JP6097791B2 - 話題継続願望判定装置、方法、及びプログラム - Google Patents
話題継続願望判定装置、方法、及びプログラム Download PDFInfo
- Publication number
- JP6097791B2 JP6097791B2 JP2015123890A JP2015123890A JP6097791B2 JP 6097791 B2 JP6097791 B2 JP 6097791B2 JP 2015123890 A JP2015123890 A JP 2015123890A JP 2015123890 A JP2015123890 A JP 2015123890A JP 6097791 B2 JP6097791 B2 JP 6097791B2
- Authority
- JP
- Japan
- Prior art keywords
- utterance
- feature
- flag
- user
- topic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Landscapes
- Machine Translation (AREA)
Description
本発明は、ユーザとの間で対話を行う対話システムにおいて、ユーザ発話の後、ユーザが該ユーザ発話の直前のシステム発話の話題を継続したがっているか否かを判定するための話題継続願望判定装置、方法、及びプログラムに関する。
一般に対話における発話には、その内容の対象となっている事物を表す焦点が存在する。図5のシステム発話とユーザ発話のカラムは、対話を行っているシステムとユーザの発話列を示すもので、最初の行から順に各行において、システム発話・ユーザ発話の順で発話がされたことを示す。各行の焦点は、一つ前の行のユーザ発話までの発話列からシステムが抽出した焦点を表している。焦点抽出は、ルールベースないし機械学習の手法を用いて行う。システムは、この抽出した焦点について言及した文を、発話知識データから選択ないし生成して、該文を次発話として発する。当該行のシステム発話が、この次発話である。
以下の非特許文献1の手法は、上記に述べたようなやり方を取っている。
東中竜一郎, "雑談対話システムに向けた取り組み," 人工知能研資, Vol.SIG-SLUD-70, pp.65-70, Mar. 2014.
上記で述べた、焦点に基づいて発されたシステム発話の話題が、ユーザにとって継続したい場合と、したくない場合がある。図5の1〜3行目のユーザ発話を見ると、ユーザは直前のシステム発話の話題を継続したがっている。しかし、4〜5行目のユーザ発話を見ると、ユーザは直前のシステム発話の話題を継続したがっていない。6行目のユーザ発話を見ると、ユーザは直前のシステム発話の話題に興味を持ち、継続したがっている。
ユーザが直前のシステム発話の話題を継続したがっている場合は、システムは、同じ話題を継続するか、あるいは、適宜、話題を変更するのがよいと言える。一方、ユーザが直前のシステム発話の話題を継続したがっていない場合は、システムは、話題を必ず変更する必要がある。このように、システムが適切な発話を行うには、ユーザが直前のシステム発話の話題を継続したがっているか否かの情報が必要となる。
しかしながら現状の対話技術においては、ユーザが直前のシステム発話の話題を継続したがっているか否かを判定する機構がない。このため、ユーザが直前のシステム発話の話題を継続したがっていないにも関わらず、同じ話題を継続することがあり、対話に対するユーザの満足度が低いものとなる。これを解決するため、常に定期的に(例えば2、3システム発話ごとに)話題を変更する処置を取っても、今度は、ユーザが直前のシステム発話と同じ話題を継続したがっている場合でも、話題が変わってしまい、対話に対するユーザの満足度が低いものとなることは解決されない。このように、適切な発話戦略を取ることができないため、対話に対するユーザの満足度が低いという課題がある。
本発明は、上記課題を解決するためのものであり、ユーザが直前のシステム発話の話題を継続したがっているか否かを判定することができる話題継続願望判定装置、方法、及びプログラムを提供することを目的としている。
上記課題を解決するため、第1の発明に係る話題継続願望判定装置は、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する学習手段と、発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定する判定手段とを含むことを特徴とする。
また第2の発明に係る話題継続願望判定方法は、学習手段及び判定手段を含む話題継続願望判定装置における話題継続願望判定方法であって、前記学習手段が、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成するステップと、判定手段が、発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定するステップとを含むことを特徴とする。
また、上記の前記学習手段と前記判定手段で用いる素性値は、発話中の単語や単語n-gramの頻度、または、発話中の単語の意味カテゴリの頻度、または、発話に対応する概念ベクトルの各要素値、または、発話中の文末表現の有無、または、発話中のポジティブ表現やネガティブ表現の頻度、または、発話中の文字数、または、発話中の文字種の字数、または、発話に対応する対話行為の有無、または、発話間の類似度、または、同一話題の連続出現回数、または、発話から抽出される他の任意の素性の値であることを特徴とする。
また、本発明のプログラムは、コンピュータを、上記の話題継続願望判定装置を構成する各手段として機能させるためのプログラムである。
本発明により、判定手段の入力となる発話列Aに対し、学習手段の入力となった学習データにおいて、傾向がAと類似した発話列に対応するフラグが判定結果となるので、適切な判定結果を得ることが可能となる。
本発明により、ユーザが直前のシステム発話の話題を継続したがっているか否かを判定することができ、次発話として相応しい発話をシステムが返すことにより、システムとユーザとのインタラクションが円滑になるという効果を奏する。
以下、図面とともに本発明の実施の形態を説明する。
<本発明の実施の形態に係る話題継続願望判定装置の構成>
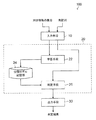
本発明の第1の実施の形態に係る話題継続願望判定装置の構成について説明する。図1は、本発明の話題継続願望判定装置の構成例である。図1に示すように、本発明の実施の形態に係る話題継続願望判定装置100は、CPUと、RAMと、後述する学習処理ルーチン及び判定処理ルーチンを実行するためのプログラムや各種データを記憶したROMと、を含むコンピュータで構成することが出来る。この話題継続願望判定装置100は、機能的には図1に示すように入力手段10と、演算手段20と、出力手段30とを備えている。
入力手段10は、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として受け付ける。上記図5のシステム発話とユーザ発話とフラグのカラムが、そのような対話情報の一例である。フラグは、ユーザが直前のシステム発話の話題を継続する願望を持っている場合、1とし、持っていない場合、0とする。このフラグは、人が発話列の内容を見て付与するものである。フラグを、発話列中の一部のユーザ発話に対してのみ付与するというようにしてもよい。また、入力手段10は、最後がユーザ発話である発話列を受け付ける。
演算手段20は、学習手段22と、分類モデル記憶部24と、判定手段26とを含んで構成されている。
学習手段22では、入力手段10によって受け付けられた対話情報の集合の各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。
以下、素性とその素性値の種類の例を述べる。素性は、種類が異なれば、同じ素性文字列でも別物として扱う。
例えば、素性として発話中の単語を、素性値としてその頻度を取ることができる。また、対象発話として、該フラグに対応するユーザ発話や、その直前のシステム発話等を取ることができ、異なる発話中の同一素性は別物とすることもできる。このことは、以降の説明で述べる他の素性についても同様である。
上記図5の1行目のユーザ発話を対象としたとき、(素性:素性値)として、(ラーメン:1)、(が:1)、(好き:1)、(です:1)が取れる。素性の個数は、学習手段22の入力となるデータ中のユーザ発話に出現する単語の異なりの総数であり、3行目のユーザ発話に出現する単語「思う」は一素性であるが、1行目のユーザ発話に対しては、この素性「思う」に対する(素性:素性値)は(思う:0)となる。以後の説明において、素性値が0の(素性:素性値)は、断りが無い限り、明示しないものとする。また、(ラーメン:1)、(好き:1)のように、内容語のみを素性として取ることもできる。
素性として発話中の単語n-gramを、素性値としてその頻度を取ることができる。n=2としたとき、上記図5の1行目のユーザ発話から、(素性:素性値)として、(ラーメン/が:1)、(が/好き:1)、(好き/です:1)が取れる。
素性として発話中の単語の意味カテゴリを、素性値としてその頻度を取ることができる。ここで、意味カテゴリとは、類義する単語を一つのカテゴリとしてまとめ上げたものを意味している。例えば、「ラーメン」の意味カテゴリが「麺類」で、「好き」の意味カテゴリが「+評価」であったとき、上記図5の1行目のユーザ発話から、(素性:素性値)として、(麺類:1)、(+評価:1)が取れる。
素性として発話に対応する概念ベクトルの各要素を、素性値としてその要素値を取ることができる。ここで概念ベクトルとは、例えば、非特許文献2の手法によって生成する単語概念ベクトルを用いて、対象発話中の単語の単語概念ベクトルを合成して得られるものである。
[非特許文献2]別所克人, 内山俊郎, 内山匡, 片岡良治, 奥雅博,“単語・意味属性間共起に基づくコーパス概念ベースの生成方式,”情報処理学会論文誌, Dec. 2008, Vol.49, No.12, pp.3997-4006.
素性として発話中の文末表現を、素性値としてその有無(有る場合:1、無い場合:0)を取ることができる。ここで、文末表現とは、文末部分の付属語等を連結して得られる文字列である。(素性:素性値)として、上記図5の1行目のユーザ発話から、(です:1)が取れ、2行目のユーザ発話から、(だよ:1)が取れる。
素性として発話中のポジティブ表現やネガティブ表現の文字列を、素性値としてその頻度を取ることができる。上記図5の1行目のユーザ発話からは、「好き」がポジティブ表現の文字列なので、(素性:素性値)として、(好き:1)が取れる。また、素性を「ポジティブ表現」と「ネガティブ表現」とし、素性値を、各表現に属する発話中文字列の頻度の和としてもよい。この場合、上記図5の1行目のユーザ発話からは、(素性:素性値)として、(ポジティブ表現:1)が取れる。
また、素性値として発話中の文字数を取ることができる。上記図5の1行目のユーザ発話からは、(素性:素性値)として、(文字数:9)が取れる。
素性として発話中の文字種を、素性値としてその文字種の字数を取ることができる。上記図5の1行目のユーザ発話からは、(素性:素性値)として、(ひらがな:4)、(カタカナ:4)、(漢字:1)が取れる。
これまでに説明した素性の種類の中で、単語、単語n-gram、単語意味カテゴリ、ポジティブ・ネガティブ表現(及びその文字列)、発話中の文字種については、それぞれの素性の種類において、各素性の素性値として、該素性に対応する頻度を、全素性に対応する頻度の総和に占める割合としてもよい。例えば、発話中の文字種については、上記図5の1行目のユーザ発話からは、(素性:素性値)として、(ひらがな:4/9)、(カタカナ:4/9)、(漢字:1/9)が取れる。
素性として発話に対応する対話行為を、素性値としてその有無(有る場合:1、無い場合:0)を取ることができる。ここで、発話の対話行為とは、その発話をした話者の発話意図であり、あらかじめ一定個数のものを定めておく。対象発話としては、該フラグに対応するユーザ発話までの一定個数の発話を取る。例えば、対象発話を、該フラグに対応するユーザ発話までの2個の発話(即ち該ユーザ発話とその直前のシステム発話)とする。各発話に対し、機械学習等の手法を用いて、対応する対話行為を導出する。(素性:素性値)として、上記図5の1行目のシステム発話から、(質問_評価:1)が取れ、1行目のユーザ発話から、(自己開示_評価+:1)が取れる。
素性値として、該フラグに対応するユーザ発話までの発話列中のある2発話(例えば、該ユーザ発話とその直前のシステム発話)の間の類似度を取ることができる。発話間の類似度は、各発話に対応するベクトルの間の余弦測度等を取ることができる。ここで、発話に対応するベクトルとして、これまでに説明した素性と素性値の組の集合である、単語頻度ベクトル、または、単語n-gram頻度ベクトル、または、単語意味カテゴリ頻度ベクトル、または、概念ベクトル等を取ることができる。あるいは発話間の類似度を、各発話から抽出された焦点集合の間に交わりが有る場合、1とし、無い場合、0とするというようにしてもよい。
素性値として、該フラグに対応するユーザ発話までの、システム発話あるいはユーザ発話において、直近の発話に至るまで、同一の話題が連続して出現した回数を取ることができる。話題としては、発話から抽出された焦点を取ることができる。システム発話に対してであれば、該システム発話を選定する基となった焦点(上記図5の焦点カラムの値)を取ることもできる。この場合、上記図5の6行目のフラグに対しては、直近のシステム発話に至るまで、同一焦点(「ラーメン」)が連続して出現した回数は5となる。同一の話題と認定する他のやり方として、各発話の概念ベクトル等の話題ベクトルと、直近の発話の話題ベクトルとの類似度が、ある閾値以上ならば、該発話群の話題は同一であるとするやり方も考えられる。
その他、該フラグに対応するユーザ発話までの発話列から抽出される任意の素性とその素性値を、以降の処理に利用することができる。
学習手段22は、上記に述べた素性の種類の中で、いくつかの種類の素性とその素性値の組の集合である素性ベクトルを、各フラグに対し生成する。図2は、各フラグと対応する素性ベクトルとの組の集合の例である。
次に、学習手段22は、各フラグを分類カテゴリとみなし、各フラグと対応する素性ベクトルとの組の集合から、サポートベクタマシン等の分類アルゴリズムを用いて、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する。そして、学習手段22は、生成された分類モデルを分類モデル記憶部24に格納する。
分類モデル記憶部24には、学習手段22によって生成された分類モデルが格納される。
判定手段26は、入力手段10によって受け付けられた、最後がユーザ発話である発話列を入力とし、該発話列から学習手段22で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。そして、分類モデル記憶部24に格納された前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定する。判定結果のフラグが1であれば、ユーザは直前のシステム発話の話題を継続したがっていると推定し、判定結果のフラグが0であれば、ユーザは直前のシステム発話の話題を継続したがっていないと推定する。
出力手段30は、判定手段26によって得られた判定結果を出力する。
<話題継続願望判定装置の作用>
図3は、話題継続願望判定装置100の学習処理フローの一例である。図3に沿って、話題継続願望判定装置100の学習処理の処理内容を説明する。
図3は、話題継続願望判定装置100の学習処理フローの一例である。図3に沿って、話題継続願望判定装置100の学習処理の処理内容を説明する。
まず、ステップS100において、入力手段10は、対話情報の集合を受け付ける。
ステップS102において、学習手段22は、上記ステップS100で受け付けた対話情報の集合の各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。
ステップS104において、学習手段22は、各フラグを分類カテゴリとみなし、上記ステップS102で生成された、各フラグと対応する素性ベクトルとの組の集合から、サポートベクタマシン等の分類アルゴリズムを用いて、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する。
ステップS106において、学習手段22は、上記ステップS104で生成された分類モデルを分類モデル記憶部24に格納し、学習処理ルーチンを終了する。
図4は、話題継続願望判定装置100の判定処理フローの一例である。図4に沿って、話題継続願望判定装置100の判定処理の処理内容を説明する。
ステップS200において、入力手段10は、最後がユーザ発話である発話列を受け付ける。
ステップS202において、判定手段26は、上記ステップS200で受け付けた発話列から学習手段22で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成する。
ステップS204において、判定手段26は、分類モデル記憶部24に格納された分類モデルを参照して、上記ステップS202で生成された素性ベクトルに対応するフラグを判定する。
ステップS206において、出力手段30は、上記ステップS204で得られた判定結果を出力して、判定処理ルーチンを終了する。
これまで述べた処理をプログラムとして構築し、当該プログラムを通信回線または記録媒体からインストールし、CPU等の手段で実施することが可能である。
なお、本発明は、上記の実施例に限定されることなく、特許請求の範囲内において、種々変更・応用が可能である。
本発明は、システムとユーザとの円滑なインタラクションを実現する対話処理技術に適用可能である。
10 入力手段
20 演算手段
22 学習手段
24 分類モデル記憶部
26 判定手段
30 出力手段
100 話題継続願望判定装置
20 演算手段
22 学習手段
24 分類モデル記憶部
26 判定手段
30 出力手段
100 話題継続願望判定装置
Claims (5)
- システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成する学習手段と、
発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定する判定手段と
を含むことを特徴とする話題継続願望判定装置。 - 前記学習手段と前記判定手段で用いる素性値は、発話中の単語や単語n-gramの頻度、または、発話中の単語の意味カテゴリの頻度、または、発話に対応する概念ベクトルの各要素値、または、発話中の文末表現の有無、または、発話中のポジティブ表現やネガティブ表現の頻度、または、発話中の文字数、または、発話中の文字種の字数、または、発話に対応する対話行為の有無、または、発話間の類似度、または、同一話題の連続出現回数、または、発話から抽出される他の任意の素性の値であることを特徴とする
請求項1記載の話題継続願望判定装置。 - 学習手段及び判定手段を含む話題継続願望判定装置における話題継続願望判定方法であって、
前記学習手段が、システムとユーザとの間の対話における発話の列と、該列における各ユーザ発話に対しあらかじめ付与された、該ユーザ発話の後、該ユーザが直前のシステム発話の話題を継続する願望を持っているか否かを示すフラグの列とを含む対話情報の集合を入力として、各対話情報中の各フラグに対し、該フラグに対応する発話までの発話列から、あらかじめ定めた素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、各フラグと対応する素性ベクトルとの組の集合から、任意の素性ベクトルに対応するフラグを判定するための分類モデルを生成するステップと、
前記判定手段が、発話列を入力とし、該発話列から学習手段で用いた各素性に対する素性値を抽出して、素性とその素性値の組の集合である素性ベクトルを生成し、前記分類モデルを参照して、該素性ベクトルに対応するフラグを判定するステップと
を含むことを特徴とする
話題継続願望判定方法。 - 前記学習手段と前記判定手段で用いる素性値は、発話中の単語や単語n-gramの頻度、または、発話中の単語の意味カテゴリの頻度、または、発話に対応する概念ベクトルの各要素値、または、発話中の文末表現の有無、または、発話中のポジティブ表現やネガティブ表現の頻度、または、発話中の文字数、または、発話中の文字種の字数、または、発話に対応する対話行為の有無、または、発話間の類似度、または、同一話題の連続出現回数、または、発話から抽出される他の任意の素性の値であることを特徴とする
請求項3記載の話題継続願望判定方法。 - コンピュータを、請求項1又は請求項2に記載の話題継続願望判定装置を構成する各手段として機能させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015123890A JP6097791B2 (ja) | 2015-06-19 | 2015-06-19 | 話題継続願望判定装置、方法、及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015123890A JP6097791B2 (ja) | 2015-06-19 | 2015-06-19 | 話題継続願望判定装置、方法、及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017010207A JP2017010207A (ja) | 2017-01-12 |
| JP6097791B2 true JP6097791B2 (ja) | 2017-03-15 |
Family
ID=57761736
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015123890A Active JP6097791B2 (ja) | 2015-06-19 | 2015-06-19 | 話題継続願望判定装置、方法、及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6097791B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6794921B2 (ja) * | 2017-05-01 | 2020-12-02 | トヨタ自動車株式会社 | 興味判定装置、興味判定方法、及びプログラム |
| JP6998517B2 (ja) | 2017-06-14 | 2022-01-18 | パナソニックIpマネジメント株式会社 | 発話継続判定方法、発話継続判定装置およびプログラム |
| US20210065708A1 (en) * | 2018-02-08 | 2021-03-04 | Sony Corporation | Information processing apparatus, information processing system, information processing method, and program |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006201870A (ja) * | 2005-01-18 | 2006-08-03 | Toyota Central Res & Dev Lab Inc | 対話処理装置 |
| JP5300497B2 (ja) * | 2009-01-07 | 2013-09-25 | 株式会社東芝 | 対話装置、対話プログラムおよび対話方法 |
| WO2014103645A1 (ja) * | 2012-12-28 | 2014-07-03 | 株式会社ユニバーサルエンターテインメント | 話題提供システム、会話制御端末装置、及び保守装置 |
-
2015
- 2015-06-19 JP JP2015123890A patent/JP6097791B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2017010207A (ja) | 2017-01-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113962315B (zh) | 模型预训练方法、装置、设备、存储介质以及程序产品 | |
| CN112673421B (zh) | 训练和/或使用语言选择模型以自动确定用于口头话语的话音辨识的语言 | |
| CN112417102B (zh) | 一种语音查询方法、装置、服务器和可读存储介质 | |
| CN110210029B (zh) | 基于垂直领域的语音文本纠错方法、系统、设备及介质 | |
| JP6884947B2 (ja) | 対話システム及びそのためのコンピュータプログラム | |
| US10811013B1 (en) | Intent-specific automatic speech recognition result generation | |
| CN115309877A (zh) | 对话生成方法、对话模型训练方法及装置 | |
| CN109791549A (zh) | 面向对话的机器用户交互 | |
| US9922650B1 (en) | Intent-specific automatic speech recognition result generation | |
| CN111428487B (zh) | 模型训练方法、歌词生成方法、装置、电子设备及介质 | |
| KR101677859B1 (ko) | 지식 베이스를 이용하는 시스템 응답 생성 방법 및 이를 수행하는 장치 | |
| Adel et al. | Features for factored language models for code-Switching speech. | |
| Dethlefs et al. | Conditional random fields for responsive surface realisation using global features | |
| CN117892736B (zh) | 基于情境感知与情绪推理的共情对话生成方法 | |
| CN111309893A (zh) | 基于源问题生成相似问题的方法和装置 | |
| CN110019691A (zh) | 会话消息处理方法和装置 | |
| CN109753661A (zh) | 一种机器阅读理解方法、装置、设备及存储介质 | |
| JP2016001242A (ja) | 質問文生成方法、装置、及びプログラム | |
| JP6097791B2 (ja) | 話題継続願望判定装置、方法、及びプログラム | |
| CN109658931B (zh) | 语音交互方法、装置、计算机设备及存储介质 | |
| JP2011242613A (ja) | 音声認識装置、音声認識方法、プログラム、及びプログラムを配信する情報処理装置 | |
| JP5136512B2 (ja) | 応答生成装置及びプログラム | |
| JP4992925B2 (ja) | 音声対話装置及びプログラム | |
| CN119741915B (zh) | 基于大模型的交互方法、训练方法、装置及智能体 | |
| WO2020199590A1 (zh) | 情绪检测分析方法及相关装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170214 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170220 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6097791 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |