JP5737909B2 - Image processing apparatus, image processing method, and program - Google Patents
Image processing apparatus, image processing method, and program Download PDFInfo
- Publication number
- JP5737909B2 JP5737909B2 JP2010250207A JP2010250207A JP5737909B2 JP 5737909 B2 JP5737909 B2 JP 5737909B2 JP 2010250207 A JP2010250207 A JP 2010250207A JP 2010250207 A JP2010250207 A JP 2010250207A JP 5737909 B2 JP5737909 B2 JP 5737909B2
- Authority
- JP
- Japan
- Prior art keywords
- dictionary
- recognition
- face
- image
- dictionaries
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images










Landscapes
- Image Processing (AREA)
- Closed-Circuit Television Systems (AREA)
- Studio Devices (AREA)
- Image Analysis (AREA)
Description
本発明は、カメラから取得されるフレーム画像等から物体を認識する技術に関するものである。 The present invention relates to a technique for recognizing an object from a frame image or the like acquired from a camera.
従来より、店舗等の入り口や通路を通行する人をカメラで撮影し、撮影した映像より人物の顔の位置を検出して、通過した人数を計測したり、予め登録されている人物の顔であるかを認識したりする技術が開示されている。 Conventionally, a person passing through an entrance or a passage of a store is photographed with a camera, the position of a person's face is detected from the photographed image, and the number of people passing is measured, or a person's face registered in advance A technique for recognizing whether or not there is disclosed.
このような所定領域における通行人をカメラ映像から自動的にカウントする技術としては、例えば、下記の特許文献1がある。この特許文献1では、通路の上方から真下に向けてカメラを設置する。カメラ上方から見た人物の頭の形状が円であることから、カメラ映像から円形の物体を抽出することで人物を検知、カウントするようにしている。 As a technique for automatically counting passers-by in such a predetermined area from a camera video, for example, there is Patent Document 1 below. In this patent document 1, a camera is installed from the upper side of the passage toward directly below. Since the shape of the head of the person viewed from above the camera is a circle, the person is detected and counted by extracting a circular object from the camera image.
一方、近年、画像から顔を検出する技術の実用化が進んでいる。このような技術を利用して、後述する図1に示すように通路の前方にカメラを設置して、カメラ映像から顔を検出することで人物をカウントすることも可能である。 On the other hand, in recent years, a technique for detecting a face from an image has been put into practical use. Using such a technique, it is possible to count a person by installing a camera in front of the passage and detecting a face from the camera image as shown in FIG.
ここで、カメラが広い範囲を撮影するほど、カメラと人物の位置関係で、顔の向きが異なって撮影されることになる。そして、顔の向きが変化すると、顔の特徴が異なってくる。従って、認識が困難になる。 Here, the more the camera captures a wider area, the more the face is photographed depending on the positional relationship between the camera and the person. And if the orientation of the face changes, the facial features will change. Therefore, recognition becomes difficult.
この課題に対応するために、下記の特許文献2では、顔の向きに応じて認識辞書を用意し、フレーム画像を複数の領域に分け、それぞれの領域で適用する認識辞書を変更していた。ここで、例として図11の場合を挙げる。 In order to cope with this problem, in Patent Document 2 below, a recognition dictionary is prepared according to the orientation of the face, the frame image is divided into a plurality of regions, and the recognition dictionary applied in each region is changed. Here, the case of FIG. 11 is given as an example.
図11は、カメラからの距離に応じて撮影される顔の向きが異なることを説明する模式図である。
図11において、1101は通路の天井であり、1102は床である。1103がカメラであり、天井1101に設置され、通路を斜め上より撮影している。1104のようにカメラ1103から遠い位置に人物がいた場合、撮影された顔の垂直方向の向きは小さい角度になるが、1105のようにカメラ1103から近い位置に人物がいた場合、顔の垂直方向の向きは大きな角度になる。
FIG. 11 is a schematic diagram for explaining that the orientation of the face to be photographed varies depending on the distance from the camera.
In FIG. 11, 1101 is the ceiling of the passage, and 1102 is the floor.
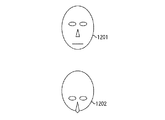
図12は、顔の特徴が見え方によって変化することを説明する模式図である。
1201が、人物1104のようにカメラ1103から遠い位置に人物がいる時であり、1202が、人物1105のようにカメラ1103に近い位置に人物がいるときである。この図12からもわかるように、顔の特徴が見え方によって変化する。
FIG. 12 is a schematic diagram for explaining that facial features change depending on how they are seen.
1201 is when a person is far from the
図13は、従来技術による課題を説明するための模式図である。
そこで、図13のように、フレーム画像1301を、1302と1303の2つの領域に分け、1302の領域に対しては角度が小さい顔を認識する辞書を用い、1303の領域に対しては角度が大きな顔を認識する辞書を用いるようにしている。即ち、前記例において、1304が、人物1104の位置に人物がいるときに認識される顔のフレーム画像内の位置であり、認識辞書は角度が小さい顔用の辞書が用いられる。また、1305が、人物1105の位置に人物がいるときに認識される顔のフレーム画像内の位置であり、認識辞書は角度が大きい顔用の辞書が用いられる。
FIG. 13 is a schematic diagram for explaining a problem due to the prior art.
Therefore, as shown in FIG. 13, the
しかしながら、特許文献2では、各認識辞書を適用する領域の境界にあたる位置に顔があると認識が難しくなる。前述の例では、図13の1306の位置に顔があるような場合である。このような位置での顔の角度は、中間的な角度となる。つまり、角度が小さい顔用の辞書からも、角度が大きい顔用の辞書からも、その特徴の変動が最も大きくなる。従って、どちらの認識辞書を用いても認識精度が低くなってしまう傾向にあるため、認識が難しくなるのである。
However, in Patent Document 2, it is difficult to recognize if there is a face at a position corresponding to the boundary of a region to which each recognition dictionary is applied. In the above example, there is a case where a face exists at the
本発明は、このような問題点に鑑みてなされたものであり、認識する物体の向きが画面内で変化する場合であっても、精度良く物体を認識することができる仕組みを提供することを目的とする。 The present invention has been made in view of such problems, and provides a mechanism that can accurately recognize an object even when the direction of the object to be recognized changes within the screen. Objective.
前述した目的を達成するために、本発明は、同一の物体の異なる方向に対応した複数の辞書のデータを格納する辞書記憶手段と、前記複数の辞書のそれぞれに対してフレーム画像における適用領域を、少なくとも2つの辞書の適用領域に重複する領域を含んで設定する設定手段と、前記複数の辞書のそれぞれを用いて当該辞書に対して設定された適用領域において前記物体を認識する認識手段とを備え、前記認識手段は、少なくとも2つの辞書で重複する適用領域に対して、連続する複数のフレーム画像においてフレーム画像ごとに使用する辞書を切り替え、そのフレーム画像ごとの認識結果を統合することを特徴とする画像処理装置等、を提供する。 In order to achieve the above-described object, the present invention provides dictionary storage means for storing data of a plurality of dictionaries corresponding to different directions of the same object, and an application area in a frame image for each of the plurality of dictionaries. Setting means for setting an area that overlaps application areas of at least two dictionaries; and recognition means for recognizing the object in the application area set for the dictionary using each of the plurality of dictionaries. And the recognition means switches the dictionary to be used for each frame image in a plurality of consecutive frame images with respect to an application region that overlaps at least two dictionaries, and integrates the recognition results for each frame image. An image processing apparatus is provided.
本発明によれば、認識する物体の向きが画面内で変化する場合であっても、精度良く物体を認識することができる。 According to the present invention, an object can be recognized with high accuracy even when the direction of the recognized object changes in the screen.
以下に、図面を参照しながら、本発明を実施するための形態(実施形態)について説明する。 Hereinafter, embodiments (embodiments) for carrying out the present invention will be described with reference to the drawings.
なお、以下に挙げる実施形態は、通路を通過する人数を計測する例で説明する。
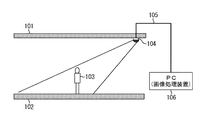
図1は、本発明の実施形態に係る画像処理装置の設置例を示す模式図である。
101は、通路の天井であり、102は通路の床である。103は通路を通行している人物である。104は撮像部(カメラ)であり、人物103を斜め上から撮影できるように、天井101に設置してある。105はLANケーブルであり、撮像部104で撮像される映像を送信する。106は、映像を解析し、計数する画像処理装置となるPCである。
In addition, embodiment mentioned below demonstrates by the example which measures the number of people who pass a passage.
FIG. 1 is a schematic diagram illustrating an installation example of an image processing apparatus according to an embodiment of the present invention.
101 is the ceiling of the passage and 102 is the floor of the passage.
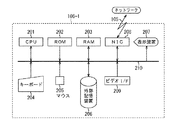
図2は、本発明の実施形態に係る画像処理装置106のハードウェア構成の一例を示すブロック図である。
図2において、201はCPUであり、本実施形態の画像処理装置106における各種制御を実行する。202はROMであり、本画像処理装置106の立ち上げ時に実行されるブートプログラムや各種データを格納する。203はRAMであり、CPU201が処理するための制御プログラムを格納するとともに、CPU201が各種制御を実行する際の作業領域を提供する。204はキーボード、205はマウスであり、ユーザによる各種入力操作環境を提供する。
FIG. 2 is a block diagram illustrating an example of a hardware configuration of the
In FIG. 2,
206は外部記憶装置であり、ハードディスクやフレキシブルディスク、光ディスク、磁気ディスク、光磁気ディスク、磁気テープ等で構成される。ただし、外部記憶装置206は、制御プログラムや各種データを全てROM202に持つようにすれば、必ずしも必要な構成要素ではない。本実施形態においては、本発明の処理に係る制御プログラムは、ROM202(或いは外部記憶装置206)に格納されているものとする。
207は表示装置であり、ディスプレイなどで構成され、結果等をユーザに対して表示する。208はネットワークインターフェース(NIC)であり、ネットワーク上の撮像部104とLANケーブル105を介した通信を可能とする。209はビデオインターフェース(ビデオI/F)であり、撮像部104と同軸ケーブルを解したフレーム画像の取り込みを可能とする。また、210は上記の各構成を接続するバスである。
図3は、本発明の実施形態に係る画像処理装置106の機能構成の一例を示すブロック図である。
10は、撮像レンズ、及び、CCD、CMOSなどの撮像センサからなる撮像手段である。この撮像手段10は、図1の撮像部104に相当するものである。
FIG. 3 is a block diagram illustrating an example of a functional configuration of the
30は、画像取得手段であり、撮像手段10で撮像した画像データを所定時間間隔で取得し、時間的に連続した複数フレーム単位で出力する。フレーム画像は、撮像部104から、LANケーブル105を介してhttpプロトコルのパケットデータとして送られ、画像処理装置106上のネットワークインターフェース208を介して取得する。或いは、105を同軸ケーブルで構成し、画像処理装置106上のビデオインターフェース209で取得するようにしてもよい。
40は、物体認識手段であり、画像取得手段30で取得した画像データに所望の物体が映っているかどうかを認識処理する。具体的に、物体認識手段40は、物体に係る辞書を用いて所定方向の物体を認識する処理を行う。
50は、認識結果分析・出力手段であり、物体認識手段40で認識した結果を分析し、分析した結果を、例えば、表示装置207に表示するように出力する。
60は、物体辞書記憶手段であり、物体認識手段40で用いる所望の認識対象に対応する物体辞書を記憶したメモリである。具体的に、物体辞書記憶手段60は、同一の物体の異なる方向に対応した複数の辞書のデータを格納する。物体辞書は、数多くの所定方向の物体パターンから機械学習により予め求められたものである。外部記憶装置206に記憶され、プログラムの起動時などにRAM203に読み込まれる。なお、本実施形態では、顔の垂直方向の角度に応じた、複数の認識辞書を用意しているものとする。もちろん、角度が異なる方向(水平方向等)の角度に応じて認識辞書を分けてもよいが、説明を簡単にするために、以降、垂直方向の角度に応じた認識辞書の例で説明する。
70は、辞書・照合領域設定手段であり、物体辞書記憶手段60に記憶されている複数の認識辞書から使用する認識辞書の選択と、選択された認識辞書を切替えて使用して照合を行ってフレーム画像内の領域ごとに物体認識手段40に設定する。即ち、辞書・照合領域設定手段70は、フレーム画像の領域ごとに複数の辞書を切り替えて物体認識手段40に適用する切替え手段を構成する。
80は、辞書適用領域決定手段であり、物体辞書記憶手段60に記憶された認識辞書に対するフレーム画像内の照合領域を決定する。
90は、辞書適用領域記憶手段あり、辞書適用領域決定手段80で決定された認識辞書に対するフレーム画像内の照合領域を記憶する。
図3の画像取得手段30、物体認識手段40、辞書・照合領域設定手段70、辞書適用領域決定手段80は、例えば、図2のCPU201及びROM202(或いは外部記憶装置206)に格納されている制御プログラム、並びにRAM203から構成されている。また、認識結果分析・出力手段50は、例えば、図2のCPU201及びROM202(或いは外部記憶装置206)に格納されている制御プログラム、RAM203、並びに、表示装置207から構成されている。また、物体辞書記憶手段60、辞書適用領域記憶手段90は、例えば、図2の外部記憶装置に構成される。
The image acquisition means 30, the object recognition means 40, the dictionary / collation area setting means 70, and the dictionary application area determination means 80 in FIG. 3 are, for example, controls stored in the
図4は、本発明の実施形態に係る画像処理装置106による画像処理方法の処理手順の一例を示すフローチャートである。
FIG. 4 is a flowchart showing an example of the processing procedure of the image processing method by the
まず、ステップS400において、辞書適用領域決定手段80は、フレーム画像内で適用できる、顔の角度の範囲が異なる複数の認識辞書のそれぞれが適用できる領域を決定する。これは、フレーム画像内の顔の位置と、その位置に顔が存在するときの顔の角度との関係より決定できる。なお、本実施形態では、垂直方向の角度であるものとして説明する。
First, in step S400, the dictionary application
顔の角度は、人物が直立しているときの水平方向を0度として現される、図5のΘとして示した角度である。
図5は、本発明の実施形態を示し、顔の角度を説明する模式図である。
ここで、図5の501は通路の天井、502は通路の床、503は撮像部(カメラ)、504は人物である。
The angle of the face is an angle shown as Θ in FIG. 5 expressed as 0 degrees in the horizontal direction when the person is standing upright.
FIG. 5 is a schematic diagram illustrating an embodiment of the present invention and explaining a face angle.
Here, 501 in FIG. 5 is a ceiling of the passage, 502 is a floor of the passage, 503 is an imaging unit (camera), and 504 is a person.
図5にも示している通り、Θは天井に沿った直線と、カメラ503から人物504の顔まで引いた直線(図5の実線)とのなす角に等しい。従って、カメラ503から人物504までの距離(図5中のX)と(カメラ503の地面からの高さ−顔の地面からの高さ)(図5中のY)を求めることにより、Θは、以下の数式(1)で求めることができる。
Θ=tan-1((カメラ503の地面からの高さ−顔の地面からの高さ)/カメラ503から人物までの距離) ・・・(1)
As shown in FIG. 5, Θ is equal to an angle formed by a straight line along the ceiling and a straight line drawn from the
Θ = tan −1 ((the height of the
Θの範囲は、どの範囲を撮影できるかによるので、カメラ503の画角と設置時のカメラ503の角度で決まる。図5の例では、点線が撮影できる範囲である。人物504の顔の高さは、例えば平均的な身長の人物を想定すればよいので、カメラ503の設置条件(カメラの高さ、カメラの角度、カメラの画角)が決まれば、計算により求めることができる。そこで、カメラ503の設置条件をユーザに入力させ、数式(1)によってフレーム画像内の顔の位置と顔の角度の関係を求めることができる。
Since the range of Θ depends on which range can be photographed, it is determined by the angle of view of the
また、フレーム画像内の任意の位置(y)と顔の角度Θの関係式(Θ=f(y))を定義し、設置時にいくつかの値を入力して、f(y)を求めるようにしてもよい。例えば、フレーム画像内の任意の位置(y)と顔の角度Θが以下の数式(2)の一次式で表せるとする。
Θ=ay+b ・・・(2)
そうすると、2つ以上のフレーム画面内の位置と顔の角度を予め計測しておけば、係数a、定数bを求めることができる。よって、実際にカメラ503の前に人物504を2地点以上立たせ、それぞれのフレーム画面内の位置とカメラ503からの距離を入力するようにして、係数a、定数bを求めるようにしてもよい。
Also, a relational expression (Θ = f (y)) between an arbitrary position (y) in the frame image and the face angle Θ is defined, and several values are input at the time of installation to obtain f (y). It may be. For example, it is assumed that an arbitrary position (y) in the frame image and the face angle Θ can be expressed by the following linear expression (2).
Θ = ay + b (2)
Then, if the position and the face angle in two or more frame screens are measured in advance, the coefficient a and the constant b can be obtained. Accordingly, the coefficient a and the constant b may be obtained by actually standing the
次に、認識辞書について説明する。
認識辞書は、その適用できる顔の角度の範囲が重なるように作成されたものを用いる。
図6は、本発明の実施形態を示し、認識辞書A及びBの適用できる顔の角度と認識精度との関係を示した模式図である。
Next, the recognition dictionary will be described.
The recognition dictionary is created so that the range of applicable face angles overlaps.
FIG. 6 is a schematic diagram showing the relationship between the face angle applicable to the recognition dictionaries A and B and the recognition accuracy according to the embodiment of the present invention.
図6では、横軸に認識辞書が適用可能な顔の角度、縦軸に認識精度を示しており、601は認識辞書A、602は認識辞書Bを示している。このとき、認識辞書A(601)の適用可能な顔の角度の範囲は603(Θ1)から604(Θ3)、認識辞書B(602)の適用可能な顔の角度の範囲は605(Θ2)から606(Θ4)である。なお、Θ1<Θ2<Θ3<Θ4である。 In FIG. 6, the horizontal axis indicates the face angle to which the recognition dictionary can be applied, the vertical axis indicates the recognition accuracy, 601 indicates the recognition dictionary A, and 602 indicates the recognition dictionary B. At this time, the applicable face angle range of the recognition dictionary A (601) is 603 (Θ1) to 604 (Θ3), and the applicable face angle range of the recognition dictionary B (602) is 605 (Θ2). 606 (Θ4). Note that Θ1 <Θ2 <Θ3 <Θ4.
既に、[発明が解決しようとしている課題]で述べたように、適用できる顔の角度の範囲の端に近くなると認識精度が落ちてくる。そこで、本実施形態では、2つの認識辞書によって、認識精度の低下を補完しあえるように、適用可能な顔の角度の範囲(画像の領域)が重複するように辞書を作成する。図6の例では、605(Θ2)から604(Θ3)の範囲が相当する。重なりの大きさは、認識精度の許容範囲をどの程度にするかによって決定できる。このようにして作成された2つの認識辞書A及びBを用いることによって、常に認識精度の高い顔検出を可能とする。また、認識辞書A及びBを適用するフレーム画像内の領域は、前述のフレーム画像内の顔の位置と顔の角度との関係を用いて、次のように重複するように決められる。 As already described in [Problems to be Solved by the Invention], the accuracy of recognition decreases when it comes close to the end of the range of applicable face angles. Therefore, in the present embodiment, the two recognition dictionaries are created so that the range of applicable face angles (image regions) overlap so that the reduction in recognition accuracy can be complemented. In the example of FIG. 6, the range from 605 (Θ2) to 604 (Θ3) corresponds. The size of the overlap can be determined by how much the allowable range of the recognition accuracy is set. By using the two recognition dictionaries A and B created in this way, face detection with high recognition accuracy is always possible. The areas in the frame image to which the recognition dictionaries A and B are applied are determined so as to overlap as follows using the relationship between the face position and the face angle in the frame image.
図7は、本発明の実施形態を示し、認識辞書A及びBの適用できる領域を説明する模式図である。
図7の例では、図7(a)の701(斜線領域)は、顔の位置が上端から下端に向かうに従って、顔の角度がΘ1からΘ3まで変化する。そこで、この領域については、認識辞書A(601)が適用可能である。
FIG. 7 is a schematic diagram illustrating an area to which the recognition dictionaries A and B can be applied according to the embodiment of the present invention.
In the example of FIG. 7, in 701 (shaded area) in FIG. 7A, the face angle changes from Θ <b> 1 to Θ <b> 3 as the face position moves from the upper end to the lower end. Therefore, the recognition dictionary A (601) can be applied to this area.
図7(b)の702(斜線領域)は顔の位置が上端から下端に向かうに従って、顔の角度が角度Θ2からΘ4まで変化する。そこで、この領域については、認識辞書B(602)が適用可能である。図7(a)及び(b)を重ねて描くと、図7(c)のようになり、704(横線領域)の部分はΘ2<Θ3の領域であり、認識辞書A及び認識辞書Bの両方が適用可能である。即ち、領域704においては、画像の領域に用いられる認識辞書の適用領域は、重複している。
In 702 (shaded area) in FIG. 7B, the face angle changes from the angle Θ2 to Θ4 as the face position moves from the upper end to the lower end. Therefore, the recognition dictionary B (602) can be applied to this area. 7A and 7B are drawn as shown in FIG. 7C, the portion 704 (horizontal line region) is a region of Θ2 <Θ3, and both the recognition dictionary A and the recognition dictionary B Is applicable. That is, in the
以上のようにして、顔の角度の範囲が異なる複数の認識辞書のそれぞれが適用できる領域を決定することができる。これらの領域は、辞書適用領域記憶手段90に保存される。
As described above, an area to which each of a plurality of recognition dictionaries having different face angle ranges can be determined. These areas are stored in the dictionary application
ここで、再び、図4の説明に戻る。
ステップS400の処理が終了すると、ステップS401に進む。
ステップS401に進むと、画像処理装置106は、処理を終了するか否かを判断する。
Here, it returns to description of FIG. 4 again.
When the process of step S400 ends, the process proceeds to step S401.
In step S401, the
ステップS401の判断の結果、電源OFFやキーボード204やマウス205を介してユーザから処理の終了の指示があると、本フローチャートの処理を終了する。
As a result of the determination in step S401, if there is an instruction to end the process from the user via the power OFF or the
一方、ステップS401の判断の結果、ユーザから処理の終了の指示がなかった場合、ステップS402に進む。即ち、ユーザから処理の終了の指示があるまで、ステップS402〜ステップS406の処理を繰り返し行う。 On the other hand, if the result of determination in step S401 is that there is no instruction to end processing from the user, processing proceeds to step S402. That is, the processes in steps S402 to S406 are repeated until the user gives an instruction to end the process.
ステップS402に進むと、画像取得手段30は、撮像手段10へ入力された映像から、前述した方法によりフレーム画像として取得する。
ここで読み込まれた画像データは、例えば、8ビットの画素により構成される2次元配列のデータであり、R、G、Bの3つの面により構成される。このとき、画像データがJPEG等の方式により圧縮されている場合には、画像データを所定の解凍方式にしたがって解凍し、RGB各画素により構成される画像データとする。さらに、本実施形態では、RGBデータを輝度データに変換し、輝度画像データを以後の処理に適用するものとし、画像メモリ(例えば、図2の外部記憶装置206)に格納する。画像データとしてYCrCbのデータを入力する場合には、Y成分をそのまま輝度データとしてもよい。
In step S402, the
The image data read here is, for example, data of a two-dimensional array composed of 8-bit pixels, and is composed of three planes R, G, and B. At this time, if the image data is compressed by a method such as JPEG, the image data is decompressed according to a predetermined decompression method to obtain image data composed of RGB pixels. Further, in the present embodiment, RGB data is converted into luminance data, and the luminance image data is applied to subsequent processing, and is stored in an image memory (for example, the
続いて、ステップS403において、物体認識手段40は、内部の画像メモリに転送された画像データから、辞書・照合領域設定手段70で設定された辞書データと照合を行い、所望の物体を認識する。
Subsequently, in step S403, the
ここで、まず、一般的な物体認識方法について説明する。
公知技術1や公知技術2で提案されている方法が知られている。
例えば、公知技術1では、ニューラル・ネットワークにより画像中の顔パターンを検出する技術である。以下、その方法について簡単に説明する。
First, a general object recognition method will be described.
The methods proposed in the known technique 1 and the known technique 2 are known.
For example, the known technique 1 is a technique for detecting a face pattern in an image using a neural network. The method will be briefly described below.
まず、顔の検出を対象とする画像データをメモリに読み込み、顔と照合する所定の領域を読み込んだ画像中から切り出す。そして、切り出した領域の画素値の分布を入力としてニューラル・ネットワークによる演算で1つの出力を得る。このとき、ニューラル・ネットワークの重み、閾値が膨大な顔画像パターンと非顔画像パターンにより予め学習されており、例えば、ニューラル・ネットワークの出力が0以上なら顔、それ以外は非顔であると判別する。ここで、重みや閾値が辞書データとなる。そして、ニューラル・ネットワークの入力である顔と照合する画像パターンの切り出し位置を、例えば、図8に示すように、画像全域から縦横順次に走査していくことにより、画像中から顔を検出する。
図8は、画像から顔パターンの探索を行う方法を説明する図である。
具体的には、画像全域801を縦横順次に走査して、照合するパターン802を抽出し。この照合するパターン802に対して、顔判別処理803を行う。
First, image data for face detection is read into a memory, and a predetermined area to be matched with the face is cut out from the read image. Then, one output is obtained by calculation using a neural network with the distribution of pixel values in the cut-out area as an input. At this time, the weight and threshold of the neural network are learned in advance using a face image pattern and a non-face image pattern, and for example, a face is determined if the output of the neural network is 0 or more, and a non-face is determined otherwise To do. Here, the weight and threshold value are dictionary data. Then, the face is detected from the image by scanning the cutout position of the image pattern to be collated with the face which is an input of the neural network, for example, as shown in FIG.
FIG. 8 is a diagram for explaining a method for searching for a face pattern from an image.
Specifically, the
また、処理の高速化に着目した例としては、公知技術2がある。この技術の中では、AdaBoostを使って多くの弱判別器を有効に組合せて顔判別の精度を向上させる一方、夫々の弱判別器をHaarタイプの矩形特徴量で構成し、しかも矩形特徴量の算出を、積分画像を利用して高速に行っている。また、AdaBoost学習によって得た判別器を直列に繋ぎ、カスケード型の顔検出器を構成するようにしている。このカスケード型の顔検出器は、まず前段の単純な判別器を使って明らかに顔でないパターンの候補をその場で除去する。そして、それ以外の候補に対してのみ、より高い識別性能を持つ後段の複雑な判別器を使って顔かどうかの判定を行っている。これにより、すべての候補に対して複雑な判定を行う必要がないので高速である。なお、公知技術1と同様に判別器で用いる重みや閾値が辞書データとなる。 Further, as an example paying attention to the speeding up of processing, there is known technique 2. In this technology, AdaBoost is used to effectively combine many weak classifiers to improve the accuracy of face discrimination, while each weak classifier is configured with a Haar type rectangular feature quantity, The calculation is performed at high speed using the integral image. In addition, the discriminators obtained by AdaBoost learning are connected in series to form a cascade type face detector. This cascade type face detector first removes a pattern candidate that is clearly not a face on the spot using a simple discriminator in the previous stage. Only for the other candidates, it is determined whether or not it is a face using a later complex discriminator having higher discrimination performance. As a result, it is not necessary to make a complicated determination for all candidates, which is fast. Note that the weights and threshold values used in the discriminator are dictionary data as in the known technique 1.
次に、本実施形態において、特徴的な辞書・照合領域設定手段70等による動作について、図9のフローチャートを用いて説明する。
図9は、本発明の実施形態を示し、辞書と照合領域を切り替える動作を説明するフローチャートである。
Next, in this embodiment, the operation by the characteristic dictionary / collation area setting means 70 will be described with reference to the flowchart of FIG.
FIG. 9 is a flowchart illustrating an operation of switching between a dictionary and a collation area according to the embodiment of this invention.
まず、ステップS900において、辞書・照合領域設定手段70は、全てのフレームについて処理が行われたか否かを判断する。この判断の結果、全てのフレームについて処理が行われた場合には、本フローチャートの処理を終了する。 First, in step S900, the dictionary / collation region setting means 70 determines whether or not processing has been performed for all frames. As a result of this determination, if all the frames have been processed, the processing of this flowchart is terminated.
一方、全てのフレームについては未だ処理が行われていない場合には、ステップS901に進む。即ち、全てのフレームについては未だ処理が行われていない場合には、ステップS901〜ステップS909又はS910までの処理を繰り返す。 On the other hand, if all the frames have not been processed, the process proceeds to step S901. That is, if the processing has not been performed for all the frames, the processing from step S901 to step S909 or S910 is repeated.
続いて、ステップS901において、辞書・照合領域設定手段70は、物体辞書記憶手段60から読み込まれた複数の認識辞書の中から、認識辞書Aを選択し、物体認識手段40へ設定する。
Subsequently, in step S <b> 901, the dictionary / collation
続いて、ステップS902において、辞書・照合領域設定手段70は、認識辞書Aの照合領域を、辞書適用領域記憶手段90から読み出して、物体認識手段40へ設定する。前述の通り認識辞書Aの照合領域は図7(a)の701になる。
Subsequently, in step S <b> 902, the dictionary / collation
続いて、ステップS903において、物体認識手段40は、ステップS901で設定された認識辞書Aを用いて、ステップS902で設定された照合領域の範囲で、辞書との照合を行う。
Subsequently, in step S903, the
続いて、ステップS904において、辞書・照合領域設定手段70は、物体辞書記憶手段60から読み込まれた複数の認識辞書の中から、認識辞書Bを選択し、物体認識手段40へ設定する。
Subsequently, in step S <b> 904, the dictionary / collation
続いて、ステップS905において、辞書・照合領域設定手段70は、認識辞書Bの照合領域を、辞書適用領域記憶手段90より読み出して、物体認識手段40へ設定する。前述の通り認識辞書Bの照合領域は図7(b)の702になる。
In step S 905, the dictionary / collation
続いて、ステップS906において、物体認識手段40は、ステップS904で設定された認識辞書Bを用いて、ステップS905で設定された照合領域の範囲で、辞書との照合を行う。
Subsequently, in step S906, the
次に、様々な大きさの顔の認識に対応するために、以降の処理で、フレーム画像を縮小して照合を繰り返す。
まず、ステップS907において、例えば、物体認識手段40(或いは辞書・照合領域設定手段70)は、縮小が十分で行われたか否かを判断する。ここでは、照合に用いる画像パターンと同じサイズまで縮小したとき、フレーム画像内で最大の顔を検出することになる。
Next, in order to deal with recognition of faces of various sizes, the frame image is reduced and matching is repeated in the subsequent processing.
First, in step S907, for example, the object recognition unit 40 (or the dictionary / collation region setting unit 70) determines whether or not the reduction has been sufficiently performed. Here, when the image pattern is reduced to the same size as the image pattern used for collation, the maximum face is detected in the frame image.
ステップS907の判断の結果、縮小が十分でない、即ち、照合に用いる画像パターンよりも小さくならない範囲で縮小可能であるときには、ステップS908へ進む。 If the result of determination in step S907 is that the reduction is not sufficient, that is, it can be reduced within a range that does not become smaller than the image pattern used for collation, the process proceeds to step S908.
ステップS908に進むと、物体認識手段40は、所定の縮小率でフレーム画像を縮小する。
In step S908, the
続いて、ステップS909において、辞書・照合領域設定手段70は、認識辞書Aと認識辞書Bの照合領域を、ステップS908と同じ縮小率で縮小する。そして、その後、ステップS901へ戻る。
Subsequently, in step S909, the dictionary / collation
以降、ステップS908において縮小されたフレーム画像に対して、ステップS901〜ステップS906の処理を行う。ここで、ステップS902とステップS905で設定される照合領域には、ステップS909で縮小された領域を用いられる。 Thereafter, the processes in steps S901 to S906 are performed on the frame image reduced in step S908. Here, the area reduced in step S909 is used as the collation area set in steps S902 and S905.
以上のように、1枚のフレーム画像に対して、ステップS901〜ステップS909の処理を繰り返す。 As described above, the processes in steps S901 to S909 are repeated for one frame image.
一方、ステップS907の判断の結果、照合に用いる画像パターンと同じサイズまで縮小したときには、ステップS910へ進み、画像取得手段30は、次のフレーム画像を取得し、ステップS900へ戻る。
On the other hand, as a result of the determination in step S907, when the image pattern is reduced to the same size as the image pattern used for collation, the process proceeds to step S910, and the
以上の処理によって、顔の角度の適用範囲が重なっている2つの認識辞書A及びBを用いることで、顔がフレーム画像内のどの位置にあっても、高精度な認識ができるようになる。しかしながら、毎フレーム、認識辞書Aと認識辞書Bの両方を用いると、重なり部分(図7(c)の704)は2重に認識辞書との照合(ステップS903とステップS906)が行われることになる。これでは、演算コストが増大してしまう。そこで、以下の方法によって、この課題を回避することが可能である。 Through the above processing, by using the two recognition dictionaries A and B where the application range of the face angle is overlapped, it becomes possible to recognize the face with high accuracy regardless of the position in the frame image. However, when both the recognition dictionary A and the recognition dictionary B are used for each frame, the overlapping portion (704 in FIG. 7C) is double-checked with the recognition dictionary (steps S903 and S906). Become. This increases the calculation cost. Therefore, this problem can be avoided by the following method.
Nフレーム目とN+1フレーム目で、使用する認識辞書と照合領域を変更する(ただし、Nには自然数が入る)。即ち、Nフレームでは、辞書・照合領域設定手段70は、認識辞書Aを設定し、照合は画像全体ではなく図7(a)の701の領域に対してのみ行う。そして、N+1フレームでは辞書・照合領域設定手段70は、認識辞書Bを設定し、図7(b)の702の領域に対してのみ行う。このように連続したフレームごとに使用する辞書と、照合の領域を切り替えながら、認識を行う。これにより、顔がフレーム画像内のどの位置にあってもNフレームかN+1フレームのどちらかで認識されることになる。また、フレームごとの照合の領域が制限されるので、フレーム画像の全領域について照合を行う場合に比べて、演算コストが少なくてすむ。
The recognition dictionary and collation area to be used are changed between the Nth frame and the (N + 1) th frame (where N is a natural number). That is, in the N frame, the dictionary / collation area setting means 70 sets the recognition dictionary A, and collation is performed only on the
なお、認識結果としては、NフレームとN+1フレームを論理和したものを使用すればよい。重なりの部分において、Nフレーム目とN+1フレーム目の両方で認識されても、前後のフレーム間の時間差が十分に小さければ、位置はほとんど変わらないので、同じものであると判定することは容易である。 As a recognition result, a logical sum of N frames and N + 1 frames may be used. Even if the overlap is recognized in both the Nth frame and the (N + 1) th frame, if the time difference between the previous and next frames is sufficiently small, the position will hardly change, so it is easy to determine that they are the same. is there.
ここで、再び、図4の説明に戻る。
ステップS403の処理が終了すると、続いて、ステップS404に進む。
ステップS404に進むと、認識結果分析・出力手段50は、現在から所定時間前までの間に検出された被写体領域をRAM203より読み出して、軌跡を生成する。これは、所定時間内に検出された複数ある顔のうち、どれが同一の人物の動きに対応するかを求める処理である。
Here, it returns to description of FIG. 4 again.
When the process of step S403 ends, the process proceeds to step S404.
In step S404, the recognition result analyzing / outputting
この処理の詳細について、図10を用いて説明する。
図10は、本発明の実施形態を示し、軌跡の生成とカウントの一例を示した模式図である。
Details of this processing will be described with reference to FIG.
FIG. 10 is a schematic diagram illustrating an example of generation and counting of a trajectory according to the embodiment of the present invention.
図10において、1001は撮像しているフレーム全体である。ここに、所定の時間に検出された顔の領域を、矩形で表現して重ね描きしている(1003〜1005)。図10の例では、3フレーム分を重ね描きしており、最も古いフレームでは1003が、次のフレームでは1004が、その次の現在のフレームでは、1005が検出されているものとする。これらの軌跡を求める方法としては、各領域の中心を求め、各領域の中心間の距離が最小となるもの同士を同一の被写体とみなし、線分で接続するようにすればよい。このようにして求めた軌跡が、図10の例では1009となる。
In FIG. 10,
続いて、ステップS405において、認識結果分析・出力手段50は、ステップS404で作成された軌跡が、所定の条件を満たすかどうかをチェックし、条件を満たしていればカウントする。ここで所定の条件とは、例えば、図10に示した1002のような計測ラインを横切っているかどうか、である。計測ライン1002は、ユーザによってフレーム画面内に設定される。図10の例では、軌跡1009が計測ライン1002を横切っているので、1とカウントされる。もし、まだ、計測ライン1002を横切っていない軌跡が存在すれば、この時点では、カウントされない。
Subsequently, in step S405, the recognition result analysis /
続いて、ステップS406において、認識結果分析・出力手段50は、カウントした結果をユーザに対して表示する。
Subsequently, in step S406, the recognition result analysis /
その後、再び、ステップS401に戻る。 Then, it returns to step S401 again.
以上のように、適用範囲が重なる辞書を複数用意し、奇数フレームと偶数フレームで使用する辞書と照合範囲を切り替えるようにした。これにより、認識する物体の向きが画面内で変化する場合であっても精度よく認識することができる。 As described above, a plurality of dictionaries with overlapping application ranges are prepared, and the dictionary and collation range used in odd frames and even frames are switched. Thereby, even if the direction of the recognized object changes in the screen, it can be recognized with high accuracy.
本実施形態では、辞書・照合領域設定手段70が使用する認識辞書と照合する範囲をフレームごとに交互に変更したが、次のような方法であっても良い。即ち、図7(c)の703の範囲については、認識辞書Aを用いて照合を行う。重なりの領域704に対しても、まずは認識辞書Aを用いて照合を行うが、このとき、認識辞書との照合の結果得られる確からしさ(尤度)を元に、尤度マップを作成する。尤度は、辞書との照合の際の、閾値処理を施す前の演算結果より得られる。
In the present embodiment, the range to be collated with the recognition dictionary used by the dictionary / collation
次に、尤度マップを参照し、尤度が所定値以下の部分に対してのみ認識辞書Bを用いて照合を行う。図7(c)の705に対しては、認識辞書Bを用いて照合を行う。このようにすると、図7(c)の704については部分的に2重に照合を行うことになるが、公知技術2のカスケード型の判別器を用いる場合には、尤度が低いものは、前段の判別器で判定できるため、照合にかかる時間は極めて少なくなる。従って、演算コストは大きく増えることはない。 Next, the likelihood map is referred to and collation is performed using the recognition dictionary B only for a portion where the likelihood is a predetermined value or less. For 705 in FIG. 7C, collation is performed using the recognition dictionary B. In this way, 704 in FIG. 7C is partially double-checked. However, when the cascade type discriminator of publicly known technology 2 is used, the one with low likelihood is Since it can be determined by the discriminator in the previous stage, the time required for collation is extremely small. Therefore, the calculation cost does not increase greatly.
本実施形態では、顔の位置を検出する例で説明したが、人体全体や上半身、頭部など人物の様々な部位や、自動車や自転車など、様々な物体においても適用可能である。また、特定の人物であるかどうかを個人の顔の特徴から弁別するような場合でも適用可能である。 In the present embodiment, the example in which the position of the face is detected has been described. However, the present invention can be applied to various parts of a person such as the entire human body, the upper body, and the head, and various objects such as a car and a bicycle. Further, the present invention can also be applied to the case of discriminating whether or not a person is a specific person from the facial features of the individual.
本実施形態では、顔の垂直方向の角度で説明したが、もちろん、水平方向の角度に関しても同様である。 In the present embodiment, the angle in the vertical direction of the face has been described. Of course, the same applies to the angle in the horizontal direction.
また、本実施形態では、認識結果分析・出力手段50は、通路を通行する人数をカウントする例を説明した。しかしながら、所定のエリアの混雑率を計測したり、動線を分析したり、特定の人物に対してアラームを発生させるなど、様々な用途に適用可能である。
Further, in the present embodiment, the example in which the recognition result analysis /
また、本実施形態では、PCである画像処理装置106において認識、計数、表示まで行うように構成したが、これに限ったものではない。例えば、物体認識手段40から辞書適用領域記憶手段90までの全てをチップに納め、撮像部104と一体化させることにより、計数結果のみLANケーブル105を介して画像処理装置106にて受信し、計数結果を閲覧するようにしてもよい。或いは、物体認識手段40、辞書・照合領域設定手段70、物体辞書記憶手段60、辞書適用領域決定手段80、辞書適用領域記憶手段90を撮像部104と一体化する。そして、認識結果のみLANケーブル105を介して画像処理装置106にて受信して画像処理装置106において計数するようにしてもよい。
なお、本実施形態は、コンピュータ内でプログラムを実行することによっても実現することができることは当然である。
In this embodiment, the
Naturally, the present embodiment can also be realized by executing a program in a computer.
また、本実施形態では、フレーム画像の領域ごとに複数の辞書を切り替える例を説明したが、例えば、画像が時間的に連続した画像であって、画像ごとに使用する辞書を切り替える形態も適用可能である。 Further, in this embodiment, an example of switching a plurality of dictionaries for each region of a frame image has been described. However, for example, a mode in which images are temporally continuous images and a dictionary to be used for each image is switched is also applicable. It is.
(その他の実施形態)
また、本発明は、以下の処理を実行することによっても実現される。
即ち、上述した実施形態の機能を実現するソフトウェア(プログラム)を、ネットワーク又は各種記憶媒体を介してシステム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)がプログラムを読み出して実行する処理である。
このプログラム及び当該プログラムを記憶したコンピュータ読み取り可能な記録媒体は、本発明に含まれる。
(Other embodiments)
The present invention can also be realized by executing the following processing.
That is, software (program) that realizes the functions of the above-described embodiments is supplied to a system or apparatus via a network or various storage media, and a computer (or CPU, MPU, or the like) of the system or apparatus reads the program. It is a process to be executed.
This program and a computer-readable recording medium storing the program are included in the present invention.
10 撮像手段、30 画像取得手段、40 物体認識手段、50 認識結果分析・出力手段、60 物体辞書記憶手段、70 辞書・照合領域設定手段、80 辞書適用領域決定手段、90 辞書適用領域記憶手段 10 imaging means, 30 image acquisition means, 40 object recognition means, 50 recognition result analysis / output means, 60 object dictionary storage means, 70 dictionary / collation area setting means, 80 dictionary application area determination means, 90 dictionary application area storage means
Claims (3)
前記複数の辞書のそれぞれに対してフレーム画像における適用領域を、少なくとも2つの辞書の適用領域に重複する領域を含んで設定する設定手段と、
前記複数の辞書のそれぞれを用いて当該辞書に対して設定された適用領域において前記物体を認識する認識手段と
を備え、
前記認識手段は、少なくとも2つの辞書で重複する適用領域に対して、連続する複数のフレーム画像においてフレーム画像ごとに使用する辞書を切り替え、そのフレーム画像ごとの認識結果を統合することを特徴とする画像処理装置。 Dictionary storage means for storing data of a plurality of dictionaries corresponding to different directions of the same object;
Setting means for setting an application area in a frame image for each of the plurality of dictionaries, including an area overlapping with an application area of at least two dictionaries ;
Recognizing means for recognizing the object in an application area set for the dictionary using each of the plurality of dictionaries,
The recognition unit is configured to switch a dictionary to be used for each frame image in a plurality of continuous frame images with respect to an application region that overlaps at least two dictionaries, and to integrate the recognition results for the frame images. Image processing device.
前記複数の辞書のそれぞれを用いて当該辞書に対して設定された適用領域において前記物体を認識する認識ステップと
を備え、
前記認識ステップでは、少なくとも2つの辞書で重複する適用領域に対して、連続する複数のフレーム画像においてフレーム画像ごとに使用する辞書を切り替え、そのフレーム画像ごとの認識結果を統合することを特徴とする画像処理方法。 A setting step for setting an application area in the frame image for each of a plurality of dictionaries corresponding to different directions of the same object, including an area overlapping the application areas of at least two dictionaries ;
Recognizing the object in an application area set for the dictionary using each of the plurality of dictionaries, and
In the recognition step, for an application region that overlaps at least two dictionaries, a dictionary to be used for each frame image in a plurality of continuous frame images is switched, and a recognition result for each frame image is integrated. Image processing method.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010250207A JP5737909B2 (en) | 2010-11-08 | 2010-11-08 | Image processing apparatus, image processing method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010250207A JP5737909B2 (en) | 2010-11-08 | 2010-11-08 | Image processing apparatus, image processing method, and program |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2012104964A JP2012104964A (en) | 2012-05-31 |
| JP2012104964A5 JP2012104964A5 (en) | 2013-12-26 |
| JP5737909B2 true JP5737909B2 (en) | 2015-06-17 |
Family
ID=46394893
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010250207A Expired - Fee Related JP5737909B2 (en) | 2010-11-08 | 2010-11-08 | Image processing apparatus, image processing method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5737909B2 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6409929B1 (en) | 2017-09-19 | 2018-10-24 | 日本電気株式会社 | Verification system |
| WO2021186576A1 (en) * | 2020-03-17 | 2021-09-23 | 日本電気株式会社 | Gate system, gate device, image processing method therefor, program, and arrangement method for gate device |
| JP7545228B2 (en) | 2020-04-07 | 2024-09-04 | キヤノン株式会社 | Image processing device and method, and imaging device and control method thereof |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61292003A (en) * | 1986-04-04 | 1986-12-22 | Hitachi Ltd | Method and device for position detection |
| JPH04367987A (en) * | 1991-06-17 | 1992-12-21 | Nippon Telegr & Teleph Corp <Ntt> | Pattern detector |
| JP2000276596A (en) * | 1999-03-25 | 2000-10-06 | Nec Corp | Automatic tracking device |
| JP2007025767A (en) * | 2005-07-12 | 2007-02-01 | Nikon Corp | Image recognition system, image recognition method, and image recognition program |
| JP2008040736A (en) * | 2006-08-04 | 2008-02-21 | Aisin Aw Co Ltd | Vehicle detector and vehicle detecting method |
| JP4975666B2 (en) * | 2008-03-19 | 2012-07-11 | セコム株式会社 | Monitoring device |
| JP5159390B2 (en) * | 2008-03-28 | 2013-03-06 | キヤノン株式会社 | Object detection method and apparatus |
-
2010
- 2010-11-08 JP JP2010250207A patent/JP5737909B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2012104964A (en) | 2012-05-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5398341B2 (en) | Object recognition apparatus and object recognition method | |
| JP5693094B2 (en) | Image processing apparatus, image processing method, and computer program | |
| EP2601615B1 (en) | Gesture recognition system for tv control | |
| US8649575B2 (en) | Method and apparatus of a gesture based biometric system | |
| JP4642128B2 (en) | Image processing method, image processing apparatus and system | |
| US8300950B2 (en) | Image processing apparatus, image processing method, program, and storage medium | |
| US8447100B2 (en) | Detecting apparatus of human component and method thereof | |
| CN110348270B (en) | Image object identification method and image object identification system | |
| KR101364571B1 (en) | Apparatus for hand detecting based on image and method thereof | |
| WO2012039139A1 (en) | Pupil detection device and pupil detection method | |
| WO2005008593A1 (en) | Image processing device, imaging device, image processing method | |
| US9972094B2 (en) | Foreground extracting method and apparatus | |
| US11272163B2 (en) | Image processing apparatus and image processing method | |
| JP2014093023A (en) | Object detection device, object detection method and program | |
| JP5290229B2 (en) | Learning device and object detection device | |
| WO2012046426A1 (en) | Object detection device, object detection method, and object detection program | |
| JP5879188B2 (en) | Facial expression analysis apparatus and facial expression analysis program | |
| JP5737909B2 (en) | Image processing apparatus, image processing method, and program | |
| JPWO2008035411A1 (en) | Mobile object information detection apparatus, mobile object information detection method, and mobile object information detection program | |
| US20090245578A1 (en) | Method of detecting predetermined object from image and apparatus therefor | |
| JP5376403B2 (en) | Video display device and program | |
| JP2012100082A (en) | Image processing device, image processing method, and program | |
| JP4074464B2 (en) | Method and apparatus for detecting motion with periodicity | |
| JP2011198006A (en) | Object detecting apparatus, object detecting method, and object detecting program | |
| JP2006293720A (en) | Face detection apparatus, face detection method, and face detection program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131108 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20131108 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20140626 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140701 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140829 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20150324 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150421 |
|
| LAPS | Cancellation because of no payment of annual fees |