JP5675840B2 - クエリー管理 - Google Patents
クエリー管理 Download PDFInfo
- Publication number
- JP5675840B2 JP5675840B2 JP2012546227A JP2012546227A JP5675840B2 JP 5675840 B2 JP5675840 B2 JP 5675840B2 JP 2012546227 A JP2012546227 A JP 2012546227A JP 2012546227 A JP2012546227 A JP 2012546227A JP 5675840 B2 JP5675840 B2 JP 5675840B2
- Authority
- JP
- Japan
- Prior art keywords
- query
- interval
- data
- engine
- storage medium
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 claims description 89
- 230000008569 process Effects 0.000 claims description 62
- 238000012545 processing Methods 0.000 claims description 62
- 238000004590 computer program Methods 0.000 claims description 10
- 230000004044 response Effects 0.000 claims description 5
- 238000013500 data storage Methods 0.000 description 13
- 230000009471 action Effects 0.000 description 9
- 238000010586 diagram Methods 0.000 description 6
- 230000008520 organization Effects 0.000 description 6
- 238000007726 management method Methods 0.000 description 4
- 230000008901 benefit Effects 0.000 description 3
- 238000012913 prioritisation Methods 0.000 description 3
- 238000013459 approach Methods 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 238000013499 data model Methods 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
Images















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2453—Query optimisation
- G06F16/24532—Query optimisation of parallel queries
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本出願は、参照により本明細書に組み込まれる2009年12月23日出願の米国特許出願第61/289778号に対する優先権を主張するものである。
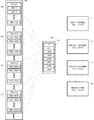
図1を参照すると、いくつかの問題が分散クエリー管理において発生し得る。例えば、先入れ先出し法でデータ記憶システムのクエリーエンジンにクエリーが引き渡されると、システムはバックログになる可能性がある。いくつかのケースでは、引き渡されたクエリーは、あまりリソースを必要とせずに迅速に実行される短いクエリー102、104、108、112、118と、実行するのにより長い時間を必要とし、大量のシステム・リソースを使用する長いクエリー110、114、116と、短いクエリーと長いクエリーの間のどこかに入るクエリーとを含む可能性がある。特定のクエリーが実行される前にそのクエリーが要求するシステム・リソースの量をあらかじめ決めることは実用的ではない可能性がある。図1は、複数のクエリーエンジンを使用してクエリーを処理するためのシステムの一例を示している。クエリーは、非同期的に受信されて、待ち行列101に記憶され、データ記憶システムのクエリーサーバ100上で実行されるクエリーエンジンによって処理される機会を待つ。この例では、初めに、長いクエリー116が処理のために第1のクエリーエンジン120に割り当てられ、短いクエリー118が処理のために第2のクエリーエンジン122に割り当てられる。図2を参照すると、短い時間の後に短いクエリー118は完了した可能性があり、次に並んでいるクエリーである長いクエリー114が空いているクエリーエンジン122に割り当てられる。この時点で残りのクエリー102、104、108、110、112は、長いクエリー116、114のうちの一方が処理を完了し、クエリーエンジン内の処理リソースを解放するまで待つ。この現象は短いクエリーの待ち時間を増やすものであり、迅速応答が期待されているクエリーにおいて受け入れがたい遅延を引き起こす可能性がある。
図5Aを参照すると、一連のクエリーA502、B504、C506、及びD508が、異なるクエリーに関係付けられた時間間隔を示す図に示されている。クエリーが引き渡された順序で実行される場合、クエリーAは間隔502の間に実行されて完了し、次にクエリーBは間隔504の間に実行されて完了し、次に間隔506の間のクエリーCと間隔508の間のクエリーDが続く。これらの条件下では、クエリーAは時間510で完了するまで結果を返さず、クエリーBは時間512で完了するまで結果を返さず、クエリーCは時間514で完了するまで結果を返さず、クエリーDは時間516で完了するまで結果を返さないであろう。クエリーDは短いクエリーであるが、たまたま他の長いクエリーの後ろに位置していたので結果を返すのに長い時間を要する。
仲介データベースは個々のクエリーに関係付けられた優先順位を記憶し得る。この優先順位は、クエリーが実行される頻度及び方法に影響し得る。図7Aを参照すると、優先順位の高いクエリーAには、クエリーB(間隔704の間に処理される)又は優先順位が低いクエリーC(間隔706の間に処理される)より大きい実行間隔702が提供され得る。この例では、優先順位の高いクエリーAにはクエリーBに提供される実行間隔704より大きい実行間隔702が提供され、クエリーBには優先順位の低いクエリーCに提供される実行間隔706より大きい実行間隔704が提供される。或いは、図7Bを参照すると、優先順位の高いクエリーAには標準的な優先順位のクエリーB(間隔710の間に処理される)より高い頻度の実行間隔708が提供され、標準的な優先順位のクエリーBには優先順位の低いクエリーC(間隔712の間に処理される)より高い頻度の実行間隔が提供され得る。図7Cを参照すると、ある状況では、クエリーAには、クエリーAが(間隔714後に)実行を完了するまで他のクエリーB及びCの処理が中断されるように十分高い優先順位が提供され、実行を完了した時点で、それぞれ間隔716と718の間で交互に、中断されたクエリーB及びCの実行が再開される。
多くのシステムにとって、複数のクエリーを一度に実行することが有利であり得る。例えば、単一システム上で実行されている2つのクエリーは、1つのシステム上で実行される単一クエリーよりも改善されたパフォーマンスを実現(experience)しうる。これは、例えば、第2のクエリーが異なるリソースを使用している間に一方のクエリーが1つのコンピューティング・リソースを使用できるために生じ得る。一度に両方のクエリーを実行することによって、スループットは改善される。いくつかの実装例では、図8を参照すると、優先順位の高いクエリー802は、複数のクエリースライス804、806、808、810、812に分割される。各スライスは、個別のクエリーエンジン814、816、818、820、822によって処理され得る。
あらかじめ指定された基準によって定義されたトリガが満たされると、システムは通知を行う。図3を参照すると、新しいクエリーがフロントエンド・サービス302にサブミットされる場合、このサブミットは、条件が満たされた時に(フロントエンド・サービス302を介して)リクエスタに通知するよう仲介サーバ304に要求する情報を含み得る。ある編成では、この条件は、特定の数の結果データ要素がリクエスタによってアクセスできる状態になった時の通知であり得る。例えば、リクエスタは、100個の結果レコードの準備ができた時に通知され得る。いくつかケースでは、リクエスタは、通知の前に準備ができなければならない結果データ要素の数を指定し得る。他のケースでは、リクエスタは、リクエスタが通知を受ける前に満たさなければならない他の基準を提供し得る。例えば、リクエスタは、クエリーが中断された時又はすべての処理が完了した時に通知を受けたいと希望する可能性がある。いくつかのケースでは、トリガ基準は、仲介データベース308内で追跡された状態情報に制限されるかも知れない。他のケースでは、トリガ基準は制限がないかも知れない。トリガは、いくつかの異なる方法で仲介サーバ304に提供され得る。例えば、トリガは、それぞれのクエリー間隔後に仲介サーバ304が実行するスクリプトとして、又は所定のアプリケーション・プログラミング・インターフェース(API)に適合するコンパイル済みクラスとして、提供され得る。いくつかのケースでは、例えば、100個の結果レコードが発見されたという条件など、その条件が一度しか発生しない可能性がある。他の編成では、例えば、100個の追加の結果レコードが発見されるごとに通知を求める要求など、その条件が再発する可能性もある。
いくつかの実装例では、仲介サーバ304はクエリーの処理を中断することができる。仲介サーバは、そのクエリーに中断というマークを付けることができ、そのクエリーが再開されるまでいかなる処理も行われない。クエリーの中断とともに、クエリーサーバはクエリーの状態を保存し得る。この状態はクエリーのプロセスの表示要素である。例えば、この状態は索引付き圧縮データ・ストアへのオフセットになる場合もあれば、B木内で最後に処理されたノードを含む場合もある。
図10を参照すると、フローチャート1000は、外部要求なしにクエリーの処理を中断すべきかどうかに関する判断を含む、仲介サーバ304の動作の模範的な編成を表している。
Claims (60)
- 1つ又は複数のデータ・ソースについて実行されるクエリーを管理するための方法であって、
少なくとも第1のクエリーを記憶媒体に記憶することと、
処理のために前記第1のクエリーを選択することと、
第1のクエリー間隔に対して前記1つ又は複数のデータ・ソースにおけるデータの第1の部分についての前記第1のクエリーを処理するようにクエリーエンジンに指示することと、
前記データの第1の部分についての前記第1のクエリーの処理に基づいて前記クエリーエンジンから第1の結果データを受信することと、
前記第1のクエリー間隔後に前記第1のクエリーの状態を前記記憶媒体に保存することと、
前記第1のクエリー間隔後の第2のクエリー間隔の間に第2のクエリーを処理するように前記クエリーエンジンに指示することと、
前記第1のクエリーに関連付けられた優先順位を変更することと、
前記第2のクエリーの処理に基づいて前記クエリーエンジンから第2の結果データを受信することと、
前記第2のクエリーが中断され、前記クエリーエンジンによって処理されないように、前記第1のクエリーに関連付けられた前記優先順位に基づいて前記第2のクエリーを中断することを決定することと、
前記第2のクエリー間隔後の第3のクエリー間隔の間に前記1つ又は複数のデータ・ソース内の第2のデータ部分についての前記第1のクエリーを処理するように前記クエリーエンジンに指示すること
を含む、方法。 - 前記第1のクエリーに関係付けられた前記優先順位を前記記憶媒体に記憶することをさらに含み、
前記第1のクエリーに関係付けられた前記優先順位を変更することは、処理のために前記第1のクエリーを選択する前に行われ、
処理のために前記第1のクエリーを選択することが部分的に前記優先順位に基づいて前記クエリーを選択することを含む、請求項1記載の方法。 - 前記第1のクエリー間隔が所定の時間量によって定義される、請求項1記載の方法。
- 前記第1のクエリーに関連付けられた前記優先順位は、前記1つ又は複数のデータ・ソース内の前記データのうちのどのくらいの量が、前記第1のクエリー間隔に対して前記第1のクエリーが実行される前記データの第1の部分に含まれるか、に影響する、請求項3記載の方法。
- 前記第1のクエリーを記憶することが、前記第1のクエリーを提供したリクエスタに通知される前に使用可能になるべき前記第1の結果データの量の通知しきい値を記憶することを含む、請求項1記載の方法。
- 前記第1の結果データの前記量が前記通知しきい値を超えた時に前記リクエスタに通知することをさらに含み、前記第1のクエリーの前記状態を保存することが前記クエリーエンジンから受信した前記第1の結果データの前記量を記憶することを含む、請求項5記載の方法。
- 前記リクエスタからの要求による前記第1の結果データを返すことと、前記リクエスタに返された前記第1の結果データの前記量を前記記憶媒体に記憶すること、をさらに含む、請求項6記載の方法。
- 前記第1のクエリーを選択することが、前記クエリーエンジンから受信した前記第1の結果データの前記量と前記リクエスタに返された前記第1の結果データの前記量に基づくものである、請求項7記載の方法。
- 前記第1のクエリーの前記状態を保存することが、
前記第1のクエリーを中断するよう前記クエリーエンジンに指示することと、
前記第1のクエリーが中断された後に前記第1のクエリーの状態を保存すること、
を含む、請求項1記載の方法。 - 前記第2のデータ部分に関する前記第1のクエリーを処理するように前記クエリーエンジンに指示することが、
前記第1のクエリーの前記保存状態をロードすることと、
前記第1のクエリーを再開するように前記クエリーエンジンに指示すること、
を含む、請求項9記載の方法。 - 前記第1のクエリーの前記状態を保存することが、二次索引へのオフセットを保存することを含む、請求項9記載の方法。
- 前記二次索引がブロック圧縮索引付きファイルの索引である、請求項11記載の方法。
- 前記第1のクエリーを複数の副クエリーに分割することと、前記副クエリーのうちの少なくともいくつかを同時に処理するよう前記クエリーエンジンに指示すること、をさらに含む、請求項1記載の方法。
- 前記第1のクエリー間隔が始まった後で前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項1記載の方法。
- 前記第1のクエリー間隔が始まる前に前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項1記載の方法。
- 1つ又は複数のデータ・ソースについて実行されるクエリーを管理するためのコンピュータ・プログラムを記憶するコンピュータ可読記憶媒体であって、前記コンピュータ・プログラムが、
少なくとも第1のクエリーを記憶媒体に記憶することと、
処理のために前記第1のクエリーを選択することと、
第1のクエリー間隔に対して前記1つ又は複数のデータ・ソース内のデータの第1の部分についての前記第1のクエリーを処理するようにクエリーエンジンに指示することと、
前記データの第1の部分についての前記第1のクエリーの処理に基づいて前記クエリーエンジンから第1の結果データを受信することと、
前記第1のクエリー間隔後に前記第1のクエリーの状態を前記記憶媒体に保存することと、
前記第1のクエリー間隔後の第2のクエリー間隔の間に第2のクエリーを処理するように前記クエリーエンジンに指示することと、
前記第1のクエリーに関連付けられた優先順位を変更することと、
前記第2のクエリーの処理に基づいて前記クエリーエンジンから第2の結果データを受信することと、
前記第2のクエリーが中断され、前記クエリーエンジンによって処理されないように、前記第1のクエリーに関連付けられた前記優先順位に基づいて前記第2のクエリーを中断することを決定することと、
前記第2のクエリー間隔後の第3のクエリー間隔の間に前記1つ又は複数のデータ・ソース内の第2のデータ部分についての前記第1のクエリーを処理するように前記クエリーエンジンに指示することと、
をコンピュータに実行させるための命令を含む、コンピュータ可読記憶媒体。 - 1つ又は複数のデータ・ソースについて実行されるクエリーを管理するためのシステムであって、前記システムが、
少なくとも第1のクエリーを記憶する記憶媒体と、
前記1つ又は複数のデータ・ソース内のデータに関するクエリーを処理するように構成されたクエリーエンジンと、
サーバであって、
処理のために前記第1のクエリーを選択し、
第1のクエリー間隔に対して前記1つ又は複数のデータ・ソース内のデータの第1の部分についての前記第1のクエリーを処理するように前記クエリーエンジンに指示し、
前記データの第1の部分についての前記第1のクエリーの処理に基づいて前記クエリーエンジンから第1の結果データを受信し、
前記第1のクエリー間隔後に前記第1のクエリーの状態を前記記憶媒体に保存し、
前記第1のクエリー間隔後の第2のクエリー間隔の間に第2のクエリーを処理するように前記クエリーエンジンに指示し、
前記第1のクエリーに関連付けられた優先順位を変更し、
前記第2のクエリーの処理に基づいて前記クエリーエンジンから第2の結果データを受信し、
前記第2のクエリーが中断され、前記クエリーエンジンによって処理されないように、前記第1のクエリーに関連付けられた前記優先順位に基づいて前記第2のクエリーを中断することを決定し、
前記第2のクエリー間隔後の第3のクエリー間隔の間に前記1つ又は複数のデータ・ソース内の第2のデータ部分についての前記第1のクエリーを処理するように前記クエリーエンジンに指示する、
ように構成されたサーバと、
を含む、システム。 - 前記コンピュータ・プログラムが、
前記第1のクエリーに関係付けられた前記優先順位を前記記憶媒体に記憶すること、
をコンピュータに実行させる命令をさらに含み、
前記第1のクエリーに関係付けられた前記優先順位を変更することは、処理のために前記第1のクエリーを選択する前に行われ、
処理のために前記第1のクエリーを選択することが部分的に前記優先順位に基づいて前記クエリーを選択することを含む、請求項16記載のコンピュータ可読記憶媒体。 - 前記第1のクエリー間隔が所定の時間量によって定義される、請求項16記載のコンピュータ可読記憶媒体。
- 前記第1のクエリーに関連付けられた前記優先順位は、前記1つ又は複数のデータ・ソース内の前記データのうちのどのくらいの量が、前記第1のクエリー間隔に対して前記第1のクエリーが実行される前記データの第1の部分に含まれるか、に影響する、請求項19記載のコンピュータ可読記憶媒体。
- 前記第1のクエリーを記憶することが、前記第1のクエリーを提供したリクエスタに通知される前に使用可能になるべき前記第1の結果データの量の通知しきい値を記憶することを含む、請求項16記載のコンピュータ可読記憶媒体。
- 前記コンピュータ・プログラムが、前記第1の結果データの前記量が前記通知しきい値を超えた時に前記リクエスタに通知することをコンピュータに実行させる命令をさらに含み、前記第1のクエリーの前記状態を保存することが前記クエリーエンジンから受信した前記第1の結果データの前記量を記憶することを含む、請求項21記載のコンピュータ可読記憶媒体。
- 前記コンピュータ・プログラムが、前記リクエスタからの要求に対して前記第1の結果データを返すことと、前記リクエスタに返された前記第1の結果データの前記量を前記記憶媒体に記憶することと、をコンピュータに実行させる命令を含む、請求項22記載のコンピュータ可読記憶媒体。
- 前記第1のクエリーを選択することが、前記クエリーエンジンから受信した前記第1の結果データの前記量と前記リクエスタに返された前記第1の結果データの前記量とに基づく、請求項23記載のコンピュータ可読記憶媒体。
- 前記第1のクエリーの前記状態を保存することが、
前記第1のクエリーを中断するよう前記クエリーエンジンに指示することと、
前記第1のクエリーが中断された後に前記第1のクエリーの状態を保存すること、
を含む、請求項16記載のコンピュータ可読記憶媒体。 - 前記第2のデータ部分に関する前記第1のクエリーを処理するように前記クエリーエンジンに指示することが、
前記第1のクエリーの前記保存状態をロードすることと、
前記第1のクエリーを再開するように前記クエリーエンジンに指示することと、
を含む、請求項25記載のコンピュータ可読記憶媒体。 - 前記第1のクエリーの前記状態を保存することが、二次索引へのオフセットを保存することを含む、請求項25記載のコンピュータ可読記憶媒体。
- 前記二次索引がブロック圧縮索引付きファイルの索引である、請求項27記載のコンピュータ可読記憶媒体。
- 前記コンピュータ・プログラムが、前記第1のクエリーを複数の副クエリーに分割することと、前記副クエリーのうちの少なくともいくつかを同時に処理するよう前記クエリーエンジンに指示すること、をコンピュータに実行させる命令を含む、請求項16記載のコンピュータ可読記憶媒体。
- 前記第1のクエリー間隔が始まった後で前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項16記載のコンピュータ可読記憶媒体。
- 前記第1のクエリー間隔が始まる前に前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項16記載のコンピュータ可読記憶媒体。
- 前記サーバは、
前記第1のクエリーに関係付けられた前記優先順位を前記記憶媒体に記憶し、
処理のために前記第1のクエリーを選択する前に前記第1のクエリーに関係付けられた前記優先順位を変更し、
処理のために前記第1のクエリーを選択することが部分的に前記優先順位に基づいて前記クエリーを選択することを含む、
ようにさらに構成されている、請求項17記載のシステム。 - 前記第1のクエリー間隔が所定の時間量によって定義される、請求項17記載のシステム。
- 前記第1のクエリーに関連付けられた前記優先順位は、前記1つ又は複数のデータ・ソース内の前記データのうちのどのくらいの量が、前記第1のクエリー間隔に対して前記第1のクエリーが実行される前記データの第1の部分に含まれるか、に影響する、請求項33記載のシステム。
- 前記第1のクエリーを記憶することが、前記第1のクエリーを提供したリクエスタに通知される前に使用可能になるべき前記第1の結果データの量の通知しきい値を記憶することを含む、請求項17記載のシステム。
- 前記サーバは、前記第1の結果データの前記量が前記通知しきい値を超えた時に前記リクエスタに通知するようにさらに構成され、前記第1のクエリーの前記状態を保存することが前記クエリーエンジンから受信した前記第1の結果データの前記量を記憶することを含む、請求項35記載のシステム。
- 前記サーバは、前記リクエスタからの要求に対して前記第1の結果データを返し、前記リクエスタに返された前記第1の結果データの前記量を前記記憶媒体に記憶するようにさらに構成されている、請求項36記載のシステム。
- 前記第1のクエリーを選択することが、前記クエリーエンジンから受信した前記第1の結果データの前記量と前記リクエスタに返された前記第1の結果データの前記量に基づくものである、請求項37記載のシステム。
- 前記第1のクエリーの前記状態を保存することが、
前記第1のクエリーを中断するよう前記クエリーエンジンに指示することと、
前記第1のクエリーが中断された後に前記第1のクエリーの状態を保存すること、
を含む、請求項17記載のシステム。 - 前記第2のデータ部分に関する前記第1のクエリーを処理するように前記クエリーエンジンに指示することが、
前記第1のクエリーの前記保存状態をロードすることと、
前記第1のクエリーを再開するように前記クエリーエンジンに指示すること、
を含む、請求項39記載のシステム。 - 前記第1のクエリーの前記状態を保存することが、二次索引へのオフセットを保存することを含む、請求項39記載のシステム。
- 前記二次索引がブロック圧縮索引付きファイルの索引である、請求項41記載のシステム。
- 前記サーバは、前記第1のクエリーを複数の副クエリーに分割し、前記副クエリーのうちの少なくともいくつかを同時に処理するよう前記クエリーエンジンに指示するようにさらに構成されている、請求項17記載のシステム。
- 前記第1のクエリー間隔が始まった後で前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項17記載のシステム。
- 前記第1のクエリー間隔が始まる前に前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項17記載のシステム。
- 1つ又は複数のデータ・ソースについて実行されるクエリーを管理するためのシステムであって、
少なくとも第1のクエリーを記憶する手段と、
処理のために前記第1のクエリーを選択する手段と、
第1のクエリー間隔に対して前記1つ又は複数のデータ・ソース内のデータの第1の部分についての前記第1のクエリーを処理するようにクエリーエンジンに指示する手段と、
前記データの第1の部分についての前記第1のクエリーの処理に基づいて前記クエリーエンジンから第1の結果データを受信する手段と、
前記第1のクエリー間隔後に前記第1のクエリーの状態を前記記憶媒体に保存する手段と、
前記第1のクエリー間隔後の第2のクエリー間隔の間に第2のクエリーを処理するように前記クエリーエンジンに指示する手段と、
前記第1のクエリーに関連付けられた優先順位を変更する手段と、
前記第2のクエリーの処理に基づいて前記クエリーエンジンから第2の結果データを受信する手段と、
前記第2のクエリーが中断され、前記クエリーエンジンによって処理されないように、前記第1のクエリーに関連付けられた前記優先順位に基づいて前記第2のクエリーを中断することを決定する手段と、
前記第2のクエリー間隔後の第3のクエリー間隔の間に前記1つ又は複数のデータ・ソース内の第2のデータ部分についての前記第1のクエリーを処理するように前記クエリーエンジンに指示する手段と
を含む、システム。 - 前記第1のクエリーに関係付けられた前記優先順位を前記記憶媒体に記憶する手段をさらに含み、
前記第1のクエリーに関係付けられた前記優先順位の前記変更は、処理のために前記第1のクエリーを選択する前に行われ、
処理のために前記第1のクエリーを選択することが部分的に前記優先順位に基づいて前記クエリーを選択することを含む、請求項46記載のシステム。 - 前記第1のクエリー間隔が所定の時間量によって定義される、請求項46記載のシステム。
- 前記第1のクエリーに関連付けられた前記優先順位は、前記1つ又は複数のデータ・ソース内の前記データのうちのどのくらいの量が、前記第1のクエリー間隔に対して前記第1のクエリーが実行される前記データの第1の部分に含まれるか、に影響する、請求項48記載のシステム。
- 前記第1のクエリーを記憶することが、前記第1のクエリーを提供したリクエスタに通知される前に使用可能になるべき前記第1の結果データの量の通知しきい値を記憶することを含む、請求項46記載のシステム。
- 前記第1の結果データの前記量が前記通知しきい値を超えた時に前記リクエスタに通知する手段をさらに含み、
前記第1のクエリーの前記状態を保存することが前記クエリーエンジンから受信した前記第1の結果データの前記量を記憶することを含む、請求項50記載のシステム。 - 前記リクエスタからの要求に対して前記第1の結果データを返し、前記リクエスタに返された前記第1の結果データの前記量を前記記憶媒体に記憶する手段をさらに含む、請求項51記載のシステム。
- 前記第1のクエリーを選択することが、前記クエリーエンジンから受信した前記第1の結果データの前記量と前記リクエスタに返された前記第1の結果データの前記量に基づくものである、請求項52記載のシステム。
- 前記第1のクエリーの前記状態を保存することが、
前記第1のクエリーを中断するよう前記クエリーエンジンに指示することと、
前記第1のクエリーが中断された後に前記第1のクエリーの状態を保存すること、
を含む、請求項46記載のシステム。 - 前記第2のデータ部分に関する前記第1のクエリーを処理するように前記クエリーエンジンに指示することが、
前記第1のクエリーの前記保存状態をロードすることと、
前記第1のクエリーを再開するように前記クエリーエンジンに指示すること、
を含む、請求項54記載のシステム。 - 前記第1のクエリーの前記状態を保存することが、二次索引へのオフセットを保存することを含む、請求項54記載のシステム。
- 前記二次索引がブロック圧縮索引付きファイルの索引である、請求項56記載のシステム。
- 前記第1のクエリーを複数の副クエリーに分割し、前記副クエリーのうちの少なくともいくつかを同時に処理するよう前記クエリーエンジンに指示する手段をさらに含む、請求項46記載のシステム。
- 前記第1のクエリー間隔が始まった後で前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項46記載のシステム。
- 前記第1のクエリー間隔が始まる前に前記第2のクエリーが受信され、前記記憶媒体に記憶される、請求項46記載のシステム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US28977809P | 2009-12-23 | 2009-12-23 | |
| US61/289,778 | 2009-12-23 | ||
| PCT/US2010/061979 WO2011079251A1 (en) | 2009-12-23 | 2010-12-23 | Managing queries |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2013516008A JP2013516008A (ja) | 2013-05-09 |
| JP2013516008A5 JP2013516008A5 (ja) | 2014-02-13 |
| JP5675840B2 true JP5675840B2 (ja) | 2015-02-25 |
Family
ID=43513581
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012546227A Active JP5675840B2 (ja) | 2009-12-23 | 2010-12-23 | クエリー管理 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US10459915B2 (ja) |
| EP (1) | EP2517124A1 (ja) |
| JP (1) | JP5675840B2 (ja) |
| KR (2) | KR20150042876A (ja) |
| CN (1) | CN102687144B (ja) |
| AU (1) | AU2010336363B2 (ja) |
| CA (1) | CA2785398C (ja) |
| WO (1) | WO2011079251A1 (ja) |
Families Citing this family (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7725453B1 (en) | 2006-12-29 | 2010-05-25 | Google Inc. | Custom search index |
| US10061562B2 (en) | 2012-09-29 | 2018-08-28 | Pivotal Software, Inc. | Random number generator in a parallel processing database |
| US8874602B2 (en) * | 2012-09-29 | 2014-10-28 | Pivotal Software, Inc. | Random number generator in a MPP database |
| US9984083B1 (en) * | 2013-02-25 | 2018-05-29 | EMC IP Holding Company LLC | Pluggable storage system for parallel query engines across non-native file systems |
| US9454573B1 (en) | 2013-02-25 | 2016-09-27 | Emc Corporation | Parallel processing database system with a shared metadata store |
| US20150074084A1 (en) * | 2013-09-12 | 2015-03-12 | Neustar, Inc. | Method and system for performing query processing in a key-value store |
| WO2016004594A2 (en) | 2014-07-09 | 2016-01-14 | Splunk Inc. | Managing datasets produced by alert-triggering search queries |
| US9679015B2 (en) * | 2014-09-03 | 2017-06-13 | Bank Of America Corporation | Script converter |
| US10241828B2 (en) | 2015-04-03 | 2019-03-26 | Oath Inc. | Method and system for scheduling transactions in a data system |
| CN106294451B (zh) * | 2015-05-28 | 2020-01-14 | 阿里巴巴集团控股有限公司 | 一种数据处理中显示处理进度的方法及其装置 |
| US10360267B2 (en) * | 2015-06-10 | 2019-07-23 | Futurewei Technologies, Inc. | Query plan and operation-aware communication buffer management |
| US20180246987A1 (en) * | 2015-09-04 | 2018-08-30 | Entit Software Llc | Graph database management |
| WO2017044119A1 (en) | 2015-09-11 | 2017-03-16 | Hewlett Packard Enterprise Development Lp | Graph database and relational database mapping |
| CN106570022B (zh) * | 2015-10-10 | 2020-06-23 | 菜鸟智能物流控股有限公司 | 一种跨数据源查询方法、装置及系统 |
| CN106888135B (zh) * | 2015-12-15 | 2020-03-24 | 阿里巴巴集团控股有限公司 | 一种任务状态的查询方法和装置 |
| US10198474B2 (en) * | 2016-01-19 | 2019-02-05 | Quest Software Inc. | Delaying one or more searches to cause multiple searches to load and evaluate segments together |
| KR101883991B1 (ko) * | 2016-02-12 | 2018-07-31 | 경희대학교 산학협력단 | 데이터 중개 장치 그리고 이를 이용한 데이터 중개 방법 |
| US10318346B1 (en) | 2016-09-23 | 2019-06-11 | Amazon Technologies, Inc. | Prioritized scheduling of data store access requests |
| JP7086661B2 (ja) * | 2018-03-20 | 2022-06-20 | ヤフー株式会社 | 情報処理システム、情報処理方法、およびプログラム |
| CN108549683B (zh) * | 2018-04-03 | 2022-04-22 | 联想(北京)有限公司 | 数据查询方法以及系统 |
| US11755658B2 (en) * | 2018-06-12 | 2023-09-12 | Nuvolo Technologies Corporation | Intelligent buffering of queries from a mobile application |
| US10922316B2 (en) | 2018-06-13 | 2021-02-16 | Amazon Technologies, Inc. | Using computing resources to perform database queries according to a dynamically determined query size |
| US12013856B2 (en) | 2018-08-13 | 2024-06-18 | Amazon Technologies, Inc. | Burst performance of database queries according to query size |
| US11194815B1 (en) * | 2019-02-11 | 2021-12-07 | Amazon Technologies, Inc. | Constrained query execution |
| US11327970B1 (en) | 2019-03-25 | 2022-05-10 | Amazon Technologies, Inc. | Context dependent execution time prediction for redirecting queries |
| US11308100B2 (en) | 2019-06-25 | 2022-04-19 | Amazon Technologies, Inc. | Dynamically assigning queries to secondary query processing resources |
| US10990879B2 (en) | 2019-09-06 | 2021-04-27 | Digital Asset Capital, Inc. | Graph expansion and outcome determination for graph-defined program states |
| US11132403B2 (en) * | 2019-09-06 | 2021-09-28 | Digital Asset Capital, Inc. | Graph-manipulation based domain-specific execution environment |
| US11204922B2 (en) * | 2020-01-13 | 2021-12-21 | Google Llc | Optimal query scheduling for resource utilization optimization |
| AU2021202904A1 (en) * | 2020-05-15 | 2021-12-02 | Vail Systems, Inc. | A data management system using attributed data slices |
| US11537616B1 (en) | 2020-06-29 | 2022-12-27 | Amazon Technologies, Inc. | Predicting query performance for prioritizing query execution |
| US11687833B2 (en) * | 2020-08-27 | 2023-06-27 | Google Llc | Data management forecasting from distributed tracing |
| US11762860B1 (en) | 2020-12-10 | 2023-09-19 | Amazon Technologies, Inc. | Dynamic concurrency level management for database queries |
| KR102605930B1 (ko) * | 2022-07-21 | 2023-11-30 | 스마트마인드 주식회사 | 데이터베이스 상에서 정형 데이터와 비정형 데이터를 처리하는 방법 및 이러한 방법을 제공하는 데이터 처리 플랫폼 |
| US20240143674A1 (en) * | 2022-10-27 | 2024-05-02 | Onetrust Llc | Processing and publishing scanned data for detecting entities in a set of domains via a parallel pipeline |
| KR102668905B1 (ko) * | 2023-07-10 | 2024-05-24 | 스마트마인드 주식회사 | 서버 마이그레이션 방법 및 이러한 방법을 수행하는 장치 |
| US12117980B1 (en) * | 2023-09-11 | 2024-10-15 | Oracle International Corporation | Auto recognition of big data computation engine for optimized query runs on cloud platforms |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08292956A (ja) * | 1995-04-20 | 1996-11-05 | Mitsubishi Electric Corp | データベース管理装置及びデータベース管理方法 |
| JPH08314965A (ja) * | 1995-05-19 | 1996-11-29 | Toshiba Corp | 文書検索装置 |
| US6956941B1 (en) * | 2000-04-12 | 2005-10-18 | Austin Logistics Incorporated | Method and system for scheduling inbound inquiries |
| GB2361555A (en) * | 2000-04-17 | 2001-10-24 | Apama Inc | Method of evaluating queries against received event information |
| US7143080B2 (en) * | 2001-12-27 | 2006-11-28 | Tedesco Michael A | Method, system and apparatus for separately processing database queries |
| US7155459B2 (en) | 2002-06-28 | 2006-12-26 | Miccrosoft Corporation | Time-bound database tuning |
| US20040172385A1 (en) * | 2003-02-27 | 2004-09-02 | Vikram Dayal | Database query and content transmission governor |
| US7472112B2 (en) | 2003-06-23 | 2008-12-30 | Microsoft Corporation | Distributed query engine pipeline method and system |
| WO2005072877A1 (en) * | 2004-01-30 | 2005-08-11 | Mmd Design & Consultancy Limited | Rotating mineral breaker |
| JP4379374B2 (ja) * | 2005-02-21 | 2009-12-09 | ブラザー工業株式会社 | コンテンツ提供システム、及び、プログラム |
| US8239383B2 (en) * | 2006-06-15 | 2012-08-07 | International Business Machines Corporation | System and method for managing execution of queries against database samples |
| EP2038739A4 (en) * | 2006-06-26 | 2012-05-30 | Datallegro Inc | LOAD MANAGER FOR RELATIONAL DATABASE MANAGEMENT SYSTEMS |
| US7536383B2 (en) * | 2006-08-04 | 2009-05-19 | Apple Inc. | Method and apparatus for searching metadata |
| US7792819B2 (en) | 2006-08-31 | 2010-09-07 | International Business Machines Corporation | Priority reduction for fast partitions during query execution |
| US8229902B2 (en) * | 2006-11-01 | 2012-07-24 | Ab Initio Technology Llc | Managing storage of individually accessible data units |
| US20080133608A1 (en) * | 2006-12-05 | 2008-06-05 | Douglas Brown | System for and method of managing workloads in a database system |
| US20090083238A1 (en) * | 2007-09-21 | 2009-03-26 | Microsoft Corporation | Stop-and-restart style execution for long running decision support queries |
| WO2011019586A1 (en) * | 2009-08-12 | 2011-02-17 | 4Raytheon Company | Method and system for querying an ontology model |
-
2010
- 2010-12-23 EP EP10799246A patent/EP2517124A1/en not_active Ceased
- 2010-12-23 KR KR20157008410A patent/KR20150042876A/ko not_active Application Discontinuation
- 2010-12-23 WO PCT/US2010/061979 patent/WO2011079251A1/en active Application Filing
- 2010-12-23 CA CA2785398A patent/CA2785398C/en active Active
- 2010-12-23 KR KR1020127016852A patent/KR101721892B1/ko active IP Right Grant
- 2010-12-23 CN CN201080058553.2A patent/CN102687144B/zh active Active
- 2010-12-23 US US12/977,594 patent/US10459915B2/en active Active
- 2010-12-23 AU AU2010336363A patent/AU2010336363B2/en active Active
- 2010-12-23 JP JP2012546227A patent/JP5675840B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN102687144A (zh) | 2012-09-19 |
| AU2010336363A1 (en) | 2012-06-14 |
| US10459915B2 (en) | 2019-10-29 |
| KR20150042876A (ko) | 2015-04-21 |
| JP2013516008A (ja) | 2013-05-09 |
| WO2011079251A9 (en) | 2012-07-12 |
| AU2010336363A9 (en) | 2016-03-03 |
| EP2517124A1 (en) | 2012-10-31 |
| CA2785398C (en) | 2020-12-29 |
| CN102687144B (zh) | 2017-02-15 |
| CA2785398A1 (en) | 2011-06-30 |
| AU2010336363B2 (en) | 2016-03-03 |
| KR101721892B1 (ko) | 2017-04-10 |
| WO2011079251A1 (en) | 2011-06-30 |
| US20110153662A1 (en) | 2011-06-23 |
| KR20120109533A (ko) | 2012-10-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5675840B2 (ja) | クエリー管理 | |
| US11593404B2 (en) | Multi-cluster warehouse | |
| US10831387B1 (en) | Snapshot reservations in a distributed storage system | |
| Cho et al. | Natjam: Design and evaluation of eviction policies for supporting priorities and deadlines in mapreduce clusters | |
| US7827167B2 (en) | Database management system and method including a query executor for generating multiple tasks | |
| US8924981B1 (en) | Calculating priority indicators for requests in a queue | |
| Luo et al. | On performance stability in LSM-based storage systems (extended version) | |
| US8516488B1 (en) | Adjusting a resource estimate in response to progress of execution of a request | |
| US8966493B1 (en) | Managing execution of multiple requests in a job using overall deadline for the job | |
| US10817380B2 (en) | Implementing affinity and anti-affinity constraints in a bundled application | |
| US8745032B1 (en) | Rejecting a request in a database system | |
| US20090320022A1 (en) | File System Object Node Management | |
| WO2020057369A1 (zh) | 一种查询计划的获取方法、数据查询方法及装置 | |
| US10824640B1 (en) | Framework for scheduling concurrent replication cycles | |
| US7721287B2 (en) | Organizing transmission of repository data | |
| US20230010652A1 (en) | Systems and methods for automatic index creation in database deployment | |
| Saranya et al. | Scheduling of Intermittent Query Processing. | |
| JP2016184272A (ja) | データベース管理システム、そのバッファリング方法およびコンピュータ・プログラム | |
| Park et al. | CMU-PDL-17-107 November 2017 | |
| Hussain et al. | Parallel Query in RAC: by Riyaj Shamsudeen |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131220 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20131220 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20140523 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140616 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20140911 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20140919 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20141016 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20141203 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20141224 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5675840 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |