JP5246512B2 - Voice reading system and voice reading terminal - Google Patents
Voice reading system and voice reading terminal Download PDFInfo
- Publication number
- JP5246512B2 JP5246512B2 JP2009178921A JP2009178921A JP5246512B2 JP 5246512 B2 JP5246512 B2 JP 5246512B2 JP 2009178921 A JP2009178921 A JP 2009178921A JP 2009178921 A JP2009178921 A JP 2009178921A JP 5246512 B2 JP5246512 B2 JP 5246512B2
- Authority
- JP
- Japan
- Prior art keywords
- reading
- word
- terminal
- speech
- combination
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


















Abstract
Description
本発明は、音声読み上げシステムに関し、特に、複数の読みを持つ名称に優先する読みを決定する音声読み上げシステムに関する。 The present invention relates to a speech-to-speech system, and more particularly to a speech-to-speech system that determines a reading that has priority over a name having a plurality of readings.
近年、自動車に搭載されるカーナビゲーション装置、ならびに公共機関および交通機関において自動放送をする装置など、読み上げる対象となるテキストを音声データに自動変換し、音声によるアナウンスとして出力する装置が広く普及している。これらの装置を用いるシステムには、録音した音声を接続して再生する録音編集方法を用いるシステムと、発音を表した文字または符号列から音声を合成する規則合成方法を用いるシステムとがある。 In recent years, devices that automatically convert text to be read into speech data and output it as speech announcements, such as car navigation devices mounted on automobiles and devices that automatically broadcast in public and transportation facilities, have become widespread. Yes. Systems using these apparatuses include a system that uses a recording and editing method that connects and reproduces recorded speech, and a system that uses a rule synthesis method that synthesizes speech from characters or code strings that represent pronunciation.
録音編集方法は、従来、鉄道等の自動音声案内において用いられてきた。鉄道等において用いられる自動音声案内は、定型的な表現が多く使用される。このため、録音編集方法は、定型的な表現を、録音された音声の部品としてあらかじめ複数用意し、それらの録音された音声の部品を要求に従って適宜組み合わせることによって、音声を生成する方法である。しかし、録音編集方法は、あらかじめ定められた表現を組合せることによって、音声を生成するが、それ以外の手段によって、音声を生成できない。 The recording / editing method has been conventionally used in automatic voice guidance for railways and the like. Automatic voice guidance used in railways and the like often uses a fixed expression. For this reason, the recording editing method is a method of generating a sound by preparing a plurality of standard expressions as recorded sound parts in advance and appropriately combining the recorded sound parts as required. However, the recording and editing method generates sound by combining predetermined expressions, but cannot generate sound by any other means.
一方、規則合成方法は、入力された任意のテキストを音声に変換する方法である。録音編集方法は、あらかじめ想定される表現を音声によって録音しておく必要があったが、規則合成方法は、テキストのみを入力し、入力されたテキストを音声に自動変換する。このため、規則合成方法を用いるシステムは、日々更新されるニュースおよび緊急情報など、頻繁に更新される内容を読み上げるシステムとして、自動車に搭載されるカーナビゲーション装置など様々な場所において利用される。 On the other hand, the rule synthesis method is a method of converting an input arbitrary text into speech. In the recording and editing method, it is necessary to record a presumed expression by voice. In the rule synthesis method, only text is input, and the input text is automatically converted into voice. For this reason, a system using the rule composition method is used in various places such as a car navigation device mounted on an automobile as a system that reads out frequently updated contents such as daily updated news and emergency information.
一般的な規則合成方法は、まず、入力されたテキストに後述の言語処理を行い、そして、読みおよびアクセントの情報を示す中間記号列を生成した後、基本周波数パタン(すなわち、声の高さに対応する声帯の振動周期)および音素継続時間長(すなわち、発声速度に対応する各音素の長さ)などの韻律パラメータを決定する。続いて、規則合成方法は、波形生成処理によって、韻律パラメータにあわせた音声波形を生成する。韻律パラメータから音声波形を生成する方法には、音素または音節に対応する音声素片を組み合わせる、波形接続型音声合成が広く用いられる。 A general rule synthesis method first performs linguistic processing, which will be described later, on an input text, generates an intermediate symbol string indicating reading and accent information, and then sets a fundamental frequency pattern (ie, voice pitch). Prosodic parameters such as the corresponding vocal cord vibration period) and phoneme duration (ie, the length of each phoneme corresponding to the speaking rate) are determined. Subsequently, the rule synthesis method generates a speech waveform according to the prosodic parameter by waveform generation processing. As a method for generating a speech waveform from prosodic parameters, waveform connected speech synthesis is widely used in which speech segments corresponding to phonemes or syllables are combined.
前述の言語処理は、通常、入力されたテキストをそのまま読み上げるように、テキストに読みを付与する処理を含む。すなわち、「国分寺」というテキストが入力された場合には、「国分寺」というテキストには、「こくぶんじ」という読みが付与される。 The language processing described above usually includes a process of giving a reading to the text so that the input text is read as it is. That is, when the text “Kokubunji” is input, the text “Kokubunji” is given the reading “Kokubunji”.
例えば、カーナビゲーション装置において、地名、交差点名、および建物名などのような地点名称(POI、Point Of Interest)には、複数の読み方の情報が設定される場合がある。この複数の読み方の情報は、カーナビゲーション装置における目的地設定のための音声認識処理において、利用者がどの読み方によって指定しても目的の地点を設定できるようにするために用いられる情報である。 For example, in a car navigation device, information on a plurality of readings may be set for point names (POI, Point Of Interest) such as place names, intersection names, and building names. The information on the plurality of readings is information used for setting the target point regardless of the reading method specified by the user in the voice recognition processing for setting the destination in the car navigation apparatus.
しかしながら、この読み方の情報は、一般的に利用者からの発声を認識する音声認識において用いられ、カーナビゲーション装置が音声を読み上げるために用いられることは少ない。カーナビゲーション装置が音声を読み上げる音声読み上げにおいて、カーナビゲーション装置が地名を読み上げる場合も、利用者が発声した読み方によって読み上げられることができれば、利用者にとって利便性が向上する。 However, this reading information is generally used in voice recognition for recognizing a utterance from a user, and is rarely used by a car navigation device to read out a voice. When the car navigation apparatus reads out the voice when the car navigation apparatus reads out the voice, if the car navigation apparatus reads out the place name, the convenience can be improved for the user if it can be read out by the reading method spoken by the user.
また、従来の手段を用いて、利用者による音声によって入力した読み方を記録し、記録された読み方を用いて音声を読み上げる際の読み方を決定しても、利用者が音声によって入力したことのない地点名について、利用者が呼ぶであろう読み方を決定することはできない。 Moreover, even if the reading method input by the voice by the user is recorded using the conventional means and the reading method when the voice is read out using the recorded reading method is determined, the user has not input by the voice. It is not possible to determine the reading that the user will call for the location name.
本発明は、上記の問題を鑑みてなされたものであり、地点名称を、利用者が使用している読み方、または利用者が使用すると推測される読み方で読み上げる手法、およびその読み上げ装置を提供することを目的とする。 The present invention has been made in view of the above problems, and provides a method for reading a point name by a reading method used by a user or a reading method that is assumed to be used by a user, and a reading device therefor. For the purpose.
なお、前述の課題は、カーナビゲーション装置における課題によって例示したが、音声を読み上げる装置であれば、すべて同じ課題を持つ。 In addition, although the above-mentioned subject was illustrated by the subject in a car navigation apparatus, if it is an apparatus which reads out a sound, all have the same subject.
本発明の代表的な一例を示せば以下の通りである。すなわち、複数の単語を読み上げる(例えば、音声にて出力する)複数の音声読み上げ端末と、ネットワークを介して前記音声読み上げ端末と接続される読み情報更新サーバとを備える音声読み上げシステムであって、前記音声読み上げ端末は、前記単語と、前記単語に指定される読みとの組み合わせを保持し、前記組み合わせを、前記読み情報更新サーバに送信し、前記読み情報更新サーバは、複数の前記音声読み上げ端末から送信された、複数の前記組み合わせを保持し、前記組み合わせから、前記読みが指定されていない前記単語を取得し、複数の前記組み合わせの中から、前記単語における前記読みが、当該組み合わせの前記単語における前記読みと類似する複数の他の前記組み合わせを特定し、前記複数の他の組み合わせから、当該組み合わせにおいて前記読みが指定されていない前記単語の前記読みを抽出し、前記抽出された読みによって、前記読みが指定されていない単語の前記読みを指定し、前記単語と前記指定された読みとによって、前記組み合わせを更新し、前記更新された組み合わせを前記音声読み上げ端末に送信し、前記音声読み上げ端末は、保持された前記組み合わせを、前記送信された組み合わせによって更新し、前記更新された組み合わせに基づいて、前記単語を読み上げる。 A typical example of the present invention is as follows. That is, a speech-to-speech system comprising a plurality of speech-to-speech terminals that read a plurality of words (for example, output by speech) and a reading information update server connected to the speech-to-speech terminal via a network, The speech reading terminal holds a combination of the word and the reading specified for the word, and transmits the combination to the reading information update server. The reading information update server receives a plurality of the speech reading terminals from The transmitted plurality of the combinations are retained, and the word for which the reading is not designated is acquired from the combination, and the reading in the word is selected from the plurality of the combinations in the word of the combination. A plurality of other combinations similar to the reading are identified, and the plurality of other combinations are Extracting the reading of the word for which the reading is not specified in a combination, specifying the reading of the word for which the reading is not specified by the extracted reading, and by the word and the specified reading , Update the combination, and send the updated combination to the speech-reading terminal, the speech-reading terminal updates the held combination with the transmitted combination, and based on the updated combination Read the word.
本発明の一実施形態によると、利用者が使用している読み方で音声を読み上げる装置を提供できる。 According to an embodiment of the present invention, it is possible to provide an apparatus that reads out a voice in a reading method used by a user.
(第1の実施形態)
図1は、本発明の第1の実施形態の端末側装置100、およびサーバ側装置101の構成を示すブロック図である。
(First embodiment)
FIG. 1 is a block diagram illustrating configurations of a terminal-
本発明において用いられる装置は、端末側装置100およびサーバ側装置101の組合せを基本とする。
The apparatus used in the present invention is basically a combination of the terminal-
図1に示す端末側装置100は、利用者によってテキストが入力され、入力されたテキストを音声として読み上げる装置である。また、図1に示すサーバ側装置101は、端末側装置100に、地点名称などの読み方、または、最も利用者が呼ぶ可能性の高い読み方を示す読み優先順を送信する装置である。
A terminal-
図1に示す端末側装置100は、読み上げるテキストが入力されるテキスト入力手段1、入力されたテキストの読みを決定する読み決定手段2、決定された読みに従って入力されたテキストを音声に変換する音声合成手段3、変換された音声を利用者に読み上げる音声出力手段9、端末側装置100に利用者が発した音声を入力する音声入力手段7、利用者によって入力された音声に従って記録されている読み履歴を更新する読み履歴更新手段6、地点名称などの読み方、読み優先順および利用者が音声入力した読み履歴などを保存した読み履歴記憶手段5、記録されている読み履歴をサーバ側装置101に送信する読み履歴送信手段4、および、サーバ側装置101から通知された読み優先順の情報を受信して読み履歴記憶手段5の情報を更新する読み優先順受信手段8を、少なくとも備える。
A terminal-
図1に示すサーバ側装置101は、端末側装置100から送信される読み履歴ベクトル情報を受信する読み履歴受信手段11、複数の端末側装置100から受信した読み履歴ベクトル情報を保存する読み履歴記憶手段13、保存される読み履歴ベクトル情報に基づいて地点名称などの読み方、および読み優先順を決定する読み優先順決定手段14、決定された読み優先順を端末側装置100に通知する読み優先順送信手段12を、少なくとも備える。さらに、サーバ側装置101が新規の地点名称を追加する機能を有する場合には、サーバ側装置101は、新規読み受信手段15を備える。
A
図2は、本発明の第1の実施形態の端末側装置100およびサーバ側装置101のハードウェアを示すブロック図である。
FIG. 2 is a block diagram illustrating hardware of the
端末側装置100は、CPU21、メモリ22、入力装置23、出力装置24、およびNWインターフェース25を備える。また、サーバ側装置101は、CPU26、メモリ27、入力装置28、出力装置29、およびNWインターフェース30を備える。
The terminal-
前述の各手段は、各々メモリ22またはメモリ27に含まれるプログラムによって実行され、必要に応じて、メモリ22またはメモリ27を参照および更新する手段である。
Each of the means described above is executed by a program included in the
音声出力手段9は、スピーカなどの出力装置24によって実装され、音声入力手段7は、マイクロフォンなどの入力装置23によって実装される。プログラムは、CPU21またはCPU26によって実行される。また、端末側装置100とサーバ側装置101との間は、インターネット、LANまたはWANなどのネットワーク20によって接続される。
The audio output means 9 is implemented by an
なお、複数個の端末側装置100が、サーバ側装置101に接続されてよい。
A plurality of terminal-
第1の実施形態においては、図1に示す端末側装置100がカーナビゲーション装置に備わる場合を例に、端末側装置100およびサーバ側装置101に実行される処理を示す。
In the first embodiment, processing executed by the terminal-
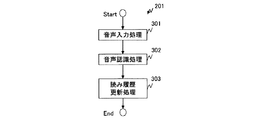
図3は、本発明の第1の実施形態の端末側装置100の処理を示す説明図である。
FIG. 3 is an explanatory diagram illustrating processing of the terminal-
図3に示す説明図は、端末側装置100による音声を入力する処理と読み方の情報を更新する処理とを示す。カーナビゲーション装置において一般的に実施される、音声の意味を解析するなどの処理は、図3において省略される。端末側装置100とカーナビゲーション装置とは、物理的に別のハードウェアを用いてもよいし、または、ハードウェアを共用し、プログラムによってわけられていてもよい。
The explanatory diagram shown in FIG. 3 shows a process of inputting voice and a process of updating reading information by the terminal-
第1の実施形態の端末側装置100は、音声入力処理201、音声合成処理202、または読み優先順更新処理203のいずれかを実行する。そして、各々の処理の後、次の処理を待つという状態を繰り返す。
The terminal-
音声入力処理201は、利用者が発声した音声を端末側装置100に入力する処理である。音声入力処理201は、読み履歴更新手段6、音声入力手段7によって実行される。音声合成処理202は、入力された音声を合成する処理である。音声合成処理202は、テキスト入力手段1、読み決定手段2、音声合成手段3、および、音声出力手段9によって実行される。読み優先順更新処理203は、読み履歴送信手段4、読み履歴記憶手段5、および読み優先順受信手段8によって実行される。
The
図4は、本発明の第1の実施形態の端末側装置100の音声入力処理201を示す説明図である。
FIG. 4 is an explanatory diagram illustrating the
端末側装置100は、音声入力処理201において、音声入力処理301、音声認識処理302、および読み履歴更新処理303を実行する。音声入力処理301および音声認識処理302は、図1に示す音声入力手段7によって実行され、読み履歴更新処理303は、図1に示す読み履歴更新手段6によって実行される。
In the
以下に示す音声入力処理201の処理は、例えば、利用者がカーナビゲーション装置に目的地を設定するために、利用者が地点名称を意味する音声を発してカーナビゲーション装置に地点名称を入力する場合の処理である。
The following
音声入力処理201が起動された場合、まず音声入力処理301が実行される。カーナビゲーション装置の利用者、すなわち運転者が発した音声が、音声入力処理301によって端末側装置100に入力される。
When the
音声入力処理201は、利用者によって、または自動的に起動される。端末側装置100は、音声入力処理301において、マイクロフォンなどの入力装置を介して利用者が発した音声を、端末側装置100に入力する。端末側装置100は、入力された音声を示す音声データを音声認識処理302へ送る。
The
ここで、利用者が、音声入力処理301において「こくぶんじひたち」という音声を発した場合を以下に示す。
Here, the case where the user utters the voice “Kokubunji Hitachi” in the
続いて、端末側装置100は、音声認識処理302によって、利用者によって入力された音声データを認識する。音声認識処理302における音声データの認識は、既存の音声認識アルゴリズムを利用してもよい(例えば、非特許文献1、2参照)。非特許文献1には、音声データを、テキストデータに変換する音声認識アルゴリズムが記載されている。
Subsequently, the terminal-
この音声認識処理302の結果、利用者によって入力された音声データは、テキストデータに変換される。利用者が「こくぶんじひたち」と発声した場合、入力された音声データは、音声認識処理302によって、「こくぶんじひたち」というカナのテキストデータに変換される。
As a result of the
一般的なカーナビゲーション装置は、このような音声認識の処理によって認識されたテキストデータに基づいて、メモリに備わる地点名称データベースを検索し、利用者が発声した地点が具体的にどの地点を示すかを判定する。そして、カーナビゲーション装置は、判定された地点を、目的地を設定する処理などに送る。 A general car navigation apparatus searches a point name database provided in a memory based on text data recognized by such voice recognition processing, and specifically shows a point indicated by a point uttered by a user. Determine. Then, the car navigation device sends the determined point to a process for setting the destination.
ここで、音声認識処理302において認識されたテキストデータに基づいて、利用者が発声した地点が具体的にどの地点をさすかを判定する処理の例を、後述する。
Here, an example of processing for determining which point the user utters specifically refers to based on the text data recognized in the
図5は、本発明の第1の実施形態の端末側装置100による経路誘導等において用いられる地点情報が含まれた地点名称データベース400の説明図である。
FIG. 5 is an explanatory diagram of the
なお、地点名称データベース400は、カーナビゲーション装置に備わるメモリに保存されてもよいし、端末側装置100に備わるメモリに保存されてもよい。また、カーナビゲーション装置および端末側装置100が共有するメモリに保存されてもよい。地点名称データベース400は、必要に応じて、カーナビゲーション装置または端末側装置100から参照または更新される。
The
図5に示す地点名称データベース400には、カーナビゲーション装置において用いられる可能性のある地点のリストと、それらの地点を音声によって入力された場合に、入力された音声データを照合する地点名称読みデータとが、複数含まれる。地点名称データベース400は、地点毎に一意に付された識別子である地点ID401、地点の一般的な名称を示す地点名称402、および、地点名称の読み方を示す地点名称読み403を、少なくとも含む。
The
図5に示す地点名称データベース400において、地点ID401が「1」を示す地点名称402は、「日立国分寺店」であり、地点名称402が「日立国分寺店」を示す地点名称読み403は、第1候補が「ひたちこくぶんじてん」、第2候補が「こくぶんじひたち」、第3候補が「ひたちこくぶんじ」である。
In the
図4に示す音声認識処理302の結果、入力された音声データが「こくぶんじひたち」であると認識された場合、端末側装置100は、図5に示す地点名称データベース400を検索し、地点ID401が「1」である地点名称読み403の第2候補と、入力された音声データとが一致すると判定する。その結果、端末側装置100は、入力された音声データが示す地点の地点名称402は、地点ID401が「3」である「日立国分寺店」であると判定する。
As a result of the speech recognition processing 302 shown in FIG. 4, when the input speech data is recognized as “Kokubunji Hitachi”, the terminal-
音声認識処理302において判定された地点名称402は、一般的に、カーナビゲーション装置における目的地を設定する処理などに送られる。本発明の第1の実施形態における音声認識処理302において判定された地点名称402は、読み履歴更新処理303に送られる。
The
音声認識処理302から送られた音声データの判定結果に基づいて、端末側装置100は、読み履歴更新処理303において、読み履歴データベース500の更新処理を実行する。読み履歴データベース500の更新処理を、図6および図7を用いて示す。
Based on the determination result of the voice data sent from the
図6は、本発明の第1の実施形態の端末側装置100における読み履歴データベース500を示す説明図である。
FIG. 6 is an explanatory diagram illustrating the reading
図6に示す読み履歴データベース500は、図1に示す読み履歴記憶手段5によって保存され、読み決定手段2によって参照されるデータベースである。読み履歴データベース500が保存されるメモリは、地点名称データベース400と同じく、端末側装置100から参照できれば、カーナビゲーション装置または端末側装置100のいずれの装置にあってもよい。なお、読み履歴データベース500は、図5に示す地点名称データベース400と同じデータによって構成されるため、後述するように地点名称データベース400を用いてもよい。
A reading
読み履歴データベース500は、地点名称を示す地点表記501、および地点名称の読み方を示す地点読み順502を、少なくとも含む。地点表記501は、地点名称データベース400における地点名称402と同じである。地点読み順502は、利用者によって最近使用された地点名称に基づいて、順位が付されており、最近使用された地点名称の読み方には、第1候補が付される。
The reading
端末側装置100は、読み履歴更新処理303において、音声認識処理302から送られた音声データの判定結果を、読み履歴データベース500において検索する。本実施形態における端末側装置100は、音声認識処理302の判定結果である地点名称の「日立国分寺店」を、読み履歴データベース500において検索し、地点表記501における「日立国分寺店」と、地点読み順502において第2候補である「こくぶんじひたち」とを、音声入力処理301において入力された音声データであると判定する。
In the reading
続いて、端末側装置100は、読み履歴更新処理303において、読み履歴データベース500の地点読み順502において、判定された「こくぶんじひたち」を、最近使用された地点名称の読み方であるため、第2候補から第1候補に更新する。この読み履歴更新処理303の結果を、図7に示す。
Subsequently, since the terminal-
図7は、本発明の第1実施形態の端末側装置100における読み履歴データベース500を示す説明図である。
FIG. 7 is an explanatory diagram illustrating the reading
地点表記501が「日立国分寺店」である地点読み順502のうち「ひたちこくぶんじてん」は、図6に示す地点読み順502において第2候補であったが、読み履歴更新処理303によって、図7に示す地点読み順502の下線601に示すように第1候補に更新される。また、地点表記501が「日立国分寺店」である地点読み順502のうち「ひたちこくぶんじてん」は、図6に示す地点読み順502において第1候補であったが、読み履歴更新処理303によって、図7に示す地点読み順502の下線602に示すように第2候補に更新される。
Of the
なお、本実施形態の端末側装置100は、読み履歴更新処理303においても図5に示す地点名称データベース400を用い、複数の音声入力処理201が同時に並行して処理される場合、読み履歴更新処理303における更新と音声認識処理302における検索とが同時に処理されることによって、音声認識処理302の検索結果に影響を受けることはない。
Note that the terminal-
端末側装置100は、読み履歴更新処理303の後、音声入力処理201を終了する。
After the reading
前述の音声入力処理201によって、端末側装置100は、利用者から入力された音声を地点名称として認識し、利用者が最近使用した地点名称の読みを、地点名称の読みの第1候補とすることができる。
By the voice input processing 201 described above, the terminal-
次に、図3に示す音声合成処理202を、説明する。
Next, the
図8は、本発明の第1の実施形態の端末側装置100における音声合成処理202を示す説明図である。
FIG. 8 is an explanatory diagram illustrating the
音声合成処理202は、カーナビゲーション装置において、例えば、目的地へ至る経路に沿って利用者を誘導する音声を読み上げる場合などに、起動される。音声合成処理202において、端末側装置100は、テキスト入力処理701、読み決定処理702、および音声合成処理703を実行する。テキスト入力処理701は、テキスト入力手段1によって実行され、読み決定処理702は、読み決定手段2によって実行され、音声合成処理703は、音声合成手段3によって実行される。
The
まず、端末側装置100は、音声合成処理202によってカーナビゲーション装置が読み上げようとする音声を示すテキストデータを、テキスト入力処理701において入力される。このテキストデータは、カーナビゲーション装置において行われる、目的地へ至る経路に沿って利用者を誘導する音声をカーナビゲーション装置が読み上げる処理から送られたり、センターサーバから受信した配信情報およびメール情報などを音声としてカーナビゲーション装置が読み上げる処理から送られたりする。
First, in the
続いて、テキスト入力処理701によって入力されたテキストデータ、すなわち、カーナビゲーション装置から読み上げられる音声を示すテキストデータは、読み決定処理702へ送られる。読み決定処理702は、漢字かな混じり文として送られたテキストデータに、テキストデータに含まれる文字列の読みを付与する。
Subsequently, the text data input by the
テキストデータに含まれる文字列の読みを付与する処理は、広義には、従来の音声合成技術における言語処理(読み付与処理)も含まれる。一方でこの読み決定処理702において、特定の地点名に対して振り仮名を付与するように、部分的な文字列に対して読みを指定する処理とすることも可能である。
The process of giving the reading of the character string included in the text data broadly includes language processing (reading giving process) in the conventional speech synthesis technology. On the other hand, in this
従来の音声合成技術における読み付与処理は、形態素解析処理に基づいて構成される。形態素解析処理については、例えば文献「自然言語処理」(長尾真編、岩波書店、1996年発行)に詳細な記述がある。 The reading imparting process in the conventional speech synthesis technique is configured based on the morphological analysis process. The morpheme analysis process is described in detail in, for example, the document “Natural Language Processing” (Masao Nagao, Iwanami Shoten, 1996).
図9は、本発明の第1の実施形態の端末側装置100の音声合成処理において用いられる単語辞書800を示す説明図である。
FIG. 9 is an explanatory diagram illustrating a
この形態素解析処理は、一般に、図9に示す単語辞書800を参照して解析処理が行われる。音声合成のための形態素解析処理において用いられる単語辞書800は、少なくとも表記801(単語エントリーとして検索される)、品詞802、アクセントを含む読み803が含まれる。
This morpheme analysis process is generally performed with reference to the
例えば、読み決定処理702に、漢字かな混じりテキスト「日立国分寺店の先を右折です」が入力され、従来の読みを付与する処理を行う場合、端末側装置100は、形態素解析処理の単語辞書に含まれる読み情報を用いて、「ひたちこくぶんじてんのさきをうせつです」のように読みを決定する。
For example, when the kanji-kana mixed text “Hitachi Kokubunji store is right-turned” is input to the
本発明における端末側装置100は、読み決定処理702において、図9に示す単語辞書800に加えて、図6または図7に示す読み履歴データベース500を用いる。
The terminal-
具体的には、端末側装置100は、従来の形態素解析処理における形態素の辞書検索処理において、図9に示す単語辞書800よりも優先して読み履歴データベース500を検索し、読み履歴データベース500に含まれる地点表記501を、単語エントリーとして検索する。
Specifically, the terminal-
これによって、端末側装置100は、読み履歴データベース500における地点表記501と地点読み順502とを優先して検索することができ、読みを付与する処理に反映することができる。具体的には、端末側装置100は、テキスト入力処理701において入力されたテキストデータに含まれる地点表記の文字列「日立国分寺店」に、図6に示す読み履歴データベース500の状態においては「ひたちこくぶんじてん」という読みが、図7に示す読み履歴データベース500の状態においては「こくぶんじひたち」という読みを、読み決定処理702において付与する。
As a result, the terminal-
この結果、前述の例に示した「日立国分寺店の先を右折です」が入力された場合、端末側装置100は、図7に示す読み履歴データベース500の状態において、入力されたテキストデータに「こくぶんじひたちのさきをうせつです」という読みを付与する。
As a result, when “turn right at the end of the Hitachi Kokubunji store” as shown in the above example is input, the terminal-
前述の処理によって読みが付与されたテキストデータは、続いて、音声合成処理703に送られ、音声に変換される。この音声合成処理703は、例えば、非特許文献1、2に記載されている方法を用いればよい。そして、端末側装置100は、音声に変換されたデータを、図1に示す音声出力手段9によって読み上げてもよいし、カーナビゲーション装置の処理に出力を戻してもよい。
The text data to which reading is given by the above processing is then sent to the
以上の処理によって、第1の実施形態における端末側装置100を備えるカーナビゲーション装置は、あらかじめ端末側装置100に登録されている地点名称を音声として読み上げる場合、利用者が音声によって入力したことのある読みによって読み上げることができる。すなわち、「日立国分寺店」という地点を、「こくぶんじひたち」と呼んでいる利用者には、カーナビゲーション装置も「こくぶんじひたち」という音声を読み上げ、「ひたちこくぶんじ」と呼んでいる利用者には、カーナビゲーション装置も「ひたちこくぶんじ」という音声を読み上げることができる。
Through the above processing, the car navigation device including the terminal-
これによって、本発明を適用したカーナビゲーション装置は、利用者が慣れ親しんだ名称の呼び方によって、音声ガイダンスをすることが可能となり、利用者にとって利便性が向上する。 As a result, the car navigation device to which the present invention is applied can provide voice guidance according to the name familiar to the user, which improves convenience for the user.
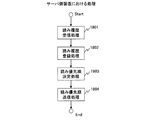
次に、図3に示す読み優先順更新処理203を、図10を用いて説明する。
Next, the reading priority
図10は、本発明の第1の実施形態の端末側装置100の読み優先順更新処理203の処理を示す説明図である。
FIG. 10 is an explanatory diagram illustrating processing of the reading priority
読み優先順更新処理203は、図1に示す読み履歴送信手段4と読み優先順受信手段8とによって実行される。
The reading priority
カーナビゲーション装置は、登録されている地点情報(地点名称を含む)が更新されることがある。具体的には、カーナビゲーション装置が備える経路誘導用の地図データは、定期的に更新されることが多く、POI(Point Of Interest:地点)または道路情報などが、追加、修正、または削除される。 In the car navigation apparatus, registered spot information (including spot names) may be updated. Specifically, the route guidance map data provided in the car navigation device is often updated regularly, and POI (Point Of Interest) or road information is added, modified, or deleted. .
従来は、利用者がカーディーラー等の店舗に行って、CD−ROM、またはDVD−ROMなどの地図情報記録メディアを交換することによって、カーナビゲーション装置が備える地図データは、更新されていた。しかし、今後のカーナビゲーション装置は、カーナビゲーション装置に接続された携帯電話、または無線LANなどを用いて、ネットワーク経由によって更新される場合が増えていくと推測される。 Conventionally, the map data provided in the car navigation apparatus has been updated by a user going to a store such as a car dealer and exchanging map information recording media such as a CD-ROM or DVD-ROM. However, it is speculated that future car navigation devices will be increasingly updated via a network using a mobile phone connected to the car navigation device or a wireless LAN.
カーナビゲーション装置は、本実施形態における読み優先順更新処理203を起動および実行するように構成すれば、手動によって更新しても自動によって更新しても、いずれの更新の方法を採ってもよい。本実施形態においては、ネットワーク経由において地図データを自動的に更新される場合を後述する。
As long as the car navigation apparatus is configured to activate and execute the reading
カーナビゲーション装置において、地図データの更新処理が起動された場合、本発明の端末側装置100における読み優先順更新処理203が同時に実行される。
In the car navigation apparatus, when the map data update process is activated, the reading priority
読み優先順更新処理203は、図10に示すように、読み履歴ベクトル作成処理901、読み履歴送信処理902、読み優先順受信処理903、および、読み履歴更新処理904の順に処理される。
As shown in FIG. 10, the reading priority
読み優先順更新処理203が起動されると、まず、読み履歴ベクトル作成処理901が実行される。
When the reading priority
読み履歴ベクトル作成処理901は、カーナビゲーション装置の利用者が地点をどのように呼んだか、すなわちその地点の名称がどのように音声として入力されたかを指定する読み履歴ベクトル情報1000を作成する処理である。
The reading history
図11は、本発明の第1の実施形態の端末側装置100の読み履歴送信手段4から送信される読み履歴ベクトル情報1000の説明図である。
FIG. 11 is an explanatory diagram of the reading
読み履歴ベクトル情報1000は、地点名称に関する様々な情報を含んでもよいが、最も簡単には、例えば、図11に示すように、利用者が端末側装置100に音声入力し、読み履歴更新処理303によって更新された読み履歴データベース500内における地点表記501と地点読み順502の第1候補との組みあわせを列挙したベクトル形式であってもよい。図11に示す地点表記1001は、図6に示す地点表記501であり、図11に示す地点読み第1候補1002は、図6に示す地点読み順502の第1候補である。
The reading
また、前述のように、読み履歴データベース500と地点データベース400とを共用する場合の、読み履歴ベクトル情報1000を示す。
Further, as described above, the reading
図12は、本発明の第1の実施形態の端末側装置100の読み履歴送信手段4から送信される読み履歴ベクトル情報1000の説明図である。
FIG. 12 is an explanatory diagram of the reading
図12に示す読み履歴ベクトル情報1000は、地点ID1101ごとの地点読み第1候補1102を列挙したベクトル形式によって示される。図12に示す地点読み第1候補1102のうち「−」を示す行は、利用者による音声の入力がまだなされていない、すなわち、読み履歴更新処理303が行われていない地点を示す。
The reading
読み履歴ベクトル作成処理901によって作成された読み履歴ベクトル情報1000は、読み履歴送信処理902によって、サーバ側装置101へ送信される。
The reading
読み履歴ベクトル作成処理901と、読み履歴送信処理902とは、読み履歴送信手段4によって実行される。
The reading history
読み履歴ベクトル情報1000は、端末側装置100からサーバ側装置101へ、前述に示したカーナビゲーション装置の地図データの更新と同じく、携帯電話または無線LANのようなネットワークを経由して自動的に送信されてもよい。また、例えば、USBメモリまたはSDメモリカードのようなデータ記録メディアを用いた手作業によって、カーディーラー店舗に設置された地図データを更新するサーバ装置に入力され、カーディーラー店舗に設置されたサーバ装置からサーバ側装置101に送られてもよい。
The reading
読み履歴ベクトル送信処理902が終了すると、続いて読み優先順受信処理903が実行される。読み優先順受信処理903において、端末側装置100は、サーバ側装置101から読み優先順データ1200が送信されるまで待機する。
When the reading history
図13は、本発明の第1の実施形態の端末側装置100の読み優先順受信手段8によって受信される読み優先順データ1200を示す説明図である。
FIG. 13 is an explanatory diagram illustrating the
図13に示す読み優先順データ1200は、図12に示す読み履歴ベクトル情報1000と同じく地点ID1201ごとに読み優先順データ1200が示される形式であるが、前述のように図11に示す読み履歴ベクトル情報1000と同じベクトル形式であってもよい。
The reading
サーバ側装置101から送信される読み優先順データ1200は、端末側装置100において新たに追加すべき地点を示す地点ID1201と、その読みを示す地点読み第1候補1202とを含む。
The reading
図12に示す読み履歴ベクトル情報1000において、地点ID1101が「2」であるエントリーは、地点読み第1候補1102に「−」と記載されていた。これに対し、図13に示す読み優先順データ1200において、地点ID1201が「2」であるエントリーは、地点ID1201の地点読み第1候補1202に、「ひたちほんしゃ」という読みが指定される。すなわち、サーバ側装置101は、読みが記載されていなかった地点IDに読みを指定して、読みを指定した地点IDを端末側装置100に送る。
In the reading
このように、図13に示す読み優先順データ1200は、読みを追加すべき地点と読みの組みあわせを、サーバ側装置101によって0個以上指定された情報を含む。なお、サーバ側装置101によって読みを指定された地点ID1201には、端末側装置100において新たに追加すべき旨を示すフラグを付加してもよい。
As described above, the reading
端末側装置100は、サーバ側装置101から図13に示す読み優先順データ1200を受信すると、続いて読み履歴更新処理904を実行する。
Upon receiving the reading
読み履歴更新処理904は、サーバ側装置101から受信した読み優先順データ1200に基づいて、読み履歴データベース500を更新する。すなわち、読み履歴データベース500に保存される各地点の地点読み順502に、受信した読み優先順データ1200に指定された読みを第1候補として設定する。
The reading
例えば、図13に示す読み優先順データ1200を受信した場合、地点ID1201が「2」である地点と、その地点読み第1候補1202が示す読みとは、新たに読み履歴データベース500に追加すべき地点とその読みとを示す。
For example, when the reading
端末側装置100は、読み優先順受信処理903において受信した読み優先順データ1200から、追加すべき地点と読みとの組み合わせをすべて抽出する。そして、抽出された組み合わせを、対応する読み履歴データベース500の地点表記501と地点読み順502とに、第1候補として追加する。
The terminal-
この結果、図7に示す読み履歴データベース500、または図5に示す地点データベース400は、それぞれ図14、および図15に示す内容に更新される。
As a result, the reading
図14は、本発明の第1の実施形態の端末側装置100における読み履歴データベース500を示す説明図である。
FIG. 14 is an explanatory diagram illustrating the reading
端末側装置100は、地点表記501が「日立本店」を示すエントリーの地点読み順502に、「ひたちほんしゃ」という読みを下線1301に示すように第1候補として追加する。
The terminal-
端末側装置100は、読み優先順データ1200から抽出した組み合わせのうち、地点ID1201について、地点データベース400において検索してから、地点表記501を検索してもよい。
The terminal-
図15は、本発明の第1の実施形態の端末側装置100の経路誘導等において用いられる地点情報が含まれた地点データベース400を示す説明図である。
FIG. 15 is an explanatory diagram illustrating a
端末側装置100は、地点表記401が「2」を示すエントリーの地点名称読み403に、「ひたちほんしゃ」という読みを下線1401に示すように第1候補として追加する。
The terminal-
読み履歴データベース500、または地点データベース400の更新が終了すると、読み優先順更新処理203が終了する。
When the update of the reading
前述の通り、読み優先順更新処理203によって、カーナビゲーション装置の利用者がこれまで音声によって入力したことのない地点「日立本店」に、優先すべき読み「ひたちほんしゃ」が指定される。そして、読み優先順更新処理203が行われた後、カーナビゲーション装置は、利用者に経路を誘導するために読み上げる音声に、例えば「日立本店の先を右折です」というテキストが指定された場合、前述の音声合成処理202における読み決定処理302によって、「ひたちほんしゃのさきをうせつです」という読みを読み上げる。
As described above, the reading priority
次に、端末側装置100と連携するサーバ側装置101の処理について示す。
Next, processing of the
サーバ側装置101の構成は、図1に示される。以下、この図1に従って、サーバ側装置101における処理を示す。
The configuration of the
図16は、本発明の第1の実施形態のサーバ側装置101の処理を示す説明図である。
FIG. 16 is an explanatory diagram illustrating processing of the server-
まず、図11または図12に示す読み履歴ベクトル情報1000は、端末側装置100の読み履歴送信手段4によって、サーバ側装置101に送信される。読み履歴ベクトル情報1000は、サーバ側装置101において、読み履歴送信手段4に対応する受信手段である読み履歴受信手段11によって受信され、続いて、読み履歴記憶手段13へ送られる(読み履歴受信処理1801)。
First, the reading
なお、サーバ側装置101は、複数の端末側装置100から送信される複数の読み履歴ベクトル情報1000を受信できる。その場合、サーバ側装置101は、一つの端末側装置100から読み履歴ベクトル情報1000を受信してから、その端末側装置100に読み優先順データ1200を送信するまでの間、他の端末側装置100からの読み履歴ベクトル情報1000の送信要求を承認せず、他の端末側装置100を待機させておいてもよい。また、複数の端末側装置100からの送信要求を、並列に処理してもよい。後者の場合、サーバ側装置101は、後述する読み履歴記憶手段13および読み優先順決定手段14を排他的に処理する。
The
以下に示す本実施形態のサーバ側装置101は、一つの端末側装置100から送信された読み履歴ベクトル情報1000について処理する。
The
読み履歴ベクトル情報1000は、端末側装置100から送信され、読み履歴受信手段11によって受信されると、読み履歴記憶手段13に送られて読み履歴ベクトルデータベース1500に保存される(読み履歴登録処理1802)。
When the reading
図17は、本発明の第1の実施形態の読み履歴記憶手段13によって保存される読み履歴ベクトルデータベース1500を示す説明図である。
FIG. 17 is an explanatory diagram illustrating a reading
読み履歴ベクトルデータベース1500は、各端末側装置100から送信される読み履歴ベクトル情報1000を、端末側装置100を一意に識別する端末ID1501とともに保存する。例えば、端末ID1501が「1」(以降、端末ID1と記載する)である端末側装置100から図11または図12に示す読み履歴ベクトル情報1000が送られた場合、サーバ側装置101の読み履歴ベクトルデータベース1500には、図17に示すように端末ID1のエントリーに、受信された読み履歴ベクトル情報1000が保存される。以降、各端末ID1501に対応するエントリーを、読み履歴ベクトルと記載する。
The reading
具体的には、端末側装置100から送信された読み履歴ベクトル情報1000の地点ID1101が「1」を示す地点読み第1候補1102の値は、読み履歴ベクトルデータベース1500において、一意に決定される端末ID1501の地点ID1として保存される。また、読み履歴ベクトル情報1000の地点ID1101が「2」を示す地点読み第1候補1102の値は、読み履歴ベクトルデータベース1500における地点ID2に保存される。
Specifically, the value of the point reading
他の端末ID1501が示す端末側装置100から読み履歴ベクトル情報1000が送信された場合も同じく、サーバ側装置101は、対応する端末ID1501の読み履歴ベクトルへ送られた読み履歴ベクトル情報1000を保存する。
Similarly, when the reading
読み履歴登録処理1802は、読み履歴記憶手段13によって保存される読み履歴ベクトルデータベース1500の読み履歴ベクトルを作成し、作成された読み履歴ベクトルを読み履歴ベクトルデータベース1500に登録する処理である。
The reading
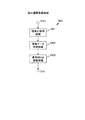
図18は、本発明の第1の実施形態のサーバ側装置の読み履歴登録処理1802を示す説明図である。
FIG. 18 is an explanatory diagram illustrating the reading
読み履歴登録処理1802は、受信した読み履歴ベクトル情報1000に対応する端末ID1501を取得し(端末ID取得処理1901)、取得した端末ID1501を付与された読み履歴ベクトルデータベース1500の読み履歴ベクトルを作成し(登録データ作成処理1902)、読み履歴ベクトルデータベース1500に登録する(排他的DB登録処理1903)。
The reading
読み履歴登録処理1802に続いて、後述する読み優先順決定処理1803が実行される。
Subsequent to the reading
読み優先順決定処理1803は、読み履歴ベクトル情報1000を送信した端末側装置100に、その端末側装置100の利用者がまだ音声によって入力していない地点、すなわち受信した読み履歴ベクトル情報1000内に読みが指定されていない地点の、読みを決定する。なお、読み優先順決定処理1803は、読み優先順決定手段14によって実行される。
The reading priority
図19は、本発明の第1の実施形態のサーバ側装置101の読み優先順決定処理1803を示すフローチャートである。
FIG. 19 is a flowchart illustrating the reading priority
ここで、読み履歴登録処理1802において、端末側装置100から送信された読み履歴ベクトル情報1000は、端末ID1の読み履歴ベクトルに保存されたとする。
Here, in the reading
サーバ側装置101は、読み優先順決定処理1803において、まず、読み履歴ベクトルデータベース1500から、端末ID1の読み履歴ベクトルと比較する他の読み履歴ベクトルを取得する(S2001)。
In the reading priority
そして、サーバ側装置101は、取得された読み履歴ベクトルと端末ID1の読み履歴ベクトルとの距離、すなわち類似性を、後述する手段によって算出する(S2002)。
Then, the
サーバ側装置101は、読み履歴ベクトルデータベース1500に含まれる全読み履歴ベクトルと、端末ID1の読み履歴ベクトルとの比較が、すべて終了したか否かを判定する(S2003)。
The server-
終了していない場合、サーバ側装置101は、S2001に戻り、まだ端末ID1の読み履歴ベクトルと比較していない読み履歴ベクトルを取得する。
If not completed, the server-
終了した場合は、サーバ側装置101は、S2002において算出された距離の中から、最小の距離となる読み履歴ベクトルを取得する(S2004)。
When the processing is completed, the server-
サーバ側装置101は、最小の距離となる読み履歴ベクトルと、端末ID1の読み履歴ベクトルとを比較し、端末ID1の読み履歴ベクトルにおいて指定されていない地点IDに、最小の距離となる読み履歴ベクトルにおける同じ地点IDを持つ値をコピーする(S2005)。
The
最後に、サーバ側装置101は、S2005によって地点IDの値をコピーされた読み履歴ベクトルによって、読み履歴ベクトルデータベース1500を更新する(S2006)。
Finally, the
S2003の詳細を、後述する。 Details of S2003 will be described later.
ここで、読み優先順決定手段14(すなわち、読み優先順決定処理1803)によって決定される読みは、利便性の向上のため、その端末側装置100の利用者が今後、その地点を音声によって入力する場合に使用する可能性の高い読みである必要がある。
Here, the reading determined by the reading priority order determination means 14 (that is, the reading priority order determination processing 1803) is used by the user of the terminal-
利用者によって使用される可能性の高い読みを決定するためのS2003の方法には、例えば、後述する方法がある。 Examples of the method of S2003 for determining readings that are likely to be used by the user include a method described later.
まず、サーバ側装置101は、読み履歴記憶手段13によって読み履歴ベクトルデータベース1500に保存される読み履歴ベクトルのうち、読み履歴ベクトル情報1000を送信した端末側装置100、すなわち本実施形態においては、端末ID1の読み履歴ベクトルに最も近い読み履歴ベクトルを検索する。
First, the
なお、最も近い読み履歴ベクトル、すなわち最も類似している読み履歴ベクトルを検索するために、地点ID1およびその他の地点IDの値の各々を要素ととらえ、一つの読み履歴ベクトルが複数の要素によってベクトルを構成しているとみなし、そのベクトルの距離を算出することによって、最も類似する読み履歴ベクトルを検索する。
In order to search for the nearest reading history vector, that is, the most similar reading history vector, each of the values of the
ここで、ベクトルの距離には、例えば、読みの一致または不一致する地点IDの個数によって算出するハミング距離、すなわち読みが一致しなかった地点IDの個数を用いることができる。このとき、読みが指定されていない地点ID(図17に示す「−」という記号が記載されている要素)は、読みが一致したものとして算出する。 Here, for the vector distance, for example, the Hamming distance calculated by the number of spot IDs that match or do not match, that is, the number of spot IDs that do not match the readings can be used. At this time, the point ID for which reading is not designated (the element in which the symbol “-” shown in FIG. 17 is described) is calculated as the reading matches.
具体的には、図17に示す地点ID1、地点ID2、地点ID1000以外の要素には、「−」が記載されている場合、端末ID1の読み履歴ベクトルと、端末ID1501が「2」(以降、端末ID2と記載する)を示す読み履歴ベクトルとのベクトルの距離は、地点ID1において、双方の値が一致しないため、1と算出される。また、端末ID1の読み履歴ベクトルと、端末ID1501が「100」(以降、端末ID100と記載する)を示す読み履歴ベクトルとのベクトルの距離は、地点ID1において、双方の値が一致し、他のすべての値も一致しているとみなせるため、0と算出される。
Specifically, when “−” is described in the elements other than the
なお、ベクトルの距離は、ハミング距離そのものではなく、距離を算出する二つの読み履歴ベクトルが各々示すベクトルにおいて算出されたハミング距離を、「−」が記載されていない地点IDの個数によって割った値を距離としてもよい。 Note that the vector distance is not the Hamming distance itself, but is a value obtained by dividing the Hamming distance calculated in the vectors respectively indicated by the two reading history vectors for calculating the distance by the number of point IDs where "-" is not described. May be a distance.
また、ベクトルの距離は、あらかじめ地点IDごとに重みを設定しておいて、読みが一致しない地点の重みを合計した値を距離としてもよい。 In addition, the vector distance may be set to a weight for each point ID in advance, and a value obtained by summing the weights of points where readings do not match may be used as the distance.
このベクトルの距離を計算する処理の結果、最も距離の値が低い読み履歴ベクトルの組み合わせが、最も近い読み履歴ベクトルであると判定される。前述の具体例において、端末ID1の読み履歴ベクトルに最も近い読み履歴ベクトルを持つ端末側装置100は、ベクトルの距離が0と算出された、端末ID100を示す端末側装置100であると判定される。
As a result of the process of calculating the vector distance, it is determined that the combination of the reading history vectors having the lowest distance value is the closest reading history vector. In the specific example described above, the terminal-
続いて、サーバ側装置101は、端末ID1を示す読み履歴ベクトルから最もベクトルの距離が近いと判定された読み履歴ベクトルの中から、端末ID1の読み履歴ベクトルに読みが指定されていない地点IDを検索し、その地点IDの読みを抽出する。前述の具体例において、サーバ側端末101は、最も近いと判定された端末ID100の読み履歴ベクトルから、端末ID1の読み履歴ベクトルには読みが指定されていない読み、すなわち、地点ID2における読み「ひたちほんしゃ」を抽出する。
Subsequently, the server-
前述の具体例においては一つの地点とその読みとが抽出されたが、当然ながら、複数の地点とその読みとの組み合わせが抽出されてもよい。 In the above-described specific example, one point and its reading are extracted, but it goes without saying that a combination of a plurality of points and their readings may be extracted.
前述に示す読み優先順決定処理1803によれば、端末ID1から受信した読み履歴ベクトルにおいて指定されていない読みを、最も距離の近い読み履歴ベクトルから抽出し、読みを指定することができる。
According to the reading priority
しかし、図19に示す処理のように最も距離の近い読み履歴ベクトルを取得するのではなく、任意の距離に存在する複数の読み履歴ベクトルから、指定されていない読みを抽出してもよい。これによって、受信した読み履歴ベクトルにおいても読みが指定されていなく、また、最も距離の近い読み履歴ベクトルにおいても読みが指定されていない場合に、2番目以降に距離が近い読み履歴ベクトルに指定されている読みから抽出することによって、り指定されていない読みをより減らすことが可能となる。 However, instead of acquiring the closest reading history vector as in the process shown in FIG. 19, unspecified readings may be extracted from a plurality of reading history vectors existing at an arbitrary distance. As a result, when the reading is not specified even in the received reading history vector, and when reading is not specified even in the reading history vector closest to the distance, it is specified as the reading history vector closest to the second or later distance. By extracting from the readings that are present, it is possible to further reduce the readings that are not specified.
任意の距離に存在する複数の読み履歴ベクトルから読みを抽出する場合、サーバ側装置101は、図19に示すS2004において、あらかじめ定められた任意の距離に存在する読み履歴ベクトルを取得する。そして、S2005において、最も距離の近い読み履歴ベクトルから、受信した読み履歴ベクトルにおいて読みを指定されていなかった地点IDを検索し、最も距離の近い読み履歴ベクトルの地点IDに読みが指定されていない場合は、2番目に距離の近い読み履歴ベクトルを検索する。このように、読みが指定されている読み履歴ベクトルを検索し、指定されている読みの中でも距離が近い読みを抽出する。
When extracting readings from a plurality of reading history vectors existing at an arbitrary distance, the server-
以上の読み優先順決定処理1803は、複数の地点の読み方が同じ利用者間において、どちらか一方の利用者がいまだ音声によって入力していなかった地点を初めて呼ぶ場合、もう一方の利用者が用いる読み方と同じ読み方によって、呼ぶ傾向が高いという特徴を利用している。すなわち、「日立国分寺店」を「こくぶんじひたち」と呼ぶ端末ID1に対応する端末側装置100の利用者は、「日立国分寺店」を「こくぶんじひたち」と呼ぶ端末ID100に対応する端末側装置100の利用者と同じじように「日立本店」という地名を、「ひたちほんしゃ」と呼ぶ可能性が高い。
The reading priority
図12に示す読み履歴ベクトル情報1000は、前述の通り読み優先順決定処理1803によって更新され、図13に示す読み優先順データ1200のように変更される。図13に示される読み優先順データ1200は、読み優先順決定手段14から読み優先順送信手段12へ送られ、その後、携帯電話、または無線LANなどのネットワークを介して端末側装置100へ送信される(読み優先順送信処理1804)。
The reading
以上によって、サーバ側装置101における、読み履歴ベクトルへの処理を終了する。
Thus, the processing for the reading history vector in the
サーバ側装置101は、新たな地点情報が追加される場合、サーバ側装置101に備わる新規読み受信手段15が実行され、新たな地点IDが追加される。
When new point information is added, the server-
新たな地点情報を追加する処理は、まず、図17に示す読み履歴ベクトルデータベース1500において、新たな地点IDの列を追加し、新たな地点IDの列の値に未設定を示す「−」を記載する。前述のサーバ側装置101の処理は、地点の読み履歴ベクトルデータベース1500の変更のみであるため、新たに追加された地点の名称およびそれらの地点に対応する複数の読み候補を、端末側装置100に送信することができない。新たな地点情報を、端末側装置100に追加する処理は、例えばカーナビゲーション装置に備わる地図データ更新技術などを用いて、別途、カーナビゲーション装置から端末側装置100に送信されてもよい。
In the process of adding new point information, first, in the reading
しかし、新たな地点情報を追加する処理によって、読み履歴ベクトルデータベース1500の読みの値に「−」を記載するだけでは、端末側装置100に優先すべき読みを送信できない。これは新たに追加された地点への読みは、すべての端末側装置101の利用者が入力していないため、前述の読み履歴ベクトルの距離、すなわち類似性に基づく読み優先順決定処理1803によって読みを決定できないためである。
However, by adding “−” to the reading value of the reading
後述の読み決定方法は、読み履歴ベクトルデータベース1500において、地点IDが示す地点名称の文字列を形態素解析し、解析結果の距離が近い地点IDに指定されている読みをもとにして、追加された地点の読みを決定する方法である。
The reading determination method to be described later is added based on the reading specified in the point ID having a short distance in the analysis result by performing a morphological analysis on the character string of the point name indicated by the point ID in the reading
なお、後述の読み決定方法は、前述の読み履歴ベクトルの距離、すなわち類似性に基づく読み決定手法の代わりに読み優先順決定処理1803において用いられてもよい。
Note that the reading determination method described later may be used in the reading priority
以下、具体例を挙げて説明する。以下の説明において、サーバ側装置101は、端末ID1に対応する端末側装置100の利用者に、読み優先順決定処理1803をする。
Hereinafter, a specific example will be described. In the following description, the server-
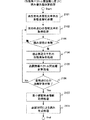
図20は、本発明の第1の実施形態のサーバ側装置101の形態素解析処理に基づく読み優先順決定処理1803を示すフローチャートである。
FIG. 20 is a flowchart illustrating the reading priority
まず、読み履歴ベクトルデータベース1500に、新たに「日立新宿店」という地点名称の文字列が追加されたとする。サーバ側装置101は、新規読み受信手段15によって、新たな地点名称である「日立新宿店」を受信し、受信した新たな地点名称に一意な地点IDを割り当て、読み履歴ベクトルデータベース1500の列を作成する。
First, it is assumed that a character string having a location name “Hitachi Shinjuku store” is newly added to the reading
サーバ側装置101は、この文字列に形態素解析処理を行う(S2101)。ここで用いる形態素解析処理は、端末側装置100による読み決定処理702において用いられる処理と同じである。
The
この形態素解析処理の結果、サーバ側装置101は、「日立新宿店」から図21に示す解析結果1600を得る。
As a result of the morphological analysis process, the server-
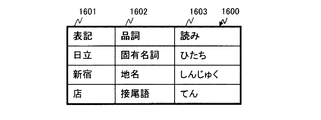
図21は、本発明の第1の実施形態のサーバ側装置101の読み優先順決定手段14による地点名称の解析結果1600を示す説明図である。
FIG. 21 is an explanatory diagram illustrating a spot
図21に示す解析結果1600は、図9に示す単語辞書800と同じ列を含む。解析結果1600は、表記1601、品詞1602、および読み1603を含む。本実施形態のサーバ側装置101は、図21に示すように、地点「日立新宿店」の文字列を、「日立」、「新宿」、および「店」の形態素に分割する。
The
また、サーバ側装置101は、解析結果1600のうち、品詞1602の列のみを抽出し、追加された地点の品詞情報ベクトルを取得する。
Further, the server-
次に、サーバ側装置101は、読み履歴ベクトルデータベース1500の端末ID1の読み履歴ベクトルにおいて、地点IDの読みを取得する(S2102)。そして、取得した地点IDに既に指定されている読みが有るか無しかを判定する(S2103)。指定されている読みがない場合、サーバ側装置101は、S2102に戻り、次の地点IDを取得する。
Next, the
指定されている読みが有る場合、サーバ側装置101は、取得された地点IDに対応する地点名称の表記文字列を、S2101の処理と同じく形態素解析する(S2104)。なお、形態素解析処理は、地点情報が追加された際に一度だけ実行し、その解析結果を保存しておいてもよい。
When there is a designated reading, the server-
例えば、サーバ側装置101は、地点ID1に対応する地点「日立国分寺店」の文字列から、形態素解析によって、図22に示す解析結果1700を取得する。
For example, the server-
図22は、本発明の第1の実施形態のサーバ側装置101の読み優先順決定手段14による地点名称の解析結果1700を示す説明図である。
FIG. 22 is an explanatory diagram illustrating a point
読み優先順決定手段14による解析結果1700は、図21と同じく図9に示す単語辞書800と同じ列を含む。本実施形態のサーバ側装置は、図22に示すように、地点「日立国分寺店」の文字列を、「日立」、「国分寺」、および「店」に分割する。
The
そして、解析結果1700のうち品詞1602の列のみを抽出し、既に読みが指定されている地点IDの品詞情報ベクトルを取得する。そして、サーバ側装置101は、S2102において取得された追加された地点の品詞情報ベクトルと、既に読みが指定されている地点の品詞情報ベクトルとの距離を算出する(S2105)。この距離計算には、前述した一致および不一致によるハミング距離などを用いてもよい。また、距離計算の手段には、品詞情報ベクトルだけではなく、表記1601または読み1603を各々情報ベクトルとし、各々の情報ベクトル間の距離を算出し、算出した距離に重みをつけて加算するなどをしてもよい。
Then, only the part-of-
次に、サーバ側装置101は、既に読みが指定されているすべての地点IDについて、追加された地点の品詞情報ベクトルからの距離を算出したか否かを判定する(S2106)。すべての地点IDについて距離を算出していない場合、サーバ側装置101は、S2102に戻る。すべての地点IDについて距離を算出した場合、サーバ側装置101は、追加された地点から最も距離が小さい地点を取得する(S2107)。
Next, the server-
ここで、品詞情報ベクトルによって、最も距離が小さい(近い)地点を検索した結果、端末ID1において、地点「日立新宿店」から最も距離が近い地点として、地点「日立国分寺店」が取得されたとする。 Here, the point “Hitachi Kokubunji store” is acquired as the closest point from the point “Hitachi Shinjuku store” in the terminal ID1 as a result of searching for the point with the smallest (closest) distance using the part of speech information vector. .
次に、サーバ側装置101は、読み履歴ベクトルデータベース1500を参照し、S2107において取得された最も距離が近い地点における、形態素解析結果の読み情報の順序と、その地点IDに設定された読み情報とを比較する。
Next, the server-
例えば、読み履歴ベクトルデータベース1500の端末ID1において、地点「日立国分寺店」は、「こくぶんじひたち」という読みを優先すべきものとして指定されているとする。そして、図22に示す解析結果1700の読み1603を用いて、「こくぶんじひたち」という読みを構成できるか否かを判定する。この判定処理には、入力文字列「こくぶんじひたち」に、図22に示す読み1603を用いて、最長一致法アルゴリズムによって全体が一致する文字列を構成できるか否かを判定してもよい。なお、この判定によって、読みを構成できないと判定された場合、サーバ側装置101は、S2107に戻り、次に距離が近い地点を取得してもよい。
For example, in the
その結果、サーバ側装置101は、図22に示す2行目の形態素の読み1603の「こくぶんじ」と、1行目の形態素の読み1603「ひたち」とを結合することによって「こくぶんじひたち」という読みが構成できると判定する。
As a result, the server-
そして、サーバ側装置101は、この2行目の形態素の品詞1602「地名」と、1行目の形態素の品詞1602「固有名詞」の順番を、追加された地点名称の解析結果1600に適用し、「しんじゅくひたち」という読みを生成する(S2108)。
Then, the server-
前述の処理の結果から、端末ID1の利用者は、追加された地点「日立新宿店」を、「しんじゅくひたち」という呼び方によって呼ぶ可能性が高いことが推測される。この読み「しんじゅくひたち」は、図17に示す読み履歴ベクトルデータベース1500に、追加された地点「日立新宿店」に対応する地点IDに保存され、前述の処理に従って端末側装置100へ図13に示す読み優先順データ1200の形式によって送信される。
From the result of the above-described processing, it is presumed that the user of the
この結果、端末側装置100は、新たに追加された地点「日立新宿店」に「しんじゅくひたち」という読みを第1候補として設定される。そして、端末側装置100が備わるカーナビゲーション装置における音声ガイダンスは、これ以降、文字列「日立新宿店」に「しんじゅくひたち」という音声を読み上げる。
As a result, the terminal-
なお、図20に示す処理は、前述の新規に追加される地名にも、またはどの端末ID1501においても読みが指定されていない未知地名にも、適用することができる読み優先順決定処理1803である。図19および図20に示す処理は、読み履歴ベクトルデータベース1500の読み履歴ベクトル間の距離を算出する処理であり、同様の流れによって行われる。ただし、図20においては、サーバ側装置101から読み優先順データを送信する対象となる端末側装置100を示す端末ID1501の読み履歴ベクトルのみを用いる。
The process shown in FIG. 20 is a reading priority
また、前述において読み履歴ベクトル間の距離を取得するために、品詞情報ベクトルを用いたが、品詞情報のほかにも様々な言語情報またはPOIに関する補足情報(飲食店、施設名などのカテゴリ情報など)を解析結果に含めてもよい。また、S2105における距離を算出するためのアルゴリズムには、前述の品詞情報ベクトル間におけるハミング距離のほかにも、品詞またはPOIカテゴリの近さを考慮した重み付き距離などの様々な方法を用いてもよい。 In addition, the part-of-speech information vector is used in order to obtain the distance between the reading history vectors in the above description, but in addition to the part-of-speech information, various language information or supplementary information on POI (category information such as restaurants and facility names) ) May be included in the analysis results. In addition to the hamming distance between the part of speech information vectors described above, various methods such as a weighted distance considering the proximity of the part of speech or the POI category may be used as the algorithm for calculating the distance in S2105. Good.
この図20に示す処理は、対象となった読み履歴ベクトルのすべての未知地名に読み情報が指定されるまで繰り返されてもよい。 The processing shown in FIG. 20 may be repeated until reading information is specified for all unknown place names of the target reading history vector.
(第2の実施形態)
第2の実施形態では、端末側装置100およびサーバ側装置101という区別を設けずに、同じ装置によって本発明の処理を行う。第2の実施形態は、例えば、外部との通信機能を持たないカーナビゲーション装置においても適用できるし、また、通信機能を有していても、利用者の読み履歴情報をサーバ側装置101に送信することができない場合(セキュリティ等)にも適用できる。
(Second Embodiment)
In the second embodiment, the processing of the present invention is performed by the same device without distinguishing between the
図23は、本発明の第2の実施形態の端末側装置2200の構成を示すブロック図である。
FIG. 23 is a block diagram illustrating a configuration of the terminal-
第2の実施形態において、サーバ側装置101は使用されない。このため、端末側装置2200は、第1の実施形態における端末側装置100が備える手段と同様な手段を備えるが、読み履歴ベクトル送信手段4および読み優先順受信手段8を備えない。また、読み優先順受信手段8の代わりに、第1の実施形態においてサーバ側装置101に備えられた読み優先順決定手段14と同じ機能を持つ読み優先順決定手段2208を備える。第1の実施形態における端末側装置100に備わる手段と異なる手段は、この読み優先順決定手段2208のみであるため、この手段についてのみ後述し、その他の手段については省略する。
In the second embodiment, the
この第2の実施形態において、端末側装置2200は、第1の実施形態のように他の端末側装置100の読み履歴ベクトル情報1000、または読み優先順データ1200を用いて、未知、すなわち新規の地名に読み優先順を決定できない。そのため、読み優先順決定手段2208では、第1の実施形態における読み優先順決定処理1803の中でも、形態素および品詞情報に基づく読み決定処理、すなわち、図20に示す形態素ベクトル間距離に基づく読み優先順決定処理を行うことによって、未知、すなわち新規の地名に読み優先順を決定する。これによって、端末側装置2200のみによって処理する構成が可能となる。
In the second embodiment, the
すなわち、第2の実施の形態によれば、端末側装置は、複数の単語を音声にて出力し、前記単語と、当該単語に対応する読みとの組み合わせを保持し、前記保持された単語を形態素解析によって、品詞毎の単位文字列に分割し、前記分割された単位文字列が同じ品詞である場合、前記単位文字列の読みが類似する単語を取得し、前記取得された単語の読みに基づいて、前記単位文字列を並べる順番を特定し、前記特定された単位文字列の順番によって、当該取得された単語と単位文字列の品詞の配列が類似する単語の単位文字列を並べ、前記並べられた単位文字列に基づいて、当該単語の読みを生成し、前記生成された読みによって、前記組み合わせに含まれる単語の読みを更新し、前記更新された組み合わせを用いて、前記単語を音声にて出力するためのデータを作成することを特徴とする。 That is, according to the second embodiment, the terminal-side device outputs a plurality of words by voice, holds a combination of the word and a reading corresponding to the word, and stores the held word. Dividing into unit character strings for each part of speech by morphological analysis, and when the divided unit character strings are the same part of speech, obtain a word whose reading of the unit character string is similar, and read the acquired word Based on the order of arranging the unit character strings, and by arranging the unit character strings of the words that are similar in order of part of speech of the acquired word and the unit character string according to the order of the specified unit character string, A reading of the word is generated based on the arranged unit character strings, the reading of the word included in the combination is updated by the generated reading, and the word is sounded using the updated combination. At Characterized by generating data for force.
(第3の実施形態)
また、第1および第2の実施形態の中間段階として、第3の実施形態の端末側装置100は、サーバ側装置101に利用者の読み履歴ベクトル情報1000全体を送らずに、読み優先順を決定したい地点IDのみを送信し、サーバ側装置101によって処理された結果の読み優先順データ1200を受信してもよい。この場合、第2の実施形態と同じく読み履歴ベクトル間の距離計算ができないため、サーバ側装置101における読み優先順決定処理1803において、形態素および品詞情報の近さに基づく図20の処理を行う。
(Third embodiment)
As an intermediate stage between the first and second embodiments, the terminal-
例えば、端末側装置100は、通信手段を持つがサーバ側装置101に大量のデータを送ることができない場合、または端末側装置100ではCPUの処理性能などの制限によって、第2の実施形態を適用できない場合などに、第3の実施形態は適用可能である。
For example, the terminal-
本発明の第1ないし第3の実施形態によれば、例えばカーナビゲーション装置に備わる端末側装置100は、音声入力された地点名の読み情報を記録しておく読み履歴記憶手段5と、その情報を音声入力ごとに更新する読み履歴更新手段6と、記憶されている読み履歴ベクトル情報1000をサーバ側装置101に送信する読み履歴送信手段4と、サーバ側装置101から送信される読み優先順情報を受信する読み優先順受信手段8と、読み履歴記憶手段5に格納されている読み履歴ベクトル情報1000を利用して漢字かなテキストへの読みを付与する読み決定手段2とを備えることによって、利用者が音声によって入力した地点名の呼び方を用いて、以降の音声ガイダンスを行うことができる。また、端末側装置100は、利用者がまだ入力していない地点名称にも、サーバ側装置101から送信された読みを用いることによって、利用者がその地点名称を呼ぶ可能性の高い読みによって地点名を読み上げることができる。
According to the first to third embodiments of the present invention, for example, the terminal-
すなわち、第3の実施の形態によれば、端末側装置は、前記組み合わせのうち、一部の単語と、当該単語に対応する読みとの組み合わせを前記サーバに送信し、前記サーバ側装置は、前記送信された一部の組み合わせを使用する。 That is, according to the third embodiment, the terminal-side device transmits a combination of a part of the words and a reading corresponding to the word to the server, and the server-side device Use the transmitted partial combination.
100 端末側装置
101 サーバ側装置
1 テキスト入力手段
2 読み決定手段
3 音声合成手段
4 読み履歴送信手段
5 読み履歴記憶手段
6 読み履歴更新手段
7 音声入力手段
8 読み優先順受信手段
9 音声出力手段
11 読み履歴受信手段
12 読み優先順送信手段
13 読み履歴記憶手段
14 読み優先順決定手段
15 新規読み受信手段
1000 読み履歴ベクトル情報
1200 読み優先順データ
1500 読み履歴ベクトルデータベース
DESCRIPTION OF
Claims (5)
前記音声読み上げ端末は、
前記単語と、前記単語に指定される読みとの組み合わせを保持し、
前記組み合わせを、前記読み情報更新サーバに送信し、
前記読み情報更新サーバは、
複数の前記音声読み上げ端末から送信された、複数の前記組み合わせを保持し、
前記組み合わせから、前記読みが指定されていない前記単語を取得し、
複数の前記組み合わせの中から、前記単語における前記読みが、当該組み合わせの前記単語における前記読みと類似する複数の他の前記組み合わせを特定し、
前記複数の他の組み合わせから、当該組み合わせにおいて前記読みが指定されていない前記単語の前記読みを抽出し、
前記抽出された読みによって、前記読みが指定されていない単語の前記読みを指定し、
前記単語と前記指定された読みとによって、前記組み合わせを更新し、
前記更新された組み合わせを前記音声読み上げ端末に送信し、
前記音声読み上げ端末は、
保持された前記組み合わせを、前記送信された組み合わせによって更新し、
前記更新された組み合わせに基づいて、前記単語を読み上げることを特徴とする音声読み上げシステム。 A speech reading system comprising a plurality of speech reading terminals that read out a plurality of words, and a reading information update server connected to the voice reading terminals via a network,
The voice reading terminal is
Holding a combination of the word and the reading specified for the word;
Sending the combination to the reading information update server;
The reading information update server
Transmitted from a plurality of said voice reading terminal, a plurality of the combinations held,
Obtaining the word for which the reading is not specified from the combination;
Among the plurality of combinations, the reading in the word identifies a plurality of other combinations similar to the reading in the word of the combination;
Extracting the reading of the word for which the reading is not specified in the combination from the other combinations,
The extracted readings specify the readings of words for which the reading is not specified,
Updating the combination with the word and the specified reading;
Sending the updated combination to the voice reading terminal;
The voice reading terminal is
Updating the retained combination with the transmitted combination;
A speech-to-speech system, wherein the word is read out based on the updated combination.
前記組み合わせに含まれる前記単語に、利用者によって入力された前記単語に対する読みを指定し、
前記単語を読み上げる場合に、前記指定された読みを優先して用いることを特徴とする請求項1に記載の音声読み上げシステム。 The voice reading terminal is
Specify the reading for the word input by the user for the word included in the combination,
2. The speech reading system according to claim 1, wherein when the word is read out, the designated reading is preferentially used.
新たな単語を、前記組み合わせに追加し、
前記新たな単語を追加された前記組み合わせを、前記音声読み上げ端末に送信することを特徴とする請求項1に記載の音声読み上げシステム。 The reading information update server
Add a new word to the combination,
The speech reading system according to claim 1, wherein the combination to which the new word is added is transmitted to the speech reading terminal.
前記音声読み上げ端末は、 The voice reading terminal is
前記単語と、前記単語に指定される読みとの組み合わせを保持し、 Holding a combination of the word and the reading specified for the word;
前記組み合わせを、前記読み情報更新サーバに送信し、 Sending the combination to the reading information update server;
前記読み情報更新サーバは、 The reading information update server
複数の前記音声読み上げ端末から送信された、複数の前記組み合わせを保持し、 Holding a plurality of the combinations transmitted from a plurality of the speech reading terminals,
前記複数の単語を形態素解析によって、品詞毎の単位文字列に分け、 Dividing the plurality of words into unit character strings for each part of speech by morphological analysis,
同じ前記品詞において、前記文字列が当該単語の文字列と類似する他の前記単語を取得し、 In the same part of speech, obtaining the other word whose character string is similar to the character string of the word,
前記他の単語に指定される前記読みに基づいて、前記単位文字列を並べる順番を特定し、 Based on the reading specified for the other word, identify the order in which the unit character strings are arranged,
前記特定された単位文字列の順番に基づいて、前記単語の単位文字列を並べ、 Arranging the unit character strings of the words based on the order of the specified unit character strings,
前記並べられた単位文字列から、単語の読みを生成し、 Generate word readings from the aligned unit strings,
前記生成された読みによって、前記組み合わせの前記読みを更新し、 Updating the reading of the combination with the generated reading;
前記更新された組み合わせを前記音声読み上げ端末に送信し、 Sending the updated combination to the voice reading terminal;
前記音声読み上げ端末は、 The voice reading terminal is
保持された前記組み合わせを、前記送信された組み合わせによって更新し、 Updating the retained combination with the transmitted combination;
前記更新された組み合わせに基づいて、前記単語を読み上げることを特徴とする音声読み上げシステム。 A speech-to-speech system, wherein the word is read out based on the updated combination.
前記単語と、前記単語に指定される読みとの組み合わせを保持し、 Holding a combination of the word and the reading specified for the word;
新たな前記単語を、前記組み合わせに追加し、 Add the new word to the combination,
前記複数の単語を形態素解析によって、品詞毎の単位文字列に分け、 Dividing the plurality of words into unit character strings for each part of speech by morphological analysis,
同じ前記品詞において、前記文字列が当該単語の文字列と類似する他の前記単語を取得し、 In the same part of speech, obtaining the other word whose character string is similar to the character string of the word,
前記他の単語に指定される前記読みに基づいて、前記単位文字列の順番を特定し、 Based on the reading specified for the other word, specify the order of the unit character string,
前記特定された単位文字列の順番に基づいて並べられた前記単語の文字列から、前記単語の読みを抽出し、 Extracting the reading of the word from the character string of the word arranged based on the order of the specified unit character string,
前記抽出された読みによって、前記組み合わせの前記読みを更新することを特徴とする音声読み上げ端末。 A speech-to-speech terminal, wherein the reading of the combination is updated by the extracted reading.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009178921A JP5246512B2 (en) | 2009-07-31 | 2009-07-31 | Voice reading system and voice reading terminal |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009178921A JP5246512B2 (en) | 2009-07-31 | 2009-07-31 | Voice reading system and voice reading terminal |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011033764A JP2011033764A (en) | 2011-02-17 |
| JP5246512B2 true JP5246512B2 (en) | 2013-07-24 |
Family
ID=43762916
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009178921A Expired - Fee Related JP5246512B2 (en) | 2009-07-31 | 2009-07-31 | Voice reading system and voice reading terminal |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5246512B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023073949A1 (en) * | 2021-10-29 | 2023-05-04 | パイオニア株式会社 | Voice output device, server device, voice output method, control method, program, and storage medium |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4097901B2 (en) * | 2001-01-24 | 2008-06-11 | 松下電器産業株式会社 | Language dictionary maintenance method and language dictionary maintenance device |
-
2009
- 2009-07-31 JP JP2009178921A patent/JP5246512B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2011033764A (en) | 2011-02-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2477186B1 (en) | Information retrieving apparatus, information retrieving method and navigation system | |
| CN107590135B (en) | Automatic translation method, device and system | |
| US20230317074A1 (en) | Contextual voice user interface | |
| CN106663424B (en) | Intention understanding device and method | |
| JP3962767B2 (en) | Dialogue support device | |
| EP2259252B1 (en) | Speech recognition method for selecting a combination of list elements via a speech input | |
| US8380505B2 (en) | System for recognizing speech for searching a database | |
| US7552045B2 (en) | Method, apparatus and computer program product for providing flexible text based language identification | |
| JP2009169139A (en) | Voice recognizer | |
| JP2010055044A (en) | Device, method and system for correcting voice recognition result | |
| JP5335165B2 (en) | Pronunciation information generating apparatus, in-vehicle information apparatus, and database generating method | |
| JP2012168349A (en) | Speech recognition system and retrieval system using the same | |
| JP2002297374A (en) | Voice retrieving device | |
| CN107885720B (en) | Keyword generation device and keyword generation method | |
| JP5246512B2 (en) | Voice reading system and voice reading terminal | |
| JP3911178B2 (en) | Speech recognition dictionary creation device and speech recognition dictionary creation method, speech recognition device, portable terminal, speech recognition system, speech recognition dictionary creation program, and program recording medium | |
| JP2016102899A (en) | Voice recognition device, voice recognition method, and voice recognition program | |
| JP2008021235A (en) | Reading and registration system, and reading and registration program | |
| JP2009282835A (en) | Method and device for voice search | |
| JP6009396B2 (en) | Pronunciation providing method, apparatus and program thereof | |
| US20150206539A1 (en) | Enhanced human machine interface through hybrid word recognition and dynamic speech synthesis tuning | |
| Kiruthiga et al. | Annotating Speech Corpus for Prosody Modeling in Indian Language Text to Speech Systems | |
| JP2013250379A (en) | Voice recognition device, voice recognition method and program | |
| JP2000330588A (en) | Method and system for processing speech dialogue and storage medium where program is stored | |
| Thirion et al. | The South African directory enquiries (SADE) name corpus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20120224 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120309 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20121210 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20121218 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130215 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130312 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130327 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20160419 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |