JP5672155B2 - Speaker discrimination apparatus, speaker discrimination program, and speaker discrimination method - Google Patents
Speaker discrimination apparatus, speaker discrimination program, and speaker discrimination method Download PDFInfo
- Publication number
- JP5672155B2 JP5672155B2 JP2011122808A JP2011122808A JP5672155B2 JP 5672155 B2 JP5672155 B2 JP 5672155B2 JP 2011122808 A JP2011122808 A JP 2011122808A JP 2011122808 A JP2011122808 A JP 2011122808A JP 5672155 B2 JP5672155 B2 JP 5672155B2
- Authority
- JP
- Japan
- Prior art keywords
- speaker
- frame
- area
- unit
- audio data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images











Description
本発明は、話者判別装置、話者判別プログラム及び話者判別方法に関する。 The present invention relates to a speaker discrimination device, a speaker discrimination program, and a speaker discrimination method.
複数の話者によってなされる会話の各場面において各話者のうち誰が発話しているのかを判別する技術が知られている。 There is known a technique for discriminating who is speaking from each speaker in each scene of a conversation made by a plurality of speakers.
かかる話者の判別を閾値判定により実現する技術の一例として、音声認識装置が挙げられる。この音声認識装置には、各参加者に対応してマイクロホンが接続される。このような構成の下、音声認識装置は、マイクロホンによって出力される音声信号のパワーがパワー閾値を超えてから下回るまでの区間の音声信号を音声認識の対象として記憶部の所定のエリアへ記録する。その上で、音声認識装置は、記憶部に記録した音声信号を音声認識した後に、発言者を特定するためのデータとしてマイクロホンの識別情報を紐付けて音声認識の結果を記憶部の議事録エリアへ記録する。 An example of a technique for realizing such speaker determination by threshold determination is a voice recognition device. A microphone is connected to this speech recognition apparatus corresponding to each participant. Under such a configuration, the speech recognition apparatus records the speech signal in the section from when the power of the speech signal output by the microphone exceeds the power threshold to below it as a speech recognition target in a predetermined area of the storage unit. . In addition, the voice recognition device recognizes the voice signal recorded in the storage unit, and then associates the microphone identification information as data for specifying the speaker, and displays the result of the voice recognition in the minutes area of the storage unit. To record.
また、話者の判別を音源定位により実現する技術の一例としては、発話イベント分離システムが挙げられる。この発話イベント分離システムでは、それぞれ異なる方向に放射状に向けた複数のマイクロホンを有するマイクロホンアレイが用いられる。発話イベント分離システムは、音源定位のアルゴリズムを用いて、マイクロホンアレイによって収録された多チャネルの音声データを解析して時刻毎に音の到来方向を推定する。また、発話イベント分離システムは、音源となる話者の存在範囲を推定する。その上で、発話イベント分離システムは、音源定位の結果と、話者の存在範囲の推定結果から、時刻毎にどの話者が発話しているかを同定する。 An example of a technique for realizing speaker discrimination by sound source localization is an utterance event separation system. In this utterance event separation system, a microphone array having a plurality of microphones radially directed in different directions is used. The utterance event separation system uses a sound source localization algorithm to analyze multi-channel audio data recorded by a microphone array and estimate the direction of arrival of sound at each time. Also, the utterance event separation system estimates the existence range of speakers as sound sources. Then, the utterance event separation system identifies which speaker is speaking at each time from the result of sound source localization and the estimation result of the presence range of the speaker.
しかしながら、上記の従来技術では、以下に説明するように、話者の判別を簡易かつ正確に行うことができないという問題がある。 However, the above-described prior art has a problem that it is not possible to easily and accurately determine the speaker as described below.
例えば、上記の音声認識装置は、音声信号のパワーがパワー閾値を超過するか否かによって話者が発話しているか否かを判定するものである。このため、上記の音声認識装置では、話者を判別する精度はパワー閾値に依存するが、人間が発話する音声には個人差があるので、パワー閾値に適切な値を設定することは困難である。それゆえ、上記の音声認識装置では、話者の判別を正確に行うことができない。 For example, the speech recognition apparatus described above determines whether or not the speaker is speaking depending on whether or not the power of the speech signal exceeds the power threshold. For this reason, in the above speech recognition apparatus, the accuracy of determining the speaker depends on the power threshold, but since there are individual differences in the speech uttered by humans, it is difficult to set an appropriate value for the power threshold. is there. Therefore, the above speech recognition apparatus cannot accurately determine the speaker.
また、上記の発話イベント分離システムでは、音源定位により音の到来方向を推定するのに複雑なアルゴリズムを使用する必要がある。さらに、上記の発話イベント分離システムでは、話者の存在範囲を推定するために、会議に参加する人数等を予め学習させておく必要もある。よって、上記の発話イベント分離システムでは、話者の判別を簡易に行うことはできない。 In the above utterance event separation system, it is necessary to use a complicated algorithm to estimate the direction of arrival of sound by sound source localization. Furthermore, in the above utterance event separation system, it is necessary to learn in advance the number of people participating in the conference in order to estimate the range of speakers. Therefore, in the above utterance event separation system, it is not possible to easily determine the speaker.
開示の技術は、上記に鑑みてなされたものであって、話者の判別を簡易かつ正確に行うことができる話者判別装置、話者判別プログラム及び話者判別方法を提供することを目的とする。 The disclosed technique has been made in view of the above, and an object thereof is to provide a speaker discrimination device, a speaker discrimination program, and a speaker discrimination method capable of easily and accurately discriminating a speaker. To do.
本願の開示する話者判別装置は、各々の話者に配置される複数のマイクから各々の音声データを取得する取得部を有する。さらに、前記話者判別装置は、前記取得部によって取得された音声データを所定の区間のフレームにフレーム化するフレーム化部を有する。さらに、前記話者判別装置は、第1の確率モデルに基づいて、前記フレーム化部によってフレーム化されたフレームが有声音領域または無声音領域のいずれであるかを識別する第1の識別部を有する。さらに、前記話者判別装置は、各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する有効化部を有する。さらに、前記話者判別装置は、第2の確率モデルに基づいて、前記有効化部によって有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する第2の識別部を有する。 The speaker discrimination device disclosed in the present application includes an acquisition unit that acquires each voice data from a plurality of microphones arranged for each speaker. Further, the speaker discrimination device has a framing unit that frames the voice data acquired by the acquisition unit into frames of a predetermined section. Furthermore, the speaker discrimination device has a first identification unit that identifies whether the frame framed by the framing unit is a voiced sound region or an unvoiced sound region based on a first probability model. . Further, the speaker discrimination device has the largest energy among the frames identified as the voiced sound area in the same section when the voiced sound area is identified in duplicate in the frame of the same section in each audio data. An enabling unit that validates the frame identification result; Further, the speaker discriminating device uses a second probability model to identify a speech area and a silence area in each speech data from a frame identification result after being validated by the validation unit. It has an identification part.
本願の開示する話者判別装置の一つの態様によれば、話者の判別を簡易かつ正確に行うことができるという効果を奏する。 According to one aspect of the speaker discrimination device disclosed in the present application, it is possible to easily and accurately perform speaker discrimination.
以下に、本願の開示する話者判別装置、話者判別プログラム及び話者判別方法の実施例を図面に基づいて詳細に説明する。なお、この実施例は開示の技術を限定するものではない。そして、各実施例は、処理内容を矛盾させない範囲で適宜組み合わせることが可能である。 Embodiments of a speaker discrimination device, a speaker discrimination program, and a speaker discrimination method disclosed in the present application will be described below in detail with reference to the drawings. Note that this embodiment does not limit the disclosed technology. Each embodiment can be appropriately combined within a range in which processing contents are not contradictory.
まず、本実施例に係る話者判別装置を含む会話分析装置の機能的構成について説明する。図1は、実施例1に係る会話分析装置の機能的構成を示すブロック図である。図1に示す会話分析装置10は、話者A、話者B及び話者Cにそれぞれ対応して設けられた接話マイク30A〜30Cを介して集音した複数の音声データから、話者A〜話者Cの会話に関する特性を抽出して会話スタイルを分析するものである。
First, the functional configuration of the conversation analysis device including the speaker discrimination device according to the present embodiment will be described. FIG. 1 is a block diagram illustrating a functional configuration of the conversation analysis apparatus according to the first embodiment. The
この会話分析装置10には、接話マイク30A〜30Cの3つのマイクが接続される。これら接話マイク30A〜30Cは、話者によって装着される接話型マイクロホン(close‐talking microphone)である。かかる接話マイクの一態様としては、ラペルマイクやヘッドセットマイクなどが挙げられる。以下では、接話マイク30A〜30Cのことを区別なく総称する場合には「接話マイク30」と記載する場合がある。
Three conversation microphones 30A to 30C are connected to the
なお、図1の例では、接話型マイクロホンを用いる場合を例示したが、必ずしも接話型マイクロホンを用いる必要はなく、各々の話者に他の話者よりも接近して配置するのであれば任意のマイクを採用できる。また、図1の例では、3つのマイクを用いて話者A〜話者Cの3人の会話を集音する場合を例示するが、2つのマイクを用いて2人の会話を集音することとしてもよいし、また、4つ以上のマイクを用いて4人以上の会話を集音することとしてもかまわない。 In the example of FIG. 1, the case of using a close-talking microphone is illustrated, but it is not always necessary to use a close-talking microphone, as long as each speaker is arranged closer to the other speakers. Any microphone can be used. Further, in the example of FIG. 1, a case where three conversations of speakers A to C are collected using three microphones is illustrated, but two conversations are collected using two microphones. It is also possible to collect four or more conversations using four or more microphones.
登録部31は、接話マイク30によって集音された音声信号を会話分析装置10の記憶部11へ登録する処理部である。一態様としては、登録部31は、接話マイク30から音声入力されたアナログ信号にA/D(Analog/Digital)変換を実行することによりデジタル信号に変換した上で音声記憶部11へ登録する。なお、以下では、接話マイク30Aから音声入力されたアナログ信号がA/D変換されたデジタル信号のことを「第1の音声データ」と記載する場合がある。また、接話マイク30Bから音声入力されたアナログ信号がA/D変換されたデジタル信号のことを「第2の音声データ」と記載する場合がある。さらに、接話マイク30Cから音声入力されたアナログ信号がA/D変換されたデジタル信号のことを「第3の音声データ」と記載する場合がある。
The registration unit 31 is a processing unit that registers the audio signal collected by the close-talking microphone 30 in the
図1に示すように、会話分析装置10は、音声記憶部11と、抽出部13と、分析部14とを有する。なお、会話分析装置10は、図1に示した機能部以外にも既知のコンピュータが有する各種の機能部、例えば各種の入力デバイスや音声出力デバイスなどを始め、他の装置との通信を制御する通信インターフェースなどの機能部を有するものとする。
As shown in FIG. 1, the
音声記憶部11は、音声データを記憶する記憶部である。この音声記憶部11は、第1の音声データ12Aと、第2の音声データ12Bと、第3の音声データ12Cとを記憶する。
The
これら第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cは、話者A〜話者Cが装着する接話マイク30によって集音された音声信号がA/D変換されたデジタルデータである。このうち、第1の音声データ12Aには、話者Aの音声だけでなく、話者Bおよび話者Cの音声も含み得るが、話者Aから接話マイク30Aまでの距離が話者Bや話者Cに比べて接近している。よって、第1の音声データ12Aに含まれる音声は、話者Aと話者Bや話者Cとの間で同時に発話がなされていた場合でも、話者Aによって発話された音声のエネルギーが最も高くなる。同様に、第2の音声データ12Bに含まれる音声は、話者Bによって発話された音声のエネルギーが最も高くなり、第3の音声データ12Cに含まれる音声は、話者Cによって発話された音声のエネルギーが最も高くなる。
The
なお、上記の音声記憶部11などの記憶部には、半導体メモリ素子や記憶装置を採用できる。例えば、半導体メモリ素子としては、VRAM(Video Random Access Memory)、RAM(Random Access Memory)、ROM(Read Only Memory)やフラッシュメモリ(flash memory)などが挙げられる。また、記憶装置としては、ハードディスク、光ディスクなどの記憶装置が挙げられる。
Note that a semiconductor memory element or a storage device can be adopted as the storage unit such as the
ここで、話者によって発話される有声音および無声音について説明する。図2は、有声音および無声音の一例を示す図である。図2の例では、サンプリング周波数が16kHzである接話マイクを用いて取得した音声データが示されている。図2の例では、横軸は時間を示し、縦軸は周波数を示し、図中の濃淡はスペクトルエントロピーの大小を示す。 Here, voiced and unvoiced sounds uttered by the speaker will be described. FIG. 2 is a diagram illustrating an example of voiced and unvoiced sounds. In the example of FIG. 2, voice data acquired using a close-talking microphone with a sampling frequency of 16 kHz is shown. In the example of FIG. 2, the horizontal axis indicates time, the vertical axis indicates frequency, and the shading in the figure indicates the magnitude of spectral entropy.
図2に示すように、有声音V(Voiced)は、スペクトルエントロピーの変化が大きく、無声音U(Unvoiced)よりも低い周波数の音である。有声音の一例としては、母音「a」、「i」、「u」、「e」、「o」などが挙げられる。また、無声音Uは、有声音Vよりも高い周波数の音である。無声音の一例としては、母音以外の音、例えば「s」、「p」、「h」などが挙げられる。これら有声音および無声音の特徴は、話者によって発話される言語に依存せず、日本語、英語や中国語などの任意の言語において共通する。 As shown in FIG. 2, the voiced sound V (Voiced) is a sound having a large spectrum entropy change and a frequency lower than that of the unvoiced sound U (Unvoiced). Examples of voiced sounds include vowels “a”, “i”, “u”, “e”, “o”, and the like. The unvoiced sound U is a sound having a higher frequency than the voiced sound V. Examples of unvoiced sounds include sounds other than vowels, such as “s”, “p”, “h”, and the like. The characteristics of these voiced sounds and unvoiced sounds do not depend on the language spoken by the speaker, and are common to arbitrary languages such as Japanese, English, and Chinese.
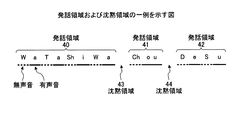
次に、有声音および無声音と発話領域および沈黙領域との関係について説明する。図3は、発話領域および沈黙領域の一例を示す図である。発話領域は、話者によって発話がなされている領域を指し、無声音領域および有声音領域を含む。なお、図3の例では、話者によって「WaTaShiWa Chou DeSu」と発話された場合を示す。 Next, the relationship between voiced and unvoiced sounds and utterance areas and silence areas will be described. FIG. 3 is a diagram illustrating an example of a speech area and a silence area. The utterance area refers to an area where an utterance is made by a speaker, and includes an unvoiced sound area and a voiced sound area. Note that the example of FIG. 3 shows a case where the speaker utters “WaTaShiWa Chou DeSu”.
図3に示す発話の例では、「WaTaShiWa」の発話領域40と、「Chou」の発話領域41と、「DeSu」の発話領域42との間に、沈黙領域43および沈黙領域44が存在することを示す。このうち、発話領域40には、無声音「W」、有声音「a」、無声音「T」、有声音「a」、無声音「Sh」、有声音「i」、無声音「W」、有声音「a」が含まれる。また、発話領域41には、無声音「Ch」、有声音「ou」が含まれる。さらに、発話領域42には、無声音「D」、有声音「e」、無声音「S」、有声音「u」が含まれる。
In the example of the utterance shown in FIG. 3, there are a
図1の説明に戻り、会話分析装置10は、複数の話者によってなされる会話の各場面において各話者のうち誰が発話しているのかを判別する話者判別装置50を有する。
Returning to the description of FIG. 1, the
ここで、本実施例に係る話者判別装置50は、接話マイク30A〜30Cから第1の音声データ、第2の音声データ及び第3の音声データを取得する。さらに、本実施例に係る話者判別装置50は、第1の音声データ、第2の音声データ及び第3の音声データを所定の区間のフレームにフレーム化する。さらに、本実施例に係る話者判別装置50は、第1の確率モデルに基づいて、フレームが有声音領域または無声音領域のいずれであるかを識別する。さらに、本実施例に係る話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する。その上で、本実施例に係る話者判別装置50は、第2の確率モデルに基づいて、有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する。 Here, the speaker discrimination device 50 according to the present embodiment acquires the first voice data, the second voice data, and the third voice data from the close-talking microphones 30A to 30C. Furthermore, the speaker discrimination device 50 according to the present embodiment frames the first voice data, the second voice data, and the third voice data into frames of a predetermined section. Furthermore, the speaker discrimination device 50 according to the present embodiment identifies whether the frame is a voiced sound area or an unvoiced sound area based on the first probability model. Furthermore, the speaker discrimination device 50 according to the present embodiment, when the voiced sound area is identified redundantly in the frames of the same section in each audio data, among the frames identified as the voiced sound area in the same section Enable identification results for frames with maximum energy. Then, the speaker discriminating apparatus 50 according to the present embodiment identifies the speech area and the silence area in each voice data from the identification result of the validated frame based on the second probability model.
図4を用いて、上記の話者判別方法について説明する。図4は、話者判別方法を説明するための図である。図4の上段には、各フレームの有声音領域または無声音領域の識別結果が図示されている。図4の中段には、最大のエネルギーを持つフレームの有声音領域の識別結果が有効化された後の各フレームの識別結果が図示されている。図4の下段には、各々の音声データにおける発話領域および沈黙領域の識別結果が図示されている。 The above speaker discrimination method will be described with reference to FIG. FIG. 4 is a diagram for explaining a speaker discrimination method. The upper part of FIG. 4 shows the identification result of the voiced sound area or the unvoiced sound area of each frame. The middle part of FIG. 4 shows the identification result of each frame after the identification result of the voiced sound area of the frame having the maximum energy is validated. The lower part of FIG. 4 shows the results of identifying speech areas and silence areas in each audio data.
図4の上段に示すように、話者判別装置50は、第1の確率モデルに基づいて、第1の音声データ、第2の音声データ及び第3の音声データからフレーム化した各フレームが有声音領域または無声音領域のいずれであるかを識別する。ここで、図4の例では、記号「●」、記号「○」、記号「△」がそれぞれ音声データのフレームを表し、記号「●」及び記号「○」が有声音領域であることを示し、記号「△」が無声音領域であることを示す。図4に示す記号「●」のフレームは、図4に示す記号「○」のフレームよりも高いエネルギーを有することを示す。これら第1の音声データ、第2の音声データおよび第3の音声データの識別結果からは、話者A〜話者Cのうち話者Bと話者Cが会話しており、話者Bが話者Cよりも大声で発話していることが推定できる。なお、以下では、第1の音声データから得られた各フレームのことを観測順に第1フレーム(1)・・・第1フレーム(n)と記載する場合がある。また、第2の音声データから得られた各フレームのことを観測順に第2フレーム(1)・・・第2フレーム(m)と記載する場合がある。さらに、第3の音声データから得られた各フレームのことを観測順に第3フレーム(1)・・・第3フレーム(m)と記載する場合がある。 As shown in the upper part of FIG. 4, the speaker discriminating device 50 has each frame formed from the first voice data, the second voice data, and the third voice data based on the first probability model. It is identified whether it is a voice sound area or an unvoiced sound area. Here, in the example of FIG. 4, the symbol “●”, the symbol “◯”, and the symbol “△” each represent a frame of audio data, and the symbol “●” and the symbol “◯” indicate that they are voiced sound regions. , Symbol “Δ” indicates an unvoiced sound region. The frame indicated by the symbol “●” shown in FIG. 4 has higher energy than the frame indicated by the symbol “◯” shown in FIG. From the identification results of the first voice data, the second voice data, and the third voice data, the speaker B and the speaker C are talking among the speakers A to C, and the speaker B It can be estimated that the speaker speaks louder than the speaker C. In the following, each frame obtained from the first audio data may be described as first frame (1)... First frame (n) in the order of observation. Also, each frame obtained from the second audio data may be described as second frame (1)... Second frame (m) in the order of observation. Furthermore, the frames obtained from the third audio data may be described as the third frame (1)... Third frame (m) in the order of observation.
また、図4の中段に示すように、話者判別装置50は、各音声データの同一の区間のフレームで有声音領域が重複する場合に、最大のエネルギーを持つフレームの識別結果を有効化する。この例では、第2の音声データ及び第3の音声データを構成するフレームのうち、下記のように、同一区間のフレームで互いに識別結果が有声音領域と識別されている。すなわち、第2フレーム(1)と第3フレーム(1)、第2フレーム(6)と第3フレーム(6)、第2フレーム(10)と第3フレーム(10)において互いの識別結果が有声音領域と識別されている。さらに、第2フレーム(13)と第3フレーム(13)、第2フレーム(18)と第3フレーム(18)において互いの識別結果が有声音領域と識別されている。この場合には、いずれのフレームについても第2の音声データのエネルギーの方が高いので、第3フレーム(1)、第3フレーム(6)、第3フレーム(10)、第3フレーム(13)及び第3フレーム(18)の識別結果が有声音から無声音に置き換えられる。 In addition, as shown in the middle part of FIG. 4, the speaker discrimination device 50 validates the identification result of the frame having the maximum energy when the voiced sound regions overlap in the frames of the same section of each voice data. . In this example, among the frames constituting the second audio data and the third audio data, as described below, the identification results are identified as voiced sound regions in the frames of the same section as described below. That is, the second frame (1) and the third frame (1), the second frame (6) and the third frame (6), and the second frame (10) and the third frame (10) have mutual identification results. It is identified as a voice sound area. Further, in the second frame (13) and the third frame (13), and in the second frame (18) and the third frame (18), the mutual identification results are identified as voiced sound regions. In this case, since the energy of the second audio data is higher in any frame, the third frame (1), the third frame (6), the third frame (10), and the third frame (13). And the identification result of the third frame (18) is replaced from voiced sound to unvoiced sound.
さらに、図4の下段に示すように、話者判別装置50は、第2の確率モデルに基づいて、有効化後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する。この例では、第2の音声データのフレームのうち下線が引かれた領域が話者Bの発話領域として識別されている。さらに、第3の音声データのフレームのうち下線が引かれた領域が話者Cの発話領域として識別されている。この場合には、話者Bの発話領域と話者Cの発話領域が重複するフレーム、すなわち第2フレーム(7)〜第2フレーム(13)の区間が同時発話として判別される。 Furthermore, as shown in the lower part of FIG. 4, the speaker discriminating device 50 identifies the speech area and the silence area in each voice data from the identification result of the validated frame based on the second probability model. In this example, the underlined region of the second audio data frame is identified as the speaker B's speech region. Furthermore, the underlined region of the third audio data frame is identified as the utterance region of the speaker C. In this case, a frame in which the utterance area of the speaker B and the utterance area of the speaker C overlap, that is, a section from the second frame (7) to the second frame (13) is determined as the simultaneous utterance.
このように、本実施例に係る話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、最大のエネルギーを持つフレームの識別結果だけを有効化して各々の音声データの発話領域および沈黙領域を識別する。このため、本実施例に係る話者判別装置50は、各音声データを構成する同一区間のフレーム間で閾値を用いて判定せずとも、話者を判別することができる。さらに、本実施例に係る話者判別装置50では、話者の判別に複雑なアルゴリズムを用いる必要はなく、事前に学習を行う必要もない。したがって、本実施例に係る話者判別装置50によれば、話者の判別を簡易かつ正確に行うことができる。 As described above, the speaker discrimination device 50 according to the present embodiment effectively uses only the identification result of the frame having the maximum energy when the voiced sound area is identified in duplicate in the frame of the same section in each audio data. To identify the speech area and silence area of each voice data. For this reason, the speaker discriminating apparatus 50 according to the present embodiment can discriminate a speaker without using a threshold between frames in the same section constituting each audio data. Further, in the speaker discrimination device 50 according to the present embodiment, it is not necessary to use a complicated algorithm for speaker discrimination, and it is not necessary to perform learning in advance. Therefore, according to the speaker discriminating apparatus 50 according to the present embodiment, the speaker can be discriminated easily and accurately.
また、本実施例に係る話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が単独で識別された場合には、エネルギーの大小に関係なく、有声音領域と識別された識別結果を維持する。一般に、発話は、有声音と無声音が混在して構成されるので、複数の話者によって同時に発話された場合でも、同時発話で有声音領域が完全に重複する可能性は低く、有声音領域が単独で識別される機会が残る可能性は高い。例えば、図4の下段の例で言えば、話者Cの発話の音量が話者Bの発話の音量よりも低くても、第3フレーム(7)、第3フレーム(9)及び第3フレーム(12)の識別結果は有声音のまま維持される。それゆえ、本実施例に係る話者判別装置50では、話者が発話する音量に開きがある場合でも、同時発話を判別することもできる。 Further, the speaker discrimination device 50 according to the present embodiment is identified as the voiced sound area regardless of the magnitude of energy when the voiced sound area is identified independently in the frames of the same section in each audio data. Maintain identification results. In general, utterances are composed of a mixture of voiced and unvoiced sounds, so even if multiple speakers speak at the same time, it is unlikely that voiced sound areas will overlap completely. There is a high probability that an opportunity to be identified alone will remain. For example, in the example in the lower part of FIG. 4, even if the volume of the utterance of the speaker C is lower than the volume of the utterance of the speaker B, the third frame (7), the third frame (9), and the third frame The identification result of (12) is maintained as a voiced sound. Therefore, the speaker discrimination device 50 according to the present embodiment can discriminate simultaneous utterances even when there is a gap in the volume of the utterance by the speaker.
さらに、話者判別装置50を詳細に説明する。図1に示すように、話者判別装置50は、取得部51と、フレーム化部52と、第1の識別部53と、有効化部54と、第2の識別部55とを有する。
Further, the speaker discrimination device 50 will be described in detail. As shown in FIG. 1, the speaker discrimination device 50 includes an acquisition unit 51, a framing
取得部51は、第1の音声データ、第2の音声データおよび第3の音声データを取得する処理部である。一態様としては、取得部51は、音声記憶部11に記憶された第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cを読み出す。他の一態様としては、取得部51は、登録部31によってA/D変換された第1の音声データ、第2の音声データおよび第3の音声データをストリームデータとして取得することもできる。更なる一態様としては、取得部51は、ネットワークを介して図示しない外部装置から第1の音声データ、第2の音声データおよび第3の音声データを取得することもできる。
The acquisition unit 51 is a processing unit that acquires first audio data, second audio data, and third audio data. As an aspect, the acquisition unit 51 reads the
フレーム化部52は、取得部51によって取得された第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cを所定の区間のフレームにフレーム化する処理部である。一態様としては、フレーム化部52は、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cそれぞれの長さを比較する。そして、フレーム化部52は、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cの長さの差が許容誤差範囲内でない場合には、図示しない表示部等にエラーメッセージを出力し、以降の処理を行わない。一方、フレーム化部52は、第1の音声データ12A、第2の音声データ12B及び第3の音声データの長さが同一であるか、あるいは許容誤差範囲内である場合には、下記のような処理を実行する。すなわち、フレーム化部52は、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cをフレーム化する。一例を挙げれば、フレーム化部52は、下記の式(1)、式(2)を用いて、各々の音声データを、長さを256msとするフレーム化を行う。このとき、フレーム化部52は、前後のフレームの重複部分の長さが128msとなるようにする。なお、上記のフレームの長さ、前後のフレームの重複部分の長さは、あくまでも一例であり、任意の値を採用できる。
S=floor(Y/X)・・・・・・・・・・・・・・・・式(1)
m=floor((S−256)/128)+1・・・・・・・・式(2)
なお、「floor(x)」は、x以下の最大の整数を算出するための関数であり、Yは、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cそれぞれのデータ量(byte)であり、Xは、1(byte)のデータに対応する長さ(ms)である。
The framing
S = floor (Y / X) ... Formula (1)
m = floor ((S-256) / 128) +1 (2)
Note that “floor (x)” is a function for calculating the maximum integer equal to or smaller than x, and Y is the
第1の識別部53は、第1の確率モデルに基づいて、フレーム化部52によってフレーム化されたフレームが有声音領域または無声音領域のいずれであるかを識別する処理部である。一態様としては、第1の識別部53は、第1フレーム(1)〜第1フレーム(m)、第2フレーム(1)〜第2フレーム(m)、第3フレーム(1)〜第3フレーム(m)の各々の音声データごとに、下記の処理を実行する。すなわち、第1の識別部53は、自己相関係数のピークの数、自己相関係数のピークの最大値及びスペクトルエントロピーの3つの特徴量を抽出する。さらに、第1の識別部53は、先に抽出した3つの特徴量それぞれの平均値および標準偏差を各々の音声データごとに算出する。その上で、第1の識別部53は、確率モデルである隠れマルコフモデル(Hidden Markov Model;HMM)を用いて、有声音領域および無声音領域を各々の音声データごとに識別する。
The first identifying
ここで、有声音領域および無声音領域の識別方法について説明する。図5は、隠れマルコフモデルにおける状態遷移図の一例を示す図である。図5に示すように、第1の識別部53は、上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果(observation)とし、EM法(Expectation-Maximization algorithm)を用いて、状態遷移確率(transition possibility)Ptを算出する。
Here, a method for identifying the voiced sound area and the unvoiced sound area will be described. FIG. 5 is a diagram illustrating an example of a state transition diagram in the hidden Markov model. As shown in FIG. 5, the
かかる状態遷移確率Ptは、例えば、有声音の状態のままでいる確率、有声音の状態から無声音の状態に遷移する確率、無声音の状態のままでいる確率、無声音の状態から有声音の状態に遷移する確率を指す。図5に示す例で言えば、発話は、有声音および無声音の両方とも同一の確率で開始すると仮定して、発話の開始における有声音および無声音の状態の確率がいずれも「0.5」と設定されている。さらに、初期の状態遷移確率Ptとして、有声音の状態のままでいる確率が「0.95」に設定されるとともに、有声音の状態から無声音の状態に遷移する確率が「0.05」に設定されている。さらに、初期の状態遷移確率Ptとして、無声音の状態のままでいる確率が「0.95」に設定されるとともに、無声音の状態から有声音の状態に遷移する確率が「0.05」に設定されている。このような設定の下、第1の識別部53は、状態遷移確率Ptを算出することを所定回数繰り返す。これによって、精度の高い状態遷移確率Ptを算出することができる。
The state transition probability P t is, for example, the probability of remaining a voiced sound state, the probability of transitioning from a voiced sound state to an unvoiced sound state, the probability of remaining an unvoiced sound state, and the state of a voiced sound to a voiced sound state Indicates the probability of transition to. In the example shown in FIG. 5, assuming that both voiced and unvoiced sounds start with the same probability, the probability of the state of voiced and unvoiced sounds at the start of the utterance is both “0.5”. Is set. Furthermore, as the initial state transition probability P t , the probability that the voiced sound state remains is set to “0.95”, and the probability that the voiced sound state changes to the unvoiced sound state is “0.05”. Is set to Furthermore, as the initial state transition probability P t , the probability of remaining unvoiced sound is set to “0.95”, and the probability of transition from unvoiced sound to voiced sound is set to “0.05”. Is set. Under such setting, the
さらに、第1の識別部53は、上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果とし、ビタビアルゴリズム(Viterbi algorithm)により、観測確率(observation possibility)Poを各々の音声データごとに算出する。ここで、観測確率Poは、例えば、有声音の状態から観測(observed)を出力する確率、有声音の状態から非観測(not observed)を出力する確率、無声音の状態から観測を出力する確率および無声音の状態から非観測を出力する確率である。なお、観測確率は、出力確率(emission possibility)とも称される。
Furthermore, the first identifying
これら状態遷移確率Ptおよび観測確率Poを算出した後に、第1の識別部53は、上記の3つの特徴量に基づいて、ビタビアルゴリズムを用いて、次のような処理を実行する。すなわち、第1の識別部53は、発話が行われている各フレームにおいて発話されている音が有声音であるか、あるいは無声音であるかを識別する。その上で、第1の識別部53は、有声音と識別された領域を有声音領域とし、無声音と識別された領域を無声音領域とする。
After calculating the state transition probability P t and the observation probability Po , the
このように、第1の識別部53は、自己相関係数のピークの数、自己相関係数のピークの最大値及びスペクトルエントロピーなどの特徴量を用いて、有声音領域および無声音領域を識別する。したがって、第1の識別部53では、周囲のノイズの影響によって有声音領域および無声音領域を識別する精度が低下することを抑制できる。また、第1の識別部53は、周囲のノイズに強い特徴量を用いるため、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cをフレーム化する場合に、フレームの個数をより少なくすることができる。それゆえ、第1の識別部53では、より簡易な処理で有声音領域および無声音領域を識別できる。
As described above, the first identifying
有効化部54は、各音声データにおける同一区間のフレームで有声音領域が重複する場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する。 The validation unit 54 validates the identification result of the frame having the maximum energy among the frames identified as the voiced sound area in the same section when the voiced sound areas overlap in the same section frame in each audio data. To do.
一態様としては、有効化部54は、各音声データにおける同一区間のフレームで第1の識別部53による識別結果を比較する。このとき、有効化部54は、同一区間のフレームで有声音領域が重複する場合に、当該有声音領域と識別されたフレームのエネルギーを演算する。そして、有効化部54は、当該同一区間で有声音領域と識別されたフレームのうち最大エネルギーを持つフレームを特定する。その上で、有効化部54は、最大エネルギーを持つフレーム以外の識別結果を有声音領域から無声音領域に置き換える。その後、有効化部54は、各音声データ間で同一区間のフレームを全て処理するまで、識別結果の比較、フレームの特定、識別結果の置き換えを繰り返し実行する。なお、上記のエネルギーは、各々の音声データのフレームに高速フーリエ変換、いわゆるFFT(Fast Fourier Transform)を実行して周波数解析を行った上で周波数成分ごとの振幅値を平均化することにより算出される。
As one aspect, the enabling unit 54 compares the identification results obtained by the first identifying
ここで、有効化部54による識別結果の置換要領について説明する。図6は、有声音領域および無声音領域の識別結果の一例を示す図である。図7は、図6に示した識別結果の置換結果の一例を示す図である。図6に示すように、「12時00分00.000秒」から「12時00分00.010秒」までの区間では、第1フレーム、第2フレーム及び第3フレームの全ての識別結果が有声音領域と識別されている。この場合には、有効化部54は、図7に示すように、第1フレーム、第2フレーム及び第3フレームのうちエネルギーが最大である第1フレームを除き、第2フレーム及び第3フレームの識別結果を有声音領域「V」から無声音領域「U」へ置き換える。また、図6に示す「12時00分00.010秒」から「12時00分00.020秒」までの区間では、第1フレーム及び第2フレームの識別結果が有声音領域と識別されている。この場合には、有効化部54は、図7に示すように、第1フレーム及び第2フレームのうちエネルギーが最大である第1フレームの識別結果を維持する一方で、最大でない第2フレームの識別結果を有声音領域「V」から無声音領域「U」へ置き換える。さらに、図6に示すように、「12時00分00.020秒」から「12時00分00.030秒」までの区間では、第2フレームの識別結果だけが有声音領域と識別されている。この場合には、有効化部54は、同一区間のフレームで有声音領域が重複しないので、図7に示すように、第2フレームの識別結果を維持する。 Here, the replacement procedure of the identification result by the validation unit 54 will be described. FIG. 6 is a diagram illustrating an example of identification results of voiced sound areas and unvoiced sound areas. FIG. 7 is a diagram illustrating an example of a replacement result of the identification result illustrated in FIG. As shown in FIG. 6, in the section from “12: 00: 00.000” to “12: 00: 0.0010”, all the identification results of the first frame, the second frame, and the third frame are displayed. It is identified as a voiced sound area. In this case, as shown in FIG. 7, the enabling unit 54, except for the first frame having the maximum energy among the first frame, the second frame, and the third frame, The identification result is replaced from the voiced sound area “V” to the unvoiced sound area “U”. Further, in the section from “12: 00: 0.0010 seconds” to “12: 00: 0.0020 seconds” shown in FIG. 6, the identification results of the first frame and the second frame are identified as voiced sound regions. Yes. In this case, the enabling unit 54 maintains the identification result of the first frame having the maximum energy among the first frame and the second frame, as shown in FIG. The identification result is replaced from the voiced sound area “V” to the unvoiced sound area “U”. Further, as shown in FIG. 6, in the section from “12: 00: 0.020 second” to “12: 00: 0.0030 second”, only the identification result of the second frame is identified as the voiced sound region. Yes. In this case, the enabling unit 54 maintains the identification result of the second frame, as shown in FIG. 7, because the voiced sound regions do not overlap in the frames of the same section.
第2の識別部55は、第2の確率モデルに基づいて、有効化部54による有効化がなされた後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する処理部である。 The second identification unit 55 is a processing unit that identifies a speech region and a silence region in each audio data from the identification result of the frame after the validation by the validation unit 54 based on the second probability model. is there.
ここで、発話領域および沈黙領域の識別方法について説明する。図8は、隠れマルコフモデルにおける状態遷移図の一例を示す図である。図8に示す状態遷移確率Ptおよび観測確率Poは、予め定められた値である。かかる状態遷移確率Ptは、例えば、沈黙の状態である沈黙状態のままでいる確率、沈黙状態から発話の状態である発話状態に遷移する確率、発話状態のままでいる確率および発話状態から沈黙状態に遷移する確率を示す。図8に示す例で言えば、発話は、有声音および無声音の両方とも同一の確率で開始すると仮定して、発話の開始における沈黙状態および発話状態の確率がいずれも「0.5」に設定されている。また、状態遷移確率Ptとして、沈黙状態のままでいる確率が「0.999」に設定されるとともに、沈黙状態から発話状態に遷移する確率が「0.001」に設定されている。さらに、状態遷移確率Ptとして、発話状態のままでいる確率が「0.999」設定されるとともに、発話状態から沈黙状態に遷移する確率が「0.001」に設定されている。 Here, a method for identifying a speech area and a silence area will be described. FIG. 8 is a diagram illustrating an example of a state transition diagram in the hidden Markov model. The state transition probability P t and the observation probability P o shown in FIG. 8 are predetermined values. The state transition probability P t is, for example, the probability of staying in a silence state that is a silence state, the probability of transitioning from the silence state to the utterance state that is an utterance state, the probability of remaining in the utterance state, and the silence from the utterance state Indicates the probability of transition to a state. In the example shown in FIG. 8, assuming that both voiced and unvoiced sounds start with the same probability, both the silence state and the utterance state probabilities at the start of the utterance are set to “0.5”. Has been. Further, as the state transition probability P t , the probability of remaining silent is set to “0.999”, and the probability of transition from the silent state to the speech state is set to “0.001”. Further, as the state transition probability P t , the probability of remaining in the speech state is set to “0.999”, and the probability of transition from the speech state to the silence state is set to “0.001”.
また、観測確率Poは、例えば、沈黙状態において無声音が検出される確率、沈黙状態において有声音が検出される確率、発話状態において無声音が検出される確率、および発話状態において有声音が検出される確率を指す。図8の例で言えば、観測確率Poとして、沈黙状態において無声音が検出される確率が「0.99」に設定されるとともに、沈黙状態において有声音が検出される確率が「0.01」に設定されている。また、観測確率Poとして、発話状態において無声音が検出される確率が「0.5」に設定されるとともに、発話状態において有声音が検出される確率が「0.5」に設定されている。 The observation probability Po is, for example, the probability that an unvoiced sound is detected in the silence state, the probability that the voiced sound is detected in the silence state, the probability that the unvoiced sound is detected in the utterance state, and the voiced sound in the utterance state. Indicates the probability. In the example of FIG. 8, the probability that an unvoiced sound is detected in the silence state is set to “0.99” as the observation probability Po , and the probability that the voiced sound is detected in the silence state is “0.01”. "Is set. Further, as the observation probability P o , the probability that an unvoiced sound is detected in an utterance state is set to “0.5”, and the probability that a voiced sound is detected in an utterance state is set to “0.5”. .
なお、図8の例では、発話状態において無声音が検出される確率および発話状態において有声音が検出される確率をともに「0.5」に設定する場合を例示したが、同時発話の場合には他の話者よりも音量が小さい発話を行う話者の無声音が増加することも想定される。よって、発話状態において無声音が検出される確率を「0.5」よりも大きく設定することにより、他の話者よりも音量が小さい発話を行う話者の無声音の増加を抑制することもできる。 In the example of FIG. 8, the case where both the probability that an unvoiced sound is detected in the utterance state and the probability that the voiced sound is detected in the utterance state is set to “0.5” is illustrated. It is also assumed that the unvoiced sound of a speaker who makes an utterance whose volume is lower than that of other speakers increases. Therefore, by setting the probability that an unvoiced sound is detected in an utterance state to be larger than “0.5”, it is possible to suppress an increase in the unvoiced sound of a speaker who makes an utterance whose volume is lower than that of other speakers.
このような設定の下、第2の識別部55は、ビタビアルゴリズムを用いて、有効化部54による有効化がなされた後の有声音および無声音から、各々の音声データにおける沈黙領域および発話領域であるかを識別する。これによって、第1の音声データにおける話者Aの発話領域および沈黙領域、第2の音声データにおける話者Bの発話領域および沈黙領域、さらには、第3の音声データにおける話者Cの発話領域および沈黙領域が識別される。 Under such a setting, the second identification unit 55 uses the Viterbi algorithm from the voiced sound and the unvoiced sound after being validated by the validation unit 54 in the silence area and the speech area in each voice data. Identify if there is. Thus, the utterance area and silence area of the speaker A in the first audio data, the utterance area and silence area of the speaker B in the second audio data, and the utterance area of the speaker C in the third audio data And silence regions are identified.
会話分析装置10の説明に戻り、抽出部13は、各々の音声データから会話特性を抽出する処理部である。一態様としては、抽出部13は、第2の識別部55によって識別された第1の音声データにおける話者Aの発話領域をもとに有声音領域の数、有声音領域の長さの平均値および有声音領域の長さの標準偏差を算出する。また、抽出部13は、第2の識別部55によって識別された第1の音声データにおける話者Aの発話領域をもとに発話領域の数、発話領域の長さの平均値および発話領域の長さの標準偏差を算出する。さらに、抽出部13は、第2の識別部55によって識別された第1の音声データにおける話者Aの沈黙領域をもとに、沈黙領域の数、沈黙領域の長さの平均値および沈黙領域の長さの標準偏差を算出する。
Returning to the description of the
また、抽出部13は、会話全体の時間の長さに対する話者Aの発話時間の長さの割合を算出する。このとき、抽出部13は、話者Aの発話領域の長さの合計を、話者Aの発話時間の長さとして、上記の割合を算出する。また、抽出部13は、話者Bの発話時間に対する話者Aの発話時間の割合を算出する。さらに、抽出部13は、話者Cの発話時間に対する話者Aの発話時間の割合も算出する。また、抽出部13は、話者Aの発話領域をもとに、音量の標準偏差およびスペクトルエントロピーの標準偏差を算出する。さらに、抽出部13は、話者Aの発話領域をもとに算出した音量の標準偏差と、スペクトルエントロピーの標準偏差との和を、変化の度合いとして算出する。なお、ここでは、話者Aの会話特性を抽出する場合を例示したが、話者Bおよび話者Cについても、上記の話者Aと同様にして、会話特性を抽出する。 Further, the extraction unit 13 calculates the ratio of the length of the utterance time of the speaker A to the length of time of the entire conversation. At this time, the extraction unit 13 calculates the above ratio by regarding the total length of the utterance area of the speaker A as the length of the utterance time of the speaker A. Further, the extraction unit 13 calculates the ratio of the speaking time of the speaker A to the speaking time of the speaker B. Further, the extraction unit 13 also calculates the ratio of the utterance time of the speaker A to the utterance time of the speaker C. Further, the extraction unit 13 calculates the standard deviation of the volume and the standard deviation of the spectral entropy based on the utterance area of the speaker A. Furthermore, the extraction unit 13 calculates the sum of the standard deviation of the volume calculated based on the utterance area of the speaker A and the standard deviation of the spectral entropy as the degree of change. Here, the case where the conversation characteristic of the speaker A is extracted is illustrated, but the conversation characteristic is also extracted for the speaker B and the speaker C in the same manner as the speaker A described above.
このようにして算出された有声音領域の数、有声音領域の長さの平均値および有声音領域の長さの標準偏差の各会話特性は、有声音の長さがどの位長いのかを示す指標となる。また、発話領域の数、発話領域の長さの平均値、および発話領域の長さの標準偏差の各会話特性は、対応する人物が、常に会話において長く続けて話すのか、あるいは少ししか話さないのかを示す指標となる。また、沈黙領域の数、沈黙領域の長さの平均値および沈黙領域の長さの標準偏差の各会話特性は、話者の話し方が、長く続けて話すのか、あるいは中断(沈黙)を多くはさみながら話すのかを示す指標となる。また、会話全体の時間の長さに対するある人物の発話時間の長さの割合および他の人物の発話時間に対するある人物の発話時間の割合Rtの各会話特性は、会話の参加状態を示す指標となる。また、音量の標準偏差、スペクトルエントロピーの標準偏差および変化の度合いの各会話特性は、感情の変化が激しい情熱的な話者であるのか、あるいは感情の変化が小さい静かな話者であるのかを示す指標となる。 Each conversation characteristic of the number of voiced sound areas, the average value of the length of the voiced sound area, and the standard deviation of the length of the voiced sound area thus calculated indicates how long the length of the voiced sound area is. It becomes an indicator. In addition, the number of utterance areas, the average value of the utterance area lengths, and the standard deviations of the utterance area lengths indicate that the corresponding person always speaks for a long time in the conversation or speaks little. It becomes an index indicating whether or not. In addition, the number of silence areas, the average value of the silence area lengths, and the standard deviation of the silence area lengths, the conversation characteristics, whether the speaker speaks for a long time, or is often interrupted (silence). It becomes an index that shows how to talk. Further, each conversation characteristics of speech time ratio R t of a person to the length speech time parts and other persons in the speech time of a person to the length of the entire conversation time index indicating the participation status of the conversation It becomes. In addition, the conversation characteristics of volume standard deviation, spectral entropy standard deviation, and degree of change indicate whether the speaker is a passionate speaker with a strong emotional change or a quiet speaker with a small emotional change. It becomes an indicator to show.
分析部14は、抽出部13によって抽出された会話特性に基づいて、会話スタイルを分析する処理部である。一態様としては、分析部14は、他の人物の発話時間に対するある人物の発話時間の割合Rtが、所定値、例えば1.5以上である場合には、この「ある人物」は、会話においてよく話す人物であると分析する。また、分析部14は、割合Rtが所定値、例えば0.66以下である場合には、この「ある人物」は、会話においてあまり話さない、いわゆる聞き役の人物であると分析する。なお、分析部14は、割合Rtが、所定値、例えば0.66より大きく、1.5未満である場合には、会話に対する参加状況において両者は対等であると分析する。
The
他の一態様としては、分析部14は、ある人物の発話領域の数に対する有声音領域の数の割合および発話領域の長さの平均値が、他の人物の発話領域の数に対する有声音領域の数の割合および発話領域の長さの平均値よりも大きい場合には、次のように分析する。すなわち、分析部14は、「ある人物」は会話において長く続けて話しがちな人物であると分析する。また、分析部14は、ある人物の沈黙領域の長さの平均値が他の人物の沈黙領域の長さの平均値よりも大きく、かつある人物の沈黙領域の長さの標準偏差が所定値、例えば、6.0以上である場合には、次のように分析する。すなわち、分析部14は、「ある人物」は、相手の話を聞いて、相手の内容に合わせて自分の発話を中断するため、発話の長さが一定しない人物であると分析する。
As another aspect, the
更なる一態様としては、分析部14は、ある人物の音量の標準偏差、スペクトルエントロピーの標準偏差または変化の度合いが、それぞれに対応する基準値以上である場合には、「ある人物」は感情の変化が激しい情熱的な話者であると分析する。また、分析部14は、ある人物の音量の標準偏差、スペクトルエントロピーの標準偏差または変化の度合いが、それぞれに対応する基準値未満である場合には、「ある人物」は感情の変化が小さい静かな話者であると分析する。
As a further aspect, when the standard deviation of the volume of a certain person, the standard deviation of the spectral entropy, or the degree of change is equal to or greater than the corresponding reference value, the
他の一態様としては、分析部14は、ある人物と他の人物との関係を分析することもできる。例えば、分析部14は、他の人物の発話時間に対するある人物の発話時間の割合Rtが所定値、例えば1.0以上である場合には、「ある人物」は「他の人物」に対してよく話しかけているため、ある人物と他の人物との関係が友達や家族であると分析できる。一方、割合Rtが所定値、例えば1.0未満である場合には、この「ある人物」は「他の人物」の話を聞こうとしているため、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
As another aspect, the
更なる一態様としては、分析部14は、ある人物と他の人物との会話においてある人物の発話領域の長さの平均値が所定値、例えば、1.85(s)以上である場合には、ある人物と他の人物との関係が友達や家族であると分析できる。これは、「ある人物」が「他の人物」に対してよく話しかけているためである。一方、分析部14は、ある人物と他の人物との会話においてある人物の発話領域の長さの平均値が所定値、例えば、1.85(s)未満である場合には、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
As a further aspect, the
他の一態様としては、分析部14は、ある人物と他の人物との会話においてある人物の沈黙領域の長さの平均値が所定値、例えば、3.00(s)以下である場合には、同様の理由で、ある人物と他の人物との関係が友達や家族であると分析できる。一方、分析部14は、ある人物の沈黙領域の長さの平均値が所定値、例えば、3.00(s)より大きい場合には、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
As another aspect, the
更なる一態様としては、分析部14は、ある人物と他の人物との会話においてある人物の変化の度合いが所定値、例えば、0.33以上である場合には、同様の理由で、ある人物と他の人物との関係が友達や家族であると分析できる。一方、分析部14は、ある人物の変化の度合いが所定値、例えば、0.33未満である場合には、ある人物と他の人物との関係が会社の同僚やビジネスパートナーであると分析できる。
As a further aspect, the
これらの分析を行った後に、分析部14は、分析結果を所定の出力先の装置、例えば会話分析装置10が有する表示部や話者A〜話者Cが利用する情報処理装置などに出力することができる。
After performing these analyses, the
なお、話者判別装置50、抽出部13及び分析部14には、各種の集積回路や電子回路を採用できる。また、話者判別装置50に含まれる機能部の一部を別の集積回路や電子回路とすることもできる。例えば、集積回路としては、ASIC(Application Specific Integrated Circuit)が挙げられる。また、電子回路としては、CPU(Central Processing Unit)やMPU(Micro Processing Unit)などが挙げられる。
Note that various integrated circuits and electronic circuits can be adopted for the speaker discrimination device 50, the extraction unit 13, and the
続いて、本実施例に係る会話分析装置の処理の流れについて説明する。なお、ここでは、会話分析装置10によって実行される(1)会話分析処理を説明した後に、話者判別装置50によって実行される(2)有効化処理を説明する。
Next, the process flow of the conversation analysis apparatus according to this embodiment will be described. Here, after (1) conversation analysis processing executed by the
(1)会話分析処理
図9及び図10は、実施例1に係る会話分析処理の手順を示すフローチャートである。この会話分析処理は、一例として、図示しない入力部から会話分析処理を実行する指示を受け付けた場合に処理が起動する。
(1) Conversation Analysis Processing FIGS. 9 and 10 are flowcharts illustrating the procedure of conversation analysis processing according to the first embodiment. As an example, the conversation analysis process is started when an instruction to execute the conversation analysis process is received from an input unit (not shown).
図9に示すように、取得部51は、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cを取得する(ステップS101)。そして、フレーム化部52は、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cそれぞれの長さが同一であるか否かを判定する(ステップS102)。なお、ここで言う「同一」は、長さの差が許容誤差範囲内である場合も含む。
As illustrated in FIG. 9, the acquisition unit 51 acquires the
このとき、各々の音声データの長さが同一でない場合(ステップS102否定)には、フレーム化部52は、エラーメッセージを図示しない表示部に出力し(ステップS103)、処理を終了する。
At this time, if the lengths of the respective audio data are not the same (No at Step S102), the framing
一方、各々の音声データの長さが同一である場合(ステップS102肯定)には、フレーム化部52は、第1の音声データ12A、第2の音声データ12B及び第3の音声データ12Cをフレーム化する(ステップS104)。
On the other hand, when the lengths of the respective audio data are the same (Yes at step S102), the framing
その後、第1の識別部53は、自己相関係数のピークの数、自己相関係数のピークの最大値およびスペクトルエントロピーの3つの特徴量を各々の音声データごとに抽出する(ステップS105)。そして、第1の識別部53は、各々の音声データごとに抽出した3つの特徴量それぞれの平均値および標準偏差を算出する(ステップS106)。
After that, the
続いて、第1の識別部53は、変数Nに0を設定し(ステップS107)、隠れマルコフモデルにおける有声音および無声音の状態遷移について初期の状態遷移確率Ptを設定する(ステップS108)。
Subsequently, the first identifying
そして、第1の識別部53は、変数Nの値を1つインクリメントする(ステップS109)。このとき、変数Nの値が5以上でない場合(ステップS110否定)には、第1の識別部53は、各々の音声データごとに抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果とし、EM法を用いて、状態遷移確率Ptを算出し(ステップS111)、ステップS109へ移行する。
Then, the
一方、変数Nの値が5以上である場合(ステップS110肯定)には、第1の識別部53は、各々の音声データごとに抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果とし、EM法を用いて、状態遷移確率Ptを算出する(ステップS112)。
On the other hand, when the value of the variable N is 5 or more (Yes at Step S110), the
そして、第1の識別部53は、各々の音声データごとに抽出した上記の3つの特徴量、並びに、各特徴量の平均値および標準偏差を観測結果とし、ビタビアルゴリズムを用いて、観測確率Poを算出する(ステップS113)。
Then, the
その後、第1の識別部53は、各々の音声データごとに抽出した上記の3つの特徴量に基づいて、ビタビアルゴリズムを用いて、次のような処理を行う。すなわち、第1の識別部53は、発話が行われている各フレームにおいて、発話されている音が有声音であるか、あるいは無声音であるかを識別する。そして、第1の識別部53は、有声音が検出された領域を有声音領域とし、無声音が検出された領域を無声音領域とする(ステップS114)。
Thereafter, the
ここで、有効化部54は、各音声データにおける同一区間のフレームで有声音領域が重複する場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する「有効化処理」を実行する(ステップS115)。 Here, when the voiced sound area overlaps the frames in the same section in each audio data, the enabling unit 54 identifies the frame having the maximum energy among the frames identified as the voiced sound area in the same section. An “validation process” is performed to validate (step S115).
その後、第2の識別部55は、有効化部54による有効化後の有声音および無声音に基づいて、ビタビアルゴリズムを用いて、沈黙状態であるか、あるいは発話状態であるかを検出することで、沈黙領域および発話領域を識別する(ステップS116)。 After that, the second identification unit 55 detects whether it is a silence state or a speech state by using the Viterbi algorithm based on the voiced sound and the unvoiced sound after the activation by the activation unit 54. Then, the silence area and the speech area are identified (step S116).
続いて、抽出部13は、図10に示すように、ある話者が発話したと特定されたフレームから、有声音領域の数、有声音領域の長さの平均値および有声音領域の長さの標準偏差を算出する(ステップS117)。 Subsequently, as shown in FIG. 10, the extraction unit 13 determines the number of voiced sound regions, the average value of the lengths of the voiced sound regions, and the length of the voiced sound regions from the frame identified as being uttered by a certain speaker. Is calculated (step S117).
さらに、抽出部13は、ある話者が発話したと特定されたフレームから、発話領域の数、発話領域の長さの平均値および発話領域の長さの標準偏差を算出する(ステップS118)。その後、抽出部13は、ある話者の沈黙領域のフレームから、沈黙領域の数、沈黙領域の長さの平均値および沈黙領域の長さの標準偏差を算出する(ステップS119)。 Further, the extraction unit 13 calculates the number of utterance areas, the average value of the lengths of the utterance areas, and the standard deviation of the length of the utterance areas from the frame specified that a certain speaker has uttered (step S118). Thereafter, the extraction unit 13 calculates the number of silence areas, the average value of the silence area lengths, and the standard deviation of the silence area lengths from the frame of the silence area of a certain speaker (step S119).
そして、抽出部13は、会話全体の時間の長さに対するある話者の発話時間の長さの割合を算出する(ステップS120)。さらに、抽出部13は、他の話者の発話時間に対するある話者の発話時間の割合を算出する(ステップS121)。 Then, the extraction unit 13 calculates the ratio of the length of the utterance time of a certain speaker to the length of time of the entire conversation (step S120). Further, the extraction unit 13 calculates the ratio of the utterance time of a certain speaker to the utterance time of another speaker (step S121).
続いて、抽出部13は、ある話者が発話したと特定されたフレームから、音量の標準偏差およびスペクトルエントロピーの標準偏差を算出する(ステップS122)。抽出部13は、ある話者が発話したと特定されたフレームから算出した音量の標準偏差と、スペクトルエントロピーの標準偏差との和を、変化の度合いとして算出する(ステップS123)。 Subsequently, the extraction unit 13 calculates the standard deviation of the sound volume and the standard deviation of the spectral entropy from the frame specified that a certain speaker has spoken (step S122). The extraction unit 13 calculates, as the degree of change, the sum of the standard deviation of the volume calculated from the frame identified as being spoken by a certain speaker and the standard deviation of the spectral entropy (step S123).
そして、全ての話者の会話特性を抽出するまで(ステップS124否定)、上記のステップS117〜ステップS123までの処理を繰り返し実行する。その後、全ての話者の会話特性を抽出すると(ステップS124肯定)、分析部14は、抽出部13によって抽出された会話特性に基づいて、会話スタイルを分析する(ステップS125)。最後に、分析部14は、分析結果を所定の出力先の装置へ出力し(ステップS126)、処理を終了する。
Until the conversation characteristics of all the speakers are extracted (No at Step S124), the processes from Step S117 to Step S123 are repeated. Thereafter, when the conversation characteristics of all the speakers are extracted (Yes at Step S124), the
(2)有効化処理
図11は、実施例1に係る有効化処理の手順を示すフローチャートである。この有効化処理は、図9に示したステップS115に対応する処理であり、有声音領域および無声音領域が識別された後に処理が起動する。
(2) Validation Process FIG. 11 is a flowchart illustrating the validation process procedure according to the first embodiment. This validation process is a process corresponding to step S115 shown in FIG. 9, and starts after the voiced sound area and the unvoiced sound area are identified.
図11に示すように、有効化部54は、各音声データにおける同一区間のフレームで第1の識別部53による識別結果を比較する(ステップS301)。このとき、同一区間のフレームで有声音領域が重複する場合(ステップS302肯定)には、有効化部54は、当該有声音領域と識別されたフレームのエネルギーを演算する(ステップS303)。なお、同一区間のフレームで有声音領域が重複しない場合(ステップS302否定)には、ステップS306へ移行する。
As illustrated in FIG. 11, the enabling unit 54 compares the identification results obtained by the first identifying
そして、有効化部54は、当該同一区間で有声音領域と識別されたフレームのうち最大エネルギーを持つフレームを特定する(ステップS304)。その上で、有効化部54は、最大エネルギーを持つフレーム以外の識別結果を有声音領域から無声音領域に置き換える(ステップS305)。 Then, the enabling unit 54 specifies the frame having the maximum energy among the frames identified as the voiced sound area in the same section (step S304). Then, the enabling unit 54 replaces the identification result other than the frame having the maximum energy from the voiced sound region to the unvoiced sound region (step S305).
その後、各音声データ間で同一区間のフレームを全て処理するまで(ステップS306否定)、上記のステップS301〜ステップS305までの処理を繰り返し実行する。そして、各音声データ間で同一区間のフレームを全て処理すると(ステップS306肯定)、処理を終了する。 Thereafter, the processing from step S301 to step S305 is repeated until all the frames in the same section are processed between the audio data (No in step S306). Then, when all the frames in the same section are processed between the respective audio data (Yes at step S306), the process is terminated.
[実施例1の効果]
上述してきたように、本実施例に係る話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、最大のエネルギーを持つフレームの識別結果だけを有効化して各々の音声データの発話領域および沈黙領域を識別する。このため、本実施例に係る話者判別装置50は、各音声データを構成する同一区間のフレーム間で閾値を用いて判定せずとも、話者を判別することができる。さらに、本実施例に係る話者判別装置50では、話者の判別に複雑なアルゴリズムを用いる必要はなく、事前に学習を行う必要もない。したがって、本実施例に係る話者判別装置50によれば、話者の判別を簡易かつ正確に行うことができる。
[Effect of Example 1]
As described above, the speaker discriminating apparatus 50 according to the present embodiment can identify only the identification result of the frame having the maximum energy when the voiced sound area is identified in duplicate in the same section frame in each voice data. Is activated to identify the speech area and silence area of each audio data. For this reason, the speaker discriminating apparatus 50 according to the present embodiment can discriminate a speaker without using a threshold between frames in the same section constituting each audio data. Further, in the speaker discrimination device 50 according to the present embodiment, it is not necessary to use a complicated algorithm for speaker discrimination and it is not necessary to perform learning in advance. Therefore, according to the speaker discriminating apparatus 50 according to the present embodiment, the speaker can be discriminated easily and accurately.
また、本実施例に係る話者判別装置50は、各音声データにおける同一区間のフレームで有声音領域が単独で識別された場合には、エネルギーの大小に関係なく、有声音領域と識別された識別結果を維持する。一般に、発話は、有声音と無声音が混在して構成されるので、複数の話者によって同時に発話された場合でも、同時発話で有声音領域が完全に重複する可能性は低く、有声音領域が単独で識別される機会が残る可能性は高い。それゆえ、本実施例に係る話者判別装置50では、話者が発話する音量に開きがある場合でも、同時発話を判別することもできる。 Further, the speaker discrimination device 50 according to the present embodiment is identified as the voiced sound area regardless of the magnitude of energy when the voiced sound area is identified independently in the frames of the same section in each audio data. Maintain identification results. In general, utterances are composed of a mixture of voiced and unvoiced sounds, so even if multiple speakers speak at the same time, it is unlikely that voiced sound areas will overlap completely. There is a high probability that an opportunity to be identified alone will remain. Therefore, the speaker discrimination device 50 according to the present embodiment can discriminate simultaneous utterances even when there is a gap in the volume of the utterance by the speaker.
さらに、本実施例に係る話者判別装置50は、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレーム以外の識別結果を無声音領域に置き換える。このため、本実施例に係る話者判別装置50では、識別情報の置換という簡易な処理によって最大のエネルギーを持つフレームの識別結果だけを有効化できる結果、話者の判別を簡易に実現できる。 Furthermore, the speaker discrimination device 50 according to the present embodiment replaces the identification result other than the frame having the maximum energy among the frames identified as the voiced sound region in the same section with the unvoiced sound region. For this reason, in the speaker discriminating apparatus 50 according to the present embodiment, only the discriminating result of the frame having the maximum energy can be validated by a simple process of replacing the discriminating information, so that the discrimination of the speaker can be realized easily.
さて、これまで開示の装置に関する実施例について説明したが、本発明は上述した実施例以外にも、種々の異なる形態にて実施されてよいものである。そこで、以下では、本発明に含まれる他の実施例を説明する。 Although the embodiments related to the disclosed apparatus have been described above, the present invention may be implemented in various different forms other than the above-described embodiments. Therefore, another embodiment included in the present invention will be described below.
[エネルギー]
例えば、上記の実施例1では、最大エネルギーを持つフレームの識別結果だけを有効化する場合を例示したが、エネルギーに関連する他の指標が最大となるフレームの識別結果だけを有効化することもできる。一例としては、開示の装置は、フレームで観測される振幅の最大値および最小値の差が最大であるフレームの識別結果だけを有効化することもできる。この場合には、エネルギーの演算処理よりも簡易な演算により、識別結果の置換を実現できる。
[energy]
For example, in the first embodiment, the case where only the identification result of the frame having the maximum energy is validated is illustrated. However, only the identification result of the frame where the other index related to energy is maximized may be validated. it can. As an example, the disclosed apparatus can validate only the identification result of the frame that has the largest difference between the maximum and minimum amplitudes observed in the frame. In this case, the replacement of the identification result can be realized by a simpler calculation than the energy calculation process.
[マイク]
また、上記の実施例1では、接話型マイクロホンを適用する場合を例示したが、開示の装置はこれに限定されず、必ずしもマイクを装着する話者以外の他の話者をマイクから遠ざける必要はない。例えば、指向性を持つマイクを適用することができる。この場合には、話者Aが発話する方向の感度が他の方向の感度よりも強くなるように話者Aまたは指向性マイクを配置し、また、話者Bおよび話者Cについても同様にして指向性マイクを用いればよい。なお、指向性マイクを用いる場合についても、話者は複数であればよく、2人であっても4人以上であっても開示の装置を適用できる。
[Microphone]
In the first embodiment, the case where a close-talking microphone is applied has been exemplified. However, the disclosed apparatus is not limited to this, and it is not necessary to keep other speakers other than the speaker wearing the microphone away from the microphone. There is no. For example, a microphone having directivity can be applied. In this case, the speaker A or the directional microphone is arranged so that the sensitivity in the direction in which the speaker A speaks is stronger than the sensitivity in the other direction, and the same applies to the speaker B and the speaker C. A directional microphone may be used. In the case of using a directional microphone, the number of speakers may be plural, and the disclosed device can be applied to two or more speakers.
[分散および統合]
また、図示した各装置の各構成要素は、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、話者判別装置50、抽出部13または分析部14を会話分析装置の外部装置としてネットワーク経由で接続するようにしてもよい。また、話者判別装置50、抽出部13または分析部14を別の装置がそれぞれ有し、ネットワーク接続されて協働することで、上記の話者判別装置の機能を実現するようにしてもよい。
[Distribution and integration]
In addition, each component of each illustrated apparatus does not necessarily need to be physically configured as illustrated. In other words, the specific form of distribution / integration of each device is not limited to that shown in the figure, and all or a part thereof may be functionally or physically distributed or arbitrarily distributed in arbitrary units according to various loads or usage conditions. Can be integrated and configured. For example, the speaker discrimination device 50, the extraction unit 13, or the
[話者判別プログラム]
また、上記の実施例で説明した各種の処理は、予め用意されたプログラムをパーソナルコンピュータやワークステーションなどのコンピュータで実行することによって実現することができる。そこで、以下では、図12を用いて、上記の実施例と同様の機能を有する話者判別プログラムを実行するコンピュータの一例について説明する。
[Speaker discrimination program]
The various processes described in the above embodiments can be realized by executing a prepared program on a computer such as a personal computer or a workstation. In the following, an example of a computer that executes a speaker discrimination program having the same function as that of the above embodiment will be described with reference to FIG.
図12は、実施例1及び実施例2に係る話者判別プログラムを実行するコンピュータの一例について説明するための図である。図12に示すように、コンピュータ100は、操作部110aと、スピーカ110bと、マイク110cと、ディスプレイ120と、通信部130とを有する。さらに、このコンピュータ100は、CPU150と、ROM160と、HDD170と、RAM180と有する。これら110〜180の各部はバス140を介して接続される。
FIG. 12 is a schematic diagram illustrating an example of a computer that executes a speaker discrimination program according to the first and second embodiments. As shown in FIG. 12, the
HDD170には、図12に示すように、上記の実施例1で示した取得部51と、フレーム化部52と、第1の識別部53と、有効化部54と、第2の識別部55と同様の機能を発揮する話者判別プログラム170aが予め記憶される。この話者判別プログラム170aについては、図1に示した各々の取得部51、フレーム化部52、第1の識別部53、有効化部54及び第2の識別部55の各構成要素と同様、適宜統合又は分離しても良い。すなわち、HDD170に格納される各データは、常に全てのデータがHDD170に格納される必要はなく、処理に必要なデータのみがHDD170に格納されれば良い。
As shown in FIG. 12, the HDD 170 includes the acquisition unit 51, the framing
そして、CPU150が、話者判別プログラム170aをHDD170から読み出してRAM180に展開する。これによって、図12に示すように、話者判別プログラム170aは、話者判別プロセス180aとして機能する。この話者判別プロセス180aは、HDD170から読み出した各種データを適宜RAM180上の自身に割り当てられた領域に展開し、この展開した各種データに基づいて各種処理を実行する。なお、話者判別プロセス180aは、図1に示した取得部51、フレーム化部52、第1の識別部53、有効化部54及び第2の識別部55にて実行される処理、例えば図9〜図11に示す処理を含む。また、CPU150上で仮想的に実現される各処理部は、常に全ての処理部がCPU150上で動作する必要はなく、処理に必要な処理部のみが仮想的に実現されれば良い。
Then, the
なお、上記の話者判別プログラム170aについては、必ずしも最初からHDD170やROM160に記憶させておく必要はない。例えば、コンピュータ100に挿入されるフレキシブルディスク、いわゆるFD、CD−ROM、DVDディスク、光磁気ディスク、ICカードなどの「可搬用の物理媒体」に各プログラムを記憶させる。そして、コンピュータ100がこれらの可搬用の物理媒体から各プログラムを取得して実行するようにしてもよい。また、公衆回線、インターネット、LAN、WANなどを介してコンピュータ100に接続される他のコンピュータまたはサーバ装置などに各プログラムを記憶させておき、コンピュータ100がこれらから各プログラムを取得して実行するようにしてもよい。
Note that the
10 会話分析装置
11 音声記憶部
12A 第1の音声データ
12B 第2の音声データ
12C 第3の音声データ
30A,30B,30C 接話マイク
31 登録部
50 話者判別装置
51 取得部
52 フレーム化部
53 第1の識別部
54 有効化部
55 第2の識別部
DESCRIPTION OF
Claims (4)
前記取得部によって取得された音声データを所定の区間のフレームにフレーム化するフレーム化部と、
第1の確率モデルに基づいて、前記フレーム化部によってフレーム化されたフレームが有声音領域または無声音領域のいずれであるかを識別する第1の識別部と、
各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化する有効化部と、
第2の確率モデルに基づいて、前記有効化部によって有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する第2の識別部と
を有することを特徴とする話者判別装置。 An acquisition unit for acquiring each voice data from a plurality of microphones arranged in each speaker;
A framing unit that frames the audio data acquired by the acquiring unit into frames of a predetermined section;
A first identification unit that identifies whether the frame framed by the framing unit is a voiced sound region or an unvoiced sound region based on a first probability model;
Effective when the voiced sound area is identified in duplicate in the same interval frame in each audio data, and the identification result of the frame having the maximum energy among the frames identified as the voiced sound area in the same interval is valid And
A second identification unit for identifying a speech area and a silence area in each voice data from the identification result of the frame after being validated by the validation unit based on a second probability model, Speaker discrimination device.
各々の話者に配置される複数のマイクから各々の音声データを取得し、
取得された音声データを所定の区間のフレームにフレーム化し、
第1の確率モデルに基づいて、前記フレームが有声音領域または無声音領域のいずれであるかを識別し、
各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化し、
第2の確率モデルに基づいて、有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する
各処理を実行させることを特徴とする話者判別プログラム。 On the computer,
Acquire each voice data from multiple microphones placed in each speaker,
The acquired audio data is framed into frames of a predetermined section,
Identifying whether the frame is a voiced sound region or an unvoiced sound region based on a first probability model;
When the voiced sound area is identified in duplicate in the same interval frame in each audio data, the identification result of the frame having the maximum energy among the frames identified as the voiced sound area in the same interval is enabled,
A speaker discrimination program for executing each process for identifying a speech area and a silence area in each voice data from a validated frame identification result based on a second probability model.
各々の話者に配置される複数のマイクから各々の音声データを取得し、
取得された音声データを所定の区間のフレームにフレーム化し、
第1の確率モデルに基づいて、前記フレームが有声音領域または無声音領域のいずれであるかを識別し、
各音声データにおける同一区間のフレームで有声音領域が重複して識別された場合に、当該同一区間で有声音領域と識別されたフレームのうち最大のエネルギーを持つフレームの識別結果を有効化し、
第2の確率モデルに基づいて、有効化された後のフレームの識別結果から各々の音声データにおける発話領域および沈黙領域を識別する
各処理を実行することを特徴とする話者判別方法。 Computer
Acquire each voice data from multiple microphones placed in each speaker,
The acquired audio data is framed into frames of a predetermined section,
Identifying whether the frame is a voiced sound region or an unvoiced sound region based on a first probability model;
When the voiced sound area is identified in duplicate in the same interval frame in each audio data, the identification result of the frame having the maximum energy among the frames identified as the voiced sound area in the same interval is enabled,
A speaker discrimination method, comprising: executing each process for identifying a speech area and a silence area in each voice data based on a validated frame identification result based on a second probability model.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011122808A JP5672155B2 (en) | 2011-05-31 | 2011-05-31 | Speaker discrimination apparatus, speaker discrimination program, and speaker discrimination method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011122808A JP5672155B2 (en) | 2011-05-31 | 2011-05-31 | Speaker discrimination apparatus, speaker discrimination program, and speaker discrimination method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2012252060A JP2012252060A (en) | 2012-12-20 |
| JP5672155B2 true JP5672155B2 (en) | 2015-02-18 |
Family
ID=47524961
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011122808A Expired - Fee Related JP5672155B2 (en) | 2011-05-31 | 2011-05-31 | Speaker discrimination apparatus, speaker discrimination program, and speaker discrimination method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5672155B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115881131B (en) * | 2022-11-17 | 2023-10-13 | 广东保伦电子股份有限公司 | Voice transcription method under multiple voices |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS5895399A (en) * | 1981-11-30 | 1983-06-06 | 松下電工株式会社 | Voice message identification system |
| IT1229725B (en) * | 1989-05-15 | 1991-09-07 | Face Standard Ind | METHOD AND STRUCTURAL PROVISION FOR THE DIFFERENTIATION BETWEEN SOUND AND DEAF SPEAKING ELEMENTS |
| JP3297156B2 (en) * | 1993-08-17 | 2002-07-02 | 三菱電機株式会社 | Voice discrimination device |
| JP3721948B2 (en) * | 2000-05-30 | 2005-11-30 | 株式会社国際電気通信基礎技術研究所 | Voice start edge detection method, voice section detection method in voice recognition apparatus, and voice recognition apparatus |
| JP2001343985A (en) * | 2000-06-02 | 2001-12-14 | Nippon Telegr & Teleph Corp <Ntt> | Method of voice switching and voice switch |
| JP2006086877A (en) * | 2004-09-16 | 2006-03-30 | Yoshitaka Nakajima | Pitch frequency estimation device, silent signal converter, silent signal detection device and silent signal conversion method |
| JP2006208482A (en) * | 2005-01-25 | 2006-08-10 | Sony Corp | Device, method, and program for assisting activation of conference, and recording medium |
-
2011
- 2011-05-31 JP JP2011122808A patent/JP5672155B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2012252060A (en) | 2012-12-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Luo et al. | Speaker-independent speech separation with deep attractor network | |
| US9626970B2 (en) | Speaker identification using spatial information | |
| US9293133B2 (en) | Improving voice communication over a network | |
| US8589167B2 (en) | Speaker liveness detection | |
| Krishnamurthy et al. | Babble noise: modeling, analysis, and applications | |
| JP5607627B2 (en) | Signal processing apparatus and signal processing method | |
| US9959886B2 (en) | Spectral comb voice activity detection | |
| CN110970053A (en) | Multichannel speaker-independent voice separation method based on deep clustering | |
| KR20190015081A (en) | System, device and method of automatic translation | |
| Bramsløw et al. | Improving competing voices segregation for hearing impaired listeners using a low-latency deep neural network algorithm | |
| JP2010054733A (en) | Device and method for estimating multiple signal section, its program, and recording medium | |
| Gogate et al. | Deep neural network driven binaural audio visual speech separation | |
| JP2017032857A (en) | Voice processing device and voice processing method | |
| JP5549506B2 (en) | Speech recognition apparatus and speech recognition method | |
| CN109473102A (en) | A kind of robot secretary intelligent meeting recording method and system | |
| Dekens et al. | Body conducted speech enhancement by equalization and signal fusion | |
| JP2007288242A (en) | Operator evaluation method, device, operator evaluation program, and recording medium | |
| Pasha et al. | Blind speaker counting in highly reverberant environments by clustering coherence features | |
| WO2020195924A1 (en) | Signal processing device, method, and program | |
| Heracleous et al. | Analysis of the visual Lombard effect and automatic recognition experiments | |
| Grondin et al. | WISS, a speaker identification system for mobile robots | |
| Xiong et al. | Channel selection using neural network posterior probability for speech recognition with distributed microphone arrays in everyday environments | |
| JP6480124B2 (en) | Biological detection device, biological detection method, and program | |
| JP5672155B2 (en) | Speaker discrimination apparatus, speaker discrimination program, and speaker discrimination method | |
| KR101023211B1 (en) | Microphone array based speech recognition system and target speech extraction method of the system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20140304 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20141118 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20141125 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20141208 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5672155 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |