JP5792402B2 - グラフィックス処理ユニット上でのグラフィックスアプリケーションおよび非グラフィックスアプリケーションの実行 - Google Patents
グラフィックス処理ユニット上でのグラフィックスアプリケーションおよび非グラフィックスアプリケーションの実行 Download PDFInfo
- Publication number
- JP5792402B2 JP5792402B2 JP2014560926A JP2014560926A JP5792402B2 JP 5792402 B2 JP5792402 B2 JP 5792402B2 JP 2014560926 A JP2014560926 A JP 2014560926A JP 2014560926 A JP2014560926 A JP 2014560926A JP 5792402 B2 JP5792402 B2 JP 5792402B2
- Authority
- JP
- Japan
- Prior art keywords
- shader
- instructions
- gpu
- graphics application
- graphics
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012545 processing Methods 0.000 title claims description 41
- 238000000034 method Methods 0.000 claims description 71
- 230000005540 biological transmission Effects 0.000 claims description 2
- 230000004044 response Effects 0.000 claims description 2
- 230000002452 interceptive effect Effects 0.000 claims 1
- 230000006870 function Effects 0.000 description 72
- 238000010586 diagram Methods 0.000 description 8
- 230000015556 catabolic process Effects 0.000 description 4
- 238000006731 degradation reaction Methods 0.000 description 4
- 239000012634 fragment Substances 0.000 description 4
- 230000008901 benefit Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 230000010387 memory retrieval Effects 0.000 description 1
- 230000005055 memory storage Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5044—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering hardware capabilities
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5094—Allocation of resources, e.g. of the central processing unit [CPU] where the allocation takes into account power or heat criteria
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Image Generation (AREA)
- Image Processing (AREA)
Description
以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
[C1]
グラフィックス処理ユニット(GPU)を用いて、グラフィックスアプリケーションのために確保された、前記GPUのシェーダプロセッサのシェーダコアの第1のセットの指示を受信することと、
前記GPUを用いて、非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの第2の異なるセットの指示を受信することと、
前記GPUを用いて、前記グラフィックスアプリケーションの命令を受信することと、
前記GPUを用いて、前記非グラフィックスアプリケーションの命令を受信することと、
前記GPUを用いて、シェーダコアの前記第1のセットで前記グラフィックスアプリケーションの前記命令を実行することと、
前記グラフィックスアプリケーションの前記命令を実行するのと実質的に同時に、前記GPUを用いて、シェーダコアの前記第2のセットで前記非グラフィックスアプリケーションの前記命令を実行することと
を備える方法。
[C2]
シェーダコアの前記第1のセットの前記指示を受信することが、前記GPUの第1のコマンドプロセッサを用いて、シェーダコアの前記第1のセットの前記指示を受信することを備え、シェーダコアの前記第2のセットの前記指示を受信することが、前記GPUの第2の異なるコマンドプロセッサを用いて、シェーダコアの前記第2のセットの前記指示を受信することを備える、C1に記載の方法。
[C3]
シェーダコアの前記第1のセットの前記指示を受信することが、前記GPUのコマンドプロセッサを用いて、シェーダコアの前記第1のセットの前記指示を受信することを備え、シェーダコアの前記第2のセットの前記指示を受信することが、同じコマンドプロセッサを用いて、シェーダコアの前記第2のセットの前記指示を受信することを備える、C1に記載の方法。
[C4]
シェーダコアの前記第1のセットで前記非グラフィックスアプリケーションの前記命令を実行しないことと、
シェーダコアの前記第2のセットで前記グラフィックスアプリケーションの前記命令を実行しないことと
をさらに備える、C1に記載の方法。
[C5]
前記非グラフィックスアプリケーションの命令を受信することが、前記グラフィックスアプリケーションの命令を受信するのと同時に前記非グラフィックスアプリケーションの前記命令を受信することを備える、C1に記載の方法。
[C6]
第1の作業負荷分配ユニットを用いて、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断することと、
第2の異なる作業負荷分配ユニットを用いて、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断することと
をさらに備え、
前記グラフィックスアプリケーションの前記命令を実行することは、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて前記グラフィックスアプリケーションの前記命令を実行することを備え、
前記非グラフィックスアプリケーションの前記命令を実行することは、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて前記非グラフィックスアプリケーションの前記命令を実行することを備える、C1に記載の方法。
[C7]
前記グラフィックスアプリケーションの前記命令の前記実行の結果を前記GPU内のメモリキャッシュに記憶することを前記非グラフィックスアプリケーションの前記命令の前記実行の結果を前記GPU内の前記メモリキャッシュに記憶することよりも優先させること
をさらに備える、C1に記載の方法。
[C8]
シェーダコアの前記第1のセットの前記指示を受信することが、前記GPUの第1のコマンドプロセッサを用いて、シェーダコアの前記第1のセットの前記指示を受信することを備え、シェーダコアの前記第2のセットの前記指示を受信することが、前記GPUの第2の異なるコマンドプロセッサを用いて、シェーダコアの前記第2のセットの前記指示を受信することを備え、前記方法は、
前記非グラフィックスアプリケーションの命令がないとき、前記第2のコマンドプロセッサの電源を切断するための指示を受信することと、
前記指示を受信したことに応答して前記第2のコマンドプロセッサの電源を切断することと
をさらに備える、C1に記載の方法。
[C9]
シェーダコアの前記第1のセットのシェーダコアの数がシェーダコアの前記第2のセットのシェーダコアの数とは異なる、C1に記載の方法。
[C10]
プロセッサ上のドライバを用いて、シェーダコアの第1のセット上で実行されるべきグラフィックスアプリケーションのために確保された、グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアの前記第1のセットを判断することと、
前記プロセッサ上の前記ドライバを用いて、シェーダコアの第2の異なるセットによって実行されるべき非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの前記第2のセットを判断することと、
シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を備える方法。
[C11]
シェーダコアの前記第1のセットを判断することは、前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが前記グラフィックスアプリケーションのために確保されるべきかを判断することを備え、シェーダコアの前記第2のセットを判断することは、前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが前記非グラフィックスアプリケーションのために確保されるべきかを判断することを備える、C10に記載の方法。
[C12]
シェーダコアの前記第1のセットがシェーダコアの前記第2のセットよりも多くのシェーダコアを含むと判断すること
をさらに備える、C10に記載の方法。
[C13]
シェーダコアの前記第1のセットを判断することが、前記グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第1のセットを判断することを備える、C10に記載の方法。
[C14]
シェーダコアの前記第2のセットを判断することが、前記非グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第2のセットを判断することを備える、C10に記載の方法。
[C15]
送信することが、
シェーダコアの前記第1のセットの前記指示を前記GPU内の第1のコマンドプロセッサに送信することと、
シェーダコアの前記第2のセットの前記指示を前記GPU内の第2の異なるプロセッサに送信することと
を備える、C10に記載の方法。
[C16]
送信することが、
シェーダコアの前記第1のセットの前記指示を前記GPU内のコマンドプロセッサに送信することと、
シェーダコアの前記第2のセットの前記指示を前記GPU内の同じコマンドプロセッサに送信することと
を備える、C10に記載の方法。
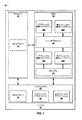
[C17]
複数のシェーダコアを含むシェーダプロセッサと、
グラフィックスアプリケーションの命令を実行するために確保された前記シェーダコアの第1のセットの指示を受信し、前記グラフィックスアプリケーションの前記命令を受信するように構成された第1のコマンドプロセッサと、
非グラフィックスアプリケーションの命令を実行するために確保された前記シェーダコアの第2の異なるセットの指示を受信し、前記非グラフィックスアプリケーションの前記命令を受信するように構成された第2のコマンドプロセッサと
を備えるグラフィックス処理ユニット(GPU)。
[C18]
前記第1のコマンドプロセッサが前記第2のコマンドプロセッサとは異なる、C17に記載のGPU。
[C19]
前記第1のコマンドプロセッサが前記第2のコマンドプロセッサと同じである、C17に記載のGPU。
[C20]
前記シェーダコアの前記第1のセットが、前記グラフィックスアプリケーションの前記命令を実行するように構成され、
前記グラフィックスアプリケーションの前記命令の前記実行と実質的に同時に、前記シェーダコアの前記第2のセットが、前記非グラフィックスアプリケーションの前記命令を実行するように構成された、C17に記載のGPU。
[C21]
シェーダコアの前記第1のセットが、前記非グラフィックスアプリケーションの命令を実行しないように構成され、
シェーダコアの前記第2のセットが、前記グラフィックスアプリケーションの命令を実行しないように構成された、C17に記載のGPU。
[C22]
前記第1のコマンドプロセッサは、前記第2のコマンドプロセッサが前記非グラフィックスアプリケーションの前記命令を受信するのと同時に前記グラフィックスアプリケーションの前記命令を受信するように構成された、C17に記載のGPU。
[C23]
前記シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するように構成された第1の作業負荷分配ユニットと、
前記シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するように構成された第2の異なる作業負荷分配ユニットと
をさらに備え、
前記シェーダコアの前記第1のセットが、前記第1の作業負荷分配ユニットの前記判断に基づいて前記グラフィックスアプリケーションの前記命令を実行するように構成され、
前記シェーダコアの前記第2のセットが、前記第2の作業負荷分配ユニットの前記判断に基づいて前記非グラフィックスアプリケーションの前記命令を実行するように構成された、C17に記載のGPU。
[C24]
メモリキャッシュ
をさらに備え、
前記第1のコマンドプロセッサおよび前記第2のコマンドプロセッサのうちの少なくとも1つが、前記メモリキャッシュへの前記グラフィックスアプリケーションの前記命令の前記実行の結果の記憶を前記メモリキャッシュへの前記非グラフィックスアプリケーションの前記命令の前記実行の結果の記憶よりも優先させるように構成された、C17に記載のGPU。
[C25]
前記GPUは、前記非グラフィックスアプリケーションの命令がないとき、前記第2のコマンドプロセッサの電源を切断するための指示を受信し、電源を切断するための前記指示の前記受信に応答して前記第2のコマンドプロセッサの電源を切断するように構成された、C17に記載のGPU。
[C26]
前記シェーダコアの前記第1のセットのシェーダコアの数が前記シェーダコアの前記第2のセットのシェーダコアの数とは異なる、C17に記載のGPU。
[C27]
シェーダコアの第1のセット上で実行されるべきグラフィックスアプリケーションのために確保された、グラフィックス処理ユニット(GPU)のシェーダプロセッサの前記シェーダコアの前記第1のセットを判断することと、
シェーダコアの第2の異なるセットによって実行されるべき非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの前記第2のセットを判断することと、
シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を行うように構成されたプロセッサ。
[C28]
前記プロセッサが、前記判断と前記GPUへの前記送信とを行うドライバを実行する、C27に記載のプロセッサ。
[C29]
前記プロセッサは、シェーダコアの前記第1のセットを判断するために、前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが前記グラフィックスアプリケーションのために確保されるべきかを判断し、シェーダコアの前記第2のセットを判断するために、前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが前記非グラフィックスアプリケーションのために確保されるべきかを判断するように構成された、C27に記載のプロセッサ。
[C30]
前記プロセッサは、シェーダコアの前記第1のセットがシェーダコアの前記第2のセットよりも多くのシェーダコアを含むと判断するように構成された、C27に記載のプロセッサ。
[C31]
前記プロセッサが、前記グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第1のセットを判断するように構成された、C27に記載のプロセッサ。
[C32]
前記プロセッサが、前記非グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第2のセットを判断するように構成された、C27に記載のプロセッサ。
[C33]
前記プロセッサが、
前記シェーダコアの前記第1のセットの前記指示を前記GPUの第1のコマンドプロセッサに送信することと、
前記シェーダコアの前記第2のセットの前記指示を前記GPUの第2の異なるコマンドプロセッサに送信することと
を行うように構成された、C27に記載のプロセッサ。
[C34]
前記プロセッサが、
前記シェーダコアの前記第1のセットの前記指示を前記GPUのコマンドプロセッサに送信することと、
前記シェーダコアの前記第2のセットの前記指示を前記GPUの同じコマンドプロセッサに送信することと
を行うように構成された、C27に記載のプロセッサ。
[C35]
グラフィックス処理ユニット(GPU)であって、
グラフィックスアプリケーションのために確保された、前記GPUのシェーダプロセッサのシェーダコアの第1のセットの指示を受信するための第1の手段と、
非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの第2の異なるセットの指示を受信するための第2の手段と、
前記グラフィックスアプリケーションの命令を受信するための第3の手段と、
前記非グラフィックスアプリケーションの命令を受信するための第4の手段と、
シェーダコアの前記第1のセットで前記グラフィックスアプリケーションの前記命令を実行するための手段と、
前記グラフィックスアプリケーションの前記命令を実行するのと同時に、シェーダコアの前記第2のセットで前記非グラフィックスアプリケーションの前記命令を実行するための手段と
を備えるGPU。
[C36]
受信するための前記第1の手段および受信するための前記第2の手段が、受信するための異なる手段を備える、C35に記載のGPU。
[C37]
1つまたは複数のプロセッサに、
グラフィックス処理ユニット(GPU)を用いて、グラフィックスアプリケーションのために確保された、前記GPUのシェーダプロセッサのシェーダコアの第1のセットの指示を受信することと、
前記GPUを用いて、非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの第2の異なるセットの指示を受信することと、
前記GPUを用いて、前記グラフィックスアプリケーションの命令を受信することと、
前記GPUを用いて、前記非グラフィックスアプリケーションの命令を受信することと、
前記GPUを用いて、シェーダコアの前記第1のセットで前記グラフィックスアプリケーションの前記命令を実行することと、
前記グラフィックスアプリケーションの前記命令を実行するのと同時に、前記GPUを用いて、シェーダコアの前記第2のセットで前記非グラフィックスアプリケーションの前記命令を実行することと
を行わせる命令を備えるコンピュータ可読記憶媒体。
[C38]
シェーダコアの前記第1のセットの前記指示を受信するための前記命令が、第1のコマンドプロセッサを用いてシェーダコアの前記第1のセットの前記指示を受信するための命令を備え、シェーダコアの前記第2のセットの前記指示を受信するための前記命令が、第2の異なるコマンドプロセッサを用いてシェーダコアの前記第2のセットの前記指示を受信するための命令を備える、C37に記載のコンピュータ可読記憶媒体。
[C39]
シェーダコアの第1のセット上で実行されるべきグラフィックスアプリケーションのために確保された、グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアの前記第1のセットを判断するための手段と、
シェーダコアの第2の異なるセットによって実行されるべき非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの前記第2のセットを判断するための手段と、
シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信するための手段と
を備えるプロセッサ。
[C40]
1つまたは複数のプロセッサに、
前記1つまたは複数のプロセッサ上のドライバを用いて、シェーダコアの第1のセット上で実行されるべきグラフィックスアプリケーションのために確保された、グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアの前記第1のセットを判断することと、
前記1つまたは複数のプロセッサ上の前記ドライバを用いて、シェーダコアの第2の異なるセットによって実行されるべき非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの前記第2のセットを判断することと、
シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を行わせる命令を備えるコンピュータ可読記憶媒体。
[C41]
プロセッサと、
グラフィックス処理ユニット(GPU)と
を備え、
前記プロセッサが、
シェーダコアの第1のセット上で実行されるべきグラフィックスアプリケーションのために確保された、前記GPUのシェーダプロセッサの前記シェーダコアの前記第1のセットを判断することと、
シェーダコアの第2の異なるセットによって実行されるべき非グラフィックスアプリケーションのために確保された、前記GPUの前記シェーダプロセッサのシェーダコアの前記第2のセットを判断することと、
シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を行うように構成され、
前記GPUが、
シェーダコアの前記第1のセットとシェーダコアの前記第2のセットとを含む複数のシェーダコアを含む前記シェーダプロセッサと、
前記グラフィックスアプリケーションの命令を実行するために確保された前記シェーダコアの前記第1のセットの前記指示を受信し、前記グラフィックスアプリケーションの前記命令を受信するように構成された第1のコマンドプロセッサと、
前記非グラフィックスアプリケーションの命令を実行するために確保された前記シェーダコアの前記第2の異なるセットの前記指示を受信し、前記非グラフィックスアプリケーションの前記命令を受信するように構成された第2のコマンドプロセッサと
を備える、装置。
Claims (34)
- グラフィックス処理ユニット(GPU)を用いて、グラフィックスアプリケーションの命令を実行するために確保された、前記GPUのシェーダプロセッサのシェーダコアの第1のセットの指示を受信することと、
前記GPUを用いて、非グラフィックスアプリケーションの命令を実行するために確保された、同じGPUの同じシェーダプロセッサのシェーダコアの第2の異なるセットの指示を受信することと、
前記GPUを用いて、前記グラフィックスアプリケーションの前記命令を受信することと、
前記GPUを用いて、前記非グラフィックスアプリケーションの前記命令を受信することと、
前記GPUの第1の作業負荷分配ユニットを用いて、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断することと、
前記GPUの第2の異なる作業負荷分配ユニットを用いて、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断することと、
前記GPUを用いて、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて、他のシェーダコアではなく、シェーダコアの前記第1のセットで前記グラフィックスアプリケーションの前記命令のすべてを実行することと、
前記グラフィックスアプリケーションの前記命令を実行するのと実質的に同時に、前記GPUを用いて、前記非グラフィックスアプリケーションの前記実行と前記グラフィックスアプリケーションの前記実行とをインターリーブすることなく、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて、他のシェーダコアではなく、シェーダコアの前記第2のセットで前記非グラフィックスアプリケーションの前記命令のすべてを実行することと
を備える方法。 - シェーダコアの前記第1のセットの前記指示を受信することが、前記GPUの第1のコマンドプロセッサを用いて、シェーダコアの前記第1のセットの前記指示を受信することを備え、シェーダコアの前記第2のセットの前記指示を受信することが、前記GPUの第2の異なるコマンドプロセッサを用いて、シェーダコアの前記第2のセットの前記指示を受信することを備える、請求項1に記載の方法。
- シェーダコアの前記第1のセットの前記指示を受信することが、前記GPUのコマンドプロセッサを用いて、シェーダコアの前記第1のセットの前記指示を受信することを備え、シェーダコアの前記第2のセットの前記指示を受信することが、同じコマンドプロセッサを用いて、シェーダコアの前記第2のセットの前記指示を受信することを備える、請求項1に記載の方法。
- 前記非グラフィックスアプリケーションの命令を受信することが、前記グラフィックスアプリケーションの命令を受信するのと同時に前記非グラフィックスアプリケーションの前記命令を受信することを備える、請求項1に記載の方法。
- 前記グラフィックスアプリケーションの前記命令の前記実行の結果を前記GPU内のメモリキャッシュに記憶することを、前記非グラフィックスアプリケーションの前記命令の前記実行の結果を前記GPU内の前記メモリキャッシュに記憶することよりも優先させること
をさらに備える、請求項1に記載の方法。 - シェーダコアの前記第1のセットの前記指示を受信することが、前記GPUの第1のコマンドプロセッサを用いて、シェーダコアの前記第1のセットの前記指示を受信することを備え、シェーダコアの前記第2のセットの前記指示を受信することが、前記GPUの第2の異なるコマンドプロセッサを用いて、シェーダコアの前記第2のセットの前記指示を受信することを備え、前記方法は、
前記非グラフィックスアプリケーションの命令がないとき、前記第2のコマンドプロセッサの電源を切断するための指示を受信することと、
前記指示を受信したことに応答して前記第2のコマンドプロセッサの電源を切断することと
をさらに備える、請求項1に記載の方法。 - シェーダコアの前記第1のセットのシェーダコアの数がシェーダコアの前記第2のセットのシェーダコアの数とは異なる、請求項1に記載の方法。
- プロセッサ上のドライバを用いて、グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアがグラフィックスアプリケーションのために確保されるかを判断することと、前記グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第1のセットを備え、前記グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第1のセット上で実行されるべきである、
前記プロセッサ上の前記ドライバを用いて、同じGPUの同じシェーダプロセッサの前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが非グラフィックスアプリケーションのために確保されるかを判断することと、前記非グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第2の異なるセットを備え、前記非グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第2のセットによって実行されるべきである、
前記GPUが、前記非グラフィックスアプリケーションと前記グラフィックスアプリケーションの前記実行をインターリーブすることなく、実質的に同時に前記グラフィックスアプリケーションの命令と前記非グラフィックスアプリケーションの命令とを実行することを可能にするために、シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を備える方法。 - より多くのシェーダコアが前記グラフィックスアプリケーションを実行するために利用可能であるように、シェーダコアの前記第1のセットがシェーダコアの前記第2のセットよりも多くのシェーダコアを含むと判断すること
をさらに備える、請求項8に記載の方法。 - シェーダコアの前記第1のセットを判断することが、前記グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第1のセットを判断することを備える、請求項8に記載の方法。
- シェーダコアの前記第2のセットを判断することが、前記非グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第2のセットを判断することを備える、請求項8に記載の方法。
- 送信することが、
シェーダコアの前記第1のセットの前記指示を前記GPU内の第1のコマンドプロセッサに送信することと、
シェーダコアの前記第2のセットの前記指示を前記GPU内の第2の異なるプロセッサに送信することと
を備える、請求項8に記載の方法。 - 送信することが、
シェーダコアの前記第1のセットの前記指示を前記GPU内のコマンドプロセッサに送信することと、
シェーダコアの前記第2のセットの前記指示を前記GPU内の同じコマンドプロセッサに送信することと
を備える、請求項8に記載の方法。 - 複数のシェーダコアを含むシェーダプロセッサと、
グラフィックスアプリケーションの命令を実行するために確保された前記シェーダプロセッサの前記シェーダコアの第1のセットの指示を受信し、前記グラフィックスアプリケーションの前記命令を受信するように構成された第1のコマンドプロセッサと、
非グラフィックスアプリケーションの命令を実行するために確保された同じシェーダプロセッサの前記シェーダコアの第2の異なるセットの指示を受信し、前記非グラフィックスアプリケーションの前記命令を受信するように構成された第2のコマンドプロセッサと、
前記シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するように構成された第1の作業負荷分配ユニットと、
前記シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するように構成された第2の異なる作業負荷分配ユニットと、
を備え、
他のシェーダコアではなく、前記シェーダコアの前記第1のセットが、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記第1の作業負荷分配ユニットの前記判断に基づいて、前記グラフィックスアプリケーションの前記命令のすべてを実行するように構成され、
他のシェーダコアではなく、前記シェーダコアの前記第2のセットが、前記グラフィックスアプリケーションの前記命令の前記実行と実質的に同時に、前記非グラフィックスアプリケーションの前記実行と前記グラフィックスアプリケーションの前記実行とをインターリーブすることなく、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記第2の作業負荷分配ユニットの前記判断に基づいて、前記非グラフィックスアプリケーションの前記命令のすべてを実行するように構成された、
グラフィックス処理ユニット(GPU)。 - 前記第1のコマンドプロセッサが前記第2のコマンドプロセッサとは異なる、請求項14に記載のGPU。
- 前記第1のコマンドプロセッサが前記第2のコマンドプロセッサと同じである、請求項14に記載のGPU。
- 前記第1のコマンドプロセッサは、前記第2のコマンドプロセッサが前記非グラフィックスアプリケーションの前記命令を受信するのと同時に前記グラフィックスアプリケーションの前記命令を受信するように構成された、請求項14に記載のGPU。
- メモリキャッシュ
をさらに備え、
前記第1のコマンドプロセッサおよび前記第2のコマンドプロセッサのうちの少なくとも1つが、前記メモリキャッシュへの前記グラフィックスアプリケーションの前記命令の前記実行の結果の記憶を、前記メモリキャッシュへの前記非グラフィックスアプリケーションの前記命令の前記実行の結果の記憶よりも優先させるように構成された、請求項14に記載のGPU。 - 前記GPUは、前記非グラフィックスアプリケーションの命令がないとき、前記第2のコマンドプロセッサの電源を切断するための指示を受信し、電源を切断するための前記指示の前記受信に応答して前記第2のコマンドプロセッサの電源を切断するように構成された、請求項14に記載のGPU。
- 前記シェーダコアの前記第1のセットのシェーダコアの数が前記シェーダコアの前記第2のセットのシェーダコアの数とは異なる、請求項14に記載のGPU。
- グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアがグラフィックスアプリケーションのために確保されるかを判断することと、前記グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第1のセットを備え、前記グラフィックスアプリケーションのすべての命令は、前記シェーダコアの前記第1のセット上で実行されるべきである、
同じGPUの同じシェーダプロセッサの前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが非グラフィックスアプリケーションのために確保されるかを判断することと、前記非グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第2の異なるセットを備え、前記非グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第2のセットによって実行されるべきである、
前記GPUが、前記非グラフィックスアプリケーションと前記グラフィックスアプリケーションの前記実行をインターリーブすることなく、実質的に同時に前記グラフィックスアプリケーションの命令と前記非グラフィックスアプリケーションの命令とを実行することを可能にするために、シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を行うように構成されたプロセッサ。 - 前記プロセッサが、前記判断と前記GPUへの前記送信とを行うドライバを実行する、請求項21に記載のプロセッサ。
- 前記プロセッサは、より多くのシェーダコアが前記グラフィックスアプリケーションを実行するために利用可能であるように、シェーダコアの前記第1のセットがシェーダコアの前記第2のセットよりも多くのシェーダコアを含むと判断するように構成された、請求項21に記載のプロセッサ。
- 前記プロセッサが、前記グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第1のセットを判断するように構成された、請求項21に記載のプロセッサ。
- 前記プロセッサが、前記非グラフィックスアプリケーションのキューイングされた命令の数に基づいてシェーダコアの前記第2のセットを判断するように構成された、請求項21に記載のプロセッサ。
- 前記プロセッサが、
前記シェーダコアの前記第1のセットの前記指示を前記GPUの第1のコマンドプロセッサに送信することと、
前記シェーダコアの前記第2のセットの前記指示を前記GPUの第2の異なるコマンドプロセッサに送信することと
を行うように構成された、請求項21に記載のプロセッサ。 - 前記プロセッサが、
前記シェーダコアの前記第1のセットの前記指示を前記GPUのコマンドプロセッサに送信することと、
前記シェーダコアの前記第2のセットの前記指示を前記GPUの同じコマンドプロセッサに送信することと
を行うように構成された、請求項21に記載のプロセッサ。 - グラフィックス処理ユニット(GPU)であって、
グラフィックスアプリケーションの命令を実行するために確保された、前記GPUのシェーダプロセッサのシェーダコアの第1のセットの指示を受信するための第1の手段と、
非グラフィックスアプリケーションの命令を実行するために確保された、同じGPUの同じシェーダプロセッサのシェーダコアの第2の異なるセットの指示を受信するための第2の手段と、
前記グラフィックスアプリケーションの前記命令を受信するための第3の手段と、
前記非グラフィックスアプリケーションの前記命令を受信するための第4の手段と、
シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するための手段と、
シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するための手段と、
シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて、他のシェーダコアではなく、シェーダコアの前記第1のセットで前記グラフィックスアプリケーションの前記命令のすべてを実行するための手段と、
前記グラフィックスアプリケーションの前記命令を実行するのと同時に、前記非グラフィックスアプリケーションの前記実行と前記グラフィックスアプリケーションの前記実行とをインターリーブすることなく、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて、他のシェーダコアではなく、シェーダコアの前記第2のセットで前記非グラフィックスアプリケーションの前記命令のすべてを実行するための手段と
を備えるGPU。 - 受信するための前記第1の手段および受信するための前記第2の手段が、受信するための異なる手段を備える、請求項28に記載のGPU。
- グラフィックス処理ユニット(GPU)に、
前記GPUを用いて、グラフィックスアプリケーションの命令を実行するために確保された、前記GPUのシェーダプロセッサのシェーダコアの第1のセットの指示を受信することと、
前記GPUを用いて、非グラフィックスアプリケーションの命令を実行するために確保された、同じGPUの同じシェーダプロセッサのシェーダコアの第2の異なるセットの指示を受信することと、
前記GPUを用いて、前記グラフィックスアプリケーションの前記命令を受信することと、
前記GPUを用いて、前記非グラフィックスアプリケーションの前記命令を受信することと、
前記GPUの第1の作業負荷分配ユニットを用いて、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断することと、
前記GPUの第2の異なる作業負荷分配ユニットを用いて、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断することと、
前記GPUを用いて、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて、他のシェーダコアではなく、シェーダコアの前記第1のセットで前記グラフィックスアプリケーションの前記命令のすべてを実行することと、
前記グラフィックスアプリケーションの前記命令を実行するのと同時に、前記GPUを用いて、前記非グラフィックスアプリケーションの前記実行と前記グラフィックスアプリケーションの前記実行とをインターリーブすることなく、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記判断に基づいて、他のシェーダコアではなく、シェーダコアの前記第2のセットで前記非グラフィックスアプリケーションの前記命令のすべてを実行することと
を行わせる命令を備える、非一時的コンピュータ可読記憶媒体。 - シェーダコアの前記第1のセットの前記指示を受信するための前記命令が、第1のコマンドプロセッサを用いてシェーダコアの前記第1のセットの前記指示を受信するための命令を備え、シェーダコアの前記第2のセットの前記指示を受信するための前記命令が、第2の異なるコマンドプロセッサを用いてシェーダコアの前記第2のセットの前記指示を受信するための命令を備える、請求項30に記載の非一時的コンピュータ可読記憶媒体。
- グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアがグラフィックスアプリケーションのために確保されるかを判断するための手段と、前記グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第1のセットを備え、前記グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第1のセット上で実行されるべきである、
同じGPUの同じシェーダプロセッサの前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが非グラフィックスアプリケーションのために確保されるかを判断するための手段と、前記非グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第2の異なるセットを備え、前記非グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第2のセットによって実行されるべきである、
前記GPUが、前記非グラフィックスアプリケーションと前記グラフィックスアプリケーションの前記実行をインターリーブすることなく、実質的に同時に前記グラフィックスアプリケーションの命令と前記非グラフィックスアプリケーションの命令とを実行することを可能にするために、シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信するための手段と
を備えるプロセッサ。 - 1つまたは複数のプロセッサに、
前記1つまたは複数のプロセッサ上のドライバを用いて、グラフィックス処理ユニット(GPU)のシェーダプロセッサのシェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアがグラフィックスアプリケーションのために確保されるかを判断することと、前記グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第1のセットを備え、前記グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第1のセット上で実行されるべきである、
前記1つまたは複数のプロセッサ上の前記ドライバを用いて、同じGPUの同じシェーダプロセッサの前記シェーダコアのうちのいくつのシェーダコアおよびどのシェーダコアが非グラフィックスアプリケーションのために確保されるかを判断することと、前記非グラフィックスアプリケーションのために確保された前記判断されたシェーダコアは、シェーダコアの第2の異なるセットを備え、前記非グラフィックスアプリケーションのすべての命令は、シェーダコアの前記第2のセットによって実行されるべきである、
前記GPUが、前記非グラフィックスアプリケーションと前記グラフィックスアプリケーションの前記実行をインターリーブすることなく、実質的に同時に前記グラフィックスアプリケーションの命令と前記非グラフィックスアプリケーションの命令とを実行することを可能にするために、シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を行わせる命令を備える、非一時的コンピュータ可読記憶媒体。 - プロセッサと、
グラフィックス処理ユニット(GPU)と
を備え、
前記プロセッサが、
シェーダコアの第1のセット上で実行されるべきグラフィックスアプリケーションのために確保された、前記GPUのシェーダプロセッサの前記シェーダコアの前記第1のセットを判断することと、
シェーダコアの第2の異なるセットによって実行されるべき非グラフィックスアプリケーションのために確保された、同じGPUの同じシェーダプロセッサのシェーダコアの前記第2のセットを判断することと、
前記GPUが、互いに干渉せずに実質的に同時に前記グラフィックスアプリケーションの命令と前記非グラフィックスアプリケーションの命令とを実行することを可能にするために、シェーダコアの前記第1のセットの指示とシェーダコアの前記第2のセットの指示とを前記GPUに送信することと
を行うように構成され、
前記GPUが、
シェーダコアの前記第1のセットとシェーダコアの前記第2のセットとを含む複数のシェーダコアを含む前記シェーダプロセッサと、
前記グラフィックスアプリケーションの命令を実行するために確保された前記シェーダコアの前記第1のセットの前記指示を受信し、前記グラフィックスアプリケーションの前記命令を受信するように構成された第1のコマンドプロセッサと、
前記非グラフィックスアプリケーションの命令を実行するために確保された前記シェーダコアの前記第2の異なるセットの前記指示を受信し、前記非グラフィックスアプリケーションの前記命令を受信するように構成された第2のコマンドプロセッサと
前記シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するように構成された第1の作業負荷分配ユニットと、
前記シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかを判断するように構成された第2の異なる作業負荷分配ユニットと、
を備え、
他のシェーダコアではなく、前記シェーダコアの前記第1のセットが、シェーダコアの前記第1のセットのうちのどのシェーダコアが前記グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記第1の作業負荷分配ユニットの前記判断に基づいて、前記グラフィックスアプリケーションの前記命令のすべてを実行するように構成され、
他のシェーダコアではなく、前記シェーダコアの前記第2のセットが、前記グラフィックスアプリケーションの前記命令の前記実行と実質的に同時に、前記非グラフィックスアプリケーションの前記実行と前記グラフィックスアプリケーションの前記実行とをインターリーブすることなく、シェーダコアの前記第2のセットのうちのどのシェーダコアが前記非グラフィックスアプリケーションの前記命令のうちのどの命令を実行するかの前記第2の作業負荷分配ユニットの前記判断に基づいて、前記非グラフィックスアプリケーションの前記命令のすべてを実行するように構成された、装置。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/414,450 US9019289B2 (en) | 2012-03-07 | 2012-03-07 | Execution of graphics and non-graphics applications on a graphics processing unit |
| US13/414,450 | 2012-03-07 | ||
| PCT/US2013/026596 WO2013133957A1 (en) | 2012-03-07 | 2013-02-18 | Execution of graphics and non-graphics applications on a graphics processing unit |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2015515052A JP2015515052A (ja) | 2015-05-21 |
| JP2015515052A5 JP2015515052A5 (ja) | 2015-07-30 |
| JP5792402B2 true JP5792402B2 (ja) | 2015-10-14 |
Family
ID=47833377
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014560926A Active JP5792402B2 (ja) | 2012-03-07 | 2013-02-18 | グラフィックス処理ユニット上でのグラフィックスアプリケーションおよび非グラフィックスアプリケーションの実行 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US9019289B2 (ja) |
| EP (1) | EP2823459B1 (ja) |
| JP (1) | JP5792402B2 (ja) |
| KR (1) | KR101552079B1 (ja) |
| CN (1) | CN104160420B (ja) |
| ES (1) | ES2572555T3 (ja) |
| HU (1) | HUE027044T2 (ja) |
| WO (1) | WO2013133957A1 (ja) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102007054876A1 (de) * | 2006-11-22 | 2008-06-19 | Sms Demag Ag | Verfahren und Vorrichtung zur Wärmebehandlung von Schweißnähten |
| US10817043B2 (en) * | 2011-07-26 | 2020-10-27 | Nvidia Corporation | System and method for entering and exiting sleep mode in a graphics subsystem |
| US10198788B2 (en) * | 2013-11-11 | 2019-02-05 | Oxide Interactive Llc | Method and system of temporally asynchronous shading decoupled from rasterization |
| CN105786449B (zh) * | 2014-12-26 | 2018-07-24 | 龙芯中科技术有限公司 | 基于图形处理的指令调度方法及装置 |
| US20160210231A1 (en) * | 2015-01-21 | 2016-07-21 | Mediatek Singapore Pte. Ltd. | Heterogeneous system architecture for shared memory |
| US20160260246A1 (en) * | 2015-03-02 | 2016-09-08 | Advanced Micro Devices, Inc. | Providing asynchronous display shader functionality on a shared shader core |
| US9799089B1 (en) * | 2016-05-23 | 2017-10-24 | Qualcomm Incorporated | Per-shader preamble for graphics processing |
| US20180033114A1 (en) * | 2016-07-26 | 2018-02-01 | Mediatek Inc. | Graphics Pipeline That Supports Multiple Concurrent Processes |
| US10417731B2 (en) * | 2017-04-24 | 2019-09-17 | Intel Corporation | Compute optimization mechanism for deep neural networks |
| US10417734B2 (en) | 2017-04-24 | 2019-09-17 | Intel Corporation | Compute optimization mechanism for deep neural networks |
| US11037356B2 (en) | 2018-09-24 | 2021-06-15 | Zignal Labs, Inc. | System and method for executing non-graphical algorithms on a GPU (graphics processing unit) |
| US10861126B1 (en) | 2019-06-21 | 2020-12-08 | Intel Corporation | Asynchronous execution mechanism |
| US11436783B2 (en) | 2019-10-16 | 2022-09-06 | Oxide Interactive, Inc. | Method and system of decoupled object space shading |
| US11282160B2 (en) * | 2020-03-12 | 2022-03-22 | Cisco Technology, Inc. | Function-as-a-service (FaaS) model for specialized processing units |
| GB2600712B (en) * | 2020-11-04 | 2024-08-28 | Advanced Risc Mach Ltd | Data processing systems |
| JP2022187116A (ja) * | 2021-06-07 | 2022-12-19 | 富士通株式会社 | 多重制御プログラム、情報処理装置および多重制御方法 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070204268A1 (en) | 2006-02-27 | 2007-08-30 | Red. Hat, Inc. | Methods and systems for scheduling processes in a multi-core processor environment |
| WO2008021310A2 (en) | 2006-08-14 | 2008-02-21 | Wms Gaming Inc. | Applying graphical characteristics to graphical objects in a wagering game machine |
| US20090305790A1 (en) * | 2007-01-30 | 2009-12-10 | Vitie Inc. | Methods and Apparatuses of Game Appliance Execution and Rendering Service |
| US8922565B2 (en) | 2007-11-30 | 2014-12-30 | Qualcomm Incorporated | System and method for using a secondary processor in a graphics system |
| WO2009085063A1 (en) | 2007-12-21 | 2009-07-09 | Studio Gpu, Inc. | Method and system for fast rendering of a three dimensional scene |
| DE102008005124A1 (de) | 2008-01-18 | 2009-07-23 | Kuka Roboter Gmbh | Computersystem, Steuerungsvorrichtung für eine Maschine, insbesondere für einen Industrieroboter, und Industrieroboter |
| WO2011023204A1 (en) | 2009-08-24 | 2011-03-03 | Abb Research Ltd. | Simulation of distributed virtual control systems |
| US8310492B2 (en) * | 2009-09-03 | 2012-11-13 | Ati Technologies Ulc | Hardware-based scheduling of GPU work |
| US9142057B2 (en) | 2009-09-03 | 2015-09-22 | Advanced Micro Devices, Inc. | Processing unit with a plurality of shader engines |
| US20110063309A1 (en) * | 2009-09-16 | 2011-03-17 | Nvidia Corporation | User interface for co-processing techniques on heterogeneous graphics processing units |
| US20110212761A1 (en) | 2010-02-26 | 2011-09-01 | Igt | Gaming machine processor |
| EP2383648B1 (en) * | 2010-04-28 | 2020-02-19 | Telefonaktiebolaget LM Ericsson (publ) | Technique for GPU command scheduling |
| US9311102B2 (en) * | 2010-07-13 | 2016-04-12 | Advanced Micro Devices, Inc. | Dynamic control of SIMDs |
| US20120229481A1 (en) * | 2010-12-13 | 2012-09-13 | Ati Technologies Ulc | Accessibility of graphics processing compute resources |
| US20130141447A1 (en) * | 2011-12-06 | 2013-06-06 | Advanced Micro Devices, Inc. | Method and Apparatus for Accommodating Multiple, Concurrent Work Inputs |
-
2012
- 2012-03-07 US US13/414,450 patent/US9019289B2/en active Active
-
2013
- 2013-02-18 HU HUE13707979A patent/HUE027044T2/en unknown
- 2013-02-18 WO PCT/US2013/026596 patent/WO2013133957A1/en active Application Filing
- 2013-02-18 JP JP2014560926A patent/JP5792402B2/ja active Active
- 2013-02-18 KR KR1020147027883A patent/KR101552079B1/ko active IP Right Grant
- 2013-02-18 CN CN201380012480.7A patent/CN104160420B/zh active Active
- 2013-02-18 EP EP13707979.4A patent/EP2823459B1/en active Active
- 2013-02-18 ES ES13707979.4T patent/ES2572555T3/es active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US9019289B2 (en) | 2015-04-28 |
| US20130235053A1 (en) | 2013-09-12 |
| HUE027044T2 (en) | 2016-08-29 |
| CN104160420A (zh) | 2014-11-19 |
| WO2013133957A1 (en) | 2013-09-12 |
| KR20140138842A (ko) | 2014-12-04 |
| EP2823459A1 (en) | 2015-01-14 |
| JP2015515052A (ja) | 2015-05-21 |
| ES2572555T3 (es) | 2016-06-01 |
| KR101552079B1 (ko) | 2015-09-09 |
| CN104160420B (zh) | 2016-08-24 |
| EP2823459B1 (en) | 2016-02-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5792402B2 (ja) | グラフィックス処理ユニット上でのグラフィックスアプリケーションおよび非グラフィックスアプリケーションの実行 | |
| KR101707289B1 (ko) | 그래픽 병렬 처리 유닛에 대한 버퍼 관리 | |
| JP6136033B2 (ja) | 方法、コンピューティングデバイス、およびプログラム | |
| TWI622015B (zh) | 用於處理單元之以訊框為基礎之時脈速率調整 | |
| JP2018533112A (ja) | コマンドストリームヒントを使用したgpu作業負荷の特徴づけおよび電力管理 | |
| US20170053374A1 (en) | REGISTER SPILL MANAGEMENT FOR GENERAL PURPOSE REGISTERS (GPRs) | |
| CN111737019B (zh) | 一种显存资源的调度方法、装置及计算机存储介质 | |
| US9779473B2 (en) | Memory mapping for a graphics processing unit | |
| US20170116701A1 (en) | Gpu operation algorithm selection based on command stream marker | |
| KR102521654B1 (ko) | 컴퓨팅 시스템 및 컴퓨팅 시스템에서 타일-기반 렌더링의 그래픽스 파이프라인을 수행하는 방법 | |
| KR102223446B1 (ko) | 비특권 애플리케이션에 의한 그래픽 작업부하 실행의뢰 | |
| WO2021236263A1 (en) | Gpr optimization in a gpu based on a gpr release mechanism | |
| US11055808B2 (en) | Methods and apparatus for wave slot management | |
| US9489707B2 (en) | Sampler load balancing | |
| TW202341063A (zh) | 動態波配對 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150612 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150612 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20150612 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20150630 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20150707 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150805 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5792402 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |