JP5508654B2 - Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions - Google Patents
Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions Download PDFInfo
- Publication number
- JP5508654B2 JP5508654B2 JP2001577530A JP2001577530A JP5508654B2 JP 5508654 B2 JP5508654 B2 JP 5508654B2 JP 2001577530 A JP2001577530 A JP 2001577530A JP 2001577530 A JP2001577530 A JP 2001577530A JP 5508654 B2 JP5508654 B2 JP 5508654B2
- Authority
- JP
- Japan
- Prior art keywords
- multimeric
- tetramers
- double
- unit
- units
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images





































































































































































































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6834—Enzymatic or biochemical coupling of nucleic acids to a solid phase
- C12Q1/6837—Enzymatic or biochemical coupling of nucleic acids to a solid phase using probe arrays or probe chips
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6827—Hybridisation assays for detection of mutation or polymorphism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
- C12Q1/6874—Methods for sequencing involving nucleic acid arrays, e.g. sequencing by hybridisation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- H—ELECTRICITY
- H05—ELECTRIC TECHNIQUES NOT OTHERWISE PROVIDED FOR
- H05K—PRINTED CIRCUITS; CASINGS OR CONSTRUCTIONAL DETAILS OF ELECTRIC APPARATUS; MANUFACTURE OF ASSEMBLAGES OF ELECTRICAL COMPONENTS
- H05K999/00—PRINTED CIRCUITS; CASINGS OR CONSTRUCTIONAL DETAILS OF ELECTRIC APPARATUS; MANUFACTURE OF ASSEMBLAGES OF ELECTRICAL COMPONENTS dummy group
- H05K999/99—PRINTED CIRCUITS; CASINGS OR CONSTRUCTIONAL DETAILS OF ELECTRIC APPARATUS; MANUFACTURE OF ASSEMBLAGES OF ELECTRICAL COMPONENTS dummy group dummy group
Description
本発明は、国立衛生研究所補助金番号GM-41337-06、GM-43552-05、GM-42722-07およびGM-51628-02の政府資金を用いて開発された。合衆国政府は一定の権利を有しうる。 The present invention was developed using government funds from National Institutes of Health grant numbers GM-41337-06, GM-43552-05, GM-42722-07 and GM-51628-02. The US government may have certain rights.
発明の属する分野
本発明は、複数の捕捉オリゴヌクレオチドプローブが狭い範囲の融解温度を有し、相補的オリゴヌクレトチドがほとんどミスマッチなくハイブリダイズする支持体上で使用するための複数の捕捉オリゴヌクレオチドプローブを設計する方法に関する。本発明の別の局面は、支持体上に固定された複数のオリゴヌクレオチドプローブを有する支持体、複数の標的ヌクレオチド配列における単一塩基変化、挿入、欠失または転座を検出するために支持体を使用する方法、およびオリゴヌクレオチドが固定されている支持体を含むそのような検出用のキットに関する。
The present invention relates to a plurality of capture oligonucleotides for use on a support in which a plurality of capture oligonucleotide probes have a narrow range of melting temperatures and to which complementary oligonucleotides hybridize with little mismatch. The present invention relates to a method for designing a probe. Another aspect of the invention is a support having a plurality of oligonucleotide probes immobilized on a support, a support for detecting single base changes, insertions, deletions or translocations in a plurality of target nucleotide sequences And a kit for such detection comprising a support on which oligonucleotides are immobilized.
発明の背景
配列の差異の検出
多型度の高い遺伝子座の大規模多重分析は、実父確定検査および法科学(Reynoldsら、Anal.Chem.、63:2〜15(1991))、臓器移植におけるドナーとレシピエントの組み合わせ(Buyseら、Tissue Antigens、41:1〜14(1993)ならびにGyllenstenら、PCR Meth.Appl.1:91〜98(1991))、遺伝病の診断、予後ならびに出生前カウンセリング(Chamberlainら、Nucleic Acids Res.、16:11141〜11156(1988)ならびにL.C.Tsui、Human Mutat.、1:197〜203(1992))、および発癌性変異の研究(Hollsteinら、Science、253:49〜53(1991))などにおける個人の同定に役立てるために必要とされている。また、核酸分析による感染症診断の費用効果は、パネルテストの多重度により大きく変動する。上述の適用の多くでは、空間的に近接する場合もある様々な遺伝子座における一塩基の差の識別を基礎としている。Background of the Invention
Detection of sequence differences Large-scale multiplex analysis of highly polymorphic loci can be found in paternity testing and forensic science (Reynolds et al., Anal. Chem., 63: 2-15 (1991)), donors and recipes in organ transplantation. Combinations of ents (Buyse et al., Tissue Antigens, 41: 1-14 (1993) and Gyllensten et al., PCR Meth. Appl. 1: 91-98 (1991)), diagnosis of genetic disease, prognosis and prenatal counseling (Chamberlain et al. Nucleic Acids Res., 16: 11141-11156 (1988) and LCTsui, Human Mutat., 1: 197-203 (1992)), and oncogenic mutation studies (Hollstein et al., Science, 253: 49-53 (1991). )) Etc. to help with identification of individuals. In addition, the cost effectiveness of infectious disease diagnosis by nucleic acid analysis varies greatly depending on the multiplicity of panel tests. Many of the above applications are based on the identification of single base differences at various loci that may be spatially close.
多数の配列からなる領域を含む試料中の一つまたは複数のポリヌクレオチド配列の存在を検出するには、様々なDNAハイブリダイゼーション法を利用することができる。断片の捕獲および標識に基づく簡単な方法では、特定の配列を含む断片を、固定化したプローブに対するハイブリダイゼーションで捕獲する。捕獲断片は、検出用レポーター部分を含む別のプローブとのハイブリダイゼーションで標識される。 A variety of DNA hybridization methods can be utilized to detect the presence of one or more polynucleotide sequences in a sample containing a region of multiple sequences. In a simple method based on fragment capture and labeling, a fragment containing a specific sequence is captured by hybridization to an immobilized probe. The capture fragment is labeled by hybridization with another probe containing a reporter moiety for detection.
広く用いられている他の方法にはサザンブロット法がある。本方法では、試料中のDNA断片の混合物をゲル電気泳動で分画した後にニトロセルロースフィルターに固定する。ハイブリダイゼーション条件下でフィルターを一つまたは複数の標識プローブと反応させることで、プローブ配列を含むバンドの存在を同定することができる。本方法は、制限酵素によるDNA切断物中の断片(任意のプローブ配列を含む)の同定、および制限断片長多型(「RFLP」)の分析に特に有用である。 Another widely used method is the Southern blot method. In this method, a mixture of DNA fragments in a sample is fractionated by gel electrophoresis and then fixed to a nitrocellulose filter. By reacting the filter with one or more labeled probes under hybridization conditions, the presence of a band containing the probe sequence can be identified. This method is particularly useful for the identification of fragments (including any probe sequences) in DNA digests by restriction enzymes and the analysis of restriction fragment length polymorphisms ("RFLP").
ポリヌクレオチド試料に含まれる任意の配列または配列群の存在を検出する別の方法には、ポリメラーゼ連鎖反応(ムリス(Mullis)らによる米国特許第4,683,202号、およびサイキ(R.K.Saiki)らによる論文(Science 230:1350(1985)))による配列(または配列群)の選択的な増幅がある。本方法では、特定配列(または配列群)の反対側の端に相補的なプライマーを用いて、プライマーから開始される連続的な複製を加熱サイクルで進める。増幅後の配列は、種々の方法で容易に同定することができる。本方法は例えば、体液試料中の病原体配列の検出といった、ポリヌクレオチド試料に含まれる低コピー配列を検出する際に特に有用である。 Other methods for detecting the presence of any sequence or group of sequences contained in a polynucleotide sample include the polymerase chain reaction (US Pat. No. 4,683,202 by Mullis et al., And the paper by RKSaiki et al. (Science). 230: 1350 (1985))) and selective amplification of sequences (or sequences). In this method, a primer that is complementary to the opposite end of a specific sequence (or group of sequences) is used to drive successive replications initiated by the primer in a heating cycle. The amplified sequence can be easily identified by various methods. The method is particularly useful in detecting low copy sequences contained in a polynucleotide sample, for example, detection of pathogen sequences in a body fluid sample.
さらに最近では、プローブ連結法で既知の標的配列を同定する方法が、ホワイトリー(N.M.Whiteley)らによる米国特許第4,883,750号、ウー(D.Y.Wu)らによる論文(Genomics 4:560(1989))、ランデグレン(U.Landegren)らによる論文(Science 241:1077(1988))、およびウィンディーン(E.Winn-Deen)らによる論文(Clin.Chem.37:1522(1991))に記載されている。オリゴヌクレオチド連結アッセイ法(OLA)として知られている方法では、対象標的領域にまたがる2本のプローブまたはプローブエレメントと標的領域との間でハイブリッドを形成させる。プローブエレメントが、隣接する標的塩基と、プローブエレメントの直面する端で対合する(塩基対を形成する)と、2本のエレメントを例えばリガーゼで処理して連結させることができる。連結したプローブエレメントを対象として次にアッセイ法を行い、標的配列の存在を明らかにする。 More recently, methods for identifying known target sequences by probe ligation methods include US Pat. No. 4,883,750 by NMWhiteley et al., DYWu et al. (Genomics 4: 560 (1989)), This is described in a paper by U. Landegren et al. (Science 241: 1077 (1988)) and a paper by E. Winn-Deen et al. (Clin. Chem. 37: 1522 (1991)). In a method known as oligonucleotide ligation assay (OLA), a hybrid is formed between two probes or probe elements spanning the target region of interest and the target region. When the probe element is paired with an adjacent target base at the facing end of the probe element (forms a base pair), the two elements can be ligated, eg, treated with ligase. An assay is then performed on the linked probe elements to determine the presence of the target sequence.
本アプローチの変法では、連結プローブエレメントを、相補的なプローブエレメント対の鋳型として働かせる。変性、ハイブリダイゼーションおよび連結のサイクルを2通りの相補的なプローブエレメント対の存在下で続けることで、標的配列は幾何級数的(すなわち指数関数的)に増幅されて、微量の標的配列が検出および/または増幅される。本方法はリガーゼ連鎖反応(「LCR」)と呼ばれる(F.Barany「クローニングされた熱耐性リガーゼを用いた遺伝病検出およびDNA増幅(Genetic Disease Detection and DNA Amplification Using Cloned Thermostable Ligase)」(Proc.Natl.Acad.Sci.USA.88:189〜93(1991)および、F.Barany、「PCR界におけるリガーゼ連鎖反応(LCR)(The Ligase Chain Reaction(LCR)in a PCR World)」(PCR Methods and Applications、1:5〜16(1991))。 In a variation of this approach, the linking probe element serves as a template for a complementary probe element pair. By continuing the cycle of denaturation, hybridization and ligation in the presence of two complementary probe element pairs, the target sequence is amplified exponentially (ie, exponentially) to detect and detect trace amounts of target sequence. / Or amplified. This method is called ligase chain reaction (“LCR”) (F. Barany “Genetic Disease Detection and DNA Amplification Using Cloned Thermostable Ligase”) (Proc. Acad. Sci. USA 88: 189-93 (1991) and F. Barany, “The Ligase Chain Reaction (LCR) in a PCR World” (PCR Methods and Applications) 1: 5-16 (1991)).
検出用標識をもち、[電荷]/[並進運動に伴う摩擦抵抗]比が顕著な配列特異的プローブと標的をハイブリダイズさせて相互に連結可能であるグロスマン(Grossman)らによる米国特許第5,470,705号において、核酸配列差の多重検出に関する他の方式が開示されている。本方法はグロスマンらによる論文(「High-density Multiplex Detection of Nucleic Acid Sequences: Oligonucleotide Ligation Assay and Sequence-coded Separation」Nucleic Acids Res.、22(21):4527〜34(1994))において、嚢胞性線維症の膜貫通調節遺伝子を対象とした大規模多重分析に使用されている。 US Pat. No. 5,470,705 to Grossman et al. Which has a label for detection and is capable of hybridizing and linking the sequence-specific probe and target with a significant [charge] / [frictional resistance associated with translation] ratio. Discloses another method for multiplex detection of nucleic acid sequence differences. This method is described in a paper by Grossman et al. ("High-density Multiplex Detection of Nucleic Acid Sequences: Oligonucleotide Ligation Assay and Sequence-coded Separation" Nucleic Acids Res., 22 (21): 4527-34 (1994)). It is used for large-scale multiplex analysis for the transmembrane regulatory gene of the disease.
ジョー(Jou)らによる論文(「Deletion Detection in Dystrophin Gene by Multiplex Gap Ligase Chain Reaction and Immunochromatographic Strip Technology」Human Mutation 5:86〜93(1995))では、複数のエキソンの特定領域を増幅して、各エキソンに対するプローブ上の様々なハプテンの差に特異的な抗体を有する免疫クロマトグラフィー・ストリップ上で増幅産物を読み取る、いわゆる「ギャップリガーゼ連鎖反応」の過程の利用について記載されている。 In a paper by Jou et al. (“Deletion Detection in Dystrophin Gene by Multiplex Gap Ligase Chain Reaction and Immunochromatographic Strip Technology” Human Mutation 5: 86-93 (1995)), specific regions of multiple exons were amplified and The use of the so-called “gap ligase chain reaction” process, in which amplification products are read on immunochromatographic strips with antibodies specific for different hapten differences on the probe to exons, is described.
例えば遺伝子スクリーニングの分野において、標的ポリヌクレオチドに含まれる多くの配列のそれぞれの有無の検出に有用な方法はますます必要とされている。例えば嚢胞性線維症には400種もの多様な変異が関与している。この疾患の遺伝的素因に対するスクリーニングでは、被験者のゲノムDNA中に含まれうる遺伝子配列上の多様な変異を調べることで「嚢胞性線維症」陽性者を同定することが最適である。生じうるあらゆる変異部位の有無を1回のアッセイ法で調べることが理想的であろう。しかしながら、上述の先行技術の方法を簡便かつ自動化された1回のアッセイ法で特定配列群の検出に応用することは困難である。 For example, in the field of genetic screening, there is an increasing need for methods useful for detecting the presence or absence of each of a number of sequences contained in a target polynucleotide. For example, cystic fibrosis involves as many as 400 different mutations. Screening for a genetic predisposition to this disease is best done by identifying individuals who are positive for “cystic fibrosis” by examining various variations in the genetic sequence that can be included in the subject's genomic DNA. Ideally it would be a single assay to check for any possible mutation sites. However, it is difficult to apply the above-described prior art method to detection of a specific sequence group by a simple and automated single assay method.
固相ハイブリダイゼーションアッセイ法では、複数の液体処理段階が必要であり、一部のインキュベーション温度および洗浄温度を注意深く制御して、一ヌクレオチドの誤対合を識別するために必要な厳密さを保たなければならない。本方法の多重化は、最適なハイブリダイゼーション条件がプローブ配列により大きく変わることから困難である。 Solid-phase hybridization assays require multiple liquid processing steps, and some incubation and wash temperatures are carefully controlled to maintain the rigor required to identify single nucleotide mismatches. There must be. Multiplexing of this method is difficult because the optimal hybridization conditions vary greatly depending on the probe sequence.
対立遺伝子に特異的なPCR産物は一般にサイズが同じであり、任意の増幅用チューブは、各反応チューブと関連するゲル・レーンにおける産物バンドの有無により評価される(Gibbsら、Nucleic Acids Res.、17:2437〜2448(1989))。このような方法は、多様なプライマーの組み合わせを用いた複数の反応チューブ中の試験試料の分離を必要とすることから、アッセイ法に要する費用は増大する。PCRでもまた、競合する対立遺伝子用プライマーに様々な蛍光色素を結合させることで、1本の反応チューブで対立遺伝子を識別することができる(F.F.Chehabら、Proc.Natl.Acad.Sci.USA.86:9178〜9182(1989))が、このような方式による多重分析は、既存の装置および色素化学の知見を利用して経済的な方法でスペクトルに分解可能な色素種がそれほど多くないことから規模の拡大は限られる。大きな側鎖をもつように修飾した塩基の取り込みを、電気泳動の移動度を元に対立遺伝子のPCR産物を識別する際に利用することができるものの、本方法は、修飾塩基がポリメラーゼにより良好に取り込まれることと、これらの基の一つのサイズが異なる比較的大きなPCR産物を分解する電気泳動の能力による制限を受ける(Livakら、Nucleic Acids Res.、20:4831〜4837(1989))。各PCR産物は一つの変異のみを探索するために用いられ、多重化は困難である。 Allele-specific PCR products are generally the same size, and any amplification tube is evaluated by the presence or absence of product bands in the gel lane associated with each reaction tube (Gibbs et al., Nucleic Acids Res., 17: 2437-2448 (1989)). Such a method requires the separation of test samples in multiple reaction tubes using various primer combinations, thus increasing the cost of the assay. PCR can also identify alleles in a single reaction tube by attaching various fluorescent dyes to competing allele primers (FFChehab et al., Proc. Natl. Acad. Sci. USA. 86: 9178 ~ 9182 (1989)), but the multiplex analysis by this method is because there are not so many dye species that can be decomposed into spectra by an economical method using existing equipment and knowledge of dye chemistry. Scale expansion is limited. Although the incorporation of bases modified to have large side chains can be used to identify allelic PCR products based on electrophoretic mobility, this method is better suited for modified bases by polymerase. Limited by the incorporation and ability of electrophoresis to degrade relatively large PCR products that differ in the size of one of these groups (Livak et al., Nucleic Acids Res., 20: 4831-4837 (1989)). Each PCR product is used to search for only one mutation and is difficult to multiplex.
対立遺伝子特異的プローブの連結では、固相捕獲法(U.Landegrenら、Science、241:1077〜1080(1988);Nickersonら、Proc.Natl.Acad.Sci.USA.87:8923〜8927(1990))またはサイズに依存した分離法(D.Y.Wuら、Genomics、4:560〜569(1989)および、F.Barany、Proc.Natl.Acad.Sci.、88:189〜193(1991))を利用して対立遺伝子のシグナルを分解することが一般的である。しかし後者の方法は、連結用プローブのサイズ幅が狭いことから多重化において制限を受ける。ギャップリガーゼ連鎖反応では、追加的なステップ、すなわちポリメラーゼによる伸長が必要である。より複雑な多重化に対して電荷/並進運動に伴う摩擦抵抗の比が顕著なプローブを使用する場合は、電気泳動時間を長くする必要があるほか、別の検出法の利用が求められる。 For ligation of allele-specific probes, solid phase capture (U. Landegren et al., Science, 241: 1077-1080 (1988); Nickerson et al., Proc. Natl. Acad. Sci. USA. 87: 8923-8927 (1990) )) Or size-dependent separation methods (DYWu et al., Genomics, 4: 560-569 (1989) and F. Barany, Proc. Natl. Acad. Sci., 88: 189-193 (1991)) It is common to resolve allele signals. However, the latter method is limited in multiplexing because the size of the connecting probe is narrow. The gap ligase chain reaction requires an additional step, ie, extension with a polymerase. When using a probe with a significant friction / resistance ratio accompanying charge / translational motion for more complex multiplexing, it is necessary to lengthen the electrophoresis time and use another detection method.
したがって、ポリヌクレオチド試料に含まれる複数の特定配列の有無を検出するための迅速な単回アッセイ法が必要であることは変わらない。 Thus, there remains a need for a rapid single assay method for detecting the presence or absence of multiple specific sequences contained in a polynucleotide sample.
核酸分析のためのオリゴヌクレオチドアレイの利用
固相支持体に固定化したオリゴヌクレオチドが整然と並んだアレイは、DNAの配列決定、分類(sorting)、単離および操作における利用が提案されている。任意の長さのあらゆるオリゴヌクレオチドプローブに対する、クローン化された1本鎖DNA分子のハイブリダイゼーションでは、分子内に存在する対応する相補的DNAセグメントを理論的に同定可能であることが認められている。このようなアレイでは、個々のオリゴヌクレオチドプローブは、固相支持体上のあらかじめ決めた様々な位置に固定化される。DNA分子中のあらゆるオリゴヌクレオチドセグメントは、このようなアレイを利用して調べることができる。 Use of Oligonucleotide Arrays for Nucleic Acid Analysis Arrays of ordered oligonucleotides immobilized on a solid support have been proposed for use in DNA sequencing, sorting, isolation and manipulation. It has been observed that hybridization of cloned single-stranded DNA molecules to any oligonucleotide probe of any length can theoretically identify the corresponding complementary DNA segment present in the molecule. . In such arrays, individual oligonucleotide probes are immobilized at various predetermined locations on the solid support. Any oligonucleotide segment in the DNA molecule can be examined using such an array.
オリゴヌクレオチドアレイを用いてDNA分子の配列を決定する手順の一例が、ドルマナク(Drmanac)らによる米国特許第5,202,231号に開示されている。この特許は、複数のオリゴヌクレオチドを結合させた固相支持体に対する標的DNAの利用に関する。配列は、標的DNAセグメントとオリゴヌクレオチドのハイブリダイゼーションおよびハイブリッドを形成したオリゴヌクレオチドの重複セグメントの集合により読み取られる。アレイには11〜22程度のヌクレオチドの長さのあらゆるオリゴヌクレオチドを利用することができるが、この種のアレイの構築法に関する情報は極めて少ない。本件に関しては、チェトベリン(A.B.Chetverin)らによる論文(「Sequencing of Pools of Nucleic Acids on Oligonucleotide Arrays」 BioSystems、30:215〜31(1993))、クラプコ(Khrapko)らによる国際公開公報第92/16655号、クズネツォバ(Kuznetsova)らによる論文(「DNA Sequencing by Hybridization with Oligonucleotides Immbilized in Gel. chemical Ligation as a Method of Expanding the Prospects for the Method」Mol.Biol.28(20); 290〜99(1994))、リビッツ(M.A.Livits)らによる論文(「Dissociation of Duplexes Formed by Hybridization of DNA with Gel-Immobilized Oligonucleotides」J.Biomolec.Struct. & Dynam.、11(4):783〜812(1994))も参照されたい。 An example of a procedure for sequencing DNA molecules using an oligonucleotide array is disclosed in US Pat. No. 5,202,231 by Drmanac et al. This patent relates to the use of target DNA on a solid support to which a plurality of oligonucleotides are attached. The sequence is read by hybridization of the target DNA segment to the oligonucleotide and the collection of overlapping segments of the oligonucleotide that formed a hybrid. Although any oligonucleotide with a length on the order of 11-22 nucleotides can be used in the array, there is very little information on how to construct this type of array. Regarding this matter, a paper by ABChetverin et al. ("Sequencing of Pools of Nucleic Acids on Oligonucleotide Arrays" BioSystems, 30: 215-31 (1993)), International Publication No. 92/16655 by Khrapko et al. , Kuznetsova et al. (“DNA Sequencing by Hybridization with Oligonucleotides Immbilized in Gel. Chemical Ligation as a Method of Expanding the Prospects for the Method” Mol. Biol. 28 (20); 290-99 (1994)), See also the paper by MALivits et al. ("Dissociation of Duplexes Formed by Hybridization of DNA with Gel-Immobilized Oligonucleotides" J. Biomolec. Struct. & Dynam., 11 (4): 783-812 (1994)). .
サザン(Southern)による国際公開公報第89/10977号では、既知の点変異、ゲノムフィンガープリント法、連鎖解析および配列決定に関する核酸試料の分析に利用するハイブリダイゼーション反応が可能なオリゴヌクレオチドアレイをもつ支持体の利用について開示されている。ヌクレオチド塩基を、特定のパターンで支持体上に配してマトリックスを作製することができる。国際公開公報第89/10977号では、ペンプロッターまたはマスキングにより集合させるオリゴヌクレオチドを有する支持体に水酸基リンカーを利用することができることが記載されている。 WO 89/10977 by Southern supports with oligonucleotide arrays capable of hybridization reactions used for analysis of nucleic acid samples for known point mutations, genomic fingerprinting, linkage analysis and sequencing The use of the body is disclosed. Nucleotide bases can be placed on a support in a specific pattern to create a matrix. WO 89/10977 describes that a hydroxyl linker can be used for a support having oligonucleotides that are assembled by pen plotter or masking.
キャンター(Cantor)による国際公開公報第94/11530号もまた、ハイブリダイゼーションによる配列決定の過程を実施するためのオリゴヌクレオチドアレイの利用に関する。オリゴヌクレオチドは突出部分をもつ2本鎖であり、この突出部分に標的核酸が結合して2本鎖の非突出部分と連結される。このようなアレイは、ビオチン化されたオリゴヌクレオチドを捕獲するストレプトアビジン被覆濾紙を用いて構築され、集合後に結合させる。 International Publication No. 94/11530 by Cantor also relates to the use of oligonucleotide arrays to perform the sequencing process by hybridization. The oligonucleotide is double-stranded with an overhang, and the target nucleic acid binds to this overhang and is linked to the double-stranded non-overhang. Such arrays are constructed using streptavidin-coated filter paper that captures biotinylated oligonucleotides and are attached after assembly.
チェトベリン(Chetverin)による国際公開公報第93/17126号では、核酸を分類して調べる目的で区分化した2成分からなるオリゴヌクレオチドアレイを使用している。このアレイでは、不変ヌクレオチド配列が、可変ヌクレオチド配列に隣接して結合しており、いずれの配列も共有結合部を介して固相支持体に結合される。不変ヌクレオチド配列には、ハイブリッドを形成した鎖をPCRで増幅可能とするプライミング領域がある。次に、可変領域に対するハイブリダイゼーションによる分類を行う。2成分アレイ上における断片化核酸の、配列決定、単離、分類、および操作についても開示されている。感度を強化した一つの態様では、固定化されたオリゴヌクレオチドには、それとハイブリッドを形成して、カバーされていないオリゴヌクレオチドの部分を残す短い相補的領域がある。このアレイを次にハイブリダイゼーション条件下におくと、固定化されたオリゴヌクレオチドに相補的な核酸がアニールする。次にDNAリガーゼを用いて、短い相補的領域と、アレイ上にある相補的な核酸を連結する。オリゴヌクレオチドアレイの調製法に関してはほとんど開示されていない。 International Publication No. 93/17126 by Chetverin uses a two-component oligonucleotide array for the purpose of classifying and examining nucleic acids. In this array, invariant nucleotide sequences are bound adjacent to the variable nucleotide sequences, and either sequence is bound to the solid support via a covalent bond. The invariant nucleotide sequence has a priming region that allows PCR to amplify the hybridized strand. Next, classification is performed on the variable region by hybridization. Sequencing, isolation, classification, and manipulation of fragmented nucleic acids on a two-component array is also disclosed. In one embodiment with enhanced sensitivity, the immobilized oligonucleotide has a short complementary region that hybridizes therewith leaving a portion of the oligonucleotide uncovered. The array is then subjected to hybridization conditions, and nucleic acids complementary to the immobilized oligonucleotides anneal. DNA ligase is then used to link the short complementary region and the complementary nucleic acid on the array. Little is disclosed about the preparation of oligonucleotide arrays.
フォドル(Fodor)らによる国際公開公報第92/10588号では、オリゴヌクレオチドアレイに対するハイブリダイゼーションによる核酸の配列決定、フィンガープリント法、およびマッピングの過程が開示されている。オリゴヌクレオチドアレイは、大規模かつ多様なオリゴヌクレオチドの合成が可能な極めて大規模に固定化された重合体合成により調製される。この手法では、基盤表面を機能状態とし、オリゴヌクレオチドを基盤上に集合させるためのリンカー基を導入する。オリゴヌクレオチドを結合させる領域には、選択的に活性化される保護基が(基盤または各ヌクレオチドサブユニット上に)ある。通常本方法では、曝露領域を脱保護するための多様な形状のマスクを用いて、光によるアレイの画像化が必要である。脱保護領域では保護されたヌクレオチドと化学反応が起きて、オリゴヌクレオチド配列が伸長することで画像化される。2成分マスキング法を用いることで、任意の時間内に2種またはそれ以上のアレイを構築することができる。検出は、ハイブリッドが形成された領域の位置を決めることでなされる。これについては、フォドルらによる米国特許第5,324,633号および第5,424,186号、ピルング(Pirrung)らによる米国特許第5,143,854号および5,405,783号、ピルングによる国際公開公報第90/15070号、ピース(A.C.Pease)らによる論文(「Light-generated Oligonucleotide Arrays for Rapid DNA Sequence Analysis」Proc.Natl.Acad.Sci USA 91:5022〜26(1994))も参照されたい。ビーティー(K.L.Beattie)らによる論文(「Advances in Genosensor Research」Clin.Chem.、41(5):700〜09(1995))では、集合済みのオリゴヌクレオチドプローブを固相支持体に結合させる方法について説明されている。 International Publication No. 92/10588 by Fodor et al. Discloses nucleic acid sequencing, fingerprinting and mapping processes by hybridization to oligonucleotide arrays. Oligonucleotide arrays are prepared by the synthesis of polymers immobilized on a very large scale capable of synthesizing large-scale and diverse oligonucleotides. In this method, the substrate surface is put into a functional state, and a linker group for assembling oligonucleotides on the substrate is introduced. In the region where the oligonucleotide is attached, there is a protective group (on the base or on each nucleotide subunit) that is selectively activated. Typically, this method requires imaging the array with light using a variety of mask shapes to deprotect the exposed areas. In the deprotected region, a chemical reaction occurs with the protected nucleotide, and the oligonucleotide sequence is extended to be imaged. By using a two-component masking method, two or more arrays can be constructed in any time. The detection is performed by determining the position of the region where the hybrid is formed. For this, see US Pat. Nos. 5,324,633 and 5,424,186 by Fodor et al., US Pat. Nos. 5,143,854 and 5,405,783 by Pirrung et al., International Publication No. 90/15070 by Pilung, ACPease et al. See also the paper ("Light-generated Oligonucleotide Arrays for Rapid DNA Sequence Analysis" Proc. Natl. Acad. Sci USA 91: 5022-26 (1994)). In a paper by KLBeattie et al. ("Advances in Genosensor Research" Clin. Chem., 41 (5): 700-09 (1995)), a method for binding assembled oligonucleotide probes to a solid support. Explained.
アレイに対するハイブリダイゼーションに基づく上述の配列決定法には欠点が多い。第一に、極めて多数のオリゴヌクレオチドを合成する必要がある。第二に、正しくハイブリダイズしたもの、相応に対合した2本鎖、および誤対合したもの、の識別が困難である。さらに、ある種のオリゴヌクレオチドは、標準的な条件下でハイブリッドを形成しにくく、オリゴヌクレオチドが同定能力を得るようになるためには、詳細なハイブリダイゼーション条件の検討が必要となる。 The above-described sequencing method based on hybridization to an array has many drawbacks. First, it is necessary to synthesize a very large number of oligonucleotides. Second, it is difficult to distinguish correctly hybridized, correspondingly paired duplexes, and mispaired ones. Furthermore, certain oligonucleotides are unlikely to form hybrids under standard conditions, and detailed hybridization conditions must be considered in order for the oligonucleotide to gain identification ability.
本発明は、先行技術における欠点を克服することを目的としている。 The present invention aims to overcome the disadvantages in the prior art.
発明の概要
本発明は、複数の捕捉オリゴヌクレオチドプローブが狭い範囲の融解温度を有し、相補的オリゴヌクレトチドがほとんどミスマッチなくハイブリダイズする支持体上で使用するための複数の捕捉オリゴヌクレオチドプローブを設計する方法に関する。本方法の第1段階は、(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在せず、かつ(4)1以下または3以上のヌクレオチドGまたはCを有する四量体はセット内に存在しない、互いに連結された4個のヌクレオチドである、複数の四量体の第1のセットを提供する段階を含む。第1のセットの2個から4個の四量体の群は多量体ユニットの集合を形成するために互いに連結される。多量体ユニットの集合から、同じ四量体から形成された全ての多量体ユニット、および多量体ユニットを形成する四量体の数の4倍未満の融解温度(摂氏)を有する全ての多量体ユニットが、多量体ユニットの修飾型集合を形成するために除去される。多量体ユニットの修飾型集合は一覧において融解温度順に配置される。多量体ユニットの修飾型集合の順番は、融解温度の2℃の増分内で無作為化される。一覧中の交互の多量体ユニットはその後、第1および第2の亜集合に分割され、各々は融解温度順に配置される。2番目の亜集合の順番を反転させた後、二重多量体ユニットの集合を形成するために、反転された2番目の集合に第1の集合が順に連結される。二重多量体ユニットの修飾型集合を形成するために、二重多量体ユニットの集合から、(1)四量体の数の11倍未満および四量体の数の15倍超の融解温度(摂氏)を有する、(2)同じ3個の四量体が相互に連結された二重多量体ユニット、および(3)同じ4個の四量体が分断ありでまたはなしで相互に連結された二重多量体ユニットを有するそれらのユニットが除去される。
SUMMARY OF THE INVENTION The present invention relates to a plurality of capture oligonucleotide probes for use on a support in which a plurality of capture oligonucleotide probes have a narrow range of melting temperatures and complementary oligonucleotides hybridize with little mismatch. On how to design. The first step of the method is (1) each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, and (2) two tetramers complementary to each other are set. A tetramer that is not present in (3) a palindrome or a repeat of 2 nucleotides is not present in the set, and (4) a tetramer having 1 or more or 3 or more nucleotides G or C Providing a first set of tetramers, which are four nucleotides linked together, not present in the set. Groups of 2 to 4 tetramers in the first set are linked together to form a set of multimeric units. From a set of multimeric units, all multimeric units formed from the same tetramer, and all multimeric units having a melting temperature (Celsius) less than 4 times the number of tetramers that form the multimeric unit Are removed to form a modified set of multimeric units. The modified set of multimeric units is arranged in the order of melting temperature in the list. The order of the modified set of multimeric units is randomized within 2 ° C increments of melting temperature. The alternating multimeric units in the list are then divided into first and second subsets, each arranged in order of melting temperature. After reversing the order of the second sub-set, the first set is sequentially connected to the inverted second set to form a set of double multimeric units. In order to form a modified set of double multimeric units, a set of double multimeric units is (1) a melting temperature of less than 11 times the number of tetramers and more than 15 times the number of tetramers ( (2) a double multimer unit in which the same three tetramers are interconnected, and (3) the same four tetramers are interconnected with or without fragmentation Those units with double multimeric units are removed.
本発明の別の局面は、支持体および支持体上の異なる部位の二重多量体ユニットオリゴヌクレオチドの集合を含むので、固体支持体上に固定された相補的オリゴヌクレオチドが異なる位置に捕捉されることができる、オリゴヌクレオチドアレイに関する。相補的オリゴヌクレオチドは、24℃超の狭い温度範囲内で二重多量体ユニットオリゴヌクレオチドの集合の構成員にほとんどミスマッチなくハイブリダイズすると考えられる。(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、および(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在しない、四量体セットから二重多量体ユニットオリゴヌクレオチドが形成され、二重多量体ユニットオリゴヌクレオチドの集合はそれから以下のオリゴヌクレオチドを除去した:(1)四量体の数の12.5倍未満および四量体の数の14倍超の融解温度(摂氏)を有するオリゴヌクレオチド、(2)同じ3つの四量体が相互に連結された二重多量体ユニット、および(3)同じ4つの四量体が分断ありでまたはなしで相互に連結された多量体ユニット。 Another aspect of the invention involves the support and a collection of double multimeric unit oligonucleotides at different sites on the support so that complementary oligonucleotides immobilized on the solid support are captured at different locations. It relates to an oligonucleotide array. Complementary oligonucleotides are thought to hybridize with little mismatch to members of the assembly of double multimeric unit oligonucleotides within a narrow temperature range above 24 ° C. (1) Each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, (2) no two tetramers complementary to each other are present in the set, and ( 3) A tetramer that is a palindrome or a repeat of 2 nucleotides is not present in the set, a double multimer unit oligonucleotide is formed from the tetramer set, and the assembly of double multimer unit oligonucleotides is then Were removed: (1) oligonucleotides with a melting temperature (Celsius) of less than 12.5 times the number of tetramers and more than 14 times the number of tetramers, (2) the same three tetramers Double multimer units interconnected, and (3) multimer units in which the same four tetramers are interconnected with or without fragmentation.
本発明のさらに別の局面は、複数の標的ヌクレオチド配列における一つまたは複数の単一塩基変化、挿入、欠失または転座により異なる、一つまたは複数の配列を同定する方法に関する。この方法は複数の配列差異を有する一つまたは複数の標的ヌクレオチド配列を潜在的に含む試料を提供することを含む。複数のオリゴヌクレオチドプローブセットにはまた、(a)標的特異的部分および位置特定可能なアレイ特異的部分を有する第1のオリゴヌクレオチドプローブ、および(b)標的特異的部分および検出可能なレポーター標識を含む第2のオリゴヌクレオチドプローブにより特徴付けられる各セットが提供される。特定のセットにおけるオリゴヌクレオチドプローブは、相当する標的ヌクレオチド配列上で互いに隣接してハイブリダイズする時には、相互連結されるのに適切であるが、しかし試料中に存在するその他の任意のヌクレオチド配列にハイブリダイズする場合はそのような連結を妨害するミスマッチを有する。リガーゼにはまた、試料、複数のオリゴヌクレオチドプローブセット、および混合液を形成するために混濁されたリガーゼが提供される。任意のハイブリダイズしているオリゴヌクレオチドが標的ヌクレオチド配列から分離される変性処理、および、もし試料中に存在するならば各々の標的ヌクレオチド配列に、塩基特異的な様式でオリゴヌクレオチドプローブセットが隣接部位でハイブリダイズし、および(a)位置特定可能なアレイ特異的部分、(b)互いに連結された標的特異的部分、および(c)検出可能なレポーター標識を含む、連結産物配列を形成するために互いに連結される、ハイブリダイゼーション処理を含む一回または複数のリガーゼ検出反応サイクルにこの混合液は供される。オリゴヌクレオチドプローブセットは各々の標的ヌクレオチド配列以外の、試料中に存在するヌクレオチド配列にハイブリダイズしうるが、しかし一つまたは複数のミスマッチの存在のために相互に連結されず、変性処理で個々に分離される。捕捉オリゴヌクレオチドが位置特定可能なアレイ特異的部分に相補的なヌクレオチド配列を有し、二重多量体ユニットオリゴヌクレオチドの集合から形成される、異なる部位に固相化された異なる捕捉オリゴヌクレオチドが支持体に提供される。位置特定可能なアレイ特異的部分を有するオリゴヌクレオチドは、多量体ユニット内の四量体の数の4倍超の狭い温度範囲内で、捕捉オリゴヌクレオチドの集合の構成員に、ほとんどミスマッチなくハイブリダイズすると考えられる。(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、および(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在しない四量体セットから二重多量体ユニットオリゴヌクレオチドが形成される。二重多量体ユニットの修飾型集合を形成するために、二重多量体ユニットオリゴヌクレオチドの集合はそれから以下のオリゴヌクレオチドを除去している:(1)四量体の数の11倍未満および四量体の数の15倍超の融解温度(摂氏)を有するオリゴヌクレオチド、(2)同じ3つの四量体が相互に連結された二重多量体ユニット、および(3)同じ4つの四量体が分断ありでまたはなしで相互に連結された二重多量体ユニット。混合液を一回または複数のリガーゼ検出反応サイクルに供した後に、位置特定可能なアレイ特異的部分が捕捉オリゴヌクレオチドプローブに塩基特異的様式でハイブリダイズし、それにより位置特定可能なアレイ特異的部分が、相補的捕捉オリゴヌクレオチドを有する部位に支持体上で捕捉されるのに有効な条件下で混合液が支持体に接触される。特定部位において支持体に捕捉された連結産物のレポーター標識が検出され、試料中に一つまたは複数の標的ヌクレオチド配列が存在することを示す。 Yet another aspect of the invention relates to a method for identifying one or more sequences that differ by one or more single base changes, insertions, deletions or translocations in a plurality of target nucleotide sequences. The method includes providing a sample that potentially includes one or more target nucleotide sequences having a plurality of sequence differences. The plurality of oligonucleotide probe sets also includes (a) a first oligonucleotide probe having a target-specific portion and a positionable array-specific portion, and (b) a target-specific portion and a detectable reporter label. Each set characterized by a second oligonucleotide probe comprising is provided. Oligonucleotide probes in a particular set are suitable to be interconnected when hybridized adjacent to each other on the corresponding target nucleotide sequence, but hybridize to any other nucleotide sequence present in the sample. When soybeans have mismatches that interfere with such ligation. The ligase is also provided with a sample, a plurality of oligonucleotide probe sets, and a ligase that is turbid to form a mixture. A denaturation process in which any hybridizing oligonucleotide is separated from the target nucleotide sequence, and, if present in the sample, each target nucleotide sequence is adjacent to the oligonucleotide probe set in a base-specific manner. To form a ligation product sequence comprising: (a) a positionable array specific portion, (b) a target specific portion linked to each other, and (c) a detectable reporter label The mixture is subjected to one or more ligase detection reaction cycles that include a hybridization process that are linked together. Oligonucleotide probe sets can hybridize to nucleotide sequences present in the sample other than each target nucleotide sequence, but are not ligated together due to the presence of one or more mismatches and are individually To be separated. The capture oligonucleotide has a nucleotide sequence that is complementary to the positionable array-specific portion and is supported by different capture oligonucleotides immobilized at different sites, formed from a collection of double multimeric unit oligonucleotides Provided to the body. Oligonucleotides with an array-specific portion that can be localized hybridize with little mismatch to members of the collection of capture oligonucleotides within a narrow temperature range of more than four times the number of tetramers in the multimer unit. I think that. (1) Each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, (2) no two tetramers complementary to each other are present in the set, and ( 3) A tetramer that is a palindrome or a repeat of 2 nucleotides forms a double multimeric unit oligonucleotide from a tetramer set that is not present in the set. In order to form a modified set of double multimeric units, the set of double multimeric unit oligonucleotides has then removed the following oligonucleotides: (1) less than 11 times the number of tetramers and four An oligonucleotide with a melting temperature (Celsius) greater than 15 times the number of monomers, (2) a double multimer unit in which the same three tetramers are linked together, and (3) the same four tetramers Double multimer units interconnected with or without fragmentation. After subjecting the mixture to one or more ligase detection reaction cycles, the positionable array-specific portion hybridizes to the capture oligonucleotide probe in a base-specific manner, thereby allowing the positionable array-specific portion. However, the mixture is contacted with the support under conditions effective to be captured on the support at sites having complementary capture oligonucleotides. The reporter label of the ligation product captured on the support at a specific site is detected, indicating that one or more target nucleotide sequences are present in the sample.
本発明の別の局面は、複数の標的ヌクレオチド配列における1塩基の変化、挿入、欠失または転座により異なる一つまたは複数の配列を同定するキットに関する。リガーゼに加えて、そのキットは、特定のセットにおけるオリゴヌクレオチドプローブは、各々の標的ヌクレオチド配列上で互いに隣接してハイブリダイズする時は互いに連結されるのに適切であるが、しかしに存在するその他のヌクレオチド配列にハイブリダイズする時はそのような連結を妨害するミスマッチを有する、(a)標的配列特異的部分および位置特定可能なアレイ特異的部分を有する第1のオリゴヌクレオチドプローブ、および(b)標的配列特異的部分および検出可能なレポーター部分を含む第2のオリゴヌクレオチドプローブにより各々が特徴付けられる複数のオリゴヌクレオチドプローブセットを含む。捕捉オリゴヌクレオチドが位置特定可能なアレイ特異的部分に相補的なヌクレオチド配列を有し、二重多量体ユニットオリゴヌクレオチドの集合から形成される、異なる部位に固相化された異なる捕捉オリゴヌクレオチドを有する支持体もまたキット中に見出される。位置特定可能なアレイ特異的部分を有するオリゴヌクレオチドは、多量体ユニット内の四量体の数の4倍超の狭い温度範囲内で、捕捉オリゴヌクレオチドの集合の構成員にほとんどミスマッチなくハイブリダイズすると考えられる。(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、および(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在しない、四量体セットから、二重多量体ユニットオリゴヌクレオチドが形成される。二重多量体ユニットオリゴヌクレオチドの集合はそれから以下のオリゴヌクレオチドを除去している:捕捉オリゴヌクレオチドが位置特定可能なアレイ特異的部分に相補的なヌクレオチド配列を有する、(1)四量体の数の11倍未満および四量体の数の15倍超の融解温度(摂氏)を有するオリゴヌクレオチド、(2)同じ3つの四量体が相互に連結された二重多量体ユニット、および(3)同じ4つの四量体が分断ありまたはなしで相互に連結された二重多量体ユニット。
Another aspect of the invention relates to a kit for identifying one or more sequences that differ by single base changes, insertions, deletions or translocations in a plurality of target nucleotide sequences. In addition to ligase, the kit is suitable for the oligonucleotide probes in a particular set to be linked together when hybridized adjacent to each other on each target nucleotide sequence, but others present (A) a first oligonucleotide probe having a target sequence-specific portion and a positionable array-specific portion, and (b) having a mismatch that prevents such ligation when hybridizing to the nucleotide sequence of A plurality of oligonucleotide probe sets, each characterized by a second oligonucleotide probe comprising a target sequence specific portion and a detectable reporter portion. The capture oligonucleotide has a nucleotide sequence complementary to a positionable array-specific portion and has different capture oligonucleotides immobilized at different sites formed from a collection of double multimeric unit oligonucleotides A support is also found in the kit. Oligonucleotides with an array-specific portion that can be localized hybridize with little mismatch to members of the collection of capture oligonucleotides within a narrow temperature range of more than four times the number of tetramers in the multimer unit. Conceivable. (1) Each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, (2) no two tetramers complementary to each other are present in the set, and ( 3) From the tetramer set, double multimeric unit oligonucleotides are formed, where tetramers that are palindromic or 2 nucleotide repeats are not present in the set. The collection of double multimer unit oligonucleotides then removes the following oligonucleotides: (1) Number of tetramers, where the capture oligonucleotide has a nucleotide sequence that is complementary to a positionable array specific portion An oligonucleotide having a melting temperature (Celsius) less than 11 times the number of tetramers and more than 15 times the number of tetramers, (2) a double multimeric unit in which the same three tetramers are linked together, and (3) A double multimeric unit in which the same four tetramers are interconnected with or without fragmentation.
本発明の別の局面は、固体支持体上で捕捉オリゴヌクレオチドに不適切に交叉ハイブリダイゼーションすると考えられるリガーゼ検出反応オリゴヌクレオチドを合成することを避ける方法に関する。この方法は、リガーゼ検出反応オリゴヌクレオチドを捕捉オリゴヌクレオチドと比較すること、およびリガーゼ検出反応オリゴヌクレオチドと交叉ハイブリダイゼーションする可能性が高い任意の捕捉オリゴヌクレオチドを同定することを含む。 Another aspect of the invention relates to a method that avoids synthesizing ligase detection reaction oligonucleotides that would be improperly cross-hybridized to capture oligonucleotides on a solid support. The method includes comparing the ligase detection reaction oligonucleotide to a capture oligonucleotide and identifying any capture oligonucleotide that is likely to cross-hybridize with the ligase detection reaction oligonucleotide.
発明および図面の詳細な説明
本発明は、複数の捕捉オリゴヌクレオチドプローブが狭い範囲の融解温度を有し、相補的オリゴヌクレトチドがほとんどミスマッチなくハイブリダイズする支持体上で使用するための複数の捕捉オリゴヌクレオチドプローブを設計する方法に関する。本方法の第1段階は、(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在せず、かつ(4)1以下または3以上のヌクレオチドGまたはCを有する四量体はセット内に存在しない、互いに連結された4個のヌクレオチドである、複数の四量体の第1のセットを提供する段階を含む。第1のセットの2個から4個の四量体の群は多量体ユニットの集合を形成するために互いに連結される。多量体ユニットの集合から、同じ四量体から形成された全ての多量体ユニット、および多量体ユニットを形成する四量体の数の4倍未満の融解温度(摂氏)を有する全ての多量体ユニットが、多量体ユニットの修飾型集合を形成するために除去される。多量体ユニットの修飾型集合は一覧において融解温度順に配置される。多量体ユニットの修飾型集合の順番は、融解温度の2℃の増分内で無作為化される。一覧中の交互の多量体ユニットはその後、第1および第2の亜集合に分割され、各々は融解温度順に配置される。2番目の亜集合の順番を反転させた後、二重多量体ユニットの集合を形成するために、反転された2番目の集合に第1の集合が順に連結される。二重多量体ユニットの修飾型集合を形成するために、二重多量体ユニットの集合から、(1)四量体の数の11倍未満および四量体の数の15倍超の融解温度(摂氏)を有する、(2)同じ3個の四量体が相互に連結された二重多量体ユニット、および(3)同じ4個の四量体が分断ありでまたはなしで相互に連結された二重多量体ユニットを有するそれらのユニットが除去される。
Detailed Description of the Invention and Drawings The present invention provides a plurality of capture oligonucleotide probes for use on a support having a narrow range of melting temperatures and to which complementary oligonucleotides hybridize with little mismatch. It relates to a method of designing a capture oligonucleotide probe. The first step of the method is (1) each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, and (2) two tetramers complementary to each other are set. A tetramer that is not present in (3) a palindrome or a repeat of 2 nucleotides is not present in the set, and (4) a tetramer having 1 or more or 3 or more nucleotides G or C Providing a first set of tetramers, which are four nucleotides linked together, not present in the set. Groups of 2 to 4 tetramers in the first set are linked together to form a set of multimeric units. From a set of multimeric units, all multimeric units formed from the same tetramer, and all multimeric units having a melting temperature (Celsius) less than 4 times the number of tetramers that form the multimeric unit Are removed to form a modified set of multimeric units. The modified set of multimeric units is arranged in the order of melting temperature in the list. The order of the modified set of multimeric units is randomized within 2 ° C increments of melting temperature. The alternating multimeric units in the list are then divided into first and second subsets, each arranged in order of melting temperature. After reversing the order of the second sub-set, the first set is sequentially connected to the inverted second set to form a set of double multimeric units. In order to form a modified set of double multimeric units, a set of double multimeric units is (1) a melting temperature of less than 11 times the number of tetramers and more than 15 times the number of tetramers ( (2) a double multimer unit in which the same three tetramers are interconnected, and (3) the same four tetramers are interconnected with or without fragmentation Those units with double multimeric units are removed.
本発明の別の局面は、支持体および支持体上の異なる部位の二重多量体ユニットオリゴヌクレオチドの集合を含むので、固体支持体上に固定された相補的オリゴヌクレオチドが異なる位置に捕捉されることができる、オリゴヌクレオチドアレイに関する。相補的オリゴヌクレオチドは、24℃超の狭い温度範囲内で二重多量体ユニットオリゴヌクレオチドの集合の構成員にほとんどミスマッチなくハイブリダイズすると考えられる。(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、および(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在しない、四量体セットから二重多量体ユニットオリゴヌクレオチドが形成され、二重多量体ユニットオリゴヌクレオチドの集合はそれから以下のオリゴヌクレオチドを除去した:(1)四量体の数の12.5倍未満および四量体の数の14倍超の融解温度(摂氏)を有するオリゴヌクレオチド、(2)同じ3つの四量体が相互に連結された二重多量体ユニット、および(3)同じ4つの四量体が分断ありでまたはなしで相互に連結された多量体ユニット。 Another aspect of the invention involves the support and a collection of double multimeric unit oligonucleotides at different sites on the support so that complementary oligonucleotides immobilized on the solid support are captured at different locations. It relates to an oligonucleotide array. Complementary oligonucleotides are thought to hybridize with little mismatch to members of the assembly of double multimeric unit oligonucleotides within a narrow temperature range above 24 ° C. (1) Each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, (2) no two tetramers complementary to each other are present in the set, and ( 3) A tetramer that is a palindrome or a repeat of 2 nucleotides is not present in the set, a double multimer unit oligonucleotide is formed from the tetramer set, and the assembly of double multimer unit oligonucleotides is then Were removed: (1) oligonucleotides with a melting temperature (Celsius) of less than 12.5 times the number of tetramers and more than 14 times the number of tetramers, (2) the same three tetramers Double multimer units interconnected, and (3) multimer units in which the same four tetramers are interconnected with or without fragmentation.
本発明のさらに別の局面は、複数の標的ヌクレオチド配列における一つまたは複数の単一塩基変化、挿入、欠失または転座により異なる、一つまたは複数の配列を同定する方法に関する。この方法は複数の配列差異を有する一つまたは複数の標的ヌクレオチド配列を潜在的に含む試料を提供することを含む。複数のオリゴヌクレオチドプローブセットにはまた、(a)標的特異的部分および位置特定可能なアレイ特異的部分を有する第1のオリゴヌクレオチドプローブ、および(b)標的特異的部分および検出可能なレポーター標識を含む第2のオリゴヌクレオチドプローブにより特徴付けられる各セットが提供される。特定のセットにおけるオリゴヌクレオチドプローブは、相当する標的ヌクレオチド配列上で互いに隣接してハイブリダイズする時には、相互連結されるのに適切であるが、しかし試料中に存在するその他の任意のヌクレオチド配列にハイブリダイズする場合はそのような連結を妨害するミスマッチを有する。リガーゼにはまた、試料、複数のオリゴヌクレオチドプローブセット、および混合液を形成するために混濁されたリガーゼが提供される。任意のハイブリダイズしているオリゴヌクレオチドが標的ヌクレオチド配列から分離される変性処理、および、もし試料中に存在するならば各々の標的ヌクレオチド配列に、塩基特異的な様式でオリゴヌクレオチドプローブセットが隣接部位でハイブリダイズし、および(a)位置特定可能なアレイ特異的部分、(b)互いに連結された標的特異的部分、および(c)検出可能なレポーター標識を含む、連結産物配列を形成するために互いに連結される、ハイブリダイゼーション処理を含む一回または複数のリガーゼ検出反応サイクルにこの混合液は供される。オリゴヌクレオチドプローブセットは各々の標的ヌクレオチド配列以外の、試料中に存在するヌクレオチド配列にハイブリダイズしうるが、しかし一つまたは複数のミスマッチの存在のために相互に連結されず、変性処理で個々に分離される。捕捉オリゴヌクレオチドが位置特定可能なアレイ特異的部分に相補的なヌクレオチド配列を有し、二重多量体ユニットオリゴヌクレオチドの集合から形成される、異なる部位に固相化された捕捉オリゴヌクレオチドが支持体に提供される。位置特定可能なアレイ特異的部分を有するオリゴヌクレオチドは、多量体ユニット内の四量体の数の4倍超の狭い温度範囲内で、捕捉オリゴヌクレオチドの集合の構成員に、ほとんどミスマッチなくハイブリダイズすると考えられる。(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、および(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在しない四量体セットから二重多量体ユニットオリゴヌクレオチドが形成される。二重多量体ユニットの修飾型集合を形成するために、二重多量体ユニットオリゴヌクレオチドの集合はそれから以下のオリゴヌクレオチドを除去している:(1)四量体の数の11倍未満および四量体の数の15倍超の融解温度(摂氏)を有するオリゴヌクレオチド、(2)同じ3つの四量体が相互に連結された二重多量体ユニット、および(3)同じ4つの四量体が分断ありでまたはなしで相互に連結された二重多量体ユニット。混合液を一回または複数のリガーゼ検出反応サイクルに供した後に、位置特定可能なアレイ特異的部分が捕捉オリゴヌクレオチドプローブに塩基特異的様式でハイブリダイズし、それにより位置特定可能なアレイ特異的部分が、相補的捕捉オリゴヌクレオチドを有する部位に支持体上で捕捉されるのに有効な条件下で混合液が支持体に接触される。特定部位において支持体に捕捉された連結産物のレポーター標識が検出され、試料中に一つまたは複数の標的ヌクレオチド配列が存在することを示す。 Yet another aspect of the invention relates to a method for identifying one or more sequences that differ by one or more single base changes, insertions, deletions or translocations in a plurality of target nucleotide sequences. The method includes providing a sample that potentially includes one or more target nucleotide sequences having a plurality of sequence differences. The plurality of oligonucleotide probe sets also includes (a) a first oligonucleotide probe having a target-specific portion and a positionable array-specific portion, and (b) a target-specific portion and a detectable reporter label. Each set characterized by a second oligonucleotide probe comprising is provided. Oligonucleotide probes in a particular set are suitable to be interconnected when hybridized adjacent to each other on the corresponding target nucleotide sequence, but hybridize to any other nucleotide sequence present in the sample. When soybeans have mismatches that interfere with such ligation. The ligase is also provided with a sample, a plurality of oligonucleotide probe sets, and a ligase that is turbid to form a mixture. A denaturation process in which any hybridizing oligonucleotide is separated from the target nucleotide sequence, and, if present in the sample, each target nucleotide sequence is adjacent to the oligonucleotide probe set in a base-specific manner. To form a ligation product sequence comprising: (a) a positionable array specific portion, (b) a target specific portion linked to each other, and (c) a detectable reporter label The mixture is subjected to one or more ligase detection reaction cycles that include a hybridization process that are linked together. Oligonucleotide probe sets can hybridize to nucleotide sequences present in the sample other than each target nucleotide sequence, but are not ligated together due to the presence of one or more mismatches and are individually To be separated. The capture oligonucleotide has a nucleotide sequence that is complementary to a positionable array-specific portion and is formed from a collection of double multimer unit oligonucleotides and is supported by a capture oligonucleotide immobilized on different sites. Provided to. Oligonucleotides with an array-specific portion that can be localized hybridize with little mismatch to members of the collection of capture oligonucleotides within a narrow temperature range of more than four times the number of tetramers in the multimer unit. I think that. (1) Each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, (2) no two tetramers complementary to each other are present in the set, and ( 3) A tetramer that is a palindrome or a repeat of 2 nucleotides forms a double multimeric unit oligonucleotide from a tetramer set that is not present in the set. In order to form a modified set of double multimeric units, the set of double multimeric unit oligonucleotides has then removed the following oligonucleotides: (1) less than 11 times the number of tetramers and four An oligonucleotide with a melting temperature (Celsius) greater than 15 times the number of monomers, (2) a double multimer unit in which the same three tetramers are linked together, and (3) the same four tetramers Double multimer units interconnected with or without fragmentation. After subjecting the mixture to one or more ligase detection reaction cycles, the positionable array-specific portion hybridizes to the capture oligonucleotide probe in a base-specific manner, thereby allowing the positionable array-specific portion. However, the mixture is contacted with the support under conditions effective to be captured on the support at sites having complementary capture oligonucleotides. The reporter label of the ligation product captured on the support at a specific site is detected, indicating that one or more target nucleotide sequences are present in the sample.
本発明の別の局面は、複数の標的ヌクレオチド配列における1塩基の変化、挿入、欠失または転座により異なる一つまたは複数の配列を同定するキットに関する。リガーゼに加えて、そのキットは、特定のセットにおけるオリゴヌクレオチドプローブは、各々の標的ヌクレオチド配列上で互いに隣接してハイブリダイズする時は互いに連結されるのに適切であるが、しかしに存在するその他のヌクレオチド配列にハイブリダイズする時はそのような連結を妨害するミスマッチを有する、(a)標的配列特異的部分および位置特定可能なアレイ特異的部分を有する第1のオリゴヌクレオチドプローブ、および(b)標的配列特異的部分および検出可能なレポーター部分を含む第2のオリゴヌクレオチドプローブにより各々が特徴付けられる複数のオリゴヌクレオチドプローブセットを含む。捕捉オリゴヌクレオチドが位置特定可能なアレイ特異的部分に相補的なヌクレオチド配列を有し、二重多量体ユニットオリゴヌクレオチドの集合から形成される、異なる部位に固相化された異なる捕捉オリゴヌクレオチドを有する支持体もまたキット中に見出される。位置特定可能なアレイ特異的部分を有するオリゴヌクレオチドは、多量体ユニット内の四量体の数の4倍超の狭い温度範囲内で、捕捉オリゴヌクレオチドの集合の構成員にほとんどミスマッチなくハイブリダイズすると考えられる。(1)セット内の各四量体がセット内の他の全ての四量体と少なくとも2ヌクレオチド塩基異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、および(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在しない、四量体セットから、二重多量体ユニットオリゴヌクレオチドが形成される。二重多量体ユニットオリゴヌクレオチドの集合はそれから以下のオリゴヌクレオチドを除去している:捕捉オリゴヌクレオチドが位置特定可能なアレイ特異的部分に相補的なヌクレオチド配列を有する、(1)四量体の数の11倍未満および四量体の数の15倍超の融解温度(摂氏)を有するオリゴヌクレオチド、(2)同じ3つの四量体が相互に連結された二重多量体ユニット、および(3)同じ4つの四量体が分断ありまたはなしで相互に連結された二重多量体ユニット。 Another aspect of the invention relates to a kit for identifying one or more sequences that differ by single base changes, insertions, deletions or translocations in a plurality of target nucleotide sequences. In addition to ligase, the kit is suitable for the oligonucleotide probes in a particular set to be linked together when hybridized adjacent to each other on each target nucleotide sequence, but others present (A) a first oligonucleotide probe having a target sequence-specific portion and a positionable array-specific portion, and (b) having a mismatch that prevents such ligation when hybridizing to the nucleotide sequence of A plurality of oligonucleotide probe sets, each characterized by a second oligonucleotide probe comprising a target sequence specific portion and a detectable reporter portion. The capture oligonucleotide has a nucleotide sequence complementary to a positionable array-specific portion and has different capture oligonucleotides immobilized at different sites formed from a collection of double multimeric unit oligonucleotides A support is also found in the kit. Oligonucleotides with an array-specific portion that can be localized hybridize with little mismatch to members of the collection of capture oligonucleotides within a narrow temperature range of more than four times the number of tetramers in the multimer unit. Conceivable. (1) Each tetramer in the set differs from all other tetramers in the set by at least 2 nucleotide bases, (2) no two tetramers complementary to each other are present in the set, and ( 3) From the tetramer set, double multimeric unit oligonucleotides are formed, where tetramers that are palindromic or 2 nucleotide repeats are not present in the set. The collection of double multimer unit oligonucleotides then removes the following oligonucleotides: (1) Number of tetramers, where the capture oligonucleotide has a nucleotide sequence that is complementary to a positionable array specific portion An oligonucleotide having a melting temperature (Celsius) less than 11 times the number of tetramers and more than 15 times the number of tetramers, (2) a double multimeric unit in which the same three tetramers are linked together, and (3) A double multimeric unit in which the same four tetramers are interconnected with or without fragmentation.
しばしば、複数の異なる単一塩基の変異、挿入、もしくは欠失が、目的配列の同一ヌクレオチド位置で起こることがある。この方法は、第2のオリゴヌクレオチドプローブが共通で検出可能な標識を含み、かつ第1のオリゴヌクレオチドプローブが異なる位置特定可能なアレイに特異的な部分および標的特異的な部分を有するオリゴヌクレオチドセットの使用を含む。第1のオリゴヌクレオチドプローブは、ミスマッチなしに被検配列にハイブリダイズする場合には、第1の連結接合部で第2の隣接したオリゴヌクレオチドプローブに連結させるために好ましいものである。異なる第1の隣接するオリゴヌクレオチドプローブは、接合部位に別の識別塩基を含み、ミスマッチを含まないハイブリダイゼーションのみが接合部位置で連結可能となるものである。各々の第1の隣接したオリゴヌクレオチドは、異なる位置特定可能なアレイに特異的な部分を含み、従って、特異的塩基の変化が異なるアドレス(address)での捕獲によって識別される。このスキームでは、少なくとも1つの塩基により、他の核酸と異なる別の核酸配列の多重検出を行うために、複数の異なる捕獲オリゴヌクレオチドを、固体支持体上の異なる位置に結合させてある。または、第1のオリゴヌクレオチドプローブは、共通の位置特定可能なアレイに特異的な部分を含み、第2のオリゴヌクレオチドプローブは異なる検出可能な標識および標的特異的な部分を有する。 Often, multiple different single base mutations, insertions or deletions may occur at the same nucleotide position of the target sequence. This method comprises a set of oligonucleotides wherein the second oligonucleotide probe comprises a common detectable label and the first oligonucleotide probe has a different positionable array specific part and a target specific part Including the use of The first oligonucleotide probe is preferred for ligation to the second adjacent oligonucleotide probe at the first linking junction when it hybridizes to the test sequence without mismatch. Different first contiguous oligonucleotide probes contain different discriminating bases at the junction site, and only hybridization without mismatches can be linked at the junction position. Each first contiguous oligonucleotide contains a portion specific for a different positionable array, so that specific base changes are identified by capture at different addresses. In this scheme, a plurality of different capture oligonucleotides are attached to different positions on a solid support for multiplex detection of another nucleic acid sequence that differs from other nucleic acids by at least one base. Alternatively, the first oligonucleotide probe includes a portion that is specific to a common positionable array, and the second oligonucleotide probe has a different detectable label and a target-specific portion.
このような配置により、少なくとも1つの塩基が他の核酸と異なる別の核酸配列の多重検出が可能となる。このような多重検出を実施する際には、該核酸配列が同一もしくは異なる対立遺伝子上に存在する。 Such an arrangement enables multiplex detection of another nucleic acid sequence having at least one base different from other nucleic acids. In carrying out such multiplex detection, the nucleic acid sequences are present on the same or different alleles.
本発明はまた、リガーゼを含む本発明の方法を実施するためのキット、複数の異なるオリゴヌクレオチドプローブのセット、および捕獲オリゴヌクレオチドを固定化した固体支持体に関する。標的塩基配列の予備的増幅に用いるプライマーもキットに含まれる。増幅をポリメラーゼ連鎖反応で実施する場合には、ポリメラーゼもキットに含まれる。 The invention also relates to kits for carrying out the methods of the invention including ligases, sets of different oligonucleotide probes, and solid supports on which capture oligonucleotides are immobilized. Primers used for preliminary amplification of the target nucleotide sequence are also included in the kit. If amplification is performed by polymerase chain reaction, a polymerase is also included in the kit.
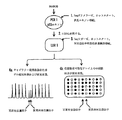
図1および図2には、キャピラリー電気泳動もしくはゲル電気泳動/蛍光の定量化を利用した先行技術のリガーゼによる検出反応と比較した本発明の方法の流れ図を示す。図1は生殖系列の変異検出に関し、図2は癌の検出を示す。 1 and 2 show a flow chart of the method of the present invention compared to a prior art ligase detection reaction using capillary electrophoresis or gel electrophoresis / fluorescence quantification. FIG. 1 relates to germline mutation detection and FIG. 2 illustrates cancer detection.
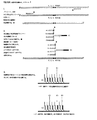
図1は、リ-フラウメニ症候群(Li-Fraumenisyndrome)の原因となるp53変異等の生殖系列における点突然変異の検出を示す。段階1において、DNA試料の調製後、Taq(すなわち、Thermusaquaticus)ポリメラーゼを用いホットスタートの条件下でエキソン5〜8をPCR増幅した。反応の最後に、プロテイナーゼKを用いた処理によりTaqポリメラーゼを失活させる。段階2では、該産物を対立遺伝子特異的および共通のLDRプローブを含む新しいLDR緩衝液で20倍に希釈する。チューブは、通常、各プライマーを約500フェムトモル含む。段階3では、リガーゼによる検出反応は、Taqリガーゼの添加によりホットスタート条件下で開始する。LDRプローブは、接合部部位における完全な相補性を示す標的配列の存在下でのみ隣接したプローブと連結する。産物は2つの異なる形態で検出される。第1の形態4aでは、当先行技術分野において用いられる、蛍光標識されたLDRプローブは、異なる長さのポリAもしくは酸化ヘキサエチレン・テールを含む。従って、僅かに異なる易動度を有する正常DNAに対する連結で生じる各々のLDR産物はピークのラダーを与える。生殖系列の突然変異によって、電気泳動像に新たなピークが生成する。新しいピークのサイズは、概ねもとの試料に存在する変異の量に相当する。ホモ接合体の正常で0%、ヘテロ接合体の担体で50%、ホモ接合体の変異体では100%である。第2の形態4bにおいては、本発明に従って、各々の対立遺伝子特異的プローブは、例えば、付加的な24ヌクレオチド塩基をその5'末端に含む。これらの配列は、位置特定可能なアレイ上で相補的アドレス配列に特異的にハイブリダイズする単一の位置特定可能な配列である。LDR反応では、各々の対立遺伝子特異的プローブは、対応する標的配列の存在下で隣接する蛍光標識した共通プローブに対して連結を行うことができる。野生型および変異体の対立遺伝子は、アレイ上の隣接したアドレスに捕獲される。未反応のプローブを洗い流す。黒いドットは、野性型対立遺伝子に関して100%のシグナルを示す。白いドットは、変異体の対立遺伝子に関して0%のシグナルを示す。斜線で示されたドットは、生殖系列の突然変異における1つの位置での各々の対立遺伝子に関して50%のシグナルを示す。 FIG. 1 shows the detection of point mutations in the germline, such as the p53 mutation, that causes Li-Fraumenisyndrome. In
図2は、p53腫瘍抑制性遺伝子における体細胞変異の検出を表すが、いずれも通常、低感度の変異検出に関するものである。段階1では、DNA試料を調製し、蛍光PCRプライマーを用いてエキソン5〜9を3つの断片としてPCRで増幅する。これにより、段階2でのキャピラリー電気泳動もしくはゲル電気泳動を用いたPCR産物の蛍光の定量化が可能となる。段階3では、マーカーDNAの1/100希釈(3つの断片あ各々に対し)で産物が急増する。癌細胞では観察されない変異を含むが、適当なLDRプローブで容易に検出されること以外は、このDNAは、野性型DNAに相同である。段階4の混合したDNA産物を変異体もしくはマーカー対立遺伝子に対してのみ特異的な全LDRプローブを含む緩衝液で20倍に希釈する。段階5では、リガーゼ検出反応を、Taqリガーゼの添加によりホットスタート条件下で開始した。接合部部位における完全な相補性を与える標的配列の存在下でのみ、隣接したプローブに対してLDRプローブの連結が起こる。図1に記載される同一の2つの形態で、産物が検出される。段階6aの当先行技術分野において用いられる形態では、産物はキャピラリー電気泳動もしくはゲル電気泳動で分離し、蛍光シグナルを定量する。変異体ピークのマーカーピークに対する比は、100分割したもとの試料に存在する癌の突然変異量の概算を与える。段階6bの形態では、本発明に基づいて、位置特定可能なアレイ上の相補的配列に対する特異的ハイプリダイゼーションで産物を検出する。マーカードットに対する変異体ドットの蛍光シグナル比は、100分割したもとの試料に存在する癌の突然変異量の概算を与える。 FIG. 2 represents detection of somatic mutations in the p53 tumor suppressor gene, both of which are usually related to low sensitivity mutation detection. In
本発明のリガーゼによる検出反応の方法は、図3〜図15を参照することによって最もよく理解される。一般的には、これは、Baranyらの国際公開公報第90/17239号;F.Baranyらの「耐熱性DNAリガーゼをコードする遺伝子のクローニング、過剰発現および塩基配列(Cloning, Overexpression and Nucleotide Sequence of a Thermostable DNA Ligase-encoding Gene)」(Gene. 109:1-11(1991))、およびF.Baranyらの「クローン化耐熱のリガーゼを用いた遺伝病の検出およびDNA増幅(Genetic Disease Detection and DNA Amplification Using Cloned Thermostable Ligase)」(Proc.Natl.Acad.Sci.USA. 88:189-193(1991))等に記載されており、これらの開示は参照として本明細書に組み入れられる。本発明のリガーゼによる検出反応には、2セットの相補的オリゴヌクレオチドを用いることができる。ヒれは、直ぐ上に示した3つの参考文献に記載のリガーゼ連鎖反応として知られるものであり、参照として本明細書に組み入れられる。または、リガーゼによる検出反応は、オリゴヌクレオチド連結アッセイ法として知られる単一サイクルを含む。Landegrenらの「リガーゼによる遺伝子検出技術(A Ligase-Mediated Gene Detection Technique)」Science 241:1077-80(1988);Landegren らの「DNA診断薬−分子技術と自動化(DNA Diagnostics-Molecular Techniques and Automation)」、Science 242:229-37(1988);およびLandegrenらの米国特許第4,988,617号を参照のこと。The method of the detection reaction by the ligase of the present invention is best understood by referring to FIGS. In general, this is described in Barany et al., International Publication No. 90/17239; F. Barany et al., “Cloning, Overexpression and Nucleotide Sequence of Cloning, Overexpression and Nucleotide Sequence of Genes Encoding Thermostable DNA Ligase. a Thermostable DNA Ligase-encoding Gene) ( Gene. 109: 1-11 (1991)) and F. Barany et al., “Genetic Disease Detection and DNA Amplification Using Cloned Thermostable Ligase” Amplification Using Cloned Thermostable Ligase ”( Proc. Natl. Acad. Sci. USA. 88: 189-193 (1991)) and the like, the disclosures of which are incorporated herein by reference. Two sets of complementary oligonucleotides can be used in the detection reaction by the ligase of the present invention. Fins are known as the ligase chain reaction described in the three references listed immediately above and are incorporated herein by reference. Alternatively, the detection reaction with ligase involves a single cycle known as an oligonucleotide ligation assay. Landegren et al. “A Ligase-Mediated Gene Detection Technique” Science 241: 1077-80 (1988); Landegren et al. “DNA Diagnostics-Molecular Techniques and Automation” Science 242: 229-37 (1988); and Landegren et al., US Pat. No. 4,988,617.
方法のリガーゼによる検出反応期の際、ハイブリダイゼーションは50〜85℃で起こるが、変性処理は80〜105℃で実施する。各々のサイクルは、変性処理および全体として約1〜5分の加熱ハイブリダイゼーション処理からなる。通常、連結による検出反応は、2〜50サイクルの繰り返し変性とハイブリダイゼーションを行うことを含む。該方法のリガーゼによる検出反応段階にかかる全体の時間は1〜250分である。 During the detection reaction phase of the method with ligase, hybridization occurs at 50-85 ° C, while denaturation is performed at 80-105 ° C. Each cycle consists of a denaturation treatment and a heat hybridization treatment as a whole for about 1-5 minutes. Usually, the detection reaction by ligation involves 2 to 50 cycles of repeated denaturation and hybridization. The total time required for the detection reaction step by ligase of the method is 1 to 250 minutes.
オリゴヌクレオチドプローブのセットは、リボヌクレオチド、デオキシヌクレオチド、修飾リボヌクレオチド、修飾デオキシリボヌクレオチド、ペプチドヌクレオチド類縁体、修飾ペプチドヌクレオチド類縁体、修飾リン酸塩・糖鎖骨格オリゴヌクレオチド、ヌクレオチド類縁体、およびその混合物の形態であってもよい。 The set of oligonucleotide probes includes ribonucleotides, deoxynucleotides, modified ribonucleotides, modified deoxyribonucleotides, peptide nucleotide analogs, modified peptide nucleotide analogs, modified phosphate / sugar backbone oligonucleotides, nucleotide analogs, and mixtures thereof It may be a form.
一つの変法において、オリゴヌクレオチドプローブのセットのオリゴヌクレオチドは、各々が66〜70℃のハイブリダイゼーションもしくは融解温度(すなわち、Tm)を有する。これらのオリゴヌクレオチドは20〜28ヌクレオチドの長さである。 In one variation, the oligonucleotides of the set of oligonucleotide probes each have a hybridization or melting temperature (ie, Tm) of 66-70 ° C. These oligonucleotides are 20-28 nucleotides in length.
DNAアレイ上に連結産物を捕獲する前に位置特定可能なヌクレオチドアレイ特異的な部分を含む未変換のLDRオリゴヌクレオチドプローブを化学的もしくは酵素的に破壊することが望ましい。これを行わない場合、このような未変換のプローブは、相補的配列を含む固体支持体のアレイ上のアドレスで、結合に関して連結産物と競合する。破壊はエキソヌクレアーゼIII等(L-H Guo and R.Wu、Methods in Enzymology 100:60-96(1985)、これは参照として本明細書に組み入れられる)のエキソヌクレアーゼを利用し、端でブロックされ、互いにプローブの連結には含まれないLDRプローブと組み合わせることによって達成できる。ブロッキング部分は、レポーター基もしくはホスホロチオエート基を含むことができる(T.T.Nikiforow らの「単一鎖PCR産物の調製のためのホスホロチオエートプライマーおよびエキソヌクレアーゼ加水分解の利用と固相ハイブリダイゼーションによる検出(The Use of Phosphorothioate Primers and Exonuclease Hydrolysis for the Preparation of Single-stranded PCR Products and their Detection by Solid-phase Hybridization)」、PCR Methods and Applications.3:p.285-291(1994)、これは参照として本明細書に組み入れられる)。LDR法の後に、連結の起こらなかったプローブは、反応混合物をエキソヌクレアーゼと反応させて選択的に破壊する。連結の起こったプローブは、エキソヌクレアーゼ反応の開始に必要なフリーの3'末端の除去により保護される。このアプローチにより、特にLDR反応が少量の産物のみを形成する場合にシグナル対雑音比の増加が起こる。連結の起こらなかったオリゴヌクレオチドは、捕獲に関して捕獲オリゴヌクレオチドと競合するので、このような連結の起こったオリゴヌクレオチドとの競合はシグナルを低下させる。このアプローチの別の利点は、ハイブリダイズしていない標識を含む配列が分解し、したがって、標的に依存しないバックグラウンドシグナルを生じづらくなることである。何故ならば、洗浄によってDNAアレイからより容易に除去され得るからである。It is desirable to chemically or enzymatically destroy unconverted LDR oligonucleotide probes containing nucleotide array-specific portions that can be located before capturing the ligation product on the DNA array. If this is not done, such unconverted probes will compete with the ligation product for binding at addresses on the array of solid supports containing complementary sequences. The disruption utilizes exonucleases such as exonuclease III and others (LH Guo and R. Wu, Methods in Enzymology 100: 60-96 (1985), which is incorporated herein by reference), blocked at the ends and This can be achieved by combining with an LDR probe that is not included in probe ligation. The blocking moiety can contain a reporter group or a phosphorothioate group (TTNikiforow et al., “Use of Phosphorothioate Primer and Exonuclease Hydrolysis for the Preparation of Single-Strand PCR Products and Detection by Solid Phase Hybridization (The Use of Phosphorothioate Primers and Exonuclease Hydrolysis for the Preparation of Single-stranded PCR Products and their Detection by Solid-phase Hybridization), PCR Methods and Applications. 3: p.285-291 (1994), which is incorporated herein by reference. ). After the LDR method, probes that have not been ligated are selectively destroyed by reacting the reaction mixture with exonuclease. The ligated probe is protected by removal of the free 3 'end necessary to initiate the exonuclease reaction. This approach results in an increase in signal to noise ratio, especially when the LDR reaction forms only a small amount of product. Since oligonucleotides that have not been ligated compete with the capture oligonucleotide for capture, competition with such ligated oligonucleotides reduces the signal. Another advantage of this approach is that sequences containing unhybridized labels are degraded, thus making it difficult to generate a target-independent background signal. This is because it can be more easily removed from the DNA array by washing.
上記のオリゴヌクレオチドプローブのセットは、検出に好ましいレポーター標識を有する。有用な標識は、発色基、蛍光部分、酵素、抗原、重金属、磁気プローブ、色素、燐光基、放射線物質、化学発光部位、および電気化学的検出部位を含む。捕獲オリゴヌクレオチドは、リボヌクレオチド、デオキシリボヌクレオチド、修飾リボヌクレオチド、修飾デオキシリボヌクレオチド、ペプチドヌクレオチド類縁体、修飾ペプチドヌクレオチド類縁体、修飾リン酸塩-糖骨格オリゴヌクレオチド、ヌクレオチド類縁体、およびその混合物の形態であり得る。本発明の方法が複数のオリゴヌクレオチドセットの使用を含む場合、第2のオリゴヌクレオチドプローブは同一でもよいが、第1のオリゴヌクレオチドプローブの位置特定可能なアレイに特異的な部位は異なっている。または、第1のオリゴヌクレオチドプローブの位置特定可能なアレイに特異的な部位は同一でもよいが、第2のオリゴヌクレオチドプローブのレポーター標識は異なる。 The above set of oligonucleotide probes has a preferred reporter label for detection. Useful labels include chromophores, fluorescent moieties, enzymes, antigens, heavy metals, magnetic probes, dyes, phosphorescent groups, radioactive materials, chemiluminescent sites, and electrochemical detection sites. Capture oligonucleotides are in the form of ribonucleotides, deoxyribonucleotides, modified ribonucleotides, modified deoxyribonucleotides, peptide nucleotide analogs, modified peptide nucleotide analogs, modified phosphate-sugar backbone oligonucleotides, nucleotide analogs, and mixtures thereof. possible. If the method of the invention involves the use of multiple oligonucleotide sets, the second oligonucleotide probe may be the same, but the site specific for the positionable array of the first oligonucleotide probe is different. Alternatively, the site specific to the positionable array of the first oligonucleotide probe may be the same, but the reporter label of the second oligonucleotide probe is different.
本発明の連結による検出反応期前に、好ましくは、最初の標的核酸の増幅法で試料を増幅する。これにより、試料中の標的塩基配列の量が増加する。例えば、最初の標的核酸の増幅が、ポリメラーゼ連鎖反応法、配列の自己複製、もしくはQ-βレプリカーゼによって媒介されるRNA増幅を用いて達成される。ポリメラーゼ連鎖反応法は、好ましい増幅法であり、H.Erlichらの「ポリメラーゼ連鎖反応における最近の進歩(Recent Advances in the Polymerase Chain Reaction)」(Science 252:1643-50(1991);M.Innisらの「PCRプロトコール:方法と応用の指針(A Guide to Methods and Applications)」(Academic Press: New York(1990));およびR.Saikiらの「耐熱性DNAポリメラーゼによるDNAのプライマー特異的な酵素的増幅(Primer-directed Enzymatic Amplification of DNA with a Thermostable DNA Polymerase)」(Science 239:487-91(1988))等に詳細に記載されており、これらは参照として本明細書に組み入れられる。参照として本明細書に組み入れられるJ.Guatelliらの「レトロウイルスの複製をモデルにしたマルチ酵素反応による核酸の等熱インビトロ増幅(Isothermal, invitro Amplification of Nucleic Acids by a Multienzyme Reaction Modeled After Retroviral Replication)」(Proc.Natl.Acad.Sci.USA 87:1874-78(1990))には、配列の自己複製法に関して記載がある。Qβレプリカーゼによって媒介されるRNA増幅は、F.Kramerらの「複製可能なRNAレポーター(Replicatable RNA Reporters)」(Nature 339:401-02(1989))に開示されており、これは参照として本明細書に組み入れられる。Prior to the detection reaction phase by the ligation of the present invention, the sample is preferably amplified by the first target nucleic acid amplification method. This increases the amount of the target base sequence in the sample. For example, amplification of the initial target nucleic acid is accomplished using polymerase chain reaction, sequence self-replication, or RNA amplification mediated by Q-β replicase. The polymerase chain reaction method is a preferred amplification method and is described in H. Erlich et al., “Recent Advances in the Polymerase Chain Reaction” ( Science 252: 1643-50 (1991); M. Innis et al. "PCR protocol: A Guide to Methods and Applications" (Academic Press: New York (1990)); and R. Saiki et al., "Primer-specific enzymatic of DNA with thermostable DNA polymerase." Amplification (Primer-directed Enzymatic Amplification of DNA with a Thermostable DNA Polymerase) "( Science 239: 487-91 (1988)) and the like, which are incorporated herein by reference. J. Guatelli et al., “Isothermal, invitro Amplification of Nucleic Acids by a Multienzyme Reaction Mod, modeled on retroviral replication. eled After Retroviral Replication ”( Proc. Natl. Acad. Sci. USA 87: 1874-78 (1990)) describes a method for self-replication of sequences. RNA amplification mediated by Qβ replicase is described in F. Kramer et al., “Replicatable RNA Reporters” ( Nature 339: 401-02 (1989)), which is incorporated herein by reference.
本発明のポリメラーゼ連鎖反応法の使用およびその後のリガーゼによる検出法の使用を図3に示す。ここで二つの多型におけるホモもしくはヘテロ接合性(すなわち、対立遺伝子としての差異)は、同一遺伝子上にある。または、このような対立遺伝子の差異は異なる遺伝子上にあってもよい。 The use of the polymerase chain reaction method of the present invention and the subsequent detection method with ligase is shown in FIG. Here the homozygosity or heterozygosity (ie allelic difference) in the two polymorphisms is on the same gene. Alternatively, such allelic differences may be on different genes.
図3に示されるように、標的核酸が二本鎖DNA分子の形態である場合、変性して鎖を分離させる。これは、80〜105℃程度の温度に加熱することによって達成する。次に、ポリメラーゼ連鎖反応のプライマーを加え、通常、20〜85℃程度の温度で鎖にハイブリダイズさせる。また、耐熱性ポリメラーゼ(例えば、Thermusaquaticusポリメラーゼ)を添加し、温度を50〜85℃に調整して、プライマーがハイブリダイズする核酸の長さに沿ってプライマーを伸長させる。ポリメラーゼ連鎖反応の伸長の段階後に、得られた二本鎖分子を80〜105℃の温度に加熱し、分子を変性させ鎖を分離させる。これらのハイブリダイゼーション、伸長、および変性の段階を、何回も繰り返して標的を適当なレベルに増幅する。 As shown in FIG. 3, when the target nucleic acid is in the form of a double-stranded DNA molecule, it is denatured to separate the strands. This is accomplished by heating to a temperature on the order of 80 to 105 ° C. Next, a polymerase chain reaction primer is added and hybridized to the strand, usually at a temperature of about 20 to 85 ° C. In addition, a thermostable polymerase (for example, Thermosaquaticus polymerase) is added, the temperature is adjusted to 50 to 85 ° C., and the primer is extended along the length of the nucleic acid to which the primer hybridizes. After the extension step of the polymerase chain reaction, the resulting double-stranded molecule is heated to a temperature of 80 to 105 ° C. to denature the molecule and separate the strands. These hybridization, extension, and denaturation steps are repeated many times to amplify the target to the appropriate level.
方法のポリメラーゼ連鎖反応期が完了すると、図3に示す連結による検出反応期が開始される。二本鎖DNA分子の状態であれば、80〜105℃の温度、好ましくは94℃で標的核酸を変性させた後、標的塩基配列の一方の鎖に対する連結による検出反用のオリゴヌクレオチドプローブをリガーゼ(例えば、図3に示す耐熱性リガーゼ様のThermusaquaticusリガーゼ)とともに加える。次に、オリゴヌクレオチドプローブを標的核酸分子にハイブリダイズさせ、通常、45-85℃、好ましくは65℃の温度で連結を行う。連結接合部に完全な相補性があれば、オリゴヌクレオチドはともに連結することができる。置換可能なヌクレオチドがTまたはAであるとき、標的塩基配列にTが存在すれは、位置特定可能なアレイに特異的な部位Z1を有するオリゴヌクレオチドプローブがレポーター標識Fを有するオリゴヌクレオチドプローブに連結し、また標的塩基配列にAが存在すれば、位置特定可能なアレイに特異的な部位Z2を有するオリゴヌクレオチドプローブがレポーター標識Fを有するオリゴヌクレオチドプローブに連結する。同様に、変化可能なヌクレオチドがAまたはGであるときには、標的塩基配列にTが存在すれば、位置特定可能なアレイに特異的な部位Z4を有するオリゴヌクレオチドプローブがレポーター標識Fを有するオリゴヌクレオチドプローブに連結し、また標的塩基配列にCが存在すれば、位置特定可能なアレイに特異的な部位Z3を有するオリゴヌクレオチドプローブがレポーター標識Fを有するオリゴヌクレオチドプローブと連結する。連結後に、材料を再び変性させてハイブリダイズしている鎖を分離する。ハイブリダイゼーション/連結および変性の段階は、一つもしくは複数のサイクル(例えば、1〜50サイクル)を経て標的シグナルを増幅する。蛍光連結産物(同様に、位置特定可能なアレイに特異的な部位を有する、連結されなかったオリゴヌクレオチドプローブ)は、位置特定可能なアレイ上の特定のアドレスにおけるZ1、Z2、Z3、およびZ4部位に相補的な捕獲プローブへのハイブリダイゼーションにより捕獲される。次に、オリゴヌクレオチドの一方に前もって存在する標識Fで、連結の起こったオリゴヌクレオチドの存在を検出する。図3において、連結産物の配列は、位置特定可能なアレイに特異的な部位Z1およびZ3に相補的な捕獲オリゴヌクレオチドでアレイのアドレスにハイブリダイズするが、連結の起こらなかった位置特定可能なアレイに特異的な部位Z2およびZ4を有するオリゴヌクレオチドプローブは、その相補的捕獲オリゴヌクレオチドにハイブリダイズする。しかしながら、連結産物の配列のみが標識Fを有するので、それらのみの存在が検出される。 When the polymerase chain reaction phase of the method is completed, the detection reaction phase by ligation shown in FIG. 3 is started. In the case of a double-stranded DNA molecule, the target nucleic acid is denatured at a temperature of 80 to 105 ° C., preferably 94 ° C., and then an oligonucleotide probe for detection reaction by ligation to one strand of the target base sequence is ligated. (For example, heat-resistant ligase-like Thermusaquaticus ligase shown in FIG. 3). Next, the oligonucleotide probe is hybridized to the target nucleic acid molecule, and ligation is usually performed at a temperature of 45-85 ° C., preferably 65 ° C. If the ligation junction is perfectly complementary, the oligonucleotides can be ligated together. When the substitutable nucleotide is T or A, if T is present in the target base sequence, the oligonucleotide probe having the site Z1 specific to the localizable array is linked to the oligonucleotide probe having the reporter label F. If A is present in the target base sequence, the oligonucleotide probe having the site Z2 specific to the position-identifiable array is linked to the oligonucleotide probe having the reporter label F. Similarly, when the variable nucleotide is A or G, the oligonucleotide probe having the site Z4 specific to the positionable array is the oligonucleotide probe having the reporter label F if T is present in the target base sequence. In addition, if C is present in the target base sequence, an oligonucleotide probe having a site Z3 specific to a position-identifiable array is linked to an oligonucleotide probe having a reporter label F. After ligation, the material is denatured again to separate the hybridized strands. The hybridization / ligation and denaturation steps amplify the target signal through one or more cycles (eg, 1-50 cycles). Fluorescent ligation products (also non-ligated oligonucleotide probes with sites specific to the localizable array) are the Z1, Z2, Z3, and Z4 sites at specific addresses on the localizable array Captured by hybridization to a complementary capture probe. Next, the presence of the ligated oligonucleotide is detected with a pre-existing label F on one of the oligonucleotides. In FIG. 3, the sequence of the ligation product is a positionable array that hybridizes to the address of the array with capture oligonucleotides complementary to sites Z1 and Z3 specific for the positionable array, but no ligation has occurred. An oligonucleotide probe having specific sites Z2 and Z4 hybridizes to its complementary capture oligonucleotide. However, only the sequences of the ligation products have the label F, so their presence is detected.
図4において、共通のオリゴヌクレオチドプローブが位置特異的な部分を有する一方で対立遺伝子特異的なプローブが異なる標識を有する、ということを除いては、図4は図3に類似している。 In FIG. 4, FIG. 4 is similar to FIG. 3, except that the common oligonucleotide probe has a position-specific portion while the allele-specific probe has a different label.
図5は、本発明のPCR/LDRの段階に関する流れ図であり、与えらた部位がいずれの塩基あっても識別できる。位置特定可能なアレイに特異的な部位Z1、Z2、Z3、およびZ4に相補的なアドレスの蛍光シグナルの出現は、標的塩基配列における、それぞれ、A、G、C、およびT対立遺伝子の存在を示す。ここで、標的塩基配列A、およびC対立遺伝子の存在は、部位Z1およびZ3にそれぞれ相補的な捕獲オリゴヌクレオチドプローブで固体支持体上のアドレスの蛍光で示される。図5では、位置特定可能なアレイに特異的な部位が識別オリゴヌクレオチドプローブ上にあり、識別塩基がこれらのプローブの3'末端にあることに留意されたい。 FIG. 5 is a flow chart relating to the PCR / LDR stage of the present invention, and it is possible to identify any given base at any site. The emergence of fluorescent signals at addresses complementary to sites Z1, Z2, Z3, and Z4 specific to the localizable array indicates the presence of A, G, C, and T alleles in the target sequence, respectively. Show. Here, the presence of the target base sequences A and C alleles is indicated by address fluorescence on the solid support with capture oligonucleotide probes complementary to sites Z1 and Z3, respectively. Note that in FIG. 5, the site specific to the localizable array is on the discriminating oligonucleotide probes and the discriminating base is at the 3 ′ end of these probes.
図6において、共通のオリゴヌクレオチドプローブが位置特異的な部分を有する一方で対立遺伝子特異的なプローブが異なる標識を有する、ということを除いては、図6は図5に類似している。 In FIG. 6, FIG. 6 is similar to FIG. 5 except that the common oligonucleotide probe has a position-specific portion while the allele-specific probe has a different label.
図7は、本発明の2カ所の近接部位における可能な塩基の存在の検出に関するPCR/LDRの段階の流れ図である。ここで、LDRプライマーは重複していてもよいが、接合部に完全な相補性がある場合に連結が可能である。このことが、重複プライマーが互いに阻害を起こす対立遺伝子特異的PCR等のほかのアプローチと、LDRが異なる点である。図7においては、第1のヌクレオチドの位置は、AおよびCの対立遺伝子でヘテロ接合体であるが、第2のヌクレオチドの位置はG、CおよびTの対立遺伝子でヘテロ接合体である。図5に示すように、位置特定可能なアレイに特異的な部位は識別オリゴヌクレオチドプローブ上にあり、識別塩基はこれらのプローブの3'末端にある。レポーター基(例えば、蛍光標識)は、共通オリゴヌクレオチドプローブの3'末端にある。例えば、各々の個体が、2つの正常遺伝子および2つの偽遺伝子を有し、2カ所のスプライス部位(ヌクレオチド656)に3つの可能な単一塩基(G、A、およびC)が存在する場合の21ヒドロキシラーゼ遺伝子に関して、これが可能である。また、これを用いて薬剤耐性(例えば、AZTに対する)株の出現を示すHIV感染における低レベルの変異を検出できる。図7に戻って、位置特定可能なアレイに特異的な部位Z1、Z2、Z3、Z4、Z5、Z6、Z7、およびZ8に相補的なアドレスの蛍光シグナルの出現は、ヘテロ接合体の部位のAおよびC対立遺伝子における、それぞれ、A、G、C、およびTの存在、およびヘテロ接合体部位のG、C、およびT対立遺伝子における、それぞれA、G、C、およびTの存在を示す。 FIG. 7 is a flow chart of the PCR / LDR stage for detecting the presence of possible bases at two adjacent sites of the present invention. Here, the LDR primers may overlap, but can be linked when the junction has complete complementarity. This is the difference in LDR from other approaches such as allele-specific PCR where overlapping primers inhibit each other. In FIG. 7, the first nucleotide position is heterozygous for the A and C alleles, while the second nucleotide position is heterozygous for the G, C and T alleles. As shown in FIG. 5, the site specific to the localizable array is on the discriminating oligonucleotide probe and the discriminating base is at the 3 ′ end of these probes. A reporter group (eg, a fluorescent label) is at the 3 ′ end of the common oligonucleotide probe. For example, if each individual has two normal genes and two pseudogenes, and there are three possible single bases (G, A, and C) at two splice sites (nucleotide 656) This is possible for the 21 hydroxylase gene. It can also be used to detect low level mutations in HIV infection that indicate the emergence of drug resistant (eg, against AZT) strains. Returning to FIG. 7, the appearance of fluorescent signals with addresses complementary to sites Z1, Z2, Z3, Z4, Z5, Z6, Z7, and Z8 specific to the localizable array The presence of A, G, C, and T, respectively, in the A and C alleles, and the presence of A, G, C, and T, respectively, in the G, C, and T alleles at the heterozygote site are indicated.
図8において、共通のオリゴヌクレオチドプローブが位置特異的な部分を有する一方で対立遺伝子特異的なプローブが異なる標識を有する、ということを除いては、図8は図7に類似している。 In FIG. 8, FIG. 8 is similar to FIG. 7, except that the common oligonucleotide probe has a position-specific portion while the allele-specific probe has a different label.
図9は、本発明のPCR/LDRの段階に関する流れ図であり、挿入(左上部のプローブセット)および欠失(右下部のプローブセット)を識別する。左では、正常配列がポリAテールに5つのAを含む。変異体の配列は、さらに2つのAがテール内に挿入されている。したがって、位置特定可能なアレイに特異的な部位Z1(正常の配列を表す)およびZ3(2塩基対の挿入を表す)を有するLDR産物は、共通プライマーに連結することによって蛍光標識されている。LDR法(例えば、耐熱性リガーゼ酵素を用いる)は、単一ヌクレオチド反複における単一塩基の挿入もしくは欠失を簡単に識別できるが、対立遺伝子特異的PCRでは、このような差異を識別できない。なぜならば、3'塩基が両方の対立遺伝子に存在するためである。右では、正常配列は5つの(CA)反復(すなわち、CACACACACA)である。変異体では、正常配列と比較して2つ少ないCA塩基を含む(すなわち、CACACA)。これらは、特定位置特定可能なアレイに特異的な部位Z8(正常の配列を表す)およびZ6(2つのCA欠失を表す)アドレスにおける、蛍光LDR産物として検出される。また、さまざまな感染病原体の薬剤に対する耐性は、本発明を用いて調べることができる。図9では、Z1およびZ3に相補的な捕獲オリゴヌクレオチドを有するアドレスにおける蛍光標識Fで示される連結産物の配列の存在は、正常および変異体のポリA配列の両方の存在を示す。同様に、Z6およびZ8に相補的な捕獲オリゴヌクレオチドを有するアドレスの蛍光標識Fで示される連結産物の配列の存在は、正常なCAの繰り返し配列および繰り返しユニットが1つ欠失した配列の両方の存在を示す。 FIG. 9 is a flow chart for the PCR / LDR stage of the present invention, identifying insertions (upper left probe set) and deletions (lower right probe set). On the left, the normal sequence contains 5 As in the poly A tail. The mutant sequence has two additional A's inserted in the tail. Thus, LDR products with sites Z1 (representing normal sequence) and Z3 (representing a 2 base pair insertion) specific to the localizable array are fluorescently labeled by ligation to a common primer. LDR methods (eg, using thermostable ligase enzymes) can easily identify single base insertions or deletions in single nucleotide repeats, but allele-specific PCR cannot distinguish such differences. This is because the 3 ′ base is present in both alleles. On the right, the normal sequence is 5 (CA) repeats (ie CACACACACA). Variants contain 2 fewer CA bases compared to the normal sequence (ie CACACA). These are detected as fluorescent LDR products at specific sites Z8 (representing the normal sequence) and Z6 (representing two CA deletions) addresses specific to the localizable array. Also, the resistance of various infectious agents to drugs can be examined using the present invention. In FIG. 9, the presence of the sequence of the ligation product indicated by the fluorescent label F at the address with capture oligonucleotides complementary to Z1 and Z3 indicates the presence of both normal and mutant poly A sequences. Similarly, the presence of the sequence of the ligation product indicated by the fluorescent label F of the address with capture oligonucleotides complementary to Z6 and Z8 is both the normal CA repeat sequence and the sequence lacking one repeat unit. Indicates existence.
図10において、共通のオリゴヌクレオチドプローブが位置特異的な部分を有する一方で対立遺伝子特異的なプローブが異なる標識を有する、ということを除いては、図10は図9に類似している。 In FIG. 10, FIG. 10 is similar to FIG. 9 except that the common oligonucleotide probe has a position-specific portion while the allele-specific probe has a different label.
図11は、過剰の正常配列の存在における低レベルの変異を検出する位置特定可能なアレイに特異的な部位を用いた 本発明のPCR/LDRの段階に関する流れ図である。図11は、K-ras遺伝子のグリシン(Gly)をコードするコドン12の配列GGTを示す。ごく一部の細胞が、アスパラギン酸(Asp)をコードするGATにおけるGからAへの変異を含む。野生型のLDRプローブ(すなわち、正常配列)は、反応から除外される。正常LDRプローブ(識別塩基=Gを有する)を含む場合、これらを共通プローブに対して連結さることによって、変異体の標的に由来するシグナルより強めることができる。代ゎりに、図11に示されるように、蛍光標識Fを有する連結産物の配列の存在は、位置特定可能なアレイに特異的な部位Z4に相補的な捕獲オリゴヌクレオチドを有するアドレスにおけるアスパラギン酸をコードする変異体の存在を示す。 FIG. 11 is a flow chart for the PCR / LDR stage of the present invention using a site specific to a positionable array that detects low level mutations in the presence of excess normal sequence. FIG. 11 shows the sequence GGT of
図12において、共通のオリゴヌクレオチドプローブが位置特異的な部分を有する一方で対立遺伝子特異的なプローブが異なる標識を有する、ということを除いては、図12は図11に類似している。 In FIG. 12, FIG. 12 is similar to FIG. 11 except that the common oligonucleotide probe has a position specific portion while the allele specific probe has a different label.
図13は、本発明のPCR/LDRの段階に関する流れ図であり、位置特定可能なアレイに特異的な部位が、共通のオリゴヌクレオチドプローブに配置されおり、識別オリゴヌクレオチドプローブはレポーター標識を有する。対立遺伝子の差異は、異なる蛍光シグナルF1、F2、F3、およびF4で識別される。この方法により、より高密度なアレイの使用が可能となる。なぜならば、各々の位置は、特定の基で発光すると予測されるからである。エミッションスペクトルにおいて最小重複を有し、多重走査が必要な蛍光基を必要とするという不利な点を有する。これは低レベルの対立遺伝子(例えば、癌に関連した変異)の検出に理想的といえるほど好適ではない。 FIG. 13 is a flow chart for the PCR / LDR stage of the present invention, where a site specific to a positionable array is located on a common oligonucleotide probe, and the identification oligonucleotide probe has a reporter label. Allelic differences are distinguished by different fluorescent signals F1, F2, F3, and F4. This method allows the use of higher density arrays. This is because each position is predicted to emit light with a specific group. It has the disadvantage of requiring fluorescent groups that have minimal overlap in the emission spectrum and require multiple scanning. This is not ideally suited for detecting low levels of alleles (eg, mutations associated with cancer).
図14は、本発明のPCR/LDRの段階に関する流れ図であり、隣接および近傍の対立遺伝子の両方が検出される。隣接した変異は、互いの右隣にあり、1セットのオリゴヌクレオチドプローブが接合部の3'末端の塩基を識別する(異なる位置特定可能なアレイに特異的な部位Z1、Z2、Z3、およびZ4の使用によって)が、もう一方のオリゴヌクレオチドプローブのセットは、接合部の5'末端の塩基を識別する(異なる蛍光レポーター標識F1、F2、F3、およびF4の使用)。図14では、疾患遺伝子(例えば、嚢胞性線維症CFTR)のGlyおよびアルギニン(Arg)をコードするコドンが、それぞれ、生殖系列の突然変異の候補である。図14の検出結果は、Gly(GGA;連結産物の配列を有する部位Z2および標識F2で示される)がグルタミン酸(Glu)(GAA;部位Z2および標識F1を有する連結産物の配列で示される)に突然変異を起こしており、Arg(CGG;部位Z7および標識F2を有する連結産物の配列で示される)がトリプトファン(Trp)(TGG;部位Z8および標識F2を有する連結産物の配列で示される)に突然変異を起こしていることを示している。したがって、患者は、複合ヘテロ接合型の個体である(すなわち、両方の遺伝子に変異体対立遺伝子を有する)。 FIG. 14 is a flow chart for the PCR / LDR stage of the present invention, in which both flanking and nearby alleles are detected. Adjacent mutations are right next to each other, and a set of oligonucleotide probes identifies the base at the 3 'end of the junction (sites Z1, Z2, Z3, and Z4 specific for different positionable arrays However, the other set of oligonucleotide probes identifies the base at the 5 ′ end of the junction (use of different fluorescent reporter labels F1, F2, F3, and F4). In FIG. 14, the codons encoding Gly and arginine (Arg) of the disease gene (eg, cystic fibrosis CFTR) are each a candidate for germline mutation. The detection results in FIG. 14 show that Gly (GGA; indicated by site Z2 with the sequence of the ligation product and labeled F2) is glutamic acid (Glu) (GAA; indicated by sequence of the ligation product with site Z2 and label F1). Mutated and Arg (CGG; indicated by sequence of ligation product with site Z7 and labeled F2) in tryptophan (Trp) (TGG; indicated by sequence of ligation product with site Z8 and label F2) Indicates that a mutation has occurred. Thus, the patient is a compound heterozygous individual (ie, having mutant alleles in both genes).
図15は、本発明のPCR/LDRの段階に関する流れ図であり、単一コドンに関して可能な単一塩基の変異すべてが検出される。通常アミノ酸のコドンは3番目の塩基が縮重しているのでこれら可能な変異すべてについて、蛋白質レベルで最初の2つの位置を決定できる。これらのアミノ酸には、アルギニン、ロイシン、セリン、トレオニン、プロリン、アラニン、グリシン、およびバリンを含む。しかしながら、幾つかのアミノ酸については、コドンの3つの塩基すべてを調べるので、3箇所の隣接した位置の変異を識別するオリゴヌクレオチドプローブが必要となる。図15に示すように、3'末端に対する最後から2番目の位置に4種の可能な塩基を含む4つのオリゴヌクレオチドプローブを設計し、また3'末端に4種の考え得る塩基を含む別の4つの捕獲オリゴヌクレオチドを設計し、この問題を解決する。レポーター標識のみを有する共通オリゴヌクレオチドプローブはコドンの縮重に対応し、同一のアレイアドレスで捕獲され異なる連結産物の配列間の識別ができる2つの蛍光基を有している。例えば、図15に示されるように、グルタミン(Gln)をコードするコドン(すなわち、CAAおよびCAG)の存在が、部位Z1および標識F2を含む連結産物の配列の存在によって示される。同様に、ヒスチジン(His)をコードする変異(コドンCACでコードされる)に対するGlnの存在は、部位Z1および標識F2を有する連結産物の配列の存在ならびに部位Z7および標識F2を有する連結産物の配列の存在によって示される。プライマーZ1およびZ7が同一の配列を有するという事実に起因し、このアッセイ法に冗長性が内在する。 FIG. 15 is a flow chart for the PCR / LDR stage of the present invention, in which all possible single base variations for a single codon are detected. Since the amino acid codon is usually degenerate at the third base, the first two positions can be determined at the protein level for all these possible mutations. These amino acids include arginine, leucine, serine, threonine, proline, alanine, glycine, and valine. However, for some amino acids, all three bases of the codon are examined, so an oligonucleotide probe that distinguishes mutations at three adjacent positions is required. As shown in Figure 15, we designed 4 oligonucleotide probes containing 4 possible bases in the penultimate position relative to the 3 'end and another containing 4 possible bases at the 3' end. Four capture oligonucleotides are designed to solve this problem. A common oligonucleotide probe having only a reporter label corresponds to codon degeneracy and has two fluorescent groups that can be captured at the same array address and discriminated between sequences of different ligation products. For example, as shown in FIG. 15, the presence of codons encoding glutamine (Gln) (ie, CAA and CAG) is indicated by the presence of the sequence of the ligation product containing site Z1 and label F2. Similarly, the presence of Gln for a mutation encoding histidine (His) (encoded by codon CAC) indicates the presence of the sequence of the ligation product with site Z1 and label F2, and the sequence of the ligation product with site Z7 and label F2. Indicated by the presence of. Due to the fact that primers Z1 and Z7 have the same sequence, redundancy is inherent in this assay.
本発明の特に重要な局面は、試料中の標的塩基配列の量が定量可能であることである。内部(すなわち、該試料を用いた増幅・検出により得られる標準材料)もしくは外部(すなわち、得られる標準物質は増幅されないが該試料を用いて検出される)標準を得ることによって、これを様々な方法で達成することができる。 A particularly important aspect of the present invention is that the amount of target base sequence in a sample can be quantified. By obtaining an internal (ie, standard material obtained by amplification and detection using the sample) or an external (ie, the resulting standard is not amplified but detected using the sample), this is Can be achieved in a way.
ある定量法に従って、レポーター標識により生成したシグナルは、分析試料より生産された連結産物の配列の捕獲によって生じ検出されるものである。このシグナル強度は、生成した既知の量の標的塩基配列を有する試料中に存在する連結産物の配列の捕獲によって生じるシグナルによって得られる検量線と比較する。その結果、分析試料中の標的塩基配列の量を調べることができる。本技術は、外部標準の使用を含む。 According to a certain quantitative method, the signal generated by the reporter label is generated and detected by capturing the sequence of the ligation product produced from the analytical sample. This signal intensity is compared with a calibration curve obtained by the signal generated by the capture of the sequence of ligation products present in a sample having a known amount of target base sequence generated. As a result, the amount of the target base sequence in the analysis sample can be examined. The technology involves the use of external standards.
本発明の別の定量法は、内部標準に関する。ここでは、既知の量の一つもしくは複数のマーカー標的塩基配列を試料に添加する。さらに、複数のマーカー特異的オリゴヌクレオチドプローブのセットをリガーゼ、上記のオリゴヌクレオチドプローブのセットおよび試料とともに混合物に添加する。マーカー特異的オリゴヌクレオチドプローブのセットは、(1)マーカー標的塩基配列に相補的な標的特異的な部位ならびに支持体上の捕獲オリゴヌクレオチドに相補的な位置特定可能なアレイに特異的な部位を有する第1のオリゴヌクレオチドプローブ、(2)マーカー標的塩基配列に相補的な標的特異的な部位ならびに検出可能なレポーター標識を有する第2のオリゴヌクレオチドプローブを含む。特定のマーカー特異的オリゴヌクレオチドセットにおけるオリゴヌクレオチドプローブは、対応するマーカー標的塩基配列上で相互に隣接してハイブリダイズし、互いに連結することにおいて適切である。しかしながら、試料中の他のヌクレオチド配列または添加したマーカー配列にハイブリダイズする場合には、このような連結を阻害するミスマッチが存在する。支持体上に捕獲された連結産物の配列の存在は、レポーター標識の検出によって同定される。次に、既知の量のマーカー標的塩基配列から生成し捕獲された連結産物の量を捕獲された他の連結産物の配列の量と比較することによって、試料中の標的塩基配列の量を決定する。 Another quantification method of the invention relates to an internal standard. Here, a known amount of one or more marker target base sequences is added to the sample. In addition, a set of marker specific oligonucleotide probes is added to the mixture along with the ligase, the set of oligonucleotide probes and the sample. The set of marker-specific oligonucleotide probes has (1) a target-specific site complementary to the marker target base sequence as well as a site specific to the localizable array complementary to the capture oligonucleotide on the support. A first oligonucleotide probe, (2) a second oligonucleotide probe having a target-specific site complementary to the marker target base sequence and a detectable reporter label. Oligonucleotide probes in a particular marker specific oligonucleotide set are suitable in hybridizing adjacent to each other on the corresponding marker target base sequence and ligating together. However, when hybridizing to other nucleotide sequences or added marker sequences in the sample, there are mismatches that inhibit such ligation. The presence of the sequence of the ligation product captured on the support is identified by detection of the reporter label. Next, the amount of target base sequence in the sample is determined by comparing the amount of ligation product generated and captured from a known amount of marker target base sequence with the amount of sequence of other captured ligation products. .
本発明の別の定量法は、複数の配列上の差異を有する2つもしくはそれ以上の複数の標的塩基配列を含む試料の解析を含む。ここでは、標的塩基配列に対応する連結産物の配列が、上記のいずれかの技術によって検出・識別される。次に、生成し捕獲された連結産物の配列の相対量を比較して、試料中の標的塩基配列の相対量を定量する。これは、試料における標的塩基配列の相対的レベルの定量的尺度を提供する。 Another quantification method of the present invention includes analysis of a sample containing two or more target base sequences having a plurality of sequence differences. Here, the sequence of the ligation product corresponding to the target base sequence is detected and identified by any of the above techniques. Next, the relative amount of the sequence of the ligation product generated and captured is compared, and the relative amount of the target base sequence in the sample is quantified. This provides a quantitative measure of the relative level of the target base sequence in the sample.
本発明のリガーゼによる検出反応法の段階の前に、リガーゼ連鎖反応法を行い、オリゴヌクレオチド産物を増幅することもできる。本方法は、F.Baranyらの「耐熱性DNAリガーゼをコードする遺伝子のクローニング、過剰発現および塩基配列(Cloning, Overexpression and Nucleotide Sequence of a Thermostable DNA Ligase-encoding Gene)」、Gene 109:1-11(1991)、およびF.Baranyらの「クローン化耐熱のリガーゼを用いた遺伝病の検出およびDNA増幅(Genetic Disease Detection and DNA Amplification Using Cloned Thermostable Ligase)」(Proc.Natl.Acad.Sci.USA 88:189-93(1991))に完全な記載があり、これらは参照として本明細書に組み入れられる。増幅にリガーゼ連鎖反応を用いる代わりに、転写に基づく増幅法を利用することもできる。Prior to the detection reaction method step using the ligase of the present invention, the ligase chain reaction method may be performed to amplify the oligonucleotide product. This method is described by F. Barany et al., “Cloning, Overexpression and Nucleotide Sequence of a Thermostable DNA Ligase-encoding Gene”, Gene 109: 1-11 (1991), and F. Barany et al., “Genetic Disease Detection and DNA Amplification Using Cloned Thermostable Ligase” ( Proc. Natl. Acad. Sci. USA 88 : 189-93 (1991)), which are incorporated herein by reference. Instead of using ligase chain reaction for amplification, transcription-based amplification methods can also be used.
好ましい耐熱性リガーゼはThermusaquaticus由来のものである。本酵素はこの生物から単離できる(M.Takahashiら「好熱性DNAリガーゼ(Thermophillic DNA ligase)」(J.Biol.Chem. 259:10041-47(1984));これは参照として本明細書に組み入れられる)。または、リコンビナントで調製することもできる。このような単離法は、リコンビナントThermusaquaticusリガーゼの産生(およびThermusthemophilusリガーゼ)とともに、Baranyらの国際公開公報第90/17239号、およびF.Baranyらの「耐熱性DNAリガーゼをコードする遺伝子のクローニング、過剰発現および塩基配列(Cloning, Overexpression and Nucleotide Sequence of a Thermostable DNA Ligase-encoding Gene)」(Gene.109:1-11(1991))等に開示されており、参照として本明細書に組み入れられる。これらの文献は、このリガーゼおよびこれをコードするDNAの完全な配列情報を含む。他の好ましいリガーゼとしては、E.coliリガーゼ、T4リガーゼ、Thermussp.AK16リガーゼ、Aquifexaeolicusリガーゼ、Thermotogamaritimaリガーゼおよび、Pyrococcusリガーゼを含む。A preferred thermostable ligase is from Thermusaquaticus. The enzyme can be isolated from this organism (M. Takahashi et al., “Thermophillic DNA ligase” ( J. Biol. Chem. 259: 10041-47 (1984)); this is hereby incorporated by reference. Incorporated). Alternatively, it can be prepared with a recombinant. Such isolation methods include the production of recombinant Thermusaquaticus ligase (and Thermosthemophilus ligase), as well as Barany et al., International Publication No. 90/17239, and F. Barany et al., “Cloning of a gene encoding a thermostable DNA ligase, Overexpression and Nucleotide Sequence of a Thermostable DNA Ligase-encoding Gene "( Gene. 109: 1-11 (1991)) and the like, which are incorporated herein by reference. These documents contain complete sequence information of this ligase and the DNA encoding it. Other preferred ligases include E. coli ligase, T4 ligase, Thermussp.AK16 ligase, Aquifexaeolicus ligase, Thermotogamaritima ligase and Pyrococcus ligase.
連結増幅混合物は、サケ精子DNA等の担体DNAを含んでいてもよい。 The ligated amplification mixture may contain carrier DNA such as salmon sperm DNA.
好ましくは加熱ハイブリダイゼーション処理であるハイブリダイゼーションの段階では、連結接合部における識別ヌクレオチドに基づく塩基配列間での識別を行う。標的塩基配列間の差異は、例えば、単一核酸塩基の差、核酸の欠失、再構成である。1塩基以上を含むこのような配列の差異も検出できる。好ましくは、オリゴヌクレオチドプローブのセットは実質的に同一の長さを有し、それらを実質的に同様なハイブリダイゼーション条件で標的塩基配列にハイブリダイズする。その結果、本発明の方法は、感染性疾患、遺伝病、および癌を検出できる。また、環境モニタリング、法医科学、および食品科学においても有用である。 In the hybridization stage, which is preferably a heat hybridization treatment, discrimination between base sequences based on identification nucleotides at the ligation junction is performed. Differences between target base sequences are, for example, single nucleobase differences, nucleic acid deletions, and rearrangements. Such sequence differences including one or more bases can also be detected. Preferably, the set of oligonucleotide probes have substantially the same length and hybridize to the target base sequence under substantially similar hybridization conditions. As a result, the method of the present invention can detect infectious diseases, genetic diseases, and cancer. It is also useful in environmental monitoring, forensic science, and food science.
広く多様な感染性疾患は、本発明の方法で検出できる。通常、これらは細菌性、ウイルス性、寄生性、および真菌性の感染病原体によっておこる。また、さまざまな感染病原体の薬剤に対する耐性は、本発明を用いて調べることができる。 A wide variety of infectious diseases can be detected by the method of the present invention. These are usually caused by bacterial, viral, parasitic, and fungal infectious agents. Also, the resistance of various infectious agents to drugs can be examined using the present invention.
本発明で検出する細菌性感染病原体は、大腸菌、サルモネラ菌(Salmonella)、赤痢菌(Shigella)、クレブシエラ(Klebsiella)、シュードモナス(Pseudomonas)、リステリア菌(Listeria monocytogenes)、結核菌(Mycobacterium tuberculosis)、ミコバクテリアアビウム-イントラセルラ(Mycobacterium avium-intracellulare)、エルシニア(Yersinia)、フランシセラ(Francisella)、パスツレラ(Pasteurella)、ブルセラ(Brucella)、クロストリジウム(Clostridia)、百日咳菌(Bordetella pertussis)、バクテロイド(Bacteroides)、黄色ブドウ球菌(Staphylococcus aureus)、スタフィロコッカスニューモニア(Streptococcus pneumonia)、B-溶連菌(B-Hemolyticstrep.)、コリネバクテリア(Corynebacteria)、レジオネラ(Legionella)、ミコプラズマ(Mycoplasma)、ウレアプラズマ(Ureaplasma)、クラミジア(Chlamydia)、淋菌(Neisseriagonorrhea)、髄膜炎菌(Neisserimeningitides)、ヘモフィルスインフルエンザ(Hemophilus influenza)、エンテロコッカスファエカリス(Enterococcus faecalis)、プロテウスブルガリス(Proteus vulgaris)、プロテウスミラビリス(Proteus mirabilis)、ヘリコバクターピロリ(Helicobacter pylori)、梅毒トレポネーマ(Treponema palladium)、ボレリアバーグドーフェリ(Borreliaburgdorferi)、ボレリアレクレンティス(Borrelia recurrentis)、リケッチア(Rickettsial)の病原、ノカルジア(Nocardia)、およびアシトノマイセス(Acitnomycetes)を含む。 Bacterial infectious agents detected in the present invention include Escherichia coli, Salmonella, Shigella, Klebsiella, Pseudomonas, Listeria monocytogenes, Mycobacterium tuberculosis, Mycobacteria Mycobacterium avium-intracellulare, Yersinia, Francisella, Pasturella, Brucella, Clostridia, Bordetella pertussis, Bacteroides, yellow Staphylococcus aureus, Staphylococcus pneumonia, B-Hemolyticstrep., Corynebacteria, Legionella, Mycoplasma, Ureaplasma, Ureaplasma Chlamydia (Chlam ydia, Neisseriagonorrhea, Neisserimeningitides, Hemophilus influenza, Enterococcus faecalis, Proteus vulgaris, Proteus mirabilis (Proteus helicobacter) Includes pylori, Treponema palladium, Borreliaburgdorferi, Borrelia recurrentis, Rickettsial pathology, Nocardia, and Acitnomycetes.
本発明で検出される真菌性感染病原体は、クリプトコッカスネオフォルマンス(Cryptococcus neoformans)、ブラストミセスデルマティティディス(Blastomyces dermatitidis)、ヒストプラズマカプスラタム(Histoplasma capsulatum)、コクシジウムイミティス(Coccidioides immitis)、パラコクシシオイデスブラシリアンシス(Paracoccicioides brasiliensis)、カンジダアルビカンス(Candidaalbicans)、アスペルギルスフミガーツス(Aspergillus fumigautus)、フィコマイセテス(Phycomycetes)(リゾプス(Rhizopus))、スポロスリックスシェンキー(Sporothrix schenckii)、クロモミコシス(Chromomycosis)、およびマズロミコシス(Maduromycosis)を含む。 Fungal infectious agents detected in the present invention include Cryptococcus neoformans, Blastomyces dermatitidis, Histoplasma capsulatum, Coccidioides immitis, para Coccionioides brasiliensis, Candidaalbicans, Aspergillus fumigautus, Phycomycetes (Rhizopus), Spiis thrix ), And Maduromycosis.
本発明で検出されるウイルス性感染病原体は、ヒト免疫不全症ウイルス、ヒトT細胞リンパ球親和性ウイルス、肝炎ウイルス(例えば、B型肝炎ウイルスおよびC型肝炎ウイルス)、エプスタイン・バーウイルス、サイトメガロウイルス、ヒトパピローマウイルス、オルトミクソウイルス、パラミクソウイルス、アデノウイルス、コロナウイルス、ラブドウイルス、ポリオウイルス、トガウイルス、バンヤウイルス、アレナウイルス、ルベラウイルス、およびレオウイルスを含む。 Viral infectious agents detected in the present invention include human immunodeficiency virus, human T cell lymphocyte affinity virus, hepatitis virus (eg, hepatitis B virus and hepatitis C virus), Epstein Barr virus, cytomegalo Including viruses, human papillomaviruses, orthomyxoviruses, paramyxoviruses, adenoviruses, coronaviruses, rhabdoviruses, polioviruses, togaviruses, vanyaviruses, arenaviruses, rubella viruses, and reoviruses.
本発明で検出される寄生性作用病原体は、プラスモジウムファルシパラム(Plasmodium falciparum)、プラスモジウムマラリア(Plasmodium malaria)、プラスモジウムビバックス(Plasmodium vivax)、プラスモジウムオーバル(Plasmodium ovale)、オンコバルバボルブラス(Onchovervavolvulus)、レーシュマニア(Leishmania)、トリパノソーマ(Trypanosoma)種、住血吸虫(Schistosoma)種、エンタモエバヒストリチカ(Entamoebahistolytica)、クリプトスポリジウム(Cryptosporidum)、ギアルディア(Giardia)種、トリチモナス(Trichimonas)、バラチジウムコーライ(Balatidiumcoli)、ウチェレリアバンクロフティ(Wuchereriabancrofti)、トキソプラズマ(Toxoplasma)種、エンテロビウスバーミキュラシス(Enterobiusvermicularis)、アスカリスラムブリコイデス(Ascarislumbricoides)、トリチュリストリチウラ(Trichuristrichiura)、ドラカムクルスメディネシス(Dracunculusmedinesis)、吸虫(trematodes)、ジフィロボツリウムラタン(Diphyllobothriumlatum)、条虫(Taenia)種、ニューモシスティスカリニー(Pneumocystiscarinii)、及びネカターアメリカニス(Necatoramericanis)を含む。 Parasitic acting pathogens detected in the present invention include Plasmodium falciparum, Plasmodium malaria, Plasmodium vivax, Plasmodium ovale, Onchovervavolvulus, Leishmania, Trypanosoma species, Schistosoma species, Entamoebahistolytica, Cryptosporidum, Giardia species, Giardia species (Trichimonas), Balatidiumcoli, Wuchereriabancrofti, Toxoplasma sp., Enterobiusvermicularis, Ascarislumbricoides, Trichu Trichuristrichiura, Dracunculusmedinesis, trematodes, Diphyllobothriumlatum, Taenia species, Pneumocystiscarinii, and Necatoramericanis )including.
本発明はまた、感染性因子による薬剤耐性の検出にも有用である。例えば、バンコマイシン耐性エンテロコッカスファエシウム(Enterococcus faecium)、メチシリン耐性黄色ブドウ球菌、ペニシリン耐性肺炎連鎖球菌(Streptococcus pneumoniae)、多剤耐性結核菌(Mycobacterium tuberculosis)、およびAZT耐性ヒト免疫不全ウイルスはいずれも本発明で同定できる。 The present invention is also useful for detecting drug resistance by infectious agents. For example, vancomycin-resistant Enterococcus faecium, methicillin-resistant Staphylococcus aureus, penicillin-resistant Streptococcus pneumoniae, Mycobacterium tuberculosis, and AZT-resistant human immunodeficiency virus are all included in the present invention. Can be identified.
遺伝性疾患は、本発明の方法で検出できる。これは染色体および遺伝的異常の出生前スクリーニングもしくは遺伝病の出生後スクリーニングで実施可能である。検出可能な遺伝病の例としては、21ヒドロキシラーゼ欠損、嚢胞性線維症、脆弱X症候群、ターナー症候群、デュシェーヌ筋ジストロフィー、ダウン症候群もしくはその他のトリソミー、心臓疾患、単一遺伝子疾患、HLAタイピング、フェニルケトン尿症、鎌状細胞貧血、テイ-サックス病、タラセミア、クラインフェルトラー症候群、ハンチントン病、自己免疫疾患、脂肪代謝異常症、肥満症、血友病、先天性代謝異常、および糖尿病があげられる。 Genetic diseases can be detected by the method of the present invention. This can be done by prenatal screening for chromosomal and genetic abnormalities or postnatal screening for genetic diseases. Examples of detectable genetic diseases include 21 hydroxylase deficiency, cystic fibrosis, fragile X syndrome, Turner syndrome, Duchenne muscular dystrophy, Down's syndrome or other trisomy, heart disease, single gene disease, HLA typing, phenyl ketone Examples include urine disease, sickle cell anemia, Tay-Sachs disease, thalassemia, Kleinfelder syndrome, Huntington's disease, autoimmune disease, fat metabolism disorder, obesity, hemophilia, inborn errors of metabolism, and diabetes.
本発明の方法で検出される癌は、通常、癌遺伝子、腫瘍抑制性遺伝子、もしくはDNA増幅に関与する遺伝子、複製、組換え、もしくは修復を含む。これらの例は、BRCA1遺伝子、p53遺伝子、家族性大腸ポリポーシス、Her2/Neu増幅、Bcr/AbI、K-ras遺伝子、ヒトパピローマウイルスのタイプ16および18、白血病、大腸癌、乳癌、肺癌、前立腺癌、脳腫瘍、中枢神経系腫瘍、膀胱腫瘍、メラノーマ、肝癌、骨肉腫およびその他の骨癌、睾丸癌および卵巣癌、耳鼻咽喉科の腫瘍、およびヘテロ接合性の消失を含む。 The cancer detected by the method of the present invention usually includes an oncogene, a tumor suppressor gene, or a gene involved in DNA amplification, replication, recombination, or repair. Examples of these include BRCA1 gene, p53 gene, familial colon polyposis, Her2 / Neu amplification, Bcr / AbI, K-ras gene,
環境モニタリングの分野においては、本発明は、都市廃水浄化システムおよび貯水器等の天然の、および工学的な生態系ならびに微小生態系もしくは生物的環境浄化を行っている汚染域における病原性および常在微生物の検出、同定、およびモニタリングに用いられる。集団動態研究における特異的標的微生物のモニタリング、または環境および工業用植物における改変微生物における遺伝学的検出、同定、もしくはモニタリングのいずれかのために、非生体物質を代謝する遺伝子を含むプラスミドの検出をおこなうことも可能である。 In the field of environmental monitoring, the present invention relates to pathogenicity and presence in natural and engineered ecosystems such as municipal wastewater purification systems and reservoirs and in contaminated areas that are purifying microecosystems or biological environments. Used for the detection, identification and monitoring of microorganisms. Detection of plasmids containing genes that metabolize non-biological substances, either for monitoring specific target microorganisms in population dynamics studies, or for genetic detection, identification, or monitoring in modified microorganisms in environmental and industrial plants It is also possible to do it.
本発明は、軍人、および犯罪捜査におけるヒトの識別、父性検査および家族関係解析、HLA適合性タイピング、および血液、精子、もしくは移植臓器の汚染スクリーニングを含む多様な法医学的分野においても用いることができる。 The invention can also be used in a variety of forensic fields, including military and criminal human identification, paternity testing and family relationship analysis, HLA compatibility typing, and blood, sperm, or transplant organ contamination screening. .
食品および飼料工業においては、本発明は広く多様な応用を有する。例えば、ビール、ワイン、チーズ、ヨーグルト、パン、その他の産生に関わる酵母等の産生用微生物の同定および特徴付けに用いることができる。利用に関する別の分野は、産物の品質管理および検定ならびに工法(例えば、家畜、殺菌、および食肉加工)における汚染に関する。その他の利用としては、育種目的の植物、球根、および種子の特徴付け、植物特異的病原体の存在同定、ならびに家畜感染の検出および同定があげられる。 In the food and feed industry, the present invention has a wide variety of applications. For example, it can be used for identification and characterization of production microorganisms such as beer, wine, cheese, yogurt, bread and other yeasts involved in production. Another area of use relates to contamination in product quality control and verification and construction methods (eg livestock, sterilization, and meat processing). Other uses include characterization of plants, bulbs and seeds for breeding purposes, identification of the presence of plant-specific pathogens, and detection and identification of livestock infections.
望ましくは、オリゴヌクレオチドプローブは、連結接合部において完全な相補性に基づき、対応する標的塩基配列上で相互に隣接してハイブリダイズする場合の、連結接合部における連結に好ましいものである。しかしながら、該セットにおけるオリゴヌクレオチドプローブは、試料中の他のいずれかのヌクレオチド配列にハイブリダイズする場合には、連結を阻害する連結接合部位置の塩基にミスマッチが存在する。最も好ましくは、ミスマッチは連結接合部の3'塩基に隣接した位置の塩基に存在する。または、ミスマッチは、連結接合部の塩基に隣接した塩基にあってもよい。 Desirably, oligonucleotide probes are preferred for ligation at ligation junctions when hybridizing adjacent to each other on corresponding target sequences based on perfect complementarity at the ligation junction. However, when the oligonucleotide probes in the set hybridize to any other nucleotide sequence in the sample, there is a mismatch in the base at the ligation junction that inhibits ligation. Most preferably, the mismatch is present at the base adjacent to the 3 ′ base of the ligation junction. Alternatively, the mismatch may be in a base adjacent to the base at the junction junction.
本発明の方法は、第1および第2の塩基配列を100アトモルから250フェムトモルの量で試料中に検出することができる。LDR段階を第1のポリメラーゼ特異的増幅段階とカップルさせ、本発明の完全な方法では、単一分子程度を含む試料において標的塩基配列を検出することができる。さらに、ピコモル量であることの多いPCR増幅産物は上記範囲で容易に希釈できる。このリガーゼによる検出反応では、ミスマッチ連結産物の配列の形成速度は、マッチした連結産物の配列の形成速度の0.005より低い。 According to the method of the present invention, the first and second base sequences can be detected in a sample in an amount of 100 to 250 femtomole. By coupling the LDR step with a first polymerase specific amplification step, the complete method of the invention can detect the target base sequence in a sample containing as much as a single molecule. Furthermore, PCR amplification products that are often in picomolar amounts can be easily diluted within the above range. In this ligase detection reaction, the rate of formation of the mismatched ligation product sequence is less than 0.005 of the rate of formation of the matched ligation product sequence.
連結期が完了すると、捕獲期が開始される。本方法の捕獲期では、混合物は25〜90℃、好ましくは60℃〜80℃の温度で、かつ10〜180分間、好ましくは60分までので時間、固体支持体と接触させる。ハイブリダイゼーションは、ハイブリダイゼーション中に連結混合物を混合すること、または容積排除、カオトロピック薬剤、テトラメチルアンモニウム塩、もしくはN,N,N,トリメチルグリシン(ベタイン一水和物)を添加することによって加速もしくは改善される。アレイが数十から数百のアドレスからなる場合、正しい連結産物が適当なアドレスでハイブリダイズする機会を有することが重要である。これは、用いる高い温度におけるオリゴヌクレオチドの熱運動、アレイ表面と接触する液体の機械的運動、もしくは電界によるアレイ全域にゎたるオリゴヌクレオチドの運動によって達成することができる。ハイブリダイゼーショ後にハイブリダイズしていないプローブを除去し、捕獲されたプローブの検出の最適化を図るために、アレイを緩衝液で洗浄する。または、アレイを順次洗浄する。 Once the concatenation period is complete, the capture period begins. In the capture phase of the method, the mixture is contacted with the solid support at a temperature of 25-90 ° C., preferably 60 ° C.-80 ° C., and for 10-180 minutes, preferably up to 60 minutes. Hybridization can be accelerated by mixing the ligation mixture during hybridization or by adding volume exclusion, chaotropic agents, tetramethylammonium salts, or N, N, N, trimethylglycine (betaine monohydrate) or Improved. If the array consists of tens to hundreds of addresses, it is important to have the opportunity for the correct ligation product to hybridize at the appropriate address. This can be accomplished by thermal motion of the oligonucleotide at the high temperature used, mechanical motion of the liquid in contact with the array surface, or motion of the oligonucleotide across the array by an electric field. To remove unhybridized probes after hybridization and optimize the detection of captured probes, the array is washed with buffer. Alternatively, the array is washed sequentially.
ハイブリダイゼーションの特異性は、ハイブリダイゼーション溶液への、非特異的競合DNA(例えばニシン精子DNA)の添加および/またはホルムアミドの添加により促進されてもよい。洗浄の厳密度はまた洗浄温度の上昇および/または洗浄緩衝液へのホルムアミドの添加により増大されうる。図16は標準的ハイブリダイゼーションおよび洗浄条件への上記の変更の様々な組み合わせによる結果を示す。 Hybridization specificity may be facilitated by the addition of non-specific competitor DNA (eg, herring sperm DNA) and / or the addition of formamide to the hybridization solution. Wash stringency can also be increased by increasing the wash temperature and / or adding formamide to the wash buffer. FIG. 16 shows the results from various combinations of the above changes to standard hybridization and wash conditions.
好ましくは、固体支持体は、アクリルアミドとカルボン酸塩、アルデヒド、もしくはアミノ基を含む機能性のモノマーとの組み合わせで構成される親水性ポリマーの多孔性表面を有する。この表面は、支持体を、ポリアクリルアミドに基づくゲルでコーティングするによって形成する。好ましい配合は、アクリルアミド/アクリル酸およびN,N-ジメチルアクリルアミド/グリセロールモノメタクリレートである。クロスリンカーN,N'-メチレンビスアクリルアミドは、50:1以下のレベル、好ましくは500:1以下のレベルである。 Preferably, the solid support has a porous surface of a hydrophilic polymer composed of a combination of acrylamide and a carboxylate, aldehyde, or functional monomer containing an amino group. This surface is formed by coating the support with a gel based on polyacrylamide. Preferred formulations are acrylamide / acrylic acid and N, N-dimethylacrylamide / glycerol monomethacrylate. The crosslinker N, N′-methylenebisacrylamide is at a level of 50: 1 or less, preferably 500: 1 or less.
固体支持体を連結混合物に接触させている間の陰性電荷のマスキングに関する一態様は、二価カチオンの利用によって達成される。二価カチオン、Mg2+、Ca2+、MN2+、もしくはCo2+でよい。通常、二価カチオンによるマスキングは、カチオンを含むハイブリダイゼーション緩衝液により10mMの最小濃度で室温で15分間、固体支持体のプレハイブリダイゼーションを行うことによって実施する。One aspect related to masking negative charges while contacting a solid support with a ligation mixture is achieved through the use of divalent cations. It may be a divalent cation, Mg 2+ , Ca 2+ , MN 2+ , or Co 2+ . Usually, masking with divalent cations is performed by pre-hybridizing the solid support with a hybridization buffer containing cations at a minimum concentration of 10 mM for 15 minutes at room temperature.
固体支持体を連結混合物に接触させている間の陰性電荷のマスキングに関する別の態様は、pH6.0もしくはそれ以下のpHで接触させることによって実施する。これを固体支持体に接触させる前もしくは接触中に連結混合物に緩衝液を添加することが効果的である。好ましい緩衝液は、2-(N-モルフォリノ)エタンスルフォン酸(MES)、リン酸ナトリウム、およびリン酸カリウムを含む。 Another embodiment for masking negative charges while contacting a solid support with a ligation mixture is performed by contacting at a pH of pH 6.0 or lower. It is advantageous to add a buffer to the ligation mixture before or during contact with the solid support. A preferred buffer comprises 2- (N-morpholino) ethanesulfonic acid (MES), sodium phosphate, and potassium phosphate.
固体支持体を連結混合物に接触させている間の陰性電荷のマスキングに関する別の態様は、ポリマーの親水性を抑えながら遊離のカルボン酸基を中和剤でキャッピングすることによって実施する。好ましい中和剤は、エタノールアミン、ジエタノールアミン、プロパノールアミン、ジプロパノールアミン、イソプロパノールアミン、およびジイソプロパノールアミンを含む。通常、中和剤によるマスキングは、1-[(3-ジメチルアミノ)プロピル]-3-エチルカルボジイミド塩酸塩およびN-ヒドロキシこはく酸イミドを用い固体支持体内でカルボン酸基を活性化した後、クロロフォルム、ジクロロメタン、もしくはテトラヒドロフラン等の極性非プロトン性溶媒中で中和剤溶液による処理を行うことによって実施する。 Another embodiment for masking negative charges while the solid support is in contact with the ligation mixture is performed by capping free carboxylic acid groups with a neutralizing agent while reducing the hydrophilicity of the polymer. Preferred neutralizing agents include ethanolamine, diethanolamine, propanolamine, dipropanolamine, isopropanolamine, and diisopropanolamine. Masking with a neutralizing agent is usually performed by activating carboxylic acid groups in a solid support with 1-[(3-dimethylamino) propyl] -3-ethylcarbodiimide hydrochloride and N-hydroxysuccinimide, followed by chloroform. , By treatment with a neutralizer solution in a polar aprotic solvent such as dichloromethane or tetrahydrofuran.
本発明による陰性電荷のマスキングによって、連結の起こらなかったオリゴヌクレオチドプローブの存在下における連結された産物の存在の検出が向上する。特に、連結の起こらなかったオリゴヌクレオチドプローブに対する比が1:300未満、好ましくは1:900未満、さらに好ましくは1:3000未満、最も好ましくは1:9000未満である場合の連結産物の存在の検出に、本発明は効果的である。 Negative charge masking according to the present invention improves detection of the presence of ligated products in the presence of oligonucleotide probes that have not been ligated. In particular, the detection of the presence of a ligation product when the ratio to oligonucleotide probes that have not been ligated is less than 1: 300, preferably less than 1: 900, more preferably less than 1: 3000, most preferably less than 1: 9000. In addition, the present invention is effective.
さらに、本発明による陰性電荷のマスキングによって、非標的ヌクレオチド配列とは異なる標的塩基配列を有する標的塩基配列の存在を非標的ヌクレオチド配列から単一塩基の差によって識別検出する能力が向上する。特に、標的塩基配列の非標的ヌクレオチド配列に対する比が1:20未満、好ましくは1:50未満、より好ましくは1:100未満、最も好ましくは1:200未満である場合の標的塩基配列の検出に、本発明は有効である。 Furthermore, the masking of negative charges according to the present invention improves the ability to discriminate and detect the presence of a target base sequence having a target base sequence different from the non-target nucleotide sequence by a single base difference. In particular, for detection of a target base sequence when the ratio of target base sequence to non-target nucleotide sequence is less than 1:20, preferably less than 1:50, more preferably less than 1: 100, and most preferably less than 1: 200. The present invention is effective.
安定にハイブリダイズする捕獲オリゴヌクレオチドおよび位置特定可能な塩基配列の選択が重要である。このために、オリゴヌクレオチドセットおよび捕獲オリゴヌクレオチドを、位置特定可能なアレイに特異的な部位に捕獲オリゴヌクレオチドがハイブリダイズする温度以下の温度で標的塩基配列にオリゴヌクレオチドセットハイブリダイズするように設計する必要がある。オリゴヌクレオチドをこのように設計しなかった場合、標的にハイブリダイズする同一のオリゴヌクレオチドセットから隣接した未反応のオリゴヌクレオチドを捕獲してしまうことで偽陽性シグナルが生じる。 The selection of capture oligonucleotides and positionable base sequences that hybridize stably is important. For this purpose, the oligonucleotide set and capture oligonucleotide are designed to hybridize to the target base sequence at a temperature below the temperature at which the capture oligonucleotide hybridizes to a site specific to the positionable array. There is a need. If oligonucleotides are not designed in this way, false positive signals are generated by capturing adjacent unreacted oligonucleotides from the same set of oligonucleotides that hybridize to the target.
特定のオリゴヌクレオチドセットの連結が起こり、連結が被検試料中の標的塩基配列の有無と相関する場合には、本方法の検出期は走査と同定を含む。走査は、走査電子顕微鏡法、共焦点顕微鏡法、電荷結合素子、走査トンネル電子顕微鏡法、赤外線顕微鏡法、原子間力顕微鏡法、電導度、および蛍光もしくは燐光撮像技術によって実施可能である。相関付けはコンピュータで行う。 If ligation of a particular oligonucleotide set occurs and the ligation correlates with the presence or absence of the target base sequence in the test sample, the detection phase of the method includes scanning and identification. Scanning can be performed by scanning electron microscopy, confocal microscopy, charge coupled devices, scanning tunneling electron microscopy, infrared microscopy, atomic force microscopy, conductivity, and fluorescence or phosphorescent imaging techniques. Correlation is performed by a computer.
本発明の別の局面は、支持体上のオリゴヌクレオチドのアレイ形成法に関する。この方法は、各々がオリゴヌクレオチドの付加に適切である部位のアレイを有する支持体を提供することを含む。各々のアレイ位置において支持体へのオリゴヌクレオチドの結合に好ましいリンカー、もしくは支持体(好ましくは非加水分解性)は固体支持体に結合している。固体支持体上のオリゴヌクレオチドのアレイは、多量体ヌクレオチドの付加のための選択されたアレイ位置の活性化および活性アレイ位置における多量体ヌクレオチドの付加の一連のサイクルによって形成される。 Another aspect of the present invention relates to a method for forming an array of oligonucleotides on a support. The method includes providing a support having an array of sites, each of which is suitable for oligonucleotide addition. A preferred linker or support (preferably non-hydrolyzable) for attachment of the oligonucleotide to the support at each array position is attached to the solid support. An array of oligonucleotides on a solid support is formed by a series of cycles of activation of selected array positions for the addition of multimeric nucleotides and addition of multimeric nucleotides at the active array positions.
本発明のさらに別の局面は、支持体上のオリゴヌクレオチドのアレイそのものに関する。支持体は、オリゴヌクレオチドの付加に各々好適である部位のアレイを有する。オリゴヌクレオチドの支持体への結合に好ましいリンカー、もしくは支持体(好ましくは非加水分解性)は、アレイの各々の位置において支持体に結合している。オリゴヌクレオチドのアレイは、支持体上の16ヌクレオチド以上を有するオリゴヌクレオチドで占められる少なくとも一部のアレイの位置に配置される。 Yet another aspect of the invention relates to the oligonucleotide array itself on the support. The support has an array of sites that are each suitable for the addition of oligonucleotides. A preferred linker or support (preferably non-hydrolyzable) for binding the oligonucleotide to the support is attached to the support at each position of the array. The array of oligonucleotides is disposed at least in some array positions occupied by oligonucleotides having 16 nucleotides or more on the support.
アレイ形成法においては、異なる多量体オリゴヌクレオチドセットに由来する多量体オリゴヌクレオチドは、支持体上の異なるアレイ位置で結合する。その結果、支持体は異なる位置に結合した多量体オリゴヌクレオチドの異なる基を有する位置のアレイを含む。 In array formation methods, multimeric oligonucleotides from different multimeric oligonucleotide sets bind at different array locations on the support. As a result, the support includes an array of positions having different groups of multimeric oligonucleotides attached to different positions.
異なる1,000のアドレスは、LDRオリゴヌクレオチドプローブの標的特異的配列(例えば、約20〜25mer)と共有結合で連結したユニークな捕獲オリゴヌクレオチド(例えば、24mer)であってもよい。捕獲オリゴヌクレオチドプローブの配列は、試料中に存在するゲノム上の標的配列もしくは他の配列のいずれかに対して如何なる相同性をも示さないものである。次に、このオリゴヌクレオチドプローブを、位置特定可能なアレイに特異的な部位、位置特定可能な支持体アレイ上の捕獲オリゴヌクレオチドに相補的な配列に捕獲させる。この概念を、可能な2つの形態で示し、例えば、p53R248変異(図17A〜図17C)の検出があげられる。 The 1,000 different addresses may be unique capture oligonucleotides (eg, 24 mer) covalently linked to the target specific sequence (eg, about 20-25mer) of the LDR oligonucleotide probe. The sequence of the capture oligonucleotide probe is one that does not show any homology to either the target sequence on the genome or other sequences present in the sample. The oligonucleotide probe is then captured in a site specific to the localizable array, a sequence complementary to the capture oligonucleotide on the localizable support array. This concept is shown in two possible forms, for example, detection of the p53R248 mutation (FIGS. 17A-17C).
図17A〜図17Cには、p53腫瘍抑制性遺伝子のコドン248における生殖系列変異の存在を同定するためのオリゴヌクレオチドプローブの設計に関するほかの2つの形態を示す。野性型配列はアルギニン(R248)をコードするが、癌の変異では、トリプトファン(R248W)をコードする。下部の図は捕獲オリゴヌクレオチドの模式図である。太い水平の線は位置特定可能なアレイを含むメンブレンもしくは表面を表す。細い曲線は、柔軟なリンカーアームを示す。さらに太い線は、CからN方向で固体表面に結合した捕獲オリゴヌクレオチド配列を示す。例示の目的において、部分Bにおけるリンカーアームが「引き延ばされた」ように捕獲オリゴヌクレオチドを垂直に描いている。アームは柔軟なため、塩基対相補性により捕獲オリゴヌクレオチドは各々において5'をCにおよび3'をNにハイブリダイズすることができる。オリゴヌクレオチドがN末端においてメンブレンに結合する場合、同一方向のオリゴヌクレオチドハイブリダイゼーションが可能となる。この場合、DNA/PNAハイブリダイゼーションは、通常5'から3'、および3'から5'への逆平行にある。他の修飾された糖リン酸骨格も同様に用いられる。図17Bは、3'末端における塩基CもしくはTの識別を含むことにより野生型および変異体p53を識別するように設計された2つのLDRプローブを示す。正しい標的DNAおよびTthリガーゼの存在においては、識別プローブは共有結合で下流の共通オリゴヌクレオチドに結合する。下流のオリゴヌクレオチドは、蛍光標識されている。識別オリゴヌクレオチドは、各々の5'末端における単一の位置特定可能なアレイに特異的な部位Z1およびZ2の存在によって識別される。黒いドットは、標的依存性の連結が起こっていることを示す。連結後に、オリゴヌクレオチドプローブを、アレイ上での単一アドレスにおける相補的な位置特定可能アレイに特異的な部位によって捕獲してもよい。連結したオリゴヌクレオチドプローブおよび未反応のオリゴヌクレオチドプローブのいずれもが、オリゴヌクレオチドアレイによって捕獲される。未反応の蛍光標識した共通プライマーおよび標的DNAを、高温(約65℃〜80℃)および低塩濃度で洗い流す。変異シグナルは、位置特定可能なアレイに特異的な部位Z1に相補的な捕獲オリゴヌクレオチドにおける蛍光シグナルの検出によって識別するが、野性型シグナルは、位置特定可能なアレイに特異的な部位Z2に相補的な捕獲オリゴヌクレオチドに出現する。ヘテロ接合性は、位置特定可能なアレイに特異的な部位Z1およびZ2に相補的な捕獲オリゴヌクレオチドにおける同程度のシグナルによって示されるのである。シグナルは蛍光撮影装置を用いて定量される。この形態では各々の対立遺伝子に関して単一アドレスを用い、低レベルのシグナル(30〜100アトモルのLDR産物)の非常に正確な検出の達成に好適である。図17Cは、識別シグナルが蛍光撮影装置を用いて定量できることを示す。この形態では、異なる蛍光基をF1およびF2を5'末端に有することによってオリゴヌクレオチドプローブを識別する単一アドレスを用いる。オリゴヌクレオチドプローブのいずれかが、3'末端に位置特定可能なアレイに特異的な部位Z1を含む共通の下流オリゴヌクレオチドプローブに連結することができる。この形態においては、野性型および変異体LDRの両方がアレイ上の同一のアドレスに捕獲され、異なる蛍光で識別される。この形態では、アレイのより好ましい利用が可能であり、数百もの潜在する生殖系列の突然変異を検出する場合には好適である。 FIGS. 17A-17C show two other forms for designing oligonucleotide probes to identify the presence of a germline mutation at
支持体は、広く多様な材料から作製することが可能である。基質は、生物学的、非生物学的、有機、無機、もしくはこれらのいずれの組み合わせでもよく、粒子、鎖、沈殿、ゲル、シート、管状材料、球状、容器、毛細管、パッド、スライス、フィルム、プレート、スライド、ディスク、メンブレン、その他として存在するものである。基質は、盤、四角形、円形、その他等の通常の形状を有する。基質は、好ましくは平坦なものであるが、様々な異なる表面配置をとってもよい。例えば、基質は合成の起こる隆起もしくは陥没した領域を有していてもよい。基質およびその表面は、好ましくはその上で本明細書に記載の反応を起こさせる固い支持体を形成する。また、基質およびその表面は、適当な光吸収特性を提供するように選択したものである。例えば、基質は、重合Langmuir Blodgettフィルム、機能化ガラス、Si、Ge、GaAs、GaP、SiO2、SiN4、修飾シリコン、または広く多様なゲルのいずれか、もしくは(ポリ)テトラフルオロエチレン、(ポリ)ビニリデンジフルオリド、ポリスチレン、ポリカーボネート、ポリエチレン、ポリプロピレン、塩化ポリビニル、ポリ(メチルアクリレート)、ポリ(メチルメタクリレート)、もしくはその組み合わせ等のポリマーでもよい。当業者であれば、他の基質材料についても、本開示の記載により容易に理解できる。好ましい態様においては、基質は平坦なガラスもしくは単一結晶シリコンである。 The support can be made from a wide variety of materials. The substrate may be biological, non-biological, organic, inorganic, or any combination thereof, particles, chains, precipitates, gels, sheets, tubular materials, spheres, containers, capillaries, pads, slices, films, It exists as a plate, slide, disk, membrane, etc. The substrate has a normal shape such as a board, a square, a circle, or the like. The substrate is preferably flat, but may take a variety of different surface configurations. For example, the substrate may have raised or depressed areas where synthesis occurs. The substrate and its surface preferably form a rigid support on which to carry out the reactions described herein. Also, the substrate and its surface are selected to provide suitable light absorption properties. For example, the substrate can be polymerized Langmuir Blodgett film, functionalized glass, Si, Ge, GaAs, GaP, SiO2, SiN4, modified silicon, or a wide variety of gels, or (poly) tetrafluoroethylene, (poly) vinylidene Polymers such as difluoride, polystyrene, polycarbonate, polyethylene, polypropylene, polyvinyl chloride, poly (methyl acrylate), poly (methyl methacrylate), or combinations thereof may be used. Those skilled in the art can easily understand other matrix materials from the description of the present disclosure. In a preferred embodiment, the substrate is flat glass or single crystal silicon.
幾つかの態様においては、所望の表面特性を与えるように、基質表面を既知の技術を用いてエッチングする。例えば、トレンチ、V字溝、丘段構造、切り上がりプラットフォーム等の方法で形成し、合成領域は蛍光源等からの集光を最大限にするための反射「鏡」構造で得られる照射光の焦点内により近接して配置する。 In some embodiments, the substrate surface is etched using known techniques to provide the desired surface properties. For example, trenches, V-grooves, hill structures, rounded platforms, etc. are used, and the synthesis region is a reflection “mirror” structure that maximizes the concentration of light from fluorescent sources. Place it closer to the focal point.
基質上の表面は、常にではないが通常は、基質と同一材料で構成する。従って、表面は、広汎な材料、例えば、ポリマー、プラスチック、セラミック、多糖、シリカもしくはシリカに基づく材料、炭素、金属、無機ガラス、メンブレン、もしくはそれらの組み合わせのいずれかで構成される。基質表面にしっかりと結合した結合部材で表面を官能基化する。好ましくは、表面の官能基は、シラノール、オレフィン、アミノ、ヒドロキシル、アルデヒド、ケト、ハロ、ハロゲン化アシルもしくはカルボキシル基等の反応基である。ある場合においては、このような官能基は予め基質に内在する。例えば、シリカに基づく材料はシラノール基を有し、多糖はヒドロキシル基を有し、また合成ポリマーは、それを生じるモノマーに依存して多様な官能基を含む。または、基質が所望の官能基を含まない場合には、このような基は、1段階もしくは複数の段階において基質に結合させることができる。 The surface on the substrate is usually but not always composed of the same material as the substrate. Thus, the surface is composed of any of a wide variety of materials such as polymers, plastics, ceramics, polysaccharides, silica or silica-based materials, carbon, metals, inorganic glasses, membranes, or combinations thereof. The surface is functionalized with a binding member firmly bonded to the substrate surface. Preferably, the functional group on the surface is a reactive group such as silanol, olefin, amino, hydroxyl, aldehyde, keto, halo, acyl halide or carboxyl group. In some cases, such functional groups are pre-existing in the substrate. For example, silica-based materials have silanol groups, polysaccharides have hydroxyl groups, and synthetic polymers contain a variety of functional groups depending on the monomer that produces them. Alternatively, if the substrate does not contain the desired functional group, such groups can be attached to the substrate in one or more steps.
好適に修飾されたガラス、プラスチック、または炭水化物による表面もしくは多様なメンブレンを含む多様な市販材料を用いることができる。材料に依存して、表面の官能基(例えば、シラノール、ヒドロキシル、カルボキシル、アミノ)は(おそらく、コーティング・ポリマーの一部として)最初から存在する、もしくは、官能基の導入のために別の方法(例えば、プラズマアニメーション、クロム酸酸化、官能基化側鎖のアルキルトリクロロシランによる処理を必要とする)。複数の方法でヒドロキシル基を安定なカルバミン酸(ウレタン)結合に組み込む。アミノ官能基は直接アセチル化することができるが、カルボキシル基は活性化(例えば、N,N'-カルボジイミダゾールもしくは水溶性カルボジイミド)し、アミノで官能基化した化合物と反応させる。図18に示すように、支持体は出発官能基Xを有するメンブレンもしくは表面であってもよい。官能基の変換は、基Y*との共有結合における1つのパートナーを表す基X*を提供する(必要に応じて)多様な方法で行うことができる。図18は、PEG(すなわち、ポリエチレングリコール)のグラフトを具体的に示すが、同一レパートリーの反応を、炭水化物(ヒドロキシルを有する)、リンカー(カルボキシルを有する)、および/もしくは好ましい官能基(アミノもしくはカルボキシル)によって伸長したオリゴヌクレオチドを付加させるために用いることができる(ただし、必要であれば)。ある場合においては、基X*もしくはY*は予め活性化される(別の反応で単離可能な種)。または、活性化はインサイチューで起こる。図18に記載のPEGを参照すると、YおよびY*は同一(同一二元官能基)でも異なって(異質二元官能基)いてもよい。後者の場合、Yはさらに化学的コントロールを行うために保護することができる。未反応のアミノ基をアセチル化、スクシニル化でブロックし、過剰のハイブリダイズしていないDNAを「排除する」中性もしくは陰性に荷電した環境を保つ。負荷レベルは、標準的な分析法で調べることができる。Fieldsらの「固相ペプチド合成の原理および実施(Principles and Practice of Solid-Phase Peptide Synthesis)」(合成ペプチド:ユーザー指針(Svnthetic Peptides: A User's Guide)G.Grant、Editor、W.H.Freeman and Co.: New York.p.77-183(1992))、これは参照として本明細書に組み入れられる。A variety of commercially available materials can be used, including suitably modified glass, plastic, or carbohydrate surfaces or various membranes. Depending on the material, surface functional groups (eg silanol, hydroxyl, carboxyl, amino) are present from the outset (possibly as part of the coating polymer) or another method for the introduction of functional groups (For example, plasma animation, chromic acid oxidation, functionalized side chain treatment with alkyltrichlorosilane is required). The hydroxyl group is incorporated into a stable carbamic acid (urethane) linkage in several ways. The amino functional group can be directly acetylated, while the carboxyl group is activated (eg, N, N′-carbodiimidazole or water soluble carbodiimide) and reacted with an amino functionalized compound. As shown in FIG. 18, the support may be a membrane or surface having a starting functional group X. The transformation of the functional group can be done in a variety of ways (where appropriate) providing a group X * that represents one partner in a covalent bond with the group Y * . FIG. 18 illustrates the grafting of PEG (ie, polyethylene glycol), but the same repertoire of reactions can be carried out with carbohydrates (with hydroxyl), linkers (with carboxyl), and / or preferred functional groups (amino or carboxyl). ) Can be used to add the extended oligonucleotide (if necessary). In some cases, the group X * or Y * is preactivated (a species that can be isolated in another reaction). Alternatively, activation occurs in situ. Referring to the PEG described in FIG. 18, Y and Y * may be the same (identical binary functional group) or different (heterogeneous binary functional group). In the latter case, Y can be protected for further chemical control. Unreacted amino groups are blocked by acetylation and succinylation to maintain a neutral or negatively charged environment that “eliminates” excess unhybridized DNA. The load level can be examined by standard analytical methods. Fields et al. "Principles and Practice of Solid-Phase Peptide Synthesis" (Svnthetic Peptides: A User's Guide) G. Grant, Editor, WH Freeman and Co .: New York. P. 77-183 (1992)), which is incorporated herein by reference.
シリカに基づく支持体表面に官能基を付加する一つのアプローチとしては、所望の官能基(例えば、オレフィン、アミノ、ヒドロキシル、アルデヒド、ケト、ハロ、ハロゲン化アシルもしくはカルボキシル)を有する分子、もしくは所望の官能基を含む別の分子Bに結合することのできる分子Aのいずれかでシラン化することがあげられる。前者の場合、ガラスもしくはシリカに基づく支持体の、例えば、アミノ基による官能基化は、3-アミノプロピルトリエトキシシラン、3-アミノプロピルメチルジエトキシシラン、3-アミノプロピルジメチルエトキシシラン、3-アミノプロピルトリメトキシシラン、N-(2-アミノエチル)-3-アミノプロピルメチルジメトキシシラン、N-(2-アミノエチル-3-アミノプロピル)トリメトキシシラン、アミノフェニルトリメトキシシラン、4-アミノブチルジメチルメトキシシラン、4-アミノブチルトリエトキシシラン、アミノエチルアミノメチルフェネチルトリメトキシシラン、もしくはその混合物等のアミン化合物で実施する。後者の場合には、分子Aは、好ましくはビニル、アクリレート、メタクリレート、もしくはアリル等のオレフィン基を含むが、分子Bはオレフィン基および所望の官能基を含む。この場合、分子AおよびBは、互いに重合する。ある場合においては、その性質を修飾するために(例えば、生体適合性を付与するおよび機械的安定性を向上させるために)。シラン化した表面を修飾することが好ましい。これは、分子A、B、およびCを含むポリマーネットワークを得るために、分子Bとともにオレフィン分子Cを添加することによって達成できる。 One approach to adding functional groups to a silica-based support surface includes molecules with the desired functional group (eg, olefin, amino, hydroxyl, aldehyde, keto, halo, acyl halide or carboxyl), or the desired Examples include silanization with any molecule A that can bind to another molecule B containing a functional group. In the former case, the functionalization of the support based on glass or silica, for example with amino groups, is performed by 3-aminopropyltriethoxysilane, 3-aminopropylmethyldiethoxysilane, 3-aminopropyldimethylethoxysilane, 3-aminopropyltriethoxysilane, Aminopropyltrimethoxysilane, N- (2-aminoethyl) -3-aminopropylmethyldimethoxysilane, N- (2-aminoethyl-3-aminopropyl) trimethoxysilane, aminophenyltrimethoxysilane, 4-aminobutyl It is carried out with an amine compound such as dimethylmethoxysilane, 4-aminobutyltriethoxysilane, aminoethylaminomethylphenethyltrimethoxysilane, or a mixture thereof. In the latter case, molecule A preferably contains an olefin group such as vinyl, acrylate, methacrylate or allyl, while molecule B contains an olefin group and the desired functional group. In this case, molecules A and B polymerize with each other. In some cases, to modify its properties (eg, to impart biocompatibility and improve mechanical stability). It is preferred to modify the silanized surface. This can be achieved by adding an olefin molecule C along with molecule B to obtain a polymer network comprising molecules A, B, and C.
分子Aは、以下の化学式で定義される:

R2は(C=O)-O-R6で、官能置換基を有するもしくは有さない脂肪族基、官能置換基を有するもしくは有さない芳香族基、または官能置換基を有するもしくは有さない脂肪族/芳香族基の混合したものである。
R3はO-アルキル、アルキルもしくはハロゲン基である。
R4は、O-アルキル、アルキルもしくはハロゲン基である。
R5はO-アルキル、アルキルもしくはハロゲン基であり、また
R6は、官能置換基を有するもしくは有さない脂肪族基、官能置換基を有するもしくは有さない芳香族基、または官能置換基を有するもしくは有さない脂肪族/芳香族基の混合したものである。分子Aの例は、3-(トリメトキシシリル)プロピルメタクリレート、N-[3-(トリメトキシシリル)プロピル]-N'-(4-ビニルベンジル)エチレンジアミン、トリエトキシビニルシシラン、トリエチルビニルシシラン、ビニルトリクロロシシラン、ビニルトリメトキシシラン、およびビニルトリメチルシシランを含む。Molecule A is defined by the following chemical formula:
R 2 is (C═O) —OR 6 , an aliphatic group with or without a functional substituent, an aromatic group with or without a functional substituent, or a fat with or without a functional substituent A mixture of aromatic / aromatic groups.
R 3 is an O-alkyl, alkyl or halogen group.
R 4 is an O-alkyl, alkyl or halogen group.
R 5 is an O-alkyl, alkyl or halogen group, and
R 6 is an aliphatic group with or without a functional substituent, an aromatic group with or without a functional substituent, or a mixture of aliphatic / aromatic groups with or without a functional substituent. It is. Examples of molecule A are 3- (trimethoxysilyl) propyl methacrylate, N- [3- (trimethoxysilyl) propyl] -N '-(4-vinylbenzyl) ethylenediamine, triethoxyvinylsilane, triethylvinylsilane , Vinyltrichlorosilane, vinyltrimethoxysilane, and vinyltrimethylsilane.
分子Bは、上記の一つもしくは複数の官能基を含むモノマーである。分子Bは、以下の化学式で定義される:
R2は(C=O)、および
R3はOHもしくはClである;
または
(ii)R1はHもしくはCH3、およびR2は(C=O)-O-R4、官能置換基を有するもしくは有さない脂肪族基、官能置換基を有するもしくは有さない芳香族基、または官能置換基を有するもしくは有さない脂肪族/芳香族基の混合したものである。また、R3はOH、COOH、NH2、ハロゲン、SH、COCl、もしくは活性エステル等の官能基、およびR4は官能置換基を有するもしくは有さない脂肪族基、官能置換基を有するもしくは有さない芳香族基、または官能置換基を有するもしくは有さない脂肪族/芳香族基の混合したものである。分子Bの例は、アクリル酸、アクリルアミド、メタクリル酸、ビニル酢酸、4-ビニル安息香酸、イタコン酸、アリルアミン、アリルエチルアミン、4-アミノスチレン、2-アミノエチルメタクリレート、塩化アクリロイル、塩化メタクリロイル、クロロスチレン、ジクロロスチレン、4-ヒドロキシスチレン、ヒドロキシメチルスチレン、ビニルベンジルアルコール、アリルアルコール、2-ヒドロキシエチルメタクリラート、もしくはポリ(エチレングリコール)メタクリレートを含む。Molecule B is a monomer containing one or more functional groups as described above. Molecule B is defined by the following chemical formula:
R 2 is (C = O), and
R 3 is OH or Cl;
Or (ii) R 1 is H or CH 3 , and R 2 is (C═O) —OR 4 , an aliphatic group with or without a functional substituent, an aromatic group with or without a functional substituent Or a mixture of aliphatic / aromatic groups with or without functional substituents. R 3 has a functional group such as OH, COOH, NH 2 , halogen, SH, COCl, or an active ester, and
分子Cは、分子A、分子B、もしくは両方に重合可能な分子であり、選択的に上記の一つもしくは複数の官能基を含む。分子Cは、アクリル酸、メタクリル酸、ビニル酢酸、4-ビニル安息香酸、イタコン酸、アリルアミン、アリルエチルアミン、4-アミノスチレン、2-アミノエチルメタクリレート、塩化アクリロイル、塩化メタクリロイル、クロロスチレン、ジクロロスチレン、4-ヒドロキシスチレン、ヒドロキシメチルスチレン、ビニルベンジルアルコール、アリルアルコール、2-ヒドロキシエチルメタクリラート、ポリ(エチレングリコール)メタクリレート、アクリル酸メチル、メチルメタクリレート、エチルアクリレート、エチルメタクリレート、スチレン、1-ビニルイミダゾール、2-ビニルピリジン、4-ビニルピリジン、ジビニルベンゼン、エチレングリコールジメタクリルアクリレート、N,N'-メチレンジアクリルアミド、N,N'-フェニレンジアクリルアミド、3,5-ビス(アクリロイルアミド)安息香酸、ペンタエリスリトールトリアクリレート、トリメチロールプロパントリメタクリレート、ペンタエリスリトールテトラアクリレート、トリメチロールプロパンエトキシレート(14/3EO/OH)トリアクリレート、トリメチロールプロパンエトキシレート(7/3EO/OH)トリアクリレート、トリエチロールプロパンプロポキシレート(1PO/OH)トリアクリレート、もしくはトリメチロールプロパンプロポキシレート(2PO/PHトリアクリレート)等のモノマーもしくはクロスリンカーであってもよい。 Molecule C is a molecule polymerizable to molecule A, molecule B, or both, and optionally includes one or more functional groups as described above. Molecule C includes acrylic acid, methacrylic acid, vinyl acetic acid, 4-vinylbenzoic acid, itaconic acid, allylamine, allylethylamine, 4-aminostyrene, 2-aminoethyl methacrylate, acryloyl chloride, methacryloyl chloride, chlorostyrene, dichlorostyrene, 4-hydroxystyrene, hydroxymethylstyrene, vinylbenzyl alcohol, allyl alcohol, 2-hydroxyethyl methacrylate, poly (ethylene glycol) methacrylate, methyl acrylate, methyl methacrylate, ethyl acrylate, ethyl methacrylate, styrene, 1-vinylimidazole, 2-vinylpyridine, 4-vinylpyridine, divinylbenzene, ethylene glycol dimethacrylate acrylate, N, N'-methylenediacrylamide, N, N'-phenylenediacrylamide, 3 , 5-Bis (acryloylamide) benzoic acid, pentaerythritol triacrylate, trimethylolpropane trimethacrylate, pentaerythritol tetraacrylate, trimethylolpropane ethoxylate (14 / 3EO / OH) triacrylate, trimethylolpropane ethoxylate (7 / 3EO / OH) triacrylate, triethylolpropane propoxylate (1PO / OH) triacrylate, or a monomer such as trimethylolpropane propoxylate (2PO / PH triacrylate) or a crosslinker may be used.
通常、官能基は最終的には支持体に結合するオリゴヌクレオチドのための出発点として働く。これらの官能基は、支持体に結合する有機基に反応性であるか、またはリンカーもしくはハンドルの利用によってこのような基に反応性となるように修飾することができる。官能基は、支持体にさまざまな所望の性質を付与することができる。 Usually, the functional group serves as a starting point for the oligonucleotide that ultimately binds to the support. These functional groups can be reactive to organic groups attached to the support or can be modified to be reactive to such groups through the use of linkers or handles. Functional groups can impart various desired properties to the support.
支持体を(必要に応じて)官能基化した後、相補的オリゴヌクレオチド捕獲プローブの担体部位として働く活性化された官能基を含むテーラーメイドのポリマーネットワークを支持体に植え込む。従って、このアプローチの利点としては、捕獲プローブの負荷容量を有意に増加させることができ、中間体としての固相対液相の物理的性質が制御しやすくなる。最適化を受けるパラメータは、官能基を含むモノマーの種類と濃度、および用いるクロスリンカーの種類と相対的濃度を含む。 After functionalization of the support (optional), a tailor-made polymer network containing activated functional groups that serve as carrier sites for complementary oligonucleotide capture probes is implanted into the support. Thus, the advantage of this approach is that the loading capacity of the capture probe can be significantly increased and the physical properties of the solid phase versus the liquid phase as an intermediate can be easily controlled. Parameters subject to optimization include the type and concentration of monomers containing functional groups, and the type and relative concentration of crosslinkers used.
リンカー分子は本発明に必要な要素ではないものと理解されるが、官能基化した基質表面は、好ましくはリンカー分子層とともに提供される。作製した基質においてポリマーが基質に暴露された分子と自由に相互作用できるように、リンカー分子は、好ましくは充分な長さのものである。充分に暴露されるように、リンカー分子は、6〜50原子の長さであることが必要である。リンカー分子、例えば、アリールアセチレン、2〜10モノマーユニットを含むエチレングリコールオリゴマー、ジアミン類、2価酸、アミノ酸類、もしくはその組み合わせである。 Although it is understood that a linker molecule is not a necessary element of the present invention, a functionalized substrate surface is preferably provided with a linker molecule layer. The linker molecule is preferably of sufficient length so that in the prepared substrate the polymer can freely interact with the molecule exposed to the substrate. The linker molecule needs to be 6-50 atoms long so that it is fully exposed. Linker molecules such as aryl acetylene, ethylene glycol oligomers containing 2 to 10 monomer units, diamines, divalent acids, amino acids, or combinations thereof.
別の態様においては、リンカー分子をその親水性/疎水性の性質に基づいて選択し、特定の受容体に対する合成ポリマーの提示について改善する。例えば、親水性受容体の場合には、親水性リンカー分子は、受容体が合成ポリマーにより近接して近づくことが可能であることが好ましい。 In another embodiment, linker molecules are selected based on their hydrophilic / hydrophobic nature to improve the presentation of synthetic polymers to specific receptors. For example, in the case of a hydrophilic receptor, the hydrophilic linker molecule is preferably such that the receptor can be closer to the synthetic polymer.
もう一つの別の態様においては、リンカー分子は中間位置に光開裂性の基を有するものとして提供される。光開裂性の基は、保護基とは異なる波長で開裂することが好ましい。これにより、異なる光波長に暴露する方法で合成完了後に、さまざまなポリマーの除去を可能にする。 In another alternative embodiment, the linker molecule is provided as having a photocleavable group at an intermediate position. The photocleavable group is preferably cleaved at a wavelength different from that of the protecting group. This allows for the removal of various polymers after synthesis is completed by exposure to different light wavelengths.
リンカー分子は、炭素と炭素の間の結合で、例えば、(ポリ)トリフルオロクロロエチレン表面を用いて、もしくは、好ましくは、シロキサン結合(例えば、ガラスもしくは酸化シリコン表面を用いて)で基質に結合できる。基質表面とのシロキサン結合は、一態様においては、トリクロロシリル基を有するリンカー分子の反応によって形成する。リンカー分子は、選択的に整列アレイ(すなわち、重合化単層にその頭部が平らに並んだものとして)に結合していてもよい。別の態様においては、リンカー分子は基質表面に吸着している。 The linker molecule is bonded to the substrate with a bond between carbons, for example using a (poly) trifluorochloroethylene surface, or preferably with a siloxane bond (for example using a glass or silicon oxide surface). it can. In one embodiment, the siloxane bond with the substrate surface is formed by the reaction of a linker molecule having a trichlorosilyl group. The linker molecule may be selectively attached to an aligned array (ie, as if its heads are flat in a polymerized monolayer). In another embodiment, the linker molecule is adsorbed on the substrate surface.
多量体を用いてアレイを組み立てる例として、そのような組み立てが四量体を用いて達成されることが可能である。4つの塩基が四量体として配置されることが可能である256(44)の可能な方法のうち、固有の配列を有する36個を選択することができる。選択された四量体のおのおのは他の全てのものと少なくとも2塩基異なり、どの2つの二量体も互いに相補的ではない。さらにアドレスの自己対合またはヘアピン形成につながると考えられる四量体は除去された。As an example of assembling an array using multimers, such assembly can be accomplished using tetramers. Of the 256 (4 4 ) possible methods in which 4 bases can be arranged as a tetramer, 36 with a unique sequence can be selected. Each selected tetramer differs from all others by at least 2 bases, and no two dimers are complementary to each other. Furthermore, tetramers thought to lead to address self-pairing or hairpin formation were removed.
最終的な四量体は表1に列記されており、1から36に任意に番号付けされている。この固有の四量体セットは、時に所望の24mer捕捉オリゴヌクレオチドアドレス配列の設計モジュールとして使用される。その構造は段階的に(一度に1塩基)または収束的(四量体構築ブロック)合成戦略により組み立てられることが可能と考えられる。上記の規則に従う多くの他の四量体セットが設計されてもよい。区分化法は四量体のみに制限されたものではなく、他のユニット、すなわち二量体、三量体、五量体または六量体も使用できると考えられる。 The final tetramers are listed in Table 1 and are arbitrarily numbered from 1 to 36. This unique tetramer set is sometimes used as a design module for the desired 24mer capture oligonucleotide address sequence. It is believed that the structure can be assembled by stepwise (one base at a time) or convergent (tetramer building block) synthesis strategy. Many other tetramer sets that follow the above rules may be designed. It is believed that the segmentation method is not limited to tetramers only, but other units can be used, ie dimers, trimers, pentamers or hexamers.
[表1] 互いに少なくとも2塩基異なる四量体PNA配列および相補的DNA配列のリスト
四量体の番号付けスキームでは、各々のアドレスが6つの数字で略称されることに留意されたい(例えば、下記の表2第2列)。36の四量体単一セットで設計された24merアドレスの概念(表1)から、可能な構造は膨大な数となる(366=2,176,782,336)。Note that in the tetramer numbering scheme, each address is abbreviated with six numbers (eg, Table 2, second column below). From the concept of 24mer addresses (Table 1) designed with a single set of 36 tetramers, the number of possible structures is vast (36 6 = 2,176,782,336).
図19には、少なくとも2塩基互いに異なる36の四量体で多数の可能な設計のうちの1つを示す。チェッカーボード・パターンは、256の可能な全四量体を示す。四角形は、チェッカーボードにおける左の最初の2塩基とそれに続く上部の2塩基を表す。各々の四量体は少なくとも互いに2塩基異なる必要があり、非相補的である必要がある。四量体を白いボックスで示し、その相補鎖を(番号)としてリストに載せた。従って、このスキームにおいて、相補的配列GACC(20)およびGGTC(20')はお互いに排除的である。さらに、四量体は、非回文構造的でなくてはならない、例えば、TCGA(黒い対角線のボックス)、および非繰り返しでなくてはならない、例えば、CACA(黒い対角線のボックス、上部の左から下部右)。36の四量体とは、僅か1塩基しか異ならないその他の配列はいずれも、明るい灰色で斜線付けされている。4つの潜在的四量体(白いボックス)は、すべてがA*TもしくはすべてがG*Cである塩基のいずれかであるために選択されなかった。しかしながら、下記に示されるように、A*T塩基のTm値をほぼG*C塩基のレベルに上げることは可能である。従って、すべてがA*TもしくはすべてがG*C塩基である四量体(白ボックス中のものを含む)は、潜在的に四量体設計用いることができる。さらに、捕獲オリゴヌクレオチドアドレスの配列内で、およびオリゴヌクレオチドプローブの位置特定可能なアレイに特異的な部位であれば、チミンは5-プロピニルウリジンで置換できる。これにより、A*T塩基対のTmは約1.7℃増加する。従って、個々の四量体のTm値は、約15.1℃から15.7℃となるはずである。完全長24merのTm値は95℃以上となるはずである。 FIG. 19 shows one of many possible designs with 36 tetramers differing from each other by at least 2 bases. The checkerboard pattern shows 256 possible total tetramers. The square represents the first two bases on the left on the checkerboard followed by the upper two bases. Each tetramer must be at least two bases different from each other and non-complementary. The tetramer is indicated by a white box and its complementary strand is listed as (number). Thus, in this scheme, the complementary sequences GACC (20) and GGTC (20 ′) are mutually exclusive. Furthermore, the tetramer must be non-palindromic, eg TCGA (black diagonal box), and non-repeating, eg CACA (black diagonal box, from top left) Bottom right). All other sequences that differ from the 36 tetramer by only one base are shaded in light gray. Four potential tetramers (white boxes) were not selected because they are either either A * T or all G * C bases. However, as shown below, it is possible to raise the Tm value of A * T base to approximately the level of G * C base. Thus, tetramers (including those in white boxes) that are all A * T or all G * C bases can potentially be used for tetramer design. In addition, thymine can be replaced with 5-propynyluridine provided it is a site specific to the sequence of the capture oligonucleotide address and to the positionable array of oligonucleotide probes. This increases the Tm of A * T base pairs by about 1.7 ° C. Thus, the Tm value for individual tetramers should be about 15.1 ° C to 15.7 ° C. The full length 24mer Tm value should be above 95 ° C.
この概念を例示する目的で、36の四量体配列のうちで6つからなるサブセットを用いて、アレイ:1=TGCG;2=ATCG;3=CAGC;4=GGTA;5=GACC;および6=ACCTを構築した。所望の24merの位置特定可能なアレイに特異的な部位および24merの相補的捕獲オリゴヌクレオチドのアドレス配列設計モジュールとして、この単一の四量体セットを用いることができる。この態様は、5つの位置特定可能なアレイに特異的な部位(表2のリストに載せた配列)の合成を含む。四量体の番号付けスキームで、各々の部位の略称(「Zip#」と称する)が6つの数字で示されている(「Zipコード」と称する)ことに留意されたい。 For the purpose of illustrating this concept, a subset of 6 of 36 tetramer sequences was used and the arrays: 1 = TGCG; 2 = ATCG; 3 = CAGC; 4 = GGTA; 5 = GACC; and 6 = Constructed ACCT. This single tetramer set can be used as an address sequence design module for the site specific to the desired 24mer positionable array and the 24mer complementary capture oligonucleotide. This embodiment involves the synthesis of five site-specific arrays specific sites (sequences listed in Table 2). Note that in the tetramer numbering scheme, each site abbreviation (referred to as “Zip #”) is indicated by six numbers (referred to as “Zip code”).
[表2] 5つのDNA/PNAオリゴヌクレオチドアドレス配列全ての一覧
これらのオリゴマーは各々、5'末端に酸化ヘキサエチレン・リンカーアーム(P.Grossmanら、Nucleic Acids Res.、22:4527-4534(1994)は参照として本明細書に組み入れられる)、およびスライドグラス表面への結合に好適である最終的なアミノ官能基、もしくは別の物質を含む。結合方法は、フリーの表面官能基に依存する(Y.Zhangら、Nucleic Acids Res.、19:3929-3933(1991)およびZ.Guoら、Nucleic Acids Res.、34:5456-5465(1994)は参照として本明細書に組み入れられる)。 Each of these oligomers has a hexaethylene oxide linker arm at the 5 ′ end (P. Grossman et al., Nucleic Acids Res., 22: 4527-4534 (1994) is incorporated herein by reference), and a glass slide surface Contains the final amino functional group, which is suitable for attachment to, or another substance. The attachment method depends on free surface functional groups (Y. Zhang et al., Nucleic Acids Res., 19: 3929-3933 (1991) and Z. Guo et al., Nucleic Acids Res., 34: 5456-5465 (1994). Are incorporated herein by reference).
合成オリゴヌクレオチド(正常および相補的方向、捕獲ハイブリダイゼーションもしくはハイブリダイゼーション/連結のいずれか)は、天然の塩基もしくはヌクレオチド類似体のいずれかを有するDNAもしくはPNAのいずれかとして調製する。このような類似体は完全な相補性で天然の塩基と対をなすが、Tm値は増加する(例えば、5-プロピニルウラシル)。 Synthetic oligonucleotides (either normal and complementary orientation, either capture hybridization or hybridization / ligation) are prepared as either DNA or PNA with either natural bases or nucleotide analogs. Such analogs are perfectly complementary and pair with natural bases, but the Tm value is increased (eg, 5-propynyluracil).
本発明にしたがって、DNA合成エラーから生じる偽ハイブリダイゼーションシグナルは避けられる。アドレスは、正しくないアドレスに対してはハイブリダイゼーションTm値に非常に大きな差異があるように設計することができる。対照的に、直接ハイブリダイゼーション法は微細な差異に依存する。本発明はまた、DNA合成エラー、バンド拡張、または偽バンド移動のいずれかに起因するゲル電気泳動またはキャピラリー電気泳動を用いた誤ったデータ解釈の問題も除去する。 In accordance with the present invention, false hybridization signals resulting from DNA synthesis errors are avoided. Addresses can be designed such that there is a very large difference in hybridization Tm values for incorrect addresses. In contrast, direct hybridization methods rely on small differences. The present invention also eliminates the problem of erroneous data interpretation using gel electrophoresis or capillary electrophoresis due to either DNA synthesis errors, band expansion, or pseudo-band migration.
連結産物の存在を検出するための捕捉オリゴヌクレオチドの使用は、差異的ハイブリダイゼーションを用いてオリゴヌクレオチドの一塩基差異を検出する必要性を除去する。対立遺伝子特異的PCR、差異的ハイブリダイゼーションまたはハイブリダイゼーションによる配列決定法に依存する先行技術の他の既存の方法は、解析される新規配列の各々に対して個別にハイブリダイゼーション条件を最適化しなければならない。多数の変異を同時に検出することを試みるとき、ハイブリダイゼーション条件を最適化することは困難または不可能になる。対照的に、本発明は、標的配列に依存せず、均一のハイブリダイゼーション条件下で、正しいシグナルを高精度に検出する一般的方法である。本発明は、先行技術内で現在利用可能な任意の方法によるよりも、有意に高い精度で異なるオリゴヌクレオチド配列間を識別する柔軟な方法を生み出す。 The use of capture oligonucleotides to detect the presence of ligation products eliminates the need to detect single base differences in oligonucleotides using differential hybridization. Other existing methods of the prior art that rely on allele-specific PCR, differential hybridization or sequencing by hybridization must optimize the hybridization conditions individually for each new sequence to be analyzed. Don't be. When attempting to detect multiple mutations simultaneously, it becomes difficult or impossible to optimize hybridization conditions. In contrast, the present invention is a general method that accurately detects the correct signal under uniform hybridization conditions, independent of the target sequence. The present invention creates a flexible method of discriminating between different oligonucleotide sequences with significantly higher accuracy than by any method currently available within the prior art.
本発明のアレイは普遍的であり、癌変異、遺伝性(生殖細胞系列)変異、および伝染病の検出に有用である。さらなる恩典はアレイを再利用できることから得られ、試料あたりの費用を低下させる。 The arrays of the present invention are universal and useful for detecting cancer mutations, hereditary (germline) mutations, and infectious diseases. Further benefits come from the ability to reuse the array, reducing the cost per sample.
本発明はまたオリゴヌクレオチドの合成および支持体へのその固着において大きな柔軟性もまた提供する。オリゴヌクレオチドは支持体から離れて合成され、それから支持体上の固有の表面に付着されることができる。中間介在物のバックボーン保護(たとえばPNA)を必要としない、オリゴヌクレオチド多量体の分節を合成し、固体支持体上に連結することができる。これらの合成法を捕捉オリゴヌクレオチドアドレスの設計と統合することが可能であることにより、更なる利点が達成される。固体支持体のそのような作製は自動化作製になじみやすく、ヒトの介入の必要性およびその結果としての汚染の懸念を未然に防ぐ。 The present invention also provides great flexibility in the synthesis of the oligonucleotide and its anchoring to the support. Oligonucleotides can be synthesized away from the support and then attached to a unique surface on the support. Oligonucleotide multimeric segments that do not require backbone protection of intermediate inclusions (eg, PNA) can be synthesized and linked onto a solid support. Further advantages are achieved by being able to integrate these synthetic methods with the design of capture oligonucleotide addresses. Such fabrication of solid supports is amenable to automated fabrication and obviates the need for human intervention and the resulting contamination concerns.
本発明のアレイの重要な利点は、以前に固着された捕捉オリゴヌクレオチドとともにアレイが再利用可能であることである。そのような再利用のための固体支持体を調整するために、捕捉されたオリゴヌクレオチドを固体支持体に連結している連結成分を除去することなく、捕捉されたオリゴヌクレオチドは除去されなければならない。この目的を達成するためには多様な手段が利用可能である。例えば、固体支持体を95℃〜100℃の蒸留水中で処理する、室温で0.01N水酸化ナトリウムに供する、90℃〜95℃で50%ジメチルホルムアミドに接触する、または90℃〜95℃で50%ホルムアミドで処理することが可能である。一般的には、この手段は捕捉されたオリゴヌクレオチドを約5分で除去するために使用することができる。これらの条件はDNA-DNAハイブリダイゼーションを破壊するのに適している。DNA-PNAハイブリダイゼーションは他の破壊条件を必要とする。 An important advantage of the arrays of the present invention is that the arrays can be reused with previously attached capture oligonucleotides. In order to prepare a solid support for such reuse, the captured oligonucleotide must be removed without removing the linking component that links the captured oligonucleotide to the solid support. . Various means are available to achieve this goal. For example, the solid support is treated in distilled water at 95 ° C to 100 ° C, subjected to 0.01 N sodium hydroxide at room temperature, contacted with 50% dimethylformamide at 90 ° C to 95 ° C, or 50 at 90 ° C to 95 ° C. It can be treated with% formamide. In general, this means can be used to remove captured oligonucleotides in about 5 minutes. These conditions are suitable for disrupting DNA-DNA hybridization. DNA-PNA hybridization requires other disruption conditions.
本発明は、これに制限されないが、以下の実施例により説明される。 The present invention is illustrated by the following examples without being limited thereto.
実施例
実施例1 物質および方法
オリゴヌクレオチド合成および精製
オリゴヌクレオチドはIDT社(コラルビル(Coralville)、アイオワ州)のカスタム合成産物として獲得され、または標準的なホスホアミダイト化学を用いてABI394DNA合成機(PEバイオシステムズ社、フォスターシティ、カリフォルニア州)上で組織内で合成された。スペーサーホスホアミダイト18、3'-アミノ-修飾基C3 CPGおよび3'-フルオレセインCPGはグレンリサーチ(Glen Research)(スターリング(Sterling)、バージニア州)から購入した。その他全ての試薬はPEバイオシステムズから購入した。標識および非標識オリゴヌクレオチドの両者は12%変性ポリアクリルアミドゲル電気泳動により精製された。バンドはUV付影処理により可視化され、ゲルから切り出され、0.5M NaCl、5mM EDTA、pH8.0中で37℃にて一晩溶出された。オリゴヌクレオチド溶液はC18 Sep-Paks(ウォーターズコーポレーション(Waters Corporation)、ミルフォード、マサチューセッツ州)上でメーカーの指示書に従い精製され、続いてオリゴヌクレオチドが乾燥するまで濃縮され(スピードバック(Speed-Vac))および-20℃で保存された。EXAMPLES Example 1 Materials and Methods Oligonucleotide Synthesis and Purification Oligonucleotides were obtained as custom synthesis products from IDT (Coralville, Iowa) or using standard phosphoramidite chemistry (PE) Synthesized in-house on Biosystems, Foster City, Calif.).
顕微鏡スライドの洗浄
ガラス顕微鏡スライド(VWR、前清浄化、3in.×1in.×1.2mm)を沸騰した濃NH4OH-30%H2O2-H2O(1:1:5、v/v/v)中で10分間インキュベーションし、蒸留水で洗浄した。2回目のインキュベーションは沸騰した濃HCl-30%H2O2-H2O中で10分間実施された。参照として本明細書に組み入れられる、U.Jonssonら、「良く特性化されたシリカ表面におけるフィブロネクチンの吸収挙動(Absorption Behavior of Fibronectin on Well Characterized Silica Surfaces)」、J.Colloid Interface Sci.90:148〜163(1982)を参照されたい。スライドは蒸留水、メタノールおよびアセトンで完全に洗浄され、室温で風乾された。Microscope slide cleaning Concentrated NH 4 OH-30% H 2 O 2 -H 2 O (1: 1: 5, v / v) glass microscope slide (VWR, precleaned, 3 in. × 1 in. × 1.2 mm) Incubated in v / v) for 10 minutes and washed with distilled water. The second incubation was performed in boiling concentrated HCl-30% H 2 O 2 —H 2 O for 10 minutes. U. Jonsson et al., “Absorption Behavior of Fibronectin on Well Characterized Silica Surfaces”, J. Colloid Interface Sci. 90: 148—incorporated herein by reference. 163 (1982). Slides were thoroughly washed with distilled water, methanol and acetone and air dried at room temperature.
ポリマー被膜スライド
清浄に続いてすぐに、スライド(フィッシャーサイエンスティフィック(Fisher Scientific)、前洗浄化、3in.×1in.×1.2mm)は、CHCl3中2%メタクリルオキシプロピルトリメトキシシラン、0.2%トリエチルアミン中に25℃30分間浸され、その後CHCl3で洗浄された(15分を2回)。単量体溶液(20μL:8%アクリルアミド、2%アクリル酸、0.02%N,N'-メチレン-ビスアクリルアミド(単量体:架橋剤比は500:1の比)、0.8%過硫酸アンモニウムラジカル重合開始剤)をスライドの一端に付着させ、事前にシラン化処理(CHCl3中5%(CH3)2SiCl2)されたカバースリップ(24×50mm)を用いて広げた。重合はスライドを70℃ホットプレート上で4.5分間加熱することにより達成された。ホットプレートからスライドを取り除いて、カバースリップを直ちに単一切れ刃のかみそり刃を用いて引き剥がした。被膜化されたスライドを脱イオン水で洗浄し、開放空気中で乾燥させ、周囲条件下で保存した。Polymer-coated slides Immediately following cleaning, slides (Fisher Scientific, pre-cleaned, 3 in.
Zipコード(Zip-Code)アレイの調製
重合体被膜化スライドはそれらを、0.1M K2HPO4/KH2PO4、pH6.0中において0.1Mである1-[3-(ジメチルアミノ)プロピル]-3-エチルカルボジイミド塩酸塩に20mM N-ヒドロキシスクシンイミドを添加した溶液に25℃30分間浸すことにより事前に活性化された。活性化されたスライドを水で洗浄し、その後65℃オーブンで乾燥させた。それらはドライアライト(Drierite)を入れたデシケーター内で25℃にて6ヶ月またはそれより長く保存において安定であった。Preparation of Zip-Code Arrays Polymer-coated slides are 1- [3- (dimethylamino) propyl] which is 0.1M in 0.1MK 2 HPO 4 / KH 2 PO 4 , pH 6.0 It was activated in advance by immersing it in a solution of -3-ethylcarbodiimide hydrochloride with 20 mM N-hydroxysuccinimide added at 25 ° C. for 30 minutes. The activated slide was washed with water and then dried in a 65 ° C. oven. They were stable on storage for 6 months or longer at 25 ° C. in a desiccator with Drierite.
アレイはカルテシアンテクノロジーピクシス(Cartesian Technologies Pixsys)5500ロボットにて、0.2M K2HPO4/KH2PO4、pH8.3中500μMのZipコードオリゴヌクレオチド溶液を用いて、25℃および70%相対湿度下でスポットされた。各アドレスは4重にスポットされた。加えて、Cy3、Cy5およびフルオレセイン基準が各アレイの右手上下に沿って印刷された。スポッテイングに続いて、未結合オリゴヌクレオチドが、スライドを300mMビシン、pH8.0、300mM NaCl、0.1%SDS中に65℃30分間浸すこと、水で洗浄すること、および乾燥することにより、重合体表面から除去された。アレイは必要となるまでスライド箱中で25℃で保存された。Array is
K-ras DNA試料のPCR増幅
PCR増幅は、10mMトリスHCl、pH8.3、4mM MgCl2、50mM KCl、800μM dNTPs、1μMのフォワードおよびリバースプライマー(各プライマー50pmol、K-rasEx1フォワードおよびK-rasEx1リバース(表3))、1Uのアンプリタックゴールド(Ampli Taq Gold)およびパラファイン包埋腫瘍または細胞株から抽出された100ngのゲノムDNAを含む50μL反応混合液中でパラフィンオイル下で実施された。反応液は95℃10分間、前インキュベーションされた。増幅は40ラウンドの94℃30秒間、60℃1分間、および72℃1分間の温度サイクル、続く72℃5分間の最終伸長により達成された。PCR後、1μLのプロテイナーゼK(18mg/mL)を添加し、反応液を70℃で10分間加熱し、その後95℃で15分間反応を停止させた。予測された大きさの増幅産物の存在を確認するために各PCR産物2μLを3%アガロースゲル上で解析した。PCR amplification of K-ras DNA samples
PCR amplification consisted of 10 mM Tris HCl, pH 8.3, 4 mM MgCl 2 , 50 mM KCl, 800 μM dNTPs, 1 μM forward and reverse primers (each
K-ras DNA試料のLDR
LDRは、20mMトリスHCl、pH8.5、5mM MgCl2、100mM KCl、10mM DTT、1mM NAD+、10pmol総LDRプローブ(500fmolの各蛍光標識識別プローブ(Cy3、Cy5および蛍光標識のK-rasc32Wt、Cy3標識K-rasc12.2D、Cy5標識K-rasc12.2A、蛍光標識K-rasc12.2V、Cy3標識K-rasc12.1S、Cy5標識K-rasc12.1R、蛍光標識K-rasc12.1C、Cy3標識K-rasc13.4D)に、合計5pmolの共通プローブ(各1500fmolのK-rascd32Com9cZip1、K-rascd12Com2cZip2、およびK-rascd12Com1cZip3、および500fmolのK-rascd13Com4cZip4(表3))、細胞株または腫瘍試料由来の2μLのPCR産物を含む20μL容量中でパラフィンオイル下で実施された。反応混合液は94℃2分間事前加熱され、その後25fmolの野生型TthDNAリガーゼが添加された。LDR反応混合液は94℃30秒および65℃4分で20ラウンドサイクルされた。LDR of K-ras DNA sample
LDR consists of 20 mM Tris HCl, pH 8.5, 5 mM MgCl 2 , 100 mM KCl, 10 mM DTT, 1 mM NAD + , 10 pmol total LDR probe (500 fmol of each fluorescence labeled identification probe (Cy3, Cy5 and fluorescently labeled K-rasc32Wt, Cy3 Labeled K-rasc12.2D, Cy5 labeled K-rasc12.2A, fluorescent labeled K-rasc12.2V, Cy3 labeled K-rasc12.1S, Cy5 labeled K-rasc12.1R, fluorescent labeled K-rasc12.1C, Cy3 labeled K -rasc13.4D) with a total of 5 pmol of common probe (each 1500 fmol of K-rascd32Com9cZip1, K-rascd12Com2cZip2, and K-rascd12Com1cZip3, and 500 fmol of K-rascd13Com4cZip4 (Table 3)), 2 μL from cell lines or tumor samples The reaction mixture was run under paraffin oil in a 20 μL volume containing the PCR product, the reaction mixture was pre-heated at 94 ° C. for 2 minutes, and then 25 fmol of wild-type TthDNA ligase was added. 20 round cycles at 65 ° C for 4 minutes.
K-ras LDR産物のDNAアレイへのハイブリダイゼーション
LDR反応混合液は最終緩衝液濃度300mM MES、pH6.0、10mM MgCl2、0.1%SDSになるように20μLの2×ハイブリダイゼーション緩衝液を用いて希釈され、94℃で3分間変性され、氷上で冷却された。アレイは1×ハイブリダイゼーション緩衝液中で25℃15分間事前インキュベーションされた。カバーウェル(グレイス(Grace)社、サンリバー、オレゴン州)をアレイに付着させ、30μLの希釈LDR反応混合液で満たした。アレイは加湿された培養チューブ中に設置され、65℃で1時間、20rpmで、回転式ハイブリダイゼーション用オーブン中でインキュベーションされた。ハイブリダイゼーションに続いて、アレイは300mMビシン、pH8.0、10mM MgCl2、0.1%SDS中に25℃10分間洗浄された。蛍光シグナルはスキャンアレイ(Scanarray)5000(GSIルモニクス(Lumonics))を用いて測定された。Hybridization of K-ras LDR product to DNA array
The LDR reaction mixture is diluted with 20 μL of 2X hybridization buffer to a final buffer concentration of 300 mM MES, pH 6.0, 10 mM MgCl 2 , 0.1% SDS, denatured at 94 ° C. for 3 minutes, and on ice Cooled by. The array was preincubated for 15 minutes at 25 ° C. in 1 × hybridization buffer. Coverwell (Grace, Sun River, Oreg.) Was attached to the array and filled with 30 μL of diluted LDR reaction mixture. The array was placed in a humidified culture tube and incubated in a rotary hybridization oven at 65 rpm for 1 hour at 20 rpm. Following hybridization, the arrays were washed in 300 mM bicine, pH 8.0, 10 mM MgCl 2 , 0.1% SDS for 10 minutes at 25 ° C. The fluorescence signal was measured using a Scanarray 5000 (GSI Lumonics).
位置特定可能なユニバーサルマイクロアレイ上の7種の特定のK-ras変異のLDR検出は図36中に示されている。各アレイの右側の上部に沿った3つのシグナルおよび下部のそれらは位置決めに使用される基準である。第2列に渡る続く4つのアドレスは、各々cZip1、cZip2、cZip3、およびcZip4に相補的であるアドレス#1、#2、#3および#4に相当する。8種の、細胞株(すなわちCOL0205、LS180、SW1116、SW480およびDLD1)および腫瘍試料(G12S、G12RおよびG12C)は存在する変異が正確に同定された。野生型細胞株COL0205はCy3、Cy5およびフルオレセインシグナルをアドレス#1に与える。アドレス#1の野生型シグナルは全試験の対照として使用された。Asp12変異を含むLS180細胞株はアドレス#2にCy3シグナルを与えた。Ala12変異を含むSW1116細胞株はアドレス#2にCy5シグナルを与えた。Val12変異を含むSW480細胞株はアドレス#2にフルオレセインシグナルを与えた。Ser12変異を含むG12S腫瘍試料はアドレス#3にCy3シグナルを与えた。Arg12変異を含むG12R腫瘍試料はアドレス#3にCy5シグナルを与えた。Cys12変異を含むG12C腫瘍試料はアドレス#3にフルオレセインシグナルを与えた。Asp13変異を含むDLD1細胞株はアドレス#4にCy3シグナルを与えた。LS180およびSW1116試料のZip4に見られる不正確なシグナルは試料の汚染によるものであった。 LDR detection of seven specific K-ras mutations on a localizable universal microarray is shown in FIG. The three signals along the top right side of each array and those at the bottom are the criteria used for positioning. The following four addresses across the second column correspond to
[表3] PCR/LDR/アレイハイブリダイゼーションによるK-ras変異検出用に設計されたプライマー
K-ras DNA試料のLDR
LDR反応は、20mMトリスHCl、pH8.5、5mM MgCl2、100mM KCl、10mM DTT、1mM NAD+、合計8pmolのLDRプローブ(500fmolの各識別プローブに4pmolの蛍光標識共通プローブを加えたもの)、細胞株または腫瘍試料由来の1pmolのPCR産物を含む20μL容量中でパラフィンオイル下で実施された。各々が7個の変異特異的プローブ、3つの共通プローブおよびコドン12に対する野生型識別プローブまたはコドン13に対するもののいずれかを各々含む、2つのプローブ混合物が調整された(表3)。LDR of K-ras DNA sample
The LDR reaction consists of 20 mM Tris HCl, pH 8.5, 5 mM MgCl 2 , 100 mM KCl, 10 mM DTT, 1 mM NAD + , a total of 8 pmol LDR probe (4 fmol fluorescence labeled common probe added to each identification probe of 500 fmol), It was performed under paraffin oil in a 20 μL volume containing 1 pmol of PCR product from a cell line or tumor sample. Two probe mixtures were prepared, each containing either seven mutation-specific probes, three common probes and either a wild type discrimination probe for
反応混合液は94℃2分間事前加熱され、その後25fmolの野生型TthDNAリガーゼが添加された。LDR反応は94℃15秒および65℃4分で20ラウンドサイクルされた。各反応液の2μLアリコートを2μLのゲルローディング緩衝液(8%ブルーデキストラン、50mM EDTA、pH8.0-ホルムアミド(1:5))と混合し、94℃で2分間変性させ、氷上で冷却した。各混合液の1μLを10%変性ポリアクリルアミドゲルにロードし、ABI377 DNAシークエンサー上で1500Vで電気泳動させた。 The reaction mixture was preheated at 94 ° C. for 2 minutes, after which 25 fmol of wild type TthDNA ligase was added. The LDR reaction was cycled 20 rounds at 94 ° C for 15 seconds and 65 ° C for 4 minutes. A 2 μL aliquot of each reaction was mixed with 2 μL of gel loading buffer (8% blue dextran, 50 mM EDTA, pH 8.0-formamide (1: 5)), denatured at 94 ° C. for 2 minutes, and cooled on ice. 1 μL of each mixture was loaded onto a 10% denaturing polyacrylamide gel and electrophoresed at 1500 V on an ABI377 DNA sequencer.
K-ras LDR産物のDNAアレイへのハイブリダイゼーション
LDR反応液(17μL)は最終緩衝液濃度300mM MES、pH6.0、10mM MgCl2、0.1%SDSになるように40μLの1.4×ハイブリダイゼーション緩衝液を用いて希釈された。アレイは1×ハイブリダイゼーション緩衝液中で25℃15分間事前インキュベーションされた。カバーウェル(グレイス社、サンリバー、オレゴン州)を30μLの希釈したLDR反応液で満たし、アレイに付着させた。アレイは加湿された培養チューブ中に設置され、65℃で1時間および回転式ハイブリダイゼーション用オーブン中で20rpmでインキュベーションされた。ハイブリダイゼーションに続いて、アレイは300mMビシン、pH8.0、10mM MgCl2、0.1%SDS中に25℃10分間洗浄された。蛍光シグナルは以下の段落で記載されているように、顕微鏡/CCDを用いて測定された。Hybridization of K-ras LDR product to DNA array
The LDR reaction solution (17 μL) was diluted with 40 μL of 1.4 × hybridization buffer to a final buffer concentration of 300 mM MES, pH 6.0, 10 mM MgCl 2 , 0.1% SDS. The array was preincubated for 15 minutes at 25 ° C. in 1 × hybridization buffer. Coverwell (Grace, Sun River, OR) was filled with 30 μL of diluted LDR reaction and allowed to attach to the array. The array was placed in a humidified culture tube and incubated at 65 ° C. for 1 hour and 20 rpm in a rotary hybridization oven. Following hybridization, the arrays were washed in 300 mM bicine, pH 8.0, 10 mM MgCl 2 , 0.1% SDS for 10 minutes at 25 ° C. The fluorescence signal was measured using a microscope / CCD as described in the following paragraphs.
画像化
アレイはモレキュラーダイナミクスフルオロイメージャー595(Molecular Dynamics FluorImager 595)(サニーベール(Sunnyvale)、カリフォルニア州)またはプリンストンインスツルメント(Princeton Instruments)TE/CCD-512 TKBM1カメラ(トレントン、ニュージャージー州)を備えたオリンパスAX70落射けい光顕微鏡(メルビル、ニューヨーク州)を用いて画像化された。フルオロイメージャー上の蛍光標識プローブの解析に関しては、488nm励起が530/30発光フィルターとともに使用された。スキャニングの空間的分解能はピクセルあたり100μmである。結果は、機器とともに提供されたImageQuaNTソフトウェアを用いて解析された。落射蛍光顕微鏡は100W水銀ランプ、FITCフィルターキューブ(励起480/40、二色性ビーム分離器505、発光535/50)、テキサスレッドフィルターキューブ(励起560/55、二色性ビーム分離器595、発光645/75)および100mmのマクロ対物レンズを装備している。マクロ対物レンズは直径15mmまでの対象視野の図解を可能にし、7×7mmのアレイ面積を12.3×12.3mmのCCDマトリックスに投影する。画像はカメラとともに提供されたWinview32ソフトウェアを用いて16ビットモードで収集された。解析はスキオン(Scion)画像(スキオン社、フレドリック、メリーランド州)を用いて実施された。Imaging Arrays include a Molecular Dynamics FluorImager 595 (Sunnyvale, CA) or Princeton Instruments TE / CCD-512 TKBM1 camera (Trenton, NJ) Imaged using an Olympus AX70 epifluorescence microscope (Melville, NY). For analysis of fluorescently labeled probes on the fluoroimager, 488 nm excitation was used with a 530/30 emission filter. The spatial resolution of scanning is 100 μm per pixel. Results were analyzed using ImageQuaNT software provided with the instrument. Epi-illumination microscope is 100W mercury lamp, FITC filter cube (
実施例2 野生型および変異体対立遺伝子PCR/PCR/LDR検出用BRCA1およびBRCA2エキソンの増幅
リガーゼ検出反応(「LDR」)(参照として本明細書に組み入れられる、Khanna、Mら、「原発大腸腫瘍のK-ras変異検出のための多重PCR/LDR(Multiplex PCR/LDR for Detection of K-ras Mutations in Primary Colon Tumors)」Oncogene、18:27〜38(1999))が引き続く、各アンプリコンを均等に増幅する修飾型PCR(PCR/PCR)(参照として本明細書に組み入れられる、Belgraderら、「ヒト同一性テスト用の多重PCR-リガーゼ検出反応アッセイ法(A Mulitplex PCR-Ligase Detection Reaction Assay for Human Identity Testing)」、Genome Science and Technology 1:77〜87(1996))を用いて小さな挿入および欠失を検出するために、多重アッセイ法が使用された。全産物を均等に増幅することを確実にするためにいかに適切なエキソンの多重増幅が実施されるかを図20は示している:遺伝子特異的プライマーを用いて限られた数のPCRサイクルが実施され、PCRプライマーの最も5'端に位置する普遍的配列からプライミングする更なる数ラウンドの増幅がされた。この方法はプライマー特異的効果に基づく増幅バイアスを最小限にする。LDRは次に、照会配列の野生型および変異体版の両方を検出するために使用される。連結オリゴヌクレオチドプローブは野生型および変異体産物の両方にハイブリダイズするが、しかし両方のプローブがギャップまたは重複なく完全に一致したときのみ連結される。産物は同定のために、電気泳動的に分離されるかまたはマイクロアレイにハイブリダイズされるのいずれかが可能である。Example 2 Amplification of BRCA1 and BRCA2 exons for wild-type and mutant allele PCR / PCR / LDR detection Ligase detection reaction (“LDR”) (Khanna, M et al., “Primary colorectal tumors, incorporated herein by reference) Multiple PCR / LDR for Detection of K-ras Mutations in Primary Colon Tumors (Oncogene, 18: 27-38 (1999)) followed by equal amplicons Modified PCR (PCR / PCR) that amplifies to (incorporated herein by reference, Belgrader et al., “A Mulitplex PCR-Ligase Detection Reaction Assay for Human Identity Testing), Genome Science and Technology 1: 77-87 (1996)) was used to detect small insertions and deletions. Figure 20 shows how appropriate exon multiplex amplification is performed to ensure that all products are amplified evenly: a limited number of PCR cycles are performed using gene-specific primers. And several additional rounds of amplification priming from the universal sequence located at the 5 'end of the PCR primer. This method minimizes amplification bias based on primer-specific effects. LDR is then used to detect both wild type and mutant versions of the query sequence. Ligated oligonucleotide probes hybridize to both wild type and mutant products, but are ligated only when both probes are perfectly matched without gaps or overlaps. Products can be either electrophoretically separated or hybridized to a microarray for identification.
PCRはBRCA1エキソン2およびエキソン20およびBRCA2エキソン11を同時に増幅するために単一チューブ多重反応として実施された。ゲノムDNAはアシュケナジーム(Ashkenazi)ユダヤ人の個人の血液試料から抽出され、100ng DNA、400μMの各dNTP、4mM MgCl2を補完された1×PCR緩衝液II(10mMトリスHCl、25℃でpH8.3、50mM KCl)、1Uアンプリタックゴールドおよび5'端にユニバーサルプライマーAまたはBのいずれかを含む各遺伝子特異的プライマー2pmolを有する25μL反応混合液中で増幅された。表4は以下のようにPCR/LDR/アレイハイブリダイゼーションを用いたBRCA1およびBRCA2変異の検出用のプライマーおよびプローブを示す。PCR was performed as a single tube multiplex reaction to simultaneously amplify
[表4]
PCR/LDR/アレイハイブリダイゼーションによるBRCA1およびBRCA2変異検出用に設計されたプライマーおよびプローブ
Primers and probes designed for BRCA1 and BRCA2 mutation detection by PCR / LDR / array hybridization
反応液はミネラルオイルで重層され、95℃で10分間事前インキュベーションされた。増幅は以下のように15サイクル実施された:94℃15秒、65℃1分間。各ユニバーサルプライマーAおよびBを含む2番目の反応混合液の25μLアリコートが25pmolのミネラルオイルを通して添加された。サイクルは55℃アニーリング温度を用いて反復された。反応液は続いて、1mg/mlのプロテイナーゼK/50mM EDTAの2μL溶液を用いて55℃で10分間消化された。プロテイナーゼKは90℃15分間の最終インキュベーションにより消去された。LDRに関しては、オリゴヌクレオチド合成および精製は以前に記載されているように(参照として本明細書に組み入れられる、Khanna、Mら、「原発大腸腫瘍のK-ras変異検出のための多重PCR/LDR(Multiplex PCR/LDR for Detection of K-ras Mutations in Primary Colon Tumors)」Oncogene 18:27〜38(1999))実施された。Tth DNAリガーゼは別に記載されているように過剰生産および精製された(参照として本明細書に組み入れられる、Luoら、「サーマスサーモフィルスDNAリガーゼの必須残基の同定(Identification of Essential Residues in Thermus Thermophilus DNA Ligase)」、Nucleic Acids Research 24:3079〜3085(1996)およびBaranyら「耐熱性DNAリガーゼ遺伝子のクローン化、過剰発現およびヌクレオチド配列(Cloning, Overexprescion, and Nucleotide Sequence of a Thermostable DNA Ligase Gene)」Gene 109:1〜11(1991))。LDRは、500fmolの各プローブ、2μLの増幅されたDNAおよび20mMトリスHCl、pH7.6、10mM MgCl2、100mM KCl、10mM DTT、1mM NAD+を含む20μLの反応液中で実施された。反応液は25fmolのTth DNAリガーゼ添加前に94℃まで1.5分間加熱され、その後94℃15秒および65℃4分に20サイクル供された(表4を参照されたい)。The reaction was overlaid with mineral oil and preincubated at 95 ° C. for 10 minutes. Amplification was performed for 15 cycles as follows: 94 ° C for 15 seconds, 65 ° C for 1 minute. A 25 μL aliquot of the second reaction mixture containing each universal primer A and B was added through 25 pmol of mineral oil. The cycle was repeated using a 55 ° C. annealing temperature. The reaction was then digested for 10 minutes at 55 ° C. with 2 μL of 1 mg / ml proteinase K / 50 mM EDTA. Proteinase K was erased by a final incubation at 90 ° C. for 15 minutes. For LDR, oligonucleotide synthesis and purification is as previously described (Khanna, M et al., “Multiple PCR / LDR for detection of K-ras mutations in primary colon tumors, incorporated herein by reference. (Multiplex PCR / LDR for Detection of K-ras Mutations in Primary Colon Tumors) "Oncogene 18: 27-38 (1999)). Tth DNA ligase was overproduced and purified as described separately (Luo et al., “Identification of Essential Residues in Thermus Thermophilus, incorporated herein by reference. “Nucleic Acids Research 24: 3079-3085 (1996)” and Barany et al. “Cloning, Overexprescion, and Nucleotide Sequence of a Thermostable DNA Ligase Gene” Gene 109: 1-11 (1991)). LDR was performed in a 20 μL reaction containing 500 fmol of each probe, 2 μL of amplified DNA and 20 mM Tris HCl, pH 7.6, 10 mM MgCl 2 , 100 mM KCl, 10 mM DTT, 1 mM NAD + . The reaction was heated to 94 ° C. for 1.5 minutes before addition of 25 fmol of Tth DNA ligase and then subjected to 20 cycles at 94 ° C. for 15 seconds and 65 ° C. for 4 minutes (see Table 4).
モデル系としてアシュケナジームユダヤ人集団の3つのBRCA1およびBRCA2の創始変異(founder mutation)(BRCA1 185delAG、BRCA1 5382insC、BRCA2 6174delT)(参照として本明細書に組み入れられる、Rahmanら、「乳癌感受性の遺伝学(The Genetics of Breast Cancer Susceptibility)」、Annu.Rev.Genet.32:95〜121(1998))を用いて、そのアッセイ法は80超のDNA試料における多重化反応内でこれらの変異を容易に検出した。図21Aは3つのBRCA変異を検出する代表的なLDRゲルを示す。識別上流オリゴヌクレオチドをFAM(野生型に対して)またはTET(変異体に関して)のいずれかを用いて蛍光末端標識することにより、かつLDRオリゴヌクレオチドプローブに異なる長さの「尾」を添加することにより、連結産物は標識およびポリアクリルアミドゲル上の移動度に基づいて容易に識別された。野生型産物はゲルの右側に同定される。変異体産物はゲルの上部に同定される。電気泳動分離は8M尿素-10%ポリアクリルアミドゲルおよびABI373 DNAシークエンサーを用いて1400Vで実施された。蛍光連結産物はABIジーンスキャン(GeneScan)672ソフトウェアを用いて解析および定量された。 Three BRCA1 and BRCA2 founder mutations (BRCA1 185delAG, BRCA1 5382insC, BRCA2 6174delT) from the Ashkenazi Jewish population as model systems (Rahman et al., “Genetics of Breast Cancer Susceptibility, incorporated herein by reference. (The Genetics of Breast Cancer Susceptibility), Annu. Rev. Genet. 32: 95-121 (1998)), the assay facilitates these mutations in multiplexed reactions in more than 80 DNA samples. Detected. FIG. 21A shows a representative LDR gel that detects three BRCA mutations. Adding different length “tails” to the LDR oligonucleotide probe by fluorescently end-labeling the discriminating upstream oligonucleotide with either FAM (relative to the wild type) or TET (for mutants) The ligation products were easily identified based on the label and mobility on the polyacrylamide gel. Wild-type products are identified on the right side of the gel. Mutant products are identified at the top of the gel. Electrophoretic separation was performed at 1400 V using an 8M urea-10% polyacrylamide gel and an ABI373 DNA sequencer. Fluorescent ligation products were analyzed and quantified using
解析は続いてDNAのプールされた試料における変異を検出するために拡張された。既知の変異を有するDNAが、PCR増幅の前に野生型DNAを用いて1:2、1:5、1:10および1:20で希釈され、その後LDRに供された。これらの模擬実験は、増幅の前に野生型DNAを用いて既知の変異体DNAが1:20に希釈された時、PCR/PCR/LDRが成功裏に全ての3つの変異の存在を検出できたことを示していた。図21Bは、プールされたDNA試料のBRCA1およびBRCA2の変異検出を示す。既知の変異を有するDNAが、増幅の前に野生型DNA中に希釈された。多重LDRの連結産物が各希釈に対して示される。BRCA1delAG、BRCA1insC、およびBRCA2delTは、ただ1つの変異のみが存在することを意味する。変異体配列のみに向けられた多重LDRは500fmolの各LDRオリゴヌクレオチドプローブを使用する。3変異は全3個の変異が存在することを意味する。変異配列のみに向けられた多重LDRは500fmolの各LDRオリゴヌクレオチドを使用する。1:20の3変異+野生型対照は全3個の変異が存在することを意味する。多重LDRは、各々500fmolおよび25fmolの各LDRオリゴヌクレオチドプローブを使用して、変異体および野生型配列の両方に向けられる。プールされた実験は249個の盲検化されたアシュケナジームユダヤ人のDNA試料を用いて繰り返された。盲検化されたDNAを含むチューブは9×9格子形式に配置され、各行および各列の統合されたDNAを1つのチューブに生産するために、各チューブからのアリコートは行にわたって、次に列を下って統合された。格子形式における交差点を用いて各試料を一意に分類するためにこれがなされた。プールされたDNAはその後上述のように増幅およびLDRに供された。249個の試料のうち248個が正確にタイピングされた。野生型として不正確に同定された1つの試料は非常に希釈されすぎていることが証明され、より濃度の高い他の9個の試料と混合したとき検出限界以下に落ちた。実施された個々の反応の数は、この戦略により249から96に減少された(55個のプール試料および確認用に使用された41個の個別の試料)。 The analysis was subsequently extended to detect mutations in DNA pooled samples. DNA with known mutations was diluted 1: 2, 1: 5, 1:10 and 1:20 with wild-type DNA prior to PCR amplification and then subjected to LDR. These simulations show that PCR / PCR / LDR can successfully detect the presence of all three mutations when known mutant DNA is diluted 1:20 using wild-type DNA prior to amplification. It showed that. FIG. 21B shows BRCA1 and BRCA2 mutation detection in pooled DNA samples. DNA with known mutations was diluted in wild type DNA prior to amplification. Multiple LDR ligation products are shown for each dilution. BRCA1delAG, BRCA1insC, and BRCA2delT mean that there is only one mutation. Multiplexed LDRs directed only to mutant sequences use 500 fmol of each LDR oligonucleotide probe. Three mutations means that there are all three mutations. Multiple LDRs directed to mutant sequences only use 500 fmol of each LDR oligonucleotide. 1:20 3 mutations + wild type control means that all 3 mutations are present. Multiplexed LDRs are directed to both mutant and wild type sequences using 500 fmol and 25 fmol of each LDR oligonucleotide probe, respectively. The pooled experiment was repeated using 249 blinded Ashkenazi Jewish DNA samples. The tubes containing the blinded DNA are arranged in a 9x9 grid format, and aliquots from each tube span the rows and then the columns to produce the combined DNA for each row and each column in one tube. Integrated down. This was done to uniquely classify each sample using intersections in a grid format. The pooled DNA was then subjected to amplification and LDR as described above. Of the 249 samples, 248 were correctly typed. One sample that was incorrectly identified as the wild type proved to be too dilute and fell below the detection limit when mixed with the other nine samples with higher concentrations. The number of individual reactions performed was reduced from 249 to 96 by this strategy (55 pool samples and 41 individual samples used for validation).
ゲルに基づく検出に加えて、変異同定はまた普遍的DNAマイクロアレイを用いて反応産物をスクリーニングすることによっても達成された(参照として本明細書に組み入れられる、Gerryら、「少量の点変異の多重検出のための普遍的DNAマイクロアレイ法(Universal DNA Microarray Method for Multiplex Detection of Low Abundance Point Mutations)」J.Mol.Biol. 292:251〜262(1999))。マイクロアレイは、加湿チャンバー(カルテシアンテクノロジー、アーバイン、カリフォルニア州)内に封入されたピクシス5500ロボットを用いて以前に記載されたように処理およびスポットされた(参照として本明細書に組み入れられる、Gerryら、「少量の点変異の多重検出のための普遍的DNAマイクロアレイ法」J.Mol.Biol. 292:251〜262(1999))。簡単には、LDR反応液は回転チャンバー内で65℃1時間、300mM MES、pH6.0、10mM MgCl2、0.1%SDSを含む32μL中でハイブリダイズされた。300mM ビシン、pH8.0、10mM MgCl2、0.1%SDS中で25℃10分間洗浄された後、100W水銀バーナー、テキサスレッドフィルターキューブ、およびプリンストンインスツルメントTEK512/CCDカメラを用いてオリンパスプロビスAX70顕微鏡上で画像化された。16ビットグレイスケール画像はメタモルフ(MetaMorph)イメージングシステム(ユニバーサルイメージングコーポレーション、ウエストチェスター、ペンシルベニア州)を用いて捕捉され、8ビットグレイスケールに変換する前により狭くLDRシグナルを区分するために再スケリーングされた。8ビット画像はアドビ(Adobe)フォトショップを用いてCy3シグナルに赤を与えるためにカラー化された。In addition to gel-based detection, mutation identification was also achieved by screening reaction products using universal DNA microarrays (Gerry et al., “Multiple of small point mutations, incorporated herein by reference. Universal DNA Microarray Method for Multiplex Detection of Low Abundance Point Mutations "J. Mol. Biol. 292: 251-262 (1999)). The microarray was processed and spotted as previously described using a
ゲルに基づく形式で設計されたプローブ(すなわち差異的に標識された識別プローブおよび同じ共通プローブ)を用いた予備的なマイクロアレイ実験は3つのBRCA配列の野生型および変異体版がアレイ上で容易に検出されることを証明した(参照として本明細書に組み入れられる、Baranyらに与えられたWO97/31256を参照されたい)。この版においては、両配列型は同じアドレスに向けられた(例えばBRCA1 185delAGおよびBRCA1 185野生型は両者ともZipコード1に向けられた)。この形式は成功することが証明されたが、PCR/PCR/LDRは単一チューブ反応において数100の変異を検出する能力を有しており、かつこの設計はそのような大規模変異同定実験用のアレイの最良の適用ではない。将来の研究のために実験パラダイムを確立するために、LDR連結産物を対照として使用する配列を各アンプリコンの中で選択することにより位置特定可能な形式は拡張された。したがって、各変異体LDR産物に対して野生型配列を検出する必要があるというよりも、この形式はあるアンプリコン内の多数の異なる配列変異体の陽性対照として機能する単一産物を使用する(図22を参照されたい)。この形式の1つの利点はオリゴヌクレオチド合成を最小化することである。付加的には、64部位の各々の使用が最大化される。単一のアドレスで検出可能なLDR連結産物の数は現在利用可能なスペクトルで分離されている蛍光標識の数で制限されているので、対照をアレイの特定の領域に制限することは、残りの各々のアドレスにおいてさらに1つの配列変異体の検出を可能にする。下記に記載される実験においては、紹介された部位に対する対照および変異体LDR連結産物は、64部位アレイ上の6個の離れたアドレスに向けられた。 Preliminary microarray experiments using probes designed in a gel-based format (ie, differentially labeled discriminating probes and the same common probe) facilitated the wild-type and mutant versions of the three BRCA sequences on the array (See WO97 / 31256 to Barany et al., Incorporated herein by reference). In this edition, both sequence types were directed to the same address (eg, BRCA1 185delAG and
全部で3つのフレームシフト変異が普遍的アレイへのハイブリダイゼーションにより検出可能であった(図23)。図23Aは対照および変異体配列の各々をアレイ表面上の特定のアドレスに配置することを示している。対照シグナルは上部の3つのアドレスに向けられた。変異体シグナルは下部の3つに向けられた。図23Bは野生型DNAにより生じるシグナルを示す。図23C、EおよびGは個々のDNA試料の代表的ハイブリダイゼーションを示す。図23D、FおよびHはアシュケナジーム個人由来のプールされたDNA試料を用いた各変異の代表的ハイブリダイゼーションを示す。変異は最も右に同定されている。 All three frameshift mutations were detectable by hybridization to a universal array (Figure 23). FIG. 23A shows that each of the control and variant sequences are placed at specific addresses on the array surface. Control signals were directed to the top three addresses. Mutant signals were directed to the bottom three. FIG. 23B shows the signal generated by wild type DNA. Figures 23C, E and G show representative hybridization of individual DNA samples. FIGS. 23D, F and H show representative hybridization of each mutation using pooled DNA samples from Ashkenazi individuals. Mutations are identified on the far right.
6個の可能なアドレスの組み合わせのみがハイブリダイゼーションに続いて可視化可能になり、他のいかなる未使用アドレスにおいても付加的なシグナルは検出されなかった。したがって、Zipコードハイブリダイゼーションは非常に特異的である。対照および変異体シグナルは、単一の個人由来のDNA試料に由来する各変異に対して明確に存在していた(図23C、EおよびG)。上記の249個のDNA試料を解析する際に使用されたプールされたDNAは、ゲルに基づくアッセイ法で見出されたものと同じ変異シグナルを生じた(図23D、FおよびH)。各々のケースにおいて、アレイはゲルの結果を再現した。 Only six possible address combinations became visible following hybridization, and no additional signal was detected at any other unused addresses. Thus, Zip code hybridization is very specific. Control and mutant signals were clearly present for each mutation derived from a DNA sample from a single individual (FIGS. 23C, E and G). The pooled DNA used in analyzing the 249 DNA samples above produced the same mutated signal as found in the gel-based assay (FIGS. 23D, F and H). In each case, the array reproduced the gel results.
これらの結果は、PCR/PCR/LDR産物の普遍的マイクロアレイ解析が、臨床診断および集団研究の両方の状況において、小さな挿入および欠失変異の迅速な同定を可能にすることを証明している。 These results demonstrate that universal microarray analysis of PCR / PCR / LDR products allows for the rapid identification of small insertion and deletion mutations in both clinical diagnostic and population study situations.
実施例3 p53チップハイブリダイゼーションおよび洗浄条件
どの方法がシグナルを有意に失うことなく最小のバックグラウンドノイズを生じうるかを決定するために、3つのパラメーター(非特異的競合DNAの存在または非存在、温度、および洗浄緩衝液組成)を異なる組み合わせで変更したた。ハイブリダイゼーションは100μg/mlのせん断サケ精子DNA(図16B、D、JおよびL)、250μg/mlのせん断サケ精子DNA(図16F、H、NおよびP)、または非特異的競合DNA(図16A、C、E、G、I、K、MおよびO)を用いて実施された。洗浄は4つの異なる条件を用いて10分間実施された。標準洗浄緩衝液(300mMビシン、pH8.0、10mM MgCl2、0.1%SDS)を用いて室温(図16A、B、EおよびF)。10%ホルムアミドを追加した標準洗浄緩衝液を用いて室温(図16I、J、MおよびN)。標準洗浄緩衝液を用いて50℃(図16C、D、GおよびH)または10%ホルムアミドを追加した標準洗浄緩衝液を用いて50℃(図16K、L、OおよびP)。各パネルの右上の数は各条件に対するp53エキソン5対照(Zipコード1)のピクセル密度を示す。数字の右側に示された損失割合は計算された割合に直接隣接する左および右のパネルを比較している。基準(Cy3、Cy5およびフルオレセイン)は方向性を与えるために、チップの左上に水平におよび右下の領域に垂直にスポットされている。Zipコード1は左上領域の基準の直下に位置している。引き続くZipコードは数字の順に左から右の様式でスポットされている。Example 3 p53 chip hybridization and wash conditions To determine which method can produce minimal background noise without significant loss of signal, three parameters (presence or absence of non-specific competitive DNA, temperature , And wash buffer composition) were changed in different combinations. Hybridization was performed at 100 μg / ml sheared salmon sperm DNA (FIGS. 16B, D, J and L), 250 μg / ml sheared salmon sperm DNA (FIGS. 16F, H, N and P), or non-specific competitor DNA (FIG. 16A). , C, E, G, I, K, M and O). Washing was performed for 10 minutes using 4 different conditions. Standard wash buffer (300 mM bicine, pH8.0,10mM MgCl 2, 0.1% SDS ) at room temperature using a (FIG. 16A, B, E and F). Room temperature (Figure 16I, J, M and N) using standard wash buffer supplemented with 10% formamide. 50 ° C. using standard wash buffer (FIGS. 16C, D, G and H) or 50 ° C. using standard wash buffer supplemented with 10% formamide (FIGS. 16K, L, O and P). The number in the upper right of each panel indicates the pixel density of
p53エキソン5および7を同時に増幅するために、PCRは単一チューブ多重反応として実施された。白血球由来の市販のゲノムDNAは、100ng DNA、400μMの各dNTP、4mM MgCl2を補完された1×PCR緩衝液II(10mMトリスHCl、25℃でpH8.3、50mM KCl)、1Uアンプリタックゴールドおよび5'端にユニバーサルプライマーAまたはBのいずれかを持つ2pmolの各々の遺伝子特異的プライマーを含む25μL反応混合液中で増幅された(表5を参照されたい)。反応液をミネラルオイルで重層し、95℃で10分間事前加熱処理された。増幅は以下を15サイクル実施した:94℃15秒、65℃1分間。25pmolの各ユニバーサルプライマーAおよびBを含む、2番目の反応混合液の25μLアリコートが、ミネラルオイルを通して添加された。サイクルは55℃アニーリング温度を用いて反復された。反応液は続いて、1mg/mlのプロテイナーゼK/50mM EDTAの2μL溶液を用いて55℃で10分間消化された。プロテイナーゼKは90℃15分間の最終インキュベーションにより消去された。LDRに関しては、オリゴヌクレオチド合成および精製は以前に記載されているように(参照として本明細書に組み入れられる、Khanna、Mら、「原発大腸腫瘍のK-ras変異検出のための多重PCR/LDR(Multiplex PCR/LDR for Detection of K-ras Mutations in Primary Colon Tumors)」Oncogene 18:27〜38(1999))実施された。Tth DNAリガーゼは別に記載されているように過剰生産および精製された(参照として本明細書に組み入れられる、Luoら、「サーマスサーモフィルスDNAリガーゼの必須残基の同定(Identification of Essential Residues in Thermus Thermophilus DNA Ligase)」、Nucleic Acids Research 24:3079〜3085(1996)およびBaranyら「耐熱性DNAリガーゼ遺伝子のクローン化、過剰発現およびヌクレオチド配列(Cloning, Overexpression, and Nucleotide Sequence of a Thermostable DNA Ligase Gene)」Gene 109:1〜11(1991))。LDRは、500fmolの各プローブ、2μLの増幅されたDNAおよび20mMトリスHCl、pH7.6、10mM MgCl2、100mM KCl、10mM DTT、1mM NAD+を含む20μLの反応液中で実施された。反応物を94℃で1.5分間加熱して25fmolのTth DNAリガーゼを添加し、その後94℃15秒および65℃4分の20サイクルに供した。以下のようにPCR/LDR/アレイハイブリダイゼーションによるp53変異の検出用に設計されたオリゴヌクレオチドプライマーおよびプローブを示す表5を参照されたい。PCR was performed as a single tube multiplex reaction to amplify
[表5]
PCR/LDR/アレイハイブリダイゼーションによるp53変異検出用に設計されたプライマーおよびプローブ
Primers and probes designed for p53 mutation detection by PCR / LDR / array hybridization
PCRプライマーはp53遺伝子内および周囲の領域を増幅するために特異的に設計される。より長い遺伝子特異的プライマー(各反応につき1〜2pmol)を用いて高いTm(すなわち65℃)での15ラウンドの増幅の後、2つのユニバーサルプライマー(太大文字)が50μL中に50pmolで添加され、かつ産物はさらに20ラウンドの増幅にサイクルされる。 PCR primers are specifically designed to amplify regions within and around the p53 gene. After 15 rounds of amplification at a high Tm (
対立遺伝子特異的LDRプローブは5'端に蛍光標識(Fam、Tet、Cy3またはCy5)および3'端に識別塩基を含んでいた。ゲルに基づくアッセイ用に最終の連結産物の大きさを調節するためにいくつかのプローブの5'端に非ゲノム配列が付加された(太小文字で指定されている)。共通LDRプローブはその3'端に5'リン酸基(p)およびC-3封鎖基(B)を含んでいた。アレイに基づく検出で使用される共通LDRプローブはその3'端にZipコード配列を有している(小文字で指定されている)。 Allele-specific LDR probes contained a fluorescent label (Fam, Tet, Cy3 or Cy5) at the 5 ′ end and a discriminating base at the 3 ′ end. A non-genomic sequence was added to the 5 'end of some probes (designated in bold) to control the size of the final ligation product for gel-based assays. The common LDR probe contained a 5 'phosphate group (p) and a C-3 blocking group (B) at its 3' end. A common LDR probe used in array-based detection has a Zip coding sequence at its 3 'end (designated in lower case).
LDR反応液は回転チャンバー内で65℃1時間、100μg/mlのせん断サケ精子DNAを含むまたは含まない、300mM MES、pH6.0、10mM MgCl2、0.1%SDSを含む32μL中でハイブリダイズされた。10%ホルムアミドを含むまたは含まない、300mM ビシン、pH8.0、10mM MgCl2、0.1%SDS中で25℃10分間または50℃10分間洗浄された後、100W水銀バーナー、テキサスレッドフィルターキューブ、およびプリンストンインスツルメントTEK512/CCDカメラを用いてオリンパスプロビスAX70顕微鏡上で画像化された。16ビットグレイスケール画像はメタモルフイメージングシステム(ユニバーサルイメージングコーポレーション)を用いて捕捉され、8ビットグレイスケールに変換する前により狭くLDRシグナルを区分するために再スケリーングされた。この8ビット画像はアドビフォトショップを用いてCy3シグナルに黒を与えるために反転された。LDR reaction was hybridized in 32 μL with 300 mM MES, pH 6.0, 10 mM MgCl 2 , 0.1% SDS with or without 100 μg / ml sheared salmon sperm DNA at 65 ° C. for 1 hour in a rotating chamber . 100 W mercury burner, Texas Red Filter Cube, and Princeton after washing in 300 mM bicine, pH 8.0, 10 mM MgCl 2 , 0.1% SDS at 25 ° C. for 10 minutes or 50 ° C. for 10 minutes with or without 10% formamide It was imaged on an Olympus Provis AX70 microscope using an instrument TEK512 / CCD camera. The 16-bit grayscale image was captured using a metamorph imaging system (Universal Imaging Corporation) and rescaled to narrow the LDR signal more narrowly before conversion to 8-bit grayscale. This 8-bit image was inverted using Adobe Photoshop to give the Cy3 signal black.
実施例4 大腸腫瘍由来DNAにおける変異の存在を示すp53チップハイブリダイゼーンョン
p53チップはエキソン5、6、7および8に存在する75個の異なる変異の存在を検出することが可能であり、144個のLDRオリゴヌクレオチドを使用する(表5を参照されたい)。図24は大腸腫瘍由来DNAを用いたマイクロアレイに基づくp53変異検出の例である。各試料の変異の状態およびシグナルを捕捉することが期待されるZipコードは各パネルの右に示されている。その図は、スポットされたZipコード内の汚染蛍光に起因するCy3バックグラウンドを右側最下のパネルに示している(図24H)。p53エキソン5、6、7および8を同時に増幅するために、PCRは単一チューブ多重反応として実施された。大腸腫瘍から抽出されたゲノムDNAは、100ng DNA、400μMの各dNTP、4mM MgCl2を補完された1×PCR緩衝液II(10mMトリスHCl、25℃でpH8.3、50mM KCl)、1Uアンプリタックゴールドおよび5'端にユニバーサルプライマーAまたはBのいずれかを持つ2pmolの各遺伝子特異的プライマーを含む25μL反応混合液中で増幅された(表5を参照されたい)。反応液にはミネラルオイルが重層され、95℃で10分間事前加熱処理された。増幅は以下のように15サイクル実施された:94℃15秒、65℃1分間。25pmolの各ユニバーサルプライマーAおよびBを含む2番目の反応混合液の25uLアリコートがミネラルオイルを通して添加された。サイクルは55℃アニーリング温度を用いて反復された。反応液は続いて、1mg/mlのプロテイナーゼK/50mM EDTAの2μL溶液を用いて55℃で10分間消化された。プロテイナーゼKは90℃15分間の最終インキュベーションにより消去された。LDRに関しては、オリゴヌクレオチド合成および精製は以前に記載されているように(参照として本明細書に組み入れられる、Khanna、Mら、「原発大腸腫瘍のK-ras変異検出のための多重PCR/LDR(Multiplex PCR/LDR for Detection of K-ras Mutations in Primary Colon Tumors)」Oncogene 18:27〜38(1999))実施された。Tth DNAリガーゼは別に記載されているように過剰生産および精製された(参照として本明細書に組み入れられる、Luoら、「サーマスサーモフィルスDNAリガーゼの必須残基の同定(Identification of Essential Residues in Thermus Thermophilus DNA Ligase)」、Nucleic Acids Research 24:3079〜3085(1996)およびBaranyら「耐熱性DNAリガーゼ遺伝子のクローン化、過剰発現およびヌクレオチド配列(Cloning, Overexpression, and Nucleotide Sequence of a Thermostable DNA Ligase Gene)」Gene 109:1〜11(1991))。LDRは、500fmolの各プローブ、2μLの増幅されたDNAおよび20mMトリスHCl、pH7.6、10mM MgCl2、100mM KCl、10mM DTT、1mM NAD+を含む20μLの反応液中で実施された。p53配列の上側鎖または下側鎖にハイブリダイズするように設計されたLDRプローブを含む各試料に関して2つの反応が実施された。反応液は25fmolのTth DNAリガーゼ添加前に94℃で1.5分間加熱され、その後94℃15秒および65℃4分に20サイクル供された(表5を参照されたい)。LDR反応液は回転チャンバー内で65℃1時間、100μg/mlのせん断サケ精子DNAを含む、300mM MES、pH6.0、10mM MgCl2、0.1%SDSを含む32μL中でハイブリダイズされた。300mM ビシン、pH8.0、10mM MgCl2、0.1%SDS中で50℃10分間洗浄された後、100W水銀バーナー、テキサスレッドフィルターキューブ、およびプリンストンインスツルメントTEK512/CCDカメラを用いてオリンパスプロビスAX70顕微鏡上で画像化された。16ビットグレイスケールイメージはメタモルフイメージングシステム(ユニバーサルイメージングコーポレーション)を用いて捕捉され、8ビットグレイスケールに変換する前により狭くLDRシグナルを区分するために再スケリーングされた。8ビット画像はアドビフォトショップを用いて最初Cy3シグナルに黒を与えるために反転され、その後p53配列の上側鎖または下側鎖を標的としたLDRを用いたハイブリダイゼーションに由来する各試料の画像が重層および重ね合わせされた。この処理の結果は図24に示されている。Example 4 p53 chip hybridization indicating the presence of mutations in colorectal tumor-derived DNA The p53 chip is capable of detecting the presence of 75 different mutations present in
実施例5 四量体を用いた最適化Zipコード配列構築
普遍的DNAアレイは、各々が固有の部位に捕捉されるようにLDR産物をユニークにタグ付けするために、拡散した配列を用いるというコンセプトに基づいて設計されている。このコンセプトの中心は、各々が他のいずれとも少なくとも2塩基異なる36個の四量体の設計である(表6を参照されたい)。Example 5 Optimized Zip Coding Sequence Construction Using Tetramer Universal DNA array is a concept that uses diffuse sequences to uniquely tag LDR products so that each is captured at a unique site. Designed based on. The heart of this concept is a design of 36 tetramers, each differing by at least 2 bases from each other (see Table 6).
1296アレイは、所定の四量体セットの交互タイリング(alternate tiling)のコンセプトに基づいて設計することが可能である。これらの捕捉オリゴヌクレオチドはその近傍物と3つの交互部位において異なるが、しかし他の3つの部位においては同じである、すなわち(第1=A、第3=Cおよび第5=E部位)。したがって、各捕捉オリゴヌクレオチドは他の任意の1つと24部位のうち少なくとも6個異なっていた。さらにこれらの差異は捕捉オリゴヌクレオチドの長さに渡り分布していた。正しい捕捉オリゴヌクレオチドを誤ったアドレスに配置する時、Tmの差異は24℃超になると予測された。それにもかかわらず、この設計型の可能性の1つは、所定の部位のセットにおける3つの隣接する四量体(すなわちABC)が別の捕捉オリゴヌクレオチドに一致するが、しかし異なる部位のセット(すなわちBCD)においてであることである。 The 1296 array can be designed based on the concept of alternate tiling of a given set of tetramers. These capture oligonucleotides differ from their neighbors in three alternating sites, but are the same in the other three sites, ie (first = A, third = C and fifth = E sites). Thus, each capture oligonucleotide differed from any other one by at least 6 out of 24 sites. Furthermore, these differences were distributed over the length of the capture oligonucleotide. When the correct capture oligonucleotide was placed at the wrong address, the Tm difference was expected to be above 24 ° C. Nevertheless, one possibility of this design type is that three adjacent tetramers (ie ABC) in a given set of sites match another capture oligonucleotide, but a different set of sites ( That is, in BCD).
最適表面は3次元多孔性表面であるので、所定のLDR産物が正確なアドレスに捕捉される多大な機会を有する。たとえLDR産物が一過性に正確なアドレス内の所定のオリゴヌクレオチドから解離したとしても、同じアドレス内の別のオリゴヌクレオチドを迅速に発見し、ハイブリダイズする。予備試験的な研究において、Tmを変化させると予測される変化(すなわちプロピニル誘導体の使用)は正確にハイブリダイズした産物の収量には大きくは影響しなかった。したがってハイブリダイゼーションは速度論的に制御可能でありうる。2つのよく関連したオリゴヌクレオチド間の低いレベルの交互ハイブリダイゼーションでさえ、その可能性を最小化するためには、24mer捕捉オリゴヌクレオチドを有する四量体の順序間の差異を最大化するように配列を設計することが可能である。 Since the optimal surface is a three-dimensional porous surface, there is a great opportunity for a given LDR product to be captured at the correct address. Even if the LDR product is transiently dissociated from a given oligonucleotide in the correct address, another oligonucleotide in the same address is quickly found and hybridized. In preliminary studies, changes expected to change Tm (ie use of propynyl derivatives) did not significantly affect the yield of correctly hybridized products. Thus, hybridization can be kinetically controllable. To minimize the possibility of even a low level of alternating hybridization between two well-related oligonucleotides, sequence to maximize the difference between the order of the tetramers with a 24mer capture oligonucleotide Can be designed.
そのような配列を設計するための概要は以下のとおりである。 An overview for designing such an arrangement is as follows.
1. 36個の四量体の3セットの、全46,656個(=36×36×36)の順列を含む3つの列を作製する。1. Create three rows of 3 sets of 36 tetramers, including a total of 46,656 permutations (= 36 × 36 × 36).
2. モレキュラーバイオロジーインサイト(Molecular Biology Insights)社(カスケード、コロラド州)のオリゴ6.0プログラムを用いて46,656個の12merのTmをコンピューター計算し、予測Tm値に従い一覧を並び替える。2. Computer-calculate 46,656 12mer Tm using the Molecular 6.0 Biology Insights (Cascade, CO) Oligo 6.0 program and sort the list according to the predicted Tm value.
3. 各四量体に1つのGC塩基を含む12mer(四量体#1〜#7)または各四量体に3つのGC塩基を含む12mer(四量体#28〜#36)を取り除く。この過程はTm値の極値を取り除く。24℃未満のTm値の12mer取り除く。3つの反復された四量体を有する、残る12mer(すなわち9-9-9)を取り除く。3. Remove 12mer (
4. Tmが2度上がるごとに新しい群として、12merのセットをTmにより群分けする。Tmを2で割って、整数に切り捨てることによって値を決定した。4. Each time Tm rises twice, a 12-mer set is grouped by Tm as a new group. The value was determined by dividing Tm by 2 and rounding down to an integer.
5. 一覧を無作為化し、奇数および偶数の12merに分割する。2番目の一覧を反転させ、最初の一覧の最後に追加し、6個の四量体=12,880個のアドレス候補を形成する。配列を連結し、24merのTm値を決定する。5. Randomize the list and split it into odd and even 12mers. Invert the second list and add it to the end of the first list to form 6 tetramers = 12,880 address candidates. The sequences are ligated to determine the 24mer Tm value.
6. Tm値が75から84の間である6個の四量体のみを選抜する。未使用の三量体を再生し、Tmを増加させた新規の6個の四量体を作成し、一覧に戻し加える。6. Select only 6 tetramers with Tm values between 75 and 84. Regenerate unused trimers, create 6 new tetramers with increased Tm, and add them back to the list.
7. 表7に記載されているような13個の選抜条件を用いて、一覧を削る。「1」はその部位で一致していることを示し、「0」は一致がないことを示す。2つの候補アドレスが条件の1つにおいて一致する時はいつでも、それは候補一覧から除去され、未使用三量体一覧に戻された。7. Cut down the list using 13 selection conditions as listed in Table 7. “1” indicates that there is a match at the site, and “0” indicates that there is no match. Whenever two candidate addresses match in one of the conditions, it was removed from the candidate list and returned to the unused trimer list.
8. 上記の13条件は一覧を9,650個のアドレス候補に減少させた。8. The above 13 conditions reduced the list to 9,650 address candidates.
9. 上記の13条件は連続した4個の一致を取り除き、別の1つと同じ配置である連続した3つの一致を取り除く。しかし、類似しているが1個または2個の四量体ユニットによって転換された配列は取り除かれない。これらの種類のアーチファクトを消去するために、もともとの6個の四量体の下にコピーし、以下の図8にあるように1つまたは2つの四量体によって補正した。9. The 13 conditions above remove 4 consecutive matches and remove 3 consecutive matches that are in the same arrangement as another one. However, sequences that are similar but converted by one or two tetramer units are not removed. To eliminate these types of artifacts, they were copied under the original six tetramers and corrected with one or two tetramers as shown in Figure 8 below.
10. これら3つの選抜は、64×64アドレスアレイの4,096個の標的より4,798個多い8,894個の候補捕捉オリゴヌクレオチドを一覧から精選した。これらの捕捉オリゴヌクレオチド配列は以下の特性を有している。(1)捕捉オリゴヌクレオチド配列が互いに配置されたとき、または互いに補正または分割したときのいずれかで、同一である連続した4個の四量体の例はない。(2)捕捉オリゴヌクレオチド配列が1つの端から互いに配置されたとき、行において同一である3個の四量体の例はない。(3)6個の四量体のうち4個の四量体が同一部位にある例はない。10. These three selections screened a list of 8,894 candidate capture oligonucleotides, 4,798 more than 4,096 targets in a 64 × 64 address array. These capture oligonucleotide sequences have the following characteristics: (1) There are no examples of four consecutive tetramers that are identical, either when the capture oligonucleotide sequences are placed together, or corrected or split from each other. (2) There is no example of three tetramers that are identical in a row when the capture oligonucleotide sequences are placed from one end to each other. (3) There is no example in which 4 tetramers out of 6 tetramers are in the same site.
11. 更なる選抜には、補正された連続する3つの配列を表9のように消去した。11. For further selection, three consecutive corrected sequences were deleted as shown in Table 9.
12. これらの6個の選抜は、50×50アドレスアレイの2,500個のより選択的な標的より多い3,038個の候補捕捉オリゴヌクレオチドを一覧から精選した。これらの捕捉オリゴヌクレオチド配列は以下の特性を有している。(1)捕捉オリゴヌクレオチド配列が互いに配置されたとき、または互いに補正されたときのいずれかにおいて同一である連続した4個の四量体の例はない。(2)捕捉オリゴヌクレオチド配列が1つの端から互いに配置されたとき、または互いに補正されたいずれかのときに、同一である連続した3個の四量体の例はない。(3)6個の四量体のうち4個の四量体が同一部位にある例はない。12. These 6 selections screened from a list of 3,038 candidate capture oligonucleotides, more than 2,500 more selective targets in a 50 × 50 address array. These capture oligonucleotide sequences have the following characteristics: (1) There is no example of four consecutive tetramers that are identical either when the capture oligonucleotide sequences are placed together or corrected for each other. (2) There is no example of three consecutive tetramers that are identical when the capture oligonucleotide sequences are either positioned from one end to each other or corrected for each other. (3) There is no example in which 4 tetramers out of 6 tetramers are in the same site.
13. 四量体の順番は反転され、新しいTm値が計算され、(6,076)に足し戻され、その後、上の7〜11の段階に記載されているように余計なものを取り除かれた。候補一覧は3,270個とわずかに増加した。したがって、未使用三量体を濃縮する方法が必要とされた。13. The order of the tetramer was reversed and a new Tm value was calculated and added back to (6,076), after which excess was removed as described in steps 7-11 above. The list of candidates increased slightly to 3,270. Therefore, a method for concentrating unused trimers was needed.
14. 全ての部位において使用された三量体の一覧が、利用可能な(未使用の)三量体を決定し、新しい6個の四量体セットを構築するために使用された。Tm値が75℃〜84℃の範囲の6個の四量体の割合を増加させるために、予測Tm値が34℃〜50℃の三量体が互いに反転され、使用された(すなわちTm34の三量体ABCがTm50の三量体DEFに融合され、Tm38の三量体ABCがTm46の三量体DEFに融合された、など)。14. A list of trimers used at all sites was used to determine the available (unused) trimers and build a new set of 6 tetramers. In order to increase the proportion of 6 tetramers with Tm values in the range of 75 ° C to 84 ° C, trimers with predicted Tm values of 34 ° C to 50 ° C were inverted and used together (ie Tm34's Trimer ABC fused to Tm50 trimer DEF, Tm38 trimer ABC fused to Tm46 trimer DEF, etc.).
15. 6個の四量体のセットが構築され、接合部に作製された三量体(すなわち部位BCDおよびCDE)が使用済み三量体一覧に対して再試験され、それらの一致しなかった6個の四量体が再利用された。それらの不一致でなかった6個の四量体は3,270個の候補一覧に付加され、再度並び替えられ、段階7〜11に記載されているように余計なものを取り除かれた。候補一覧は4,035に拡大した。15. A set of 6 tetramers was constructed and the trimers created at the junction (ie, sites BCD and CDE) were retested against the used trimer list and they did not match Six tetramers were reused. The six tetramers that were not those discrepancies were added to the 3,270 candidate list, reordered, and the extras removed as described in steps 7-11. The candidate list has been expanded to 4,035.
16. 64×64アドレスアレイの4,096の標的より537配列多い、4,633個の捕捉オリゴヌクレオチドの最終一覧を作製するために、もう2回この過程が繰り返された(表6の四量体を参照する図25)。これらの捕捉オリゴヌクレオチド配列は以下の特性を有している。(1)捕捉オリゴヌクレオチド配列が互いに配置されたとき、または互いに補正されたときのいずれかで、同一である連続した4個の四量体の例はない。(2)捕捉オリゴヌクレオチド配列が1つの端から互いに配置されたとき、または互いに補正されたときのいずれかで、同一である連続した3個の四量体の例はない。(3)6個の四量体のうち4個の四量体が同一部位にある例はない。16. This process was repeated two more times to create a final list of 4,633 capture oligonucleotides, 537 sequences more than 4,096 targets in the 64x64 address array (see tetramers in Table 6). Figure 25). These capture oligonucleotide sequences have the following characteristics: (1) There is no example of four consecutive tetramers that are identical, either when the capture oligonucleotide sequences are placed together or corrected for each other. (2) There is no example of three consecutive tetramers that are identical, either when the capture oligonucleotide sequences are positioned from one end to each other or when corrected for each other. (3) There is no example in which 4 tetramers out of 6 tetramers are in the same site.
17. 4,633個の捕捉オリゴヌクレオチド一覧を用いて、8×8=64アドレスアレイ、8×12=96アドレスアレイ、16×24=384アドレスアレイ、および20×20=400アドレスアレイのためのより小さな一覧が作成された。選抜基準として、四量体対を共通に共有する捕捉オリゴヌクレオチドは選択的に一覧から除かれた。所定の部位において同一である全ての二量体対(すなわちAB=AB)を淘汰することで一覧は465個の捕捉オリゴヌクレオチド配列に減少した(表6の四量体を参照する図26)。隣接部位において類似している二量体対(すなわちAB=BC、BC=CDなど)の2度目の淘汰により、および2回超使用されている全ての二量体対を取り除くことにより、セットは96個の捕捉オリゴヌクレオチド配列に減少した(表6の四量体を参照する図27)。最終的にどの二量体も1回超使用されないことを保証することで65個の捕捉オリゴヌクレオチド配列の一覧が作製された(表6の四量体を参照する図28)。17. Using a list of 4,633 capture oligonucleotides, smaller for 8 × 8 = 64 address array, 8 × 12 = 96 address array, 16 × 24 = 384 address array, and 20 × 20 = 400 address array A list has been created. As selection criteria, capture oligonucleotides that share a common tetramer pair were selectively removed from the list. By listing all dimer pairs that were identical at a given site (ie, AB = AB), the list was reduced to 465 capture oligonucleotide sequences (FIG. 26 with reference to tetramers in Table 6). By a second round of dimer pairs that are similar in adjacent sites (ie AB = BC, BC = CD, etc.) and by removing all dimer pairs that have been used more than twice, the set Reduced to 96 capture oligonucleotide sequences (Figure 27 with reference to tetramer in Table 6). Finally, a list of 65 capture oligonucleotide sequences was generated by ensuring that no dimer was used more than once (Figure 28 with reference to tetramer in Table 6).
18. 4,633個のそのような捕捉オリゴヌクレオチドの一覧を含む図29(表6の四量体を参照する)に示されているように、捕捉オリゴヌクレオチドはまたPNA(すなわち、ペプチドヌクレオチド類似体)であることもできる。PNA捕捉オリゴヌクレオチドは20merユニットの型である。PNAは平均で1塩基にっき1.0℃から1.5℃オリゴヌクレオチドのTmを増加させる利点を提供する。そのため図29に列記されたオリゴマーのTm値はPNA型として合成されるとき平均で20℃(またはそれを超えて)高いと考えられる。したがってアドレスはPNA型ではわずか20mer以下であれさえすえればよいと考えられる。これらの配列は、2つの代替法を考慮することにより、より迅速な合成に適合しやすい。最初の方法では、表6に列記された36個の四量体が最初に合成され、その後、図29に列記されている配列を形成するために正確な順に5個の四量体が連結される。または、PNAオリゴマーはリソグラフィック合成法を用いて合成されると考えられる。標準的なリソグラフィック合成では4塩基、すなわちA-C-G-Tを第1の部位に、A-C-G-Tを第2の部位になどが何度となく使用され、4×20=80のマスキングが必要とされると考えられる。図29に列記されている現在の配列は62回の、またはマスキングの頂番を変更することにより更に少ない、マスキングにより合成に適合しやすい。62回のマスキングは以下の順番でPNA単量体を付加することを可能にすると考えられる。
所定の配列に関して、次の塩基においてその配列を許すマスキングはそのアドレスにおいて開放されている。一例として、もし配列が
全アドレスは75〜84℃の間のTm値を有するように選択された。Tm値の分布は多かれ少なかれ捕捉オリゴヌクレオチドの数とは独立している。一般的には高いG+C含量を有するアドレスがより高いTm値を与えた一方で、単純なTm=4(G+C)+2(A+T)則は多くの例において最大10℃まで狂う。96、465および4,633個の捕捉オリゴヌクレオチドの値が図30、31および32にそれぞれ示されている。捕捉オリゴヌクレオチドプローブの4,633個の一覧の並び替えられたTm値は図33に示されている。Tm値の勾配は相対的に平坦であり、大部分の捕捉オリゴヌクレオチド(80%)は両端を含む75℃から80℃からのTm値を有する。図34は、本発明にしたがって作製された65、96、465および4633個の捕捉オリゴヌクレオチドの一覧における四量体の利用度を示す。もし四量体の分布が完全に無作為であれば、各四量体は2.7%の回数で提示されるはずである。しかしながら選抜はより高いTmの捕捉オリゴヌクレオチドプローブの側に偏向されている。したがって、Tm値を減少させる傾向のある四量体、すなわち#7=TACAは過小提示される一方、Tm値を増加させる傾向のある四量体、すなわち#29=TGCGは過剰提示される。 All addresses were selected to have Tm values between 75-84 ° C. The distribution of Tm values is more or less independent of the number of capture oligonucleotides. In general, a simple Tm = 4 (G + C) +2 (A + T) rule is up to 10 ° C in many cases, while addresses with high G + C content gave higher Tm values Go crazy. Values for 96, 465, and 4,633 capture oligonucleotides are shown in FIGS. 30, 31, and 32, respectively. The sorted Tm values for the 4,633 list of capture oligonucleotide probes are shown in FIG. The slope of the Tm value is relatively flat and most capture oligonucleotides (80%) have Tm values from 75 ° C to 80 ° C including both ends. FIG. 34 shows the utilization of tetramers in a list of 65, 96, 465 and 4633 capture oligonucleotides made in accordance with the present invention. If the tetramer distribution is completely random, each tetramer should be presented at a rate of 2.7%. However, the selection is biased towards higher Tm capture oligonucleotide probes. Thus, tetramers that tend to decrease Tm values,
変異検出の本方法は3つの直交する構成要素を有する。(1)第1のPCR増幅、(2)液相LDR検出、および(3)固相ハイブリダイゼーション捕捉。したがって、各段階からのバックグラウンドシグナルは最小化することが可能であり、結果として本方法の全体の感度および精度は、他の戦略で提供されるそれらに対して有意に増強される。例えば「ハイブリダイゼーションによる配列決定」法は、処理能力を制限する、(1)複数ラウンドのPCRまたはPCR/T7転写、(2)それらを断片化または1本鎖にするためにPCR増幅産物を処理すること、および(3)長いハイブリダイゼーション時間(10時間またはそれ以上)、を必要とする(参照として本明細書に組み入れられる、Guoら、Nucleic Acids Research 22:5456〜5465(1994)、Haciaら、Nat.Genet. 14441〜447(1996)、Cheeら、Science 274:610〜614(1996)、Croninら、Human Mutation 7:244〜255(1996)、Wangら、Science 280:1077〜1082(1998)、Schenaら、Proc. Natl. Acd. Sci. USA 93:10614〜10619(1996)およびShalonら、Genome Res. 6:639〜645(1996))。付加的には、これらのアレイ上の固相化プローブは広範囲のTmを有するので、ハイブリダイゼーションを0℃から44℃の温度で実施する必要がある。結果として、例えば反復配列における小さな挿入および欠失に関して、ミスマッチハイブリダイゼーションおよび非特異的結合に起因するバックグラウンドノイズの増加および偽シグナルを生じる(参照として本明細書に組み入れられる、Haciaら、Nat.Genet. 14441〜447(1996)、Croninら、Human Mutation 7:244〜255(1996)、Wangら、Science 280:1077〜1082(1998)、およびSouthern E.M.、Trends in Genet、12:110〜115(1996))。対照的に本発明の方法は単一反応における多重PCRを可能にし(参照として本明細書に組み入れられる、Belgraderら、Genome Sci.Technol. 1:77〜87(1996))、産物を1本鎖型に変換する付加的な段階を必要とせず、反復配列におけるずれを含む全ての点変異を容易に識別することが可能である(参照として本明細書に組み入れられる、Dayら、Genomics、29:152〜162(1995))。別のDNAアレイは、配列の変動または試料中に存在する標的の量に起因する、異なるハイブリダイゼーション効率の影響を受ける。類似した熱力学的特性を有する拡散したアドレス配列を設計する本方法を用いることにより、ハイブリダイゼーションは65℃で実施することが可能であり、より厳密および迅速なハイブリダイゼーションに結果としてなる。変異検出段階をハイブリダイゼーション段階から脱共役することで、すでにゲルに基づくLDR検出を用いて達成されているLDR産物の定量の目途を提供する。 This method of mutation detection has three orthogonal components. (1) first PCR amplification, (2) liquid phase LDR detection, and (3) solid phase hybridization capture. Thus, the background signal from each stage can be minimized, and as a result, the overall sensitivity and accuracy of the method is significantly enhanced relative to those provided by other strategies. For example, the “sequencing by hybridization” method limits throughput, (1) multiple rounds of PCR or PCR / T7 transcription, (2) processes PCR amplification products to make them fragmented or single stranded And (3) long hybridization times (10 hours or longer), Guo et al., Nucleic Acids Research 22: 5456-5465 (1994), Hacia et al., Incorporated herein by reference. Nat. Genet. 14441-447 (1996), Chee et al., Science 274: 610-614 (1996), Cronin et al., Human Mutation 7: 244-255 (1996), Wang et al., Science 280: 1077-1082 (1998). Schena et al., Proc. Natl. Acd. Sci. USA 93: 10614-10619 (1996) and Shalon et al., Genome Res. 6: 639-645 (1996)). In addition, since the immobilized probes on these arrays have a wide range of Tm, it is necessary to perform the hybridization at a temperature of 0 ° C. to 44 ° C. The result is increased background noise and spurious signals due to mismatch hybridization and non-specific binding, for example for small insertions and deletions in repetitive sequences (Hacia et al., Nat. Genet. 14441-447 (1996), Cronin et al., Human Mutation 7: 244-255 (1996), Wang et al., Science 280: 1077-1082 (1998), and Southern EM, Trends in Genet, 12: 110-115 ( 1996)). In contrast, the method of the present invention allows for multiplex PCR in a single reaction (Belgrader et al., Genome Sci. Technol. 1: 77-87 (1996), incorporated herein by reference), and the product is single stranded. All point mutations, including shifts in repetitive sequences, can be easily identified without the need for additional steps to convert to type (Day et al., Genomics, 29: incorporated herein by reference). 152-162 (1995)). Another DNA array is subject to different hybridization efficiencies due to sequence variations or the amount of target present in the sample. By using this method of designing diffuse address sequences with similar thermodynamic properties, hybridization can be performed at 65 ° C, resulting in more stringent and rapid hybridization. Uncoupling the mutation detection step from the hybridization step provides an aim for quantification of LDR products that has already been achieved using gel-based LDR detection.
多量体表面にスポットされたアレイは、ガラス表面にスポットまたは直接インサイチュー合成されたアレイと比較して、シグナル捕捉において大きな改善を提供する(参照として本明細書に組み入れられる、Drobyshevら、Gene、188:45〜52(1997)、Yershovら、Proc. Natl. Acd. Sci. USA 94:4913〜4918(1996)およびParinovら、Nucleic Acids Res. 24:2998〜3004(1996))。しかしながら、本発明の多量体表面は容易に24merの捕捉オリゴヌクレオチドが浸透および共有結合することを可能にする一方で、他者により記載された多量体は8から10merのアドレスを使用することに制限されている。さらに60から75ヌクレオチド塩基長のLDR産物もまた浸透し、引き続いて正確なアドレスにハイブリダイズすることが見出された。付加的な利点として、多量体はほとんどまたは全くバックグラウンド蛍光を生じず、蛍光標識オリゴヌクレオチドの非特異的結合を示さない。最後に、別個のアドレスにスポットおよび共有結合された捕捉オリゴヌクレオチドは近接スポットに「流出(bleed over)」せず、例えばゲルパッドを切断することなどにより、物理的に部位を隔離する必要性を取り除く。 Arrays spotted on multimeric surfaces provide a significant improvement in signal capture compared to arrays spotted or directly in situ synthesized on glass surfaces (Drobyshev et al., Gene, incorporated herein by reference). 188: 45-52 (1997), Yershov et al., Proc. Natl. Acd. Sci. USA 94: 4913-4918 (1996) and Parinov et al., Nucleic Acids Res. 24: 2998-3004 (1996)). However, the multimeric surface of the present invention allows 24mer capture oligonucleotides to easily penetrate and covalently bind, while multimers described by others are limited to using 8 to 10mer addresses. Has been. It was further found that
本発明は、文献で以前に提示された他のアレイに基づく検出システムとは大きく異なる、高処理変異検出のための戦略に関連する。溶液で実施されるポリメラーゼ連鎖反応/リガーゼ検出反応(PCR/LDR)アッセイ法と共同して、遺伝的およびその遺伝子の配列の50%として存在する、または散発性および野生型の配列の1%以下で存在するのいずれかであれ、本発明のアレイは一塩基変異の正確な検出を可能にする。LDRプローブの拡散した位置特定可能なアレイ特異的部分は各LDR産物をDNAアレイ上の指定されたアドレスに導く一方で、耐熱性DNAリガーゼは変異識別の特異性を提供するので、この感度が達成される。アドレス配列は一定のままで、相補体は任意のLDRプローブセットに付加することができるので、本発明の位置特定可能なアレイは普遍的である。したがって、単一アレイ設計は広範囲の遺伝的変異を検出するようにプログラムされることができる。 The present invention relates to a strategy for high-throughput mutation detection that differs significantly from other array-based detection systems previously presented in the literature. Coordinated with polymerase chain reaction / ligase detection reaction (PCR / LDR) assay performed in solution, present as 50% of genetic and its gene sequences, or less than 1% of sporadic and wild type sequences The arrays of the present invention allow for the accurate detection of single base mutations. This sensitivity is achieved because the diffusely localizable array-specific portion of the LDR probe directs each LDR product to a specified address on the DNA array, while thermostable DNA ligase provides the specificity of mutation discrimination Is done. The addressable array of the present invention is universal because the address sequence remains constant and the complement can be added to any LDR probe set. Thus, a single array design can be programmed to detect a wide range of genetic variations.
多数の遺伝子の多量の潜在的部位における迅速な変異検出の確固とした方法は、癌患者の診断および治療の改善を強く約束する。唾液、喀痰、尿および糞の脱落(shed)細胞の変異解析のための非侵襲試験は、高危険度集団のサーベランスを有意に簡便化および改善し、内視鏡検査の費用および不快さを減少させ、早期で治療可能な段階のより効果的な癌診断につながることが可能と考えられる。脱落変異の検出の実現可能性は既知および遺伝的に特性化された腫瘍を有する患者において明確に証明されたが(参照として本明細書に組み入れられる、Sidranskyら、Science、256:102〜105(1992)、Nollauら、Int.J.Cancer、66:332〜336(1996)、Calasら、Cancer Research、54:3568〜73(1994)、Hasegawaら、Oncogene 10:1413〜16(1995)およびWuら、「癌分子マーカーの早期検出(Early Detection of Cancer Molecular Marker)」(Lippmanら編集)(1994))、症状が現れる前の効果的なスクリーニングは、無数の低頻度の潜在的な変異が最小の偽陽性および偽陰性シグナルで同定されることが必要となろう。さらに、腫瘍の遺伝的変化を決定する技術を、治療応答の可能性についての臨床情報と統合することは、より進行した腫瘍を有する患者を治療のためにいかに選択するかに関して、根本的に変更しうる。信頼度の高い遺伝的マーカーの同定および確認には、多くの候補遺伝子が大規模臨床試験において試験される必要がある。高費用の微細加工チップは100,000アドレスを有する形で作製可能であるが、それらのどれも、そのような臨床試験において変異プロファイルを正確にスコア化することひ必要とされているような低頻度の変異を同定する能力は証明されていない(参照として本明細書に組み入れられる、Haciaら、Nat.Genet. 14441〜447(1996)、Cheeら、Science 274:610〜614(1996)、Kozalら、Nat.Med. 2:753〜759(1996)および、Wangら、Science 280:1077〜1082(1998)。本発明の普遍的位置特定可能なアレイ法は、腫瘍進行に関連する多数の遺伝子の欠失および増幅の定量ならびに、無数の遺伝子において多数のコドンにおける低頻度変異を迅速および高信頼度で同定する能力を有する。加えて、mRNA発現プロファイルに関しては、LDR普遍的アレイはK-、N-およびH-rasのような非常に類似した遺伝子を識別することを可能にする。さらに、特定の遺伝子または特定の変異タンパク質を標的とした新しい治療が開発されるにつれて、迅速および正確な高処理能力の遺伝的試験の重要性は間違いなく増加すると考えられる。 A robust method for rapid mutation detection at large potential sites of a large number of genes strongly promises improved diagnosis and treatment of cancer patients. Non-invasive testing for mutation analysis of saliva, sputum, urine and fecal shed cells significantly simplifies and improves surveillance in high-risk populations and reduces the cost and discomfort of endoscopy It is considered possible to lead to more effective cancer diagnosis at an early and treatable stage. The feasibility of detecting a drop-off mutation has been clearly demonstrated in patients with known and genetically characterized tumors (Sidransky et al., Science, 256: 102-105, incorporated herein by reference). 1992), Nollau et al., Int. J. Cancer, 66: 332-336 (1996), Calas et al., Cancer Research, 54: 3568-73 (1994), Hasegawa et al., Oncogene 10: 1413-16 (1995) and Wu. Et al., “Early Detection of Cancer Molecular Marker” (edited by Lippman et al.) (1994), effective screening before symptoms appear, with a myriad of infrequent potential mutations being minimal Would need to be identified with false positive and false negative signals. In addition, the integration of techniques for determining genetic changes in tumors with clinical information about the likelihood of a therapeutic response will fundamentally change how patients with more advanced tumors are selected for treatment. Yes. Many candidate genes need to be tested in large clinical trials for the identification and confirmation of reliable genetic markers. High-cost microfabricated chips can be made with 100,000 addresses, but none of them are infrequently required to accurately score mutation profiles in such clinical trials. The ability to identify mutations has not been demonstrated (Hacia et al., Nat. Genet. 14441-447 (1996), Chee et al., Science 274: 610-614 (1996), Kozal et al., Incorporated herein by reference. Nat. Med. 2: 753-759 (1996) and Wang et al., Science 280: 1077-1082 (1998) The universal positionable array method of the present invention eliminates a large number of genes associated with tumor progression. Loss and amplification quantification and the ability to quickly and reliably identify low frequency mutations at multiple codons in a myriad of genes.In addition, for mRNA expression profiles, LDR universal arrays are K-, N- And very similar like H-ras In addition, as new therapies targeting specific genes or specific mutant proteins are developed, the importance of rapid and accurate high-throughput genetic testing is undoubtedly important It is thought to increase.
実施例6:標的配列への結合を回避する位置特定可能なアレイの設計用のコンピューターソフトウェア
位置特定可能なアレイの設計において、標的配列がアレイ上の捕捉プローブにハイブリダイズしないことを保証することが重要である。以下に記載されているように、コンピュータープログラムがこの目的のために設計された。プログラムは、任意のアレイ配列に一致する一続きの配列をN個の隣接ヌクレオチド部位のN-x個に位置させる。パラメーターxおよびNは使用者により設定される。Example 6: Computer software for designing a positionable array that avoids binding to the target sequence In designing a positionable array, ensuring that the target sequence does not hybridize to the capture probes on the array is important. A computer program was designed for this purpose, as described below. The program places a series of sequences that match any array sequence in Nx N adjacent nucleotide sites. Parameters x and N are set by the user.
プログラムは出力をスクリーンおよびファイルに送達する。スクリーン出力は、最長の一致がM塩基のうちのiである、MがNよりも大きいまたは等しい、かつ、iがM-xよりも大きいまたは等しい、配列比較の数を要約している。出力ファイルは、スクリーンに提供された情報の概要を与えることならびに各配列セットの実際の一致を示す。ファイル出力の例は以下に示される。
プログラムはプラットフォーム間の可搬性を目的として、ANSI Cにて記載されている。使用された正確なソフトウェアは図35に記載されている。プログラムは一直線のテキスト形式の入力ファイルを受け入れる。配列は標準的な不明瞭コード(例えば、コードYはCまたはTのいずれかに相当する)を含んでもよい。 The program is written in ANSI C for the purpose of portability between platforms. The exact software used is described in FIG. The program accepts a straight text input file. The sequence may include a standard ambiguity code (eg, code Y corresponds to either C or T).
入力ファイル#1のF1配列の各々は入力ファイル#2のF2配列の各々と比較され、全体でF1×F2比較となる。各セットに関して、2つの配列が全ての可能性のある配置に関して一時にN個の連続した部位で比較される。N個の隣接部位のうち少なくともN-x個の一致が検出されるならば、比較される部位は1ずつ増加される(すなわち、i増加の後、一致基準はN+i部位のうちN-x+iとなる)。この処理は、一致基準を満たす一致が見出されなくなるまで繰り返される。配列対の最長一致は、N-x+iの最長値に対立するものとして、N+iの最長値を含む一致として定義される。したがって、使用者は、異なるレベルの厳密度を有する全ての解析を明らかに繰り返すべきである(すなわち、x=0、x=1、x=2....)。もし使用者が、完全な、または完全に近い一致がより長い範囲に渡るより低い完成度の一致によりマスキングされてしまうかもしれないとの懸念を有している場合に、これは重要である。例えば、7一致部位中の7個は、(1)1セットの配列が10部位中8で一致している、および(2)一致基準が2つのミスマッチを許容する、ならば報告されないと考えられる。 Each of the F1 sequences in the
発明は例示の目的で詳細に記載されているが、そのような詳細は単にその目的のためだけであること、および、添付の特許請求の範囲のみにより定義される発明の精神および範囲を逸脱することなく当業者により変更可能であることが、理解される。 While the invention has been described in detail for purposes of illustration, such details are for that purpose only and depart from the spirit and scope of the invention as defined solely by the appended claims. It will be understood that modifications can be made by those skilled in the art without any problem.
Claims (11)
(1)セット内の各四量体は、セット内のすべての他の四量体と少なくとも2つのヌクレオチド塩基が異なり、(2)互いに相補的な2つの四量体はセット内に存在せず、(3)回文構造または2ヌクレオチドの反復である四量体はセット内に存在せず、かつ(4)1以下または3以上のヌクレオチドGまたはCを有する四量体はセット内に存在しない、4つのヌクレオチドが互いに結合した複数の四量体の第1のセットを提供する段階;
第1のセット内の2つから4つの四量体群を共に連結させて、多量体ユニットの集合(collection)を形成する段階;
多量体のユニットの集合から、同じ四量体から形成された全ての多量体ユニット、および多量体ユニットを形成する四量体の数の4倍未満の温度(摂氏)の融解温度を有する全ての多量体ユニットを除去して、多量体ユニットの修正された集合を形成する段階;
多量体ユニットの修正された集合を融解温度順に配置してから、融解温度が2度上がるごとに異なる多量体ユニットの新しい群として多量体ユニットを群分けする段階;
多量体ユニットの群の順番を、無作為化する(randomize)段階;
無作為化する段階により生じた順番に基づいて多量体ユニットの群を交互に、第1および第2の亜集合(sub collection)に分割する段階;
第1および第2の亜集合の両方を融解温度の低い順または高い順に並べる段階;
第2の亜集合の順番を逆にする段階;
第1の亜集合の多量体ユニットを、逆にした第2の亜集合の多量体ユニットに順に結合させ、二重多量体ユニットの集合を形成する段階;ならびに
二重多量体ユニットの集合から、(1)四量体の数の11倍未満の融解温度(摂氏)を有する二重多量体ユニットおよび四量体の数の15倍を上回る融解温度(摂氏)を有する二重多量体ユニット、(2)同じ四量体が3つ連結した二重多量体ユニット、および(3)同じ四量体が中断ありまたはなしで4つ連結した二重多量体ユニットを除去して、二重多量体ユニットの修正された集合を形成する段階。
A method for designing multiple capture oligonucleotide probes for use on a support where complementary oligonucleotide probes hybridize with little mismatch, wherein the multiple capture oligonucleotide probes have a narrow range of melting temperatures, comprising: Method including stages:
(1) Each tetramer in the set differs from all other tetramers in the set by at least two nucleotide bases, and (2) no two tetramers complementary to each other are present in the set. (3) tetramers that are palindromic or 2 nucleotide repeats are not present in the set, and (4) tetramers having one or more or three or more nucleotides G or C are not present in the set Providing a first set of tetramers having four nucleotides attached to each other;
Connecting together two to four tetramer groups in the first set to form a collection of multimeric units;
From a set of multimeric units, all multimeric units formed from the same tetramer, and all having a melting temperature less than 4 times the number of tetramers that form the multimeric unit (in Celsius) Removing multimeric units to form a modified set of multimeric units;
Placing a modified set of multimeric units in order of melting temperature and then grouping the multimeric units as a new group of different multimeric units each time the melting temperature is raised twice;
Randomizing the order of groups of multimeric units;
Alternately dividing a group of multimeric units into first and second sub collections based on the order generated by the randomizing step;
Arranging both the first and second subsets in order of increasing or decreasing melting temperature;
Reversing the order of the second subset;
Sequentially coupling the first sub-multimeric unit to the inverted second sub-multimeric unit to form a double multimeric unit set; and from the double multimeric unit set; (1) a double multimer unit having a melting temperature (Celsius) less than 11 times the number of tetramers and a double multimer unit having a melting temperature (Celsius) greater than 15 times the number of tetramers, ( 2) Double multimer unit with 3 identical tetramers connected and 3) Double multimer unit with 4 identical tetramers connected with or without interruption Forming a modified set of.
支持体上で固定化されるべき相補的なオリゴヌクレオチドをその位置で捕捉できるように、二重多量体ユニットの修正された集合を支持体上の位置に配置する段階。
The method of claim 1 further comprising the following steps:
Placing a modified collection of double multimeric units at a position on the support so that a complementary oligonucleotide to be immobilized on the support can be captured at that position.
The collection of double multimeric units to be removed has a melting temperature (Celsius) greater than 14 times the number of multimer units and tetramers with a melting temperature (Celsius) less than 12.5 times the number of tetramers 2. The method of claim 1, comprising a multimeric unit.
The method of claim 1, wherein the multimeric unit has 12 mer, the double multimeric unit has 24 mer, and the melting temperature of the double multimeric unit is 75 ° C. to 84 ° C.
四量体の数の11倍未満の融解温度(摂氏)を有する二重多量体ユニットおよび四量体の数の15倍を上回る融解温度(摂氏)を有する二重多量体ユニットを回収する(reclaim)段階;
回収した二重多量体ユニットの連結を離して、各々が多量体ユニット対を形成する段階;
四量体の数の11倍を上回り、四量体の数の17倍未満の融解温度(摂氏)を有する多量体ユニットを選択する段階;ならびに
選択された多量体ユニットを該方法に再度組み込む段階。
The method of claim 1 further comprising the following steps:
Recover double multimer units with a melting temperature (Celsius) less than 11 times the number of tetramers and double multimer units with a melting temperature (Celsius) greater than 15 times the number of tetramers (reclaim) ) Stage;
Separating the recovered double multimeric units, each forming a multimeric unit pair;
Selecting a multimeric unit having a melting temperature (Celsius) greater than 11 times the number of tetramers and less than 17 times the number of tetramers; and reincorporating the selected multimeric unit into the method .
8. The method of claim 7, wherein the steps of collecting, releasing the linkage to form a multimeric unit pair, selecting, and re-installing are repeated.
The multimer of the first sub-assembly according to claim 1, wherein the set of double multimer units is selected from the double multimer unit shown in ZIP ID # 1-465 of claim 3 2. The method of claim 1, wherein the unit is a double multimer unit in the step of binding the inverted second sub-assembly multimeric unit to form a double multimeric unit assembly.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US19727100P | 2000-04-14 | 2000-04-14 | |
| US60/197,271 | 2000-04-14 | ||
| PCT/US2001/010958 WO2001079548A2 (en) | 2000-04-14 | 2001-04-04 | Method of designing addressable array for detection of nucleic acid sequence differences using ligase detection reaction |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013222860A Division JP5992895B2 (en) | 2000-04-14 | 2013-10-28 | Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2004526402A JP2004526402A (en) | 2004-09-02 |
| JP2004526402A5 JP2004526402A5 (en) | 2012-12-06 |
| JP5508654B2 true JP5508654B2 (en) | 2014-06-04 |
Family
ID=22728709
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2001577530A Expired - Lifetime JP5508654B2 (en) | 2000-04-14 | 2001-04-04 | Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions |
| JP2013222860A Expired - Fee Related JP5992895B2 (en) | 2000-04-14 | 2013-10-28 | Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions |
| JP2016097780A Pending JP2016174613A (en) | 2000-04-14 | 2016-05-16 | Method for designing addressable array for detecting difference of nucleic acid sequence by using ligase detection reaction |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013222860A Expired - Fee Related JP5992895B2 (en) | 2000-04-14 | 2013-10-28 | Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions |
| JP2016097780A Pending JP2016174613A (en) | 2000-04-14 | 2016-05-16 | Method for designing addressable array for detecting difference of nucleic acid sequence by using ligase detection reaction |
Country Status (6)
| Country | Link |
|---|---|
| US (5) | US7455965B2 (en) |
| EP (1) | EP1303639A2 (en) |
| JP (3) | JP5508654B2 (en) |
| AU (1) | AU2001293366A1 (en) |
| CA (1) | CA2405412A1 (en) |
| WO (1) | WO2001079548A2 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016174613A (en) * | 2000-04-14 | 2016-10-06 | コーネル・リサーチ・ファンデーション・インコーポレイテッドCornell Research Foundation, Incorporated | Method for designing addressable array for detecting difference of nucleic acid sequence by using ligase detection reaction |
Families Citing this family (49)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6852487B1 (en) | 1996-02-09 | 2005-02-08 | Cornell Research Foundation, Inc. | Detection of nucleic acid sequence differences using the ligase detection reaction with addressable arrays |
| CN1304559C (en) * | 2001-10-09 | 2007-03-14 | 杭州康科生物技术有限公司 | Oncolytic microorganism expressing heat shock protein and its application |
| AU2003253651C1 (en) | 2002-06-14 | 2010-06-03 | Gen-Probe Incorporated | Compositions and methods for detecting hepatitis B virus |
| KR100695123B1 (en) * | 2003-12-03 | 2007-03-14 | 삼성전자주식회사 | Polynucleotide microarray comprising 2 or more groups of probe polynucleotide immobilized on a substrate in accordance with Tm and method for detecting a target polynucleotide |
| EP1561823A1 (en) * | 2004-02-04 | 2005-08-10 | Biotez Berlin-Buch GmbH | Method for the detection of single nucleotid polymorphisms (SNP) of genes of drug metabolism and test system for performing such a method |
| US7785843B2 (en) * | 2004-06-23 | 2010-08-31 | Sequenom, Inc. | Target-specific compomers and methods of use |
| US20060110744A1 (en) * | 2004-11-23 | 2006-05-25 | Sampas Nicolas M | Probe design methods and microarrays for comparative genomic hybridization and location analysis |
| KR100653975B1 (en) * | 2004-11-30 | 2006-12-05 | 한국과학기술원 | PNA Chip Using Zip-code and Fabricating Method Thereof |
| US7977108B2 (en) * | 2005-07-25 | 2011-07-12 | Roche Molecular Systems, Inc. | Method for detecting a mutation in a repetitive nucleic acid sequence |
| ITMI20060529A1 (en) * | 2006-03-22 | 2007-09-23 | Consiglio Nazionale Ricerche | METHOD FOR THE DETERMINATION OF LACTOPROTEIC POLYMORPHISMS IN CATTLE |
| JP5165936B2 (en) * | 2007-06-20 | 2013-03-21 | 日本碍子株式会社 | Method and array for detecting mutations in target nucleic acid |
| WO2009046445A1 (en) * | 2007-10-04 | 2009-04-09 | Halcyon Molecular | Sequencing nucleic acid polymers with electron microscopy |
| US20140342940A1 (en) | 2011-01-25 | 2014-11-20 | Ariosa Diagnostics, Inc. | Detection of Target Nucleic Acids using Hybridization |
| US11203786B2 (en) | 2010-08-06 | 2021-12-21 | Ariosa Diagnostics, Inc. | Detection of target nucleic acids using hybridization |
| US20130040375A1 (en) | 2011-08-08 | 2013-02-14 | Tandem Diagnotics, Inc. | Assay systems for genetic analysis |
| US8700338B2 (en) | 2011-01-25 | 2014-04-15 | Ariosa Diagnosis, Inc. | Risk calculation for evaluation of fetal aneuploidy |
| US20130261003A1 (en) | 2010-08-06 | 2013-10-03 | Ariosa Diagnostics, In. | Ligation-based detection of genetic variants |
| US20120034603A1 (en) | 2010-08-06 | 2012-02-09 | Tandem Diagnostics, Inc. | Ligation-based detection of genetic variants |
| US11031095B2 (en) | 2010-08-06 | 2021-06-08 | Ariosa Diagnostics, Inc. | Assay systems for determination of fetal copy number variation |
| US10167508B2 (en) | 2010-08-06 | 2019-01-01 | Ariosa Diagnostics, Inc. | Detection of genetic abnormalities |
| US10533223B2 (en) | 2010-08-06 | 2020-01-14 | Ariosa Diagnostics, Inc. | Detection of target nucleic acids using hybridization |
| US8756020B2 (en) | 2011-01-25 | 2014-06-17 | Ariosa Diagnostics, Inc. | Enhanced risk probabilities using biomolecule estimations |
| US9994897B2 (en) | 2013-03-08 | 2018-06-12 | Ariosa Diagnostics, Inc. | Non-invasive fetal sex determination |
| US11270781B2 (en) | 2011-01-25 | 2022-03-08 | Ariosa Diagnostics, Inc. | Statistical analysis for non-invasive sex chromosome aneuploidy determination |
| WO2012103031A2 (en) | 2011-01-25 | 2012-08-02 | Ariosa Diagnostics, Inc. | Detection of genetic abnormalities |
| US10131947B2 (en) | 2011-01-25 | 2018-11-20 | Ariosa Diagnostics, Inc. | Noninvasive detection of fetal aneuploidy in egg donor pregnancies |
| US20120219950A1 (en) | 2011-02-28 | 2012-08-30 | Arnold Oliphant | Assay systems for detection of aneuploidy and sex determination |
| EP2744916A4 (en) | 2011-07-13 | 2015-06-17 | Primeradx Inc | Multimodal methods for simultaneous detection and quantification of multiple nucleic acids in a sample |
| US8712697B2 (en) | 2011-09-07 | 2014-04-29 | Ariosa Diagnostics, Inc. | Determination of copy number variations using binomial probability calculations |
| CA2863257C (en) * | 2012-02-14 | 2021-12-14 | Cornell University | Method for relative quantification of nucleic acid sequence, expression, or copy changes, using combined nuclease, ligation, and polymerase reactions |
| US10289800B2 (en) | 2012-05-21 | 2019-05-14 | Ariosa Diagnostics, Inc. | Processes for calculating phased fetal genomic sequences |
| CN104583421A (en) | 2012-07-19 | 2015-04-29 | 阿瑞奥萨诊断公司 | Multiplexed sequential ligation-based detection of genetic variants |
| DE102013001417B4 (en) | 2013-01-24 | 2016-02-18 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Reflective optical element for a dynamic deflection of a laser beam and a method for its production |
| WO2014160199A1 (en) | 2013-03-14 | 2014-10-02 | Cornell University | Method for relative quantification of changes in dna methylation, using combined nuclease, ligation, and polymerase reactions |
| GB2584364A (en) | 2013-03-15 | 2020-12-02 | Abvitro Llc | Single cell bar-coding for antibody discovery |
| AU2014278730B2 (en) | 2013-06-13 | 2020-12-10 | F. Hoffmann-La Roche Ag | Statistical analysis for non-invasive sex chromosome aneuploidy determination |
| DE102013011304A1 (en) | 2013-07-02 | 2015-01-22 | Technische Universität Dresden | Method and device for detecting binding events of molecules |
| EP3726213A1 (en) | 2013-08-19 | 2020-10-21 | Singular Bio Inc. | Assays for single molecule detection and use thereof |
| US11447814B2 (en) * | 2013-10-18 | 2022-09-20 | Seegene, Inc. | Detection of target nucleic acid sequence on solid phase by PTO cleavage and extension using HCTO assay |
| US10260111B1 (en) | 2014-01-20 | 2019-04-16 | Brett Eric Etchebarne | Method of detecting sepsis-related microorganisms and detecting antibiotic-resistant sepsis-related microorganisms in a fluid sample |
| ES2807222T3 (en) | 2014-04-01 | 2021-02-22 | Univ Cornell | Detection of DNA methylation using combined ligation and nuclease reactions |
| US20160032281A1 (en) * | 2014-07-31 | 2016-02-04 | Fei Company | Functionalized grids for locating and imaging biological specimens and methods of using the same |
| SG11201702060VA (en) | 2014-09-15 | 2017-04-27 | Abvitro Inc | High-throughput nucleotide library sequencing |
| JP6580331B2 (en) * | 2015-01-30 | 2019-09-25 | 倉敷紡績株式会社 | Method for preparing single-stranded DNA product |
| JP6616574B2 (en) * | 2015-01-30 | 2019-12-04 | 倉敷紡績株式会社 | Visually identifiable genetic test |
| US11739371B2 (en) | 2015-02-18 | 2023-08-29 | Invitae Corporation | Arrays for single molecule detection and use thereof |
| CN104862401B (en) * | 2015-05-29 | 2017-10-31 | 沈阳优吉诺生物科技有限公司 | Detect primer, kit and its PCR method of KRAS gene hot mutant sites |
| JPWO2021162028A1 (en) * | 2020-02-14 | 2021-08-19 | ||
| CN111560457A (en) * | 2020-05-26 | 2020-08-21 | 上海市农业科学院 | PCR/LDR molecular marker and method for identifying rice fragrance allele Badh2-E2 |
Family Cites Families (91)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5258506A (en) | 1984-10-16 | 1993-11-02 | Chiron Corporation | Photolabile reagents for incorporation into oligonucleotide chains |
| US4883750A (en) | 1984-12-13 | 1989-11-28 | Applied Biosystems, Inc. | Detection of specific sequences in nucleic acids |
| US6060237A (en) * | 1985-02-26 | 2000-05-09 | Biostar, Inc. | Devices and methods for optical detection of nucleic acid hybridization |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US5525464A (en) | 1987-04-01 | 1996-06-11 | Hyseq, Inc. | Method of sequencing by hybridization of oligonucleotide probes |
| US5202231A (en) | 1987-04-01 | 1993-04-13 | Drmanac Radoje T | Method of sequencing of genomes by hybridization of oligonucleotide probes |
| GB8810400D0 (en) | 1988-05-03 | 1988-06-08 | Southern E | Analysing polynucleotide sequences |
| US4988617A (en) | 1988-03-25 | 1991-01-29 | California Institute Of Technology | Method of detecting a nucleotide change in nucleic acids |
| US5700637A (en) | 1988-05-03 | 1997-12-23 | Isis Innovation Limited | Apparatus and method for analyzing polynucleotide sequences and method of generating oligonucleotide arrays |
| AU629845B2 (en) | 1988-08-30 | 1992-10-15 | Abbott Laboratories | Detection and amplification of target nucleic acid sequences |
| ATE157404T1 (en) | 1989-03-17 | 1997-09-15 | Abbott Lab | METHOD AND DEVICE FOR HYBRIDIZING NUCLEIC ACID WITH IMPROVED REACTION KINETICS |
| WO1990011372A1 (en) | 1989-03-21 | 1990-10-04 | Collaborative Research, Inc. | Multiplex dna diagnostic test |
| US5035996A (en) | 1989-06-01 | 1991-07-30 | Life Technologies, Inc. | Process for controlling contamination of nucleic acid amplification reactions |
| US5424186A (en) | 1989-06-07 | 1995-06-13 | Affymax Technologies N.V. | Very large scale immobilized polymer synthesis |
| US5744101A (en) | 1989-06-07 | 1998-04-28 | Affymax Technologies N.V. | Photolabile nucleoside protecting groups |
| US5143854A (en) | 1989-06-07 | 1992-09-01 | Affymax Technologies N.V. | Large scale photolithographic solid phase synthesis of polypeptides and receptor binding screening thereof |
| US5527681A (en) | 1989-06-07 | 1996-06-18 | Affymax Technologies N.V. | Immobilized molecular synthesis of systematically substituted compounds |
| US5104792A (en) | 1989-12-21 | 1992-04-14 | The United States Of America As Represented By The Department Of Health And Human Services | Method for amplifying unknown nucleic acid sequences |
| US5516663A (en) | 1990-01-26 | 1996-05-14 | Abbott Laboratories | Ligase chain reaction with endonuclease IV correction and contamination control |
| US5494810A (en) | 1990-05-03 | 1996-02-27 | Cornell Research Foundation, Inc. | Thermostable ligase-mediated DNA amplifications system for the detection of genetic disease |
| DK0528882T3 (en) | 1990-05-03 | 2008-01-14 | Cornell Res Foundation Inc | DNA amplification system for detection of genetic diseases by thermostable ligase |
| ATE176002T1 (en) | 1990-07-24 | 1999-02-15 | Hoffmann La Roche | REDUCING NON-SPECIFIC AMPLIFICATION DURING (IN VITRO) NUCLEIC ACID AMPLIFICATION USING MODIFIED NUCLEIC ACID BASES |
| CA2046713A1 (en) | 1990-10-16 | 1992-04-17 | Richard M. Martinelli | Amplification of midivariant dna templates |
| CA2055755A1 (en) | 1990-11-22 | 1992-05-23 | Toshihiko Kishimoto | Method of immobilizing single-stranded dna on carrier at terminal |
| DE69132843T2 (en) | 1990-12-06 | 2002-09-12 | Affymetrix Inc N D Ges D Staat | Identification of nucleic acids in samples |
| DE4039348A1 (en) | 1990-12-10 | 1992-06-11 | Henkel Kgaa | CARPET CLEANER |
| WO1992010566A1 (en) | 1990-12-13 | 1992-06-25 | Board Of Regents, The University Of Texas System | In-situ hybridization probes for identification and banding of specific human chromosomes and regions |
| EP0566670A4 (en) | 1990-12-17 | 1993-12-08 | Idexx Laboratories, Inc. | Nucleic acid sequence detection by triple helix formation |
| US5290925A (en) | 1990-12-20 | 1994-03-01 | Abbott Laboratories | Methods, kits, and reactive supports for 3' labeling of oligonucleotides |
| RU1794088C (en) | 1991-03-18 | 1993-02-07 | Институт Молекулярной Биологии Ан@ Ссср | Method of dna nucleotide sequence determination and a device for its realization |
| AU2170092A (en) | 1991-05-24 | 1992-12-30 | President And Fellows Of Harvard College, The | Parallel sequential reactor |
| US5278298A (en) | 1991-05-29 | 1994-01-11 | Merck & Co., Inc. | Eimeria brunetti 16s rDNA probes |
| DK0519338T3 (en) | 1991-06-20 | 1996-10-28 | Hoffmann La Roche | Improved Methods for Nucleic Acid Amplification |
| US5371241A (en) | 1991-07-19 | 1994-12-06 | Pharmacia P-L Biochemicals Inc. | Fluorescein labelled phosphoramidites |
| WO1993004199A2 (en) | 1991-08-20 | 1993-03-04 | Scientific Generics Limited | Methods of detecting or quantitating nucleic acids and of producing labelled immobilised nucleic acids |
| DE69223980T2 (en) | 1991-10-15 | 1998-05-28 | Multilyte Ltd | BINDING TEST USING A MARKED REAGENT |
| DE69232753T2 (en) | 1991-11-01 | 2003-05-15 | Diatech Pty Ltd | SOLIDS PHASE EXPANSION PROCESS |
| US5594121A (en) | 1991-11-07 | 1997-01-14 | Gilead Sciences, Inc. | Enhanced triple-helix and double-helix formation with oligomers containing modified purines |
| US5412087A (en) | 1992-04-24 | 1995-05-02 | Affymax Technologies N.V. | Spatially-addressable immobilization of oligonucleotides and other biological polymers on surfaces |
| US5324633A (en) | 1991-11-22 | 1994-06-28 | Affymax Technologies N.V. | Method and apparatus for measuring binding affinity |
| AU3728093A (en) | 1992-02-19 | 1993-09-13 | Public Health Research Institute Of The City Of New York, Inc., The | Novel oligonucleotide arrays and their use for sorting, isolating, sequencing, and manipulating nucleic acids |
| CA2133220A1 (en) | 1992-03-31 | 1993-10-14 | Stanley R. Bouma | Method of multiplex ligase chain reaction |
| WO1993020236A1 (en) | 1992-04-03 | 1993-10-14 | Applied Biosystems, Inc. | Probe composition and method |
| US5470705A (en) | 1992-04-03 | 1995-11-28 | Applied Biosystems, Inc. | Probe composition containing a binding domain and polymer chain and methods of use |
| ATE198358T1 (en) | 1992-04-27 | 2001-01-15 | Dartmouth College | DETECTION OF GENE SEQUENCES IN BIOLOGICAL LIQUIDS |
| WO1993025563A1 (en) | 1992-06-17 | 1993-12-23 | City Of Hope | A method of detecting and discriminating between nucleic acid sequences |
| US5981176A (en) | 1992-06-17 | 1999-11-09 | City Of Hope | Method of detecting and discriminating between nucleic acid sequences |
| WO1994001446A2 (en) | 1992-07-09 | 1994-01-20 | Beckman Instruments, Inc. | Derivatized organic solid support for nucleic acid synthesis |
| US5700672A (en) | 1992-07-23 | 1997-12-23 | Stratagene | Purified thermostable pyrococcus furiousus DNA ligase |
| US5674698A (en) * | 1992-09-14 | 1997-10-07 | Sri International | Up-converting reporters for biological and other assays using laser excitation techniques |
| WO1994009022A1 (en) | 1992-10-09 | 1994-04-28 | Oncor, Inc. | Methods for the detection of chromosome structural abnormalities by in situ hybridization to fixed tissue |
| US5795714A (en) | 1992-11-06 | 1998-08-18 | Trustees Of Boston University | Method for replicating an array of nucleic acid probes |
| JP2575270B2 (en) | 1992-11-10 | 1997-01-22 | 浜松ホトニクス株式会社 | Method for determining base sequence of nucleic acid, method for detecting single molecule, apparatus therefor and method for preparing sample |
| US5556749A (en) * | 1992-11-12 | 1996-09-17 | Hitachi Chemical Research Center, Inc. | Oligoprobe designstation: a computerized method for designing optimal DNA probes |
| EP0686200A4 (en) | 1993-01-27 | 1997-07-02 | Oncor Inc | Amplification of nucleic acid sequences |
| US5593840A (en) | 1993-01-27 | 1997-01-14 | Oncor, Inc. | Amplification of nucleic acid sequences |
| WO1994017206A1 (en) | 1993-01-27 | 1994-08-04 | Oncor, Inc. | Method for amplifying nucleic acid sequences |
| US5422252A (en) | 1993-06-04 | 1995-06-06 | Becton, Dickinson And Company | Simultaneous amplification of multiple targets |
| CA2122203C (en) | 1993-05-11 | 2001-12-18 | Melinda S. Fraiser | Decontamination of nucleic acid amplification reactions |
| SG63589A1 (en) | 1993-05-14 | 1999-03-30 | Johnson & Johnson Clin Diag | Diagnostic compositions elements methods and test kits for amplification and detection of two or more dna's using primers having matched melting temperatures |
| DK72493D0 (en) | 1993-06-18 | 1993-06-18 | Risoe Forskningscenter | SOLID SUPPORTS FOR USE IN PEPTIDE SYNTHESIS AND ASSAYS |
| US5858659A (en) | 1995-11-29 | 1999-01-12 | Affymetrix, Inc. | Polymorphism detection |
| US5837832A (en) | 1993-06-25 | 1998-11-17 | Affymetrix, Inc. | Arrays of nucleic acid probes on biological chips |
| US5731171A (en) | 1993-07-23 | 1998-03-24 | Arch Development Corp. | Sequence independent amplification of DNA |
| US5415839A (en) | 1993-10-21 | 1995-05-16 | Abbott Laboratories | Apparatus and method for amplifying and detecting target nucleic acids |
| US6156501A (en) | 1993-10-26 | 2000-12-05 | Affymetrix, Inc. | Arrays of modified nucleic acid probes and methods of use |
| US5352582A (en) | 1993-10-28 | 1994-10-04 | Hewlett-Packard Company | Holographic based bio-assay |
| US5429807A (en) | 1993-10-28 | 1995-07-04 | Beckman Instruments, Inc. | Method and apparatus for creating biopolymer arrays on a solid support surface |
| WO1995035390A1 (en) | 1994-06-22 | 1995-12-28 | Mount Sinai School Of Medicine Of The City University Of New York | Ligation-dependent amplification for the detection of infectious pathogens and abnormal genes |
| US5942391A (en) | 1994-06-22 | 1999-08-24 | Mount Sinai School Of Medicine | Nucleic acid amplification method: ramification-extension amplification method (RAM) |
| US5876924A (en) | 1994-06-22 | 1999-03-02 | Mount Sinai School Of Medicine | Nucleic acid amplification method hybridization signal amplification method (HSAM) |
| US5834181A (en) | 1994-07-28 | 1998-11-10 | Genzyme Corporation | High throughput screening method for sequences or genetic alterations in nucleic acids |
| ATE226983T1 (en) | 1994-08-19 | 2002-11-15 | Pe Corp Ny | COUPLED AMPLICATION AND LIGATION PROCEDURE |
| US5648213A (en) | 1994-08-30 | 1997-07-15 | Beckman Instruments, Inc. | Compositions and methods for use in detection of analytes |
| US5695934A (en) | 1994-10-13 | 1997-12-09 | Lynx Therapeutics, Inc. | Massively parallel sequencing of sorted polynucleotides |
| US5512441A (en) | 1994-11-15 | 1996-04-30 | American Health Foundation | Quantative method for early detection of mutant alleles and diagnostic kits for carrying out the method |
| WO1996015271A1 (en) | 1994-11-16 | 1996-05-23 | Abbott Laboratories | Multiplex ligations-dependent amplification |
| US5667974A (en) | 1995-06-07 | 1997-09-16 | Abbott Laboratories | Method for detecting nucleic acid sequences using competitive amplification |
| US5728526A (en) | 1995-06-07 | 1998-03-17 | Oncor, Inc. | Method for analyzing a nucleotide sequence |
| US5723320A (en) | 1995-08-29 | 1998-03-03 | Dehlinger; Peter J. | Position-addressable polynucleotide arrays |
| WO1997019193A2 (en) | 1995-11-21 | 1997-05-29 | Yale University | Unimolecular segment amplification and detection |
| US6852487B1 (en) | 1996-02-09 | 2005-02-08 | Cornell Research Foundation, Inc. | Detection of nucleic acid sequence differences using the ligase detection reaction with addressable arrays |
| AU735440B2 (en) * | 1996-02-09 | 2001-07-05 | Cornell Research Foundation Inc. | Detection of nucleic acid sequence differences using the ligase detection reaction with addressable arrays |
| US5868136A (en) | 1996-02-20 | 1999-02-09 | Axelgaard Manufacturing Co. Ltd. | Medical electrode |
| US6458530B1 (en) | 1996-04-04 | 2002-10-01 | Affymetrix Inc. | Selecting tag nucleic acids |
| EP1736554B1 (en) | 1996-05-29 | 2013-10-09 | Cornell Research Foundation, Inc. | Detection of nucleic acid sequence differences using coupled ligase detection and polymerase chain reactions |
| US6312892B1 (en) | 1996-07-19 | 2001-11-06 | Cornell Research Foundation, Inc. | High fidelity detection of nucleic acid differences by ligase detection reaction |
| US5932711A (en) | 1997-03-05 | 1999-08-03 | Mosaic Technologies, Inc. | Nucleic acid-containing polymerizable complex |
| GB9902970D0 (en) * | 1999-02-11 | 1999-03-31 | Zeneca Ltd | Novel matrix |
| US6506594B1 (en) | 1999-03-19 | 2003-01-14 | Cornell Res Foundation Inc | Detection of nucleic acid sequence differences using the ligase detection reaction with addressable arrays |
| AU2001293366A1 (en) * | 2000-04-14 | 2001-10-30 | Cornell Research Foundation, Inc. | Method of designing addressable array for detection of nucleic acid sequence differences using ligase detection reaction |
-
2001
- 2001-04-04 AU AU2001293366A patent/AU2001293366A1/en not_active Abandoned
- 2001-04-04 US US10/257,158 patent/US7455965B2/en not_active Expired - Fee Related
- 2001-04-04 JP JP2001577530A patent/JP5508654B2/en not_active Expired - Lifetime
- 2001-04-04 CA CA002405412A patent/CA2405412A1/en not_active Abandoned
- 2001-04-04 WO PCT/US2001/010958 patent/WO2001079548A2/en active Application Filing
- 2001-04-04 EP EP01969050A patent/EP1303639A2/en not_active Withdrawn
-
2008
- 2008-10-15 US US12/252,169 patent/US8492085B2/en not_active Expired - Fee Related
-
2013
- 2013-07-22 US US13/947,777 patent/US9340834B2/en not_active Expired - Fee Related
- 2013-10-28 JP JP2013222860A patent/JP5992895B2/en not_active Expired - Fee Related
-
2016
- 2016-04-12 US US15/096,446 patent/US9725759B2/en not_active Expired - Fee Related
- 2016-05-16 JP JP2016097780A patent/JP2016174613A/en active Pending
-
2017
- 2017-07-07 US US15/644,273 patent/US10131938B2/en not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016174613A (en) * | 2000-04-14 | 2016-10-06 | コーネル・リサーチ・ファンデーション・インコーポレイテッドCornell Research Foundation, Incorporated | Method for designing addressable array for detecting difference of nucleic acid sequence by using ligase detection reaction |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2004526402A (en) | 2004-09-02 |
| EP1303639A2 (en) | 2003-04-23 |
| JP5992895B2 (en) | 2016-09-14 |
| AU2001293366A1 (en) | 2001-10-30 |
| US10131938B2 (en) | 2018-11-20 |
| WO2001079548A2 (en) | 2001-10-25 |
| US8492085B2 (en) | 2013-07-23 |
| US20050142543A1 (en) | 2005-06-30 |
| US20130345072A1 (en) | 2013-12-26 |
| WO2001079548A3 (en) | 2003-02-06 |
| US7455965B2 (en) | 2008-11-25 |
| JP2016174613A (en) | 2016-10-06 |
| US9340834B2 (en) | 2016-05-17 |
| US20160215329A1 (en) | 2016-07-28 |
| US20180002744A1 (en) | 2018-01-04 |
| CA2405412A1 (en) | 2001-10-25 |
| US9725759B2 (en) | 2017-08-08 |
| US20120283139A1 (en) | 2012-11-08 |
| JP2014068651A (en) | 2014-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5508654B2 (en) | Method for designing positionable arrays for detection of nucleic acid sequence differences using ligase detection reactions | |
| JP4766750B2 (en) | Detection of nucleic acid sequence differences using a ligase detection reaction with a positionable array | |
| JP4294732B2 (en) | Detection of nucleic acid sequence differences using ligase detection reactions in addressable arrays | |
| JP2003520570A5 (en) |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080331 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20090305 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110221 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20110520 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20110527 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110819 |
|
| A524 | Written submission of copy of amendment under article 19 pct |
Free format text: JAPANESE INTERMEDIATE CODE: A524 Effective date: 20110819 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120423 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120720 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20120727 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20121022 |
|
| A524 | Written submission of copy of amendment under article 19 pct |
Free format text: JAPANESE INTERMEDIATE CODE: A524 Effective date: 20121022 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130627 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131028 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131108 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20131202 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140127 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140128 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140219 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140324 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5508654 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |