JP5929786B2 - 信号処理装置、信号処理方法及び記憶媒体 - Google Patents
信号処理装置、信号処理方法及び記憶媒体 Download PDFInfo
- Publication number
- JP5929786B2 JP5929786B2 JP2013045230A JP2013045230A JP5929786B2 JP 5929786 B2 JP5929786 B2 JP 5929786B2 JP 2013045230 A JP2013045230 A JP 2013045230A JP 2013045230 A JP2013045230 A JP 2013045230A JP 5929786 B2 JP5929786 B2 JP 5929786B2
- Authority
- JP
- Japan
- Prior art keywords
- signal
- masking
- signal processing
- voice
- sound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000012545 processing Methods 0.000 title claims description 130
- 238000003672 processing method Methods 0.000 title claims description 5
- 230000000873 masking effect Effects 0.000 claims description 277
- 230000005236 sound signal Effects 0.000 claims description 184
- 230000006870 function Effects 0.000 claims description 33
- 230000003111 delayed effect Effects 0.000 claims description 7
- 238000012546 transfer Methods 0.000 claims description 6
- 238000004891 communication Methods 0.000 claims description 5
- 230000004044 response Effects 0.000 claims description 5
- 230000001934 delay Effects 0.000 claims description 3
- 230000004048 modification Effects 0.000 description 26
- 238000012986 modification Methods 0.000 description 26
- 238000010586 diagram Methods 0.000 description 17
- 238000004458 analytical method Methods 0.000 description 14
- 230000015572 biosynthetic process Effects 0.000 description 10
- 238000003786 synthesis reaction Methods 0.000 description 10
- 230000005540 biological transmission Effects 0.000 description 7
- 238000000034 method Methods 0.000 description 7
- 230000007274 generation of a signal involved in cell-cell signaling Effects 0.000 description 5
- 230000000052 comparative effect Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 230000002194 synthesizing effect Effects 0.000 description 3
- 238000004590 computer program Methods 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 125000002066 L-histidyl group Chemical group [H]N1C([H])=NC(C([H])([H])[C@](C(=O)[*])([H])N([H])[H])=C1[H] 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 210000005069 ears Anatomy 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 230000003584 silencer Effects 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
Images












Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/012—Comfort noise or silence coding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K11/00—Methods or devices for transmitting, conducting or directing sound in general; Methods or devices for protecting against, or for damping, noise or other acoustic waves in general
- G10K11/16—Methods or devices for protecting against, or for damping, noise or other acoustic waves in general
- G10K11/175—Methods or devices for protecting against, or for damping, noise or other acoustic waves in general using interference effects; Masking sound
- G10K11/1752—Masking
- G10K11/1754—Speech masking
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/06—Transformation of speech into a non-audible representation, e.g. speech visualisation or speech processing for tactile aids
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04K—SECRET COMMUNICATION; JAMMING OF COMMUNICATION
- H04K3/00—Jamming of communication; Counter-measures
- H04K3/40—Jamming having variable characteristics
- H04K3/46—Jamming having variable characteristics characterized in that the jamming signal is produced by retransmitting a received signal, after delay or processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04K—SECRET COMMUNICATION; JAMMING OF COMMUNICATION
- H04K3/00—Jamming of communication; Counter-measures
- H04K3/80—Jamming or countermeasure characterized by its function
- H04K3/82—Jamming or countermeasure characterized by its function related to preventing surveillance, interception or detection
- H04K3/825—Jamming or countermeasure characterized by its function related to preventing surveillance, interception or detection by jamming
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04K—SECRET COMMUNICATION; JAMMING OF COMMUNICATION
- H04K2203/00—Jamming of communication; Countermeasures
- H04K2203/10—Jamming or countermeasure used for a particular application
- H04K2203/12—Jamming or countermeasure used for a particular application for acoustic communication
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04K—SECRET COMMUNICATION; JAMMING OF COMMUNICATION
- H04K3/00—Jamming of communication; Counter-measures
- H04K3/20—Countermeasures against jamming
- H04K3/28—Countermeasures against jamming with jamming and anti-jamming mechanisms both included in a same device or system, e.g. wherein anti-jamming includes prevention of undesired self-jamming resulting from jamming
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04K—SECRET COMMUNICATION; JAMMING OF COMMUNICATION
- H04K3/00—Jamming of communication; Counter-measures
- H04K3/40—Jamming having variable characteristics
- H04K3/45—Jamming having variable characteristics characterized by including monitoring of the target or target signal, e.g. in reactive jammers or follower jammers for example by means of an alternation of jamming phases and monitoring phases, called "look-through mode"
Landscapes
- Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computer Networks & Wireless Communication (AREA)
- Computational Linguistics (AREA)
- Human Computer Interaction (AREA)
- Data Mining & Analysis (AREA)
- Quality & Reliability (AREA)
- General Health & Medical Sciences (AREA)
- Telephone Function (AREA)
- Soundproofing, Sound Blocking, And Sound Damping (AREA)
Description
1.本開示の一実施形態に係る信号処理装置の概要
2.実施形態
2−1.第1の実施形態
(2−1−1.スマートフォンの構成)
(2−1−2.動作処理)
(2−1−3.変形例1)
2−2.第2の実施形態
2−3.第3の実施形態
(2−3−1.基本形態)
(2−3−2.変形例2)
(2−3−3.変形例3)
3.まとめ
図1を参照して、本開示の一実施形態に係る信号処理装置の概要を説明する。図1は、本開示の一実施形態に係る信号処理装置の概要を示す説明図である。図1に示すように、本実施形態に係る信号処理装置は、一例としてスマートフォン1により実現される。
<2−1.第1の実施形態>
[2−1−1.スマートフォンの構成]
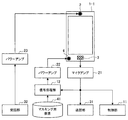
まず、図3を参照して、本実施形態に係るスマートフォン1−1の構成について説明する。図3は、第1の実施形態に係るスマートフォン1−1の構成を示すブロック図である。図3に示した各ブロックは、スマートフォン1−1が内部に有している。図3に示すように、スマートフォン1−1は、通話用スピーカ2、マイク3、マスキング用スピーカ4、制御部11、信号処理部12、マイクアンプ21、パワーアンプ22、パワーアンプ23、送話部31、受話部32、およびマスキング用音源41を有する。以下、スマートフォン1−1の各構成要素について詳細に説明する。
受話部32は、外部からのオーディオ信号を受信する通信部としての機能を有する。具体的には、受話部32は、通話相手の端末から通話相手の音声を示すオーディオ信号を受信する。受話部32は、受信したオーディオ信号をパワーアンプ23に出力する。
パワーアンプ23は、受話部32から出力されたオーディオ信号を増幅する機能を有する。パワーアンプ23は、増幅したオーディオ信号を通話用スピーカ2に出力する。
通話用スピーカ2は、パワーアンプ23から出力されたオーディオ信号を再生する出力装置である。なお、本実施形態では、ユーザ8が通話用スピーカ2に耳を当てながらスマートフォン1−1を使用することを想定している。
マイク3は、ユーザ音声を収音し、オーディオ信号を生成する収音部としての機能を有する。より詳しくは、マイク3は、ユーザ8が発話した音声を収音して、オーディオ信号を生成する。このとき、マイク3は、後述するマスキング用スピーカ4により再生されたマスキング音声信号もユーザ8の音声と共に収音して、オーディオ信号を生成し得る。つまり、マイク3が生成するオーディオ信号には、ユーザ音声およびマスキング音声信号が含まれ得る。以下では、マイク3が生成するオーディオ信号を、収音信号とも称する。マイク3は、生成した収音信号をマイクアンプ21に出力する。
マイクアンプ21は、マイク3から出力された収音信号を増幅する機能を有する。マイクアンプ21は、増幅した収音信号を制御部11、送話部31、および信号処理部12に出力する。
制御部11は、演算処理装置および制御装置として機能し、各種プログラムに従ってスマートフォン1−1内の動作全般を制御する。制御部11は、例えばCPU(Central Processing Unit)、マイクロプロセッサによって実現される。なお、制御部11は、使用するプログラムや演算パラメータ等を記憶するROM(Read Only Memory)、および適宜変化するパラメータ等を一時記憶するRAM(Random Access Memory)を含んでいてもよい。
送話部31は、収音信号を外部に送信する通信部としての機能を有する。より詳しくは、送話部31は、マイクアンプ21から出力された収音信号を、通話相手の端末に送信する。
パワーアンプ22は、後述の信号処理部12から出力されたマスキング音声信号を増幅する機能を有する。パワーアンプ22は、増幅した収音信号をマスキング用スピーカ4に出力する。なお、パワーアンプ22は、マスキング用スピーカ4により再生されるマスキング音声信号が周囲の他人9に聞こえ、且つ、周囲の他人9がユーザ8の発話内容を聞き取れない程度の音量となるよう増幅する。
マスキング用スピーカ4は、マスキング音声信号を再生する出力装置(第1のスピーカ)である。より詳しくは、マスキング用スピーカ4は、パワーアンプ22から出力されたマスキング音声信号を再生する。
マスキング用音源41は、マスキング音声信号を生成するための元となる音源を記録する記録部としての機能を有する。例えば、マスキング用音源41は、音源として、300Hz〜3kHzとされる音声帯域の帯域ノイズ、無意味列の音声信号、男女含む複数名による人声、白色雑音、有色雑音などの多様なノイズを記録する。他にも、マスキング用音源41は、音源として、マイク3により収音されたユーザ音声を記録してもよい。後述する信号処理部12は、マスキング用音源41に記録された音源に基づいて、マスキング音声信号を生成する。
信号処理部12は、収音信号に応じて、ユーザ音声をマスキングするためのマスキング音声信号を生成する。より詳しくは、信号処理部12は、マイクアンプ21から出力された収音信号に基づいて、マスキング用音源41に記録された音源を用いたマスキング音声信号を生成する。ここで、ユーザ音声をマスキングするとは、ユーザ8の発話をマスキング用スピーカ4により再生されるマスキング音声信号に埋没させて、他人9に聞き取られないよう秘匿することを指す。このような、ユーザ音声をマスキングするためのマスキング音声信号には、多様な種類が考えられる。
解析用BPF群121は、複数のBPFのアレイから成るフィルタバンクである。解析用BPF群121は、ユーザ音声を組成する周波数帯域成分ごとに、振幅等のデータ量に基づいて対応係数を算出する。例えば、解析用BPF群121を構成する解析用BPFは、それぞれ所定の周波数帯域を通過させて、所定時間幅でのデータ二乗和により対応係数を算出する。ここで、対応係数は、ユーザ音声を組成する各周波数帯域成分の構成比率を示し、信号処理部12−1が生成するマスキング音声信号の、各周波数帯域成分の配分比となる。解析用BPF群121を構成する解析用BPFは、それぞれ対応する可変ゲインブロック群122を構成する可変ゲインブロックに、算出した対応係数を出力する。
可変ゲインブロック群122は、マスキング用音源41から取得した音声信号を増幅する機能を有する。可変ゲインブロック群122を構成する可変ゲインブロックは、対応する解析用BPFから出力された対応係数によりマスキング用音源41から取得した音声信号を増幅して、それぞれ対応する合成用BPF群123を構成する合成用BPFに出力する。
合成用BPF群123は、複数のBPFのアレイから成るフィルタバンクである。合成用BPF群123を構成する合成用BPFは、対応する可変ゲインブロックから出力された音声信号から、対応する解析用BPFと同じ周波数帯域成分を通過させて、合成用音声信号を生成する。合成用BPF群123は、生成した音声信号を加算器124に出力する。
加算器124は、合成用BPF群123から出力された音声信号を合成することで、マスキング音声信号を生成する。
VAD125は、入力された収音信号から、音声が発話された音声区間とそれ以外のノイズ区間とを検出する機能を有する。VAD125は、音声区間かノイズ区間かに応じて、スイッチ126を制御する。
スイッチ126は、VAD125による制御に基づいて、マスキング用音源41から取得した音声信号を通過または非通過させて、マスキング音声信号として出力する。より詳しくは、スイッチ126は、収音信号の音声区間に相当する時間区間ではマスキング用音源41から取得した音声信号を通過させ、ノイズ区間に相当する時間区間では非通過とする。
なお、スマートフォン1−1は、ADC(Analog−to−Digital Converter)およびDAC(Digital−to−Analog Converter)を有していてもよい。ADCとは、アナログ信号をデジタル信号に変換する電子回路であり、DACとは、デジタル信号をアナログ信号に変換する電子回路である。例えば、マイクアンプ21の後段にADCが設けられていてもよい。また、パワーアンプ22、およびパワーアンプ23の前段にDACが設けられていてもよい。
続いて、図7を参照して、スマートフォン1−1の動作処理について説明する。図7は、第1の実施形態に係るスマートフォン1−1の動作を示すフローチャートである。なお、他の実施形態における動作は、スマートフォン1−1の動作と同様である。図7に示すように、まず、ステップS11で、マイク3は、ユーザ音声を収音し、収音信号を生成する。
本変形例は、通話用スピーカ2が、通話相手の音声と共にマスキング音声信号を再生する形態である。以下、図8を参照して、本変形例に係るスマートフォン1−2について説明する。
本実施形態は、マスキング用スピーカ4から再生されたマスキング音声信号がマイク3により収音された場合に、電気的に収音信号からマスキング音声信号成分を除去する形態である。マスキング用スピーカ4から再生されたマスキング音声信号は、マイク3とマスキング用スピーカ4との位置関係や向き、再生音量、収音感度等によってはマイク3に収音されてしまい、通話や音声認識の妨げになり得る。この点、本実施形態によれば、収音信号からマスキング音声信号成分を除去することで、雑音を低減した高品質な通話や音声認識を実現することができる。以下、図9を参照して、本実施形態に係るスマートフォン1−3について説明する。
エコーキャンセラ14は、マスキング用スピーカ4から再生されたマスキング音声信号がマイク3により収音された場合に、収音信号からマスキング音声信号を除去する、除去部としての機能を有する。なお、エコーキャンセラ14および後述の加算器15により、除去部として機能すると捉えてもよい。
加算器15は、収音信号から、エコーキャンセラ14により生成されたマスキング音声信号を減算する機能を有する。このため、収音信号から、マスキング用スピーカ4から再生されマイク3により収音されたマスキング音声信号が除去される。加算器15は、マスキング音声信号を除去した収音信号を、制御部11、送話部31、および信号処理部12に出力する。
[2−3−1.基本形態]
本実施形態は、マスキング音声信号を再生するスピーカを複数設け、互いに打ち消し合わせることで、空間音響的に収音信号からマスキング音声信号成分を除去する形態である。以下、図10を参照して、本実施形態に係るスマートフォン1−4について説明する。なお、以下ではマスキング音声信号を再生するスピーカを2つ設ける例を説明するが、3つ以上であってもよい。
逆相信号生成部16は、信号処理部12から出力されたマスキング音声信号の逆相信号を生成する機能を有する。逆相信号生成部16は、生成した逆相信号をパワーアンプ24に出力する。
パワーアンプ24は、逆相信号生成部16から出力された逆相信号を増幅する機能を有する。パワーアンプ24は、パワーアンプ22と同程度に増幅してもよい。パワーアンプ24は、増幅した逆相信号をマスキング用スピーカ4−2に出力する。
マスキング用スピーカ4−2は、マスキング音声信号の逆相信号を再生する出力装置(第2のスピーカ)である。具体的には、マスキング用スピーカ4−2は、パワーアンプ24から出力された逆相信号を、マスキング用スピーカ4−1によるマスキング音声信号の再生と同時に再生する。マスキング用スピーカ4−2は、マスキング用スピーカ4−1より再生されたマスキング音声信号と、マスキング用スピーカ4−2より再生された逆相信号とが、マイク3が収音する空間において打ち消し合うよう設置される。マスキング用スピーカ4−2は、マスキング用スピーカ4−1と同一のスピーカ特性を有する。また、図10に示したように、マスキング用スピーカ4−2は、マイク3の位置を中心として、マスキング用スピーカ4−1と幾何学的に対称な位置に設置される。
本変形例は、マスキング用スピーカ4−2は、遅延させた逆相信号を再生することで、マスキング用スピーカ4−1およびマスキング用スピーカ4−2の中間地点以外の領域にキャンセル領域を形成する形態である。以下、図11(B)を参照し、本変形例に係るスマートフォン1−5について説明する。
ディレイ17は、入力された音声信号を遅延させて出力する機能を有する。本変形例では、ディレイ17は、逆相信号生成部16により生成された逆相信号を遅延させる遅延部として機能する。より詳しくは、ディレイ17は、マスキング用スピーカ4−1より再生されたマスキング音声信号とマスキング用スピーカ4−2より再生された逆相信号とが、マイク3が収音する空間において打ち消し合うよう、逆相信号を遅延させる。ディレイ17は、遅延させた逆相信号を、パワーアンプ24に出力する。なお、ディレイ17は、特定のフィルタ形式であってもよい。
本変形例は、ヘッドセット6により、本開示の一実施形態に係る信号処理装置を実現する形態である。以下、図12を参照し、本変形例に係るヘッドセット6について説明する。
以上説明したように、本開示の一実施形態に係るスマートフォン1は、ユーザ音声に応じたマスキング音声信号を生成および再生することで、ユーザ8の発話内容が聞き取られることを防ぐことができる。より詳しくは、スマートフォン1は、他人9に対して混同を生じさせる、または注意を逸らせるマスキング音声信号を生成および再生することで、ユーザ8の発話をマスキング音声信号に埋没させ、発話内容の聞き取りを妨害することができる。また、スマートフォン1は、収音信号のうちユーザ音声が含まれる時間区間にのみマスキング音声信号を再生することで、他人9がマスキング音声信号に耳慣れすることを防止することができる。
(1)
ユーザ音声を収音し、オーディオ信号を生成する収音部と、
前記オーディオ信号に応じて、前記ユーザ音声をマスキングするためのマスキング音声信号を生成する信号処理部と、
前記マスキング音声信号を再生する第1のスピーカと、
を備える信号処理装置。
(2)
前記信号処理部は、前記オーディオ信号のうち前記ユーザ音声が含まれる時間区間にのみ前記マスキング音声信号を生成する、前記(1)に記載の信号処理装置。
(3)
前記信号処理装置は、除去部をさらに備え、
前記除去部は、前記収音部が前記第1のスピーカから再生された前記マスキング音声信号を前記ユーザ音声と共に収音して前記オーディオ信号を生成した場合、特定の伝達関数および前記信号処理部が生成した前記マスキング音声信号に基づいて、前記収音部により生成された前記オーディオ信号から前記マスキング音声信号を除去する、前記(1)または(2)に記載の信号処理装置。
(4)
前記信号処理装置は、前記マスキング音声信号の逆相信号を再生する第2のスピーカをさらに備え、
前記第2のスピーカは、前記第1のスピーカより再生された前記マスキング音声信号と前記第2のスピーカより再生された前記逆相信号とが前記収音部が収音する空間において打ち消し合うよう設置される、前記(1)〜(3)のいずれか一項に記載の信号処理装置。
(5)
前記信号処理装置は、前記逆相信号を遅延させる遅延部をさらに備え、
前記第2のスピーカは、前記遅延部により遅延された前記逆相信号を再生する、前記(4)に記載の信号処理装置。
(6)
前記信号処理部は、前記ユーザ音声を組成する周波数成分ごとのデータ量に応じて前記マスキング音声信号を生成する、前記(1)〜(5)のいずれか一項に記載の信号処理装置。
(7)
前記マスキング音声信号は、音声帯域の帯域ノイズである、前記(1)〜(6)のいずれか一項に記載の信号処理装置。
(8)
前記マスキング音声信号は、母音を主な成分とする音声信号である、前記(1)〜(6)のいずれか一項に記載の信号処理装置。
(9)
前記信号処理装置は、前記収音部により収音された前記ユーザ音声を記録する記録部をさらに備え、
信号処理部は、前記記録部により記録された前記ユーザ音声により前記マスキング音声信号を生成する、前記(1)〜(8)のいずれか一項に記載の信号処理装置。
(10)
前記信号処理装置は、前記収音部により収音される前記ユーザ音声の言語を認識する言語認識部をさらに備え、
前記信号処理部は、前記言語認識部により認識された前記言語に応じて前記マスキング音声信号を生成する、前記(1)〜(9)のいずれか一項に記載の信号処理装置。
(11)
前記信号処理部は、前記言語認識部により認識された前記言語と同じ言語により前記マスキング音声信号を生成する、前記(10)に記載の信号処理装置。
(12)
前記信号処理部は、前記言語認識部により認識された前記言語と異なる言語により前記マスキング音声信号を生成する、前記(10)に記載の信号処理装置。
(13)
前記信号処理装置は、前記オーディオ信号を外部に送信し、外部からのオーディオ信号を受信する通信部をさらに備える、前記(1)〜(12)のいずれか一項に記載の信号処理装置。
(14)
前記信号処理装置は、
前記オーディオ信号から制御情報を認識する制御情報認識部と、
前記制御情報認識部により認識された前記制御情報に基づいて前記信号処理装置を制御する制御部と、
をさらに備える、前記(1)〜(13)のいずれか一項に記載の信号処理装置。
(15)
ユーザ音声を収音し、オーディオ信号を生成するステップと、
前記オーディオ信号に応じて、前記ユーザ音声をマスキングするためのマスキング音声信号を生成するステップと、
前記マスキング音声信号を再生するステップと、
を備える信号処理方法。
(16)
コンピュータに、
ユーザ音声を収音し、オーディオ信号を生成するステップと、
前記オーディオ信号に応じて、前記ユーザ音声をマスキングするためのマスキング音声信号を生成するステップと、
前記マスキング音声信号を再生するステップと、
を実行させるためのプログラムが記憶された記憶媒体。
2 通話用スピーカ
3 マイク
4、4−1、4−2 マスキング用スピーカ
5−1、5−2 キャンセル領域
6 ヘッドセット
8 ユーザ
9 他人
11 制御部
12、12−1、12−2 信号処理部
13 加算器
14 エコーキャンセラ
15 加算器
16 逆相信号生成部
17 ディレイ
21 マイクアンプ
22、23、24 パワーアンプ
31 送話部
32 受話部
41 マスキング用音源
100 スマートフォン
120−1、120−2 音声信号例
121 解析用BPF群
122 可変ゲインブロック群
123 合成用BPF群
124 加算器
125 VAD
126 スイッチ
Claims (15)
- ユーザ音声を収音し、オーディオ信号を生成する収音部と、
前記オーディオ信号に応じて、前記ユーザ音声をマスキングするためのマスキング音声信号を生成する信号処理部と、
前記マスキング音声信号を再生する第1のスピーカと、
前記マスキング音声信号の逆相信号を再生する第2のスピーカと、
を備え、
前記逆相信号は、前記第1のスピーカより再生された前記マスキング音声信号と前記第2のスピーカより再生された前記逆相信号とが前記収音部が収音する空間において打ち消し合うよう再生される、信号処理装置。 - 前記信号処理部は、前記オーディオ信号のうち前記ユーザ音声が含まれる時間区間にのみ前記マスキング音声信号を生成する、請求項1に記載の信号処理装置。
- 前記信号処理装置は、除去部をさらに備え、
前記除去部は、前記収音部が前記第1のスピーカから再生された前記マスキング音声信号を前記ユーザ音声と共に収音して前記オーディオ信号を生成した場合、特定の伝達関数および前記信号処理部が生成した前記マスキング音声信号に基づいて、前記収音部により生成された前記オーディオ信号から前記マスキング音声信号を除去する、請求項1に記載の信号処理装置。 - 前記信号処理装置は、前記逆相信号を遅延させる遅延部をさらに備え、
前記第2のスピーカは、前記遅延部により遅延された前記逆相信号を再生する、請求項1に記載の信号処理装置。 - 前記信号処理部は、前記ユーザ音声を組成する周波数成分ごとのデータ量に応じて前記マスキング音声信号を生成する、請求項1に記載の信号処理装置。
- 前記マスキング音声信号は、音声帯域の帯域ノイズである、請求項1に記載の信号処理装置。
- 前記マスキング音声信号は、母音を主な成分とする音声信号である、請求項1に記載の信号処理装置。
- 前記信号処理装置は、前記収音部により収音された前記ユーザ音声を記録する記録部をさらに備え、
信号処理部は、前記記録部により記録された前記ユーザ音声により前記マスキング音声信号を生成する、請求項1に記載の信号処理装置。 - 前記信号処理装置は、前記収音部により収音される前記ユーザ音声の言語を認識する言語認識部をさらに備え、
前記信号処理部は、前記言語認識部により認識された前記言語に応じて前記マスキング音声信号を生成する、請求項1に記載の信号処理装置。 - 前記信号処理部は、前記言語認識部により認識された前記言語と同じ言語により前記マスキング音声信号を生成する、請求項9に記載の信号処理装置。
- 前記信号処理部は、前記言語認識部により認識された前記言語と異なる言語により前記マスキング音声信号を生成する、請求項9に記載の信号処理装置。
- 前記信号処理装置は、前記オーディオ信号を外部に送信し、外部からのオーディオ信号を受信する通信部をさらに備える、請求項1に記載の信号処理装置。
- 前記信号処理装置は、
前記オーディオ信号から制御情報を認識する制御情報認識部と、
前記制御情報認識部により認識された前記制御情報に基づいて前記信号処理装置を制御する制御部と、
をさらに備える、請求項1に記載の信号処理装置。 - ユーザ音声を収音し、オーディオ信号を生成するステップと、
前記オーディオ信号に応じて、前記ユーザ音声をマスキングするためのマスキング音声信号を生成するステップと、
前記マスキング音声信号を再生するステップと、
前記マスキング音声信号の逆相信号を再生するステップと、
を備え、
前記逆相信号は、再生された前記マスキング音声信号と再生された前記逆相信号とが前記ユーザ音声が収音される空間において打ち消し合うよう再生される、信号処理方法。 - コンピュータに、
ユーザ音声を収音し、オーディオ信号を生成するステップと、
前記オーディオ信号に応じて、前記ユーザ音声をマスキングするためのマスキング音声信号を生成するステップと、
前記マスキング音声信号を再生するステップと、
前記マスキング音声信号の逆相信号を再生するステップと、
を実行させるためのプログラムが記憶された記憶媒体であり、
前記逆相信号は、再生された前記マスキング音声信号と再生された前記逆相信号とが前記ユーザ音声が収音される空間において打ち消し合うよう再生される、記憶媒体。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013045230A JP5929786B2 (ja) | 2013-03-07 | 2013-03-07 | 信号処理装置、信号処理方法及び記憶媒体 |
| US14/154,357 US9336786B2 (en) | 2013-03-07 | 2014-01-14 | Signal processing device, signal processing method, and storage medium |
| CN201410073433.XA CN104036771A (zh) | 2013-03-07 | 2014-02-28 | 信号处理装置、信号处理方法和存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013045230A JP5929786B2 (ja) | 2013-03-07 | 2013-03-07 | 信号処理装置、信号処理方法及び記憶媒体 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2014174255A JP2014174255A (ja) | 2014-09-22 |
| JP2014174255A5 JP2014174255A5 (ja) | 2015-03-26 |
| JP5929786B2 true JP5929786B2 (ja) | 2016-06-08 |
Family
ID=51467518
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013045230A Expired - Fee Related JP5929786B2 (ja) | 2013-03-07 | 2013-03-07 | 信号処理装置、信号処理方法及び記憶媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US9336786B2 (ja) |
| JP (1) | JP5929786B2 (ja) |
| CN (1) | CN104036771A (ja) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3048608A1 (en) * | 2015-01-20 | 2016-07-27 | Fraunhofer Gesellschaft zur Förderung der angewandten Forschung e.V. | Speech reproduction device configured for masking reproduced speech in a masked speech zone |
| CN106558303A (zh) * | 2015-09-29 | 2017-04-05 | 苏州天声学科技有限公司 | 阵列式声音掩蔽器及声音掩蔽方法 |
| JPWO2019012661A1 (ja) * | 2017-07-13 | 2020-05-07 | 住友電気工業株式会社 | 音声制御装置 |
| CN107483142B (zh) * | 2017-08-03 | 2019-11-08 | 厦门大学 | 一种基于海洋环境的定向干扰装置 |
| JP6972858B2 (ja) * | 2017-09-29 | 2021-11-24 | 沖電気工業株式会社 | 音響処理装置、プログラム及び方法 |
| JPWO2019171963A1 (ja) * | 2018-03-07 | 2021-02-18 | ソニー株式会社 | 信号処理システム、信号処理装置および方法、並びにプログラム |
| JP6457682B1 (ja) * | 2018-04-16 | 2019-01-23 | パスロジ株式会社 | 認証システム、認証方法、ならびに、プログラム |
| JP7073910B2 (ja) * | 2018-05-24 | 2022-05-24 | 日本電気株式会社 | 音声型認証装置、音声型認証方法、及びプログラム |
| US10622003B2 (en) * | 2018-07-12 | 2020-04-14 | Intel IP Corporation | Joint beamforming and echo cancellation for reduction of noise and non-linear echo |
| US11363147B2 (en) | 2018-09-25 | 2022-06-14 | Sorenson Ip Holdings, Llc | Receive-path signal gain operations |
| US10777177B1 (en) | 2019-09-30 | 2020-09-15 | Spotify Ab | Systems and methods for embedding data in media content |
| EP3800900B1 (en) * | 2019-10-04 | 2024-11-06 | GN Audio A/S | A wearable electronic device for emitting a masking signal |
| JP2021135361A (ja) * | 2020-02-26 | 2021-09-13 | 沖電気工業株式会社 | 音響処理装置、音響処理プログラム及び音響処理方法 |
| WO2023047911A1 (ja) * | 2021-09-21 | 2023-03-30 | インターマン株式会社 | 通話システム |
| JPWO2023127292A1 (ja) * | 2021-12-27 | 2023-07-06 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08296335A (ja) * | 1995-04-25 | 1996-11-12 | Matsushita Electric Ind Co Ltd | アクティブ防音フード装置 |
| US7016844B2 (en) * | 2002-09-26 | 2006-03-21 | Core Mobility, Inc. | System and method for online transcription services |
| JP4336552B2 (ja) * | 2003-09-11 | 2009-09-30 | グローリー株式会社 | マスキング装置 |
| US20060109983A1 (en) * | 2004-11-19 | 2006-05-25 | Young Randall K | Signal masking and method thereof |
| US7599719B2 (en) * | 2005-02-14 | 2009-10-06 | John D. Patton | Telephone and telephone accessory signal generator and methods and devices using the same |
| JP4761506B2 (ja) * | 2005-03-01 | 2011-08-31 | 国立大学法人北陸先端科学技術大学院大学 | 音声処理方法と装置及びプログラム並びに音声システム |
| JP4640801B2 (ja) * | 2005-06-27 | 2011-03-02 | 富士通株式会社 | 電話機 |
| EP1770685A1 (en) * | 2005-10-03 | 2007-04-04 | Maysound ApS | A system for providing a reduction of audiable noise perception for a human user |
| JP5103974B2 (ja) * | 2007-03-22 | 2012-12-19 | ヤマハ株式会社 | マスキングサウンド生成装置、マスキングサウンド生成方法およびプログラム |
| JP5511342B2 (ja) * | 2009-12-09 | 2014-06-04 | 日本板硝子環境アメニティ株式会社 | 音声変更装置、音声変更方法および音声情報秘話システム |
| JP2012119785A (ja) | 2010-11-29 | 2012-06-21 | Yamaha Corp | 通信システム |
-
2013
- 2013-03-07 JP JP2013045230A patent/JP5929786B2/ja not_active Expired - Fee Related
-
2014
- 2014-01-14 US US14/154,357 patent/US9336786B2/en not_active Expired - Fee Related
- 2014-02-28 CN CN201410073433.XA patent/CN104036771A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20140257802A1 (en) | 2014-09-11 |
| CN104036771A (zh) | 2014-09-10 |
| US9336786B2 (en) | 2016-05-10 |
| JP2014174255A (ja) | 2014-09-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5929786B2 (ja) | 信号処理装置、信号処理方法及び記憶媒体 | |
| JP2014174255A5 (ja) | ||
| US11569789B2 (en) | Compensation for ambient sound signals to facilitate adjustment of an audio volume | |
| CN103650533B (zh) | 在电子装置上产生掩蔽信号 | |
| CN102056036B (zh) | 再现设备、头戴式耳机和再现方法 | |
| KR101444100B1 (ko) | 혼합 사운드로부터 잡음을 제거하는 방법 및 장치 | |
| KR101606966B1 (ko) | 공간 선택적 오디오 증강을 위한 시스템들, 방법들, 장치들, 및 컴퓨터 판독가능 매체들 | |
| CN101277331B (zh) | 声音再现设备和声音再现方法 | |
| JP5644359B2 (ja) | 音声処理装置 | |
| CN111464905A (zh) | 基于智能穿戴设备的听力增强方法、系统和穿戴设备 | |
| US8532987B2 (en) | Speech masking and cancelling and voice obscuration | |
| US20120101819A1 (en) | System and a method for providing sound signals | |
| KR101647974B1 (ko) | 스마트 믹싱 모듈을 갖춘 스마트 이어폰, 스마트 믹싱 모듈을 갖춘 기기, 외부음과 기기음을 혼합하는 방법 및 시스템 | |
| WO2022135340A1 (zh) | 一种主动降噪的方法、设备及系统 | |
| CN101410900A (zh) | 用于可佩戴装置的数据处理 | |
| CN111683319A (zh) | 一种通话拾音降噪方法及耳机、存储介质 | |
| KR20030009504A (ko) | 선택적 잡음 억제 기능을 가진 능동적 잡음 제거 헤드셋및 디바이스 | |
| US20120057717A1 (en) | Noise Suppression for Sending Voice with Binaural Microphones | |
| CN112767908B (zh) | 基于关键声音识别的主动降噪方法、电子设备及存储介质 | |
| US10510361B2 (en) | Audio processing apparatus that outputs, among sounds surrounding user, sound to be provided to user | |
| US20220070593A1 (en) | Hearing aid comprising a record and replay function | |
| WO2019228329A1 (zh) | 个人听力装置、外部声音处理装置及相关计算机程序产品 | |
| US20110105034A1 (en) | Active voice cancellation system | |
| JP2007187748A (ja) | 音選択加工装置 | |
| CN113038318B (zh) | 一种语音信号处理方法及装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150203 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150203 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20150403 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20150602 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150723 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20160405 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20160418 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 5929786 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |