JP5826260B2 - 関連データセットの処理 - Google Patents
関連データセットの処理 Download PDFInfo
- Publication number
- JP5826260B2 JP5826260B2 JP2013516735A JP2013516735A JP5826260B2 JP 5826260 B2 JP5826260 B2 JP 5826260B2 JP 2013516735 A JP2013516735 A JP 2013516735A JP 2013516735 A JP2013516735 A JP 2013516735A JP 5826260 B2 JP5826260 B2 JP 5826260B2
- Authority
- JP
- Japan
- Prior art keywords
- data set
- data
- records
- record
- field
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/23—Updating
- G06F16/2365—Ensuring data consistency and integrity
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/61—Indexing; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2455—Query execution
- G06F16/24564—Applying rules; Deductive queries
- G06F16/24565—Triggers; Constraints
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/70—Information retrieval; Database structures therefor; File system structures therefor of video data
- G06F16/71—Indexing; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/80—Information retrieval; Database structures therefor; File system structures therefor of semi-structured data, e.g. markup language structured data such as SGML, XML or HTML
- G06F16/84—Mapping; Conversion
- G06F16/86—Mapping to a database
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/40—Searching chemical structures or physicochemical data
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/90—Programming languages; Computing architectures; Database systems; Data warehousing
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H70/00—ICT specially adapted for the handling or processing of medical references
- G16H70/40—ICT specially adapted for the handling or processing of medical references relating to drugs, e.g. their side effects or intended usage
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical & Material Sciences (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computer Security & Cryptography (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computing Systems (AREA)
- Crystallography & Structural Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Bioethics (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Evolutionary Biology (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Computer Hardware Design (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Medicinal Chemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Toxicology (AREA)
- Epidemiology (AREA)
- Primary Health Care (AREA)
- Public Health (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本出願は2010年6月22日出願の米国仮特許出願第61/357,376号からの優先権を主張し、参照のためその全体を本明細書に援用する。
本明細書は関連データセットの処理に関する。
1つの態様では、通常、関連データセットの処理方法は、複数のデータセットから入力装置またはポート上でレコードを受信する工程であって、所与のデータセットのレコードは1つまたは複数のそれぞれのフィールドの1つまたは複数の値を有する、工程と、複数のデータセットのそれぞれからのレコードをデータ処理システムにおいて処理する工程と、を含む。この処理は、複数のデータセットの処理順序を決定するためにデータ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、制約仕様は複数のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、決定された処理順序で、複数のデータセットのそれぞれからのレコードに1つまたは複数の変換を適用する工程であって、変換が複数のデータセットの第2のデータセットからのレコードに適用される前に、変換が複数のデータセットの第1のデータセットからのレコードに適用され、第2のデータセットからのレコードに適用される変換は、第1のデータセットからのレコードに変換を適用した結果と、制約仕様により規定される第1のデータセットと第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、複数のデータセットのそれぞれからレコードへの変換の結果を格納または出力する工程と、を含む。
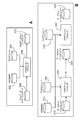
図1に、データセット処理技術を使用することができる例示的なデータ処理システム100を示す。システム100は、それぞれが様々な格納フォーマット(例えば、データベーステーブル、スプレッドシートファイル、フラットテキストファイルまたはメインフレームにより使用される固有フォーマット)の任意のものでデータセットを格納することができる記憶装置またはオンラインデータストリームへの接続等の1つまたは複数のデータソースを含んでよいデータソース102を含む。実行環境104は前処理モジュール106と処理モジュール112を含む。実行環境104は、UNIX(登録商標)オペレーティングシステム等の好適なオペレーティングシステムの制御下で1つまたは複数の汎用コンピュータ上でホストされてもよい。例えば、実行環境104は、複数の中央処理装置(CPU)を使用するコンピュータシステムの構成を含むマルチプルノードパラレルコンピューティング環境を含むことができる。この環境は、ローカル(例えば、SMPコンピュータ等のマルチプロセッサシステム)、または局地分散型(例えば、クラスタまたはMPPとして結合されるマルチプルプロセッサ)、またはリモート、またはリモート分散型(例えば、ローカルエリアネットワーク(LAN)および/または広域ネットワーク(WAN)を介して結合される複数のプロセッサ)、またはその任意の組み合せのいずれかである。
Claims (48)
- 関連データセットの処理方法であって、
入力装置またはポート上で、複数のデータセットから1つまたは複数のそれぞれのフィールドの1つまたは複数の値を有する所与のデータセットのレコードを受信する工程と、
前記複数のデータセットのそれぞれからのレコードをデータ処理システムにおいて処理する工程とを含み、前記処理は、
前記複数のデータセットの処理順序を決定するために、データ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記複数のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
前記決定された処理順序で、前記複数のデータセットのそれぞれからのレコードに1つまたは複数の変換を適用する工程であって、前記変換が複数のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記複数のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される前記変換は、前記第1のデータセットからの前記レコードに前記変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記複数のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、を含む方法。 - 前記制約仕様により規定される参照整合性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドの値の前記第1のデータセットのフィールドの値への依存性に基づく、請求項1に記載の方法。
- 前記変換が前記第2のデータセットからのレコードに適用される前に、および前記変換が前記第1のデータセットからのレコードに適用された後に、前記変換は前記複数のデータセットの第3のデータセットからのレコードに適用される、請求項1に記載の方法。
- 前記制約仕様により規定される統計的一貫性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドと前記第1のデータセットのフィールドとの間の関係に基づく、請求項1に記載の方法。
- 前記第1のデータセットの前記フィールドと前記第2のデータセットの前記フィールドは、結合演算のためのキーを導出するために使用可能である、請求項4に記載の方法。
- 複数のフィールドに関連する統計を決定するために、関連データセットの前記グループ内の前記データセットをプロファイリングする工程をさらに含み、前記複数のフィールドは、前記第1のデータセットの少なくとも1つのフィールドと、前記第1のデータセットの前記フィールドと等価であると前記制約仕様により示される前記第2のデータセットの少なくとも1つのフィールドとを含む、請求項1に記載の方法。
- 前記第2のデータセットからの前記レコードに適用される前記1つまたは複数の変換は、前記決定された統計と前記第1のデータセットからの前記レコードに前記変換を適用した結果とに従って前記第1のデータセットの前記フィールド内の値の分布と前記第2のデータセットの前記フィールド内の値の分布との間の統計的一貫性を維持することに少なくとも部分的に基づいて適用される、請求項6に記載の方法。
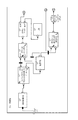
- 前記1つまたは複数の変換は、データ処理構成要素間のレコードの流れを表すリンクにより接続されたデータ処理構成要素を表すノードを含む少なくとも1つのデータフローグラフにより適用され、前記変換が適用される各データセットは前記データフローグラフにレコードの入力フローを提供する、請求項1に記載の方法。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値に基づき前記所与のデータセット内のレコードの数を低減するサブセット化変換を含む、請求項1に記載の方法。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記データセットの少なくとも1つのフィールド内の値を修正する修正変換を含む、請求項1に記載の方法。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値の重複に基づき前記所与のデータセット内のレコードの数を増加する拡張変換を含む、請求項1に記載の方法。
- 変換を複数のデータセットのそれぞれからのレコードに適用した結果のデータセットの処理順序を決定するために、データ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記結果のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
1つまたは複数の変換を、前記決定された処理順序で、前記結果のデータセットのそれぞれからのレコードに適用する工程であって、前記変換が前記結果のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記結果のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記結果のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、をさらに含む請求項1に記載の方法。 - 関連データセットを処理するためのコンピュータプログラムであって、前記コンピュータプログラムはコンピュータに、
入力装置またはポート上で、複数のデータセットから1つまたは複数のそれぞれのフィールドの1つまたは複数の値を有する所与のデータセットのレコードを受信させ、
前記複数のデータセットのそれぞれからのレコードをデータ処理システムにおいて処理させる、命令を含み、前記処理は、
前記複数のデータセットの処理順序を決定するためにデータ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記複数のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
前記決定された処理順序で、前記複数のデータセットのそれぞれからのレコードに1つまたは複数の変換を適用する工程であって、前記変換が前記複数のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記複数のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記複数のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、を含む、コンピュータプログラム。 - 関連データセットを処理するためのデータ処理システムであって、前記システムは、
データ記憶システムと、
複数のデータセットから1つまたは複数のそれぞれのフィールドの1つまたは複数の値を有する所与のデータセットのレコードを受信するように構成された入力装置またはポートと、
前記入力装置またはポートと前記データ記憶システムと通信する少なくとも1つのプロセッサであって、前記複数のデータセットのそれぞれからのレコードを処理するように構成された少なくとも1つのプロセッサと、を含み、前記処理は、
前記複数のデータセットの処理順序を決定するために前記データ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記複数のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
前記決定された処理順序で、前記複数のデータセットのそれぞれからのレコードに1つまたは複数の変換を適用する工程であって、前記変換が前記複数のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記複数のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記複数のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、を含む、システム。 - 関連データセットを処理するためのデータ処理システムであって、前記システムは、
複数のデータセットからレコードを受信する手段であって、所与のデータセットの前記レコードは1つまたは複数のそれぞれのフィールドの1つまたは複数の値を有する、手段と、
前記複数のデータセットのそれぞれからのレコードを処理する手段と、を含み、前記処理は、
前記複数のデータセットの処理順序を決定するためにデータ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記複数のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
前記決定された処理順序で、前記複数のデータセットのそれぞれからのレコードに1つまたは複数の変換を適用する工程であって、前記変換が前記複数のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記複数のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記複数のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、を含む、システム。 - 前記制約仕様により規定される参照整合性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドの値の前記第1のデータセットのフィールドの値への依存性に基づく、請求項14に記載のシステム。
- 前記変換が前記第2のデータセットからのレコードに適用される前に、および前記変換が前記第1のデータセットからのレコードに適用された後に、前記変換は前記複数のデータセットの第3のデータセットからのレコードに適用される、請求項14に記載のシステム。
- 前記制約仕様により規定される統計的一貫性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドと前記第1のデータセットのフィールドとの間の関係に基づく、請求項14に記載のシステム。
- 前記第1のデータセットの前記フィールドと前記第2のデータセットの前記フィールドは、結合演算のためのキーを導出するために使用可能である、請求項18に記載のシステム。
- 前記処理は、複数のフィールドに関連する統計を決定するために、関連データセットの前記グループ内の前記データセットをプロファイリングする工程をさらに含み、前記複数のフィールドは、前記第1のデータセットの少なくとも1つのフィールドと、前記第1のデータセットの前記フィールドと等価であると前記制約仕様により示される前記第2のデータセットの少なくとも1つのフィールドとを含む、請求項14に記載のシステム。
- 前記第2のデータセットからの前記レコードに適用される前記1つまたは複数の変換は、前記決定された統計と前記第1のデータセットからの前記レコードに前記変換を適用した結果とに従って前記第1のデータセットの前記フィールド内の値の分布と前記第2のデータセットの前記フィールド内の値の分布との間の統計的一貫性を維持することに少なくとも部分的に基づいて適用される、請求項20に記載のシステム。
- 前記1つまたは複数の変換は、データ処理構成要素間のレコードの流れを表すリンクにより接続されたデータ処理構成要素を表すノードを含む少なくとも1つのデータフローグラフにより適用され、前記変換が適用される各データセットは前記データフローグラフにレコードの入力フローを提供する、請求項14に記載のシステム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値に基づき前記所与のデータセット内のレコードの数を低減するサブセット化変換を含む、請求項14に記載のシステム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記データセットの少なくとも1つのフィールド内の値を修正する修正変換を含む、請求項14に記載のシステム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値の重複に基づき前記所与のデータセット内のレコードの数を増加する拡張変換を含む、請求項14に記載のシステム。
- 前記処理は、
変換を複数のデータセットのそれぞれからのレコードに適用した結果のデータセットの処理順序を決定するために、データ記憶システム内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記結果のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
1つまたは複数の変換を、前記決定された処理順序で、前記結果のデータセットのそれぞれからのレコードに適用する工程であって、前記変換が前記結果のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記結果のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記結果のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、をさらに含む請求項14に記載のシステム。 - 前記制約仕様により規定される参照整合性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドの値の前記第1のデータセットのフィールドの値への依存性に基づく、請求項15に記載のシステム。
- 前記変換が前記第2のデータセットからのレコードに適用される前に、および前記変換が前記第1のデータセットからのレコードに適用された後に、前記変換は前記複数のデータセットの第3のデータセットからのレコードに適用される、請求項15に記載のシステム。
- 前記制約仕様により規定される統計的一貫性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドと前記第1のデータセットのフィールドとの間の関係に基づく、請求項15に記載のシステム。
- 前記第1のデータセットの前記フィールドと前記第2のデータセットの前記フィールドは、結合演算のためのキーを導出するために使用可能である、請求項29に記載のシステム。
- 複数のフィールドに関連する統計を決定するために、関連データセットの前記グループ内の前記データセットをプロファイリングする手段をさらに含み、前記複数のフィールドは、前記第1のデータセットの少なくとも1つのフィールドと、前記第1のデータセットの前記フィールドと等価であると前記制約仕様により示される前記第2のデータセットの少なくとも1つのフィールドとを含む、請求項15に記載のシステム。
- 前記第2のデータセットからの前記レコードに適用される前記1つまたは複数の変換は、前記決定された統計と前記第1のデータセットからの前記レコードに前記変換を適用した結果とに従って前記第1のデータセットの前記フィールド内の値の分布と前記第2のデータセットの前記フィールド内の値の分布との間の統計的一貫性を維持することに少なくとも部分的に基づいて適用される、請求項31に記載のシステム。
- 前記1つまたは複数の変換は、データ処理構成要素間のレコードの流れを表すリンクにより接続されたデータ処理構成要素を表すノードを含む少なくとも1つのデータフローグラフにより適用され、前記変換が適用される各データセットは前記データフローグラフにレコードの入力フローを提供する、請求項15に記載のシステム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値に基づき前記所与のデータセット内のレコードの数を低減するサブセット化変換を含む、請求項15に記載のシステム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記データセットの少なくとも1つのフィールド内の値を修正する修正変換を含む、請求項15に記載のシステム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値の重複に基づき前記所与のデータセット内のレコードの数を増加する拡張変換を含む、請求項15に記載のシステム。
- 変換を複数のデータセットのそれぞれからのレコードに適用した結果のデータセットの処理順序を決定するために、データ記憶システム内に格納された少なくとも1つの制約仕様を分析する手段であって、前記制約仕様は前記結果のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、手段と、
1つまたは複数の変換を、前記決定された処理順序で、前記結果のデータセットのそれぞれからのレコードに適用する手段であって、前記変換が前記結果のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記結果のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、手段と、
前記結果のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する手段と、をさらに含む請求項15に記載のシステム。 - 前記制約仕様により規定される参照整合性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドの値の前記第1のデータセットのフィールドの値への依存性に基づく、請求項13に記載のコンピュータプログラム。
- 前記変換が前記第2のデータセットからのレコードに適用される前に、および前記変換が前記第1のデータセットからのレコードに適用された後に、前記変換は前記複数のデータセットの第3のデータセットからのレコードに適用される、請求項13に記載のコンピュータプログラム。
- 前記制約仕様により規定される統計的一貫性を維持するための少なくとも1つの制約は、前記第2のデータセットのフィールドと前記第1のデータセットのフィールドとの間の関係に基づく、請求項13に記載のコンピュータプログラム。
- 前記第1のデータセットの前記フィールドと前記第2のデータセットの前記フィールドは、結合演算のためのキーを導出するために使用可能である、請求項40に記載のコンピュータプログラム。
- 前記処理は、複数のフィールドに関連する統計を決定するために、関連データセットの前記グループ内の前記データセットをプロファイリングする工程をさらに含み、前記複数のフィールドは、前記第1のデータセットの少なくとも1つのフィールドと、前記第1のデータセットの前記フィールドと等価であると前記制約仕様により示される前記第2のデータセットの少なくとも1つのフィールドとを含む、請求項13に記載のコンピュータプログラム。
- 前記第2のデータセットからの前記レコードに適用される前記1つまたは複数の変換は、前記決定された統計と前記第1のデータセットからの前記レコードに前記変換を適用した結果とに従って前記第1のデータセットの前記フィールド内の値の分布と前記第2のデータセットの前記フィールド内の値の分布との間の統計的一貫性を維持することに少なくとも部分的に基づいて適用される、請求項42に記載のコンピュータプログラム。
- 前記1つまたは複数の変換は、データ処理構成要素間のレコードの流れを表すリンクにより接続されたデータ処理構成要素を表すノードを含む少なくとも1つのデータフローグラフにより適用され、前記変換が適用される各データセットは前記データフローグラフにレコードの入力フローを提供する、請求項13に記載のコンピュータプログラム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値に基づき前記所与のデータセット内のレコードの数を低減するサブセット化変換を含む、請求項13に記載のコンピュータプログラム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記データセットの少なくとも1つのフィールド内の値を修正する修正変換を含む、請求項13に記載のコンピュータプログラム。
- 所与のデータセットのレコードに適用される前記1つまたは複数の変換は、前記所与のデータセットの少なくとも1つのフィールド内の値の重複に基づき前記所与のデータセット内のレコードの数を増加する拡張変換を含む、請求項13に記載のコンピュータプログラム。
- 前記処理は、
変換を複数のデータセットのそれぞれからのレコードに適用した結果のデータセットの処理順序を決定するために、データ記憶媒体内に格納された少なくとも1つの制約仕様を分析する工程であって、前記制約仕様は前記結果のデータセットを含む関連データセットのグループ間の参照整合性または統計的一貫性を維持するための1つまたは複数の制約を規定する、工程と、
1つまたは複数の変換を、前記決定された処理順序で、前記結果のデータセットのそれぞれからのレコードに適用する工程であって、前記変換が前記結果のデータセットの第2のデータセットからのレコードに適用される前に、前記変換が前記結果のデータセットの第1のデータセットからのレコードに適用され、前記第2のデータセットからの前記レコードに適用される変換は、前記第1のデータセットからの前記レコードに変換を適用した結果と、前記制約仕様により規定された前記第1のデータセットと前記第2のデータセットとの間の少なくとも1つの制約と、に少なくとも部分的に基づいて適用される、工程と、
前記結果のデータセットのそれぞれからの前記レコードへの前記変換の結果を格納または出力する工程と、をさらに含む請求項13に記載のコンピュータプログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US35737610P | 2010-06-22 | 2010-06-22 | |
| US61/357,376 | 2010-06-22 | ||
| PCT/US2011/041452 WO2011163363A1 (en) | 2010-06-22 | 2011-06-22 | Processing related datasets |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2013529814A JP2013529814A (ja) | 2013-07-22 |
| JP2013529814A5 JP2013529814A5 (ja) | 2014-08-07 |
| JP5826260B2 true JP5826260B2 (ja) | 2015-12-02 |
Family
ID=44533077
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013516735A Active JP5826260B2 (ja) | 2010-06-22 | 2011-06-22 | 関連データセットの処理 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US8775447B2 (ja) |
| EP (1) | EP2585949B1 (ja) |
| JP (1) | JP5826260B2 (ja) |
| KR (2) | KR20150042872A (ja) |
| CN (2) | CN106294853B (ja) |
| AU (1) | AU2011271002B2 (ja) |
| CA (1) | CA2801079C (ja) |
| HK (1) | HK1179006A1 (ja) |
| WO (1) | WO2011163363A1 (ja) |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101889120B1 (ko) | 2011-01-28 | 2018-08-16 | 아브 이니티오 테크놀로지 엘엘시 | 데이터 패턴 정보 생성 |
| US20130006961A1 (en) * | 2011-06-29 | 2013-01-03 | Microsoft Corporation | Data driven natural interface for automated relational queries |
| KR102129643B1 (ko) | 2012-10-22 | 2020-07-02 | 아브 이니티오 테크놀로지 엘엘시 | 소스 추적으로 데이터 프로파일링 |
| US9087138B2 (en) * | 2013-01-15 | 2015-07-21 | Xiaofan Zhou | Method for representing and storing hierarchical data in a columnar format |
| US9892026B2 (en) | 2013-02-01 | 2018-02-13 | Ab Initio Technology Llc | Data records selection |
| US9195470B2 (en) | 2013-07-22 | 2015-11-24 | Globalfoundries Inc. | Dynamic data dimensioning by partial reconfiguration of single or multiple field-programmable gate arrays using bootstraps |
| WO2015012867A1 (en) | 2013-07-26 | 2015-01-29 | Hewlett Packard Development Company, L.P. | Data view based on context |
| US9535936B2 (en) * | 2013-09-05 | 2017-01-03 | The Boeing Company | Correlation of maximum configuration data sets |
| EP3055786A4 (en) * | 2013-10-09 | 2017-05-17 | Google, Inc. | Automatic definition of entity collections |
| US11487732B2 (en) * | 2014-01-16 | 2022-11-01 | Ab Initio Technology Llc | Database key identification |
| JP6427592B2 (ja) | 2014-03-07 | 2018-11-21 | アビニシオ テクノロジー エルエルシー | データ型に関連するデータプロファイリング操作の管理 |
| US9317558B2 (en) * | 2014-05-13 | 2016-04-19 | Sap Se | Intelligent unmasking in an in-memory database |
| US9830343B2 (en) | 2014-09-02 | 2017-11-28 | Ab Initio Technology Llc | Compiling graph-based program specifications |
| EP3189418B1 (en) | 2014-09-02 | 2022-02-23 | AB Initio Technology LLC | Visually specifying subsets of components in graph-based programs through user interactions |
| CA2960417C (en) | 2014-09-08 | 2023-12-19 | Ab Initio Technology Llc | Data-driven testing framework |
| WO2016054491A1 (en) | 2014-10-03 | 2016-04-07 | Infinity Pharmaceuticals, Inc. | Heterocyclic compounds and uses thereof |
| US10176234B2 (en) * | 2014-11-05 | 2019-01-08 | Ab Initio Technology Llc | Impact analysis |
| US10360520B2 (en) * | 2015-01-06 | 2019-07-23 | International Business Machines Corporation | Operational data rationalization |
| KR102281454B1 (ko) * | 2015-05-27 | 2021-07-23 | 삼성에스디에스 주식회사 | 리버스 데이터 모델링 관계선 설정 방법 및 그 장치 |
| US10762074B2 (en) * | 2015-10-20 | 2020-09-01 | Sanjay JAYARAM | System for managing data |
| US11989096B2 (en) * | 2015-12-21 | 2024-05-21 | Ab Initio Technology Llc | Search and retrieval data processing system for computing near real-time data aggregations |
| US10169364B2 (en) * | 2016-01-13 | 2019-01-01 | International Business Machines Corporation | Gauging accuracy of sampling-based distinct element estimation |
| US20170242876A1 (en) * | 2016-02-22 | 2017-08-24 | Ca, Inc. | Maintaining Database Referential Integrity Using Different Primary and Foreign Key Values |
| CN107330796B (zh) * | 2016-04-29 | 2021-01-29 | 泰康保险集团股份有限公司 | 组件化生成表单的数据处理方法及系统 |
| US11243938B2 (en) * | 2016-05-31 | 2022-02-08 | Micro Focus Llc | Identifying data constraints in applications and databases |
| WO2017214269A1 (en) | 2016-06-08 | 2017-12-14 | Infinity Pharmaceuticals, Inc. | Heterocyclic compounds and uses thereof |
| US10311057B2 (en) | 2016-08-08 | 2019-06-04 | International Business Machines Corporation | Attribute value information for a data extent |
| US10360240B2 (en) * | 2016-08-08 | 2019-07-23 | International Business Machines Corporation | Providing multidimensional attribute value information |
| US10657120B2 (en) * | 2016-10-03 | 2020-05-19 | Bank Of America Corporation | Cross-platform digital data movement control utility and method of use thereof |
| US10593080B2 (en) * | 2017-04-27 | 2020-03-17 | Daegu Gyeongbuk Institute Of Science And Technology | Graph generating method and apparatus |
| US10176217B1 (en) | 2017-07-06 | 2019-01-08 | Palantir Technologies, Inc. | Dynamically performing data processing in a data pipeline system |
| US11055074B2 (en) * | 2017-11-13 | 2021-07-06 | Ab Initio Technology Llc | Key-based logging for processing of structured data items with executable logic |
| US11068540B2 (en) | 2018-01-25 | 2021-07-20 | Ab Initio Technology Llc | Techniques for integrating validation results in data profiling and related systems and methods |
| US10838915B2 (en) * | 2018-09-06 | 2020-11-17 | International Business Machines Corporation | Data-centric approach to analysis |
| EP4285237A1 (en) * | 2021-01-31 | 2023-12-06 | Ab Initio Technology LLC | Dataset multiplexer for data processing system |
| US20230403218A1 (en) * | 2022-06-08 | 2023-12-14 | Vmware, Inc. | State consistency monitoring for plane-separation architectures |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05204727A (ja) * | 1992-01-27 | 1993-08-13 | Hitachi Ltd | デ−タベ−ス管理方法およびそのシステム |
| US5966072A (en) | 1996-07-02 | 1999-10-12 | Ab Initio Software Corporation | Executing computations expressed as graphs |
| US20030055828A1 (en) * | 2001-03-29 | 2003-03-20 | Koch Kevin S. | Methods for synchronizing on-line and off-line transcript projects |
| CA2409079A1 (en) * | 2002-10-21 | 2004-04-21 | Ibm Canada Limited-Ibm Canada Limitee | Creating multiple and cascading business interpretations from raw application data using transformation layering |
| WO2004063943A2 (en) * | 2003-01-15 | 2004-07-29 | Luke Leonard Martin Porter | Time in databases and applications of databases |
| US20050004918A1 (en) * | 2003-07-02 | 2005-01-06 | International Business Machines Corporation | Populating a database using inferred dependencies |
| US7849075B2 (en) | 2003-09-15 | 2010-12-07 | Ab Initio Technology Llc | Joint field profiling |
| US7181472B2 (en) * | 2003-10-23 | 2007-02-20 | Microsoft Corporation | Method and system for synchronizing identity information |
| JP4343752B2 (ja) * | 2004-03-31 | 2009-10-14 | キヤノン株式会社 | 色処理装置およびその方法 |
| GB2414337B (en) * | 2004-05-19 | 2008-10-29 | Macrovision Europ Ltd | The copy protection of optical discs |
| US7716630B2 (en) | 2005-06-27 | 2010-05-11 | Ab Initio Technology Llc | Managing parameters for graph-based computations |
| CN101141754B (zh) * | 2006-09-05 | 2010-05-12 | 中兴通讯股份有限公司 | 一种增值业务分析系统及其方法 |
| CN101911859B (zh) * | 2008-01-11 | 2012-12-05 | 富士机械制造株式会社 | 部件安装系统及部件安装方法 |
| JP4870700B2 (ja) * | 2008-03-11 | 2012-02-08 | 株式会社リコー | 通信システム |
| CN101452072B (zh) * | 2008-12-26 | 2011-07-27 | 东南大学 | 一种用于土地监测的电子信息化系统及其方法 |
| CN102098175B (zh) * | 2011-01-26 | 2015-07-01 | 浪潮通信信息系统有限公司 | 一种移动互联网告警关联规则获取方法 |
-
2011
- 2011-06-22 WO PCT/US2011/041452 patent/WO2011163363A1/en active Application Filing
- 2011-06-22 AU AU2011271002A patent/AU2011271002B2/en active Active
- 2011-06-22 KR KR20157008140A patent/KR20150042872A/ko not_active Application Discontinuation
- 2011-06-22 CN CN201610703060.9A patent/CN106294853B/zh active Active
- 2011-06-22 US US13/166,365 patent/US8775447B2/en active Active
- 2011-06-22 CA CA2801079A patent/CA2801079C/en active Active
- 2011-06-22 JP JP2013516735A patent/JP5826260B2/ja active Active
- 2011-06-22 EP EP11741007.6A patent/EP2585949B1/en active Active
- 2011-06-22 CN CN201180040706.5A patent/CN103080932B/zh active Active
- 2011-06-22 KR KR1020137001439A patent/KR101781416B1/ko active IP Right Grant
-
2013
- 2013-05-21 HK HK13105994.0A patent/HK1179006A1/xx unknown
Also Published As
| Publication number | Publication date |
|---|---|
| EP2585949B1 (en) | 2015-03-25 |
| KR20130095250A (ko) | 2013-08-27 |
| EP2585949A1 (en) | 2013-05-01 |
| KR101781416B1 (ko) | 2017-09-25 |
| WO2011163363A1 (en) | 2011-12-29 |
| CA2801079C (en) | 2016-05-03 |
| AU2011271002B2 (en) | 2015-08-20 |
| CA2801079A1 (en) | 2011-12-29 |
| CN103080932B (zh) | 2016-08-31 |
| HK1179006A1 (en) | 2013-09-19 |
| AU2011271002A1 (en) | 2012-12-13 |
| CN103080932A (zh) | 2013-05-01 |
| JP2013529814A (ja) | 2013-07-22 |
| KR20150042872A (ko) | 2015-04-21 |
| CN106294853A (zh) | 2017-01-04 |
| US20110313979A1 (en) | 2011-12-22 |
| CN106294853B (zh) | 2019-10-11 |
| US8775447B2 (en) | 2014-07-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5826260B2 (ja) | 関連データセットの処理 | |
| US11281596B2 (en) | Mapping attributes of keyed entities | |
| CN110168515B (zh) | 用于分析数据关系以支持查询执行的系统 | |
| JP5372850B2 (ja) | データプロファイリング | |
| KR102031402B1 (ko) | 데이터 모델에서의 엔티티 매핑 | |
| Dallachiesa et al. | NADEEF: a commodity data cleaning system | |
| US9767100B2 (en) | Visualizing relationships between data elements | |
| Vassiliadis et al. | Modeling ETL activities as graphs. | |
| Junghanns et al. | Analyzing extended property graphs with Apache Flink | |
| JP2017525039A (ja) | 系統情報の管理 | |
| AU2016219432A1 (en) | Filtering data lineage diagrams | |
| Zou et al. | Lachesis: automatic partitioning for UDF-centric analytics | |
| Kulkarni et al. | A Survey on Apriori algorithm using MapReduce |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140619 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20140619 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20150325 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20150417 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150714 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20150812 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20150903 |
|
| R155 | Notification before disposition of declining of application |
Free format text: JAPANESE INTERMEDIATE CODE: R155 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20151013 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5826260 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |