JP5800720B2 - Information processing apparatus, information processing method, and program - Google Patents
Information processing apparatus, information processing method, and program Download PDFInfo
- Publication number
- JP5800720B2 JP5800720B2 JP2012011738A JP2012011738A JP5800720B2 JP 5800720 B2 JP5800720 B2 JP 5800720B2 JP 2012011738 A JP2012011738 A JP 2012011738A JP 2012011738 A JP2012011738 A JP 2012011738A JP 5800720 B2 JP5800720 B2 JP 5800720B2
- Authority
- JP
- Japan
- Prior art keywords
- query
- search
- query statement
- search condition
- extraction process
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、データベースを効率的に検索するための技術に関する。 The present invention relates to a technique for efficiently searching a database.
データベース管理システムにおいて、データ参照(SQLのSELECT文に相当)やデータ更新(SQLのUPDATE文に相当)のために発行される問合せ文の実行時間は、一般に、問合せ文において、選択処理(SQLのWHERE句に相当)として記述された複数の検索条件(以下、「条件」又は「条件式」ともいう)の評価順序に大きく依存する。
また、記述された条件式を、他の等価な条件式に置き換えられる場合、複数ある等価な候補の中から実行コストが最も低い候補を選択することで、問合せの実行時間を短縮することができる。
In a database management system, the execution time of a query statement issued for data reference (corresponding to an SQL SELECT statement) or data update (corresponding to an SQL UPDATE statement) is generally selected in the query statement (SQL This greatly depends on the evaluation order of a plurality of search conditions (hereinafter also referred to as “conditions” or “conditional expressions”) described as “where clause”.
When the described conditional expression can be replaced with another equivalent conditional expression, the execution time of the query can be shortened by selecting the candidate with the lowest execution cost from a plurality of equivalent candidates. .
なお、実行コストとは、データベースの検索処理に必要なリソースの消費量のことであり、例えば、ディスク・アクセスの回数やCPU(Central Processing Unit)の負荷などである。
前述のように、一般的に、実行コストが低いと問い合わせの実行時間も短いという関係にある。
The execution cost is the amount of resource consumption required for the database search process, and is, for example, the number of disk accesses or the load on the CPU (Central Processing Unit).
As described above, generally, when the execution cost is low, the execution time of the query is short.
このような、問合せの実行計画最適化に関する技術は数多く研究されている。
例えば、特許文献1においては、データベース管理システムが外部関数を利用した参照を行う場合、単一、あるいは、複数の外部関数参照により記述される条件に関して、同一の結果が得られる全ての書き換えを考慮した上で、実行コスト評価に基づいた実行計画の最適化を実現する技術が開示されている。
Many techniques relating to such query execution plan optimization have been studied.
For example, in
一方で、ある条件式を形成する演算や関数の実行コストが、他の演算や関数の実行コストと比較して十分に高い場合、該条件の実行処理における並列多重度を増やし、複数レコードに対する該処理を同時実行することが、問合せ実行の高速化に有効である。
ただし、並列化によるオーバーヘッドが存在するため、実行コストが低い処理に関しては、並列化しない方が実行速度の面で有利であることが多い。
このように、高コスト処理と低コスト処理とで、並列度を使い分けられることが要求される。
On the other hand, if the execution cost of an operation or function that forms a certain conditional expression is sufficiently high compared to the execution cost of another operation or function, the parallel multiplicity in the execution processing of the condition is increased, and Simultaneous processing is effective for speeding up query execution.
However, since there is overhead due to parallelization, it is often advantageous in terms of execution speed not to parallelize a process with low execution cost.
In this way, it is required that the degree of parallelism be properly used for high-cost processing and low-cost processing.
しかしながら、従来の実行計画最適化技術の範疇では、使用するデータベース管理システムによっては、複数レコードに対する同時実行を実現するような、並列化の仕組みを組み込むことが困難であった。 However, in the category of conventional execution plan optimization techniques, depending on the database management system used, it has been difficult to incorporate a parallel mechanism that realizes simultaneous execution of a plurality of records.
例として、データベース管理システムとして、オープンソースのPostgreSQL 9.0(以下、単にPostgreSQL)を使用する場合を考える。
特許文献1の方法を単純に適用すると、問合せに用いるSQL文の選択処理に該当するWHERE句が、最適な条件に書き換えられる。
しかしながら、PostgreSQLでは、WHERE句の評価はレコード単位の逐次処理として実行されるため、PostgreSQL本体を改修しない限り、複数レコードを同時に処理する並列化の機構を単純に組み入れることはできない。
したがって、また、高コスト処理と低コスト処理とで並列度を使い分けることもできない。
As an example, consider a case where an open source PostgreSQL 9.0 (hereinafter simply “PostgreSQL”) is used as a database management system.
When the method of
However, in PostgreSQL, evaluation of the WHERE clause is executed as sequential processing in units of records. Therefore, unless the PostgreSQL body is modified, a parallel mechanism for simultaneously processing a plurality of records cannot be simply incorporated.
Therefore, the parallelism cannot be properly used for high cost processing and low cost processing.
本発明は、上記のような課題を解決することを主な目的としており、検索条件の実行コストの高低に応じて抽出処理における並列度を使い分けることを可能にし、問合せの実行時間の短縮を図ることを主な目的とする。 The main object of the present invention is to solve the above-described problems. The parallelism in the extraction process can be properly used according to the execution cost of the search condition, and the execution time of the query is shortened. The main purpose.
本発明に係る情報処理装置は、
検索の対象となる検索対象テーブルから複数の検索条件の組合せに適合するレコードを抽出するようデータベースサーバ装置に要求する問合せ文を入力する問合せ文入力部と、
前記問合せ文入力部により入力された入力問合せ文の検索条件ごとに、検索実行時の実行コストが閾値以上であるか否かを判断し、検索実行時の実行コストが閾値未満である検索条件を第1の検索条件カテゴリーに分類し、検索実行時の実行コストが閾値以上である検索条件を第2の検索条件カテゴリーに分類する検索条件分類部と、
前記第1の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを前記検索対象テーブルから抽出する第1の抽出処理と、前記第1の抽出処理により抽出されたレコードから前記第2の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを抽出する第2の抽出処理とを実行するよう前記データベースサーバ装置に要求する問合せ文を、前記入力問合せ文を変換して生成する問合せ文変換部とを有することを特徴とする。
An information processing apparatus according to the present invention includes:
A query statement input unit that inputs a query statement that requests the database server device to extract records that match a combination of a plurality of search conditions from a search target table to be searched;
For each search condition of the input query sentence input by the query sentence input unit, it is determined whether or not the execution cost at the time of executing the search is greater than or equal to a threshold, and the search condition that the execution cost at the time of executing the search is less than the threshold. A search condition classifying unit that classifies the search condition into a second search condition category that is classified into a first search condition category and that has a search execution cost equal to or higher than a threshold;
A first extraction process for extracting records that match a combination of search conditions classified into the first search condition category from the search target table, and the second extraction from the records extracted by the first extraction process. A query generated by converting the input query statement to request the database server device to execute a second extraction process for extracting a record that matches a combination of search conditions classified in the search condition category And a sentence conversion unit.
本発明によれば、検索実行時の実行コストに基づいて、問合せ文に含まれる検索条件を第1の検索条件カテゴリーと第2の検索条件カテゴリーとに分類し、第1の検索条件カテゴリーについて抽出処理と、第2の検索条件カテゴリーについての抽出処理とを区別するため、実行コストの高低に応じて並列度を使い分けることができ、問合せの実行時間の短縮を図ることができる。 According to the present invention, the search conditions included in the query statement are classified into the first search condition category and the second search condition category based on the execution cost at the time of executing the search, and the first search condition category is extracted. Since the process and the extraction process for the second search condition category are distinguished, the degree of parallelism can be properly used according to the execution cost, and the execution time of the query can be shortened.
実施の形態1.
実施の形態1〜3では、実行計画の最適化と、複数レコードを同時処理する並列化とを両立する、問合せ変換装置を説明する。
実施の形態1〜3における問合せ変換装置は、入力、出力共に問合せ文である。
問合せ文のレベルで、実行計画最適化と並列化を両立するための処理命令を組み込むことにより、既存のデータベース管理システムを改修することなく、問合せ実行時間の短縮効果を得ることが可能となる。
具体的には、問合せ文の選択処理として記述された条件のうち、低コストの条件を優先的に評価し、絞込み処理を効率化すると共に、高コストの検索条件のみをレコード単位で並列化することで、問合せの実行時間を短縮することが可能となる。
In the first to third embodiments, a query conversion apparatus that achieves both optimization of an execution plan and parallelization for simultaneously processing a plurality of records will be described.
In the query conversion devices in the first to third embodiments, both input and output are query statements.
By incorporating processing instructions for achieving both execution plan optimization and parallelism at the query statement level, it is possible to obtain the effect of shortening the query execution time without modifying the existing database management system.
Specifically, among the conditions described as the query statement selection process, low-cost conditions are preferentially evaluated, the narrowing process is made more efficient, and only high-cost search conditions are parallelized in units of records. As a result, the execution time of the query can be shortened.
以下の説明では、問合せ変換装置を、データベース管理システムに適用した例を挙げる。
なお、実施の形態1及び実施の形態2では、データベースを利用するアプリケーションを具体的に定めずに、問合せ変換装置の一般的な構成や動作について説明する。
具体的なアプリケーションへの適用については、実施の形態3で説明する。
In the following description, an example in which the query conversion device is applied to a database management system will be given.
In the first and second embodiments, the general configuration and operation of the query conversion apparatus will be described without specifically defining an application that uses a database.
Specific application to the application will be described in Embodiment 3.
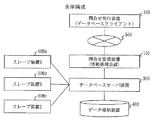
図1は、本実施の形態の問合せ変換装置を適用した、データベース管理システムの構成例を示す。
問合せ発行装置200(データベースクライアントに相当)は、ネットワーク500を通じて、問合せ変換装置100と接続される。
問合せ変換装置100は、データベースサーバ装置300と接続されており、データベースサーバ装置300はデータ格納装置400と接続されている。
また、データベースサーバ装置300には、複数のスレーブ装置600が接続されている。
スレーブ装置600は、データベースサーバ装置300の外部の計算機であってもよいし、データベースサーバ装置300がマルチプロセスに対応している場合はデータベースサーバ装置300で実行される各プロセスであってもよい。
図1の例では、データベースサーバ装置300の外部の3台の計算機をスレーブ装置600としている。
スレーブ装置600は、データベースサーバ装置300の管理下で、データ格納装置400の種々のデータを参照することができる。
FIG. 1 shows a configuration example of a database management system to which the query conversion apparatus according to this embodiment is applied.
The query issuing device 200 (corresponding to a database client) is connected to the
The
In addition, a plurality of slave devices 600 are connected to the
The slave device 600 may be a computer external to the
In the example of FIG. 1, three computers outside the
The slave device 600 can refer to various data in the
問合せ発行装置200は、ユーザの要求に応じて問合せ文を生成し、データベースサーバ装置300へ発行する。
問合せ文を記述するデータベース言語としては、例えば、標準SQLや、各データベース管理システムで独自に拡張されたSQL言語が挙げられる。
The
Examples of the database language for describing the query sentence include standard SQL and the SQL language that is uniquely extended by each database management system.
問合せ変換装置100は、問合せ発行装置200が発行した問合せ文を受け取り、問合せ文が選択処理(SQLのWHERE句に相当)を含む場合に、問合せ文を目的の形に変換し、データベースサーバ装置300へ発行する。
問合せ文が選択処理を含まない場合には、問合せ文を変換せずに、データベースサーバ装置300へ発行する。
問合せ変換装置100は、情報処理装置の例に相当する。
The
If the query statement does not include a selection process, the query statement is issued to the
The
データベースサーバ装置300は、問合せ変換装置100から受け取った問合せ文の解析を行い、問合せ(データ格納装置400内のデータの検索)を実行する。
問合せの実行時には、必要であれば、データ格納装置400に格納された種々のデータを参照、または、変更する。
The
When executing the query, if necessary, various data stored in the
図2は、データ格納装置400の詳細を示したものである。
データ格納装置400には、少なくともデータ410、カタログ情報420、演算コスト情報430を含む種々のデータが格納されている。
データ410は、データベース管理システムにおいて、管理情報を含まないデータそのものを指す。
カタログ情報420は、データベースカタログ情報を含むデータが格納される。
演算コスト情報430は、データベース管理システムで定義された演算や関数の実行コスト情報を含むデータが格納されている。
演算コスト情報430を参照することで、問合せ変換装置100、および、データベースサーバ装置300は、問合せに記述される各演算の実行コストを見積もることができる。
FIG. 2 shows details of the
The
The
The calculation cost
By referring to the operation cost
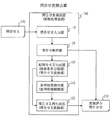
次に、問合せ変換装置100の詳細な構成を、図3を用いて説明する。
問合せ変換装置100は、問合せ文入力部110、問合せ解析部120、副問合せ文生成部130、並列処理指示部140、問合せ文再生成部150から構成される。
Next, a detailed configuration of the
The
問合せ文入力部110は、問合せ発行装置200がネットワーク500を介して発行した問合せ文101を受け取り、問合せ変換装置100へ入力する。
問合せ文101は、データ格納装置400のデータ410内の検索の対象となるテーブル(検索対象テーブル)から、複数の検索条件の組合せに適合するレコードを抽出するよう要求するメッセージである。
The query
The
問合せ解析部120は、入力された問合せ文101の解析を行い、問合せ変換に必要な情報を取得する。
問合せ解析部120は、必要に応じて、カタログ情報420や演算コスト情報430などの管理情報を参照する。
問合せ文101が選択処理を含まない場合は、問合せ文101を変換せずに、変換済み問合せ文102として出力する。
The
The
When the
副問合せ文生成部130は、問合せ文101に選択処理が含まれる場合に、問合せ解析部120による解析結果を元に、選択処理の中から、高コスト処理を除いた、低コスト処理のみで形成される副問合せ文(第1の問合せ文の例)を生成する。
副問合せ文生成部130は、必要に応じて、カタログ情報420や演算コスト情報430などの管理情報を参照する。
When the
The
副問合せ文生成部130は、より具体的には、問合せ文101の検索条件ごとに、検索実行時の実行コストが閾値以上であるか否かを判断し、検索実行時の実行コストが閾値未満である検索条件を低コストの検索条件(第1の検索条件カテゴリーの例)に分類し、検索実行時の実行コストが閾値以上である検索条件を高コストの検索条件(第2の検索条件カテゴリーの例)に分類する。
なお、以下では、低コストの検索条件を低コスト処理、高コストの検索条件を高コスト処理という。
また、副問合せ文生成部130は、低コスト処理に分類された検索条件の組合せに適合するレコードを検索対象テーブルから抽出する第1の抽出処理の実行を要求する副問合せ文を、問合せ文101を変換して生成する。
副問合せ文生成部130は、検索条件分類部の例に相当する。
また、副問合せ文生成部130は、後述の問合せ文再生成部150とともに、問合せ文変換部の例に相当する。
More specifically, the
In the following, low-cost search conditions are referred to as low-cost processing, and high-cost search conditions are referred to as high-cost processing.
In addition, the
The
The sub-query
並列処理指示部140は、副問合せ文生成部130において除かれた、0個以上の各高コスト処理に対して、処理を並列化することを指示する命令を出力する。
並列処理指示部140は、より具体的には、データベースサーバ装置300に、第1の抽出処理により抽出された複数のレコードを、それぞれが1つ以上のレコードで構成される複数のブロックに分割し、後述の第2の抽出処理を複数のブロックに対して並列に実行するよう指示する。
並列処理指示部140は、並列処理制御部の例に相当する。
The parallel
More specifically, the parallel
The parallel
問合せ文再生成部150は、副問合せ文生成部130で生成された副問合せ文と、副問合せ文生成部130において除かれた、0個以上の高コスト処理とを入力に持ち、問合せ文101における選択処理の結果を入力とするような後続の処理を実行するのに十分なデータの集合を出力するような関数(選択処理実行関数)の出力を、前記後続の処理への入力とするような問合せ文(第2の問合せ文の例)を再生成する。
つまり、問合せ文再生成部150は、副問合せ文生成部130で生成された副問合せ文を含み、副問合せ文の実行(第1の抽出処理の実行)により抽出されたレコードから高コスト処理に分類された検索条件の組合せに適合するレコードを抽出する第2の抽出処理を実行するよう要求する問合せ文を、問合せ文101を変換して生成する。
そして、問合せ文再生成部150は、再生成した問合せ文を、変換済み問合せ文102として出力する。
なお、変換済み問合せ文102の生成の具体的な方法は、問合せ変換装置100の動作説明において説明する。
問合せ文再生成部150は、前述の副問合せ文生成部130とともに、問合せ文変換部の例に相当する。
The
That is, the query
Then, the query
A specific method for generating the converted
The query
次に、問合せ変換装置100の動作について図4を用いて説明する。
Next, the operation of the
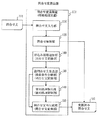
問合せ変換装置100に問合せ文101が到着すると、問合せ文入力部110は、問合せ文101を受け取る(S110)。
問合せ解析部120は、問合せ文101を解析する(S120)。
解析の結果、問合せ文101が、選択処理(SQLのWHERE句に相当)を含む場合は(S130でYES)、副問合せ文生成部130が、選択処理の中から、高コスト処理を除いた、低コスト処理のみで形成される副問合せ文を生成する(S140)。
問合せ文101が、選択処理を含まない場合は(S130でNO)、問合せ文101を変換せずに、問合せ解析部120が、変換済み問合せ文102として出力する(S180)。
When the
The
As a result of the analysis, when the
If the
S140において除かれた、0個以上の高コスト処理に対して、並列化するよう予めシステムで設定されている場合は(S150でYES)、並列処理指示部140が、処理S140において除かれた、0個以上の各高コスト処理に対して、処理を並列化することを指示する命令をデータベースサーバ装置300に出力する(S160)。
高コスト処理に対する並列化が設定されていない場合は、処理S160を飛ばし、処理S170に進む。
If the system is set in advance to perform parallel processing for zero or more high-cost processes removed in S140 (YES in S150), the parallel
If parallelization for high-cost processing is not set, processing S160 is skipped and processing proceeds to processing S170.
問合せ文再生成部150は、処理S140で生成された副問合せ文、0個以上の高コスト処理、および、処理S160で出力された並列化処理命令を入力として、問合せ文を再生成し(S170)、再生成した問合せ文を変換済み問合せ文102として出力する(S180)。
The
処理S120で適用される問合せ文の解析技術については、公知の技術、あるいはそれらの自明な拡張で実現可能である。
例えば、オープンソースのデータベース管理システムPostgreSQLでは、SQL解析処理を含む全ソースコードが公開されている。
The query sentence analysis technique applied in step S120 can be realized by a known technique or a trivial extension thereof.
For example, in the open source database management system PostgreSQL, all source codes including SQL analysis processing are disclosed.
処理S130では、SQLの場合、選択処理を含む問合せ文として、少なくとも、WHERE句を含むSELECT文、および、UPDATE文が含まれる。 In the process S130, in the case of SQL, at least a SELECT statement including a WHERE clause and an UPDATE statement are included as a query statement including a selection process.
処理S140の動作を、具体例を交えて説明する。次のSQL文を考える(数1)。 The operation of process S140 will be described with a specific example. Consider the following SQL statement (Equation 1).
![]()
![]()
ここで、op_i(i=1,2,…,N)は適当な二項演算子である。
重要なのは、n個の条件式が論理積で結合されている点である。
更に、各op_iには、実行コストが設定されているものとする。
実行コストは演算コスト情報430に格納されており、問合せ解析部120、あるいは、副問合せ文生成部130において参照される。
ここでは、簡単のため、演算op_iには実行コスト(100*i)が設定されているものとする。すなわち、iが大きいほど、演算op_iの実行コストが大きく、実行時間がかかるという状況である。
Here, op_i (i = 1, 2,..., N) is an appropriate binary operator.
What is important is that n conditional expressions are connected by AND.
Furthermore, it is assumed that an execution cost is set for each op_i.
The execution cost is stored in the
Here, for simplicity, it is assumed that the execution cost (100 * i) is set in the operation op_i. That is, the larger i is, the higher the execution cost of the operation op_i is, and the longer the execution time is.
このとき、システム管理者等によって、予め閾値θが設定されているとする。
この閾値θは、副問合せ文生成部130において、高コスト処理と低コスト処理とを分ける基準となる。
実行コストが閾値θ未満となる演算がop_i(1=1,2,…,K)であったとすると、副問合せ文生成部130は、低コスト処理のみで形成される副問合せ文SubQryを次にように生成する(数2)。
At this time, it is assumed that the threshold value θ is set in advance by a system administrator or the like.
This threshold value θ is a criterion for separating high cost processing and low cost processing in the
Assuming that the operation whose execution cost is less than the threshold value θ is op_i (1 = 1, 2,..., K), the

副問合せ文を生成する目的は、選択処理の絞込み効率向上を目的としているため、副問合せ文を形成する条件群は、元の問合せ文101において、論理積により切り離されていることが要件となる。
また、副問合せ文生成の際に除かれた高コスト処理、および、カラムcの射影処理を後に実行可能とするために、高コスト処理で使用するカラム群、および、カラムcを、副問合せ文内で選択されるカラムに全て含める必要がある。
Since the purpose of generating the subquery is to improve the efficiency of selection processing, it is a requirement that the group of conditions forming the subquery is separated by logical product in the
Further, in order to make it possible to execute the high-cost processing and the projection processing of the column c that are removed at the time of generating the sub-query statement later, the column group and the column c used in the high-cost processing are changed to the sub-query statement. Must be included in all selected columns.
数1による例は最も基本的な場合であるが、ここから様々な応用を考えることができる。
例えば、一般の論理式は、論理積標準形に代表されるように、論理積で結合された形式で表すことが可能であるため、次のような一般形を想定することができる(数3)。
The example according to
For example, since a general logical expression can be expressed in a form combined with logical product, as represented by the logical product standard form, the following general form can be assumed (Equation 3) ).
![]()
![]()
ここで、cond_i(i=1,2,…,N)は適当な論理式である。
数3では、各cond_iを形成する演算子が単一であるとは限らないため、各論理式の実行コストを、各cond_iを形成する演算子の中で最も実行コストが大きいもの、として定義することで、数1の場合と同様の副問合せ文生成手法が適用できる。
Here, cond_i (i = 1, 2,..., N) is an appropriate logical expression.
In Equation 3, since the operator forming each cond_i is not necessarily a single operator, the execution cost of each logical expression is defined as the one having the highest execution cost among the operators forming each cond_i. Thus, the same subquery generation method as in the case of
数3の特別な場合として、高コスト処理を形成する論理式と、低コスト処理を形成する論理式とが、論理積で結合されている場合がある(数4)。 As a special case of Expression 3, there is a case where a logical expression that forms a high-cost process and a logical expression that forms a low-cost process are combined by a logical product (Expression 4).
![]()
![]()
数4において、higher_cost_partとlower_cost_partは適当な論理式であり、lower_cost_partが実行コストの小さい処理に対応する。数4に対応する副問合せ文SubQryは数5のようになる。 In Equation 4, high_cost_part and lower_cost_part are appropriate logical expressions, and lower_cost_part corresponds to processing with a low execution cost. The subquery sentence SubQry corresponding to Equation 4 is as shown in Equation 5.
![]()
![]()
ここで、higher_select_listは、高コスト処理higher_cost_partを実行するために必要なカラム群を指す。 Here, high_select_list refers to a column group necessary for executing the high cost processing high_cost_part.
なお、数1、数3、数5はいずれもSELECT文の例であるが、UPDATE文の場合も同様に考えることができる。
ここでは、数1に対応するUPDATE文の例を挙げる(数6)。
Note that Equations (1), (3), and (5) are all examples of the SELECT statement, but the case of the UPDATE statement can be considered similarly.
Here, an example of the UPDATE statement corresponding to
数6に対応する副問合せ文SubQryは数7のようになる。 The subquery sentence SubQry corresponding to Expression 6 is as shown in Expression 7.
ここで、PRIMARYKEYはテーブル内の主キーを指す。
UPDATE文の場合に、副問合せ文内で主キーを選択する理由については、後で説明する。
副問合せ文生成の目的は、選択処理の絞込み効率向上であるため、元の問合せ文がUPDATE文であっても、副問合せ文はSELECT文となることに注意されたい。
Here, PRIMARYKEY indicates a primary key in the table.
The reason for selecting the primary key in the subquery in the case of the UPDATE statement will be described later.
Note that the purpose of subquery generation is to improve the narrowing efficiency of the selection process, so that even if the original query is an UPDATE statement, the subquery is a SELECT statement.
次に、処理S170の動作を、具体例を交えて説明する。
処理S170において、問合せ文再生成部150は、処理S140で生成された副問合せ文と、処理S140において除かれた、0個以上の高コスト処理を形成する論理式とを入力に持ち、問合せ文101における選択処理の結果を入力とするような後続の処理を実行するのに十分なデータの集合を出力するような関数(選択処理実行関数)の出力を、前記後続の処理への入力とするような問合せ文を再生成する。
Next, operation | movement of process S170 is demonstrated with a specific example.
In process S170, the
ここで、「選択処理の結果を入力とするような後続の処理」の、具体例を挙げる。数1で表されるSELECT文の場合、この後続の処理は、カラムcへの射影処理を指す。
また、数6で表されるUPDATE文の場合、後続の処理は、「c=c*1.1」で表されるカラムcの更新処理を指す。
Here, a specific example of “subsequent processing using the result of the selection processing as input” will be described. In the case of the SELECT statement expressed by
Further, in the case of the UPDATE statement expressed by Equation 6, the subsequent processing indicates update processing of the column c expressed by “c = c * 1.1”.
図5にSELECT文再生成の具体例を示す。
図5の例は、数1を用いた例であり、コスト情報の設定等も数1の例と同様である。
変換後の問合せ文において、FROM句に表れるFuncが上述の選択処理実行関数に相当する。
関数Funcの引数は、処理S140で生成した副問合せ文SubQry、および、処理S140で除かれた高コスト処理群である。
関数Funcの戻り値は、後の射影処理で必要となるカラムcを含むような、選択結果のデータ集合である。
FIG. 5 shows a specific example of SELECT statement regeneration.
The example of FIG. 5 is an
In the converted query statement, Func appearing in the FROM phrase corresponds to the above-described selection process execution function.
The arguments of the function Func are the sub-query sentence SubQry generated in the process S140 and the high cost process group removed in the process S140.
The return value of the function Func is a data set of selection results including the column c necessary for the subsequent projection processing.
図6にSELECT文再生成の別の具体例を示す。
図6の例では、処理S160で出力された並列処理命令を選択処理実行関数Funcに引数として与える例である。
高コスト処理「a_N op_n b_N」の次の引数「0」が、並列処理対象か否かのフラグとなっている。
また、変形例として、並列多重度を自然数として渡す方法が挙げられる。
また、図6のように、並列処理命令を明示的に引数とするのではなく、与えられた高コスト処理は、暗黙的に全て並列化対象として扱う、というようにシステム管理者等が設定するという方法もある。
FIG. 6 shows another specific example of SELECT statement regeneration.
The example of FIG. 6 is an example in which the parallel processing instruction output in step S160 is given as an argument to the selection processing execution function Func.
The next argument “0” of the high-cost process “a_N op_n b_N” is a flag indicating whether or not it is a target for parallel processing.
Further, as a modification, a method of passing the parallel multiplicity as a natural number can be mentioned.
In addition, as shown in FIG. 6, the system administrator or the like sets that a given high-cost process is implicitly treated as a parallel object rather than explicitly using a parallel processing instruction as an argument. There is also a method.
図7にUPDATE文再生成の具体例を示す。図の例は、数6を用いた例であり、コスト情報の設定等は数1の例と同様である。
ここで、PRIMARYKEYはテーブル内の主キーを表す。
基本的な考え方は、SELECT文のときと同様であるが、UPDATE文においては、選択処理を実行するテーブルと更新対象のテーブルが同一のテーブルであるという規則があるため、変換に工夫が必要となる。
そこで、関数Funcによる選択結果として生成される一時テーブル(図7のsub_t)と、更新対象のテーブル(図7のt)とを、主キーによって結合することで、この問題を解決している。
このため、本方法を用いる限り、更新対象のテーブルには主キー、あるいは、それに準じるカラムが設定されていることが要件となる。
FIG. 7 shows a specific example of UPDATE statement regeneration. The example shown in the figure is an example using Equation 6, and the setting of cost information and the like are the same as those in
Here, PRIMARYKEY represents a primary key in the table.
The basic idea is the same as in the SELECT statement. However, in the UPDATE statement, there is a rule that the table for executing the selection process and the table to be updated are the same table. Become.
Therefore, this problem is solved by joining the temporary table (sub_t in FIG. 7) generated as a selection result by the function Func and the table to be updated (t in FIG. 7) with the primary key.
Therefore, as long as this method is used, it is a requirement that the table to be updated has a primary key or a column corresponding to it.
選択処理実行関数Funcは、適当なプログラミング言語で作成されたユーザ定義の関数として実現することができる。
多くのデータベース管理システムでは、ユーザが独自に定義した関数、演算をデータベース言語に組み入れて利用することが可能となっている。
例えば、オープンソースのデータベース管理システムPostgreSQLや、商用データベースであるOracle Database 11gでは、演算による選択結果のデータ集合を、一時テーブルとして出力することが可能とする機能を、ユーザ定義のC言語関数においてサポートしており、本実施の形態を適用することができる。
The selection process execution function Func can be realized as a user-defined function created in an appropriate programming language.
In many database management systems, functions and operations defined by users can be incorporated into a database language and used.
For example, in the open source database management system PostgreSQL and the commercial database Oracle Database 11g, a function that enables a data set of selection results obtained by calculation to be output as a temporary table is supported by a user-defined C language function. Therefore, the present embodiment can be applied.
選択処理実行関数の動作について、図8を用いて説明する。
選択処理実行関数はデータベースサーバ装置300によって、問合せ実行時に呼び出される。
選択処理実行関数が起動されると、選択処理実行関数は、呼び出し元のデータベースサーバ装置300を呼び出し、入力された副問合せ文を実行させ、結果を受け取る(S210)。
入力された高コスト処理のうち、未処理のものがあれば(S220)、未処理の高コスト処理を1つ選択し実行し、結果を受け取る(S230)。
この際、処理S160により並列処理命令が併せて入力されている場合は、並列多重度を増やして(並列処理命令に適合する並列多重度にして)、処理を実行する。
未処理の高コスト処理がなくなれば(S220)、結果を出力し、処理を完了する(S240)。
The operation of the selection process execution function will be described with reference to FIG.
The selection process execution function is called by the
When the selection process execution function is activated, the selection process execution function calls the caller
If there is an unprocessed high-cost process that has been input (S220), one unprocessed high-cost process is selected and executed, and the result is received (S230).
At this time, if a parallel processing instruction is also input in step S160, the parallel multiplicity is increased (the parallel multiplicity is adapted to the parallel processing instruction), and the process is executed.
If there is no unprocessed high-cost process (S220), the result is output and the process is completed (S240).
処理S210では、例えばPostgreSQLの場合、SPI(Server Programming Interface)というインタフェースを利用して、C言語のユーザ定義関数からPostgreSQLサーバを呼び出し、データ集合の受け渡しが可能である。
商用データベースであるOracle(登録商標) Database 11gにおいても、OCI(Oracle(登録商標) Call Interface)を利用して、同様の操作が可能である。
In the process S210, for example, in the case of PostgreSQL, it is possible to call a PostgreSQL server from a C-defined user-defined function using an interface called SPI (Server Programming Interface), and to exchange a data set.
In Oracle (registered trademark) Database 11g which is a commercial database, the same operation can be performed using OCI (Oracle (registered trademark) Call Interface).
処理S210において、未処理の高コスト処理を1つ選択する方法として、実行コストの小さい順に選択するという方法がある。
こうすることで、絞込み効率を向上させることができる。
As a method of selecting one unprocessed high-cost process in the process S210, there is a method of selecting in ascending order of execution cost.
By doing so, the narrowing efficiency can be improved.
ここで、変換済み問合せ文102を入力したデータベースサーバ装置300で行われる動作の具体例を図15及び図16を参照して説明する。
図15は、データベースサーバ装置300が検索対象とする検索対象テーブルの概略を示している。
図16は、データベースサーバ装置300が副問い合わせ文SubQryを実行して抽出したレコードに対する、スレーブ装置600の並列処理を説明している。
Here, a specific example of an operation performed by the
FIG. 15 shows an outline of a search target table to be searched by the
FIG. 16 illustrates parallel processing of the slave device 600 with respect to a record extracted by the
図15のa_1、a_2、a_K、a_(K+1)、a_(K+2)、a_Nはカラム名を示しており(つまり、図15の例では、K=3、N=6)、図5の条件式(a_1 op_1 b_1)等に対応する。
また、図15のcもカラム名を示している。
c_1、c_2、c_3等はカラムcの値である。
c_1、c_2、c_3等は各レコードを識別できる値である。
更に、図15の「X」は、検索条件に合致していることを示している。
例えば、図15のc_1レコードでは、カラムa_1に「X」が示されているが、これはc_1レコードは検索条件(a_1 op_1 b_1)に合致していることを意味する。
図16においても、これらは同じである。
15, a_1, a_2, a_K, a_ (K + 1), a_ (K + 2), and a_N indicate column names (that is, K = 3, N = 6 in the example of FIG. 15), and the conditional expression of FIG. (A_1 op_1 b_1) and the like.
Also, c in FIG. 15 indicates the column name.
c_1, c_2, c_3, etc. are the values of the column c.
c_1, c_2, c_3, etc. are values that can identify each record.
Furthermore, “X” in FIG. 15 indicates that the search condition is met.
For example, in the c_1 record of FIG. 15, “X” is shown in the column a_1, which means that the c_1 record matches the search condition (a_1 op_1 b_1).
These are the same in FIG.
データベースサーバ装置300では、図5の副問い合わせ文SubQryを実行する。
図15の例では、データベースサーバ装置300は、低コストの検索条件(a_1 op_1 b_1)、(a_2 op_2 b_2)、(a_K op_K b_K)の組合せに適合するレコードのレコード名cと、そのレコードにおけるカラムa_(K+1)、a_(K+2、a_Nの値を抽出する(第1の抽出処理)。
副問い合わせ文SubQryの実行の結果、図15の例では、矢印が示されているレコードが抽出される。
In the
In the example of FIG. 15, the
As a result of the execution of the subquery sentence SubQry, a record indicated by an arrow is extracted in the example of FIG.
そして、並列処理指示部140により並列化が指示されている場合(図4のS150でYESの場合)に、データベースサーバ装置300は、高コストの検索条件についての抽出処理を複数のスレーブ装置600に並列に実行させる。
例えば、データベースサーバ装置300は、副問い合わせ文SubQryの実行により得られたレコード群を、所定の単位で分割し、分割により得られたブロックを複数のスレーブ装置600に出力し、複数のスレーブ装置600にブロックごとの抽出処理を並列に実行させる。
図16の例では、データベースサーバ装置300は、副問い合わせ文SubQryの実行により得られたレコード群を2レコード単位で分割し、3つのスレーブ装置600の各々に2レコードごとのブロックを出力する。
そして、各スレーブ装置600では、高コストの検索条件(a_(K+1) op_(K+1) b_(K+1))、(a_(K+2) op_(K+2) b_(K+2))、(a_N op_N b_N)の組合せに適合するレコードのレコード名cを抽出し(第2の抽出処理)、データベースサーバ装置300に出力する。
When parallel processing is instructed by the parallel processing instructing unit 140 (YES in S150 of FIG. 4), the
For example, the
In the example of FIG. 16, the
In each slave device 600, a combination of high-cost search conditions (a_ (K + 1) op_ (K + 1) b_ (K + 1)), (a_ (K + 2) op_ (K + 2) b_ (K + 2)), (a_N op_N b_N) Is extracted (second extraction process) and output to the
なお、図16では、高コストの並列処理を全てスレーブ装置600で実行することとしているが、並列処理の一部をデータベースサーバ装置300が実行するようにしてもよい。
また、データベースサーバ装置300がマルチプロセスに対応している場合には、データベースサーバ装置300で全ての並列処理を実行するようにしてもよい。
In FIG. 16, all the high-cost parallel processing is executed by the slave device 600, but the
Further, when the
また、図15の例では、説明の簡明のために、カラム数が少ないテーブルを例にして説明を行ったが、どのような大きさのテーブルであっても、同様の手順により問合せ実行時間の短縮を図ることができる。 Further, in the example of FIG. 15, for the sake of simplicity of explanation, the description has been given by taking a table with a small number of columns as an example. However, the query execution time of a table of any size can be determined by the same procedure. Shortening can be achieved.
以上で述べたように、実施の形態1においては、問合せ変換装置100に入力された問合せ文101に対して、適切な問合せ文変換を施すことで、問合せの実行結果を変えることなく、実行計画の最適化と、複数レコードを同時処理する並列化とを両立させることが可能となる。
問合せ文のレベルで、実行計画最適化と並列化を両立するための処理命令を組み込むことにより、既存のデータベース管理システムを改修することなく、問合せ実行時間の短縮効果を得ることが可能となる。
このように、本実施の形態では、検索実行時の実行コストに基づいて、問合せ文に含まれる検索条件を低コストと高コストに分類し、低コストの検索条件について抽出処理と、高コストの検索条件についての抽出処理とを区別するため、実行コストの高低に応じて並列度を使い分けることができ、問合せの実行時間の短縮を図ることができる。
As described above, in the first embodiment, by executing appropriate query statement conversion on the
By incorporating processing instructions for achieving both execution plan optimization and parallelism at the query statement level, it is possible to obtain the effect of shortening the query execution time without modifying the existing database management system.
As described above, in this embodiment, based on the execution cost at the time of search execution, the search conditions included in the query statement are classified into low cost and high cost. In order to distinguish from the extraction process for the search condition, the degree of parallelism can be properly used according to the execution cost, and the execution time of the query can be shortened.
以上、本実施の形態では、
データベース管理システムにおいて、選択処理を含む問合せ文を変換する問合せ変換装置であって、
1)問合せ文を入力する問合せ文入力部と、
2)入力された問合せ文の解析を行う問合せ解析部と、
3)問合せ解析結果と、演算の実行コスト情報とを元に、前記問合せ文の選択処理の中から、高コスト処理を除いた、低コスト処理のみで形成される副問合せ文を生成する、副問合せ文生成部と、
4)少なくとも、前記副問合せ文と、前記副問合せ文生成部において除かれた、0個以上の高コスト処理とを入力に持ち、前記問合せ文において、前記選択処理の結果を入力とするような後続の処理を実行するのに十分なデータの集合を出力するような関数(選択処理実行関数)の出力を、前記後続の処理への入力とするような問合せ文を再生成する、問合せ文再生成部と
を有する問合せ変換装置を説明した。
As described above, in the present embodiment,
In a database management system, a query conversion device for converting a query statement including a selection process,
1) a query statement input unit for inputting a query statement;
2) a query analysis unit for analyzing the input query statement;
3) Based on the query analysis result and the execution cost information of the operation, a sub-query sentence formed only by the low-cost process excluding the high-cost process is generated from the query sentence selection process. A query statement generation unit;
4) At least the sub-query sentence and zero or more high-cost processes removed by the sub-query sentence generation unit are input, and the result of the selection process is input to the query sentence. Query statement regeneration that regenerates a query statement that uses the output of a function (selection process execution function) that outputs a set of data sufficient to execute subsequent processing as input to the subsequent processing. A query conversion apparatus having a component has been described.
また、本実施の形態では、
前記問合せ変換装置は、
前記副問合せ文生成部において除かれた、0個以上の各高コスト処理に対して、処理を並列化することを指示する命令を、前記選択処理実行関数へ入力する並列処理指示部を有することを説明した。
In the present embodiment,
The inquiry conversion device includes:
A parallel processing instruction unit for inputting, to the selection processing execution function, an instruction for instructing parallel processing for each of zero or more high-cost processes excluded in the sub-query generation unit; Explained.
また、本実施の形態では、
前記問合せ文はデータ参照文であって、前記問合せ変換装置は、
前記選択処理の結果を入力とするような後続の処理は、射影処理である
ことを説明した。
In the present embodiment,
The query statement is a data reference statement, and the query conversion device
It has been described that the subsequent process that uses the result of the selection process as an input is a projection process.
また、本実施の形態では、
前記問合せ文はデータ更新文であって、前記問合せ変換装置は、
前記選択処理の結果を入力とするような後続の処理は、更新処理である
ことを説明した。
In the present embodiment,
The query statement is a data update statement, and the query conversion device
It has been described that the subsequent process using the result of the selection process as an input is an update process.
また、本実施の形態では、
データベース管理システムにおいて、選択処理を含む問合せ文を変換する問合せ変換方法であって、
1)問合せ文を入力する問合せ文入方法と、
2)入力された問合せ文の解析を行う問合せ解析方法と、
3)問合せ解析結果と、演算の実行コスト情報とを元に、前記問合せ文の選択処理の中から、高コスト処理を除いた、低コスト処理のみで形成される副問合せ文を生成する、副問合せ文生成方法と、
4)少なくとも、前記副問合せ文と、前記副問合せ文生成方法において除かれた、0個以上の高コスト処理とを入力に持ち、前記問合せ文において、前記選択処理の結果を入力とするような後続の処理を実行するのに十分なデータの集合を出力するような関数(選択処理実行関数)の出力を、前記後続の処理への入力とするような問合せ文を再生成する、問合せ文再生成方法と
を有する問合せ変換方法を説明した。
In the present embodiment,
In a database management system, a query conversion method for converting a query statement including a selection process,
1) A query statement input method for inputting a query statement;
2) a query analysis method for analyzing the input query statement;
3) Based on the query analysis result and the execution cost information of the operation, a sub-query sentence formed only by the low-cost process excluding the high-cost process is generated from the query sentence selection process. A query statement generation method,
4) At least the subquery sentence and zero or more high-cost processes excluded in the subquery sentence generation method are input, and the result of the selection process is input to the query sentence. Query statement regeneration that regenerates a query statement that uses the output of a function (selection process execution function) that outputs a set of data sufficient to execute subsequent processing as input to the subsequent processing. A query transformation method having a composition method has been described.
実施の形態2.
本実施の形態では、問合せ変換装置を、データベース管理システムに適用した別の例を挙げる。
本実施の形態は、実施の形態1と比較して、システムの構成のみが異なる。
そこで、本実施の形態では、システムの構成のみを説明する。
In this embodiment, another example in which the query conversion apparatus is applied to a database management system will be given.
The present embodiment is different from the first embodiment only in the system configuration.
Therefore, in the present embodiment, only the system configuration will be described.
図9は、本実施の形態の問合せ変換装置を適用した、データベース管理システムを示す構成図である。
問合せ発行装置200a(データベースクライアントに相当)は、ネットワーク500を通じて、データベースサーバ装置300と接続されており、データベースサーバ装置300はデータ格納装置400と接続されている。
また、データベースサーバ装置300には、複数のスレーブ装置600が接続されている。
問合せ変換装置100aは、問合せ発行装置200aの部分装置として適用される。
FIG. 9 is a configuration diagram showing a database management system to which the query conversion apparatus according to this embodiment is applied.
The query issuing device 200a (corresponding to a database client) is connected to the
In addition, a plurality of slave devices 600 are connected to the
The inquiry conversion device 100a is applied as a partial device of the inquiry issuing device 200a.
問合せ発行装置200aでは、問合せ文生成部201が、ユーザの要求に応じて問合せ文を生成し、生成された問合せ文を発行する前に、問合せ変換装置100aが、必要に応じて問合せ文を変換する。
その後、問合せ発行装置200aは、変換済みの問合せ文を問合せ変換装置100aから受け取り、データベースサーバ装置300へ変換済みの問合せ文を発行する。
この点以外は、実施の形態1と同様であるため、説明を省略する。
なお、本実施の形態では、問合せ文生成部201及び問合せ変換装置100aを含む問合せ発行装置200aが情報処理装置の例に相当する。
In the query issuing device 200a, the query
Thereafter, the query issuing device 200a receives the converted query statement from the query conversion device 100a and issues the converted query statement to the
Other than this point, the second embodiment is the same as the first embodiment, and a description thereof will be omitted.
In the present embodiment, the query issuing device 200a including the query
実施の形態3.
本実施の形態では、問合せ変換装置を、カラム単位で暗号化されたデータを格納するデータベースを扱うシステム(以下、「暗号化データベースシステム」という)へ適用した例を挙げる。
本実施の形態は、実施の形態1や実施の形態2の構成に、暗号化に対応させた構成を追加することで実現する。
そこで、本実施の形態では、実施の形態1との差異部分のみを説明する。
Embodiment 3 FIG.
In the present embodiment, an example in which the query conversion apparatus is applied to a system that handles a database that stores data encrypted in column units (hereinafter referred to as “encrypted database system”) will be described.
This embodiment is realized by adding a configuration corresponding to encryption to the configuration of the first embodiment or the second embodiment.
Therefore, in the present embodiment, only differences from the first embodiment will be described.
暗号化データベースシステムへ適用した構成図は、図1、図10、および図11で示される。
図10で示されるデータ格納装置400、および、図11で示される絞込み処理追加部160が、実施の形態1との差異部分である。
本実施の形態では、絞込み処理追加部160も問合せ文変換部の例に相当する。
Configuration diagrams applied to the encrypted database system are shown in FIG. 1, FIG. 10, and FIG.
The
In the present embodiment, the narrowing
図10で示されるデータ格納装置400では、カラム毎に適用される暗号化方式を記録した暗号化方式情報440、および、カラム毎に設定された機密度に関する機密度情報450が追加の情報となっている。
これら追加の情報は、他の情報と同様に、問合せ変換装置100、および、データベースサーバ装置300から参照することができる。
In the
These additional information can be referred to from the
絞込み処理追加部160を追加した問合せ変換装置100の動作を、図12を用いて説明する。
ここでは、処理S190が追加されている。
The operation of the
Here, processing S190 is added.
絞込み処理追加部160は、特定のカラムを参照する演算処理において、処理を高速化するための絞込み処理用カラムが別途用意されている場合に、問合せ解析部120による解析結果を元に、問合せ文101の選択処理結果の正確さを損なわないような絞込み処理用カラムによる処理を追加し、処理を追加した問合せ文を、副問合せ文生成部130への入力とする(S190)。
The narrowing
絞込み処理追加の具体例を説明する。
データの暗号化方式として、表1の3種類の方式をカラムの機密度毎に使い分ける場合を考える。
なお、以降で使用する「確定的暗号」「確率的暗号」「検索可能暗号」といった用語は、一定の性質を持つ暗号化方式の種類を表すものであり、個別の暗号化方式を特定するものではない。
A specific example of adding a narrowing process will be described.
As a data encryption method, a case will be considered in which the three types shown in Table 1 are properly used for each column sensitivity.
The terms “deterministic cryptography”, “probabilistic cryptography”, and “searchable cryptography” to be used in the following refer to the types of encryption schemes having a certain property, and specify individual encryption schemes. is not.
表1の「確定的暗号」は、平文と暗号文とが一対一に対応する方式であり、完全一致比較が可能である。
この比較は平文カラムの比較性能と同等性能で実現できる。
確定的暗号は、頻度解析に弱いという欠点があるため、暗号強度の面で確率的暗号に劣る。
The “deterministic cipher” in Table 1 is a scheme in which plaintext and ciphertext correspond one-to-one, and complete match comparison is possible.
This comparison can be realized with the same performance as that of the plaintext column.
Since deterministic encryption has the disadvantage of being weak in frequency analysis, it is inferior to stochastic encryption in terms of encryption strength.
表中の「確率的暗号」は、暗号強度の高い適当な確率的暗号方式で対象データを暗号化するため、完全一致比較を含む任意の演算が利用できない。
そこで、「確率的暗号」が適用されたカラムに関しては、検索可能暗号を検索に利用することを考える。
The “probabilistic encryption” in the table encrypts the target data with an appropriate probabilistic encryption method with high encryption strength, and therefore cannot use any operation including exact match comparison.
Therefore, for a column to which “probabilistic encryption” is applied, consider using searchable encryption for the search.
検索可能暗号とは、以下の参考文献に端を発し研究が進んでいる、データを暗号化したまま検索可能な暗号化方式を指す。
検索可能暗号により、データベースサーバ装置300に平文および検索語の内容を漏らすことなく、検索結果を得ることが可能となる。
Searchable encryption refers to an encryption method that can be searched while data is encrypted, which has been researched with reference to the following references.
With the searchable encryption, it is possible to obtain a search result without leaking the contents of the plain text and the search word to the
参考文献:
D.X. Song, D. Wagner and A. Perrig, “Practical Techniques for Searches on Encrypted Data”, IEEE, 2000.
References:
D. X. Song, D.C. Wagner and A.W. Perrig, “Practical Technologies for Searches on Encrypted Data”, IEEE, 2000.
検索可能暗号は、検索に使用する専用タグ(以下、「暗号化タグ」という)のみを生成する。
専用のトラップドア(暗号化した検索語のようなもの)を発行し、暗号化タグとの照合を実施する。
検索可能暗号から元の平文の情報を復元することはできず、あくまで、検索のためだけの付加情報である。
「確率的暗号」を適用したカラムでは、暗号化データを格納したカラムとは別に、検索に使用するための暗号化タグを格納するカラムを用意する。
The searchable encryption generates only a dedicated tag (hereinafter referred to as “encryption tag”) used for search.
Issue a dedicated trapdoor (similar to an encrypted search term) and check against the encryption tag.
The original plaintext information cannot be restored from the searchable encryption, and is additional information only for search.
In a column to which “probabilistic encryption” is applied, a column for storing an encryption tag for use in a search is prepared separately from a column for storing encrypted data.
暗号化タグとトラップドアの照合処理は、高いセキュリティ強度を保証するが、照合速度は遅く、「実行コストが高い処理」に該当する。 The verification process between the encryption tag and the trap door guarantees high security strength, but the verification speed is slow and corresponds to “processing with high execution cost”.
更に、暗号化タグとトラップドアの照合処理に関して、絞込みを高速化するための索引カラムが別途用意されているとする。
これは、例えば、暗号化前の平文データを入力とする精度の荒いハッシュ値で実現できる。
このハッシュ値による絞込み処理を前処理として行うことで、速度の遅い暗号化タグとトラップドアとの照合処理量を削減することができる。
Further, it is assumed that an index column for speeding up the narrowing is separately prepared for the verification process of the encryption tag and the trapdoor.
This can be realized, for example, with a hash value having rough accuracy with plaintext data before encryption as an input.
By performing the narrowing process based on the hash value as a pre-process, it is possible to reduce the amount of verification processing between the slow-speed encryption tag and the trap door.
以上の状況の下で、絞込み処理追加部160を含めた問合せ変換の具体例を図13、図14に示す。
図13は、検索対象となるテーブルの定義文をSQLで記述したものである。
カラムc_3が確率的暗号により暗号化されるカラムであり、検索用のカラムとして、検索可能暗号で生成される暗号化タグを格納するカラムc_3_tagと、絞り込み用の索引カラムc_3_idxが付加されている。
Under the above situation, specific examples of query conversion including the narrowing
FIG. 13 shows the definition sentence of the table to be searched in SQL.
The column c_3 is a column encrypted by probabilistic encryption, and a column c_3_tag for storing an encryption tag generated by the searchable encryption and an index column c_3_idx for narrowing down are added as search columns.
図14は、SQLで記述された問合せ文の具体的な変換方法を示している。
図14における変換前のSQL文において、関数encrypt_dtr(),gen_trapdoor()は、それぞれ、確定的暗号方式による暗号化、トラップドアの生成を表している。
但し、ここでは、簡単のため、鍵などの引数は一切省略し、暗号化対象となるデータに関する引数のみを記載している。
このように省略しても、本実施の形態を説明する上では支障をきたさない。
また、collate()は、暗号化タグとトラップドアの照合処理を実行するため関数である。
FIG. 14 shows a specific method for converting a query statement described in SQL.
In the SQL sentence before conversion in FIG. 14, functions encrypt_dtr () and gen_trapdoor () respectively represent encryption by a deterministic encryption method and generation of a trap door.
However, here, for the sake of simplicity, no arguments such as a key are omitted, and only arguments relating to data to be encrypted are described.
Even if it omits in this way, there will be no trouble in explaining the present embodiment.
Further, “collate ()” is a function for executing verification processing between the encryption tag and the trapdoor.
図14における副問合せ文では、カラムc_1,c_2に関する低コスト処理に加え、カラムc_3の暗号化タグ照合処理の絞込みを実施するため、索引カラムc_3_idxによる処理が追加されている。
前述したように、索引カラムc_3_idxと暗号化前の平文データのハッシュ値(hash(123456789))との照合処理を追加することで、暗号化タグ(c_3_tag)とトラップドア(trapdoor(123456789))との照合処理を高速化することができる。
絞込み処理追加部160は、索引カラムc_3_idxを絞り込み処理に用いられる絞り込み処理用カラムとして指定し、更に、絞り込み処理を定義する問合せ文(c_3_idx=gen_hash(123456789)を生成し、当該問合せ文を副問合せ文生成部130に出力する(図12のS190)。
副問合せ文生成部130は、絞込み処理追加部160からの問合せ文を含む副問合せ文を生成する(図12のS140)。
なお、副問合せ文を生成した後は、実施の形態1で説明したように問合せ文を再生成すればよい。
図14における変換後のSQL文は、再生成された問合せ文を表している。
In the subquery in FIG. 14, in addition to the low-cost processing for the columns c_1 and c_2, processing by the index column c_3_idx is added in order to narrow down the encryption tag matching processing for the column c_3.
As described above, by adding a collation process between the index column c_3_idx and the hash value (hash (123456789)) of the plaintext data before encryption, the encryption tag (c_3_tag) and the trap door (trapdoor (123456789)) Can be speeded up.
The narrowing
The
Note that after generating the sub-query text, the query text may be re-generated as described in the first embodiment.
The converted SQL statement in FIG. 14 represents the regenerated query statement.
このように、本実施の形態では、図14に示すように、副問合せ文に、低コストであるカラムc_1,c_2についての抽出処理(第1の抽出処理)が示されるとともに、絞り込み処理として、索引カラムc_3_idxと暗号化前の平文データのハッシュ値との照合処理が示される。
この絞り込み処理は、高コストであるc_3_tagについての抽出処理(第2の抽出処理)が対象とするレコードを、カラムc_1,c_2についての抽出処理(第1の抽出処理)で得られるレコードよりも絞り込むことができる。
そして、c_3_tagについての抽出処理(第2の抽出処理)では、絞り込み処理により絞り込まれたレコードを対象にした抽出が行われるため、処理の高速化が図られる。
As described above, in the present embodiment, as shown in FIG. 14, the subquery statement indicates the extraction process (first extraction process) for the columns c_1 and c_2, which are low in cost, and as the narrowing process, A collation process between the index column c_3_idx and the hash value of plaintext data before encryption is shown.
In this narrowing-down process, the records targeted by the high-cost extraction process (second extraction process) for c_3_tag are narrower than the records obtained by the extraction process (first extraction process) for columns c_1 and c_2. be able to.
In the extraction process (second extraction process) for c_3_tag, the extraction is performed on the records narrowed down by the narrowing process, so that the processing speed is increased.
対象カラムが、暗号化されている暗号化カラムである場合に、絞込み処理追加部160は、対象カラムの暗号化方式(暗号化強度)に応じて、追加する絞込み処理の内容を変更させるようにしてもよい。
例えば、「確率的暗号」が適用されたカラムについて、暗号化方式の強度に比例して、索引カラムに使用するハッシュの精度を荒くするという方法がある。
これは、強度の高い暗号化方式を適用しているカラムは、機密度が高い可能性が高いため、索引による絞込み効率の向上よりも、セキュリティを優先するべきという考え方に基づいている。
この場合は、当然ながら、データ格納時には、対応するハッシュ関数を用いて、索引カラムのデータを作っておく必要がある。
When the target column is an encrypted encrypted column, the narrowing
For example, for a column to which “stochastic encryption” is applied, there is a method in which the accuracy of the hash used for the index column is roughened in proportion to the strength of the encryption method.
This is based on the idea that security should be prioritized over improvement of narrowing efficiency by index because a column to which a high-strength encryption method is applied is likely to have high confidentiality.
In this case, of course, when storing data, it is necessary to create index column data using a corresponding hash function.
また、対象カラムが、機密度が設定されている機密度設定カラムである場合に、絞込み処理追加部160は、対象カラムに設定された機密度に応じて、追加する絞込み処理の内容を変更させるようにしてもよい。
例えば、設定された機密度が高いほど、索引カラムに使用するハッシュの精度を荒くするという方法がある。
これは、機密度が高いカラムであるほど、索引による絞込み効率の向上よりも、セキュリティを優先するべきという考え方に基づいている。
この場合は、当然ながら、データ格納時には、対応するハッシュ関数を用いて、索引カラムのデータを作っておく必要がある。
In addition, when the target column is a sensitivity setting column in which the sensitivity is set, the narrowing
For example, there is a method of increasing the accuracy of the hash used for the index column as the set confidentiality is higher.
This is based on the idea that the higher the sensitivity of the column, the higher the priority should be given to security than the improvement of the narrowing efficiency by the index.
In this case, of course, when storing data, it is necessary to create index column data using a corresponding hash function.
以上で述べたように、実施の形態3においては、問合せ変換装置100に入力された問合せ文101に対して、適切な問合せ文変換を施すことで、問合せの実行結果を変えることなく、実行計画の最適化と、複数レコードを同時処理する並列化とを両立させることができ、更に、適当な絞込み処理を自動追加することで、問合せの実行時間を短縮することが可能となる。
As described above, in the third embodiment, the execution plan is changed without changing the execution result of the query by performing appropriate query statement conversion on the
以上、本実施の形態では、
問合せ変換装置は、
特定のカラムを参照する演算処理において、処理を高速化するための絞込み処理用カラムが別途用意されている場合に、問合せ解析部による解析結果を元に、選択処理結果の正確さを損なわないような絞込み処理用カラムによる処理を追加する、絞込み処理追加部を有し、
絞込み処理追加部の出力を副問合せ文生成部への入力とする
ことを説明した。
As described above, in the present embodiment,
The query conversion device
In the calculation processing that refers to a specific column, when a narrowing processing column for speeding up the processing is prepared separately, the accuracy of the selection processing result should not be impaired based on the analysis result by the query analysis unit. There is a refinement process addition part that adds a process by a narrow refinement process column,
Explained that the output of the refinement processing addition unit is the input to the subquery generation unit.
また、本実施の形態では、
前記問合せ変換装置が適用されるデータベース管理システムは、
カラム単位で暗号化されたデータを格納するテーブルへの問合せを含み、かつ、
カラム毎のデータの暗号化方式を管理しており、
前記絞込み処理追加部は、
問合せに記述された条件が参照するカラムの暗号化方式に応じて、絞込み処理を追加する
ことを説明した。
In the present embodiment,
A database management system to which the query conversion device is applied is as follows.
Contains a query to a table that stores data encrypted in column units, and
Manages the data encryption method for each column,
The narrowing process addition unit
Explained that the refinement process is added according to the encryption method of the column referenced by the condition described in the query.
また、本実施の形態では、
前記問合せ変換装置が適用されるデータベース管理システムは、
カラム単位で暗号化されたデータを格納するテーブルへの問合せを含み、かつ、
カラム毎のデータの機密度を管理しており、
前記絞込み処理追加部は、
問合せに記述された条件が参照するカラムの機密度に応じて、絞込み処理を追加する
ことを説明した。
In the present embodiment,
A database management system to which the query conversion device is applied is as follows.
Contains a query to a table that stores data encrypted in column units, and
It manages the sensitivity of data for each column,
The narrowing process addition unit
It was explained that the refinement process is added according to the sensitivity of the column referenced by the condition described in the query.
最後に、実施の形態1〜3に示した問合せ変換装置100のハードウェア構成例について説明する。
図17は、実施の形態1〜3に示す問合せ変換装置100のハードウェア資源の一例を示す図である。
なお、図17の構成は、あくまでも問合せ変換装置100のハードウェア構成の一例を示すものであり、問合せ変換装置100のハードウェア構成は図17に記載の構成に限らず、他の構成であってもよい。
Finally, a hardware configuration example of the
FIG. 17 is a diagram illustrating an example of hardware resources of the
Note that the configuration in FIG. 17 is merely an example of the hardware configuration of the
図17において、問合せ変換装置100は、プログラムを実行するCPU911(中央処理装置、処理装置、演算装置、マイクロプロセッサ、マイクロコンピュータ、プロセッサともいう)を備えている。
CPU911は、バス912を介して、例えば、ROM(Read Only Memory)913、RAM(Random Access Memory)914、通信ボード915、表示装置901、キーボード902、マウス903、磁気ディスク装置920と接続され、これらのハードウェアデバイスを制御する。
更に、CPU911は、FDD904(Flexible Disk Drive)、コンパクトディスク装置905(CDD)、プリンタ装置906、スキャナ装置907と接続していてもよい。また、磁気ディスク装置920の代わりに、SSD(Solid State Drive)、光ディスク装置、メモリカード(登録商標)読み書き装置などの記憶装置でもよい。
RAM914は、揮発性メモリの一例である。ROM913、FDD904、CDD905、磁気ディスク装置920の記憶媒体は、不揮発性メモリの一例である。これらは、記憶装置の一例である。
通信ボード915、キーボード902、マウス903、スキャナ装置907などは、入力装置の一例である。
また、通信ボード915、表示装置901、プリンタ装置906などは、出力装置の一例である。
In FIG. 17, the
The
Further, the
The
A
The
通信ボード915は、図1に示すように、ネットワークに接続されている。
例えば、通信ボード915は、LAN(ローカルエリアネットワーク)、インターネット、WAN(ワイドエリアネットワーク)、SAN(ストレージエリアネットワーク)などに接続されている。
As shown in FIG. 1, the
For example, the
磁気ディスク装置920には、オペレーティングシステム921(OS)、ウィンドウシステム922、プログラム群923、ファイル群924が記憶されている。
プログラム群923のプログラムは、CPU911がオペレーティングシステム921、ウィンドウシステム922を利用しながら実行する。
The
The programs in the
また、RAM914には、CPU911に実行させるオペレーティングシステム921のプログラムやアプリケーションプログラムの少なくとも一部が一時的に格納される。
また、RAM914には、CPU911による処理に必要な各種データが格納される。
The
The
また、ROM913には、BIOS(Basic Input Output System)プログラムが格納され、磁気ディスク装置920にはブートプログラムが格納されている。
問合せ変換装置100の起動時には、ROM913のBIOSプログラム及び磁気ディスク装置920のブートプログラムが実行され、BIOSプログラム及びブートプログラムによりオペレーティングシステム921が起動される。
The
When the
上記プログラム群923には、実施の形態1〜3の説明において「〜部」として説明している機能を実行するプログラムが記憶されている。プログラムは、CPU911により読み出され実行される。
The
ファイル群924には、実施の形態1〜3の説明において、「〜の判断」、「〜の解析」、「〜の検索」、「〜の抽出」、「〜の生成」、「〜の再生成」、「〜の比較」、「〜の照合」、「〜の更新」、「〜の設定」、「〜の登録」、「〜の選択」、「〜の入力」、「〜の出力」等として説明している処理の結果を示す情報やデータや信号値や変数値や暗号鍵・復号鍵や乱数値やパラメータが、「〜ファイル」の各項目として記憶されている。
「〜ファイル」は、ディスクやメモリなどの記憶媒体に記憶される。
ディスクやメモリなどの記憶媒体に記憶された情報やデータや信号値や変数値やパラメータは、読み書き回路を介してCPU911によりメインメモリやキャッシュメモリに読み出される。
そして、読み出された情報やデータや信号値や変数値やパラメータは、抽出・検索・参照・比較・演算・計算・処理・編集・出力・印刷・表示などのCPUの動作に用いられる。
抽出・検索・参照・比較・演算・計算・処理・編集・出力・印刷・表示のCPUの動作の間、情報やデータや信号値や変数値やパラメータは、メインメモリ、レジスタ、キャッシュメモリ、バッファメモリ等に一時的に記憶される。
また、実施の形態1〜3で説明しているフローチャートの矢印の部分は主としてデータや信号の入出力を示す。
データや信号値は、RAM914のメモリ、FDD904のフレキシブルディスク、CDD905のコンパクトディスク、磁気ディスク装置920の磁気ディスク、その他光ディスク、ミニディスク、DVD等の記憶媒体に記録される。
また、データや信号は、バス912や信号線やケーブルその他の伝送媒体によりオンライン伝送される。
In the description of the first to third embodiments, the
The “˜file” is stored in a storage medium such as a disk or a memory.
Information, data, signal values, variable values, and parameters stored in a storage medium such as a disk or memory are read out to the main memory or cache memory by the
The read information, data, signal value, variable value, and parameter are used for CPU operations such as extraction, search, reference, comparison, calculation, calculation, processing, editing, output, printing, and display.
Information, data, signal values, variable values, and parameters are stored in the main memory, registers, cache memory, and buffers during the CPU operations of extraction, search, reference, comparison, calculation, processing, editing, output, printing, and display. It is temporarily stored in a memory or the like.
In addition, the arrows in the flowcharts described in
Data and signal values are recorded in a storage medium such as a memory of the
Data and signals are transmitted online via a bus 912, signal lines, cables, or other transmission media.
また、実施の形態1〜3の説明において「〜部」として説明しているものは、「〜回路」、「〜装置」、「〜機器」であってもよく、また、「〜ステップ」、「〜手順」、「〜処理」であってもよい。
すなわち、実施の形態1〜3で説明したフローチャートに示すステップ、手順、処理により、本発明に係る「情報処理方法」を実現することができる。
また、「〜部」として説明しているものは、ROM913に記憶されたファームウェアで実現されていても構わない。
或いは、ソフトウェアのみ、或いは、素子・デバイス・基板・配線などのハードウェアのみ、或いは、ソフトウェアとハードウェアとの組み合わせ、さらには、ファームウェアとの組み合わせで実施されても構わない。
ファームウェアとソフトウェアは、プログラムとして、磁気ディスク、フレキシブルディスク、光ディスク、コンパクトディスク、ミニディスク、DVD等の記憶媒体に記憶される。
プログラムはCPU911により読み出され、CPU911により実行される。
すなわち、プログラムは、実施の形態1〜3の「〜部」としてコンピュータを機能させるものである。あるいは、実施の形態1〜3の「〜部」の手順や方法をコンピュータに実行させるものである。
In addition, what is described as “˜unit” in the description of the first to third embodiments may be “˜circuit”, “˜device”, “˜device”, and “˜step”, It may be “˜procedure” or “˜processing”.
That is, the “information processing method” according to the present invention can be realized by the steps, procedures, and processes shown in the flowcharts described in the first to third embodiments.
Further, what is described as “˜unit” may be realized by firmware stored in the
Alternatively, it may be implemented only by software, or only by hardware such as elements, devices, substrates, and wirings, by a combination of software and hardware, or by a combination of firmware.
Firmware and software are stored as programs in a storage medium such as a magnetic disk, a flexible disk, an optical disk, a compact disk, a mini disk, and a DVD.
The program is read by the
That is, the program causes the computer to function as “to part” in the first to third embodiments. Alternatively, the computer executes the procedure and method of “to part” in the first to third embodiments.
このように、実施の形態1〜3に示す問合せ変換装置100は、処理装置たるCPU、記憶装置たるメモリ、磁気ディスク等、入力装置たるキーボード、マウス、通信ボード等、出力装置たる表示装置、通信ボード等を備えるコンピュータである。
そして、上記したように「〜部」として示された機能をこれら処理装置、記憶装置、入力装置、出力装置を用いて実現するものである。
As described above, the
Then, as described above, the functions indicated as “˜units” are realized using these processing devices, storage devices, input devices, and output devices.
100 問合せ変換装置、101 問合せ文、102 変換済み問合せ文、110 問合せ文入力部、120 問合せ解析部、130 副問合せ文生成部、140 並列処理指示部、150 問合せ文再生成部、160 絞込み処理追加部、200 問合せ発行装置、201 問合せ文生成部、300 データベースサーバ装置、400 データ格納装置、410 データ、420 カタログ情報、430 演算コスト情報、440 暗号化方式情報、450 機密度情報、500 ネットワーク、600 スレーブ装置。
100 Query Conversion Device, 101 Query Statement, 102 Converted Query Statement, 110 Query Statement Input Unit, 120 Query Analysis Unit, 130 Subquery Statement Generation Unit, 140 Parallel Processing Instruction Unit, 150 Query Statement Regeneration Unit, 160
Claims (13)
前記問合せ文入力部により入力された入力問合せ文の検索条件ごとに、検索実行時の実行コストが閾値以上であるか否かを判断し、検索実行時の実行コストが閾値未満である検索条件を第1の検索条件カテゴリーに分類し、検索実行時の実行コストが閾値以上である検索条件を第2の検索条件カテゴリーに分類する検索条件分類部と、
前記第1の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを前記検索対象テーブルから抽出する第1の抽出処理と、前記第1の抽出処理により抽出されたレコードから前記第2の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを抽出する第2の抽出処理とを実行するよう前記データベースサーバ装置に要求する問合せ文を、前記入力問合せ文を変換して生成する問合せ文変換部とを有することを特徴とする情報処理装置。 A query statement input unit that inputs a query statement that requests the database server device to extract records that match a combination of a plurality of search conditions from a search target table to be searched;
For each search condition of the input query sentence input by the query sentence input unit, it is determined whether or not the execution cost at the time of executing the search is greater than or equal to a threshold, and the search condition that the execution cost at the time of executing the search is less than the threshold. A search condition classifying unit that classifies the search condition into a second search condition category that is classified into a first search condition category and that has a search execution cost equal to or higher than a threshold;
A first extraction process for extracting records that match a combination of search conditions classified into the first search condition category from the search target table, and the second extraction from the records extracted by the first extraction process. A query generated by converting the input query statement to request the database server device to execute a second extraction process for extracting a record that matches a combination of search conditions classified in the search condition category An information processing apparatus having a sentence conversion unit.
前記入力問合せ文を変換して、前記第1の抽出処理の実行を前記データベースサーバ装置に要求する第1の問合せ文を生成し、
更に、前記第1の問合せ文を含み、前記第1の問合せ文の実行により抽出されたレコードに対して前記第2の抽出処理を実行するよう前記データベースサーバ装置に要求する第2の問合せ文を、前記入力問合せ文を変換して生成することを特徴とする請求項1に記載の情報処理装置。 The query statement conversion unit
Converting the input query statement to generate a first query statement that requests the database server device to execute the first extraction process;
Further, a second query statement that includes the first query statement and requests the database server device to execute the second extraction process on the record extracted by executing the first query statement. The information processing apparatus according to claim 1, wherein the input query sentence is generated by conversion.
前記検索対象テーブルを管理しているデータベースサーバ装置に、生成した前記第2の問合せ文を出力することを特徴とする請求項2に記載の情報処理装置。 The query statement conversion unit
The information processing apparatus according to claim 2 , wherein the generated second query statement is output to a database server apparatus that manages the search target table.
文字列引数により指定された任意の問合せ文の実行を前記データベースサーバ装置に要求する関数を含み、
前記関数の前記文字列引数として前記第1の問合せ文を含む第2の問合せ文を生成することを特徴とする請求項2に記載の情報処理装置。 The query statement conversion unit
A function for requesting the database server device to execute an arbitrary query specified by a string argument;
The information processing apparatus according to claim 2, wherein a second query sentence including the first query sentence is generated as the character string argument of the function.
前記第1の抽出処理により抽出された複数のレコードを、それぞれが1つ以上のレコードで構成される複数のブロックに分割させ、前記第2の抽出処理を複数のブロックに対して並列に実行させるための制御情報を、前記第2の問合せ文に含めるよう前記問合せ文変換部に指示する並列処理制御部を有することを特徴とする請求項3又は4に記載の情報処理装置。 The information processing apparatus further includes:
The plurality of records extracted by the first extraction process are divided into a plurality of blocks each composed of one or more records, and the second extraction process is executed in parallel on the plurality of blocks. 5. The information processing apparatus according to claim 3, further comprising a parallel processing control unit that instructs the query statement conversion unit to include control information for inclusion in the second query statement.
2つ以上のスレーブ装置を管理しており、
前記並列処理制御部は、
前記第1の抽出処理は、前記データベースサーバ装置に実行させ、前記第2の抽出処理は、前記データベースサーバ装置の管理下で前記2つ以上のスレーブ装置に、複数のブロックに対して並列に実行させるための制御情報を、前記第2の問合せ文に含めるよう前記問合せ文変換部に指示することを特徴とする請求項5に記載の情報処理装置。 The database server device
Manage two or more slave devices,
The parallel processing control unit
The first extraction process is executed by the database server device, and the second extraction process is executed in parallel to a plurality of blocks by the two or more slave devices under the management of the database server device. 6. The information processing apparatus according to claim 5, wherein the query information conversion unit is instructed to include control information for causing the query information to be included in the second query statement.
前記第2の抽出処理の処理結果に影響を与えることなく前記第2の抽出処理が対象とするレコードを前記第1の抽出処理により抽出されたレコードよりも絞り込む絞り込み処理を定義するとともに、
前記第1の抽出処理と、前記絞り込み処理と、前記絞り込み処理により絞り込まれたレコードから前記第2の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを抽出する第2の抽出処理とを実行するよう要求する問合せ文を、前記入力問合せ文を変換して生成することを特徴とする請求項1〜6のいずれかに記載の情報処理装置。 The query statement conversion unit
Defining a narrowing process that narrows down the records that are targeted by the second extraction process, rather than the records extracted by the first extraction process, without affecting the processing result of the second extraction process;
A first extraction process, a narrowing process, and a second extraction process for extracting a record that matches a combination of search conditions classified into the second search condition category from the records narrowed down by the narrowing process; The information processing apparatus according to claim 1, wherein a query sentence requesting to execute the command is generated by converting the input query sentence.
前記検索対象テーブルに含まれるいずれかのカラムを、絞り込み処理に用いられる絞り込み処理用カラムとして指定するとともに、
絞り込み処理用カラムに記述されているデータ値を基準にして前記第2の抽出処理が対象とするレコードを絞り込む絞り込み処理を定義することを特徴とする請求項7に記載の情報処理装置。 The query statement conversion unit
One of the columns included in the search target table is designated as a refinement processing column used for refinement processing,
8. The information processing apparatus according to claim 7, wherein a narrowing process for narrowing down records targeted by the second extraction process is defined based on a data value described in the narrowing process column.
データ値が暗号化されているカラムである暗号化カラムが前記検索対象テーブルに含まれており、暗号化カラムが前記第2の検索条件カテゴリーに分類されている場合に、
前記第2の検索条件カテゴリーに分類された暗号化カラムの暗号化強度に応じて、絞り込み処理の内容を決定することを特徴とする請求項8に記載の情報処理装置。 The query statement conversion unit
When an encrypted column, which is a column in which a data value is encrypted, is included in the search target table, and the encrypted column is classified into the second search condition category,
The information processing apparatus according to claim 8, wherein the content of the narrowing-down process is determined according to an encryption strength of the encrypted column classified into the second search condition category.
機密度が設定されているカラムである機密度設定カラムが前記検索対象テーブルに含まれており、機密度設定カラムが前記第2の検索条件カテゴリーに分類されている場合に、
前記第2の検索条件カテゴリーに分類された機密度設定カラムに設定されている機密度に応じて、絞り込み処理の内容を決定することを特徴とする請求項8又は9に記載の情報処理装置。 The query statement conversion unit
When the sensitivity setting column, which is a column for which sensitivity is set, is included in the search target table, and the sensitivity setting column is classified into the second search condition category,
10. The information processing apparatus according to claim 8, wherein the content of the narrowing-down process is determined in accordance with the confidentiality set in the confidentiality setting column classified into the second search condition category.
問合せ文を生成する問合せ文生成部を有し、
前記問合せ文入力部は、
前記問合せ文生成部により生成された問合せ文を入力することを特徴とする請求項1〜10のいずれかに記載の情報処理装置。 The information processing apparatus further includes:
A query statement generation unit for generating a query statement;
The query statement input unit
The information processing apparatus according to claim 1, wherein the inquiry sentence generated by the inquiry sentence generation unit is input.
前記コンピュータが、前記問合せ文入力ステップにより入力された入力問合せ文の検索条件ごとに、検索実行時の実行コストが閾値以上であるか否かを判断し、検索実行時の実行コストが閾値未満である検索条件を第1の検索条件カテゴリーに分類し、検索実行時の実行コストが閾値以上である検索条件を第2の検索条件カテゴリーに分類する検索条件分類ステップと、
前記第1の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを前記検索対象テーブルから抽出する第1の抽出処理と、前記第1の抽出処理により抽出されたレコードから前記第2の検索条件カテゴリーに分類され検索条件の組合せに適合するレコードを抽出する第2の抽出処理とを実行するよう前記データベースサーバ装置に要求する問合せ文を、前記コンピュータが、前記入力問合せ文を変換して生成する問合せ文変換ステップとを有することを特徴とする情報処理方法。 A query statement input step in which a computer inputs a query statement that requests the database server device to extract records that match a combination of a plurality of search conditions from a search target table to be searched; and
The computer determines, for each search condition of the input query sentence input by the query sentence input step, whether or not the execution cost at the time of executing the search is equal to or greater than a threshold, and the execution cost at the time of executing the search is less than the threshold A search condition classification step for classifying a search condition into a first search condition category and classifying a search condition whose execution cost at the time of search execution is equal to or greater than a threshold into a second search condition category;
A first extraction process for extracting records that match a combination of search conditions classified into the first search condition category from the search target table, and the second extraction from the records extracted by the first extraction process. The computer converts the input query statement into a query statement that requests the database server device to execute a second extraction process that extracts records that are classified into search condition categories and that match a combination of search conditions. An information processing method comprising: generating a query statement conversion step.
前記問合せ文入力ステップにより入力された入力問合せ文の検索条件ごとに、検索実行時の実行コストが閾値以上であるか否かを判断し、検索実行時の実行コストが閾値未満である検索条件を第1の検索条件カテゴリーに分類し、検索実行時の実行コストが閾値以上である検索条件を第2の検索条件カテゴリーに分類する検索条件分類ステップと、
前記第1の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを前記検索対象テーブルから抽出する第1の抽出処理と、前記第1の抽出処理により抽出されたレコードから前記第2の検索条件カテゴリーに分類された検索条件の組合せに適合するレコードを抽出する第2の抽出処理とを実行するよう前記データベースサーバ装置に要求する問合せ文を前記入力問合せ文を変換して生成する問合せ文変換ステップとをコンピュータに実行させることを特徴とするプログラム。 A query statement input step for inputting a query statement for requesting the database server device to extract a record that matches a combination of a plurality of search conditions from a search target table to be searched;
For each search condition of the input query sentence input by the query sentence input step, it is determined whether or not the execution cost at the time of search execution is equal to or higher than a threshold, and the search condition that the execution cost at the time of search execution is less than the threshold A search condition classification step for classifying the search condition into a second search condition category, which is classified into a first search condition category and whose execution cost at the time of search execution is equal to or greater than a threshold;
A first extraction process for extracting records that match a combination of search conditions classified into the first search condition category from the search target table, and the second extraction from the records extracted by the first extraction process. A query statement generated by converting the input query statement to generate a query statement that requests the database server device to execute a second extraction process for extracting a record that matches a combination of search conditions classified in the search condition category A program for causing a computer to execute the conversion step.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012011738A JP5800720B2 (en) | 2012-01-24 | 2012-01-24 | Information processing apparatus, information processing method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012011738A JP5800720B2 (en) | 2012-01-24 | 2012-01-24 | Information processing apparatus, information processing method, and program |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2013152512A JP2013152512A (en) | 2013-08-08 |
| JP2013152512A5 JP2013152512A5 (en) | 2014-12-25 |
| JP5800720B2 true JP5800720B2 (en) | 2015-10-28 |
Family
ID=49048823
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012011738A Expired - Fee Related JP5800720B2 (en) | 2012-01-24 | 2012-01-24 | Information processing apparatus, information processing method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5800720B2 (en) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6186387B2 (en) * | 2015-03-19 | 2017-08-23 | 株式会社日立製作所 | Confidential data processing system |
| JP6441160B2 (en) * | 2015-04-27 | 2018-12-19 | 株式会社東芝 | Concealment device, decryption device, concealment method and decryption method |
| WO2017122326A1 (en) | 2016-01-14 | 2017-07-20 | 三菱電機株式会社 | Confidential search system, confidential search method and confidential search program |
| JP6038427B1 (en) | 2016-01-15 | 2016-12-07 | 三菱電機株式会社 | ENCRYPTION DEVICE, ENCRYPTION METHOD, ENCRYPTION PROGRAM, AND STORAGE DEVICE |
| WO2017221308A1 (en) * | 2016-06-20 | 2017-12-28 | 三菱電機株式会社 | Data management device, data management method, data management program, search device, search method, and search program |
| CN110546631A (en) | 2017-04-25 | 2019-12-06 | 三菱电机株式会社 | Search device, search system, search method, and search program |
| CN110019274B (en) | 2017-12-29 | 2023-09-26 | 阿里巴巴集团控股有限公司 | Database system and method and device for querying database |
| JP6971929B2 (en) * | 2018-07-20 | 2021-11-24 | Kddi株式会社 | Inquiry statement output device and inquiry statement output method |
| CN111046066B (en) * | 2019-12-09 | 2023-05-12 | 上海达梦数据库有限公司 | Remote database object optimization method, device, equipment and storage medium |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0581330A (en) * | 1991-09-20 | 1993-04-02 | Nec Corp | Inquiry optimizing device of data base |
| JPH05334368A (en) * | 1992-06-02 | 1993-12-17 | Hitachi Ltd | Data base inquiry processing method |
| JPH07105238A (en) * | 1993-09-29 | 1995-04-21 | Omron Corp | Device and method for data base retrieval |
| US6339768B1 (en) * | 1998-08-13 | 2002-01-15 | International Business Machines Corporation | Exploitation of subsumption in optimizing scalar subqueries |
| JP2000163446A (en) * | 1998-11-30 | 2000-06-16 | Nec Corp | Extendable inquiry processor |
| JP3694193B2 (en) * | 1999-05-28 | 2005-09-14 | 富士通株式会社 | Database search apparatus and program recording medium |
| JP2001331463A (en) * | 2000-05-23 | 2001-11-30 | Nec Corp | Data base construction method and recording medium having the program recorded thereon |
| JP3303881B2 (en) * | 2001-03-08 | 2002-07-22 | 株式会社日立製作所 | Document search method and apparatus |
| US6598044B1 (en) * | 2002-06-25 | 2003-07-22 | Microsoft Corporation | Method for choosing optimal query execution plan for multiple defined equivalent query expressions |
| JP4575064B2 (en) * | 2004-07-29 | 2010-11-04 | 三菱電機株式会社 | Information retrieval device |
| US20080040334A1 (en) * | 2006-08-09 | 2008-02-14 | Gad Haber | Operation of Relational Database Optimizers by Inserting Redundant Sub-Queries in Complex Queries |
| JP4571609B2 (en) * | 2006-11-08 | 2010-10-27 | 株式会社日立製作所 | Resource allocation method, resource allocation program, and management computer |
| JP5011006B2 (en) * | 2007-07-03 | 2012-08-29 | 株式会社日立製作所 | Resource allocation method, resource allocation program, and resource allocation device |
| JP2011159015A (en) * | 2010-01-29 | 2011-08-18 | Fujitsu Frontech Ltd | Program, apparatus and method for supporting search |
| US20110202774A1 (en) * | 2010-02-15 | 2011-08-18 | Charles Henry Kratsch | System for Collection and Longitudinal Analysis of Anonymous Student Data |
| US8484243B2 (en) * | 2010-05-05 | 2013-07-09 | Cisco Technology, Inc. | Order-independent stream query processing |
-
2012
- 2012-01-24 JP JP2012011738A patent/JP5800720B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2013152512A (en) | 2013-08-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5800720B2 (en) | Information processing apparatus, information processing method, and program | |
| CN109299131B (en) | Spark query method and system supporting trusted computing | |
| Wang et al. | Performance prediction for apache spark platform | |
| CN106897322B (en) | A kind of access method and device of database and file system | |
| JP2019194882A (en) | Mounting of semi-structure data as first class database element | |
| Alshammari et al. | H2hadoop: Improving hadoop performance using the metadata of related jobs | |
| US10482263B2 (en) | Computing on encrypted data using deferred evaluation | |
| JP5791149B2 (en) | Computer-implemented method, computer program, and data processing system for database query optimization | |
| CN111737720B (en) | Data processing method and device and electronic equipment | |
| Zhang et al. | Privacy preservation over big data in cloud systems | |
| EP2778953A1 (en) | Encoded-search database device, method for adding and deleting data for encoded search, and addition/deletion program | |
| US20160342652A1 (en) | Database query cursor management | |
| Achichi et al. | Automatic key selection for data linking | |
| Li et al. | Juxtapp and dstruct: Detection of similarity among android applications | |
| JP2019537097A (en) | Tracking I-node access patterns and prefetching I-nodes | |
| JP2015179449A (en) | Virtual database system management device, management method, and management program | |
| WO2017168798A1 (en) | Encryption search index merge server, encryption search index merge system, and encryption search index merge method | |
| Xu et al. | Learning to optimize federated queries | |
| Verginadis et al. | Metadata schema for data-aware multi-cloud computing | |
| US10657126B2 (en) | Meta-join and meta-group-by indexes for big data | |
| US20190095538A1 (en) | Method and system for generating content from search results rendered by a search engine | |
| JP5162215B2 (en) | Data processing apparatus, data processing method, and program | |
| JP2018060379A (en) | Searching means selecting program, searching means selecting method and searching means selecting device | |
| Wang et al. | Tunnel security management based on association rule mining under Hadoop platform | |
| JP6644637B2 (en) | Speed-up device, computer system and data processing method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20141110 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20141110 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20150722 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20150728 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150825 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5800720 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |