JP6069913B2 - 情報処理システム、情報処理システムの制御方法及び制御プログラム - Google Patents
情報処理システム、情報処理システムの制御方法及び制御プログラム Download PDFInfo
- Publication number
- JP6069913B2 JP6069913B2 JP2012152261A JP2012152261A JP6069913B2 JP 6069913 B2 JP6069913 B2 JP 6069913B2 JP 2012152261 A JP2012152261 A JP 2012152261A JP 2012152261 A JP2012152261 A JP 2012152261A JP 6069913 B2 JP6069913 B2 JP 6069913B2
- Authority
- JP
- Japan
- Prior art keywords
- information processing
- task
- reduce
- map
- job
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/06—Protocols specially adapted for file transfer, e.g. file transfer protocol [FTP]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L67/00—Network arrangements or protocols for supporting network services or applications
- H04L67/01—Protocols
- H04L67/10—Protocols in which an application is distributed across nodes in the network
- H04L67/1097—Protocols in which an application is distributed across nodes in the network for distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS]
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Information Transfer Between Computers (AREA)
Description
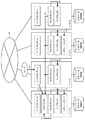
図1に、第1の実施の形態におけるシステムの概要を示す。ネットワーク51及び52は、例えばLAN(Local Area Network)であり、WAN(Wide Area Network)の回線を介して接続されている。ネットワーク51には、データセンタ1におけるノード11及びノード12が接続されており、ネットワーク52には、データセンタ2におけるノード21及び22が接続されている。本実施の形態においては、例えばデータセンタ1が東京に設けられており、データセンタ2がニューヨークに設けられている等、広域でマップリデュースジョブを実行することを想定している。
CWCは、処理対象となる文書のデータに含まれるユニークワードの数によって効果の大きさが変わる。ユニークワードの数が少なすぎると、もともとHadoopに用意されているコンバイナによってデータの量はかなり削減されるため、CWCによる効果が目立ちにくくなる。逆に、ユニークワードの数が多すぎると、1段階目において実行する複数のマップタスクの間で共通のキーを有するレコードが少なくなるため、CWCを実行してもデータセンタ内においてはレコードがあまり縮約されない。それどころか、マップリデュースジョブを2段階に分割するためのオーバーヘッドにより、却ってマップリデュースジョブのスループットが低下することがある。そこで、本実施の形態においては、以下のような処理を実行する。
本付録においては、本実施の形態に関連する技術について説明する。
Hadoopは、大量のデータをクラスタノードが並列に読み込み、高速にバッチ処理(Hadoopジョブ又は単にジョブとも呼ばれる)を実行するためのフレームワークである。
WANを介して接続された複数のデータセンタを跨ってHadoopジョブを実行する場合、例えば図18に示すように、複数のデータセンタを跨ってクラスタを構築する。広域のクラスタを構築する場合にも、論理的な構成は上で説明したものと変わらない。通常、ジョブトラッカーはいずれかのデータセンタ内に設けられる。ジョブクライアントはクラスタにおける各ノード上で動作するため、ユーザは任意のノードにおいてHadoopジョブの実行を指示することができる。
Hadoopストリーミングインタフェースは、マップ関数及びリデュース関数の入出力として標準入出力を利用できるようにすることで、Java(登録商標)以外のプログラミング言語でマップ関数及びリデュース関数を記述できるようにする仕組みである。Hadoopジョブを起動する際は、コマンドの引数でマップ関数、リデュース関数、入力ファイル及び出力ファイル等を指定する。
複数の情報処理装置を有する情報処理システムにおいて、
前記複数の情報処理装置のうちいずれかの情報処理装置が、
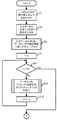
前記複数の情報処理装置が接続されたネットワークに含まれる複数のサブネットワークの各々について、当該サブネットワーク内の情報処理装置の中から1の情報処理装置を特定し、当該情報処理装置に対して、当該サブネットワーク内の情報処理装置が所持するデータに対して実行されたマップ処理の結果を集約する処理である第1のリデュース処理を割り当てる第1割り当て部と、
前記複数のサブネットワークの各々について実行された前記第1のリデュース処理の結果を集約する処理である第2のリデュース処理を、前記複数の情報処理装置のうちいずれかの情報処理装置に割り当てる第2割り当て部と
を有することを特徴とする情報処理システム。
前記第1のリデュース処理を割り当てられた情報処理装置が、
同じサブネットワークに属する情報処理装置から前記マップ処理の結果を収集し、収集した前記マップ処理の結果を集約し、
前記第2のリデュース処理を割り当てられた情報処理装置が、
前記第1のリデュース処理を実行した情報処理装置から前記第1のリデュース処理の結果を収集し、収集した前記第1のリデュース処理の結果を集約する
ことを特徴とする付記1記載の情報処理システム。
前記マップ処理は、文書における単語の出現回数を計数する処理であり、
前記複数の情報処理装置のうちいずれかの情報処理装置が、
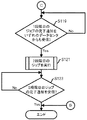
前記複数の情報処理装置が所持しているデータに対しユニークワードの数を計数する処理を実行し、計数された前記ユニークワードの数が予め定められた値の範囲内である場合に、前記第1割り当て部及び前記第2割り当て部に処理を実行させる実行制御部
をさらに有する付記1又は2記載の情報処理システム。
前記サブネットワークはLAN(Local Area Network)であり、
前記複数のサブネットワークを含むネットワークはWAN(Wide Area Network)である
ことを特徴とする付記1乃至3のいずれか1つ記載の情報処理システム。
前記第2割り当て部は、
前記複数の情報処理装置のうちユーザから指定された情報処理装置に前記第2リデュース処理を割り当てる
ことを特徴とする付記1乃至4のいずれか1つ記載の情報処理システム。
複数の情報処理装置を含む情報処理システムの制御方法において、
前記複数の情報処理装置のうちいずれかの情報処理装置が、
前記複数の情報処理装置が接続されたネットワークに含まれる複数のサブネットワークの各々について、当該サブネットワーク内の情報処理装置の中から1の情報処理装置を特定し、当該情報処理装置に対して、当該サブネットワーク内の情報処理装置が所持するデータに対して実行されたマップ処理の結果を集約する処理である第1のリデュース処理を割り当て、
前記複数のサブネットワークの各々について実行された前記第1のリデュース処理の結果を集約する処理である第2のリデュース処理を、前記複数の情報処理装置のうちいずれかの情報処理装置に割り当てる
ことを特徴とする情報処理システムの制御方法。
複数の情報処理装置を含む情報処理システムの制御プログラムにおいて、
前記複数の情報処理装置のうちいずれかの情報処理装置に、
前記複数の情報処理装置が接続されたネットワークに含まれる複数のサブネットワークの各々について、当該サブネットワーク内の情報処理装置の中から1の情報処理装置を特定させ、当該情報処理装置に対して、当該サブネットワーク内の情報処理装置が所持するデータに対して実行されたマップ処理の結果を集約する処理である第1のリデュース処理を割り当てさせ
前記複数のサブネットワークの各々について実行された前記第1のリデュース処理の結果を集約する処理である第2のリデュース処理を、前記複数の情報処理装置のうちいずれかの情報処理装置に割り当てさせる
ことを特徴とする情報処理システムの制御プログラム。
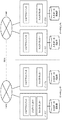
112,122,212,222 ジョブクライアント 113 ジョブトラッカー
1131 第1割当部 1132 第2割当部
114,124,214,224 タスクトラッカー
115,125,215,225 実行結果格納部
116,126,216,226 入力データ格納部
51,52 ネットワーク
Claims (4)
- 各々複数のローカルエリアネットワークのいずれかに接続される複数の情報処理装置
を有し、
前記複数の情報処理装置のうち第1の情報処理装置が、
前記複数のローカルエリアネットワークの各々について、当該ローカルエリアネットワークに接続された情報処理装置の中から1の情報処理装置を特定し、当該情報処理装置に対して、当該ローカルエリアネットワーク内の情報処理装置が所持する文書データにおいて各単語が出現する回数を計数する処理であるマップ処理の結果を集約する処理である第1のリデュース処理を割り当てる第1割り当て部と、
前記複数の情報処理装置のうちいずれかの情報処理装置に対して、前記複数のローカルエリアネットワークの各々において実行された前記第1のリデュース処理の結果を、前記複数のローカルエリアネットワークの各々に接続されるワイドエリアネットワークを介して収集し、且つ、収集された前記第1のリデュース処理の結果を集約する処理である第2のリデュース処理を割り当てる第2割り当て部と、
前記複数の情報処理装置が所持する文書データに対しユニークワードの数を計数する処理を実行し、計数された前記ユニークワードの数が予め定められた範囲内である場合に、前記第1割り当て部及び前記第2割り当て部に処理を実行させる実行制御部と、
を有することを特徴とする情報処理システム。 - 前記第1のリデュース処理を割り当てられた情報処理装置が、
同じローカルエリアネットワークに属する情報処理装置から前記マップ処理の結果を収集し、収集した前記マップ処理の結果を集約する、
ことを特徴とする請求項1記載の情報処理システム。 - 各々複数のローカルエリアネットワークのいずれかに接続される複数の情報処理装置を含む情報処理システムの制御方法であって、
前記複数の情報処理装置のうち第1の情報処理装置が、
前記複数の情報処理装置が所持する文書データに対しユニークワードの数を計数する処理を実行し、
計数された前記ユニークワードの数が予め定められた範囲内である場合に、
前記複数のローカルエリアネットワークの各々について、当該ローカルエリアネットワークに接続された情報処理装置の中から1の情報処理装置を特定し、当該情報処理装置に対して、当該ローカルエリアネットワーク内の情報処理装置が所持する文書データにおいて各単語が出現する回数を計数する処理であるマップ処理の結果を集約する処理である第1のリデュース処理を割り当て、
前記複数の情報処理装置のうちいずれかの情報処理装置に対して、前記複数のローカルエリアネットワークの各々において実行された前記第1のリデュース処理の結果を、前記複数のローカルエリアネットワークの各々に接続されるワイドエリアネットワークを介して収集し、且つ、収集された前記第1のリデュース処理の結果を集約する処理である第2のリデュース処理を割り当てる
処理を実行する制御方法。 - 複数の情報処理装置を含む情報処理システムの制御プログラムであって、
前記複数の情報処理装置の各々は、複数のローカルエリアネットワークのいずれかに接続され、
前記複数のローカルエリアネットワークの各々は、ワイドエリアネットワークに接続され、
前記複数の情報処理装置のうち第1の情報処理装置に、
前記複数の情報処理装置が所持する文書データに対しユニークワードの数を計数する処理を実行し、
計数された前記ユニークワードの数が予め定められた範囲内である場合に、
前記複数のローカルエリアネットワークの各々について、当該ローカルエリアネットワークに接続された情報処理装置の中から1の情報処理装置を特定し、当該情報処理装置に対して、当該ローカルエリアネットワーク内の情報処理装置が所持する文書データにおいて各単語が出現する回数を計数する処理であるマップ処理の結果を集約する処理である第1のリデュース処理を割り当て、
前記複数の情報処理装置のうちいずれかの情報処理装置に対して、前記複数のローカルエリアネットワークの各々において実行された前記第1のリデュース処理の結果を、前記複数のローカルエリアネットワークの各々に接続されるワイドエリアネットワークを介して収集し、且つ、収集された前記第1のリデュース処理の結果を集約する処理である第2のリデュース処理を割り当てる
処理を実行させるための制御プログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012152261A JP6069913B2 (ja) | 2012-07-06 | 2012-07-06 | 情報処理システム、情報処理システムの制御方法及び制御プログラム |
| US13/912,158 US9124587B2 (en) | 2012-07-06 | 2013-06-06 | Information processing system and control method thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012152261A JP6069913B2 (ja) | 2012-07-06 | 2012-07-06 | 情報処理システム、情報処理システムの制御方法及び制御プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014016700A JP2014016700A (ja) | 2014-01-30 |
| JP6069913B2 true JP6069913B2 (ja) | 2017-02-01 |
Family
ID=49879324
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012152261A Expired - Fee Related JP6069913B2 (ja) | 2012-07-06 | 2012-07-06 | 情報処理システム、情報処理システムの制御方法及び制御プログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US9124587B2 (ja) |
| JP (1) | JP6069913B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003095390A1 (fr) * | 2002-05-10 | 2003-11-20 | Ikuyoshi Kojima | Procede de production de carreau de type tenmoku denature par cuisson |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150326644A1 (en) * | 2014-05-07 | 2015-11-12 | Microsoft Corporation | Traveling map-reduce architecture |
| US10606804B2 (en) * | 2015-01-28 | 2020-03-31 | Verizon Media Inc. | Computerized systems and methods for distributed file collection and processing |
| US20160275123A1 (en) * | 2015-03-18 | 2016-09-22 | Hitachi, Ltd. | Pipeline execution of multiple map-reduce jobs |
| KR102592611B1 (ko) * | 2016-02-18 | 2023-10-23 | 한국전자통신연구원 | 맵 리듀스 장치, 맵 리듀스 제어장치 및 그 방법 |
| CN108259568B (zh) * | 2017-12-22 | 2021-05-04 | 东软集团股份有限公司 | 任务分配方法、装置、计算机可读存储介质及电子设备 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004110318A (ja) * | 2002-09-18 | 2004-04-08 | Nec Corp | 階層的分散処理システムおよび階層的分散処理方法 |
| US8181262B2 (en) * | 2005-07-20 | 2012-05-15 | Verimatrix, Inc. | Network user authentication system and method |
| JP5229731B2 (ja) * | 2008-10-07 | 2013-07-03 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 更新頻度に基づくキャッシュ機構 |
| JP5245711B2 (ja) * | 2008-10-17 | 2013-07-24 | 日本電気株式会社 | 分散データ処理システム、分散データ処理方法および分散データ処理用プログラム |
-
2012
- 2012-07-06 JP JP2012152261A patent/JP6069913B2/ja not_active Expired - Fee Related
-
2013
- 2013-06-06 US US13/912,158 patent/US9124587B2/en active Active
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003095390A1 (fr) * | 2002-05-10 | 2003-11-20 | Ikuyoshi Kojima | Procede de production de carreau de type tenmoku denature par cuisson |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014016700A (ja) | 2014-01-30 |
| US9124587B2 (en) | 2015-09-01 |
| US20140012890A1 (en) | 2014-01-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10003649B2 (en) | Systems and methods to improve read/write performance in object storage applications | |
| Xu et al. | Stateful serverless application placement in MEC with function and state dependencies | |
| US11175954B2 (en) | Multi-layer QoS management in a distributed computing environment | |
| Zaharia et al. | Job scheduling for multi-user mapreduce clusters | |
| Chowdhury et al. | Coflow: A networking abstraction for cluster applications | |
| CN103414761B (zh) | 一种基于Hadoop架构的移动终端云资源调度方法 | |
| US10296386B2 (en) | Processing element management in a streaming data system | |
| US10489176B2 (en) | Method, system and apparatus for creating virtual machine | |
| US10572290B2 (en) | Method and apparatus for allocating a physical resource to a virtual machine | |
| JP6069913B2 (ja) | 情報処理システム、情報処理システムの制御方法及び制御プログラム | |
| CN107222531B (zh) | 一种容器云资源调度方法 | |
| TWI408934B (zh) | 網路介面技術 | |
| US20130074091A1 (en) | Techniques for ensuring resources achieve performance metrics in a multi-tenant storage controller | |
| JP6783850B2 (ja) | データトラフィックを制限するための方法及びシステム | |
| CN104428752A (zh) | 将虚拟机流卸载至物理队列 | |
| Li et al. | OFScheduler: a dynamic network optimizer for MapReduce in heterogeneous cluster | |
| CN107818013A (zh) | 一种应用调度方法及装置 | |
| KR20190007043A (ko) | 재구성가능한 분산 처리 | |
| US20170344266A1 (en) | Methods for dynamic resource reservation based on classified i/o requests and devices thereof | |
| Siapoush et al. | Software-defined networking enabled big data tasks scheduling: A tabu search approach | |
| Dai et al. | Scheduling for response time in Hadoop MapReduce | |
| JP2016225877A (ja) | サービス提供システム、サービス提供方法、およびサービス提供プログラム | |
| Morla et al. | High-performance network traffic analysis for continuous batch intrusion detection | |
| CN118660017B (zh) | 接收队列调度方法、设备、介质及计算机程序产品 | |
| Wu et al. | Improving mapreduce performance by streaming input data from multiple replicas |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150406 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160113 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160216 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160413 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160920 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161116 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20161206 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20161219 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6069913 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |