本実施形態では、「単位時間」あたりの「処理要求数」における「レスポンス時間」の増減に基づいて、ソフトウェアの性能障害の予兆を検出する。これにより、ソフトウェアの要因で性能が頭打ちになる事象(以下、性能限界と記す)を早期に検出することができる。性能限界を超えている場合は、少しの処理要求数の増加で、例えばレスポンス時間が急増するので、対処が間に合わず、業務に影響を及ぼしてしまう場合があったが、これを防ぐことができる。また、ソフトウェアの特性としての性能限界を検出する事で、精度の高い予兆監視が可能となり、最適なタイミングでのシステム構成変更や運用警告、適正なリソース配置が可能となる。
性能異常が検出されると、次に、性能異常を解決するための処理が行われる。本実施形態では、ソフトウェアの観点からシステム構成の変更が行われる。すなわち、異常が検出されたソフトウェアの設定の変更がなされる。
性能異常を解決するための対応処理として、具体的には本実施形態では、ソフトウェアの、チューニング項目である多重度の変更を行う。多重度は、要求された処理を平行して処理する為のソフトウェア(アプリケーション及びミドルウェア)の設定項目であり、同時に並行して処理可能な処理(タスク)またはプロセス(スレッド)の最大数である。また、多重度はソフトウェアのパラメータとして設定可能な項目であるため、既存のシステムに対する改造を加えなくてもよい。さらに、多重度は、多くのソフトウェアで共通で利用されているチューニング項目であるため、複数のソフトウェアを跨って統合的な制御がしやすいという面がある。
ソフトウェアの多重度を変更する場合は、変更するソフトウェアの処理に関連する他のソフトウェアの多重度の変更も行う。関連するソフトウェア間の処理の依存関係に基づいて、多重度を変更する順番が制御される。これにより、システム全体の処理におけるボトルネックの発生を回避することができ、システム全体としての処理性能を改善できる。また、一つ一つのソフトウェアについて手作業で設定変更を行うことと比較して、作業負荷を軽減することができる。さらに、システム管理者は、特定サーバの設定変更時に、関連サーバに跨る影響範囲の調査が不要になり、対処漏れを防ぐことができる。
このようなソフトウェアの多重度の変更により、性能異常が解決される場合とそうでない場合がある。ハードウェアリソース的に性能限界まで余裕が有る状態では、多重度を変更する事で、ミドルウェアの処理限界を上げて、トランザクション量を上げることができるので、処理性能の改善につながる。逆に、ハードウェアリソース的に性能限界まで余裕が無い状態では、ミドルウェアの「多重度」関連のパラメータを変更しても、トランザクション量は上がらず、処理性能は改善されない。
言い換えると、多重度を変更することにより性能異常が解決される場合は、性能異常の原因がソフトウェアにあった場合である。しかし、多重度を変更しても性能異常が解決されない場合は、性能異常の原因がハードウェアにある場合である。性能異常の原因がハードウェアにある場合は、ソフトウェアの多重度を変更しても性能異常は解決されないため、本実施形態では、多重度を変更しても性能異常が解決されない場合は、変更した多重度を変更前の状態に戻す。これにより、無駄なソフトウェア資源の消費を防ぐ。多重度を変更(上げる)と、リソース(メモリやスレッド)の管理情報も増え、処理コストも比例して上がる。その為、過度に大きい値を設定し続けることを避けることができる。
本実施形態では、さらに、多重度を変更してシステムを運用した結果、変更した多重度が要求される処理に見合っているか否かを判定する。要求される処理に比べて、多重度が大きく設定されており、システムの資源が無駄になっている場合には、ソフトウェアを退縮させるなどの制御を行う。これにより、CPU、メモリなどのリソースを節約することができる。
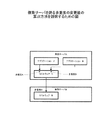
図1は、本実施形態にかかる情報処理装置の機能ブロック図の一例である。
情報処理装置1は、蓄積部2、検知部3、算出部4、決定部5、変更部6、及び再設定部7を含む。
蓄積部2は、処理要求に対するソフトウェアの応答時間を平均化して得られる平均化応答時間を、ソフトウェアに対する単位時間当たりの処理要求受信数ごとに蓄積する。
検知部3は、蓄積部2が蓄積した第1の処理要求受信数と第2の処理要求受信数との差分に対する第1の平均化応答時間差分と、第2の処理要求受信数よりそれぞれ大きい第3の処理要求受信数と第4の処理要求受信数との差分に対する第2の平均化応答時間差分と、に基づいて、ソフトウェアの障害の予兆を検知する。
算出部4は、蓄積部2が蓄積した複数の処理要求受信数と処理要求受信数に対応する平均化応答時間を用いて、第1の処理要求受信数を含む第1の範囲内から、第1の処理要求受信数の代表値である第1の代表処理要求受信数と、第1の代表処理要求受信数に対応する第1の代表応答時間と、第2の処理要求受信数を含む第2の範囲内から、第2の処理要求受信数の代表値である第2の代表処理要求受信数と、第2の代表処理要求受信数に対応する第2の代表応答時間と、第3の処理要求受信数を含む第3の範囲内から、第3の処理要求受信数の代表値である第3の代表処理要求受信数と、第3の代表処理要求受信数に対応する第3の代表応答時間と、第4の処理要求受信数を含む第4の範囲内から、第4の処理要求受信数の代表値である第4の代表処理要求受信数と、第4の代表処理要求受信数に対応する第4の代表応答時間と、を算出する。また、検知部3は、第1の代表処理要求受信数と第2の代表処理要求受信数との差分に対する第1の代表応答時間差分と、第3の代表処理要求受信数と第4の代表処理要求受信数との差分に対する第2の代表応答時間差分と、に基づいて、ソフトウェアの障害の予兆を検知する。
決定部5は、第1の範囲、第2の範囲、第3の範囲、及び第4の範囲の幅を、ソフトウェアにおいて並列して実行可能な処理数を示す多重度に基づいて決定する。
変更部6は、ソフトウェアの障害の予兆が検知された場合、ソフトウェアの多重度を変更する。また、変更部6は、ソフトウェアの障害の予兆が検知された場合、ソフトウェアに対して処理要求を送信または受信する関連ソフトウェアの多重度と、ソフトウェアの多重度との比率に基づいて、関連ソフトウェアの多重度を変更する。さらに、変更部6は、ソフトウェアの障害の予兆が検知された場合、ソフトウェアに対して処理要求を送信または受信する関連ソフトウェアの多重度と、ソフトウェアの多重度との比が変化しない順番で、ソフトウェアと関連ソフトウェアの多重度を変更する。
再設定部7は、ソフトウェアの多重度が変更された後に、検知部3が再び障害の予兆を検知した場合、変更された多重度を変更前の多重度に戻す。
図2は、本実施形態の情報処理システムの構成の一例を示す。
情報処理システム100、業務処理サーバA(101)、B(102)、及び管理サーバ103を含む。なお、図2では、管理サーバ103は業務処理サーバ101、102と別筐体の例を示しているが、いずれかの業務処理サーバに同居しても良い。
業務処理サーバ101は、端末装置116、情報処理システム111、アプリケーションプログラム112等の処理要求元115にネットワークまたはバスを介して接続される。また、業務処理サーバ101、業務処理サーバ102、及び、管理サーバ103は、ネットワークまたはバスを介して互いに接続される。
業務処理サーバ101、102では、アプリケーションA、B(113)やミドルウェアA、B(114)が稼働する。また、業務処理サーバ101は、処理要求元115から処理要求を受信する。受信された処理は、業務処理サーバ101、102で稼働するアプリケーション113及びミドルウェア114で実行される。処理が完了すると、業務処理サーバ101は、完了した処理の結果を処理要求元115に返す。
アプリケーション113に対し処理要求を行なう処理要求元115の一例としては、端末装置116や情報処理システム111(例えば他部門または他社システムを含む)等がある。または、処理要求元115の一例としては、別システムのアプリケーション112(例えばWebブラウザを含むアプリケーションクライアント)等がある。あるいは、処理要求元115の一例としては、システムが発行するメッセージ(例えば、イベントログ、Syslog、ネットワークのTrapメッセージ等)がある。尚、処理要求を行う端末装置116、情報処理システム111、アプリケーション112の数は、図2に示す数に限定されない。
管理サーバ103は、業務処理サーバ101、102で稼働するソフトウェア(アプリケーション及びミドルウェア)の処理性能を監視し、処理性能の低下を検出する。また、管理サーバ103は、処理性能の低下を検出すると、業務処理サーバ102、103で稼働するアプリケーション及びミドルウェアの多重度の変更を行う。尚、以下の説明では、業務処理サーバ102、103で稼働するアプリケーション及びミドルウェアをまとめてソフトウェアと記す場合がある。
管理サーバ103では、自動チューニングプログラム104が稼働している。自動チューニングプログラム104は、アプリケーション及びミドルウェアの処理性能を監視し、多重度の変更を行うプログラムである。自動チューニングプログラム104は、性能情報収集部105、性能診断部106、定義変更処理部107を含む。また、管理サーバ103は、自動チューニングプログラムにより使用される、処理ルート定義108、ノード定義109、処理要求数履歴110を含む。
性能情報収集部105は、蓄積部2、算出部4、及び決定部5の一例として挙げられる。性能診断部106は、検知部3の一例として挙げられる。定義変更処理部107は、変更部6、及び再設定部7の一例として挙げられる。
性能情報収集部105は、管理対象の業務処理サーバ102、103のアプリケーション及びミドルウェアの性能情報を収集する。性能情報の収集は、各ソフトウェアが提供するコマンド等のインターフェースを利用して行われる。また、性能情報収集部105は、処理ルート定義108及びノード定義109の情報を参照し、各ソフトウェアの性能情報を取得するためのインターフェースの情報を取得する。そして、取得したインターフェースの情報を用いて、性能情報収集部105は、各ソフトウェアの性能情報を収集する。そして、性能情報収集部105は、収集した各ソフトウェアの性能情報を処理要求数履歴110に格納する。性能情報の収集方法の詳細については、後ほど説明する。
性能診断部106は、処理ルート定義108、ノード定義109、及び処理要求数履歴110の情報を用いて、ソフトウェアの処理性能の低下を検出する。そして、性能診断部106は、処理性能の低下を検出すると、定義変更処理部107に、ソフトウェアの多重度を変更するように通知する。処理性能の低下の検出方法の詳細については後ほど説明する。
定義変更処理部107は、性能診断部106からソフトウェアの多重度の変更指示を受信すると、ソフトウェアの多重度を変更する。定義変更処理部107は、ノード定義109を参照して、処理ルートの途中で処理待ちが発生しないように、処理性能の低下が検出されたソフトウェアに関連するソフトウェアを特定し、適切な順番で特定したソフトウェアの多重度を変更する。多重度の変更については、定義変更処理部107は、処理ルート定義108及びノード定義109から、多重度の変更を行うためのインターフェースの情報を取得して、取得したインターフェースを用いて多重度の変更を行う。各ソフトウェアの多重度の変更の具体的な方法については、後ほど詳しく説明する。多重度を変更すると、定義変更処理部107は、変更の内容をノード定義109に反映する。
処理ルート定義108は多重度の変更に使用される処理ルートの制御情報が格納される。ここで、処理要求元115から要求される特定の処理において呼び出される、一連のアプリケーション及びミドルウェアの情報を処理ルートと記す。すなわち、処理ルートは、ミドルウェア及びアプリケーションが呼び出されるルートであり、処理ルートに含まれるノードは、ルート上のミドルウェア、アプリケーションを表し、ノードの前後関係はノード名の値で表現される。
図3は、処理ルート定義108の構成の一例を示す図である。
処理ルート定義108は、処理ルート定義名201、多重度増分比率202、多重度減分比率203、性能限界判断比率204、及び定義変更実施警戒レベル205の項目を含む。
処理ルート定義名201は、処理ルートを一意に識別するための識別情報である。多重度増分比率202は、処理ルート単位で指定する多重度変更実施時の多重度の増分比率を示す情報である。多重度減分比率203は、処理ルート単位で指定する多重度変更実施時の多重度の減分比率を示す情報である。性能限界判断比率204は、ソフトウェアの処理性能の低下を判定するために使用されるレスポンス時間の増加比率の閾値を示す情報である。定義変更実施警戒レベル205は、処理性能の低下を検出するために使用される情報である警戒レベルを示す情報である。警戒レベルは、例えば、レスポンス悪化の危険度を数値化したデータで0(安全)〜3(危険)の4段階を保持するフラグである。処理ルート定義108のそれぞれの情報がどのように使用されるかは、後ほど説明する。
図4は、ノード定義109の構成の一例を示す図である。ノード定義109は、処理ルートにおけるノード、すなわち、処理ルート上のミドルウェア及びアプリケーションに関する情報が格納される。
ノード定義109は、処理ルート定義名301、ノード名302、コマンド303、現多重度304、前多重度305、及び最大多重度306の項目を含む。
処理ルート定義名301は、処理ルートを一意に識別するための識別情報である。この処理ルート定義名301は、処理ルート定義108の処理ルート定義名201に対応する。
ノード名302は、処理ルートに含まれるノード(ミドルウェアまたはアプリケーション)を一意に識別するための識別情報である。
コマンド303は、処理ルート定義名301のノード名302で示されるノードの情報を収集するためのコマンド、及び、多重度を変更するためのコマンドの情報である。
現多重度304は、処理ルート定義名301のノード名302で示されるノードの現在の多重度を示す情報である。
前多重度305は、処理ルート定義名301のノード名302で示されるノードの、現在の多重度に変更される直前の多重度を示す情報である。
最大多重度306は、処理ルート定義名301のノード名302で示されるノードにおいて設定可能な多重度の最大値を示す情報である。
ここで、ノード名302について説明する。ノード名302はノードを一意に識別するための識別情報であるとともに、処理ルートにおけるノードの接続関係を示す。ノード名302は、処理ルートのノードの接続関係において、前後関係(階層関係)を示す番号と並列関係を示す枝番の情報を含む。尚、以下の説明では、前後関係を示す番号を1次キーと記し、並列関係を示す枝番を2次キーと記す場合がある。
ノード名の採番方法について説明する。図5(A)及び図5(B)は、ノード名の採番方法を説明するための図である。図5(A)のノード50〜55は、1つの処理ルートに含まれるノードを示しており、図5(B)のノード60〜66も、1つの処理ルートに含まれるノードを示している。尚、図5(A)及び図5(B)では、ノード52〜55、ノード60〜64のノード名は、「1次キー − 2次キー」の形式で示される。
先ず、処理ルートの先頭ノード(最初の呼び出し元)に1次キー「1」が付与される。図5(A)の例では、処理ルート定義の最初の呼び出し元ノードであるノード50に対して、1次キー「1」が付与される。そして、呼出先のノードが、呼出元のノードに対し1大きい数となるように番号が振られる。図5(A)の例では、ノード50から呼び出されるノード51には、1次キー「2」が付与される。また、呼出元から並列に呼び出される複数のノードが存在する場合は、並列関係を示す枝番(2次キー)が付与される。図5(A)の例では、ノード51から並列に呼び出されるノード52とノード53は、それぞれ2次キー「3-1」、「3-2」が振られる。さらに、呼び出し元が複数ある場合には、最大の1次キーを持つ呼び出し元に対し1大きい数が振られる。図5(B)の例では、ノード65は、ノード60、62、63、64から呼び出されているが、そのうち、最大の1次キーを持つノードであるノード63、64より1大きい数である、「3」が付与される。
尚、処理ルートでは、提供するサービスが同じサーバを同じ並列関係となるように定義してもよい。例えば、Web機能を提供するWebサーバ群に含まれる複数のサーバ同士を並列関係となるように定義してもよい。同様に、例えば、アプリケーションサーバ群に含まれる複数のサーバ同士を並列関係となるように定義してもよい。
処理要求数履歴110は、性能情報収集部105により、収集されたソフトウェアに関する性能情報が格納される。処理要求数履歴110は、履歴情報400と平均レスポンステーブル500を含む。
履歴情報400は、一定間隔で計測された、単位時間あたりの処理要求数、およびその処理要求数下での平均レスポンス時間の情報である。また、履歴情報400は、処理ルート単位で管理される。図6は、履歴情報400の構成の一例を示す図である。
履歴情報400は、処理ルート定義名401、ノード名402、履歴番号403、取得時刻404、処理要求数405、及び、レスポンス時間406の項目を含む。
処理ルート定義名401は、処理ルートを一意に識別するための識別情報である。この処理ルート定義名401は、処理ルート定義108の処理ルート定義名201、及びノード定義109の処理ルート定義名301と対応する。
ノード名402は、処理ルートに含まれるノード(ミドルウェアまたはアプリケーション)を一意に識別するための識別情報である。このノード名は、ノード定義109のノード名302に対応する。
履歴番号403は、変更された処理ルート定義毎に一意に振られた識別番号である。
取得時刻404は、性能情報収集部105が、レコードに含まれる性能情報を取得した時刻である。
処理要求数405は、取得時刻に取得された、単位時間当たりの処理要求の数である。ここで、処理要求数とは、業務処理サーバ101、102に要求された、あるいは、業務処理サーバ101、102から要求する単位時間当たりの処理数である。
レスポンス時間406は、同一レコードの処理要求数にカウントされた処理要求のレスポンス時間の平均値である。ここで、レスポンス時間406の算出は、単純平均による算出に限定されず、種々の平均化手法を用いて算出してもよい。また、平均化手法以外に、種々のデータの端数処理または丸め処理による手法を用いて算出してもよい。
平均レスポンステーブル500は、性能情報収集部105により生成される単位時間当たりの処理要求に対するレスポンス時間の平均値の情報である。平均レスポンステーブル500の情報は、性能診断部106によりソフトウェアの処理性能の低下の検出のために使用される。図7は、平均レスポンステーブルの構成の一例を示す図である。
平均レスポンステーブル500は、処理ルート定義名501、ノード名502、区間代表値503、平均レスポンス504、差分情報505、警戒レベル情報506、及び定義変更フラグ507の項目を含む。
処理ルート定義名501は、処理ルートを一意に識別するための識別情報である。この処理ルート定義名501は、処理ルート定義108、ノード定義109、及び履歴情報400の処理ルート定義名201、301、401と対応する。
ノード名502は、処理ルートに含まれるノード(ミドルウェアまたはアプリケーション)を一意に識別するための識別情報である。このノード名502は、ノード定義109及び履歴情報400のノード名302、402に対応する。
区間代表値503は、所定の値毎に設定された処理要求数の代表値の情報である。
平均レスポンス504は、履歴情報400のレスポンス時間406から算出された、区間代表値503に対応するレスポンス時間を平均化した値の情報である。ここで、平均レスポンス504の算出は、レスポンス時間の単純平均による算出に限定されず、種々の平均化手法を用いて算出してもよい。また、平均化手法以外に、種々のデータの端数処理または丸め処理による手法を用いて算出してもよい。
差分情報505は、同一レコードの区間代表値503における平均レスポンス504と、1つ前のレコードの区間代表値503における平均レスポンス504との差分(傾き)の情報である。
警戒レベル情報506は、処理ルートの性能悪化危険度を数値化した情報である。警戒レベル情報506には、例えば、0(安全)〜3(危険)の4段階が設定される。
定義変更フラグ507は、処理ルートが定義変更を実施されたかを示すフラグである。定義変更フラグ507には、例えば、0(定義変更なし)〜1(定義情報変更済)の番号が設定される。
次に、複数サーバを跨る性能情報収集と定義変更処理(多重度変更処理)について説明する。図8は、複数サーバを跨る性能情報収集と定義変更処理について説明するための図である。図8の例は、処理ルートが、業務処理サーバAで稼動するアプリケーションA、アプリケーションB、ミドルウェアA、及び、業務処理サーバBで稼動するミドルウェアBを含む例を示している。
業務処理サーバAは、ミドルウェアAにおける、アプリケーションAからの処理要求数とレスポンス時間、アプリケーションBからの処理要求数とレスポンス時間を定期的に採取する。また、業務処理サーバBは、ミドルウェアBにおけるミドルウェアAからの処理要求数とレスポンス時間を採取する。
そして、図8に示すように、自動チューニングプログラム104の性能情報収集部105は、業務処理サーバA及び業務処理サーバBに対して、処理要求数とレスポンス情報を送信するよう通知する。業務処理サーバA及び業務処理サーバBは、性能情報収集部105から通知を受信すると、定期的に採取していた処理要求数とレスポンス時間を、単位時間当たりの処理要求数と平均レスポンス時間に情報集約したうえで管理サーバ103に通知する。
また、定義変更処理部107は、業務処理サーバAに対し、ミドルウェアAにおける、アプリケーションAからの処理を受け付けるプロセス(スレッド)の多重度と、アプリケーションBからの処理を受け付けるプロセス(スレッド)の多重度を変更するよう通知する。また、定義変更処理部107は、業務処理サーバBに対し、ミドルウェアBにおける、ミドルウェアAからの処理を受け付けるプロセス(スレッド)の多重度の変更を実施するよう通知する。
性能情報収集と多重度の変更の通知は、いずれも、管理サーバ103から業務処理サーバA、Bに対し、リモート呼び出しでコマンドを発行する方式で実行される。この方式には、例えば、設定値を変更する対象のミドルウェアやアプリケーションが提供するパフォーマンス情報表示や定義変更コマンドのインターフェースを利用した操作、または、OSのコマンドを使用したパフォーマンス情報採取や定義ファイルの編集等がある。また、性能情報収集と多重度の変更の通知で実行するコマンドなどの情報は、ノード定義109のコマンド303に記憶されている。
本実施形態における性能情報収集と多重度の変更操作は、既存のミドルウェアやアプリケーションが提供するインターフェースを用いる方式のため、既存の業務システムに対する改造を加えることなく導入する事が可能である。
次に、ソフトウェアの処理性能の低下、すなわち性能障害の予兆検出方法について説明する。
図8で説明したように、各業務処理サーバは、各ミドルウェア及びアプリケーション単位に、発生した処理要求とその処理要求に対してかかったレスポンス時間を定期的に採取しておく。
性能情報収集部105は、定期的に、各サーバに記録されたソフトウェア毎の、単位時間当たりの処理要求数と平均レスポンス時間を取得する。尚、平均レスポンス時間は、区間毎に最新の所定サイズ分(例えば100回)が保持され、古い情報は破棄される。
そして、性能情報収集部105は、取得した単位時間当たりの処理要求数と平均レスポンス時間を用いて、処理要求数の代表値と、その代表値に対応するように補正した平均レスポンス情報を算出する。
ここで、処理要求数の代表値について図9を参照して説明する。図9は、処理要求数の代表値と平均レスポンス時間の一例を示す図である。
図9は、性能情報収集部105が取得した単位時間当たりの処理要求数を横軸とし、平均レスポンス時間を縦軸にとったグラフである。図9に示すように、横軸を所定の間隔で分割した処理要求区間を定義する。各処理要求区間の幅は、対象のソフトウェアの多重度を予め定められた区間数で割った値である。例えば、図9の例では、ソフトウェアの多重度が100であり、予め定められた区関数が10とすると、各処理要求区間の幅は100÷10=10となる。すると、0〜10、10〜20、・・・、50〜60、60〜70要求/秒の処理要求区間が設定される。尚、処理要求区間は、処理要求区間値の幅で、多重度を超えて区間作成が可能である。尚、多重度が変更されると、性能情報収集部105により処理要求区間の幅も変更される。
このように、多重度の観点で単位時間当たりの処理要求数の計測区間(刻み幅)を決定するのは、以下の理由による。すなわち、様々な規模(負荷大/小)に適用されるシステムにおいて、固定の刻み幅や導入するミドルウェア(機能)の最大多重度を任意の数で分割する刻み幅では、適用するシステム規模に相応した負荷範囲の区切りとならない場合があるからである。
例えば、図10に示すように、性能評価を行う区間の一部にしかデータが計測されない場合がある。図10は、システムの設定値は多重度=50であるが、ミドルウェアが許容する最大同時接続数(250)の固定値をもとに10分割した例である。図10に示すように、一部の区間にしかデータが計測されない。
また、例えば、図11に示すように、評価区間が狭すぎてレスポンス増分特性を捉えられない場合がある。図11は、当初多重度=50のシステムが多重度=250多重に拡張された場合に、当初の区間幅のまま細分された固定値で計測を行う例である。多重度が拡張された後も、当初の区間幅のままであるため、区間幅が狭く、区間にデータが計測されたとしても、マクロ的なレスポンス増分特性を捉えられない。
さらに、例えば、図12に示すように、評価区間が広すぎて集計対象の性能情報を削減できない例がある。図12は、多重度=200をもとに4分割の区間幅で計測を行う例である。この場合は、区間幅が広すぎるため、評価区間が全区間に及び集計対象の性能情報を削減できない。
本実施形態では、多重度の観点で単位時間当たりの処理要求数の計測区間を決定しているので、システム規模の拡大または縮小に応じ、適切な処理要求区間の区間幅に自動調整することができる。
これまでの実績から、設定した多重度の10分割程度の刻み幅が好適な計測区間数と判明している。
このように定義された処理要求区間において、処理要求区間毎に代表値が設定される。代表値は、各処理要求区間の中央に設定される。すなわち、図9の例では、区間0〜10の代表値は5、区間10〜20の代表値は15、・・・、区間50〜60の代表値は55、区間60〜70の代表値は65のように設定される。以上が代表値の説明である。尚、代表値は各処理要求区間の中央に限定されず、要求区間のうちの所定の値としてもよい。
性能情報収集部105は、先ず、取得した処理要求数が含まれる要求区間の代表値を求める。そして、性能情報収集部105は、レスポンス補正値を以下の式により算出する。
レスポンス補正値(秒)=取得したレスポンス時間(秒)×(代表値÷取得した単位時間当たりの処理要求数)
例えば、図9の例において、取得した処理要求数が54.7[処理要求数/秒]の場合、この値は、処理要求区間50〜60[処理要求数/秒]に含まれるので、区間代表値は55になる。すると、レスポンス補正値は、取得したレスポンス時間に55/54.7を掛けた値となる。尚、性能情報の収集回数が多ければほぼ中央値になるので、誤差が少なくなる。
次に、性能情報収集部105は、各処理要求区間の直前の区間からの平均レスポンス時間の増分値(傾き)を求める。尚、以下の説明では、各処理要求区間のうち、最も代表値が小さい区間を初回区間、2番目に代表値が小さい区間を第2区間、最も代表値が大きい区間を最終区間と記す。
図9の例を参照すると、初回区間(処理要求数の代表値が5の区間)から最終区間(処理要求数の代表値が65の区間)までの増分は、それぞれ、0.2、0.1、0.3、0.1、0.2、1秒である。
次に、性能診断部106は、各区間の増分値と第2区間の増分値との比率が閾値以上であるか否かを判定する。この閾値は、処理ルート定義108の性能限界判断比率204の値である。そして、各区間の増分値と第2区間との増分値の比率が、性能限界判断比率以上であると判定した場合は、性能診断部106はソフトウェアに性能障害が発生していると判定する。
図9の例を参照すると、15要求/秒に達した時の増分が0.2秒であり、65要求/秒に達した時の増分が1秒であるので、代表値が65の区間の増分比率は5倍である。この増分比率が性能限界判断比率以上である場合、性能診断部106はソフトウェアに性能障害が発生していると判定する。
性能診断部106は、ソフトウェアに性能障害が発生していると判定すると、定義変更処理部107に、ソフトウェアの設定を変更(拡大)するように通知する。尚、設定値の拡大は許容限界値として設定されるCPU、メモリ等のリソース使用量より相当の余裕があることが前提で行われる。
図9に示すグラフにおいて、平均レスポンス値の傾きが急激に大きくなる特徴点が顕著となる場合もあるが、境界が顕著でない場合もある。いずれの場合も限界値をある程度超えると平均レスポンス値の傾きは増大していくため、初回区間との比較を行う事で、性能限界を確実に捉えることができる。
各区間の増分比率が性能限界判断比率以上となるのは、処理要求数の大きい区間から発生する傾向にある。よって、各区間の増分比率の算出は、最終区間もしくは最終区間に近い区間について行えばよく、それ以外の区間については、増分比率の算出を行わない。これにより、性能以上の予兆検出にかかる計算量を削減することができる。
例えば、図9の例においては、最終区間の増分比率を算出するためには、図9のグラフのすべての代表値及び平均レスポンス時間を算出せずに、最終区間とその直前の区間、第2区間と初回区間の4つの区間の平均レスポンス値を算出すれば十分である。すなわち、性能情報収集部105は、最終区間(代表値65)、最終区間の直前の区間(代表値55)、第2区間(代表値15)、初回区間(代表値5)の4つの区間の平均レスポンス値を取得する。そして、最終区間と第2区間の増分値を算出し、算出した値を用いて、最終区間の増分比率を算出する。
また、増分比率の算出を最終区間からどの程度の区間について行うかについては、システムに応じた性能限界検出感度の調節と誤検出防止のために種々の区間数に設定することができる。本実施形態では、警戒レベルのビット処理によって、複数区間(例えば、1〜3個)連続で条件が満たされた場合、性能限界とみなす考慮を行う。すなわち、警戒レベルを上げることにより、平均レスポンス値を取得する、最終区間の直前の複数区間の数を増加させる。
また、性能診断部106が単一区間のレスポンス時間拡大が見られた時に障害を検出するか、複数区間のレスポンス時間が拡大した時に障害を検出するかについては、障害の検出判断までの回数(警戒レベル)は調節可能とする。これは、システムのレスポンス保障の許容度のポリシに依存するためである。
性能診断部106により性能障害が検出されると、性能障害が検出されたソフトウェアの多重度を変更する処理が行われる。本実施形態では、複数サーバに跨って、変更するソフトウェアの処理に関連するソフトウェアの多重度の変更も行う。また、関連するソフトウェア間の処理の依存関係に基づいて、多重度を変更する順番を制御する。
図13は、複数サーバを跨る多重度の変更値の算出方法を説明するための図である。図13に示すように、複数の業務処理サーバA、Bに跨って、アプリケーションA−ミドルウェアA−ミドルウェアBと、アプリケーションB−ミドルウェアA−ミドルウェアBのルートで呼び出される処理ルートが存在するとする。そして、アプリケーションAに対して処理を受け付けるミドルウェアAの多重度を多重度Aとし、アプリケーションBに対して処理を受け付けるミドルウェアAの多重度を多重度Bとする。また、ミドルウェアAに対して処理を受け付けるミドルウェアBの多重度を多重度Cとする。このとき、各ソフトウェアの多重度は、多重度A+多重度B≦多重度Cを満たすように設定する。この理由は、処理ルートの途中で処理待ちやボトルネックが発生し、トラブル要因となる場合を排除するためである。
図13の例において、アプリケーションBに関わる業務処理量が増加したとする。この場合は、多重度を当初の多重度A+多重度B:多重度Cの比率を維持するように、多重度Cの値も増加させる。例えば、当初の、多重度A、多重度B、多重度Cの値が、それぞれ、10、15、35であるとする。すると、多重度A+多重度B:多重度Cは、10+15:35、すなわち5:7である。このとき、多重度Bが30に増加したとする。すると、多重度の比率(多重度A+多重度B:多重度C)が5:7を維持するように、多重度Cの値を56に拡張する。
逆に、アプリケーションBの処理が減少した場合も、当初の多重度A+多重度B:多重度Cの比率を維持するように、多重度Cの値を減少する。
ここで、多重度を変更する順番にも留意する。図13の例において、多重度Bを15から30にいきなり変更すると、10(多重度A)+30(多重度B)>35(多重度C)となり、大小関係の整合が崩れてしまう。
そこで、処理ルートに存在する変更が必要な多重度のうち、呼出元よりも変更後の値が大きい呼出先から多重度の変更を実施するよう制御する。図13の例においては、呼出先である多重度Cを先に変更し、次いで多重度Bを変更する。
逆に、多重度を減少させる場合は、変更後の値が小さい呼出元から定義変更を実施する。
尚、処理ルートにおいて位置関係が並列のノードの多重度は、例えば、すべて同じ値に設定されてもよいし、多重度の変更の順番はランダムでよい。
図13の例は、業務処理サーバA、B内に、1つのミドルウェアが配置された構成であるが、業務処理サーバ内に複数のミドルウェアやアプリケーションが配置されてもよい。また、1つのミドルウェアやアプリケーション内に複数の多重度設定パラメータが存在する構成としてもよい。また、呼出先が複数に分岐する構成においても、処理ルートの呼出元または呼出先で大小関係が維持されていれば良い。
このように、複数サーバを跨って影響あるパラメータ変更を順序整合を維持し自動実施する事で、設定変更の影響範囲の調査が不要となり、構築者が退出する運用フェーズにおいても、変更漏れを防止し安全にシステムを維持する事ができる。
なお、ミドルウェアやアプリケーションよっては、起動中に多重度を変更する活性変更ができない場合がある。この場合は、図8を参照して説明したリモート呼び出しによるコマンド発行方式により、業務抑止、製品の設定値変更前後の停止または起動も同時に実施する。
次に、変更した多重度の確定について説明する。図14は、仮定した多重度の確定方法を説明するための図である。
図9の例において多重度を増加させた結果、図14の(1)のように、最終区間のレスポンス時間の増分値が減少したとする。この場合、最終区間の平均レスポンス時間の増分比率は閾値以下となっており、変更後の多重度は適切であると判定され、変更後の多重度の値が確定する。この場合は、性能障害の予兆が検出され、多重度が変更されることによって、性能障害を回避することができる場合である。
一方、図9の例において多重度を増加させた結果、図14の(2)のように、最終区間のレスポンス時間の変化がほとんどなかったとする。この場合は、最終区間の平均レスポンス時間の増分比率は閾値以上のままであり、変更後の多重度は不適切であると判定される。
この場合は、定義変更処理部107は、関連して変更したソフトウェアの多重度を含めて変更した多重度を変更前の設定値に戻す。
多重度を変更しても効果がみられない場合は、ソフトウェアの設定に起因する性能障害ではなく、ハードウェアに起因する性能障害である可能性がある。すなわち、多重度を変更しても性能が改善しない場合は、スケールアップ、スケールアウトといったハード増強が必要と判断される。そのため、定義変更処理部107は、システム増強が必要である旨メッセージを出力してシステム管理者に通知する。効果のない多重度の設定を変更前の状態に戻すことによって、メモリやCPUの過剰な消費を抑制する。
尚、多重度の変更後の、最終区間の増分比率を算出する方法は、図9を用いて説明したものと同様である。例えば、多重度を増加させた結果、最終区間のレスポンス時間が、(2)に示す値となった場合を説明すると、この場合は、初回区間のレスポンス増分が0.2秒であり、(2)の増分0.8秒である。よって、性能診断部106は、0.8/0.2を計算し、最終区間の平均レスポンス時間の増分比率が4であると算出する。
変更した多重度が適切であるか否かの判定結果に応じて、多重度を変更前の状態に戻す処理を行うため、多重度の確定前は、変更前の処理要求数とレスポンス時間の代表値、及び変更前の多重度は保持しておき判定後破棄する。確定後は新たな多重度を基準にして図8に示した方式に従って新たに性能情報を蓄積していく。
多重度を変更しても効果がみられない場合であって、負荷分散機能を導入している場合には、定義変更処理部107は、性能障害が検出されたノードに対する同時処理要求数を、現在の多重度未満に制限する。負荷分散の論理に、本条件を上限値として追加することで、性能障害予兆が検出されたサーバ以外に処理を振り分ける。不可分散の論理とは、例えば、例えば、ラウンドロビン、静的な重み付きラウンドロビン、最小コネクション数、最小クライアント数、最小データ通信量、最小応答時間、最小サーバ負荷に基づくものである。これによって、特定サーバでレスポンス時間が急増し業務に影響を与えるような性能障害を回避する事ができる。
また、多重度を変更した結果、性能診断部106は、変更した多重度の妥当性の検証を行う。すなわち、性能診断部106は、規定時間以上の時間、単位時間当たりの処理要求数が最終区間代表値の所定の閾値未満である場合は多重度を減少させる。これにより、多重度が大きく設定されすぎているために使用されないリソースを節約することができる。
例えば、図9の例において、一ヶ月以上、処理要求数が32.5/秒未満であった場合は多重度の値を減少させ、使用メモリやCPUを少なくすることができる。
次に、性能情報収集部105による性能情報収集処理の手順について説明する。性能情報収集部105は、定期的に、各処理ルート単位の処理要求数と処理要求数あたりの平均レスポンス時間を収集し記録する処理を行う。性能情報収集処理は外部のタイマなどにより定期的に実行される処理である。
図15は、性能情報収集部105による性能情報収集処理の動作フローを示す。尚、図15のフローは、処理ルート毎に呼び出される(S601)ものとし、以下の図15の説明においては、処理対象となる処理ルートを対象処理ルートと記す。
先ず、性能情報収集部105は、ノード定義109を参照して、対象の処理ルートに含まれるノードを読み込む(S602)。具体的には、性能情報収集部105は、ノード定義109において、対象処理ルートに対応する処理ルート定義名301のレコードのうちの一つのレコードを順次読み込み、そのレコードのノード名302及びコマンド303の情報を取得する。尚、S602〜S606、またはS602〜S611は処理ループとなっているが、1度のループで読み込まれるのは一つのレコードであり、次のループでは、未だ読み込まれていないレコードのうちの一つが読み込まれる。
S602において、性能情報収集部105は、対象処理ルートに対応する処理ルート定義名のレコードのうち、未だ読み込まれていないレコードが存在するか否かを判定する(S603)。未だ読み込まれていないレコードが存在しない場合(S603でNo)、処理は、性能診断部106による性能診断処理に移行する(S604)。
S603において、未だ読み込まれていないレコードが存在すると判定した場合S603でYes)、性能情報収集部105は、S602で取得したノード名のノードが稼動するサーバに対して、処理要求数とレスポンス情報の取得依頼を行う(S605)。具体的には、性能情報収集部105は、S602で取得した性能情報収集コマンドを発行することにより、処理要求数とレスポンス情報の取得依頼を行う。
サーバは、処理要求数とレスポンス情報の測定依頼を受けた場合、単位時間当たりの処理要求数と平均レスポンス時間を、測定の結果を性能情報収集部105に返す。そして、性能情報収集部105は、サーバで測定された単位時間あたりの処理要求数、及び平均レスポンス時間を受信する(S606)。
次に、性能情報収集部105は、S606で受信した単位時間当たりの処理要求数が、初回区間〜第2区間、もしくは、最終区間前の所定の区間〜最終区間の間にあるか否かを判定する(S607)。ここで、最終区間前の所定の区間は、最終区間を第N(Nは任意の整数)区間とすると、第(N−(警戒レベル+1))の区間であらわされる区間のことである。この警戒レベルは、平均レスポンステーブル500の警戒レベル情報506の値である。尚、警戒レベルの値は0以上の整数とする。
S606で受信した処理要求数が、初回区間〜第2区間、及び、最終区間前の所定の区間〜最終区間の間にないと判定された場合は(S607でNo)、処理はS602に遷移する。初回区間〜第2区間、及び、最終区間前の所定の区間〜最終区間の間にない場合は、S608〜S611の処理を行わないことで、処理コストを削減できる。尚、性能情報収集部105は、S605における性能情報の取得依頼の際、処理要求数が、初回区間〜第2区間、及び、最終区間前の所定の区間〜最終区間の間にない場合は、性能情報を性能情報収集部105へ返信しないように指示してもよい。
S607において、S606で受信した処理要求数が、初回区間〜第2区間、もしくは、最終区間前の所定の区間〜最終区間にあると判定された場合は(S607でYes)、性能情報収集部105は、S606で受信した平均レスポンス時間を補正する(S608)。すなわち、性能情報収集部105は、S606で受信した処理要求数が含まれる処理要求区間の区間代表値を算出し、その区間代表値に応じて、S606で受信した平均レスポンス時間を補正する。尚、以下の説明では、S606で受信した処理要求数が含まれる処理要求区間の区間代表値を対象区間代表値と記し、補正した平均レスポンス時間を補正レスポンス情報と記す場合がある。
次に、性能情報収集部105は、対象区間代表値に対応する過去に測定されたレスポンス情報と、補正レスポンス情報を用いて、対象区間代表値の平均レスポンス情報を算出する(S609)。具体的には、性能情報収集部105は、平均レスポンステーブル500から、処理ルート定義名501が対象処理ルートであり、ノード名502がS602で取得したノード名であるレコードのうち、区間代表値503が対象区間代表値に等しいレコードを抽出する。そして、性能情報収集部105は、抽出したレコードの平均レスポンス504と、補正レスポンス情報を用いて、補正レスポンス情報を平均値の算出の際に加えた、新たな平均レスポンス情報を算出する。尚、平均レスポンス情報は、最大で、処理要求数履歴情報において、処理ルート定義、ノード名、区間代表値の組み合わせにおいて、保持することが可能なレコード数の平均値となる。
次に、性能情報収集部105は、補正レスポンス情報と、対象区間代表値の前後の平均レスポンス情報との間の差分(傾き)を算出する(S610)。具体的には、差分は以下の式により算出される。
差分(傾き)=|(対象区間代表値の前(または後)の区間代表値の平均レスポンス値(秒)−補正レスポンス値(秒))|/処理要求区間の幅
次に、性能情報収集部105は、S606で受信した情報を履歴情報400に格納し、S609で算出した補正レスポンス情報と、S610で算出した差分情報を平均レスポンステーブル500に格納する(S611)。具体的には、性能情報収集部105は、履歴情報400に新たなレコードを作成し、そのレコードの各項目に対応する情報を格納する。すなわち、性能情報収集部105は、処理ルート定義名401に対象処理ルートの識別情報を、ノード名402にS602で取得したノード名を、履歴番号403に初期値(例えば1等)を格納する。また、性能情報収集部105は、取得時刻404、処理要求数405、レスポンス時間406に、それぞれ、S606で情報を受信した時刻、S606で受信した単位時間当たりの処理要求数、S606で受信した平均レスポンス時間を格納する。また、性能情報収集部105は、平均レスポンステーブル500において、処理ルート定義名501が対象処理ルートであり、ノード名502がS602で取得したノード名であり、区間代表値503が対象区間代表値に等しいレコードを抽出する。そして、性能情報収集部105は、抽出したレコードの平均レスポンス504にS609で算出した補正レスポンス情報を格納し、差分情報505に、S610で算出した差分情報を格納する。
そして、処理は、S602に遷移する。
次に、性能診断部106の性能障害の予兆検出処理手順について説明する。
性能診断部106は、性能情報収集部105から呼び出されると、収集した性能情報を元に、性能障害の予兆を検出する。予兆を検出すると、性能診断部106は、定義変更処理部107に、多重度を変更するための対象の処理ルート定義番号と処理を渡す。
処理要求数の増加に伴い、最終区間の位置が変化した場合は、新しい最終区間の情報を書き込む際に、収集対象区間外となった履歴情報や平均レスポンステーブルの格納情報は破棄する。
図16は、性能診断部106の性能障害の予兆検出処理の動作フローを示す。
図16のS604において、性能情報収集部105から通知を受けると(S701)、先ず、性能診断部106は、平均レスポンステーブル500から、対象処理ルートの区間代表値毎の差分情報505を順番に読み込む(S702)。ここで読み込んだ差分情報505に対応する区間代表値503の区間を、以下の説明では対象区間と記す。尚、S702〜S713は処理ループとなっているが、1度のループで読み込まれるのは一つの対象処理ルートの区間代表値毎の差分情報あり、次のループでは、未だ読み込まれていない対象処理ルートの区間代表値毎の差分情報のうちの一つが読み込まれる。
S702において、読み込み対象の差分情報505が存在したか否かを、性能診断部106は判定する(S703)。読み込み対象の差分情報505が存在しなかった場合(S703でNo)、処理は終了する(S704)。尚、読み込み対象の差分情報505が存在しなかった場合とは、言い換えると、対象処理ルートにおいて記録されたすべての差分情報505の読み込みが終了した場合である。
読み込み対象の差分情報505が存在した場合(S703でYes)、性能診断部106は、対象区間のレスポンス増分比率を算出し、算出した増分比率が所定の閾値である性能限界判断比率以上であるか否かを判定する(S705)。対象区間の増分比率の算出は、S702で読み込んだ差分情報を第2区間の差分情報で割ることにより算出される。尚、閾値として使用される性能限界判断比率は、処理ルート定義108において、処理ルート定義名201が対象処理ルートであるレコードの性能限界判断比率204の値である。
対象区間の増分比率が性能限界判断比率以上である場合(S705でYes)、性能診断部106は、警戒レベルを引き上げる(1加算する)(S706)。すなわち、性能診断部106は、平均レスポンステーブル500において、処理ルート定義名501が対象処理ルートであるレコードの警戒レベル情報506の値を取得し、取得した値に1加算する。そして、処理はS708に遷移する。
対象区間の増分比率が性能限界判断比率未満である場合(S705でNo)、性能診断部106は、警戒レベルを0に初期化する(S707)。すなわち、性能診断部106は、平均レスポンステーブル500において、処理ルート定義名501が対象処理ルートであるレコードの警戒レベル情報506の値を0に更新する。この警戒レベルの初期化は、警戒レベル設定時の異常レスポンスは一時的なものであり今後の業務性能に影響を与えない可能性があることを考慮して行うものである。
次に、性能診断部106は、平均レスポンステーブル500の対象処理ルートの対象ノードの警戒レベル情報506を、S706またはS707で変更した値に更新する(S708)。
次に、性能診断部106は、S706またはS707で変更した警戒レベルが定義変更実施警戒レベル以下か否かを判定する(S709)。定義変更対象警戒レベルは、対象処理ルートに対応する処理ルート定義108の定義変更実施警戒レベル205の情報である。
変更した警戒レベルが定義変更実施警戒レベル以下である場合(S709でYes)、処理はS702に遷移する。
変更した警戒レベルが定義変更実施警戒レベルより大きい場合(S709でNo)、性能診断部106は、対象処理ルートの定義変更フラグ507の値が1であるか否かを判定する(S710)。
対象処理ルートの定義変更フラグ507の値が1である場合(S710でYes)、性能診断部106は、定義変更処理による性能改善の効果がないと判断し、性能頭打ちである旨の通知処理を行う(S711)。尚、定義変更フラグ507の値が1であることは、既に一度多重度の変更が行われていることを示している。そして、処理は終了する(S714)。
対象処理ルートの定義変更フラグ507の値が1でない場合(S710でNo)、性能診断部106は、定義変更処理部107に対して、ノードで性能障害の予兆が検出されたことを通知する。すなわち、性能診断部106は、定義変更処理部107に対して、S702で読み込んだレコードの処理ルート定義名501のノード名502のノードで性能障害の予兆が検出されたとして多重度の変更をするように通知する(S712)。具体的には、性能診断部106は、対象処理ルートの処理ルート定義名と多重度の増分比率を引数にして定義変更処理部107を呼び出す。ここで、多重度の増分比率は、処理ルート定義108において処理ルート定義名201が対象処理ルートであるレコードの多重度増分比率202の値である。
次に、性能診断部106は、処理ルート定義108における、平均レスポンステーブル500の定義変更フラグ507を1に変更する(S713)。さらに、性能診断部106は、S702で読み込んだレコードの平均レスポンス504の値をクリアする。これは多重度変更後のレスポンス観察を行うためであり、全ての処理要求区間の平均レスポンス504をクリアしないのは、多重度変更前との差分を監察するためである。そして、処理はS702に遷移する。
尚、S711において、一度定義変更処理が行われた後で、その定義変更処理に効果があるか否かを確認するための処理が行われる場合は、変更した多重度を変更前の多重度に戻すように、性能診断部106は定義変更処理部107に通知してもよい。
次に、定義変更処理部107による多重度変更処理について説明する。図17は、定義変更処理部107による多重度変更処理の動作フローを示す。
定義変更処理部107は、性能診断部106からの性能障害が発生していると判断された処理ルート定義名、多重度増減比率の通知(S712)をトリガに処理を開始する(S801)。多重度増減比率は性能診断部106から通知される値であり、増加の場合は1.2、減少の場合は0.7といった、処理ルート毎に予め定義された調整可能な値を元に設定される。
定義変更処理部107は、通知された処理ルート定義名、多重度増減比率を元に、処理ルート定義から、対象処理ルートに含まれるノードの関係(呼出元と呼出先)を把握し、各ノードの変更後の多重度を算出する(S802)。変更後の多重度は、現多重度にS712で通知された多重度増減比率を掛けることにより算出する。
そして、定義変更処理部107は、算出した各ノードの多重度を多重度管理表として管理する。多重度管理表は、図17における多重度変更処理において用いられる作業用の情報である。図18は、多重度管理表の構成の一例を示す。説明のために多重度管理表を用いるとしたが、これに限定されない。
多重度管理表900は、処理ルート定義名901、ノード名902、多重度変更のコマンド903、現多重度904、及び変更後多重度905を含む。処理ルート定義名901、ノード名902、及び現多重度904は、それぞれ、ノード定義109における、処理ルート定義名301、ノード名302、現多重度304と同様である。また、多重度変更のコマンド903は、ノード定義109におけるコマンド303に含まれる多重度変更コマンドと同様である。変更後多重度905は、処理ルート定義名901のノード名902で示されるノードの変更後の多重度を示す情報である。処理ルート定義名901、ノード名902、多重度変更のコマンド903、及び現多重度904は、ノード定義109から対象処理ルートのレコードの対応する情報が格納される。変更後多重度905は、S802で算出した変更後の多重度が格納される。
次に、定義変更処理部107は、S801で通知された多重度増減比率が1より大きいか否かを判定する(S803)。多重度増減比率が1より大きい場合(S803でYes)、定義変更処理部107は、多重度管理表900のレコードに対して、ノード名の1次キーの降順にレコードを並べ替える(S804)。その後、処理はS806に遷移する。
S803において、多重度増減比率が1以下である場合(S803でNo)、定義変更処理部107は、多重度管理表900のレコードに対して、ノード名の1次キーの昇順にレコードを並べ替える(S805)。
次に、定義変更処理部107は、多重度管理表900のレコードを1次キーの順に読み出す(S806)。尚、S806〜S811は、ループ処理となっているが、S806では、1度のループにおいて、数字が同じ1次キーのレコードが読み出される。
次に、S806で読み出したレコードのうち、定義変更処理部107は、多重度管理表900の2次キーを指定してレコードを読み出す(S807)。尚、S807〜S809は、ループ処理となっているが、1度のループにおいて、S807では、2次キーが異なるレコードが1つずつ読み出される。
次に、定義変更処理部107は、S807で読み込んだレコードのノード名のノードに対して、多重度の変更処理を行う(S808)。具体的には、定義変更処理部107は、多重度管理表900の多重度変更のコマンド903を参照し、そのコマンドを用いて、ノード名902のノードの多重度を変更後多重度905の多重度に変更する処理を行う。
そして、定義変更処理部107は、S806で読み出したレコードのうち、次の2次キーのレコード(未読の2次キーのレコード)が存在するか否かを判定する(S809)。次の2次キーのレコードが存在すると判定された場合(S809でYes)、処理はS807に遷移する。次の2次キーのレコードが存在しないと判定した場合(S809でNo)、定義変更処理部107は、S808で発行した全てのコマンドが完了するまで待機する(S810)。
次に、定義変更処理部107は、次の1次キーのレコード(未読の1次キーのレコード)が存在するか否かを判定する(S811)。次の1次キーのレコードが存在すると判定された場合(S811でYes)、処理はS806に遷移する。次の1次キーのレコードが存在しないと判定した場合(S811でNo)、定義変更処理部107は、ノード定義109の対象処理ルートの各ノードの現多重度304と前多重度305の値を更新する(S812)。
そして、処理は性能診断部106の呼び出しステップ(S712)に復帰する(S813)。
復帰後は、性能診断部106にて変更した多重度が処理性能に対して有効であるか否かの検証が行われる。性能診断部106にて定義変更の効果が無いと判断された場合の定義を元に戻す場合も、同様の処理である。この場合、S711において、変更した多重度を変更前の多重度に戻すように、性能診断部106は、定義変更処理部107に通知する。但し、S802において、変更前の多重度に戻すところが異なる。尚、変更前の多重度は、ノード定義109の前多重度305の値として保存されている。定義変更の効果があったと判断された場合は、性能診断部106にて、仮定した多重度を正式値として処理ルート定義を更新し仮定値は破棄する。これら多重度の確定時には、処理要求区間の幅はリセットされ、履歴情報400及び平均レスポンステーブル500は破棄され、定義変更フラグ507も0に戻される。
尚、S802において、変更後の多重度がノード定義109の最大多重度306を超える場合は、変更後の多重度は最大多重度とする。その場合、最大多重度に到達した旨を通知する処理をおこなってもよい。
図19は、本実施形態に係る管理サーバ103、及び業務処理サーバ101、102のハードウェア構成の一例を示す。管理サーバ103、業務処理サーバ101、102は、図19に示すように、CPU1001、メモリ1002、記憶装置1003、読取部1004、通信インターフェース1006を含む。なお、CPU1001、メモリ1002、記憶装置1003、読取部1004、通信インターフェース1006は、例えば、バス1007を介して互いに接続されている。
CPU1001は、メモリ1002を利用して上述のフローチャートの手順を記述したプログラム、及び、自動チューニングプログラム104を実行する。CPU1001は、管理サーバ103においては、性能情報収集部105、性能診断部106、定義変更処理部107の機能の一部または全部を提供する。業務処理サーバ101、102においては、CPU1001は、性能情報を定期的に採取し、記憶装置1003に保存する。
メモリ1002は、例えば半導体メモリであり、RAM(Random Access Memory)領域およびROM(Read Only Memory)領域を含んで構成される。
記憶装置1003は、例えばハードディスクであり、管理サーバ103においては、処理ルート定義108、ノード定義109、処理要求数履歴110の情報が格納される。なお、記憶装置1003は、フラッシュメモリ等の半導体メモリであってもよい。また、記憶装置1003は、外部記録装置であってもよい。また、業務処理サーバ101、102においては、記憶装置1003は、定期的に採取する性能情報を保存する領域として使用される。
読取部1004は、CPU1001の指示に従って着脱可能記録媒体1005にアクセスする。着脱可能記録媒体1005は、たとえば、半導体デバイス(USBメモリ等)、磁気的作用により情報が入出力される媒体(磁気ディスク等)、光学的作用により情報が入出力される媒体(CD−ROM、DVD等)などにより実現される。
通信インターフェース1006は、CPU1001の指示に従ってネットワークを介してデータを送受信する。通信インターフェース1006は管理サーバ103においては、業務処理サーバ101、102と接続するインターフェースに対応する。業務処理サーバ101、102においては、通信インターフェース1006は、処理要求元115と接続するインターフェース、及び、管理サーバ103と接続するインターフェースに対応する。
実施形態を実現するための自動チューニングプログラム104は、例えば、下記の形態で管理サーバ103に提供される。
(1)記憶装置1003に予めインストールされている。
(2)着脱可能記憶媒体1005により提供される。
(3)ネットワークを介して提供される。
尚、CPU1001は、例えば、ASIC等の回路であってもよい。
尚、本実施形態は、以上に述べた実施の形態に限定されるものではなく、本実施形態の要旨を逸脱しない範囲内で種々の構成または実施形態を取ることができる。
尚、本実施形態では例えばテスト工程において、業務で発生する処理要求数が分かるのであれば、予め性能シミュレーションを稼働前に実施して、システムが最も性能を発揮できる設定値を事前に求めたり、ハードウェア規模の妥当性を評価することも可能である。
上記実施形態に関し、更に以下の付記を開示する。
(付記1)
コンピュータに、
処理要求に対するソフトウェアの応答時間を平均化して得られる平均化応答時間を、前記ソフトウェアに対する単位時間当たりの処理要求受信数ごとに蓄積し、
第1の処理要求受信数と第2の処理要求受信数との差分に対する第1の平均化応答時間差分と、前記第2の処理要求受信数よりそれぞれ大きい第3の処理要求受信数と第4の処理要求受信数との差分に対する第2の平均化応答時間差分と、に基づいて、前記ソフトウェアの障害の予兆を検知する
処理を実行させることを特徴とする障害検知プログラム。
(付記2)
コンピュータに、
複数の前記蓄積した処理要求受信数と該処理要求受信数に対応する前記平均化応答時間を用いて、前記第1の処理要求受信数を含む第1の範囲内から、該第1の処理要求受信数の代表値である第1の代表処理要求受信数と、該第1の代表処理要求受信数に対応する第1の代表応答時間と、前記第2の処理要求受信数を含む第2の範囲内から、該第2の処理要求受信数の代表値である第2の代表処理要求受信数と、該第2の代表処理要求受信数に対応する第2の代表応答時間と、前記第3の処理要求受信数を含む第3の範囲内から、該第3の処理要求受信数の代表値である第3の代表処理要求受信数と、該第3の代表処理要求受信数に対応する第3の代表応答時間と、前記第4の処理要求受信数を含む第4の範囲内から、該第4の処理要求受信数の代表値である第4の代表処理要求受信数と、該第4の代表処理要求受信数に対応する第4の代表応答時間と、を算出し、
前記第1の代表処理要求受信数と前記第2の代表処理要求受信数との差分に対する第1の代表応答時間差分と、前記第3の代表処理要求受信数と前記第4の代表処理要求受信数との差分に対する第2の代表応答時間差分と、に基づいて、前記ソフトウェアの障害の予兆を検知する
処理を実行させることを特徴とする付記1に記載の障害検知プログラム。
(付記3)
コンピュータに、
前記第1の範囲、前記第2の範囲、前記第3の範囲、及び前記第4の範囲の幅を、前記ソフトウェアにおいて並列して実行可能な処理数を示す多重度に基づいて決定する
処理を実行させることを特徴とする付記2に記載の障害検知プログラム。
(付記4)
コンピュータに、
前記ソフトウェアの障害の予兆を検知した場合、前記ソフトウェアの多重度を変更する
処理を実行させることを特徴とする付記1〜3のうちいずれか1項に記載の障害検知プログラム。
(付記5)
コンピュータに、
前記ソフトウェアの障害の予兆を検知した場合、前記ソフトウェアに対して処理要求を送信または受信する関連ソフトウェアの多重度と、前記ソフトウェアの多重度との比率に基づいて、前記関連ソフトウェアの多重度を変更する
処理を実行させることを特徴とする付記1〜4のうちいずれか1項に記載の障害検知プログラム。
(付記6)
コンピュータに、
前記ソフトウェアの多重度を変更した後に、再び前記障害の予兆を検知した場合、前記変更した多重度を変更前の多重度に戻す
処理を実行させることを特徴とする付記4または5に記載の障害検知プログラム。
(付記7)
コンピュータに、
前記ソフトウェアの障害の予兆を検知した場合、前記ソフトウェアに対して処理要求を送信または受信する関連ソフトウェアの多重度と、前記ソフトウェアの多重度との比率が変化しない順番で、前記ソフトウェアと前記関連ソフトウェアの多重度を変更する
処理を実行させることを特徴とする付記5に記載の障害検知プログラム。
(付記8)
処理要求に対するソフトウェアの応答時間を平均化して得られる平均化応答時間を、前記ソフトウェアに対する単位時間当たりの処理要求受信数ごとに蓄積し、
第1の処理要求受信数と第2の処理要求受信数との差分に対する第1の平均化応答時間差分と、前記第2の処理要求受信数よりそれぞれ大きい第3の処理要求受信数と第4の処理要求受信数との差分に対する第2の平均化応答時間差分と、に基づいて、前記ソフトウェアの障害の予兆を検知する
ことを特徴とする障害検知方法。
(付記9)
複数の前記蓄積した処理要求受信数と該処理要求受信数に対応する前記平均化応答時間を用いて、前記第1の処理要求受信数を含む第1の範囲内から、該第1の処理要求受信数の代表値である第1の代表処理要求受信数と、該第1の代表処理要求受信数に対応する第1の代表応答時間と、前記第2の処理要求受信数を含む第2の範囲内から、該第2の処理要求受信数の代表値である第2の代表処理要求受信数と、該第2の代表処理要求受信数に対応する第2の代表応答時間と、前記第3の処理要求受信数を含む第3の範囲内から、該第3の処理要求受信数の代表値である第3の代表処理要求受信数と、該第3の代表処理要求受信数に対応する第3の代表応答時間と、前記第4の処理要求受信数を含む第4の範囲内から、該第4の処理要求受信数の代表値である第4の代表処理要求受信数と、該第4の代表処理要求受信数に対応する第4の代表応答時間と、を算出し、
前記第1の代表処理要求受信数と前記第2の代表処理要求受信数との差分に対する第1の代表応答時間差分と、前記第3の代表処理要求受信数と前記第4の代表処理要求受信数との差分に対する第2の代表応答時間差分と、に基づいて、前記ソフトウェアの障害の予兆を検知する
ことを特徴とする付記8に記載の障害検知方法。
(付記10)
前記第1の範囲、前記第2の範囲、前記第3の範囲、及び前記第4の範囲の幅を、前記ソフトウェアにおいて並列して実行可能な処理数を示す多重度に基づいて決定する
ことを特徴とする付記9に記載の障害検知方法。
(付記11)
前記ソフトウェアの障害の予兆を検知した場合、前記ソフトウェアの多重度を変更する
ことを特徴とする付記8〜10のうちいずれか1項に記載の障害検知方法。
(付記12)
処理要求に対するソフトウェアの応答時間を平均化して得られる平均化応答時間を、前記ソフトウェアに対する単位時間当たりの処理要求受信数ごとに蓄積する蓄積部と、
第1の処理要求受信数と第2の処理要求受信数との差分に対する第1の平均化応答時間差分と、前記第2の処理要求受信数よりそれぞれ大きい第3の処理要求受信数と第4の処理要求受信数との差分に対する第2の平均化応答時間差分と、に基づいて、前記ソフトウェアの障害の予兆を検知する検知部と、
を備えることを特徴とする情報処理装置。
(付記13)
前記情報処理装置は、さらに、
複数の前記蓄積された処理要求受信数と該処理要求受信数に対応する前記平均化応答時間を用いて、前記第1の処理要求受信数を含む第1の範囲内から、該第1の処理要求受信数の代表値である第1の代表処理要求受信数と、該第1の代表処理要求受信数に対応する第1の代表応答時間と、前記第2の処理要求受信数を含む第2の範囲内から、該第2の処理要求受信数の代表値である第2の代表処理要求受信数と、該第2の代表処理要求受信数に対応する第2の代表応答時間と、前記第3の処理要求受信数を含む第3の範囲内から、該第3の処理要求受信数の代表値である第3の代表処理要求受信数と、該第3の代表処理要求受信数に対応する第3の代表応答時間と、前記第4の処理要求受信数を含む第4の範囲内から、該第4の処理要求受信数の代表値である第4の代表処理要求受信数と、該第4の代表処理要求受信数に対応する第4の代表応答時間と、を算出する算出部と、
を備え、
前記検知部は、前記第1の代表処理要求受信数と前記第2の代表処理要求受信数との差分に対する第1の代表応答時間差分と、前記第3の代表処理要求受信数と前記第4の代表処理要求受信数との差分に対する第2の代表応答時間差分と、に基づいて、前記ソフトウェアの障害の予兆を検知する
ことを特徴とする付記12に記載の情報処理装置。
(付記14)
前記情報処理装置は、さらに、
前記第1の範囲、前記第2の範囲、前記第3の範囲、及び前記第4の範囲の幅を、前記ソフトウェアにおいて並列して実行可能な処理数を示す多重度に基づいて決定する決定部
を備えることを特徴とする付記13に記載の情報処理装置。
(付記15)
前記情報処理装置は、さらに、
前記ソフトウェアの障害の予兆が検知された場合、前記ソフトウェアの多重度を変更する変更部
を備えることを特徴とする付記12〜14のうちいずれか1項に記載の情報処理装置。