JP5149840B2 - ストリームデータ処理方法、ストリームデータ処理プログラム、および、ストリームデータ処理装置 - Google Patents
ストリームデータ処理方法、ストリームデータ処理プログラム、および、ストリームデータ処理装置 Download PDFInfo
- Publication number
- JP5149840B2 JP5149840B2 JP2009048792A JP2009048792A JP5149840B2 JP 5149840 B2 JP5149840 B2 JP 5149840B2 JP 2009048792 A JP2009048792 A JP 2009048792A JP 2009048792 A JP2009048792 A JP 2009048792A JP 5149840 B2 JP5149840 B2 JP 5149840B2
- Authority
- JP
- Japan
- Prior art keywords
- query
- stream data
- data processing
- group
- scheduler
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5083—Techniques for rebalancing the load in a distributed system
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
前記ストリームデータ処理装置が、前記ストリームデータを格納する記憶手段と、前記ストリームデータ処理装置を制御するストリーム制御部と、前記ストリームデータに対して前記クエリ演算処理を実行するクエリ実行部と、前記ストリームデータ処理装置の計算機資源を割り当てるスケジューラと、を有し、
前記スケジューラが、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化し、そのクエリグループを単位として前記計算機資源のスレッドに割り当てることで、前記クエリ実行部に前記クエリ演算処理を実行させ、
所定クエリグループへのデータ停滞が発生すると、
前記所定クエリグループを構成するクエリごとに、そのクエリの入力流量情報およびレイテンシ情報の内の少なくとも1つの情報を前記記憶手段から読み取り、そのクエリの負荷評価値を計算し、
前記所定クエリグループを構成するクエリを、互いにクエリの負荷評価値の和が略均等になるように、複数のクエリグループへと分割し、
前記分割後の複数のクエリグループを、それぞれ異なる前記計算機資源のスレッドに再割り当てするように、前記ストリーム制御部に指示することを特徴とする。
その他の手段は、後記する。
ストリームソース41から配信されるストリームデータの一例を示す。ストリームデータ「S1」は、3つの整数型の変数(a,b,c)と、1つの浮動小数点型の変数(x)とで1つのタプルを構成する。このストリームデータ「S1」は、以下のように定義される。
register stream S1
(a int, b int, c int, x float)
なお、プロセッサ91は、マルチコアを有するハードウェアとして構成されていてもよいし、マルチスレッドをサポートしたハードウェアとして構成されていてもよい。これらのハードウェアを機能させるためのOSがプロセッサ91によって動作する。つまり、サーバ装置2には、複数のスレッドを割り当てるための計算機資源が搭載されている。
なお、スレッド(thread)とは、CPUを利用してプログラムを実行するときの実行単位である。
コマンド解析部21は、コマンド42を構文解析する。
コマンド42は、ストリーム制御部11に対して入力される、ストリーム処理部10の制御情報である。コマンド42は、サーバ装置2の入力装置93から入力されてもよいし、クライアント装置1に入力された後にネットワーク9を経由して受信してもよい。
コマンド実行部22は、コマンド解析部21が解析したコマンド42を、コマンド管理部23に登録する。
クエリ解析部31は、クエリ43を構文解析してから最適化して実行形式に変換し、クエリリポジトリ36に格納する。
クエリ43は、サーバ装置2の入力装置93から入力されてもよいし、クライアント装置1に入力された後にネットワーク9を経由して受信してもよい。
統計情報取得部34は、クエリ43ごとの実行時の統計情報をクエリ実行部35から取得して、統計情報テーブル38(図6参照)に書き込む。
入力キュー46は、インタフェース部12を介して入力されたストリームデータを格納する。
クエリ43(Q1→Q2→Q3)は、入力キュー46に入力されたストリームデータを、Q1→Q2→Q3の順に処理する処理内容を示す。
出力キュー47は、クエリ43(Q3)の処理結果を格納する。
図4は、図3で示すクエリグループ45を示すクエリグループ管理テーブル37内の登録情報を示す。図3(a)と図4(a)、図3(b)と図4(b)、および、図3(c)と図4(c)、はそれぞれ対応する。
以下、図3および図4を参照して、クエリグループ45の分割処理を説明する。
register query Q1
select S1.a,S1,b,S1.x from S1[rows 10] where S1.a > 0
register query Q2
select Q1.a,Q1.b,avg(Q1.x) from Q1 groupby Q1.a,Q1.b
register query Q3
select Q1.a,Q1.x from Q2
where Q1.x > Q1.a and Q1.x < Q1.b
register query Q4
select max(Q3.x) from Q3
register query Q5
istream(select * from Q4 where S1.x > 1000)
図4(a)に示すクエリグループ管理テーブル37は、クエリグループ45と、そのクエリグループ45を構成するクエリ43と、そのクエリグループ45に割り当てられているスレッドとを対応づけて管理する。
入力されるストリームデータのタプルは、まず、入力キュー46に格納される。クエリグループ45(G1)の先頭クエリ43(Q1)は、入力キュー46からタプルを順に読み出して、クエリ演算処理を実行する。クエリ43(Q1)は、実行結果を次のクエリ43(Q2)に渡す。そして、クエリグループ45(G1)の末尾クエリ43(Q5)は、クエリ43(Q4)から入力されるタプルの実行結果を、出力キュー47へと出力する。
図5では、図3のクエリ43(Q1)が、3つのオペレータによって構成されるため、そのオペレータそれぞれにクエリグループ45を割り当てる例を示している。
オペレータ「RowWindow」というウィンドウ演算は、クエリ43(Q1)の「from S1[rows 10]」に対応する。
オペレータ「Filter」という条件指定のフィルタリング演算は、クエリ43(Q1)の「where S1.a >0」に対応する。
オペレータ「Projection」という射影演算は、クエリ43(Q1)の「select S1.a,S1.b,S1.x」に対応する。
このように、クエリ43単位のクエリグループ45の分割では充分なスループットが得られない場合には、オペレータ単位のクエリグループ45の定義により、スループットをさらに向上させることができる。
統計情報テーブル38は、クエリ43と、入力流量と、レイテンシと、負荷評価値とを対応づけて管理する。
「入力流量」は、対応するクエリ43の単位時間当たりのタプルの入力件数であり、単位は[タプル/秒]である。
「レイテンシ」は、対応するクエリ43に入力されたタプルの、入力されてから出力されるまでの平均時間を示し、単位は[ミリ秒]である。この「レイテンシ」は、タプルの平均時間について、実測値による統計情報を設定してもよいし、クエリ43のオペレータをプログラム解析した理論見積値としてもよい。なお、クエリ43の「入力流量」が、そのクエリ43の最大スループット(「レイテンシ」の逆数)を上回るときには、クエリ43の処理がおいつかないため、データあふれが発生する。
・負荷評価値=「入力流量」
・負荷評価値=「レイテンシ」の実測値
・負荷評価値=「レイテンシ」の理論見積値
ここで、負荷評価値に着目して、図6(a)と図6(b)とを比較すると、図6(b)のほうが負荷評価値が高い。つまり、図6(b)は、データの停滞時の状態になっている。
S102において、パラメータ「システム起動時刻」に、現在時刻を設定する。
S104において、クエリ43(Qi)のタプル(Tj)の入力時刻に、現在時刻を設定する。
S105において、クエリ実行部35のクエリ43(Qi)に対して、タプル(Tj)の出力が発生したか否かを判定する。S105でYesならS106へ進み、NoならS103へ戻る。
具体的には、クエリ43(Qi)のデータ入力量に、タプル(Tj)の分(値=1)を加算する。クエリ43(Qi)の処理時間に、タプル(Tj)の処理時間(現在時刻−「クエリ43(Qi)のタプル(Tj)の入力時刻」)を加算する。
そして、以下の式により、統計情報テーブル38のクエリ43(Qi)の列の値を更新する。
クエリ43(Qi)の入力流量=クエリ43(Qi)のデータ入力量÷(現在時刻−システム起動時刻)
クエリ43(Qi)のレイテンシ=クエリ43(Qi)の処理時間÷クエリ43(Qi)のデータ入力量
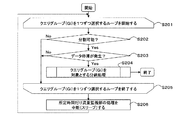
S201において、クエリグループ管理テーブル37からクエリグループ45を1つずつ選択するループを開始する。なお、現在選択されているクエリグループ45を、クエリグループ45(Gi)と表記する。
S202において、クエリグループ45(Gi)が分割可能か否かを判定する。ここで、分割可能とは、例えば、クエリグループ45(Gi)に2つ以上のクエリ43が含まれている場合としてもよいし(図3などを参照)、クエリグループ45(Gi)に1つのクエリ43が含まれており、かつ、そのクエリ43に2つ以上のオペレータが含まれている場合としてもよい(図5などを参照)。S202でYesならS203へ進み、NoならS205へ進む。
S203において、クエリグループ45(Gi)に対して、データ停滞が発生しているか否かを判定する。データ停滞の検知手法は、後記する。S203でYesならS204へ進み、NoならS205へ進む。
S204において、クエリグループ45(Gi)を対象とする分割処理を起動して(図9の処理を呼び出して)、本フローチャートを終了する。なお、起動した分割処理から、本フローチャートのS201が再起動される。
S205において、S201からのループ処理を終了する。
S206において、所定時間だけ流量監視部32の処理を中断(スリープ)した後、S201へ戻る。このように、クエリグループ45の分割処理を繰り返すことで、必要なだけクエリグループ45の分割を行い、相応するスループットを得ることができる。
10×(40÷40)
+8×(30÷40)
+16×(30÷40)
+4×(25÷40)
+2×(20÷40)=31.5(ミリ秒)。
(入力流量X=40)>1000÷(平均レイテンシY=31.5)
であり、40>31.7なので、データ停滞発生あり、と判定される。
S302において、クエリグループ45(Gi)の分割位置を決定するため、図10の処理を呼び出す。
(1)分割前のクエリグループ45(Gi)の入力位置に存在するキュー(入力キュー46または中間キュー48)からのクエリグループ45(Gi)へのデータ入力を停止させる。
(2)分割前のクエリグループ45(Gi)が処理中であるデータが、クエリグループ45(Gi)の出力位置に存在するキュー(出力キュー47または中間キュー48)にすべて出力されるまで、クエリ演算処理の実行を待つ。
(3)S302で決定した分割位置に従って、1つのクエリグループ45(Gi)を、2つのクエリグループ45へと分割する。分割後の第1クエリグループ45は、クエリグループ45(Gi)が含むクエリ43のうちの分割位置より前側にあるクエリ43を含む。分割後の第2クエリグループ45は、クエリグループ45(Gi)が含むクエリ43のうちの分割位置より後側にあるクエリ43を含む。
(4)分割後の第1クエリグループ45と第2クエリグループ45との間を、中間キュー48で接続する。
(5)第1クエリグループ45には分割前のクエリグループ45(Gi)と同じスレッドを割り当て、第2クエリグループ45には新しいスレッドを割り当てる。
S313において、「負荷評価値」の和A,Bをそれぞれ計算する。
「負荷評価値」の和A=クエリグループ45(Gi)を構成する先頭のクエリ43から、クエリ43(Qj)までの各クエリ43における「負荷評価値」の総和
「負荷評価値」の和B=クエリグループ45(Gi)を構成する先頭のクエリ43から、クエリ43(Q(j−1))までの各クエリ43における「負荷評価値」の総和
S315において、「負荷評価値」の和Aが、「負荷評価値」の和Bよりも分割基準点Wに近いか否かを判定する。具体的には、「負荷評価値」の和それぞれと、分割基準点Wとの距離を求める。S315でYesならS316へ進み、NoならS317へ進む。
S316において、クエリ43(Qj)とクエリ43(Q(j+1))との間に、分割点を設定する。
S317において、クエリ43(Q(j−1))とクエリ43(Qj)との間に、分割点を設定する。
S318において、S312からのループを終了する。
第1クエリグループ45(Q1,Q2)=「負荷評価値」の和が「640」
第2クエリグループ45(Q3,Q4,Q5)=「負荷評価値」の和が「620」
という分割位置が、略均等になる。
なお、分割対象のクエリグループ45は、以前分割されたクエリグループ45であってもよい。これにより、負荷の高いクエリグループ45が、1回以上の分割処理によって、適切な粒度のクエリグループ45へと分割される。
さらに、スケジューラ33は、クエリグループ45の分割処理の契機を、そのクエリグループ45へのデータ停滞の発生時期とすることにより、到来するデータ入力速度に対して充分処理を実行できるクエリグループ45への分割を抑制し、処理速度、使用資源への影響を最小限に保つことができる。
1a アプリケーション処理部
2 サーバ装置(ストリームデータ処理装置)
9 ネットワーク
10 ストリーム処理部
11 ストリーム制御部
12 インタフェース部
20 コマンド処理部
21 コマンド解析部
22 コマンド実行部
23 コマンド管理部
30 クエリ処理部
31 クエリ解析部
32 流量監視部
33 スケジューラ
34 統計情報取得部
35 クエリ実行部
36 クエリリポジトリ
37 クエリグループ管理テーブル
38 統計情報テーブル
41 ストリームソース
42 コマンド
43 クエリ
44 クエリ処理結果
45 クエリグループ
46 入力キュー
47 出力キュー
48 中間キュー
91 プロセッサ
92 主記憶装置
93 入力装置
94 出力装置
95 補助記憶装置
Claims (18)
- 入力され続けるストリームデータを受け付け、クエリ演算処理を実行するストリームデータ処理装置によるストリームデータ処理方法であって、
前記ストリームデータ処理装置は、前記ストリームデータを格納する記憶手段と、前記ストリームデータ処理装置を制御するストリーム制御部と、前記ストリームデータに対して前記クエリ演算処理を実行するクエリ実行部と、前記ストリームデータ処理装置の計算機資源を割り当てるスケジューラと、を有し、
前記スケジューラは、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化し、そのクエリグループを単位として前記計算機資源のスレッドに割り当てることで、前記クエリ実行部に前記クエリ演算処理を実行させ、
所定クエリグループへのデータ停滞が発生すると、
前記所定クエリグループを構成するクエリごとに、そのクエリの入力流量情報およびレイテンシ情報の内の少なくとも1つの情報を前記記憶手段から読み取り、そのクエリの負荷評価値を計算し、
前記所定クエリグループを構成するクエリを、互いにクエリの負荷評価値の和が略均等になるように、複数のクエリグループへと分割し、
前記分割後の複数のクエリグループを、それぞれ異なる前記計算機資源のスレッドに再割り当てするように、前記ストリーム制御部に指示することを特徴とする
ストリームデータ処理方法。 - 前記スケジューラは、前記所定クエリグループへの前記ストリームデータの入力流量が、前記所定クエリグループを構成する各クエリの処理流量の平均値を超えたときに、前記所定クエリグループへのデータ停滞を検知することを特徴とする
請求項1に記載のストリームデータ処理方法。 - 前記スケジューラは、前記所定クエリグループへの前記ストリームデータの入力流量が、所定閾値を超えたときに、前記所定クエリグループへのデータ停滞を検知することを特徴とする
請求項1に記載のストリームデータ処理方法。 - 前記スケジューラは、前記ストリームデータ処理装置の前記計算機資源のスレッドについて、割当済みのスレッド数が利用可能なスレッド数以上の場合には、前記所定クエリグループを複数のクエリグループへと分割する処理を省略することを特徴とする
請求項1ないし請求項3のいずれか1項に記載のストリームデータ処理方法。 - 前記スケジューラは、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化するときに、クエリの構成要素であるオペレータをクエリグループとしてグループ化することを特徴とする
請求項1ないし請求項4のいずれか1項に記載のストリームデータ処理方法。 - 前記スケジューラは、クエリごとの負荷評価値を計算するときに、そのクエリの入力流量と、そのクエリのレイテンシとの積を、負荷評価値とすることを特徴とする
請求項1ないし請求項5のいずれか1項に記載のストリームデータ処理方法。 - 入力され続けるストリームデータを受け付け、クエリ演算処理を実行するストリームデータ処理装置により実行されるストリームデータ処理プログラムであって、
前記ストリームデータ処理装置は、前記ストリームデータを格納する記憶手段と、前記ストリームデータ処理装置を制御するストリーム制御部と、前記ストリームデータに対して前記クエリ演算処理を実行するクエリ実行部と、前記ストリームデータ処理装置の計算機資源を割り当てるスケジューラと、を有し、
前記スケジューラに、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化し、そのクエリグループを単位として前記計算機資源のスレッドに割り当てることで、前記クエリ実行部に前記クエリ演算処理を実行させる手順と、
所定クエリグループへのデータ停滞が発生すると、
前記所定クエリグループを構成するクエリごとに、そのクエリの入力流量情報およびレイテンシ情報の内の少なくとも1つの情報を前記記憶手段から読み取り、そのクエリの負荷評価値を計算する手順と、
前記所定クエリグループを構成するクエリを、互いにクエリの負荷評価値の和が略均等になるように、複数のクエリグループへと分割する手順と、
前記分割後の複数のクエリグループを、それぞれ異なる前記計算機資源のスレッドに再割り当てするように、前記ストリーム制御部に指示する手順と、を実行させることを特徴とする
ストリームデータ処理プログラム。 - 前記スケジューラに、前記所定クエリグループへの前記ストリームデータの入力流量が、前記所定クエリグループを構成する各クエリの処理流量の平均値を超えたときに、前記所定クエリグループへのデータ停滞を検知する手順を実行させることを特徴とする
請求項7に記載のストリームデータ処理プログラム。 - 前記スケジューラに、前記所定クエリグループへの前記ストリームデータの入力流量が、所定閾値を超えたときに、前記所定クエリグループへのデータ停滞を検知する手順を実行させることを特徴とする
請求項7に記載のストリームデータ処理プログラム。 - 前記スケジューラに、前記ストリームデータ処理装置の前記計算機資源のスレッドについて、割当済みのスレッド数が利用可能なスレッド数以上の場合には、前記所定クエリグループを複数のクエリグループへと分割する処理を省略する手順を実行させることを特徴とする
請求項7ないし請求項9のいずれか1項に記載のストリームデータ処理プログラム。 - 前記スケジューラに、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化するときに、クエリの構成要素であるオペレータをクエリグループとしてグループ化する手順を実行させることを特徴とする
請求項7ないし請求項10のいずれか1項に記載のストリームデータ処理プログラム。 - 前記スケジューラに、クエリごとの負荷評価値を計算するときに、そのクエリの入力流量と、そのクエリのレイテンシとの積を、負荷評価値とする手順を実行させることを特徴とする
請求項7ないし請求項11のいずれか1項に記載のストリームデータ処理プログラム。 - 入力され続けるストリームデータを受け付け、クエリ演算処理を実行するストリームデータ処理装置であって、
前記ストリームデータ処理装置は、前記ストリームデータを格納する記憶手段と、前記ストリームデータ処理装置を制御するストリーム制御部と、前記ストリームデータに対して前記クエリ演算処理を実行するクエリ実行部と、前記ストリームデータ処理装置の計算機資源を割り当てるスケジューラと、を有し、
前記スケジューラは、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化し、そのクエリグループを単位として前記計算機資源のスレッドに割り当てることで、前記クエリ実行部に前記クエリ演算処理を実行させ、
所定クエリグループへのデータ停滞が発生すると、
前記所定クエリグループを構成するクエリごとに、そのクエリの入力流量情報およびレイテンシ情報の内の少なくとも1つの情報を前記記憶手段から読み取り、そのクエリの負荷評価値を計算し、
前記所定クエリグループを構成するクエリを、互いにクエリの負荷評価値の和が略均等になるように、複数のクエリグループへと分割し、
前記分割後の複数のクエリグループを、それぞれ異なる前記計算機資源のスレッドに再割り当てするように、前記ストリーム制御部に指示することを特徴とする
ストリームデータ処理装置。 - 前記スケジューラは、前記所定クエリグループへの前記ストリームデータの入力流量が、前記所定クエリグループを構成する各クエリの処理流量の平均値を超えたときに、前記所定クエリグループへのデータ停滞を検知することを特徴とする
請求項13に記載のストリームデータ処理装置。 - 前記スケジューラは、前記所定クエリグループへの前記ストリームデータの入力流量が、所定閾値を超えたときに、前記所定クエリグループへのデータ停滞を検知することを特徴とする
請求項13に記載のストリームデータ処理装置。 - 前記スケジューラは、前記ストリームデータ処理装置の前記計算機資源のスレッドについて、割当済みのスレッド数が利用可能なスレッド数以上の場合には、前記所定クエリグループを複数のクエリグループへと分割する処理を省略することを特徴とする
請求項13ないし請求項15のいずれか1項に記載のストリームデータ処理装置。 - 前記スケジューラは、
前記クエリ演算処理を定義する1つ以上のクエリをクエリグループとしてグループ化するときに、クエリの構成要素であるオペレータをクエリグループとしてグループ化することを特徴とする
請求項13ないし請求項16のいずれか1項に記載のストリームデータ処理装置。 - 前記スケジューラは、クエリごとの負荷評価値を計算するときに、そのクエリの入力流量と、そのクエリのレイテンシとの積を、負荷評価値とすることを特徴とする
請求項13ないし請求項17のいずれか1項に記載のストリームデータ処理装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009048792A JP5149840B2 (ja) | 2009-03-03 | 2009-03-03 | ストリームデータ処理方法、ストリームデータ処理プログラム、および、ストリームデータ処理装置 |
| US12/627,726 US8533730B2 (en) | 2009-03-03 | 2009-11-30 | Stream data processing method, stream data processing program and stream data processing apparatus for runtime query group data stagnation detection and load balancing |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009048792A JP5149840B2 (ja) | 2009-03-03 | 2009-03-03 | ストリームデータ処理方法、ストリームデータ処理プログラム、および、ストリームデータ処理装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2010204880A JP2010204880A (ja) | 2010-09-16 |
| JP2010204880A5 JP2010204880A5 (ja) | 2011-05-06 |
| JP5149840B2 true JP5149840B2 (ja) | 2013-02-20 |
Family
ID=42679389
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009048792A Expired - Fee Related JP5149840B2 (ja) | 2009-03-03 | 2009-03-03 | ストリームデータ処理方法、ストリームデータ処理プログラム、および、ストリームデータ処理装置 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US8533730B2 (ja) |
| JP (1) | JP5149840B2 (ja) |
Families Citing this family (76)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5586417B2 (ja) * | 2010-10-25 | 2014-09-10 | 株式会社日立製作所 | ストリームデータ処理における性能保証方法および装置 |
| JP5472885B2 (ja) * | 2010-11-02 | 2014-04-16 | 株式会社日立製作所 | プログラム、ストリームデータ処理方法及びストリームデータ処理計算機 |
| KR20120072252A (ko) * | 2010-12-23 | 2012-07-03 | 한국전자통신연구원 | 분산 데이터 스트림 처리 시스템에서 연속 처리 태스크를 병렬 처리하기 위한 장치 및 그 방법 |
| JP5664230B2 (ja) * | 2010-12-28 | 2015-02-04 | コニカミノルタ株式会社 | 画像読み込みシステムおよび読み込み画像処理システム |
| KR101770736B1 (ko) | 2011-03-17 | 2017-09-06 | 삼성전자주식회사 | 응용프로그램의 질의 스케쥴링을 이용한 시스템의 소모전력 절감 방법 및 그 방법을 이용하여 소모전력을 절감하는 휴대단말기 |
| KR101752699B1 (ko) * | 2011-07-18 | 2017-07-03 | 한국전자통신연구원 | 폭증 데이터 스트림 처리 방법 및 장치 |
| US8560526B2 (en) * | 2011-07-26 | 2013-10-15 | International Business Machines Corporation | Management system for processing streaming data |
| US8959313B2 (en) | 2011-07-26 | 2015-02-17 | International Business Machines Corporation | Using predictive determinism within a streaming environment |
| US8990452B2 (en) * | 2011-07-26 | 2015-03-24 | International Business Machines Corporation | Dynamic reduction of stream backpressure |
| US9148495B2 (en) | 2011-07-26 | 2015-09-29 | International Business Machines Corporation | Dynamic runtime choosing of processing communication methods |
| US9286354B2 (en) * | 2011-08-15 | 2016-03-15 | Software Ag | Systems and/or methods for forecasting future behavior of event streams in complex event processing (CEP) environments |
| US9396157B2 (en) * | 2011-08-26 | 2016-07-19 | International Business Machines Corporation | Stream application performance monitoring metrics |
| JP5927871B2 (ja) * | 2011-11-30 | 2016-06-01 | 富士通株式会社 | 管理装置、情報処理装置、管理プログラム、管理方法、プログラムおよび処理方法 |
| JP5862245B2 (ja) * | 2011-11-30 | 2016-02-16 | 富士通株式会社 | 配置装置、配置プログラムおよび配置方法 |
| KR101951747B1 (ko) * | 2012-01-18 | 2019-02-26 | 삼성전자 주식회사 | Dsms에서 사용자 정의 연산자의 스케쥴링 장치 및 방법 |
| US9405553B2 (en) | 2012-01-30 | 2016-08-02 | International Business Machines Corporation | Processing element management in a streaming data system |
| KR101827369B1 (ko) | 2012-02-21 | 2018-02-09 | 한국전자통신연구원 | 데이터 스트림 분산 병렬 처리 서비스 관리 장치 및 방법 |
| WO2013145310A1 (ja) * | 2012-03-30 | 2013-10-03 | 富士通株式会社 | データストリームの並列処理プログラム、方法、及びシステム |
| US9146775B2 (en) | 2012-04-26 | 2015-09-29 | International Business Machines Corporation | Operator graph changes in response to dynamic connections in stream computing applications |
| JP5858371B2 (ja) * | 2012-05-31 | 2016-02-10 | 株式会社日立製作所 | 解析システム、計算機システム及び解析方法 |
| US10652318B2 (en) * | 2012-08-13 | 2020-05-12 | Verisign, Inc. | Systems and methods for load balancing using predictive routing |
| WO2014041673A1 (ja) * | 2012-09-14 | 2014-03-20 | 株式会社日立製作所 | ストリームデータ多重処理方法 |
| US9158795B2 (en) | 2012-09-28 | 2015-10-13 | International Business Machines Corporation | Compile-time grouping of tuples in a streaming application |
| US9497250B2 (en) | 2012-10-29 | 2016-11-15 | International Business Machines Corporation | Runtime grouping of tuples in a streaming application |
| US9930081B2 (en) | 2012-11-13 | 2018-03-27 | International Business Machines Corporation | Streams optional execution paths depending upon data rates |
| US9400823B2 (en) * | 2012-12-20 | 2016-07-26 | Hitachi, Ltd. | Stream data processing method on recursive query of graph data |
| US9390135B2 (en) * | 2013-02-19 | 2016-07-12 | Oracle International Corporation | Executing continuous event processing (CEP) queries in parallel |
| US9087082B2 (en) * | 2013-03-07 | 2015-07-21 | International Business Machines Corporation | Processing control in a streaming application |
| US9329970B2 (en) * | 2013-03-15 | 2016-05-03 | International Business Machines Corporation | Selecting an operator graph configuration for a stream-based computing application |
| US20140278336A1 (en) * | 2013-03-15 | 2014-09-18 | International Business Machines Corporation | Stream input reduction through capture and simulation |
| US9910896B2 (en) * | 2013-03-15 | 2018-03-06 | Cisco Technology, Inc. | Suspending and resuming continuous queries over data streams |
| US9571545B2 (en) | 2013-03-15 | 2017-02-14 | International Business Machines Corporation | Evaluating a stream-based computing application |
| US9147010B2 (en) | 2013-04-17 | 2015-09-29 | International Business Machines Corporation | Reconfiguring an operator graph based on attribute usage |
| US9384302B2 (en) * | 2013-06-17 | 2016-07-05 | International Business Machines Corporation | Generating differences for tuple attributes |
| JP6204753B2 (ja) * | 2013-08-28 | 2017-09-27 | Kddi株式会社 | 分散クエリ処理装置、処理方法及び処理プログラム |
| US9379950B2 (en) | 2013-11-07 | 2016-06-28 | International Business Machines Corporation | Using cloud resources to improve performance of a streaming application |
| US9237079B2 (en) | 2013-11-19 | 2016-01-12 | International Business Machines Corporation | Increasing performance of a streaming application by running experimental permutations |
| US20150154257A1 (en) * | 2013-12-04 | 2015-06-04 | Nec Laboratories America, Inc. | System and method for adaptive query plan selection in distributed relational database management system based on software-defined network |
| JP6197659B2 (ja) * | 2014-01-20 | 2017-09-20 | 富士ゼロックス株式会社 | 検出制御装置、プログラム及び検出システム |
| CN107729147B (zh) | 2014-03-06 | 2021-09-21 | 华为技术有限公司 | 流计算系统中的数据处理方法、控制节点及流计算系统 |
| EP3127006B1 (en) | 2014-03-31 | 2019-06-05 | Huawei Technologies Co. Ltd. | Event processing system |
| CN104052811B (zh) * | 2014-06-17 | 2018-01-02 | 华为技术有限公司 | 一种业务调度的方法、装置及系统 |
| US9959301B2 (en) | 2014-07-25 | 2018-05-01 | Cisco Technology, Inc. | Distributing and processing streams over one or more networks for on-the-fly schema evolution |
| JP6413789B2 (ja) | 2015-01-22 | 2018-10-31 | 富士通株式会社 | ジョブ管理プログラム、ジョブ管理方法及びジョブ管理装置 |
| US10509684B2 (en) | 2015-04-06 | 2019-12-17 | EMC IP Holding Company LLC | Blockchain integration for scalable distributed computations |
| US10122806B1 (en) * | 2015-04-06 | 2018-11-06 | EMC IP Holding Company LLC | Distributed analytics platform |
| US10541938B1 (en) | 2015-04-06 | 2020-01-21 | EMC IP Holding Company LLC | Integration of distributed data processing platform with one or more distinct supporting platforms |
| US10331380B1 (en) | 2015-04-06 | 2019-06-25 | EMC IP Holding Company LLC | Scalable distributed in-memory computation utilizing batch mode extensions |
| US10511659B1 (en) | 2015-04-06 | 2019-12-17 | EMC IP Holding Company LLC | Global benchmarking and statistical analysis at scale |
| US10404787B1 (en) | 2015-04-06 | 2019-09-03 | EMC IP Holding Company LLC | Scalable distributed data streaming computations across multiple data processing clusters |
| US10496926B2 (en) | 2015-04-06 | 2019-12-03 | EMC IP Holding Company LLC | Analytics platform for scalable distributed computations |
| US10015106B1 (en) | 2015-04-06 | 2018-07-03 | EMC IP Holding Company LLC | Multi-cluster distributed data processing platform |
| US10505863B1 (en) | 2015-04-06 | 2019-12-10 | EMC IP Holding Company LLC | Multi-framework distributed computation |
| US10812341B1 (en) | 2015-04-06 | 2020-10-20 | EMC IP Holding Company LLC | Scalable recursive computation across distributed data processing nodes |
| US10541936B1 (en) | 2015-04-06 | 2020-01-21 | EMC IP Holding Company LLC | Method and system for distributed analysis |
| US10528875B1 (en) | 2015-04-06 | 2020-01-07 | EMC IP Holding Company LLC | Methods and apparatus implementing data model for disease monitoring, characterization and investigation |
| US10515097B2 (en) | 2015-04-06 | 2019-12-24 | EMC IP Holding Company LLC | Analytics platform for scalable distributed computations |
| US10425350B1 (en) | 2015-04-06 | 2019-09-24 | EMC IP Holding Company LLC | Distributed catalog service for data processing platform |
| US10776404B2 (en) | 2015-04-06 | 2020-09-15 | EMC IP Holding Company LLC | Scalable distributed computations utilizing multiple distinct computational frameworks |
| US10348810B1 (en) | 2015-04-06 | 2019-07-09 | EMC IP Holding Company LLC | Scalable distributed computations utilizing multiple distinct clouds |
| US10366111B1 (en) | 2015-04-06 | 2019-07-30 | EMC IP Holding Company LLC | Scalable distributed computations utilizing multiple distinct computational frameworks |
| US10791063B1 (en) | 2015-04-06 | 2020-09-29 | EMC IP Holding Company LLC | Scalable edge computing using devices with limited resources |
| US10706970B1 (en) | 2015-04-06 | 2020-07-07 | EMC IP Holding Company LLC | Distributed data analytics |
| US10860622B1 (en) | 2015-04-06 | 2020-12-08 | EMC IP Holding Company LLC | Scalable recursive computation for pattern identification across distributed data processing nodes |
| US10198298B2 (en) * | 2015-09-16 | 2019-02-05 | Salesforce.Com, Inc. | Handling multiple task sequences in a stream processing framework |
| US10191768B2 (en) | 2015-09-16 | 2019-01-29 | Salesforce.Com, Inc. | Providing strong ordering in multi-stage streaming processing |
| US9965330B2 (en) | 2015-09-18 | 2018-05-08 | Salesforce.Com, Inc. | Maintaining throughput of a stream processing framework while increasing processing load |
| US10146592B2 (en) | 2015-09-18 | 2018-12-04 | Salesforce.Com, Inc. | Managing resource allocation in a stream processing framework |
| WO2017104072A1 (ja) * | 2015-12-18 | 2017-06-22 | 株式会社日立製作所 | ストリームデータの分散処理方法、ストリームデータの分散処理システム及び記憶媒体 |
| US10656861B1 (en) | 2015-12-29 | 2020-05-19 | EMC IP Holding Company LLC | Scalable distributed in-memory computation |
| US10437635B2 (en) | 2016-02-10 | 2019-10-08 | Salesforce.Com, Inc. | Throttling events in entity lifecycle management |
| US11074254B2 (en) | 2016-03-23 | 2021-07-27 | International Business Machines Corporation | Performance management using thresholds for queries of a service for a database as a service |
| US10049133B2 (en) * | 2016-10-27 | 2018-08-14 | International Business Machines Corporation | Query governor across queries |
| US10374968B1 (en) | 2016-12-30 | 2019-08-06 | EMC IP Holding Company LLC | Data-driven automation mechanism for analytics workload distribution |
| US10417239B2 (en) * | 2017-01-13 | 2019-09-17 | International Business Machines Corporation | Reducing flow delays in a data streaming application caused by lookup operations |
| US10157048B2 (en) * | 2017-02-03 | 2018-12-18 | International Business Machines Corporation | Splitting operators in a streaming application |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3266351B2 (ja) * | 1993-01-20 | 2002-03-18 | 株式会社日立製作所 | データベース管理システムおよび問合せの処理方法 |
| US6795868B1 (en) * | 2000-08-31 | 2004-09-21 | Data Junction Corp. | System and method for event-driven data transformation |
| US7251294B2 (en) * | 2001-09-17 | 2007-07-31 | Digeo, Inc. | System and method for concurrently demodulating and decoding multiple data streams |
| JP3808394B2 (ja) | 2002-04-02 | 2006-08-09 | 松下電器産業株式会社 | ストリームデータ処理装置、ストリームデータ処理方法、プログラム、及び、媒体 |
| US7010538B1 (en) * | 2003-03-15 | 2006-03-07 | Damian Black | Method for distributed RDSMS |
| JP4687253B2 (ja) * | 2005-06-03 | 2011-05-25 | 株式会社日立製作所 | ストリームデータ処理システムのクエリ処理方法 |
| JP4723301B2 (ja) * | 2005-07-21 | 2011-07-13 | 株式会社日立製作所 | ストリームデータ処理システムおよびストリームデータ処理方法 |
| US20070088828A1 (en) * | 2005-10-18 | 2007-04-19 | International Business Machines Corporation | System, method and program product for executing an application |
| JP2007199804A (ja) * | 2006-01-24 | 2007-08-09 | Hitachi Ltd | データベース管理方法、データベース管理プログラム、データベース管理装置、および、データベース管理システム |
| US20070250365A1 (en) * | 2006-04-21 | 2007-10-25 | Infosys Technologies Ltd. | Grid computing systems and methods thereof |
| US7493406B2 (en) * | 2006-06-13 | 2009-02-17 | International Business Machines Corporation | Maximal flow scheduling for a stream processing system |
| JP4933222B2 (ja) * | 2006-11-15 | 2012-05-16 | 株式会社日立製作所 | インデックス処理方法及び計算機システム |
| US8321849B2 (en) * | 2007-01-26 | 2012-11-27 | Nvidia Corporation | Virtual architecture and instruction set for parallel thread computing |
| WO2009033248A1 (en) * | 2007-09-10 | 2009-03-19 | Novell, Inc. | A method for efficient thread usage for hierarchically structured tasks |
| US9727373B2 (en) * | 2008-03-27 | 2017-08-08 | Apple Inc. | Providing resumption data in a distributed processing system |
-
2009
- 2009-03-03 JP JP2009048792A patent/JP5149840B2/ja not_active Expired - Fee Related
- 2009-11-30 US US12/627,726 patent/US8533730B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010204880A (ja) | 2010-09-16 |
| US8533730B2 (en) | 2013-09-10 |
| US20100229178A1 (en) | 2010-09-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5149840B2 (ja) | ストリームデータ処理方法、ストリームデータ処理プログラム、および、ストリームデータ処理装置 | |
| AU2023201395B2 (en) | Data stream processing language for analyzing instrumented software | |
| JP5887418B2 (ja) | ストリームデータ多重処理方法 | |
| US8595743B2 (en) | Network aware process scheduling | |
| US10417239B2 (en) | Reducing flow delays in a data streaming application caused by lookup operations | |
| Hesse et al. | Conceptual survey on data stream processing systems | |
| Gautam et al. | A survey on job scheduling algorithms in big data processing | |
| JP5552449B2 (ja) | データ分析及び機械学習処理装置及び方法及びプログラム | |
| US20120324454A1 (en) | Control Flow Graph Driven Operating System | |
| US20120222043A1 (en) | Process Scheduling Using Scheduling Graph to Minimize Managed Elements | |
| US10560537B2 (en) | Function based dynamic traffic management for network services | |
| JP5478526B2 (ja) | データ分析及び機械学習処理装置及び方法及びプログラム | |
| US8458136B2 (en) | Scheduling highly parallel jobs having global interdependencies | |
| Cho et al. | Performance modeling of parallel loops on multi-socket platforms using queueing systems | |
| CN105229608A (zh) | 基于协处理器的面向数组的数据库处理 | |
| Kougka et al. | Optimization of data flow execution in a parallel environment | |
| CN110362387B (zh) | 分布式任务的处理方法、装置、系统和存储介质 | |
| WO2013165460A1 (en) | Control flow graph driven operating system | |
| Wachs et al. | Analysis of geospatial data loading | |
| Körber et al. | Event stream processing on heterogeneous system architecture | |
| Du et al. | New techniques to curtail the tail latency in stream processing systems | |
| US9304829B2 (en) | Determining and ranking distributions of operations across execution environments | |
| Kougka et al. | Modeling data flow execution in a parallel environment | |
| Schneider et al. | Language Runtime and Optimizations in IBM Streams. | |
| US12169498B1 (en) | Creating and searching tiered metric time series object storage |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110318 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110318 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20121101 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20121113 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121130 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151207 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |