JP6127624B2 - Information processing program, information processing method and apparatus - Google Patents
Information processing program, information processing method and apparatus Download PDFInfo
- Publication number
- JP6127624B2 JP6127624B2 JP2013056543A JP2013056543A JP6127624B2 JP 6127624 B2 JP6127624 B2 JP 6127624B2 JP 2013056543 A JP2013056543 A JP 2013056543A JP 2013056543 A JP2013056543 A JP 2013056543A JP 6127624 B2 JP6127624 B2 JP 6127624B2
- Authority
- JP
- Japan
- Prior art keywords
- book
- video
- data
- user
- specific
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 7
- 238000003672 processing method Methods 0.000 title description 4
- 238000000034 method Methods 0.000 claims description 43
- 238000000605 extraction Methods 0.000 claims description 14
- 239000000284 extract Substances 0.000 claims description 10
- 238000013075 data extraction Methods 0.000 description 36
- 238000013500 data storage Methods 0.000 description 29
- 238000010586 diagram Methods 0.000 description 21
- 238000005516 engineering process Methods 0.000 description 9
- 238000004891 communication Methods 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 238000012800 visualization Methods 0.000 description 3
- 208000025174 PANDAS Diseases 0.000 description 2
- 208000021155 Paediatric autoimmune neuropsychiatric disorders associated with streptococcal infection Diseases 0.000 description 2
- 240000004718 Panda Species 0.000 description 2
- 235000016496 Panda oleosa Nutrition 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 235000009508 confectionery Nutrition 0.000 description 2
- 230000001965 increasing effect Effects 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000005065 mining Methods 0.000 description 1
- 230000008450 motivation Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
Images
















Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
本技術は、書籍の推薦情報の提供技術に関する。 The present technology relates to a technology for providing book recommendation information.
図書館は、利用者が1冊でも多くの本と出合ってそれらの本を借りるという機会を増やして、図書館の利用率を高めて行くことを1つの目的としていることが多い。 Libraries often have one purpose to increase the library's usage rate by increasing the chances of users meeting and borrowing as many books as possible.
近年、書籍のドラマ化や映画化など映像化が増加している。利用者の中には、映像コンテンツの原作書籍の存在を知る前に映像コンテンツを観てしまい、原作書籍を先に読んでおけば良かったと後悔したり、先に原作書籍を読もうと思っていたのに、テレビで放送されている場に出くわしてしまい観てしまうということがある。 In recent years, the visualization of books such as dramas and movies has increased. Some users have watched the video content before knowing the existence of the original video content book, and regretted that they should have read the original book first, or would like to read the original book first. However, sometimes I come across a TV broadcast and watch it.
このような利用者は、映像コンテンツを観る前に原作書籍を読み切ることを欲していることがあるが、映像化自体に気付かない場合も多い。さらに、映像化される番組名又は映画名と原作書籍名とが異なる場合においては、原作書籍が何であるかを知ることさえ難しい。 Such users may want to read through the original book before watching the video content, but often do not realize the visualization itself. Further, when the name of the program or movie to be visualized is different from the original book name, it is difficult to even know what the original book is.
一方、図書館側は、利用者が借りたいと思った時に書籍を貸し出したい。そのためにはできるだけ回転率良く書籍を貸し出したいと考えており、それは話題となる本になればなるほど高まる。このような映像化の発表によって、原作書籍が広く知られた場合、その原作書籍は、再度着目されたり、突然脚光を浴びて、書籍の貸し出しが集中することがある。このような状況において、図書館側では、できるだけ多くの利用者に、放送予定日や公開予定日までに、原作書籍や関連書籍を貸し出す機会を提供することが望ましい。 On the other hand, the library wants to lend a book when the user wants to borrow it. To that end, he wants to lend books as quickly as possible, and the more it becomes a topical book, the more it becomes. When the original book is widely known due to such announcement of visualization, the original book may be noticed again or suddenly attracted attention, and the lending of the book may be concentrated. In such a situation, it is desirable for the library side to provide as many users as possible with the opportunity to lend original books and related books by the scheduled broadcast date or the scheduled release date.
但し、利用者毎に読書速度や読書頻度、さらには個人的な事情は異なっており、映像コンテンツの放送予定日又は公開予定日前に原作書籍を読み終わるか否かは利用者毎に異なっている。 However, reading speed, reading frequency, and personal circumstances are different for each user, and whether or not to finish reading the original book before the scheduled broadcast date or release date of the video content is different for each user. .
従って、本技術の目的は、一側面によれば、利用者に対して映像コンテンツに関連する書籍を適切に推薦できるようにするための技術を提供することである。 Therefore, according to one aspect, an object of the present technology is to provide a technology for enabling a user to appropriately recommend a book related to video content to a user.
本技術に係る情報処理方法は、(A)放送又は公開が予定されている映像に関するデータ及び当該映像に関連する書籍に関するデータを検索により取得し、映像の識別子と放送又は公開予定日と書籍の識別データと書籍の分量とを第1のデータ格納部に格納し、(B)ユーザ毎に当該ユーザの読書速度及び読書頻度を格納する第2のデータ格納部から、特定のユーザの読書速度及び読書頻度を読み出し、(C)第1のデータ格納部に識別データが格納されている各書籍の分量と、読み出された特定のユーザの読書速度及び読書頻度とから、各書籍について特定のユーザが読み終わるまでにかかる期間を算出し、(D)各書籍について算出された期間と第1のデータ格納部に格納されている各書籍の放送又は公開予定日とから、特定のユーザが読み終わる書籍を特定し、(E)特定された書籍に関連するデータを特定のユーザ宛に送信する処理を含む。 In the information processing method according to the present technology, (A) data related to a video scheduled to be broadcast or released and data related to a book related to the video are obtained by searching, and an identifier of the video, a broadcast or scheduled release date, and a book The identification data and the amount of the book are stored in the first data storage unit, and (B) from the second data storage unit that stores the reading speed and reading frequency of the user for each user, Read the reading frequency, and (C) a specific user for each book from the amount of each book whose identification data is stored in the first data storage unit and the reading speed and reading frequency of the read specific user Is calculated from the period calculated for each book and the broadcast or scheduled release date of each book stored in the first data storage unit. Identify the book to be completely seen, it includes a process of transmitting to the particular addressed to the user data associated with the book identified (E).
一側面によれば、利用者に対して映像コンテンツに関連する書籍を適切に推薦できるようにする。 According to one aspect, a book related to video content can be appropriately recommended to a user.
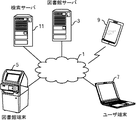
本技術の実施の形態に係るシステムの概要を図1に示す。例えばインターネットや図書館内のLAN(Local Area Network)であるネットワーク1には、1又は複数の図書館端末5と、本実施の形態における主要な処理を実行する図書館サーバ3とが接続される。ネットワーク1が、インターネットなどの図書館外部のネットワークに接続する場合や図書館LANが解放されている場合には、ユーザ端末7も接続される場合がある。また、本実施の形態では、ユーザの読書状況に関するデータを収集するので、例えばスマートフォン、タブレットなどの携帯端末9も、インターネットなどを介して図書館サーバ3に接続される。さらに、本実施の形態では、ネットワーク1には、インターネット検索を行うための検索サーバ11も接続されている。このような検索サーバ11の機能については、一般に知られているのでここでは説明を省略する。
An overview of a system according to an embodiment of the present technology is shown in FIG. For example, one or a plurality of library terminals 5 and a library server 3 that executes main processing in the present embodiment are connected to a
図書館端末5は、例えば図書館館内に設置され、例えばタッチパネル式の表示部等を備える。ハードウエアのキーボードを備えている場合もある。また、図書館端末5は、Web(ウェブ)ブラウザを実行しているものとする。ユーザ端末7も、Webブラウザを実行しているものとする。さらに、携帯端末9には、書籍のリーダプログラムがインストールされており、当該リーダプログラムを実行すると、書籍のデータを図書館サーバ3からダウンロードすると共に、携帯端末9の表示部に書籍のデータを表示する。さらに、リーダプログラムは、所定のタイミングで、ユーザの読書頻度及び読書速度を算出するための読書状況データを、図書館サーバ3に送信する。より具体的には、書籍を読み終わった後に、読んだページ数、読書時間、読書日数等のデータを図書館サーバ3に送信する。 The library terminal 5 is installed in, for example, a library hall, and includes, for example, a touch panel display unit. May have a hardware keyboard. The library terminal 5 is assumed to be running a Web browser. It is assumed that the user terminal 7 is also executing a Web browser. Further, a book reader program is installed in the portable terminal 9. When the reader program is executed, the book data is downloaded from the library server 3 and the book data is displayed on the display unit of the portable terminal 9. . Furthermore, the reader program transmits reading status data for calculating the reading frequency and reading speed of the user to the library server 3 at a predetermined timing. More specifically, after the reading of the book is completed, data such as the number of pages read, the reading time, and the reading days are transmitted to the library server 3.
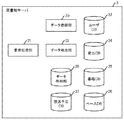
図2に、図書館サーバ3の機能ブロック図を示す。図書館サーバ3は、要求処理部31と、データ抽出部32と、データ登録部39と、ユーザデータベース(DB)33と、貸出DB34と、書籍DB35と、ペースDB36と、放送予定DB37と、データ格納部38とを有する。
FIG. 2 shows a functional block diagram of the library server 3. The library server 3 includes a
要求処理部31は、例えば、図書館端末5やユーザ端末7からユーザがログインしてきた場合に、要求されたデータ等を含むウェブページデータを生成して、要求元の図書館端末5やユーザ端末7へ送信する。なお、要求処理部31は、このウェブページデータに書籍に関するデータ等を含める場合があり、その場合には、データ抽出部32に対してデータ抽出処理を指示する。
For example, when the user logs in from the library terminal 5 or the user terminal 7, the
データ抽出部32は、以下で説明するように、ユーザDB33と、貸出DB34と、書籍DB35と、ペースDB36と、放送予定DB37と、データ格納部38とを用いて、放送予定又は公開予定の映像コンテンツに関連する書籍に関するデータを抽出し、要求処理部31に出力する。
As will be described below, the
また、データ登録部39は、例えば携帯端末9からユーザの読書状況に関するデータを受信すると、ペースDB36に登録する。
Moreover, the
ユーザDB33には、例えば図3に示すようなデータが格納されている。図3の例では、ユーザ毎に、ユーザIDと、パスワードと、氏名と、住所などが登録されるようになっている。
For example, data as shown in FIG. 3 is stored in the
また、貸出DB34には、例えば図4に示すようなデータが格納されている。図4の例では、書籍ID毎に、書籍名と、貸出先のユーザIDと、貸出日と、返却期限(返却予定日)と、貸出状況とが登録されるようになっている。
Further, for example, data as shown in FIG. 4 is stored in the
さらに、書籍DB35には、例えば図5に示すようなデータが格納されている。図5の例では、書籍名と、作者名と、出版社名と、総ページ数と、書籍IDとが登録されるようになっている。複数冊同一書籍があれば、複数の書籍IDが登録される。
Further, the
また、ペースDB36には、例えば図6に示すようなデータが格納されている。図6の例では、ユーザIDと、読んだ書籍毎の書籍名と実読書時間と実読書日数と総ページ数とを含む読書状況データと、全体平均読書頻度と、全体平均読書速度とが登録されるようになっている。携帯端末9から書籍名と実読書時間と実読書日数と総ページ数とを含む読書状況データを受信すると、データ登録部39は、携帯端末9のユーザのユーザIDに対応付けて、ペースDB36に登録する。また、データ登録部39は、実読書時間の総和/実読書日数の総和により全体平均読書頻度を算出して登録し、さらに実読書時間の総和×60/総ページ数の総和により全体平均読書速度を算出して登録する。このような処理は、本実施の形態の主要部ではないので、これ以上述べない。
The
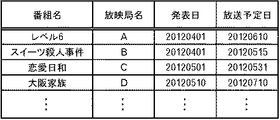
さらに、放送予定DB37には、例えば図7に示すようなデータが格納されている。図7の例では、番組名と、放送局名と、発表日と、放送予定日とが登録されるようになっている。本実施の形態では、映像コンテンツとして、テレビのドラマ番組を一例としているが、映画の放送、映画の劇場公開などであってもよい。さらに、後にも述べるが、ドラマ番組ではなく、他のカテゴリに属する番組、例えば旅行記、動物関係、スポーツ関係などであっても良い。
Further, the
次に、図8乃至図18を用いて、図1に示したシステムの処理内容について説明する。なお、以下の処理については、既にユーザが図書館端末5(ユーザ端末7、携帯端末9であっても良い)を操作して、図書館サーバ3へログインしており、図書館サーバ3側ではアクセス元ユーザのユーザIDを識別しているものとする。 Next, processing contents of the system shown in FIG. 1 will be described with reference to FIGS. For the following processing, the user has already operated the library terminal 5 (may be the user terminal 7 or the portable terminal 9) to log in to the library server 3, and the library server 3 side is the access source user. It is assumed that the user ID is identified.
まず、図書館端末5は、ユーザからの指示に応じてメニューページにアクセスすると(図8:ステップS1)、図書館サーバ3の要求処理部31は、メニューページデータを要求元の図書館端末5へ返信する(ステップS3)。図書館端末5は、図書館サーバ3からメニューページデータを受信し、表示部に表示する(ステップS5)。
First, when the library terminal 5 accesses the menu page according to an instruction from the user (FIG. 8: step S1), the
例えば、図9に示すような画面表示が行われる。図9の画面例では、メニュー項目として、図書館からのメッセージ、予約状況、本のご紹介としてドラマ化予定の本及びランキングといった項目が含まれている。 For example, a screen display as shown in FIG. 9 is performed. In the screen example of FIG. 9, menu items include items such as messages from the library, reservation status, books to be dramaized and rankings as introductions of books.
ここでは、ユーザがドラマ化予定の本というメニュー項目(一般化すれば映像関連書籍の紹介)を選択すると、図書館端末5は、映像関連書籍の紹介というメニュー項目の選択指示を受け付け、本メニュー項目の選択指示を図書館サーバ3へ送信する(ステップS7)。図書館サーバ3の要求処理部31は、図書館端末5から、映像関連書籍の紹介という選択指示を受信すると(ステップS9)、要求処理部31は、読書期間の指定ページデータを、図書館端末5へ送信する(ステップS11)。
Here, when the user selects a menu item called a book to be dramaized (introduction of a video-related book if generalized), the library terminal 5 accepts an instruction to select a menu item called introduction of a video-related book, and this menu item Is sent to the library server 3 (step S7). When the
図書館端末5は、図書館サーバ3から、読書期間の指定ページデータを受信すると、表示部に表示する(ステップS13)。例えば図10に示すような画面が表示される。図10の例では、読書期間を指定することを通知するためのボタンと、読書期間を指定しないことを通知するためのボタンと、読書期間を指定する場合には、読書期間の初日及び最終日を指定するためのプルダウンとが設けられている。 When the library terminal 5 receives the designated page data for the reading period from the library server 3, the library terminal 5 displays it on the display unit (step S13). For example, a screen as shown in FIG. 10 is displayed. In the example of FIG. 10, a button for notifying that the reading period is specified, a button for notifying that the reading period is not specified, and the first and last days of the reading period when the reading period is specified. And a pull-down for designating.
ユーザは、読書期間を指定しない場合には、そのためのボタンを押し、読書期間を指定する場合には、読書期間の初日及び最終日を指定した上で、そのためのボタンを押す。 When not specifying the reading period, the user presses a button for that purpose, and when specifying the reading period, the user specifies the first day and the last day of the reading period and then presses the button for that purpose.
図書館端末5は、ユーザから、読書期間の指定(指定無しを含む)を受け付け、読書期間の指定データを図書館サーバ3へ送信する(ステップS15)。図書館サーバ3の要求処理部31は、図書館端末5から読書期間の指定データを受信すると(ステップS17)、ユーザID及び読書期間の指定データを含む映像関連書籍の抽出要求を、データ抽出部32に出力する。
The library terminal 5 accepts a reading period designation (including no designation) from the user, and transmits reading period designation data to the library server 3 (step S15). When the
データ抽出部32は、映像関連書籍の抽出要求を受け取ると、映像関連書籍の抽出処理を実行する(ステップS19)。この映像関連書籍の抽出処理については、図11乃至図16を用いて説明する。
Upon receiving the video-related book extraction request, the
まず、データ抽出部32は、関連書籍抽出処理を実行する(図11:ステップS31)。関連書籍抽出処理については、図12及び図13を用いて説明する。
First, the
データ抽出部32は、まず、放送予定DB37から未処理のレコードを1つ読み出す(図12:ステップS151)。そして、データ抽出部32は、読み出したレコードに含まれるデータを基に、番組紹介ページを検索するように検索サーバ11に要求する(ステップS153)。そして、データ抽出部32は、検索サーバ11から検索結果を受信する。例えば、番組名及び放送局名などを検索条件として含む検索要求を検索サーバ11に出力し、検索要求に応じた検索を実行させる。
First, the
その後、データ抽出部32は、検索サーバ11からの検索結果が、読み出したレコードについての何らかの検索データを含むか否かを判断する(ステップS155)。検索サーバ11からの検索結果が、読み出したレコードについての何らかの検索データを含んでいない場合には、処理はステップS165に移行する。
Thereafter, the
一方、検索サーバ11からの検索結果が、読み出したレコードについての何らか検索データを含む場合には、データ抽出部32は、原作書籍名、作家名及び出版社名を、抽出された番組紹介ページのデータから抽出する処理を実行する(ステップS157)。例えば、番組紹介ページのデータ及びリンク先のページのデータを収集して、その中で原作書籍名、作家名及び出版社名を、収集されたデータの中からテキストマイニングなどの技術によって抽出する処理を実行する。
On the other hand, when the search result from the
そして、データ抽出部32は、ステップS157で、原作書籍名、作家名及び出版社名を抽出できたか判断する(ステップS159)。原作書籍名、作家名及び出版社名を抽出できなければ、処理はステップS165に移行する。なお、出版社名が抽出できなくても、原作書籍名及び作家名が抽出できればよいことにする場合もある。それらを抽出できなければ、処理はステップS165に移行する。
Then, the
一方、原作書籍名、作家名及び出版社名を抽出できた場合には、データ抽出部32は、抽出された原作書籍名、作家名及び出版社名で書籍DB35を検索し、書籍ID及び総ページ数を抽出する(ステップS161)。そして、データ抽出部32は、放送予定DB37から読み出したレコードのデータ及び抽出されたデータを、データ格納部38における関連付けテーブルに登録する(ステップS163)。
On the other hand, when the original book name, the author name, and the publisher name can be extracted, the
例えば、図13に示すような関連付けテーブルが生成される。図13の例では、番組名と、原作書籍名と、作者名と、出版社名と、放送予定日と、日数と、総ページ数と、書籍IDとが登録されるようになっている。番組名及び放送予定日は、放送予定DB37から抽出されたデータであり、原作書籍名、作者名及び出版社名についてはウェブ検索などで得られたデータであり、総ページ数及び書籍IDについては書籍DB35から抽出されたデータである。日数については、以下の処理にて設定される。
For example, an association table as shown in FIG. 13 is generated. In the example of FIG. 13, the program name, original book name, author name, publisher name, scheduled broadcast date, number of days, total number of pages, and book ID are registered. The program name and the scheduled broadcast date are data extracted from the broadcast planned
そして、データ抽出部32は、放送予定DB37において未処理のレコード(放送予定DB37に存在し、かつ関連付けテーブルにレコードが存在しないレコード)が存在しているか判断する(ステップS165)。未処理のレコードが存在していれば、ステップS151に戻る。未処理のレコードが存在していなければ、処理は呼出元の処理(ステップS31)に戻る。
Then, the
以上のような処理を行うことで、映像に関連する書籍のデータが得られるようになる。 By performing the processing as described above, book data related to the video can be obtained.
なお、このような処理は、ユーザによるアクセス毎に実行するのではなく、例えば毎日一回前処理として実行するようにしても良い。また、放送予定DB37が更新される毎に実行するようにしても良い。
Note that such processing may not be executed every time the user accesses, but may be executed as a pre-processing once a day, for example. Alternatively, it may be executed every time the
さらに、上で述べたような処理ではなく、例えば電子番組表のデータを放送で又はネットワーク1を介して受信して、各番組について、関連する書籍を抽出するようにしても良い。すなわち、電子番組表のデータには、番組名、カテゴリや放送内容についての説明文が含まれているので、これらのデータから類似度が高い書籍を特定するようにしても良い。例えば、北海道旅行についての番組であれば、北海道に関連する書籍を抽出するようにしたり、パンダについての番組であれば、パンダに関連する書籍を検索サーバ11又はデータが拡充されている書籍DB35から抽出するようにしても良い。さらに、映画の公開予定又は放送予定を放送予定DB37に登録して同様の処理で関連付けテーブルを生成するようにしても良い。なお、カテゴリについては、ユーザのプリファレンスを予めユーザDB33に登録しておき、そのカテゴリに合致する番組及び書籍のみを抽出するようにしても良い。
Further, instead of the processing described above, for example, electronic program guide data may be received by broadcasting or via the
図11の処理の説明に戻って、データ抽出部32は、関連付けテーブルにレコードが含まれているか判断する(ステップS33)。関連付けテーブルにレコードが含まれていない場合、すなわち映像に関連する書籍が見つからなかった場合には、処理は端子Aを介して図16の処理に移行する。
Returning to the description of the processing in FIG. 11, the
一方、関連付けテーブルにレコードが含まれている場合には、データ抽出部32は、関連付けテーブルの各レコードにおける書籍IDで貸出DB34を検索する(ステップS35)。そして、データ抽出部32は、未貸し出しの書籍が存在しているか判断する(ステップS37)。例えば、関連付けテーブルのコピーのテーブル(以下、第2関連付けテーブルと呼ぶ)において、貸出中の書籍の書籍IDを削除することで、この第2関連付けテーブルにおいて書籍IDがいずれかのレコードに残っているか否かを判断する。未貸し出しの書籍が存在している場合には、処理は端子Bを介して図15の処理に移行する。
On the other hand, when a record is included in the association table, the
一方、未貸し出しの書籍が全く存在していない場合、データ抽出部32は、関連付けテーブルにおける各レコードの原作書籍名及び作者名で書籍DB35を検索して、出版社名が異なる同一書籍を抽出する(ステップS39)。データ抽出部32は、ステップS39において追加で抽出された書籍が存在しているか判断する(ステップS41)。追加で抽出された書籍が存在していない場合には、処理は端子Aを介して図16の処理に移行する。一方、追加で抽出された書籍が存在する場合には、データ抽出部32は、追加で抽出された書籍の書籍IDで貸出DB34を検索する(ステップS43)。そして、データ抽出部32は、追加で抽出された書籍に未貸し出しの書籍が存在するか判断する(ステップS45)。未貸し出しの書籍が存在しない場合には、処理は端子Aを介して図16の処理に移行する。一方、未貸し出しの書籍が存在する場合には、処理は端子Bを介して図15の処理に移行する。なお、未貸し出しの書籍のデータで、上で述べた第2関連付けテーブルを更新する。すなわち、出版社名を、未貸し出しの書籍についての出版社に置換し、総ページ数を、未貸し出しの書籍についての総ページ数に置換し、書籍IDを未貸し出しの書籍の書籍IDで置換する。貸し出し済みのため書籍IDが全く登録されていないレコードについては削除してしまっても良い。
On the other hand, if there are no unrented books, the
さらに、ステップS39乃至S45の処理については、関連付けテーブルにおいていずれの原作書籍についても未貸し出しの書籍が存在していない場合に実行するようにしていたが、未貸し出しの書籍が存在しない原作書籍毎に実行するようにしても良い。 Further, the processing in steps S39 to S45 is executed when there is no unrented book for any original book in the association table, but for each original book for which there is no unrented book. You may make it perform.
例えば、第2関連付けテーブルは、図13に示した関連付けテーブルが図14に示すようなテーブルに変更される。この例では、「レベル6」という書籍については書籍IDが1つも含まれていないので、未貸し出し書籍は存在していない。「スイーツ殺人事件」についても書籍IDが1つ削除されている。さらに、「恋愛日和」についても出版社、ページ数及び書籍IDが置換され、異なる出版社の書籍のデータになっている。 For example, the second association table is changed from the association table shown in FIG. 13 to the table shown in FIG. In this example, since no book ID is included for the book of “level 6”, there is no unrented book. One book ID has also been deleted for the “Sweets Murder Case”. Furthermore, the publisher, the page number, and the book ID are also replaced for the “love weather”, and the book data of different publishers is obtained.
処理は端子Bを介して図15の処理に移行して、データ抽出部32は、要求元ユーザのユーザIDでペースDB36を検索して、ユーザの全体平均読書速度及び全体平均読書頻度のデータを抽出する(ステップS47)。なお、このステップにおいてデータが抽出できない場合には、端子Aを介して図16の処理に移行するようにしても良い。
The processing shifts to the processing of FIG. 15 via the terminal B, and the
そして、データ抽出部32は、第2関連付けテーブルにおいて未貸し出しの書籍が存在する原作書籍の各々について、総ページ数と要求元ユーザの全体平均読書速度及び全体平均読書頻度とから、読み終わるまでの日数を算出する(ステップS49)。具体的には、総ページ数×全体平均読書速度/60/全体平均読書頻度により読み終わるまでの日数を算出する。ここで、例えば現在日付から放送予定日までの第1の日数と、読み終わるまでの第2の日数とを、第2関連付けテーブルに登録する。例えば、図14の「スイーツ殺人事件」の場合、現在日付が2012年5月10日であれば、第1の日数は「5」であり、第2の日数は「3」となる。すなわち、第2の日数はユーザ毎に異なる。
Then, the
そして、データ抽出部32は、ユーザによる読書期間の指定があるか判断する(ステップS51)。ユーザによる読書期間の指定がある場合には、データ抽出部32は、未貸し出し書籍がある原作書籍のうち、放送予定日が読書期間終了後であり且つ指定された読書期間で読み終わる原作書籍を抽出する(ステップS53)。ユーザの都合を考慮して放送予定日までに読み終わるか否かを判断する。そして処理は端子Cを介して図16の処理に移行する。
And the
一方、ユーザによる読書期間の指定がない場合には、データ抽出部32は、貸出DB34をユーザIDで検索して貸出中の他の書籍が存在するか否かを判断する(ステップS55)。貸出中の他の書籍が存在する場合には、データ抽出部32は、貸出中書籍のうち返却予定日が最も遅い日を特定する(ステップS57)。そして、データ抽出部32は、特定された日から第2の日数(ステップS49で算出された日数)後以降に放送予定日が設定されている原作書籍を抽出する(ステップS59)。このようにすれば、現在借りている書籍を読まずに返却するといった非効率な現象を回避することができるようになる。そして処理は端子Cを介して図16の処理に移行する。
On the other hand, when the reading period is not designated by the user, the
一方、貸出中の他の書籍が存在しない場合には、データ抽出部32は、本日から第2の日数(ステップS49で算出された日数)後以降に放送予定日が設定されている原作書籍を抽出する(ステップS61)。具体的には、第1の日数>第2の日数であるか否かを判断する。そして、処理は端子Cを介して図16の処理に移行する。
On the other hand, when there are no other books that are lent out, the
図16の処理の説明に移行して、データ抽出部32は、ステップS53、S59又はS61のいずれかで原作書籍が抽出されたか判断する(ステップS63)。抽出されていない場合には、データ抽出部32は、該当する書籍がない旨のデータを、要求処理部31に出力する。そして、要求処理部31は、該当する書籍がない旨を表すメッセージを含むページデータを生成する(ステップS67)。そして処理は呼出元の処理(ステップS19)に戻る。
Moving to the description of the processing in FIG. 16, the
一方、原作書籍が抽出された場合には、データ抽出部32は、抽出された原作書籍のデータ及び当該原作書籍に関連する番組のデータを要求処理部31に出力する。要求処理部31は、抽出された原作書籍のデータ及び当該原作書籍に関連する番組のデータを含む紹介ページデータを生成する(ステップS65)。そして処理は呼出元の処理(ステップS19)に戻る。
On the other hand, when the original book is extracted, the
このようにすれば、放送予定又は公開予定の映像コンテンツに関連し、放送予定日又は公開予定日までに読み終わると推定される書籍のデータが抽出され、それを提示できるようになる。読み終わらないような書籍を提示しても、図書館側では効率的な書籍貸し出しに繋がらず、ユーザに対して気付きを与えることは不適切なので、これを回避している。 In this way, it is possible to extract the data of the book estimated to be read by the scheduled broadcast date or the scheduled release date related to the video content scheduled to be broadcast or released, and present it. Presenting a book that does not finish reading does not lead to efficient book lending on the library side, and this is avoided because it is inappropriate to give the user awareness.
図8の処理に戻って、要求処理部31は、要求元の図書館端末5へ、紹介ページデータを送信する(ステップS21)。図書館端末5は、図書館サーバ3から紹介ページデータを受信し、表示部に表示する(ステップS23)。
Returning to the process of FIG. 8, the
例えば、図17に示すような画面が表示される。図17の例では、原作書籍名及び作者名と、番組名及び第1の日数とを含むメッセージが表示されるようになっている。ここでは1冊のみ提示しているが、抽出された原作書籍が複数であれば複数提示しても良い。一方、ユーザ「山田」よりも読書頻度が低いユーザ「本田」の場合には5日後の書籍は読み終わらないので、図18に示すような画面が表示される。図18では、第1の日数がより多い番組についての原作書籍が紹介されている。なお、第1の日数ではなく、放送予定日であってもよい。また、第2の日数を提示するようにしても良い。 For example, a screen as shown in FIG. 17 is displayed. In the example of FIG. 17, a message including the original book name and author name, the program name, and the first number of days is displayed. Although only one book is presented here, a plurality of original books may be presented as long as there are a plurality of extracted original books. On the other hand, in the case of the user “Honda” whose reading frequency is lower than that of the user “Yamada”, reading of the book after 5 days is not finished, so a screen as shown in FIG. 18 is displayed. In FIG. 18, an original book about a program having a larger number of first days is introduced. Note that the scheduled broadcast date may be used instead of the first number of days. Further, the second number of days may be presented.
以上本技術の実施の形態を説明したが、本技術はこれに限定されるものではない。例えば、処理フローについては処理結果が変わらない限り処理ステップの順番を入れ替えたり、複数の処理ステップを並列に実行するようにしても良い。 Although the embodiment of the present technology has been described above, the present technology is not limited to this. For example, as for the processing flow, as long as the processing result does not change, the order of the processing steps may be changed, or a plurality of processing steps may be executed in parallel.
さらに、ウェブベースのシステムを説明したが、例えば端末側に専用のアプリケーションをインストールして実行させるようにしても良い。図2の機能ブロック図も一例であって、プログラムモジュール構成及びデータベース構成と一致しない場合もある。 Furthermore, although the web-based system has been described, for example, a dedicated application may be installed and executed on the terminal side. The functional block diagram of FIG. 2 is also an example, and may not match the program module configuration and the database configuration.
さらに、上で述べた図書館サーバ3の機能は、複数のコンピュータにて実装される場合もある。 Further, the functions of the library server 3 described above may be implemented by a plurality of computers.
さらに、関連書籍抽出処理については、データ抽出部32が実行する例を示したが、事前に実行する場合には、前処理部を別途設けるようにしても良い。また、書籍の紹介は、メールなどで行っても良い。
Furthermore, although the example which the
なお、紹介する本のさらなる絞込みの要素として、ドラマのターゲット層(出演者、放映時間帯、ジャンル等がドラマ化の制作発表等の場で公開されるものとする)の情報や、利用者の特性(年齢、性別、職業、過去に借りたDVDや本の履歴等)をDBに格納しておき、最も利用者に合う本をおすすめ本として情報提供しても良い。例えば、出演者:過去に借りたDVDに同じ俳優が出演しているという条件、主演と利用者が同年代という条件、放映時間帯:昼ドラマであれば昼間に家でそのドラマを観られる可能性が高い専業主婦向けという条件、ジャンル:戦闘であれば男性向けという条件、アニメ化であれば子供向けという条件で絞り込むようにしても良い。 In addition, as an element of further narrowing down the books to be introduced, information on the target layer of the drama (performers, broadcast times, genres, etc. shall be released at the place of drama production announcements, etc.) Characteristics (age, gender, occupation, DVD or book history borrowed in the past, etc.) may be stored in the DB, and the book that best suits the user may be provided as a recommended book. For example, performer: the condition that the same actor appears on a DVD borrowed in the past, the condition that the lead and the user are the same age, airing time: if it is a daytime drama, the possibility of watching the drama at home in the daytime It may be narrowed down according to the condition for a full-time housewife who is high, genre: a condition for men if it is a battle, and a condition for kids if it is animated.
なお、上で述べた図書館サーバ3、図書館端末5、ユーザ端末7及び検索サーバ11は、コンピュータ装置であって、図19に示すように、メモリ2501とCPU(Central Processing Unit)2503とハードディスク・ドライブ(HDD:Hard Disk Drive)2505と表示装置2509に接続される表示制御部2507とリムーバブル・ディスク2511用のドライブ装置2513と入力装置2515とネットワークに接続するための通信制御部2517とがバス2519で接続されている。オペレーティング・システム(OS:Operating System)及び本実施例における処理を実施するためのアプリケーション・プログラムは、HDD2505に格納されており、CPU2503により実行される際にはHDD2505からメモリ2501に読み出される。CPU2503は、アプリケーション・プログラムの処理内容に応じて表示制御部2507、通信制御部2517、ドライブ装置2513を制御して、所定の動作を行わせる。また、処理途中のデータについては、主としてメモリ2501に格納されるが、HDD2505に格納されるようにしてもよい。本技術の実施例では、上で述べた処理を実施するためのアプリケーション・プログラムはコンピュータ読み取り可能なリムーバブル・ディスク2511に格納されて頒布され、ドライブ装置2513からHDD2505にインストールされる。インターネットなどのネットワーク及び通信制御部2517を経由して、HDD2505にインストールされる場合もある。このようなコンピュータ装置は、上で述べたCPU2503、メモリ2501などのハードウエアとOS及びアプリケーション・プログラムなどのプログラムとが有機的に協働することにより、上で述べたような各種機能を実現する。
The library server 3, library terminal 5, user terminal 7 and
以上述べた本実施の形態をまとめると、以下のようになる。 The above-described embodiment can be summarized as follows.
本実施の形態に係る情報処理方法は、(A)放送又は公開が予定されている映像に関するデータ及び当該映像に関連する書籍に関するデータを検索により取得し、映像の識別子と放送又は公開予定日と書籍の識別データと書籍の分量とを第1のデータ格納部に格納し、(B)ユーザ毎に当該ユーザの読書速度及び読書頻度を格納する第2のデータ格納部から、特定のユーザの読書速度及び読書頻度を読み出し、(C)第1のデータ格納部に識別データが格納されている各書籍の分量と、読み出された特定のユーザの読書速度及び読書頻度とから、各書籍について特定のユーザが読み終わるまでにかかる期間を算出し、(D)各書籍について算出された期間と第1のデータ格納部に格納されている各書籍の放送又は公開予定日とから、特定のユーザが読み終わる書籍を特定し、(E)特定された書籍に関連するデータを特定のユーザ宛に送信する処理を含む。 In the information processing method according to the present embodiment, (A) data related to a video scheduled to be broadcasted or released and data related to a book related to the video are obtained by searching, and an identifier of the video and a scheduled broadcast or release date are obtained. The identification data of the book and the amount of the book are stored in the first data storage unit, and (B) a specific user's reading from the second data storage unit that stores the reading speed and reading frequency of the user for each user. Read the speed and reading frequency, and (C) specify each book from the amount of each book whose identification data is stored in the first data storage unit and the reading speed and reading frequency of the read specific user (D) a specific user is calculated from the period calculated for each book and the broadcast or scheduled release date of each book stored in the first data storage unit. Identify the book The finishes reading, including a process of transmitting to the particular addressed to the user data associated with the book identified (E).
このようにすれば、映像コンテンツに関連する書籍のうち特定のユーザが放送又は公開予定日までに読み終わると推定される書籍のデータを特定のユーザに提供することができるので、適切な書籍を推薦できるようになる。 In this way, it is possible to provide the specific user with the data of the book that is estimated to be read by the specific user by the broadcast or scheduled release date among the books related to the video content. Can be recommended.
また、上で述べた期間を算出する処理又は上で述べた書籍を特定する処理において、書籍の識別データ毎に貸し出しの有無を格納する第3のデータ格納部に基づき、第1のデータ格納部に識別データが格納されている書籍を絞り込むようにしても良い。このようにすれば、図書館のように未貸し出し書籍の効率利用が図られるようになる。 Further, in the process of calculating the period described above or the process of specifying the book described above, the first data storage unit based on the third data storage unit that stores the presence / absence of lending for each identification data of the book You may make it narrow down the book in which identification data is stored in. In this way, efficient use of unrented books can be achieved like a library.
さらに、上で述べた書籍を特定する処理が、(d1)書籍の識別データに対応付けて貸出先のユーザの識別子と返却期限とを格納する第4のデータ格納部に基づき、特定のユーザが他の書籍を借りていれば、当該他の書籍の返却期限のうち最も遅い返却期限を特定し、(d2)最も遅い返却期限から放送又は公開予定日までの期間が、算出された期間より長いか否かを判断する処理を含むようにしても良い。このようにすれば、特定のユーザの書籍貸し出し状況に応じて、貸出中の書籍が無駄にならないように情報の提供を行うことができるようになる。 Further, the process for specifying the book described above is based on the fourth data storage unit that stores (d1) the identifier of the borrowed user and the return deadline in association with the identification data of the book. If other books are borrowed, the latest return deadline of the other books is identified, and (d2) the period from the latest return deadline to the broadcast or release date is longer than the calculated period It may be possible to include a process for determining whether or not. If it does in this way, according to the book rental condition of a specific user, information will be provided so that the book currently lent may not be wasted.
さらに、上で述べた送信する処理が、特定された書籍に対応する映像に関するデータを特定のユーザ宛に送信するようにしても良い。映像に関するデータは、例えば番組名や放送予定日などであり、これによって書籍を借りる動機付けが高められる。 Furthermore, the transmission process described above may transmit data related to the video corresponding to the specified book to a specific user. The data relating to the video is, for example, a program name, a scheduled broadcast date, and the like, thereby enhancing the motivation for borrowing a book.
なお、上で述べたような処理をコンピュータに実施させるためのプログラムを作成することができ、当該プログラムは、例えばフレキシブル・ディスク、CD−ROMなどの光ディスク、光磁気ディスク、半導体メモリ(例えばROM)、ハードディスク等のコンピュータ読み取り可能な記憶媒体又は記憶装置に格納される。なお、処理途中のデータについては、RAM等の記憶装置に一時保管される。 It is possible to create a program for causing a computer to carry out the processing described above, such as a flexible disk, an optical disk such as a CD-ROM, a magneto-optical disk, and a semiconductor memory (for example, ROM). Or a computer-readable storage medium such as a hard disk or a storage device. Note that data being processed is temporarily stored in a storage device such as a RAM.
以上の実施例を含む実施形態に関し、さらに以下の付記を開示する。 The following supplementary notes are further disclosed with respect to the embodiments including the above examples.
(付記1)
放送又は公開が予定されている映像に関するデータ及び当該映像に関連する書籍に関するデータを検索により取得し、前記映像の識別子と放送又は公開予定日と前記書籍の識別データと前記書籍の分量とを第1のデータ格納部に格納し、
ユーザ毎に当該ユーザの読書速度及び読書頻度を格納する第2のデータ格納部から、特定のユーザの読書速度及び読書頻度を読み出し、
前記第1のデータ格納部に識別データが格納されている各書籍の分量と、読み出された前記特定のユーザの読書速度及び読書頻度とから、前記各書籍について前記特定のユーザが読み終わるまでにかかる期間を算出し、
前記各書籍について算出された前記期間と前記第1のデータ格納部に格納されている前記各書籍の放送又は公開予定日とから、前記特定のユーザが読み終わる書籍を特定し、
特定された前記書籍に関連するデータを前記特定のユーザ宛に送信する
処理を、コンピュータに実行させるためのプログラム。
(Appendix 1)
Data related to a video scheduled to be broadcast or released and data related to a book related to the video are obtained by searching, and an identifier of the video, a scheduled date of broadcasting or release, identification data of the book, and an amount of the book are obtained. 1 in the data storage unit,
Read the reading speed and reading frequency of a specific user from the second data storage unit that stores the reading speed and reading frequency of the user for each user,
From the amount of each book whose identification data is stored in the first data storage unit and the reading speed and reading frequency of the read specific user until the specific user finishes reading the book To calculate the period of time
From the period calculated for each book and the broadcast or scheduled release date of each book stored in the first data storage unit, identify the book that the specific user finishes reading,
A program for causing a computer to execute a process of transmitting data related to the specified book to the specific user.
(付記2)
前記期間を算出する処理又は前記書籍を特定する処理において、
書籍の識別データ毎に貸し出しの有無を格納する第3のデータ格納部に基づき、前記第1のデータ格納部に識別データが格納されている書籍を絞り込む
付記1記載のプログラム。
(Appendix 2)
In the process of calculating the period or the process of specifying the book,
The program according to
(付記3)
前記書籍を特定する処理が、
書籍の識別データに対応付けて貸出先のユーザの識別子と返却期限とを格納する第4のデータ格納部に基づき、前記特定のユーザが他の書籍を借りていれば、当該他の書籍の返却期限のうち最も遅い返却期限を特定し、
前記最も遅い返却期限から前記放送又は公開予定日までの期間が、算出された前記期間より長いか否かを判断する
処理を含む付記1又は2記載のプログラム。
(Appendix 3)
The process of identifying the book is
If the specific user borrows another book based on the fourth data storage unit that stores the identifier of the borrowed user and the return deadline in association with the identification data of the book, the other book is returned. Identify the latest return deadline,
The program according to
(付記4)
前記送信する処理が、
特定された前記書籍に対応する映像に関するデータを前記特定のユーザ宛に送信する
処理を含む付記1乃至3のいずれか1つ記載のプログラム。
(Appendix 4)
The process to send is
The program according to any one of
(付記5)
放送又は公開が予定されている映像に関するデータ及び当該映像に関連する書籍に関するデータを検索により取得し、前記映像の識別子と放送又は公開予定日と前記書籍の識別データと前記書籍の分量とを第1のデータ格納部に格納し、
ユーザ毎に当該ユーザの読書速度及び読書頻度を格納する第2のデータ格納部から、特定のユーザの読書速度及び読書頻度を読み出し、
前記第1のデータ格納部に識別データが格納されている各書籍の分量と、読み出された前記特定のユーザの読書速度及び読書頻度とから、前記各書籍について前記特定のユーザが読み終わるまでにかかる期間を算出し、
前記各書籍について算出された前記期間と前記第1のデータ格納部に格納されている前記各書籍の放送又は公開予定日とから、前記特定のユーザが読み終わる書籍を特定し、
特定された前記書籍に関連するデータを前記特定のユーザ宛に送信する
処理を含み、コンピュータにより実行される情報処理方法。
(Appendix 5)
Data related to a video scheduled to be broadcast or released and data related to a book related to the video are obtained by searching, and an identifier of the video, a scheduled date of broadcasting or release, identification data of the book, and an amount of the book are obtained. 1 in the data storage unit,
Read the reading speed and reading frequency of a specific user from the second data storage unit that stores the reading speed and reading frequency of the user for each user,
From the amount of each book whose identification data is stored in the first data storage unit and the reading speed and reading frequency of the read specific user until the specific user finishes reading the book To calculate the period of time
From the period calculated for each book and the broadcast or scheduled release date of each book stored in the first data storage unit, identify the book that the specific user finishes reading,
An information processing method including a process of transmitting data related to the specified book to the specific user and executed by a computer.
(付記6)
放送又は公開が予定されている映像に関するデータ及び当該映像に関連する書籍に関するデータを検索により取得し、前記映像の識別子と放送又は公開予定日と前記書籍の識別データと前記書籍の分量とを第1のデータ格納部に格納し、ユーザ毎に当該ユーザの読書速度及び読書頻度を格納する第2のデータ格納部から、特定のユーザの読書速度及び読書頻度を読み出し、前記第1のデータ格納部に識別データが格納されている各書籍の分量と、読み出された前記特定のユーザの読書速度及び読書頻度とから、前記各書籍について前記特定のユーザが読み終わるまでにかかる期間を算出し、前記各書籍について算出された前記期間と前記第1のデータ格納部に格納されている前記各書籍の放送又は公開予定日とから、前記特定のユーザが読み終わる書籍を特定するデータ抽出部と、
特定された前記書籍に関連するデータを前記特定のユーザ宛に送信する送信部と、
を有する情報処理装置。
(Appendix 6)
Data related to a video scheduled to be broadcast or released and data related to a book related to the video are obtained by searching, and an identifier of the video, a scheduled date of broadcasting or release, identification data of the book, and an amount of the book are obtained. The first data storage unit reads out the reading speed and reading frequency of a specific user from a second data storage unit that stores the reading speed and reading frequency of the user for each user. From the amount of each book in which the identification data is stored in and the reading speed and reading frequency of the specific user that has been read, the period of time until the specific user finishes reading for each book is calculated, The specific user reads from the period calculated for each book and the broadcast or scheduled release date of each book stored in the first data storage unit. A data extraction unit that specifies the Waru books,
A transmission unit that transmits data related to the identified book to the specific user;
An information processing apparatus.
31 要求処理部
32 データ抽出部
33 ユーザDB
34 貸出DB
35 書籍DB
36 ペースDB
37 放送予定DB
38 データ格納部
39 データ登録部
31
34 Rental DB
35 Book DB
36 pace DB
37 Broadcast Schedule DB
38
Claims (7)
映像の公開予定日又は放送予定日と当該映像に関連する書籍の分量とが対応付いて記憶された第2記憶部を参照し、特定された前記読書速度と映像に関する書籍の分量とに応じて、映像の公開予定日又は放送予定日までに読み終えると判定された特定の書籍を抽出し、
抽出された前記特定の書籍の情報を出力する、
処理をコンピュータに実行させることを特徴とする書籍抽出プログラム。 When the identification information is acquired, the reading speed of the specific user corresponding to the acquired identification information is specified with reference to the first storage unit storing the reading speed for each user,
According to the specified reading speed and the amount of the book related to the video with reference to the second storage unit in which the scheduled release date or scheduled broadcast date of the video and the amount of the book related to the video are stored in association with each other , Extract a specific book that was determined to be read by the scheduled release date or broadcast date,
Outputting the extracted information of the specific book;
A book extraction program that causes a computer to execute processing .
前記特定のユーザの読書頻度にさらに応じて前記特定の書籍を抽出する、
ことを特徴とする、請求項1に記載の書籍抽出プログラム。 In the process of extracting the specific book,
Extracting the specific book further according to the reading frequency of the specific user;
The book extraction program according to claim 1, wherein:
書籍毎に貸出の有無を記憶した第3記憶部を参照し、前記第2記憶部に分量が記憶された書籍のうち貸し出されていない書籍の中から前記特定の書籍を抽出する、
ことを特徴とする、請求項1又は2に記載の書籍抽出プログラム。 In the process of extracting the specific book,
Referring to the third storage unit storing the presence or absence of lending for each book, and extracting the specific book from books that are not lent out of the books whose amount is stored in the second storage unit;
The book extraction program according to claim 1 or 2, characterized by the above-mentioned .
貸し出された書籍毎にユーザの識別子と返却期限とを記憶した第4記憶部を参照し、前記特定のユーザが借りている他の書籍の返却予定日から起算して前記映像の公開予定日又は放送予定日までに読み終えるか否かを判定する
ことを特徴とする、請求項1乃至3のいずれか1つに記載の書籍抽出プログラム。 In the process of extracting the specific book,
Refer to the fourth storage unit that stores the identifier and return deadline of the user for each book that has been rented, and the scheduled release date of the video calculated from the scheduled return date of other books borrowed by the specific user or Judge whether to finish reading by the scheduled broadcast date
The book extraction program according to any one of claims 1 to 3, wherein
処理を前記コンピュータにさらに実行させることを特徴とする、請求項1乃至4のいずれか1つに記載の書籍抽出プログラム。 Output information about video corresponding to the specific book
The book extraction program according to claim 1, further causing the computer to execute processing .
映像の公開予定日又は放送予定日と当該映像に関連する書籍の分量とが対応付いて記憶された第2記憶部を参照し、特定された前記読書速度と映像に関する書籍の分量とに応じて、映像の公開予定日又は放送予定日までに読み終えると判定された特定の書籍を抽出し、
抽出された前記特定の書籍の情報を出力する、
処理をコンピュータが実行することを特徴とする書籍抽出方法。 When the identification information is acquired, the reading speed of the specific user corresponding to the acquired identification information is specified with reference to the first storage unit storing the reading speed for each user,
According to the specified reading speed and the amount of the book related to the video with reference to the second storage unit in which the scheduled release date or scheduled broadcast date of the video and the amount of the book related to the video are stored in association with each other , Extract a specific book that was determined to be read by the scheduled release date or broadcast date,
Outputting the extracted information of the specific book;
A book extraction method, wherein a computer executes processing .
映像の公開予定日又は放送予定日と当該映像に関連する書籍の分量とが対応付いて記憶された第2記憶部を参照し、前記特定部により特定された前記読書速度と映像に関する書籍の分量とに応じて、映像の公開予定日又は放送予定日までに読み終えると判定された特定の書籍を抽出する抽出部と、
前記抽出部により抽出された前記特定の書籍の情報を出力する出力部と、
を有する情報処理装置。 When acquiring the identification information, the first storage unit storing the reading speed for each user is referred to, and a specific unit that specifies the reading speed of the specific user corresponding to the acquired identification information;
Referring to the second storage unit in which the scheduled release date or broadcast date of the video and the amount of the book related to the video are stored in association with each other, the reading speed specified by the specifying unit and the amount of the book related to the video And an extraction unit that extracts a specific book determined to be read by the scheduled release date or scheduled broadcast date of the video,
An output unit that outputs information of the specific book extracted by the extraction unit;
An information processing apparatus.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013056543A JP6127624B2 (en) | 2013-03-19 | 2013-03-19 | Information processing program, information processing method and apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013056543A JP6127624B2 (en) | 2013-03-19 | 2013-03-19 | Information processing program, information processing method and apparatus |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014182579A JP2014182579A (en) | 2014-09-29 |
| JP6127624B2 true JP6127624B2 (en) | 2017-05-17 |
Family
ID=51701236
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013056543A Active JP6127624B2 (en) | 2013-03-19 | 2013-03-19 | Information processing program, information processing method and apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6127624B2 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108961878A (en) * | 2018-08-31 | 2018-12-07 | 广州双快数码科技有限公司 | A kind of innovative learning platform Internet-based |
| JP7110924B2 (en) * | 2018-11-09 | 2022-08-02 | 富士通株式会社 | Library management program, method and apparatus |
| CN109741646A (en) * | 2018-12-18 | 2019-05-10 | 广雅传媒(武汉)有限公司 | A kind of psychological health education books read recommender system and method |
| CN112328885A (en) * | 2020-11-10 | 2021-02-05 | 福州米鱼信息科技有限公司 | Book purchasing method and system based on reading terminal |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001051961A (en) * | 1999-08-10 | 2001-02-23 | Hitachi Ltd | Device and system for distributing information |
| JP2002108185A (en) * | 2000-09-29 | 2002-04-10 | Akihiro Kawamura | Information providing device, information providing system, and information providing method |
| JP2005031943A (en) * | 2003-07-11 | 2005-02-03 | Fujitsu Ltd | Lending information management method and lending information management program |
| JP4254610B2 (en) * | 2004-05-14 | 2009-04-15 | ソニー株式会社 | User terminal, screen data generation method, and computer program |
-
2013
- 2013-03-19 JP JP2013056543A patent/JP6127624B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014182579A (en) | 2014-09-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11741110B2 (en) | Aiding discovery of program content by providing deeplinks into most interesting moments via social media | |
| US11550451B2 (en) | Systems and methods for providing and updating live-streaming online content in an interactive web platform | |
| US11463767B2 (en) | Temporary modifying of media content metadata | |
| JP5981024B2 (en) | Sharing TV and video programs via social networking | |
| WO2018192437A1 (en) | Media content recommendation method, server, client and storage medium | |
| CN105659206B (en) | Generating playlists for a content sharing platform based on user actions | |
| JP2020504475A (en) | Providing related objects during video data playback | |
| US9712879B2 (en) | Information processing apparatus, information processing method, and information processing program | |
| US10554924B2 (en) | Displaying content between loops of a looping media item | |
| US10755037B1 (en) | Media object annotation with interactive elements | |
| CN102971762A (en) | Facilitating interaction among users of a social network | |
| US11966433B1 (en) | Subscribe to people in videos | |
| US20170272793A1 (en) | Media content recommendation method and device | |
| JP6127624B2 (en) | Information processing program, information processing method and apparatus | |
| US8775321B1 (en) | Systems and methods for providing notification of and access to information associated with media content | |
| US9940645B1 (en) | Application installation using in-video programming | |
| US9189547B2 (en) | Method and apparatus for presenting a search utility in an embedded video | |
| CN117786159A (en) | Text material acquisition method, apparatus, device, medium and program product | |
| JP2013142906A (en) | Event evaluation device and event evaluation method | |
| JP6262926B1 (en) | Information processing apparatus, information processing method, program, and storage medium | |
| JP6139617B2 (en) | Information providing system, information providing server, information providing method, and program for information providing system | |
| JP5757886B2 (en) | Television broadcast recording reservation method, apparatus and system | |
| US20130136426A1 (en) | Web feed based recording schedule | |
| US20150106849A1 (en) | System and Method for Automatic Video Program Channel Generation | |
| WO2016004478A1 (en) | Method and platform for handling audio content |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151007 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160722 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160809 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161011 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170314 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170327 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6127624 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |