JP6127670B2 - Case information processing method, case information processing program, and information processing apparatus - Google Patents
Case information processing method, case information processing program, and information processing apparatus Download PDFInfo
- Publication number
- JP6127670B2 JP6127670B2 JP2013082104A JP2013082104A JP6127670B2 JP 6127670 B2 JP6127670 B2 JP 6127670B2 JP 2013082104 A JP2013082104 A JP 2013082104A JP 2013082104 A JP2013082104 A JP 2013082104A JP 6127670 B2 JP6127670 B2 JP 6127670B2
- Authority
- JP
- Japan
- Prior art keywords
- case
- information
- cluster
- factor estimation
- vehicle
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images























Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、事例情報処理方法、事例情報処理プログラム、及び情報処理装置に関する。 The present invention relates to a case information processing method, a case information processing program, and an information processing apparatus.
運輸業務等において、車両事故には至らなかったがその可能性があった事例(以下、「ヒヤリハット事例」という)を収集し、収集したヒヤリハット事例を共有することは、事故を削減して安心、安全な運行を実現するために有効である。ヒヤリハット事例を共有化する手法としては、例えばヒヤリハット多発地点を地図上にマッピングしたヒヤリハットマップが存在する。ヒヤリハット地点にユーザの車が接近したとき、その地点の情報と、現在の車の運転状況とを比較し、比較結果に基づいてユーザに警告を与える手法が存在する(例えば、特許文献1参照)。 In transportation operations, etc., cases that did not lead to vehicle accidents but could have been collected (hereinafter referred to as “near incidents”), and sharing the collected incidents near accidents, reduces accidents, It is effective for realizing safe operation. As a method for sharing near-miss cases, for example, there is a near-hat map in which near-miss frequent occurrence points are mapped on a map. When a user's vehicle approaches a near-miss point, there is a method of comparing the information of the point with the current driving state of the vehicle and giving a warning to the user based on the comparison result (see, for example, Patent Document 1). .
ヒヤリハット事例の多発地点の自動検知手法としては、分析対象とするエリアをグリッドに分割し、グリッド毎に事例の発生件数を集計し、発生件数が多いグリッドを多発地点(多発グリッド)として検出する方法が広く用いられている。一方、グリッドを設けず、発生地点の近い事例をまとめ上げていくことで事例のクラスタを作成し、事例数の多いクラスタを多発地点として検知する手法も考えられる。このようなクラスタを作成する手法はクラスタリングと呼ばれる既存技術が流用可能である。 As an automatic detection method of near-miss points of near-miss cases, the area to be analyzed is divided into grids, the number of occurrences of cases is counted for each grid, and a grid with a large number of occurrences is detected as a frequent occurrence point (multiple occurrence grid) Is widely used. On the other hand, it is also possible to create a cluster of cases by collecting cases close to each other without providing a grid, and detect a cluster with a large number of cases as a frequent occurrence point. An existing technique called clustering can be used as a method for creating such a cluster.
しかしながら、分析対象とするエリアをグリッドに分割する方式は、グリッドの切り方によって件数が変わってしまい。そのため、例えばグリッド内に複数の多発地点が存在する場合には、それらを一つのグリッドとして集計してしたり、本来は同一地点での発生とみなすべき事例がたまたまグリッド境界により分割されてしまい、適切な多発地点が検知されないといった問題がある。 However, in the method of dividing the analysis target area into grids, the number of cases changes depending on how the grid is cut. Therefore, for example, when there are multiple frequent occurrence points in the grid, they are aggregated as one grid, or cases that should be regarded as occurring at the same point are accidentally divided by the grid boundary, There is a problem that an appropriate frequent occurrence point is not detected.
一方、グリッドを設けず、発生地点間の距離に基づいてクラスタリングを行う方法では、発生位置は近いが異なる要因で発生している事例もまとめ上げてしまう。多発地点を検知して、その発生要因を検討し、対策を施行するという目的を達成するには、これらは別のクラスタとすべきであるが、一般的なクラスタリングでは、このような処理は実現できない。 On the other hand, in the method of performing clustering based on the distance between the occurrence points without providing the grid, cases where the occurrence positions are close but are caused by different factors are summarized. In order to achieve the purpose of detecting multiple occurrence points, examining their causes, and implementing countermeasures, these should be separate clusters, but in general clustering such processing is realized. Can not.
1つの側面では、本発明は、事例の適切なクラスタリングを実現することを目的とする。 In one aspect, the present invention aims to achieve proper clustering of cases.
一態様における事例情報処理方法は、情報処理装置が、車両事故に至る可能性がある事例に関する情報である事例情報を記憶部より取得する工程と、取得した前記事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成する工程と、形成された前記複数の集合のそれぞれについて、前記事例の車両の進行方向の平均と車両の速度の平均を算出することで代表ベクトルを算出し、該複数の集合のそれぞれについて、最前方の前記事例情報に含まれる事例の発生位置に当該最前方の事例情報に含まれる車両の速度に対応する制動距離をプラスした第1の座標と、前記代表ベクトルの重心に該制動距離をプラスした第2の座標とを通る線分を直径とする円を求めることにより、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求める工程と、求めた各要因推定域間において重複部分があるか否かを判断し、重複部分があると判断した要因推定域に対応する集合を、同じ事物が要因となって引き起こされた事例の集合として、一つの集合の組にまとめる工程と、前記集合の組を出力する工程とを実行する。
The case information processing method in one aspect includes a step in which the information processing apparatus acquires from the storage unit case information that is information related to a case that may lead to a vehicle accident, and an occurrence position of the case included in the acquired case information Forming a plurality of sets relating to the case based on the identity of the vehicle and the traveling direction of the vehicle, and for each of the formed sets, the average of the traveling direction of the vehicle in the case and the vehicle speed A representative vector is calculated by calculating an average, and for each of the plurality of sets, braking corresponding to the speed of the vehicle included in the forefront case information at the position where the case included in the forefront case information is generated distance and first coordinates were positive by determining a circle whose diameter a line segment passing through the second coordinates plus the braking distance to the center of gravity of the representative vector, pulling the case Factors things that caused cause is judged that step asking you to factor estimating range to estimate the extent present, whether there is an overlap portion between each factor estimation range determined, it is judged that there is overlapping portion the set corresponding to the estimated area, the same things as the set of cases caused by a factor, to execute the steps summarized in pairs of one set, and a step of outputting a set of said set.
事例の適切なクラスタリングを実現することができる。 Appropriate clustering of cases can be realized.
以下、添付図面を参照しながら実施例について詳細に説明する。 Hereinafter, embodiments will be described in detail with reference to the accompanying drawings.
<情報処理装置の機能構成例>
図1は、情報処理装置の機能構成の一例を示す図である。図1に示す情報処理装置10は、入力部の一例である事例情報入力部11と、事例まとめ処理部12と、出力部の一例である多発地点出力部13とを有する。事例まとめ処理部12は、第1まとめ処理部21と、第2まとめ処理部22とを有する。第2まとめ処理部22は、候補クラスタ選定部31と、要因推定域割り当て部32と、組選定部33と、クラスタ処理部34とを有する。クラスタ処理部34は、要因推定域処理部41を有する。
<Functional configuration example of information processing apparatus>
FIG. 1 is a diagram illustrating an example of a functional configuration of the information processing apparatus. The
事例情報入力部11は、予め蓄積された事例情報51の入力を受け付ける。事例情報51は、例えば「ヒヤリハット事例」に関する情報であり、例えば日時情報や位置情報、進行方向、速度等の情報を有するが、これに限定されるものではない。事例情報入力部11は、例えばユーザからの指示等によりデータベース等の記憶部に予め記憶されている事例情報51を入力するが、これに限定されるものではない。
The case
事例まとめ処理部12は、事例情報入力部11から得られた事例情報51を用いて、例えば、各事例の発生位置や車両の進行方向の類似性等に基づいて、同一の原因に起因した事例のクラスタリングを行う。
The case
第1まとめ処理部21は、例えば事例情報51から得られるヒヤリハット事例の発生位置(位置情報)と、車両の進行方向との同一性に基づいて複数のクラスタ(集合)を形成する。なお、同一性とは、例えば車両の進行方向が所定の角度範囲内で、ヒヤリハットの発生時点(位置情報)が所定の領域内である場合であるが、これに限定されるものではない。
For example, the first
第2まとめ処理部22は、第1まとめ処理部21でまとめられた結果(各クラスタ)のそれぞれについて、例えばクラスタ間距離が近く、かつ進行方向前方エリアが共通するクラスタをまとめる。なお、第2まとめ処理部22では、前方エリアが一致するという条件だけでクラスタ同士をまとめると、例えばそれぞれの車線沿いに施設やわき道等の別のヒヤリハット発生要因があるクラスタの組を、同一要因として1つのクラスタにまとめてしまう可能性がある。
For each result (each cluster) summarized by the first
そこで、第2まとめ処理部22は、例えばクラスタ毎にヒヤリハット事例を引き起こす要因となった事物が存在する範囲を推定した要因推定域を求め、求めた各要因推定域の相互関係に基づいて、各クラスタをまとめるか否かを決定する。相互関係とは、例えば各要因推定域の位置や領域を基準にした相互の関係であるが、これに限定されるものではない。例えば、第2まとめ処理部22は、まとめようとする複数のクラスタのそれぞれについて、ヒヤリハット発生要因が存在しうる領域を求め、この要因推定域に重複部分があれば、重複した各クラスタを1つのクラスタの組にまとめる。また、第2まとめ処理部22は、要因推定域に重複部分がなければ、各クラスタをまとめない。
Therefore, the second
候補クラスタ選定部31は、第1まとめ処理部21でまとめられたクラスタから、予め設定された候補クラスタ情報に類似するクラスタ情報を選定する。
The candidate
要因推定域割り当て部32は、候補クラスタ選定部31により選定された候補クラスタに対して初期値としての要因推定域を割り当てる。また、要因推定域割り当て部32は、第1まとめ処理部21でまとめられたクラスタに対し、例えばそれぞれの代表ベクトルの始点と向きとから、要因推定域を求めることができるが、これに限定されるものではない。代表ベクトルとは、例えばクラスタ内に含まれる各事例の方向の平均と、速度の平均とを有するベクトル量であるが、これに限定されるものではない。
The factor estimation
また、要因推定域割り当て部32は、組選定部33により選定されたクラスタの組(例えば、クラスタAとBとがまとめられたクラスタAB)に対する要因推定域を求めることもできる。
In addition, the factor estimation
組選定部33は、選定されたクラスタの全ての組み合わせに対してクラスタ間距離を算出する。また、組選定部33は、クラスタ間距離から候補クラスタの組を選定する。例えば、組選定部33は、クラスタ間距離が所定の閾値L以下で、かつ、まとめ上げから除外する対象でないクラスタの組の中で、クラスタ間距離が最小となるクラスタの組を選定することができるが、これに限定されるものではない。
The
クラスタ処理部34の要因推定域処理部41は、組選定部33が選定した候補クラスタの組に対して要因推定域割り当て部32から得られる要因推定域に基づいて、所定の条件を用いたクラスタまとめ上げ処理を行う。例えば、要因推定域処理部41は、クラスタ処理部34により得られる要因推定域に基づいて、要因推定域の重複部分の有無を判定する。
The factor estimation
また、要因推定域処理部41は、要因推定域同士に重複部分があると判定された場合に、対象の各クラスタを組としてまとめ上げる。このとき、要因推定域処理部41は、まとめ上げたクラスタに対して新たな要因推定域を求め、求めた要因推定域を用いて他の要因推定域との重複部分の有無を判定してもよい。なお、上述した第2まとめ処理部22の処理は、まとめ上げ対象のクラスタがなくなるまで、繰り返し行われる。
In addition, when it is determined that there is an overlapping portion between the factor estimation areas, the factor estimation
多発地点出力部13は、要因推定域処理部41で得られた結果に基づいて、ヒヤリハットが多発する地点を出力する。多発地点出力部13は、例えば事例まとめ処理部12により、まとめ上げられた少なくとも一つの集合のうちの所定数以上の事例を有する集合を、事例発生の多発地点として出力する。また、多発地点出力部13は、ドライバ(車両)の現在地、運転状況等に対応させたヒヤリハット多発地点を出力してもよい。
Based on the result obtained by the factor estimation
多発地点出力部13は、例えばディスプレイやモニタ等の表示部であるが、これに限定されるものではなく、例えばプリンタ等の印刷部でもよく、外部装置に通信により出力する通信部であってもよい。また、多発地点出力部13は、多発地点情報52をデータベース等の記憶部に記憶させてもよい。
The frequent occurrence
上述した事例情報51や多発地点情報52等の情報は、例えば情報処理装置10が有する記憶部に記憶されてもよい。また、上述した各情報は、例えばインターネットやLocal Area Network(LAN)に代表される通信ネットワークを介してデータの送受信が可能な状態で接続される外部記憶装置等に記憶されていてもよい。
Information such as the
上述した本実施形態により、例えば前方エリアは一致するが、それぞれの車線沿いに要因があるクラスタの組を別々のクラスタとしてヒヤリハット多発地点マップ等に表示することができる。これにより、ドライバは、当該地点を通過する事前に注意を向けるべきポイントを明確に意識することが可能になる。したがって、本実施形態では、事故の未然防止に有効な手段を提供することができる。 According to the above-described embodiment, for example, a set of clusters having the same area but having factors along each lane can be displayed as a separate cluster on the near-miss frequent occurrence point map or the like. As a result, the driver can clearly recognize the point to which attention should be paid before passing the point. Therefore, in this embodiment, it is possible to provide an effective means for preventing accidents.
上述した情報処理装置10は、例えばPersonal Computer(PC)やサーバ等であるが、これに限定されるものではなく、例えばタブレット端末等の通信端末であってもよい。
The
<情報処理装置のハードウェア構成例>
図2は、情報処理装置のハードウェア構成の一例を示す図である。図2に示す情報処理装置10は、入力装置61と、出力装置62と、ドライブ装置63と、補助記憶装置64と、主記憶装置65と、各種制御を行うCentral Processing Unit(CPU)66と、ネットワーク接続装置67とを有し、これらはシステムバスBで相互に接続されている。
<Example of hardware configuration of information processing apparatus>
FIG. 2 is a diagram illustrating an example of a hardware configuration of the information processing apparatus. 2 includes an
入力装置61は、ユーザ等が操作するキーボード及びマウス等のポインティングデバイスや、マイクロフォン等の音声入力デバイスを有しており、ユーザ等からのプログラムの実行指示、各種操作情報、ソフトウェア等を起動するための情報等の入力を受け付ける。
The
出力装置62は、情報処理装置10を操作するのに必要な各種ウィンドウやデータ等を表示するディスプレイを有し、CPU66が有する制御プログラムによりプログラムの実行経過や結果等を表示する。
The
ここで、コンピュータの一例である情報処理装置10にインストールされる実行プログラムは、例えば、Universal Serial Bus(USB)メモリやCD−ROM、DVD等の可搬型の記録媒体68等により提供される。プログラムを記録した記録媒体68は、ドライブ装置63にセット可能であり、CPU66からの制御信号に基づき、記録媒体68に含まれる実行プログラムが、記録媒体68からドライブ装置63を介して補助記憶装置64にインストールされる。
Here, the execution program installed in the
補助記憶装置64は、例えばハードディスクドライブやSolid State Drive(SSD)等のストレージ手段等である。補助記憶装置64は、CPU66からの制御信号に基づき、本実施形態における実行プログラムや、情報処理装置10に予め設けられた制御プログラム等を記憶し、必要に応じて入出力を行うことができる。補助記憶装置64は、CPU66からの制御信号等に基づいて、記憶された各情報から必要な情報を読み出したり、書き込むことができる。
The
主記憶装置65は、CPU66により補助記憶装置64から読み出された実行プログラム等を格納する。主記憶装置65は、Read Only Memory(ROM)やRandom Access Memory(RAM)等である。
The
CPU66は、オペレーティングシステム等の制御プログラム、及び主記憶装置65に格納されている実行プログラムに基づいて、各種演算や各ハードウェア構成部とのデータの入出力等、情報処理装置10における全体の処理を制御して各処理を実現することができる。プログラムの実行中に必要な各種情報等は、補助記憶装置64から取得することができ、また実行結果等を格納することもできる。
Based on a control program such as an operating system and an execution program stored in the
具体的には、CPU66は、例えば入力装置61から得られるプログラムの実行指示等に基づき、補助記憶装置64にインストールされたプログラムを実行させることにより、主記憶装置65上でプログラムに対応する処理を行う。例えば、CPU66は、事例情報処理プログラムを実行させることで、上述した事例情報入力部11による事例情報51の入力、事例まとめ処理部12による事例のクラスタリング、多発地点出力部13によるヒヤリハット多発地点情報の出力等の処理を行う。CPU66における処理内容は、これに限定されるものではない。CPU66により実行された内容は、必要に応じて補助記憶装置64に記憶される。
Specifically, the
ネットワーク接続装置67は、CPU66からの制御信号に基づき、通信ネットワーク等と接続することにより、実行プログラムやソフトウェア、設定情報等を、通信ネットワークに接続されている外部装置等から取得する。また、ネットワーク接続装置67は、プログラムを実行することで得られた実行結果又は本実施形態における実行プログラム自体を外部装置等に提供することができる。
The
上述したようなハードウェア構成により、本実施形態における事例情報処理を実行することができる。また、事例情報処理プログラムをインストールすることにより、汎用のPCや通信端末等のコンピュータで本実施形態における事例情報処理を容易に実現することができる。 The case information processing in the present embodiment can be executed by the hardware configuration as described above. In addition, by installing the case information processing program, the case information processing in the present embodiment can be easily realized by a computer such as a general-purpose PC or a communication terminal.
<本実施形態における事例情報処理の概要例>
ここで、本実施形態における事例情報処理の概要例について、図を用いて説明する。図3は、本実施形態における事例情報処理の概要の一例を示す図である。図3では、説明の便宜上、従来手法との課題も含めて説明する。図3の各点は、ヒヤリハット事例を示し、点から出た矢印は、車両の進行方向を示す。また、矢印は、速度と長さとが対応付けられたベクトル量である。
<Example of outline of case information processing in this embodiment>
Here, an outline example of case information processing in the present embodiment will be described with reference to the drawings. FIG. 3 is a diagram showing an example of an outline of case information processing in the present embodiment. In FIG. 3, for the convenience of explanation, the problem with the conventional method will be described. Each point in FIG. 3 indicates a near-miss example, and an arrow from the point indicates the traveling direction of the vehicle. An arrow indicates a vector quantity in which speed and length are associated with each other.
従来では、図3(A)に示すように各事例が「集中」しているかどうかを判定する方法の1つとして、地理的に近接している(場所が近い)ヒヤリハット事例同士を1つのクラスタにする。しかしながら、図3(B)に示すように、「近接」の判定値が不適切だと、ヒヤリハットの要因が異なる事例同士も、1つのクラスタにしてしまう。例えば、図3(B)の例では、コンビニエンスストア(以下、「コンビニ」という)とバス停とが地理的に近接しているため、1つのクラスタにまとめてしまう。 Conventionally, as shown in FIG. 3A, as one method of determining whether or not each case is “concentrated”, near-close cases (close to each other) that are geographically close to each other are clustered. To. However, as shown in FIG. 3B, if the “proximity” determination value is inappropriate, cases with different near-miss factors also form one cluster. For example, in the example of FIG. 3B, since a convenience store (hereinafter referred to as “convenience store”) and a bus stop are geographically close to each other, they are combined into one cluster.
この場合、図3(B)に示すように、ヒヤリハット警告の際、ドライバに注意を向けてほしい要因を誤って伝えてしまい、逆にドライバを危険にさらす恐れがある。例えば、図3(B)の例では、ドライバがバス停のクラスタに接近した際、「コンビニからの出入りに注意して下さい」といった誤った警告を出してしまう。したがって、事例のクラスタリングは、要因別に行う必要がある。 In this case, as shown in FIG. 3 (B), in the case of a near-miss warning, the driver may be erroneously notified of a factor that he / she wants to pay attention to, and conversely, the driver may be put in danger. For example, in the example of FIG. 3B, when the driver approaches the cluster at the bus stop, an erroneous warning such as “Be careful about entering and exiting a convenience store” is issued. Therefore, case clustering must be done by factor.
そこで、本実施形態では、図3(C)に示すように、ヒヤリハットの要因は進行方向前方にあることが多いことを利用し、前方エリアが共通する事例同士は1つのクラスタにまとめる。 Therefore, in the present embodiment, as shown in FIG. 3C, the fact that the near-miss factor is often in the forward direction is utilized, and cases having a common front area are combined into one cluster.
なお、別々の事物が原因で存在するクラスタの組であっても、前方エリアが共通ならば1つにまとめてしまい、別々のクラスタとして区別することができない場合がある。例えば、図3(D)に示すように、ある施設の駐車場に出入りする場合や、わき道等の生活道路等の交差点、T字路等の場合には、前方エリアが異なるが、同じクラスタに含まれる情報である。 Even if a set of clusters exists due to different things, they may be grouped together if the front area is common and cannot be distinguished as separate clusters. For example, as shown in FIG. 3 (D), the front area is different when entering or leaving a parking lot of a certain facility, at an intersection such as a living road such as a side road, T-junction, etc. It is included information.
そこで、本実施形態では、上述したように、クラスタ毎にその事例が発生した事物が存在する範囲を推定した要因推定域を求め、あるクラスタ事例同士をまとめ上げるかどうかは、求めた要因推定域に重複部分があるかどうかで決定する。 Therefore, in the present embodiment, as described above, a factor estimation area that estimates the range in which the thing in which the case occurred for each cluster exists is obtained, and whether or not a certain cluster case is collected is determined by the obtained factor estimation area. This is determined by whether or not there is an overlapping part.
例えば、図3(E)に示すように、各クラスタに対して、例えばベクトルの向き毎の要因推定域を割り当て、割り当てた要因推定域同士を比較して重複部分があるか否かにより、各クラスタをまとめ上げるか否かを決定することができる。図3(E)の斜線部分は、まとめ上げた発生要因の要因推定域である。 For example, as shown in FIG. 3 (E), for each cluster, for example, a factor estimation area for each vector direction is allocated, and the allocated factor estimation areas are compared to determine whether or not there is an overlapping portion. You can decide whether to cluster the cluster. The hatched portion in FIG. 3E is a factor estimation area for the generated factors.
更に、本実施形態では、図3(F)に示すように、要因推定域が3つ以上重なる場合がある。その場合には、例えば全ての重なり部分をまとめ上げてもよく、少なくとも2つが重なっているものをまとめ上げてもよいが、これに限定されるものではない。これにより、本実施形態では、複数の要因推定域の重なり部分に基づいて各クラスタを適切にまとめ上げることができる。 Furthermore, in this embodiment, as shown in FIG. 3F, there are cases where three or more factor estimation areas overlap. In that case, for example, all the overlapping portions may be collected together, or at least two overlapping portions may be collected together, but this is not a limitation. Thereby, in this embodiment, each cluster can be gathered up appropriately based on the overlapping part of a some factor estimation area.
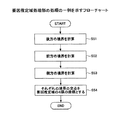
<情報処理装置10の処理の一例>
情報処理装置10の処理の一例について、フローチャートを用いて説明する。図4は、情報処理装置の処理の一例を示すフローチャートである。図4の例において、情報処理装置10の事例情報入力部11は、ヒヤリハットの事例情報51の入力を受け付ける。情報処理装置10の事例まとめ処理部12は、S01の処理で得られた事例情報51に対して、例えば所定条件(第1の条件)に該当する事例を集合(クラスタ)としてまとめる第1段階の事例まとめ上げ処理を行う(S02)。S02の処理では、例えば事例情報51に含まれる事例の発生位置と車両の進行方向との同一性に基づいてまとめ上げ、事例に関する複数の集合を形成する。
<Example of Processing of
An example of processing of the
次に、情報処理装置10の事例まとめ処理部12は、S02の処理により得られた複数の集合のそれぞれについて、別の所定条件(第2の条件)に該当する集合をまとめる第2段階の事例まとめ上げ処理を行う(S03)。S03の処理では、例えば複数の集合のそれぞれについて、事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求め、求めた各要因推定域の相互関係に基づいて各集合をまとめるか否かを決定する。更に、S03の処理では、まとめると決定した集合の組を一つの集合としてまとめ上げる。なお、S03の処理は、それ以上まとめられる組み合わせがなくなるまで、まとめ上げ処理を行う。
Next, the case
情報処理装置10の多発地点出力部13は、S03の処理後に得られた各集合から、例えばドライバ(車両)の現在地、運転状況等に対応させてヒヤリハット多発地点の出力を行う(S04)。
The frequent occurrence
<事例情報51のデータ例>
次に、上述した事例情報51のデータ例について、具体的に説明する。図5は、事例情報のデータ例を示す図である。図5に示す事例情報51は、項目として、例えば「事例ID」、「日時」、「位置情報」、「進行方向(方位(°))」、及び「速度(Km/h)」等であるが、これに限定されるものではない。
<Example data of
Next, a data example of the
事例IDは、ヒヤリハット事例を識別するための識別情報である。事例情報51では、処理対象とするヒヤリハット事例を識別するためのIDが設定され、日時、位置情報、及び、進行方向、速度等が記録される。
The case ID is identification information for identifying a near-miss case. In the
日時は、例えば事例IDに対応する事例情報が記録された時間情報、又は対応するヒヤリハットが発生した時間情報である。日時は、例えば図5に示すように日付及び時刻を有していてもよく、また時刻のみでもよい。 The date and time is, for example, time information when the case information corresponding to the case ID is recorded, or time information when the corresponding near-miss occurs. The date and time may have a date and time as shown in FIG. 5, for example, or may be only the time.
位置情報は、例えばヒヤリハットが発生したときの発生地点である。位置情報は、例えば緯度経度(例えば、東経、北緯)情報であってもよく、また予め設定されたマップ上に定義された所定の座標情報であってもよい。なお、位置情報は、例えばGlobal Positioning System(GPS)等を用いて測位した位置情報でもよいが、これに限定されるものではない。 The position information is an occurrence point when a near-miss occurs, for example. The position information may be, for example, latitude and longitude (for example, east longitude, north latitude) information, or may be predetermined coordinate information defined on a preset map. The position information may be position information measured using, for example, a Global Positioning System (GPS), but is not limited to this.
進行方向は、例えばその車両に対する位置情報の時間的な経緯(履歴情報)から得られる車両の進行方向の方位である。なお、車両内に方位計を有する場合には、その方位計から進行方向を取得してもよい。 The traveling direction is, for example, the direction of the traveling direction of the vehicle obtained from the time history (history information) of the position information for the vehicle. In addition, when it has an azimuth meter in a vehicle, you may acquire the advancing direction from the azimuth meter.
速度は、ヒヤリハット時点又はヒヤリハット直前の車両速度である。速度は、例えば車両に搭載された速度計から速度を取得してもよく、また日時と位置情報との経緯(履歴情報)に基づいて速度を計算してもよい。 The speed is the vehicle speed immediately before or near the near-miss. For example, the speed may be obtained from a speedometer mounted on the vehicle, or the speed may be calculated based on the history (history information) of the date and position information.
また、事例情報51は、例えばタコグラフ等の運行記録計から取得することができる。例えば運行記録計には、運用時間中の走行速度や位置情報、進行方向等の情報が記録されている。そこで、記録された情報から、例えば走行中の速度が急激に減速した場合をヒヤリハットが発生したものと判断し、事例情報51として記憶することができる。なお、ヒヤリハット事例情報の取得例は、これに限定されるものではない。
Further, the
<第1まとめ処理部21の処理例>
次に、上述した第1まとめ処理部21の処理例について、フローチャートを用いて説明する。図6は、第1まとめ処理部の処理の一例を示すフローチャートである。図6の例において、第1まとめ処理部21は、入力された全事例の全ての組み合わせに対して距離行列を算出する(S11)。具体的には、各事例の発生地点間の距離と、2つの事例の進行方向のなす角を算出し、ij成分Dijが所定の性質を持つ行列(距離行列)を作成する。
<Processing Example of First
Next, a processing example of the first
例えば、事例iと事例jとの距離をdij、事例iと事例jの進行方向のなす角θijについて、θijが小さい場合には、dij以下の値とする。また、θijが大きい場合には、dij以上の値とし、特にθijが180°に近い場合には非常に大きな値とする。 For example, the distance between the case i and the case j is d ij , and the angle θ ij between the traveling direction of the case i and the case j is set to a value less than d ij when θ ij is small. In addition, when θ ij is large, the value is greater than or equal to d ij , and particularly when θ ij is close to 180 °, the value is very large.
<距離行列のij成分Dij算出例1>
第1まとめ処理部21は、例えば距離行列のij成分Dijを以下のルールにより算出する。なお、以下の説明において、Θは90°以下の正値定数、αは非常に大きな正値定数とする。
Dij=dij if θij<Θ
Dij=α otherwise
<距離行列のij成分Dij算出例2>
また、第1まとめ処理部21は、例えば、距離行列のij成分Dijを以下の式で算出する。
なお、以下の説明において、εは微小な正値定数、nは1以上の定数とする。
Dij=dij/(1+ε+cosnθij) if θij<180°/n
Dij=dij/ε otherwise
次に、第1まとめ処理部21は、クラスタを接続する基準となる初期閾値を設定し(S12)、接続行列を算出する(S13)。具体的には、S11で算出された距離行列より、ij成分Cijが以下のような接続行列を作成する。なお、Lは、所定の閾値定数である。
Cij= 1 if Dij≦L
Cij= 0 otherwise
なお、第1まとめ処理部21は、上述した定数Lを複数個設定し、それぞれの定数で上述の処理を行い、処理結果を既存のクラスタリング評価方式によって評価し、最も評価が良いときのクラスタリング結果を採用するようにしてもよい。
<Ij component of the distance matrix D ij calculated Example 1>
For example, the first
D ij = d ij if θ ij <Θ
D ij = α otherwise
<Ij component of the distance matrix D ij calculated Example 2>
Moreover, the 1st
In the following description, ε is a small positive constant and n is a constant of 1 or more.
D ij = d ij / (1 + ε + cosnθ ij ) if θ ij <180 ° / n
D ij = d ij / ε otherwise
Next, the first
C ij = 1 if D ij ≦ L
C ij = 0 otherwise
The first
例えば、第1まとめ処理部21は、S13の処理で得られた接続行列をグラフとみなし、互いに連結されていない部分グラフに分割し(S14)、各部分グラフをそれぞれ一つのクラスタとする。これにより、例えば一箇所に事例が集中している多発地点だけでなく、ある区間に渡る多発区間も一つのクラスタとすることが可能となる。
For example, the first
更に、第1まとめ処理部21は、分割されたクラスタに対して、複数の異なる定数Lを用いて接続行列を算出して評価値を算出する(S15)。
Further, the first
次に、第1まとめ処理部21は、S15の処理により算出された評価値の結果が、メモリ等の記憶部に記憶されている評価値よりも良いか否かを判断する(S16)。第1まとめ処理部21は、算出された評価値がメモリ等に記憶されている評価値よりも良い場合(S16において、YES)、評価値とクラスタリングの結果をメモリ等に記憶する(S17)。また、第1まとめ処理部21は、算出された評価値がメモリ等に記憶されている評価値よりも良くない場合(S16において、NO)、又は、S17の処理が終了後、S12の処理で設定したクラスタを接続する基準となる閾値を更新する(S18)。
Next, the first
第1まとめ処理部21は、処理を終了するか否かを判断し、処理を終了しない場合(S19において、NO)、S13の処理に戻る。また、第1まとめ処理部21は、ユーザ等の指示や予め設定された条件等により全ての処理を終了しない場合(S19において、NO)、メモリ等に記憶されているクラスタリングの結果(例えば、クラスタ一覧等)を出力して処理を終了する。
The first
ここで、図7は、第1まとめ処理の概要を説明するための図である。図7(A)は、まとめ上げ処理前の各事例を示している。図7(A)に示すようなヒヤリハット事例に対し、上述した図6に示すような第1まとめ処理を実施することで、各事例の方向毎に各クラスタが形成される。 Here, FIG. 7 is a diagram for explaining an outline of the first summary processing. FIG. 7A shows each case before the grouping process. Each cluster is formed for each direction of the case by performing the first summary process as shown in FIG. 6 on the near-miss case as shown in FIG. 7A.
図7(B)の例では、6種類のクラスタ(A〜F)が示されている。また、図7(B)の例では、クラスタC,D,Eが重なり部分が多く存在している。そこで、本実施形態では、第2まとめ処理部22における第2まとめ処理により要因推定域を用いたまとめ上げを行う。
In the example of FIG. 7B, six types of clusters (A to F) are shown. In the example of FIG. 7B, the clusters C, D, and E have many overlapping portions. Therefore, in the present embodiment, the second summarization process in the second
図8は、第1まとめ処理後のクラスタ一覧の例を示す図である。図8に示すクラスタ一覧の項目としては、例えば「クラスタID」、「事例ID」、「代表ベクトル」等であるが、これに限定されるものではない。クラスタIDは、第1まとめ処理部21でまとめられた各クラスタを識別するための識別情報である。事例IDは、各クラスタに含まれる事例を識別するための識別情報である。
FIG. 8 is a diagram illustrating an example of a cluster list after the first summary processing. The items of the cluster list shown in FIG. 8 include, for example, “cluster ID”, “example ID”, “representative vector”, but are not limited thereto. The cluster ID is identification information for identifying each cluster collected by the first
代表ベクトルは、重心の座標(東経、北緯)と進行方向(方位)とを有するが、これに限定されるものではない。重心の座標とは、例えばクラスタに含まれる各事例を囲んだ事例領域の重心の座標であるが、これに限定されるものではない。 The representative vector has coordinates of the center of gravity (east longitude, north latitude) and a traveling direction (azimuth), but is not limited thereto. The coordinates of the center of gravity are, for example, the coordinates of the center of gravity of a case area surrounding each case included in the cluster, but are not limited to this.
図8の例において、例えばクラスタAでは、3つの事例(A1〜A3)を有し、その代表ベクトルは、東経がx_A、北緯がy_A、方位がθ_Aであることを示している。図8に示すクラスタ一覧には、他のクラスタ(クラスタB〜F)についてもクラスタAと同様に各項目の情報が設定される。 In the example of FIG. 8, for example, cluster A has three cases (A1 to A3), and the representative vectors indicate that east longitude is x_A, north latitude is y_A, and orientation is θ_A. In the cluster list shown in FIG. 8, information of each item is set for the other clusters (clusters B to F) similarly to the cluster A.
<第2まとめ処理部22の処理例>
次に、上述した第2まとめ処理部22の処理例について、フローチャートを用いて説明する。図9は、第2まとめ処理部の処理の一例を示すフローチャートである。図9の例において、第2まとめ処理部22の候補クラスタ選定部31は、上述した第1まとめ処理で得られた各クラスタを構成する事例間距離の最大値が所定の閾値以下のクラスタをまとめ上げ候補クラスタとして選定する(S31)。なお、S31の処理において、第2まとめ処理部22は、多発区間とみなせるクラスタは、まとめ上げ候補としないようにしてもよい。
<Processing Example of Second
Next, a processing example of the above-described second
次に、第2まとめ処理部22の要因推定域割り当て部32は、S31の処理により選定されたクラスタについて、各クラスタを構成する事例情報を用いて、始点をクラスタ重心、向きを進行方向平均とする長さl(lは所定の値)のベクトルを代表ベクトルとして算出する(S32)。なお、第2まとめ処理部22は、上述した第1まとめ処理により代表ベクトルが取得できている場合には、S32の処理を行わなくてもよい。
Next, the factor estimation
次に、第2まとめ処理部22の要因推定域割り当て部32は、すでに要因推定域を保持しているか否かを判断し(S33)、保持していない場合(S33において、NO)、要因推定域の初期値を算出する(S34)。
Next, the factor estimation
また、S33の処理において、すでに要因推定域を保持している場合(S33において、YES)、又は、S34の処理後、第2まとめ処理部22の組選定部33は、例えば選定されたクラスタの全ての組み合わせに対してクラスタ間距離を算出する(S35)。
In the process of S33, when the factor estimation area is already held (YES in S33), or after the process of S34, the
次に、第2まとめ処理部22の組選定部33は、S35の処理で得られた結果に基づいて候補クラスタ組を選定する(S36)。S36の処理において、組選定部33は、例えばクラスタ間距離が所定の閾値L以下で、かつ、まとめ上げから除外する対象でないクラスタの組の中で、クラスタ間距離が最小となるクラスタ組(例えば、クラスタA、B)を選定する。
Next, the
第2まとめ処理部22の組選定部33は、S36の処理結果に基づき、選定されたクラスタの候補があるか否かを判断し(S37)、候補がある場合(S37において、YES)、第2まとめ処理部22のクラスタ処理部34は、まとめ上げ判定を行う(S38)。S38の処理において、クラスタ処理部34は、例えばクラスタ組A、Bの要因推定域に重複部分があれば、まとめ上げを行うと判定する。
The
第2まとめ処理部22のクラスタ処理部34は、S38の処理結果から、まとめ上げを実施するか否かを判断し(S39)、まとめ上げを実施する場合(S39において、YES)、候補クラスタ組をまとめ上げる(S41)。次に、クラスタ処理部34は、重複部分の値を付与し(S42)、S32の処理に戻る。また、第2まとめ処理部22のクラスタ処理部34は、S39の処理において、まとめ上げを実施しない場合(S39において、NO)、S36の処理に戻る。
The
第2まとめ処理部22の組選定部33は、S37の処理において、候補がない場合(S37において、NO)、第2まとめ処理を終了する。
The
ここで、図10は、第2まとめ処理の概要を説明するための図である。また、図11〜図15は、第2まとめ処理における各データの遷移を説明するための図(その1〜その5)である。なお、図11(A)〜図15(A)はクラスタ一覧を示し、図11(B)〜図15(B)は、まとめ上げ対象リストを示し、図11(C)〜図15(C)は、まとめ上げ除外クラスタ組リストを示し、図11(D)〜図15(D)は、要因推定域データを示している。図11〜図15に示す各データは、情報処理装置10が有する記憶部等に記憶される。
Here, FIG. 10 is a diagram for explaining an overview of the second summary processing. Moreover, FIGS. 11-15 is a figure (the 1-the 5) for demonstrating the transition of each data in a 2nd summary process. 11A to 15A show a list of clusters, FIGS. 11B to 15B show a list to be collected, and FIGS. 11C to 15C. Indicates a list of cluster exclusion groups, and FIGS. 11D to 15D show factor estimation area data. Each data shown in FIGS. 11 to 15 is stored in a storage unit or the like included in the
図11(A)に示すクラスタ一覧の項目は、上述した図8と同様であるため、ここでの説明は省略する。図11(B)〜図15(B)に示すまとめ上げ対象リスト、及び図11(C)〜図15(C)に示すまとめ上げ除外クラスタ組リストの項目としては、例えば「クラスタID」があるが、これに限定されるものではない。また、図11(D)〜図15(D)に示す要因推定域データの項目としては、例えば「クラスタID」、「要因推定域の座標」等があるが、これに限定されるものではない。「要因推定域の座標」は、例えば要因推定域を矩形としたときの4点の頂点の座標(東経、北緯)が記憶される。なお、要因推定域の座標情報は、これに限定されるものではなく、例えば要因推定域が円形である場合には、中心位置と半径情報を記憶し、三角形等の多角形の場合には、それぞれの頂点の座標を記憶してもよい。 Since the items in the cluster list shown in FIG. 11A are the same as those in FIG. 8 described above, description thereof is omitted here. As an item of the grouping target list shown in FIGS. 11B to 15B and the grouping exclusion cluster group list shown in FIGS. 11C to 15C, there is, for example, “cluster ID”. However, the present invention is not limited to this. The items of the factor estimation area data illustrated in FIGS. 11D to 15D include, for example, “cluster ID”, “coordinates of the factor estimation area”, and the like, but are not limited thereto. . The “coordinates of the factor estimation area” stores, for example, the coordinates of vertices of four points (east longitude, north latitude) when the factor estimation area is rectangular. The coordinate information of the factor estimation area is not limited to this. For example, when the factor estimation area is circular, the center position and radius information are stored, and in the case of a polygon such as a triangle, You may memorize | store the coordinate of each vertex.
第1まとめ処理の終了後におけるクラスタ一覧は、例えば上述した図8に示すデータ例である。また、第1まとめ処理の終了後では、上述したまとめ上げ対象リスト、まとめ上げ除外リスト、要因推定域データには、何もデータが入っていない。 The cluster list after the end of the first summary process is, for example, the data example illustrated in FIG. 8 described above. In addition, after the first summarization process is completed, no data is contained in the above-described summarization target list, summarization exclusion list, and factor estimation area data.
第2まとめ処理部22は、図10(A)に示すクラスタA〜Fについて、何れも事例間の最大距離が所定閾値L以下であるため、まとめ上げ候補とする。したがって、第2まとめ処理部22は、各クラスタに対して代表ベクトルを算出する。なお、図10の例において、代表ベクトルは、◆を重心とし、矢印の方向のベクトルを持つクラスタとする。
The second
次に、第2まとめ処理部22は、図10(B)に示すように、クラスタC、D、Eを第1まとめ処理と同様の処理でまとめ、クラスタCDEを作成する。具体的には、第2まとめ処理部22は、クラスタA〜Fのうち、CとDのクラスタ間距離が最も近いため、最初にCとDとの重複部分の有無を判定し、重複があるためクラスタCDとしてまとめる。更に、第2まとめ処理部22は、クラスタCDとEとの重複部分の有無を判定し、重複があるためクラスタCDEとしてまとめる。
Next, as shown in FIG. 10B, the second
まとめられた結果は、クラスタ一覧(図11(A))、まとめ上げ対象リスト(図11(B))、要因推定域データ(図11(D))にそれぞれ記憶される。図11(D)示す要因推定域データの場合には、クラスタCDとクラスタEの重複部分がクラスタCDEの要因推定域として紐付けられる。 The collected results are stored in a cluster list (FIG. 11A), a compilation target list (FIG. 11B), and factor estimation area data (FIG. 11D). In the case of the factor estimation area data shown in FIG. 11D, the overlapping part of the cluster CD and the cluster E is linked as the factor estimation area of the cluster CDE.
次に、第2まとめ処理部22は、図10(C)に示すクラスタA、B、CDE、Fの各候補クラスタの中で、クラスタ間距離が閾値L以下で、かつ最も近いクラスタAとクラスタBについて、要因推定域の重複部分の有無を判定する。第2まとめ処理部22は、クラスタAとクラスタBのそれぞれの要因推定域の重複部分が存在するため、2つのクラスタをまとめる。まとめられたクラスタABは、図12(A)に示すクラスタ一覧、図12(B)に示すまとめ上げ対象リストに保持する。また、図12(D)に示す要因推定域データには、クラスタAとBの重複部分がクラスタABの要因推定域として紐付けられる。
Next, the second
次に、第2まとめ処理部22は、まとめ上げ対象リストを参照し、図10(D)に示す候補クラスタの中で、クラスタ間距離が閾値L以下で、かつ、最も近いクラスタABとクラスタCDEについて、要因推定域の重複部分の有無を判定する。第2まとめ処理部22は、クラスタABとCDEとの要因推定域に重複部分があるかを判定し、重複部分がないためまとめない。その場合、第2まとめ処理部22は、クラスタABとCDEとの組を図13(C)に示すまとめ上げ除外クラスタ組リストに追加する。なお、図13(C)に示す「(AB,CDE)」は、クラスタABとクラスタCDEはまとめ上げないことを意味するが、記述形式はこれに限定されるものではない。
Next, the second
次に、第2まとめ処理部22は、まとめ上げ対象リストを参照し、図10(E)に示す各クラスタAB、CDE、Fの中で、クラスタ間距離が閾値L以下で、かつ、最も近いクラスタCDEとクラスタFについて、要因推定域の重複部分の有無を判定する。第2まとめ処理部22は、重複部分がないため、まとめない。したがって、第2まとめ処理部22は、図14(C)に示すように、上述の情報をまとめ上げ除外クラスタ組リストに追加する。また、第2まとめ処理部22は、クラスタABとクラスタCDEは、すでにまとめ上げ除外クラスタ組リストに記憶されているため、重複部分の有無の判定は行わず、まとめ上げも行わない。更に、クラスタCDEは、他の全てのクラスタと重複があるかをチェックしたため、まとめ上げ対象リストから削除する(図14(B))。
Next, the second
また、第2まとめ処理部22は、まとめ上げ対象リストを参照し、クラスタABとクラスタFについて重複部分の有無を判定し、重複部分がないため、クラスタABとクラスタFの組を、図15(C)に示すように、まとめ上げ除外クラスタ組リストに追加する。また、第2まとめ処理部22は、クラスタABとクラスタFとを、図15(B)に示すように、まとめ上げ対象リストから削除する。
Further, the second
第2まとめ処理部22は、図15(B)に示すように、まとめ上げ対象リストに対象の候補クラスタが存在しなくなったため、図15(A)に示すクラスタ一覧、図15(D)に示す要因推定域データ等が出力される。
As shown in FIG. 15B, the second
<S34:要因推定域の初期値算出例>
次に、上述した第2まとめ処理部22の要因推定域割り当て部32における上述したS34の要因推定域の初期値算出処理について、フローチャートを用いて説明する。図16は、要因推定域処理部の処理の一例を示すフローチャートである。図16の例において、第2まとめ処理部22の要因推定域割り当て部32は、要因推定域を算出する対象クラスタの後方の境界を取得し(S51)、前方の境界を取得し(S52)、側方の境界を取得する(S53)。なお、S51〜S53の処理の順序においては、図16の例に限定されるものではなく、他の順序であってもよい。
<S34: Example of initial value calculation of factor estimation area>
Next, the initial value calculation process of the factor estimation area in S34 described above in the factor estimation
次に、第2まとめ処理部22の要因推定域割り当て部32は、S51〜S53の各処理で得られた結果に基づいて、それぞれの境界の交点を求め、その交点を要因推定域の4隅の座標として、要因推定域を設定する。
Next, the factor estimation
<S51:後方の境界取得処理>
次に、上述したS51の後方の境界取得処理の一例について、フローチャートを用いて説明する。図17は、後方の境界取得処理の一例を示すフローチャートである。図17の例において、要因推定域割り当て部32は、クラスタの重心の座標を通り、代表ベクトルに直交する直線(m)を計算する(S61)。
<S51: Rear boundary acquisition process>
Next, an example of the boundary acquisition process behind S51 described above will be described using a flowchart. FIG. 17 is a flowchart illustrating an example of a rear boundary acquisition process. In the example of FIG. 17, the factor estimation
次に、要因推定域割り当て部32は、クラスタ内の全ての事例の座標について、直線mからの距離を符号付きで求め、その距離が最もマイナスとなる事例iを選択する(S62)。次に、要因推定域割り当て部32は、事例iの座標を通り、代表ベクトルと直交する直線nを後方の境界とする(S63)。
Next, the factor estimation
ここで、図18は、要因推定域(後方)の決め方の一例を示す図である。なお、本実施形態では、例えば地図情報(施設・交差点の有無、道路幅)や車両の向き、走行速度、制動距離、車種、車重等の各情報によらない平均的な要因推定域の推定を行っているが、これに限定されるものではなく、上述した各情報のうち少なくとも1つを用いて要因推定域を推定してもよい。 Here, FIG. 18 is a diagram illustrating an example of how to determine the factor estimation area (rear). In this embodiment, for example, estimation of an average factor estimation area that does not depend on information such as map information (presence / absence of facilities / intersections, road width), vehicle orientation, travel speed, braking distance, vehicle type, vehicle weight, etc. However, the present invention is not limited to this, and the factor estimation area may be estimated using at least one of the above-described pieces of information.
ヒヤリハットの要因は、進行方向の前方に存在することが多く、側方からの飛び出しを要因とする場合も存在する。したがって、本実施形態では、後方、前方、側方に対する要因推定域を、クラスタやクラスタの重心の向き等に対して概略的に図18(A)に示すように設定される。なお、図18の例において、要因推定域は、矩形で設定されているがこれに限定されるものではない。 The near-miss factor often exists in front of the traveling direction, and may be caused by a jump from the side. Therefore, in the present embodiment, factor estimation areas for the rear, the front, and the side are set as schematically shown in FIG. 18A with respect to the cluster, the direction of the center of gravity of the cluster, and the like. In the example of FIG. 18, the factor estimation area is set as a rectangle, but is not limited thereto.
ここで、要因推定域割り当て部32は、要因推定域後方の筐体の決め方としては、第1の方法として代表ベクトルの重心の座標を通り、代表ベクトルに直交する直線を決める(図18(B)の(1))。また、要因推定域割り当て部32は、第2の方法として、クラスタの最後方にある事例ベクトルの座標を通り、代表ベクトルに直交する直線を決める(図18(B)の(2))。
Here, the factor estimation
例えば、ある施設の出入り口付近の事例ベクトルは、上述したS02に示す1段階目のまとめ上げ処理により、向き毎に異なるクラスタに分類される(図18(C))。 For example, case vectors near the entrance / exit of a facility are classified into different clusters for each direction by the first-stage grouping process shown in S02 described above (FIG. 18C).
ここで、後方の境界を上述した第1の方法で求めると、例えば向きが対向するクラスタ組の代表ベクトルの重心座標が互いに近くても、要因推定域に重複部分が存在しない場合がある(図18(D))。このように重複部分がない場合には、第2まとめ処理部22におけるまとめ上げ処理により、上述したクラスタはどちらも施設の出入り口付近のクラスタであるにもかかわらず、別々のクラスタとみなされてしまう。一方、後方の境界を上述した第2の方法で求めると、重複部分ができ、同じ要因のクラスタと見なせる。
Here, when the rear boundary is obtained by the above-described first method, for example, even if the centroid coordinates of the representative vectors of the cluster groups whose directions are opposite to each other are close to each other, there may be no overlapping portion in the factor estimation area (see FIG. 18 (D)). When there is no overlapping part as described above, the above-described cluster is regarded as a separate cluster by the grouping process in the second
<S52:前方の境界取得処理>
次に、上述したS52の前方の境界取得処理の一例について、フローチャートを用いて説明する。図19は、前方の境界取得処理の一例を示すフローチャートである。図19の例において、要因推定域割り当て部32は、クラスタ内の全ての事例について、直前の速度を計算し(S71)、例えば速度と制動距離の対応表等を参照して各事例の制動距離を計算する(S72)。なお、速度に対応する制動距離は、車種や車重に関係なく予め設定された平均的な値でもよく、車種や車重等に対応させて設定してもよい。
<S52: Front boundary acquisition process>
Next, an example of the boundary acquisition process in front of S52 described above will be described using a flowchart. FIG. 19 is a flowchart illustrating an example of a front boundary acquisition process. In the example of FIG. 19, the factor estimation
次に、要因推定域割り当て部32は、各事例に対する平均の制動距離の値dBを計算し(S73)、後方の境界の計算で求めた直線nをdBだけプラスの方向に平行移動した直線を前方の境界とする(S74)。
Next, the factor estimation
ここで、図20は、要因推定域(前方)の決め方の一例を示す図である。例えば、図20(A)に示すようにヒヤリハットして急ブレーキをかける場合は、ドライバが前方の障害物(車両、歩行者等)とぶつかってしまうと判断したときである。また、ぶつかってしまうという状態は、現在の走行速度の制動距離の範囲内に障害物が進入した状態であると解釈できる。したがって、本実施形態では、急ブレーキをかけたときの走行速度の制動距離を、前方の境界とする。つまり、図20(B)に示すように、クラスタ内の各事例の制動距離の平均を前方の境界とする。例えば図20(B)の例では、クラスタ内に3つの事例ベクトルが存在し、各事例ベクトルは、それぞれ「速度:30Km/h(制動距離:9m)」、「速度:40Km/h(制動距離:16m)」、「速度:50Km/h(制動距離:20m)」である。この場合、要因推定域割り当て部32は、例えば制動距離の平均「(9+16+20)/3=15m」を求め、すでに求められている要因推定域の後方の位置を基準として、そこから15m前の位置を要因推定域の前方とする。
Here, FIG. 20 is a diagram illustrating an example of how to determine the factor estimation area (front). For example, as shown in FIG. 20A, when a near-miss and sudden braking is applied, it is when it is determined that the driver hits an obstacle (a vehicle, a pedestrian, etc.) ahead. Moreover, the state of hitting can be interpreted as a state in which an obstacle has entered within the braking distance range of the current travel speed. Therefore, in the present embodiment, the braking distance of the traveling speed when sudden braking is applied is set as the front boundary. That is, as shown in FIG. 20B, the average of the braking distances of the cases in the cluster is set as the front boundary. For example, in the example of FIG. 20B, there are three case vectors in the cluster, and each case vector has “speed: 30 Km / h (braking distance: 9 m)” and “speed: 40 Km / h (braking distance). : 16 m) "," speed: 50 Km / h (braking distance: 20 m) ". In this case, the factor estimation
<S53:側方の境界取得処理>
次に、上述したS53の側方の境界取得処理の一例について、フローチャートを用いて説明する。図21は、側方の境界取得処理の一例を示すフローチャートである。
<S53: Side boundary acquisition process>
Next, an example of the side boundary acquisition process of S53 described above will be described using a flowchart. FIG. 21 is a flowchart illustrating an example of a side boundary acquisition process.
図21の例において、要因推定域割り当て部32は、クラスタ内の全ての事例の座標から代表ベクトルの延長線に垂線を下し、それぞれの交点を求める(S81)。
In the example of FIG. 21, the factor estimation
次に、要因推定域割り当て部32は、それぞれの事例について、交点までの距離を符号付きで求める(S82)。ここで、要因推定域割り当て部32は、代表ベクトルを対象軸として最左端と最右端の事例の座標を選択する(S83)。
Next, the factor estimation
次に、要因推定域割り当て部32は、最左端の事例の直前の速度を取得し(S84)、例えば予め設定された速度と制動距離との対応表等を参照して、最左端の事例の制動距離(dBL)を取得する(S85)。次に、要因推定域割り当て部32は、最左端の事例の座標から代表ベクトルの延長線までの直線距離(dL)を計算する(S86)。
Next, the factor estimation
次に、要因推定域割り当て部32は、最右端の事例の直前の速度を取得し(S87)、速度と制動距離との対応表等を参照して最右端の事例の制動距離(dBR)を取得する(S88)。次に、要因推定域割り当て部32は、最右端の事例の座標から代表ベクトルの延長線までの直線距離(dR)を計算する(S89)。なお、要因推定域割り当て部32は、上述したS84〜S86の処理とS87〜S89の処理の順序を入れ替えてもよい。
Next, the factor estimation
次に、要因推定域割り当て部32は、例えば最左端と最右端の直線距離と制動距離との和(dBL+dL+dR+dBR)が、最左端、最右端の直線を基準にした所定の長さ(例えば、3倍(3(dL+dR)))より大きいか否かを判断する(S90)。
Next, the factor estimation
要因推定域割り当て部32は、所定の長さ(例えば、3倍)より大きい場合(S90において、YES)、最左端の事例の座標を通り、代表ベクトルに平行な直線を、dBLだけ左に平行移動した直線を左側方の境界とする(S91)。また、要因推定域割り当て部32は、最右端の事例の座標を通り、代表ベクトルに平行な直線を、dBRだけ右に平行移動した直線を右側方の境界とする(S92)。
If the factor estimation
また、要因推定域割り当て部32は、S90の処理において、所定の長さ(例えば、3倍)以下である場合(S90において、NO)、最左端の事例の座標を通り、代表ベクトルに平行な直線を、2dLだけ左に平行移動した直線を左側方の境界とする(S93)。また、要因推定域割り当て部32は、最右端の事例の座標を通り、代表ベクトルに平行な直線を、2dRだけ右に平行移動した直線を右側方の境界とする(S94)。なお、上述したS90の処理における所定の長さ(3倍)及び、S91〜S94の処理における平行移動の距離については、任意に設定することができる。
In addition, in the process of S90, the factor estimation
ここで、図22、図23は、要因推定域(側方)の決め方の一例を示す図(その1、その2)である。例えば、ヒヤリハット発生時の要因となった障害物(例えば、車両、歩行者等)の位置は、図22(A)に示すように、自車線上、対向車線上、進行方向が交差する地点が考えられる。自車線上とは、例えば中央線がない幅の狭い道路や生活道路等であり、対向車線上とは、例えば中央線のある道路、幹線道路等であり、進行方向が交差する地点とは、例えば生活道路の一時停止線付近、幹線道路の交差点付近、施設の出入り口付近等である。 Here, FIGS. 22 and 23 are diagrams (No. 1 and No. 2) showing an example of how to determine the factor estimation area (side). For example, as shown in FIG. 22A, the position of an obstacle (for example, a vehicle, a pedestrian, etc.) that has caused a near-miss occurs at a point where the traveling direction intersects on the own lane, on the opposite lane, and so on. Conceivable. On the own lane is, for example, a narrow road or a living road with no central line, and on the opposite lane is, for example, a road with a central line, a main road, etc. For example, near a temporary stop line of a living road, near an intersection of a main road, near an entrance of a facility, and the like.
したがって、要因推定域割り当て部32は、上述したそれぞれの場合に対して所定の方法で、クラスタの要因推定域の側方の境界を決める。要因推定域割り当て部32は、自車線上の場合に、図22(A)に示すように、例えばクラスタの代表ベクトルを対称軸としたときの事例間最大距離(例えば、自車線の道路幅の近似計算)を求める。また、要因推定域割り当て部32は、対向車線上の場合に、例えば事例間最大距離の2倍(例えば、自車線の道路幅と対向車線の道路幅との和の近似計算)を求める。また、要因推定域割り当て部32は、進行方向が交差する地点の場合には、例えば事例間最大距離の2倍(例えば、自車線の道路幅と障害物の占有面積との和の近似計算)を求める。
Therefore, the factor estimation
なお、地図情報を使用しない場合には、あるクラスタの障害物の位置が上述した3つのパターン(自車線上、対向車線上、進行方向が交差する地点)のうち、どのパターンであるかがわからない。そこで、本実施形態では、どのパターンでもよいように、側方の境界を例えば事例間最大距離の3倍のように予め設定された値にする。 In addition, when map information is not used, it is not known which pattern is the position of the obstacle in a certain cluster among the above-described three patterns (on the own lane, on the opposite lane, and where the traveling direction intersects). . Therefore, in this embodiment, the side boundary is set to a preset value such as three times the maximum distance between cases so that any pattern may be used.
なお、単純に事例間最大距離の3倍とすると、図22(B)に示すようにコンビニ等の駐車スペースのように車両がどこからでも出入りができる場所付近のクラスタ等では、あまり適切とはいえない。一般に、ドライバは施設を出入りする際、速度を車線走行時よりかなり落とすため、制動距離も短くなる。そのような低速度でヒヤリハットするとすれば、障害物は自車のすぐ近くに位置する可能性が高く、事例間最大距離の3倍を要因推定域の側方の境界とするのは冗長であり、図22(B)に示すように異なる要因の他のクラスタも1つのクラスタに纏められてしまう。また、単純に事例間最大距離の3倍の領域を用いると、道路幅より大きくなりすぎる場合がある。 If it is simply 3 times the maximum distance between cases, it is not so appropriate in a cluster near a place where a vehicle can enter and exit from anywhere such as a parking space such as a convenience store as shown in FIG. Absent. In general, when a driver enters or leaves a facility, the speed is considerably reduced as compared to when driving in a lane, so the braking distance is also shortened. If it is a near-miss incident at such a low speed, the obstacle is likely to be located in the immediate vicinity of the vehicle, and it is redundant to set the side boundary of the factor estimation area to be three times the maximum distance between cases. As shown in FIG. 22B, other clusters having different factors are also combined into one cluster. In addition, if an area that is three times the maximum distance between cases is simply used, it may be too large.
更に、図23(A)に示すように、単純に事例間最大距離の3倍の領域を用いると、要因とは無関係の空間まで含んでしまい、要因の異なるクラスタ同士をまとめてしまう可能性がある。 Furthermore, as shown in FIG. 23A, if an area that is three times the maximum distance between cases is simply used, a space that is unrelated to the factor is included, and clusters having different factors may be collected. is there.
そこで、要因推定域割り当て部32は、図23(B)に示すように、「事例間最大距離の3倍」と、「事例間最大距離の1倍と制動距離との和」等のように複数の側方境界候補を設定する。なお、上述した制動距離とは、例えば事例間最大距離の算出に使われた2つの事例のヒヤリハット直前の速度から得られる制動距離であるが、これに限定されるものではない。また、制動距離は、図23(B)に示すように、事例間最大距離に対する左右の領域に追加される。
Therefore, as shown in FIG. 23B, the factor estimation
要因推定域割り当て部32は、上述した複数の側方境界候補のそれぞれの長さを比較し、最も短い方を側方の境界として決定する。なお、側方境界候補の設定例については、上述の例に限定されるものではない。図23(B)の例では、「事例間最大距離の1倍と制動距離との和」の方が「事例間最大距離の3倍」よりも長さが短いため、斜線部分が要因推定域に決定する。
The factor estimation
要因推定域割り当て部32は、上述した手法により得られた後方、前方、側方の要因推定域の交点を結んで得られる矩形を最終的な要因推定域として設定する。なお、要因推定域割り当て部32は、クラスタ毎に上述した要因推定域の割り当てを行う。また、要因推定域割り当て部32は、まとめ上げられたクラスタに対して要因推定域の割り当てを行ってもよい。
The factor estimation
<要因推定域の他の割り当て例>
ここで、要因推定域割り当て部32における要因推定域の他の割り当て例について、図を用いて説明する。図24は、要因推定域の他の割り当て例を示す図である。
<Other examples of factor estimation areas>
Here, another example of allocation of the factor estimation area in the factor estimation
図24の例では、前提は上述した矩形の要因推定域の割り当て例の場合と同じである。また、ヒヤリハット事例の発生地点における地図情報(例えば、施設・交差点の有無、道路幅)を利用せず、ヒヤリハット発生時の座標、車両の向き、走行速度、走行速度と制動距離の(車種や車重によらない平均的な)対応表のデータを用いる。 In the example of FIG. 24, the premise is the same as that in the above-described example of allocation of rectangular factor estimation areas. In addition, map information (for example, the presence / absence of facilities / intersections, road width) at the occurrence point of near-miss cases is not used, but the coordinates, vehicle direction, travel speed, travel speed and braking distance at the time of near-miss occurrence (vehicle type and vehicle Use data from an average correspondence table that does not depend on weight.
図24の例において、要因推定域割り当て部32は、例えばクラスタ内の最前方の事例ベクトルの座標とクラスタの重心を結ぶ線分(直線)を設定する。更に、要因推定域割り当て部32は、上述した線分を基準に、最前方の事例ベクトルの座標から速度データ(例えば、ヒヤリハット直前の速度)に対応する制動距離をプラスした座標71と、クラスタ重心に制御距離をプラスした座標72を設定し、座標71,72を通る直線を直径とする円を要因推定域73として割り当てる。これにより、後方、前方、側方でそれぞれ設定する必要がなく、簡単な処理で要因推定域を求めることができ、事例の発生要因毎に適切なクラスタリングを実現することができる。
In the example of FIG. 24, the factor estimation
<事例情報51に含まれる日時情報等を考慮した実施例>
次に、事例情報51に含まれる日時情報等を考慮した実施例について説明する。例えば、同じ道路でも、時間帯によりヒヤリハット地点になる場合とならない場合がある。例えば、学校やオフィス沿いにある道路では、ヒヤリハット事例が朝と夕方に集中している可能性があり、見通しの悪くなる交差点では、ヒヤリハット事例が西日の差す時間帯や雨で視界が悪くなる日に集中している可能性がある。
<Example in consideration of date and time information included in
Next, an embodiment that considers the date and time information included in the
そこで、本実施形態では、収集したヒヤリハット事例を、時間帯又はその日の天候毎に分けて上述したクラスタリングを行う運用が考えられる。なお、事例情報51は、例えば運送会社のトラックや一般乗用車のドライブレコーダ、カーナビゲーションシステム等から収集することができるが、これに限定されるものではない。また、一般乗用車のデータについてはドライバ(ユーザ)から許可が得られたデータのみ使用するようにしてもよい。
Therefore, in the present embodiment, an operation of performing the above-described clustering by dividing the collected near-miss cases for each time zone or weather of the day can be considered. The
上述したように、本実施形態では、事例の発生要因毎に適切なクラスタリングを実現することができる。事例のクラスタリングを行うにあたり、近接した事例同士であっても、要因が互いに異なる事例は1つのクラスタにまとめないようなクラスタリング方法を実現する。 As described above, in the present embodiment, appropriate clustering can be realized for each occurrence factor of the case. When clustering cases, a clustering method is realized in which cases that are close to each other but having different factors are not combined into one cluster.
これにより、例えば、前方エリアは、一致するがそれぞれの車線沿いに要因があるクラスタ組を、別々のクラスタとしてヒヤリハット多発地点マップに表示することができる。したがって、本実施形態では、ドライバにヒヤリハット多発地点を警告する際、正しい要因への注意を与えることが可能になる。また、ドライバは、当該地点を通過する前に注意を向けるべきポイントを明確に意識することができる。したがって、事故の未然防止を実現することができる。 Thereby, for example, a cluster set that matches the front area but has a factor along each lane can be displayed as a separate cluster on the near-miss frequent occurrence point map. Therefore, in the present embodiment, it is possible to give attention to the correct factor when warning the driver of frequent incidents. In addition, the driver can clearly recognize a point to which attention should be directed before passing the point. Therefore, accident prevention can be realized.
なお、上述の例では、地図情報や車両情報等を考慮せずにヒヤリハット事例に基づくヒヤリハット多発地点の設定を行ったが、これに限定するものではなく、例えば地図情報を用いて事例をクラスタリングしたり、車両情報等を用いて細かくクラスタリングすることもできる。 In the above-described example, near-miss frequent occurrence points are set based on near-miss cases without considering map information, vehicle information, etc., but the present invention is not limited to this. For example, map information is used to cluster cases. Or finely clustering using vehicle information or the like.
以上、各実施例について詳述したが、特定の実施例に限定されるものではなく、特許請求の範囲に記載された範囲内において、上記変形例以外にも種々の変形及び変更が可能である。 Each embodiment has been described in detail above. However, the present invention is not limited to the specific embodiment, and various modifications and changes other than the above-described modification are possible within the scope described in the claims. .
なお、以上の実施例に関し、更に以下の付記を開示する。
(付記1)
情報処理装置が、
車両事故に至る可能性がある事例に関する情報である事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成し、
形成された前記複数の集合のそれぞれについて、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求め、
求めた各要因推定域の相互関係に基づいて各集合をまとめるか否かを決定する、
ことを特徴とする事例情報処理方法。
(付記2)
前記各集合に対応する要因推定域に重複部分があるか否かを判断し、前記重複部分のあった集合を一つの集合の組にまとめることを特徴とする付記1に記載の事例情報処理方法。
(付記3)
形成された前記複数の集合のそれぞれについて、集合に含まれる事例から代表ベクトルを取得し、取得した前記代表ベクトルに基づいて、前記車両の前方、後方、及び側方の境界を求めて前記要因推定域を設定することを特徴とする付記1又は2に記載の事例情報処理方法。
(付記4)
形成された前記複数の集合のそれぞれについて、集合に含まれる最前方の事例ベクトルの座標と、前記集合の重心と、前記最前方の事例ベクトルの速度データに対応する制動距離とに基づいて前記要因推定域を求めることを特徴とする付記1又は2に記載の事例情報処理方法。
(付記5)
前記各集合のうち、所定数以上の事例を含む集合を事例発生の多発地点として出力することを特徴とする付記1乃至4の何れか1項に記載の事例情報処理方法。
(付記6)
車両事故に至る可能性がある事例に関する情報である事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成し、
形成された前記複数の集合のそれぞれについて、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求め、
求めた各要因推定域の相互関係に基づいて各集合をまとめるか否かを決定する、
処理をコンピュータに実行させるための事例情報処理プログラム。
(付記7)
車両事故に至る可能性がある事例に関する情報である事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成する第1まとめ処理部と、
前記第1まとめ処理部により得られる前記複数の集合のそれぞれについて、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求め、求めた各要因推定域の相互関係に基づいて各集合をまとめるか否かを決定する第2まとめ処理部とを有することを特徴とする情報処理装置。
In addition, the following additional remarks are disclosed regarding the above Example.
(Appendix 1)
Information processing device
Based on the identity between the occurrence position of the case and the traveling direction of the vehicle included in the case information that is information about the case that may lead to a vehicle accident, a plurality of sets related to the case is formed,
For each of the plurality of formed sets, estimate the range in which the thing that caused the case is present to obtain a factor estimation area,
Decide whether or not to collect each set based on the interrelationship of each factor estimation area
Case information processing method characterized by this.
(Appendix 2)
The case information processing method according to
(Appendix 3)
For each of the plurality of formed sets, a representative vector is acquired from examples included in the set, and the factor estimation is performed by obtaining front, rear, and side boundaries of the vehicle based on the acquired representative vector. The case information processing method according to
(Appendix 4)
For each of the plurality of sets formed, the factor based on the coordinates of the foremost case vector included in the set, the center of gravity of the set, and the braking distance corresponding to the velocity data of the foremost case vector The case information processing method according to
(Appendix 5)
5. The case information processing method according to any one of
(Appendix 6)
Based on the identity between the occurrence position of the case and the traveling direction of the vehicle included in the case information that is information about the case that may lead to a vehicle accident, a plurality of sets related to the case is formed,
For each of the plurality of formed sets, estimate the range in which the thing that caused the case is present to obtain a factor estimation area,
Decide whether or not to collect each set based on the interrelationship of each factor estimation area
A case information processing program for causing a computer to execute processing.
(Appendix 7)
A first summary processing unit that forms a plurality of sets related to the case based on the identity of the occurrence position of the case and the traveling direction of the vehicle included in the case information that is information about the case that may lead to a vehicle accident; ,
For each of the plurality of sets obtained by the first summary processing unit, a factor estimation area is obtained by estimating a range in which the thing that causes the case is present, and a correlation between the obtained factor estimation areas is obtained. An information processing apparatus comprising: a second summarization processing unit that determines whether or not to collect each set based on the second summarization processing unit.
10 情報処理装置
11 事例情報入力部(入力部)
12 事例まとめ処理部
13 多発地点出力部(出力部)
21 第1まとめ処理部
22 第2まとめ処理部
31 候補クラスタ選定部
32 要因推定域割り当て部
33 組選定部
34 クラスタ処理部
41 要因推定域処理部
51 事例情報
52 多発地点情報
61 入力装置
62 出力装置
63 ドライブ装置
64 補助記憶装置
65 主記憶装置
66 CPU
67 ネットワーク接続装置
68 記録媒体
71,72 座標
73 要因推定域
10
12 Case
DESCRIPTION OF
67
Claims (4)
車両事故に至る可能性がある事例に関する情報である事例情報を記憶部より取得する工程と、
取得した前記事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成する工程と、
形成された前記複数の集合のそれぞれについて、前記事例の車両の進行方向の平均と車両の速度の平均を算出することで代表ベクトルを算出し、該複数の集合のそれぞれについて、最前方の前記事例情報に含まれる事例の発生位置に当該最前方の事例情報に含まれる車両の速度に対応する制動距離をプラスした第1の座標と、前記代表ベクトルの重心に該制動距離をプラスした第2の座標とを通る線分を直径とする円を求めることにより、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求める工程と、
求めた各要因推定域間において重複部分があるか否かを判断し、重複部分があると判断した要因推定域に対応する集合を、同じ事物が要因となって引き起こされた事例の集合として、一つの集合の組にまとめる工程と、
前記集合の組を出力する工程と
を実行することを特徴とする事例情報処理方法。 Information processing device
A step of acquiring from the storage unit case information that is information about cases that may lead to a vehicle accident ;
Forming a plurality of sets related to the case based on the identity of the occurrence position of the case included in the acquired case information and the traveling direction of the vehicle;
For each of the plurality of sets formed, a representative vector is calculated by calculating an average of the traveling direction of the vehicle and an average of the vehicle speed of the case, and for each of the plurality of sets, the frontmost case A first coordinate obtained by adding a braking distance corresponding to the speed of the vehicle included in the foremost case information to the occurrence position of the case included in the information, and a second coordinate obtained by adding the braking distance to the center of gravity of the representative vector. by determining a circle whose diameter a line segment passing through the coordinates, and a step asking you to factor estimating range to estimate the extent to which things that caused it to cause the case is present,
It is determined whether there is an overlap between each calculated factor estimation area, and the set corresponding to the factor estimation area that is determined to have an overlap is set as a set of cases caused by the same thing as a factor. The process of grouping together into a single set;
Outputting the set of sets;
A case information processing method characterized by executing
取得した前記事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成する工程と、
形成された前記複数の集合のそれぞれについて、前記事例の車両の進行方向の平均と車両の速度の平均を算出することで代表ベクトルを算出し、該複数の集合のそれぞれについて、最前方の前記事例情報に含まれる事例の発生位置に当該最前方の事例情報に含まれる車両の速度に対応する制動距離をプラスした第1の座標と、前記代表ベクトルの重心に該制動距離をプラスした第2の座標とを通る線分を直径とする円を求めることにより、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求める工程と、
求めた各要因推定域間において重複部分があるか否かを判断し、重複部分があると判断した要因推定域に対応する集合を、同じ事物が要因となって引き起こされた事例の集合として、一つの集合の組にまとめる工程と、
前記集合の組を出力する工程と
をコンピュータに実行させるための事例情報処理プログラム。 A step of acquiring from the storage unit case information that is information about cases that may lead to a vehicle accident ;
Forming a plurality of sets related to the case based on the identity of the occurrence position of the case included in the acquired case information and the traveling direction of the vehicle;
For each of the plurality of sets formed, a representative vector is calculated by calculating an average of the traveling direction of the vehicle and an average of the vehicle speed of the case, and for each of the plurality of sets, the frontmost case A first coordinate obtained by adding a braking distance corresponding to the speed of the vehicle included in the foremost case information to the occurrence position of the case included in the information, and a second coordinate obtained by adding the braking distance to the center of gravity of the representative vector. by determining a circle whose diameter a line segment passing through the coordinates, and a step asking you to factor estimating range to estimate the extent to which things that caused it to cause the case is present,
It is determined whether there is an overlap between each calculated factor estimation area, and the set corresponding to the factor estimation area that is determined to have an overlap is set as a set of cases caused by the same thing as a factor. The process of grouping together into a single set;
Outputting the set of sets;
Case information processing program for causing a computer to execute the.
取得した前記事例情報に含まれる事例の発生位置と車両の進行方向との同一性に基づいて、前記事例に関する複数の集合を形成する第1まとめ処理部と、
前記第1まとめ処理部により得られる前記複数の集合のそれぞれについて、前記事例の車両の進行方向の平均と車両の速度の平均を算出することで代表ベクトルを算出し、該複数の集合のそれぞれについて、最前方の前記事例情報に含まれる事例の発生位置に当該最前方の事例情報に含まれる車両の速度に対応する制動距離をプラスした第1の座標と、前記代表ベクトルの重心に該制動距離をプラスした第2の座標とを通る線分を直径とする円を求めることにより、前記事例を引き起こす要因となった事物が存在する範囲を推定して要因推定域を求め、求めた各要因推定域間において重複部分があるか否かを判断し、重複部分があると判断した要因推定域に対応する集合を、同じ事物が要因となって引き起こされた事例の集合として、一つの集合の組にまとめる第2まとめ処理部と、
前記集合の組を出力する出力部と
を有することを特徴とする情報処理装置。 An acquisition unit that acquires case information that is information about a case that may lead to a vehicle accident from the storage unit;
A first summary processing unit that forms a plurality of sets related to the case based on the identity between the occurrence position of the case included in the acquired case information and the traveling direction of the vehicle;
For each of the plurality of sets obtained by the first summary processing unit, a representative vector is calculated by calculating the average of the traveling direction of the vehicle and the average of the speed of the vehicle in the case, and for each of the plurality of sets The first coordinate obtained by adding the braking distance corresponding to the speed of the vehicle included in the forefront case information to the occurrence position of the case included in the forefront case information, and the braking distance at the center of gravity of the representative vector By calculating a circle whose diameter is a line that passes through the second coordinate plus the point, the range where the thing that caused the case is present is estimated to obtain the factor estimation area, and each factor estimation obtained Determine whether there is an overlap between areas, and set the set corresponding to the factor estimation area determined to have an overlap as one set of cases caused by the same thing as a factor. And the second summarizing processing unit are summarized in case of a set,
An information processing apparatus comprising: an output unit that outputs the set of sets .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013082104A JP6127670B2 (en) | 2013-04-10 | 2013-04-10 | Case information processing method, case information processing program, and information processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013082104A JP6127670B2 (en) | 2013-04-10 | 2013-04-10 | Case information processing method, case information processing program, and information processing apparatus |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014203437A JP2014203437A (en) | 2014-10-27 |
| JP6127670B2 true JP6127670B2 (en) | 2017-05-17 |
Family
ID=52353778
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013082104A Active JP6127670B2 (en) | 2013-04-10 | 2013-04-10 | Case information processing method, case information processing program, and information processing apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6127670B2 (en) |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4815943B2 (en) * | 2005-08-19 | 2011-11-16 | 株式会社デンソー | Hazardous area information display device |
| JP2008181252A (en) * | 2007-01-23 | 2008-08-07 | Toyota Motor Corp | Danger information collection and distribution system, and danger information sending/receiving device and danger information collection and distribution device constituting this system |
| JP4930321B2 (en) * | 2007-10-25 | 2012-05-16 | 株式会社デンソー | Potential danger point detection device and in-vehicle danger point notification device |
| JP5447371B2 (en) * | 2008-04-15 | 2014-03-19 | 日本電気株式会社 | Mobile object warning device, mobile object warning method, and mobile object warning program |
| JP6159052B2 (en) * | 2011-05-20 | 2017-07-05 | 富士通株式会社 | Information providing method and information providing apparatus |
-
2013
- 2013-04-10 JP JP2013082104A patent/JP6127670B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014203437A (en) | 2014-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6925796B2 (en) | Methods and systems, vehicles, and computer programs that assist the driver of the vehicle in driving the vehicle. | |
| JP6832421B2 (en) | Simulation-based evaluation method for sensing requirements of self-driving cars | |
| US10698106B2 (en) | Obstacle detecting method and apparatus, device and storage medium | |
| US9727820B2 (en) | Vehicle behavior prediction device and vehicle behavior prediction method, and driving assistance device | |
| CN111680362B (en) | Automatic driving simulation scene acquisition method, device, equipment and storage medium | |
| JP6800575B2 (en) | Methods and systems to assist drivers in their own vehicles | |
| JP7023299B2 (en) | How to manage mobile objects, systems, computer programs, and their recording media | |
| CN112572424B (en) | Vehicle control method, device, equipment and medium based on obstacle recognition | |
| CN110325935A (en) | The lane guide line based on Driving Scene of path planning for automatic driving vehicle | |
| JP2018081673A (en) | Determination improvement system based on plan feedback for autonomous driving vehicle | |
| CN107389085B (en) | Method and device for determining road traffic attributes, computer and storage medium | |
| JP2016075905A (en) | Joint probabilistic modeling and inference of intersection structure | |
| US10762782B2 (en) | On-street parking map generation | |
| KR20140019501A (en) | Method for producing classification for recognizing object | |
| US10745010B2 (en) | Detecting anomalous vehicle behavior through automatic voting | |
| CN113924459B (en) | Dynamic sensor range detection for vehicle navigation | |
| US9478137B1 (en) | Detecting and communicating lane splitting maneuver | |
| US11580856B2 (en) | Identification of a poorly parked vehicle and performance of a first group of actions to cause one or more other devices to perform a second group of actions | |
| CN111323035A (en) | Detection method and detection device for driving yaw and readable storage medium | |
| So et al. | Analysis on autonomous vehicle detection performance according to various road geometry settings | |
| JP2018136890A (en) | Road network change detection apparatus, road network change detection method, computer program, and recording medium recording the computer program | |
| JP6127670B2 (en) | Case information processing method, case information processing program, and information processing apparatus | |
| JP2013196366A (en) | Risk detection device, risk detection method and program | |
| JP6070123B2 (en) | Position information concealment method, position information concealment device, and position information concealment program | |
| Bhuyan et al. | Affinity propagation clustering in defining level of service criteria of urban streets |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160113 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160930 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161004 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161117 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170104 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170228 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170314 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170327 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6127670 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |