JP5455355B2 - Speech recognition apparatus and program - Google Patents
Speech recognition apparatus and program Download PDFInfo
- Publication number
- JP5455355B2 JP5455355B2 JP2008302231A JP2008302231A JP5455355B2 JP 5455355 B2 JP5455355 B2 JP 5455355B2 JP 2008302231 A JP2008302231 A JP 2008302231A JP 2008302231 A JP2008302231 A JP 2008302231A JP 5455355 B2 JP5455355 B2 JP 5455355B2
- Authority
- JP
- Japan
- Prior art keywords
- word
- name
- speech recognition
- information
- utterance
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Description
本発明は、音声認識装置及びプログラムに係り、特に、入力音声に対する音声認識の結果の候補となる単語を制限する音声認識装置及びプログラムに関する。 The present invention relates to a speech recognition apparatus and program, and more particularly, to a speech recognition apparatus and program for restricting words that are candidates for speech recognition results for input speech.
従来より、利用状況に応じて音声認識辞書の語彙制限を行うと共に、ユーザの発話を促して、効率的に音声認識処理を行う音声認識装置が知られている(特許文献1)。この音声認識装置では、例えば、入力待ち情報種別が「施設名称」で、検索範囲が「愛知県」の場合、「愛知県の施設名称を入力して下さい」という応答文を生成している。 2. Description of the Related Art Conventionally, there has been known a speech recognition apparatus that performs speech recognition processing efficiently by restricting the vocabulary of a speech recognition dictionary according to usage conditions and encouraging the user to speak. In this speech recognition apparatus, for example, when the input waiting information type is “facility name” and the search range is “Aichi Prefecture”, a response sentence “Please input the facility name of Aichi Prefecture” is generated.
また、音声認識装置の利用方法に対する熟知度合が異なる各利用者のいずれにとっても使い勝手を良くする音声認識装置が知られている(特許文献2)。この音声認識装置では、「目的地の設定が行えます」のように、音声入力にて指示可能な設定項目自体を案内したり、「目的地を設定するときは都道府県名から入力して下さい」というように、入力方法の説明を、ガイド内容として報知している。また、「例えば愛知県刈谷市昭和町と入力して下さい」というように、具体的な入力例をガイド内容として報知している。
しかしながら、上記の特許文献1に記載の技術では、ユーザは「何を」入力すれば良いかがわかるという利点があるものの、「どのように」入力したら良いかまではわからない、という問題がある。例えば、施設名称を単独で「名古屋大学」のように入力すべきなのか、地名と組み合わせて「千種区の名古屋大学」と入力すべきなのか、まではわからない、という問題がある。
However, although the technique described in
また、上記の特許文献2に記載の技術では、「例えば愛知県刈谷市昭和町と入力して下さい」のように、どのように音声入力すべきかを報知するものの、音声認識の結果の候補を制限する場合に、認識できない単語を用いて報知してしまう場合があるため、認識可能な発話内容を教示することができない、という問題がある。 Further, in the technique described in Patent Document 2 above, although a notification of how to input speech is made, such as “Please enter Showamachi, Kariya City, Aichi Prefecture”, for example, candidates for the result of speech recognition are displayed. In the case of restriction, there is a case in which notification is performed using an unrecognizable word, and therefore there is a problem that the recognizable utterance content cannot be taught.
本発明は、上記の問題点を解決するためになされたもので、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる音声認識装置及びプログラムを提供することを目的とする。 The present invention has been made to solve the above problems, and an object of the present invention is to provide a speech recognition apparatus and program capable of simultaneously teaching a user to a recognizable utterance content and utterance method. And
上記の目的を達成するために第1の発明に係る音声認識装置は、自装置の位置を検出する位置検出手段と、地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段と、前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、前記位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段と、前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を複数生成する生成手段と、前記生成手段によって生成された前記複数の発話例を出力装置に出力させる発話例出力制御手段と、前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段と、前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段とを含んで構成されている。 In order to achieve the above object, a speech recognition apparatus according to a first invention comprises a position detection means for detecting the position of its own apparatus, a word representing an area name, a word representing an industry name, and a word representing a facility name. A dictionary registration unit that stores a plurality of words including a word dictionary that stores location information corresponding to each of the word that represents the area name and the word that represents the facility name, and the dictionary registration unit From the registered word dictionary, based on position information registered in the word dictionary, a word group related to a predetermined range including the position of the own device detected by the position detecting unit is recognized by voice recognition for input speech. the selecting means for selecting as a result of the candidate, the combination of the connected words and words representing a word and the facility name representing the area name included in the group of words selected by the selection means Generating means for generating a plurality of utterance examples, utterance example output control means for outputting the plurality of utterance examples generated by the generation means to an output device, and a word group selected by the selection means, Search for information related to words obtained as a result of speech recognition by the speech recognition means from speech recognition means for performing speech recognition of input speech input for search and an information database storing information related to the plurality of words Information search means.
第2の発明に係るプログラムは、コンピュータを、地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段、前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、自装置の位置を検出する位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段、前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を複数生成する生成手段、前記生成手段によって生成された前記複数の発話例を出力装置に出力させる発話例出力制御手段、前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段、及び前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段として機能させるためのプログラムである。 A program according to a second invention stores a plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name, and the word representing the area name and the facility name. Based on the position information registered in the word dictionary from the word dictionary registered in the dictionary registering means in which a word dictionary storing position information is registered corresponding to each of the words representing And selecting means for selecting a word group related to a predetermined range including the position of the own apparatus detected by the position detecting means for detecting the position of the own apparatus as a candidate of a result of speech recognition for the input voice, by the selecting means generating means for generating a plurality utterance example using the word representing the words and the facility name representing the area name included in the selected word group the combination of the connection word, Speech example output control means for outputting the plurality of utterance examples generated by the writing generation means to an output device, and speech recognition of input speech input for information retrieval using the word group selected by the selection means And a program for functioning as an information retrieval unit for retrieving information on a word obtained as a result of speech recognition by the speech recognition unit from an information database storing information on the plurality of words. .
第1の発明及び第2の発明によれば、位置検出手段によって、自装置の位置を検出する。選択手段によって、辞書登録手段に登録された単語辞書から、単語辞書に登録されている位置情報に基づいて、位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する。 According to the first and second inventions, the position of the device itself is detected by the position detection means. From the word dictionary registered in the dictionary registration unit by the selection unit , based on the position information registered in the word dictionary, a word group related to a predetermined range including the position of the own device detected by the position detection unit, It selects as a candidate of the result of the speech recognition with respect to the input speech.
そして、生成手段によって、選択手段によって選択された単語群に含まれる地域名を表わす単語及び施設名を表わす単語と接続語との組み合わせを用いた発話例を複数生成し、発話例出力制御手段によって、生成手段によって生成された複数の発話例を出力装置に出力させる。 Then, the generation unit generates a plurality of utterance examples using a combination of a word representing a region name and a facility name included in the word group selected by the selection unit, and the utterance example output control unit The output device outputs a plurality of utterance examples generated by the generating means.
そして、音声認識手段によって、選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行い、情報検索手段によって、複数の単語に関する情報を格納した情報データベースから、音声認識手段による音声認識の結果として得られた単語に関する情報を検索する。 The speech recognition means performs speech recognition of the input speech input for information retrieval using the word group selected by the selection means, and stores information related to a plurality of words by the information retrieval means Then, information regarding words obtained as a result of speech recognition by the speech recognition means is retrieved.
このように、単語辞書から、自装置の位置を含む所定範囲に関連する単語群を音声認識の結果の候補として選択し、選択された単語群に含まれる地域名を表わす単語及び施設名を表わす単語のうち少なくとも1つを用いた発話例を複数生成して、出力装置に出力させることにより、情報検索のための音声認識処理の認識率を向上させることができると共に、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。 As described above, a word group related to a predetermined range including the position of the own device is selected from the word dictionary as a candidate for the result of speech recognition, and a word representing a region name and a facility name included in the selected word group are represented. By generating a plurality of utterance examples using at least one of the words and outputting them to the output device, it is possible to improve the recognition rate of the speech recognition processing for information retrieval, and to recognize the user Possible utterance contents and utterance methods can be taught simultaneously.
第3の発明に係る音声認識装置は、自装置の位置を検出する位置検出手段と、地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段と、前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、前記位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段と、前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を生成すると共に、前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を生成する生成手段と、前記生成手段によって生成された前記発話例及び前記発話禁止例を出力装置に出力させる発話例出力制御手段と、前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段と、前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段とを含んで構成されている。 A voice recognition device according to a third aspect of the present invention stores position detection means for detecting the position of its own device, a plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name. , Corresponding to each of the word representing the region name and the word representing the facility name, a dictionary registration unit in which a word dictionary storing location information is registered, and the word dictionary registered in the dictionary registration unit, Selection for selecting a word group related to a predetermined range including the position of the own device detected by the position detection unit as a candidate of a result of speech recognition for the input speech based on position information registered in the word dictionary means and, when generating the speech example using a combination of access word a word representing the words and the facility name representing the area name included in the group of words selected by the selection means co , Among the plurality of words stored in the word dictionary, to generate an utterance prohibition example using a combination of access word a word representing the words and the facility name representing the locality names which are not selected by said selection means For information retrieval using a generation means, an utterance example output control means for outputting the utterance example and the utterance prohibition example generated by the generation means to an output device, and a word group selected by the selection means Speech recognition means for performing speech recognition of input speech that has been input, and information search means for searching for information on words obtained as a result of speech recognition by the speech recognition means from an information database storing information on the plurality of words It is comprised including.
第4の発明に係るプログラムは、コンピュータを、地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段、前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、自装置の位置を検出する位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段、前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を生成すると共に、前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を生成する生成手段、前記生成手段によって生成された前記発話例及び前記発話禁止例を出力装置に出力させる発話例出力制御手段、前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段、及び前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段として機能させるためのプログラムである。 According to a fourth aspect of the present invention, a program stores a plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name, and the word representing the area name and the facility name. Based on the position information registered in the word dictionary from the word dictionary registered in the dictionary registering means in which a word dictionary storing position information is registered corresponding to each of the words representing And selecting means for selecting a word group related to a predetermined range including the position of the own apparatus detected by the position detecting means for detecting the position of the own apparatus as a candidate of a result of speech recognition for the input voice, by the selecting means to generate a speech example using a combination of access word a word representing the words and the facility name representing the area name included in the selected word group, the single Among the plurality of words stored in the dictionary, generation means for generating a speech prohibited example using a combination of access word a word representing the words and the facility name representing the locality names which are not selected by said selecting means, An utterance example output control means for causing the output device to output the utterance example and the utterance prohibition example generated by the generation means, and an input speech input for information retrieval using the word group selected by the selection means And a speech recognition means for performing speech recognition, and an information retrieval means for retrieving information on words obtained as a result of speech recognition by the speech recognition means from an information database storing information on the plurality of words. It is a program.
第3の発明及び第4の発明によれば、位置検出手段によって、自装置の位置を検出する。選択手段によって、辞書登録手段に登録された単語辞書から、単語辞書に登録されている位置情報に基づいて、位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する。 According to 3rd invention and 4th invention, the position of an own apparatus is detected by a position detection means. From the word dictionary registered in the dictionary registration unit by the selection unit , based on the position information registered in the word dictionary, a word group related to a predetermined range including the position of the own device detected by the position detection unit, It selects as a candidate of the result of the speech recognition with respect to the input speech.
そして、生成手段によって、選択手段によって選択された単語群に含まれる地域名を表わす単語及び施設名を表わす単語と接続語との組み合わせを用いた発話例を生成すると共に、単語辞書に格納された複数の単語のうち、選択手段によって選択されなかった地域名を表わす単語及び施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を生成する。発話例出力制御手段によって、生成手段によって生成された発話例及び発話禁止例を出力装置に出力させる。 Then, the generation unit generates an utterance example using a combination of a word representing a region name and a word representing a facility name and a connected word included in the word group selected by the selection unit, and stored in the word dictionary An utterance prohibition example using a combination of a word representing a region name and a word representing a facility name that has not been selected by the selection means and a connected word among a plurality of words is generated. The utterance example output control means causes the output device to output the utterance example and the utterance prohibition example generated by the generation means.
そして、音声認識手段によって、選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行い、情報検索手段によって、複数の単語に関する情報を格納した情報データベースから、音声認識手段による音声認識の結果として得られた単語に関する情報を検索する。 The speech recognition means performs speech recognition of the input speech input for information retrieval using the word group selected by the selection means, and stores information related to a plurality of words by the information retrieval means Then, information regarding words obtained as a result of speech recognition by the speech recognition means is retrieved.
このように、単語辞書から、自装置の位置を含む所定範囲に関連する単語群を音声認識の結果の候補として選択し、選択された単語群に含まれる地域名を表わす単語及び施設名を表わす単語のうち少なくとも1つを用いた発話例と、選択されなかった地域名を表わす単語及び施設名を表わす単語のうち少なくとも1つを用いた発話禁止例とを生成して、出力装置に出力させることにより、情報検索のための音声認識処理の認識率を向上させることができると共に、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。 As described above, a word group related to a predetermined range including the position of the own device is selected from the word dictionary as a candidate for the result of speech recognition, and a word representing a region name and a facility name included in the selected word group are represented. An utterance example using at least one of the words and an utterance prohibition example using at least one of the word representing the area name and the facility name not selected are generated and output to the output device. As a result, the recognition rate of the speech recognition process for information retrieval can be improved, and the recognizable utterance content and utterance method can be simultaneously taught to the user.
第5の発明に係る音声認識装置は、自装置の位置を検出する位置検出手段と、地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段と、前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、前記位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段と、前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を複数生成する生成手段と、前記生成手段によって生成された前記複数の発話禁止例を出力装置に出力させる発話例出力制御手段と、前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段と、前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段とを含んで構成されている。 According to a fifth aspect of the present invention, there is provided a speech recognition apparatus for storing a plurality of words including a position detection means for detecting the position of the own apparatus, a word representing an area name, a word representing an industry name, and a word representing a facility name. , Corresponding to each of the word representing the region name and the word representing the facility name, a dictionary registration unit in which a word dictionary storing location information is registered, and the word dictionary registered in the dictionary registration unit, Selection for selecting a word group related to a predetermined range including the position of the own device detected by the position detection unit as a candidate of a result of speech recognition for the input speech based on position information registered in the word dictionary union of means, among the plurality of words stored in the word dictionary, the access word with words representing a word and the facility name representing the locality names which are not selected by said selection means Was a generation unit configured to generate a plurality of speech prohibited example using a speech example output control means for outputting said plurality of utterance prohibition examples generated by the generating means to the output device, group of words selected by the selection means Obtained as a result of speech recognition by the speech recognition means from speech recognition means for performing speech recognition of input speech input for information retrieval and an information database storing information on the plurality of words And information search means for searching for information related to words.
第6の発明に係るプログラムは、コンピュータを、地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段、前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、自装置の位置を検出する位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段、前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を複数生成する生成手段、前記生成手段によって生成された前記複数の発話禁止例を出力装置に出力させる発話例出力制御手段、前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段、及び前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段として機能させるためのプログラムである。 A program according to a sixth invention stores a plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name, and the word representing the area name and the facility name. Based on the position information registered in the word dictionary from the word dictionary registered in the dictionary registering means in which a word dictionary storing position information is registered corresponding to each of the words representing Selection means for selecting a word group related to a predetermined range including the position of the own apparatus detected by the position detection means for detecting the position of the own apparatus as a candidate for a result of speech recognition for the input voice; among the plurality of words stored, using a combination of access word a word representing the words and the facility name representing the locality names which are not selected by said selection means Information search using a generation unit that generates a plurality of prohibited speech examples, a speech example output control unit that causes the output unit to output the plurality of prohibited speech examples generated by the generating unit, and a word group selected by the selection unit Information about a word obtained as a result of speech recognition by the speech recognition means is retrieved from speech recognition means for performing speech recognition of input speech inputted for the purpose and an information database storing information on the plurality of words This is a program for functioning as information retrieval means.
第5の発明及び第6の発明によれば、位置検出手段によって、自装置の位置を検出する。選択手段によって、辞書登録手段に登録された単語辞書から、単語辞書に登録されている位置情報に基づいて、位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する。 According to the fifth and sixth inventions, the position of the device itself is detected by the position detection means. From the word dictionary registered in the dictionary registration unit by the selection unit , based on the position information registered in the word dictionary, a word group related to a predetermined range including the position of the own device detected by the position detection unit, It selects as a candidate of the result of the speech recognition with respect to the input speech.
そして、生成手段によって、単語辞書に格納された複数の単語のうち、選択手段によって選択されなかった地域名を表わす単語及び施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を複数生成する。発話例出力制御手段によって、生成手段によって生成された複数の発話禁止例を出力装置に出力させる。 Then, a plurality of utterance prohibition examples using a combination of a word representing a region name and a word representing a facility name and a connected word out of a plurality of words stored in the word dictionary by the generating unit. Generate. The utterance example output control means causes the output device to output a plurality of utterance prohibition examples generated by the generation means.
そして、音声認識手段によって、選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行い、情報検索手段によって、複数の単語に関する情報を格納した情報データベースから、音声認識手段による音声認識の結果として得られた単語に関する情報を検索する。 The speech recognition means performs speech recognition of the input speech input for information retrieval using the word group selected by the selection means, and stores information related to a plurality of words by the information retrieval means Then, information regarding words obtained as a result of speech recognition by the speech recognition means is retrieved.
このように、単語辞書から、自装置の位置を含む所定範囲に関連する単語群を音声認識の結果の候補として選択し、選択されなかった地域名を表わす単語及び施設名を表わす単語のうち少なくとも1つを用いた発話禁止例を複数生成して、出力装置に出力させることにより、情報検索のための音声認識処理の認識率を向上させることができると共に、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。 Thus, from the word dictionary, a word group related to a predetermined range including the position of its own device is selected as a candidate for the result of speech recognition, and at least of the word representing the area name and the facility name not selected By generating a plurality of utterance prohibition examples using one and outputting them to the output device, it is possible to improve the recognition rate of the speech recognition processing for information retrieval and to recognize the utterance that can be recognized by the user The contents and the utterance method can be taught at the same time.
上記の情報データベースには、地域名と業種名と施設名とが対応して格納されており、情報検索手段は、情報データベースから、音声認識手段による音声認識の結果として得られた単語が表わす地域名及び業種名に対応する施設名を検索することができる。 In the above information database, a region name, a business type name, and a facility name are stored in correspondence with each other, and the information retrieval means is a region represented by a word obtained as a result of speech recognition by the speech recognition means from the information database. The facility name corresponding to the name and the industry name can be searched.
上記の情報データベースには、単語が表わす施設名の位置情報と地図情報とが格納されており、情報検索手段は、情報データベースの位置情報から、音声認識手段による音声認識の結果として得られた単語が表わす施設名の位置情報を検索すると共に、情報データベースの地図情報に基づいて、自装置の位置から位置情報が示す位置までの経路を探索することができる。 In the information database, the location information of the facility name represented by the word and the map information are stored, and the information retrieval means obtains the word obtained as a result of speech recognition by the speech recognition means from the location information in the information database. The location information of the facility name represented by can be searched, and the route from the location of the own device to the location indicated by the location information can be searched based on the map information of the information database.
以上説明したように、本発明の音声認識装置及びプログラムによれば、情報検索のための音声認識処理の認識率を向上させることができると共に、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる、という効果が得られる。 As described above, according to the speech recognition apparatus and program of the present invention, it is possible to improve the recognition rate of speech recognition processing for information retrieval, and to recognize the utterance contents and the utterance method that can be recognized by the user. Can be taught at the same time.
以下、図面を参照して本発明の実施の形態を詳細に説明する。なお、本実施の形態では、車両用ナビゲーションシステムに本発明を適用した場合について説明する。 Hereinafter, embodiments of the present invention will be described in detail with reference to the drawings. In the present embodiment, a case where the present invention is applied to a vehicle navigation system will be described.
図1に示すように、第1の実施の形態に係る車両用ナビゲーションシステム10は、マイクロホンで構成され、かつ、ユーザ発話を集音して音声信号を生成する入力部12と、音声認識開始を指示するためのPTT(Push To Talk)スイッチ14と、ユーザが操作するための操作部16と、GPS(Global Positioning System)からの信号を受信して現在の自車位置を検出するGPSセンサ18と、GPSセンサ18によって検出された自車位置に基づいて、発話例を生成すると共に、入力部12によって入力された音声信号に基づいて、施設名の検索や経路の探索を行うコンピュータ20と、スピーカで構成され、かつ、生成された発話例を音声出力する音声出力部22と、施設名の検索や経路の探索の結果を表示するディスプレイ24とを備えている。
As shown in FIG. 1, the
操作部16は、システムの機能を選択したり、目的地を検索したり、目的地を設定するとき等、所定の情報を入力するためにユーザが操作するものであり、例えば、ボタン、ジョイスティック等が該当する。なお、操作部16及びディスプレイ24の代わりに、いわゆるタッチパネルを設けてもよい。
The
コンピュータ20は、CPUと、RAMと、後述する情報検索処理ルーチンを実行するためのプログラムを記憶したROMとを備え、機能的には次に示すように構成されている。コンピュータ20は、複数の単語を格納した単語辞書が登録された音声認識データベース26と、入力部12から入力された信号から、入力音声を示す音声信号を切り出すと共に、音声認識データベース26に登録された単語辞書を参照して、音声信号に基づいて、ユーザ発話を認識する音声認識部28と、システム上の様々なデータが記憶されたシステムデータベース30と、地図データや施設データ等を記憶した地図データベース32と、単語辞書における音声認識結果の候補となる範囲の制限や、発話例の生成、施設名の検索、ルート探索、その他のシステム全体の制御を行う対話制御部34と、音声合成を行う音声合成部36と、ディスプレイ24の表示制御を行う表示制御部38と、を備えている。
The
音声認識データベース26には、入力音声の特徴量とマッチングするための音響モデルと、単語と音響モデルの並び方(音素表記列)との関係を表す単語辞書と、が記憶されている。
The
図2は、音声認識データベース26に記憶されている単語辞書の構成を示す図である。単語辞書は、例えば、単語、音素表記列、位置情報、及び情報種別の各項目から構成されている。ここで、単語辞書に登録される単語は、目的地となりうるすべての単語や、情報検索の入力となりうる単語が該当し、例えば、地域名(都道府県名、市町村名、地名、通り名、交差点名など)、施設名(娯楽施設、レストラン、デパート、個人宅など)、業種名などが該当する。また、単語辞書に登録される単語として、接続語も該当する。
FIG. 2 is a diagram showing the configuration of the word dictionary stored in the
単語辞書では、各々の単語には、その音素表記列、その単語によって表されたものが存在する位置情報(緯度及び経度)、及びその単語を表す情報種別が対応付けて格納されている。情報種別としては、例えば、地域名、施設名、業種名、接続語などが該当する。なお、業種名や接続語のように、表わされるものが存在する位置情報を特定できない単語については、「位置情報なし」を対応付けて格納しておけばよい。 In the word dictionary, each word stores a phoneme notation string, position information (latitude and longitude) where the word represented by the word exists, and an information type representing the word in association with each other. As the information type, for example, a region name, a facility name, an industry name, a connection word, and the like are applicable. It should be noted that for words that cannot identify position information where there is a representation, such as a business name or connection word, “no position information” may be stored in association with each other.
音声認識部28は、PTTスイッチ14がオンになると、入力部12に入力された音声について音声認識処理を実行する。具体的には、音声認識部28は、入力された音声について音声分析を行って特徴量を抽出する。次に、音声認識部28は、特徴量と音響モデルとのマッチングを行い、さらに、音声認識データベース26に記憶されている単語辞書のうち、後述するように、音声認識結果の候補として選択された単語群を参照して、音素表記列に対応する単語を認識する。音声認識部28は、このようにして得られた認識結果を対話制御部34に供給する。
When the
対話制御部34は、ユーザとシステムとの対話を円滑に制御するための対話インタフェース部34aを有している。また、対話制御部34は、以下に説明するように、音声入力を用いた施設検索又は目的地設定のための発話例教示処理を行う。
The
まず、GPSセンサ18から自車位置を取得する。
First, the vehicle position is acquired from the
そして、地域に基づく音声認識結果の候補制限を行うために、音声認識データベース26の単語辞書のうち、音声認識結果の候補となる単語群を選択する。音声認識結果の候補となる単語群の選択は、以下のように行われる。
Then, in order to perform candidate restriction on the speech recognition result based on the region, a word group as a speech recognition result candidate is selected from the word dictionary in the
まず、取得した自車位置に基づき、音声認識対象とする地域範囲を決定する。地域範囲による制限を行う理由は、地域を制限することによって、音声認識結果の候補となる単語数(市区町村名、該当地域の施設名)を限定および削減できるため、音声認識処理の認識率を、地域制限しない場合より向上させることができるからである。 First, based on the acquired vehicle position, an area range to be subjected to speech recognition is determined. The reason for restricting by area range is that by limiting the area, the number of words that are candidates for speech recognition results (city names, facility names in the area) can be limited and reduced. This is because it can be improved as compared with the case where the area is not restricted.
地域範囲の決定方法としては、自車位置を中心に半径R[km](R:任意)内の地域を、音声認識対象の地域範囲とする方法を用いてもよいし、予め地域を細分して(例えば、都道府県単位や市町村単位で細分して)ブロック化し、自車位置が存在するブロックを、音声認識対象の地域範囲とする方法を用いてもよい。例えば、自車位置を中心に半径30[km]の範囲を、音声認識対象の地域範囲とする。なお、以下の具体例では、自車位置が、JR名古屋駅周辺であり、自車位置を中心に半径30kmの範囲を、音声認識対象の地域範囲とする場合を例に説明する。 As a method for determining the area range, a method in which an area within a radius R [km] (R: arbitrary) around the position of the host vehicle is used as the area range for speech recognition may be used. For example, a method may be used in which blocks are divided into units of prefectures or municipalities, and blocks where the own vehicle position exists are used as a speech recognition target area range. For example, a range having a radius of 30 [km] centering on the vehicle position is set as a regional range for speech recognition. In the following specific example, a case where the own vehicle position is around JR Nagoya Station and a range having a radius of 30 km centering on the own vehicle position is set as a speech recognition target area range will be described as an example.
そして、単語辞書に各単語と対応して登録されている位置情報に基づいて、音声認識データベース26の単語辞書の単語から、決定された地域範囲外の位置情報に対応する単語を除外し、残りの単語を、決定された地域範囲に関連する単語であるとし、音声認識結果の候補となる単語群として選択する。
Then, based on the position information registered corresponding to each word in the word dictionary, the words corresponding to the position information outside the determined area range are excluded from the words in the word dictionary of the
なお、「位置情報なし」が対応付けられている、業種名や接続語を表わす単語については、決定された地域範囲外の位置情報に対応する単語ではないため、音声認識結果の候補となる単語群として選択される。 Note that a word representing an industry name or a connection word associated with “no position information” is not a word corresponding to position information outside the determined region range, and is therefore a word that is a candidate for a speech recognition result. Selected as a group.
次に、以下に説明するように、施設検索又は目的地設定のための発話例を生成する。 Next, as described below, an utterance example for facility search or destination setting is generated.
まず、操作部16の操作によって、施設検索機能が選択されている場合について説明する。本実施の形態では、「地域名(駅名含む)」と「業種名」とを音声入力し、施設検索を行う場合を例に説明する。
First, the case where the facility search function is selected by the operation of the
ここで、音声入力は、“「地域名」+「接続語」+「業種名」”(例えば、「名古屋市のデパート」)の形式で行われるものとする。 Here, it is assumed that the voice input is performed in the form of ““ region name ”+“ connecting word ”+“ business name ”” (for example, “department in Nagoya City”).
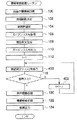
まず、上記で選択された音声認識結果の候補となる単語群から、認識対象となる地域範囲(今回は30[km])の境界近くにある市区町村名または駅名を、東西南北の各々について抽出する。例えば、図3に示すように、「関市」、「豊田市」、「半田駅」、及び「いなべ市」が抽出される。
First, from the word groups that are candidates for the speech recognition result selected above, the city name or station name that is near the boundary of the region range to be recognized (this
また、選択された音声認識結果の候補となる単語群から、「業種名」を表わす単語を複数抽出する。例えば、「業種名」として、「ラーメン店」、「動物園」、「デパート」が抽出される。なお、発話例の生成で用いられる「業種名」を表わす単語を予め設定しておいてもよい。 In addition, a plurality of words representing “business name” are extracted from the selected word recognition candidate group. For example, “ramen store”, “zoo”, and “department store” are extracted as “industry name”. Note that a word representing “business name” used in generating an utterance example may be set in advance.
また、発話例の生成で用いるために予め設定された接続語を取得する。例えば、図3に示すように、「接続語」を表わす単語として、一般的に使用される「の」や「にある」などが取得される。 Also, a connection word set in advance for use in generating an utterance example is acquired. For example, as shown in FIG. 3, “no”, “in”, and the like that are generally used are acquired as words representing “connection words”.
そして、「地域名」、「接続語」、「業種名」の組み合わせで、発話例を複数種類生成する。例えば、図4に示すように、「地域名」、「接続語」、「業種名」の各要素ができるだけ連続して出現しない順番で、発話例(例えば、「関市のラーメン店」、「豊田市の動物園」)を複数種類生成する。 Then, a plurality of types of utterance examples are generated by a combination of “region name”, “connection word”, and “business name”. For example, as shown in FIG. 4, utterance examples (for example, “Seki-shi ramen shop”, “ Toyota City Zoo))).
次に、操作部16の操作によって、目的地設定が選択されている場合について説明する。本実施の形態では、「地域名(駅名含む)」と「施設名」とを音声入力し、目的地設定を行う場合を例に説明する。
Next, a case where the destination setting is selected by operating the
ここで、音声入力は、“「地域名」+「接続語」+「施設名」”(例えば、「中区の三越」)の形式で行われるものとする。 Here, it is assumed that the voice input is performed in the format of ““ area name ”+“ connecting word ”+“ facility name ”(for example,“ Naka-ku Mitsukoshi ”).
まず、上記の施設検索の場合と同様に、選択された音声認識結果の候補となる単語群から、制限された地域範囲(今回は30[km])の境界近くにある市区町村名または駅名を、東西南北の各々について抽出する。例えば、図5に示すように、「関市」、「豊田市」、「半田駅」、及び「いなべ市」が抽出される。 First, as in the case of the facility search described above, the city name or station name near the boundary of the restricted area range (30 km in this case) from the word group that is the candidate for the selected speech recognition result. Are extracted for each of east, west, south, and north. For example, as shown in FIG. 5, “Seki City”, “Toyota City”, “Handa Station”, and “Inabe City” are extracted.
また、選択された音声認識結果の候補となる単語群から、「施設名」を表わす単語を複数抽出する。例えば、図5に示すように、「施設名」として、「三越」、「餃子の王将」、及び「ジャスコ」が抽出される。 In addition, a plurality of words representing “facility names” are extracted from the selected word recognition candidate group. For example, as shown in FIG. 5, “Mitsukoshi”, “Kyoza no Osho”, and “Jusco” are extracted as “facility names”.
また、発話例の生成で用いられるように予め設定された接続語を取得する。例えば、図5に示すように、「接続語」を表わす単語として、「の」や「周辺の」などが取得される。 In addition, a connection word set in advance so as to be used in generation of an utterance example is acquired. For example, as shown in FIG. 5, “no”, “periphery”, and the like are acquired as words representing “connection words”.
そして、「地域名」、「接続語」、「施設名」の組み合わせで、発話例を複数種類生成する。例えば、図6に示すように、「地域名」、「接続語」、「施設名」の各要素ができるだけ連続して出現しない順番で、発話例(例えば、「半田駅周辺の餃子の王将」、「豊田市のジャスコ」)を複数種類生成する。 Then, a plurality of types of utterance examples are generated by a combination of “area name”, “connection word”, and “facility name”. For example, as shown in FIG. 6, utterance examples (for example, “a dumpling king general around Handa Station” in an order in which the elements of “region name”, “connecting word”, and “facility name” do not appear as consecutively as possible. , “Toyota City Jusco”).
次に、生成された複数種類の発話例を音声合成部36及び音声出力部22を介して音声出力して、ユーザに教示する。出力タイミングは、音声入力用の発話開始ボタンが押された後のガイダンス時とし、自車位置が変化しない限り、図4又は図6に示すような複数の発話例を、上から順番に選択して音声出力する。
Next, a plurality of types of generated utterance examples are output as speech via the
例えば、ガイダンスとして、「地域名と業種名を入力して施設検索できます。」と音声出力した後に、発話例として、「関市のラーメン店、のように発話して入力してください。」と音声出力する。続いて、発話例として、「豊田市の動物園、のように発話して入力してください。」と音声出力して、順番に複数種類の発話例を音声出力する。 For example, as a guidance, “You can search for facilities by entering the area name and industry name.” After voice output, as an utterance example, “Speak and enter like a ramen shop in Seki City.” Is output. Subsequently, as an utterance example, “Speak and input like a zoo in Toyota City” is output as a voice, and a plurality of types of utterance examples are sequentially output as a voice.
そして、全ての発言例を音声出力した場合には、最初の発話例にもどり、発話例を音声出力する。 When all the utterance examples are output by voice, the first utterance example is returned and the utterance example is output by voice.
なお、上記のガイダンスについては、システムデータベース30に記憶されているガイダンス文に基づいて、音声出力すればよく、各種機能に応じて、ガイダンス文を予め設定しておけばよい。
In addition, about said guidance, what is necessary is just to output audio | voice based on the guidance sentence memorize | stored in the
以上説明したように、対話制御部34は、音声入力を用いた施設検索又は目的地設定のための発話例教示処理を行う。
As described above, the
システムデータベース30には、施設名と業種名と位置情報(経度と緯度)とが対応して多数登録された施設情報テーブルが記憶されている。施設検索機能が選択され、音声入力されると、対話制御部34は、音声認識の結果として得られた地域名と業種名とに基づいて、施設情報テーブルから、得られた地域名及び業種名に対応する施設名を検索して、検索結果を、表示制御部38を介してディスプレイ24に表示させる。
The
また、対話制御部34は、GPSセンサ18で検出された現在の自車位置(緯度及び経度)と、地図データベース32に記憶された地図データとに基づいて、表示制御部38を介して、現在の自車位置周辺の地図をディスプレイ24に表示させる。
In addition, the
また、目的地設定機能が選択されているときに、ユーザから音声入力されると、対話制御部34は、音声認識の結果として得られた地域名と施設名とに基づいて、地図データベース32に記憶された施設データから、目的地として、地域名及び施設名が表わす施設の位置情報を検索し、地図データベース32に記憶された地図データに基づいて、現在の自車位置から目的地までのルートを探索して、表示制御部38を介してディスプレイ24に表示させる。
When the destination setting function is selected and the user inputs a voice, the
次に、第1の実施の形態に係る車両用ナビゲーションシステム10の作用について説明する。
Next, the operation of the
ユーザが、操作部16を操作して、施設検索機能を選択すると共に、PTTスイッチ14を押下すると、コンピュータ20において、図7に示すような、情報検索処理ルーチンが実行される。
When the user operates the
まず、ステップ100において、GPSセンサ18より検出された自車位置(経度及び緯度)を取得し、ステップ102において、上記ステップ100で得られた自車位置を中心とし半径を所定距離とした地域範囲を、音声認識対象とする地域範囲として決定する。
First, in
そして、ステップ104において、単語辞書に登録されている単語から、上記ステップ102で決定された地域範囲外の位置情報に対応する単語を除外して、残りの単語群を、音声認識結果の候補となる単語群として選択する。
In
次のステップ106では、施設検索機能に対応して予め設定されているガイダンス文(例えば、「地域名と業種名を入力して施設検索できます。」)を取得する。そして、ステップ108において、上記ステップ104で選択された音声認識結果の候補となる単語群の単語を用いて、施設検索機能において音声入力となる発話例文を複数種類生成し、生成された複数種類の発話例文を順番に並べて記憶しておく。
In the
ステップ110では、上記ステップ106で取得したガイダンス文を音声合成し、音声出力部22に出力して、ガイダンスを音声出力させる。そして、ステップ112において、発話例文を識別するための変数tを初期値の1に設定し、ステップ114において、t番目の発話例文を音声合成し、音声出力部22に出力して、発話例を音声出力させる。
In
そして、ステップ116において、音声が入力されたか否かを判定する。上記ステップ116では、入力部12から入力された信号から、入力音声を示す音声信号が切り出されたか否かを判断し、入力音声を示す音声信号が切り出されなかった場合には、ステップ118へ移行して、変数tをインクリメントし、ステップ114へ戻り、次の発話例を音声出力させる。
In
一方、上記ステップ116で、入力部12によってユーザによる発話に応じた音声信号が生成され、入力音声を示す音声信号が切り出された場合には、ステップ120において、上記ステップ104で選択された、単語辞書に登録されている単語のうちの音声認識結果の候補となる単語群を参照して、入力された音声信号に基づいて、ユーザ発話(例えば、「関市のラーメン店」)が表わす地域名、接続語、及び業種名を認識する。
On the other hand, when a voice signal corresponding to the user's utterance is generated by the
そして、ステップ122において、上記ステップ120で認識されたユーザ発話が表わす地域名及び業種名に基づいて、システムデータベース30の施設情報テーブルに対して施設検索を行い、ステップ124において、上記ステップ122で検索された施設情報をディスプレイ24に表示させて、情報検索処理ルーチンを終了する。
In
そして、コンピュータ20は、ユーザによる操作部16の操作又は音声入力により、ディスプレイ24に表示した施設情報の中から、所望の施設名が選択されると、その施設が存在する位置を、目的地として設定する。また、コンピュータ20は、現在の自車位置から目的地までのルートを探索して、ディスプレイ24に表示させる。
Then, when the desired facility name is selected from the facility information displayed on the
上記の情報検索処理ルーチンでは、施設検索機能が指示された場合を例に説明したが、目的地設定機能が選択された場合には、各ステップの処理を、以下のように置き換えて、情報検索処理ルーチンが実行される。 In the above information search processing routine, the case where the facility search function is instructed has been described as an example. However, when the destination setting function is selected, the processing in each step is replaced as follows to search for information. A processing routine is executed.
上記ステップ106で、目的地設定機能に対応して予め設定されているガイダンス文(例えば、「地域名と施設名を入力して目的地設定できます。」)を取得する。また、上記ステップ108において、上記ステップ104で選択された音声認識結果の候補となる単語群の単語を用いて、目的地設定機能における音声入力となる発話例文を複数種類生成する。
In
また、上記ステップ120において、入力された音声信号に基づいて、ユーザ発話(例えば、「豊田市のジャスコ」)が表わす地域名、接続語、及び施設名を認識する。上記ステップ122では、上記ステップ120で認識されたユーザ発話が表わす地域名及び施設名に基づいて、地図データベース32に記憶された施設データから、該当する施設を検索して、目的地として設定する。また、地図データベース32に記憶された地図データから、現在の自車位置から目的地までのルートを探索する。上記ステップ124では、探索されたルートを、ディスプレイ24に表示させる。
In
以上説明したように、第1の実施の形態に係る車両用ナビゲーションシステムによれば、単語辞書から、自車位置を中心とした地域範囲に関連する単語群を、音声認識の結果の候補として選択することにより、施設検索や目的地設定のために入力される音声に対する音声認識処理の認識率を向上させることができる。また、選択された単語群を用いた複数種類の発話例を生成して、音声出力させることにより、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。 As described above, according to the vehicle navigation system of the first embodiment, a word group related to a regional range centered on the vehicle position is selected as a candidate for the result of speech recognition from the word dictionary. By doing this, it is possible to improve the recognition rate of the speech recognition processing for the speech input for facility search and destination setting. In addition, by generating a plurality of types of utterance examples using the selected word group and outputting the voice, it is possible to simultaneously teach the user about the recognizable utterance contents and the utterance method.
また、音声認識の結果の候補として選択された単語群を用いた複数種類の発話例を音声出力することにより、間接的に、認識可能な単語の範囲を教示することができる。 In addition, by outputting a plurality of types of utterance examples using a word group selected as a speech recognition result candidate, a recognizable word range can be indirectly taught.
また、自車位置に応じて、音声認識処理で参照する単語辞書の単語制限を行う音声認識システムにおいて、受付可能な発話内容と発話方法の両方が理解できるような発話例を、自車位置に応じて動的に複数種類生成し、ユーザにそれらを提示することによって、ユーザはシステムに対し「どのように」かつ「何を」入力したら良いかがわかるため、音声入力を有効に実施することが可能になり、製品に対する利便性および満足度が向上する。 Also, in the speech recognition system that restricts words in the word dictionary that is referred to in the speech recognition process according to the vehicle position, an utterance example that can understand both acceptable utterance content and utterance method is Create multiple types dynamically and present them to the user so that the user knows how to input “what” and “what” to the system, so voice input should be performed effectively This will improve the convenience and satisfaction of the product.
次に、第2の実施の形態について説明する。なお、第2の実施の形態に係る車両用ナビゲーションシステムの構成は、第1の実施の形態と同様の構成となっているため、同一符号を付して説明を省略する。 Next, a second embodiment will be described. In addition, since the structure of the navigation system for vehicles which concerns on 2nd Embodiment is the structure similar to 1st Embodiment, it attaches | subjects the same code | symbol and abbreviate | omits description.
第2の実施の形態では、発話例文を生成すると共に、発話禁止例文を生成して、音声出力している点が、第1の実施の形態と主に異なっている。 The second embodiment is mainly different from the first embodiment in that an utterance example sentence is generated and an utterance prohibition example sentence is generated and output as a voice.
第2の実施の形態では、対話制御部34によって、以下に説明するように、音声入力を用いた施設検索又は目的地設定のための発話例教示処理を行う。
In the second embodiment, the
まず、第1の実施の形態と同様に、GPSセンサ18から自車位置を取得し、音声認識データベース26の単語辞書から、音声認識結果の候補となる単語群を選択する。
First, as in the first embodiment, the vehicle position is acquired from the
そして、第1の実施の形態と同様に、施設検索又は目的地設定のための発話例を複数種類生成すると共に、以下に説明するように、発話禁止例を複数種類生成する。 Then, as in the first embodiment, a plurality of types of utterance examples for facility search or destination setting are generated, and a plurality of types of utterance prohibited examples are generated as described below.
まず、操作部16の操作によって、施設検索機能が選択されている場合について説明する。
First, the case where the facility search function is selected by the operation of the
選択された音声認識結果の候補となる単語群以外の単語から、制限された地域範囲外にある「地域名」(例えば、市区町村名または駅名)を複数抽出する。 A plurality of “region names” (for example, city names or station names) outside the restricted region range are extracted from words other than the word group that is a candidate for the selected speech recognition result.
また、選択された音声認識結果の候補となる単語群から、「業種名」を表わす単語を複数抽出し、発話例の生成で用いるために予め設定された接続語を取得する。そして、「地域名」、「接続語」、「施設名」の組み合わせで、発話禁止例(例えば、「浜松市のラーメン店」)を複数種類生成する。 Further, a plurality of words representing “business name” are extracted from the selected word recognition candidate group, and a connection word set in advance for use in generating an utterance example is acquired. Then, a plurality of types of speech prohibition examples (for example, “Hamamatsu City ramen shop”) are generated by a combination of “area name”, “connecting word”, and “facility name”.
また、操作部16の操作によって、目的地設定機能が選択されている場合には、上記の施設検索機能が選択されている場合と同様に、選択された音声認識結果の候補となる単語群以外の単語から、制限された地域範囲外にある「地域名」を、東西南北の各々について抽出する。また、選択された音声認識結果の候補となる単語群から、「施設名」を表わす単語を複数抽出し、発話例の生成で用いるために予め設定された接続語を取得する。そして、「地域名」、「接続語」、「施設名」の組み合わせで、発話禁止例(例えば、「浜松市のジャスコ」)を複数種類生成する。
In addition, when the destination setting function is selected by the operation of the
次に、生成された複数種類の発話例及び複数種類の発話禁止例を、音声合成部36及び音声出力部22を介して音声出力して、ユーザに教示する。
Next, the generated plurality of types of utterance examples and the plurality of types of utterance prohibitions are output via the
例えば、ガイダンスとして、「地域名と業種名を入力して施設検索できます。」と音声出力した後に、発話例「関市のラーメン店、のように発話して入力してください。」と音声出力する。続いて、発話禁止例「浜松市の動物園は、地域範囲が認識対象外のため入力することができません。」を音声出力し、その後も、交互に発話例と発話禁止例とを音声出力する。 For example, as a guidance, after outputting a voice saying “Enter a region name and industry name to search for facilities.”, Utterance example “Please speak and enter like a ramen shop in Seki city.” Output. Subsequently, an utterance prohibition example “The zoo in Hamamatsu City cannot be input because the area range is outside the recognition target.”, And thereafter, the utterance example and the utterance prohibition example are alternately output by voice.
なお、第2の実施の形態に係る車両用ナビゲーションシステムの他の構成及び作用については、第1の実施の形態と同様であるため、説明を省略する。 In addition, about the other structure and effect | action of the vehicle navigation system which concern on 2nd Embodiment, since it is the same as that of 1st Embodiment, description is abbreviate | omitted.
このように、単語辞書から、自車位置を中心とした地域範囲に関連する単語群を、音声認識の結果の候補として選択することにより、施設検索や目的地設定のために入力される音声に対する音声認識処理の認識率を向上させることができる。また、選択された単語群を用いた発話例を生成すると共に、選択されなかった単語を用いた発話禁止例を生成して、音声出力させることにより、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。 In this way, by selecting a word group related to the area range centered on the vehicle position from the word dictionary as a candidate for the result of speech recognition, the speech input for facility search and destination setting is selected. The recognition rate of voice recognition processing can be improved. In addition, the utterance example using the selected word group is generated, and the utterance prohibition example using the unselected word is generated and output by voice so that the user can recognize the utterance content that can be recognized. The utterance method can be taught at the same time.
音声認識の結果の候補として選択された単語群を用いた発話例と、選択されなかった単語を用いた発話禁止例とを音声出力することにより、間接的に、認識可能な単語の範囲を教示することができる。 Instructs the range of recognizable words indirectly by outputting a speech example using a word group selected as a candidate for speech recognition results and a speech prohibition example using a word not selected can do.
次に、第3の実施の形態について説明する。なお、第3の実施の形態に係る車両用ナビゲーションシステムの構成は、第1の実施の形態と同様の構成となっているため、同一符号を付して説明を省略する。 Next, a third embodiment will be described. In addition, since the structure of the vehicle navigation system which concerns on 3rd Embodiment is the structure similar to 1st Embodiment, it attaches | subjects the same code | symbol and abbreviate | omits description.
第3の実施の形態では、複数種類の発話禁止例を生成して、音声出力している点が、第1の実施の形態と主に異なっている。 The third embodiment is mainly different from the first embodiment in that a plurality of types of speech prohibition examples are generated and output as speech.
第3の実施の形態では、対話制御部34によって、以下に説明するように、音声入力を用いた施設検索又は目的地設定のための発話例教示処理を行う。
In the third embodiment, the
まず、第1の実施の形態と同様に、GPSセンサ18から自車位置を取得し、音声認識データベース26の単語辞書から、音声認識結果の候補となる単語群を選択する。
First, as in the first embodiment, the vehicle position is acquired from the
そして、以下に説明するように、発話禁止例を複数種類生成する。 Then, as described below, a plurality of types of speech prohibition examples are generated.
まず、操作部16の操作によって、施設検索機能が選択されている場合について説明する。
First, the case where the facility search function is selected by the operation of the
選択された音声認識結果の候補となる単語群以外の単語から、制限された地域範囲外にある「地域名」(例えば、市区町村名または駅名)を、東西南北の各々について抽出する。 “Region names” (for example, city names or station names) outside the restricted area range are extracted for each of the east, west, north, and south from words other than the word group that is the candidate for the selected speech recognition result.
また、選択された音声認識結果の候補となる単語群から、「業種名」を表わす単語を複数抽出し、発話例の生成で用いるために予め設定された接続語を取得する。そして、「地域名」、「接続語」、「施設名」の組み合わせで、発話禁止例(例えば、「浜松市のラーメン店」)を複数生成する。 Further, a plurality of words representing “business name” are extracted from the selected word recognition candidate group, and a connection word set in advance for use in generating an utterance example is acquired. Then, a plurality of utterance prohibition examples (for example, “Hamamatsu ramen shop”) are generated by a combination of “area name”, “connecting word”, and “facility name”.
また、操作部16の操作によって、目的地設定機能が選択されている場合には、上記の施設検索機能が選択されている場合と同様に、選択された音声認識結果の候補となる単語群以外の単語から、制限された地域範囲外にある「地域名」を、東西南北の各々について抽出する。また、選択された音声認識結果の候補となる単語群から、「施設名」を表わす単語を複数抽出し、発話禁止例の生成で用いるために予め設定された接続語を、取得する。そして、「地域名」、「接続語」、「施設名」の組み合わせで、発話禁止例(例えば、「浜松市のジャスコ」)を複数種類生成する。
In addition, when the destination setting function is selected by the operation of the
次に、生成された複数種類の発話禁止例を、音声合成部36及び音声出力部22を介して音声出力して、ユーザに教示する。
Next, a plurality of types of utterance prohibition examples that have been generated are output to the user via the
例えば、ガイダンスとして、「地域名と業種名を入力して施設検索できます。」と音声出力した後に、発話禁止例「浜松市の動物園は、地域範囲が認識対象外のため入力することができません。」と音声出力する。続いて、発話禁止例「津市のラーメン店は、地域範囲が認識対象外のため入力することができません。」と順番に発話禁止例を音声出力する。 For example, as a guidance, after voice output saying “You can search for facilities by entering the region name and industry name”, the utterance prohibition example “The zoo in Hamamatsu City cannot be entered because the region range is not recognized. . " Subsequently, the utterance prohibited example is output in the order of voice prohibition example, “The Ramen shop in Tsu City cannot be input because the area range is not recognized.”
なお、第3の実施の形態に係る車両用ナビゲーションシステムの他の構成及び作用については、第1の実施の形態と同様であるため、説明を省略する。 In addition, about the other structure and effect | action of the vehicle navigation system which concern on 3rd Embodiment, since it is the same as that of 1st Embodiment, description is abbreviate | omitted.
このように、選択されなかった単語を用いた複数種類の発話禁止例を生成して、音声出力させることにより、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。また、選択されなかった単語を用いた複数種類の発話禁止例を音声出力することにより、間接的に、認識可能な単語の範囲を教示することができる。 As described above, by generating a plurality of types of utterance prohibition examples using unselected words and outputting them by voice, it is possible to teach the user the recognizable utterance contents and the utterance method at the same time. . In addition, by outputting a plurality of types of speech prohibition examples using unselected words, it is possible to indirectly teach a range of recognizable words.
次に、第4の実施の形態について説明する。なお、第1の実施の形態と同様の構成になっている部分については、同一符号を付して説明を省略する。 Next, a fourth embodiment will be described. In addition, about the part which has the structure similar to 1st Embodiment, the same code | symbol is attached | subjected and description is abbreviate | omitted.
第4の実施の形態では、発話例をディスプレイに表示することにより、ユーザに教示している点が第1の実施の形態と主に異なっている。 The fourth embodiment is mainly different from the first embodiment in that a user is taught by displaying an utterance example on a display.
第4の実施の形態では、対話制御部34によって、音声入力を用いた施設検索又は目的地設定のための発話例教示処理において、生成された複数種類の発話例を、表示制御部38及びディスプレイ24を介して表示して、ユーザに教示する。出力タイミングは、音声入力用の発話開始ボタンが押された後のガイダンス時とし、自車位置が変化しない限り、上記図4又は図6の発話候補の上から順に複数選択して同時に表示する。
In the fourth embodiment, a plurality of types of utterance examples generated by the
例えば、ガイダンスとして、「地域名と業種名を入力して施設検索できます。」と音声出力した後に、図8に示すように、複数種類の発話例「関市のラーメン店」、「豊田市の動物園」、「半田駅のデパート」を、同時に表示し、その後に、続いて、順番に、複数種類の発話例を同時に表示する。 For example, as a guidance, after outputting a voice saying “You can search for facilities by entering the area name and industry name.”, As shown in FIG. 8, multiple types of utterance examples such as “Ramen shop in Seki city”, “Toyota city” "Zoo no Zoo" and "Department of Handa Station" are displayed at the same time, and subsequently, a plurality of types of utterance examples are simultaneously displayed in order.
そして、全ての発言例を提示した場合は、最初の発話例にもどり、発話例を複数種類表示する。 And when all the utterance examples are shown, it returns to the first utterance example and displays plural kinds of utterance examples.
次に、第4の実施の形態における情報検索処理ルーチンについて図9を用いて説明する。なお、第1の実施の形態と同様の処理については、同一符号を付して詳細な説明を省略する。また、ユーザが、操作部16を操作して、施設検索機能を選択した場合を例に説明する。
Next, an information search processing routine according to the fourth embodiment will be described with reference to FIG. In addition, about the process similar to 1st Embodiment, the same code | symbol is attached | subjected and detailed description is abbreviate | omitted. Further, a case where the user operates the
まず、ステップ100において、GPSセンサ18より検出された自車位置(経度及び緯度)を取得し、ステップ102において、上記ステップ100で得られた自車位置を中心とし半径を所定距離とした地域範囲を、音声認識対象とする地域範囲として決定する。
First, in
そして、ステップ104において、単語辞書に登録されている単語から、音声認識結果の候補となる単語群を選択する。次のステップ106では、施設検索機能に対応して予め設定されているガイダンス文を取得し、ステップ108において、上記ステップ104で選択された音声認識結果の候補となる単語群の単語を用いて、施設検索機能における音声入力となる発話例文を複数種類生成する。
In
ステップ110では、上記ステップ106で取得したガイダンス文を音声合成し、音声出力部22に出力して、ガイダンスを音声出力させる。そして、ステップ112において、発話例文を識別するための変数tを初期値の1に設定し、ステップ400において、t番目〜t+2番目の3種類の発話例文を表示した画面を、ディスプレイ24に表示させる。
In
そして、ステップ116において、音声が入力されたか否かを判定する。音声が入力されていない場合には、ステップ402へ移行して、変数tを3つ増加させて、ステップ114へ戻り、表示していない発話例を複数種類表示させる。
In
一方、上記ステップ116で、音声が入力されたと判定された場合には、ステップ120において、上記ステップ104で選択された、単語辞書に登録されている単語のうちの音声認識結果の候補となる単語群を参照して、ユーザ発話を認識する。そして、ステップ122において、上記ステップ120で認識されたユーザ発話に基づいて、システムデータベース30の施設情報テーブルから、施設検索を行い、ステップ124において、上記ステップ122で検索された施設情報をディスプレイ24に表示させて、情報検索処理ルーチンを終了する。
On the other hand, if it is determined in
このように、音声認識の結果の候補として選択された単語群を用いた複数種類の発話例を生成して、複数種類の発話例を同時にディスプレイに表示させることにより、ユーザに対して、認識可能な発話内容と発話方法とを同時に教示することができる。 In this way, a plurality of types of utterance examples using a word group selected as a candidate for the result of speech recognition are generated, and a plurality of types of utterance examples are displayed on the display at the same time, so that the user can recognize them. It is possible to teach the utterance contents and the utterance method at the same time.
なお、上記の実施の形態では、発話例をディスプレイに表示させる場合を例に説明したが、これに限定されるものではなく、発話例をディスプレイに表示させると共に、同時に発話例を音声出力するようにしてもよい。また、第2の実施の形態及び第3の実施の形態と同様に生成された発話禁止例をディスプレイに表示させると共に、同時に発話禁止例を音声出力するようにしてもよい。 In the above embodiment, the case where the utterance example is displayed on the display has been described as an example. However, the present invention is not limited to this, and the utterance example is displayed on the display and the utterance example is output at the same time. It may be. In addition, the utterance prohibition example generated in the same manner as in the second and third embodiments may be displayed on the display, and at the same time, the utterance prohibition example may be output as a voice.
また、上記の実施の形態を第2の実施の形態及び第3の実施の形態に適用しても良い。例えば、発話例と発話禁止例とをディスプレイに表示させるようにしてもよい。 Further, the above embodiment may be applied to the second embodiment and the third embodiment. For example, an utterance example and an utterance prohibition example may be displayed on the display.
次に、第5の実施の形態について説明する。なお、第5の実施の形態に係る車両用ナビゲーションシステムの構成は、第1の実施の形態と同様の構成となっているため、同一符号を付して説明を省略する。 Next, a fifth embodiment will be described. Since the configuration of the vehicle navigation system according to the fifth embodiment is the same as that of the first embodiment, the same reference numerals are given and the description thereof is omitted.
第5の実施の形態では、単語辞書から、音声認識結果の候補として選択される単語数が制限されている点が、第1の実施の形態と主に異なっている。 The fifth embodiment is mainly different from the first embodiment in that the number of words selected from the word dictionary as a speech recognition result candidate is limited.
第5の実施の形態では、システムデータベース30に、図10に示すような、認識対象優先度テーブルが記憶されている。認識対象優先度テーブルには、都道府県別に、単語辞書における業種毎の施設名の登録数が格納されており、また、各業種に対応する項目が、優先度順に上から順番に並んでいる。
In the fifth embodiment, a recognition target priority table as shown in FIG. 10 is stored in the
また、施設名の選択制限数として一定値(例えば、5000語)が予め設定されており、都道府県別に、音声認識結果の候補として選択すべき施設名を示す単語が、選択制限数を超えないように、業種毎に施設名の選択可否が格納されている。 In addition, a fixed value (for example, 5000 words) is preset as the facility name selection limit number, and the word indicating the facility name to be selected as a speech recognition result candidate for each prefecture does not exceed the selection limit number. As described above, whether or not a facility name can be selected is stored for each type of business.
例えば、選択制限数を5000語とした場合、「愛知県」については、上位6つの業種の施設名の登録数の累計が4850語となるため、「小中学校」以降の優先順位となる業種の施設名は選択されない。「岐阜県」については、全ての業種の施設名の登録数の累計が3260語であるため、全ての業種の施設名が登録可能である。「東京都」については、上位4つの業種の施設名の登録数の累計が4600語となるため、「コンビニエンスストア」以降の優先順位となる業種の施設名は選択されない。 For example, if the number of selection restrictions is 5000 words, the total number of registered facility names for the top six industries for Aichi Prefecture is 4850 words. The facility name is not selected. For “Gifu Prefecture”, the total number of registered facility names for all industries is 3260 words, so that facility names for all industries can be registered. For “Tokyo”, the total number of registered facility names of the top four industries is 4600 words, and therefore, the facility names of the industries that are priorities after “Convenience Store” are not selected.
対話制御部34は、音声入力を用いた施設検索又は目的地設定のための発話例教示処理において、以下のように、音声認識結果の候補となる単語群を選択する。
In the utterance example teaching process for facility search or destination setting using voice input, the
まず、取得した自車位置に基づき、自車位置が存在する都道府県の範囲を、音声認識対象とする地域範囲として決定する。 First, based on the acquired own vehicle position, the range of the prefecture where the own vehicle position exists is determined as an area range to be subjected to speech recognition.
そして、単語辞書に各単語と対応して登録されている位置情報に基づいて、音声認識データベース26の単語辞書の単語から、決定された地域範囲外(自車位置が存在する都道府県外)の位置情報に対応する単語を除外すると共に、認識対象優先度テーブル及び施設情報テーブルに基づいて、選択されないように定められている業種の施設名を表わす単語を除外し、残りの単語を、決定された地域範囲に関連する単語であるとして、音声認識結果の候補となる単語群として選択する。
Then, based on the position information registered corresponding to each word in the word dictionary, from the words in the word dictionary of the
なお、第5の実施の形態に係る車両用ナビゲーションシステムの他の構成及び作用については、第1の実施の形態と同様であるため、説明を省略する。 In addition, about the other structure and effect | action of the vehicle navigation system which concern on 5th Embodiment, since it is the same as that of 1st Embodiment, description is abbreviate | omitted.
このように、予め定めた業種の認識対象優先度テーブルに基づき、音声認識結果の候補として選択される単語が表わす施設名の業種を制限することができる。 As described above, based on the recognition target priority table of a predetermined industry, the industry of the facility name represented by the word selected as the speech recognition result candidate can be limited.
なお、上記の第1の実施の形態〜第5の実施の形態では、ガイダンスを、音声出力する場合を例に説明したが、これに限定されるものではなく、ディスプレイにガイダンス文を表示するようにしてもよい。 In the first to fifth embodiments described above, the guidance is described as an example in which the voice is output. However, the present invention is not limited to this, and the guidance text is displayed on the display. It may be.
また、音声認識データベース、システムデータベース、及び地図データベースが、コンピュータの内部に設けられている場合を例に説明したが、これに限定するものではなく、音声認識データベース、システムデータベース、及び地図データベースをコンピュータの外部に設け、これらのデータベースとコンピュータとをネットワークで接続し、コンピュータがネットワークを介してこれらのデータベースにアクセスするようにしてもよい。 Moreover, although the case where the speech recognition database, the system database, and the map database are provided inside the computer has been described as an example, the present invention is not limited thereto, and the speech recognition database, the system database, and the map database are stored in the computer. These databases may be connected to a computer via a network, and the computer may access these databases via the network.
また、本発明に係るプログラムを、記録媒体に格納して提供することも可能である。 The program according to the present invention can be provided by being stored in a recording medium.
10 車両用ナビゲーションシステム
12 入力部
18 GPSセンサ
20 コンピュータ
22 音声出力部
24 ディスプレイ
26 音声認識データベース
28 音声認識部
30 システムデータベース
32 地図データベース
34 対話制御部
36 音声合成部
38 表示制御部
DESCRIPTION OF
Claims (8)
地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段と、
前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、前記位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段と、
前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を複数生成する生成手段と、
前記生成手段によって生成された前記複数の発話例を出力装置に出力させる発話例出力制御手段と、
前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段と、
前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段と、
を含む音声認識装置。 Position detecting means for detecting the position of the device itself;
A plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name are stored, and position information corresponding to each of the word representing the area name and the word representing the facility name is stored. A dictionary registration means in which a word dictionary for storing
From the word dictionary registered in the dictionary registration unit, based on the position information registered in the word dictionary, a group of words related to a predetermined range including the position of the own device detected by the position detection unit, A selection means for selecting as a candidate for the result of speech recognition for the input speech;
Generating means for generating a plurality of utterance examples using a combination of a word representing the area name and a word representing the facility name included in the word group selected by the selecting means;
Utterance example output control means for causing the output device to output the plurality of utterance examples generated by the generating means;
Speech recognition means for performing speech recognition of input speech input for information retrieval using the word group selected by the selection means;
Information retrieval means for retrieving information on words obtained as a result of speech recognition by the speech recognition means from an information database storing information on the plurality of words;
A speech recognition device.
地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段と、
前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、前記位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段と、
前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を生成すると共に、前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を生成する生成手段と、
前記生成手段によって生成された前記発話例及び前記発話禁止例を出力装置に出力させる発話例出力制御手段と、
前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段と、
前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段と、
を含む音声認識装置。 Position detecting means for detecting the position of the device itself;
A plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name are stored, and position information corresponding to each of the word representing the area name and the word representing the facility name is stored. A dictionary registration means in which a word dictionary for storing
From the word dictionary registered in the dictionary registration unit, based on the position information registered in the word dictionary, a group of words related to a predetermined range including the position of the own device detected by the position detection unit, A selection means for selecting as a candidate for the result of speech recognition for the input speech;
An utterance example using a combination of a word representing the area name and a word representing the facility name and a connected word included in the word group selected by the selecting means is generated, and a plurality of words stored in the word dictionary are stored. Generating means for generating an utterance prohibition example using a combination of a word representing the area name and a word representing the facility name and a connected word among the words not selected by the selecting means;
Utterance example output control means for causing the output device to output the utterance example generated by the generating means and the utterance prohibition example;
Speech recognition means for performing speech recognition of input speech input for information retrieval using the word group selected by the selection means;
Information retrieval means for retrieving information on words obtained as a result of speech recognition by the speech recognition means from an information database storing information on the plurality of words;
A speech recognition device.
地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段と、
前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、前記位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段と、
前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を複数生成する生成手段と、
前記生成手段によって生成された前記複数の発話禁止例を出力装置に出力させる発話例出力制御手段と、
前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段と、
前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段と、
を含む音声認識装置。 Position detecting means for detecting the position of the device itself;
A plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name are stored, and position information corresponding to each of the word representing the area name and the word representing the facility name is stored. A dictionary registration means in which a word dictionary for storing
From the word dictionary registered in the dictionary registration unit, based on the position information registered in the word dictionary, a group of words related to a predetermined range including the position of the own device detected by the position detection unit, A selection means for selecting as a candidate for the result of speech recognition for the input speech;
Generate a plurality of utterance prohibition examples using a combination of a word representing the area name and a word representing the facility name that has not been selected by the selection means and a connected word among a plurality of words stored in the word dictionary Generating means;
Utterance example output control means for causing the output device to output the plurality of utterance prohibition examples generated by the generation means;
Speech recognition means for performing speech recognition of input speech input for information retrieval using the word group selected by the selection means;
Information retrieval means for retrieving information on words obtained as a result of speech recognition by the speech recognition means from an information database storing information on the plurality of words;
A speech recognition device.
前記情報検索手段は、前記情報データベースから、前記音声認識手段による音声認識の結果として得られた単語が表わす地域名及び業種名に対応する施設名を検索する請求項1〜請求項3の何れか1項記載の音声認識装置。 In the information database, region names, industry names, and facility names are stored correspondingly,
4. The information search unit according to claim 1, wherein the information search unit searches the information database for a facility name corresponding to a region name and a business type name represented by a word obtained as a result of voice recognition by the voice recognition unit. The speech recognition apparatus according to claim 1.
前記情報検索手段は、前記情報データベースの位置情報から、前記音声認識手段による音声認識の結果として得られた単語が表わす施設名の位置情報を検索すると共に、前記情報データベースの地図情報に基づいて、自装置の位置から前記位置情報が示す位置までの経路を探索する請求項1〜請求項3の何れか1項記載の音声認識装置。 In the information database, location information of the facility name represented by the word and map information are stored,
The information search means searches the position information of the facility name represented by the word obtained as a result of the voice recognition by the voice recognition means from the position information of the information database, and based on the map information of the information database, The voice recognition device according to any one of claims 1 to 3, wherein a route from a position of the device itself to a position indicated by the position information is searched.
地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段、
前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、自装置の位置を検出する位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段、
前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を複数生成する生成手段、
前記生成手段によって生成された前記複数の発話例を出力装置に出力させる発話例出力制御手段、
前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段、及び
前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段
として機能させるためのプログラム。 Computer
A plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name are stored, and position information corresponding to each of the word representing the area name and the word representing the facility name is stored. A dictionary registration means in which a word dictionary for storing
From the word dictionary registered in the dictionary registration means, within a predetermined range including the position of the own apparatus detected by the position detection means for detecting the position of the own apparatus based on the position information registered in the word dictionary A selection means for selecting a related word group as a candidate of a result of speech recognition for the input speech;
Generating means for generating a plurality of utterance examples using a combination of a word representing the area name and a word representing the facility name included in the word group selected by the selecting means;
Utterance example output control means for causing the output device to output the plurality of utterance examples generated by the generating means;
Speech recognition means for performing speech recognition of input speech input for information retrieval using the word group selected by the selection means, and the speech recognition means from an information database storing information on the plurality of words A program for functioning as an information search means for searching for information on a word obtained as a result of voice recognition by the computer.
地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段、
前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、自装置の位置を検出する位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段、
前記選択手段によって選択された単語群に含まれる前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話例を生成すると共に、前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を生成する生成手段、
前記生成手段によって生成された前記発話例及び前記発話禁止例を出力装置に出力させる発話例出力制御手段、
前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段、及び
前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段
として機能させるためのプログラム。 Computer
A plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name are stored, and position information corresponding to each of the word representing the area name and the word representing the facility name is stored. A dictionary registration means in which a word dictionary for storing
From the word dictionary registered in the dictionary registration means, within a predetermined range including the position of the own apparatus detected by the position detection means for detecting the position of the own apparatus based on the position information registered in the word dictionary A selection means for selecting a related word group as a candidate of a result of speech recognition for the input speech;
An utterance example using a combination of a word representing the area name and a word representing the facility name and a connected word included in the word group selected by the selecting means is generated, and a plurality of words stored in the word dictionary are stored. Generating means for generating an utterance prohibition example using a combination of a word representing the region name and a word representing the facility name and a connected word among the words not selected by the selecting means;
Utterance example output control means for causing the output device to output the utterance example generated by the generating means and the utterance prohibition example,
Speech recognition means for performing speech recognition of input speech input for information retrieval using the word group selected by the selection means, and the speech recognition means from an information database storing information on the plurality of words A program for functioning as an information search means for searching for information on a word obtained as a result of voice recognition by the computer.
地域名を表わす単語、業種名を表わす単語、及び施設名を表わす単語を含む複数の単語を格納すると共に、前記地域名を表わす単語及び前記施設名を表わす単語の各々に対応して、位置情報を格納する単語辞書が登録された辞書登録手段、
前記辞書登録手段に登録された前記単語辞書から、前記単語辞書に登録されている位置情報に基づいて、自装置の位置を検出する位置検出手段によって検出された自装置の位置を含む所定範囲に関連する単語群を、入力音声に対する音声認識の結果の候補として選択する選択手段、
前記単語辞書に格納された複数の単語のうち、前記選択手段によって選択されなかった前記地域名を表わす単語及び前記施設名を表わす単語と接続語との組み合わせを用いた発話禁止例を複数生成する生成手段、
前記生成手段によって生成された前記複数の発話禁止例を出力装置に出力させる発話例出力制御手段、
前記選択手段によって選択された単語群を用いて、情報検索のために入力された入力音声の音声認識を行う音声認識手段、及び
前記複数の単語に関する情報を格納した情報データベースから、前記音声認識手段による音声認識の結果として得られた単語に関する情報を検索する情報検索手段
として機能させるためのプログラム。 Computer
A plurality of words including a word representing an area name, a word representing an industry name, and a word representing a facility name are stored, and position information corresponding to each of the word representing the area name and the word representing the facility name is stored. A dictionary registration means in which a word dictionary for storing
From the word dictionary registered in the dictionary registration means, within a predetermined range including the position of the own apparatus detected by the position detection means for detecting the position of the own apparatus based on the position information registered in the word dictionary A selection means for selecting a related word group as a candidate of a result of speech recognition for the input speech;
Generate a plurality of utterance prohibition examples using a combination of a word representing the area name and a word representing the facility name that has not been selected by the selection means and a connected word among a plurality of words stored in the word dictionary Generating means,
Utterance example output control means for causing the output device to output the plurality of utterance prohibition examples generated by the generation means;
Speech recognition means for performing speech recognition of input speech input for information retrieval using the word group selected by the selection means, and the speech recognition means from an information database storing information on the plurality of words A program for functioning as an information search means for searching for information on a word obtained as a result of voice recognition by the computer.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008302231A JP5455355B2 (en) | 2008-11-27 | 2008-11-27 | Speech recognition apparatus and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008302231A JP5455355B2 (en) | 2008-11-27 | 2008-11-27 | Speech recognition apparatus and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010128144A JP2010128144A (en) | 2010-06-10 |
| JP5455355B2 true JP5455355B2 (en) | 2014-03-26 |
Family
ID=42328586
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008302231A Active JP5455355B2 (en) | 2008-11-27 | 2008-11-27 | Speech recognition apparatus and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5455355B2 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015102082A1 (en) * | 2014-01-06 | 2015-07-09 | 株式会社Nttドコモ | Terminal device, program, and server device for providing information according to user data input |
| JP6358949B2 (en) * | 2014-12-25 | 2018-07-18 | アルパイン株式会社 | RECOMMENDATION INFORMATION PROVIDING SYSTEM, SERVER DEVICE, INFORMATION PROCESSING DEVICE, AND RECOMMENDATION INFORMATION PROVIDING METHOD |
| JP6393219B2 (en) * | 2015-03-12 | 2018-09-19 | アルパイン株式会社 | Voice input device and computer program |
| CN110910872B (en) * | 2019-09-30 | 2023-06-02 | 华为终端有限公司 | Voice interaction method and device |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3710493B2 (en) * | 1992-09-14 | 2005-10-26 | 株式会社東芝 | Voice input device and voice input method |
| JP2001249686A (en) * | 2000-03-08 | 2001-09-14 | Matsushita Electric Ind Co Ltd | Method and device for recognizing speech and navigation device |
| JP2002123279A (en) * | 2000-10-16 | 2002-04-26 | Pioneer Electronic Corp | Institution retrieval device and its method |
| JP4498906B2 (en) * | 2004-12-03 | 2010-07-07 | 三菱電機株式会社 | Voice recognition device |
| JP2006184669A (en) * | 2004-12-28 | 2006-07-13 | Nissan Motor Co Ltd | Device, method, and system for recognizing voice |
| JP4781368B2 (en) * | 2006-01-06 | 2011-09-28 | パイオニア株式会社 | Voice recognition apparatus, display method, and display processing program |
-
2008
- 2008-11-27 JP JP2008302231A patent/JP5455355B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010128144A (en) | 2010-06-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4270611B2 (en) | Input system | |
| US7664597B2 (en) | Address input method and apparatus for navigation system | |
| JP4466379B2 (en) | In-vehicle speech recognition device | |
| JP2010139826A (en) | Voice recognition system | |
| JP4642953B2 (en) | Voice search device and voice recognition navigation device | |
| JP5455355B2 (en) | Speech recognition apparatus and program | |
| JP2009140287A (en) | Retrieval result display device | |
| WO2006137246A1 (en) | Speech recognizing device, speech recognizing method, speech recognizing program, and recording medium | |
| JP2005275228A (en) | Navigation system | |
| JP4381632B2 (en) | Navigation system and its destination input method | |
| JP6100101B2 (en) | Candidate selection apparatus and candidate selection method using speech recognition | |
| US20040015354A1 (en) | Voice recognition system allowing different number-reading manners | |
| JP2011232668A (en) | Navigation device with voice recognition function and detection result presentation method thereof | |
| EP1895508B1 (en) | Speech recognizing device, information processing device, speech recognizing method, program, and recording medium | |
| WO2006028171A1 (en) | Data presentation device, data presentation method, data presentation program, and recording medium containing the program | |
| US20150192425A1 (en) | Facility search apparatus and facility search method | |
| JPH11325945A (en) | On-vehicle navigation system | |
| JP2008046758A (en) | On-vehicle information terminal, and operation method and menu item retrieval method for information terminal | |
| JP2009025105A (en) | Data retrieval system | |
| JP2006039954A (en) | Database retrieval system, program, and navigation system | |
| JP2005316022A (en) | Navigation device and program | |
| JP2006178898A (en) | Spot retrieval device | |
| JP2009026004A (en) | Data retrieval device | |
| JPH11325946A (en) | On-vehicle navigation system | |
| JP2003140682A (en) | Voice recognition device and voice dictionary generation method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20111010 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20111012 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20111012 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120720 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120821 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20121001 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130402 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130523 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20131210 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140107 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 5455355 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |