JP6070064B2 - Node device, cluster system, failover method and program - Google Patents
Node device, cluster system, failover method and program Download PDFInfo
- Publication number
- JP6070064B2 JP6070064B2 JP2012237731A JP2012237731A JP6070064B2 JP 6070064 B2 JP6070064 B2 JP 6070064B2 JP 2012237731 A JP2012237731 A JP 2012237731A JP 2012237731 A JP2012237731 A JP 2012237731A JP 6070064 B2 JP6070064 B2 JP 6070064B2
- Authority
- JP
- Japan
- Prior art keywords
- node
- processing
- node device
- storage
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Description
本発明はノード装置、クラスタシステム、フェイルオーバー方法およびプログラムに関し、特に異常発生時に短時間にフェイルオーバー処理を可能とするノード装置等に関する。 The present invention relates to a node device, a cluster system, a failover method, and a program, and more particularly, to a node device that enables failover processing in a short time when an abnormality occurs.
企業などで利用されるコンピュータシステムにおいては、短時間の停止であっても、その間に発生した業務の停止によって巨額の損失が発生することがある。そのため、そのようなコンピュータシステムにおいては「高可用性(High Availability)」、より具体的には「稼働率99.99%以上(年間停止時間52分以下)」が求められている。そのようなコンピュータシステムでは、サーバクラスタと呼ばれる構成が多く利用されている。 In a computer system used in a company or the like, even if it is stopped for a short period of time, a huge loss may occur due to the stoppage of business during that time. Therefore, in such a computer system, “High Availability”, more specifically “operation rate of 99.99% or more (annual downtime of 52 minutes or less)” is required. In such a computer system, a configuration called a server cluster is often used.
サーバクラスタは、同一のNAS(Network Attached Storage、ネットワーク接続ストレージ)を参照する複数台のサーバコンピュータが1台の仮想サーバとして動作するように構成したものである。サーバクラスタは、このNASの利用形態により、「アクティブ−アクティブ構成」と「アクティブ−パッシブ構成」の2種類に分類される。 The server cluster is configured such that a plurality of server computers that refer to the same NAS (Network Attached Storage) operate as one virtual server. Server clusters are classified into two types, “active-active configuration” and “active-passive configuration”, according to the usage form of NAS.
アクティブ−アクティブ構成のサーバクラスタは、当該サーバクラスタを構成する各サーバがいずれも稼働系サーバとして動作して処理を行う。このため、オフロード(off-load、負荷分散)も兼ねることができ、システム全体でのパフォーマンスを向上させることも可能である。 In an active-active server cluster, each server constituting the server cluster operates as an active server for processing. For this reason, it can also serve as off-load (load distribution), and it is also possible to improve the performance of the entire system.
図10は、特許文献1に記載されている、既存のクラスタシステム901の構成について示す説明図である。クラスタシステム901は、第一ノード910および第二ノード920という各々のコンピュータ装置(サーバ)と、その他多数のクライアント装置940とが、ネットワーク941を介して相互に接続されて構成されている。
FIG. 10 is an explanatory diagram showing the configuration of an existing cluster system 901 described in
第一ノード910および第二ノード920は、共有の外部記憶装置である共有ストレージ930と接続されている。そして、第一ノード910および第二ノード920は、処理にかかる負荷を相互に分散しつつ、記憶されているデータを互いにミラーリングして、どちらか一方に故障が発生した場合にその故障した方の装置で行われていた処理を残る一方が引き継いで続行する(これをフェイルオーバーという)ことができる構成となっている。
The
第一ノード910は、コンピュータプログラムを実行する主体であるプロセッサ911と、処理中のデータを一時的に記憶する不揮発性の主記憶装置であるNVRAM(Non-Volatile RAM)912と、処理されたデータを共有ストレージ930に固定的に記憶する外部ストレージ接続手段913と、ネットワーク941を介して第二ノード920や各クライアント装置940との間で通信を行う通信手段914とが備えられている。
The
プロセッサ911は、クライアント装置940からの依頼に基づく処理を行うアプリケーションソフトを実行してそのデータをNVRAM912に書き込むアプリケーション実行部951と、NVRAM912との間のデータ交換を仲介するデバイスドライバを動作させるNVRAMドライバ実行部952と、外部ストレージ接続手段913を経由して共有ストレージ930との間のデータ交換を仲介するデバイスドライバを動作させるストレージ装置ドライバ実行部953と、通信手段14との間のデータ交換を仲介するデバイスドライバを動作させる外部通信ドライバ954として機能する。
The
NVRAM912は、第一ノード910で行われる処理についてデータを一時的に書き込む第一ノード用領域912aと、第二ノード920で行われる処理で後述のNVRAM922に書き込まれたデータをミラーリングする第二ノード用領域912bとに分かれている。第一ノード910では、クライアント装置940からの依頼に応じて第一ノード用領域912aに対してデータ処理を行い、その内容を第二ノード920側の第一ノード用領域922aにもコピーして反映させる。
The NVRAM 912 is a
プロセッサ911はさらに、各々のプログラムの動作により、アプリケーション実行部951がクライアント装置940からの依頼に応じて第一ノード用領域912aに書き込んだデータを第二ノード920の第一ノード用領域922aにコピーして反映させるミラーリング処理部955と、そのデータを共有ストレージ930に記憶するストレージ記憶部956と、第二ノード920で異常が発生した場合にその処理を引き継ぐフェイルオーバー処理部957としても機能する。
The
第二ノード920は、ハードウェア的にもソフトウェア的にも、次に説明する点を除いては第一ノード910と同一の構成を有するので、呼称は全て同一とし、参照番号は各々+10ずつしていう。即ち、ハードウェアとしてはプロセッサ921、NVRAM922…などのようにいい、ソフトウェアとしてはアプリケーション実行部961、NVRAMドライバ実行部962…などのようにいう。
The
第二ノード920の、第一ノード910と比べての唯一の相違点について説明する。NVRAM922は、第一ノード910で行われる処理でNVRAM912に書き込まれたデータをミラーリングする第一ノード用領域922aと、第二ノード920で行われる処理についてデータを一時的に書き込む第二ノード用領域922bとに分かれている。第二ノード920では、クライアント装置940からの依頼に応じて第二ノード用領域922bに対してデータ処理を行い、その内容を第一ノード910側の第二ノード用領域912bにもコピーして反映させる。
The only difference between the
第一ノード910のアプリケーション実行部951がデータをNVRAM912の第一ノード用領域912aに書き込む際には、既にファイルシステムに書き込み可能な状態で記憶させる。第二ノード920のアプリケーション実行部961がデータをNVRAM922の第二ノード用領域922bに書き込む際も同様である。この状態のデータに対して、第一ノード910および第二ノード920は互いにミラーリング処理部955および965によってNVRAM912および922のデータを相互にミラーリングし、そしてストレージ記憶部956もしくは966によって共有ストレージ930に記憶させる。
When the
ここで、たとえば第一ノード910で、NVRAM912上に共有ストレージ930に未反映のデータが残った状態で異常が発生した場合には、第二ノード920側でフェイルオーバー処理部967が、第一ノード用領域922a上のデータに対してリカバリ処理、即ち共有ストレージ930に記憶させる処理を行った後で、各クライアント装置940からのアクセス受付を再開させる。第二ノード920で同様の異常が発生した場合には、第一ノード910がこれと同様の動作を行う。
Here, for example, if an abnormality occurs in the
このように構成することで、第一ノード910と第二ノード920とで各クライアント装置940からのアクセスにかかる処理の負荷を分散しつつ、一方で異常が発生した時には残る一方ですぐに処理を再開することが可能となる。この構造は、自ノード用の領域を使用する限りにおいては、シングルシステムと同様の構造で動作することができる。このため、クラスタ構成として特別な改造が必要なく、通常運用での構造変更を必要としないでクラスタシステムの構築が可能となる。
By configuring in this way, the
他にこれに関連する技術文献として、たとえば次の各文献がある。その中でも特許文献2には、NVRAMを複数ブロックに分割して各ブロックごとにリード/ライトプロテクトすることが可能であるというディスク制御装置について記載されている。特許文献3には、遠隔地に設置されたリモートサイトにデータをミラーリングするシステムについて記載されている。非特許文献1および2には、NASクラスタモデルの基本的な構成について記載されている。
Other technical documents relating to this include the following documents, for example. Among them, Patent Document 2 describes a disk control device that can divide NVRAM into a plurality of blocks and perform read / write protection for each block. Patent Document 3 describes a system that mirrors data at a remote site installed at a remote location. Non-Patent
図10で説明した特許文献1記載の既存のクラスタシステム901は、前述したように、通常動作時には負荷を分散しつつ、異常発生時にもすぐに処理を再開することが可能である。
As described above, the existing cluster system 901 described in
しかしながらこの構成では、NVRAM912または922上のデータを共有ストレージ930に反映を完了させないと、データの整合性を保つことができない。この処理の途中で異常が発生した場合、共有ストレージ930に途中まで書き込んでいたデータの整合性は失われてしまう。
However, in this configuration, data consistency cannot be maintained unless data on the
前述の第一ノード910で異常が発生した場合の例でいえば、第二ノード920側で第一ノード用領域922a上のデータに対するリカバリ処理、即ち当該データを共有ストレージ930に記憶させる処理が、第二ノード920が第一ノード910の動作を引き継ぐためには必要である。第二ノード920で異常が発生した場合も同様である。
Speaking of an example when an abnormality occurs in the
従って、そのリカバリ処理を行うための時間が必要であり、クライアント装置940に異常の発生を報告する必要が生じることともなる。この問題を解決しうる技術は、残る特許文献2〜3および非特許文献1〜2にも記載されていない。 Therefore, it takes time to perform the recovery process, and it becomes necessary to report the occurrence of an abnormality to the client device 940. The technology that can solve this problem is not described in the remaining Patent Documents 2-3 and Non-Patent Documents 1-2.
本発明の目的は、クライアント装置側に異常の発生を意識させることなく、ごく短時間でフェイルオーバー処理を行うことを可能とするクラスタシステム、ノード、フェイルオーバー方法およびプログラムを提供することにある。 An object of the present invention is to provide a cluster system, a node, a failover method, and a program capable of performing failover processing in a very short time without making the client device aware of the occurrence of an abnormality.
上記目的を達成するため、本発明に係るノード装置は、他のノード装置と相互に接続されてクラスタシステムを構成すると共に、他のノード装置との間で共有される外部記憶装置である共有ストレージに接続されてなるノード装置であって、メモリと、接続された各クライアント装置のIPアドレスと当該クライアント装置のためのメモリとの間の対応関係を予め記憶しているIPアドレステーブル記憶手段と、クライアント装置からの要求に基づいて予め装備されたアプリケーションソフトを実行して処理を行い、これによって得られる処理データを処理依頼元のクライアント装置のIPアドレスにメモリに記憶させるアプリケーションソフト実行部と、記憶された処理データを他のノード装置のメモリに記憶させるミラーリング処理部と、他のノード装置のメモリに記憶させられた後の処理データを共有ストレージに書き込むストレージ記憶部と、他のノード装置のメモリに処理データが残った状態で当該他のノード装置に異常が発生した場合に、IPアドレステーブル記憶手段に記憶された対応関係を変更して当該他のノード装置による処理を引き継ぐフェイルオーバー処理部と、を有することを特徴とする。 To achieve the above object, the shared storage is the node device according to the present invention, are interconnected with other node devices with configuring the cluster system, which is an external storage device that is shared with another node device a connected the node device to be a memory, an IP address table memory means a correspondence relationship stored in advance between the memory for the connected IP address and the client device of each client apparatus, An application software execution unit for executing processing by executing pre-installed application software based on a request from the client device, and storing processing data obtained thereby in the memory at the IP address of the client device of the processing request source, and storage mirroring processing unit for storing the processed data in the memory of another node device A storage memory unit for writing the processed data after it has been stored in the memory of another node device to the shared storage, when an abnormality to the other node device occurs when the processing data remains in the memory of another node device And a failover processing unit that changes the correspondence stored in the IP address table storage unit and takes over the processing by the other node device .
上記目的を達成するため、本発明に係るクラスタシステムは、第1および第2のノード装置と、第1および第2のノード装置の間で共有される外部記憶装置である共有ストレージとが相互に接続されて構築されたクラスタシステムであって、第1および第2のノード装置が、請求項1又は2に記載のノード装置であることを特徴とする。
In order to achieve the above object, in the cluster system according to the present invention, the first and second node devices and the shared storage that is an external storage device shared between the first and second node devices are mutually connected. A cluster system constructed by being connected, wherein the first and second node devices are the node devices according to
上記目的を達成するため、本発明に係るフェイルオーバー方法は、他のノード装置と相互に接続されてクラスタシステムを構成すると共に、他のノード装置との間で共有される外部記憶装置である共有ストレージに接続されてなるノード装置にあって、接続された各クライアント装置のIPアドレスと当該クライアント装置のためのメモリとの間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、アプリケーションソフトをアプリケーションソフト実行部が実行し、アプリケーションソフトによって得られた処理データをクライアント装置のIPアドレスに対応するメモリ上にアプリケーションソフト実行部が一時的に保存し、記憶された処理データをミラーリング処理部が他のノード装置の対応する記憶領域に記憶させ、他のノード装置のメモリに記憶させられた後の処理データをストレージ記憶部が共有ストレージに書き込み、他のノード装置のメモリに処理データが残った状態で当該他のノード装置に異常が発生した場合に、IPアドレステーブル記憶手段に記憶された対応関係をフェイルオーバー処理部が変更して当該他のノード装置による処理を引き継ぐことを特徴とする。 To achieve the above object, the failover method according to the present invention, are connected to each other with other node devices with configuring the cluster system, which is an external storage device that is shared with the other node devices sharing in the node device formed by connecting to the storage, that is stored in the IP address table storage means corresponding relationship is previously provided between the memory for the connected IP address and the client device of each client apparatus with it, processing of the application software application software execution unit is executed, the application software execution unit in the memory corresponding to process data obtained by the application software to the IP address of the client device is temporarily stored, stored Data mirroring processing unit supports other node devices. Stored in the storage area, writes the processed data after it has been stored in the memory of another node device to the shared storage storage storage unit, in a state where the memory in the processing data remained in the other node devices of the other When an abnormality occurs in a node device, the failover processing unit changes the correspondence stored in the IP address table storage unit and takes over the processing by the other node device .
上記目的を達成するため、本発明に係るフェイルオーバープログラムは、他のノード装置と相互に接続されてクラスタシステムを構成すると共に、他のノード装置との間で共有される外部記憶装置である共有ストレージに接続されてなるノード装置にあって、接続された各クライアント装置のIPアドレスと当該クライアント装置のためのメモリとの間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、ノード装置が備えるプロセッサに、アプリケーションソフトを実行する手順、アプリケーションソフトによって得られた処理データをクライアント装置のIPアドレスに対応するメモリ上に一時的に保存する手順、記憶された処理データを他のノード装置の対応するメモリに記憶させる手順、他のノード装置の対応する記憶領域に記憶させられた後の処理データを共有ストレージに書き込む手順、および他のノード装置のメモリに処理データが残った状態で当該他のノード装置に異常が発生した場合に、IPアドレステーブル記憶手段に記憶された対応関係をフェイルオーバー処理部が変更して当該他のノード装置による処理を引き継ぐ手順を実行させることを特徴とする。 To achieve the above object, the failover program according to the present invention, are connected to each other with other node devices with configuring the cluster system, which is an external storage device that is shared with the other node devices sharing in the node device formed by connecting to the storage, that is stored in the IP address table storage means corresponding relationship is previously provided between the memory for the connected IP address and the client device of each client apparatus In addition, a procedure for executing application software on a processor included in the node device, a procedure for temporarily storing processing data obtained by the application software in a memory corresponding to the IP address of the client device , and stored processing data the procedure to be stored in the corresponding memory of another node device, other If an abnormality occurs in the corresponding procedure writes the processed data after it has been stored in the storage area in the shared storage, and the other node device in a state where the memory in the processing data remained of another node device over de device Further, the failover processing unit changes the correspondence stored in the IP address table storage unit, and the procedure for taking over the processing by the other node device is executed.
本発明は、上記したように、各クライアント装置のIPアドレスに対応して不揮発性メモリの記憶領域を区切って、ミラーリング処理を行ってから共有ストレージに書き込むように構成したので、一方のノード装置で異常が発生しても不揮発性メモリに記憶されたデータの整合性は保たれる。これによってクライアント装置側に異常の発生を意識させることなく、ごく短時間でフェイルオーバー処理を行うことが可能であるという、優れた特徴を持つクラスタシステム、ノード、フェイルオーバー方法およびプログラムを提供することができる。 As described above, the present invention is configured so that the storage area of the nonvolatile memory is divided in accordance with the IP address of each client device, the mirroring process is performed, and then the shared storage is written. Even if an abnormality occurs, the consistency of data stored in the nonvolatile memory is maintained. To provide a cluster system, a node, a failover method, and a program having an excellent feature that a failover process can be performed in a very short time without making the client device aware of an abnormality. Can do.
(実施形態)
以下、本発明の実施形態の構成について添付図1に基づいて説明する。
最初に、本実施形態の基本的な内容について説明し、その後でより具体的な内容について説明する。
本実施形態に係るノード装置(第一ノード10および第二ノード20)は、同一の構成を有する他のノード装置と相互に接続されてクラスタシステムを構成すると共に、他のノード装置との間で共有される同一の外部記憶装置である共有ストレージに接続されてなるノード装置である。このノード装置(第一ノード10)は、予め複数の記憶領域に区切られた不揮発性メモリ(NVRAM12)と、接続された各クライアント装置40のIPアドレスと当該クライアント装置が使用すべき不揮発性メモリの記憶領域との間の対応関係を予め記憶しているIPアドレステーブル記憶手段15と、クライアント装置からの要求に基づいて予め装備されたアプリケーションソフトを実行して処理を行い、これによって得られる処理データを処理依頼元のクライアント装置のIPアドレスに対応する記憶領域上に記憶させるアプリケーションソフト実行部101と、記憶された処理データを他のノード装置の対応する記憶領域に記憶させるミラーリング処理部105と、他のノード装置の対応する記憶領域に記憶させられた後の処理データを共有ストレージに書き込むストレージ記憶部106とを有する。
(Embodiment)
Hereinafter, the configuration of an embodiment of the present invention will be described with reference to FIG.
First, the basic content of the present embodiment will be described, and then more specific content will be described.
The node devices (
ここで、ミラーリング処理部105は、処理データを他のノード装置の対応する記憶領域に記憶させる処理の完了後、処理要求元のクライアント装置40に書き込み終了通知を返信する機能を有する。さらに、他のノード装置の不揮発性メモリに処理データが残った状態で当該他のノード装置に異常が発生した場合に、IPアドレステーブル記憶手段に記憶された対応関係を変更して当該他のノード装置による処理を引き継ぐフェイルオーバー処理部107も備える。
Here, the
以上の構成を備えることにより、ノード装置(第一ノード10)は、クライアント装置側に異常の発生を意識させることなく、ごく短時間でフェイルオーバー処理を行うことが可能となる。
以下、これをより詳細に説明する。
With the above configuration, the node device (first node 10) can perform failover processing in a very short time without making the client device aware of the occurrence of an abnormality.
Hereinafter, this will be described in more detail.
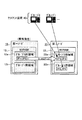
図1は、本発明の実施形態に係るクラスタシステム1の構成について示す説明図である。クラスタシステム1は、第一ノード10および第二ノード20という各々のコンピュータ装置(サーバ)と、その他多数のクライアント装置40とが、ネットワーク41を介して相互に接続されて構成されている。
FIG. 1 is an explanatory diagram showing the configuration of the
第一ノード10および第二ノード20は、単にクライアント装置40から受信したデータを保存するファイルサーバでもよいし、また受信したデータに対して何らかの処理を行ってから保存するデータベースシステム、ウェブサーバ、業務システムなどでもよい。
The
またここで、第一ノード10および第二ノード20とクライアント装置40との間で利用される通信方式は、クライアント装置40のOS(Operating System: 基本ソフト)がたとえばウィンドウズ(登録商標)であればCIFS(Common Internet File System)を利用することができるし、UNIX(登録商標)であればNIS(Network File System)を利用することができる。これら以外にも、利用可能な通信方式であれば任意のものを使用することができる。
Here, the communication method used between the
ここでサーバクラスタを構成している第一ノード10および第二ノード20は、共有の外部記憶装置である共有ストレージ30と接続されている。そして、第一ノード10および第二ノード20は、処理にかかる負荷を相互に分散しつつ、記憶されているデータを互いにミラーリングして、どちらか一方に故障が発生した場合にその故障した方の装置で行われていた処理を残る一方が引き継いで続行する(これをフェイルオーバーという)ことができる構成となっている。
Here, the
第一ノード10は、コンピュータプログラムを実行する主体であるプロセッサ11と、処理中のデータを一時的に記憶する不揮発性の主記憶装置であるNVRAM12と、処理されたデータを共有ストレージ30に固定的に記憶する外部ストレージ接続手段13と、ネットワーク41を介して第二ノード20や各クライアント装置40との間で通信を行う通信手段14と、後述のIPアドレステーブル記憶手段15とが備えられている。
The
NVRAM12は、ICA(InterConnectAccess)カードとして第一ノード10内に実装されている。この方式によって接続されることにより、NVRAM12はプロセッサ11上で動作するオペレーティングシステムを経由することなく、RDMA(Remote Direct Memory Access)プロトコルによってデータを第二ノード20に転送することが可能となるであるというメリットがある。他にも、NVRAM12を実装する上では、任意の接続方式を利用することができる。
The
プロセッサ11は、クライアント装置40からの依頼に基づく処理を行うアプリケーションソフトを実行してそのデータをNVRAM12に書き込むアプリケーション実行部101と、NVRAM12との間のデータ交換を仲介するデバイスドライバを動作させるNVRAMドライバ実行部102と、外部ストレージ接続手段13を経由して共有ストレージ30との間のデータ交換を仲介するデバイスドライバを動作させるストレージ装置ドライバ実行部103と、通信手段14との間のデータ交換を仲介するデバイスドライバを動作させる外部通信ドライバ実行部104として機能する。
The
NVRAM12には、第一ノード10および第二ノード20で各々行われる処理について、後述するようにクライアント装置40のIPアドレスのグループに応じてグループ0用領域12aおよびグループ1用領域12bとに分かれている。第一ノード10では、「グループ0」に属するクライアント装置40からの依頼に応じてグループ0用領域12aに対してデータ処理を行い、その内容を第二ノード20側の同領域にもコピーして反映する。
The
プロセッサ11はさらに、各々のプログラムの動作により、アプリケーション実行部101が「グループ0」に属するクライアント装置40からの依頼に応じてグループ0用領域12aに書き込んだデータを第二ノード20のグループ0用領域22aにコピーして反映させるミラーリング処理部105と、そのデータを共有ストレージ30に記憶するストレージ記憶部106と、第二ノード20で異常が発生した場合にその処理を引き継ぐようIPアドレステーブル記憶手段15の記憶内容を変更するフェイルオーバー処理部107としても機能する。
The
第二ノード20は、第一ノード10と、ハードウェア的にもソフトウェア的にも同一の構成を有している。従って、第二ノード20の各機能部については、第一ノード10と呼称を全て同一とし、参照番号は最上位の「1」を「2」に代えた以外は全て第一ノード10と同一とする。即ち、ハードウェア的にはプロセッサ21、NVRAM22…などのようにいい、ソフトウェア的にはアプリケーション実行部201、NVRAMドライバ実行部202…などのようにいう。
The
図2は、図1に示した第一ノード10に備えられるIPアドレステーブル記憶手段15の記憶内容について示す説明図である。クライアント装置40は、各々のIPアドレスのグループに応じて「グループ0」および「グループ1」の2グループに分かれる。IPアドレステーブル記憶手段15には、各クライアント装置40のIPアドレスと、それに該当するクライアント装置40が「グループ0」および「グループ1」のうちのいずれに属するかについて記憶されている。第二ノード20にも、これと同一の内容を記憶するIPアドレステーブル記憶手段25が存在する。
FIG. 2 is an explanatory diagram showing the contents stored in the IP address table storage means 15 provided in the
ここでいう「グループ0」および「グループ1」の分け方については、たとえばIPアドレスの範囲によって分けてもよいし、1個ごとのIPアドレスについて「グループ0」もしくは「グループ1」を指定してもよい。また、IPアドレスではなくホスト名で「グループ0」もしくは「グループ1」に分類してもよい。
The “
図3は、図1に示したクラスタシステム1で、第一ノード10および第二ノード20の正常動作時の処理の分担について示す説明図である。第一ノード10のNVRAM12は前述のようにグループ0用領域12aおよびグループ1用領域12bとに分かれ、第二ノード20のNVRAM22も同様にグループ0用領域22aおよびグループ1用領域22bとに分かれる。
FIG. 3 is an explanatory diagram showing the sharing of processing during normal operation of the
IPアドレステーブル記憶手段15(25)に記憶された各クライアント装置40の「グループ0」および「グループ1」の区分について、第一ノード10のアプリケーション実行部101は、「グループ0」に属するクライアント装置40からの依頼に応じて処理を行い、その処理結果をNVRAM12のグループ0用領域12aに書き込む。第二ノード20のアプリケーション実行部201は、「グループ1」に属するクライアント装置40からの依頼に応じて処理を行い、その処理結果をNVRAM22のグループ1用領域22bに書き込む。
For the “
そして、「グループ0」に属するクライアント装置40からの依頼に応じた処理の場合、第一ノード10のアプリケーション実行部101がデータ処理を行った後で第一ノード10および第二ノード20のミラーリング処理部105および205は、NVRAM12および22の相互の内容をコピーしあい、そして第一ノード10のストレージ記憶部106がそのデータをストレージ装置ドライバ実行部103および外部ストレージ接続手段13を介して共有ストレージ30にそのデータを記憶する。
In the case of processing according to a request from the client device 40 belonging to “
「グループ1」に属するクライアント装置40からの依頼に応じた処理の場合は、第二ノード20のアプリケーション実行部201が先に処理を行う点以外は、「グループ0」の場合と同一である。
The processing in response to the request from the client device 40 belonging to “
図4は、図1に示したクラスタシステム1で、第一ノード10および第二ノード20の異常発生時の処理の分担について示す説明図である。第一ノード10の側で、共有ストレージ30への書き込みの済んでいないデータがNVRAM12に残っている状態で第一ノード10が異常を起こして停止した場合、ミラーリング処理部105によって、NVRAM22のグループ0用領域22aにその未反映データがコピーされている。
FIG. 4 is an explanatory diagram showing the sharing of processing when an abnormality occurs in the
そこで、第二ノード20が「グループ0」に属するクライアント装置40からの依頼によるその処理を引き継ぎ、クライアント装置40からの依頼に応じた処理によるデータを、NVRAM22のグループ0用領域22aにコピーされた分のデータに続いて書き込んで、これを共有ストレージ30に記憶する。
Therefore, the
図5は、図1に示したクラスタシステム1の正常時の動作について示す説明図である。図6〜7(図面の錯綜回避のため2枚に分ける)は、図1に示したクラスタシステム1の正常時の動作について示すフローチャートである。より詳しくは、図5では、「グループ0」に属するクライアント装置40からの処理依頼に応じての動作を示している。
FIG. 5 is an explanatory diagram showing the normal operation of the
クライアント装置40からデータ処理依頼がなされた場合、第一ノード10および第二ノード20のアプリケーション実行部101および201はそれぞれ、各々のIPアドレステーブル記憶手段15および25を参照して、「グループ0」および「グループ1」のどちらに属するクライアント装置40からの処理依頼かを判断する(ステップS301および351)。
When a data processing request is made from the client device 40, the
「グループ0」に属するクライアント装置40からの処理依頼だった場合、第一ノード10のアプリケーション実行部101がその依頼に対応する処理を行い、その処理結果をNVRAM12のグループ0用領域12aに書き込む(ステップS302)。そしてミラーリング処理部105がそのデータを第二ノード20のミラーリング処理部205に渡して記憶させる(ステップS303)。これを受けた第二ノード20のミラーリング処理部205は、そのデータをNVRAM22のグループ0用領域22aに書き込む(ステップS307)。
In the case of a processing request from the client device 40 belonging to “
そして、ミラーリング処理部105が依頼元のクライアント装置40に書き込み終了通知を返し(ステップS304)、ストレージ記憶部106がクライアント装置40に対して書き込み終了を通知するタイミングでそのデータをストレージ装置ドライバ実行部103および外部ストレージ接続手段13を介して共有ストレージ30にそのデータを記憶する(ステップS305)。共有ストレージ30への書き込みが終了したら、ミラーリング処理部105はそのデータをNVRAM12のグループ0用領域12aから削除する(ステップS306)。
Then, the
「グループ1」に属するクライアント装置40からの処理依頼だった場合、第二ノード20のアプリケーション実行部201がその依頼に対応する処理を行い、その処理結果をNVRAM22のグループ1用領域22bに書き込む(ステップS352)。そしてミラーリング処理部205がそのデータを第一ノード10のミラーリング処理部105に渡して記憶させる(ステップS353)。これを受けた第一ノード10のミラーリング処理部105は、そのデータをNVRAM12のグループ1用領域12bに書き込む(ステップS357)。
In the case of a processing request from the client device 40 belonging to “
そして、ミラーリング処理部205が依頼元のクライアント装置40に書き込み終了通知を返し(ステップS354)、ストレージ記憶部206がそのデータをストレージ装置ドライバ実行部203および外部ストレージ接続手段23を介して共有ストレージ30にそのデータを記憶する(ステップS355)。共有ストレージ30への書き込みが終了したら、ミラーリング処理部205はそのデータをNVRAM22のグループ1用領域22aから削除する(ステップS356)。
Then, the
図8は、図1に示したクラスタシステム1の異常発生時の動作について示す説明図である。図9は、図1に示したクラスタシステム1の異常発生時の動作について示すフローチャートである。より詳しくは、「グループ0」に属するクライアント装置40からの処理依頼に応じて第一ノード10が図5・ステップS305に示した共有ストレージ30への書き込み処理を行っている間に、この第一ノード10に故障が発生して、NVRAM12のグループ0用領域12aに共有ストレージ30へ未反映のデータが残ってしまった場合について、図8〜9では示している。
FIG. 8 is an explanatory diagram showing an operation when an abnormality occurs in the
この段階であれば、ミラーリング処理部105によって、NVRAM22のグループ0用領域22aにその未反映データがコピーされている。そこで、異常発生を検出したフェイルオーバー処理部207は(ステップS401)、第二ノード20のIPアドレステーブル記憶手段25で、「グループ0」に属するクライアント装置40の処理を第二ノード20が引き継ぐように設定し直す(ステップS402)。
At this stage, the unreflected data is copied to the
ここで、第一ノード10および第二ノード20では、互いが正常に動作していることを確認するために、常時周期的にハートビート通信を行っている。本実施形態で「NVRAMに未反映データが残ったままの状態で、一方のノードで異常が発生した」ことを検出して上記ステップS401からの動作開始は、このハートビート通信に対する返答が一定時間ないことを検出した場合をその契機とすることができる。
Here, the
これによって、NVRAM22のグループ0用領域22aに残っている未反映データの続きの処理をアプリケーション実行部201が行ってそのデータをNVRAM22のグループ0用領域22aに書き込み(ステップS403)、ミラーリング処理部205が依頼元のクライアント装置40に書き込み終了通知を返し(ステップS404)、ストレージ記憶部206がそのデータをストレージ装置ドライバ実行部203および外部ストレージ接続手段23を介して共有ストレージ30にそのデータを記憶する(ステップS405)。
As a result, the
共有ストレージ30への書き込みが終了したら、ミラーリング処理部205はそのデータをNVRAM22のグループ1用領域22aから削除する(ステップS406)。以上の処理によって、順序性をシビアに要求される処理であっても、データのリカバリ処理を行うことなく処理を継続することが可能となる。即ち、ごく短時間でサービスを復旧させることが可能となるので、クライアント装置40の側に故障の発生を意識させること自体が必要ない。
When the writing to the shared
(実施形態の全体的な動作)
次に、上記の実施形態の全体的な動作について説明する。
本実施形態に係るフェイルオーバー方法は、同一の構成を有する他のノード装置と相互に接続されてクラスタシステムを構成すると共に、他のノード装置との間で共有される同一の外部記憶装置である共有ストレージに接続されてなるノード装置(第一ノード10)にあって、予め備えられた不揮発性メモリは複数の記憶領域に区切られており、接続された各クライアント装置のIPアドレスと当該クライアント装置が使用すべき不揮発性メモリの記憶領域との間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、アプリケーションソフトをアプリケーションソフト実行部が実行し、アプリケーションソフトによって得られた処理データを不揮発性メモリ上のクライアント装置のIPアドレスに対応する記憶領域上にアプリケーションソフト実行部が一時的に保存し(図6・ステップS302または352)、記憶された処理データをミラーリング処理部が他のノード装置の対応する記憶領域に記憶させ(図6・ステップS303または353)、他のノード装置の対応する記憶領域に記憶させられた後の処理データをストレージ記憶部が共有ストレージに書き込む(図6・ステップS305または355)。
(Overall operation of the embodiment)
Next, the overall operation of the above embodiment will be described.
The failover method according to the present embodiment is the same external storage device that is interconnected with other node devices having the same configuration to form a cluster system and is shared with other node devices. In the node device (first node 10) connected to the shared storage, the nonvolatile memory provided in advance is divided into a plurality of storage areas, and the IP address of each connected client device and the client device Is stored in the IP address table storage means provided in advance, and the application software is executed by the application software execution unit and obtained by the application software. The processed data to the IP address of the client device on the non-volatile memory The application software execution unit temporarily stores the data in the storage area (FIG. 6, step S302 or 352), and the mirroring processing unit stores the stored processing data in the corresponding storage area of another node device (FIG. 6). Step S303 or 353), the processing data stored in the corresponding storage area of the other node device is written in the shared storage by the storage storage unit (FIG. 6, step S305 or 355).
そして、他のノード装置(第二ノード20)の不揮発性メモリに処理データが残った状態で当該他のノード装置に異常が発生した場合に、IPアドレステーブル記憶手段に記憶された対応関係をフェイルオーバー処理部が変更して当該他のノード装置による処理を引き継ぐ(図9・ステップS402〜403)。 Then, when an abnormality occurs in the other node device with the processing data remaining in the non-volatile memory of the other node device (second node 20), the correspondence relationship stored in the IP address table storage unit is failed. The over processing unit changes and takes over the processing by the other node device (FIG. 9, steps S402 to S403).
ここで、上記各動作ステップについては、これをコンピュータで実行可能にプログラム化し、これらを前記各ステップを直接実行するノード装置(第一ノード10)のプロセッサ11に実行させるようにしてもよい。本プログラムは、非一時的な記録媒体、例えば、DVD、CD、フラッシュメモリ等に記録されてもよい。その場合、本プログラムは、記録媒体からコンピュータによって読み出され、実行される。
この動作により、本実施形態は以下のような効果を奏する。
Here, each of the above-described operation steps may be programmed to be executable by a computer, and may be executed by the
By this operation, this embodiment has the following effects.
本実施形態によれば、第一ノード10もしくは第二ノード20のうちのいずれかに異常が発生して停止した場合でも、残る一方のノードが備えるNVRAM12または22に対応する記憶領域が存在しており、その領域に共有ストレージ30にすぐ書き込める状態のデータが、ミラーリング処理によって整合性が取れた状態で記憶されている。
According to the present embodiment, even when an abnormality occurs in either the
従って、IPアドレステーブル記憶手段15または25に記憶された各クライアント装置に属する記憶領域に応じて、データの書き込みを行う領域を切り替えれば、データのリカバリ処理を行う必要は無く、すぐに残る一方のノードで処理を引き継いで続行させることが可能となる。これによって、クライアント装置の側に故障の発生を意識させることなく、ごく短時間でサービスを復旧させることが可能となる。 Therefore, if the area where data is written is switched according to the storage area belonging to each client device stored in the IP address table storage means 15 or 25, there is no need to perform data recovery processing. It becomes possible to take over the processing at the node and continue. This makes it possible to restore the service in a very short time without making the client device aware of the occurrence of the failure.
(実施形態の拡張)
上記実施形態は、以上で説明した本発明の趣旨を改変しない範囲で、様々な拡張が可能である。以下、これについて説明する。
(Extended embodiment)
The above-described embodiment can be variously expanded without departing from the spirit of the present invention described above. This will be described below.
まず、上記実施形態は第一ノード10および第二ノード20という2台のサーバコンピュータによる構成例を示したが、これが3台以上になってももちろんよい。その場合、各クライアント装置をサーバコンピュータの台数分のグループに予め分けたIPアドレステーブルを、各々のIPアドレステーブル記憶手段に記憶させた上で、上記と同様の動作を行うこととなる。
First, although the said embodiment showed the example of a structure by two server computers called the
さらに、各サーバコンピュータが、物理的に複数台のコンピュータによって構成されてもよい。そして、各サーバコンピュータが、同一の処理をクライアント装置のグループ毎に分担してもよいし、また別々の処理を並行して行うものとしてもよい。 Furthermore, each server computer may be physically configured by a plurality of computers. Each server computer may share the same processing for each group of client devices, or may perform separate processing in parallel.
これまで本発明について図面に示した特定の実施形態をもって説明してきたが、本発明は図面に示した実施形態に限定されるものではなく、本発明の効果を奏する限り、これまで知られたいかなる構成であっても採用することができる。 The present invention has been described with reference to the specific embodiments shown in the drawings. However, the present invention is not limited to the embodiments shown in the drawings, and any known hitherto provided that the effects of the present invention are achieved. Even if it is a structure, it is employable.
上述した実施形態について、その新規な技術内容の要点をまとめると、以下のようになる。なお、上記実施形態の一部または全部は、新規な技術として以下のようにまとめられるが、本発明は必ずしもこれに限定されるものではない。 Regarding the embodiment described above, the main points of the new technical contents are summarized as follows. In addition, although part or all of the said embodiment is summarized as follows as a novel technique, this invention is not necessarily limited to this.
(付記1) 同一の構成を有する他のノード装置と相互に接続されてクラスタシステムを構成すると共に、前記他のノード装置との間で共有される同一の外部記憶装置である共有ストレージに接続されてなるノード装置であって、
予め複数の記憶領域に区切られた不揮発性メモリと、
接続された各クライアント装置のIPアドレスと当該クライアント装置が使用すべき前記不揮発性メモリの前記記憶領域との間の対応関係を予め記憶しているIPアドレステーブル記憶手段と、
前記クライアント装置からの要求に基づいて予め装備されたアプリケーションソフトを実行して処理を行い、これによって得られる処理データを処理依頼元の前記クライアント装置のIPアドレスに対応する前記記憶領域上に記憶させるアプリケーションソフト実行部と、
記憶された前記処理データを前記他のノード装置の対応する記憶領域に記憶させるミラーリング処理部と、
前記他のノード装置の対応する記憶領域に記憶させられた後の前記処理データを前記共有ストレージに書き込むストレージ記憶部と
を有することを特徴とするノード装置。
(Appendix 1) A cluster system is configured by being interconnected with other node devices having the same configuration, and is connected to a shared storage that is the same external storage device shared with the other node devices. A node device comprising:
A non-volatile memory previously partitioned into a plurality of storage areas;
IP address table storage means for storing in advance a correspondence relationship between the IP address of each connected client device and the storage area of the nonvolatile memory to be used by the client device;
Based on a request from the client device, the pre-installed application software is executed to perform processing, and processing data obtained thereby is stored in the storage area corresponding to the IP address of the client device of the processing request source. An application software execution unit;
A mirroring processing unit for storing the stored processing data in a corresponding storage area of the other node device;
A node device comprising: a storage storage unit that writes the processing data after being stored in a corresponding storage area of the other node device to the shared storage.
(付記2) 前記ミラーリング処理部が、前記処理データを前記他のノード装置の対応する記憶領域に記憶させる処理の完了後、処理要求元の前記クライアント装置に書き込み終了通知を返信する機能を有することを特徴とする、付記1に記載のノード装置。
(Additional remark 2) The said mirroring process part has a function which returns a write completion notification to the said client apparatus of a process request origin after completion of the process which memorize | stores the said process data in the corresponding storage area of the said other node apparatus. The node device according to
(付記3) 前記他のノード装置の不揮発性メモリに前記処理データが残った状態で当該他のノード装置に異常が発生した場合に、前記IPアドレステーブル記憶手段に記憶された対応関係を変更して当該他のノード装置による処理を引き継ぐフェイルオーバー処理部
を有することを特徴とする、付記1または付記2に記載のノード装置。
(Supplementary Note 3) When an abnormality occurs in another node device with the processing data remaining in the non-volatile memory of the other node device, the correspondence relationship stored in the IP address table storage unit is changed. The node device according to
(付記4) 同一の構成を有する第1および第2のノード装置と、前記第1および第2のノード装置の間で共有される同一の外部記憶装置である共有ストレージとが相互に接続されて構築されたクラスタシステムであって、
前記第1および第2のノード装置が、付記1ないし付記3のうちいずれか1項に記載のノード装置であることを特徴とするクラスタシステム。
(Additional remark 4) The 1st and 2nd node apparatus which has the same structure, and the shared storage which is the same external storage device shared between the said 1st and 2nd node apparatus are mutually connected A built cluster system,
The cluster system, wherein the first and second node devices are node devices according to any one of
(付記5) 同一の構成を有する他のノード装置と相互に接続されてクラスタシステムを構成すると共に、前記他のノード装置との間で共有される同一の外部記憶装置である共有ストレージに接続されてなるノード装置にあって、
予め備えられた不揮発性メモリは複数の記憶領域に区切られており、
接続された各クライアント装置のIPアドレスと当該クライアント装置が使用すべき前記不揮発性メモリの前記記憶領域との間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、
前記アプリケーションソフトをアプリケーションソフト実行部が実行し、
前記アプリケーションソフトによって得られた前記処理データを前記不揮発性メモリ上の前記クライアント装置のIPアドレスに対応する前記記憶領域上に前記アプリケーションソフト実行部が一時的に保存し、
記憶された前記処理データをミラーリング処理部が前記他のノード装置の対応する記憶領域に記憶させ、
前記他のノード装置の対応する記憶領域に記憶させられた後の前記処理データをストレージ記憶部が前記共有ストレージに書き込む
ことを特徴とするフェイルオーバー方法。
(Additional remark 5) It connects with the other node apparatus which has the same structure, comprises a cluster system, and is connected to the shared storage which is the same external storage device shared with the said other node apparatus. In the node device
The non-volatile memory provided in advance is divided into a plurality of storage areas,
The correspondence relationship between the IP address of each connected client device and the storage area of the nonvolatile memory to be used by the client device is stored in an IP address table storage means provided in advance,
The application software execution unit executes the application software,
The application software execution unit temporarily stores the processing data obtained by the application software on the storage area corresponding to the IP address of the client device on the nonvolatile memory,
The mirroring processing unit stores the stored processing data in a corresponding storage area of the other node device,
A failover method, wherein a storage storage unit writes the processing data after being stored in a corresponding storage area of the other node device to the shared storage.
(付記6) 前記他のノード装置の不揮発性メモリに前記処理データが残った状態で当該他のノード装置に異常が発生した場合に、前記IPアドレステーブル記憶手段に記憶された対応関係をフェイルオーバー処理部が変更して当該他のノード装置による処理を引き継ぐ
ことを特徴とする、付記5に記載のフェイルオーバー方法。
(Appendix 6) When an abnormality occurs in the other node device with the processing data remaining in the non-volatile memory of the other node device, the correspondence stored in the IP address table storage unit is failed over. The failover method according to appendix 5, wherein the processing unit changes and takes over the processing by the other node device.
(付記7) 同一の構成を有する他のノード装置と相互に接続されてクラスタシステムを構成すると共に、前記他のノード装置との間で共有される同一の外部記憶装置である共有ストレージに接続されてなるノード装置にあって、
予め備えられた不揮発性メモリは複数の記憶領域に区切られており、
接続された各クライアント装置のIPアドレスと当該クライアント装置が使用すべき前記不揮発性メモリの前記記憶領域との間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、
前記ノード装置が備えるプロセッサに、
前記アプリケーションソフトを実行する手順、
前記アプリケーションソフトによって得られた前記処理データを前記不揮発性メモリ上の前記クライアント装置のIPアドレスに対応する前記記憶領域上に一時的に保存する手順、
記憶された前記処理データを前記他のノード装置の対応する記憶領域に記憶させる手順、
および前記他のノード装置の対応する記憶領域に記憶させられた後の前記処理データを前記共有ストレージに書き込む手順
を実行させることを特徴とするフェイルオーバープログラム。
(Supplementary Note 7) A cluster system is configured by being interconnected with other node devices having the same configuration, and is connected to a shared storage that is the same external storage device shared with the other node devices. In the node device
The non-volatile memory provided in advance is divided into a plurality of storage areas,
The correspondence relationship between the IP address of each connected client device and the storage area of the nonvolatile memory to be used by the client device is stored in an IP address table storage means provided in advance,
In the processor provided in the node device,
A procedure for executing the application software;
A procedure for temporarily storing the processing data obtained by the application software on the storage area corresponding to the IP address of the client device on the nonvolatile memory;
A procedure for storing the stored processing data in a corresponding storage area of the other node device;
And a failover program for executing a procedure for writing the processing data stored in the corresponding storage area of the other node device to the shared storage.
本発明は、コンピュータにおいてデータの整合性や順序性が要求される用途のクラスタシステムにおいて適用可能である。より具体的には、ファイルサーバ、データベースシステム、ウェブサーバ、業務システムなどに適用可能である。 The present invention can be applied to a cluster system for a purpose that requires data consistency and order in a computer. More specifically, the present invention can be applied to a file server, a database system, a web server, a business system, and the like.
1 クラスタシステム
10 第一ノード
11,21 プロセッサ
12,22 NVRAM
12a,22a グループ0用領域
12b,22b グループ1用領域1
13,23 外部ストレージ接続手段
14,24 通信手段
15,25 IPアドレステーブル記憶手段
20 第二ノード
30 共有ストレージ
40 クライアント装置
41 ネットワーク
101,201 アプリケーション実行部
102,202 NVRAMドライバ実行部
103,203 ストレージ装置ドライバ実行部
104,204 外部通信ドライバ実行部
105,205 ミラーリング処理部
106,206 ストレージ記憶部
107,207 フェイルオーバー処理部
1
12a,
13, 23 External storage connection means 14, 24 Communication means 15, 25 IP address table storage means 20
Claims (5)
メモリと、
接続された各クライアント装置のIPアドレスと当該クライアント装置のための前記メモリとの間の対応関係を予め記憶しているIPアドレステーブル記憶手段と、
前記クライアント装置からの要求に基づいて予め装備されたアプリケーションソフトを実行して処理を行い、これによって得られる処理データを処理依頼元の前記クライアント装置のIPアドレスに対応する前記メモリに記憶させるアプリケーションソフト実行部と、
記憶された前記処理データを前記他のノード装置のメモリに記憶させるミラーリング処理部と、
前記他のノード装置のメモリに記憶させられた後の前記処理データを前記共有ストレージに書き込むストレージ記憶部と、
前記他のノード装置のメモリに前記処理データが残った状態で当該他のノード装置に異常が発生した場合に、前記IPアドレステーブル記憶手段に記憶された対応関係を変更して当該他のノード装置による処理を引き継ぐフェイルオーバー処理部と、
を有することを特徴とするノード装置。 A node device that is connected to another node device to form a cluster system and is connected to a shared storage that is an external storage device shared with the other node device,
Memory ,
IP address table storage means for storing in advance the correspondence between the IP address of each connected client device and the memory for the client device;
Application software that performs processing by executing pre-installed application software based on a request from the client device, and stores processing data obtained thereby in the memory corresponding to the IP address of the client device that is the processing request source The execution part;
A mirroring processing unit for storing the stored processing data in a memory of the other node device;
A storage storage unit that writes the processing data after being stored in the memory of the other node device to the shared storage ;
When an abnormality occurs in the other node device while the processing data remains in the memory of the other node device, the correspondence stored in the IP address table storage unit is changed to change the other node device. Failover processing unit that takes over the processing by
A node device comprising:
前記第1および第2のノード装置が、請求項1又は2に記載のノード装置であることを特徴とするクラスタシステム。 A first and second node devices, a shared storage is an external storage device that is shared between the first and second node devices provide a cluster system constructed are connected to each other,
The cluster system according to claim 1, wherein the first and second node devices are the node devices according to claim 1 or 2 .
接続された各クライアント装置のIPアドレスと当該クライアント装置のためのメモリとの間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、
アプリケーションソフトをアプリケーションソフト実行部が実行し、
前記アプリケーションソフトによって得られた処理データを前記クライアント装置のIPアドレスに対応する前記メモリ上に前記アプリケーションソフト実行部が一時的に保存し、
記憶された前記処理データをミラーリング処理部が前記他のノード装置の対応する記憶領域に記憶させ、
前記他のノード装置のメモリに記憶させられた後の前記処理データをストレージ記憶部が前記共有ストレージに書き込み、
前記他のノード装置のメモリに前記処理データが残った状態で当該他のノード装置に異常が発生した場合に、前記IPアドレステーブル記憶手段に記憶された対応関係をフェイルオーバー処理部が変更して当該他のノード装置による処理を引き継ぐ、
ことを特徴とするフェイルオーバー方法。 In a node device connected to another node device to form a cluster system and connected to a shared storage that is an external storage device shared with the other node device ,
The correspondence relationship between the IP address of each connected client device and the memory for the client device is stored in the IP address table storage means provided in advance,
The application software execution unit executes the application software,
The application software execution unit temporarily stores the processing data obtained by the application software on the memory corresponding to the IP address of the client device,
The mirroring processing unit stores the stored processing data in a corresponding storage area of the other node device,
Writes in the processing data storage memory unit said shared storage after being stored in the memory of the other node devices,
When an abnormality occurs in the other node device with the processing data remaining in the memory of the other node device, the failover processing unit changes the correspondence stored in the IP address table storage unit. Take over the processing by the other node device,
A failover method characterized by that.
接続された各クライアント装置のIPアドレスと当該クライアント装置のためのメモリとの間の対応関係が予め備えられたIPアドレステーブル記憶手段に記憶されたものであると共に、
前記ノード装置が備えるプロセッサに、
アプリケーションソフトを実行する手順、
前記アプリケーションソフトによって得られた処理データを前記クライアント装置のIPアドレスに対応する前記メモリ上に一時的に保存する手順、
記憶された前記処理データを前記他のノード装置の対応するメモリに記憶させる手順、
前記他のノード装置のメモリに記憶させられた後の前記処理データを前記共有ストレージに書き込む手順、
および前記他のノード装置のメモリに前記処理データが残った状態で当該他のノード装置に異常が発生した場合に、前記IPアドレステーブル記憶手段に記憶された対応関係をフェイルオーバー処理部が変更して当該他のノード装置による処理を引き継ぐ手順、
を実行させることを特徴とするフェイルオーバープログラム。 In a node device connected to another node device to form a cluster system and connected to a shared storage that is an external storage device shared with the other node device ,
The correspondence relationship between the IP address of each connected client device and the memory for the client device is stored in the IP address table storage means provided in advance,
In the processor provided in the node device,
Procedure to execute application software ,
A procedure for temporarily storing processing data obtained by the application software on the memory corresponding to the IP address of the client device;
A procedure for storing the stored processing data in a corresponding memory of the other node device;
A procedure for writing the processing data after being stored in the memory of the other node device to the shared storage ;
And the failover processing unit changes the correspondence stored in the IP address table storage means when an abnormality occurs in the other node device while the processing data remains in the memory of the other node device. To take over the processing by the other node device
Failover program characterized by causing
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012237731A JP6070064B2 (en) | 2012-10-29 | 2012-10-29 | Node device, cluster system, failover method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012237731A JP6070064B2 (en) | 2012-10-29 | 2012-10-29 | Node device, cluster system, failover method and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014089506A JP2014089506A (en) | 2014-05-15 |
| JP6070064B2 true JP6070064B2 (en) | 2017-02-01 |
Family
ID=50791381
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012237731A Active JP6070064B2 (en) | 2012-10-29 | 2012-10-29 | Node device, cluster system, failover method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6070064B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105337762A (en) * | 2015-09-28 | 2016-02-17 | 浪潮(北京)电子信息产业有限公司 | File sharing method supporting automatic failover |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001175597A (en) * | 1999-12-17 | 2001-06-29 | Hitachi Ltd | Online screen display method |
| JP4001727B2 (en) * | 2001-06-15 | 2007-10-31 | 富士通株式会社 | File access control program, file access control device, and file access control method |
| US7730153B1 (en) * | 2001-12-04 | 2010-06-01 | Netapp, Inc. | Efficient use of NVRAM during takeover in a node cluster |
| CN100461124C (en) * | 2004-11-26 | 2009-02-11 | 富士通株式会社 | Computer system and information processing method |
| JP4241660B2 (en) * | 2005-04-25 | 2009-03-18 | 株式会社日立製作所 | Load balancer |
-
2012
- 2012-10-29 JP JP2012237731A patent/JP6070064B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014089506A (en) | 2014-05-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9256605B1 (en) | Reading and writing to an unexposed device | |
| US8392680B1 (en) | Accessing a volume in a distributed environment | |
| US10067694B1 (en) | Replication ordering | |
| US8832399B1 (en) | Virtualized consistency group using an enhanced splitter | |
| US9037822B1 (en) | Hierarchical volume tree | |
| US9557925B1 (en) | Thin replication | |
| US9875042B1 (en) | Asynchronous replication | |
| US9081754B1 (en) | Method and apparatus for cascaded replication using a multi splitter | |
| US9336094B1 (en) | Scaleout replication of an application | |
| US10101943B1 (en) | Realigning data in replication system | |
| US8977593B1 (en) | Virtualized CG | |
| US9507845B1 (en) | Virtual splitter | |
| US10223007B1 (en) | Predicting IO | |
| US9189339B1 (en) | Replication of a virtual distributed volume with virtual machine granualarity | |
| US10042579B1 (en) | Crash consistent snapshot | |
| US9619543B1 (en) | Replicating in virtual desktop infrastructure | |
| US8464101B1 (en) | CAS command network replication | |
| US9081842B1 (en) | Synchronous and asymmetric asynchronous active-active-active data access | |
| US8738813B1 (en) | Method and apparatus for round trip synchronous replication using SCSI reads | |
| US9244997B1 (en) | Asymmetric active-active access of asynchronously-protected data storage | |
| US9235632B1 (en) | Synchronization of replication | |
| US8898515B1 (en) | Synchronous replication using multiple data protection appliances across multiple storage arrays | |
| EP3062226B1 (en) | Data replication method and storage system | |
| US8898409B1 (en) | Journal-based replication without journal loss | |
| US9087112B1 (en) | Consistency across snapshot shipping and continuous replication |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150909 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160615 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160726 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160923 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20161206 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20161219 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6070064 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |