JP6022604B2 - マルチバンクキャッシュメモリ - Google Patents
マルチバンクキャッシュメモリ Download PDFInfo
- Publication number
- JP6022604B2 JP6022604B2 JP2014555583A JP2014555583A JP6022604B2 JP 6022604 B2 JP6022604 B2 JP 6022604B2 JP 2014555583 A JP2014555583 A JP 2014555583A JP 2014555583 A JP2014555583 A JP 2014555583A JP 6022604 B2 JP6022604 B2 JP 6022604B2
- Authority
- JP
- Japan
- Prior art keywords
- cache memory
- data
- client
- request
- buffer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 230000015654 memory Effects 0.000 title claims description 483
- 239000000872 buffer Substances 0.000 claims description 215
- 238000000034 method Methods 0.000 claims description 46
- 230000000903 blocking effect Effects 0.000 claims 1
- 238000010586 diagram Methods 0.000 description 10
- 230000006870 function Effects 0.000 description 3
- 238000009877 rendering Methods 0.000 description 3
- 230000003139 buffering effect Effects 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000003491 array Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0844—Multiple simultaneous or quasi-simultaneous cache accessing
- G06F12/0846—Cache with multiple tag or data arrays being simultaneously accessible
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0844—Multiple simultaneous or quasi-simultaneous cache accessing
- G06F12/0855—Overlapped cache accessing, e.g. pipeline
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/084—Multiuser, multiprocessor or multiprocessing cache systems with a shared cache
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0844—Multiple simultaneous or quasi-simultaneous cache accessing
- G06F12/0846—Cache with multiple tag or data arrays being simultaneously accessible
- G06F12/0851—Cache with interleaved addressing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/10—Providing a specific technical effect
- G06F2212/1016—Performance improvement
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Description
以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
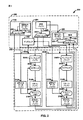
[1]複数のクライアントによってアクセス可能なキャッシュメモリシステムであって、前記キャッシュメモリシステムが複数のキャッシュメモリバンクを含む、キャッシュメモリシステムと、
前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数のペンディングバッファと、
前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数の読み出しデータバッファと、
を備え、
前記複数のキャッシュメモリバンクの各々は、
キャッシュメモリと、
前記複数のクライアントのうちの或るクライアントからのデータの要求が、前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによる要求の状態にかかわらず、前記キャッシュメモリによって満たされうるか否かを判断するように構成されたタグチェックユニットと、
を含み、
前記ペンディングバッファは、データの要求を前記複数のクライアントのうちの関連クライアントからの受信の順序にて記憶し、前記データの要求が前記キャッシュメモリによって満たされうるか否かの判断を保留するように構成され、
前記読み出しデータバッファは、前記関連クライアントによって要求された前記キャッシュメモリからのデータを、前記ペンディングバッファ内の前記関連クライアントに関連付けられたペンディングバッファによる受信の前記順序に従って記憶するように構成されている、システム。
[2]前記複数のキャッシュメモリバンクの各々は、
前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数のバッファ
をさらに含み、
前記リターンバッファは、前記タグチェックユニットが、前記データの要求が前記キャッシュメモリによって満たされうるか否かを判断した後で、前記複数のクライアントのうちの関連クライアントからの前記データの要求を記憶するように構成されている、[1]に記載のシステム。
[3]前記複数のクライアントに関連付けられた複数のデッドロック保護ユニット
をさらに含み、
前記デッドロック保護ユニットは、前記ペンディングバッファ内の前記関連クライアントのためのペンディングバッファが前記関連クライアントからの追加のデータの要求を受け付けることができるか否かを、前記追加の要求を受け付けることが前記複数のキャッシュメモリバンクの間にデッドロックの状況を引き起こすか否かに少なくとも部分的に基づいて、判断するように構成されている、[1]に記載のシステム。
[4]前記関連クライアントのための前記ペンディングバッファは、前記関連クライアントによるすべての順序の狂ったデータの要求のデータサイズの合計が、同じキャッシュメモリバンク内の前記読み出しデータバッファのサイズよりも小さい場合に、前記関連クライアントからの前記追加のデータの要求を受け付けることができる、[3]に記載のシステム。
[5]前記複数のデッドロック保護ユニットの各々は、前記関連クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファを含む、[4]に記載のシステム。
[6]前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数の書き込みデータバッファ
をさらに備え、
前記書き込みデータバッファは、前記キャッシュメモリにデータを書き込むために前記関連クライアントからの書き込み要求を受信するように構成されている、[1]に記載のシステム。
[7]前記キャッシュメモリは、前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記複数のバッファに記憶された前記データの要求をサービスするように構成されている、[2]に記載のシステム。
[8]クライアントからのデータの要求を、第1のキャッシュメモリバンクに関する前記クライアントに関連付けられたペンディングバッファに記憶することと、
前記データの要求の各々が、第2のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記第1のキャッシュメモリバンク内のキャッシュメモリによって満たされうるか否かを判断することと、
前記クライアントによって要求された前記キャッシュメモリからのデータを、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられた読み出しデータバッファによって、前記ペンディングバッファにおける前記データの要求の受信の順序に従って記憶することと
を備える、方法。
[9]前記判断の後に、前記クライアントからの前記データの要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられたリターンバッファによって記憶すること
をさらに備える、[8]に記載の方法。
[10]前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができるか否かを、前記追加の要求を受け付けることが前記第1のキャッシュメモリバンクと前記第2のキャッシュメモリバンクとの間にデッドロックの状況を引き起こすか否かに少なくとも部分的に基づいて判断すること
をさらに備える、[8]に記載の方法。
[11]前記第1のキャッシュメモリバンクによって前記クライアントから受信されたすべての順序の狂ったデータの要求のデータサイズの合計が、前記読み出しデータバッファのサイズよりも小さい場合に、前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができると判断すること
をさらに備える、[10]に記載の方法。
[12]前記ペンディングバッファが追加の要求を受け付けることができると判断することは、前記クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファに少なくとも部分的に基づく、[11]に記載の方法。
[13]前記キャッシュメモリにデータを書き込むために前記クライアントからの書き込み要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられた書き込みデータバッファによって受信すること
をさらに備える、[8]に記載の方法。
[14]前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記リターンバッファに記憶された前記データの要求を前記キャッシュメモリによってサービスすること
をさらに備える、[9]に記載の方法。
[15]第1のキャッシュメモリバンクに関するクライアントからのデータの要求を記憶するための手段と、
前記データの要求の各々が、第2のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、キャッシュメモリによって満たされうるか否かを判断するための手段と、
前記第1のメモリバンクに関する前記クライアントによって要求された前記キャッシュメモリからのデータを記憶するための手段と
を備える、装置。
[16]前記クライアントからの重要なデータの要求を記憶するための手段
をさらに備える、[15]に記載の装置。
[17]前記データの要求を受信するための手段が前記クライアントからの追加のデータの要求を受け付けることができるか否かを、前記追加の要求を受け付けることが前記第1のキャッシュメモリバンクと前記第2のキャッシュメモリバンクとの間にデッドロックの状況を引き起こすか否かに少なくとも部分的に基づいて判断するための手段
をさらに備える、[15]に記載の装置。
[18]前記データの要求を受信するための手段が前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断するための前記手段は、
前記クライアントによるすべての順序の狂ったデータの要求のデータサイズの合計が、前記要求されたキャッシュメモリからのデータを記憶するための手段のサイズよりも小さい場合に、前記データの要求を受信するための手段が前記クライアントからの追加のデータの要求を受け付けることができると判断するための手段
を備える、[17]に記載の装置。
[19]前記データの要求を受信するための手段が前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断するための前記手段は、
前記クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファ
を含む、[18]に記載の装置。
[20]前記キャッシュメモリにデータを書き込むための前記クライアントからの書き込み要求を受信するための手段
をさらに備える、[15]に記載の装置。
[21]前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記重要な要求を記憶するための手段に記憶された前記データの要求を、前記キャッシュメモリによってサービスするための手段
をさらに備える、[16]に記載の装置。
[22]第1のキャッシュメモリバンクに関するクライアントからのデータの要求を記憶し、
前記データの要求の各々が、第2のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、キャッシュメモリによって満たされうるか否かを判断し、
前記第1のメモリバンクに関する前記クライアントによって要求された前記キャッシュメモリからのデータを記憶する
ように構成された1つ以上のプロセッサを備える、装置。
[23]前記1つ以上のプロセッサは、
前記判断することの後で、前記クライアントからの前記データの要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられたリターンバッファに記憶する
ようにさらに構成されている、[22]に記載の装置。
[24]前記1つ以上のプロセッサは、
前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができるか否かを、前記追加の要求を受け付けることが前記第1のキャッシュメモリバンクと前記第2のキャッシュメモリバンクとの間にデッドロックの状況を引き起こすか否かに少なくとも部分的に基づいて判断する
ようにさらに構成されている、[22]に記載の装置。
[25]前記1つ以上のプロセッサは、
前記第1のキャッシュメモリバンクによって前記クライアントから受信されるすべての順序の狂ったデータの要求のデータサイズの合計が、前記読み出しデータバッファのサイズよりも小さい場合に、前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができると判断する
ようにさらに構成されている、[24]に記載の装置。
[26]前記ペンディングバッファが追加の要求を受け付けることができると判断することが、前記クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファに少なくとも部分的に基づく、[25]に記載の装置。
[27]前記1つ以上のプロセッサは、
前記キャッシュメモリにデータを書き込むために前記クライアントからの書き込み要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられた書き込みデータバッファによって受信する
ようにさらに構成されている、[22]に記載の装置。
[28]前記1つ以上のプロセッサは、
前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記リターンバッファに記憶された前記データの要求を、前記キャッシュメモリがサービスする
ようにさらに構成されている、[23]に記載の装置。
Claims (24)
- 複数のクライアントによってアクセス可能なキャッシュメモリシステムと、前記キャッシュメモリシステムは複数のキャッシュメモリバンクを含み、前記複数のキャッシュメモリバンクの各々のキャッシュメモリバンクは、
キャッシュメモリと、
前記複数のクライアントのうちの或るクライアントからのデータの要求が、前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによる要求の状態にかかわらず、前記キャッシュメモリによって満たされうるか否かを判断するように構成されたタグチェックユニットと、
を含み、
前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数のペンディングバッファと、前記ペンディングバッファは、データの要求を前記複数のクライアントのうちの関連クライアントからの受信の順序にて記憶し、前記データの要求が前記キャッシュメモリによって満たされうるか否かの判断を保留するように構成され、
前記複数のクライアントに関連付けられた複数のデッドロック保護ユニットと、前記デッドロック保護ユニットは、前記ペンディングバッファ内の前記関連クライアントのための前記キャッシュメモリバンクに関するペンディングバッファが、前記関連クライアントによるすべての順序の狂ったデータの要求のデータサイズの合計を、同じキャッシュメモリバンク内の読み出しデータバッファのサイズと比較することに少なくとも部分的に基づいて、前記関連クライアントからの追加のデータの要求を受け付けることができるか否かを判断するように構成され、前記デッドロック保護ユニットは、前記ペンディングバッファが前記追加のデータの要求を受け付けることができるか否かの前記判断に少なくとも部分的に基づいて、前記追加の要求を受け付けることが前記複数のキャッシュメモリバンクの間にデッドロックの状況を引き起こす場合に、前記ペンディングバッファが前記追加の要求を受け付けることを阻止するようにさらに構成され、
前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数の読み出しデータバッファと、前記読み出しデータバッファは、前記関連クライアントによって要求された前記キャッシュメモリからのデータを、前記ペンディングバッファ内の前記関連クライアントに関連付けられたペンディングバッファによる受信の前記順序に従って記憶するように構成され、
を備える、システム。 - 前記複数のキャッシュメモリバンクの各々は、
前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数のリターンバッファ、前記リターンバッファは、前記タグチェックユニットが、前記データの要求が前記キャッシュメモリによって満たされうるか否かを判断した後で、前記複数のクライアントのうちの前記関連クライアントからの前記データの要求を記憶するように構成され、
をさらに含む、請求項1に記載のシステム。 - 前記関連クライアントのための前記ペンディングバッファは、前記関連クライアントによるすべての順序の狂ったデータの要求のデータサイズの前記合計が、同じキャッシュメモリバンク内の前記読み出しデータバッファの前記サイズよりも小さい場合に、前記関連クライアントからの前記追加のデータの要求を受け付けることができる、請求項1に記載のシステム。
- 前記複数のデッドロック保護ユニットの各々は、前記関連クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファを含む、請求項3に記載のシステム。
- 前記複数のキャッシュメモリバンクに関する前記複数のクライアントに関連付けられた複数の書き込みデータバッファ、前記書き込みデータバッファは、前記キャッシュメモリにデータを書き込むために前記関連クライアントからの書き込み要求を受信するように構成され、
をさらに備える、請求項1に記載のシステム。 - 前記キャッシュメモリは、前記複数のキャッシュメモリバンク内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記複数のバッファに記憶された前記データの要求をサービスするように構成されている、請求項2に記載のシステム。
- クライアントからのデータの要求を、第1のキャッシュメモリバンクに関する前記クライアントに関連付けられたペンディングバッファに記憶することと、
前記データの要求の各々が、第2のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記第1のキャッシュメモリバンク内のキャッシュメモリによって満たされうるか否かを判断することと、
前記クライアントによるすべての順序の狂ったデータの要求のデータサイズの合計を、前記第1のキャッシュメモリバンク内の読み出しデータバッファのサイズと比較することに少なくとも部分的に基づいて、前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断することと、
前記ペンディングバッファが前記追加のデータの要求を受け付けることができるか否かの前記判断に少なくとも部分的に基づいて、前記追加の要求を受け付けることが前記第1のキャッシュメモリバンクと前記第2のキャッシュメモリバンクとの間にデッドロックの状況を引き起こす場合に、前記ペンディングバッファが前記追加の要求を受け付けることを阻止することと、
前記クライアントによって要求された前記キャッシュメモリからのデータを、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられた前記読み出しデータバッファによって、前記ペンディングバッファにおける前記データの要求の受信の順序に従って記憶することと
を備える、方法。 - 前記データの要求の各々が前記キャッシュメモリによって満たされうるか否かを判断した後に、前記クライアントからの前記データの要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられたリターンバッファによって記憶すること
をさらに備える、請求項7に記載の方法。 - 前記第1のキャッシュメモリバンクによって前記クライアントから受信されたすべての順序の狂ったデータの要求のデータサイズの前記合計が、前記読み出しデータバッファの前記サイズよりも小さい場合に、前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができると判断すること
をさらに備える、請求項7に記載の方法。 - 前記ペンディングバッファが追加の要求を受け付けることができると判断することは、前記クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファに少なくとも部分的に基づく、請求項9に記載の方法。
- 前記キャッシュメモリにデータを書き込むために前記クライアントからの書き込み要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられた書き込みデータバッファによって受信すること
をさらに備える、請求項7に記載の方法。 - 前記第1および第2のキャッシュメモリバンクの内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記リターンバッファに記憶された前記データの要求を前記キャッシュメモリによってサービスすること
をさらに備える、請求項8に記載の方法。 - 第1のキャッシュメモリバンクに関するクライアントからのデータの要求を記憶するための手段と、
前記データの要求の各々が、第2のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、キャッシュメモリによって満たされうるか否かを判断するための手段と、
前記データの要求を記憶するための手段が、前記クライアントによるすべての順序の狂ったデータの要求のデータサイズの合計を、前記第1のキャッシュメモリバンク内の読み出しデータバッファのサイズと比較することに少なくとも部分的に基づいて、前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断するための手段と、
前記データの要求を記憶するための手段が前記追加のデータの要求を受け付けることができるか否かの前記判断に少なくとも部分的に基づいて、前記追加の要求を受け付けることが前記第1のキャッシュメモリバンクと前記第2のキャッシュメモリバンクとの間にデッドロックの状況を引き起こす場合に、前記データの要求を記憶するための手段が前記追加の要求を受け付けることを阻止するための手段と、
前記第1のキャッシュメモリバンクに関する前記クライアントによって要求された前記キャッシュメモリからのデータを記憶するための手段と、前記クライアントによって要求された前記キャッシュメモリからのデータを記憶するための手段は、前記読み出しデータバッファであり、
を備える、装置。 - 前記クライアントからの、前記キャッシュメモリによって満たされ得なかったデータの要求を記憶するための手段
をさらに備える、請求項13に記載の装置。 - 前記データの要求を記憶するための手段が前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断するための前記手段は、
前記クライアントによるすべての順序の狂ったデータの要求のデータサイズの前記合計が、前記要求された前記キャッシュメモリからのデータを記憶するための手段の前記サイズよりも小さい場合に、前記データの要求を記憶するための手段が前記クライアントからの追加のデータの要求を受け付けることができると判断するための手段
を備える、請求項13に記載の装置。 - 前記データの要求を受信するための手段が前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断するための前記手段は、
前記クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファ
を含む、請求項15に記載の装置。 - 前記キャッシュメモリにデータを書き込むための前記クライアントからの書き込み要求を受信するための手段
をさらに備える、請求項13に記載の装置。 - 前記第1および第2のキャッシュメモリバンクの内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記クライアントからの、前記キャッシュメモリによって満たされ得なかったデータの要求を記憶するための手段に記憶された前記データの要求を、前記キャッシュメモリによってサービスするための手段
をさらに備える、請求項14に記載の装置。 - メモリと、
前記メモリに接続され、
第1のキャッシュメモリバンクに関するクライアントからのデータの要求を記憶し、
前記データの要求の各々が、第2のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、キャッシュメモリによって満たされうるか否かを判断し、
前記クライアントによるすべての順序の狂ったデータの要求のデータサイズの合計を、前記第1のキャッシュメモリバンク内の読み出しデータバッファのサイズと比較することに少なくとも部分的に基づいて、前記クライアントからの前記データの要求を記憶するペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができるか否かを判断し、
前記ペンディングバッファが前記追加のデータの要求を受け付けることができるか否かの前記判断に少なくとも部分的に基づいて、前記追加の要求を受け付けることが前記第1のキャッシュメモリバンクと前記第2のキャッシュメモリバンクとの間にデッドロックの状況を引き起こす場合に、前記ペンディングバッファが前記追加の要求を受け付けることを阻止し、
前記第1のキャッシュメモリバンクに関する前記クライアントによって要求された前記キャッシュメモリからのデータを記憶する
ように構成された1つ以上のプロセッサと、
を備える、装置。 - 前記1つ以上のプロセッサは、
前記データの要求の各々が前記キャッシュメモリによって満たされうるか否かを判断した後で、前記クライアントからの前記データの要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられたリターンバッファに記憶する
ようにさらに構成されている、請求項19に記載の装置。 - 前記1つ以上のプロセッサは、
前記第1のキャッシュメモリバンクによって前記クライアントから受信されるすべての順序の狂ったデータの要求のデータサイズの前記合計が、前記読み出しデータバッファの前記サイズよりも小さい場合に、前記ペンディングバッファが前記クライアントからの追加のデータの要求を受け付けることができると判断する
ようにさらに構成されている、請求項19に記載の装置。 - 前記ペンディングバッファが追加の要求を受け付けることができると判断することは、前記クライアントの要求について、有効フラグ、バンクID、およびデータサイズのうちの1つ以上を記憶するバッファに少なくとも部分的に基づく、請求項21に記載の装置。
- 前記1つ以上のプロセッサは、
前記キャッシュメモリにデータを書き込むために前記クライアントからの書き込み要求を、前記第1のキャッシュメモリバンクに関する前記クライアントに関連付けられた書き込みデータバッファによって受信する
ようにさらに構成されている、請求項19に記載の装置。 - 前記1つ以上のプロセッサは、
前記第1および第2のキャッシュメモリバンクの内の別のキャッシュメモリバンクにおける前記クライアントによるデータの要求の状態にかかわらず、前記リターンバッファに記憶された前記データの要求を、前記キャッシュメモリによってサービスする
ようにさらに構成されている、請求項20に記載の装置。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/364,901 US9274964B2 (en) | 2012-02-02 | 2012-02-02 | Multi-bank cache memory |
| US13/364,901 | 2012-02-02 | ||
| PCT/US2013/022759 WO2013116060A1 (en) | 2012-02-02 | 2013-01-23 | Multi-bank cache memory |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2015505631A JP2015505631A (ja) | 2015-02-23 |
| JP2015505631A5 JP2015505631A5 (ja) | 2016-06-16 |
| JP6022604B2 true JP6022604B2 (ja) | 2016-11-09 |
Family
ID=47790485
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014555583A Expired - Fee Related JP6022604B2 (ja) | 2012-02-02 | 2013-01-23 | マルチバンクキャッシュメモリ |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9274964B2 (ja) |
| EP (1) | EP2810172A1 (ja) |
| JP (1) | JP6022604B2 (ja) |
| KR (1) | KR101687883B1 (ja) |
| CN (1) | CN104094242B (ja) |
| WO (1) | WO2013116060A1 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10394566B2 (en) * | 2017-06-06 | 2019-08-27 | International Business Machines Corporation | Banked cache temporarily favoring selection of store requests from one of multiple store queues |
| KR20190037668A (ko) * | 2017-09-29 | 2019-04-08 | 에스케이하이닉스 주식회사 | 메모리 시스템 및 그것의 동작 방법 |
| US11853216B2 (en) * | 2021-08-16 | 2023-12-26 | Micron Technology, Inc. | High bandwidth gather cache |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3967247A (en) | 1974-11-11 | 1976-06-29 | Sperry Rand Corporation | Storage interface unit |
| JPH05210640A (ja) | 1992-01-31 | 1993-08-20 | Hitachi Ltd | マルチプロセッサシステム |
| US6745293B2 (en) | 2000-08-21 | 2004-06-01 | Texas Instruments Incorporated | Level 2 smartcache architecture supporting simultaneous multiprocessor accesses |
| US20030163643A1 (en) * | 2002-02-22 | 2003-08-28 | Riedlinger Reid James | Bank conflict determination |
| JP2004046643A (ja) * | 2002-07-12 | 2004-02-12 | Sony Corp | キャッシュ装置および記憶手段選択方法 |
| US7203775B2 (en) * | 2003-01-07 | 2007-04-10 | Hewlett-Packard Development Company, L.P. | System and method for avoiding deadlock |
| US7219185B2 (en) | 2004-04-22 | 2007-05-15 | International Business Machines Corporation | Apparatus and method for selecting instructions for execution based on bank prediction of a multi-bank cache |
| US7571284B1 (en) * | 2004-06-30 | 2009-08-04 | Sun Microsystems, Inc. | Out-of-order memory transactions in a fine-grain multithreaded/multi-core processor |
| US8560795B2 (en) * | 2005-06-30 | 2013-10-15 | Imec | Memory arrangement for multi-processor systems including a memory queue |
| WO2007003370A2 (en) * | 2005-06-30 | 2007-01-11 | Interuniversitair Microelektronica Centrum Vzw | A memory arrangement for multi-processor systems |
| US20080282034A1 (en) * | 2005-09-19 | 2008-11-13 | Via Technologies, Inc. | Memory Subsystem having a Multipurpose Cache for a Stream Graphics Multiprocessor |
| US7600080B1 (en) | 2006-09-22 | 2009-10-06 | Intel Corporation | Avoiding deadlocks in a multiprocessor system |
| KR20090110291A (ko) | 2006-10-26 | 2009-10-21 | 인터랙틱 홀딩스 엘엘시 | 병렬 컴퓨팅시스템을 위한 네트워크 인터페이스 카드 |
| US8521982B2 (en) * | 2009-04-15 | 2013-08-27 | International Business Machines Corporation | Load request scheduling in a cache hierarchy |
| US8661200B2 (en) * | 2010-02-05 | 2014-02-25 | Nokia Corporation | Channel controller for multi-channel cache |
-
2012
- 2012-02-02 US US13/364,901 patent/US9274964B2/en not_active Expired - Fee Related
-
2013
- 2013-01-23 EP EP13707465.4A patent/EP2810172A1/en not_active Withdrawn
- 2013-01-23 KR KR1020147024534A patent/KR101687883B1/ko active IP Right Grant
- 2013-01-23 CN CN201380007450.7A patent/CN104094242B/zh not_active Expired - Fee Related
- 2013-01-23 WO PCT/US2013/022759 patent/WO2013116060A1/en active Application Filing
- 2013-01-23 JP JP2014555583A patent/JP6022604B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| EP2810172A1 (en) | 2014-12-10 |
| CN104094242A (zh) | 2014-10-08 |
| US20130205091A1 (en) | 2013-08-08 |
| CN104094242B (zh) | 2017-03-01 |
| WO2013116060A1 (en) | 2013-08-08 |
| KR20140116966A (ko) | 2014-10-06 |
| US9274964B2 (en) | 2016-03-01 |
| KR101687883B1 (ko) | 2016-12-28 |
| JP2015505631A (ja) | 2015-02-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11347649B2 (en) | Victim cache with write miss merging | |
| US8521982B2 (en) | Load request scheduling in a cache hierarchy | |
| US9110830B2 (en) | Determining cache hit/miss of aliased addresses in virtually-tagged cache(s), and related systems and methods | |
| US7047322B1 (en) | System and method for performing conflict resolution and flow control in a multiprocessor system | |
| US8200939B2 (en) | Memory management unit in a microprocessor system | |
| US7644221B1 (en) | System interface unit | |
| US8352682B2 (en) | Methods and apparatus for issuing memory barrier commands in a weakly ordered storage system | |
| KR20040045035A (ko) | 힌트 버퍼를 이용한 메모리 액세스 대기시간 숨김 | |
| TW200915178A (en) | Memory device and method having on-board address protection system for facilitating interface with multiple processors, and computer system using same | |
| US20110246688A1 (en) | Memory arbitration to ensure low latency for high priority memory requests | |
| US9164912B2 (en) | Conflict resolution of cache store and fetch requests | |
| CN111684427A (zh) | 高速缓存控制感知的存储器控制器 | |
| US20060112238A1 (en) | Techniques for pushing data to a processor cache | |
| CN113826085A (zh) | 处理器中的写入流 | |
| US7529876B2 (en) | Tag allocation method | |
| JP2020030822A (ja) | インメモリコンピューティングのための大容量メモリシステム | |
| JP6022604B2 (ja) | マルチバンクキャッシュメモリ | |
| US20080307169A1 (en) | Method, Apparatus, System and Program Product Supporting Improved Access Latency for a Sectored Directory | |
| US20090144500A1 (en) | Store performance in strongly ordered microprocessor architecture | |
| US20080301376A1 (en) | Method, Apparatus, and System Supporting Improved DMA Writes | |
| US20070180157A1 (en) | Method for cache hit under miss collision handling | |
| US12066940B2 (en) | Data reuse cache | |
| US8205064B2 (en) | Latency hiding for a memory management unit page table lookup | |
| US20120054439A1 (en) | Method and apparatus for allocating cache bandwidth to multiple processors | |
| CN107408059B (zh) | 共享多级库的跨级预取 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20141016 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20151225 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151225 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160420 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20160420 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20160509 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160517 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160816 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20160906 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20161005 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6022604 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |