JP5366552B2 - 集中特化したマルチタスク及びマルチフロー処理をリアルタイム実行する手法及びシステム - Google Patents
集中特化したマルチタスク及びマルチフロー処理をリアルタイム実行する手法及びシステム Download PDFInfo
- Publication number
- JP5366552B2 JP5366552B2 JP2008538384A JP2008538384A JP5366552B2 JP 5366552 B2 JP5366552 B2 JP 5366552B2 JP 2008538384 A JP2008538384 A JP 2008538384A JP 2008538384 A JP2008538384 A JP 2008538384A JP 5366552 B2 JP5366552 B2 JP 5366552B2
- Authority
- JP
- Japan
- Prior art keywords
- auxiliary
- unit
- processing
- apun
- control unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5044—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering hardware capabilities
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
- G06F9/3851—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution from multiple instruction streams, e.g. multistreaming
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/54—Interprogram communication
- G06F9/544—Buffers; Shared memory; Pipes
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Advance Control (AREA)
- Multi Processors (AREA)
Description
・高性能:組み込み型アプリケーションはますます複雑化しつつある。それは組み込み型システムにより多くの機能を実装する必要性にせまられていること(マルチメディア、ゲーム、テレコミュニケーション、携帯電話におけるGPS機能利用等)、および、処理データ量が増大していること(ビデオセンサ、高速コンバーター等の能力向上)からも明らかである。組み込み型システムでは複数の情報処理を同時に並列処理する能力が求められている。それゆえシステム内に分散されている各ユニットにおいて並列処理に必要なすべての情報を効率的に収集、分配、処理することが独立に行われる必要がある。この多数の情報処理を同時に並列処理するという必要性は、マルチタスク実行環境においても同じである。
・柔軟性:ターゲットとなるシステムではオープン性が要求される。システムを利用するどのユーザーでも行いたい業務が自由に実行できなければならない。それゆえシステムのアーキテクチャは多様な利用用途に適するように十分な柔軟性を備えていなければならない。このオープン性ゆえにアーキテクチャ全体にわたってアプリケーションコンテンツの実行前のオフライン状態での最適化は設計段階では十分に行うことができない。アルゴリズムによってはプロセスを単に静的に分割する並列制御が適当なもの(実行前のオフライン状態でも決められるもの)もあるが、その他のアルゴリズムでは実行中の動的ストリーム制御が要求されており、組み込みアプリケーションの複雑性の増大に伴ってこの傾向はますます強まるであろう。
・動作環境への統合性:システムは動作環境に統合されるように開発されていなければならない。この統合性はリアルタイム性、消費電力、コスト、信頼性などの諸条件が反映される。
・異種処理(ヘテロプロセッシング):アプリケーションの多様性と組み込みシステムにおける制御の流れの複雑性のため、様々なタイプの処理が組み込みアーキテクチャ内で共存せざるを得ない。それゆえ、集中処理タスクはアプリケーションの異なる要素間において干渉し合っても優先されるべき制御となっているタスクとして実行される必要がある。
・ヘテロ構造:この構造はヘテロ構造で与えられたアプリケーション領域に最適化された演算ユニットが組み込まれ、コンパイル時に前もって認識されたリソースに対してタスクを分散するものである。コンパイル時にパーティション化されたソフトウェアは実行時における(動的な)タスク分散のためにそのメカニズムが簡素化されている。これらアプリケーション指向のソリューションではOMAP、VIPER、PNXおよびノマディックプラットフォームを含んでいる。
・ホモ構造:これらの構造は、IBMセルプラットフォームやARMのMPコアプラットフォームや、与えられたアプリケーション領域に最適化されたもの、例えばMPEG4−AVCコーディング/デコーディング向けに最適化されたクレイドルテクノロジー社のCT3400のように、一般的に用いられるホモ構造の演算ユニットが組み込まれたものがベースとなっている。前者は広い範囲の問題を解決することをターゲットとしている。しかし後者は明らかに特定のアプリケーション領域に最適化されている。
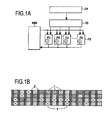
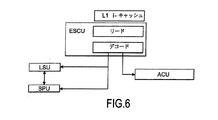
1.コントロールユニットESCU:このユニットは、命令読み込み処理と、デコード処理を担っている。このユニットの複雑さは多様である。多数の命令を同時に管理することができ、また、アプリケーションでの記述順序によらず、実行準備が整った順に命令を選ぶことができる。このユニットは命令分岐予測に必要数の予測機構を実装している。このユニットはアーキテクチャ内の他のユニットに対する命令としてコマンドを送信する。
2.演算ユニットSPU:このユニットは命令により記述されている汎用的演算の実行を担っている。このユニットはコントロールユニットESCUが複数の命令を同時に管理できるように複数の演算リソースを実装している。
3.メモリユニット:このユニットはプログラムに関連するデータと命令の格納を担っている。メモリユニットはハーバード実行モデルの2階層レベルのキャッシュメモリ階層をベースとし、統合レベルの2つのキャッシュを伴っている。
このメモリユニットは、レベル1のキャッシュメモリであるL1 D−キャッシュ、L1 I−キャッシュ、レベル2のキャッシュメモリであるL2−キャッシュを備えている。
4.ローディングユニットLSU:ローディングユニットはメモリに格納されているデータと演算ユニットSPUによって稼動しているユニットとの間にリンクを張る処理を担っている。このリンクは標準プロセッシング部SPP内のサイクルあたりの命令処理数の能力に応じて決まる数のポート数のレジスタキューという形となっている。
標準プロセッシング部SPPと補助プロセッシング部APP間の密接なカップリングを提供するため、標準的な中央プロセッサコアと比較し、コントロールユニットESCUとローディングユニットLSUに対して幾つかの特徴が加えられている。
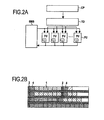
・プログラマブルユニット:このユニットタイプは、組み込み演算に対しては汎用プロセッサコア(MIPS、ARM等)または最適化プロセッサコア(DSP、ST2xx等)に相当するものである。演算に最適化されているため、結果として制御構造がシンプルなものとなっており、例えば分岐予測機構、割り込み処理機構、擬似データ処理機構などが省かれている。これらユニットは浮動小数点演算やベクトル演算などに特化した演算ユニットを構成することができる。
・リコンフィギュラブルユニット:リコンフィギュラブルユニットは演算アクセラレータ同等のものとして用いられる。大規模構造はその処理能力から再構成処理には有利であり、処理能力とフレキシビリティとはトレードオフの関係となる。小規模構成は、非常にフレキシビリティが必要とされる処理または非常に小さいサイズ(1ビットから4ビット)程度のデータ処理に適している。再構成処理のためには長い時間が必要となるため、プリエンプションによる優先割り当てを避けられるように小規模構成のリソースは別々に管理されることが好ましい。
・専用ユニット:特定のクリティカルな処理に最適化され、コンポーネントに組み込まれている。専用アクセラレータは、プログラマブルまたはリコンフィギュラブルな構成では十分な演算パワーを提供できない場合に、クリティカルな処理を担当することが想定されている。高速暗号処理や入出力ストリーム管理処理はこの専用ユニットを用いる良い対象である。
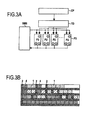
1.強い同期性:(サブシステムAPPおよびSPPの両方の)すべてのプロセッサの構成要素が同期している。この同期処理には長時間を要するので、部分的な同期手法を採ればマルチタスク処理の実行環境におけるペナルティを低減させることができる。実行環境の書き換えを高速化するためにビクティムキャッシュなどを用いて大容量メモリへ書き込む内容はしばらくの間保持される。
2.弱い同期性:標準プロセッシング部SPPに関する実行環境のみが同期しているものである。この状態では補助プロセッシングユニットAPUによりアクティブとなっているファンクションは補助プロセッシング部APPにおいて維持されている。割り当て制御ユニットACUは補助リソースの割り当てのみを担う。APPの自律的処理はスレッドが標準プロセッシング部SPPのタスクが生成したデータをコールしない限り継続される。
3.ローカル同期性:トラッピングが例えば0の除算など補助演算ユニットAPUのイベントコールを伴う場合、ユニットはトラッピングのみを管理し、他のプロセッサからは独立した同期性をとる。
−スレッドの生成/破棄すること
−タスクに関連づけてスレッドを破棄すること
−メインメモリMMからシステムバスSBへまたは逆方向へデータを転送すること
−サブシステムSPPとAPP間でデータを転送すること

Nbportは共有メモリ空間SMSのポート数又はネットワークノード数を表わし、
Tmemは最小メモリアクセスタイムを表わしている。
−補助プロセッシング部APPから標準プロセッシング部SPP間へのデータ伝送またはその逆方向のデータ伝送
−標準プロセッシング部におけるターゲットレジスタ
−補助プロセッシング部APPにおけるターゲットスレッド
−スレッドのデータ
1.Read(Rz):このコマンドは補助演算ユニットAPUの変数Rzの読み込みを行うものである。
2.Search(Ty):このコマンドは割り当て制御ユニットACUに対してどの補助演算ユニットAPUがスレッドTyを実行中であるかの識別子を送る。この識別子は、補助演算ユニットAPUの割り当て制御ユニットACU内でアクティブなスレッドに関連付けられたトランスレーションルックアサイドバッファ(TLB)と呼ばれるページのテーブルという形で示される。もしTLBが補助演算ユニットAPUの識別子を送り返して来なかった場合、標準プロセッシング部SPPが処理待ちの実行中のスレッドやタスクが存在しないことを意味する。スレッドが実行されている場合、TLBは当該スレッドを実行している補助演算ユニットAPUの識別子を送り返す。この識別子は標準プロセッシング部SPPが補助プロセッシング部APPの補助レジスタキューに送るべきデータを選択するために利用される。この識別子は共有レジスタキューSRFのリードデータを有効化するために補助演算ユニットAPUにおいても利用される。
3.Write(Rx):このコマンドは、補助プロセッシング部APPから返された書き込みデータを補助レジスタキューのレジスタRxへ書き込むものである。
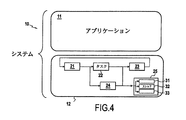
1.システムバスSBからメインメモリMMへの通信:データ通信の第1のタイプは、データをシステム外部から補助プロセッシング部APPのメインメモリMMへ取り入れることである。この伝送は制御ユニットESCUの特定命令のデコード後に発生しうる。特定命令は割り当て制御ユニットACUによりメインメモリ制御部MMCに対して割り当てられるデータ伝送処理を発生させる。後者はダイレクトメモリアクセス(DMA)制御部と同様である。同時に、メインメモリ制御部MMCはロードされているデータとメインメモリMMにおけるアドレスのリンクを確立できるようにテーブルを埋める。
2.メインメモリMMからシステムバスSBへの通信:対称的に、通信されるデータはメインメモリMMから制御ユニットESCUの特定命令により識別されるデータ伝送の到着を知らせるシステムリマインダーデータである。メインメモリMMから送信することはデータが最終結果であると通信内容のテーブル内のエントリが破棄される。制御ユニットESCUによってデコードされた特定命令は破棄伝送か破棄しない伝送かの区別を決める。
3.メインメモリMMから共有メモリ空間SMSへの通信:補助演算ユニットAPUが共有メモリ空間SMSに存在しないデータにアクセスしようとすると、共有メモリ空間SMSにデータをルーティングするため伝送要求が割り当て制御ユニットACUにより制御部MMCに送られる。補助演算ユニットAPUは伝送処理の間、ブロックされる。
4.共有メモリ空間SMSからメインメモリMMへの通信:この伝送は補助プロセッシング部APPの共有メモリ空間SMSに再リードされない最終結果の書き込みにおいて、補助演算ユニットAPUからの特定データの伝送である。これらの伝送処理は実行環境の格納において強い同期性の状態でも実行できる。例えば、共有メモリ空間SMSは割り当て制御ユニットACUを介してリクエストデータをメインメモリ制御部MMCに対して送る。
−クリティカルではないタスク処理とシステムソフトウェアサポートの実行を担う中央プロセッサコアSPP
−プログラマブルでリコンフィギュラブルまたは特定処理の高速処理に最適化された補助演算ユニットAPU
−補助演算ユニットAPUで内部ネットワークを介して共有されるメモリ空間SMS
−補助演算ユニットAPUiによる集中特化した処理の並列処理の実行を管理する補助リソースを制御し割り当てるユニットACU
Claims (16)
- 特定のマルチタスク及びマルチフロー処理をリアルタイム実行するシステムであって、
(a)タスク中の補助プロセッシング部(APP)により処理されない演算処理を実行し、タスク制御を行う中央プロセッサコアと、(b)前記補助プロセッシング部(APP)により特定の演算処理を実行することを要求する追加の命令群を処理する制御ユニット(ESCU)と、を備えた標準プロセッシング部(SPP)を備え、
前記補助プロセッシング部(APP)が、(i)それぞれが、前記特定の演算処理に関して高速処理が可能となるように最適化され、かつ与えられた時間内でタスク中の1つの命令ストリームのみを実行するN個の補助演算ユニット(APU0、・・・、APUN−1)と、(ii)エレメンタリな命令ストリームに分けられ、補助演算ユニットに割り当てる処理の並列処理を実行し、前記命令ストリームの実行環境の管理としてプリエンプション管理および前記補助演算ユニット間のデータ伝送管理を含む管理を行う補助リソース割り当て制御ユニット(ACU)と、(iii)内部ネットワークを介して前記補助演算ユニット(APU0、・・・、APUN−1)間で共有されるメモリ空間(SMS)と、を備え、
様々なシステム要素が、前記補助演算ユニット(APU0、・・・、APUN−1)と前記中央プロセッサコアとの間の通信が前記共有メモリ空間(SMS)と前記内部ネットワークとを介して行われるように配置されていることを特徴とするシステム。 - 前記補助演算ユニット(APU0,・・・,APUN−1)により取り扱うすべてのデータとプログラムを格納した大容量メモリ(MM)をさらに備えたことを特徴とする請求項1に記載のシステム。
- 前記大容量メモリ(MM)を制御するメインメモリ制御部(MMC)を備えたことを特徴とする請求項2に記載のシステム。
- 前記補助演算ユニット(APU0,・・・,APUN−1)がプログラマブルユニット、リコンフィギュラブルユニット、専用ユニットを備えたことを特徴とする請求項1から3のいずれか1項に記載のシステム。
- 前記中央プロセッサコアが、演算ユニット(SPU)と、メモリユニット(L1 D−キャッシュ,L2 I−キャッシュ,L2−キャッシュ)と、ローディングユニット(LSU)をさらに備えたことを特徴とする請求項1から4のいずれか1項に記載のシステム。
- 4から8の補助演算ユニット(APU0,・・・,APUN−1)を備えたことを特徴とする請求項1から5のいずれか1項に記載のシステム。
- 第1にシステムバス(SB)の通信を優先し、第2に入出力装置(IO)および前記大容量メモリ(MM)とともに前記中央プロセッサコアの通信を優先するように管理するバスアービター(SBA)を備えたことを特徴とする請求項2または3に記載のシステム。
- システムバス(SB)に接続された複数個のプロセッサであって、前記プロセッサがそれぞれ、前記中央プロセッサコアと、前記N個の補助演算ユニット(APU0,・・・,APUN−1)と、前記共有メモリ空間(SMS)と、前記補助リソース割り当て制御ユニット(ACU)を備えたものであることを特徴とする請求項1から7のいずれか1項に記載のシステム。
- 前記システムバス(SB)に接続されている複数個のプロセッサ間で共有するシステムバスアービター(SBA)を備えたことを特徴とする請求項8に記載のシステム。
- 中央プロセッサコアを備えた少なくとも1つの標準プロセッサ部(SPP)と、N個の補助演算ユニット(APU,・・・,APUN−1)を備えた補助プロセッシング部(APP)と、前記N個の補助演算ユニット(APU,・・・,APUN−1)で内部ネットワークを介して共有されるメモリ空間(SMS)と、前記補助プロセッシング部(APP)および前記補助演算ユニット(APU,・・・,APUN−1)にタスク中の特定の演算処理を実行することを要求する追加の命令群を処理する制御ユニット(ESCU)と、補助リソース割り当て制御ユニット(ACU)と、を備えた少なくとも1つのプロセッサを用い、特定のマルチタスク及びマルチフロー処理をリアルタイム実行する方法であって、
前記中央プロセッサコアが、タスクにおける前記補助プロセッシング部(APP)により処理されない演算処理を実行するとともにタスク制御を行い、前記補助演算ユニット(APU,・・・,APUN−1)が、それぞれ前記特定の演算処理に関して高速処理が可能となるように最適化され、かつ与えられた時間内でタスク中の1つの命令ストリームのみを実行し、前記補助リソース割り当て制御ユニット(ACU)が、エレメンタリな命令ストリームに分けられ、前記補助演算ユニット(APU,・・・,APUN−1)に割り当てる処理の並列処理を実行し、前記命令ストリームの実行環境の管理としてプリエンプション管理および前記補助演算ユニット間のデータ伝送管理を含む管理を行い、
前記補助演算ユニット(APU0、・・・、APUN−1)間の通信または前記補助演算ユニット(APU0、・・・、APUN−1)と前記中央プロセッサコアとの間の通信が前記共有メモリ空間(SMS)と前記内部ネットワークとを介して行われることを特徴とする方法。 - 各々の命令ストリームが一つの前記補助演算ユニットのみで実行されることを特徴とする請求項10に記載の方法。
- 前記補助演算ユニット(APU0,・・・,APUN−1)で取り扱われるすべてのデータおよびプログラムが大容量メモリ(MM)に格納され、前記プロセッサがシステムバス(SB)に接続され、前記中央プロセッサコア、入出力制御部(IO)および前記大容量メモリ(MM)からの前記システムバスへの通信がバスアービター(SBA)によって管理されていることを特徴とする請求項10に記載の方法。
- 前記標準プロセッサ部(SPP)に割り当てられたタスクが、特定命令が出てくるまで前記標準プロセッサ部(SPP)のサイクルごとに処理されてゆき、前記特定命令に関してはデコードされると前記割り当て制御ユニット(ACU)に対するコマンドが生成され、前記割り当て制御ユニット(ACU)の制御によって前記補助演算ユニット(APU0,・・・,APUN−1)の一つで実行される命令ストリームが生成され、ひとたび、特定命令がデコードされ、対応する前記コマンドが生成された場合に、命令ストリームが生成され前記補助演算ユニットにおける実行が管理されても、前記標準プロセッサ部では干渉を受けることなく実行中の現タスクの継続が可能であることを特徴とする請求項10から12のいずれか1項に記載の方法。
- トラッピング処理がエクセプション処理、インタラプト処理、またはトラップ処理を伴う場合、トラッピングタイプの機能として、前記プロセッサ内のすべての構成要素が同期しなければならない、強い同期処理が選択される請求項13に記載の方法。
- トラッピング処理がエクセプション処理、インタラプト処理、またはトラップ処理を伴う場合、トラッピングタイプの機能として、前記標準プロセッシング部に対応する実行環境は同期するが、補助リソース割り当て制御ユニット(ACU)は補助演算ユニットにて独立してアクティブとなっているファンクションの実行を継続させる、弱い同期処理が選択される請求項13または14に記載の方法。
- トラッピング処理が補助演算ユニットのローカルイベントを伴う場合、当該関係する前記補助演算ユニットのみが前記トラッピング処理を制御し、他のプロセッサとは独立して同期制御が実行される、選択的ローカル同期が有効となる請求項13から15のいずれか1項に記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR0511266 | 2005-11-04 | ||
| FR0511266A FR2893156B1 (fr) | 2005-11-04 | 2005-11-04 | Procede et systeme de calcul intensif multitache et multiflot en temps reel. |
| PCT/FR2006/050535 WO2007051935A1 (fr) | 2005-11-04 | 2006-06-08 | Procede et systeme de calcul intensif multitache et multiflot en temps reel |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2009515246A JP2009515246A (ja) | 2009-04-09 |
| JP2009515246A5 JP2009515246A5 (ja) | 2009-07-23 |
| JP5366552B2 true JP5366552B2 (ja) | 2013-12-11 |
Family
ID=36588738
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008538384A Expired - Fee Related JP5366552B2 (ja) | 2005-11-04 | 2006-06-08 | 集中特化したマルチタスク及びマルチフロー処理をリアルタイム実行する手法及びシステム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9052957B2 (ja) |
| EP (1) | EP1949234A1 (ja) |
| JP (1) | JP5366552B2 (ja) |
| FR (1) | FR2893156B1 (ja) |
| WO (1) | WO2007051935A1 (ja) |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2937439B1 (fr) * | 2008-10-17 | 2012-04-20 | Commissariat Energie Atomique | Procede d'execution deterministe et de synchronisation d'un systeme de traitement de l'information comportant plusieurs coeurs de traitement executant des taches systemes. |
| FR2942556B1 (fr) * | 2009-02-24 | 2011-03-25 | Commissariat Energie Atomique | Unite d'allocation et de controle |
| WO2011012157A1 (en) * | 2009-07-28 | 2011-02-03 | Telefonaktiebolaget L M Ericsson (Publ) | Apparatus and method for processing events in a telecommunications network |
| CN101872317B (zh) * | 2010-07-16 | 2012-12-26 | 山东中创软件工程股份有限公司 | VxWorks多任务同步与通信方法 |
| US9055069B2 (en) * | 2012-03-19 | 2015-06-09 | Xcelemor, Inc. | Hardware computing system with software mediation and method of operation thereof |
| FR3004274A1 (fr) * | 2013-04-09 | 2014-10-10 | Krono Safe | Procede d'execution de taches dans un systeme temps-reel critique |
| CN103618942B (zh) * | 2013-12-16 | 2016-09-28 | 乐视致新电子科技(天津)有限公司 | 智能电视及其浏览器网页视频的播放方法和装置 |
| JP5949977B1 (ja) | 2015-02-19 | 2016-07-13 | 日本電気株式会社 | 情報処理装置、情報処理方法、メインプロセッサコア、プログラム、情報処理方法、サブプロセッサコア |
| US9904580B2 (en) * | 2015-05-29 | 2018-02-27 | International Business Machines Corporation | Efficient critical thread scheduling for non-privileged thread requests |
| JP6432450B2 (ja) * | 2015-06-04 | 2018-12-05 | 富士通株式会社 | 並列計算装置、コンパイル装置、並列処理方法、コンパイル方法、並列処理プログラムおよびコンパイルプログラム |
| US11599383B2 (en) * | 2016-08-30 | 2023-03-07 | Microsoft Technology Licensing, Llc | Concurrent execution of task instances relating to a plurality of applications |
| US10284501B2 (en) * | 2016-12-08 | 2019-05-07 | Intel IP Corporation | Technologies for multi-core wireless network data transmission |
| US10871998B2 (en) * | 2018-01-18 | 2020-12-22 | Red Hat, Inc. | Usage instrumented workload scheduling |
| US11900156B2 (en) * | 2019-09-24 | 2024-02-13 | Speedata Ltd. | Inter-thread communication in multi-threaded reconfigurable coarse-grain arrays |
| CN115803724B (zh) | 2020-09-18 | 2025-09-09 | 阿里巴巴集团控股有限公司 | 一种处理单元及配置处理单元的方法 |
| US20220276914A1 (en) * | 2021-03-01 | 2022-09-01 | Nvidia Corporation | Interface for multiple processors |
| US11704067B2 (en) * | 2021-08-02 | 2023-07-18 | Nvidia Corporation | Performing multiple point table lookups in a single cycle in a system on chip |
| US12602244B2 (en) | 2021-08-02 | 2026-04-14 | Nvidia Corporation | Offloading processing tasks to decoupled accelerators for increasing performance in a system on a chip |
| US11836527B2 (en) | 2021-08-02 | 2023-12-05 | Nvidia Corporation | Accelerating table lookups using a decoupled lookup table accelerator in a system on a chip |
| TWI802302B (zh) * | 2022-03-01 | 2023-05-11 | 正大光明有限公司 | 光明燈顯示同步系統與方法 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5001624A (en) * | 1987-02-13 | 1991-03-19 | Harrell Hoffman | Processor controlled DMA controller for transferring instruction and data from memory to coprocessor |
| US4862407A (en) * | 1987-10-05 | 1989-08-29 | Motorola, Inc. | Digital signal processing apparatus |
| US5056000A (en) * | 1988-06-21 | 1991-10-08 | International Parallel Machines, Inc. | Synchronized parallel processing with shared memory |
| US5239654A (en) * | 1989-11-17 | 1993-08-24 | Texas Instruments Incorporated | Dual mode SIMD/MIMD processor providing reuse of MIMD instruction memories as data memories when operating in SIMD mode |
| US5682512A (en) * | 1995-06-30 | 1997-10-28 | Intel Corporation | Use of deferred bus access for address translation in a shared memory clustered computer system |
| US5706514A (en) * | 1996-03-04 | 1998-01-06 | Compaq Computer Corporation | Distributed execution of mode mismatched commands in multiprocessor computer systems |
| US5822553A (en) * | 1996-03-13 | 1998-10-13 | Diamond Multimedia Systems, Inc. | Multiple parallel digital data stream channel controller architecture |
| KR100308618B1 (ko) * | 1999-02-27 | 2001-09-26 | 윤종용 | 단일 칩 상의 마이크로프로세서-코프로세서 시스템을 구비한 파이프라인 데이터 처리 시스템 및 호스트 마이크로프로세서와 코프로세서 사이의 인터페이스 방법 |
| JP2002041489A (ja) * | 2000-07-25 | 2002-02-08 | Mitsubishi Electric Corp | 同期信号生成回路、それを用いたプロセッサシステムおよび同期信号生成方法 |
| GB2378271B (en) * | 2001-07-30 | 2004-12-29 | Advanced Risc Mach Ltd | Handling of coprocessor instructions in a data processing apparatus |
| US7765533B2 (en) * | 2002-04-25 | 2010-07-27 | Koninklijke Philips Electronics N.V. | Automatic task distribution in scalable processors |
| US7533382B2 (en) * | 2002-10-30 | 2009-05-12 | Stmicroelectronics, Inc. | Hyperprocessor |
| US6944747B2 (en) * | 2002-12-09 | 2005-09-13 | Gemtech Systems, Llc | Apparatus and method for matrix data processing |
-
2005
- 2005-11-04 FR FR0511266A patent/FR2893156B1/fr not_active Expired - Lifetime
-
2006
- 2006-06-08 US US12/084,495 patent/US9052957B2/en not_active Expired - Fee Related
- 2006-06-08 WO PCT/FR2006/050535 patent/WO2007051935A1/fr not_active Ceased
- 2006-06-08 JP JP2008538384A patent/JP5366552B2/ja not_active Expired - Fee Related
- 2006-06-08 EP EP06764855A patent/EP1949234A1/fr not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| EP1949234A1 (fr) | 2008-07-30 |
| JP2009515246A (ja) | 2009-04-09 |
| FR2893156A1 (fr) | 2007-05-11 |
| US20090327610A1 (en) | 2009-12-31 |
| FR2893156B1 (fr) | 2008-02-15 |
| US9052957B2 (en) | 2015-06-09 |
| WO2007051935A1 (fr) | 2007-05-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5366552B2 (ja) | 集中特化したマルチタスク及びマルチフロー処理をリアルタイム実行する手法及びシステム | |
| Wu et al. | Transparent {GPU} sharing in container clouds for deep learning workloads | |
| JP6047747B2 (ja) | 制御タイプの実行モードとデータフロータイプの実行モードとの組み合わせによりタスクを並列に実行可能な複数の処理ユニットを有するシステム | |
| JP6006230B2 (ja) | 組み合わせたcpu/gpuアーキテクチャシステムにおけるデバイスの発見およびトポロジーのレポーティング | |
| US9779042B2 (en) | Resource management in a multicore architecture | |
| US6223208B1 (en) | Moving data in and out of processor units using idle register/storage functional units | |
| US20070150895A1 (en) | Methods and apparatus for multi-core processing with dedicated thread management | |
| US7484043B2 (en) | Multiprocessor system with dynamic cache coherency regions | |
| CN112199173B (zh) | 双核cpu实时操作系统数据处理方法 | |
| KR101900436B1 (ko) | 결합된 cpu/gpu 아키텍처 시스템에서의 디바이스의 발견 및 토폴로지 보고 | |
| JP2005284749A (ja) | 並列処理コンピュータ | |
| KR20050000488A (ko) | 정보처리시스템 및 메모리 관리방법 | |
| WO2000031652A9 (en) | Reconfigurable programmable logic device computer system | |
| CN103109274A (zh) | 多处理器计算平台中的处理器间通信技术 | |
| US20140068625A1 (en) | Data processing systems | |
| KR20080072457A (ko) | 재구성 가능 멀티 프로세서 시스템에서의 매핑 및 스케줄링방법 | |
| US20110314478A1 (en) | Allocation and Control Unit | |
| CN120429370B (zh) | 数据同步方法、装置、电子设备及计算机可读存储介质 | |
| KR20010080208A (ko) | 처리 시스템 스케쥴링 | |
| Wei et al. | Agent. xpu: Efficient scheduling of agentic llm workloads on heterogeneous soc | |
| Kaminsky et al. | Special feature: Developing a multiple-instructon-stream single-chip processor | |
| JP2008152470A (ja) | データ処理システム及び半導体集積回路 | |
| JP4489958B2 (ja) | イベントベースシステムの同時処理 | |
| JPH08292932A (ja) | マルチプロセッサシステムおよびマルチプロセッサシステムにおいてタスクを実行する方法 | |
| CN116382861A (zh) | Numa架构的服务器网络进程自适应调度方法、系统及介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090608 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090608 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20111213 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120309 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20120316 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120410 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20120417 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120510 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20120517 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120606 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120608 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120703 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120927 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20121004 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130618 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130724 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130813 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130910 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |