JP6136702B2 - Location estimation method, location estimation apparatus, and location estimation program - Google Patents
Location estimation method, location estimation apparatus, and location estimation program Download PDFInfo
- Publication number
- JP6136702B2 JP6136702B2 JP2013153939A JP2013153939A JP6136702B2 JP 6136702 B2 JP6136702 B2 JP 6136702B2 JP 2013153939 A JP2013153939 A JP 2013153939A JP 2013153939 A JP2013153939 A JP 2013153939A JP 6136702 B2 JP6136702 B2 JP 6136702B2
- Authority
- JP
- Japan
- Prior art keywords
- address
- location
- information
- word
- estimation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images
















Description
本発明は、場所推定方法、場所推定装置および場所推定プログラムに関する。 The present invention relates to a location estimation method, a location estimation device, and a location estimation program.
携帯電話機やスマートフォン等に代表される端末には、GPS(Global Positioning System)のような測位機能が一般的に搭載されてきている。端末のユーザは、端末を用いて現在の場所を測位することができる。また、端末のユーザは、例えばソーシャルメディアを利用して端末から文書を送信する際に、現在の場所の情報を文書に付与することができる。 A terminal such as a mobile phone or a smartphone has generally been equipped with a positioning function such as GPS (Global Positioning System). The user of the terminal can measure the current location using the terminal. In addition, when a user of a terminal transmits a document from the terminal using social media, for example, information on the current location can be given to the document.
近年では、端末から送信される文書の中で言及されている場所を推定する方法として、辞書ベースの場所推定手法および機械学習ベースの場所推定手法が開示されている。辞書ベースの場所推定手法は、予め用意された、キーワードと当該キーワードに対応する場所との組み合わせの情報を示す辞書を利用することにより、文書の中で言及されている場所を推定する方法である。一方、機械学習ベースの場所推定手法は、文書中に現れるキーワードの傾向を学習し、場所に間接的に対応したキーワード(地域関連語)から、言及されている場所を推定する方法である。 In recent years, a dictionary-based location estimation method and a machine learning-based location estimation method have been disclosed as methods for estimating a location mentioned in a document transmitted from a terminal. The dictionary-based location estimation method is a method for estimating a location mentioned in a document by using a dictionary that is prepared in advance and that shows information on a combination of a keyword and a location corresponding to the keyword. . On the other hand, the machine learning-based location estimation method is a method of learning a tendency of keywords appearing in a document and estimating a mentioned location from a keyword (region related word) indirectly corresponding to the location.
辞書ベースの場所推定手法によれば、場所を表すキーワードが辞書に登録されており、当該キーワードに対する場所を特定できた場合は、場所を正しく推定することができる。しかしながら、例えば同一の地名が複数の地域で用いられている場合には、場所を一意に特定できない曖昧性が問題となる。例えば、文書から「港区」が抽出されたとしても、「大阪市港区」、「名古屋市港区」、「東京都港区」のいずれを意味するのかを特定するのは困難である。 According to the dictionary-based location estimation method, a keyword representing a location is registered in the dictionary, and if the location for the keyword can be identified, the location can be estimated correctly. However, for example, when the same place name is used in a plurality of regions, ambiguity that cannot uniquely identify a place becomes a problem. For example, even if “Minato Ward” is extracted from a document, it is difficult to specify whether it means “Minato Ward in Osaka City”, “Minato Ward in Nagoya City”, or “Minato Ward in Tokyo”.
また、機械学習ベースの場所推定手法によれば、おおよその場所までは特定可能であるが、詳細な場所を特定できないことがある。例えば大阪府までは特定できても、大阪府の中のどこの市町であるのかまでは特定できないことがある。このように、機械学習ベースの場所推定手法は、推定の粒度が辞書ベースの場所推定手法に比べて大きいという問題を有している。 Further, according to the machine learning-based location estimation method, an approximate location can be specified, but a detailed location may not be specified. For example, although it is possible to specify up to Osaka Prefecture, it may not be possible to specify the city or town in Osaka Prefecture. As described above, the machine learning-based location estimation method has a problem that the granularity of estimation is larger than that of the dictionary-based location estimation method.
本発明の1つの側面では、ユーザの端末から発信される文書の中で言及されている場所を推定する精度を向上させることが可能な場所推定方法、場所推定装置および場所推定プログラムを提供することを目的とする。 In one aspect of the present invention, a place estimation method, a place estimation apparatus, and a place estimation program capable of improving the accuracy of estimating a place referred to in a document transmitted from a user terminal are provided. With the goal.
発明の一観点によれば、場所推定装置によって実行される場所推定方法であって、ユーザの発信情報から第1の単語を抽出し、前記第1の単語に対応する住所に関する情報を記憶部から抽出し、前記第1の単語と前記住所に関する情報とを含む第1のキーワードに対応する第1の指標値を場所毎に算出し、前記第1の指標値に基づいて、前記発信情報が示す場所を推定する場所推定方法が提供される。 According to one aspect of the invention, there is provided a location estimation method executed by a location estimation device , wherein a first word is extracted from user transmission information, and information related to an address corresponding to the first word is stored from a storage unit. A first index value corresponding to the first keyword including the first word and the address information is extracted and calculated for each location, and the transmission information indicates based on the first index value A location estimation method for estimating a location is provided.
一実施態様によれば、ユーザの端末から発信される文書の中で言及されている場所を推定する精度を向上させることが可能な場所推定方法、場所推定装置および場所推定プログラムを提供することができる。 According to one embodiment, it is possible to provide a place estimation method, a place estimation apparatus, and a place estimation program capable of improving the accuracy of estimating a place referred to in a document transmitted from a user terminal. it can.
以下、本発明の実施形態について、図1から図24を参照して具体的に説明する。 Hereinafter, embodiments of the present invention will be specifically described with reference to FIGS. 1 to 24.
図1は、場所推定システムの一例を示す図である。図1に示すように、場所推定システムは、場所推定装置10と端末装置30とを有している。場所推定装置10と端末装置30とは、ネットワーク50を介して相互に通信可能に接続されている。
FIG. 1 is a diagram illustrating an example of a location estimation system. As shown in FIG. 1, the location estimation system includes a
場所推定装置10は、端末装置30から送信される文書を受信し、当該文書の中で言及されている場所を推定する装置である。場所推定装置10は、後述するように、例えば辞書ベースの場所推定手法と機械学習ベースの場所推定手法とを組み合わせて推定を行う。場所推定装置10は、例えばパーソナルコンピュータ(PC)、またはサーバ等によって実現される。場所推定装置10が実行する処理の方法については後述する。
The
端末装置30は、例えば文書を発信するユーザまたは場所推定装置10を利用するユーザが所有する端末であり、例えばスマートフォン、携帯電話、ノートPC(Personal Computer)、デスクトップPC、またはタブレット端末等である。ここで、文書とは、例えばニュース記事や、Twitter(登録商標)、ブログなどのソーシャルメディアに書き込まれた文章である。なお、ユーザには、後述する学習フェーズにおいて、地域分類規則を取得するために地域の付与された文書を発信するユーザも含まれる。
The
次に、場所推定装置10のハードウェア構成について説明する。
Next, the hardware configuration of the
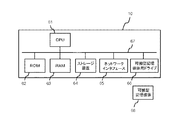
図2は、場所推定装置10のハードウェア構成の一例を示す図である。図2に示すように、場所推定装置10は、CPU(Central Processing Unit)61、ROM(Read Only Memory)62、RAM(Random Access Memory)63、ストレージ装置64、ネットワークインタフェース65、及び可搬型記憶媒体用ドライブ66等を備えている。
FIG. 2 is a diagram illustrating an example of a hardware configuration of the
場所推定装置10の構成各部は、バス67に接続されている。ストレージ装置64は、例えばHDD(Hard Disk Drive)である。場所推定装置10では、ROM62あるいはストレージ装置64に格納されているプログラム(場所推定プログラムを含む)、或いは可搬型記憶媒体用ドライブ66が可搬型記憶媒体68から読み取ったプログラム(場所推定プログラムを含む)をCPU61等のプロセッサが実行することにより、場所推定装置10の機能が実現される。
Each component of the
以下、場所推定装置10を構成する各部の機能について説明する。
Hereinafter, the function of each part which comprises the
図1に示すように、場所推定装置10は、第1記憶部11と、第2記憶部12と、受信部13と、キーワード抽出部14と、辞書検索部15と、スコア算出部16と、推定部17と、出力部18と、送信部19とを備えている。
As illustrated in FIG. 1, the
第1記憶部11は、例えば図2のROM62、ストレージ装置64、可搬型記憶媒体用ドライブ66あるいは可搬型記憶媒体68に対応する。第1記憶部11は、端末装置30から送信される文書の中で言及されている場所を推定するための場所推定プログラムを記憶することができる。
The first storage unit 11 corresponds to, for example, the
第2記憶部12は、例えば図2のROM62、RAM63、ストレージ装置64、可搬型記憶媒体用ドライブ66あるいは可搬型記憶媒体68に対応する。第2記憶部12は、場所推定装置10内で行われる各処理に用いる各種情報を記憶するためのデータベース(DB;Data Base)として用いられる。
The
受信部13は、端末装置30から地域の付与された文書を受信する。受信部13は、端末装置30と相互に通信可能に接続されており、例えば図2のネットワークインタフェース65によって実現される。
The receiving
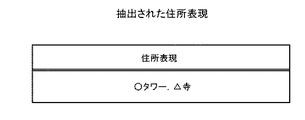
キーワード抽出部14は、受信部13が受信した文書から、単語を抽出することができる。また、キーワード抽出部14は、抽出した単語から住所表現を抽出することができる。ここで、住所表現とは、住所を有する、建造物、公園、企業、学校、または店舗等を示す名称、または住所そのものである。
The
辞書検索部15は、第2記憶部12に格納されている住所表現辞書を検索して、キーワード抽出部14が抽出した各単語に対応する住所に関する情報をそれぞれ抽出する。位置情報抽出部15は、例えば図2のCPU61あるいはMPU等のプロセッサによって実現される。
The
スコア算出部16は、後述する学習フェーズにおいて、キーワード抽出部14によって抽出された単語と、辞書検索部15によって抽出された住所表現のそれぞれについて、各地域との関連性の程度を示す地域関連スコアを地域毎に算出する。算出した地域関連スコアは、地域分類規則のデータとして用いられる。なお、地域関連スコアは、第2の指標値の一例である。
The
また、スコア算出部16は、後述する推定フェーズにおいて、キーワード抽出部14によって対象文書から抽出されたキーワード群が、どの地域に所属する(関連する)可能性が高いかを示す指標である所属スコアを地域毎に算出する。そして、地域毎に算出した所属スコアを比較することにより、文書の中で言及されている場所がどの地域に所属する可能性が高いのかを推定することができる。ここで、単語だけでなく住所を構成する文字列についても地域毎の所属スコアを算出する対象としている点が、本実施形態の特徴の一つである。スコア算出部16は、例えば図2のCPU61あるいはMPU等のプロセッサによって実現される。なお、所属スコアは、第1の指標値の一例である。
Further, the
推定部17は、スコア算出部16によって算出された所属スコアを所定の閾値と比較することによって、入力文書の中で言及されている場所(地域)を推定する。推定部17は、例えば図1のCPU61あるいはMPU等のプロセッサによって実現される。
The estimation unit 17 estimates the place (region) mentioned in the input document by comparing the affiliation score calculated by the
出力部18は、推定部17によって実行された、文書の中で言及されている場所の推定結果を出力する。出力部18は、例えば液晶ディスプレイ、プラズマディスプレイまたは有機ELディスプレイ等の表示装置である。
The
送信部19は、推定部17によって実行された、文書の中で言及されている場所の推定結果をネットワーク50に向けて送信する機能を有している。例えば、場所推定装置10を利用するユーザの端末装置30は、ネットワーク50を介して場所推定装置10から送信された推定結果を受信することができる。
The
次に、場所推定装置10による場所推定方法について説明する。
Next, the place estimation method by the
図3は、場所推定システムによる場所推定方法の一例を示すフローチャートである。 FIG. 3 is a flowchart illustrating an example of a location estimation method by the location estimation system.
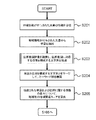
図3に示すように、場所推定装置10は、まず場所の情報の一例である地域の情報(地域情報)が付与された文書をもとに学習を行い、地域分類規則を取得する学習フェーズを実行する(S101)。続いて、場所推定装置10は、対象文書を取得し、地域分類規則をもとに、対象文書の中で言及されている場所の推定を行う推定フェーズを実行する(S102)。以降では、学習フェーズおよび推定フェーズの詳細について説明する。
As shown in FIG. 3, the
まず、S101における学習フェーズの処理の詳細について説明する。 First, the details of the learning phase processing in S101 will be described.
図4は、S101における、学習フェーズの処理の一例を示すフローチャートである。 FIG. 4 is a flowchart illustrating an example of a learning phase process in S101.
まず、受信部13は、端末装置30から地域情報が付与された文書の情報を受信する(S201)。受信部13は、受信した文書の情報を第2記憶部12に格納する。
First, the receiving
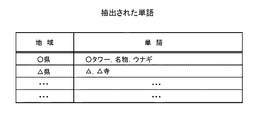
図5は、地域情報が付与された文書の情報の一例を示す図である。図5に示すように、地域情報が付与された文書の情報は、地域と文書とが対応付けられた構成を有している。地域は、例えば都道府県名である。図5の例では、文書「○タワーに行って、帰りに名物のウナギを食べた」には、地域「○県」が地域情報として付与されている。また、文書「△と言えば、やはり△寺でしょう」には、地域「△県」が地域情報として付与されている。 FIG. 5 is a diagram illustrating an example of document information to which regional information is added. As shown in FIG. 5, the document information to which the region information is added has a configuration in which the region and the document are associated with each other. The region is, for example, a prefecture name. In the example of FIG. 5, the region “○ prefecture” is assigned as the region information to the document “Going to the tower and eating the famous eel on the way home”. Further, the region “△ prefecture” is given as the region information to the document “Speaking of Δ, it will be Δ temple”.
図4に戻り、キーワード抽出部14は、地域情報が付与された文書から、単語を抽出する(S202)。S202において、キーワード抽出部14は、第2記憶部12に格納されている地域情報が付与された文書を読み出す。そして、キーワード抽出部14は、地域情報が付与された文書の中に含まれている単語を、地域情報と対応付けながら抽出する。ここで抽出される単語としては、名詞および複合名詞が好ましい。
Returning to FIG. 4, the
図6は、地域情報が付与された文書から抽出された単語のリストの一例を示す図である。図6の例では、地域「○県」に対応する単語として、「○タワー」、「名物」および「ウナギ」が抽出されている。また、地域「△県」に対応する単語として、「△」および「△寺」が抽出されている。 FIG. 6 is a diagram illustrating an example of a list of words extracted from a document with regional information. In the example of FIG. 6, “○ Tower”, “Specialties”, and “Eel” are extracted as words corresponding to the region “○ Prefecture”. In addition, “Δ” and “Δ temple” are extracted as words corresponding to the region “Δ prefecture”.
図4に戻り、辞書検索部15は、第2記憶部12に格納されている住所表現辞書を検索し、住所表現に対応する住所を構成する文字列を抽出する(S203)。以下、S203の処理の詳細について説明する。
Returning to FIG. 4, the
図7は、S203における、住所表現辞書から住所に関する情報を抽出する処理の一例を示すフローチャートである。 FIG. 7 is a flowchart illustrating an example of processing for extracting information about an address from the address expression dictionary in S203.
まず、キーワード抽出部14は、地域情報が付与された文書から住所表現を抽出し、住所表現のリストを作成する(S301)。
First, the
図8は、学習フェーズにおける、住所表現のリストの一例を示す図である。図8に示すように、住所表現のリストには、文書「○タワーに行って、帰りに名物のウナギを食べた」から抽出された「○タワー」、および文書「△と言えば、やはり△寺でしょう」から抽出された「△寺」が登録されている。S301の処理によれば、住所表現の抽出は固有表現抽出技術等を用いて行われる。固有表現抽出技術については、公知の任意の手法を用いることができる。 FIG. 8 is a diagram illustrating an example of a list of address expressions in the learning phase. As shown in FIG. 8, the list of address expressions includes “○ Tower” extracted from the document “○ went to Tower and ate the famous eel on the way back”, and document “△” “△ Temple” extracted from “It will be a temple” is registered. According to the processing of S301, the address expression is extracted using a specific expression extraction technique or the like. Any known technique can be used for the specific expression extraction technique.
図7に戻り、S301の処理の後、辞書検索部15は、住所表現のリストに住所表現が登録されているか否かを判定する(S302)。住所表現のリストに情報が登録されていると判定された場合(S302肯定)、辞書検索部15は、住所表現のリストから住所表現を1個抽出する。そして、キーワード抽出部14は、抽出した住所表現を住所表現のリストから削除する(S303)。
Returning to FIG. 7, after the process of S301, the
例えば、図8に示すように「○タワー」および「△寺」が住所表現のリストに登録されている状態で、辞書検索部15が「○タワー」を抽出したとする。このとき、辞書検索部15は、抽出した「○タワー」を住所表現のリストから削除する。その結果、「△寺」のみが住所表現のリストに残ることとなる。
For example, as shown in FIG. 8, it is assumed that the
続いて、辞書検索部15は、住所表現辞書を検索し、S303で抽出された住所表現が住所表現辞書に登録されているか否かを判定する(S304)。
Subsequently, the
図9は、住所表現辞書の一例を示す図である。住所表現辞書は、住所表現と、住所表現に対応する場所の情報とが対応付けられたリストである。住所表現辞書は、例えば図9に示すように、「住所表現」、「住所」および「座標(緯度,経度)」の欄を有している。「座標(緯度,経度)」の欄に登録されている情報は、推定フェーズにおいて使用される情報である。辞書検索部15は、抽出した住所表現が「住所表現」の欄に登録されているか否かを検索することにより、図7におけるS304の判定を行う。
FIG. 9 is a diagram illustrating an example of an address expression dictionary. The address expression dictionary is a list in which address expressions are associated with information on places corresponding to the address expressions. The address expression dictionary has columns of “address expression”, “address”, and “coordinates (latitude, longitude)” as shown in FIG. 9, for example. Information registered in the column of “coordinates (latitude, longitude)” is information used in the estimation phase. The
なお、住所表現を検索する際、辞書検索部15によって抽出された住所表現の文字列と住所表現辞書中の住所表現の文字列とが完全一致である必要はない。例えば近似マッチングによる検索手法や、抽出された文字列を正規化後に完全一致検索する手法等の、公知の任意の手法を用いることができる。
When searching for an address expression, the character string of the address expression extracted by the
S303で抽出された住所表現が住所表現辞書に含まれていると判定された場合(S304肯定)、辞書検索部15は、住所表現辞書から、当該住所表現に対応する住所を構成する文字列を抽出する。そして、辞書検索部15は、抽出した結果を第2記憶部12に格納する(S305)。
When it is determined that the address expression extracted in S303 is included in the address expression dictionary (Yes in S304), the
例えば、図9の住所表現辞書を参照すると、「住所表現」の欄に「○タワー」が登録されていることがわかる。そこで、辞書検索部15は、「○タワー」に対応する住所の欄を参照し、住所「○県,○市,○町」を構成する文字列として、「○県」、「○市」および「○町」を抽出する。S305の処理の後、S302に移り、S302以降の処理を再び実行する。
For example, referring to the address expression dictionary of FIG. 9, it can be seen that “O tower” is registered in the “address expression” column. Therefore, the
一方、抽出した住所表現が住所表現辞書に登録されていないと判定された場合(S304否定)、S302に移り、S302以降の処理を再び実行する。例えば2回目のS302の処理で、「△寺」が住所表現のリストに登録されている場合、再びS302肯定と判定される。そして、S303の処理を経てS304に移る。S304の処理において、辞書検索部15は、「△寺」に対応する住所の欄を参照し、住所「△県,△市,△町」を構成する文字列として「△県」、「△市」および「△町」をそれぞれ抽出する。
On the other hand, when it is determined that the extracted address expression is not registered in the address expression dictionary (No in S304), the process proceeds to S302, and the processes after S302 are executed again. For example, if “Δ temple” is registered in the address expression list in the second processing of S302, it is determined again as S302 affirmative. Then, the process proceeds to S304 through the process of S303. In the process of S304, the
S302において、住所表現のリストに住所表現が登録されていないと判定された場合(S302否定)、S204に移る。S302では、例えば「○タワー」および「△寺」が住所表現のリストから削除されると、住所表現のリストに登録されている住所表現がなくなるため、この場合はS302で否定判定される。そして、住所を構成する文字列を抽出する一連の処理が終了する。 In S302, when it is determined that the address expression is not registered in the list of address expressions (No in S302), the process proceeds to S204. In S302, for example, if “○ tower” and “Δ temple” are deleted from the list of address expressions, the address expressions registered in the list of address expressions disappear, so in this case, a negative determination is made in S302. And a series of processes which extract the character string which comprises an address are complete | finished.
図10は、住所表現辞書から抽出された、住所を構成する文字列のリストの一例である。 FIG. 10 is an example of a list of character strings constituting the address extracted from the address expression dictionary.
図10に示すように住所を構成する文字列は、地域と対応付けられて登録されている。このように、地域と対応付けて登録しておくことにより、後の処理で単語と住所を構成する文字列とをマージする作業が容易になる。 As shown in FIG. 10, the character string constituting the address is registered in association with the area. Thus, by registering in association with the area, the work of merging the word and the character string constituting the address in the subsequent processing becomes easy.
以上のようにして、場所推定装置10は、住所表現辞書から住所を構成する文字列を取得することができる。
As described above, the
図4に戻り、S203の処理の後、スコア算出部16は、S202で抽出された単語と、S203で抽出された住所を構成する文字列とをマージすることにより、キーワード群を構築する(S204)。
Returning to FIG. 4, after the process of S203, the
図11は、学習フェーズにおける、キーワード群の一例を示す図である。図6に示す単語のリストと図10に示す住所を構成する文字列のリストとをマージすると、図11に示すキーワード群を得ることができる。図11に示すように、キーワード群のリストには、地域の情報と、地域に対応する単語または住所に関する情報とが対応付けられて登録されている。例えば、地域「○県」には、対応する単語である「○タワー」、「名物」および「ウナギ」と、対応する住所である「○県」、「○市」および「○町」とが登録されている。また、地域「△県」には、対応する単語である「△」および「△寺」と、対応する住所を構成する文字列である「△県」、「△市」および「△町」とが登録されている。 FIG. 11 is a diagram illustrating an example of a keyword group in the learning phase. When the list of words shown in FIG. 6 and the list of character strings constituting the address shown in FIG. 10 are merged, the keyword group shown in FIG. 11 can be obtained. As shown in FIG. 11, in the keyword group list, regional information and information related to a word or address corresponding to the region are registered in association with each other. For example, in the region “○ prefecture”, the corresponding words “○ tower”, “specialties” and “eel” and the corresponding addresses “○ prefecture”, “○ city” and “○ town” It is registered. In addition, in the region “△ prefecture”, the corresponding words “△” and “△ temple” and the character strings constituting the corresponding address “△ prefecture”, “△ city”, and “△ town” Is registered.
続いて、スコア算出部16は、抽出された単語および住所を構成する文字列の各々について、地域毎の地域関連スコアを算出する(S205)。地域関連スコアおよび後述する所属スコアの算出方法としては、例えばサポートベクターマシン(Support Vector Machine,SVM)によって学習された線形分類器を用いる方法等、機械学習における公知の種々のスコア算出法を用いることができる。地域関連スコアを算出することにより、地域分類規則を取得することができる。
Subsequently, the
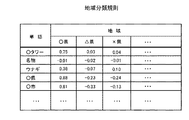
図12は、地域分類規則の一例を示す図である。図12に示すように、単語の各々について、地域毎の地域関連スコアが登録されている。図12の例では、地域を都道府県名で表している。地域関連スコアの値が大きいほど、当該地域との関連性が高いことを示している。図12によれば、例えば単語「○タワー」の場合、「○県」のスコアは0.75、「△県」のスコアは0.03、「×県」のスコアは0.04である。よって、3つの地域の中では○県との関連性が最も高いことがわかる。取得された地域分類規則は第2記憶部12に格納され、以降の推定フェーズにおいて利用される。
FIG. 12 is a diagram illustrating an example of a region classification rule. As shown in FIG. 12, for each word, a region-related score for each region is registered. In the example of FIG. 12, the region is represented by a prefecture name. It shows that the relevance with the said area is so high that the value of an area related score is large. According to FIG. 12, for example, in the case of the word “○ tower”, the score of “○ prefecture” is 0.75, the score of “Δ prefecture” is 0.03, and the score of “× prefecture” is 0.04. Therefore, it can be seen that the three regions have the highest relevance to the prefecture. The acquired area classification rule is stored in the
以上のようにして、場所推定装置10は、地域分類規則を取得する学習フェーズを実行する。
As described above, the
次に、S102における、推定フェーズの処理の詳細について説明する。 Next, the details of the estimation phase processing in S102 will be described.
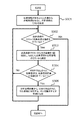
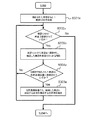
図13は、S102における、推定フェーズの処理の一例を示すフローチャートである。 FIG. 13 is a flowchart illustrating an example of the process of the estimation phase in S102.
まず、受信部13は、場所の推定を行う対象文書を端末装置30から受信する(S401)。受信部13は、受信した対象文書の情報を第2記憶部12に格納する。
First, the receiving
図14は、対象文書の情報の一例を示す図である。図14の例では、「休暇を取って△寺や△神社を見てきた」が対象文書である。図5に示す学習用の文書とは異なり、対象文書の情報には地域情報は含まれていない。そのため、対象文書と地域との対応関係が不明である。場所推定装置10は、対象文書の中で言及されている場所を推定するため、S401以降の各処理を実行する。
FIG. 14 is a diagram illustrating an example of information of a target document. In the example of FIG. 14, “Take a vacation and have seen a temple or a shrine” is the target document. Unlike the learning document shown in FIG. 5, the information of the target document does not include regional information. For this reason, the correspondence between the target document and the region is unknown. The
図13に戻り、S401の処理の後、キーワード抽出部14は、対象文書から単語を抽出する(S402)。S402において、キーワード抽出部14は、第2記憶部12に格納されている対象文書を読み出す。そして、キーワード抽出部14は、対象文書に含まれている単語を抽出する。ここでは、対象文書「休暇を取って△寺や△神社を見てきた」から単語として「休暇」、「△寺」および「△神社」が抽出される。
Returning to FIG. 13, after the processing of S401, the
続いて、キーワード抽出部14は、対象文書から住所表現を抽出する。そして、辞書検索部15は、第2記憶部12に格納されている住所表現辞書を検索して、住所表現に対応する住所を構成する文字列を抽出する(S403)。
Subsequently, the
図15は、S403における、住所表現辞書から住所を構成する文字列を抽出する処理の一例を示すフローチャートである。 FIG. 15 is a flowchart illustrating an example of processing for extracting a character string constituting an address from the address expression dictionary in S403.
まず、キーワード抽出部14は、対象文書から住所表現を抽出し、住所表現のリストを作成する(S501)。
First, the
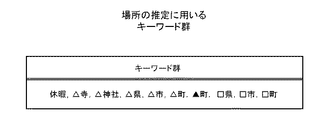
図16は、推定フェーズにおける、住所表現のリストの一例を示す図である。図16に示すように、キーワード抽出部14は、抽出された単語である「休暇」、「△寺」および「△神社」の中から、住所表現として「△寺」および「△神社」を抽出する。
FIG. 16 is a diagram illustrating an example of a list of address expressions in the estimation phase. As shown in FIG. 16, the
続いて、辞書検索部15は、住所表現のリストに情報が登録されているか否かを判定する(S502)。住所表現のリストに情報が登録されていると判定された場合(S502肯定)、辞書検索部15は、住所表現のリストから住所表現を1個抽出する。そして、辞書検索部15は、抽出した住所表現を住所表現のリストから削除する(S503)。一方、住所表現のリストに情報が登録されていないと判定された場合(S502否定)、S404に移る。
Subsequently, the
例えば、図16に示すように「△寺」および「△神社」が住所表現のリストに登録されているときに、辞書検索部15が「△寺」を住所表現のリストから抽出したとする。このとき、辞書検索部15は、「△寺」を抽出した後、「△寺」を住所表現のリストから削除する。その結果、住所表現のリストには「△神社」のみが残ることとなる。
For example, as shown in FIG. 16, it is assumed that the
続いて、辞書検索部15は、S503で抽出された住所表現が、住所表現辞書に登録されているか否かを判定する(S504)。S503で抽出された住所表現が住所表現辞書に登録されていると判定された場合(S504肯定)、辞書検索部15は、住所表現辞書から、抽出した住所表現に対応する場所の情報として住所および座標の情報を抽出する(S505)。
Subsequently, the
図17は、住所表現辞書から抽出された住所および座標の情報のリストの一例である。図17に示すように、住所表現毎に、対応する住所および座標の情報が抽出される。 FIG. 17 is an example of a list of address and coordinate information extracted from the address expression dictionary. As shown in FIG. 17, corresponding address and coordinate information is extracted for each address expression.
例えば、S504において住所表現「△寺」が住所表現辞書に登録されていると判定された場合、S505において辞書検索部15は、住所表現辞書から住所および座標の情報として「△県,△市,△町 34.xxxx,138.xxxx」を抽出する。S505の処理の後、S502に戻り、S502以降の処理を再び実行する。
For example, if it is determined in S504 that the address expression “Δ temple” is registered in the address expression dictionary, the
再び実行するS502の処理では、「△神社」が住所表現のリストに登録されている。この場合、再びS502肯定と判定される。そして、S503の処理を経てS504に移る。S504の処理において辞書検索部15は、「△神社」に対応する住所および座標の情報として、2種類の地域の情報、すなわち「△県,△市,▲町 34.xxxx,137.xxxx」および「□県,□市,□町 37.xxxx,131.xxxx」を抽出する。このように、2種類の地域の情報が抽出されたのは、「△神社」が複数の地域に存在し、住所表現辞書に2つの地域の情報が登録されているためである。S505の処理の後、S502に戻る。
In the process of S502 executed again, “Δ shrine” is registered in the address expression list. In this case, it is determined again as S502 affirmative. Then, the process proceeds to S504 through the process of S503. In the process of S504, the
3回目に実行するS502の処理では、住所表現の抽出は全て終わっているため、住所表現のリストに登録されている住所表現は存在しない。よって、辞書検索部15は、住所表現のリストに情報が登録されていないと判定し(S502否定)、S404に移る。
In the process of S502 executed for the third time, since all address expressions have been extracted, there is no address expression registered in the list of address expressions. Therefore, the
図13に戻り、キーワード抽出部14と、スコア算出部16は、S402で抽出された単語と、S403で抽出された住所を構成する文字列とをマージすることにより、キーワード群を抽出する(S404)。S404において、キーワード抽出部14は、S505で住所表現辞書から抽出された、住所および座標の情報のリストから、住所を構成する文字列を抽出する。例えば、その結果、「△県」、「△市」、「▲町」、「□県」、「□市」、および「□町」が抽出される。これらの文字列と、S402で抽出された単語である「休暇」、「△寺」および「△神社」とをマージすると、キーワード群を得ることができる。
Returning to FIG. 13, the
図18は、推定フェーズにおける、キーワード群の一例を示す図である。以上のようにして、場所の推定に用いるキーワード群を抽出する。 FIG. 18 is a diagram illustrating an example of a keyword group in the estimation phase. As described above, a keyword group used for location estimation is extracted.
図13に戻り、S404の処理の後、スコア算出部16は、キーワード群がどの地域に所属する(関連する)可能性が高いかを推定するため、所属スコアを地域毎に算出する(S405)。スコア算出部16は、キーワード群およびS101で取得した地域分類規則に基づいて、地域毎の所属スコアを算出する。
Returning to FIG. 13, after the process of S404, the
図19は、所属スコアの算出結果の一例である。図19の例においても、図12と同様に地域を都道府県名で表している。また、所属スコアの値が大きいほど、当該地域との関連性が強いことを示している。 FIG. 19 is an example of the calculation result of the affiliation score. In the example of FIG. 19 as well, the region is represented by the prefecture name as in FIG. Moreover, it shows that the relevance with the said area is so strong that the value of an affiliation score is large.
図13に戻り、S405の処理の後、推定部17は、所属スコアが所定の閾値を超えている地域のリストを作成する(S406)。具体的には、推定部17は、S405で算出した地域毎の所属スコアを参照し、所定の閾値を超えている地域を抽出する。例えば閾値を0として図17を参照すると、1.88の所属スコアを有する「△県」のみが抽出される。そこで、推定部17は、「△県」を載せた地域のリストを作成する。なお、閾値は、既に言及している場所が明らかになっている文書を用いて推定精度を測定する実験を繰り返しながら、最も推定精度が高くなるように設定することが好ましい。この方法により、推定精度の向上を図ることができる。 Returning to FIG. 13, after the process of S405, the estimation unit 17 creates a list of regions where the affiliation score exceeds a predetermined threshold (S406). Specifically, the estimation unit 17 refers to the affiliation score for each region calculated in S405, and extracts a region that exceeds a predetermined threshold. For example, referring to FIG. 17 with a threshold value of 0, only “Δ prefecture” having an affiliation score of 1.88 is extracted. Therefore, the estimation unit 17 creates a list of regions on which “Δ prefecture” is placed. Note that it is preferable to set the threshold value so that the estimation accuracy becomes the highest while repeating an experiment for measuring the estimation accuracy using a document in which a place already mentioned is known. By this method, it is possible to improve the estimation accuracy.
図20は、所属スコアが所定の閾値を超えている地域のリストの一例である。なお、図20の例では、地域として「△県」のみが地域のリストに登録されているが、閾値を超えた地域が複数存在する場合は、複数の地域が登録されることとなる。 FIG. 20 is an example of a list of regions where the affiliation score exceeds a predetermined threshold. In the example of FIG. 20, only “Δ prefecture” is registered as a region in the region list. However, when there are a plurality of regions exceeding the threshold, a plurality of regions are registered.
図13に戻り、S405の処理の後、推定部17は、地域のリストに地域の情報が登録されているか否かを判定する(S407)。 Returning to FIG. 13, after the processing of S405, the estimation unit 17 determines whether or not regional information is registered in the regional list (S407).
地域のリストに地域の情報が登録されていないと判定された場合(S407否定)、推定フェーズの処理を終了する。 If it is determined that the area information is not registered in the area list (No at S407), the process of the estimation phase ends.
一方、地域のリストに地域の情報が登録されていると判定された場合(S407肯定)、推定部17は、地域のリストから地域を一つ抽出する。そして、推定部17は、地域を抽出した後、当該地域を地域のリストから削除する(S408)。 On the other hand, when it is determined that the area information is registered in the area list (Yes in S407), the estimation unit 17 extracts one area from the area list. And the estimation part 17 deletes the said area | region from the area | region list, after extracting an area | region (S408).
例えば、推定部17は、地域の情報である「△県」のみが地域のリストに登録されている状態で、「△県」を抽出する。その後、辞書検索部15は、地域のリストから「△県」を削除する。その結果、地域のリストには、地域の情報が登録されていない状態となる。
For example, the estimation unit 17 extracts “Δ prefecture” in a state where only “Δ prefecture”, which is area information, is registered in the area list. Thereafter, the
続いて、推定部17は、抽出した地域に関連する、住所に関する情報を抽出する。そして、出力部18は、抽出結果を出力する(S409)。例えば、推定部17は、図17に示す住所および座標の情報のリストから、「△県」が含まれる一連の情報として「△寺 △県,△市,△町 34.xxxx,138.xxxx」および「△神社 △県,△市,▲町 34.xxxx,137.xxxx」を抽出する。そして、出力部18は、抽出されたこれらの情報を、推定結果として出力する。
Then, the estimation part 17 extracts the information regarding the address relevant to the extracted area. Then, the
図21は、推定結果の一例を示す図である。図21に示すように、対象文書に含まれる住所表現の各々について、場所の推定結果を出力することができる。 FIG. 21 is a diagram illustrating an example of an estimation result. As shown in FIG. 21, the location estimation result can be output for each address expression included in the target document.
図13に戻り、S409の処理の後、S407に戻る。そして、S407以降の処理を再び実行する。本実施例では、地域のリストには「△県」しか登録されていなかったため、「△県」が削除された後に実行する2回目のS407の処理では、S407否定と判定される。これにより、推定フェーズが終了となる。 Returning to FIG. 13, after the process of S409, the process returns to S407. And the process after S407 is performed again. In this embodiment, since only “Δ prefecture” is registered in the area list, it is determined that S407 is negative in the second processing of S407 executed after “Δ prefecture” is deleted. As a result, the estimation phase ends.
以上のようにして、場所推定装置10は、受信した文書の中で言及されている場所を推定することができる。
As described above, the
以下、本実施形態による効果について説明する。 Hereinafter, the effect by this embodiment is demonstrated.
図22は、対象文書から、対象文書の中で言及されている場所を推定する別の一例を示す図である。図22(a)は対象文書を示している。図22(b)は、対象文書中の住所表現に対応する、住所表現辞書から抽出された住所および座標の情報のリストを示している。図22(c)は、対象文書中の住所表現をもとに算出した、各地域に関する所属スコアの算出結果を示している。 FIG. 22 is a diagram illustrating another example of estimating the location mentioned in the target document from the target document. FIG. 22A shows the target document. FIG. 22B shows a list of address and coordinate information extracted from the address expression dictionary corresponding to the address expression in the target document. FIG. 22C shows the calculation result of the affiliation score for each area calculated based on the address expression in the target document.
図22(a)に示すように、推定フェーズにおいて、対象文書が「昨日、武蔵小杉駅を利用した」である場合には、住所表現として「武蔵小杉駅」が抽出される。そして、図22(b)を参照すると、住所表現辞書には「武蔵小杉駅」が登録されているため、住所表現辞書から、「武蔵小杉駅」に対応する住所に関する情報「神奈川県,川崎市,中原区」および座標の情報「35.5766666667,139.659444444」を抽出することができる。 As shown in FIG. 22 (a), in the estimation phase, when the target document is “Used Musashikosugi Station yesterday”, “Musashikosugi Station” is extracted as an address expression. Then, referring to FIG. 22B, since “Musashi Kosugi Station” is registered in the address expression dictionary, information on the address corresponding to “Musashi Kosugi Station” from the address expression dictionary “Kanagawa Prefecture, Kawasaki City” , Nakahara-ku ”and coordinate information“ 35.5766666667, 139.65944444 ”can be extracted.
ところが、学習フェーズにおいて、地域分類規則を作成する際に用いるキーワード群は、辞書中の全ての住所表現を網羅しているとは限らない。例えば学習フェーズにおいて、地域関連スコアを算出する際に用いられるキーワード群に「武蔵小杉駅」が含まれていなかった場合は、「武蔵小杉駅」が神奈川県にあることが学習されない。このため、図22(c)の例に示すように、神奈川県に関する所属スコアを算出した場合に、所属スコアが閾値(0.3とする)よりも低くなることがあり得る。その結果、辞書による推定において住所表現辞書により正しい推定がなされたにも関わらず、機械学習による推定において辞書による推定結果が却下され、対象文書が場所について言及していないと判定されてしまうことがあり得る。 However, in the learning phase, the keyword group used when creating the regional classification rule does not necessarily cover all address expressions in the dictionary. For example, in the learning phase, when “Musashi Kosugi Station” is not included in the keyword group used when calculating the region-related score, it is not learned that “Musashi Kosugi Station” is in Kanagawa Prefecture. For this reason, as shown in the example of FIG. 22C, when the affiliation score for Kanagawa Prefecture is calculated, the affiliation score may be lower than a threshold value (set to 0.3). As a result, in spite of the correct estimation by the address expression dictionary in the estimation by the dictionary, the estimation result by the dictionary is rejected by the estimation by the machine learning, and it is determined that the target document does not mention the place. possible.
一方、本実施形態によれば、学習フェーズおよび推定フェーズにおいて、対象文書から抽出される単語だけでなく、住所表現辞書から抽出された住所を構成する文字列も加えてキーワード群を構築している。これにより、地域関連スコアおよび所属スコアをより正確に算出することができるため、上述のように、住所表現辞書によって正しい推定がされたにも関わらず、機械学習による推定に基づいて、推定結果が却下されることを防ぐことができる。 On the other hand, according to the present embodiment, in the learning phase and the estimation phase, the keyword group is constructed by adding not only the word extracted from the target document but also the character string constituting the address extracted from the address expression dictionary. . As a result, since the region-related score and the affiliation score can be calculated more accurately, as described above, the estimation result is based on the estimation by the machine learning despite the correct estimation by the address expression dictionary. It can be prevented from being rejected.
単語だけでなく住所を構成する文字列も加えてキーワード群を構築する処理は、推定フェーズだけで行った場合においても相応の効果が期待できる。しかし、上述の処理を学習フェーズおよび推定フェーズの両方において行う方が好ましい。 The process of constructing a keyword group by adding not only words but also character strings constituting an address can be expected to have a corresponding effect even when it is performed only in the estimation phase. However, it is preferable to perform the above-described processing in both the learning phase and the estimation phase.
(変形例)
次に、本実施形態における変形例について説明する。なお、本変形例を実現するための情報処理システムは、図1および図2に例示されている場所推定システムの構成を用いることができるため、重複部分についての説明を省略する。
(Modification)
Next, a modified example in the present embodiment will be described. In addition, since the information processing system for implement | achieving this modification can use the structure of the place estimation system illustrated by FIG. 1 and FIG. 2, description about an overlapping part is abbreviate | omitted.
図23に示す実施形態では、学習フェーズにおいて、住所表現辞書から住所を構成する文字列を抽出する際に、文書から住所表現を抽出してから、各々の住所表現に対応する住所に関する情報を抽出している。これに対して本変形例では、住所表現を抽出せずに、単語に対応する住所を構成する文字列を、住所表現辞書を検索して抽出することを特徴としている。 In the embodiment shown in FIG. 23, in the learning phase, when extracting a character string that constitutes an address from the address expression dictionary, the address expression is extracted from the document, and then information related to the address corresponding to each address expression is extracted. doing. On the other hand, this modification is characterized in that the character string constituting the address corresponding to the word is extracted by searching the address expression dictionary without extracting the address expression.
図23は、学習フェーズの変形例を示すフローチャートである。なお、学習フェーズの処理を開始してからS202までの処理は、これまで説明した処理と同様であるので、説明は省略する。 FIG. 23 is a flowchart showing a modification of the learning phase. Note that the processing from the start of the learning phase processing to S202 is the same as the processing described so far, and a description thereof will be omitted.
S202の処理の後、キーワード抽出部14は、S202の処理で抽出された単語をもとに、単語リストを作成する(S301a)。
After the process of S202, the
図24は、学習フェーズにおける、単語リストの一例を示す図である。図24に示すように、単語リストには、文書「○タワーに行って帰りに名物のウナギを食べた」から抽出された「○タワー」、「名物」、「ウナギ」および文書「△と言えば、やはり△寺でしょう」から抽出された「△」、「△寺」が登録されている。 FIG. 24 is a diagram illustrating an example of a word list in the learning phase. As shown in FIG. 24, in the word list, it can be said that “○ Tower”, “Specialties”, “Eel” and the document “△” extracted from the document “○ went to the tower and ate the famous eel on the way back”. For example, “△” and “△ temple” extracted from “it will be △ temple” are registered.
図23に戻り、S301aの処理の後、辞書検索部15は、単語リストに登録されている単語について、住所表現辞書に対応する住所に関する情報があるか否かを一語ずつ検索していく。
Returning to FIG. 23, after the processing of S301a, the
まず、辞書検索部15は、単語リストに単語が登録されているか否かを判定する(S302a)。単語リストに単語が登録されていると判定された場合(S302a肯定)、辞書検索部15は、単語リストから単語を1個抽出する。そして、キーワード抽出部14は、抽出した単語を単語リストから削除する(S303a)。
First, the
続いて、辞書検索部15は、住所表現辞書を検索し、S303aで抽出した単語が住所表現辞書に登録されているか否かを判定する(S304a)。
Subsequently, the
抽出した単語が住所表現辞書に含まれていると判定された場合(S304a肯定)、辞書検索部15は、住所表現辞書から、抽出した単語に対応する住所を構成する文字列を抽出する。そして、辞書検索部15は、抽出した結果を第2記憶部12に格納する(S305a)。
When it is determined that the extracted word is included in the address expression dictionary (Yes in S304a), the
一方、抽出した単語が住所表現辞書に登録されていないと判定された場合(S304a否定)、S302aに移り、S302a以降の処理を実行する。この処理を繰り返し行っていくと、やがて単語リストに登録されている単語がなくなる。登録されている単語がなくなると、S302aにおいて、住所表現のリストに住所表現が登録されていないと判定され(S302a否定)、S204に移る。これにより、住所を構成する文字列を抽出する一連の処理が終了する。S204以降の処理は、これまで説明した処理と同様であるので、説明は省略する。 On the other hand, when it is determined that the extracted word is not registered in the address expression dictionary (No in S304a), the process proceeds to S302a, and the processes after S302a are executed. If this process is repeated, the words registered in the word list will eventually disappear. When there is no registered word, it is determined in S302a that the address expression is not registered in the list of address expressions (No in S302a), and the process proceeds to S204. Thereby, a series of processes for extracting the character string constituting the address ends. Since the processing after S204 is the same as the processing described so far, description thereof is omitted.
本変形例によれば、単語から住所表現を抽出する処理を省くことができるため、処理を簡略化することができる。また、単語からの住所表現の抽出漏れが発生する懸念を払拭することができる。 According to this modification, the process of extracting the address expression from the word can be omitted, so that the process can be simplified. In addition, it is possible to dispel the concern that omission of address expression extraction from words occurs.
以上、本発明の好ましい実施例について詳述したが、本発明は特定の実施例に限定されるものではなく、種々の変形や変更が可能である。例えば、これまで説明した場所推定装置10の処理は、辞書ベースの場所推定手法と機械学習ベースの場所推定手法とを組み合わせて推定を行うだけでなく、辞書ベースの場所推定手法のみ、あるいは機械学習ベースの場所推定手法のみのケースにおいても適用可能である。例えば機械学習ベースの場所推定手法のみを用いて推定を行う場合、抽出された単語に対応する住所に関する情報を抽出したあとに、住所に関する情報に含まれる場所の頻度をカウントし、カウント数を場所毎に比較することにより、文書が言及している場所を推定することも可能である。ここで、カウント数は、第1の指標値の別の一例である。
The preferred embodiments of the present invention have been described in detail above, but the present invention is not limited to specific embodiments, and various modifications and changes can be made. For example, the processing of the
また、例えば、上述の変形例では、学習フェーズにおいて、単語に対応する住所を構成する文字列を、住所表現辞書を検索して抽出する処理について説明した。一方、当該処理は、推定フェーズにおいて、住所表現辞書を用いて、単語に対応する住所および座標の情報を抽出する処理に適用することも可能である。 Further, for example, in the above-described modification, the process of searching the address expression dictionary and extracting the character string that forms the address corresponding to the word in the learning phase has been described. On the other hand, this process can also be applied to a process of extracting address and coordinate information corresponding to a word using an address expression dictionary in the estimation phase.
10:場所推定装置
11:第1記憶部
12:第2記憶部
13:受信部
14:キーワード抽出部
15:辞書検索部
16:スコア算出部
17:推定部
18:出力部
19:送信部
30:端末装置
50:ネットワーク
61:CPU
62:ROM
63:RAM
64:ストレージ装置
65:ネットワークインタフェース
66:可搬型記憶媒体用ドライブ
67:バス
68:可搬型記憶媒体
10: location estimation device 11: first storage unit 12: second storage unit 13: reception unit 14: keyword extraction unit 15: dictionary search unit 16: score calculation unit 17: estimation unit 18: output unit 19: transmission unit 30: Terminal device 50: Network 61: CPU
62: ROM
63: RAM
64: Storage device 65: Network interface 66: Portable storage medium drive 67: Bus 68: Portable storage medium
Claims (6)
ユーザの発信情報から第1の単語を抽出し、
前記第1の単語に対応する住所に関する情報を記憶部から抽出し、
前記第1の単語と前記住所に関する情報とを含む第1のキーワードに対応する第1の指標値を場所毎に算出し、
前記第1の指標値に基づいて、前記発信情報が示す場所を推定する、
ことを特徴とする場所推定方法。 A location estimation method executed by a location estimation device,
Extracting the first word from the user's outgoing information,
Extracting information about the address corresponding to the first word from the storage unit;
Calculating a first index value corresponding to a first keyword including the first word and information about the address for each location;
Based on the first index value, the location indicated by the transmission information is estimated.
A location estimation method characterized by that.
前記第1の指標値のうち、所定の閾値よりも大きい指標値に対応する場所を、前記発信情報が示す場所として推定し、
前記第1の指標値の中に前記所定の閾値よりも大きい指標値が存在しない場合、前記発信情報が示す場所が存在しないと推定する、
処理を含むことを特徴とする請求項1記載の場所推定方法。 The process of estimating the location is:
A location corresponding to an index value larger than a predetermined threshold value among the first index values is estimated as a location indicated by the transmission information,
When there is no index value larger than the predetermined threshold in the first index value, it is estimated that there is no place indicated by the transmission information.
The location estimation method according to claim 1, further comprising a process.
前記第1の指標値は、前記第2の指標値に基づいて算出することを特徴とする請求項1又は2に記載の場所推定方法。 Using the second keyword including the second word extracted from the document information to which the location information is assigned and the information related to the address corresponding to the second word, the second keyword and the location A process of calculating a second index value indicating the strength of relevance to each;
The location estimation method according to claim 1, wherein the first index value is calculated based on the second index value.
前記発信情報が示す場所を推定する処理は、場所毎に算出した前記第1の指標値に基づいて、前記複数の候補を絞り込むことを含む、
ことを特徴とする請求項1又は2に記載の場所推定方法。 The process of extracting from the storage unit includes extracting a plurality of candidates related to the location corresponding to the first word,
The process of estimating the location indicated by the transmission information includes narrowing down the plurality of candidates based on the first index value calculated for each location.
The location estimation method according to claim 1 or 2, characterized in that:
前記第1の単語に対応する住所に関する情報を記憶部から抽出する辞書検索部と、
前記第1の単語と前記住所に関する情報とを含む第1のキーワードに対応する第1の指標値を場所毎に算出するスコア算出部と、
前記第1の指標値に基づいて、前記発信情報が示す場所を推定する推定部と、
を有することを特徴とする場所推定装置。 A keyword extraction unit for extracting the first word from the user's transmission information;
A dictionary search unit for extracting information on an address corresponding to the first word from a storage unit;
A score calculation unit that calculates, for each place, a first index value corresponding to a first keyword including the first word and information about the address;
An estimation unit that estimates a place indicated by the transmission information based on the first index value;
A location estimation apparatus characterized by comprising:
ユーザの発信情報から第1の単語を抽出する処理と、
前記第1の単語に対応する住所に関する情報を記憶部から抽出する処理と、
前記第1の単語と前記住所に関する情報とを含む第1のキーワードに対応する第1の指標値を場所毎に算出する処理と、
前記第1の指標値に基づいて、前記発信情報が示す場所を推定する処理と、
を実行させるための場所推定プログラム。
In place estimation device,
A process of extracting the first word from the user's transmission information;
A process of extracting information about an address corresponding to the first word from a storage unit;
A process of calculating, for each location, a first index value corresponding to a first keyword including the first word and information about the address;
A process of estimating a location indicated by the transmission information based on the first index value;
Location estimation program for running.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013153939A JP6136702B2 (en) | 2013-07-24 | 2013-07-24 | Location estimation method, location estimation apparatus, and location estimation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013153939A JP6136702B2 (en) | 2013-07-24 | 2013-07-24 | Location estimation method, location estimation apparatus, and location estimation program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015026135A JP2015026135A (en) | 2015-02-05 |
| JP6136702B2 true JP6136702B2 (en) | 2017-05-31 |
Family
ID=52490772
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013153939A Active JP6136702B2 (en) | 2013-07-24 | 2013-07-24 | Location estimation method, location estimation apparatus, and location estimation program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6136702B2 (en) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6403842B1 (en) * | 2017-07-13 | 2018-10-10 | ヤフー株式会社 | Information processing apparatus, content providing system, information processing method, and program |
| JP6403855B1 (en) * | 2017-10-20 | 2018-10-10 | ヤフー株式会社 | Information processing apparatus, information processing method, and information processing program |
| EP3531303A1 (en) | 2018-02-27 | 2019-08-28 | Micware Co., Ltd. | Information retrieval apparatus, information retrieval system, information retrieval method, and program |
| JP6788637B2 (en) * | 2018-02-27 | 2020-11-25 | 株式会社 ミックウェア | Information retrieval device and information retrieval system |
| JP6570712B2 (en) * | 2018-08-01 | 2019-09-04 | ヤフー株式会社 | Information processing apparatus, information processing method, and information processing program |
| JP6568272B2 (en) * | 2018-08-01 | 2019-08-28 | ヤフー株式会社 | Information processing apparatus, information processing method, and information processing program |
| CN112819565B (en) * | 2021-01-20 | 2023-08-08 | 南方电网数字平台科技(广东)有限公司 | Method, system and storage medium for detecting buoy string |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5375056B2 (en) * | 2008-12-02 | 2013-12-25 | 沖電気工業株式会社 | POSITION EXPRESSION SPECIFIC DEVICE, POSITION EXPRESSION SPECIFICATION METHOD, AND PROGRAM |
| JP5371480B2 (en) * | 2009-02-25 | 2013-12-18 | 株式会社 ミックウェア | Information processing apparatus, information processing method, and program |
| JP2010231560A (en) * | 2009-03-27 | 2010-10-14 | Zenrin Co Ltd | Map data error correction device |
| JP5579141B2 (en) * | 2011-09-06 | 2014-08-27 | 日本電信電話株式会社 | Document specialty level judging device, method and program for region |
-
2013
- 2013-07-24 JP JP2013153939A patent/JP6136702B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015026135A (en) | 2015-02-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6136702B2 (en) | Location estimation method, location estimation apparatus, and location estimation program | |
| JP6343010B2 (en) | Identifying entities associated with wireless network access points | |
| US9959321B2 (en) | Ranking search results by social relevancy | |
| CN107771334B (en) | Automated database schema annotation | |
| US10127245B2 (en) | Systems, methods, and computer-readable media for interpreting geographical search queries | |
| CN107690637B (en) | Connecting semantically related data using large-table corpus | |
| US20170293696A1 (en) | Related entity discovery | |
| JP6853179B2 (en) | Information push method and equipment | |
| WO2015081720A1 (en) | Instant messaging (im) based information recommendation method, apparatus, and terminal | |
| US20120330955A1 (en) | Document similarity calculation device | |
| US9529822B2 (en) | Media or content tagging determined by user credibility signals | |
| US9767121B2 (en) | Location-based mobile search | |
| CN105893396B (en) | Interpreting user queries based on nearby locations | |
| JP2018055525A (en) | Text extraction device | |
| US20150334137A1 (en) | Identifying reviews from content associated with a location | |
| AU2015343949B2 (en) | Method of predicting location of rendezvous and electronic device for providing same | |
| US10922321B2 (en) | Interpreting user queries based on device orientation | |
| US20170277702A1 (en) | Interpreting user queries based on nearby locations | |
| JP6060039B2 (en) | Specific point name determination device, specific point name determination method, and specific point name determination program | |
| US8756222B1 (en) | Systems and methods for confidence-based selection of hierarchical locations | |
| US11010376B2 (en) | Methods and systems for determining search parameters from a search query | |
| US9317528B1 (en) | Identifying geographic features from query prefixes | |
| US10204139B2 (en) | Systems and methods for processing geographic data | |
| US10810236B1 (en) | Indexing data in information retrieval systems | |
| US20150234889A1 (en) | Systems and Methods for Selecting Geographic Locations for Use in Biasing Search Results |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7421 Effective date: 20160401 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160405 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170131 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170214 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170322 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170404 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170417 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6136702 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |