JP6098294B2 - 情報秘匿化装置、情報秘匿化方法 - Google Patents
情報秘匿化装置、情報秘匿化方法 Download PDFInfo
- Publication number
- JP6098294B2 JP6098294B2 JP2013070339A JP2013070339A JP6098294B2 JP 6098294 B2 JP6098294 B2 JP 6098294B2 JP 2013070339 A JP2013070339 A JP 2013070339A JP 2013070339 A JP2013070339 A JP 2013070339A JP 6098294 B2 JP6098294 B2 JP 6098294B2
- Authority
- JP
- Japan
- Prior art keywords
- input
- order
- data
- token
- storage
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


















Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
(分析データの収集)
(分析依頼)
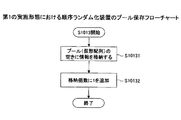
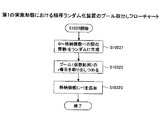
[第1の実施形態]
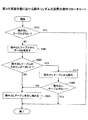
[第2の実施形態]
[第3の実施形態]
[第4の実施形態]
(付記1)
識別情報を含むデータが入力されて、入力された前記データをランダムの順序で出力する第1のランダム化装置と、
前記第1のランダム化装置から出力された前記データの前記識別情報をトークンで置換するトークン化部と、を備えた情報秘匿化装置。
(付記2)
前記第1のランダム化装置は、
所定の格納数の格納場所を有して、入力された前記データを前記格納場所に逐次格納する第1の格納部と、
前記第1の格納部の格納数に応じた第1の乱数を生成させる第1の乱数生成部と、を備え、
前記第1の乱数によってランダムに特定される前記第1の格納部の格納場所から格納された前記データを取り出して出力する付記2に記載の情報秘匿化装置。
(付記3)
前記第1の格納部の格納場所は、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に取り出す付記1又は2に記載の情報秘匿化装置。
(付記4)
前記トークンを発生させるトークン発生器と、
前記トークン発生器で発生された前記トークンが入力されて、入力された前記トークンをランダムの順序で出力する第2のランダム化装置と、をさらに備えた付記1乃至3のいずれか一に記載の情報秘匿化装置。
(付記5)
前記第2のランダム化装置は、
所定の格納数の格納場所を有して、入力された前記トークンを前記格納場所に逐次格納する第2の格納部と、
前記第2の格納部の格納数に応じた第2の乱数を生成させる第2の乱数生成部と、を備え、
前記第2の乱数によってランダムに特定される前記第2の格納部の格納場所から格納された前記トークンを取り出して出力する付記4に記載の情報秘匿化装置。
(付記6)
前記第2の格納部の格納場所は、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に取り出す付記4又は5に記載の情報秘匿化装置。
(付記7)
識別情報を含むデータが入力されて、入力された前記データをランダムの順序で出力する第1のランダム化処理と、
前記第1のランダム化処理で出力された前記データの前記識別情報をトークンで置換するトークン化処理と、をコンピュータが実行する識別情報の情報秘匿化方法。
(付記8)
前記第1のランダム化処理は、
所定の格納数の格納場所を有して、入力された前記データを前記格納場所に逐次格納する第1の格納処理と、
前記第1の格納処理の格納数に応じた第1の乱数を生成させる第1の乱数生成処理と、を備え、
前記第1の乱数によってランダムに特定される前記第1の格納処理で格納される格納場所から格納された前記データを取り出して出力する処理をコンピュータが実行する付記7に記載の識別情報の情報秘匿化方法。
(付記9)
前記第1の格納処理は、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に取り出す付記7又は8に記載の情報秘匿化方法。
(付記10)
前記トークンを発生させるトークン発生処理と、
前記トークン発生処理で発生された前記トークンが入力されて、入力された前記トークンをランダムの順序で出力する第2のランダム化処理と、をさらに備えた付記7乃至9のいずれか一に記載の情報秘匿化方法。
(付記11)
前記第2のランダム化処理は、
所定の格納数の格納場所を有して、入力された前記トークンを前記格納場所に逐次格納する第2の格納処理と、
前記第2の格納処理の格納数に応じた第2の乱数を生成させる第2の乱数生成処理と、を備え、
前記第2の乱数によってランダムに特定される前記第2の格納処理で格納される格納場所から前記トークンを取り出して出力する付記10に記載の情報秘匿化方法。
(付記12)
前記第2の格納処理は、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に取り出す付記4又は5に記載の情報秘匿化方法。
(付記13)
クエリを受け付けるコマンド処理部と、
前記コマンド処理部からの指示によって記憶しているデータを出力する記憶部と、
ランダム化装置と、を備えたデータベースシステムであって、
ランダム化装置は、
所定の格納数の格納場所を有して、前記記憶部から出力されたデータを前記格納場所に逐次格納する格納部と、
前記格納部の格納数に応じた乱数を生成させる乱数生成部と、を備えたデータベースシステム。
10 トークン化装置
101、104 順序ランダム化装置
1011、1041 格納部
1012,1042 乱数発生部
102 トークン管理部
1021 トークン化部
1022 トークン登録部
103 識別子発番対応表
105 トークン発生器
11 復元装置
12 CPU
13 記憶部
14 インタフェース
15 入力装置
16 表示部
17 バス
20 分析者端末
21、31 データベースシステム
211、311 データベース管理システム
212、312 記憶部
22 分析システム
3111 コマンド処理部
3112 順序ランダム化装置
Claims (8)
- 識別情報を含むデータが所定の格納数の格納場所に入力されて、入力された前記データを、前記格納場所から、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に、ランダムの順序で出力する第1のランダム化装置と、
前記第1のランダム化装置から出力された前記データの前記識別情報をトークンで置換するトークン化部と、を備えた情報秘匿化装置。 - 前記第1のランダム化装置は、
前記格納場所を有して、入力された前記データを前記格納場所に逐次格納する第1の格納部と、
前記第1の格納部の格納数に応じた第1の乱数を生成させる第1の乱数生成部と、を備え、
前記第1の乱数によってランダムに特定される前記第1の格納部の格納場所から格納された前記データを取り出して出力する請求項1に記載の情報秘匿化装置。 - 前記トークンを発生させるトークン発生器と、
前記トークン発生器で発生された前記トークンが入力されて、入力された前記トークンをランダムの順序で出力する第2のランダム化装置と、をさらに備えた請求項1又は2記載の情報秘匿化装置。 - 前記第2のランダム化装置は、
所定の格納数の格納場所を有して、入力された前記トークンを前記格納場所に逐次格納する第2の格納部と、
前記第2の格納部の格納数に応じた第2の乱数を生成させる第2の乱数生成部と、を備え、
前記第2の乱数によってランダムに特定される前記第2の格納部の格納場所から格納された前記トークンを取り出して出力する請求項3に記載の情報秘匿化装置。 - 前記第2の格納部の格納場所は、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に取り出す請求項4に記載の情報秘匿化装置。
- 識別情報を含むデータが所定の格納数の格納場所に入力されて、入力された前記データを、前記格納場所から、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に、ランダムの順序で出力する第1のランダム化処理と、
前記第1のランダム化処理で出力された前記データの前記識別情報をトークンで置換するトークン化処理と、をコンピュータが実行する識別情報の情報秘匿化方法。 - データに含まれる識別情報をトークンで置換するトークン化部と、
前記トークン化部で出力されたデータが所定の格納数の格納場所に入力されて、入力された該データを、前記格納場所から、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に、ランダムの順序で出力する第一のランダム化装置と、を備えたことを特徴とする識別情報の情報秘匿化装置。 - データに含まれる識別情報をトークンで置換するトークン化処理と、
前記トークン化処理で出力されたデータが所定の格納数の格納場所に入力されて、入力された該データを、前記格納場所から、入力順序が早い入力データに対して入力順序が遅い入力データを優先的に、ランダムの順序で出力する第一のランダム化処理と、をコンピュータが実行する識別情報の情報秘匿化方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013070339A JP6098294B2 (ja) | 2013-03-28 | 2013-03-28 | 情報秘匿化装置、情報秘匿化方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013070339A JP6098294B2 (ja) | 2013-03-28 | 2013-03-28 | 情報秘匿化装置、情報秘匿化方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014194621A JP2014194621A (ja) | 2014-10-09 |
| JP6098294B2 true JP6098294B2 (ja) | 2017-03-22 |
Family
ID=51839846
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013070339A Expired - Fee Related JP6098294B2 (ja) | 2013-03-28 | 2013-03-28 | 情報秘匿化装置、情報秘匿化方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6098294B2 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101704702B1 (ko) * | 2016-04-18 | 2017-02-08 | (주)케이사인 | 태깅 기반의 개인 정보 비식별화 시스템 및 방법 |
| JP6916708B2 (ja) * | 2017-10-16 | 2021-08-11 | 三菱電機インフォメーションネットワーク株式会社 | データ管理システム、サーバ装置、データ利用装置、サーバプログラムおよびデータ利用プログラム |
| US10728022B2 (en) * | 2017-12-28 | 2020-07-28 | Fujitsu Limited | Secure hash operations in a trusted execution environment |
| JP2019179346A (ja) * | 2018-03-30 | 2019-10-17 | 株式会社エクサウィザーズ | 情報処理装置、情報処理システム、プログラム |
| JP6914975B2 (ja) * | 2019-01-07 | 2021-08-04 | 株式会社東芝 | 情報処理システム、情報処理装置、情報処理方法およびプログラム |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7158979B2 (en) * | 2002-05-22 | 2007-01-02 | Ingenix, Inc. | System and method of de-identifying data |
| JP2007287102A (ja) * | 2006-04-20 | 2007-11-01 | Mitsubishi Electric Corp | データ変換装置 |
| JP2007317075A (ja) * | 2006-05-29 | 2007-12-06 | Hitachi Ltd | 個人情報分割装置及び個人情報分割方法 |
-
2013
- 2013-03-28 JP JP2013070339A patent/JP6098294B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014194621A (ja) | 2014-10-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6098294B2 (ja) | 情報秘匿化装置、情報秘匿化方法 | |
| Hankins et al. | Data morphing: an adaptive, cache-conscious storage technique | |
| CN109891402A (zh) | 可撤销和在线模式转换 | |
| US7558802B2 (en) | Information retrieving system | |
| CN103810224B (zh) | 信息持久化和查询方法及装置 | |
| US8386445B2 (en) | Reorganizing database tables | |
| CN107608773A (zh) | 任务并发处理方法、装置及计算设备 | |
| JP2011510379A5 (ja) | ||
| JP5799812B2 (ja) | データ配置・計算システム、データ配置・計算方法、マスタ装置、及びデータ配置方法 | |
| US7634487B2 (en) | System and method for index reorganization using partial index transfer in spatial data warehouse | |
| Ashkiani et al. | GPU LSM: A dynamic dictionary data structure for the GPU | |
| Andrzejewski et al. | Parallel approach to incremental co-location pattern mining | |
| US20180075080A1 (en) | Computer System and Database Management Method | |
| Oosterhuis et al. | The potential of learned index structures for index compression | |
| Lester et al. | Efficient online index construction for text databases | |
| JPWO2010084754A1 (ja) | データベースシステム、データベース管理方法、及びデータベース構造 | |
| JP2021002830A (ja) | 高度なデータベース圧縮解除 | |
| CN110008246A (zh) | 元数据管理方法及装置 | |
| Daylight et al. | Memory-access-aware data structure transformations for embedded software with dynamic data accesses | |
| Asadi et al. | Dynamic memory allocation policies for postings in real-time twitter search | |
| CN103353891B (zh) | 数据库管理系统及其数据处理方法 | |
| EP4024226A1 (en) | Query tree labeling and processing | |
| JP6402600B2 (ja) | データベース装置、データ管理方法、及びプログラム | |
| JP2019074874A (ja) | 名寄せシステムおよびプログラム | |
| JP6245571B2 (ja) | データ構造、データ生成装置、その方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151204 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161027 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161101 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161226 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170124 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170206 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6098294 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |