JP6000463B2 - 3d映像符号化の仮想深度値の方法および装置 - Google Patents
3d映像符号化の仮想深度値の方法および装置 Download PDFInfo
- Publication number
- JP6000463B2 JP6000463B2 JP2015532288A JP2015532288A JP6000463B2 JP 6000463 B2 JP6000463 B2 JP 6000463B2 JP 2015532288 A JP2015532288 A JP 2015532288A JP 2015532288 A JP2015532288 A JP 2015532288A JP 6000463 B2 JP6000463 B2 JP 6000463B2
- Authority
- JP
- Japan
- Prior art keywords
- disparity vector
- block
- view
- depth
- texture
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/56—Motion estimation with initialisation of the vector search, e.g. estimating a good candidate to initiate a search
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/513—Processing of motion vectors
- H04N19/521—Processing of motion vectors for estimating the reliability of the determined motion vectors or motion vector field, e.g. for smoothing the motion vector field or for correcting motion vectors
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
Description
視点合成予測では、両テクスチャと深度情報が視点合成予測に必要である。導出される仮想深度は、視点合成のための深度情報として用いられることができる。深度情報は、上述の導出プロセスによって得られる。後方マッピングの視点合成は、取得した深度情報に応じてテクスチャ情報を符号化されたテクスチャT0に配置する。例えば、図6では、得られた深度情報(610)は、現在のテクスチャブロック620によって仮想深度参照(610A)として用いられ、テクスチャ情報(符号化されたテクスチャT0で斜線ボックスによって図示されている)を配置する。現在のテクスチャブロックは、複数のサブブロックに分割されることができる。サブブロック視差ベクトル(符号化されたテクスチャT0で矢印により図示されている)は、対応する仮想深度サブブロック(610A)から導出できる。後方マッピングの視点合成は、仮想深度および指示されたテクスチャ情報によって行われる。合成ブロックは、予測用に参照として用いられることができる。配置されたテクスチャ情報(符号化されたテクスチャT0で斜線ボックスによって図示されている)は、合成ブロックに対応する。また、仮想深度は、前方マッピング用に参照領域を制限するように用いられることが可能である。前方および後方の両方のマッピングは、仮想深度より利点を得る。サブブロック視差ベクトルは、仮想深度マップの同一位置のサブブロック内の全ての深度値または一部の深度値の平均、最大、最小、または中間に基づいて決定されることができる。
現存するHEVCベースの3D映像符号化では、動き予測は、視差補償を視点間動き補償とし、視点間参照画像を参照リストに置き、視差ベクトルを動きベクトルとして用いる。本実施形態は、動きベクトルとして仮想深度データに基づく視差ベクトルを導出する。図7は、仮想深度を用いて、視点間動き予測用に視差ベクトル予測子を導出する例を示している。動きベクトル予測子は、仮想深度から抽出された視差ベクトルを用いることによって得られ、符号化されたビューで動きベクトルを参照することもできる。視差ベクトル予測子(DVP)または抽出された視差ベクトルは、仮想深度から変換された最大視差、平均視差、または一部の最大視差とすることができる。いくつかの映像符号化システムでは、動きベクトル予測子候補のリストが、維持され、最終の動きベクトル予測子がリストから選ばれる。この場合、抽出されたMVPまたはDVPは、候補として用いることもできる。例えば、抽出された深度情報(710)は、現在のブロック(720)によって仮想深度参照(710A)として用いられ、DVP(730)を配置する。
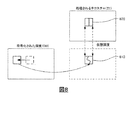
図8に示されるように、現在のブロックの分割は、仮想深度を参照して、更なる分割が必要かどうかを決定することができる。仮想深度ブロックが深度ブロックに分割が必要であると示す場合、更なる分割が現在のテクスチャブロックに適用される。例えば、図8の仮想深度ブロック(810)が仮想深度ブロックに分割が必要であると示した場合、現在のテクスチャブロック(820)も分割される。他のケースでは、仮想深度の分割が知られている場合、現在のブロックの分割は、仮想深度の分割から継承されることができる。フラグは、分割の継承が用いられるかどうかを示すのに用いられる。
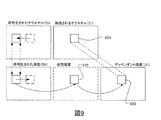
図9に示されるように、仮想深度ブロック(910)は、同一位置のテクスチャブロック(920)の視差ベクトルに応じて見つけられることができる。仮想深度ブロック(910)は、ディペンデント深度D1の深度ブロック(930)のインター/視点間予測用に参照として用いられる。
図10に示されるように、仮想深度ブロック(1010)は、同一位置のテクスチャブロック(1020)の視差ベクトルに応じて見つけられることができる。仮想深度ブロック(1010)は、ディペンデント深度D1の深度ブロック(1030)の深度イントラ予測または深度ブロック分割用に予測子として用いられることができる。
仮想深度のサブセットは、マージ/スキップモードの時間的な視点間動きベクトルのマージ候補用に視差ベクトルを導出するのに用いられることができる。マージ/スキップモードで符号化されたテクスチャまたは深度ブロックは、深度を参照して、マージ/スキップモードに用いられる視差ベクトル予測子を決定することができる。
3D−HEVCでは、視点間残差予測が用いられ、現在のビューで残差情報は、視点間視差ベクトルに基づいて符号化されたビューで参照データを用いて予測される。視点間視差ベクトルは、仮想深度から得られることができる。視点間視差ベクトルは、仮想深度の最大視差、平均視差、または一部の最大視差とすることができる。視点間視差ベクトルが得られた後、残差情報は、導出された視差ベクトルに応じて符号化されたビューで参照データによって予測できる。
Claims (23)
- ディペンデントビューでテクスチャデータの3次元若しくはマルチビュー映像符号化、又は、ディペンデントビューのテクスチャデータの3次元若しくはマルチビュー映像復号化の方法であって、前記方法は、
前記ディペンデントビューで現在のテクスチャブロックと関連した入力データを受けるステップ、
推定された視差ベクトルを導出し、符号化されたビューで対応するテクスチャブロックを配置するステップ、
前記符号化されたビューで、前記対応するテクスチャブロックと同一配置された同一位置の深度ブロックを特定するステップ、
前記符号化されたビューで前記同一位置の深度ブロックに基づいて、前記ディペンデントビューで仮想深度情報を導出するステップ、および
前記仮想深度情報を用いて入力データに符号化プロセスを適用するステップを含む方法。 - 前記推定された視差ベクトルの導出は、前記ディペンデントビューで現在のテクスチャブロックにおける視差ベクトルの候補に基づく請求項1に記載の方法。
- 前記視差ベクトルの候補は、前記ディペンデントビューで現在のテクスチャブロックと空間的/時間的に隣接するブロックから導出、または、前記現在のテクスチャブロックに対応する時間的に同一位置のテクスチャブロックと空間的/時間的に隣接する1つ以上のブロックから導出され、
前記空間的/時間的に隣接するブロックは、視差補償予測(DCP)ブロック、または視差ベクトル動き補償予測(DV−MCP)ブロックである請求項2に記載の方法。 - 前記視差ベクトルの候補は、前記空間的/時間的に隣接する1つ以上のブロックの全ての視差ベクトルまたは一部の視差ベクトルの平均、最大、最小、または中間に対応する請求項3に記載の方法。
- 前記視差ベクトルの候補は、前記ディペンデントビューで、符号化されたグローバルな幾何学モデルから導出される請求項2に記載の方法。
- 前記推定された視差ベクトルは、前記視差ベクトルの候補の優先順位または相関関係に応じて前記視差ベクトルの候補から決定される請求項2に記載の方法。
- 左上隣接ブロックと関連した第1の視差ベクトルの候補が、左隣接ブロックと関連した第3の視差ベクトルの候補よりも、上隣接ブロックと関連した第2の視差ベクトルの候補に類似する場合には、前記第2の視差ベクトルの候補は、前記推定された視差ベクトルとして選ばれ、
前記第2の視差ベクトルの候補が前記推定された視差ベクトルとして選ばれない場合には、前記第3の視差ベクトルの候補が前記推定された視差ベクトルとして選ばれる請求項2に記載の方法。 - 前記推定された視差ベクトルは、探索順序に基づいて、前記視差ベクトルの候補から決定される請求項2に記載の方法。
- 前記推定された視差ベクトルの導出するステップは、
前記視差ベクトルの候補から第1の視差ベクトルを選び、前記符号化されたビューで深度参照ブロックを得るステップ、
前記深度参照ブロックから、前記符号化されたビューで前記対応するテクスチャブロックから前記ディペンデントビューで第1の位置を指している第2の視差ベクトルを抽出するステップ、
前記第1の視差ベクトルと前記第2の視差ベクトルとの間の整合性エラーを決定するステップ、および
前記推定された視差ベクトルとして最小の整合性エラーとなる前記視差ベクトルの候補から1つの視差ベクトルの候補を選ぶステップを含む請求項2に記載の方法。 - 前記整合性エラーは、第1の視差ベクトルと第2の視差ベクトルとの間の差、または現在のテクスチャブロックの第1の位置と中心位置との間の距離に対応する請求項9に記載の方法。
- 前記推定された視差ベクトルの導出するステップは、
1つの視差ベクトルの候補に対応する前記符号化されたビューで深度参照ブロックを得るステップ、
前記深度参照ブロックから変換された視差ベクトルを抽出するステップ、
前記変換された視差ベクトルと前記1つの視差ベクトルの候補との間の整合性エラーを決定するステップ、および
前記推定された視差ベクトルとして最小の整合性エラーを有する1つの変換された視差ベクトルを選ぶステップを含む請求項2に記載の方法。 - シンタックス要素は、前記ディペンデントビューで前記テクスチャデータと関連した仮想深度情報が使用されているかどうかを示している請求項1に記載の方法。
- 前記現在のブロックをサブブロックに分割するステップ、
前記各サブブロックの仮想深度からサブブロック視差ベクトルを導出するステップ、
前記各サブブロックのサブブロック視差ベクトルに応じて視点間参照サブブロックを得るステップ、および
対応する視点間参照サブブロックを用いて各サブブロックに視点間予測の符号化を適用するステップを更に含む請求項1に記載の方法。 - 前記サブブロック視差ベクトルは、対応するサブブロックの仮想深度値から変換される請求項13に記載の方法。
- 前記サブブロック視差ベクトルは、前記対応するサブブロックの全てまたは一部の仮想深度値の平均、最大、最小、または中間に対応する請求項14に記載の方法。
- 前記仮想深度情報から導出された動きベクトル予測子または視差ベクトル予測子は、マージモード若しくはスキップモードで符号化された現在のテクスチャブロックの符号化、又は、マージモード若しくはまたはスキップモードで復号化された現在のテクスチャブロックの復号化に用いられる請求項1に記載の方法。
- 前記仮想深度情報から導出された1つの視差ベクトルは、マージモードまたはスキップモードで符号化された前記現在のテクスチャブロックの時間的な視点間動きベクトルのマージ候補を生成するために用いられる請求項1に記載の方法。
- 前記現在のテクスチャブロックの分割または現在の深度ブロックの分割は、前記仮想深度情報に基づいて継承または導出される請求項1に記載の方法。
- 前記仮想深度情報は参照ブロックを導出するために用いられ、
前記参照ブロックは、前記現在のテクスチャまたは現在の深度ブロックを視点間動き補償を用いて符号化するためのブロックである
請求項1に記載の方法。 - 前記仮想深度情報は、1つの視差ベクトルを導出するために用いられ、
前記視差ベクトルは、現在のテクスチャブロックまたは現在の深度ブロックの視点間動き補償のためのベクトルである請求項1に記載の方法。 - 動きベクトル予測子は、前記仮想深度情報から導出された前記視差ベクトルを用いて得られ、前記符号化されたビューで動きベクトルを参照する請求項20に記載の方法。
- 視点間視差ベクトルは、前記現在のテクスチャブロックまたは現在の深度ブロックと関連した残差データの視点間残差予測の前記仮想深度情報から得られる請求項1に記載の方法。
- ディペンデントビューでテクスチャデータの3次元またはマルチビュー映像符号化または復号化の装置であって、
1つ以上の電子回路を備え、
前記1つ以上の電子回路は、
前記ディペンデントビューで現在のテクスチャブロックと関連した入力データを受信し、
推定された視差ベクトルを導出し、符号化されたビューで対応するテクスチャブロックを配置し、
前記符号化されたビューで前記対応するテクスチャブロックと同一配置された同一位置の深度ブロックを特定し、
前記符号化されたビューで前記同一位置の深度ブロックに基づいて、前記ディペンデントビューの仮想深度情報を導出し、且つ、
前記仮想深度情報を用いて入力データに符号化プロセスを適用する装置。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261703901P | 2012-09-21 | 2012-09-21 | |
| US61/703,901 | 2012-09-21 | ||
| US201261711314P | 2012-10-09 | 2012-10-09 | |
| US61/711,314 | 2012-10-09 | ||
| PCT/CN2013/083659 WO2014044168A1 (en) | 2012-09-21 | 2013-09-17 | Method and apparatus of virtual depth values in 3d video coding |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2015533038A JP2015533038A (ja) | 2015-11-16 |
| JP2015533038A5 JP2015533038A5 (ja) | 2016-08-25 |
| JP6000463B2 true JP6000463B2 (ja) | 2016-09-28 |
Family
ID=50340582
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015532288A Active JP6000463B2 (ja) | 2012-09-21 | 2013-09-17 | 3d映像符号化の仮想深度値の方法および装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US10085039B2 (ja) |
| EP (1) | EP2898688B1 (ja) |
| JP (1) | JP6000463B2 (ja) |
| CN (1) | CN104662910B (ja) |
| WO (1) | WO2014044168A1 (ja) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9253486B2 (en) * | 2012-09-28 | 2016-02-02 | Mitsubishi Electric Research Laboratories, Inc. | Method and system for motion field backward warping using neighboring blocks in videos |
| CN104969556A (zh) | 2013-01-08 | 2015-10-07 | Lg电子株式会社 | 处理视频信号的方法和设备 |
| FR3002716A1 (fr) | 2013-02-26 | 2014-08-29 | France Telecom | Derivation de vecteur de mouvement de disparite, codage et decodage video 3d utilisant une telle derivation |
| US9521425B2 (en) * | 2013-03-19 | 2016-12-13 | Qualcomm Incorporated | Disparity vector derivation in 3D video coding for skip and direct modes |
| JP6196372B2 (ja) * | 2013-04-11 | 2017-09-13 | エルジー エレクトロニクス インコーポレイティド | ビデオ信号処理方法及び装置 |
| US10009621B2 (en) * | 2013-05-31 | 2018-06-26 | Qualcomm Incorporated | Advanced depth inter coding based on disparity of depth blocks |
| CA2909550C (en) * | 2013-07-15 | 2018-04-24 | Mediatek Singapore Pte. Ltd. | Method of disparity derived depth coding in 3d video coding |
| KR102378087B1 (ko) * | 2014-04-02 | 2022-03-24 | 한국전자통신연구원 | 변이 벡터를 사용한 병합 움직임 후보 유도 장치 및 방법 |
| JP6310340B2 (ja) * | 2014-06-25 | 2018-04-11 | 日本電信電話株式会社 | 映像符号化装置、映像復号装置、映像符号化方法、映像復号方法、映像符号化プログラム及び映像復号プログラム |
| US12169818B2 (en) | 2016-05-04 | 2024-12-17 | Mariella Labels Oy | Simultaneously displaying new prices linked to products via an electronic price label system |
| EP3459251B1 (en) * | 2016-06-17 | 2021-12-22 | Huawei Technologies Co., Ltd. | Devices and methods for 3d video coding |
| JP7320352B2 (ja) * | 2016-12-28 | 2023-08-03 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 三次元モデル送信方法、三次元モデル受信方法、三次元モデル送信装置及び三次元モデル受信装置 |
| US11272207B2 (en) | 2017-06-12 | 2022-03-08 | Futurewei Technologies, Inc. | Selection and signaling of motion vector (MV) precisions |
| CN118573894A (zh) * | 2017-09-19 | 2024-08-30 | 三星电子株式会社 | 对运动信息进行编码和解码的方法以及设备 |
| US20200014931A1 (en) * | 2018-07-06 | 2020-01-09 | Mediatek Inc. | Methods and Apparatuses of Generating an Average Candidate for Inter Picture Prediction in Video Coding Systems |
| WO2020056095A1 (en) * | 2018-09-13 | 2020-03-19 | Interdigital Vc Holdings, Inc. | Improved virtual temporal affine candidates |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6055274A (en) * | 1997-12-30 | 2000-04-25 | Intel Corporation | Method and apparatus for compressing multi-view video |
| US6691275B1 (en) * | 2000-12-14 | 2004-02-10 | Lsi Logic Corporation | Encoder with vector-calculated disparity logic |
| JP4793366B2 (ja) * | 2006-10-13 | 2011-10-12 | 日本ビクター株式会社 | 多視点画像符号化装置、多視点画像符号化方法、多視点画像符号化プログラム、多視点画像復号装置、多視点画像復号方法、及び多視点画像復号プログラム |
| US8953684B2 (en) * | 2007-05-16 | 2015-02-10 | Microsoft Corporation | Multiview coding with geometry-based disparity prediction |
| EP2269378A2 (en) | 2008-04-25 | 2011-01-05 | Thomson Licensing | Multi-view video coding with disparity estimation based on depth information |
| WO2010021666A1 (en) * | 2008-08-20 | 2010-02-25 | Thomson Licensing | Refined depth map |
| CN102257818B (zh) | 2008-10-17 | 2014-10-29 | 诺基亚公司 | 3d视频编码中运动向量的共享 |
| WO2010053332A2 (ko) | 2008-11-10 | 2010-05-14 | 엘지전자 주식회사 | 시점간 예측을 이용한 비디오 신호 처리 방법 및 장치 |
| KR101660312B1 (ko) * | 2009-09-22 | 2016-09-27 | 삼성전자주식회사 | 3차원 비디오의 움직임 탐색 장치 및 방법 |
| US8537200B2 (en) * | 2009-10-23 | 2013-09-17 | Qualcomm Incorporated | Depth map generation techniques for conversion of 2D video data to 3D video data |
| JP4938884B2 (ja) | 2010-09-30 | 2012-05-23 | シャープ株式会社 | 予測ベクトル生成方法、画像符号化方法、画像復号方法、予測ベクトル生成装置、画像符号化装置、画像復号装置、予測ベクトル生成プログラム、画像符号化プログラムおよび画像復号プログラム |
| CN102510500B (zh) * | 2011-10-14 | 2013-12-18 | 北京航空航天大学 | 一种基于深度信息的多视点立体视频错误隐藏方法 |
| KR101662918B1 (ko) * | 2011-11-11 | 2016-10-05 | 지이 비디오 컴프레션, 엘엘씨 | 깊이-맵 추정 및 업데이트를 사용한 효율적인 멀티-뷰 코딩 |
| US9445076B2 (en) | 2012-03-14 | 2016-09-13 | Qualcomm Incorporated | Disparity vector construction method for 3D-HEVC |
| US20130287093A1 (en) * | 2012-04-25 | 2013-10-31 | Nokia Corporation | Method and apparatus for video coding |
| US20130329007A1 (en) | 2012-06-06 | 2013-12-12 | Qualcomm Incorporated | Redundancy removal for advanced motion vector prediction (amvp) in three-dimensional (3d) video coding |
| US9258562B2 (en) * | 2012-06-13 | 2016-02-09 | Qualcomm Incorporated | Derivation of depth map estimate |
| US20130336406A1 (en) | 2012-06-14 | 2013-12-19 | Qualcomm Incorporated | Redundancy removal for merge/skip mode motion information candidate list construction |
| CN104429074B (zh) | 2012-06-28 | 2018-11-30 | 寰发股份有限公司 | 3d视频编码中视差矢量导出的方法和装置 |
| US20140071235A1 (en) | 2012-09-13 | 2014-03-13 | Qualcomm Incorporated | Inter-view motion prediction for 3d video |
| CN104769949B (zh) * | 2012-09-19 | 2018-03-13 | 高通股份有限公司 | 用于视差向量导出的图片的选择的方法和装置 |
-
2013
- 2013-09-17 US US14/429,498 patent/US10085039B2/en active Active
- 2013-09-17 CN CN201380049206.7A patent/CN104662910B/zh active Active
- 2013-09-17 WO PCT/CN2013/083659 patent/WO2014044168A1/en not_active Ceased
- 2013-09-17 EP EP13839017.4A patent/EP2898688B1/en active Active
- 2013-09-17 JP JP2015532288A patent/JP6000463B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP2898688B1 (en) | 2018-05-30 |
| JP2015533038A (ja) | 2015-11-16 |
| US20150249838A1 (en) | 2015-09-03 |
| EP2898688A1 (en) | 2015-07-29 |
| CN104662910A (zh) | 2015-05-27 |
| WO2014044168A1 (en) | 2014-03-27 |
| EP2898688A4 (en) | 2016-04-27 |
| US10085039B2 (en) | 2018-09-25 |
| CN104662910B (zh) | 2018-04-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6000463B2 (ja) | 3d映像符号化の仮想深度値の方法および装置 | |
| US9961370B2 (en) | Method and apparatus of view synthesis prediction in 3D video coding | |
| US10230937B2 (en) | Method of deriving default disparity vector in 3D and multiview video coding | |
| KR101753171B1 (ko) | 3d 비디오 코딩에서의 간략화된 뷰 합성 예측 방법 | |
| US20160309186A1 (en) | Method of constrain disparity vector derivation in 3d video coding | |
| JP2015533038A5 (ja) | ||
| US9621920B2 (en) | Method of three-dimensional and multiview video coding using a disparity vector | |
| US20150172714A1 (en) | METHOD AND APPARATUS of INTER-VIEW SUB-PARTITION PREDICTION in 3D VIDEO CODING | |
| JP6042556B2 (ja) | 3dビデオ符号化における制約される視差ベクトル導出の方法と装置 | |
| US20150365649A1 (en) | Method and Apparatus of Disparity Vector Derivation in 3D Video Coding | |
| CN104768015B (zh) | 视频编码方法及装置 | |
| CA2921759C (en) | Method of motion information prediction and inheritance in multi-view and three-dimensional video coding | |
| CN105247862A (zh) | 三维视频编码中的视点合成预测的方法及装置 | |
| CN105144714B (zh) | 三维或多视图视频编码或解码的方法及装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150320 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160324 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160405 |
|
| A524 | Written submission of copy of amendment under article 19 pct |
Free format text: JAPANESE INTERMEDIATE CODE: A524 Effective date: 20160705 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20160809 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20160830 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6000463 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |