JP5963845B2 - 一時的なデータウェアハウスにデータをロードするための方法およびシステム - Google Patents
一時的なデータウェアハウスにデータをロードするための方法およびシステム Download PDFInfo
- Publication number
- JP5963845B2 JP5963845B2 JP2014503662A JP2014503662A JP5963845B2 JP 5963845 B2 JP5963845 B2 JP 5963845B2 JP 2014503662 A JP2014503662 A JP 2014503662A JP 2014503662 A JP2014503662 A JP 2014503662A JP 5963845 B2 JP5963845 B2 JP 5963845B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- partition
- timestamp
- source
- row
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
- G06F16/254—Extract, transform and load [ETL] procedures, e.g. ETL data flows in data warehouses
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description

例示的な実施形態では、ステップ100は、N(いいえ)の典型的な値で、TVT_FILTER_HISTORYと呼ばれる履歴フィルタリングパラメータを使用する。TVT_FILTER_HISTORYがYに等しい場合、CDCシステムはW_tableの入力データに基づいてCDCの実行中に必要のない目標テーブル内のより古い履歴行を取り除く。各W_table PKのための最先のタイムスタンプは、パーティションを切られた揮発性テーブル上のフィルタとして機能する、目標テーブルの主キーのセットを構築するために問い合わせおよび比較される。派生テーブルはパーティションフィルタを適用するW_table内の主キー毎のより古いソースタイムスタンプのWITH句を使用して構築される。これは次にすべてのより古い履歴を除外する対象テーブルから必要な主キーの別個のセットを作成するために使用される。
例示的な実施形態では、ALL_VT=YおよびNUM_PARTITIONS>1であるとき、ステップ101はスナップショットをロードするために実行される(例えば、LOAD_TYPE=SまたはB)。換言すると、このステップは、別々の揮発性テーブルのテーブルの別個の論理パーティションを作成するコストがこのステップを追加するコストよりもプロセッサの使用率および/または経過実行時間を低減するために大規模なテーブル用に呼び出されてもよい。一代替案では、ステップ101はステップ100と同一の条件下で呼び出され、必要に応じて論理パーティションを別々におよび並列セッションで処理することができるように、Wテーブル、Xテーブルおよび目標テーブル用の揮発性テーブルを構築するプロセスを完了する。
[0001]例示的な実施形態では、ステップ102はスナップショットロードを実行し(例えば、LOAD_TYPE=SまたはB)、ロードタイプSおよびBの間には、ステップ102でコードの差はなくてもよい。換言すれば、暗示的削除のためのX_table行の構築は、ソースデータの完全なスナップショットが使用可能であり、その存在のために親テーブルに依存していないテーブル用であるときには、呼び出されてもよい。これらの後のケースは親―子暗示的削除である。いくつかの実施形態では、ステップ102は、変更された行のみをロードするための行修正タイムスタンプを使用するなどのような、スナップショットインターフェースへの代替手段が実用的でないときに使用される。
[0003]例示的な実施形態では、ステップ103はNORMALIZE_LATEST=Yであるとき、ロードタイプSおよびBの間でコードの違いなしでスナップショットロード(例えば、LOAD_TYPE=SまたはB)に対して実行される。このステップは、例えばテーブルが新しいコンテンツなしに新しい行のかなりの量を有するときに呼び出されてもよい。特に、このステップは目標テーブルの最新のアクティブな行よりも新しいSOURCE_START_TSで主キー毎に次の連続した行のみを排除し、他のすべての非キー属性は同じである。例えば、ステップ103はW_table行の大部分が新しいタイムスタンプで新しい属性なしで現在の目標テーブルの行を表すところで有効であってもよい。
[0005]例示的な実施形態では、ステップ104は、ソースタイムスタンプの最後の3桁以外の少なくとも1つの属性が異なるW_tableから、目標テーブル行(ALL_VT=Nのとき)またはVTに格納されたフィルタされた目標行(ALL_VT=Yのとき)から、候補行とともにX_tableをロードする。このような行は最初にETLインジケータ「I」としてコーディングされており、SOURCE START TSは必要に応じて一意に1マイクロ秒でシーケンスされる。このプロセスは、エラー中で以前に論理的に削除された最新レコードの再活性化などのような、目標テーブル内への非キー属性の変更のアップデートを(source start TSへの対応する1ミリ秒追加で)することを可能にする。これは、個別の入力データセットの行がロードされることのみを保証するために有効な時間で一意性違反を解決する。
[0010]例示的な実施形態では、ステップ105はX_tableが前のステップで候補挿入行がロードされた後で実行される。それ故選択クエリは現在の実行に関与する主キーのセットを決定するためにW_table内の入力行およびX_table内の削除行を統合する必要はない。このアプローチは結果として、特にスナップショットロードのケースでは、入力W_table行がロードされる前に除去される際に揮発性の比較的小さなテーブルとなってもよい。
[0016]例示的な実施形態では、ステップ106のシーケンスは挿入候補(例えば、削除を除く)についてX_tableおよび非コア間の完全な主キーを複製する。いくつかの実施形態では、X_table内でのシーケンシングはステップ104により実行されてもよい。ステップ106はALL_VTが有効になっているときに揮発性テーブル名に対して受け入れおよび動作をしてもよい。
[0019]例示的な実施形態では、ステップ107はALL_VTが有効になっているときに揮発性テーブル名に対して受け入れおよび動作をしてもよい。ステップ107は、主キー内のソース開始タイムスタンプでソートする直前の行と比較される際、ソース開始タイムスタンプ以外の新しいキーまたは非キー属性を含まない候補W_table行を削除する。このステップは一般的に一時的正規化と呼ばれるプロセスの圧縮ユニットを表す。
[0024]例示的な実施形態では、ステップ108はALL_VTが有効になっているときに揮発性テーブル名に対して受け入れおよび動作をしてもよい。ステップ108はこのケースでは新しいアップデートのための「I」から「U」である候補挿入行(「I」)の抽出、変換、ロード(ETL)インジケータをアップデートする2つのステップの最初のものである。ここで使用されるように、用語「より新しい」は削除済みとしてフラグが付けられていても、非コアの同じPK_latest内の最新行の主キーよりももっと後のソース開始タイムスタンプを含む、主キーを有するデータレコードを意味する。このステップは、各々が新しいコンテンツを表しステップ107で削除されていないことを提供される、主キー内の複数のX_table行のETLインジケータをアップデートすることができる。例示的な実施形態では、最新のアクティブな非コア行の終了タイムスタンプのみは最新の非コア行の終了タイムスタンプとしてその開始タイムスタンプを適用するためのPK毎の最先の「U」行のみを探し出す適用フェーズ(例えば、以下の適用ステップ202)でアップデートされる。後述するステップ110は、すべてであるが最新の行が目標の事前期限切れ内に挿入されることを反映するために、X_table内のPK毎の「U」に設定される複数の行がある際には終了タイムスタンプを提供してもよい。
[0025]例示的な実施形態では、ステップ109はALL_VTが有効になっているときに揮発性テーブル名に対して受け入れおよび動作をしてもよい。ステップ109は新しい履歴行がコンピュータデータウェアハウスに追加されることを可能にする。このステップは、このケースでは「より古い」データのアップデートのための「I」または「U」から「O」である、候補挿入行(「I」または「U」)用のETLインジケータをアップデートする2つのステップの2番目である。「Ο」:1のETLインジケータでの「古い」アップデートには2つのケースがある。ソース開始タイムスタンプは、削除済みとしてフラグが付けられていても、シーケンスアップデート外および2と呼ばれる、同じPK_latest内で最新の非コア行の前にある。開始タイムスタンプは非コアのPK_latest内の任意の行よりも新しいが、開始タイムスタンプはまた非コアの最新終了タイムスタンプよりも小さいので、ケース1は適合しない。換言すると、この行はより新しいアップデートであるが、非コア内で既にもっと後の有効期限切れ日付により既に論理的に削除され期限切れの一回入力としてマークされるであろう。定義により、この行はその開始タイムスタンプが最新の非コア開始タイムスタンプよりも新しいため、最新の行の削除ではなく既に「U」としてフラグが付けられている。
[0026]例示的な実施形態では、ステップ110はALL_VTが有効になっているときに揮発性テーブル名に対して受け入れおよび動作をしてもよい。ステップ110は、すべてであるが最新の行が非コア事前期限切れ内に挿入されるであろうことを反映するX_table内の主キー毎に「U」に設定される複数の行がある場合終了タイムスタンプを提供する。ステップ110は、非コア内の最新の行になることを予定されていないすべての事前期限切れの新しい行の終了タイムスタンプを設定する。ETLインジケータ「O」でのすべての行は終了タイムスタンプを必要とし、X_tableおよび非コア内で最新ではないETLインジケータ「U」でのこれら行のみはまた次行の開始タイムスタンプに等しい終了タイムスタンプを取得するであろう。「O」行は定義により適用フェーズ(例えば、後述の適用ステップ204)内で、それらの終了タイムスタンプをその後の非コア行から取得する。このステップはユニオンまたは例外演算子を使用することにより単一のSQLステートメントで達成されることができる。
[0027]例示的な実施形態では、ステップ111はALL_VTが有効になっているときに揮発性テーブル名に対して受け入れおよび動作をしてもよい。ステップ111は、行の正確な開始タイムスタンプがX_table内ですべての削除行(「D」ETLインジケータ)のために論理的に削除されるように設定しこの値をその行のsrc_end_ts列内に格納する。これは、削除が適用されるであろう非コアおよびXテーブル行から前の行を見つけることにより、有効期限が切れるように単一の非コア行を配置するための適用フェーズ(例えば、後述のステップ206)の正確な完全主キーを提供する。最新行および他の事前期限切れX_table行はアップデートされてもよいが、このアップデートは必須ではなく、他のステップがこれらの行を期限切れとしてもよい。削除行のソース終了タイムスタンプは有効期限が切れるように行のソース開始タイムスタンプであり、そのとき点で存在していた行の終了タイムスタンプになる。例示的な実施形態では、ステップ111は、事前CDCのステップ(例えば、図3に示すステップ92の前のステップ)が子のカスケードおよび暗示的削除を決定する際に参照整合性を維持する。ステップ111は、それにより親レコードがCDCを呼び出す前に正確なタイムスタンプを決定するために事前CDC処理を要することなくそれらに適用される対応する過去の削除を有することを確実に容易にする。
[0028]例示的な実施形態では、ステップ112はLOAD_TYPE=S(スナップショットロード)またはB(明示的および暗示的削除両方でのスナップショットロード)およびALL_VT=Y(揮発性テーブルを使用)であるときのみ実行される。ステップ112は結果データを揮発性X_tableから、並列セッションがセッション特定の揮発性テーブルを使用するテーブルデータの一意のパーティションを処理することができる実際の(例えば、永続的または「物理的」)X_tableにロードする。
[0032]例示的な実施形態では、適用ステップ201は、適用ステップ207、下記のEND TRANSACTIONステップまでのすべての後続のステップに関連付けられるSQLステートメントが完全に適用されるまたはエラーの場合にはSQLステートメント内のどこにもまったく適用されない、データベーストランザクションを開始する。これは、例えばその行が論理的に削除される限り、PK_latest毎に多くても1つのソース終了タイムスタンプで、多くても1つのアクティブな行で、有効な状態で目標テーブルをレンダリングするのを容易にする。
[0033]適用ステップ202は、1つ以上のより新しい行の到達のせいで最新の非コアタイムスタンプを期限切れとさせるETLインジケータ「U」のために論理的に削除されたとして行をマークするために両方の終了タイムスタンプ(ソースおよびCDW)を設定するPK_latest毎の1つの最新アクティブ行(ソース終了タイムスタンプがnullである)をアップデートする。すべて削除またはインジケータ「D」の処理は適用ステップ206で発生する。ステップ202で適用される条件は、終了時刻になったX_tableソース開始タイムスタンプが少なくとも非コア開始時間(例えば、期間>0)と同じ大きさであることを含む。
[0034]例示的な実施形態では、適用ステップ203は新しい行を非コアに挿入するための唯一の適用ステップである。削除を除くAll ETLインジケータは結果として新しい非コア行(I、OおよびU)となる。行は事前期限切れ(例えば、X_tableソース終了タイムスタンプ列が値を有するため)またはそうでなくてもよい。トランザクションまたはCDWタイムスタンプを割り当てることができる任意のステップのように、この値は、一定の開始CDWタイムスタンプもまた目標テーブル上でのCDCの呼び出しを一意に識別するように、典型的に適用ステップの前に決定されそれぞれに一貫して使用される、適用フェーズの現在のタイムスタンプを表す。
[0035]適用ステップ204は、適用ステップ203(「O」行の1つのケース)で挿入された新しい行が最新のソース開始タイムスタンプを有しているが、そのタイムスタンプが既に非コア内の最新のソース終了タイムスタンプよりも前のときに、以前の非コア行の終了タイムスタンプを修正する。これは、既に期限切れの行が既存の期限切れタイムスタンプより少ない開始タイムスタンプでシーケンスアップデート外で受信することであり、「O」行の比較的まれなケースである。
[0037]適用ステップ205はETLインジケータ「Ο」でマークされた行に対して呼び出される。ステップ205は、もしあれば、直前の非コア行を決定するために非コアテーブルにすべてのX_table「Ο」の行を結合し、CDW終了タイムスタンプをアップデートするのと同様に、次にこれらの行を終了タイムスタンプとしてX_table行の開始タイムスタンプでアップデートする。適用ステップ205はソースタイムスタンプ内の別個の非重複期間を提供するために、シーケンスの新しい行外用のソースタイムスタンプをラダーステッピングする処理を終了する。論理的に削除済みとしてマークされた任意の行を除き、ソース開始タイムスタンプはソース開始タイムスタンプにより主キーの残りの部分の中にソートされる際に直前の行(もしあれば)のソース終了タイムスタンプである。
[0038]適用ステップ206はETLインジケータ「D」でマークされた行のために呼び出され、非コアまたはバッチに新たにロードされたものからの過去および現在の行の両方に適用する。このプロセスは、非コアの既存の終了タイムスタンプを削除行の開始タイムスタンプ(例えば、ETLインジケータ=「D」)にアップデートする。X_tableに直接挿入された行(例えば、親−子暗示的削除)については、行を構築するプリCDCプロセスは終了タイムスタンプがまだ開始タイムスタンプより大きく、後続行のソース開始タイムスタンプより小さいか等しくなるように保証する。
[0040]最終的な適用ステップ207は、エラー発生なしで提供される、前の開始トランザクション以降のすべての以前のステートメントのトランザクション範囲を終了する、データベースのトランザクションを終了するためのSQLステートメントを提示する。既に行われていない場合、統計情報はこのとき点で目標テーブル上に収集されるまたは最新の内容にされてもよい。
ステップ100−擬似コード(TVT_FILTER_HISTORY=N、LOAD_TYPE=S):
Create volatile table_TVT as
Select * from target table
Where HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Primary Index PK Latest;
ステップ100−擬似コード(TVT_FILTER_HISTORY=Y、LOAD_TYPE=S):
WITH W table minimum primary key and src start TS where
HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Create volatile table_TVT as
Select * from target table
Where full primary key in(
Select newer rows in target table than derived W table with hash partition
Union
Select latest older row in target table relative to derived W table with hash partition
Union
Select latest row from target table)
Where HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Primary Index PK Latest;
ステップ100−擬似コード(TVT_FILTER_HISTORY=Y、LOAD_TYPE=B)。
WITH W table minimum primary key and src start TS where
HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Create volatile table_TVT as
Select * from target table
Where full primary key in(
Select newer rows in target table than derived W table with hash partition
Union
Select latest older row in target table relative to derived W table with hash partition
Union
Select latest row from target table)
Or PK_Latest in(select PK_Latest from X table where ETL_Indicator is D from hash partition)
Where HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Primary Index PK Latest;
ステップ101−擬似コード(LOAD_TYPE=S):
Create volatile table_WVT as
Select * from W table
Where HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Primary Index PK Latest;
Create volatile table_XVT as
X table with no data
Primary Index PK Latest;
ステップ101−擬似コード(LOAD_TYPE=B)。
Create volatile table_WVT as
Select * from W table
Where HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
Primary Index PK Latest;
Create volatile table_XVT as
X table with no data
Primary Index PK Latest;
Insert into_XVT(PK,4 row marking columns)
Select PK,4 row marking columns from X table
Where HASHBUCKET(HASHROW(PK Latest))MOD NUM_PARTITIONS=CURRENT_PARTITION
AND ETL_INDICATOR=‘D’
ステップ102−擬似コード:
Insert into X_table
Select[*,Current_Timestamp,‘D’]from target
WHERE PK−Latest NOT IN
(Select[PK_Latest]from W−table);
ステップ103−擬似コード:
Create VT of W table full PK’s to exclude in step 104
Select full PK from W table
Where full PK in(
Select earliest full PK row from W table joined to target table
Where target table is latest row and W table is next newest row
And all attributes of both rows are identical excluding source TS
ステップ104−擬似コード:
Insert into X_table
Select[*]from W_table−−1 microsecond sequencing added to start TS
Where * not in(−−exclude microsecond sequencing when selecting start TS
Select[*]from target);−−exclude ns sequencing when selecting start TS
Collect statistics on X_table;
ステップ105−擬似コード:
Insert into Target_Table_VT(create volatile temporary table via select statement)
Select * from Target Table where
PK_Latest in(select PK_Latest from X_table)
And(SOURCE_START_TS>=MIN SRC_START_TS in X table for that exact PK
OR SOURCE_START_TS is MAX for PK<MIN SRC_START_TS in X)
ステップ106−擬似コード:
UPDATE X−alias
FROM X−table X−alias
,(SELECT
PK_Latest
,CAST(MAX(src_start_ts)as char(23))F23C
,substring(cast(max(source_start_ts)as char(26))from 24 for 3)+1 L3C
,substring(cast(source_start_ts as char(32)),from 27 for 6)+1 L3C
FROM target
GROUP BY PK_Latest,F23C,TSTZ)QQQ
SET SRC_START_TS
=F23C||SUBSTRING(CAST((L3C/1000+
(SUBSTRING(cast(xpm.src_start_ts as char(26))FROM 24 FOR 3))/1000)AS DEC(4,3))FROM
4 FOR 3)
WHERE X−alias.PK_Latest=QQQ.PK_Latest
AND CAST(X−alias.src_start_ts AS CHAR(23))=QQQ.F23C
AND X−alias.ETL_INDICATOR=‘I’;
ステップ107−擬似コード:
Delete from X_table where PK IN(
(Select PK from
(Select A.* from
(Select *,table_source,Row_Number()from X_table union noncore
partition by PK_Latest Order by SRC_START_TS to create Row_Number)A
INNER JOIN (Select *,table_source,Row_Number()from X_table union noncore
partition by PK_Latest Order by SRC_START_TS to create Row_Number)B
Where A.PK_Latest=B.PK_Latest
and B.Row_Number=A.Row_Number−1
and all non−key attribute are the same (values equal or both null)
)
AND A.Table Source=‘X’
Left Outer Join(Select PK_Latest,If not null then Source Start TS else Year 2500,
SOURCE_END_TS
From Target partition PK_Latest and present newest Source Start ts)C ON A.PK_Latest=C.PK_Latest
WHERE(B.Table Source=‘X’
AND A.Time period is newer than the latest target row
ステップ108−擬似コード:
UPDATE X_tbl
FROM X_TABLE X_tbl
,(select PK_Latest
,max(src_start_ts)src_start_ts
from target
group by PK_Latest)NC_tbl
SET ETL_INDICATOR=‘U’
WHERE X_tbl.PK_Latest=NC_tbl.PK_Latest
AND X_tbl.SRC_START_TS>NC_tbl.SRC_START_TS
AND X_tbl.ETL_INDICATOR=‘I’;
ステップ109−擬似コード:
UPDATE X_tbl
FROM X_TABLE X_tbl
,(select PK_Latest
,max(src_end_ts)max_end_ts
,max(src_start_ts)max_start_ts
from target
group by PK_Latest)Max_tbl
SET ETL_INDICATOR=‘O’
WHERE X_tbl.PK_Latest=Max_tbl.PK_Latest
AND ((X_tbl.SRC_START_TS<Max_tbl.MAX_EN D_TS
OR(X_tbl.SRC_START_TS<Max_tbl.MAX_START_TS))
AND X_tbl.ETL_INDICATOR IN(‘I’,‘U’);
ステップ110−擬似コード:
Update X−tbl
FROM X−table X−tbl
,(Select AAA.PK−Latest, min(BBB.START_TS)as END_TS
From (Select PK
From X−table)AAA,
(Select PK
From X−table
UNION
Select PK
From target)BBB
Where BBB.PK_Latest=AAA.PK_Latest
And BBB.START_TS>AAA.START_TS
Group By AAA.PK
)QQQ
SET END_TS=QQQ.END_TS
WHERE X−table.PK=QQQ.PK
and X−table.ETL_Indicator IN(‘O’,‘U’);
ステップ111−擬似コード:
Update X−tbl
FROM X−table X−tbl
,(Select AAA.PK−Latest,min(BBB.START_TS)as END_TS
From(Select PK
From X−table)AAA,
(Select PK,Max Start TS
From X−table
UNION
Select PK,Max Start TS
From target)BBB
Where BBB.PK_Latest=AAA.PK_Latest
And BBB.START_TS>AAA.START_TS
Group By AAA.PK,BBB.Max Start TS
)QQQ
SET END_TS=QQQ.END_TS
WHERE X−table.PK=QQQ.PK and X−table.Start TS<QQQ.Start TS
and X−table.ETL_lndicator=‘D’;
ステップ112−擬似コード(NORMALIZE_LATEST=N、LOAD_TYPE=S):
INSERT INTO X−table SELECT * FROM_XVT;
DROP TABLE_XVT;
DROP TABLE_WVT;
DROP TABLE_TVT;
DROP TABLE_VT;
COLLECT STATISTICS X−table;(last partition only)
ステップ112−擬似コード(NORMALIZE_LATEST=Y、LOAD_TYPE=S):
INSERT INTO X−table SELECT * FROM_XVT;
DROP TABLE_XVT;
DROP TABLE_WVT;
DROP TABLE_TVT;
DROP TABLE_VT;
DROP TABLE_KVT
COLLECT STATISTICS X−table;(last partition only)
ステップ112−擬似コード(NORMALIZE_LATEST=N、LOAD_TYPE=B)
DELETE FROM X−table
WHERE ETL_INDICATOR=‘D’
AND HASHBUCKET(HASHROW(USAGE_INSTANCE_NUM_ID))MOD NUM_PARTITIONS=0;
INSERT INTO X−table SELECT * FROM_XVT
DROP TABLE_XVT;
DROP TABLE_WVT;
DROP TABLE_TVT;
DROP TABLE_VT;
COLLECT STATISTICS X−table;(last partition only)
ステップ201 擬似コード:
START TRANSACTION
ステップ202−擬似コード
UPDATE noncore
SET SOURCE_END_TS=MIN(X−table.SRC_START_TS)
CDW_END_TS=current timestamp for table
WHERE noncore.PK_Latest=X−table.PK_Latest
AND SOURCE_END_TS IS NULL
AND X−table.SRC_START_TS>=noncore.SOURCE_START_TS
AND X−table.ETL_INDICATOR=‘U’
AND src_start_ts is the earliest within the PK_Latest;
ステップ203−擬似コード
INSERT into noncore
Select * from X−table
Where ETL_Indicator=‘I’,‘O’or‘U’;
ステップ204−擬似コード
UPDATE NC_Tbl
FROM
noncore NC_Tbl,
(SELECT PK_Latest MAX(SOURCE_END_TS)MAX_END_TS
FROM noncore
WHERE(PK_Latest in(SELECT PK_Latest FROM X_table))
GROUP BY PK_Latest)Max_NC
SET SOURCE_END_TS=Max_NC.MAX_END_TS,
CDW_END_TS=current timestamp for table
WHERE NC_Tbl.PK_Latest=Max_NC.PK_Latest
AND NC_Tbl.SOURCE_START_TS<Max_NC.MAX_END_TS
AND NC_Tbl.SOURCE_END_TS IS NULL;
ステップ205−擬似コード
UPDATE NC_Tbl
FROM noncore NC_Tbl,
(SELECT NC_Tbl.PK_Latest
,X_Tbl.SRC_START_TS SRC_END_TS
,MAX(NC_Tbl.SOURCE_START_TS)SOURCE_START_TS
FROM(SELECT PK_Latest
,SRC_START_TS
FROM X−Table
WHERE ETL_INDICATOR=‘O’)X_Tbl
,(SELECT PK_Latest
,SOURCE_START_TS
FROM noncore)NC_Tbl
WHERE NC_Tbl.PK_Latest=X_Tbl.PK_Latest
AND NC_Tbl.SOURCE_START_TS<X_Tbl.SRC_START_TS
GROUP BY NC_Tbl.PK_Latest,X_Tbl.SRC_START_TS
)QQQ
SET SOURCE_END_TS=QQQ.SRC_END_TS,
CDW_END_TS=current timestamp for table
WHERE NC_Tbl.PK_Latest=QQQ.PK_Latest
AND NC_Tbl.SOURCE_START_TS=QQQ.SOURCE_START_TS;
ステップ206−擬似コード
UPDATE NC_Tbl
FROM noncore NC_Tbl,x table X_Tbl
Set NC_Tbl source end ts=X tbl source start ts,
NC_Tbl.cdw end ts=current timestamp for table
Where NC_Tbl.PK_latest=X_Tbl.PK_latest
And NC_Tbl.source_start_ts=X_Tbl.src_end ts−−ensures 1−to−1
And X_Table.ETL_lndicator is ‘D’
And NC_Tbl source end ts is null or greater than X table start ts
ステップ207−擬似コード
END TRANSACTION
Evaluate whether to refresh noncore statistics
また、本願は以下に記載する態様を含む。
(態様1)
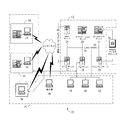
入力データセットの一時的なデータウェアハウスへのローディングに使用するためのシステム(10)であって、
一時的なデータウェアハウスおよび入力データセットを含むストレージ装置(720)と、
前記ストレージ装置に結合され、
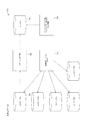
前記入力データセットを第1のパーティションおよび第2のパーティションを含む複数のパーティションに分割し、前記複数のパーティションの各パーティションは複数のデータレコードを含み、
前記第1のパーティションをプリロードテーブルにインポートし、
前記第2のパーティションを前記プリロードテーブルにインポートし、
前記プリロードテーブルを前記一時的なデータウェアハウスに適用する、
ようにプログラムされたプロセッサユニット(710)と、
を備えるシステム。
(態様2)
前記プロセッサユニット(710)は、前記入力データセットを少なくとも1つのデータレコードに対応するハッシュ値を生成するために前記少なくとも1つのデータレコードに関連付けられた主キーにハッシュ関数を適用することにより少なくとも部分的に前記複数のパーティションに分割するようにプログラムされる、態様1に記載のシステム(10)。
(態様3)
前記プロセッサユニット(710)は、前記第1のパーティションが前記テーブルにプリロードされた後、前記第2のパーティションを前記プリロードテーブルにインポートするようにさらにプログラムされる、態様1に記載のシステム(10)。
(態様4)
前記プロセッサユニット(710)は、前記第1のパーティションが前記プリロードテーブルにインポートされている間、前記第2のパーティションを前記プリロードテーブルにインポートするようにさらにプログラムされる、態様1に記載のシステム(10)。
(態様5)
前記プロセッサユニット(710)は、並列インポートの現在の量が並列インポートの所定の最大数よりも少ないことの判定に基づいて、前記第1のパーティションが前記プリロードテーブルにインポートされている間、前記第2のパーティションを前記プリロードテーブルにインポートするようにプログラムされる、態様4に記載のシステム(10)。
(態様6)
前記プロセッサユニット(710)は、少なくとも部分的に、
前記パーティションの前記データレコードを前記パーティションに対応する揮発性テーブルにインポートすることと、
前記データレコードを前記揮発性テーブルから前記プリロードテーブルにコピーすることと、
により前記第1のパーティションおよび前記第2のパーティションの少なくとも1つをインポートするようにプログラムされる、態様1に記載のシステム(10)。
(態様7)
前記プロセッサユニット(710)は、
以前にインポートされたデータレコードの非キーフィールドに等しいタイムスタンプ以外の複数のフィールドを含む前記第1のパーティション内のデータレコードを識別し、
前記第1のパーティションを前記プリロードテーブルにインポートする際に前記識別されたデータレコードを除外する、
ようにさらにプログラムされる態様1に記載のシステム(10)。
(態様8)
前記入力データは、ソースデータベース(20)からのデータのスナップショットを含み、前記プロセッサユニット(710)は、
一時的なデータウェアハウス内のアクティブデータレコードが前記入力データセット内のデータレコードに関連付けられていないことを検出し、
前記検出に基づいて前記アクティブデータレコードの暗示的削除を実行する、
ようにさらにプログラムされる、態様1に記載のシステム(10)。
(態様9)
前記プロセッサユニット(710)は、
前記入力データセット内の最初のデータレコードに関連付けられた最先のソースタイムスタンプを決定し
前記最先のソースタイムスタンプの直前のソースタイムスタンプに関連付けられた前記一時的なデータウェアハウス内のデータレコードと、
前記最先のソースタイムスタンプよりも後のソースタイムスタンプに関連付けられている前記一時的なデータウェアハウス内の1つ以上のデータレコードと、
を表す主キーのセットを識別し、
主キーの前記識別されたセットに基づいて前記第1のパーティションおよび前記第2のパーティションをインポートする、
ようにさらにプログラムされる、態様8に記載のシステム(10)。
(態様10)
一時的なデータウェアハウスへの複数のデータレコードのローディングに使用するための方法であって、
コンピューティング装置(700)により、前記データレコードを第1のパーティションおよび第2のパーティションを含む複数のパーティションに分割することと、
前記コンピューティング装置により、前記第1のパーティションをプリロードテーブルにインポートすることと、
前記コンピューティング装置により、前記第2のパーティションを前記プリロードテーブルにインポートすることと、
前記コンピューティング装置により、前記プリロードテーブルを前記一時的なデータウェアハウスに適用することと、
を備える方法。
(態様11)
前記第1のパーティションおよび前記第2のパーティションは並列にインポートされる、態様10に記載の方法。
(態様12)
並列インポートの現在の量は、並列インポートの所定の最大量よりも少ないことを判定することであって、前記判定に基づいて前記第1のパーティションおよび前記第2のパーティションは並列にインポートされる、判定することをさらに備える、態様10に記載の方法。
(態様13)
前記並列インポートの現在の量は、並列インポートの所定の最大量よりも多いか等しいことを判定することであって、前記判定に基づいて前記第1のパーティションおよび前記第2のパーティションは連続してインポートされる、判定することをさらに備える、態様10に記載の方法。
(態様14)
コンピューティング装置(700)により、前記データを前記複数のパーティションに分割することは、
少なくとも1つのデータレコードに関連付けられたハッシュ値を作成するために、ハッシュ関数を前記少なくとも1つのデータレコードに適用することと、
前記少なくとも1つのデータレコードに対応するおよび関連付けられたパーティション数を決定するためにパーティションの所定量に基づいてモジュロ演算子を前記ハッシュ値に適用することと、
を備える、態様10に記載の方法。
(態様15)
以前にインポートされたデータレコードの非キーフィールドに等しいタイムスタンプ以外の複数のフィールドを含む第1のパーティション内のデータレコードを識別することと、
前記第1のパーティションを前記プリロードテーブルにインポートする際に前記識別されたデータレコードを除外することと、
をさらに備える、態様10に記載の方法。
Claims (13)
- 入力データセットを一時的なデータウェアハウスにロードするように構成されたシステム(10、22、700)であって、
一時的なデータウェアハウスおよび入力データセットを含むストレージ装置(720)と、
前記ストレージ装置に結合されたプロセッサユニット(710)であって、該プロセッサユニットは、
前記入力データセットがソースデータベースからのデータのスナップショットを含むことを判断し、
前記入力データセット中の第1のデータレコードに関連した最も早いソースタイムスタンプを判断し、
前記最も早いソースタイムスタンプの直前のソースタイムスタンプと関連した前記一時的なデータウェアハウス中のデータレコードと、前記一時的なデータウェアハウス中の1または複数のデータレコードであって、前記最も早いソースタイムスタンプよりも遅いソースタイムスタンプに関連した1または複数のデータレコードとを示す主キーの組を認識し、
前記入力データセットを、第1のパーティションおよび第2のパーティションを含む複数のパーティションであって前記複数のパーティションの各パーティションは複数のデータレコードを含む複数のパーティションに分割し、
前記第1のパーティションを前記認識された主キーの組に基づいてプリロードテーブルにインポートし、
前記第2のパーティションを、前記認識された主キーの組に基づいて前記プリロードテーブルにインポートし、
前記プリロードテーブルを前記一時的なデータウェアハウスに適用し、
前記一時的なデータウェアハウス中のアクティブデータレコードが前記入力データセット中の前記複数のデータレコードの1つと関連していないことを検知し、
前記入力データセットが前記ソースデータベースからのデータの前記スナップショットを含むことの前記判断と前記検知とに基づいて前記アクティブデータレコードの暗示的削除を実行するようにプログラムされた、プロセッサユニット(710)とを含むシステム(10、22、700)。 - 前記プロセッサユニット(710)は、少なくとも1つのデータレコードに対応するハッシュ値を生成するために前記少なくとも1つのデータレコードに関連付けられた主キーにハッシュ関数を適用することにより少なくとも部分的に前記複数のパーティションに前記入力データセットを分割するようにプログラムされ、前記主キーは前記主キーの組に含まれる、請求項1に記載のシステム(10、22、700)。
- 前記プロセッサユニット(710)は、前記第1のパーティションが前記テーブルにプリロードされた後、前記第2のパーティションを前記プリロードテーブルにインポートするようにさらにプログラムされる、請求項1に記載のシステム(10、22、700)。
- 前記プロセッサユニット(710)は、前記第1のパーティションが前記プリロードテーブルにインポートされている間、前記第2のパーティションを前記プリロードテーブルにインポートするようにさらにプログラムされる、請求項1に記載のシステム(10、22、700)。
- 前記プロセッサユニット(710)は、並列インポートの現在の量が並列インポートの所定の最大量よりも少ないことの判定に基づいて、前記第1のパーティションが前記プリロードテーブルにインポートされている間、前記第2のパーティションを前記プリロードテーブルにインポートするようにプログラムされる、請求項4に記載のシステム(10、22、700)。
- 前記プロセッサユニット(710)は、少なくとも部分的に、
前記第1のパーティション及び前記第2のパーティションの少なくとも一方のデータレコードを前記第1のパーティション及び前記第2のパーティションの前記少なくとも一方に対応する揮発性テーブルにインポートすることと、
前記データレコードを前記揮発性テーブルから前記プリロードテーブルにコピーすることと、
により前記第1のパーティションおよび前記第2のパーティションの前記少なくとも一方をインポートするようにプログラムされる、請求項1に記載のシステム(10、22、700)。 - 前記プロセッサユニット(710)は、
以前にインポートされたデータレコードの非キーフィールドに等しいタイムスタンプ以外の複数のフィールドを含む前記第1のパーティション内のデータレコードを識別し、
前記第1のパーティションを前記プリロードテーブルにインポートする際に前記識別されたデータレコードを除外する、
ようにさらにプログラムされる請求項1に記載のシステム(10、22、700)。 - 一時的なデータウェアハウスへの複数のデータレコードのローディング方法であって、
前記データレコードがソースデータベースからのデータのスナップショットを含むことを判断すること、
前記データレコード中の第1のデータレコードと関連した最も早いタイムスタンプを判断することと、
前記最も早いソースタイムスタンプの直前のソースタイムスタンプと関連した前記一時的なデータウェアハウス中のデータレコードと、前記一時的なデータウェアハウス中の1または複数のデータレコードであって、前記最も早いソースタイムスタンプよりも遅いソースタイムスタンプに関連した1または複数のデータレコードとを示す主キーの組を認識することと、
前記データレコードを第1のパーティションおよび第2のパーティションを含む複数のパーティションに分割することと、
コンピューティング装置(700)により、前記認識された主キーの組に基づいて前記第1のパーティションをプリロードテーブルにインポートすることと、
前記コンピューティング装置により、前記認識された主キーの組に基づいて前記第2のパーティションを前記プリロードテーブルにインポートすることと、
前記プリロードテーブルを前記一時的なデータウェアハウスに適用することと、
前記コンピューティング装置により、前記一時的なデータウェアハウス中のアクティブデータレコードが前記複数のデータレコードとの1つと関連していないことを検知し、
前記コンピューティング装置により、前記データレコードが前記ソースデータベースからのデータの前記スナップショットを含むことの前記判断と前記検知とに基づいて前記アクティブデータレコードの暗示的削除を実行することと、
を備える方法。 - 前記第1のパーティションおよび前記第2のパーティションは並列にインポートされる、請求項8に記載の方法。
- 並列インポートの現在の量は、並列インポートの所定の最大量よりも少ないことを判定することであって、前記判定に基づいて前記第1のパーティションおよび前記第2のパーティションは並列にインポートされる、判定することをさらに備える、請求項8に記載の方法。
- 並列インポートの現在の量は、並列インポートの所定の最大量よりも多いか等しいことを判定することであって、前記判定に基づいて前記第1のパーティションおよび前記第2のパーティションは連続してインポートされる、判定することをさらに備える、請求項8に記載の方法。
- コンピューティング装置(700)により、前記データを前記複数のパーティションに分割することは、
少なくとも1つのデータレコードに関連付けられたハッシュ値を作成するために、ハッシュ関数を前記少なくとも1つのデータレコードに適用することと、
前記少なくとも1つのデータレコードに対応するおよび関連付けられたパーティション数を決定するためにパーティションの所定量に基づいてモジュロ演算子を前記ハッシュ値に適用することと、
を備える、請求項8に記載の方法。 - 以前にインポートされたデータレコードの非キーフィールドに等しいタイムスタンプ以外の複数のフィールドを含む第1のパーティション内のデータレコードを識別することと、
前記第1のパーティションを前記プリロードテーブルにインポートする際に前記識別されたデータレコードを除外することと、
をさらに備える、請求項8に記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/082,829 | 2011-04-08 | ||
| US13/082,829 US8688622B2 (en) | 2008-06-02 | 2011-04-08 | Methods and systems for loading data into a temporal data warehouse |
| PCT/US2012/027417 WO2012138437A1 (en) | 2011-04-08 | 2012-03-02 | Methods and systems for loading data into a temporal data warehouse |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2014512608A JP2014512608A (ja) | 2014-05-22 |
| JP2014512608A5 JP2014512608A5 (ja) | 2015-04-23 |
| JP5963845B2 true JP5963845B2 (ja) | 2016-08-03 |
Family
ID=45819282
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014503662A Active JP5963845B2 (ja) | 2011-04-08 | 2012-03-02 | 一時的なデータウェアハウスにデータをロードするための方法およびシステム |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US8688622B2 (ja) |
| EP (1) | EP2695086B1 (ja) |
| JP (1) | JP5963845B2 (ja) |
| CN (1) | CN103460208B (ja) |
| CA (1) | CA2826797C (ja) |
| RU (1) | RU2599538C2 (ja) |
| WO (1) | WO2012138437A1 (ja) |
Families Citing this family (122)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8930331B2 (en) | 2007-02-21 | 2015-01-06 | Palantir Technologies | Providing unique views of data based on changes or rules |
| US9383911B2 (en) | 2008-09-15 | 2016-07-05 | Palantir Technologies, Inc. | Modal-less interface enhancements |
| US10715457B2 (en) | 2010-06-15 | 2020-07-14 | Oracle International Corporation | Coordination of processes in cloud computing environments |
| EP2583211B1 (en) | 2010-06-15 | 2020-04-15 | Oracle International Corporation | Virtual computing infrastructure |
| US9396242B2 (en) * | 2011-04-11 | 2016-07-19 | Salesforce.Com, Inc. | Multi-master data replication in a distributed multi-tenant system |
| US9389982B2 (en) * | 2011-04-18 | 2016-07-12 | Sap Se | Method and apparatus for monitoring an in-memory computer system |
| US9268828B2 (en) * | 2011-06-15 | 2016-02-23 | Sas Institute Inc. | Computer-implemented systems and methods for extract, transform, and load user interface processing |
| US8880503B2 (en) * | 2011-06-21 | 2014-11-04 | Microsoft Corporation | Value-based positioning for outer join queries |
| US9547693B1 (en) | 2011-06-23 | 2017-01-17 | Palantir Technologies Inc. | Periodic database search manager for multiple data sources |
| US9092482B2 (en) | 2013-03-14 | 2015-07-28 | Palantir Technologies, Inc. | Fair scheduling for mixed-query loads |
| US8799240B2 (en) | 2011-06-23 | 2014-08-05 | Palantir Technologies, Inc. | System and method for investigating large amounts of data |
| US9280532B2 (en) | 2011-08-02 | 2016-03-08 | Palantir Technologies, Inc. | System and method for accessing rich objects via spreadsheets |
| US8504542B2 (en) | 2011-09-02 | 2013-08-06 | Palantir Technologies, Inc. | Multi-row transactions |
| US8875137B2 (en) * | 2011-09-05 | 2014-10-28 | Sap Se | Configurable mass data portioning for parallel processing |
| TW201322022A (zh) * | 2011-11-24 | 2013-06-01 | Alibaba Group Holding Ltd | 分散式資料流處理方法及其系統 |
| WO2013119841A1 (en) | 2012-02-10 | 2013-08-15 | Nimbula, Inc. | Cloud computing services framework |
| US20140032608A1 (en) * | 2012-07-30 | 2014-01-30 | Gregory P. Comeau | Database adapter |
| CN103838770A (zh) * | 2012-11-26 | 2014-06-04 | 中国移动通信集团北京有限公司 | 一种数据逻辑分区的方法和系统 |
| US10127292B2 (en) * | 2012-12-03 | 2018-11-13 | Ut-Battelle, Llc | Knowledge catalysts |
| US9596279B2 (en) | 2013-02-08 | 2017-03-14 | Dell Products L.P. | Cloud-based streaming data receiver and persister |
| US9191432B2 (en) | 2013-02-11 | 2015-11-17 | Dell Products L.P. | SAAS network-based backup system |
| US9141680B2 (en) | 2013-02-11 | 2015-09-22 | Dell Products L.P. | Data consistency and rollback for cloud analytics |
| US9442993B2 (en) | 2013-02-11 | 2016-09-13 | Dell Products L.P. | Metadata manager for analytics system |
| US10585896B2 (en) * | 2013-03-12 | 2020-03-10 | Red Hat, Inc. | Managing data in relational database management system |
| US10248670B1 (en) * | 2013-03-14 | 2019-04-02 | Open Text Corporation | Method and system for migrating content between enterprise content management systems |
| US10275778B1 (en) | 2013-03-15 | 2019-04-30 | Palantir Technologies Inc. | Systems and user interfaces for dynamic and interactive investigation based on automatic malfeasance clustering of related data in various data structures |
| US8930897B2 (en) | 2013-03-15 | 2015-01-06 | Palantir Technologies Inc. | Data integration tool |
| US9230280B1 (en) | 2013-03-15 | 2016-01-05 | Palantir Technologies Inc. | Clustering data based on indications of financial malfeasance |
| US8903717B2 (en) | 2013-03-15 | 2014-12-02 | Palantir Technologies Inc. | Method and system for generating a parser and parsing complex data |
| US8855999B1 (en) | 2013-03-15 | 2014-10-07 | Palantir Technologies Inc. | Method and system for generating a parser and parsing complex data |
| US9378254B2 (en) * | 2013-03-15 | 2016-06-28 | International Business Machines Corporation | Data migration in a database management system |
| GB201306033D0 (en) * | 2013-04-03 | 2013-05-22 | King Com Ltd | Database update process |
| US9146946B2 (en) | 2013-05-09 | 2015-09-29 | International Business Machines Corporation | Comparing database performance without benchmark workloads |
| US9619545B2 (en) * | 2013-06-28 | 2017-04-11 | Oracle International Corporation | Naïve, client-side sharding with online addition of shards |
| US9256634B2 (en) * | 2013-08-21 | 2016-02-09 | Business Objects Software, Ltd. | Resuming big data transformations |
| US9892178B2 (en) | 2013-09-19 | 2018-02-13 | Workday, Inc. | Systems and methods for interest-driven business intelligence systems including event-oriented data |
| US9613082B2 (en) | 2013-09-30 | 2017-04-04 | International Business Machines Corporation | Database auditing for bulk operations |
| US9116975B2 (en) | 2013-10-18 | 2015-08-25 | Palantir Technologies Inc. | Systems and user interfaces for dynamic and interactive simultaneous querying of multiple data stores |
| US9043696B1 (en) | 2014-01-03 | 2015-05-26 | Palantir Technologies Inc. | Systems and methods for visual definition of data associations |
| US10331740B2 (en) * | 2014-02-10 | 2019-06-25 | Apple Inc. | Systems and methods for operating a server-side data abstraction layer |
| US10108622B2 (en) | 2014-03-26 | 2018-10-23 | International Business Machines Corporation | Autonomic regulation of a volatile database table attribute |
| CN105210059B (zh) * | 2014-04-04 | 2018-12-07 | 华为技术有限公司 | 一种数据处理方法及系统 |
| US20150347392A1 (en) * | 2014-05-29 | 2015-12-03 | International Business Machines Corporation | Real-time filtering of massive time series sets for social media trends |
| US9710529B2 (en) * | 2014-06-02 | 2017-07-18 | Accenture Global Services Limited | Data construction for extract, transform and load operations for a database |
| US9535974B1 (en) | 2014-06-30 | 2017-01-03 | Palantir Technologies Inc. | Systems and methods for identifying key phrase clusters within documents |
| US9619557B2 (en) | 2014-06-30 | 2017-04-11 | Palantir Technologies, Inc. | Systems and methods for key phrase characterization of documents |
| US10928970B2 (en) | 2014-07-18 | 2021-02-23 | Apple Inc. | User-interface for developing applications that apply machine learning |
| US9419992B2 (en) | 2014-08-13 | 2016-08-16 | Palantir Technologies Inc. | Unwanted tunneling alert system |
| US9454281B2 (en) | 2014-09-03 | 2016-09-27 | Palantir Technologies Inc. | System for providing dynamic linked panels in user interface |
| US10417251B2 (en) * | 2014-10-31 | 2019-09-17 | The Boeing Company | System and method for storage and analysis of time-based data |
| US20160140195A1 (en) * | 2014-11-19 | 2016-05-19 | Oracle International Corporation | Custom parallization for database table loading |
| US9348920B1 (en) | 2014-12-22 | 2016-05-24 | Palantir Technologies Inc. | Concept indexing among database of documents using machine learning techniques |
| US10552994B2 (en) | 2014-12-22 | 2020-02-04 | Palantir Technologies Inc. | Systems and interactive user interfaces for dynamic retrieval, analysis, and triage of data items |
| US10362133B1 (en) | 2014-12-22 | 2019-07-23 | Palantir Technologies Inc. | Communication data processing architecture |
| US10452651B1 (en) | 2014-12-23 | 2019-10-22 | Palantir Technologies Inc. | Searching charts |
| US9817563B1 (en) | 2014-12-29 | 2017-11-14 | Palantir Technologies Inc. | System and method of generating data points from one or more data stores of data items for chart creation and manipulation |
| US10108683B2 (en) * | 2015-04-24 | 2018-10-23 | International Business Machines Corporation | Distributed balanced optimization for an extract, transform, and load (ETL) job |
| US9672257B2 (en) | 2015-06-05 | 2017-06-06 | Palantir Technologies Inc. | Time-series data storage and processing database system |
| US9384203B1 (en) | 2015-06-09 | 2016-07-05 | Palantir Technologies Inc. | Systems and methods for indexing and aggregating data records |
| US9407652B1 (en) | 2015-06-26 | 2016-08-02 | Palantir Technologies Inc. | Network anomaly detection |
| US9817876B2 (en) * | 2015-06-29 | 2017-11-14 | Planisware SAS | Enhanced mechanisms for managing multidimensional data |
| US10580006B2 (en) * | 2015-07-13 | 2020-03-03 | Mastercard International Incorporated | System and method of managing data injection into an executing data processing system |
| US9537880B1 (en) | 2015-08-19 | 2017-01-03 | Palantir Technologies Inc. | Anomalous network monitoring, user behavior detection and database system |
| US10402385B1 (en) | 2015-08-27 | 2019-09-03 | Palantir Technologies Inc. | Database live reindex |
| US9454564B1 (en) | 2015-09-09 | 2016-09-27 | Palantir Technologies Inc. | Data integrity checks |
| US10044745B1 (en) | 2015-10-12 | 2018-08-07 | Palantir Technologies, Inc. | Systems for computer network security risk assessment including user compromise analysis associated with a network of devices |
| EP3373149A4 (en) * | 2015-11-06 | 2019-04-03 | Nomura Research Institute, Ltd. | DATA MANAGEMENT SYSTEM |
| US9542446B1 (en) | 2015-12-17 | 2017-01-10 | Palantir Technologies, Inc. | Automatic generation of composite datasets based on hierarchical fields |
| US10146854B2 (en) | 2016-02-29 | 2018-12-04 | International Business Machines Corporation | Continuous automatic update statistics evaluation using change data capture techniques |
| KR101888131B1 (ko) * | 2016-05-20 | 2018-08-13 | 주식회사 리얼타임테크 | Dds-dbms 연동 도구의 실시간 변경 데이터 발간 서비스 수행 방법 |
| CN107590158B (zh) * | 2016-07-08 | 2020-12-22 | 北京京东尚科信息技术有限公司 | 一种获取数据源变更信息的方法和装置 |
| US9753935B1 (en) | 2016-08-02 | 2017-09-05 | Palantir Technologies Inc. | Time-series data storage and processing database system |
| US10514952B2 (en) * | 2016-09-15 | 2019-12-24 | Oracle International Corporation | Processing timestamps and heartbeat events for automatic time progression |
| US10311047B2 (en) * | 2016-10-19 | 2019-06-04 | Salesforce.Com, Inc. | Streamlined creation and updating of OLAP analytic databases |
| US10133588B1 (en) | 2016-10-20 | 2018-11-20 | Palantir Technologies Inc. | Transforming instructions for collaborative updates |
| US10318630B1 (en) | 2016-11-21 | 2019-06-11 | Palantir Technologies Inc. | Analysis of large bodies of textual data |
| GB2556638B (en) | 2016-12-02 | 2018-12-12 | Gurulogic Microsystems Oy | Protecting usage of key store content |
| US10884875B2 (en) | 2016-12-15 | 2021-01-05 | Palantir Technologies Inc. | Incremental backup of computer data files |
| US10346418B2 (en) * | 2016-12-16 | 2019-07-09 | Sap Se | Optimizing data access based on data aging |
| US10223099B2 (en) | 2016-12-21 | 2019-03-05 | Palantir Technologies Inc. | Systems and methods for peer-to-peer build sharing |
| US10896097B1 (en) | 2017-05-25 | 2021-01-19 | Palantir Technologies Inc. | Approaches for backup and restoration of integrated databases |
| US11222076B2 (en) * | 2017-05-31 | 2022-01-11 | Microsoft Technology Licensing, Llc | Data set state visualization comparison lock |
| GB201708818D0 (en) | 2017-06-02 | 2017-07-19 | Palantir Technologies Inc | Systems and methods for retrieving and processing data |
| US11281625B1 (en) | 2017-06-05 | 2022-03-22 | Amazon Technologies, Inc. | Resource management service |
| US11334552B2 (en) | 2017-07-31 | 2022-05-17 | Palantir Technologies Inc. | Lightweight redundancy tool for performing transactions |
| US11468781B2 (en) * | 2017-08-11 | 2022-10-11 | The Boeing Company | Simulation of an asset including message playback using nested hash tables |
| US10417224B2 (en) | 2017-08-14 | 2019-09-17 | Palantir Technologies Inc. | Time series database processing system |
| US10216695B1 (en) | 2017-09-21 | 2019-02-26 | Palantir Technologies Inc. | Database system for time series data storage, processing, and analysis |
| US11281726B2 (en) | 2017-12-01 | 2022-03-22 | Palantir Technologies Inc. | System and methods for faster processor comparisons of visual graph features |
| US10614069B2 (en) | 2017-12-01 | 2020-04-07 | Palantir Technologies Inc. | Workflow driven database partitioning |
| US11016986B2 (en) | 2017-12-04 | 2021-05-25 | Palantir Technologies Inc. | Query-based time-series data display and processing system |
| US10922908B2 (en) | 2018-02-14 | 2021-02-16 | The Boeing Company | System and method for vehicle sensor data storage and analysis |
| KR102245224B1 (ko) * | 2018-03-22 | 2021-04-28 | 스노우플레이크 인코포레이티드 | 데이터베이스 시스템 내의 점진적 기능 개발 및 워크로드 캡처 |
| US10685031B2 (en) * | 2018-03-27 | 2020-06-16 | New Relic, Inc. | Dynamic hash partitioning for large-scale database management systems |
| GB201807534D0 (en) | 2018-05-09 | 2018-06-20 | Palantir Technologies Inc | Systems and methods for indexing and searching |
| US10884644B2 (en) * | 2018-06-28 | 2021-01-05 | Amazon Technologies, Inc. | Dynamic distributed data clustering |
| GB201812375D0 (en) * | 2018-07-30 | 2018-09-12 | Ibm | Updating a table using incremental and batch updates |
| GB201816808D0 (en) * | 2018-10-16 | 2018-11-28 | Palantir Technologies Inc | Data storage method and system |
| JP6927951B2 (ja) * | 2018-12-10 | 2021-09-01 | ファナック株式会社 | 製造装置のデータ収集装置 |
| RU2749649C2 (ru) * | 2018-12-21 | 2021-06-16 | Общество С Ограниченной Ответственностью "Яндекс" | Способ и система для планирования обработки операций ввода/вывода |
| US11520752B2 (en) * | 2019-03-27 | 2022-12-06 | International Business Machines Corporation | Remote control of a change data capture system |
| US11580444B2 (en) | 2019-04-16 | 2023-02-14 | Apple Inc. | Data visualization machine learning model performance |
| GB201908091D0 (en) | 2019-06-06 | 2019-07-24 | Palantir Technologies Inc | Time series databases |
| US11372881B2 (en) | 2019-06-26 | 2022-06-28 | The Boeing Company | Time series database |
| CN110580253B (zh) * | 2019-09-10 | 2022-05-31 | 网易(杭州)网络有限公司 | 时序数据组的加载方法、装置、存储介质及电子设备 |
| US11409781B1 (en) | 2019-09-30 | 2022-08-09 | Amazon Technologies, Inc. | Direct storage loading for adding data to a database |
| CN111694860A (zh) * | 2020-04-28 | 2020-09-22 | 国家计算机网络与信息安全管理中心 | 安全检测的时序数据实时异常发现方法及电子装置 |
| US20220027379A1 (en) * | 2020-07-21 | 2022-01-27 | Observe, Inc. | Data capture and visualization system providing temporal data relationships |
| US11573936B2 (en) * | 2020-08-12 | 2023-02-07 | International Business Machines Corporation | Method for loading data in a target database system |
| US11379432B2 (en) | 2020-08-28 | 2022-07-05 | Bank Of America Corporation | File management using a temporal database architecture |
| US12045246B2 (en) * | 2020-11-20 | 2024-07-23 | AtScale, Inc. | Distributed queries through dynamic views |
| CN112381485A (zh) * | 2020-11-24 | 2021-02-19 | 金蝶软件(中国)有限公司 | 一种物料需求计划计算方法及相关设备 |
| CN112650744B (zh) * | 2020-12-31 | 2024-04-30 | 广州晟能软件科技有限公司 | 一种防止数据二次污染的数据治理方法 |
| US12045232B2 (en) | 2021-02-03 | 2024-07-23 | The Boeing Company | Preconditioning time-series data for improved efficiency |
| US11334600B1 (en) * | 2021-03-31 | 2022-05-17 | International Business Machines Corporation | Partial reloading in data synchronization |
| US11556524B2 (en) * | 2021-04-06 | 2023-01-17 | At&T Global Network Services Deutschland Gmbh | System and method to identify data flows and data mappings across systems |
| US12554704B2 (en) * | 2021-09-15 | 2026-02-17 | International Business Machines Corporation | Stale data recognition |
| CN113886896B (zh) * | 2021-11-02 | 2025-07-18 | 潍柴动力股份有限公司 | 一种识别程序数据被篡改的方法和系统 |
| US11669535B1 (en) * | 2021-11-18 | 2023-06-06 | International Business Machines Corporation | Maintaining at a target database system a copy of a source table of a source database system |
| US20240045885A1 (en) * | 2022-08-05 | 2024-02-08 | International Business Machines Corporation | Direct access method of bypassing partition overhead in massively parallel processing (mpp) environment |
| CN117421328B (zh) * | 2023-11-23 | 2024-09-03 | 上海信投数字科技有限公司 | 基于人工智能的数据治理方法、系统、设备及可读介质 |
| CN121051180B (zh) * | 2025-10-29 | 2026-03-03 | 首实安保科技有限责任公司 | 一种数据同步的方法及产品 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000276382A (ja) * | 1999-03-25 | 2000-10-06 | Nec Corp | データベースにおける時系列データ保有・追加方式 |
| AU5624700A (en) * | 1999-06-18 | 2001-01-09 | Torrent Systems, Inc. | Segmentation and processing of continuous data streams using transactional semantics |
| US7756835B2 (en) * | 2001-03-23 | 2010-07-13 | Bea Systems, Inc. | Database and operating system independent copying/archiving of a web base application |
| CN1426003A (zh) * | 2001-12-20 | 2003-06-25 | 深圳市中兴通讯股份有限公司 | 在关系数据库中获取数据最小变动集的处理方法 |
| US7647354B2 (en) * | 2002-05-24 | 2010-01-12 | Oracle International Corporation | High-performance change capture for data warehousing |
| US6954829B2 (en) * | 2002-12-19 | 2005-10-11 | Intel Corporation | Non-speculative distributed conflict resolution for a cache coherency protocol |
| CA2414980A1 (en) * | 2002-12-23 | 2004-06-23 | Ibm Canada Limited-Ibm Canada Limitee | Deferred incremental integrity maintenance of base tables having contiguous data blocks |
| US8131739B2 (en) * | 2003-08-21 | 2012-03-06 | Microsoft Corporation | Systems and methods for interfacing application programs with an item-based storage platform |
| US7415487B2 (en) * | 2004-12-17 | 2008-08-19 | Amazon Technologies, Inc. | Apparatus and method for data warehousing |
| US7478102B2 (en) * | 2005-03-28 | 2009-01-13 | Microsoft Corporation | Mapping of a file system model to a database object |
| US20060238919A1 (en) * | 2005-04-20 | 2006-10-26 | The Boeing Company | Adaptive data cleaning |
| US8271430B2 (en) | 2008-06-02 | 2012-09-18 | The Boeing Company | Methods and systems for metadata driven data capture for a temporal data warehouse |
-
2011
- 2011-04-08 US US13/082,829 patent/US8688622B2/en active Active
-
2012
- 2012-03-02 EP EP12708626.2A patent/EP2695086B1/en active Active
- 2012-03-02 CN CN201280017308.6A patent/CN103460208B/zh active Active
- 2012-03-02 WO PCT/US2012/027417 patent/WO2012138437A1/en not_active Ceased
- 2012-03-02 RU RU2013149491/08A patent/RU2599538C2/ru active
- 2012-03-02 JP JP2014503662A patent/JP5963845B2/ja active Active
- 2012-03-02 CA CA2826797A patent/CA2826797C/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP2695086B1 (en) | 2019-05-08 |
| CN103460208A (zh) | 2013-12-18 |
| RU2013149491A (ru) | 2015-05-20 |
| US20120150791A1 (en) | 2012-06-14 |
| CA2826797C (en) | 2017-04-18 |
| EP2695086A1 (en) | 2014-02-12 |
| JP2014512608A (ja) | 2014-05-22 |
| RU2599538C2 (ru) | 2016-10-10 |
| CN103460208B (zh) | 2017-04-05 |
| CA2826797A1 (en) | 2012-10-11 |
| WO2012138437A1 (en) | 2012-10-11 |
| US8688622B2 (en) | 2014-04-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5963845B2 (ja) | 一時的なデータウェアハウスにデータをロードするための方法およびシステム | |
| US8010521B2 (en) | Systems and methods for managing foreign key constraints | |
| US8271430B2 (en) | Methods and systems for metadata driven data capture for a temporal data warehouse | |
| US9747356B2 (en) | Eager replication of uncommitted transactions | |
| US9411866B2 (en) | Replication mechanisms for database environments | |
| US8751525B2 (en) | Time slider operator for temporal data aggregation | |
| US20120158795A1 (en) | Entity triggers for materialized view maintenance | |
| CN112069223B (zh) | 数据获取需求处理方法、装置、计算机设备和存储介质 | |
| US11507575B2 (en) | Complex query rewriting | |
| US11556537B2 (en) | Query plan generation and execution based on single value columns | |
| US8880485B2 (en) | Systems and methods to facilitate multi-threaded data retrieval | |
| US11106673B2 (en) | Query plan sharing | |
| US11789948B2 (en) | Computational dependency directory | |
| US8260761B2 (en) | Detecting performance degrading design and algorithm issues in database applications | |
| CN114911680A (zh) | 一种数据库性能监控方法及系统 | |
| WO2016100737A1 (en) | Method and system to search logs that contain a massive number of entries | |
| Nguyen et al. | An approach towards an event-fed solution for slowly changing dimensions in data warehouses with a detailed case study | |
| US12197460B2 (en) | Transport of master data dependent customizations | |
| Nguyen et al. | Event-feeded dimension solution |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150302 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150302 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160128 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160209 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160502 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20160531 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20160628 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5963845 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |