として記録する。
少なくともいくつかの実施形態において、サーバ134からのアウトバウンドTCPデータパケットのために、ロードバランサモジュール132はまず内部状態を確認し、パケットが、ロードバランサモジュールが管理しているアクティブな接続のためのものであるかどうかを決定する。そうでない場合、ロードバランサモジュール132はただパケットを渡す。そうである場合、ロードバランサモジュール132は発信TCPパケットを例えばUDPに従ってカプセル化し、カプセル化されたパケットをこの接続のための出口サーバ114として選択されたロードバランサノード110へと転送する。少なくともいくつかの実施形態において、ロードバランサモジュール134は発信TCPパケットにおけるTCPシーケンス番号を定数デルタにより調整して、SYN/ACKパケットを顧客160に送信したフロートラッカーノード116により生成されたシーケンス番号を整列させてもよい。
接続のトラッキング
少なくともいくつかの実施形態において、各サーバノード130上のロードバランサモジュール132はそれぞれのサーバ134へのすべてのアクティブな顧客接続のための接続の詳細を含むハッシュテーブルを管理する。少なくともいくつかの実施形態において、ハッシュテーブルのためのキーは(顧客IP:ポート、パブリックIP:ポート)タプルである。少なくともいくつかの実施形態において、各顧客接続のための接続状態は以下の1つまたは複数を含むが、それらに限定されない:
* 顧客IP:ポート
* パブリックIP:ポート
* フロートラッカー116ノードにより提供される最初のサーバのTCPシーケンス番号。
* サーバのTCPシーケンス番号デルタ。
* オリジナルの1次フロートラッカーIPアドレス。
* オリジナルの2次フロートラッカーIPアドレス。
* 最後に検知された入口サーバ112のIPアドレス。
* このエントリのための有効期限
* 最長期間未使用の(LRU)/衝突指数。
少なくともいくつかの実施形態において、各ロードバランサモジュール132はすべてのアクティブな顧客接続のための1次および2次フロートラッカーノードへの接続公開メッセージを定期的に生成する。少なくともいくつかの実施形態において、/proc/net/tcpの内容がスキャンされロードバランサモジュールのハッシュテーブルにおけるアクティブな接続と交差し、Linuxカーネルが接続のトラッキングを停止するまでフロートラッカーノードへと継続的に公開される。接続公開については本明細書にて詳細に後述される。
シーケンス番号のマングリング
上述のように少なくともいくつかの実施形態において、ロードバランサノード110はサーバ134の代わりに顧客160SYNパケットに応じて、SYN/ACKパケットを生成する。顧客160がACKパケットを送信する後にのみ(TCPスリーウェイハンドシェイク)ロードバランサモジュール110がサーバノード130上のロードバランサモジュール132へといずれかのデータを送信する。ロードバランサモジュール132が最初に顧客接続を確立するよう指示される際は、ロードバランサモジュール132がローカルでSYNパケットを作成してサーバノード130上のサーバ134を用いてTCP接続を開始し、サーバ134に対応するSYN/ACKパケットを遮断する。通常、サーバ134(例、サーバノード130上のLinuxカーネル)がSYN/ACKパケットにおいてロードバランサノード110から受信された顧客の1つとはまったく異なるTCPシーケンス番号を選択する。こうして少なくともいくつかの実施形態において、ロードバランサモジュール132は顧客160とサーバ134との間のTCP接続のすべてのパケットにおけるシーケンス番号の補正を行ってもよい。少なくともいくつかの実施形態において、ロードバランサモジュール132はロードバランサノード110により生成されたシーケンス番号とサーバ134により作成されたシーケンス番号との間の差異を計算し、その差異をデルタ値としてTCP接続のためのハッシュテーブルエントリ内に格納する。受信データパケットが顧客160から接続に到着する際には、TCPヘッダがサーバ134により用いられるシーケンス番号と整列しない確認番号を含むため、ロードバランサモジュール132はTCPヘッダにおけるシーケンス番号の数値からデルタ値を減算する(例、2つの補数を用いて)。ロードバランサモジュールはまた、サーバ134から顧客130への接続上のアウトバウンドデータパケットにおけるシーケンス番号にデルタ値を追加する。
分散型ロードバランサシステムにおけるヘルスチェック
分散型ロードバランサシステムの少なくともいくつかの実施形態において、各ロードバランサノード110はロードバランサの実装における正常なメンバー(すなわち、正常なロードバランサノード110およびサーバノード130)の一貫した見解を、少なくとも以下の理由により要求する:
* ロードバランス−ロードバランサノード110がサーバノード130の故障を検知し、顧客のトラフィックを受け入れることができる正常なサーバノード130の組において収束する必要がある。
* 分散状態の管理−ロードバランサは複数のロードバランサノード110で共有された/複製された状態を有する分散型システムである(例、一貫したハッシュ機構に従って)。顧客のトラフィックを正しく処理するために、各ロードバランサノード110は最終的にロードバランサの実装における正常なメンバーの一貫した見解を有する必要がある。
これを達成するため、分散型ロードバランサシステムの少なくともいくつかの実施形態は、ロードバランサの実装においてノードを監視し、可能な限り迅速に異常なノードを検知するヘルスチェックプロトコルの実施形態を実装してもよい。ヘルスチェックプロトコルはロードバランサの実装においてノード間にヘルス情報を伝播してもよく、正常なノードの組においてノードの収束を可能にする方法を提供してもよい。またヘルスチェックプロトコルは、ロードバランサの実装における正常/異常なノードおよび状態の変化を報告するための機構を提供してもよい。
少なくともいくつかの実施形態において、ヘルスチェックプロトコルは以下の仮定のうちの1つまたは複数に基づいてもよいが、それらに限定されない:
* ロードバランサの実装におけるすべてのノードが把握される(すなわち、ヘルスチェックプロトコルは発見を行わなくてもよい)。
* ノードの故障はすべてフェイルストップである。
* ノード間のすべてのメッセージはステートレスプロトコル(例、UDP)メッセージであり、メッセージは破棄され、遅延させられ、複製され、または破損する可能性がある。メッセージの伝達の保証はない。
少なくともいくつかの実施形態において、ロードバランサの実装におけるノード(例、ロードバランサノード110またはサーバノード130)は以下の条件の下で正常であると見なされてもよい:
* ノードの内部構成要素はすべてレディ状態である(顧客のトラフィックを処理する準備が完了している)。
* ノードの受信/発信ネットワークリンクは正常である(少なくともどの顧客のトラフィックを流すかについてのネットワークインタフェースコントローラ(NIC)に関しては)。
図12は少なくともいくつかの実施形態による、ヘルスチェック間隔に従って各ロードバランサノードにより実行されるヘルスチェック方法のハイレベルフローチャートである。1000で示すように、各ロードバランサ間隔において、例えば100ミリ秒毎に、各ロードバランサ(LB)ノード110は少なくとも1つの他のLBノード110および少なくとも1つのサーバノード130のヘルスチェックを行ってもよい。1002で示すように、ロードバランサノード110はヘルスチェックに従って、そのローカルに格納されたヘルス情報を更新してもよい。1004で示すように、ロードバランサノード110はその後、少なくとも1つの他のロードバランサノード110を無作為に選択し、そのヘルス情報を選択された1つまたは複数のロードバランサノード110へと送信してもよい。少なくともいくつかの実施形態において、ノード110はまた、正常なロードバランサノード110のリストを1つまたは複数のサーバノード130、例えばノード110によりヘルスチェックされる1つまたは複数の同一のサーバノード130へと送信してもよい。図12の要素は以下において詳細に説明される。
ヘルスチェックプロトコルの少なくともいくつかの実施形態において、ロードバランサノード110はそのヘルス状態を他のロードバランサノード110にアサートしない。その代わりに、1つまたは複数の他のロードバランサノード110がそのノード110のヘルスチェックを行ってもよい。例えば少なくともいくつかの実施形態において、各ロードバランサノード110はヘルスチェックを行う1つまたは複数の他のノード110を、定期的または非定期的に無作為に選択してもよい。別の実施例として、少なくともいくつかの実施形態において、1つまたは複数の他のロードバランサノード110、例えば一貫したハッシュリング等のノード110の番号付きリスト上の所与のロードバランサノード110の2つの最近傍ノードはそれぞれ、所与のノード110のヘルスチェックを定期的または非定期的に行ってもよい。少なくともいくつかの実施形態において、ノード110のヘルスチェックは図23で示すように、ノード110上のNIC1114へと送信されたヘルスpingの利用を含んでもよい。少なくともいくつかの実施形態において、第2のノード110が正常であると第1のノード110がヘルスチェックを通じて決定する場合、第1のノード110は、ロードバランサノード110のためのローカルヘルス情報に格納された、第2のノード110のためのハートビートカウンターを更新(例、増加)してもよい。第1のノード110はそのローカルヘルス情報をロードバランサの実装における1つまたは複数の他のロードバランサノード110へと定期的または非定期的に送信してもよく、それら1つまたは複数の他のロードバランサノード110はそのローカルヘルス情報を適宜更新(例、第2のノードのためのハートビートカウンターの増加により)し、その更新されたローカルヘルス情報を1つまたは複数の他のノード110へと送信してもよい。第2のノード110のためのハートビート情報はこうしてロードバランサの実装における他のノード110へと伝播されてもよい。第2のノード110が正常である限り、第2のノード110から到達可能な他のすべてのノード110はこのように、第2のノード110のハートビートカウンターが一定期間毎に、例えば、1秒に1回または10秒毎に一回、増加していることを確認すべきである。第2のノード110が、そのヘルスチェックを行う1つまたは複数のノード110により、異常であると検知された場合、ノード110のためのハートビートはヘルスチェックを行うノード110により一切送信されず、ある時間閾値の経過後、ロードバランサの実装110における他のノード110が、問題のノード110が異常である、またはダウンしていると見なす。
少なくともいくつかの実施形態において、ロードバランサノード110はその内部状態の1つまたは複数の態様を確認してもよく、ノード110が何らかの理由によるその異常を検知した場合、ノード110はそのヘルスチェックを行う他のノード110からのヘルスpingに対して応答を停止してもよい。したがって、異常なノード110のヘルスチェックを行うノード110は、そのノード110を以上であると見なしてもよく、そのノード110の代わりにハートビートの増加を伝播しなくてもよい。
ヘルスチェックプロトコルの説明
少なくともいくつかの実施形態において、ヘルスチェックプロトコルはハートビートカウンター技術およびゴシッププロトコル技術を活用してもよい。ヘルスチェックプロトコルは2つの主要部分−ヘルスチェックおよびゴシップ/故障検知を有すると見なされてもよい。
ヘルスチェック−ロードバランサの実装におけるすべてのロードバランサノード110は、実装における1つまたは複数の他のノード110のヘルスチェックを定期的または非定期的に行ってもよい。1つまたは複数の他のノードの決定方法は後述される。ヘルスチェックの中心となる概念は、ノード110が別のノード110のヘルスチェックを行い、他のノード110が正常であると決定する場合、そのチェックを行うノード110が他のノード110のハートビートカウンターを増加させまた伝播することにより、他のノード110が正常であるとアサートする。すなわち、ノード110はそのヘルス状態を他のノードにアサートせず、その代わりに、1つまたは複数の他のノード110がロードバランサの実装における各ノード110のヘルス状態をチェックしアサートする。
ゴシップ/故障検知−少なくともいくつかの実施形態において、ヘルスチェックプロトコルはロードバランサの実装におけるメンバーであるロードバランサノード110の間にロードバランサノード110のヘルス情報を伝播するゴシッププロトコルを活用してもよい。ゴシッププロトコルは迅速に収束し、分散型ロードバランスシステムの目的に十分な最終的な一貫性を保証する。少なくともいくつかの実施形態において、ゴシッププロトコルの利用により各ロードバランサノード110は、ロードバランサの実装における互いのノード110のためのハートビートカウンターを、例えばハートビートリストにおいて維持する。各ロードバランサノード110は上記のように少なくとも1つの他のロードバランサノード110のヘルスチェックを定期的または非定期的に行い、ヘルスチェックを通じてチェックを行ったノード110が正常であると決定した際に、ノード110のためのハートビートカウンターを増加させる。少なくともいくつかの実施形態において、各ロードバランサノード110は定期的または非定期的に、ロードバランサの実装における少なくとも1つの他のノード110を現在のハートビートリストの送信先として無作為に選択する。別のノード110からハートビートリストを受信した際に、2つのリスト(受信されたリストおよびそのリスト)上の各ノード110のための最大のハートビートカウンターを決定し、決定された最大のハートビートカウンターをそのハートビートリストにおいて利用することで、ロードバランサノード110は受信されたリストのハートビート情報をそのハートビートリストと組み合わせる。次にこのハートビートリストは別の無作為に選択されたノード110へと送信され、選択されたノード110がそのハートビートリストの更新等を適宜行う。この技術を用い、各正常なノード110のためのハートビート情報は最終的に(例、数秒後に)すべての他のロードバランサの実装におけるロードバランサノード110へと伝播される。所与のロードバランサノード110のためにハートビートカウンターし続ける限り、それは他のノード110により正常であると見なされる。ロードバランサノード110のハートビートカウンターがヘルスチェックおよびゴシップ方法により特定の期間中に増加されない場合は、他のロードバランサノード110がその後、異常であると見なされたロードバランサノード110上で収束してもよい。
ヘルスチェックを行うロードバランサノード
少なくともいくつかの実施形態による、別のロードバランサノード110により実行されてもよいロードバランサノード110のヘルスチェック方法を以下に記載する。図23に関連し、少なくともいくつかの実施形態において、ノード110のために以下の条件のうちの1つまたは複数が決定された場合、ロードバランサノード110は正常であると見なされてもよい:
* ノード110のプロセッサの閾値(例、コアパケット処理コード1108の閾値)がレディ状態(内部)である。
* ノード110がエッジルータ104のIPアドレスおよび/またはMACアドレスを把握している(内部)。
* ノード110のすべての閾値および/またはプロトコルハンドラーがレディ状態である(内部)。
* 北側(エッジルータ104/境界ネットワーク)から、また南側(サーバ130/本番ネットワーク)からの受信および発信リンクがアクティブである(外部)。
* ロードバランサの実装において用いられるネットワークインタフェースコントローラ(NIC)を通じて、ノード110がパケットを受信およびディスパッチすることが可能である。例えば図23で示される例示的なロードバランサノード110の実施形態において、ノード110は北向きのNIC1114Aおよび南向きのNIC1114Bを通じてパケットの受信およびディスパッチに成功すべきである。
1つまたは複数のこれらのヘルス条件が所与のノード110に当てはまらない場合、そのノード110は正常でないと見なされてもよい。いくつかの実施形態において、上記条件のすべてがノード110に当てはまる場合にのみ、ノード110は正常であると見なされることに留意する。
少なくともいくつかの実施形態において、上記ヘルス条件に加えて、図23においてNIC1114Cとして示され、例えば制御プレーン通信のために用いられてもよい、各ロードバランサノード110上の第3のNICもまた、NICへパケットを送信し、NICからパケットを受信することでヘルスチェックを行うノード110によりチェックされてもよく、第3のNICのチェックが失敗した場合、チェックされているノード110は異常であると見なされてもよい。
図13は少なくともいくつかの実施形態による、別のロードバランサノードからのロードバランサノードのヘルスチェック方法の実施例を示す。この実施例では、ロードバランサノード110Aはロードバランサノード110Bのヘルスチェックを行っている。ノード110Aおよび110Bはそれぞれ、北向きのNIC(図23のNIC1114A)および南向きのNIC(図23のNIC1114B)を有する。1では、ノード110Aがパケット(例、pingパケット)をその北向きのNICからノード110Bの北向きのNICへとエッジルータ104を通じて送信する。ノード110Bはその北向きのNICにおいてパケットを受信し、上記リストにおいて与えられた条件が満たされた場合、2においてその北向きのNICからノード110Aの北向きのNICへとファブリック120を通じて応答を送信する。3において、その北向きのNICで応答を受信した際に、ノード110Aはパケット(例、pingパケット)をその南向きのNICからノード110Bの南向きのNICへとファブリック120を通じて送信する。ノード110Bはその南向きのNICにおいてパケットを受信し、上記リストにおいて与えられた条件が満たされた場合、4においてその南向きのNICからノード110Aの南向きのNICへとエッジルータ104を通じて応答を送信する。その南向きのNICにおいて応答を受信した際、ノード110Aはノード110Bを正常であると見なしてノード110Bのローカルハートビートカウンターを増加させ、その後それは上述のようにゴシッププロトコルに従って他のノード110へと伝播されてもよい。
上記の代わりとして、いくつかの実施形態においては、ロードバランサノード110Bはその南向きのNICを通じて、その北向きのNICで受信された、ノード110Aの南向きのNICへの第1のpingメッセージに応答してもよく、その北向きのNICを通じて、その南向きのNICで受信されたノード110Aの北向きのNICへの第2のpingメッセージに応答してもよい。
また、いくつかの実施形態においては、ノード110Aはまた、ノード110Bが正常である場合に、それ自体の第3のNICからノード110Bの第3のNICへとpingを送り、ノード110Bの第3のNICからのその第3のNIC上のpingメッセージへの応答を受信して、(図23でNIC1114Cとして示される)制御プレーン通信のために用いられるノード110Bの第3のNICのヘルスチェックを行う。pingメッセージおよび応答は1つまたは複数の制御プレーン装置170、例えばネットワークスイッチを通過してもよい。
上記のヘルスチェック機構は、すべてのノード110BのNICと同様にすべての受信および発信リンクならびに全方向(北、南、および制御プレーンを通じて)のノード110Bのデータ経路を実行し、顧客パケットもそうするようにpingデータパケットが内部キューをトラバースしノード110Bのディスパッチを行う時に、ノード110Bの内部ヘルス状態を検証する。
ロードバランサノードへのヘルスチェックの役割の割り当て
少なくともいくつかの実施形態において、ロードバランサの実装におけるすべてのロードバランサノード110は、例えば構成関数を通じて、および/または図1で示すように構成要素としての構成サービス122を通じて、ロードバランサの実装におけるすべての他のロードバランサノード110のリスト(例、ソートされたリスト)へのアクセスを有する。少なくともいくつかの実施形態において、各ロードバランサノード110は、各ヘルスチェック間隔でヘルスチェックを行うためにリスト上の1つまたは複数の他のノード110を無作為に選択し、正常であると決定された場合にハートビートカウンターを増加させてもよい。リストはヘルスチェック機構を通じて現在正常であると見なされているものも異常であると見なされているものも関わらずロードバランサの実装におけるすべてのロードバランサノード110を含んでよく、現在異常なノード110も正常なノード110と同様にリストから無作為に選択されてヘルスチェックを行われてもよいことに留意する。こうして、現在異常なノード110は、そのノード110のヘルスチェックを行う1つまたは複数のノード110により正常であると決定されてもよく、そのハートビートカウンターが増加させられて他のノード110へと伝播されてもよく、このようにして異常なノード110が正常な状態に戻されてもよい。
その代わりにいくつかの実施形態においては、各ロードバランサノード110はリスト上の1つまたは複数の他のノード110のヘルスチェックの役割および、正常であると決定された場合のハートビートカウンターの増加の役割を担ってもよい。例えばいくつかの実施形態においては、各ノード110は2つの他のノード、例えばリスト上の「左」(すなわち前)そして「右」(すなわち次)の最近傍ノード110の役割を担ってもよい。リストは円環であってもよく、リストの「最後」のノード110がリストの「最初」のノード110のヘルスチェックの役割を担ってもよく、その逆もまた同様であることに留意する。いくつかの実施形態においては、2つの他のノード110が、例えばリスト上の次の2つの最近傍ノードとして他に選択されてもよい。いくつかの実施形態においては、各ノード110は、例えば3つまたは4つの他のノード110のような、リスト上の3つ以上のノード110のヘルスチェックの役割を担ってもよい。少なくともいくつかの実施形態において、ノード110からチェックされている近傍ノード110が異常であると決定された場合、ノード110はその後、異常な近傍ノード110がチェックする役割を担っていたリスト上の少なくとも1つのノードのヘルスチェックの役割を担ってもよい。少なくともいくつかの実施形態において、その近傍ノード110(例、「左」および「右」の近傍ノード)のヘルスチェックに加えて、各ロードバランサノード110もまた定期的または非定期的に、リング上のノード110を無作為に選択し、その無作為に選択されたノード110のヘルスチェックを行い、正常であれば無作為なノード110のハートビートを増加させ伝播させてもよい。少なくともいくつかの実施形態において、他のノード110がすでに正常であるか正常でないかのどちらに見なされているかに関わらず、番号付きリスト上のすべての他のノード110が無作為な選択およびヘルスチェックのために考慮される。
少なくともいくつかの実施形態において、各ノード110は1つまたは複数の無作為に選択されたノード110の、またはその代わりにその近傍ノード110および無作為に選択されたノードのヘルスチェックを通常の間隔で行い、その間隔はヘルスチェック間隔と称されてもよい。例えば、いくつかの実施形態においては、ハートビート間隔は100ミリ秒であってもよく、それより短い、または長い間隔も利用されてもよい。また少なくともいくつかの実施形態において、各ノード110はその現在のハートビートリストを少なくとも1つの他の無作為に選択されたノード110に通常の間隔で送信または「ゴシップ」し、それはゴシップと称されてもよい。いくつかの実施形態においては、ヘルスチェック間隔およびゴシップ間隔が同じ長さであってもよいが、必ずしも同じである必要もない。
図14は少なくともいくつかの実施形態による、1つまたは複数の他のロードバランサノードのヘルスチェックを行うロードバランサノードを図示する。この実施例においては、ロードバランサの実装における8つのロードバランサノード110A−110Hがある。破線の円は実装におけるすべてのノード110の番号付きリストを表す。いくつかの実施形態においては、各ノード110は各間隔でヘルスチェックを行う、リスト上の1つまたは複数の他のノード110を無作為に選択してもよい。その代わりとして、いくつかの実施形態においては、各ロードバランサノード110は番号付きリスト上の1つまたは複数の特定のノード110のチェックの役割を担ってもよい。例えばノード110Aは、図14に示された番号付きリストに従ってその2つの最近傍ノード110Bおよび110Hのヘルスチェックの役割を担ってもよい。またロードバランサノードもまた各ヘルスチェック間隔で、番号付きリストから別のノード110を無作為に選択してもよい。この実施例で示されるように、ノード110Aもヘルスチェックのためにノード110Fを無作為に選択している。ゴシップ間隔において、ノード110Aは何か別の正常なノード110、例えばノード110Dを無作為に選択し、その現在のハートビートリストを選択した他のノード110へと、例えばUDPメッセージで送信する。ノード110は、別のノード110からハートビートリストを受信した際に、それ自身のハートビートリストを適宜更新し、次のゴシップ間隔で、ハートビートリストを1つまたは複数の無作為に選択されたノード110に伝播してもよい。
サーバノードのヘルスチェック
上述のようなロードバランサノード110のヘルスチェックに加えて、ヘルスチェックプロトコルの実施形態は、それらノード130上のロードバランサモジュール132およびサーバ134を含むサーバノード130のヘルスチェックを行ってもよい。少なくともいくつかの実施形態において、以下の条件のうちの1つまたは両方がノード130のために決定された場合、サーバノード130は正常であると見なされてもよい:
* ロードバランサモジュール132が正常である。
* ロスping(例、L7ヘルスping)への応答に成功する。
図15は少なくともいくつかの実施形態による、サーバノードのヘルスチェックを行うロードバランサノードを示す。少なくともいくつかの実施形態において、ロードバランサの実装におけるすべてのロードバランサノード110は、ロードバランサの実装におけるすべてのサーバノード130のリストと同様に、すべての他のロードバランサの実装におけるロードバランサノード110のリストへのアクセスを有する。1つまたは複数のリストは、例えば構成関数を通じておよび/または図1で示されるように構成要素である構成サービス122を通じて取得され、更新されてもよい。少なくともいくつかの実施形態において、図15で示されるような一貫したハッシュリングを形成するために、サーバノード130は正常なロードバランサノード110に対して一貫したハッシュを行ってもよい。少なくともいくつかの実施形態において、リング内の各サーバノード130はリング内の正常なロードバランサノード110によりヘルスチェックを行う。例えば図15では、サーバノード130Aはロードバランサノード110Aおよび110Cによりヘルスチェックを行う。これら2つのノード110は、一貫したハッシュリングにおけるサーバノード130のための第1の(ノード110A)および第2の(ノード110B)ヘルスチェックノード110と称されてもよい。所与の正常なロードバランサノード110は2つ以上のサーバノード130のヘルスチェックを行ってもよいことに留意する。例えば図15において、ロードバランサノード110Aはまた、サーバノード130Bおよび130Cのヘルスチェックを行う。また所与のノードバランサノード110は、1つまたは複数の他のサーバノード130のための第1のヘルスチェックノード110および1つまたは複数のサーバノード130のための第2のヘルスチェックノード110であってもよい。例えば、図15において、ロードバランサノード110Aはサーバノード130Aおよび130Bのための第1のヘルスチェッカーノードであり、サーバノード130Cおよび130Dのための第2のヘルスチェックッカーノードである。
少なくともいくつかの実施形態において、ロードバランサノード110が故障した場合、一貫したハッシュリングにおけるメンバーシップは変更され、まだ正常でしたがって一貫したハッシュリング上にある1つまたは複数の他のロードバランサノード110が故障したノード110によってすでにヘルスチェックされたサーバノード130のヘルスチェックの役割を担ってもよい。
少なくともいくつかの実施形態において、正常なノード110はそれぞれその割り当てられたサーバノード130のヘルスチェックを通常の間隔で行い、それはサーバチェック間隔と称されてもよい。少なくともいくつかの実施形態において、サーバチェック間隔は上述のゴシップ間隔以上の長さであってもよい。
少なくともいくつかの実施形態において、サーバノード130のヘルスチェックを行うために、正常なロードバランサノード110(例、図15のノード110A)はサーバノード130(例、図15のサーバノード130A)へのヘルスpingメッセージ(例、L7 HTTPヘルスpingメッセージ)を開始する。正常である場合、サーバノード130はping応答をロードバランサノード110に返信する。少なくともいくつかの実施形態において、pingメッセージはサーバノード130上のロードバランサモジュール132により受信され処理されるため、成功した場合にはヘルスチェックpingがサーバノード130上のモジュール132が正常であることを確立する。pingへの応答時に、ロードバランサノード110はサーバノード130を正常であると見なし、サーバノード130のためのハートビートカウンターを増加させる。
少なくともいくつかの実施形態において、所与の正常なロードバランサノード110によりヘルスチェックを行われたすべてのサーバノード130のためのハートビートカウンターは、例えばすでにロードバランサノード110ハートビートカウンターのために説明された、各ノード110がそのハートビートリストを少なくとも1つの他の無作為に選択されたノード110へと通常の間隔(ゴシップ間隔)で送信するゴシップ技術に従って他のロードバランサノード110へと伝播されてもよく、また受信ノード110が2つのリスト上の最大値に従って、それ自体のハートビートリストを更新する。
故障検知およびゴシップ
少なくともいくつかの実施形態において、上記のロードバランサノード110のヘルスチェックおよびサーバノード130のヘルスチェックを通じて取得された情報は、すべてのロードバランサノード110がロードバランサの実装の一貫した見解を維持できるように、ロードバランサの実装におけるすべてのノード110へと伝播される必要があってもよい。上述の通り、少なくともいくつかの実施形態において、ロードバランサノード110はゴシッププロトコルに従って、このヘルス情報を交換し伝播するため、またロードバランサノード110およびサーバノード130の故障を検知するために、互いに通信してもよい。
少なくともいくつかの実施形態において、各ロードバランサノード110は通常の間隔(ゴシップ間隔と称する)で、別のロードバランサノード110を無作為に選択し、他のノード110にその正常なロードバランサノード110およびサーバノード130に関する見解をロードバランサノード110およびサーバノード130のためのハートビートカウンターとともに送信する。ロードバランサノードまたはサーバノード130が正常である限り、ノードはそのヘルスチェックにパスし、そのハートビートカウンターは増加し続ける。ノードのためのハートビートカウンターが特定の間隔(故障時間間隔と称されてもよい)で変化しない場合、ノードはその後ロードバランサノード110により故障を疑われる。ノードが故障を疑われると、ロードバランサノード110はノードが異常であると決定するまで特定の間隔(異常な時間間隔と称されてもよい)で待機してもよい。この異常な時間間隔により、ノードが故障したことをすべてのロードバランサノード110が把握するまでロードバランサノード110は待機することができる。
図16は少なくともいくつかの実施形態による、ロードバランサノード110により維持されてもよい別のノード(ロードバランサノード110またはサーバノード130のいずれか)のヘルス状態またはその見解を図示する。300で示すように、ロードバランサノード110がまず、問題のノードが正常であるとの見解を有すると仮定する。これはノードのためのハートビートカウンターが増加しつつあることを示す。しかし、ノードのハートビートカウンターが302で示すように特定の間隔(故障時間間隔)で増加しない場合、ロードバランサノード110はその後304で示すように、ノードが故障したことを疑う。306で示すように、ノードのハートビートカウンターが特定の間隔(異常な時間間隔)で増加しない場合、ロードバランサノード110はその後308で示すように、ノードを異常であると見なす。しかしノードのためのハートビートカウンターが310で示すように、異常な時間間隔が終了する前に増加する場合、ロードバランサノード110は再びノードを正常300であると見なす。同様に312で示すように、異常なノードのためのハートビートの増加を受信することでもノードは正常300であると見なされうる。
ノードの異常の決定には、本明細書で別に記載するように、異常なノードがロードバランサノード110またはサーバノード130のどちらであるかによって、また、ロードバランサノード110の異常なノードとの関係によって、1つまたは複数のロードバランサノード110による異なる行動を含んでもよい。
ロードバランサノードのデータ
少なくともいくつかの実施形態において、各ロードバランサノード110はロードバランサの実装の状態に関するデータを維持してもよい。少なくともいくつかの実施形態において、このデータは各ロードバランサノード110上の、正常なロードバランサノードリスト、疑わしいロードバランサノードリスト、およびハートビートリストを含むがそれらに限定されない、1つまたは複数のデータ構成において維持されてもよい。図17は正常なロードバランサノードリスト320、疑わしいロードバランサノードリスト322、異常なロードバランサノードリスト324、およびロードバランサノードのハートビートリスト326を維持するロードバランサノード110の実施例を示す。
少なくともいくつかの実施形態において各ロードバランサノード110は、例えばどのノード110が正常であるか、またそれに従ってどのノード110がゴシッププロトコルに参加するかを決定するために用いられてもよい、正常なロードバランサノード110のリストである正常なロードバランサノードリスト320を維持してもよい。リスト320上のノード110のみがゴシッププロトコルを通じたロードバランサ情報の伝播に関与し、リスト320上のノード110のみが一貫したハッシュリング内にあると見なされ、このリスト上のノード110のみがサーバノード130のヘルスチェックを行う。ノード110はこのリスト320から、そのハートビート情報の送信先となる別のノード110を無作為に選択してもよい。またハートビートカウンターは、正常なロードバランサノードリスト320上に現在あるノード110のためのみに交換される。少なくともいくつかの実施形態において、ノードNがロードバランサノード110によるヘルスチェックにパスする場合、またはロードバランサノード110がリスト320上のどれか他のロードバランサノード110からノードNに関するゴシップメッセージを受信する場合に、ロードバランサノードNは別のロードバランサノード110の正常なロードバランサノードリスト320に追加されることができる。
少なくともいくつかの実施形態において、各ロードバランサノード110は、ハートビートカウンター(ハートビートリスト326を参照)が特定の間隔(故障時間間隔と称されてもよい)で増加しなかったロードバランサノードのリストである疑わしいロードバランサノードリスト322を維持してもよい。ロードバランサノードEがロードバランサノード110の疑わしいロードバランサノードリスト322上にある場合、ロードバランサノード110はその後ノードEについてゴシップしない。正常なリスト320上の他のどれかのロードバランサノード110が、ノード110のハートビートリスト326上でノードEのためのカウンターより高いハートビートカウンターとともに、ロードバランサノード110にノードEについてゴシップする場合、ノードEはその後疑わしいリスト322から正常なリスト320へと移行される。ノードEが特定の間隔(異常な時間間隔と称されてもよい)でロードバランサノード110の疑わしいリスト322上に留まる場合、ノードEはロードバランサノード110により異常であると見なされ、異常なノードリスト324上に移行される。異常なノードリスト324上のノード110(この実施例のノードG)は、ノードGがノード110によるヘルスチェックにパスした際、またはノードGのための更新されたハートビートカウンターを別のノード110から受信した際に、ロードバランサノード110の正常なノードリスト320へと移行されてもよい。
少なくともいくつかの実施形態において、各ロードバランサノード110はすべての既知のロードバランサノード110のためのハートビートリスト326を維持してもよい。各ノード110のために、このリスト326はハートビートカウンターおよび、ハートビートカウンターが最後に変更された時を示すタイムスタンプを含んでもよい。
少なくともいくつかの実施形態において、各ロードバランサノード110はまた、図17に図示されていないすべての既知のサーバノードのためのハートビートリストを維持してもよい。このリストはロードバランサノードのハートビートリスト326に類似していてもよい。いくつかの実施形態においては、2つのリストが組み合わされてもよい。少なくともいくつかの実施形態において、サーバノード130のためのハートビート情報は、例えばゴシッププロトコルに従って、ロードバランサノード110のためのハートビート情報とともにあるいはそれに加えて、ロードバランサノード110間に伝播されてもよい。
図17は4つの個別のリストを示すが、リストは2つ以上が単一のリストに組み合わせられてもよいことに留意する。例えば、いくつかの実施形態においては、すべてのノード110の単一のリストが各ロードバランサノード110上に維持されてもよく、ビットフラッグまたは他のデータ構成は各ノードが現在正常、疑わしい、または異常のどれであるかを示すために用いられてもよい。
サーバノードデータ
少なくともいくつかの実施形態において、ノード130上のサーバノード130およびローカルロードバランサモジュール132はロードバランサノード110を含むゴシッププロトコルに参加しない。ロードバランサノード110は、ロードバランサノードヘルスチェック方法により取得された他のロードバランサノード110に関するハートビート情報およびサーバノードヘルスチェック方法により取得されたサーバノード130に関するハートビート情報を、自身らの間でのみゴシップする(特に、各ロードバランサノード110はその正常なロードバランサノードリスト320上に現在あるノードにのみゴシップする)。
しかし各サーバノード130/ロードバランサモジュール132は、サーバノード130が、サーバノード130が顧客のトラフィックを転送する先となるロードバランサノード110(特に、出口ノード)を決定し、どのロードバランサノードが接続公開情報の送信先となるかを決定できるように、ロードバランサの実装における正常なロードバランサノード110に関する情報を必要とする場合がある。少なくともいくつかの実施形態において、この情報をサーバノード130に提供するために、ロードバランサノード110は現在正常なロードバランサノード110(例、図17の正常なロードバランサノードリスト320)を特定する情報を用いて、定期的または非定期的にサーバノード130を更新してもよい。少なくともいくつかの実施形態において、所与のサーバノード130のヘルスチェックの役割を担うロードバランサノード110(図15を参照)は、現在正常なロードバランサノードを特定する情報をサーバ130へと提供する役割を担う。例えば図15を参照すると、ロードバランサノード110Aはその正常なロードバランサノードリスト320をサーバノード130A、130B、130Cおよび130Dへと送信してもよく、ロードバランサノード110Bはその正常なロードバランサノードリスト320をサーバノード130C、130D、および130E等へと送信してもよい。
ロードバランサノードの故障の処理
図18Aおよび18Bは少なくともいくつかの実施形態による、ロードバランサノードの故障の処理を示す。図18Aはロードバランサの実装の実施例を示す。現在のロードバランサの実装において、4つのロードバランサノード110A〜110Dがある。エッジルータ104は顧客(図示せず)からの受信パケットをロードバランサノード110へとルーティングする。少なくともいくつかの実施形態において、エッジルータ104は、レイヤー4のフローごとにハッシュ化されたマルチパスルーティング技術、例えば等価コストマルチパス(ECMP)ルーティング技術に従って、ルーティングの決定を行ってもよい。少なくともいくつかの実施形態においてエッジルータ104は、ロードバランサノード110の提供、例えばロードバランサノード110によって開始された境界ゲートウェイプロトコル(BGP)技術セッションを介した提供を通じて顧客のトラフィックを受信するために、ロードバランサの実装において現在利用可能なロードバランサノード110について把握する。しかし、少なくともいくつかの実施形態において、BGPセッションを通じて自身をエッジルータ104に提供するロードバランサノード110の代わりに、ロードバランサの実装における少なくとも1つの他のノード110が、BGPを通じたノード110のエッジルータ104へ提供の役割を担う。例えば図18Aで示されるようにいくつかの実施形態においては、所与のノード110の左および右の近傍ノード110が、所与のノード110をエッジルータ104に提供する。例えばロードバランサノード110Aはノード110Bおよび110Dを提供し、ロードバランサノード110Bはノード110Aおよび110Cを提供し、ロードバランサノード110Cはノード110Bおよび110Dを提供する。
図18Aの実施例において示されるように、各ロードバランサノード110はまた、例えば1つまたは複数の無作為に選択されたノード110、ロードバランサノードの番号付きリストにより決定された1つまたは複数の近傍ノード110、あるいは1つまたは複数の近傍ノードおよび1つまたは複数の無作為に選択されたノードなどの1つまたは複数の他のロードバランサノード110のヘルスチェックを定期的に行う。また各ロードバランサノード110は少なくとも1つのサーバノード130のヘルスチェックを定期的に行ってもよく、その正常なロードバランサノード110のリストをそれがヘルスチェックを行う1つまたは複数のサーバノードへと送信してもよい。ロードバランサノード110およびサーバノード130のためのヘルス情報は、例えばゴシッププロトコルに従ってノード110間に伝播されてもよい。
図18Bは、図18Aのロードバランサの実装の実施例における、単一のロードバランサノード110の故障の処理を示す。この実施例において、ロードバランサノード110Bは何らかの理由で故障している。例えば、ノード110Aおよび110Cはノード110Bのヘルスチェックを行ってもよく、両方ともノード110Bがそのヘルスチェックに失敗していることを検知してもよい。したがって、ノード110Aおよび110Cはノード110Bのためのハートビートカウンターを増加させない。ノード110Aおよび110Bの両方からのハートビート情報は、ゴシッププロトコルに従って、他の正常なロードバランサノード110(この実施例においては、唯一の他のロードバランサノードはノード110Dである)へと伝播される。すべての正常なロードバランサノード110(この実施例においては、ノード110A、110C、および110D)がノード110Bの故障において収束すると直ちに、以下のイベントの1つまたは複数が発生してもよいがそれらに限定されない。これらのイベントは必ずしもこの順序で発生するわけではないことに留意する。
* ノード110Aおよび110Cはエッジルータ104へのノード110Bの提供を停止する。少なくともいくつかの実施形態においてこれは、ノード110がエッジルータ104を用いてノード110Bを提供するために確立したBGPセッションの終了に関連する。各ノード110は、提供を行う互いのノード110のためにエッジルータ104を用いて個別のBGPセッションを確立し、そのためノード110BのためのBGPセッションの終了は提供された他のノード110に影響を与えないことに留意する。少なくともいくつかの実施形態においてノード110は、BGPセッションのためのTCPクローズまたは類似のメッセージをエッジルータ104に送信することにより、エッジルータ104を用いてBGPセッションを終了する。
* ノード110Bがどのノードからも提供されなくなったことを検知すると、それを受けてエッジルータ104が顧客データパケットのノード110Bへのルーティングを停止する。エッジルータ104はまた、顧客から残りの正常なロードバランサノード110、特にノード110上の入口サーバ112へのパケットフローを再分散するために、マルチパス(例、ECMP)ハッシュを調整する。入口サーバ112が顧客−>サーバマッピングを有しない、入口サーバ112へとルーティングされたいずれかのパケットフローのために、マッピングが顧客−>サーバ接続のためのフロートラッカーノードから取得されてもよく、またはその代わりに新規顧客−>サーバ接続が図10A〜10Gで示される技術に従って確立されてもよい。
* ノード110Aおよび110Cはそれぞれ、互いを提供するためのエッジルータ104へのBGPセッションを開始してもよい。ノード110Aおよび110Cは両方ともノード110Bと同様にロードバランサノード110Dによってエッジルータ104へと提供されるため、ノード110Bが故障時にノード110Aおよび110Bのエッジルータ104への提供を停止するかもしれないという事実が、エッジルータ104からのこれら2つのノード110へのパケットのルーティングに停止を引き起こさないことに留意する。
* 少なくともいくつかの実施形態において、ノード110Aおよび110Cはこの時点では近傍ノード110であるため、互いのヘルスチェックの役割を担ってもよい。ノード110Bは異常であると見なされてもなお、1つまたは複数の他のノード110により無作為なヘルスチェックを行われてもよいことに留意する。
* 1つまたは複数の残りの正常なロードバランサノード110は、以前はノード110Bによりトラッキングされていたフローのトラッキング接続の役割を担ってもよい。例えばノード110Cおよび/またはノード110Dは、図11Cおよび11Dで示されるように、ノード110Bが1次または2次フロートラッカーの役割を担っていた1つまたは複数の接続のための1次または2次フロートラッカーとしての役割を引き継いでもよい。
* 1つまたは複数の残りの正常なロードバランサノード110は、ノード110Bによりすでにヘルスチェックを行われたサーバノード130のヘルスチェックの役割を担ってもよい。サーバノード130は正常なロードバランサノードリスト(この時点ではノード110Bを含まない)を用いて残りのロードバランサノード110により更新される。例えば図18Bにおいて、ロードバランサノード110Aはサーバノード130Cのヘルスチェックおよび更新を開始し、ロードバランサノード110Cはサーバノード130Bのヘルスチェックおよび更新を開始する。
* エッジルータ104上で、故障したノード110BからのBGPセッションが最終的にタイムアウトする。その代わりにエッジルータ104は、ノード110Bの故障の認識時にBGPセッションを遮断してもよい。
2つのロードバランサノード110が同時に、またはほぼ同時に故障する可能性がある。2つの故障したロードバランサノードが互いに隣接していない場合、故障は独立となり、個別の単一のノード110の故障として図18Bで示す方法に従って処理されてもよい。しかし、2つの故障したノードが互いに隣接し(例、図18Aにおけるノード110Bおよび110C、その後直ちにすべての正常なロードバランサノード110(この実施例では、ノード110Aおよび110D)が故障を検知し、故障上で収束する場合に、以下のイベントの1つまたは複数が発生してもよいがそれらに限定されない。これらのイベントは必ずしもこの順序で発生するわけではないことに留意する。
* ノード110Aはノード110Bのためのエッジルータ104へのBGPセッションを終了する。
* ノード110Dはノード110Cのためのエッジルータ104へのBGPセッションを終了する。
* ノード110Aおよび110Dはエッジルータ104を用いた互いを提供するBGPセッションを開始する。
* ノード110Aおよび110Dは互いのヘルスチェックを開始する。ノード110Aおよび110Dはまた、故障したノード110のヘルスチェックを継続してもよいことに留意する。
* 残りの正常なノード110は正常なロードバランサノードリストを用いてサーバノード130を更新する。
* トラフィックはエッジルータ104からノード110Bおよび/またはノード110Cへと継続して流れてもよい。これは、これら2つのノード110がエッジルータ104への互いの提供を継続してもよいからである。しかしこれらのBGPセッションは最終的にタイムアウトし、エッジルータ104はフローを残りの提供されたノード110へと適宜、再分散させる。
* ノード110Bおよび110Cは、ノード110Bおよび110Cがいまだに正常であると判断する場合に、ノード110Aおよび110Dをそれぞれ提供する、エッジルータ104を用いたBGPセッションを終了してもよい。
接続公開
図1を再度参照すると、少なくともいくつかの実施形態において、ロードバランサの実装におけるロードバランサノード110がサーバ130への顧客TCP接続のための状態情報を維持する。この状態情報によりロードバランサノード110が、顧客の受信トラフィックをエッジルータ104からTCP接続の役割を担うサーバノード130へとルーティングできる。サーバノード130上のロードバランサモジュール132はそれぞれのサーバ134へのアクティブなTCP接続のリストを維持する。接続公開は、サーバノード130上のロードバランサモジュール132が、それを通じてロードバランサノード110へのアクティブな顧客TCP接続のリストを公開してもよい機構である。少なくともいくつかの実施形態において、接続公開データパケットはロードモジュール132によりロードバランサノード110へと、接続公開間隔と称されてもよい通常の間隔で形成され、公開される。
少なくともいくつかの実施形態において、ロードバランサノード110により維持された接続状態情報はキャッシュの形式として見なされてもよく、特定の接続のための状態情報の維持はその接続のためのロードバランサノード110上のリースの維持とみなされてもよい。キャッシュエントリが更新されない限りは、ロードバランサノード110はデータフローを処理するサーバノード130への顧客データフローをルーティングすることができない可能性がある。接続公開機構はロードバランサノード110上でサーバノード130からの現在の接続状態情報を用いて、定期的にキャッシュを、そしてその結果リースを更新し、こうしてTCPデータパケットを顧客160から適切なサーバノード130へと流し続ける。顧客160がサーバ134へのTCP接続を終了する際、その接続に関連するサーバノード130上のロードバランサモジュール132はそのアクティブな接続のリストからのリストを破棄し、したがって接続公開機構を通したTCP接続を公開することはなくなる。こうして、その接続に関連するロードバランサノード110(特に、接続のための入口サーバ112ならびに1次および2次フロートラッカー116)上の、その接続のための接続状態情報(キャッシュエントリまたはエントリ)は更新されなくなり、接続はロードバランサノード110により破棄される。少なくともいくつかの実施形態において、接続のためのキャッシュエントリまたはエントリは、他のどれかのアクティブな接続によりメモリを要求されるまで、ロードバランサノード110上のキャッシュを保持してもよい。
したがって接続公開機構は定期的または非定期的に、入口サーバ112ならびに1次および2次フロートラッカー116上で接続リースを延長し、顧客のトラフィックを流れさせる。また、接続公開機構は少なくともいくつかのロードバランサノード110の故障からの回復に貢献してもよい。顧客接続のための状態情報を保持する1つまたは複数のロードバランサノード110が故障した場合、接続公開によって残りのロードバランサノード110へと提供されたアクティブな接続情報は場合によっては接続の回復に用いられてもよい。
接続公開機構を用いて、サーバ134と顧客160との間の接続状態のためのサーバノード130は信頼すべきソースとなる。またサーバ134への接続の終了は、サーバノード130上のロードバランサモジュール132およびロードバランサノード110によって受動的に処理される。サーバノード130とロードバランサノード110との間にハンドシェイクは要求されない。すなわちロードバランサモジュール132は、特定の接続が終了したことを積極的にノードに通知するためにメッセージをロードバランサノード110に送信する必要がない。サーバ134が接続を終了する際、サーバ134は接続のための内部状態をクリアーする。ロードバランサモジュール132はサーバ134の内部状態を用いて、接続公開パケットを組み込む。接続がサーバ134の内部状態からなくなるため、接続はロードバランサノード110へと公開されない。ロードバランサノード110上の接続のためのリースはこうして終了し、ロードバランサノード110は接続に関して受動的に忘れる。接続に用いられたロードバランサノード110のキャッシュ内のメモリはその後必要に応じて、他の接続のために用いられることが可能である。
いくつかの実施形態においては、ロードバランサノード110により維持された接続のためのリースにはキャッシュ内の接続のためのタイムスタンプのエントリが関係してもよい。接続のリースが接続公開パケットにより更新された際に、タイムスタンプは更新されてもよい。サーバノード130上のロードバランサモジュール132によって接続が公開されなくなったために接続のリースが更新されない場合には、タイムスタンプはその後更新されなくなる。少なくともいくつかの実施形態において、遅延ガベージコレクション方法が用いられ、メモリが必要になるまで接続のためのエントリがキャッシュ内に保持されてもよい。例えば少なくともいくつかの実施形態において、キャッシュエントリ内のタイムスタンプがリース更新時間閾値と比較されてもよい。キャッシュエントリのためのタイムスタンプが閾値より遅い時間である場合、エントリはその後古くなり再利用されてもよい。しかしいくつかの実施形態においては、古いエントリは積極的にガベージコレクションされてもよい。
接続公開受信者
少なくともいくつかの実施形態において、各顧客TCP接続のために接続状態を維持する3つのロードバランサノード110がある−入口サーバ112の役割を担うノード110、1次フロートラッカー116の役割を担うノード110、および2次フロートラッカー116の役割を担うノードである。一貫したハッシュリングにおいて1次フロートラッカー116ノードおよびその後続ノードを見つけるためのTCPフローに対する一貫したハッシュ関数を適用することにより、所与のTCPフローのために、例えばロードバランサノード110によって1次および2次フロートラッカー116を決定することができる。TCPフローのための入口サーバ112の役を担うロードバランサノード110は、エッジルータ104の内部マルチパス(例、ECMP)ハッシュ関数に基づき、エッジルータ104からそのフローのためのトラフィックを受信するノード110である。ノード110の故障または追加がある場合には、入口サーバ112の役割を担うロードバランサノード110は多くのアクティブなTCPフローのために変更されてもよく、少なくともいくつかのアクティブなTCPフローのためのフロートラッカーの役割を担うロードバランサノード110が変更されてもよい(例、図11A〜11Dを参照)。サーバノード130上のサーバ132へのすべてのTCPフローのために、そのサーバノード130上のロードバランサモジュール132は状態情報を維持し、入口サーバ112がロードバランサノード110からのトラフィックを受信することから、どのロードバランサノード110がそのTCPフローのための入口サーバ112であるかを示す。しかし少なくともいくつかの実施形態において、ロードバランサモジュール132は使用された一貫したハッシュ関数を把握していなくてもよいため、どのロードバランサノード110がTCPフローのための1次および2次フロートラッカーの役割を担っているかを、ロードバランサモジュール132は把握しなくてよく、また決定できなくてもよい。すなわち、少なくともいくつかの実施形態において、ロードバランサモジュール132は一貫したハッシュを行わない。
アクティブな接続情報の公開
図19Aおよび19Bは少なくともいくつかの実施形態による、接続公開技術を図示する。図19Aはアクティブな接続情報をロードバランサノードに公開するロードバランサ(LB)モジュールを示す。少なくともいくつかの実施形態において、各ロードバランサモジュール132はサーバノード130上の各アクティブなTCPフローのための情報を収集し、接続公開パケットを形成する。所与のTCPフローのための情報は、フローのための入口サーバ112を担うロードバランサノード110を特定する情報を含む。接続公開パケットがレディ状態である際(例、接続公開間隔に達した際)、ロードバランサモジュール132はロードバランサノード110を、例えばすでに述べたようにサーバノード130のヘルスチェックを行うロードバランサノード110からサーバノード130へと定期的に送信される正常なロードバランサノード110のリストから、無作為に選択する。ロードバランサモジュール132はその後接続公開パケットを選択したノード110へと送信する。例えば図19Aでは、ロードバランサモジュール132Aがある接続公開パケットをロードバランサノード110Aに送信し、後ほど別の接続公開パケットをロードバランサノード110Bに送信する。
図20は少なくともいくつかの実施形態による、各ロードバランサモジュール132により実行されてもよい接続公開方法のハイレベルフローチャートである。500で示すようにロードバランサ(LB)モジュール132は、それぞれのサーバノード130上のすべてのアクティブなTCPフローのための接続公開エントリを作成する。少なくともいくつかの実施形態において、ロードバランサモジュール132はサーバノード130上のサーバ134が処理するアクティブなTCP接続の組を、例えばサーバノード130上の/proc/net/tcpから取得する。すべてのアクティブなTCP接続のために、ロードバランサモジュール132は(例、ローカルで維持されたアクティブな接続のテーブル内で)TCPフローのための入口サーバ112の役割を担うロードバランサノード110を検索し、接続のためのTCPタプル(例、顧客のIPアドレス、顧客用ポート、サーバ(パブリック)IPアドレス、およびサーバポートから成る4タプル)および接続のための入口サーバ112を示す接続公開エントリを作成する。各ロードバランサモジュール132は、接続のために受信されたパケットを最後に送信したロードバランサノード110を示す、各アクティブなTCP接続のための情報を維持すること、また、この情報が各アクティブな接続のための入口ノード110を特定するために、ロードバランサモジュール132によって用いられてもよいことに留意する。
502で示すように、ロードバランサモジュール132は接続公開パケット(1つまたは複数の接続公開エントリを含み、各アクティブなTCP接続毎に1つのエントリ)の送信先となるロードバランサノード110を無作為に選択する。少なくともいくつかの実施形態において、接続公開パケットの送信準備が完了しているとロードバランサモジュール132が決定した際に、ロードバランサモジュール110は無作為に選択されてもよい。少なくともいくつかの実施形態において、この決定は接続公開間隔に従って下される。非限定的な実施例として、接続公開間隔は100ミリ秒(ms)、または1秒であってもよい。少なくともいくつかの実施形態において、ロードバランサノード110の内の1つからすでに受信された正常なロードバランサノード110のリストから、ロードバランサモジュール110が選択される。504で示すように、ロードバランサモジュールはその後接続公開パケットを、選択されたロードバランサノード110に公開する。少なくともいくつかの実施形態において、接続公開パケットは例えばUDPパケットといったステートレスパケットである。いくつかの実施形態において接続公開パケットは、対象のロードバランサノード110へのパケットの送信前に圧縮されてもよい。少なくともいくつかの実施形態において接続公開情報は、2つ以上のパケットにおける対象のロードバランサノード110へと送信されてもよい。
要素504から要素500へと戻る矢印が示すように、ロードバランサモジュール132は継続的に接続公開データパケットを作成し、無作為なノード110を選択し、そしてパケットを選択したノードへと送信してもよい。上述のように、ロードバランサノード110がロードバランサノード110上の接続リースを維持するための現在のアクティブな接続情報を用いて比較的定期的にリフレッシュされるように、これは接続公開間隔に従って行われてもよい。
少なくともいくつかの実施形態において、接続公開データパケットはロードバランサモジュールによってロードバランサノード110へと無作為に分散されるため、接続公開パケットを受信するロードバランサノード110は、接続公開データパケットにおけるアクティブな接続情報の接続のための正しい入口/1次/2次ノード110への分散の役割を担う。図19Bならびに図21および22は、少なくともいくつかの実施形態において用いられてもよいアクティブな接続情報の分散方法を示す。
図19Bは少なくともいくつかの実施形態による、ロードバランサノード110間のアクティブな接続情報の分散を示す。ロードバランサノード110がロードバランサモジュール132から接続公開パケットを受信する際、ロードバランサノード110は、フローのための入口ノードならびに1次および2次フロートラッカーノードを決定するために、その中に示された各TCPフローのための情報を分析してもよい。ロードバランサノード110が、フローのためのそれら役割のうち1つを担っている場合、ロードバランサノード110はフローのための情報を(例、その状態情報のキャッシュの更新により)消費する。少なくともいくつかの実施形態において、ロードバランサノード110はまたフローのための情報を、フローのための他の役割を担っている1つまたは複数の他のノード110へと送信される1つまたは複数のパケットフローに盛り込んでもよい。接続公開パケットにより示される残りのフローのために、ロードバランサノード110はアクティブな接続情報を2つ以上のよりデータ量の少ないパケットに分割して各パケットを1つまたは複数の他のロードバランサノード110に送信する。例えば少なくともいくつかの実施形態において、1つまたは複数のフローのためにアクティブな接続情報を含むパケットは、1つまたは複数のフローのための入口サーバ112、1次フロートラッカー116A、および2次フロートラッカー116Bの役割を担うロードバランサノード110に送信されてもよい。
図21は、少なくともいくつかの実施形態による、対象のロードバランサノード110への接続公開パケットにおいて受信されるアクティブな接続情報の分散方法のフローチャートである。520で示すように、ロードバランサノード110はロードバランサモジュール132から接続公開パケットを受信する。ロードバランサモジュール132は、例えば図19Aおよび20に関連して上述したようにパケットを生成し、パケットを受信するためのロードバランサノード110を選択した。接続公開パケットは、受信されたパケットの送信元であるサーバノード130を特定する情報(例、サーバノード130上のロードバランサモジュール132のIPアドレス)およびアクティブなTCP接続を特定するエントリのリスト(例、各接続のための顧客のIPアドレス、顧客用ポート、サーバ(パブリック)IPアドレス、およびサーバポートから成る4タプル)を含んでもよい。
図21の要素522〜530において、ロードバランサモジュール110は受信された接続公開パケットで示されるアクティブなTCP接続情報を繰り返し処理する。522で示すようにロードバランサノード110は、それぞれのTCPフローのための入口ノード110ならびに1次および2次フロートラッカーノード110を決定するために、パケット内の次のTCPフローのためのエントリを分析する。少なくともいくつかの実施形態において、ロードバランサノード110は接続公開エントリから入口ノード110を特定する。少なくともいくつかの実施形態において、TCPフローのための1次および2次フロートラッカーノード110は一貫したハッシュ関数に従って決定されてもよい。524においてロードバランサノード110が検証中のTCPフローのための役割のうちの1つを担う場合、その後526においてロードバランサノード110がフローのための情報を、例えばその状態情報のキャッシュの更新によって消費する。528で示すように、ロードバランサノード110はTCPフローのための接続公開エントリを、構成中であり別のロードバランサノード110に送信される予定のパケットに追加してもよい。530において接続公開パケット内にフローのための接続公開エントリがさらにある場合は、その後メソッドは522へと戻り、次のエントリの処理を行う。そうでなければロードバランサノードは、それぞれがオリジナルの接続公開パケットからの接続公開エントリのサブセットを含む1つまたは複数の新規構成されたパケットを、532で示すようにパケットのための対象のロードバランサノード110へと送信する。少なくともいくつかの実施形態において、対象のロードバランサノード110に送信されるパケットは、例えばUDPデータパケットといったステートレスパケットである。いくつかの実施形態において、パケットを対象のロードバランサノード110に送信する前に、パケットは圧縮されてもよい。
このように少なくともいくつかの実施形態において、図21の要素522〜528ではフロートラッカーノード110が、受信された接続公開パケット内の接続公開エントリから522で決定された情報に従って他のノード110のうちの特定の1つへとそれぞれ送信されることになる1つまたは複数のパケット(例、UDPパケット)を構築する。少なくともいくつかの実施形態において、別のノード110に送信されるパケットは、対象のノード110が入口ノード110、1次フロートラッカーノード110、または2次フロートラッカーノード110としての役割を担うTCPフローのためのエントリを含む。いくつかの実施形態においては、所与のロードバランサノード110がTCPフローのための入口および1次フロートラッカーノードの両方の役割を担ってもよく、またはTCPフローのための入口および2次フロートラッカーノードの両方の役割を担ってもよいことに留意する。
図22は少なくともいくつかの実施形態による、対象のロードバランサノード110への接続公開パケットにおいて受信されるアクティブな接続情報の分散の代替方法を示す。550で示すように、ロードバランサノード110はロードバランサモジュール132から接続公開パケットを受信する。この方法では、552で示すように、ロードバランサモジュール110上の処理によってパケット内の接続公開エントリの分析が行われ、受信されたパケットの1つまたは複数のよりデータ量の少ないパケットへの分割が適宜行われる。ロードバランサモジュール110はこの処理の間、ローカルでフロー情報を消費しない。接続公開パケットが1つまたは複数のパケットに分割されると、パケットがその後554〜560で示すように処理される。554においてパケットのための対象のノード110がこのロードバランサノード110である場合、ロードバランサノード110はその後556で示すようにローカルでパケットを消費する。そうでなければパケットは対象のロードバランサノード110へと送信される。560において処理すべきパケットがさらにあれば、その後メソッドは554に戻る。そうでなければメソッドは完了する。
このようにしてロードバランサモジュール132から接続公開パケットを受信するロードバランサノード110は、接続公開パケットを特定の他のロードバランサノード110に特有の2つ以上のよりデータ量の少ないパケットに分割し、ロードバランサノード110により現在処理中であるいずれかのTCPフローのためのフロー情報を内部で消費しながらパケットを適宜分散してもよい。その間、他のロードバランサノード110もまた、接続公開パケットをロードバランサモジュール132から受信し、接続公開エントリを複数のよりデータ量の少ないパケットに分割し、そしてよりデータ量の少ないパケット対象のノード110に送信して、ノード110間にアクティブな接続情報を分散してもよい。
接続公開トリガ
少なくともいくつかの実施形態において、接続公開はロードバランサモジュール132上で1つまたは複数の異なるイベントによってトリガされてもよい。上述のようにいくつかの実施形態において、接続公開パケットはロードバランサノード110上のTCP接続のためのリースを更新するべく、接続公開間隔、例えば100msまたは1秒間隔に従って生成され、無作為に選択されたロードバランサノード110へと送信されてもよい。いくつかの実施形態においては、ロードバランサノード110のメンバーシップにおける変更は、即時の接続公開イベントをトリガしてもよい。少なくともいくつかの実施形態において、ロードバランサモジュール132はそれぞれのサーバノード130のヘルスチェックを行うロードバランサノード110の1つより送信された正常なロードバランサノード110のリストから変更について学習してもよい。リストに従った変更(削除または追加のいずれか)の検知時には、変更に影響されたTCP接続がロードバランサノード110によって迅速に回復できるように、ロードバランサモジュール132は接続公開パケットを生成しロードバランサノード110へと送信してもよい。
パケットループの阻止
接続公開パケットの処理の間にロードバランサレイヤーのメンバーシップが変更された場合、接続公開パケットループが発生してもよい。第1のノード110はロードバランサモジュール132から接続公開パケットを受信し、よりデータ量の少ないパケットを第2のノード110へと送信してもよい。しかしメンバーシップが変更された場合には、パケットが第1のノード110へ移行するべきであると第2のノード110が決定してもよく、その結果パケットを第1のノード110へと転送してもよい。少なくともいくつかの実施形態において、このループの発生を阻止するためにロードバランサモジュール132から受信された接続公開パケットと、ロードバランサノード110から受信されたそれらとで異なるポート番号が用いられてもよく、またロードバランサノード110は他のロードバランサノード110から受信された接続公開パケットの再分散を行わない。
接続公開パケット分散の代替方法
上記の接続公開方法において、ロードバランサモジュール132は接続公開パケットの送信先であるロードバランサノード110を無作為に選択する。しかしいくつかの実施形態においては、ロードバランサノード110の選択に他の方法が用いられてもよい。例えばいくつかの実施形態において、ロードバランサノード132は、1つまたは複数のアクティブなTCPフローの処理を行う特定の入口ノード110をそれぞれ対象とする1つまたは複数の接続公開データパケットを構築してもよく、また、1つまたは複数のパケットを1つまたは複数の対象の入口ノード110へと送信してもよい。1つまたは複数の入口ノード110はその後、アクティブな接続情報を接続のための1次および2次フロートラッカーへと再分散する。別の実施例として、いくつかの実施形態においては、接続公開パケットの単一の、無作為に選択されたノード110への送信の代わりに、各接続公開パケットがロードバランサモジュール132によって2つ以上の正常なノード110へと、またはすべての正常なノード110へと送信されてもよい。
ロードバランサノードアーキテクチャ
図23は少なくともいくつかの実施形態によるロードバランサノード110のためのソフトウェアスタックアーキテクチャの実施例を示し、限定的な意図を持たない。このソフトウェアスタックアーキテクチャの実施例においては、Java Native Interface(JNI(商標))1104技術を用いて、ロードバランササーバネイティブコード1106およびコアパケット処理コード1108、例えばIntel(商標) Dataplane Development Kit(DPDK)技術コードを含んでもよいネイティブコードのレイヤーを管理する、単一のJava(商標)技術処理1102内でロードバランサノード110が動作する。ネイティブコードは2つのネットワークインタフェースコントローラ(NIC1114Aおよび1114B)へのインターフェースとなってもよい。第1のNIC(NIC1114A)は「北」、すなわちエッジルータ104向きに面してもよい。第2のNIC(NIC1114B)は「南」、すなわちサーバノード130向きに面してもよい。少なくともいくつかの実施形態において、NIC1114Aおよび1114BはTCPスタックを維持しなくてもよい。したがって少なくともいくつかの実施形態は、ロードバランサノード110が制御プレーンを通じた処理との通信を行うことができ、またその逆も可能になるようにTCP接続をサポートする第3のNIC1114Cを含んでもよい。その代わりに、いくつかの実施形態においては、第1の、北向きのNIC1114Aおよび第2の、南向きのNIC111Bのみがロードバランサノード110において実装されてもよく、また第2の、南向きのNIC1114BがTCPスタックを実装してもよい。ロードバランサノード110はTCPスタックを通じて制御プレーンを通じた処理との通信を行ってもよい。ロードバランサノード110はまた、オペレーティングシステム(OS)技術ソフトウェア1112、例えば、Linux(商標)カーネル、およびOS技術ソフトウェア1112上のJava Virtual Machine(JVM(商標))技術ソフトウェア1110レイヤーそしてJNI1104技術を含む。
少なくともいくつかの実施形態において、分散型ロードバランスシステム内のロードバランサノード110はそれぞれ多くのデータフローを高パケットレートで同時に処理しなければならない場合がある。少なくともいくつかの実施形態において、要求レベルのスループットを達成するために、ロードバランサノード110が高性能パケット処理のためのIntel(商標) Dataplane Development Kit(DPDK)技術を活用してもよい。DPDK技術により、ユーザースペースプログラムがネットワークインタフェースコントローラ(NIC)から直接パケットを読み取ること/ネットワークインタフェースコントローラ(NIC)へと直接パケットを書き込むことが可能になり、またDPDK技術がLinuxカーネルネットワークスタックの多くのレイヤーを(Linus ixgbe基本NICドライバを除いて)バイパスする。パケット処理のためのDPDK手法は、ビジーループにおいてNICハードウェアに直接ポーリングを行う専用CPUコアのための割り込みハンドラーを利用した入力を拒否する。この手法は、専用CPUコアをビジーループにおいて継続的に動作させることで、熱出力の増加と引き換えにはるかに高いパケットレートを可能にする。DPDK技術はまた、CPUコア管理、ロックフリーのキュー、メモリプールおよび同期プリミティブを含むパケット処理ツールも提供する。図24で示されるように、DPDK技術においては、専用CPUコア600が各特定のタスクのために用いられてもよく、また非停止キュー602を用いて、あるCPUコア600Aから別のCPUコア600Bへと作業が渡される。
DPDKキュー602は高速の2のべき乗リングバッファを用いて実装されてもよく、単一および複数の生産者/消費者バリアントのサポートを行ってもよい。複数の生産者/消費者バリアントは、アクセスを同期するためにコンペアアンドスワップ(CAS)ループを含むため、真の意味でロックフリーではない。バッファへのポインタのみが読み取られキュー602に書き込まれるように、すべてのパケットバッファメモリはメモリプール内に事前割振りされてもよい。メモリプールはキューとして実装されてもよく、メモリチャネルやメモリランクをまたいでメモリを分散させるため最適化されてもよく、非一様性メモリアクセス(NUMA)により最適化された割り当てをサポートしてもよい。少なくともいくつかの実施形態において、パケットバッファにはバッファコピーを要求せずに外部ネットワークレイヤーヘッダーを追加/取り除くことができるカプセル化/脱カプセルの動作をサポートするために、各パケットバッファのヘッドルームおよびテールルームに過剰な割り当てを行うMbufパラダイムのような方法を用いてもよい。
ロードバランサノード110の少なくともいくつかの実施形態において、DPDK技術を活用するコアパケット処理アーキテクチャが実装されてもよい。各ロードバランサノード110はコアパケット処理アーキテクチャに従って、少なくとも1つの実装されたマルチコアパケットプロセッサを含んでもよい。コアパケット処理アーキテクチャはパケットフローのための、マルチコアパケットプロセッサのキューおよびコアを通じた単一の生産者/単一の消費者パラダイムを用いてもよい。このパラダイムでは、各キューはただ1つのコアへの入力を行い、各コアはただ1つのコアへの出力を互いに行い、パケットを与える。また、マルチコアパケットプロセッサにおいてコアにより用いられたメモリは共有されない。各コアにはそれ自体の別のメモリ領域がある。したがって、コア間にはメモリやキューの共有はなく、メモリやキューの競合もなく、メモリやキューにオーナーシップの要求(RFO)やコンペアアンドスワップ(CAS)等の機構の共有の必要もない。図25および26にはコアパケット処理アーキテクチャに従って実装されるマルチコアパケットプロセッサの実施例が示される。
図25は少なくともいくつかの実施形態による、データフローの処理のためにDPDK技術を活用するコアパケット処理アーキテクチャに従って実装されたマルチコアパケットプロセッサの実施例を示す。コアパケット処理アーキテクチャは単一の生産者/単一の消費者パラダイムに従って、マルチコアパケットプロセッサとして実装されてもよい。少なくともいくつかの実施形態において、図23に示されるように、ロードバランサノード110はそれぞれ2つのネットワークインタフェースコントローラ(NIC)を有する−境界ネットワーク/エッジルータ104に面する北向きのNIC1114Aおよび本番ネットワーク/サーバノード130に面する南向きのNIC1114Bである。少なくともいくつかの実施形態において、NIC1114は10GpbsNICであってもよい。ロードバランサノード110を通過するパケットの大部分がこれら2つのNIC(NIC1114Aまたは1114Bのいずれか)で受信され、処理され(例、カプセル化され、あるいは脱カプセル化され)、一方のNIC(NIC1114Bまたは1114Aのいずれか)に伝達される。
図25を参照すると、少なくともいくつかの実施形態においてロードバランサノード110は2つのCPUコア、受信(RX)コア610および伝達(TX)コア630を各NIC1114のためにスピンアップする。ロードバランサノード110も両方のNIC1114のための両方向のパケットの処理を行ういくつかの作業者コア620を行う。この実施例では4つの作業者コア620A〜620Dが用いられる。受信コア610は入力キューからの受信パケットのバッチを、それらがNIC1114に到着する際に読み取り、各パケットのための作業の大部分を行う作業者コア620へとパケットを分散させ、各受信コア610はパケットを各作業者コア620のためのそれぞれの作業者入力キュー612に与える。少なくともいくつかの実施形態において、受信コア610は各受信パケットにおいてレイヤー4「フローハッシュ」技術(上述のエッジルータ104により用いられてもよいフローごとにハッシュ化されたマルチパスルーティング技術に類似)を実行し、いずれの特定の顧客接続(IPアドレスおよびポートにより区別される)も同一の作業者コア620によって確実に処理されるようにしながらパケットを作業者コア620へと分散させてもよい。これは、各作業者コア620が常に同一のパケットのサブセットを見てもよいということを意味し、ロックを要求されないように作業者コア620が管理する状態データにおける競合を除去する。受信されたパケットへのポインタは作業者コア620が継続的に新規入力のために監視する作業者キュー622間に分散されてもよい。作業者コア620は各接続のための状態の管理の役割を担い(例えば、割り当てられたサーバノード130)、パケットをアウトバウンドキュー632の1つに転送する前のパケット上のUDPのカプセル化または脱カプセル化を行ってもよい。伝達コア630は作業者コア620アウトバウンドキュー632を通って循環し、出力パケットを、キュー632に現れるときに対応するNIC1114に書き込む。
図26は少なくともいくつかの実施形態による、データフローの処理のためにDPDK技術を活用するコアパケット処理アーキテクチャに従って実装されたマルチコアパケットプロセッサの別の実施例を示す。コアパケット処理アーキテクチャは単一の生産者/単一の消費者パラダイムに従って、マルチコアパケットプロセッサとして実装されてもよい。少なくともいくつかの実施形態において、高スループット顧客TCPフローの処理に加えて、ロードバランサノード110上のDPDKコアアーキテクチャもまたARP、DHCP、およびBGP等の他のプロトコルのための、北および南向きのNIC1114上でのパケットの送受信に用いられてもよい。図26で示す実施形態においては、作業者コア620Aはこれら他のプロトコルのためのパケットの処理専用である。これらパケットの処理は一般的に顧客TCPフローよりも低速で行われるため、この作業者コア620Aは「低速の」作業者コアと称されてもよく、一方顧客TCPフローのみを処理する他の作業者コア620B〜620Dは高速の作業者コアと称されてもよい。北向きのおよび南向きのNIC1114において受信パケットを処理するそれぞれ受信コア610Aおよび610Bは、低速の作業者コア620Aにより処理される予定のパケットを特定し、パケットを低速の作業者コア620Aのための入力キュー622へと導いてもよい。低速の作業者コア620Aはまた、Java/JNIにより生成されたパケットのための入力キュー622、およびJava/JNIへの出力パケットのための出力キュー634を監視してもよい。低速の作業者コア620Aはまた、低速の作業者コア620Aが高速の作業者コア620B〜620Dのそれぞれへとパケット例えば接続公開データパケットを送信できるように、高速の作業者コア620B〜620Dのそれぞれのための入力キュー622への出力を行ってもよい。低速の作業者コア620Aはまた伝達コア630Aおよび630Bのそれぞれに流れ込むアウトバウンドキュー632を有する。
少なくともいくつかの実施形態において、各高速の作業者コア620B〜620Dの第3の入力キュー622は低速の作業者コア620Aからの出力キューである。少なくともいくつかの実施形態において、この第3の入力キュー622は例えば、それぞれが接続状態情報を含む接続公開パケットの受信および処理のために、高速の作業者キュー620B〜620Dによって用いられてもよい。これら接続公開パケットの少なくともいくつかのためには、伝達コア630への出力はなくてもよい。代わりに、データパケットにおける接続状態情報が、例えばそれぞれの高速の作業者コア620が維持する1つまたは複数のパケットフローのための格納された状態の更新により、高速の作業者コア620から消費されてもよい。こうして、高速の作業者コア620B〜620Dへの入力を行う低速の作業者コア620Aからの出力キューが、入力キュー622以外の、受信コア610から直接の、高速の作業者コアの格納された状態の更新のためのパスを提供してもよい。
少なくともいくつかの実施形態において、図25および26のマルチコアパケットプロセッサは受信パケットをフィルターにかけ、有効なパケットのみを処理し、出力してもよい。例えば、少なくともいくつかの実施形態において、受信コア610は作業者コア620のいずれにもサポートされていないプロトコルのパケットをフィルターにかけて取り除いてもよく、その結果作業者コア620へとパケットを送信しなくてもよい。少なくともいくつかの実施形態において、作業者コア620はパケットの処理時に、それぞれがまずそれぞれの作業者入力キュー622から読み取られたパケットを分析し、パケットがさらなる処理のために受け入れられるべきか、また伝達コア630への出力を行うべきかを決定してもよく、また単に受け入れられた伝達コア630へのパケットの処理および出力を完了してもよい。受け入れられなかったパケットは破棄されてもよい。例えば作業者コア620は各パケットのアドレス情報を確認し、ロードバランスされている有効なアドレスを対象とするパケットの受け入れのみを行い、他のパケットは破棄してもよい。
境界ゲートウェイプロトコル(BGP)データの処理
少なくともいくつかの実施形態において、コアアーキテクチャの内部および外部の、BGP顧客に関連するパケットフローは以下のように処理されてもよい。NIC1114Aおよび1114BはLinuxカーネルに向かわないので、エッジルータ104へのTCP接続は図26で示されるようにコアアーキテクチャにより遮断され、出力キュー634を通じてBGPパケットをJavaスペースへと渡す低速の作業者コア622Aによって処理される。これらTCPデータパケットはBGP顧客へと伝達される前にロードバランサノード110上の1つまたは複数のモジュールによりさらに処理される。この処理にはTCP接続を管理し、パケットをTCPストリームへと効率的に変換するためのLinuxカーネルによる処理が含まれる。この設計により、標準JavaTCPソケットライブラリを用いたBGP顧客の書き込みが可能になる。
図27は少なくともいくつかの実施形態による、ロードバランサ(LB)ノード処理650による受信BGP TCPデータパケットの処理を示す。エッジルータ104からのパケットが北向きのNIC640に到着し、受信コア652のための入力キュー640に入る。受信コア652はキュー640からのパケットを読み取り、パケットをBGPパケットとして特定し、パケットを低速の作業者コア656のための入力キュー654上に配置する。低速の作業者コア656はパケットを検証し、それをJNI出力キュー658上に配置する。JNIパケット受信装置660はキュー658からのパケットを、JNIを介して読み取り、ソース/宛先アドレスをマングルし、パケットをrawソケット644に書き込む。Linuxカーネル646は生のパケットを受信し、TCPプロトコルに従ってそれを処理し、ペイロードデータをTCPソケットInputStreamへと追加する。パケットからのデータはその後BGP顧客662内のJavaTCPソケットに伝達される。
図28は少なくともいくつかの実施形態による、ロードバランサ(LB)ノード処理650による、発信BGP TCPデータパケットの処理を示す。BGP顧客662はデータをLinuxカーネル646のJavaTCPソケットへと書き込む。Linuxカーネル646はTCPプロトコルに従ってデータを処理し、データを1つまたは複数のTCPパケットへと変換する。少なくともいくつかの実施形態において、1つまたは複数のTCPパケットは127.x.x.x IPテーブルルールに適合する。1つまたは複数のTCPパケットは出力キュー648、例えばNetfilter LOCAL_OUTキュー上に配置される。JNIを通じてキュー648を監視するJNIパケット受信装置670のJavaスレッドは1つまたは複数のTCPパケットを受信し、各NF_STOLENに印を付けてカーネル646にそれらを忘れさせる。Javaスレッドはソース/宛先アドレスをマングルし、1つまたは複数のパケットを低速の作業者コア656のためのJNI入力キュー672へとJNIを通じて追加する。低速の作業者コア656はそのJNI入力キュー672から1つまたは複数のTCPパケットを受信してパケットを北向きのNIC640伝達コア666のためのアウトバウンドキュー664上に配置する。伝達コア666はその入力キュー664から1つまたは複数のTCPパケットを読み取り、それらを北向きのNIC640に書き込む。TCPパケットは、NIC640によってエッジルータに送られる。
分散型ロードバランサのシミュレーションおよびテスティング
本明細書に記載のロードバランサは、多くの独立した構成要素(例、ルータ、ロードバランサノード、ロードバランサモジュール、等)の対話を要求する分散型システムである。ノードの故障、メッセージの破棄、および遅延等のシナリオのシミュレーションと同様に、分散型構成要素、ロジック、およびプロトコルのテスティングを行うための、分散型ロードバランサを単一処理において動作できるようにするテストシステムの実施形態について記載する。単一処理においては、複雑なネットワークトポロジ(例、本番ネットワーク)において、コードを複数のホストに展開する必要なく対話のテストを行うことができる。これを達成するための、メッセージバスと称される、複数のロードバランサ構成要素を単一処理内でまたは単一処理として構成させて実行させることができるソフトウェア機構について記載する。単一処理は単一のホストシステムにおいて実行されてもよい。メッセージバス機構により、分散型ロードバランサシステムの単一処理としてのテストが、例えばロードバランサ構成要素(例、ロードバランサノードおよびロードバランサモジュール)にとっては実際の本番ネットワークで動作しているかのような単一のホストシステムにおいて可能になる。
メッセージバスは、分散型ロードバランサが単一処理として動作することを可能にするフレームワークを提供する。処理における1つまたは複数のメッセージバスレイヤーのそれぞれが分散型ロードバランサの構成要素の間のネットワーク(例、Ethernet(登録商標))セグメントのシミュレーションを行う。分散型ロードバランサシステムのソフトウェア構成要素は、構成要素をメッセージバス環境内で動作させるために特別な方法で書かれる必要はない。代わりに、分散型ロードバランサシステムの構成要素が生成するパケットを遮断し、パケットを本物の物理ネットワークの代わりにメッセージバスレイヤーに提供された模擬ネットワーク内に導き、パケットを対象の構成要素へと伝達する構成要素(メッセージバスNICまたはパケットアダプタと称されてもよい)をメッセージバスフレームワークが提供する。メッセージバスレイヤーは、構成要素間の通信のための1つまたは複数のTCP/IPスタックを実装しない。その代わりに、メッセージバスレイヤーはホストシステムのオペレーティングシステム(OS)とのインターフェースを行い、ホストシステムのTCP/IPスタックを用いる。メッセージバスレイヤーはOSにより提供されたTCP/IPスタックを、顧客およびサーバが予期するTCPストリームの、メッセージバスが遮断し伝達する個別のパケットからの、そしてそういった個別のパケットへの変換のために活用する。
少なくともいくつかの実施形態において、メッセージバスとのインターフェースを行うために、ロードバランサ構成要素は少なくとも1つのメッセージバスネットワークインタフェースコントローラ(NIC)を与えられていてもよい。各NICは有効なメディアアクセス制御(MAC)アドレスを有しており、それにより物理ネットワークとのやり取りの代わりに、メッセージバス模擬ネットワーク環境へとパケットを送信し、またそこからパケットを受信する。メッセージバスNICは物理ネットワークの代わりにメッセージバスに付随する仮想ネットワークインタフェースコントローラである。メッセージバスを通じて通信する必要のある各ロードバランサ構成要素は少なくとも1つのメッセージバスNICを要求する。メッセージバスNICはメッセージバスへのパイプライン出口の役割と、構成要素へのパイプライン入口の役割を担う。構成要素は複数のメッセージバスネットワークインターフェースを各メッセージバスNICへとインスタンス化することができる。
メッセージバスネットワークインターフェースはメッセージバスNICを通じてメッセージバスに付随する構成要素のための機構である。メッセージバスネットワークインターフェースはLinux技術におけるインターフェース構成(ifconfig)インターフェースと同義であってもよく、違いとしては、メッセージバスネットワークインターフェースが物理ネットワークの代わりにメッセージバスに付随する点である。メッセージバスネットワークインターフェースはIPアドレスを有し、メッセージバスNICの最上段にある。メッセージバスネットワークインターフェースは、構成要素によってメッセージバスからのパケットの受信のために用いられることができるパケットソースインターフェースと、構成要素によってメッセージバスへのパケットの発信のために用いられることができるパケットシンクインターフェースを公開する。
各ロードバランサノードは、パケットソースおよびパケットシンクインターフェースの実装を通じて伝達され送信される個別のネットワークパケットを処理する。メッセージバス環境における動作時には、これらのインターフェースは、レイヤー2Ethernetヘッダを追加または削除するメッセージバスネットワークインターフェースによって実装される。(ロードバランサノードのためには、これはカーネルネットワークスタックによって実行されることになる)。図29に示す本番環境においては、パケットソースおよびパケットシンクインターフェースの実装は、実際のネットワークインターフェースにおいてパケットを受信し伝達する。図30で示されるメッセージバス環境において、パケットソースおよびパケットシンクインターフェースの実装がメッセージバスレイヤーまたはレイヤーからパケットを受信し、メッセージバスレイヤーまたはレイヤーへとパケットを伝達する。
単純化のために、メッセージバスNICおよびメッセージバスインターフェースはメッセージバスパケットアダプタ、または単にパケットアダプタと総称されてもよい。例、図31および32を参照。
図29は少なくともいくつかの実施形態による、本番環境において分散型ロードバランサ700を含むロードバランスシステムを示す。ロードバランサ700はこの説明では単純化されている。ロードバランサ700は外部ネットワーク740上の顧客742へと、ロードバランサ700を実装するデータセンター等のネットワークインストールの境界ルータ702を通じて接続してもよい。ロードバランサ700はいくつかの種類の構成要素を含む−少なくとも1つのエッジルータ704、2つ以上のロードバランサ(LB)ノード710、それぞれが個別のサーバノード(図示せず)上で実装された2つ以上のロードバランサ(LB)モジュール732、ファブリック720を形成するルータやスイッチのような1つまたは複数のネットワーク構成要素、また、少なくともいくつかの実施形態において構成サービス722。少なくともいくつかの実施形態において、ロードバランサ700の各構成要素は、ラック搭載型のコモディティコンピューティング装置等の個別のコンピューティング装置上で実装されてもよい。
図30は少なくともいくつかの実施形態による、複数の分散型ロードバランスシステムの構成要素を単一処理内でまたは単一処理として構成させて実行させることができるメッセージバス機構を組み込む分散型ロードバランサテストシステム800を示す。図29に示されるロードバランサ700において、各ロードバランサソフトウェア構成要素は、個別のコンピューティング装置上でインストールされ、実行される(例、ロードバランサノード710上にロードバランサソフトウェア、また、サーバノード上にロードバランサモジュール732)。これらロードバランサソフトウェア構成要素を単一処理において実行させるため、各ロードバランサソフトウェア構成要素(図30においてロードバランサ(LB)ノード810およびロードバランサ(LB)モジュール832として示される)は、ロードバランサソフトウェア構成要素を出入りするパケットがまた、物理ネットワーク上で送受信される代わりに、メッセージバス機構を通じて遮断され、ルーティングされるように、構成要素のネットワーク接続性を抽出するコードを含んでもよい。
少なくともいくつかの実施形態において、分散型ロードバランサテストシステム800上では、メッセージバス機構は1つまたは複数の構成要素間の通信のためのTCPスタックを実装しない。その代わりに、メッセージバス機構はホストシステムのオペレーティングシステム(OS)とのインターフェースを行い、ホストシステムのTCPスタックを用いる。少なくともいくつかの実施形態において、メッセージバス機能は、ホストシステムのOSのカーネル(例、Linuxカーネル)と、カーネルの機能であるIPテーブルを通じて、ユーザーレイヤーの下で結びついている。メッセージバス機能はカーネルレベルでIPテーブルに接続され、パケットを遮断し、ルーティングのためのメッセージバス処理へとパケットを送信する。
図30において模擬エッジルータ862および模擬ファブリック864で示されるように、物理ネットワーク構成要素(例、図29のエッジルータ704およびファブリック720)の機能は、顧客860、サーバ834、構成サービス866も可能であるように、ソフトウェアにおいてシミュレーションされてもよい。しかし、少なくともいくつかの実施形態において、模擬サーバ834ではなく実物が分散型ロードバランサテストシステム800において用いられてもよいことに留意する。図30のメッセージバスレイヤー850が物理ネットワークインフラストラクチャの代わりとなる。したがって、ロードバランサソフトウェア構成要素(ロードバランサノード810およびロードバランサモジュール832)は、図29で示すように本番ネットワーク環境で実行していないことを認識しないままロードバランサテストシステム800上で動作してもよい。
いくつかの構成要素(例えば模擬ルータ)は、ネットワークセグメントをシミュレーションする異なるメッセージバスレイヤー850とパケットの送受信を行うために、2つ以上のメッセージバスレイヤー850に接続されてもよい。
分散型ロードバランステストシステム800のメッセージバスレイヤー850において実装されるメッセージバス機構は、ネットワークセグメントの「ワイヤ」をシミュレーションする。少なくともいくつかの実施形態において、メッセージバス機構は構成要素のMACアドレスに基づいて、パケットを分散型ロードバランステストシステム800内の宛先構成要素に伝達する。こうして、各ロードバランサソフトウェア構成要素(ロードバランサノード810およびロードバランサモジュール832)は、ロードバランサソフトウェア構成要素が、分散型ロードバランステストシステム800において他の構成要素から送信されたパケットを受信できるように、MACアドレスを1つまたは複数の接続されているメッセージバスレイヤー850に提供する。
メッセージバスパケットアダプタ
図31および32は少なくともいくつかの実施形態による、メッセージバスパケットアダプタを示す。少なくともいくつかの実施形態において、各ロードバランサ(LB)ソフトウェア構成要素はパケットソースおよびパケットシンクインターフェースの実装を通じて伝達され送信される個々のネットワークデータパケットを処理する。図31を参照すると、これらインターフェース(パケットソースインターフェース862およびパケットシンクインターフェース864として示される)は分散型ロードバランステストシステム800上で動作している際に、メッセージバスレイヤー850と、カーネルネットワークスタックによって実行されることになるソフトウェア構成要素870のためのレイヤー2Ethernetヘッダを追加または削除するロードバランサソフトウェア構成要素870との間のパケットアダプタ860によって実装されてもよい。図29で示されるような本番環境では、ロードバランサソフトウェア構成要素のためのパケットソースおよびパケットシンクの実装が、構成要素が実装される物理装置の実際のネットワークインターフェース上で、パケットを受信し伝達する。
図31を参照すると、少なくともいくつかの実施形態において、ロードバランサソフトウェア構成要素870がパケットを伝達する際に、パケットを構成要素の入力キューに追加することで最終的にパケットを宛先構成要素に伝達するために、パケットシンクインターフェース864の送信パケット方法を呼び出す実行スレッドがパケットアダプタ860内とメッセージバスレイヤー850内の関数チェーンをトラバースする。少なくともいくつかの実施形態において、ロードバランサソフトウェア構成要素870がパケットを受信する際に、ロードバランサソフトウェア構成要素870がパケットソースインターフェース862の受信パケット方法を呼び出し、その入力キューからパケットを読み取る。少なくともいくつかの実施形態において、メッセージバス機構はパケットの伝達のためにいかなる追加のスレッドも要求しない。
メッセージバスパケットパイプライン
図32を参照すると、少なくともいくつかの実施形態において、パケットソースインターフェース862およびパケットシンクインターフェース864のメッセージバス850側がパケットパイプラインの特徴を提供する。ロードバランサソフトウェア構成要素870がパケットシンクインターフェース864を通じてパケットを送信する際、パケットデータはメッセージバスレイヤー850に達する前に、段階のシリーズ(パケットパイプライン880)をトラバースしてもよい。これらの段階はパケットを修正し、パケットを破棄し、パケットを複製し、パケットを遅延させる等してもよい。パケットがパケットパイプライン880をトラバースしメッセージバスレイヤー850が宛先構成要素870を選択すると、パケットが宛先構成要素870の入力キューに追加される前に、宛先構成要素870に関連するパイプライン段階の第2のシリーズ(パケットパイプライン882)もまたトラバースされてもよい。
プロバイダネットワーク環境の実施例
このセクションでは、分散型ロードバランス方法および機器の実施形態が実装されてもよいプロバイダネットワーク環境の実施例を説明する。しかし、これらプロバイダネットワーク環境の実施例は制限を意図するものではない。
図33Aは少なくともいくつかの実施形態による、プロバイダネットワーク環境の実施例を示す。プロバイダネットワーク1900は、顧客に仮想化リソースのインスタンス1912のアクセス、購入、レンタル、またはその他の取得を可能にする、1つまたは複数の仮想化サービス1910を通じて顧客にリソース仮想化を提供してもよい。仮想化リソースのインスタンス1912には、1つまたは複数のデータセンター内のプロバイダネットワークまたはネットワーク内の装置に実装された計算およびストレージリソースが含まれるが、それらに限定されない。プライベートIPアドレス1916はリソースのインスタンス1912に関連してもよい。プライベートIPアドレスは、プロバイダネットワーク1900上のリソースのインスタンス1912の内部ネットワークアドレスである。いくつかの実施形態においては、プロバイダネットワーク1900はまた、顧客がプロバイダ1900から取得してもよい、パブリックIPアドレス1914および/またはパブリックIPアドレスの範囲(例、インターネット Protocolバージョン4(IPv4)またはインターネット Protocolバージョン6(IPv6)アドレス)を提供してもよい。
従来から、仮想化サービス1910を通じたプロバイダネットワーク1900により、サービスプロバイダの顧客(例、顧客ネットワーク1950Aを運用する顧客)が顧客に割り当てられた少なくともいくつかのパブリックIPアドレス1914を顧客に割り当てられた特定のリソースのインスタンス1912と動的に結びつけることができる。また、プロバイダネットワーク1900により顧客は、顧客に割り当て済みのある仮想化されたコンピューティングリソースのインスタンス1912にすでにマッピングされていたパブリックIPアドレス1914を、同様に顧客に割り当てられた別の仮想化されたコンピューティングリソースのインスタンス1912へと再度マッピングすることができる。サービスプロバイダから提供された、仮想化されたコンピューティングリソースのインスタンス1912およびパブリックIPアドレス1914を用いて、顧客ネットワーク1950Aの運用者などのサービスプロバイダの顧客は例えば、インターネットのような中間ネットワーク1940上で、顧客特有のアプリケーションを実装し、顧客のアプリケーションを提示してもよい。中間ネットワーク1940上の他のネットワークエンティティ1920はその後顧客ネットワーク1950Aによって公開された宛先パブリックIPアドレス1914へのトラフィックを生成してもよい。トラフィックはサービスプロバイダデータセンターへとルーティングされ、データセンターで、ネットワーク基盤を通じて、現在宛先パブリックIPアドレス1914にマッピングされている仮想化されたコンピューティングリソースのインスタンス1912のプライベートIPアドレス1916へとルーティングされる。同様に、仮想化されたコンピューティングリソースのインスタンス1912からの応答トラフィックはネットワーク基盤を通じて中間ネットワーク1940に戻り、ソースエンティティ1920へとルーティングされてもよい。
プライベートIPアドレスは、本明細書で用いられている通り、プロバイダネットワーク内のリソースのインスタンスの内部ネットワークアドレスを参照する。プライベートIPアドレスはプロバイダネットワーク内でのみルーティング可能である。外部のプロバイダネットワークから始まるネットワークトラフィックはプライベートIPアドレスに直接ルーティングされない。代わりにトラフィックは、リソースのインスタンスへとマッピングされたパブリックIPアドレスを用いる。プロバイダネットワークは、パブリックIPアドレスからプライベートIPアドレスへのマッピングやその逆を行うための、ネットワークアドレス変換(NAT)または類似の機能を提供するネットワーク装置または機器を含んでもよい。
パブリックIPアドレスは、本明細書で用いられている通り、サービスプロバイダまたは顧客のいずれかによってリソースのインスタンスに割り当てられた、インターネット上でルーティング可能なネットワークアドレスである。パブリックIPアドレスへとルーティングされたトラフィックは例えば1:1ネットワークアドレス変換(NAT)を通じて変換され、リソースのインスタンスのそれぞれのプライベートIPアドレスへと転送される。
いくつかのパブリックIPアドレスは、プロバイダネットワークインフラストラクチャから特定のリソースのインスタンスへと割り当てられてもよい。これらのパブリックIPアドレスは標準パブリックIPアドレス、または単に標準IPアドレスと称されてもよい。少なくともいくつかの実施形態において、標準IPアドレスのリソースのインスタンスのプライベートIPアドレスへのマッピングは、すべてのリソースのインスタンスタイプ向けのデフォルトの起動構成である。
少なくともいくつかのパブリックIPアドレスは、プロバイダネットワーク1900の顧客に割り振られるか、またはそのような顧客により取得されてもよい。顧客はその後割り振られたパブリックIPアドレスを、顧客に割り振られた特定のリソースのインスタンスに割り当ててもよい。これらのパブリックIPアドレスは、顧客パブリックIPアドレス、または単に顧客のIPアドレスと称されてもよい。標準IPアドレスと同様にプロバイダネットワーク1900によりリソースのインスタンスに割り当てられる代わりに、顧客のIPアドレスは、例えばサービスプロバイダから提供されたAPIを通じて、顧客によりリソースのインスタンスに割り当てられてもよい。標準IPアドレスとは異なり、顧客のIPアドレスは顧客アカウントに割り当てられるものであり、必要に応じてまたは希望があれば、他のリソースのインスタンスへのそれぞれの顧客による再度マッピングすることが可能である。顧客のIPアドレスは顧客のアカウントに関連し、特定のリソースのインスタンスには関連せず、顧客がそのIPアドレスのリリースを選択するまでは、自身でそれを管理する。従来の固定IPアドレスとは異なり、顧客のIPアドレスにより、顧客のパブリックIPアドレスを顧客のアカウントに関連するいずれかのリソースのインスタンスへと再度マッピングすることで、顧客はリソースのインスタンスまたはアベイラビリティーゾーンの故障をマスクすることができる。顧客のIPアドレスにより、例えば、顧客のリソースのインスタンスまたはソフトウェアの問題について顧客のIPアドレスを置き換えのリソースのインスタンスへと再度マッピングすることで、解決に向け動くことができる。
図33Bは少なくともいくつかの実施形態による、図33Aに示されるような、プロバイダネットワーク環境の実施例における分散型ロードバランサの実装を示す。プロバイダネットワーク1900は、例えば仮想ストレージサービスのようなサービス1910を顧客1960に提供してもよい。顧客1960は、例えばサービス1910への1つまたは複数のAPIを通じて、サービス1910にアクセスし、プロバイダネットワーク1900の本番ネットワーク部分における複数のサーバノード1990上に実装されたリソース(例、ストレージリソースまたは計算リソース)の利用形態を得てもよい。サーバノード1990はそれぞれ、ローカルロードバランサ(LB)モジュール1992と同様に、サーバ(図示せず)、例えばウェブサーバまたはアプリケーションサーバを実装してもよい。1つまたは複数の分散型ロードバランサ1980は、境界ネットワークと本番ネットワークとの間のロードバランサレイヤーにおいて実装されてもよい。境界ルータ1970は、顧客1960からのパケットフロー上のパケット(例、TCPデータパケット)をインターネット等の中間ネットワーク1940を通じて受信し、パケットを1つまたは複数の分散型ロードバランサ1980の1つまたは複数のエッジルータへと境界ネットワークを通じて転送してもよい。データパケットは、1つまたは複数の分散型ロードバランサ1980の1つまたは複数のエッジルータによって公開されたパブリックIPアドレスを対象としてもよい。各分散型ロードバランサ1980のエッジルータは、それぞれの分散型ロードバランサ1980のロードバランサノード間にパケットフローを分散させてもよい。少なくともいくつかの実施形態において、入口ノードの役割を担う各ロードバランサノードはエッジルータに同一のパブリックIPアドレスを提供し、エッジルータはフローごとにハッシュ化されたマルチパスルーティング技術、例えば等価コストマルチパス(ECMP)ハッシュ技術に従って、顧客1960からのパケットフローを入口サーバ間に分散させる。パケットフローのための対象のサーバノード1990を決定するため、また、サーバと顧客1960との間の接続を円滑化するために、ロードバランサノードは本明細書に記載の接続プロトコルを用いてもよい。接続が確立されると、フロートラッカーノードが接続のための状態を維持する一方で、入口ノードがフローのために受信されたパケットをカプセル化して本番ネットワーク上の対象のサーバノード1990へと発信する。サーバノード1990上のロードバランサモジュール1992は、サーバノード1960上のそれぞれのサーバが接続を受け入れるかどうかについて決断を下してもよい。ロードバランサモジュールは入口ノードからのパケットを受信して脱カプセル化し、脱カプセル化されたデータパケット(例、TCPデータパケット)をサーバノード1990上のそれぞれのサーバへと送信する。ロードバランサモジュール1992はまた、パケットフローのための出口ノードとしてロードバランサノードを選択し、フローのための発信パケットをカプセル化し、選択した出口ノードに本番ネットワークを通じて送信してもよい。次に出口ノードがパケットを脱カプセル化し、脱カプセル化されたパケットを、それぞれの顧客1960への伝達のための境界ネットワークへと送信する。
図34Aは少なくともいくつかの実施形態による、分散型ロードバランサおよびサーバノードの物理ラックの実装の実施例を示すが、制限を意図するものではない。少なくともいくつかの実施形態において、分散型ロードバランサ上の様々な構成要素が、ラック搭載型のコモディティコンピューティング装置上で、またはラック搭載型のコモディティコンピューティング装置として実装されてもよい。ラック190は、それぞれがロードバランサノードの役割を担う複数のコンピューティング装置(LBノード110A〜110F)および、それぞれがサーバノードの役割を担う複数のコンピューティング装置(サーバノード130A〜130L)を含んでもよい。ラック190はまた、少なくとも1つのエッジルータ104、ファブリック120を形成する1つまたは複数のラック搭載型ネットワーク装置(ルータ、スイッチ等)、および1つまたは複数の他の構成要素180(他のネットワーク装置、パッチパネル、電源、冷却システム、バス等)を含む。図33Aおよび33Bのプロバイダネットワーク1900を実装するデータセンターまたはセンター等のネットワーク100のインストールは、1つまたは複数のラック190を含んでもよい。
図34Bは少なくともいくつかの実施形態による、分散型ロードバランサおよびサーバノードの物理ラックの実装の別の実施例を示すが、制限を意図するものではない。図34Bはスロット搭載型コンピューティング装置、例えばブレードサーバとして実装された、ラック190上のLBノード110およびサーバノード130を示す。
図35は少なくともいくつかの実施形態による、ネットワーク上で1つまたは2つ以上の分散型ロードバランサが実装されてもよく、別途実装されたサーバノードを持つネットワーク環境の実施例を示す。この実施例では、2つの分散型ロードバランサ1980Aおよび1980Bが示される。分散型ロードバランサ1980はそれぞれ境界ネットワークを通じて顧客1960からのパケットフローを受信し、複数のサーバノード1990間にパケットフローを分散させるために本明細書に記載のロードバランス方法を実行してもよい。いくつかの実装においては、各分散型ロードバランサ1980は図34Aおよび34Bで示されるラック190に類似のラック実装であってもよいが、ロードバランサラック内にインストールされたサーバノードは含まれない。サーバノード1990は、データセンター内の1つまたは複数の個別のラック上にインストールされたブレードサーバ等のラック搭載型コンピューティング装置であってもよい。いくつかの実装においては、サーバノード1990は、プロバイダネットワークにより提供され、それぞれが異なる1つまたは複数の分散型ロードバランサ1980によりフロントに配置された、2つ以上の異なるサービスを実装してもよい。
例示的システム
少なくともいくつかの実施形態において、本明細書に記載の分散型ロードバランス方法および機器の一部またはすべてを実装するサーバは、図36に示されるコンピュータシステム2000のような、1つまたは複数のコンピュータアクセス可能な媒体を含む、またはそのような媒体にアクセスするよう構成されている汎用コンピュータシステムを含んでもよい。示された実施形態においては、コンピュータシステム2000は、入力/出力(I/O)インターフェース2030を通じてシステムメモリ2020に接続された1つまたは複数のプロセッサ2010を含む。コンピュータシステム2000は、I/Oインターフェース2030に接続されたネットワークインターフェース2040をさらに含む。
様々な実施形態において、コンピュータシステム2000は、1つのプロセッサ2010を含むユニプロセッサシステム、または、いくつかのプロセッサ2010(例、2つ、4つ、8つ、または別の適切な数)を含むマルチプロセッサシステムであってもよい。プロセッサ2010は、命令を実行する能力があるいずれかの適切なプロセッサであってもよい。例えば様々な実施形態において、プロセッサ2010は、x86、PowerPC、SPARC、またはMIPSISA等の各種の命令セットアーキテクチャ(ISA)、または他のいずれかの適切なISAを実装する汎用または埋め込みプロセッサであってもよい。マルチプロセッサシステムにおいては、プロセッサ2010のそれぞれが一般に同一のISAを実装してもよいが、必ずしもそうである必要はない。
システムメモリ2020は、1つまたは複数のプロセッサ2010によりアクセス可能な命令およびデータを格納するよう構成されてもよい。様々な実施形態において、システムメモリ2020は、スタティックランダムアクセスメモリ(SRAM)、シンクロナスダイナミックRAM(SDRAM)、不揮発性/フラッシュ型メモリ、またはその他各種メモリ等のいずれかの適切なメモリ技術を用いて実装されてもよい。示された実施形態においては、ロードバランス方法および機器のために上述された方法、技術、およびデータ等の、1つまたは複数の所望の関数を実装するプログラム命令およびデータが、システムメモリ2020内にコード2024およびデータ2026として格納されていることが示される。
1つの実施形態において、I/Oインターフェース2030は、プロセッサ2010、システムメモリ2020、およびネットワークインターフェース2040または他の周辺インターフェースを含む装置内のいずれかの周辺装置の間のI/Oトラフィックを調整するよう構成されてもよい。いくつかの実施形態においては、1つの構成要素(例、システムメモリ2020)からのデータ信号を、別の構成要素(例、プロセッサ2010)による利用に適したフォーマットへと変換するために、I/Oインターフェース2030はいかなる必要なプロトコル、タイミングまたは他のデータ媒体変換を行ってもよい。いくつかの実施形態においては、I/Oインターフェース2030は例えば、周辺構成要素相互接続(PCI)バス標準またはユニバーサルシリアルバス(USB)標準のバリアント等の様々な種類の周辺バスに付随する装置のためのサポートを含んでもよい。いくつかの実施形態においては、I/Oインターフェース2030の関数は、例えばノースブリッジおよびサウスブリッジ等の、2つ以上の個別の構成要素へと分割されてもよい。また、いくつかの実施形態においては、システムメモリ2020へのインターフェース等の、I/Oインターフェース2030の一部またはすべての機能がプロセッサ2010に直接組み込まれてもよい。
ネットワークインターフェース2040は、コンピュータシステム2000と、例えば図1〜35で示すような他のコンピュータシステムまたは装置等の、1つまたは複数のネットワーク2050に付随する他の装置2060との間でのデータ交換が可能であるように構成されてもよい。様々な実施形態において、ネットワークインターフェース2040は、例えばEthernetネットワークのような種類の、いずれかの適切な有線または無線の一般的なデータネットワークを通じた通信をサポートしてもよい。また、ネットワークインターフェース2040は、アナログ音声ネットワークまたはデジタルファイバ通信ネットワークのような遠隔通信/電話網を通した通信、Fibre Channel SAN等のストレージエリアネットワークを通じた通信、またはその他いずれかの適切な種類のネットワークおよび/またはプロトコルを通じた通信をサポートしてもよい。
いくつかの実施形態においてシステムメモリ2020は、分散型ロードバランスシステムの実施形態を実装するための図1〜35について上述したように、プログラム命令およびデータを格納するよう構成されたコンピュータアクセス可能な媒体の1つの実施形態であってもよい。しかし他の実施形態においては、異なる種類のコンピュータアクセス可能な媒体において、プログラム命令および/またはデータが受信され、送信され、または格納されてもよい。一般的に、コンピュータアクセス可能な媒体は、磁気または光学式媒体等の非一時的記憶媒体またはメモリ媒体を含んでもよい。例、I/Oインターフェース2030を通じてコンピュータシステム2000に接続されるディスクまたはDVD/CD。コンピュータアクセス可能な非一時的記憶媒体はまた、コンピュータシステム2000のいくつかの実施形態においてシステムメモリ2020または別の種類のメモリとして含まれてもよいRAM(例えば、SDRAM、DDRSDRAM、RDRAM、SRAM等)、ROM等のあらゆる揮発性または不揮発性媒体を含んでもよい。さらにコンピュータアクセス可能な媒体は、ネットワークインターフェース2040を通じて実装されてもよいネットワークおよび/または無線接続等の通信媒体を通じて伝達される電気、電磁、またはデジタル信号等の伝送媒体または信号を含んでもよい。
本開示の実施形態は、以下の節を考慮して説明することができる。
1.複数のロードバランサノードの少なくとも2つが入口サーバとして構成され、
前記複数のロードバランサノードの少なくとも2つがフロートラッカーノードとして構成される、
前記複数のロードバランサノードと、
複数のサーバノードと、
1つまたは複数の顧客からのパケットフローを、ハッシュ化されたマルチパスルーティング技術に従って、前記入口サーバへと分散させるよう構成されたルータと、
を備えた分散型ロードバランサシステムであり、
顧客のためのパケットフローにおけるパケットを前記ルータから受信し、
前記複数のサーバノードへの前記パケットフローのためのマッピングを前記入口サーバが有しないことを決定し、
前記パケットのソースおよび宛先アドレス情報に適用される一貫したハッシュ関数に従って、前記パケットフローのための少なくとも1つのフロートラッカーノードを決定し、
前記パケットフローのための前記複数のサーバノードの特定の1つへの接続のマッピングを、少なくとも1つのフロートラッカーノードから取得し、
前記特定のサーバノードへの前記パケットフローの1つ以上のパケットを送信する
ように各入口サーバが構成される、
分散型ロードバランサシステム。
2.前記パケットフローがトランスミッションコントロールプロトコル(TCP)パケットフローである、第1節に記載の分散型ロードバランサシステム。
3.前記複数のロードバランサノードの少なくとも2つが、前記1つまたは複数の顧客への前記サーバノードからの発信パケットを送信するよう構成された出口サーバとして構成され、
前記パケットフローのための前記出口サーバを選択し、
前記パケットフローのための1つまたは複数の発信パケットを、前記選択した出口サーバへと送信する、
ように前記サーバノードが構成され、
前記顧客への前記発信パケットを送信するように、前記出口サーバが構成され、
前記パケットフローのための前記選択された出口サーバが、前記パケットフローのための前記入口サーバとは異なるロードバランサノードである、
第1節に記載の分散型ロードバランサシステム。
4.前記サーバノードへの前記パケットの送信の前に、前記入口サーバが前記1つまたは複数のパケットをユーザデータグラムプロトコル(UDP)に従ってカプセル化し、前記出口サーバへの前記発信パケットの送信の前に、前記サーバノードが前記発信パケットをUDPに従ってカプセル化し、前記顧客への前記発信パケットの送信の前に、前記出口サーバが前記発信パケットから前記UDPカプセル封じを取り外す、第3節に記載の分散型ロードバランサシステム。
5.前記パケットフローのための前記出口サーバを選択し、
前記カプセル化された受信パケットを前記入口サーバから受信し、
前記パケットから前記UDPカプセル封じを取り外し、前記パケットを前記サーバノード上のサーバへと伝達させ、
前記サーバノード上の前記サーバから前記発信パケットを取得し、
UDPに従って、前記発信パケットをカプセル化し、
前記カプセル化された発信パケットを前記出口サーバへと送信する
ように構成されるロードバランサモジュールを前記サーバノードが含む、
第4節に記載の分散型ロードバランサシステム。
6.前記パケットフローのための前記複数のサーバノードの特定の1つへの接続のマッピングを前記少なくとも1つのフロートラッカーノードから取得するために、
前記パケットフローのための情報を含むメッセージを、前記入口サーバが前記パケットフローのための1次フロートラッカーへと送信し、
前記パケットフローのための前記情報を含むメッセージを、前記1次フロートラッカーが前記パケットフローのための2次フロートラッカーへと送信し、前記パケットフローのための前記1次および2次フロートラッカーが異なるロードバランサノードであり、
前記2次フロートラッカーが、前記パケットフローのための受信確認を、前記顧客へと送信し、
前記入口サーバが、受信確認パケットを前記顧客から受信し、前記受信確認パケットを前記1次フロートラッカーへと転送し、
前記1次フロートラッカーが、前記パケットフローを受信するための前記サーバノードとして、前記複数のサーバノードの中から前記特定のサーバノードを無作為に選択し、前記特定のサーバノードを示すメッセージを、前記2次フロートラッカーへと送信し、
前記2次フロートラッカーが、同期メッセージを生成して前記生成された同期メッセージを前記特定のサーバノードへと送信し、
前記2次フロートラッカーが、前記パケットフローのための接続情報を前記特定のサーバノードから受信して前記1次フロートラッカーへの前記接続情報を含むメッセージを送信し、
前記1次フロートラッカーが、前記パケットフローのための前記接続情報を含むメッセージを前記入口サーバへと送信し、前記接続情報が前記パケットフローを前記特定のサーバノードへとマッピングする、
第1節に記載の分散型ロードバランサシステム。
7.前記生成された同期メッセージを前記2次フロートラッカーから受信し、
前記サーバノード上のサーバが接続を受け入れることができることを決定し、
前記生成された同期メッセージに従って同期パケットを生成し、前記同期パケットを前記サーバノード上の前記サーバへと伝達し、
前記サーバノード上の前記サーバによって生成された受信確認パケットを遮断し、
前記接続情報を含むメッセージを前記2次フロートラッカーへと送信する、
ように構成されるロードバランサモジュールを前記サーバノードが含む、
第6節に記載の分散型ロードバランサシステム。
8.顧客からのパケットフローにおけるパケットの受信であって、1つまたは複数の顧客から一貫したハッシュ関数に従って前記複数のロードバランサノードへと前記パケットフローを分散させるルータからのパケットの受信、
前記パケットのソースおよび宛先アドレス情報に適用される一貫したハッシュ関数に従って、前記パケットフローのためのフロートラッカーノードとしての役割を担うロードバランサノードの決定、
前記パケットフローのための複数のサーバノードの1つへの接続のマッピングの、前記パケットフローのための前記フロートラッカーノードからの取得、
前記マッピングにより示された、前記サーバノードへの前記パケットフローの1つまたは複数のパケットの送信、
を、複数のロードバランサノードのひとつの入口サーバによって実行すること、
を備えた方法。
9.前記パケットフローがトランスミッションコントロールプロトコル(TCP)パケットフローである、第8節に記載の方法。
10.前記パケットフローの前記1つまたは複数のパケットの前記サーバノードへの前記送信の前に、ユーザデータグラムプロトコル(UDP)に従って前記パケットをカプセル化する前記入口サーバをさらに備えた、第8節に記載の方法。
11.前記サーバノードによる、前記パケットフローのための出口サーバとしての前記複数のロードバランサノードの1つの選択であり、前記パケットフローのための前記選択した出口サーバが、前記パケットフローのための前記入口サーバとは異なるロードバランサノードである、前記複数のロードバランサノードの1つの選択と、
前記サーバノードによる、前記パケットフローのための1つまたは複数の発信パケットの、前記選択された出口サーバへの送信と、
前記出口サーバによる前記発信パケットの、前記パケットフローの前記顧客への送信と、
をさらに備えた、第8節に記載の方法。
12.前記発信パケットの前記出口サーバへの前記送信の前に、ユーザデータグラムプロトコル(UDP)に従って前記発信パケットをカプセル化する前記サーバノードと、
前記発信パケットの顧客への前記送信の前に、前記発信パケットから前記UDPカプセル封じを取り外す前記出口サーバと、
をさらに備えた、第11節に記載の方法。
13.前記フロートラッカーノードが前記パケットフローのための1次フロートラッカーノードであり、前記一貫したハッシュ関数に従った一貫したハッシュリングにおける次のロードバランサノードが前記パケットフローのための2次フロートラッカーノードである、第8節に記載の方法。
14.前記入口サーバによる、少なくとも1つのメッセージの前記パケットフローのための前記1次フロートラッカーノードへの送信であり、各メッセージが前記ルータから受信された前記パケットフローのパケットを含む前記送信と、
前記1次フロートラッカーノードによる、前記複数のサーバノードからの前記パケットフローのための前記サーバノードの選択と、
前記1次フロートラッカーノードによる、前記選択されたサーバノードを示すパケットフロー情報の前記2次フロートラッカーノードへの送信と、
前記2次フロートラッカーノードによる、前記サーバノードと前記顧客との通信による、前記パケットフローのための前記選択されたサーバノードへの前記接続の確立の円滑化と、
前記2次フロートラッカーノードによる、前記パケットフローのための接続情報の、前記1次フロートラッカーノードを通じた前記入口サーバへの送信であり、前記接続情報が前記選択されたサーバノードへの前記パケットフローのマッピングを行う前記送信と、
を、前記パケットフローのための複数のサーバノードの1つへの接続のマッピングの、前記パケットフローのための前記フロートラッカーノードからの前記取得が備える、
第13節に記載の方法。
15.前記2次フロートラッカーノードによる、前記サーバノード上の前記ロードバランサモジュールへの、生成された同期メッセージの送信と、
前記サーバノード上のサーバが接続を受け入れることができることの決定、
前記生成された同期メッセージに従った同期パケットの生成、
前記同期パケットの、前記サーバノード上の前記サーバへの伝達、
前記サーバノード上の前記サーバにより生成された受信確認パケットの遮断と、
前記接続情報を含むメッセージの、前記2次フロートラッカーノードへの送信
を、前記サーバノード上の前記ロードバランサモジュールにより実行すること、
を、前記サーバノードと前記顧客との通信により、前記パケットフローのための前記選択されたサーバノードへの前記接続の確立を円滑化するロードバランサモジュールを前記サーバノードが含む、
第14節に記載の方法。
16.1つまたは複数の顧客からのパケットフローを一貫したハッシュ関数に従って前記複数のロードバランサノードへと分散させるルータからパケットが受信されるように、顧客のためのパケットフロー内の前記パケットを受信し、
前記パケットのソースおよび宛先アドレス情報に適用される一貫したハッシュ関数に従って、前記パケットフローのためのフロートラッカーノードとしての役割を担う、複数のロードバランサノードの1つを決定し、
前記パケットフローのための複数のサーバノードの1つへの接続のマッピングを、前記パケットフローのための前記フロートラッカーノードから取得し、
前記パケットフローの1つまたは複数のパケットを、前記マッピングにより示された前記サーバノードへと送信する、
ように各入口サーバが構成された、
複数のロードバランサノードのおのおのに入口サーバおよびフロートラッカーを実装するためにコンピュータにより実行可能なプログラム命令を格納するコンピュータアクセス可能な非一時的記憶媒体。
17.前記パケットフローのための出口サーバとして前記複数のロードバランサノードの1つを選択し、前記パケットフローのための選択した出口サーバが前記パケットフローのための入口サーバとは異なるロードバランサノードであり、
前記パケットフローのための1つまたは複数の発信パケットを前記選択された出口サーバへと送信する、
ロードバランサモジュールから受信されたパケットフロー上の発信パケットを、前記パケットフローの顧客へと送信するように各出口サーバが構成される、
ように各ロードバランサモジュールが構成され、
それぞれのロードバランサノード上に出口サーバ、複数の前記サーバノードのそれぞれの上にロードバランサモジュールを実装するために前記プログラム命令がさらにコンピュータにより実行可能である、第16節に記載のコンピュータアクセス可能な非一時的記憶媒体。
18.各入口サーバがさらに、前記パケットフローの1つまたは複数のデータパケットの前記サーバノードへの前記送信の前に、ユーザデータグラムプロトコル(UDP)に従って前記パケットをカプセル化するよう構成され、
入口サーバから受信した前記パケットから前記UDPカプセル封じを取り外し、前記パケットを前記それぞれのサーバノード上のサーバへと伝達し、
前記それぞれのサーバノード上の前記サーバからの前記発信パケットを遮断し、
出口サーバへの前記発信パケットの前記送信の前に、UDPに従って前記発信パケットをカプセル化する、
ように各ロードバランサモジュールがさらに構成され、
前記パケットフローの顧客への前記発信パケットの送信の前に、前記発信パケットから前記UDPカプセル封じを取り外すように、前記各出口サーバがさらに構成される、
第17節に記載のコンピュータアクセス可能な非一時的記憶媒体。
19.フロートラッカーノードが前記パケットフローのための1次フロートラッカーノードであり、一貫したハッシュ関数に従った一貫したハッシュリング内の次のロードバランサノードが、前記パケットフローのための2次フロートラッカーノードであり、前記パケットフローのため前記フロートラッカーノードから、前記パケットフローのための複数の1つへの接続のマッピングを取得するために、
前記入口サーバが少なくとも1つのメッセージを前記パケットフローのための前記1次フロートラッカーノードへと送信するよう構成され、各メッセージが前記ルータから受信された前記パケットフローのパケットを含み、
前記パケットフローのための前記サーバノードを前記複数のサーバノードから選択し、
前記選択されたサーバノードを示すパケットフロー情報を、前記2次フロートラッカーノードへと送信する、
ように、前記1次フロートラッカーノードが構成され、
前記サーバノードと前記顧客との間の通信により、前記パケットフローのための前記選択したサーバノードへの前記接続の確立を円滑化し、
前記パケットフローのための接続情報を前記入口サーバへと前記1次フロートラッカーノードを通じて送信し、前記接続情報が前記選択されたサーバノードへの前記パケットフローのマッピングを行う、
ように、前記2次フロートラッカーノードが構成される、
第16節に記載のコンピュータアクセス可能な非一時的記憶媒体。
20.前記プログラム命令がさらにコンピュータにより実行可能であり、複数のサーバノードのそれぞれの上にロードバランサモジュールを実装するため、また、前記サーバと前記顧客との間の通信により、前記パケットフローのための前記選択されたサーバノードへの前記接続の確立を円滑化するために、
前記2次フロートラッカーノードが生成された同期メッセージを前記サーバノード上の前記ロードバランサモジュールへと送信するよう構成され、
前記サーバノード上の前記サーバが接続を受け入れることができることを決定し、
前記生成された同期メッセージに従って同期パケットを生成し、
同期パケットを前記サーバノード上の前記サーバへと伝達し、
前記サーバノード上の前記サーバにより生成された受信確認パケットを遮断し、
前記接続情報を含むメッセージを前記2次フロートラッカーノードに送信する、
ように、前記サーバノード上の前記ロードバランサモジュールが構成される、
第19節に記載のコンピュータアクセス可能な非一時的記憶媒体。
結論
様々な実施形態は、上記のコンピュータアクセス可能な媒体に関する説明に従って実装された命令および/またはデータの受信、送信または格納をさらに含んでもよい。一般的に、コンピュータアクセス可能な媒体は、ネットワークおよび/または無線接続により伝達される通信媒体を介した電気、電磁、またはデジタル信号等の伝送媒体または信号と同様に、磁気または光学式媒体等の記憶媒体またはメモリ媒体、例、ディスクまたはDVD/CD-ROM、RAM(例えば、SDRAM、DDR、RDRAM、SRAM等)、ROM等の揮発性または不揮発性媒体を含んでもよい。
図面に示され、本明細書に記載された様々な方法は、方法の例示的な実施形態を表す。方法はソフトウェア、ハードウェア、またはそれらの組み合わせにおいて実装されてもよい。方法の順序は変更されてもよく、また、様々な要素が追加され、再整理され、組み合わされ、省略され、修正される等してもよい。
当業者には明らかであるように、本開示を利用して様々な修正や変更が加えられてもよい。本開示はそのようなすべての修正や変更を包含することを意図しており、したがって、上記記載は制限的な意味ではなく説明的な意味を持つと見なされるべきである。