複数の情報提供者から収集した、数値属性値を含むレコード群を、各レコードの情報提供者識別子(以下、単にIDと略す)を秘密にして、他者に開示又は提供したい場合がある。このとき、IDを削除して開示又は提供しても、特徴ある数値属性値を有するレコードについては他者が情報提供者を推定できてしまう場合がある。
例えば、個人の位置データの収集者が、情報提供者が分からない形で、分析者に位置データを提供することを考える。ここで、収集者としては位置データについてのサービス提供者、分析者としてはクラウドサービス提供者又はデータ二次利用者(例えば人口密度調査会社など)などが考えられる。
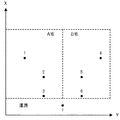
ここで、収集者が収集した位置データが図1に示すものであるとする。図1の例では、各レコードには、行番号と、IDと、X(緯度)と、Y(経度)とが含まれる。ここでは、各レコードは、A、B及びCの3人のいずれかの位置データを表しており、全部で7レコードある。すなわち、同じIDのレコードが複数回出現する場合がある。なお、IDは、個人のユーザIDである場合もあれば、測定機器のIDである場合もある。また、所属する組織のIDである場合もある。
図1に示されるデータを地図上にプロットすると、例えば図2に示すようになる。分析者は、図1及び図2のようなデータが得られれば、分析に役立てることができる。例えば、A宅及びB宅付近に人が集まっていることが分かる。
しかしながら、例えば、収集者が情報提供者との間で、匿名化しない限り他者にデータを提供しないという契約を結んでいる状況が考えられる。情報提供者は、特定の時期にどこにいたかを収集者以外に知られたくないなどの理由で、匿名化を希望する場合がある。
一方、分析者はID等の情報提供者の情報を利用しない場合もある。位置データの提供者が誰かを知らなくても人口密度調査のような分析はできるためである。
このような場合、収集者は図1のデータに対して匿名化を行って、情報提供者の推定を困難にすれば良い。
収集者による単純な匿名化方式として、IDを削除する方式がある。図1からIDを削除したデータを分析者が見ても、どのレコードが誰のデータなのかそのままでは分からない。しかし、位置データから情報提供者を推定可能なレコードがあるという問題がある。
図1からIDを削除したデータを図2のように地図上にプロットすると、例えば第1レコードの位置データ(X,Y)=(6,2)はA宅内であることが分かってしまう。すなわち、IDが削除されたデータしか見ることのできない分析者であっても、第1レコードの情報提供者がAであることが推定できてしまい、十分に匿名化されているとは言い難い。同様に、第7レコード以外は匿名化が不十分である。
従来技術として、事前に定められた、重なりのない複数の数値範囲をグループとして把握し、各グループ内のレコード群をそれらの統計値に変換する方法がある。
この従来技術では、緯度及び経度に基づいて地域をメッシングし、各メッシュ要素内のレコード群についての統計値を計算し、それを開示又は提供する。
統計値としては、例えば「メッシュ要素M1には3レコード」というように、メッシュ要素毎のレコード数が用いられる。もしくは、各レコードのIDを削除し、位置をメッシュ要素の中心点に変換しても良い。
例えば、図1の各レコードを一辺「5」のメッシュ要素によりグループ分けし、変換する場合を考える。その場合、例えば(X,Y)=([5, 10), [0, 5))などが1つのメッシュ要素、すなわちグループとなる。このメッシュ要素を仮にM10と名付けると、図1では第1レコードのみがM10に分類される。よって、「メッシュM10には1レコードあった」ことが開示される、あるいは第1レコードが(X,Y)=(7.5, 2.5)(M10の中心点)に変換され開示されることになる。
この従来技術では、メッシュサイズが十分大きければ匿名性に問題は生じないが、メッシュサイズを小さくすると匿名性が脅かされるという問題がある。例えば、メッシュ要素M10が、もしA宅の敷地内に包含された場合(例えば、A宅の敷地が(X,Y)=([2, 10], [0, 6])の場合など)、メッシュ要素M10に分類されたレコードの情報提供者はAだと推定できてしまう。メッシュサイズを小さくするほど、特定のIDしか存在し得ないような地域にメッシュ要素が包含される可能性が高くなる。
一方、メッシュサイズを大きくするほど、位置の一般化度合いが大きくなり、分析者による分析の精度に大きな悪影響を与えるという問題がある。例えば、統計調査では一辺約1kmのメッシュ要素が使われることがあるが、その結果だけを使う限り1km単位より詳細な地域に関する分析結果を出すことは一般的にはできない。
このように、この従来技術は、匿名性を担保するためにメッシュサイズを十分に大きくしなければならず、分析の精度に大きな悪影響を与えるという問題がある。
また、グループを生成する別の従来技術として、事前に決めた値d及びkに対し、大きさd未満の範囲内に、k個以上のレコードが含まれるように、且つ別の範囲と重ならないように範囲の位置を調整し、その範囲に基づきグループ化する技術がある。
この従来技術は対象データとして互いに異なるIDを有するレコード群を前提にしており、その場合は適切な匿名性が担保されるが、図1のように同じIDのレコードが複数存在し得るデータに対しては十分な匿名性を担保できないという問題がある。
例えば、この従来技術の一部を適用し、図1の各レコードを一辺「5」未満の矩形(d=(5, 5))で、3個以上(k=3)のレコードが含まれるようグループ分けする場合を考える。この場合、例えばレコード{1,2,3}を含む矩形R43:(X,Y)=([2, 6], [2, 4])と、レコード{4,5,6}を含む矩形R49:(X,Y)=([2, 6], [8, 10])の2つのグループができる。しかし、上でも述べた例と同じように、特定のIDしか存在し得ないような地域に矩形が包含される可能性がある。例えば矩形R43がA宅の敷地内に包含された場合には、矩形R43に分類されたレコード{1,2,3}の情報提供者がAだと推定できてしまう。
一般的に、図1のように同じIDのレコードが複数存在するレコード群をも取り扱うことができる手法の方が適用範囲が広くて良い。例えば、組織が情報提供者の場合は特に、複数の測定機器のデータに同じID(すなわち組織ID)が記録される場合もある。また、IDが同じ複数のレコードの存在を許すことで多くのレコードを一度に分析できるようになり、分析精度の向上が望める。しかしながら、この従来技術は、特殊な対象データでしか匿名性を担保できず、適用できる場面が少ないという問題がある。
さらに、グループ化する別の従来技術として、IDのような機密属性値の種類が各グループ内でl種類以上ある(すなわちl−多様性を満たす)ようにする技術がある。この従来技術はグループを事前に決めた大きさ未満の範囲内にすることが難しいという問題がある。事前に決めた大きさ未満の範囲内にできないと、分析の精度に大きな悪影響を与えるという問題がある。
図3に、本発明の実施の形態に係る情報処理装置100の機能ブロック図を示す。情報処理装置100は、第1データ格納部110と、設定データ格納部120と、グループ化処理部130と、第2データ格納部140と、匿名化処理部150と、第3データ格納部160と、出力部170と、メッシュ生成部180と、第4データ格納部190とを有する。
第1データ格納部110は、例えば図4に示すような匿名化前のデータを格納している。図4の例では、各レコード(データブロックとも呼ぶ)は、IDと、X(緯度)と、Y(経度)と、速さと含む。行番号は、以下の説明のために付されている。
また、設定データ格納部120は、生成すべきメッシュの種類数xと、メッシュ要素のサイズdと、度数分布についての条件(度数分布パターンとも呼ぶ)と、第1データ格納部110に格納されているデータのうちの機密属性(例えばID属性。機微属性とも呼ぶ。)及び数値属性(例えば緯度X及び経度Yを含む位置データ)の指定とが格納される。度数分布パターンは、最小種類数lと、減衰率aとを含む。最小種類数lは2以上の整数であり、減衰率aは1以下の正の実数である。例えば、l種類のIDについて度数の多い順にn番目の度数がn−1番目の度数のa倍以上であるという度数分布パターンが条件として設定される。
グループ化処理部130は、設定データ格納部120及び第4データ格納部190に格納されているデータを用いて、第1データ格納部110に格納されているレコード群をグループ化する処理を行い、処理結果を第2データ格納部140に格納する。匿名化処理部150は、グループ化の結果に基づき、各グループに属するレコードの数値属性値を変換する処理を行い、処理結果を第3データ格納部160に格納する。出力部170は、第3データ格納部160に格納されているデータを、他のコンピュータ、表示装置や印刷装置などに出力する。
メッシュ生成部180は、設定データ格納部120に格納されているメッシュの種類数x及びメッシュ要素のサイズdに従って、メッシュのデータを生成し、第4データ格納部190に格納する。
メッシュ要素のサイズdは、各数値属性で張られる空間においてメッシュ要素の辺の長さを表す正の数値列である。たとえば、数値属性が(X,Y)の2次元なら、d=(6,6)などと設定される。
メッシュの種類数xは、自然数である。例えば、異なるメッシュを6種類使うなら、x=6となる。本実施の形態では、メッシュはn次元矩形メッシュ(nは数値属性の数)とする。なお、メッシュは複数のメッシュ要素を含み、メッシュ要素間の境界(壁とも呼ぶ)は、2次元であれば辺であり、3次元であれば平面であり、4次元以上であれば超平面となる。また、メッシュは一般的には、三角形メッシュや六角形メッシュなど、数値属性の値がどのメッシュ要素に該当するかすぐに計算できるような規則に従っていれば、矩形に限らない。
次に、図5乃至図39を用いて、情報処理装置100の処理内容について説明する。
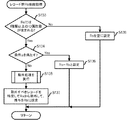
メッシュ生成部180は、メッシュ生成処理を実行し、生成されたメッシュのデータを、第4データ格納部190に格納する(図5:ステップS1)。メッシュ生成処理については、図6乃至図9を用いて説明する。
まず、メッシュ生成部180は、メッシュの空のリストMを生成する(図6:ステップS11)。また、メッシュ生成部180は、原点(0,0)をリストMに追加する(ステップS13)。まず、メッシュ要素の1辺の長さが「1」であるメッシュを生成するものとする。従って、以降の処理では、基準の点についての各次元の値域が[0,1)に入るメッシュが、リストMに追加される。
そして、メッシュ生成部180は、リストMに含まれるメッシュの種類数|M|は、指定された種類数xに達したか否かを判断する(ステップS15)。ステップS13の直後であれば、|M|=1であり、例えばx=6であるとすると、この条件を満たしていない。
ステップS15の条件を満たしていない場合には、メッシュ生成部180は、リストMに属する各メッシュの境界のうち最も近い境界との距離が最大となる点P’を選択する(ステップS19)。
本実施の形態では、リストMに含まれるメッシュの種類数|M|に応じた点(基準点とも呼ぶ)を発生させる。すなわち、c=ceil(log2(|M|+1))(ceilは天井関数)と定義して、点(2-c,2-c)を基点として、[0,1)内を幅2-c+1で変動させた点を生成する。最初は、|M|=1なので、c=1となる。従って、(1/2,1/2)のみが生成される。
さらに、メッシュ生成部180は、選択された点P’のうち、リストMに属する各メッシュの格子点のうち近い格子点との距離が最大となる点のメッシュをリストMに追加する(ステップS21)。最初は、基準点が(1/2,1/2)となるメッシュがリストMに追加される。そして処理はステップS15に戻る。
この状態では、図7に示すようなメッシュが生成されたことになる。なお、まだメッシュ要素の辺の長さは「1」のままである。
ステップS15において、リストMに含まれるメッシュの種類数|M|が、指定された種類数xに達した場合には、メッシュ生成部180は、メッシュ要素のサイズdから、各メッシュを設定し、第4データ格納部190に格納する(ステップS23)。そして処理は呼び出し元の処理に戻る。
上で述べた例では、|M|=2で次にステップS19に移行すると、c=2となるので、P={(1/4,1/4),(1/4,3/4),(3/4,1/4),(3/4,3/4)}が生成される。この段階では、どの点も、リストMに含まれる各メッシュの格子点からの距離は同じなので、ステップS21では、いずれかの点、例えばp=(1/4,1/4)を選び、リストMに追加する。すなわち、M={(0,0),(1/2,1/2),(1/4,1/4)}となる。
さらに、|M|=3で次にステップS19に移行すると、c=2のままとなる。従って、前回と同じPが生成されるが、(3/4,1/4)及び(1/4,3/4)は、(1/4,1/4)のメッシュの辺上に載るので、それより距離が遠い(3/4,3/4)が採用される。ステップS21でも、p=(3/4,3/4)が選択されて、リストMに追加される。すなわち、M={(0,0),(1/2,1/2),(1/4,1/4),(3/4,3/4)}となる。
さらに、|M|=4で次にステップS19に移行すると、c=3となるので、P={(1/8,1/8)、(1/8,3/8),...,(3/8,1/8),(3/8,3/8),...,(7/8,7/8)}が生成される。Pに含まれる点のうち、リストMの各メッシュの格子点のうち、近い点と距離が最大となる点の1つであるp(1/8,5/8)をリストMに追加する。なお、近い格子点との距離が最大とは、たとえば、最も近い格子点とのユークリッド距離が最大で、それが同じ場合次に近い格子点とのユークリッド距離が最大で、といったように以降同様に各格子点との距離を比較して決める。例を挙げると、点(1/8,5/8)の最も近い点の1つである(1/4,1/4)との距離は101/2/8だが、(1/8,3/8)の最も近い点(1/4,1/4)との距離は21/2/8であり、距離が短い後者の点は採用されない。そうすると、M={(0,0),(1/2,1/2),(1/4,1/4),(3/4,3/4),(1/8,5/8)}となる。
さらに、|M|=5で次にステップS19に移行すると、c=3のままとなる。そして同様に処理すると、(5/8,1/8)が選択されて、M={(0,0),(1/2,1/2),(1/4,1/4),(3/4,3/4),(1/8,5/8),(5/8,1/8)}となる。ここで、|M|=x=6となり、d=(6,6)から、以下のようなメッシュの基準点が生成される。M={(0,0),(3,3),(3/2,3/2),(9/2,9/2),(3/4,15/4),(15/4,3/4)}。そして、処理は呼び出し元の処理に戻る。
図6の処理フローでは、メッシュの境界を共有しないように、ずらしてメッシュを生成するようにしている。このようにずらしてメッシュを生成することで、以下で述べるグループ化処理で、固定のメッシュ要素単位でグループ化を行うが、多様なグループ化が可能になる。
なお、上で述べた基準点は、図8に示すようにばらつくようになる。2次元の矩形格子を採用しているので、メッシュがそれぞれ少しずつずらして生成されていることがこの図からも分かる。なお、図中の数字は生成順番を示している。また、図9に、実際のメッシュの重なり状態を示している。ここでは6番目に生成されるメッシュのメッシュ要素までを1つずつ示しているが、メッシュ要素の境界は共有されていない。
なお、図6の処理フローは、リストMに含まれるメッシュから最も遠い位置のメッシュをリストMに追加している処理とも言える。最も遠い位置の定義としては、以下のようなものとなる。
すなわち、リストMと、2つのメッシュm1及びm2を入力として、Mからm2の方がm1よりも遠い場合には−1を、m1の方がm2より遠い場合には1を、m1とm2が同じ遠さの場合には0を返す関数cmp(M,m1,m2):{−1,0,1}を用意して、最も遠いメッシュの集合Fは、F={m|∀m’,cmp(M,m,m’)≧0}で定義される。
例えば、図6の処理フローにおけるステップS19及びS21の処理をcmp(M,m1,m2)に当てはめると、以下のようになる。
1.m1及びm2それぞれの任意の境界(辺)と、リストMの各メッシュの境界の中で最も近い境界との距離をd1及びd2としたとき、d1<d2なら−1を返し、d1>d2なら1を返す。
2.m1及びm2それぞれの基準点と、リストMに含まれる各メッシュの格子点の中で1番目に近い頂点との距離をd1及びd2としたとき、d1<d2なら−1を返し、d1>d2なら1を返す。
3.そうでない場合、2と同様に、2番目に近い格子点との距離の比較を行って条件に合うか判断し、...、|M|番目に近い格子点との距離の比較を行って条件に合うか判断する、ということを繰り返し、条件にあった時点で−1又は1を返す。
4.そうでなければ0を返す。
このような関数cmpによってFを求め、その中から基準点が最も原点に近いメッシュを選択すればよい。
図5の処理フローの説明に戻って、グループ化処理部130は、第1データ格納部110に格納されているレコードに対して、第4データ格納部190及び設定データ格納部120に格納されているデータに従って、グループ生成処理を実行する(ステップS3)。グループ生成処理については、図10乃至図38を用いて説明する。
まず、グループ化処理部130は、第4データ格納部190におけるリストMから、未処理のメッシュmを1つ特定する(図10:ステップS31)。そして、グループ化処理部130は、第1データ格納部110に格納されているレコード群を、特定されたメッシュmのメッシュ要素で分類する(ステップS33)。
具体的には、各レコードに対してメッシュ要素識別子(ID)を算出し、IDと行番号との対応関係表を生成する。例えば、メッシュ要素IDは、floor((数値属性−m)/d)として算出する。なお、floorは床関数である。例えば、図4における行番号「8」のレコードは(X,Y)=(6,5)であり、m=(0,0),d=(6,6)であるから、(floor((6−0)/6),floor((5−0)/6))=(1,0)がメッシュ要素IDとなる。
以上のような処理を行うと、図11に示すような分類がなされる。図11の例では、3つのメッシュ要素に、各レコードが分類されている。
次に、グループ化処理部130は、レコードを含むメッシュ要素のうち、未処理のメッシュ要素sを1つ特定する(ステップS35)。例えば、メッシュ要素ID(0,0)のメッシュ要素を特定する。
そして、グループ化処理部130は、特定されたメッシュ要素s内において譲れないレコードとして第2データ格納部140に登録されているレコード以外のレコードRaを抽出する(ステップS37)。最初の場合には、譲れないレコードとして登録されているレコードは存在しない。但し、以下で述べる処理では譲れないレコードとして登録されているレコードが存在する場合には、当該レコードを除外してレコードRaを特定する。最初の例では、Ra={1,2,3,4,5,6,7}となる。
その後、グループ化処理部130は、レコード群Rs抽出処理を実行する(ステップS39)。このレコード群Rs抽出処理については、図12乃至図19を用いて説明する。なお、この処理が終了すると、処理は端子Aを介して図20の処理に移行する。
まず、グループ化処理部130は、レコードRaについての度数分布を生成し、レコードRaにはl種類以上のID属性値が含まれるか判断する(ステップS133)。レコードRaにl種類以上のID属性値が含まれない場合には、グループ化処理部130は、レコード群Rsを空に設定する(ステップS138)。そして、処理は呼び出し元に戻る。l種類以上のID属性値が含まれていない場合には、グループ化を行うことができないので、呼び出し元の処理に戻る。
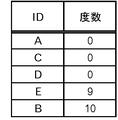
一方、レコードRaにl種類以上のID属性値が含まれる場合には、グループ化処理部130は、レコードRaについての度数分布が、度数分布パターンにおける条件a(=減衰率)を満たしているか判断する(ステップS134)。l=3及びa=0.5が設定されているものとする。度数が大きい順に並べて、n番目の度数が、n−1番目の度数のa=0.5以上であることが条件となっている。例えば{B:2,A:1,C:1}という度数分布が得られた場合には、この条件を満たしている。
減衰率aを用いるのは、度数分布の偏りが大きすぎるグループを作らない、すなわち安全性を高めるためである。減衰率aは、l種類以上あっても偏りが大きすぎる度数分布となるグループを許さないようにするための条件である。例えば、度数分布が{A:100,C:1}(Aが100個、Cが1個の意味)となるレコードを含む範囲を考える。この範囲は2種類のIDを含むので、この範囲が特定の1つのIDしか存在し得ないような地域に包含されることはない。しかし、度数の99%以上がAであり、この範囲のほとんどがAしか存在し得ないような地域である可能性がある。そうであった場合、この範囲を開示すると、この範囲のほとんどのレコードがAから提供されたことを推定しやすく問題となるからである。
レコードRaについての度数分布が、度数分布パターンにおける条件を満たしている場合には、グループ化処理部130は、レコード群Rsに、レコードRaを全て設定する(ステップS136)。そして、処理は呼出元の処理に戻る。
一方、レコードRaについての度数分布が、度数分布パターンにおける条件を満たしていない場合には、グループ化処理部130は、除外処理を実行する(ステップS135)。条件lを満たしていれば、条件aを満たすようにレコードを除外することが可能である。従って、除外処理を実行する。除外処理については、図13乃至図19を用いて説明する。
そして、グループ化処理部130は、予め定められているルールに従って、除外処理で決定された数の除外すべきレコードを特定して、レコードRaから除外して、残余をレコード群Rsに設定する(ステップS137)。所定のルールは、例えばランダムといったような単純な方法でよい。
ここで、除外処理について説明する。まず、グループ化処理部130は、レコードRaについて度数分布表Fを生成し、度数の昇順に整列させる(図13:ステップS141)。上で述べた例では、除外処理は行われないので、ここでは図14に示すような度数分布表Fが生成されたものとする。また、l=4且つa=0.5であるものとする。
そして、グループ化処理部130は、変数pを初期化し(ステップS143)、変数iを0に初期化する(ステップS145)。その後、グループ化処理部130は、iが度数分布表Fの行数|F|より小さいか判断する(ステップS147)。iが度数分布表Fの行数|F|より小さい場合には、グループ化処理部130は、i+l−1が|F|より小さいか判断する(ステップS149)。i+l−1が|F|より小さい場合には、グループ化処理部130は、変数pに対してF[i]を代入する(ステップS151)。F[i]は、Fのi+1行目の度数である。i=0であれば、変数pには、Fの1行目の度数「1」が代入される。
一方、i+l−1が|F|以上であれば、グループ化処理部130は、変数pに、min(F[i],floor(p/a))を代入する(ステップS153)。min(A,B)は、AとBのうち小さい方を出力する関数である。
ステップS151又はS153の後に、グループ化処理部130は、F[i]に、F[i]−pを代入する(ステップS155)。i=0の時に、S149を実行すると、度数分布表Fは、図15のようになる。
その後、グループ化処理部130は、変数iを1インクリメントし(ステップS157)、処理はステップS147に戻る。
2回目のステップS147では、|F|=5,i=1であるから、i<|F|となる。また、l=4であるので、i+l−1<|F|となる。従って、ステップS151でp=3であり、F[1]=3−3=0となる。そうすると、度数分布表Fは、図16のようになる。その後i=2となる。
3回目のステップS147では、|F|=5,i=2であるから、i<|F|となる。また、l=4であるので、i+l−1<|F|とはならず、ステップS153に移行して、a=0.5及びp=3であるから、min(F[i]=4,floor(p/a)=6)=4となる。従って、F[2]=4−4=0となる。そうすると、度数分布表Fは、図17のようになる。その後i=3となる。
4回目のステップS147では、|F|=5、i=3であるから、i<|F|となる。また、l=4であるので、i+l−1<|F|とはならず、ステップS153に移行して、a=0.5及びp=4であるから、min(F[i]=9,floor(p/a)=8)=8となる。従って、F[3]=9−8=1となる。そうすると、度数分布表Fは、図18のようになる。その後i=4となる。
5回目のステップS147では、|F|=5、i=4であるから、i<|F|となる。また、l=4であるので、i+l−1<|F|とはならず、ステップS153に移行して、a=0.5及びp=8であるから、min(F[i]=10,floor(p/a)=16)=10となる。従って、F[4]=10−10=0となる。そうすると、度数分布表Fは、図19のようになる。その後i=5となる。
6回目のステップS147では、|F|=5、i=5であるから、i<|F|が成り立たなくなる。そうすると、処理は呼出元の処理に戻る。すなわち、この時点における度数分布表F(図19)が、除外すべきレコードを示している。ここでは、IDが「E」のレコードを1つ除外することになる。除外するレコードについては、上で述べたように、ランダムに選択すればよい。
図10の端子Aを介して図20の処理の説明に移行する。なお、上で述べていた例のように、Ra={1,2,3,4,5,6,7}の場合、l及びaの条件を満たすので、Ra=Rsとなる。
グループ化処理部130は、レコード群Rsが空であるか判断する(ステップS41)。レコード群Rsが空であると、グループ化は行われないので、処理はステップS55に移行する。
一方、レコード群Rsが空でない場合には、グループ化処理部130は、レコード群Rsに未グルーピングのレコードが存在するか否かを判断する(ステップS43)。未グルーピングのレコードが存在しない場合には、新たなグループの生成をわざわざ行うことはないので、処理はステップS55に移行する。
一方、レコード群Rsに未グルーピングのレコードが存在する場合には、グループ化処理部130は、レコード群Rsでグループを生成する(ステップS45)。Rs={1,2,3,4,5,6,7}が1つのグループとなる。
そして、グループ化処理部130は、生成されたグループに対して譲渡可能レコードの抽出処理を実行する(ステップS47)。すなわち、生成されたグループのうち、度数分布パターンを満たす上で必須のレコード以外のレコードを抽出する処理を実行する。より具体的には、図21乃至図26を用いて説明する。
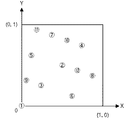
まず、グループ化処理部130は、レコードRsについて度数分布表Fを生成し、度数の昇順に整列させる(図21:ステップS171)。処理を分かり易くするために、図22に示すような度数分布表Fが生成されたものとする。
そして、グループ化処理部130は、変数ciに|F|−lを設定し、変数minに、ceil(F[ci]*a)を設定する(ステップS173)。ceil(x)は天井関数であり、実数xに対してx以上の最小の整数を出力する関数である。F[i]は度数分布表Fのi+1行目の度数を表し、|F|は度数分布表Fの行数を表す。ci=5−4=1であり、min=ceil(2*0.5)=1となる。
また、グループ化処理部130は、変数iを0に初期化し、変数maxを0に初期化する(ステップS175)。
その後、グループ化処理部130は、i<|F|であるか判断する(ステップS177)。i<|F|であれば、グループ化処理部130は、変数cを初期化する(ステップS179)。その後、グループ化処理部130は、i<ciであるか判断する(ステップS181)。i=0であれば、ci=1であるからこの条件は満たされている。
i<ciであれば、グループ化処理部130は、cに0を設定する(ステップS183)。そうすると、グループ化処理部130は、F[i]に、F[i]−cを設定する(ステップS185)。F[i]=1であり、c=0であるから、F[i]=1となる。その後、グループ化処理部130は、iを1インクリメントし(ステップS187)、処理はステップS177に戻る。
i=1になると、ステップS181では、i<ciは成り立たなくなるので、グループ化処理部130は、i+1=|F|であるか判断する(ステップS189)。i=1であれば、i+1=2であるから、この条件を満たさない。ステップS189の条件を満たさない場合には、グループ化処理部130は、cに、ceil(F[i+1]*a)を代入する(ステップS191)。c=ceil(F[2]*0.5)=2となる。そして、グループ化処理部130は、max<cであるか判断する(ステップS193)。max=0であるからこの条件を満たす。そうすると、グループ化処理部130は、maxにcを代入する(ステップS197)。すなわち、max=c=2となる。その後、処理はステップS185に移行する。従って、2回目のステップS185では、F[1]=2−2=0となる。従って、図23に示すような度数分布表Fになる。
i=2になると、ステップS181では、i<ciは成り立たなくなるので、ステップS189に移行する。但し、i+1<|F|であるから、ステップS191に処理は移行し、c=ceil(F[3]*0.5)=2となる。max=2であるから、max<cの条件を満たしていない。そうすると、グループ化処理部130は、cにminを代入する(ステップS195)。min=1であるから、c=1となる。そして処理はステップS185に移行して、3回目のステップS185では、F[2]=3−1=2となる。従って、図24に示すような度数分布表Fになる。
i=3になると、ステップS181では、i<ciは成り立たないので、ステップS189に移行する。但し、i+1<|F|であるから、ステップS191に処理は移行し、c=ceil(F[4]*0.5)=3となる。max=2でc=3であるから、max<cの条件を満たしている。従って、max=c=3となる。そして、4回目のステップS185では、F[3]=4−3=1となる。従って、図25に示すような度数分布表Fとなる。
i=4になると、ステップS181では、i<ciは成り立たないので、ステップS189に移行する。i+1=|F|を満たすので、ステップS195に処理は移行し、c=min=1となる。そして処理はステップS185に移行して、5回目のステップS185では、F[4]=F[4]−c=5−1=4となる。従って、図26に示すような度数分布表Fが得られる。
その後i=5になると、ステップS177ではi<|F|の条件を満たさなくなるので、処理は呼出元の処理に戻る。従って図26に示すように、IDがAの1レコード、IDがCの2レコード、IDがDの1レコード、及びIDがEの4レコードが、譲渡可能なレコードとして特定されたことになる。
図20の処理の説明に戻って、グループ化処理部130は、ステップS47の処理結果に基づき、予め定められているルールに従って、譲渡可能なレコードを具体的に特定する(ステップS49)。所定のルールについては、例えばランダムであっても良いし、行番号が大きい順番であっても良い。
上で述べた例では、Rs={1,2,3,4,5,6,7}のうち、譲れるレコードは{2,4,6,7}であり、譲れないレコードは{1,3,5}となる。
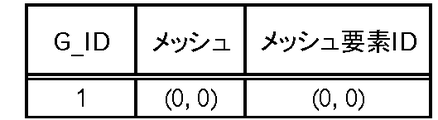
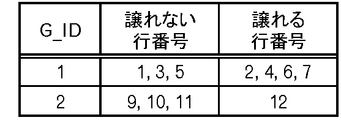
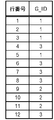
ここまでの処理によって、第2データ格納部140には、図27乃至図29のデータが格納される。図27は、グループ化が行われたメッシュ及びメッシュ要素IDとグループID(G_ID)との対応付けを行うテーブルを表している。グループIDについてはユニークになるようにシリアルに番号付けする例を示している。また、図28では、グループIDに対応付けて、当該グループに属するレコードのうち譲れないレコードの行番号集合と、譲れるレコードの行番号集合とが登録されるようになっている。さらに、図29は、行番号とグループIDとの対応付けを示している。
そして、グループ化処理部130は、他のグループから譲ってもらったレコードが存在しているか否かを判断する(ステップS51)。他のグループにグループ化されていたが、譲れるレコードに分類されていて今回生成されたグループに属するレコードが存在する場合には、所属グループを変更することになる。従って、他のグループから譲ってもらったレコードが存在している場合には、グループ化処理部130は、第2データ格納部140において、譲渡元グループから、譲ってもらったレコードの行番号を削除する(ステップS53)。一方、他のグループから譲ってもらったレコードが存在していない場合には、処理はステップS55に移行する。
そして、グループ化処理部130は、未処理のメッシュ要素が存在するか判断する(ステップS55)。未処理のメッシュ要素が存在する場合には、処理は端子Bを介して図10のステップS35に戻る。一方、未処理のメッシュ要素が存在しない場合には、グループ化処理部130は、未処理のメッシュが存在するか否かを判断する(ステップS57)。未処理のメッシュが存在する場合には、処理は端子Cを介して図10のステップS31に戻る。一方、未処理のメッシュが存在しない場合には、処理は呼び出し元の処理に戻る。
なお、上で述べた例では、メッシュ(0,0)についてメッシュ要素ID(1,0)に対する処理に移行する。但し、Ra={8}となるので、l及びaの条件を満たさないので、Rsは空に設定されて、グループ化は行われない。
また、メッシュ(0,0)についてメッシュ要素ID(1,1)に対する処理に移行する。この場合、Ra={9,10,11,12}となって、l及びaの条件を満たすので、Ra=Rs={9,10,11,12}が設定され、グループもそのまま生成される。なお、譲渡可能レコードの抽出処理(図21)を実行すると、{12}が譲れるレコードに特定されるので、譲れないレコードは{9,10,11}となる。
ここまで処理すると、第2データ格納部140には、図30乃至図32に示すようなデータが格納される。図30は、図27の後の状態を表しており、グループID「2」が、メッシュ(0,0)及びメッシュ要素ID(1,1)に付与されている。また、図31は、図28の後の状態を表しており、グループID「2」について、上で述べたように、譲れないレコードの行番号集合{9,10,11}、及び譲れるレコードの行番号集合{12}が示されている。図32は、図29の後の状態を表しており、グループID「2」についての行のデータが追加されている。
次に、メッシュ(3,3)の処理に移行して、レコードの分類を行うと、図33のような分類結果が得られる。2つのメッシュ要素に分類されたことが分かる。
まず、メッシュ要素ID(−1,0)のメッシュ要素に分類されたレコードを処理する。レコード{1,2}は、l及びaの条件を満たさないので、メッシュ要素ID(0,0)の処理に移行する。
そうすると、{3,4,5,6,7,8,9,10,11,12}のうち、これまでに生成されたグループにおいて譲れないレコードは{1,3,5,9,10,11}であるから、Ra={4,6,7,8,12}となる。このRaはl及びaの条件を満たすので、Ra=Rsとなる。
Rsの中にはレコード{8}が含まれているので、Rsでグループを生成することになる。さらに、譲渡可能レコードの抽出処理(図21)を実行すると、譲れるレコードは{7,8}と特定され、譲れないレコードは{4,6,12}となる。なお、これらは図31から分かるように既にグループ化されているので、各グループから譲ってもらうことになる。
そうすると、第2データ格納部140に格納されるデータは、図34乃至図36に示すようなデータに更新される。図34は、図30の後の状態を表しており、グループIDに対応付けてメッシュ(3,3)のメッシュ要素ID(0,0)が追加されている。さらに、図35は、図31の後の状態を表しており、グループID「3」に対応付けて、譲れないレコード{4,6,12}、及び譲れるレコード{7,8}が登録されている。レコード{8}以外は、他のグループから譲ってもらったので、グループ「1」及び「2」から、それらのグループの行番号が削除されている。図36は、図32の後の状態を表しており、レコード{8}が新たに追加され、譲ってもらったレコードについてのグループIDが変更になっている。
さらに、メッシュ(3/2,3/2)についての処理に移行する。そうすると、図37に示すような分類結果が得られる。図37からも分かるように、メッシュ要素ID(−1,0)(0,1)(1,1)はl及びaの条件を満たさない。メッシュ要素ID(0,0)の場合には、これまでに生成されたグループにおいて譲れないレコードは{1,3,4,5,6,9,10,11,12}であるから、Ra={2,7,8}となる。これは、l及びaの条件を満たすので、Ra=Rsとなる。但し、{2,7,8}は皆グルーピング済みであるので、新たなグループが生成されないことになる。
以下、他のメッシュについて処理を行っても、新たにグループが生成されることはない。
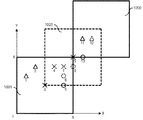
以上の処理結果を、平面上に表したのが図38である。図38において、三角はID「A」のレコードを表し、×はID「B」のレコードを表し、丸はID「C」のレコードを表し、このような記号の脇の番号は行番号を表す。
グループ「1」は矩形1001に対応し、レコード{1,2,3,5}が所属する。また、グループ「2」は矩形1002に対応し、レコード{9,10,11}が所属する。グループ「3」は矩形1003に対応し、レコード{4,6,7,8,12}が所属する。このように、重なっている領域部分に含まれるレコードを分け合っており、各矩形において特定のIDのみが所属することはない。
図5の処理の説明に戻って、匿名化処理部150は、第2データ格納部140に格納されているデータから、グループ毎に匿名化を実行し、処理結果を第3データ格納部160に格納する(ステップS5)。例えば、グループに対応するメッシュ要素の中心点に、そのグループに所属するレコードが存在するようにデータを変換すると共に、機密属性であるIDを削除する。例えば、図4に示したレコード群の場合には、図39に示すようなデータが得られる。図4の(X,Y)が、メッシュ要素の中心座標で置換されていることが分かる。このように匿名化されて、個々のレコードが特定されることはない。
そして、出力部170は、第3データ格納部160に格納されているデータを、出力装置(例えば表示装置、印刷装置やネットワークで接続された他のコンピュータ)に出力する(ステップS7)。
以上のように処理を行えば、匿名性と分析精度を両立したデータを開示することができるようになる。また、メッシュ生成は高速に行われるので、全体の匿名化処理をも高速に行える。
多様性の条件lを満たすようにグルーピングされたレコードだけが開示されるが、各グループには機密属性値についてl種類以上あるので、各グループのレコードが特定のIDしか存在し得ないようなメッシュ要素に包含されることはなく、匿名性が担保される。
また、開示される各メッシュ要素は大きさd未満となるため、小さいdを指定することで高精度な分析を期待される。但し、dが小さいほどいずれのメッシュ要素にも分類されないレコードが増え、そのようなレコードは開示されないため、dを小さくし過ぎても良くない。
さらに、複数種類のメッシュで多様性の条件lを満たすか否かを判定するため、多様性lの条件を満たさないレコード数を減らすことができる。これは、開示されるレコード数を増やす、つまり分析に使えるデータ量が増えることになるので、高精度な分析が期待される。
以上本発明の実施の形態を説明したが、本発明はこの実施の形態に限定されるものではない。例えば、図3に示した機能ブロック図は一例であって、プログラムモジュール構成やファイル構成とは一致しない場合もある。処理フローについても、処理結果が変わらない限り、ステップの順番を入れ替えたり、複数ステップを並列に実行するようにしても良い。
なお、図6のメッシュ生成処理は一例であって、他の手順で同様のメッシュを生成しても良いし、さらに異なる態様のメッシュを生成するようにしても良い。予め単位サイズのメッシュを所定種類だけ生成しておき、サイズdに応じてサイズ変換を行うようにしても良い。
なお、上で述べた情報処理装置100は、例えばコンピュータ装置であって、図40に示すように、メモリ2501とCPU2503とハードディスク・ドライブ(HDD)2505と表示装置2509に接続される表示制御部2507とリムーバブル・ディスク2511用のドライブ装置2513と入力装置2515とネットワークに接続するための通信制御部2517とがバス2519で接続されている。オペレーティング・システム(OS:Operating System)及び本実施例における処理を実施するためのアプリケーション・プログラムは、HDD2505に格納されており、CPU2503により実行される際にはHDD2505からメモリ2501に読み出される。CPU2503は、アプリケーション・プログラムの処理内容に応じて表示制御部2507、通信制御部2517、ドライブ装置2513を制御して、所定の動作を行わせる。また、処理途中のデータについては、主としてメモリ2501に格納されるが、HDD2505に格納されるようにしてもよい。本技術の実施例では、上で述べた処理を実施するためのアプリケーション・プログラムはコンピュータ読み取り可能なリムーバブル・ディスク2511に格納されて頒布され、ドライブ装置2513からHDD2505にインストールされる。インターネットなどのネットワーク及び通信制御部2517を経由して、HDD2505にインストールされる場合もある。このようなコンピュータ装置は、上で述べたCPU2503、メモリ2501などのハードウエアとOS及びアプリケーション・プログラムなどのプログラムとが有機的に協働することにより、上で述べたような各種機能を実現する。
以上述べた本実施の形態をまとめると、以下のようになる。
本実施の形態に係る匿名化データ生成方法は、(A)データ格納部に格納されており且つ各々機密属性値と数値属性値とを含む複数のデータブロックにおける各数値属性で張られる空間における複数種類のメッシュの各々について、複数のデータブロックのうち、当該メッシュの1つのメッシュ要素に含まれ且つグループ化未了の第1のデータブロックを含み且つ機密属性値の度数分布が所定の条件を満すデータブロックのグループを抽出し、(B)上記グループに属するデータブロックの数値属性値を、上記グループについての数値属性値で置換する処理を含む。
機密属性値の度数分布が所定の条件を満たすデータブロックのグループが生成されるので、確実な匿名化がなされる。また、複数種類のメッシュを用いることで、いずれかのメッシュのメッシュ要素でグループ化が行われる可能性があるため、開示されないデータブロックの数を減らすことができる。すなわち、分析に用いることができるデータ量が増加し、分析精度が向上する。また、メッシュ要素のサイズについても調整可能であり、この点についても分析精度向上の要因となる。メッシュ要素のサイズは、メッシュの各種類について同じにする場合もある。さらに、任意の位置にグループ化のための範囲を規定することによりグループ化を行う場合に比して処理が高速化される。
さらに、本匿名化データ生成方法は、上で述べたグループに属するデータブロックの機密属性値を削除する処理をさらに含むようにしても良い。これによって安全なデータを開示できるようになる。
さらに、上で述べた所定の条件が、機密属性値の種類数の下限値を含む場合もある。この場合、上で述べた抽出する処理は、(a1)グループ化未了の第1のデータブロックを含み且つ上記1つのメッシュ要素に含まれるデータブロックの集合における機密属性値の種類が、機密属性値の種類の下限値以上となっているか判断する処理を含むようにしても良い。このようにすれば、秘匿化の安全性が高まる。
さらに、上で述べた抽出する処理は、(a2)グループ化未了の第1のデータブロックを含み且つ上記1つのメッシュ要素に含まれるデータブロックの第2の集合についての機密属性値の度数分布が、所定の条件を満たすか判断し、(a3)データブロックの第2の集合についての機密属性値の度数分布が所定の条件を満たさない場合には、所定の条件を満たすようにデータブロックの第2の集合から第2のデータブロックを除外することでデータブロックのグループを生成する処理を含むようにしても良い。例えば、データブロックの第2の集合についての機密属性値の種類数が、その下限値以上となっていれば、適切なデータブロックを除外することで度数分布の条件を満たすようになる場合もある。
また、上で述べた抽出する処理は、(a4)データブロックのグループから、機密属性値の度数分布が所定の条件を満たす上で必須となるデータブロック以外の第3のデータブロックを抽出する処理を含むようにしても良い。この場合、データブロックの他のグループを抽出する処理において、第3のデータブロックが他の種類のメッシュにおけるメッシュ要素において抽出される場合もある。このようにすれば、第3のデータブロックが他のグループ生成に用いられるので、削除されてしまうデータブロックを削減することができるようになる。
なお、本実施の形態に係る匿名化データ生成方法は、(C)メッシュ要素の境界を共有しないように、複数種類のメッシュを生成する処理をさらに含む場合もある。このようにすれば、匿名化されないデータブロックをより効率的に削減できるようになる。
また、本実施の形態に係る匿名化データ生成方法は、(D)これまでに生成されたメッシュの境界のうち最も近い境界との距離が最大となり、且つこれまでに生成されたメッシュの格子点との距離が最大となる基準点を選択し、(E)選択された基準点及びメッシュ要素のサイズに基づきメッシュを生成する処理をさらに含むようにしても良い。このようにすれば、匿名化されないデータブロックをより効率的に削減できるようになる。
なお、上で述べたような処理をコンピュータに実施させるためのプログラムを作成することができ、当該プログラムは、例えばフレキシブル・ディスク、CD−ROMなどの光ディスク、光磁気ディスク、半導体メモリ(例えばROM)、ハードディスク等のコンピュータ読み取り可能な記憶媒体又は記憶装置に格納される。なお、処理途中のデータについては、RAM等の記憶装置に一時保管される。
以下、本実施の形態に係る付記を記す。
(付記1)
データ格納部に格納されており且つ各々機密属性値と数値属性値とを含む複数のデータブロックにおける各数値属性で張られる空間における複数種類のメッシュの各々について、前記複数のデータブロックのうち、当該メッシュの1つのメッシュ要素に含まれ且つグループ化未了の第1のデータブロックを含み且つ機密属性値の度数分布が所定の条件を満すデータブロックのグループを抽出し、
前記グループに属するデータブロックの数値属性値を、前記グループについての数値属性値で置換する
処理を含み、コンピュータにより実行される匿名化データ生成方法。
(付記2)
前記グループに属するデータブロックの機密属性値を削除する
処理をさらに含む付記1記載の匿名化データ生成方法。
(付記3)
前記所定の条件が、機密属性値の種類数の下限値を含み、
前記抽出する処理は、
前記グループ化未了の第1のデータブロックを含み且つ前記1つのメッシュ要素に含まれるデータブロックの集合における機密属性値の種類が、前記機密属性値の種類の下限値以上となっているか判断する
処理を含む付記1又は2記載の匿名化データ生成方法。
(付記4)
前記抽出する処理は、
前記グループ化未了の第1のデータブロックを含み且つ前記1つのメッシュ要素に含まれるデータブロックの第2の集合についての機密属性値の度数分布が、前記所定の条件を満たすか判断し、
前記データブロックの第2の集合についての機密属性値の度数分布が前記所定の条件を満たさない場合には、前記所定の条件を満たすように前記データブロックの第2の集合から第2のデータブロックを除外することでデータブロックのグループを生成する
処理を含む付記1乃至3のいずれか1つ記載の匿名化データ生成方法。
(付記5)
前記抽出する処理は、
前記データブロックのグループから、前記機密属性値の度数分布が前記所定の条件を満たす上で必須となるデータブロック以外の第3のデータブロックを抽出する処理
を含み、
データブロックの他のグループを抽出する処理において、前記第3のデータブロックが他の種類のメッシュにおけるメッシュ要素において抽出される
付記1乃至4のいずれか1つ記載の匿名化データ生成方法。
(付記6)
メッシュ要素の境界を共有しないように、前記複数種類のメッシュを生成する
処理をさらに含む付記1乃至5のいずれか1つ記載の匿名化データ生成方法。
(付記7)
これまでに生成されたメッシュの境界のうち最も近い境界との距離が最大となり、且つ前記これまでに生成されたメッシュの格子点との距離が最大となる基準点を選択し、
選択された前記基準点及び前記メッシュ要素のサイズに基づきメッシュを生成する
処理をさらに含む付記1乃至5のいずれか1つ記載の匿名化データ生成方法。
(付記8)
データ格納部に格納されており且つ各々機密属性値と数値属性値とを含む複数のデータブロックにおける各数値属性で張られる空間における複数種類のメッシュの各々について、前記複数のデータブロックのうち、当該メッシュの1つのメッシュ要素に含まれ且つグループ化未了の第1のデータブロックを含み且つ機密属性値の度数分布が所定の条件を満すデータブロックのグループを抽出し、
前記グループに属するデータブロックの数値属性値を、前記グループについての数値属性値で置換する
処理を、コンピュータに実行させるための匿名化データ生成プログラム。
(付記9)
データ格納部に格納されており且つ各々機密属性値と数値属性値とを含む複数のデータブロックにおける各数値属性で張られる空間における複数種類のメッシュの各々について、前記複数のデータブロックのうち、当該メッシュの1つのメッシュ要素に含まれ且つグループ化未了の第1のデータブロックを含み且つ機密属性値の度数分布が所定の条件を満すデータブロックのグループを抽出するグループ化処理部と、
前記グループに属するデータブロックの数値属性値を、前記グループについての数値属性値で置換する匿名化処理部と、
を有する情報処理装置。