近年、画像情報をデジタルとして取り扱い、その際、効率の高い情報の伝送、蓄積を目的とし、画像情報特有の冗長性を利用して、離散コサイン変換等の直交変換と動き補償により圧縮するMPEGなどの方式に準拠した装置が、放送局などの情報配信、及び一般家庭における情報受信の双方において普及しつつある。
特に、MPEG2(ISO/IEC 13818-2)は、汎用画像符号化方式として定義されており、飛び越し走査画像及び順次走査画像の双方、並びに標準解像度画像及び高精細画像を網羅する標準で、プロフェッショナル用途及びコンシューマー用途の広範なアプリケーションに現在広く用いられている。MPEG2圧縮方式を用いることにより、例えば720×480画素を持つ標準解像度の飛び越し走査画像であれば4〜8Mbps、1920×1088画素を持つ高解像度の飛び越し走査画像であれば18〜22Mbpsの符号量(ビットレート)を割り当てることで、高い圧縮率と良好な画質の実現が可能である。
MPEG2は主として放送用に適合する高画質符号化を対象としていたが、MPEG1より低い符号量(ビットレート)、つまりより高い圧縮率の符号化方式には対応していなかった。しかし、携帯端末の普及により、今後そのような符号化方式のニーズは高まると思われ、これに対応してMPEG4符号化方式の標準化が行われた。画像符号化方式に関しては、1998年12月にISO/IEC 14496-2としてその規格が国際標準に承認された。
さらに、近年、テレビ会議用の画像符号化を当初の目的として、JVT(ITU-T Rec. H.264 | ISO/IEC 14496−10 AVC)という標準の規格化が進んでいる。JVTはMPEG2やMPEG4といった従来の符号化方式に比べ、その符号化、復号により多くの演算量が要求されるものの、より高い符号化効率が実現されることが知られている。
ここで、MPEG2やJVTで採用されている、離散コサイン変換若しくはカルーネン・レーベ変換等の直交変換と動き補償とにより画像圧縮を実現する画像情報符号化装置の概略構成を図8に示す。図8に示すように、画像情報符号化装置100は、A/D変換部101と、画面並べ替えバッファ102と、加算器103と、直交変換部104と、量子化部105と、可逆符号化部106と、蓄積バッファ107と、逆量子化部108と、逆直交変換部109と、フレームメモリ110と、動き予測・補償部111と、レート制御部112とにより構成されている。
図8において、A/D変換部101は、入力された画像信号をデジタル信号に変換する。そして、画面並べ替えバッファ102は、A/D変換部101から供給された画像圧縮情報のGOP(Group of Pictures)構造に応じて、フレームの並べ替えを行う。ここで、画面並び替えバッファ102は、イントラ(画像内)符号化が行われる画像に関しては、フレーム全体の画像情報を直交変換部104に供給する。直交変換部104は、画像情報に対して離散コサイン変換若しくはカルーネン・レーベ変換等の直交変換を施し、変換係数を量子化部105に供給する。量子化部105は、直交変換部104から供給された変換係数に対して量子化処理を施す。
可逆符号化部106は、量子化部105から供給された量子化された変換係数や量子化スケール等から符号化モードを決定し、この符号化モードに対して可変長符号化、又は算術符号化等の可逆符号化を施し、画像符号化単位のヘッダ部に挿入される情報を形成する。符号化された符号化モードを蓄積バッファ107に供給して蓄積させる。この符号化された符号化モードは、画像圧縮情報として出力される。
また、可逆符号化部106は、量子化された変換係数に対して可変長符号化、若しくは算術符号化等の可逆符号化を施し、符号化された変換係数を蓄積バッファ107に供給して蓄積させる。この符号化された変換係数は、画像圧縮情報として出力される。
量子化部105の挙動は、レート制御部112によって制御される。また、量子化部105は、量子化後の変換係数を逆量子化部108に供給し、逆量子化部108は、その変換係数を逆量子化する。逆直交変換部109は、逆量子化された変換係数に対して逆直交変換処理を施して復号画像情報を生成し、その情報をフレームメモリ110に供給して蓄積させる。
一方、画面並び替えバッファ102は、インター(画像間)符号化が行われる画像に関しては、画像情報を動き予測・補償部111に供給する。動き予測・補償部111は、同時に参照される画像情報をフレームメモリ110より取り出し、動き予測・補償処理を施して参照画像情報を生成する。動き予測・補償部111は、この参照画像情報を加算器103に供給し、加算器103は、参照画像情報を当該画像情報との差分信号に変換する。また、動き補償・予測部111は、同時に動きベクトル情報を可逆符号化部106に供給する。
可逆符号化部106は、量子化部105から供給された量子化された変換係数や量子化スケールや、動き補償・予測部111から供給された動きベクトル情報等から符号化モードを決定し、この符号化モードに対して可変長符号化、又は算術符号化等の可逆符号化を施し、画像符号化単位のヘッダ部に挿入される情報を形成する。符号化された符号化モードを蓄積バッファ107に供給して蓄積させる。この符号化された符号化モードは、画像圧縮情報として出力される
また、可逆符号化部106は、その動きベクトル情報に対して可変長符号化若しくは算術符号化等の可逆符号化処理を施し、画像符号化単位のヘッダ部に挿入される情報を形成する。
イントラ符号化と異なり、インター符号化の場合には、直行変換部104に入力される画像情報は、加算器103より得られた差分信号である。
なお、その他の処理については、イントラ符号化を施される画像圧縮情報と同様であるため、説明を省略する。
続いて、上述した画像情報符号化装置100に対応する画像情報復号装置の概略構成を図9に示す。図9に示すように、画像情報復号装置120は、蓄積バッファ121と、可逆復号部122と、逆量子化部123と、逆直交変換部124と、加算器125と、画面並べ替えバッファ126と、D/A変換部127と、動き予測・補償部128と、フレームメモリ129とにより構成されている。
図9において、蓄積バッファ121は、入力された画像圧縮情報を一時的に格納した後、可逆復号部122に転送する。可逆復号部122は、定められた画像圧縮情報のフォーマットに基づき、画像圧縮情報に対して可変長復号若しくは算術復号等の処理を施し、ヘッダ部に格納された符号化モード情報を取得し逆量子化部123等に供給する。同様に、量子化された変換係数を取得し逆量子化部123に供給する。また、可逆復号部122は、当該フレームがインター符号化されたものである場合には、画像圧縮情報のヘッダ部に格納された動きベクトル情報についても復号し、その情報を動き予測・補償部128に供給する。
逆量子化部123は、可逆復号部122から供給された量子化後の変換係数を逆量子化し、変換係数を逆直交変換部124に供給する。逆直交変換部124は、定められた画像圧縮情報のフォーマットに基づき、変換係数に対して逆離散コサイン変換若しくは逆カルーネン・レーベ変換等の逆直交変換を施す。
ここで、当該フレームがイントラ符号化されたものである場合には、逆直交変換処理が施された画像情報は、画面並べ替えバッファ126に格納され、D/A変換部127におけるD/A変換処理の後に出力される。
一方、当該フレームがインター符号化されたものである場合には、動き予測・補償部128は、可逆復号処理が施された動きベクトル情報とフレームメモリ129に格納された画像情報とに基づいて参照画像を生成し、加算器125に供給する。加算器125は、この参照画像と逆直交変換部124の出力とを合成する。なお、その他の処理については、イントラ符号化されたフレームと同様であるため、説明を省略する。
ここで、JVTにおける、可逆符号化部106について詳細に説明する。JVTの可逆符号化部106では、量子化部105や動き予測・補償部111から入力された入力されたモード情報や動き情報、量子化された係数情報といったシンボルに対して、図10に示す様に、CABAC(Context-based Adaptive Binary Arithmetic Coding)と呼ばれる算術符号化(以下、CABAC)、もしくはCAVLC(Context-based Adaptive Variable Length Coding)と呼ばれる可変長符号化(以下、CAVLC)のどちらかの可逆符号化が適用され、画像圧縮情報(ビットストリーム)が出力される。どちらの可逆符号化が適用されるかは図10におけるCABAC/CAVLC選択情報により決められるものであり、このCABAC/CAVLC選択情報は画像情報符号化装置100で決められ、ヘッダ情報としてビットストリームに埋め込まれて出力される。
まず、図11に可逆符号化部106におけるCABACの構成図を示す。図11では、量子化部105や動き予測・補償部111から入力されたモード情報や動き情報、量子化された変換係数情報が多値シンボルとしてbinarization器131に入力される。binarization器131では、入力された多値シンボルを、あらかじめ決められた一定規則にもとづき任意の長さの2値シンボルの列に変換する。この2値シンボル列はCABAC符号化器133に入力され、CABAC符号化器133では、入力された2値シンボルに対してバイナリシンボル算術符号化が適用され、その結果をビットストリームとして出力し、蓄積バッファ107に入力する。なお、Context演算器132では、binarization器131に入力されたシンボル情報とbinarization器131からの出力である2値シンボルをもとにContextの計算を行い、CABAC符号化器133に入力する。Context演算器132におけるContextメモリ群135には、符号化処理中に随時更新されるContextとリセット時などに用いられるContextの初期状態が保存される。
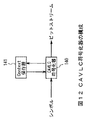
次に、図12に可逆符号化部106におけるCAVLCの構成図を示す。図12では、量子化部105や動き予測・補償部111から入力されたモード情報や動き情報、量子化された変換係数情報が多値シンボルとしてとしてCAVLC符号化器140に入力される。CAVLC符号化器140では、従来のMPEGなどで採用されている可変長符号化のように、入力された多値シンボルに対して可変長符号テーブルを適用して、ビットストリームを出力する。ここでContext保存器141では、既にCAVLC符号化器140で符号化された情報、例えば、処理中のブロックだけでなく既に処理されたブロックにおける各ブロック内の非0係数の個数や直前に符号化された係数の値などが保存される。CAVLC符号化器140は、このContext保存器141からの情報をもとにシンボルに適用する可変長符号テーブルを切り替えることが可能である。なお、Context保存器141にはリセット時などに用いられるContextの初期状態も保存される。この出力されたビットストリームは、蓄積バッファ107に入力される。
同様に、JVTにおける、可逆復号化部122について詳細に説明する。JVTの可逆復号化部122では、可逆符号化部106と同様に、入力されたビットストリームに対して、図13に示す様に、CABAC、もしくはCAVLCのどちらかの可逆復号化が適用される。どちらの可逆復号化が適用されるかは、入力されたビットストリームのヘッダ情報に埋め込まれたCABAC/CAVLC選択情報を読み込むことにより、CABACかCAVLCのどちらかを適用する。
図14に可逆復号化部122におけるCABACの構成図を示す。図14では、蓄積バッファ121より入力されたビットストリームに対しCABAC復号化器161においてバイナリシンボル算術復号化が適用され、その結果が2値シンボル列として出力される。この2値シンボル列は、逆binarization器163に入力され、逆binarization器163において、あらかじめ決められた一定規則にもとづき多値シンボルに変換される。この逆binarization器163から出力される多値シンボルは、モード情報や動きベクトル、量子化された係数情報として、逆binarization器163から出力され、逆量子化部123、動き予測・補償部128に入力される。なお、Context演算器162では、逆binarization器163に入力された2値化シンボル列と逆binarization器163からの出力である多値シンボルをもとにContextの計算を行い、CABAC復号化器161に入力する。Context演算器162におけるContextメモリ群165には、復号化処理中に随時更新されるContextとリセット時などに用いられるContextの初期状態が保存される。
次に、図15に可逆復号化部122におけるCAVLCの構成図を示す。図15では、蓄積バッファ121より入力されたビットストリームがCAVLC復号化器170に入力される。CAVLC復号化器170では、従来のMPEGなどで採用されている可変長復号化のように、入力されたビットストリームに対して可変長復号テーブルを適用して、モード情報や動き情報、量子化された変換係数情報を出力する。これら出力情報は、可逆量子化部123、動き予測・補償部128に入力される。ここでContext保存器171では、既にCAVLC復号化器170で復号化された情報、例えば、処理中のブロックだけでなく既に処理されたブロックにおける各ブロック内の非0係数の個数や直前に復号化された係数の値などが保存される。CAVLC復号化器170は、このContext保存器11からの情報をもとにシンボルに適用する可変長復号テーブルを切り替えることが可能である。なお、Context保存器141にはリセット時などに用いられるContextの初期状態も保存される。
この図11、図14に示すCABACの詳細動作として、以下にFinal Committee Draft ISO/IEC 14496-10:2002(第9.2節)におけるCABACの説明を添付する(例えば、非特許文献1参照。)。
9.2Context-based adaptive binary arithmetic coding (CABAC)
9.2.1 Decoding flow and binarization
Binarizationとはnon-binary symbolからbinary列(binと呼ばれる)への変換を行う処理のことであり、9.2.1.1 - 9.2.1.4節において、CABACの為の基本的なbinarization方式が規定される。Decoding flow、及び、全てのsyntax elementに対するbinarization方法は9.2.1.5 - 9.2.1.9 節で規定される。
9.2.1.1 Unary binarization
Unary codeによるbinalizationの最初の5 symbolに対する表をTable 9-19に示す。
Code symbol C に対しては、C個の’1’の最後に’0’を付けたbinary列が対応する。Binの最初のbitにはbin number =1が対応し、2番目のbitにはbin number=2、と、最後のbitに行くに従って対応するbin numberは増えていく。
9.2.1.2 Truncated unary (TU) binarization
Truncated unary (TU) binarizationは有限個のシンボル{0,…,Cmax}に対して適用される。Symbol C<Cmax;に対しては9.2.1.1節で規定されたunnary binarizationを行い、シンボルCmaxにはCmax 個の1を割り当てる。Bin numberの割り振り方はunary binarizationの場合と同じである。
9.2.1.3 Concatenated unary/ kth-order Exp-Golomb (UEGk) binarization
Concatenated unary/kth-order Exp-Golomb (UEGk) binarization は、Cmax=Ucoff (Ucoff:Cut off parameter)としたtruncated unary binarization code (prefix code)とk次のExp-Golomb符号 (suffix code)とが連接されたものが変換後のbinary列となる。Symbol C がC<Ucoffの場合suffix codeは無く、C≧Ucoffの場合suffix codeはsymbol C-Ucoff に対するExp-Golomb符号となる。
Symbol S に対するk次のExp-Golomb codeは以下のように構成される:
while(1) {
//first unary part of EGk
if (symbol>= (unsigned int)(1<<k)){
put(‘1’);
S = S - (1<<k);
k++;’
}
else
{
put(‘0’); //now terminating zero of unary part of EGk
while (k--) //finally binary part of EGk
put( (S>>k)&0x01 );
break;
}
}
Bin numberは、unary codeの第1ビット目をbin_num=1として、Exp-Golomb符号のLSBに向かって1づつ増えていく。
9.2.1.4 Fixed-length (FL) binarization
有限個のシンボル{0 , …, Cmax} に対し、L-bit (L= log2|Cmax|+1)のbinarizationを適用する。Bin numberはLSBをbin_num=1とし、MSBに向かって増えていく。
9.2.1.5 Binarization schemes for macroblock type and sub macroblock typeI slice中のmacroblock typeのbinarization方式はTable 9-20で規定される。ただし、adaptive_block_size_transform_flag==1であった場合には、Table 12-10に従う。
SI slice中のmacroblock typeのbinarization後のbit列はprefixとsuffix部分からなり、prefixはb1= ((mb_type = = SIntra_4x4) ? 0 : 1) で表される1bit、suffixはSintra4x4の場合(suffix無し)を除きTable 9-20に示すbinarization patternに基づく。
P, SP, B sliceのbinarizationはTable 9-21で規定される。P, SP slice中のintra macroblock type (mb_type値7〜30に相当)は、Table 9-21に示すprefixとTable 9-20に示すsuffixによってbinarizationが行われる。
B slice中のintra macroblock type (mb_type値23〜47に相当)についても、Table 9-21に示すprefixとTable 9-20に示すsuffixによってbinarizationが行われる。adaptive_block_size_transform_flag==1の場合は、Table 9-21における対応するsliceのprefixと、Table 12-10で規定されるsuffixが用いられる。
P, SP, B sliceにおけるsub_mb_typeのbinarizationはTable 9-22で与えられる。
9.2.1.6 Decoding flow and assignment of binarization schemes
この節においてcoded_block_pattern, delta_qp 及びreference picture index, motion vector data, Intra4x4 prediction modesそれぞれのsyntax elementのbinarization方式を規定する。
基本的にcoded block patternは7.4.6節で規定された関係coded_block_pattern = coded_block_patternY + 16*ncによって復号される。最初にcoded_block_pattern 中のcoded_block_patternYが、Cmax = 15 , L = 4によるfixed-length (FL) binarizationによって復号され、次に、色差のncがCmax = 2のTU binarizationによって復号される。
delta_qp parameterの復号は次に示すように2段階で行われる。最初にunsigned 値wrapped_delta_qp≧0がunary binarizationによって復号され、次に、Table 9-2に示される対応関係によって符号付きの値に直される。
Intra_4x4, Sintra_4x4のlumaに対するspatial intra prediction modesの復号は次のように規定される。最初にintra_pred_indicatorがCmax = 8のtruncated unary (TU) binarizationによって復号される。もし、intra_pred_indicatorが0であった場合、use_most_probable_mode = 1とし、intra_pred_indicator≧1の場合には、remaining_mode_selector = intra_pred_indicator - 1とする。intra_pred_modeは与えられたmost_probable_mode、remaining_mode_selectorを用い、9.1.5.1節で規定される方法で復号が行われる。復号順序はFigure 9-1 b)に示されるものと同様である。Chromaのintra_chroma_pred_modeに対しては、Cmax=3のtruncated unary (TU) binarizationを用いて復号が行われる。
Reference picture index parameterは9.2.1.1で規定されるunary binarizationを用いて復号される。
動きベクトルの符号化された各コンポーネントは、それぞれのコンポーネント毎に復号される。それぞれのコンポーネントは水平、垂直成分を含むが、水平方向に対応するものが最初に復号される。最初に絶対値abs_mvd_comp、次に、符号sign_mvd_compが復号される。abs_mvd_compに適用されるbinarizationはcut-off parameter Ucoff = 9のconcatenated unary/3rd-order Exp-Golomb (UEG3) binarizationである。Exp-Golomb復号の際には、9.2.4.3.5で規定されているDecode_eq_prob処理が適用される。
9.2.1.7 Decoding flow and binarization of transform coefficients変換係数の復号は3段階からなる。Macroblock levelでのcoded_block_patternによって係数値があることが分かっている場合、それぞれのblockに対するcoded_block_flagが復号されるが、coded_block_flagが0である場合、当該blockに対する以降の情報は復号されない。coded_block_flag != 0の場合、scanの最後の位置を除くそれぞれのscan位置 iに対するsignificant_coeff_flag[i]を復号する。significant_coeff_flag[i]が1であった場合、次にlast_significant_coeff_flag[i]が復号される。last_significant_coeff_flag[i]が1であるということは、scan位置iの係数値がscanパス順で現れる最後の係数であることを意味する。last_significant_coeff_flag[i]が1となった時には、次に、coeff_absolute_value_minus_1をscanの逆順で復号し、同様に、その次coeff_signをscanの逆順で復号する。coeff_absolute_value_minus_1はUCoff=14のunary/zero-order Exp-Golomb (UEG0) binarizationを用いて復号される。動きベクトルの絶対値復号の場合と同様に、Exp-Golomb suffixはDecode_eq_prob処理を用いて復号される。
9.2.1.8 Decoding of sign information related to motion vector data and transform coefficients
動きベクトルの符号情報sign_mvd_compと係数値の符号情報coeff_signは以下のように復号される。最初に9.2.4.3.5節で規定されるDecode_eq_prob処理を行って得られたsign_indを用い、符号情報sign_infoをsign_info = ((sign_ind = = 0) ? 1 : -1)によって得る。
9.2.1.9 Decoding of macroblock skip flag and end-of-slice flag
mb_skip_flagの復号は以下のように行われる。最初に9.2.2.2節で規定されたcontext modelを用いmb_skip_flag_decodedを復号する。次にmb_skip_flagをmb_skip_flag_decodedを反転する(i.e., mb_skip_flag = mb_skip_flag_decoded ^ 0x01)ことによって得る。
end_of_slice_flagはState = 63, MPS = 0のfixed, non-adaptive modelによって復号される。この場合、以下に示す理由によって、9.2.4.2に示される確率予測を各復号ステップで行っているにも関わらず、fixed modeとなることが示される。end_of_slice valuesがずっと’0’であった場合、 MPS symbolの観測によってもState=63は確率予測の結果State=63のままとなる。そして、LPS値’1’がend_of_slice_flagの値として復号された場合は、この時点でsliceの終わりに到達していることになるから以降の復号処理には影響しない。以上のような理由でState = 63, MPS = 0に設定することにより、fixed, non-adaptive modelが実現される。
9.2.2 Context definition and assignment
それぞれのbin numberに対して、それまでに復号されたsymbol等を含む諸条件によって決まるcontext variableが定義される。Context variableの値は特定のbin numberに対するcontext modelを定める。それぞれのbin number : bin_num に対して複数のcontext labelが定めらる場合もあるが、1つだけの場合もある。
この節ではsyntax elementを符号化する為の一般的なcontext variableの算出法であるcontext templatesを定義し、syntax elementのそれぞれのbin numberに対応するcontext variableを規定する。まず、それぞのれsyntax elementの異なるbin numberに対して与えられるcontext variableを規定する為にcontext identifier: context_idを規定するが、これは、bin number k に対するcontext variableをcontext_id[k]として表すためのものである。このcontext_id[k]は、1≦k≦N (N=max_idx_ctx_id)の範囲で規定される。
Table 9-23にそれぞれのsyntax elementのカテゴリ毎のcontext identifierの概要を示す。
対応するcontext variableについてのより詳細な記述は以降の節において記述する。それぞれのcontext identifierはcontext labelの特定の範囲に対応する。macroblock typeの場合はI, SI, P, SP,B.のそれぞれについて別々のcontext identifierが存在しており、個別のcontext labelの範囲を持つが、context labelの範囲自体は重複している。
変換係数のcontext identifierの場合、adaptive_block_size_transform_flag==1の時にはTable 12-12に示される追加のcontext label値を用いる。
9.2.2.1 Overview of assignment of context labels
Table 9-24, 9-25にcontext identifiersとそのcontext labelの範囲を示す。このcontext label(実際にはoffsetが加算されたものが参照label番号となる)とbin numberの関係によって、どのcontext variableがfixed modelを用い、どのcontext variableが複数のmodelを持つのかが分かる。
Table 9-24の特定のbin number bin_numに複数のcontext labelが割り振られているもの、また、Table 9-25におけるcontext_categoryに対して複数のcontext labelが与えられているものは、複数のmodelからの選択を行う。
9.2.2.2 Context templates using two neighbouring symbols
一般的なcontext variableの設定方法を説明するためにFigure 9-2(図22)を用いる。当該block Cに対して隣接する左blockと上blockにおける同一syntax elementのsymbolまたはbinがA,Bとして図示されている。
Contextを決める式の第一番目は以下の通りとなる。
ctx_var_spat = cond_term(A, B), (9-1)
cond_term(A, B)は隣接symbol A,Bとcontext variableの間の関係を表す関数である。
この他に、3つのテンプレートが以下のように定義される。
ctx_var_spat1 = cond_term(A) + cond_term( B), (9-2)
ctx_var_spat2 = cond_term(A) + 2*cond_term( B), (9-3)
ctx_var_spat3 = cond_term(A). (9-4)
Table 9-26 において2つの隣接symbolからのcontext variableの求め方を示す。
ctx_cbp4はTable 9-28に示される6つのblock type(Luma-DC, Luma-AC, Chroma-U-DC, Chroma-V-DC, Chroma-U-AC, Chroma-V-AC)によって決定される。
compは水平成分(h)または垂直性分(v)を意味し、A, BはFigure 9-2に示すような隣接blockを意味する。これら隣接blockは異なるmacroblock partitionに属する可能性がある為、以下のような隣接blockを特定する為の方法が規定されている。最初に4x4 blockの動きベクトルはoversampleされている、つまり、対応するblockがより粗くpartitioningされていた場合、quadtreeにおける親blockの動きベクトルを継承しているとみなす。逆に、当該block Cが隣接blockより粗くpartitioningされていた場合、隣接blockの左上のsub-blockの動きベクトルを対応動きベクトルとする。これらの処理によって隣接blockにおける対応する値を求めた後、(9-5)を用いてcontext variableを得る。
9.2.2.3 Context templates using preceding bin values
(b1, …, bN) がsymbol Cのbinarizationに相当すると仮定した場合、Cのk番目のbinに対応するcontext variableは以下のように規定される。
ctx_var_bin[k] = cond_term(b1,…,bk-1), (9-6)
ただし、1<k≦Nとする。Table 9-27において、この種のcontext variableの与え方の一覧を示す。
9.2.2.4 Additional context definitions for information related to transform coefficients
変換係数の条件付けの為には、さらに3つの異なるcontext identifierが追加で用いられる。
これらのcontext identifierはTable 9-28で示されるcontext_categoryに依存して決まる。
adaptive_block_size_transform_flag==1の場合には12.5.2節で規定されるようなcontext categoryがさらに加わる。Context identifier ctx_sigとctx_lastはbinary値を持つSIG とLAST、及び、当該blockのscanning_posによって以下のように与えられる。
ctx_sig[scanning_pos] = Map_sig( scanning_pos), (9-7)
ctx_last[scanning_pos] = Map_last(scanning_pos). (9-8)
(9-7) と (9-8) にあるMap_sigとMap_lastはblock typeに依存して変わる。
まず、context categoryが0-4の場合、それぞれ以下のような恒等写像となる。
Map_sig(scanning_pos)=Map_last(scanning_pos) = scanning_pos, if context_category =0,…,4,
scanning_pos はzig-zag scanにおけるscan位置を示す。adaptive_block_size_transform_flag==1の場合のみに使われるcontext category=5 〜7 に対するMap_sig, Map_lastは12.5.2節で与えられる。
変換係数-1を表すabs_level_m1の復号の際にはctx_abs_levelがcontext identifierとして用いられる。ctx_abs_levelはctx_abs_level[1] とctx_abs_level[2]の2つのcontext variableの値を用いて以下のように求められる。
ctx_abs_lev[1] = ((num_decod_abs_lev_gt1!=0) ? 4: min(3, num_decod_abs_lev_eq1)), (9-9)
ctx_abs_lev[2] = min(4, num_decod_abs_lev_gt1), (9-10)
num_decod_abs_lev_eq1は係数値が1の係数の数を表し、num_decod_abs_lev_gt1は係数値が1より大きな係数の数を表す。Context variable ctx_abs_level[k], k=1,2 を算出する際には当該blockの変換係数のみが必要であり、他の情報は必要とされない。
9.2.3 Initialisation of context models
9.2.3.1 Initialisation procedure
Sliceの先頭でstate numberと9.2.4.2で定義されるMPSに対応するシンボルが初期化される。それら2つを合わせて初期状態と呼ぶが、実際の初期状態は量子化パラメータQPによって以下のように定められる。
pre_stateをpre_state = (( m*(QP-12))>>4) + nによって算出する。
pre_state を P, B sliceの場合[0,101] に、I slice の場合[27,74]にクリップする。処理は以下の通り。
pre_state = min (101, max(0,pre_state)) for P- and B-slices and
pre_state = min (74, max(27,pre_state)) for I-slices;
pre_state から {state, MPS} へのmappingを以下の式に従って行う:
if (pre_state <= 50) then {state = 50-pre_state, MPS = 0} else {state = pre_state-51, MPS = 1}
9.2.3.2 Initialisation procedure
Tables 9-29−9-34に全てのsyntax elementに対する初期化parameterを示す。初期状態は9.2.3.1節に述べた方法によって得られる。
9.2.4 Table-based arithmetic coding
注- 算術符号は区間分割を行うことによって符号化を行う。与えられた’0’と’1’の予測確率p(‘0’)とp(‘1’)=1-p(‘0’)を用い、最初に与えられた区間Rはp(‘0’)´RとR-p(‘0’)´R,にそれぞれ分割される。受け取ったbinary値によって、どちらの区間を次の分割対象区間とするのかが決められる。Binary値は’0’,’1’よりも優勢シンボル(MPS)であるか劣勢シンボル(LPS)であるかが重要であり、それぞれのcontext model CTX はLPSの確率pLPSとMPSの種別(‘0’または’1’)によって決定される。
このRecommendationもしくはInternational Standardにおける算術符号エンジンは以下に示すような3つの特徴を持つ。
確率予測は64の状態を持つstate machineによって行われる。State machineは64の異なるLPSの発生確率(pLPS)に対応する状態{Pk | 0≦k<64}を表を元にして遷移する。
分割区間を表す変数 R は新しい分割区間を計算する前に4つの値{Q1,…,Q4}に量子化される。あらかじめQi´ Pkに対応する64x4種類の値を計算して保持しておくことでR´ Pkの乗算処理を省くことができる。
‘0’と’1’の発生確率がほぼ等しいとみなせるsyntax elementについては別の復号処理が適用される。
9.2.4.2 Probability estimation
確率予測はLPSの確率{Pk | 0≦k<64}と遷移法則からなるfinite-state machine (FSM)によって行われる。Table 9-35に与えられたMPSまたはLPSに対する遷移法則を示す。任意のStateからMPSまたはLPSを符号化することによってNext_State_MPS(State)またはNext_State_LPS(State)に遷移する。
状態番号はState=0がLPSの発生確率=0.5に対応し、以下、番号が増えるごとにLPSの発生確率が低くなっているものに対応する。I sliceに対しては状態を最初の24個に制限するため、Table 9-35ではその為に用いられるNext_State_MPS_INTRAがある。尚、Next_State_MPS_INTRAとNext_State_MPSが違うのは一箇所だけである。
I sliceの復号の際23より大きな状態への遷移を避けるため、Next_State_MPS(35)= 23を用いる。詳細はTable 9-35を参照のこと。
1シンボルの符号化/復号を行うたびにStateが変わり、その結果確率が更新される。
if(decision = = MPS)
State←Next_State_MPS_INTRA(State)
else
State←Next_State_LPS(State)
and all other
slice types
if(decision = = MPS)
State←Next_State_MPS(State)
else
State← Next_State_LPS(State).
LPSの発生確率が0.5、つまり、State=0の時にさらにLPSが得られた場合、LPSとMPSに対応するシンボル’0’,’1’の交換が行われる。
9.2.4.3 Description of the arithmetic decoding engine
算術符号の復号器の状態は、範囲Rの分割区間中を指す値 V によって表される。Figure 9-3に復号処理全体を示す。最初に9.2.4.3.1で規定されるInitDecoder処理を行うことによりVとRが初期化される。1回のdecisionは以下のような2ステップの処理で行われる。最初にcontext model CTXが9.2.2節で示される規則によって生成され、次に与えられたCTXに従って9.2.4.3.2節で規定されるDecode(CTX)が適用されてsymbol S が得られる。
9.2.4.3.1 Initialisation of the decoding engine
Figure 9-4に示される初期化処理において、Vには9.2.4.3.4節で示されるGetByte処理を用いて得られる2 byteの値が設定され、Rには0x8000が設定される。
9.2.4.3.2 Decoding a decision
Figure 9-5は1つのdecisionを行う処理flowchartを表す。最初のステップではLPSとMPSに対応する区間RLPS とRMPSが以下のように予測される。
与えられた区間の幅Rは、以下に示すように最初にQという値に量子化される。
Q=(R-0x4001)>>12, (9-11)
このQとStateを用いてRTABをindexingすることで以下のようにRLPSが得られる。
RLPS=RTAB[State][Q]. (9-12)
Table 9-36 にRTABを16bitで表現したものを示す。RTABは実際には8bitの精度で与えられているが、6bitの左シフトが施され形で与えられている。これは16bitアーキテクチャでの実装を容易にするためである。
次に、VとMPS区間RMPSとの比較が行われ、VがRMPS 以上であった場合LPSが復号される。同時にVからはRMPSが減ぜられ、RにはRLPSが入る。VがRMPS 未満であった場合、MPSが復号され、RにはRMPSが入る。それぞれのdecoding decisionによって、9.2.4.2節で規定される確率の更新が行われる。新しい区間値Rによっては、9.2.4.3.3節で規定されるrenormalizationが適用される。
9.2.4.3.3 Renormalization in the decoding engine (RenormD)
R enormalization処理をFigure 9-6に示す。区間値Rと0x4000の比較が最初に行われるが、Rが0x4000よりも大きかった場合renormalizationは行われず、処理は終了する。そうでない場合、renormalization loopに入る。このloop内ではRの値が2倍、つまり、1bit左にshiftされ、bit-count BGは1減らされる。BG<0となった場合はGetByteによって新たなデータが読み込まれ、Bの最下位ビットがVに設定される。
9.2.4.3.4 Input of compressed bytes (GetByte)
Figure 9-7に圧縮データの入力処理を示す。初期化時またはrenormalizationでbit-counter BGが負の値になった場合にこの処理が適用される。最初にbitstream Cから新しいbyteが読み込まれる。次に、bitstream中の位置を示すCLの値が1増やされ、bit-counterの値が7に設定される。
9.2.4.3.5 Decoder bypass for decisions with uniform pdf (Decode_eq_prob)
この処理は動きベクトルの符号、及び、変換係数の符号のように符号化symbolが等しい発生確率を持っているとみなされる場合に適用される特別な処理である。そのような場合、symbol Sを復号し、区間を分割するという通常の処理は一回の比較(V>=Rhalf?)のみで行える。RenormalizationはFigure 9-8で示されたものと似ているが以下の2点が異なる。第1点目はrescaling処理R←(R<<1)が不要なことであり、2点目は、最初の比較(R<=0x4000?)が省けることである。
以下、本発明の実施例を図面を参照しながら説明する。
図1における装置10による実施例の説明
本発明における画像符号化装置の実施例を図1に示す。図1の装置10では符号化されるべき画像信号が入力され、符号化されたビットストリームが出力される。装置10は入力バッファ11と変換処理部12とCABAC処理部13と制限監視器14と出力バッファ15により構成される。入力バッファ11では、入力画像をマクロブロック単位に分割し出力をし、後段においてマクロブロックの処理が終わる毎に、次のマクロブロックを出力する。変換処理部12では、入力されたマクロブロック画像に対して処理を行い、ヘッダ情報や量子化された係数情報をCABAC処理部13に出力する。具体的には、パラメータ設定器16により、マクロブロックのモード情報や動きベクトル情報、量子化パラメータ等のヘッダ情報を設定し、その値(シンボル)を予測器17、DCT器18、量子化器19、及び、CABAC処理部13に出力する。ここで、パラメータ設定器16は、マクロブロックのヘッダ情報のみならず、スライスやピクチャのヘッダ情報も設定し、出力することを可能とするので、ここでは、全てを総称してヘッダ情報と記載する。なお、予測器17では動き補償が、DCT器18ではDCT変換が、量子化器19では量子化処理が、それぞれ、前段からの入力信号に対して、パラメータ設定器16からの入力信号を参照して適用される。
CABAC処理部13には、ヘッダ情報と量子化された係数情報がシンボルデータとして入力され、算術符号化が適用され、ビットデータとして出力される。具体的には、入力されたシンボルデータをbinarization器20によって2値データ列に変換し、その2値データをContext演算器21からのContext情報をもとに、CABAC符号化器22でエントロピー符号化する。Context演算器21では、binarization器20に入力されるシンボルデータと、binarization器20から出力される2値データをもとにContextを更新し、また、そのContext情報をCABAC符号化部22に出力する。
制限監視器14は、CABAC符号化器22に入力される2値データの個数のカウンタと出力されるビットデータの個数のカウンタ(ビットカウンタ25)をそれぞれ独立に持ち、CABAC符号化器22へ2値データが入力されるたびに前者のカウンタを1つずつ増加させ、CABAC符号化器22からビットデータが出力されるたびに後者のカウンタを1つずつ増加させる。このカウンタはそれぞれ、マクロブロックの先頭の処理を開始するたびに0にリセットされる。これにより、各マクロブロックにおける、CABAC符号化器22の入力データと出力データのそれぞれの個数をカウントすることが可能となる。
この制限監視器14では、これらカウンタのうちのどちらか一方でも、あらかじめ設定された閾値を超えてしまった場合、その符号化データは無効であることを示す信号(以下、再符号化信号)を、出力バッファ15とContext演算器21とパラメータ設定器16に対して出力する。この再符号化信号を受け取ったパラメータ設定器16は、再度この閾値を超えない様に注意して符号化パラメータを設定し直し、符号化対象のマクロブロックデータを再符号化処理する。また、Context演算器21は、Contextメモリ群23を有しており、このContextメモリ群23は従来の技術の図103にある従来のContextメモリ群135と同様に、符号化処理中に随時更新されるContextとリセット時などに用いられるContextの初期状態が保存されるが、それと共に、マクロブロックをデータ処理する直前のContextの状態も保存しておくことが可能である。これにより、再符号化信号を受け取ったContext演算器16は、内部のContextの状態を、この新たに付け加えられたメモリに保存されているContextの値に書き換えることにより、符号化対象のマクロブロックのデータによって更新される直前のContextの状態に復元することが可能である。また、再符号化信号を受け取った出力バッファ15は、内部に蓄積された符号化対象マクロブロックのビットデータを全て削除し、新たな符号化パラメータで符号化されたマクロブロックデータの入力を待つ。逆に、対象のマクロブロックの符号化処理を終えた際に、制限監視器14のいずれのカウンタも、あらかじめ設定された閾値を超えていなければ、出力バッファ15内の対象マクロブロックのビットデータをビットストリームとして出力することが可能である。
ここまで説明した図1の装置10では、制限監視器14にあるカウンタはマクロブロックの先頭でリセットされることから、これは、マクロブロック単位で、CABAC符号化器22に入力される2値データと、出力されるビットデータの個数を監視し制限することを意味するが、このリセットのタイミングを、マクロブロック内のブロック単位に設定すれば、各ブロック単位での上記データ個数を監視し制限することが可能になる。同様にスライス単位でリセットをすれば、スライス単位で上記データ個数を監視し制限することが可能になるし、ピクチャ単位でリセットすれば、ピクチャ単位で上記データ個数を監視し制限することが可能となる。また、この様に上記データ個数を監視、制限する符号化単位を変える場合には、同時に、Context演算器21におけるContextメモリ群23にはその符号化単位の直前のContext値が保存されるため、Contextの状態復元も、その符号化単位の直前の状態に復元されることになる。また、出力バッファ15のビットデータの削除も同様の符号化単位で行われることになる。
なお、この復元の際には、Contextメモリ23群に保存されている符号化単位の直前のContext値ではなく、同様にContextメモリ群23に保存されているあらかじめ定められた初期値に復元することも可能である。
ここまで説明した図1の装置10では、制限監視器14には2つのカウンタが設定されているが、これらカウンタに設定する閾値は、それぞれ独立に自由な値を設定することが可能であり、また、2つのうちどちらか一方のみに対応するデータカウントのみを監視し、もう片方は無視する、もしくはカウンタ自体を持たない様な構成にすることも可能である。
この装置10により、1回のマクロブロック処理において、CABAC符号化器に入力、及び出力されるデータ量の上限を制限することができるため、要求されたマクロブロック1回の処理時間を満たすことが可能になる。また、要求された処理時間で復号化処理が可能なビットストリームを出力することが可能になる。
ここで、今後の説明のために、図1における変換処理部12とCABAC処理部13をまとめて表現した装置、マクロブロック処理部29を図7に示す。今後の記載におけるマクロブロック処理部29は、図1における変換処理部12とCABAC処理部13を直列でつないだ装置として、同様の振る舞いをするものとする。
図2における装置30による実施例の説明
図1で示した装置10では、制限監視器14が再符号化信号を出力するたびに、変換処理部12は再度、新たな符号化パラメータを設定して対象マクロブロックの符号化を行わなければならないし、再度設定されたパラメータによって得られたデータにより、再度、制限監視器14のカウンタが閾値を超えてしまうということが繰り返される可能性もある。そのため、1つのマクロブロックに対して複数回、符号化処理を連続的に適用しなければならず、その分、1ピクチャの符号化時間が多くかかってしまう。
ゆえに、本発明における画像符号化装置の別の実施例として、対象マクロブロックに対して異なる符号化パラメータを適用する符号化を並列に実施する例を2番目の実施例として図2に示す。
図2の装置30では、図1の装置10と同様に、符号化されるべき画像信号が入力され、符号化されたビットストリームが出力される。図2の装置30は入力バッファ31と、N個の異なる符号化パラメータによるN段の並列符号化処理を可能とするマクロブロック処理部32−1〜32−Nと、それに対応した出力バッファ33−1〜33−Nと、制限監視・経路選択器34と切替器35により構成される。
図2の装置30では、符号化対象のマクロブロックに対して、N個の異なる符号化パラメータを設定し、それぞれの符号化パラメータによる符号化処理をマクロブロック処理部32−1〜32−Nで並列に行い、その出力を出力バッファ33−1〜33−Nに蓄積する。
制限監視・経路選択器34は、マクロブロック処理部32−1〜32−Nそれぞれに対応するCABAC符号化器に対する2つの入出力データカウンタ(ビットカウンタ36)を持ち、N段の並列経路のうちから、このカウンタが閾値を超えず、かつ、符号化効率の最も優れた符号化経路を選択し、切替器35により出力する系統を選択する。
図2の装置30におけるその他の詳細な動作、及び符号化単位等のバリエーションは図1の装置10と同様のものとする。
この装置30により、符号化時に置いてCABAC符号化器に入力、及び出力されるデータ量の上限を制限することができるため、要求されたの符号化処理時間を満たすことが可能になる。また、要求された処理時間で復号化処理が可能なビットストリームを出力することが可能になる。
図3における装置40による実施例の説明
次に図3に、また別の本発明における画像符号化装置の実施例を示す。この実施例は、図1の実施例に加えて、非圧縮符号化データ、すなわち、入力されたマクロブロックに対して、圧縮しないRAWデータをそのまま符号化する経路を有している。
図3の装置40の図1の装置10との違いは、マクロブロック画像データはマクロブロック処理部41のみでなく、非圧縮符号化部43にも入力される。非圧縮符号化部43では、入力された画像情報に対して一切の変換処理とエントロピー符号化をしないデータ、すなわち、RAWデータが出力バッファB44に出力される。制限監視・経路選択器47は、図1における制限監視器14の振る舞いと同様に、ビットカウンタ49によりCABAC符号化器の入出力のデータ量を監視し、かつ、もし、その監視されているデータがあらかじめ設定されている閾値を超えた場合には、切替器46が出力バッファB44からの入力を選択し出力するようにする。逆に、閾値を超えなかった場合には、出力バッファA42、出力バッファB44のどちらの出力でも選択することが可能となっている。
ここで、制限監視・経路選択器45が出力バッファB44、すなわちRAWデータを選択した場合には、その事がマクロブロック処理部41にあるContext演算器にも通知され、Context演算器内のContext値は、Contextメモリ群に保存されたマクロブロックを処理する直前のContextの値を用いて、そのRAWデータとして処理されたマクロブロックを処理する直前の状態に復元される
なお、マクロブロックがRAWデータとして処理された場合のContextの復元方法としては、あらかじめ決められた初期状態に復元するということも可能である。
ここで、マクロブロックがRAWデータとして符号化されたかどうかを示すために、出力されるビットストリームのヘッダ情報には、そのためのデータが埋め込まれる。
RAWデータが符号化された際には、CABAC符号化部は、RAWデータをビットストリームに出力させる前に、CABACの終端処理をする。
また、非圧縮符号化器45は、RAWデータを出力する非圧縮処理装置のみでなく、DPCM符号化装置などさまざまな圧縮装置に置き換えることが可能である。
図3の装置40におけるその他の詳細な動作、及び符号化単位等のバリエーションは図1の装置10と同様のものとする。
この装置40により、符号化時に置いてCABAC符号化器に入力、及び出力されるデータ量の上限を制限することができるため、要求されたの符号化処理時間を満たすことが可能になる。また、要求された処理時間で復号化処理が可能なビットストリームを出力することが可能になる。
図4における装置50による実施例の説明
次に図4に、また別の本発明における画像符号化装置の実施例である装置50を示す。この実施例は、図2の装置30に加えて、非圧縮符号化データ、すなわち、入力されたマクロブロックに対して、圧縮しないRAWデータをそのまま符号化する経路を有している。
図4の装置の図2の装置との共通の部分の動作は、図1の装置とほとんど同じであるため、違いのみを具体的に示すと、マクロブロック画像データはマクロブロック処理部51−1〜51−Nのみでなく、非圧縮符号化部58に入力される。非圧縮符号化部58では、入力された画像情報に対して一切の変換処理とエントロピー符号化をしないデータ、すなわち、RAWデータとして出力バッファB59に出力される。制限監視・経路選択器53は、図2における制限監視・経路選択器34の振る舞いと同様に、ビットカウンタ55を監視し、もし、全ての経路1〜Nにおけるビットカウンタ(2個のうちどちらか)があらかじめ設定されている閾値を超えた場合には、信号選択器54が出力バッファB59からの入力を選択し出力するようにする。逆に、閾値を超えなかった場合には、出力バッファA52−1〜52−N、出力バッファB59のどちらの出力でも選択することが可能となっている。
なお、出力バッファB59からのRAWデータが信号選択部54で選ばれる場合には、マクロブロック処理部51−1〜51−NにあるContext演算部のContextの状態は、Contextメモリ群で記憶されたマクロブロックを処理する直前のContextの状態に復元される。なお、この復元の際には、図1の装置10でも説明したとおり、あらかじめ定められた初期値に復元することも可能である。
逆に、出力バッファからRAWデータでなく、出力バッファA52−1〜52−Nのうちの1つである出力バッファA52−iが信号選択部54で選ばれた場合には、マクロブロック処理部51−iのContext演算部のContextの状態が他のマクロブロック処理部51−1〜51−NにあるContext演算部にコピーされる。これは、その後のマクロブロックの符号化を始めるにあたって、全てのContext演算部のContextの状態が同じでなければならないからである。
ちなみに、非圧縮符号化部58は、RAWデータを出力する非圧縮処理装置のみでなく、DPCM符号化装置などさまざまな圧縮装置に置き換えることが可能である。
図4の装置50におけるその他の詳細な動作、及び符号化単位等のバリエーションは図1の装置10と同様のものとする。
この装置50により、符号化時に置いてCABAC符号化器に入力、及び出力されるデータ量の上限を制限することができるため、要求されたの符号化処理時間を満たすことが可能になる。また、要求された処理時間で復号化処理が可能なビットストリームを出力することが可能になる。
図5における装置60による実施例の説明
次に図5に、図100の可逆符号化部106としてCABACではなくCAVLCを適用する装置60を示す。この装置60は図1の装置10のCABAC処理部13をCAVLC処理器63で置き換えたものであり、CAVLC処理器63と制限監視器64以外は同じ振る舞いをするため、ここではCAVLC処理器63と制限監視器64の動作についてのみ説明をする。
CAVLC処理器63には、ヘッダ情報と量子化された係数情報がシンボルデータとして入力され、従来のMPEG2などと類似した、可変長テーブルを用いた可変長符号化が適用され、ビットデータとして出力される。ここでCAVLC処理器63は、従来の技術の図104で説明したCAVLC符号化器とContext保存器からなり、従来の保存器と同様に、既にCAVLC符号化器で符号化された情報、例えば、処理中のブロックだけでなく既に処理されたブロックにおける各ブロック内の非0係数の個数や直前に符号化された係数の値などが保存されるのに加えて、本発明におけるCAVLC処理器63では、再符号化信号が来たときにマクロブロックを符号化する直前の状態に戻れる様に、マクロブロックを符号化する直前のContextの状態を保存しておくことが可能である。CAVLC符号化器は、このContext保存器からの情報をもとにシンボルに適用する可変長符号テーブルを切り替えることが可能である。なお、Context保存器にはリセット時などに用いられるContextの初期状態も保存される。
制限監視器64は、CAVLC処理器63から出力されるビットデータの個数のカウンタ(ビットカウンタ75)を1つ持ち、CAVLC処理器63からビットデータが出力されるたびにこのカウンタを1つずつ増加させる。このカウンタは、マクロブロックの先頭の処理を開始する時に0にリセットされる。これにより、各マクロブロックにおける、CAVLC処理機63からの出力データの個数をカウントすることが可能となる。
この制限監視器64では、このカウンタ75があらかじめ設定された閾値を超えてしまった場合、その符号化データは無効であることを示す信号(以下、再符号化信号)を、出力バッファ65とパラメータ設定器66に対して出力する。この再符号化信号を受け取ったパラメータ設定器66は、再度この閾値を超えない様に注意して符号化パラメータを設定し直し、符号化対象のマクロブロックデータを再符号化処理する。また、再符号化信号を受け取った出力バッファ65は、内部に蓄積された符号化対象マクロブロックのビットデータを全て削除し、新たな符号化パラメータで符号化されたマクロブロックデータの入力を待つ。
図5の装置60におけるその他の詳細な動作、及び符号化単位等のバリエーションは図1の装置10と同様のものとする。
この装置60により、1回のマクロブロック処理において、CAVLC符号化器から出力されるデータ量の上限を制限することができるため、要求されたマクロブロック1回の処理時間を満たすことが可能になる。また、要求された処理時間で復号化処理が可能なビットストリームを出力することが可能になる。
また、図1の装置のみでなく、図2〜図4の装置に対しても、CABAC処理部をCAVLC処理部に置き換えることが可能であり、その振る舞いはここで示した実施例と同様なものとする。但し、CAVLC処理器はマクロブロックがRAWデータとして符号化されると、そのマクロブロックのContextを持てなくなるので、その様なときのためにRAWデータが符号化された際のContextの更新の仕方を定義しておく必要がある。この定義の方法は符号化装置と復号化装置間で同期が取れていればどんなものでも良い。例えば、RAWデータとして符号化されたマクロブロック内のブロックに存在している非0係数の個数は15とみなすなどである。その装置により、符号化時においてCAVLC符号化器から出力されるデータ量の上限を制限することができるため、要求されたの符号化処理時間を満たすことが可能になる。また、要求された処理時間で復号化処理が可能なビットストリームを出力することが可能になる。
図6における装置80による実施例の説明
次に、図1〜4の装置に対応した本発明における画像情報復号化装置である装置80を図6を用いて示す。なお、図1、2の装置においては、非圧縮符号化部とその経路がないため、図6の装置80において、非圧縮復号化部88への経路は選択されることはない。この様なことが明らかな場合には、この非圧縮復号化部88とその経路を実装しないことも可能である。
図6の装置80では復号化されるべきビットストリームが入力され、復号化された画像信号が出力される。図6の装置80は経路選択器A81、B85と符号化方式判定器84と逆変換処理部83とCABAC処理部82と制限監視器86と非圧縮復号化器88により構成される。
まず、各マクロブロックを処理する始めは、経路選択器A81、B85はCABAC処理部82の経路を選択している。CABAC処理部82では、入力されたビットストリームからマクロブロックを復号化する際に、まず、ビットストリームに埋め込まれた、そのマクロブロックがRAWデータかどうかを示すシンボルを復号化し、それが符号化方式判定器84でRAWデータであると判定された場合は、経路選択器A81、B85は非圧縮復号化部88の経路を選択し、非圧縮復号化部88からの出力を、画像信号として出力する様にする。ここで、非圧縮復号化部88では固定長復号化を行い画像データを取得する。この非圧縮符号化部88が選択された場合には、CABAC処理部82のContext演算部92内のContextの状態は変更しなくても構わないし、あるあらかじめ決められた値で初期化しても良いし、その他の法則を用いて変更しても構わず、符号化装置側のCABAC処理部の振る舞いと同期が取れていれば良い。また、この際に、同一ピクチャ内の後で復号化されるマクロブロックの復号化に用いられるプレディクタはあらかじめ決められた値に設定される。例えば、非圧縮復号化されたマクロブロックの動きベクトルは0に設定され、マクロブロックタイプはイントラ符号化と言った様に設定される。このプレディクタの値も符号化器側と同期が取れていればどんな値を設定しても良い。
逆に、符号化方式判定器84によって、マクロブロックデータがCABAC処理部82で処理されることが選択された場合は、引き続き入力ビットストリームはCABAC処理部82に入力される。
CABAC処理部82では、入力ビットストリームから、ヘッダ情報と量子化された係数情報がシンボルデータとして復号化され出力される。具体的には、入力されたビットストリームを、Context演算器92からのContext情報をもとに、CABAC復号化器90でエントロピー復号化し、そこで出力された2値シンボル列を逆binarization器91により、シンボルデータに変換する。Context演算器92では、逆binarization器91に入力される2値データと逆binarization器91から出力されるシンボルデータをもとにContextを更新し、また、そのContext情報をCABAC復号化部90に出力する。このCABAC処理部88の動作は、「従来の技術」で説明したJVT
FCD第9.2節の記述に準ずるものとする。
逆変換処理部83では、入力されたヘッダ情報や量子化された係数情報を、逆量子化、逆DCT、動き補償することにより画像信号を復号化し出力する。
制限監視器86は、CABAC復号化器90へ入力されるビットデータの個数のカウンタと出力される2値データの個数のカウンタ(ビットカウンタ93)をそれぞれ独立に持ち、CABAC復号化器90へビットデータが入力されるたびに前者のカウンタを1つずつ増加させ、CABAC復号化器90から2値データが出力されるたびに後者のカウンタを1つずつ増加させる。このカウンタはそれぞれ、マクロブロックの先頭の処理を開始する時に0にリセットされる。これにより、各マクロブロックにおける、CABAC復号化器90における入力データと出力データのそれぞれの個数をカウントすることが可能となる。
この制限監視部86では、これらカウンタのうちのどちらか一方が、あらかじめ設定された閾値を超えてしまった場合、エラー処理を実行する。エラー処理としては、復号化処理をいったん中止し、次のスライスヘッダやピクチャヘッダを待って再度、復号化処理を開始したり、単に警告のみを発するだけで復号化処理は引き続き続けるということが可能である。また、エラー処理をせず、復号化処理を引き続き続けるということも可能である。
この装置80により、復号化時においてCABAC復号化器90に入力、及び出力されるデータ量を監視することができるため、仮にこの上限を超えるデータ量が入出力されたとしても、要求された復号化処理時間を満たすようにエラー処理等を施すことが可能となる。
また、実装の方法としては、装置80においては、必ずしも制限監視部86は実装されるとは限らない。その場合には、CABAC符号化器90において入出力されるデータ量は監視されない。
なお、装置80ではエントロピー復号化としてCABACを適用した際の、本発明における画像情報復号化装置の実施例を示したが、既に、画像符号化装置の実施例でも示したとおり、このCABAC処理部はCAVLC処理部で置き換えることが可能であり、その実装方法は符号化装置の実施例でも説明した通り、ほとんど1対1で類似しているため、ここでは説明を割愛する。なお、その符号化装置と同様に、マクロブロックがRAWデータで符号化された際のCAVLCのContextの更新の仕方をあらかじめ定義しておく。
本発明におけるビットストリームの実施例の説明
次に、本発明における符号化されたビットストリームの実施例について示す。ここまでの説明でも述べた様に、本発明ではビットストリーム内に圧縮したデータでも、RAWデータでも符号化することが可能である。このために、本発明のビットストリームでは、マクロブロックヘッダにおいて、そのマクロブロックがRAWデータとして符号化されているかそうでないかを明示的に示すヘッダ情報を付加し、そのヘッダ情報の後にRAWデータ、もしくは、圧縮されたビットデータのどちらかを続けている。ここで、RAWデータとして符号化されているかそうでないかを明示的に示すのに、マクロブロックヘッダ情報の1つであるmacroblock typeによって明示する。逆に言うと、本発明におけるビットストリームは、異なる符号化方式をマクロブロック単位で混在させることが可能であるということである。
またここでは、マクロブロックのヘッダ情報としてそのマクロブロックの符号化方式を指定する情報が組み込まれている場合を示したが、この指定情報を、スライスヘッダやピクチャヘッダに組み込めば、それらの単位で符号化方式の混在と、その指定を行うことが可能となる。
ここで、本発明におけるビットストリームには、このヘッダ情報(例えば、macroblock type)がCABACで符号化され、続いてRAWデータ(すなわち固定長ビット列)が符号化される場合には、RAWデータを符号化する前に、CABACのの終端処理をされたビットが挿入される。
また、本発明におけるビットストリームはCABACで符号化された場合には、これまでの実施例でも述べた様に、CABAC符号化器、及び復号化器の入力と出力のビットカウンタのどちらか一方でもあらかじめ設定された閾値を超えることのないデータにより構成される。また、CAVLCで符号化された場合には、CAVLC符号化器の出力、及び復号化器の入力のビットカウンタが、あらかじめ設定された閾値を超えることのないデータにより構成される。
これらのことから、本発明におけるビットストリームにより、画像情報符号化器、及び画像情報復号化器に対して、ある一定の復号化処理時間を保証することを可能としている。