JP6067616B2 - 発話生成手法学習装置、発話生成手法選択装置、発話生成手法学習方法、発話生成手法選択方法、プログラム - Google Patents
発話生成手法学習装置、発話生成手法選択装置、発話生成手法学習方法、発話生成手法選択方法、プログラム Download PDFInfo
- Publication number
- JP6067616B2 JP6067616B2 JP2014090935A JP2014090935A JP6067616B2 JP 6067616 B2 JP6067616 B2 JP 6067616B2 JP 2014090935 A JP2014090935 A JP 2014090935A JP 2014090935 A JP2014090935 A JP 2014090935A JP 6067616 B2 JP6067616 B2 JP 6067616B2
- Authority
- JP
- Japan
- Prior art keywords
- utterance
- generation method
- sentence
- user
- text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Landscapes
- Machine Translation (AREA)
Description
<pattern> *TOEIC*</pattern>
<template>難しそうですね</template>
(参考非特許文献1:杉山弘晃、 目黒豊美、 東中竜一郎、 南泰浩:任意の話題を持つユーザ発話に対する係り受けを利用した応答文の生成、 人工知能学会研究会、 SIG-SLUD、 pp. 55-60(2013))
以下、実施例で用いるルールベース発話生成手法について概説する。実施例で用いるルールベース発話生成手法は、Artificial Intelligence Markup Languageという対話システムのルールを記述するためのマークアップ言語に則って実行される。このマークアップ言語では、ユーザ発話文とのマッチングに用いるパターンとシステム発話文の候補であるテンプレートは、例えば以下のように記述される。
[例1]
<pattern>* カラオケ* 行かれ* か</pattern>
<template>はい、よく行きます。ストレス発散にいいですよね。</template>
[例2]
<pattern>花火* 見* 行か* か</pattern>
<template>そうですね。手持ちより打ち上げが好き</template>
本実施例に用いる統計的発話生成手法として、例えば参考非特許文献1に開示された手法を用いることができる。
以下、図1、図2、図3を参照して本発明の実施例1の発話生成手法学習装置について説明する。図1は、本実施例の発話生成手法学習装置1の構成を示すブロック図である。図2は、指定情報付与済み発話データの生成過程を例示する図である。図3は、本実施例の発話生成手法学習装置1の動作を示すフローチャートである。図1に示すように、本実施例の発話生成手法学習装置1は、指定情報付与済み発話データ記憶部11と、形態素解析部12と、特徴量生成部13と、モデル学習部14と、モデル記憶部15を含む。指定情報付与済み発話データ記憶部11には、指定情報付与済み発話データが記憶されている。指定情報付与済み発話データとは、1つのユーザ発話文に対して、システムが何れの発話生成手法で返答するかを指定する情報である指定情報を付与したデータのことである。
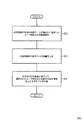
以下、図2の例を参照して、指定情報付与済み発話データの生成手順について説明する。指定情報付与済み発話データの生成は人間の手で行われる。以下、指定情報付与済み発話データの生成に関係する者をデータ生成者と総称する。データ生成者は、図2に示される指定情報付与済み発話データの例を次のように作成する。まずデータ生成者は、対話データから複数の発話文を「ユーザ発話文」として抽出する。データ生成者は、抽出された「ユーザ発話文」を、各発話生成手法を用いたモジュールに入力し、各モジュールから「システム発話文」を取得する。データ生成者は、取得した「システム発話文」一つ一つの「発話の適切さ」を評定する。図2の例では、「発話の適切さ」を評定する5段階の評定値である。データ生成者は、「発話の適切さ」により示される最も適切な発話生成手法を、対応するユーザ発話文に対して選択すべき発話生成手法であるとして指定する「指定情報」を決定し、対応するユーザ発話文に当該指定情報を付与する。ここで、複数の発話生成手法の「発話の適切さ」が同等であった場合には、何れかの発話生成手法が選択される例外ルールを定義しておいてもよい。例えばルールベース発話生成手法と統計的発話生成手法の評定値が同点の場合は、ルールベースを選んでもよい。
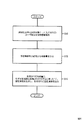
形態素解析部12は、指定情報付与済み発話データ記憶部11から選択したユーザ発話文を形態素解析する(S12)。指定情報付与済み発話データ記憶部11に各システム発話文も併せて記憶されている場合、形態素解析部12は、指定情報付与済み発話データ記憶部11から選択したシステム発話文を形態素解析することとしてもよい。例えば、ユーザ発話文「バイオハザード5(登録商標)はいつ放送するんです?」の形態素解析結果は以下のようになる。
________________________________________
バイオハザード5 名詞:固有バイオハザード5 [ ][ ][ ]オンライン百科事典A
は 連用助詞はハ[ ][ ][ ]
いつ 連用詞いつイツ[2670][ ][ ]
放送 名詞:動作放送ホウソウ[1540,1552,1120,919][ ][ ]
する 動詞接尾辞:連体するスル[2050][ ][ ]
ん 補助名詞んン[1][ ][ ]
です 判定詞:終止ですデス[ ][ ][ ]
? 句点:疑問符? [][][]
EOS
________________________________________
特徴量生成部13は、形態素解析の結果から特徴量を生成する(S13)。以下、ステップS13で用いられる特徴量について、図5を参照して説明する。図5は、特徴量を例示する図である。図5に示すように、例えば特徴量9は、ユーザ発話文または各発話生成手法から取得された各システム発話文に含まれる単語N-gram91、品詞N-gram92、意味属性N-gram(語彙大系N-gram)93、単語N-gram91をトピックモデルや行列分解を用いて圧縮・抽象化したベクトル列(意味ベクトル)91’,別途用意されたテキスト文書から予め学習された言語モデルに対するユーザ発話文またはシステム発話文のパープレキシティ94、ルールベース発話生成手法が用いるルールとユーザ発話文の一致度95、ユーザ発話文と各システム発話文の類似度96のうち何れか一つ以上のパラメータからなるものとすることができる。
パラメータとして、単語N-gram91、品詞N-gram92、意味属性N-gram(語彙大系N-gram)93を用いることが出来る。
(参考非特許文献2:D. Blei, A. Ng, and M. Jordan, "Latent Dirichlet Allocation", in Journal of Machine Learning Research, 2003, pp. 1107-1135.)
(参考非特許文献3:Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R. Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41, 391-407 (1990).)
ルールベース発話生成手法が持つルールは、事前に想定された発話に対して作られる。つまり、通常の対話で生起しやすいと思われる発話に対して作られることが多いため、通常の対話ではあまり生起しないような発話には、適切な返答を出力することが難しいと考えられる。パープレキシティ94は、言語モデルを学習したデータにおいて、その文章が生起しやすい発話であるか、生起しにくい発話であるかを表す尺度である。つまり、大量の自然文から学習した言語モデルに照らし合わせたとき、パープレキシティ94が低い発話は確率的に生起しにくい発話であり、ルールの中に適切な返答ができるものが含まれていない可能性が高い。逆に、パープレキシティ94が高い発話は確率的に生起しやすい発話であるため、適切なルールが存在する可能性が高い。このことから、パープレキシティ94を用いることで、ルールベース発話生成手法で適切な返答ができる発話か、そうでない発話であるか識別できると考えられる。そこで、言語モデルに対するユーザ発話のパープレキシティ94を、特徴量のパラメータの一つとして用いる。例えば所定の言語モデルを用いてパープレキシティ94を計算した場合、第1の発話文例「クックパッド(登録商標)見て余りもんでチャーハンをこさえるくらいはできますが料理を企画する力が全くおまへん。」ではパープレキシティ=63.4、第2の発話文例「こっちはさっきまで土砂降りでしたが、晴れてきました。」ではパープレキシティ=18.8であった。第1の発話文例のように、「クックパッド(登録商標)」のような珍しい単語や、「こさえるくらい」や「全くおまへん」といった、生起しにくい表現が含まれる発話文では、パープレキティ94が低くなる傾向にある。一方、第2の発話文例「こっちはさっきまで土砂降りでしたが、晴れてきました。」のように生起しやすい表現が多く含まれる発話文では、パープレキティ94が高くなる傾向がある。パープレキシティ94が高い発話は、通常の対話でも生起しやすい発話である可能性が高く、当該発話はルールが想定する発話である可能性が高いと期待できる。
前述のように、ルールベース発話生成手法を用いて発話を生成する際には、ユーザ発話とルール中のパターンとのTF−IDFの重み付コサイン類似度を求め、最も近いパターンを持つルールを選択することができる。ルールとの一致度が高く、よくマッチしているユーザ発話に対しては、システム発話としてルールベースの出力を採用すべきと考えられる。この一致度を反映させるため、ルールを選択する際に求めたコサイン類似度の値(ルールとの一致度95)を特徴量のパラメータの一つとする。
ルールとの一致度を計算するときと同様に、TF-IDFの重み付きコサイン類似度を求め、この値を特徴量のパラメータの一つとする。
モデル学習部14は、生成された特徴量に基づいて、選択されたユーザ発話文に対応する指定情報を出力するモデルを学習する(S14)。モデル学習部14は、学習したモデルをモデル記憶部15に記憶する。学習方法としてSupport Vector machine (SVM)や、ロジスティック回帰や、決定木などの識別モデルを学習する手法を用いることができる。これらのモデル構築の手法は、機械学習を用いる上で一般的な手法である。学習されたモデルは、モデル記憶部15に記憶される。
前述したように、モデル記憶部15には、所定のユーザ発話文に対するシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、発話生成手法ごとのシステム発話文の適切さに基づいて、ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、指定情報に対応するユーザ発話文又は各システム発話文の形態素解析の結果から生成した特徴量と、に基づいて学習されたモデルが記憶されている。
以下、引き続き図1、新たに図4を参照して本実施例の発話生成手法選択装置2について説明する。図4は、本実施例の発話生成手法選択装置2の動作を示すフローチャートである。図1に示すように、発話生成手法選択装置2は、発話生成手法学習装置1と共通の構成要素である形態素解析部12と、特徴量生成部13と、モデル記憶部15を含み、発話生成手法学習装置1に含まれない発話生成手法選択部16を含む。
以下、発話生成手法選択部16について説明する。発話生成手法選択対象として入力されたユーザ発話文、または各システム発話文に対して生成された特徴量と、モデル記憶部15に記憶されたモデルに基づいて、対応するユーザ発話文に対して選択すべき発話生成手法であるとして指定する指定情報を生成し、生成された指定情報を出力する(S16)。
本実施例で用いられるモデルの精度について、下記のような実験を行った。入力用のユーザ発話として、発明者らが収集した雑談対話のコーパスから149文、Twitter(登録商標)中のtweet80文を選択した。雑談対話のコーパスは、発明者らのルールベース対話システムのルール作成時に参考にしたデータであり、ルール作成者が事前に対話中に起こりやすいと想定した発話群であると言える。逆に、Twitter(登録商標)からは様々な話題や言い回しの発話が抽出されており、事前に想定が難しい発話であると言える。
雑談対話のコーパスから選択したユーザ発話に対しては、すべての特徴量を用いた場合が最も精度が良く、「ランダム」の条件と比較して有意に精度が向上した(マクネマー検定: p<.05)。一方で、Twitter(登録商標)中から選択したユーザ発話文に対しては、すべての特徴量を用いた場合の性能が、「ランダム」の条件における性能と変わらず、パープレキシティのみを用いた時が最も精度がよく、有意に分類精度が向上した(マクネマー検定: p<.01)。つまり、ユーザ発話が、珍しい発話かどうかで、ルールベースで返答すべきか否かが決定するということを表している。
Claims (8)
- 所定のユーザ発話文に対して、前記ユーザ発話文に対する応答であるシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、前記発話生成手法ごとのシステム発話文の適切さに基づいて、前記ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、前記指定情報に対応する前記ユーザ発話文とを対応付けて記憶する指定情報付与済み発話データ記憶部と、
前記指定情報付与済み発話データ記憶部から選択した前記ユーザ発話文を形態素解析する形態素解析部と、
前記形態素解析の結果から特徴量を生成する特徴量生成部と、
前記生成された特徴量に基づいて、前記選択されたユーザ発話文に対応する前記指定情報を出力するモデルを学習するモデル学習部と、
前記学習されたモデルを記憶するモデル記憶部と、を含む
発話生成手法学習装置。 - 所定のユーザ発話文に対して、前記ユーザ発話文に対する応答であるシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、前記発話生成手法ごとのシステム発話文の適切さに基づいて、前記ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、前記指定情報に対応する前記ユーザ発話文の形態素解析の結果から生成した特徴量と、に基づいて学習されたモデルを記憶するモデル記憶部と、
発話生成手法選択対象として入力されたユーザ発話文を形態素解析する形態素解析部と、
前記形態素解析の結果から特徴量を生成する特徴量生成部と、
前記生成された特徴量と、前記モデル記憶部に記憶されたモデルに基づいて、前記指定情報を生成し、生成された指定情報を出力する発話生成手法選択部と、を含む
発話生成手法選択装置。 - 所定のユーザ発話文に対して、前記ユーザ発話文に対する応答であるシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、前記発話生成手法ごとのシステム発話文の適切さに基づいて、前記ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、前記指定情報に対応する前記ユーザ発話文と、前記各システム発話文とを対応付けて記憶する指定情報付与済み発話データ記憶部と、
前記指定情報付与済み発話データ記憶部から選択した前記ユーザ発話文、又は前記各システム発話文を形態素解析する形態素解析部と、
前記形態素解析の結果から特徴量を生成する特徴量生成部と、
前記生成された特徴量に基づいて、前記選択されたユーザ発話文に対応する前記指定情報を出力するモデルを学習するモデル学習部と、
前記学習されたモデルを記憶するモデル記憶部と、を含む
発話生成手法学習装置。 - 所定のユーザ発話文に対して、前記ユーザ発話文に対する応答であるシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、前記発話生成手法ごとのシステム発話文の適切さに基づいて、前記ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、前記指定情報に対応する前記ユーザ発話文、又は前記各システム発話文の形態素解析の結果から生成した特徴量と、に基づいて学習されたモデルを記憶するモデル記憶部と、
発話生成手法選択対象として入力されたユーザ発話文、又は前記入力されたユーザ発話文から生成した各システム発話文を形態素解析する形態素解析部と、
前記形態素解析の結果から特徴量を生成する特徴量生成部と、
前記生成された特徴量と、前記モデル記憶部に記憶されたモデルに基づいて、前記指定情報を生成し、生成された指定情報を出力する発話生成手法選択部と、を含む
発話生成手法選択装置。 - 前記特徴量が、
前記ユーザ発話文または前記各システム発話文に含まれる単語N-gram、品詞N-gram、意味属性N-gram、単語N-gramを圧縮した意味ベクトル、別途用意されたテキスト文書から予め学習された言語モデルに対する前記ユーザ発話文または前記システム発話文のパープレキシティ、ルールベース発話生成手法が用いるルールと前記ユーザ発話文の一致度、前記ユーザ発話文と前記システム発話文の類似度のうち何れか一つ以上のパラメータからなる
請求項3又は4に記載の装置。 - 所定のユーザ発話文に対して、前記ユーザ発話文に対する応答であるシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、前記発話生成手法ごとのシステム発話文の適切さに基づいて、前記ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、前記指定情報に対応する前記ユーザ発話文とを対応付けて記憶する指定情報付与済み発話データ記憶部を含む発話生成手法学習装置が実行する、発話生成手法学習方法であって、
前記指定情報付与済み発話データ記憶部から選択した前記ユーザ発話文を形態素解析する形態素解析ステップと、
前記形態素解析の結果から特徴量を生成する特徴量生成ステップと、
前記生成された特徴量に基づいて、前記選択されたユーザ発話文に対応する前記指定情報を出力するモデルを学習するモデル学習ステップと、を含む
発話生成手法学習方法。 - 所定のユーザ発話文に対して、前記ユーザ発話文に対する応答であるシステム発話文を予め定めた複数の発話生成手法によって生成した場合の、前記発話生成手法ごとのシステム発話文の適切さに基づいて、前記ユーザ発話文に対して選択すべき発話生成手法を人手で指定した情報である指定情報と、前記指定情報に対応する前記ユーザ発話文の形態素解析の結果から生成した特徴量と、に基づいて学習されたモデルを記憶するモデル記憶部を含む発話生成手法選択装置が実行する、発話生成手法選択方法であって、
発話生成手法選択対象として入力されたユーザ発話文を形態素解析する形態素解析ステップと、
前記形態素解析の結果から特徴量を生成する特徴量生成ステップと、
前記生成された特徴量と、前記モデル記憶部に記憶されたモデルに基づいて、前記指定情報を生成し、生成された指定情報を出力する発話生成手法選択ステップと、を含む
発話生成手法選択方法。 - コンピュータを、請求項1から5の何れかに記載の装置として機能させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014090935A JP6067616B2 (ja) | 2014-04-25 | 2014-04-25 | 発話生成手法学習装置、発話生成手法選択装置、発話生成手法学習方法、発話生成手法選択方法、プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014090935A JP6067616B2 (ja) | 2014-04-25 | 2014-04-25 | 発話生成手法学習装置、発話生成手法選択装置、発話生成手法学習方法、発話生成手法選択方法、プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015210342A JP2015210342A (ja) | 2015-11-24 |
| JP6067616B2 true JP6067616B2 (ja) | 2017-01-25 |
Family
ID=54612581
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014090935A Active JP6067616B2 (ja) | 2014-04-25 | 2014-04-25 | 発話生成手法学習装置、発話生成手法選択装置、発話生成手法学習方法、発話生成手法選択方法、プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6067616B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6224857B1 (ja) * | 2017-03-10 | 2017-11-01 | ヤフー株式会社 | 分類装置、分類方法および分類プログラム |
| KR102509821B1 (ko) * | 2017-09-18 | 2023-03-14 | 삼성전자주식회사 | Oos 문장을 생성하는 방법 및 이를 수행하는 장치 |
| WO2021059771A1 (ja) | 2019-09-25 | 2021-04-01 | ソニー株式会社 | 情報処理装置、情報処理システム、および情報処理方法、並びにプログラム |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013167985A (ja) * | 2012-02-15 | 2013-08-29 | Nomura Research Institute Ltd | 談話要約生成システムおよび談話要約生成プログラム |
-
2014
- 2014-04-25 JP JP2014090935A patent/JP6067616B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015210342A (ja) | 2015-11-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Kheddar et al. | Deep transfer learning for automatic speech recognition: Towards better generalization | |
| US10936664B2 (en) | Dialogue system and computer program therefor | |
| Wu et al. | Emotion recognition from text using semantic labels and separable mixture models | |
| KR20210158344A (ko) | 디지털 어시스턴트를 위한 머신 러닝 시스템 | |
| Demir et al. | Improving named entity recognition for morphologically rich languages using word embeddings | |
| WO2017127296A1 (en) | Analyzing textual data | |
| JP5620349B2 (ja) | 対話装置、対話方法および対話プログラム | |
| Agrawal et al. | Affective representations for sarcasm detection | |
| KR101677859B1 (ko) | 지식 베이스를 이용하는 시스템 응답 생성 방법 및 이를 수행하는 장치 | |
| JP5524138B2 (ja) | 同義語辞書生成装置、その方法、及びプログラム | |
| CN104750677A (zh) | 语音传译装置、语音传译方法及语音传译程序 | |
| Chakravarty et al. | Dialog Acts Classification for Question-Answer Corpora. | |
| JP6067616B2 (ja) | 発話生成手法学習装置、発話生成手法選択装置、発話生成手法学習方法、発話生成手法選択方法、プログラム | |
| JP2018181259A (ja) | 対話ルール照合装置、対話装置、対話ルール照合方法、対話方法、対話ルール照合プログラム、及び対話プログラム | |
| Fujita et al. | Long short-term memory networks for automatic generation of conversations | |
| CN116414965A (zh) | 初始对话内容生成方法、装置、介质和计算设备 | |
| Jauk et al. | Acoustic feature prediction from semantic features for expressive speech using deep neural networks | |
| KR20230146398A (ko) | 바트 모델을 활용한 시퀀셜 텍스트 요약 처리 장치 및 그 제어방법 | |
| JP6743108B2 (ja) | パターン認識モデル及びパターン学習装置、その生成方法、それを用いたfaqの抽出方法及びパターン認識装置、並びにプログラム | |
| Zajíc et al. | First insight into the processing of the language consulting center data | |
| CN114707489A (zh) | 标注数据集获取方法、装置、电子设备及存储介质 | |
| Meechan-Maddon | The effect of noise in the training of convolutional neural networks for text summarisation | |
| Forsati et al. | Cooperation of evolutionary and statistical PoS-tagging | |
| Abdulhameed | Cross Language Information Transfer Between Modern Standard Arabic and Its Dialects–a Framework for Automatic Speech Recognition System Language Model | |
| JP6309852B2 (ja) | 強調位置予測装置、強調位置予測方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151130 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161212 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20161220 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20161221 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6067616 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |