JP6095621B2 - 回答候補間の関係を識別および表示する機構、方法、コンピュータ・プログラム、ならびに装置 - Google Patents
回答候補間の関係を識別および表示する機構、方法、コンピュータ・プログラム、ならびに装置 Download PDFInfo
- Publication number
- JP6095621B2 JP6095621B2 JP2014183049A JP2014183049A JP6095621B2 JP 6095621 B2 JP6095621 B2 JP 6095621B2 JP 2014183049 A JP2014183049 A JP 2014183049A JP 2014183049 A JP2014183049 A JP 2014183049A JP 6095621 B2 JP6095621 B2 JP 6095621B2
- Authority
- JP
- Japan
- Prior art keywords
- relationship
- answer
- term
- answer candidates
- corpus
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/338—Presentation of query results
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation or dialogue systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/3332—Query translation
- G06F16/3334—Selection or weighting of terms from queries, including natural language queries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Human Computer Interaction (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
(1)全ての回答候補に共通するタームは、また、タームと回答とに互いに関係があることを示すパッセージは何か?
(2)回答候補のサブセットに共通するタームは何か? タームと回答とが互いに関係があること示すパッセージは何か?
(3)全ての回答候補に共通する人は?
(4)2011年以降に公開された文書内で、五つの回答候補のうち少なくとも三つに共通する組織は?
(5)Wikipediaだけをソースとして用いて、全ての回答候補に共通する国は?
を尋ねるオプションがユーザに提示されうる。これらの例においては、実体関係データ構造464に各関係における実体についての実体タイプ情報が記憶されており、したがって各回答候補にどの関係が当てはまるかを識別する際に実体タイプも識別されることから、回答候補の間で共通する特定のタイプの実体に向けられた上の(3)のような質問が回答されうる。上の質問(4)に関しては、例えばコーパス405内の文書などの関係のソースに関連付けられたタイムスタンプがエントリに維持されているため、特定の時間フレームの文書内の組織の識別が識別されうる。質問(5)に関しては、実体関係データ構造464のエントリにソース情報が維持されているため、この質問も関心のある特定のソースに関して回答されうる。
カール・ヤストレムスキー:ボビー・ドーア;7
カール・ヤストレムスキー:カールトン・フィスク;8
カール・ヤストレムスキー:フレッド・リン;7
ロジャー・クレメンス:カールトン・フィスク;2
ロジャー・クレメンス:フレッド・リン;1
テッド・ウィリアムズ:ボビー・ドーア;12
テッド・ウィリアムズ:カールトン・フィスク;2
テッド・ウィリアムズ:フレッド・リン;1
(1)レッド・ソックス、ヤズの功績を称え、フェンウェイ・パークに銅像を建立−ヤズが1961年にレフトを継承したテッド・ウィリアムズの銅像と、ドム・ディマジオ、ジョニー・ペスキー、ボビー・ドーア、ウィリアムズを表した「チームメイト」の銅像との間に。
(2)カール・ヤストレムスキー、ジム・ライス、フレッド・リンの11×14写真、16×20ダブルマット額装。
(3)カール・ヤストレムスキー、カールトン・フィスク、ドワイト・エバンスのサイン入り。
(4)殿堂入りのカールトン・フィスクがマーク・マグワイア、ロジャー・クレメンスを非難
(5)だからウェイド・ボッグス、フレッド・リン、ロジャー・クレメンス、ノマー・ガルシアパーラ、ティト・フランコーナ、カールトン・フィスク、ジョニー・デイモンを始めとして、うちの選手はほとんど全員が厳しい評価を受けている。
(6)テッド・ウィリアムズのソックスでのルーキー・シーズンである1939年から、ドーアは12シーズン連続して10本以上のホームランと73打点以上をマークした;1940年には、フォックス、ウィリアムズ、クローニン、ドーアのそれぞれが105打点以上を挙げ、レッド・ソックスは100RBIの選手が4人いる大リーグ史上12番目のチームとなった。
(7)「素晴らしいわ」と、スタンドの若い女性が言った。「テッド・ウィリアムズがカールトン・フィスクに投球したなんて。これで満足して帰れるわ。」
(8)リンは、レッド・ソックスの先輩の一人であるテッド・ウィリアムズと同様に人前に出るのが嫌いな男で、パーティーでの欠席が目立つことになるだろう。
Claims (12)
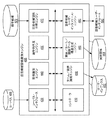
- データ処理システムにおいて、入力された質問に応答して質問応答(QA)システムに
より生成された回答候補の間の共通性を識別するための方法であって、
前記データ処理システムにより、前記QAシステムから、入力された質問への複数の回答候補を受け取るステップと;
前記データ処理システムにより、前記回答候補内に存在するタームを識別するステップと;
前記データ処理システムにより、各前記回答候補内のタームに対応する関係を決定し、
前記対応する関係に基づいて、前記複数の回答候補の少なくともサブセット内に存在する第一タームと第二タームとの間で共通する関係を決定するステップと;
前記データ処理システムにより、前記複数の回答候補と前記共通する関係とをユーザに提示するステップと
を含む、方法。 - 前記第一タームまたは前記第二タームの少なくとも一つが、実体タイプを有する実体である、請求項1に記載の方法。
- 前記共通する関係を決定するステップが、前記サブセット内の前記第一タームと前記第二タームとの間の関係の交点を決定するステップを含む、請求項1又は2に記載の方法。
- 前記共通する関係を決定するステップが、
複数のエントリを含む関係データ・ストアをサーチするステップであって、各エントリは、少なくとも一つのコーパスの文書の前処理の間に見つかった第一の見つかったタームと少なくとも一つの第二の見つかったタームとの間の関係に対応する、ステップと;
回答候補内に見つかったタームにマッチする、前記関係データ・ストア内の一つ以上のエントリを識別するステップと
を含む、請求項1乃至3のいずれかに記載の方法。 - 前記関係データ・ストア内の各エントリが、コーパスの少なくとも一つの文書の自然言語処理を通じて前記コーパスの前記少なくとも一つの文書内に識別された関係に基づいて、前記コーパスの前記少なくとも一つの文書の前処理の間に見つかった第一タームと前記コーパスの前記少なくとも一つの文書の前処理の間に見つかった第二タームとの間のペアワイズ関係を含む、請求項4に記載の方法。
- 前記関係データ・ストア内の各エントリが、前記前処理の間に前記コーパスの前記少なくとも一つの文書内に対応するペアワイズ関係が見つかった頻度を示す出現頻度値をさらに含む、請求項5に記載の方法。
- 前記複数の回答候補と前記共通する関係とをユーザに提示するステップが、各前記関係の前記出現頻度値とともに前記回答候補と前記関係との視覚的表示を生成するステップを含む、請求項6に記載の方法。
- 前記視覚的表示が、前記共通する関係を裏付ける、コーパスの少なくとも一つの文書からの少なくとも一つの証拠テキスト・パッセージをさらに含み、前記回答候補または前記証拠テキスト・パッセージの少なくとも一つの一部が、前記共通する関係の出現頻度値に対応する値に基づいて、前記視覚的表示において強調される、請求項7に記載の方法。
- 前記第一タームと前記第二タームとの間で共通する関係を決定するステップが、
前記回答候補を出力するためのグラフィカル・ユーザ・インタフェース(GUI)の第一部分と、前記回答候補間でユーザが識別を望む所望の共通する関係を指定するためにユーザが選択可能な複数のオプションを出力するための前記GUIの第二部分と、前記回答候補内の前記ターム間の関係と前記共通する関係とを出力するための前記GUIの第三部分と、前記共通する関係を裏付ける、コーパスの文書からの証拠テキスト・パッセージを出力するための前記GUIの第四部分とを提供する、前記GUIを提示するステップ
をさらに含む、請求項1乃至8のいずれかに記載の方法。 - 前記複数の回答候補と前記共通する関係とをユーザに提示するステップが、前記回答候補と、前記共通する関係を裏付ける、コーパスの少なくとも一つの文書からの少なくとも一つの証拠テキスト・パッセージとの視覚的表示を生成するステップであって、前記回答候補の少なくとも一つまたは前記少なくとも一つの証拠テキスト・パッセージの一部が、前記視覚的表示において強調されるステップを含む、請求項1乃至9のいずれかに記載の方法。
- コンピュータ・プログラムであり、コンピューティング・デバイス上で実行されると、前記コンピューティング・デバイスに、
前記QAシステムから、入力された質問への複数の回答候補を受け取るステップと;
前記回答候補内に存在するタームを識別するステップと;
各前記回答候補内のタームに対応する関係を決定し、前記対応する関係に基づいて、前記複数の回答候補の少なくともサブセット内に存在する第一タームと第二タームとの間で共通する関係を決定するステップと、;
前記複数の回答候補と前記共通する関係とをユーザに提示するステップと
を実行させるコンピュータ・プログラム。 - プロセッサと;
前記プロセッサに結合されたメモリとを含む装置であって、前記メモリは命令を含み、前記命令は、前記プロセッサにより実行されると、
前記QAシステムから、入力された質問への複数の回答候補を受け取ること;
前記回答候補内に存在するタームを識別すること;
各前記回答候補内のタームに対応する関係を決定し、前記対応する関係に基づいて、前記複数の回答候補の少なくともサブセット内に存在する第一タームと第二タームとの間で共通する関係を決定すること;および
前記複数の回答候補と前記共通する関係とをユーザに提示すること
を前記プロセッサに行わせる、
装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/097,697 US9558263B2 (en) | 2013-12-05 | 2013-12-05 | Identifying and displaying relationships between candidate answers |
| US14/097697 | 2013-12-05 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2015109068A JP2015109068A (ja) | 2015-06-11 |
| JP2015109068A5 JP2015109068A5 (ja) | 2015-11-05 |
| JP6095621B2 true JP6095621B2 (ja) | 2017-03-15 |
Family
ID=53185389
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014183049A Active JP6095621B2 (ja) | 2013-12-05 | 2014-09-09 | 回答候補間の関係を識別および表示する機構、方法、コンピュータ・プログラム、ならびに装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (2) | US9558263B2 (ja) |
| JP (1) | JP6095621B2 (ja) |
| CN (1) | CN104699730B (ja) |
| DE (1) | DE102014113870A1 (ja) |
Families Citing this family (38)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9558263B2 (en) | 2013-12-05 | 2017-01-31 | International Business Machines Corporation | Identifying and displaying relationships between candidate answers |
| US20160162582A1 (en) * | 2014-12-09 | 2016-06-09 | Moodwire, Inc. | Method and system for conducting an opinion search engine and a display thereof |
| US10783159B2 (en) * | 2014-12-18 | 2020-09-22 | Nuance Communications, Inc. | Question answering with entailment analysis |
| US10303798B2 (en) * | 2014-12-18 | 2019-05-28 | Nuance Communications, Inc. | Question answering from structured and unstructured data sources |
| US10558666B2 (en) * | 2015-07-10 | 2020-02-11 | Trendkite, Inc. | Systems and methods for the creation, update and use of models in finding and analyzing content |
| CN105589844B (zh) * | 2015-12-18 | 2017-08-08 | 北京中科汇联科技股份有限公司 | 一种用于多轮问答系统中缺失语义补充的方法 |
| CN105608183B (zh) * | 2015-12-22 | 2018-11-02 | 北京奇虎科技有限公司 | 一种提供聚合类型回答的方法和装置 |
| EP3188039A1 (en) * | 2015-12-31 | 2017-07-05 | Dassault Systèmes | Recommendations based on predictive model |
| JP6334587B2 (ja) * | 2016-03-08 | 2018-05-30 | 日本電信電話株式会社 | 単語抽出装置、方法、及びプログラム |
| US9842096B2 (en) * | 2016-05-12 | 2017-12-12 | International Business Machines Corporation | Pre-processing for identifying nonsense passages in documents being ingested into a corpus of a natural language processing system |
| US10169328B2 (en) | 2016-05-12 | 2019-01-01 | International Business Machines Corporation | Post-processing for identifying nonsense passages in a question answering system |
| US10585898B2 (en) | 2016-05-12 | 2020-03-10 | International Business Machines Corporation | Identifying nonsense passages in a question answering system based on domain specific policy |
| EP3443467B1 (en) * | 2016-05-17 | 2020-09-16 | Microsoft Technology Licensing, LLC | Machine comprehension of unstructured text |
| JP6727610B2 (ja) * | 2016-09-05 | 2020-07-22 | 国立研究開発法人情報通信研究機構 | 文脈解析装置及びそのためのコンピュータプログラム |
| US10558754B2 (en) * | 2016-09-15 | 2020-02-11 | Infosys Limited | Method and system for automating training of named entity recognition in natural language processing |
| US10824681B2 (en) * | 2016-11-21 | 2020-11-03 | Sap Se | Enterprise resource textual analysis |
| US10681572B2 (en) | 2017-03-30 | 2020-06-09 | International Business Machines Corporation | Dynamic bandwidth analysis for mobile devices |
| US11361229B2 (en) | 2017-07-24 | 2022-06-14 | International Business Machines Corporation | Post-processor for factoid answer conversions into structured relations in a knowledge base |
| US10803100B2 (en) * | 2017-11-30 | 2020-10-13 | International Business Machines Corporation | Tagging named entities with source document topic information for deep question answering |
| US10810215B2 (en) * | 2017-12-15 | 2020-10-20 | International Business Machines Corporation | Supporting evidence retrieval for complex answers |
| CN110019719B (zh) * | 2017-12-15 | 2023-04-25 | 微软技术许可有限责任公司 | 基于断言的问答 |
| US10901989B2 (en) * | 2018-03-14 | 2021-01-26 | International Business Machines Corporation | Determining substitute statements |
| US11321618B2 (en) | 2018-04-25 | 2022-05-03 | Om Digital Solutions Corporation | Learning device, image pickup apparatus, image processing device, learning method, non-transient computer-readable recording medium for recording learning program, display control method and inference model manufacturing method |
| JP7099031B2 (ja) * | 2018-04-27 | 2022-07-12 | 日本電信電話株式会社 | 回答選択装置、モデル学習装置、回答選択方法、モデル学習方法、プログラム |
| WO2019208222A1 (ja) * | 2018-04-27 | 2019-10-31 | 日本電信電話株式会社 | 回答選択装置、回答選択方法、回答選択プログラム |
| US11048878B2 (en) * | 2018-05-02 | 2021-06-29 | International Business Machines Corporation | Determining answers to a question that includes multiple foci |
| US11106664B2 (en) * | 2018-05-03 | 2021-08-31 | Thomson Reuters Enterprise Centre Gmbh | Systems and methods for generating a contextually and conversationally correct response to a query |
| CN112106056A (zh) * | 2018-05-09 | 2020-12-18 | 甲骨文国际公司 | 构造虚构的话语树来提高回答聚敛性问题的能力 |
| US11016985B2 (en) * | 2018-05-22 | 2021-05-25 | International Business Machines Corporation | Providing relevant evidence or mentions for a query |
| CN109635277B (zh) * | 2018-11-13 | 2023-05-26 | 北京合享智慧科技有限公司 | 一种获取实体信息的方法及相关装置 |
| CN112115241B (zh) * | 2019-06-21 | 2023-09-05 | 百度在线网络技术(北京)有限公司 | 问答方法、装置及设备 |
| US11521078B2 (en) * | 2019-07-10 | 2022-12-06 | International Business Machines Corporation | Leveraging entity relations to discover answers using a knowledge graph |
| US11188991B2 (en) | 2020-02-07 | 2021-11-30 | International Business Machines Corporation | Real estate advisor engine on cognitive system |
| JP7168963B2 (ja) * | 2020-04-28 | 2022-11-10 | 株式会社Askプロジェクト | 自然言語処理装置及び自然言語処理方法 |
| JP7112107B2 (ja) * | 2020-04-28 | 2022-08-03 | 株式会社Askプロジェクト | 自然言語処理装置及び自然言語処理方法 |
| US20210383075A1 (en) * | 2020-06-05 | 2021-12-09 | International Business Machines Corporation | Intelligent leading multi-round interactive automated information system |
| CN111814477B (zh) * | 2020-07-06 | 2022-06-21 | 重庆邮电大学 | 一种基于争议焦点实体的争议焦点发现方法、装置及终端 |
| CN113392321A (zh) * | 2021-06-02 | 2021-09-14 | 北京三快在线科技有限公司 | 一种信息推荐方法、装置、电子设备及存储介质 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5519608A (en) | 1993-06-24 | 1996-05-21 | Xerox Corporation | Method for extracting from a text corpus answers to questions stated in natural language by using linguistic analysis and hypothesis generation |
| JP3960530B2 (ja) | 2002-06-19 | 2007-08-15 | 株式会社日立製作所 | テキストマイニングプログラム、方法、及び装置 |
| JP2007199876A (ja) * | 2006-01-24 | 2007-08-09 | Fuji Xerox Co Ltd | 質問応答システム、質問応答処理方法及び質問応答プログラム |
| US7890521B1 (en) * | 2007-02-07 | 2011-02-15 | Google Inc. | Document-based synonym generation |
| US8275803B2 (en) | 2008-05-14 | 2012-09-25 | International Business Machines Corporation | System and method for providing answers to questions |
| CN101872349B (zh) * | 2009-04-23 | 2013-06-19 | 国际商业机器公司 | 处理自然语言问题的方法和装置 |
| US8280838B2 (en) | 2009-09-17 | 2012-10-02 | International Business Machines Corporation | Evidence evaluation system and method based on question answering |
| US20110125734A1 (en) | 2009-11-23 | 2011-05-26 | International Business Machines Corporation | Questions and answers generation |
| JP5816936B2 (ja) * | 2010-09-24 | 2015-11-18 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 質問に対する解答を自動的に生成するための方法、システム、およびコンピュータ・プログラム |
| US8738617B2 (en) | 2010-09-28 | 2014-05-27 | International Business Machines Corporation | Providing answers to questions using multiple models to score candidate answers |
| EP2622599B1 (en) | 2010-09-28 | 2019-10-23 | International Business Machines Corporation | Evidence diffusion among candidate answers during question answering |
| CN103229162B (zh) * | 2010-09-28 | 2016-08-10 | 国际商业机器公司 | 使用候选答案逻辑综合提供问题答案 |
| US8601030B2 (en) | 2011-09-09 | 2013-12-03 | International Business Machines Corporation | Method for a natural language question-answering system to complement decision-support in a real-time command center |
| US9558263B2 (en) | 2013-12-05 | 2017-01-31 | International Business Machines Corporation | Identifying and displaying relationships between candidate answers |
-
2013
- 2013-12-05 US US14/097,697 patent/US9558263B2/en active Active
-
2014
- 2014-09-05 CN CN201410450065.6A patent/CN104699730B/zh active Active
- 2014-09-09 JP JP2014183049A patent/JP6095621B2/ja active Active
- 2014-09-25 DE DE102014113870.8A patent/DE102014113870A1/de active Pending
-
2016
- 2016-02-15 US US15/043,785 patent/US9558264B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| DE102014113870A1 (de) | 2015-06-11 |
| US9558264B2 (en) | 2017-01-31 |
| JP2015109068A (ja) | 2015-06-11 |
| US20150161242A1 (en) | 2015-06-11 |
| US9558263B2 (en) | 2017-01-31 |
| CN104699730B (zh) | 2018-02-16 |
| US20160171095A1 (en) | 2016-06-16 |
| CN104699730A (zh) | 2015-06-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6095621B2 (ja) | 回答候補間の関係を識別および表示する機構、方法、コンピュータ・プログラム、ならびに装置 | |
| US10586155B2 (en) | Clarification of submitted questions in a question and answer system | |
| US10102254B2 (en) | Confidence ranking of answers based on temporal semantics | |
| US10339453B2 (en) | Automatically generating test/training questions and answers through pattern based analysis and natural language processing techniques on the given corpus for quick domain adaptation | |
| US9318027B2 (en) | Caching natural language questions and results in a question and answer system | |
| US9621601B2 (en) | User collaboration for answer generation in question and answer system | |
| US9965548B2 (en) | Analyzing natural language questions to determine missing information in order to improve accuracy of answers | |
| US9740769B2 (en) | Interpreting and distinguishing lack of an answer in a question answering system | |
| US9715531B2 (en) | Weighting search criteria based on similarities to an ingested corpus in a question and answer (QA) system | |
| US9342561B2 (en) | Creating and using titles in untitled documents to answer questions | |
| US9720962B2 (en) | Answering superlative questions with a question and answer system | |
| US20190188271A1 (en) | Supporting evidence retrieval for complex answers | |
| US9760828B2 (en) | Utilizing temporal indicators to weight semantic values | |
| US9697099B2 (en) | Real-time or frequent ingestion by running pipeline in order of effectiveness | |
| US10628749B2 (en) | Automatically assessing question answering system performance across possible confidence values | |
| US11520847B2 (en) | Learning interpretable strategies in the presence of existing domain knowledge |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150915 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150915 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160713 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20161013 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20161013 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161213 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170124 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170214 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6095621 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |